
Abstract
The identification of English consonants in quiet and multi-talker babble was examined for three groups of young adult listeners: Chinese in China, Chinese in the USA (CNU), and English-native listeners. As expected, native listeners outperformed non-native listeners. The two non-native groups had similar performance in quiet, whereas CNU listeners performed significantly better than Chinese in China listeners in babble. It is concluded that CNU listeners may benefit from English experience, for example, better use of temporal variation in noise and better capacity against informational masking, to perceive English consonants better in babble. Possible explanations regarding the differential noise effect on the three groups are discussed.
1 Introduction
Background noise frequently challenges speech communication in daily life. In particular, non-native listeners, even those with high second-language (L2) proficiency, have more difficulty understanding speech in noise than native listeners (Cutler, Weber, Smits & Cooper, 2004; Rogers, Lister, Febo, Besing & Abrams, 2006; Bradlow & Alexander, 2007; Cooke, Garcia Lecumberri & Barker, 2008; Cutler, Garcia Lecumberri, & Cooke, 2008; Broersma & Scharenborg, 2010; for a review, see Garcia Lecumberri, Cooke, & Cutler, 2010). A number of studies have reported that English-native (EN) listeners had better performance of speech perception than non-native listeners with different types of speech materials, such as phonemes and sentences, in a variety of listening conditions (e.g., speech-shaped noise (SSN) and multi-talker babble; Garcia Lecumberri & Cooke, 2006; Bradlow & Alexander, 2007; Cutler et al., 2008; Broersma & Scharenborg, 2010; Jin & Liu, 2012; Mi, Tao, Wang, Dong, Jin, & Liu, 2013). In particular, non-native listeners used acoustic-phonetic, phonological, and sematic cues less efficiently than native listeners for speech perception in noise (Bradlow & Alexander, 2007).
Several studies recently examined English consonant identification in quiet and multi-talker babble for native and non-native listeners. Cutler et al. (2004) reported that English consonant identification in consonant (C)/vowel (V) and VC contexts under six-talker babble was significantly higher for EN listeners than for Dutch-native listeners, and the non-native disadvantage was similar across different signal-to-noise ratios (SNRs). Further studies found that Dutch-native and Spanish-native listeners recognized English consonants in the CVC context in quiet with high accuracy (>90%), but were slightly lower in recognition than EN listeners (Garcia Lecumberri and Cooke, 2006; Cutler et al., 2008); however, their consonant identification scores in babble noise were much lower than their EN peers. In a later study, Broersma and Scharenborg (2010) measured English consonant recognition for Dutch- and EN listeners in quiet and in three types of noise: competing talker, SSN, and modulated SSN. The results showed that all three types of noise affected Dutch-native listeners more negatively than EN listeners for some of the 24 consonants. Altogether, results of these studies indicated that, compared with EN listeners, non-native listeners were more adversely affected by both energetic and informational masking of multi-talker babble on consonant identification (Cutler et al., 2004; Garcia Lecumberri & Cooke, 2006; Cooke et al., 2008), regardless of their native language (L1) backgrounds. In general, energetic masking refers to the interferences in time and frequency caused by competing sounds at the cochlear level, whereas informational masking is defined as the masking that occurs beyond energetic masking, equated with the central masking. In particular, the informational masking depends on the similarity between speech signal and masking noise, and the familiarity of listeners to speech and noise (Brungart et al., 2001; Durlach, Mason, Kidd, Arbogast, Colburn, & Shinn-Cunningham, 2003; Watson, 2005). In studies of speech perception, both energetic and informational masking are involved when speech babble is used as a masker that usually has great acoustic and linguistic similarity with speech signals. Overall, non-native listeners suffered more from multi-talker babbles in speech perception than native listeners, due to energetic masking, informational masking, or both, depending on speech materials and the type of babble (e.g., L1 or L2 babble and the number of the talkers in babble).
In addition to listening conditions (e.g., in quiet or in noise), non-native listeners’ English learning experience is another important factor that significantly affects their English speech perception. Generally, non-native listeners’ English phonemic perception improved with their English experience (Yamada & Tohkura, 1991; Best & Strange, 1992; Flege, Takagi, & Mann, 1996; Flege, Bohn, & Jang, 1997). Particularly, the findings of these studies suggested that listeners with long English experience (e.g., more than 5–10 years residency in English-speaking countries) showed higher accuracy in English phonemic perception than listeners with short English experience (e.g., less than five years in English-speaking countries). Although a number of studies have focused on how the length of the residency in the L2 country affects L2 speech perception, few studies have compared L2 speech recognition between a non-native group in an English-speaking country and a non-native group in the mother country. Given millions of English learners in non-English speaking countries, it is important to understand English speech perception for this population. One goal of this study was then to investigate English consonant identification in noise for Chinese-native speakers in China, and particularly, to examine whether there was a difference in English consonant perception between two groups of Chinese-native speakers: one in China and one in the USA.
Two recent studies in our laboratories investigated the effect of residency in the USA on Chinese-native speakers’ English and Chinese vowel perception in quiet and multi-talker babble (Mi et al., 2013; Li, Wang, Tao, Dong, Guan, & Liu, 2016). Mi et al. (2013) reported that for English vowel identification in multi-talker babble, Chinese-native adult listeners in the USA (CNU) performed significantly better than their peers in China (Chinese-native adult listeners in China, CNC), especially at low SNRs. The two groups of Chinese-native listeners were matched in age, English acquisition ages, and education background (undergraduate and graduate students), but differed in English experience (e.g., 1–2 year US residency for CNU, and no experience in English-speaking countries for CNC). The similar scores of English vowel perception in quiet and long-term SSN between the two groups indicated that the 1–2-year US residency did not improve their vowel perception, likely due to the lack of specific phonemic training. Mi et al. (2013) concluded that the differential effects of babble noise processing (e.g., temporal cues and informational masking in babble) might contribute to the perceptual difference between CNU and CNC listeners; that is, for English vowel identification, CNU listeners may take better advantage of temporal variations in babble (Stuart, Zhang, & Swink, 2010) and/or they are less affected by the informational masking of babble (Garcia Lecumberri & Cooke, 2006; Cooke et al., 2008) than CNC listeners. Compared with stationary noise like white noise, multi-talker babble differs in temporal variations/glimpses and informational masking. Moreover, in the task of Mandarin Chinese vowel and tone identification in Chinese multi-talker babble, CNU listeners performed significantly better than CNC listeners, but with equal performance in quiet between the two groups (Li et al., 2016). These results indicate that 1–2 years of US residency improved Chinese-native listeners’ noise processing, but it may not change their perception of Mandarin and English vowels in quiet.
According to the results of vowel perception in quiet and babble for CNU and CNC listeners, it is hypothesized in this study that the 1–2-year US residency for CNU listeners will improve their processing of babble noise rather than the capacity of English consonant identification. That is, CNU listeners’ English consonant identification in babble will be better than CNC listeners with equal performance in quiet between the two Chinese groups. Therefore, to test this hypothesis, this study investigated whether the differential effect of babble noise will emerge in English consonant identification for CNU and CNC listeners. The selection of CNU listeners with 1–2 years of US residency was mainly due to two reasons:
to be consistent with the previous studies in vowel perception in our laboratories; and
earlier studies indicate that English vowel perception results in quiet for CNU listeners with 1–2-year US residency were comparable to CNC listeners (Mi et al., 2013; Guan, Liu, Tao, Mi, Wang, & Dong, 2015a).
Three groups of listeners were recruited: EN, CNC, and CNU. The primary goal was to compare consonant identification in quiet and in noise between the two Chinese-native listener groups, with EN listeners as a control group. It was hypothesized that consonant identification in quiet would be comparable for CNU and CNC listeners, whereas CNU listeners were expected to perform better than CNC listeners in babble.
2 Consonant systems of US English and Mandarin Chinese
The consonant systems of the two languages, US English and Mandarin Chinese, are listed in Table 1. There are 10 English consonants that are not present in Mandarin Chinese (see the English consonants in gray in Table 1), whereas the remaining 14 English consonants have similar counterparts in Mandarin Chinese (Norman, 1988; Duanmu, 2007; Wang, 2007). It was expected that the identification of English consonants differed across consonant category, depending on the difference between the English consonant and its counterpart in Chinese, if any, according to L2 speech learning models (Best, 1995; Flege, 1995). Another goal of this study was then to examine the effect of English consonant category on the gap of English consonant identification in noise between English and Chinese listeners. It was hypothesized that babble noise will make the gap between native and non-native listeners larger for the difficult English consonants (e.g., low identification scores in quiet) for Chinese listeners than those easy English consonants (e.g., high identification scores in quiet).
Consonant systems of US English (upper) and Mandarin Chinese (lower) in the manner of articulation (rows) by the place of articulation (columns).
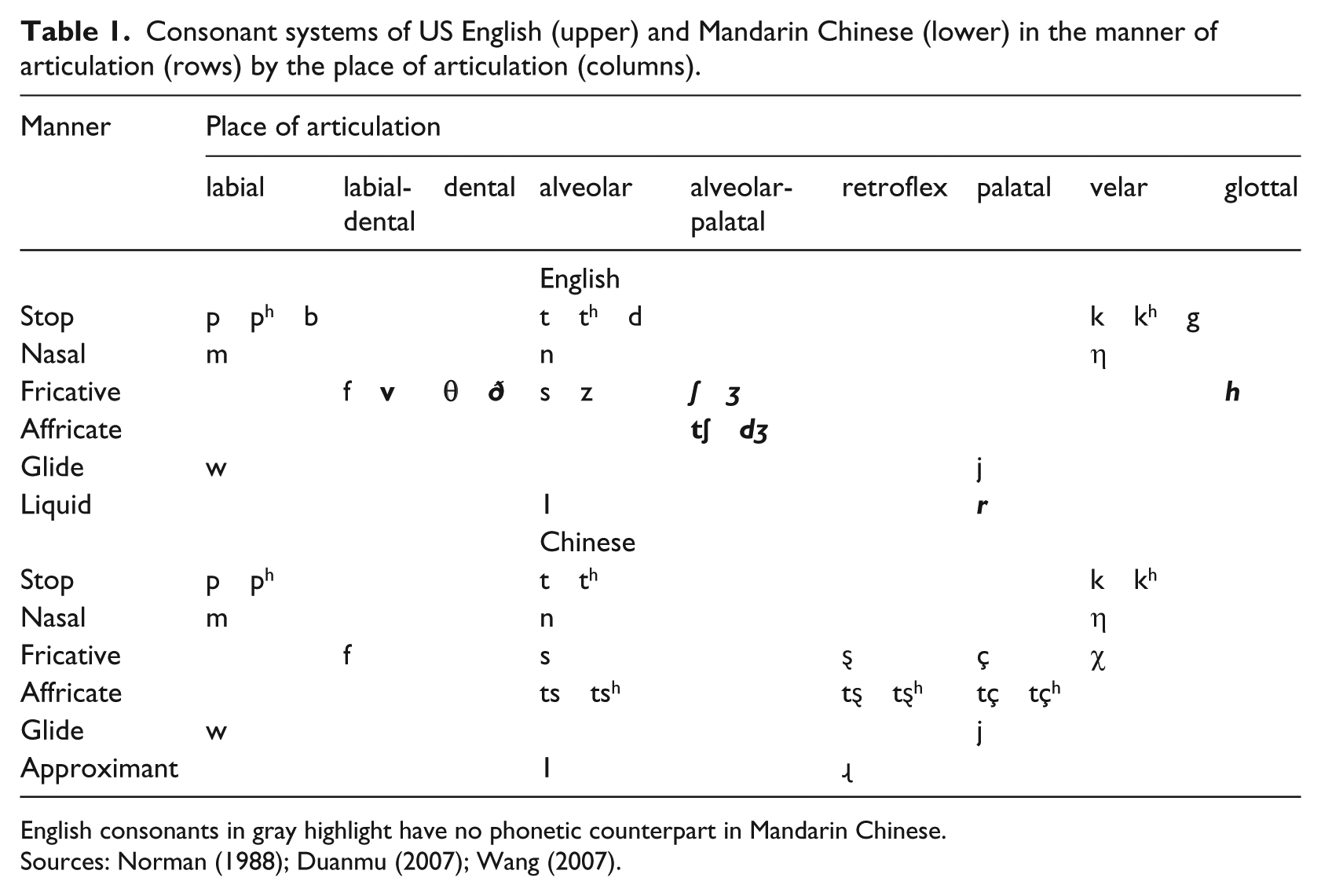
English consonants in gray highlight have no phonetic counterpart in Mandarin Chinese.
Sources: Norman (1988); Duanmu (2007); Wang (2007).
3 Method
3.1 Listeners
Three groups of young listeners between the ages of 19 and 28 years participated in this study: EN, CNU, and CNC. All listeners had normal hearing with pure-tone thresholds ⩽15 dB HL at octave intervals between 250 and 8000 Hz (ANSI, 2010). The EN and CNU groups comprised 12 students each from the University of Texas at Austin (EN: nine undergraduates and three graduates; CNU: eight undergraduates and four graduates). The CNC group comprised 12 students (nine undergraduates and three graduates) from Beijing Normal University at Beijing. All CNC listeners spoke standard Mandarin (Putonghua) with the majority from northern China (CNU: nine from northern China and three from southern China; CNC: 10 from northern China and two from southern China). None of the CNU and CNC listeners were majoring in English or other foreign languages in their undergraduate and graduate studies. The two groups of Chinese listeners received school-based English education in China at the ages of 10–12 years old (i.e., the fourth to sixth grade). The CNU listeners had a computer-based Test of English as a Foreign Language scores of at least 213 and had a US residency of one to two years. The purpose of selecting relatively short-term US residency for CNU listeners was because CNU listeners with US residency of one to two years were found to differ in speech perception in noise from CNC listeners in our previous studies (Mi et al., 2013; Guan, et al., 2015a; Li et al., 2016). The CNC listeners passed the College English Test Band 4 in China and had no residency history in English-speaking countries. Listeners were paid for their participation.
3.2 Speech stimuli and noise
Twenty-one US English consonants,/b,d,g,p,t,k,l,r,w,j,m,n,h,tʃ,dӡ,s,z,ʃ,θ,f,v/, were used as speech stimuli. Consonant stimuli were recorded in the syllable context of /aCa/ produced by a young female native speaker of US English. Each consonant was recorded three times, and the best one was selected to be used as a stimulus token. Three consonants, /η, ð, and ӡ/, were excluded because either some consonants shared the same orthographic presentations (e.g., atha for both /θ/ and /ð/) or the consonant is not placed at the beginning position of a CV syllable like /η/. Consonants were presented in quiet and in noise with five SNRs at −20, −15, −10, −5, and 0 dB. This particular English-native speaker was selected because she had high scores (>97%) in the intelligibility of consonants in an earlier study (Jin & Liu, 2014).
Similar to previous studies (Jin & Liu, 2012; Mi et al., 2013), a 12-talker babble (Kalikow, Elliot, & Stevens, 1977) of 70 dB SPL served as the masker in this experiment. The 12-talker babble was generated by recording six adult talkers (three females and three males) reading a children’s book, then combing the six speech recordings and mixing two repetitions of the six-talker babble. For each trial in the noise conditions, a 2-s segment was randomly selected from a 10-s recording of the 12-talker babble. Consonants were presented temporally in the middle of the 2-s masker (e.g., the duration of noise preceding and succeeding the consonant was equal, but varied across consonants). Signals and maskers had 10-ms rise-fall ramps. Each speech stimulus was equalized to the same root-mean-square level for calibration purposes. The sound-pressure levels of signals and maskers were calibrated in an AEC201-A IEC 60318-1 ear simulator by a Larson-Davis sound-level meter (Model 2800) with a linear weighting band.
3.3 Procedure
Consonant stimuli and noise, digitized at 24,414 Hz, were presented via SONY MDR-7506 headphones to the right ear of the listeners, who were seated in a quiet test room. The sampling rate of 24,414 Hz was used to be compatible with the hardware of sound processing. The monaural processing was used to be consistent with previous work in our laboratories and to facilitate comparisons with previous findings (Liu & Jin, 2011, 2013; Liu et al., 2012; Mi et al., 2013; Jin & Liu, 2014). Stimulus presentation was controlled by a Tucker-Davis Technologies mobile processor (RM1). Listeners were seated in front of an LCD monitor that displayed 21 response alternatives as a text box labeled with the /aCa/ context for consonants (e.g., aba, acha, ada, afa, aga, aha, aja, aka, ala, ama, ana, apa, ara, asa, asha, ata, atha, ava, awa, aya, aza) corresponding with each consonant (Figure 1). Listeners responded by using a computer mouse to click on the button corresponding with their response choice. After each consonant presentation, listeners were required to respond within 10 s. Otherwise, listeners were allowed to replay the previous stimulus and then make a response; however, such replays were strongly discouraged.
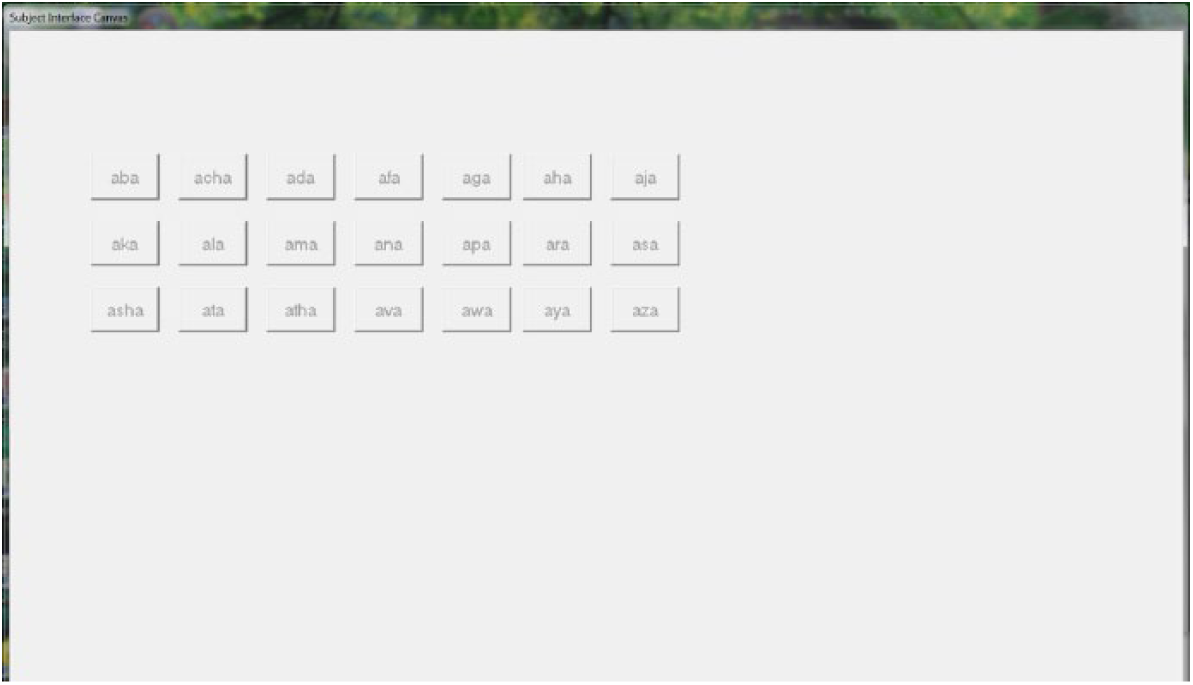
Subject response interface showing the 21 response buttons labeled with the /aCa/ context.
Before data collection began, listeners were trained with a 20-min session of consonant identification in a quiet condition to familiarize them with the experimental procedure using English consonants produced by a young male English-native speaker. Feedback was provided to indicate the correct response on each trial during the training session, but it was not provided during the test sessions.
Under each test condition (quiet or noise), consonant identification was measured in one block of 420 trials, in which 21 consonants were presented 20 times each in a random order; thus, for each condition, consonant identification in percent correctness was based on the 20 judgments for each consonant. Short breaks were provided between blocks (1–2-min break approximately every 20 min, and 5-min break approximately every 1 h), and all test conditions were completed in two sessions on different days. Each session lasted about 1.5–2 h. After the training, listeners were examined with the test session in quiet first, followed by the babble conditions, in which the order of five SNRs was randomized. The software Sykofizx (Tucker-Davis Technologies) was used to implement the procedure.
4 Results
4.1 Consonant identification in quiet
The EN group outperformed the two Chinese groups for most of the English consonants whereas there was little difference between the non-native groups (Figure 2). All three groups had an average score above 90%. Specifically, only a few consonants had the identification scores below 90%, for example, /r, θ, v/ for the CNU listeners and /tʃ, d, w, r, θ, v/ for the CNC listeners. The consonants with relatively low scores, /tʃ, θ, r, v/, had no phonetic counterparts in Mandarin Chinese (Table 1). For statistical analysis purposes to avoid the ceiling and floor effects, the percentage rates for consonant identification were converted to rationalized arcsine units (RAUs) (Studebaker, 1985) for the homogeneous variance over the full range of the scores. A two-factor (between-subjects factor: listener group; within-subjects factor: consonant category) analysis of variance (ANOVA) was conducted with the RAUs in quiet as the dependent variable. There were significant effects of listener group, F(2, 33) = 7.50, p = 0.002, ηp2 = 0.417, and consonant category, F(20, 660) = 40.93, p < 0.0001, ηp2 = 0.691, and interaction between consonant category and listener group, F(40, 660) = 1.89, p < 0.001, ηp2 = 0.409. Tukey post hoc tests indicated that the EN group had significantly higher scores than the CNU and CNC groups (p < 0.05), with no significant difference between the two Chinese groups (p = 0.86).
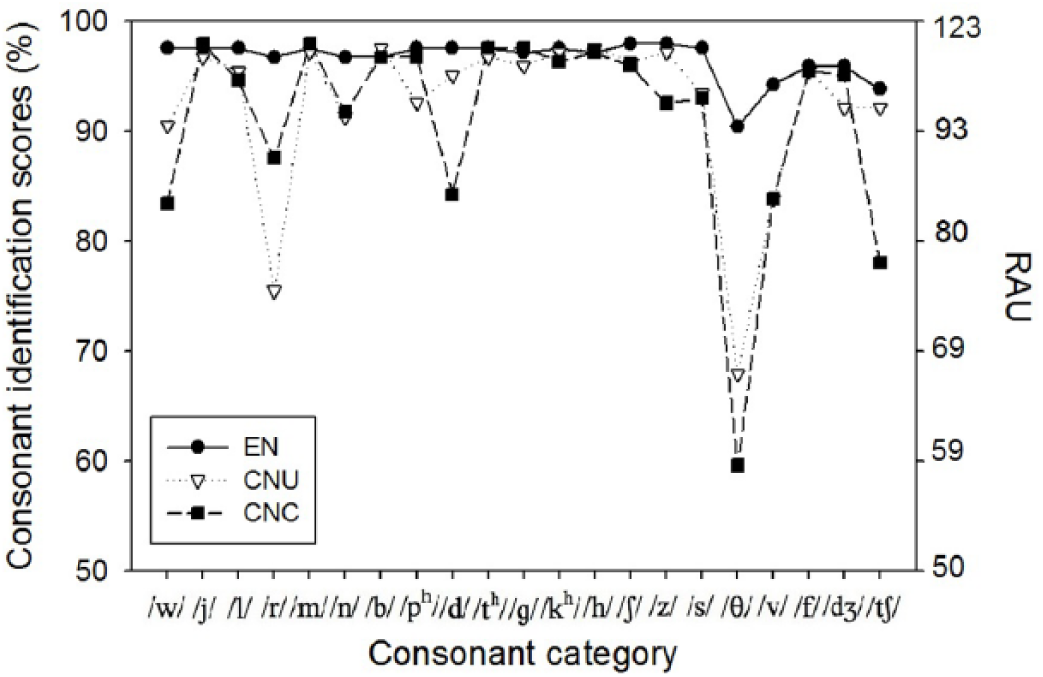
Percentage correct of consonant identification as a function of consonant category in quiet for the CNU, CNC, and EN listeners.
Because of the significant interactions of language group and consonant category, a one-factor (language group) ANOVA was conducted for each consonant category to reveal the simple main effect of language group. In order to control for Type I error rate across the 21 simple effects, the alpha level for each ANOVA was set at 0.0024 (α = 0.05/21). The results indicated a significant effect of language groups on consonant identification for consonants /w, θ, z/ (all p < 0.0024), but did not reach the significance at the adjusted alpha level for other consonants (all p > 0.0024). For consonant /θ/, Tukey post hoc tests suggested the EN group had significantly better scores than the two Chinese groups (p < 0.0024), which did not differ from each other. For consonants /w, z/, Tukey post hoc tests indicated significantly higher scores for the EN listeners than for the CNC listeners (both p < 0.0024).
4.2 Consonant identification in babble
The upper panel of Figure 3 illustrates the average identification scores for 21 consonants as a function of listening conditions for the three listener groups. As expected, consonant identification scores declined as the listening conditions became more challenging for all three groups. In addition, EN listeners performed better than the two Chinese groups in every condition. There are substantial differences in the low-SNR babble conditions between the two Chinese groups, CNU and CNC. As illustrated in the lower panel of Figure 3, the non-native disadvantage (i.e., native listeners’ scores minus non-native listeners’ scores) was flat in quiet and high-SNR conditions, and then increased at low SNRs for the CNC group, whereas the non-native disadvantage was consistent across all listening conditions for the CNU group.
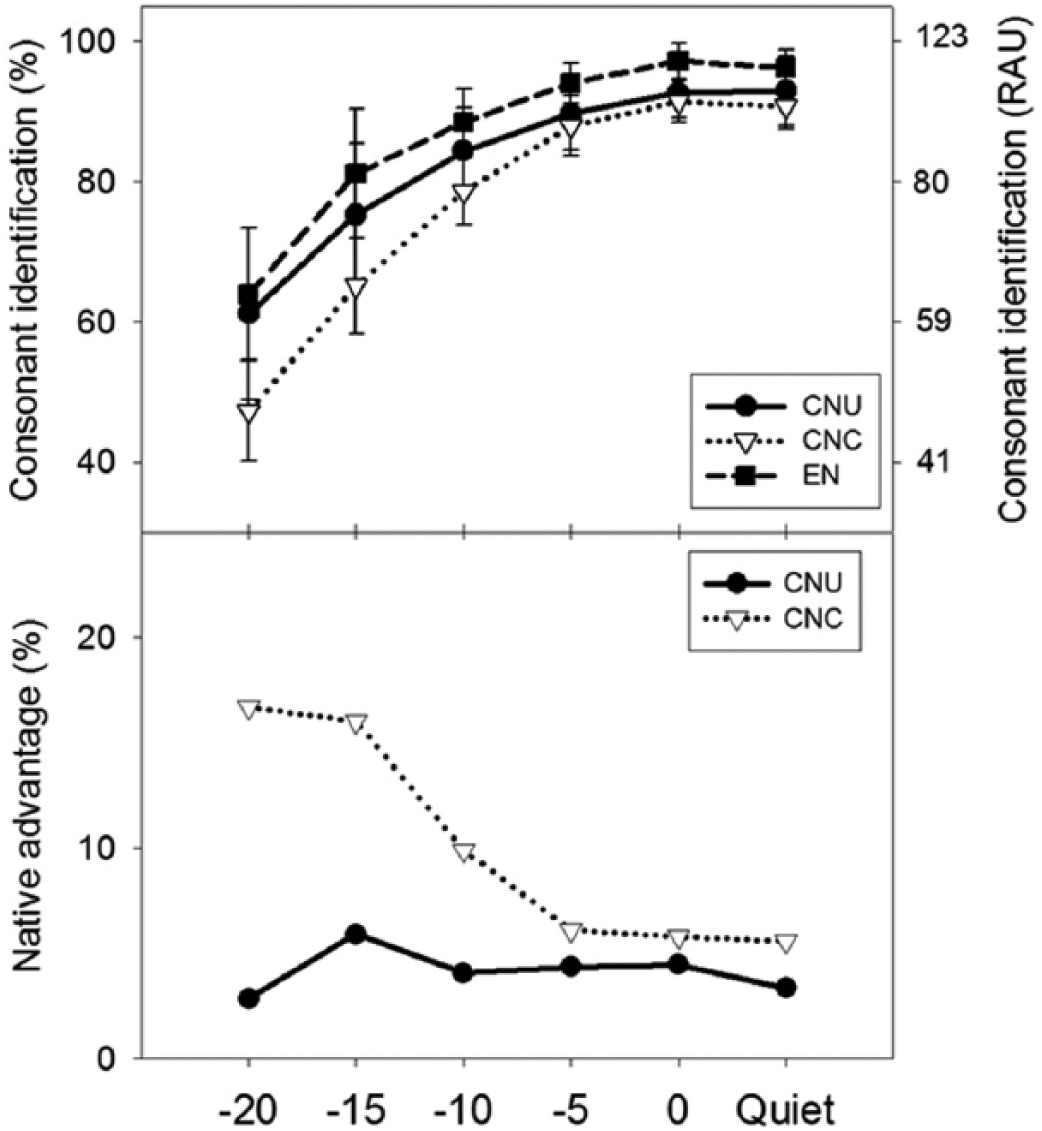
Average percentage of correct consonant identification scores and standard errors (upper) and non-native disadvantage (lower) for the 21 consonants as a function of listening conditions in quiet and multi-talker babble for the CNU, CNC, and EN listeners.
A three-factor (between-subjects factor: listener group; within-subjects factors: SNR and consonant category) ANOVA was conducted with the RAU in babble as the dependent variable. The results showed that consonant identification in babble was significantly affected by listener group, F(2, 33) = 13.70, p < 0.0001, ηp2 = 0.582, consonant category, F(20, 660) = 116.26, p < 0.0001, ηp2 = 0.812, and SNR, F(4, 132) = 347.01, p < 0.0001, ηp2 = 0.858, and all two- and three-factor interactions (all p < 0.001).
Because of the significant interaction effects of listener group and SNR, the simple effect of listener group for each SNR was examined by conducting two-factor (between-subjects factor: listener group × within-subjects factor: consonant category) ANOVAs for the SNR of 0, −5, −10, −15, and −20 dB, respectively. Similarly, to control for Type I error rate across the five simple effects, the alpha level for each ANOVA was set at 0.01 (α = 0.05/5) and the results showed a significant effect of listener group at all the SNRs (all p < 0.01). For the SNR of 0 and −5 dB, Tukey post hoc tests suggested that consonant identification was significantly better for the EN listeners than for the CNU and CNC listeners (p < 0.01), whereas there was no significant difference (p = 0.82 for the SNR of 0 dB; p = 0.76 for SNR of −5 dB) between the two Chinese groups. For the SNR of −10 dB, the EN listeners performed significantly better than the CNC listeners (p < 0.01), but there was no significant difference between CNU and EN or CNC listeners. For the SNR of −15 and −20 dB, the CNC group had significantly lower scores than the other two groups (all p < 0.01), whereas there was no significant difference between the EN and CNU groups.
It should also be noted that for each SNR, there was a significant interaction of language group and consonant category (p < 0.01). One-factor (language group) ANOVAs were then run for each consonant under each SNR with the alpha level set at 0.00048 (α = 0.01/21). Results are summarized in Table 2. In general, as the SNR decreased, more consonants were found to show a significant effect of language group. In particular, at the two lowest SNRs, the CNU listeners identified consonants with significantly higher accuracy than the CNC listeners for consonants /b, tʃ, p, v, and w/. Among these consonants, /tʃ, v/ had no phonetic counterparts in Mandarin Chinese, as shown in Table 1.
Results of one-factor (language group) ANOVAs for each consonant under each of the five SNRs (e.g., −20, −15, −10, −5, and 0 dB).

Results of Tukey post hoc tests are included in the parentheses.
p < 0.00048.
4.3 Confusion matrices of consonant identification
The major confusion consonants (e.g., confusion rate was significantly greater than the chance rate 1/21 = 4.6%, p < 0.05) were counted for the EN, CNU, and CNC listeners, respectively. In general, for all three groups of listeners, a greater number of confusion consonants were presented as listening conditions became more challenging. For example, consonant /θ/ was confused with /f/ in quiet and high SNRs, and then was confused with more consonants at low SNRs. For a given consonant category, a greater number of confusion consonants were shown for non-native listeners than for native listeners. For example, EN listeners had no confusion consonants with /r/ in quiet, whereas the two groups of Chinese listeners confused /ρ/ with /ω/ and /ϖ/ under the same listening condition. In addition, compared with the EN listeners, the CNU and CNC listeners showed a greater number of confusion consonants, especially at middle and high SNRs, for example, at the SNR of −10 dB, EN listeners had no confusion consonants with /l/, whereas CNU listeners confused /l/ with /m/ and CNC listeners confused /l/ with /m, v, and n/. A three-factor (between-subjects factor: listener group; within-subjects factor: consonant category and listening condition) ANOVA with the number of confusing consonants as the dependent variable suggested that the number of confusing consonants was significantly affected by each of the three factors: listener group: F(2, 33) = 12.17, p < 0.0001, ηp2 = 0.537, consonant category, F(20, 660) = 93.72, p < 0.0001, ηp2 = 0.713, and listening condition, F(5, 165) = 239.91, p < 0.0001, ηp2 = 0.776, but not by the two- and three-factor interactions (all p > 0.05) except the interaction of consonant category and listening condition (p < 0.05). Furthermore, Tukey post hoc tests indicated that the number of confusing consonants was less for EN listeners than for CNU and CNC listeners (both p < 0.05). These results suggest that EN listeners not only had higher scores of consonant identification than CNU and CNC listeners, but also had a smaller number of confusion consonants, especially in noise conditions.
4.4 Non-native disadvantage of CNU and CNC listeners
As shown in Table 2, among the 21 consonants, 11 showed a significant listener group effect; of these 11 consonants, six had identification scores below 90% in quiet, implying that consonants with a significant group effect in noise may be associated with the low scores of consonant identification in quiet for non-native listeners. In fact, the correlational analyses indicated that across the 21 consonants, there were significantly negative correlations between the consonant identification scores in quiet and the non-native disadvantage of consonants for the CNU and CNC listeners (R2 from 0.21 to 0.67; all p < 0.05) except at the SNR of −20 dB for the CNC listeners. The non-native disadvantage was calculated as the difference in the identification scores between native and non-native groups for a given listening condition. For example, as shown in Figure 4, the non-native disadvantage of consonant perception for the CNU and CNC listeners at the SNR of −15 dB was negatively correlated with the consonant identification scores in quiet across the 21 consonants (both p < 0.05); that is, if an English consonant had a higher identification score in quiet for non-native listeners, the non-native disadvantage of this consonant was smaller in noise.
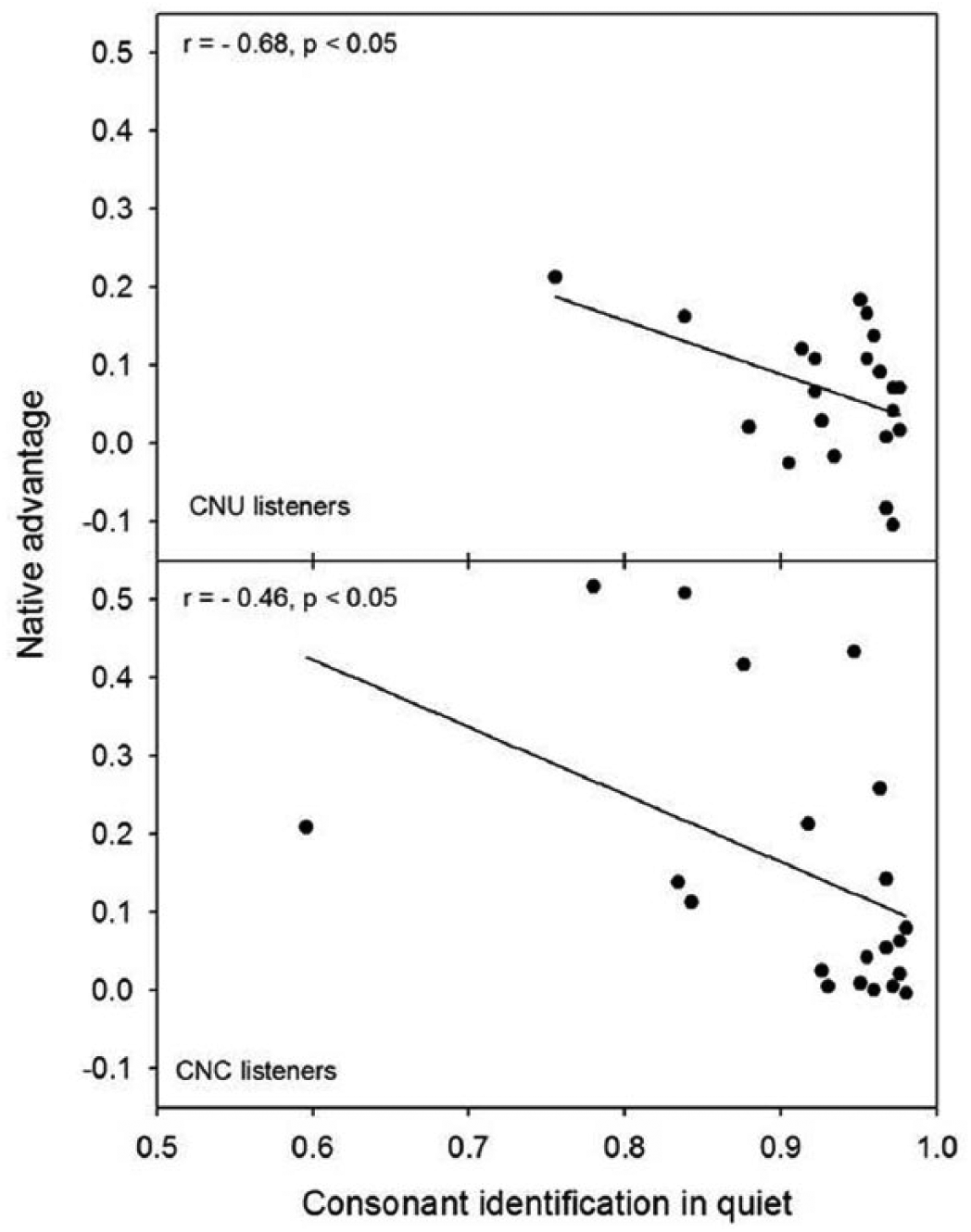
Linear regression functions for non-native disadvantage of consonant identification at the SNR of −15 dB as a function of consonant identification scores in quiet across the 21 consonants for CNU (top) and CNC listeners (bottom).
5 Discussion
The present study examined English consonant identification in multi-talker babble for EN and two groups of CN listeners. EN listeners identified consonants more accurately than CNC listeners in all listening conditions (quiet and babble) and had a small, but significant advantage over CNU listeners (2.8–5.9%). Previous studies reported that English non-native listeners residing in their home countries (e.g., Spanish- and Dutch-native listeners) were able to identify English consonants in quiet with high accuracy (>90%), which was slightly lower than English-native listeners; however, they showed markedly lower performance in babble noise than English-native listeners (Garcia Lecumberri & Cooke, 2006, Garcia Lecumberri et al., 2010; Cutler et al., 2008; Broersma & Scharenborg, 2010). These findings were consistent with the results of this study in which the non-native disadvantage was greater in babble than in quiet for the CNC listeners; however, the non-native disadvantage was relatively flat and small across all listening conditions for the CNU group. These results suggest that even though non-native listeners can recognize English consonants accurately in quiet, they may have a greater disadvantage in perceiving English consonants in babble compared with English-native listeners, particularly the non-native listeners who have limited experience with native English oral communication, such as CNC listeners.
Among the 21 English consonants, those with a similar phonetic counterpart in Mandarin Chinese did not necessarily lead to high identification scores (e.g., /w/), whereas those without a phonetic counterpart in Mandarin Chinese did not always result in low accuracy of identification (e.g., /z/). This is consistent with the findings of English vowel identification for Chinese-native listeners. For example, the English vowel /u/ has a phonetic counterpart in Mandarin Chinese, but it had low accuracy scores in quiet and noise, whereas the English vowel /æ/ has no phonetic counterpart in Mandarin Chinese, but it had relatively high accuracy scores (Mi et al., 2013).
These results suggest that English phonemic perception of Chinese-native listeners is associated with not only the similarity or difference between the phonetic system of English and Mandarin Chinese, but also with other factors such as the difficulty or easiness to build sharp phonetic categories in English, which are distinguishable from other English phonetic categories. In particular, phonemic perception of the second language may rely on two factors:
whether there is a similar counterpart in the native language, and
the number of L2 phonemes with assimilation and the consistency with which L2 phonemes are assimilated (e.g., the phonetic goodness of fit) to the L1 phoneme (Flege, 1995; Best & Tyler, 2007; Strange, 2007, 2011).
In the present study, although the English consonant /w/ has a similar phonetic counterpart in Mandarin, the identification scores of /w/ for Chinese-native listeners were significantly lower than English-native listeners. This is likely due to the fact that Chinese-native listeners had difficulty in discriminating the two phonetically close consonants in English: /w/ and /v/ (see Table 2 for the confusion between each other). Furthermore, the group difference (e.g., native vs. non-native listeners) in noise for a given consonant was significantly related to the identification score in quiet of non-native listeners for this consonant rather than whether the consonant has a phonetic counterpart in Mandarin Chinese (Table 2 and Figure 4).
One primary goal of this study was to measure the effect of non-native listeners’ English experience on consonant identification in babble. Little difference was found between the two Chinese groups in consonant identification in quiet, whereas the CNU listeners recognized consonants more accurately than the CNC listeners in babble, especially at relatively low SNRs. This is consistent with the data from vowel identification in babble (Mi et al., 2013). These results suggest that for English phoneme identification in babble, CNU listeners were able to take advantage of their English experience to perform better than their peers in China. Although native English exposure does not seem to influence Chinese-native listeners’ phonemic processing in quiet (e.g., comparable performance of vowel and consonant identification between CNU and CNC listeners), it may improve their capacity to reduce the masking effect of babble noise, in particular when SNRs are challenging.
Two speculations are proposed to explain these results. First, the CNU group might use the cue of temporal variation in the babble better than the CNC group. Stuart et al. (2010) found that for English sentence recognition, the masking release in interrupted noise was smaller for Chinese-native listeners than for English-native listeners compared with continuous noise. Moreover, the better uses of temporal variations of noise by CNU listeners than by CNC listeners were found in English vowel identification (Guan et al., 2015a), English sentence recognition (Guan, Liu, Tao, Li, Wang, & Dong, 2015b), and even their native speech—Chinese vowel and tone identification (Li et al., 2016). These studies suggested that CNU and CNC listeners showed similar performance in stationary noise, whereas CNU listeners outperformed CNC listeners in temporally modulated noise. Thus, it is also possible that CNU listeners may take greater advantage of temporal variation in noise than CNC listeners in English consonant identification.
Second, the effect of informational masking might be greater for the CNC group than for the CNU group. In general, non-native listeners were more negatively affected by the informational masking of multi-talker babble than native listeners (Garcia Lecumberri & Cooke, 2006; Cooke et al., 2008). Because English multi-talker babble carries speech-like features, speech stimuli might be less distinguishable from babble to non-native listeners than to native listeners (Garcia Lecumberri & Cooke, 2006; Cooke et al., 2008). Regular exposure to an English-speaking environment may familiarize non-native listeners with the acoustic features of English running speech and help them distinguish speech signals from babble. Therefore, further studies are needed to test our two speculations by examining English consonant identification in stationary and temporally modulated noise and investigating the informational masking effect on English consonant identification for CNU and CNC listeners.
In fact, Antoniou, Wong, and Wang (2015) recently reported that in an English word-monitoring task, CNC listeners underperformed CNU and EN listeners, particularly when the target words were produced by different talkers. In addition, CNC listeners needed more time to complete the task than CNU and EN listeners. They concluded that intensified English exposure may improve non-native listeners’ capacity to resolve talker variability. Combined with the findings of this study, one may speculate that the residency in an English-speaking country possibly helps non-native listeners’ have better performance of English speech perception in challenging conditions, for example, lower SNRs and greater talker variability. These results suggest that language immersion may reduce the cognitive load required to process L2 speech sounds, particularly in difficult situations, like perceiving L2 speech in noise or recognizing L2 speech from multiple talkers (Antoniou et al., 2015).
Some limitations also need to be considered for this study. For example, when comparing the two Chinese groups, factors of the English exposure and learning experience were not controlled (e.g., the frequency of English oral communication and English exposure) and some factors were just partially controlled (e.g., only one to two years of US residency, but not including longer US residency) in the present study. In addition, the type and amount of English exposures, for example, where (in classroom, on campus, or off campus) and how (e.g., both speaking and listening, or just listening) the English exposure is, may also play an important role. The effect of these factors on non-native speakers’ English speech perception in noise needs further investigation.
In summary, this study focused on the effect of non-native listeners’ English experience on English consonant identification in quiet and babble. As expected, EN listeners showed better performance than Chinese-native listeners in quiet and babble. The two Chinese groups had similar consonant identification scores in quiet; however, in babble with low SNRs, the CNU group outperformed the CNC group. These results indicate that, given similar performance of phonemic perception in quiet, the differential effects of babble noise on non-native listeners’ speech perception are attributed to speech materials and listeners’ English experience.
Footnotes
Acknowledgements
The authors are thankful to Lin Mi, Mingshuang Li, and Jingjing Guan for their assistance in data collection and analysis. The authors also thank Michelle Schoenecker and the Editorial Service at Beijing Normal University for their assistance in manuscript preparation.
Funding
This study was supported by the Open Funds of the National Key Laboratory of Cognitive Neuroscience and Learning at Beijing Normal University, the NSFC grants (31628009 & 30970908), and the Research Grant of the College of Communication at the University of Texas at Austin.