
Abstract
This study examined contrastive effects of neighboring tones that give rise to a systematic asymmetry in stop perception. Korean-speaking learners of Mandarin Chinese and naïve listeners labeled voiceless unaspirated stops preceded or followed by low or high extrinsic tonal context (e.g.,
1 Introduction
Identical acoustic signals may be perceived differently depending on the context in which they appear. This has been observed in both segmental and suprasegmental domains. Context-dependent processing of lexical tone, for instance, is referred to as tone normalization. As an example, Francis et al. (2006) have shown how Cantonese listeners interpret semantically neutral segmental sequences depending on the context F0. A sentence with the target syllable /ji/ in the middle was manipulated so that the F0 of the carrier phrase varied between low, neutral, and high, while /ji/ remained unchanged. The results showed that high lexical tone responses (/ji55/ ‘doctor’) were most frequent when the F0 of the carrier phrase was low, while low lexical tone responses (/ji22/ ‘two’) were favored when the F0 of the carrier phrase was high. In the neutral F0 context, the intermediate tone response (/ji33/ ‘meaning’) was most frequent. Similar findings have been observed for Mandarin (e.g., Fox & Qi, 1990; Lin & Wang, 1984; Luo & Ashmore, 2014) as well as Cantonese lexical tones (e.g., Wong & Diehl, 2003; Zhang & Chen, 2016; Zhang et al., 2012).
Compensation for coarticulation is another example of contrastive effects of context. A well-known example is the so-called alga-arda asymmetry, which refers to the pattern that emerges when an ambiguous stop spectrum is more likely to be identified as /ɡ/ when it follows an /l/, while the physically identical stop is identified as /d/ following an /ɹ/ (e.g., Fowler, 2006; Kingston et al., 2014; Lotto & Kluender, 1998; Mann, 1980). The burst spectrum of /d/ has an energy concentration at higher frequencies than that of /ɡ/ due to their different constriction locations in the vocal tract. Similarly, between the two liquids, /l/ is articulatorily more front and thus spectrally higher than /ɹ/ along the F3 parameter. It follows that spectrally lower /ɡ/ perception is elicited more often after the higher context /l/, while spectrally higher /d/ perception is triggered after the lower context /ɹ/. Similarly, categorization of an ambiguous fricative depends on the quality of the following vowel, which is referred to as the ‘sushi bias’. Specifically, when presented with an ambiguous fricative stimulus, listeners perceive it as spectrally high /s/ before a low-F2 context /u/, while the same stimulus tends to be identified as spectrally low /ʃ/ before a high-F2 context /i/ (e.g., Mitterer, 2006; Smits, 2001; Whalen, 1989).
Despite some qualitative differences, the premise of these phenomena can be reduced to one fundamental aspect of speech perception: the process of identifying a sound involves an integration of its intrinsic properties and extrinsic information, the influence of which is predominantly contrastive. Acknowledging the robustness of context sensitivity, this study extends the empirical coverage of this line of research to a novel case wherein segmental distinctions may arise from extrinsic tonal contexts. The particular case of interest is the stop laryngeal distinctions which are partially cued by differential F0 values in Korean. Specifically, fortis stops are associated with a high F0 at the vowel onset, while lenis stops are associated with a low F0 word-medially (Cho & Keating, 2001; Kagaya, 1974) as well as word-initially (Cho et al., 2002; Han, 1996; Silva, 1992). The perceived onset F0 of target stops may be conditioned by neighboring tones in a contrastive way, which, in turn, may give rise to a systematic asymmetry in stop contrasts. Though recent research has investigated specific constraints that may further refine the ways in which contrastive context effects manifest, some unsolved issues remain. Through a series of stop identification experiments, this study aims to address these issues, with an emphasis on the directionality of context effect, the interaction between the intrinsic and extrinsic tonal properties, and linguistic experience.
1.1 Directionality of contrast effects
While the majority of previous research has focused on the context that precedes ambiguous signals, a few tone normalization studies have examined both preceding and following contexts and have shown consistent contrastive effects in both directions (e.g., Francis et al., 2006; Sjerps, Zhang, & Peng, 2018; Wong & Diehl, 2003). Francis et al. (2006), in particular, have demonstrated the additive nature of tone contrast; for example, perceptual lowering of a target tone was more pronounced when contexts were high on both sides rather than on only one side.
Segmental perception, on the other hand, has been shown to be sensitive to the direction of context. Rysling, Jesse, and Kingston (2019), for example, reported a case of assimilatory perception of vowels to the following context. An ambiguous vowel was perceived more often as /o/ with a low F2 before the spectrally lower stop /p/, while an identical stimulus was perceived more often as /e/ with a high F2 before the spectrally higher stop /t/. However, the typical contrast effect is found for the preceding context; that is, more /o/ judgments after /t/ and more /e/ judgments after /p/. The authors proposed a ‘misparse’ hypothesis to account for the directional asymmetry. Assimilation from the following context results from the attribution of vowel formant transition to that of preceding target vowels. F2 lowering for the upcoming /p/, for example, is attributed to properties of the preceding vowel, and hence a back vowel /o/ is perceived. Indeed, when formant transitions were enhanced, the assimilation rate increased accordingly. Further, Rysling (2017) has identified specific conditions in which contrast effects may or may not arise. When the transition of the two sounds is so gradual that the boundary of the two sounds is less clear, assimilation takes place through the listeners’ bias toward forward attribution, and as a result, properties of the later sounds are mis-parsed as those of preceding sounds. The reverse order does not hold true because of the relatively clear separation of the vowel from the preceding stop due to the prominent stop burst in a prevocalic position. In this case, typical contrast effects are observed.
When segments and suprasegments have been compared in the same experimental setting, the difference with respect to the direction-sensitivity is indeed clearly observed. Sjerps et al. (2018) examined an F1 contrast for a CVCVCV sequence where the target vowel was either initial with a following context or final with a preceding context. The results showed that the preceding context consistently elicited a contrast along the F1 value. That is, a high F1 context led to a vowel with a lower F1, and vice versa. The following context, on the other hand, did not yield any context effect. In a similar experimental paradigm, however, contrasts along the F0 frequency were robustly observed for both immediately preceding and following contexts. The authors speculated that the scope of processing for vowels and tones might be qualitatively different; whereas vowel perception is local, tone perception may take place over a longer time frame (e.g., Cutler & Chen, 1997; Ye & Connine, 1999) so that the later tones, namely following contexts, may still be able to influence the tone perception of the preceding target.
It remains uncertain whether stop asymmetry arising from tone contrasts, if any, would be bidirectional. The present study examined the perception of stops in both preceding (/ma.
1.2 Interplay between extrinsic and intrinsic tonal properties
The effect of context is particularly evident for the perception of level lexical tones (e.g., Francis et al., 2006; Peng et al., 2012; Wong & Diehl, 2003; Zhang et al., 2012; Zhang et al., 2017). Indeed, extrinsic context has been found to elicit the activation of different lexical items. For example, for an identical sequence /ji/ in Cantonese, /ji55/ ‘a doctor’ is elicited more frequently in a low tone context, /ji33/ ‘meaning’ in an intermediate context, and /ji22/ ‘two’ in a high tone context (Francis et al., 2006). The F0 frequency of surrounding sounds makes it possible to estimate the overall F0 range of a speaker; given the particular speaker’s range, individual level tones can be identified. In particular, Peng et al. (2012) have shown an interesting asymmetry that listeners of Cantonese, a language with a rich level tone system, were more susceptible to inter-talker F0 variation in tone normalization than listeners of Mandarin Chinese, which is characterized by its multiple contour tones.
However, contour tones have also been shown to be sensitive to context to some extent. Moore and Jongman (1997) tested the factors of the distinction of two Mandarin contour tones, namely the mid-rising (X35) and low-dipping (X214) tones (Chao, 1968). In addition to the intrinsic properties of the F0 contour (e.g., F0 difference and F0 turning point), neighboring tones also influenced contour tone identification. All else being equal, Mandarin-speaking listeners identified ambiguous stimuli more frequently as mid-rising tone (X35) in the low-precursor context and as low-dipping tone (X21(4)) in the high-precursor context. Likewise, Huang and Holt (2009) have shown more frequent mid-rising tone (X35) perception after a high-context precursor, while the high-level tone (X55) perception was favored in the low-context precursor. Note another relative F0 perception here: the mid-rising tone is considered high compared to the low-dipping tone in Moore and Jongman (1997) but low compared to high-level tone in Huang and Holt (2009). Nevertheless, the results of those studies highlight the non-negligible role of context in the perception of contour tones.
Although context influences the identification of both level and contour tones, context effects are presumably not equivalent across classes of tones. Extrinsic context plays a key role in the identification of a level tone due to its simpler intrinsic F0 properties; however, extrinsic contexts are likely to play a more limited role in identifying contour tones given their more complex intrinsic F0 characteristics. One may reasonably hypothesize that perceiving the dynamic change in F0 frequency requires costly cognitive processing, and hence extrinsic F0 events may be ignored to some extent.
1
The interaction between extrinsic and intrinsic tones, to date, has not been tested explicitly in a single experimental setting. To address this issue, the present study presents two perceptual experiments that vary the target tones between level and rising (e.g., /maHI/LO.
1.3 The role of linguistic experience in context effects
Recent studies have examined the role of linguistic experience on context sensitivity, and the results, thus far, are mixed. Some studies have demonstrated the language-independent aspect of context effects (Mann, 1986; Sjerps & Smiljanić, 2013; Viswanathan et al., 2010). In Viswanathan et al. (2010), the classic alga-arda experiment was extended to include Tamil liquids, [r] (alveolar trill) and [ɭ] (retroflex), as context. Although English-speaking listeners had no experience in Tamil liquids, the results yielded more [ɡ] responses after both English [l] and Tamil [r] and more [d] responses after English [ɹ] and Tamil [ɭ]. Because this liquid pairing does not make sense in terms of spectral characteristics of the liquids (/l/ has a high F3, /ɹ, r, ɽ/ a low F3), this finding was taken to support the gestural account by the authors. The back consonant [ɡ] was chosen more frequently after the front liquids, while the front consonant [d] was chosen more frequently after the back liquids, compensating for coarticulation between adjacent sounds during perception. In a similar vein, Japanese listeners, who are well-known for having difficulties with English /r-l/ contrasts, actually showed a parallel pattern to native speakers of American English in the alga-arda experiment (Mann, 1986). This, again, suggests that prior linguistic experience is not necessary for perceptual compensation to arise.
Empirical evidence, however, exists for context effects being conditioned by phonetic knowledge of the sounds. Kang et al. (2016) have tested English and French-speaking listeners for the sushi perceptual asymmetry. Both groups of participants compensated for the /u/ vowel, giving more /s/ responses compared to the /a/ vowel. However, only French-speaking listeners were able to compensate for the /y/ vowel, while English-speaking listeners treated /y/ similarly to the unrounded vowel /a/. The results suggest that the phonetic knowledge of the /y/ vowel (e.g., lip rounding) is necessary for coarticulatory compensation. In another study, Kingston et al. (2011) demonstrated that Japanese listeners compensated more for [o] than for [u] for preceding stop spectra, an opposite pattern from English listeners. The authors conjectured that since the experimental stimuli were modeled on Japanese speech, in which the [u] vowel has a higher F2 than [o], Japanese listeners showed compensation patterns according to the actual phonetic properties of the vowels. Without such knowledge, however, English listeners process the vowels at a phonological level, namely back [u] and front [o], and compensate more for [u].
Drawing on recent findings of the effect of linguistic experience on segmental compensation, the present study takes the inquiry to the domain of tone normalization. In particular, this study was designed to test Korean-speaking listeners with or without experience in Mandarin Chinese. Past research has reported a one-to-two L2-L1 category mapping of the Mandarin unaspirated stop by Korean-speaking learners of Mandarin Chinese (“learners”, hereafter) (Ko, 2000). Specifically, the L2 category split is conditioned by lexical tones such that the Mandarin unaspirated stops (with short VOTs) carried by Tone 2 (X35) and Tone 3 (X214) beginning with a low F0 are mapped onto Korean lenis stops (low F0, long VOT), ignoring the VOT mismatch. In contrast, those stops carried by Tone 1 (X51) and Tone 4 (X51) are mapped onto Korean fortis stops (high F0, short VOT). This observation was experimentally verified by Maeng and Kwon (2008) who showed that Korean learners shifted their perception from lenis to fortis as the onset F0 of the Mandarin unaspirated stops were manipulated from low to high (Maeng & Kwon, 2008). Korean listeners with little experience in Mandarin Chinese also responded systematically to the varying F0 values in the same direction, but the effect size was notably smaller compared to that of the learners (Lee-Kim, 2020). Taken together, the learners appear to give more weight to F0 but less weight to VOT as the mapping takes place predominantly along the F0 values. Intuitively, this could be attributed to the learners’ sensitivity to F0 cues acquired through extensive training in lexical tones in Mandarin Chinese. The results of the experiment will be further reviewed in the discussion in light of what may constitute linguistic experience.
However, it remains unclear whether Korean listeners would be influenced by extrinsic tone contexts to different degrees based on their language background. If context effects arise from a spontaneous and autonomous processing, the effect of context is not expected to differ depending on linguistic experience. Context-dependent contrastive tone perception would lead to lower onset F0 perception next to a high-F0 context, and vice versa, across both groups of Korean listeners. It follows that physically identical stop sounds may be perceived more often as fortis in the low-context but more often as lenis in the high-context. On the other hand, if context effects are, to some extent, constrained by the phonetic knowledge of relevant cues, learners with an increased sensitivity to F0 cues are expected to demonstrate stronger context effects. Finally, it remains to be seen how linguistic experience further interacts with varying conditioning factors of extrinsic tonal context such as directionality and intrinsic tone properties.
2 Method
2.1 Participants
Thirty-two native speakers of Seoul Korean participated in the perception experiments, including 17 experienced learners (15 female, 2 male) and 15 naïve listeners (9 female, 6 male). They were college or graduate students aged between 18 and 33. All participants had learned English in primary and/or secondary schools as part of their mandatory second language education in Korea. Some also had experience in various foreign languages (Japanese, French, Spanish, German) for periods ranging from a few months to six years.
The language history questionnaire provided by the learners indicated that the mean length of studying Mandarin Chinese was 5.9 years (SD = 2.8). Twelve learners reported that they had lived in mainland China through various study abroad programs from as short as one month to as long as a year. Many reported having taken the HSK (Chinese Proficiency Test); six had passed Level 6 (Advanced), and five had passed Levels 4 or 5 (Intermediate). All learners had taken multiple Mandarin Chinese language courses taught exclusively in Mandarin Chinese by native Chinese instructors at college in Korea. The naïve listeners, on the other hand, were Seoul Korean speakers who had no experience in any tonal second language, including Mandarin Chinese. None of the participants reported a history of speech or listening impairments. Participants were paid a small compensation for their time.
2.2 Stimuli
Experimental stimuli were created by digitally manipulating recordings of naturally produced Mandarin Chinese speech signals. Target stops were Mandarin unaspirated stops /p t/ characterized by short VOTs and being voiceless word-initially and medially (Liu, Tseng, & Tsao, 2000; Rochet & Fei, 1991). They appeared in nonce disyllabic words as either word-medial stops with a preceding context (e.g., /ma.
Extrinsic context tones were varied between two lexical tones in Mandarin Chinese: Tone 1 (X55, high-level) for the high tone context (e.g., /maHI.pa/) and Tone 3 (X21(4), low-dipping) for the low tone context (e.g., /maLO.pa/). Although Tone 3 is formally described as X214, a high F0 offset is seldom realized in running speech, and the contour is reduced to low (X21) before other tones than Tone 3 (Zhang & Lai, 2010). A slight rise in F0 was observed in the word-final position in the recordings, but it was not significant.
Intrinsic tone properties were tested by altering target syllables in two ways. First, the tone contour of the target stops was varied between level and rising. The level tone XLEV was modeled on Mandarin Chinese Tone 1, and the rising tone XRIS on Tone 2 (X35, mid-rising). The level contour was expected to elicit a greater reliance on the extrinsic tonal context than the rising contour due to its simple intrinsic F0 property.
Because the target contours were created based on physically different tokens, it is possible that some intrinsic properties associated with the Mandarin lexical tones may bias listeners toward hearing one stop category more often than the other. Among others, voice quality operationalized by H1-H2 is known to show systematic differences between lenis and fortis stops in Korean (Cho et al., 2002; Kang & Guion, 2008; Lee & Jongman, 2012). The lenis stops, as well as the aspirated stops in Korean, are associated with positive H1-H2 values arising from significant aspiration, while fortis stops often have negative H1-H2 values reflecting the constricted glottis during articulation. In Mandarin Chinese, Tone 1 and Tone 4 have negative H1-H2 values at the beginning of the vowel (-5~10 dB in normal speech), while T2 and T3 have positive values (5~0 dB) (Kuang, 2017). This suggests that the level tone contour based on Tone 1 may bias Korean listeners toward fortis stop perception, while the rising contour based on Tone 2 may trigger more lenis responses.
To address this potential issue, voice quality was analyzed for all the stimuli used in the experiment. The corrected H1-H2 values were measured using the STRAIGHT algorithm available in VoiceSauce (Kawahara et al., 1999). The values from the onset to the midpoint of the vowels are summarized in Figure 1. The results revealed higher H1-H2 values for Tone 1 as well as Tone 2, reflecting the talker’s generally breathy phonation. The positive H1-H2 values for the stimuli suggest the listeners’ stop judgments might overall be skewed toward lenis stops, but it is unlikely that the two contours, namely level or rising, would elicit a bias in an opposite direction. 2
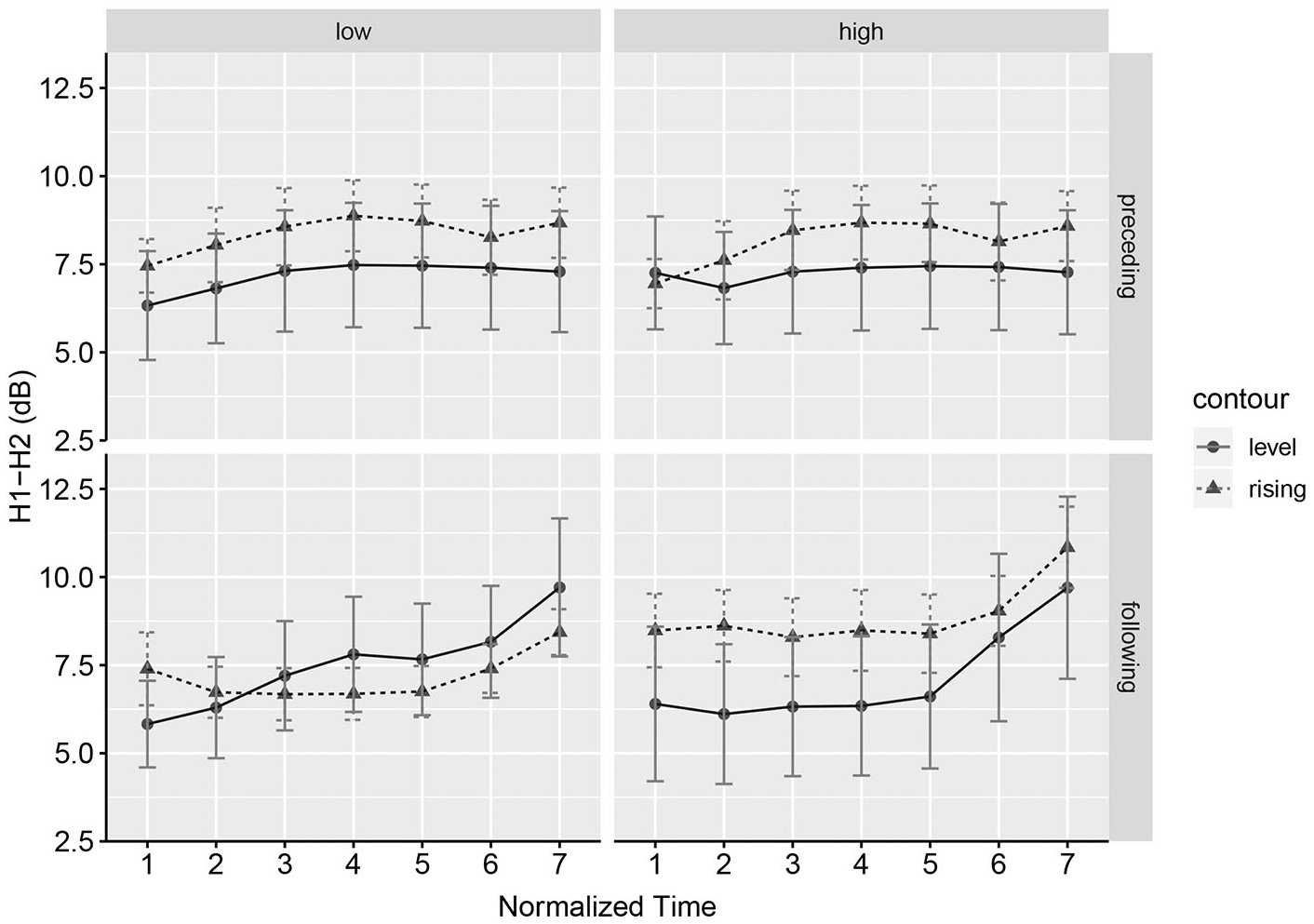
H1-H2 contours from vowel onset (Time 1) to vowel midpoint (Time 7) following the target stops /p t/. The values taken from the preceding context (i.e., /ma.
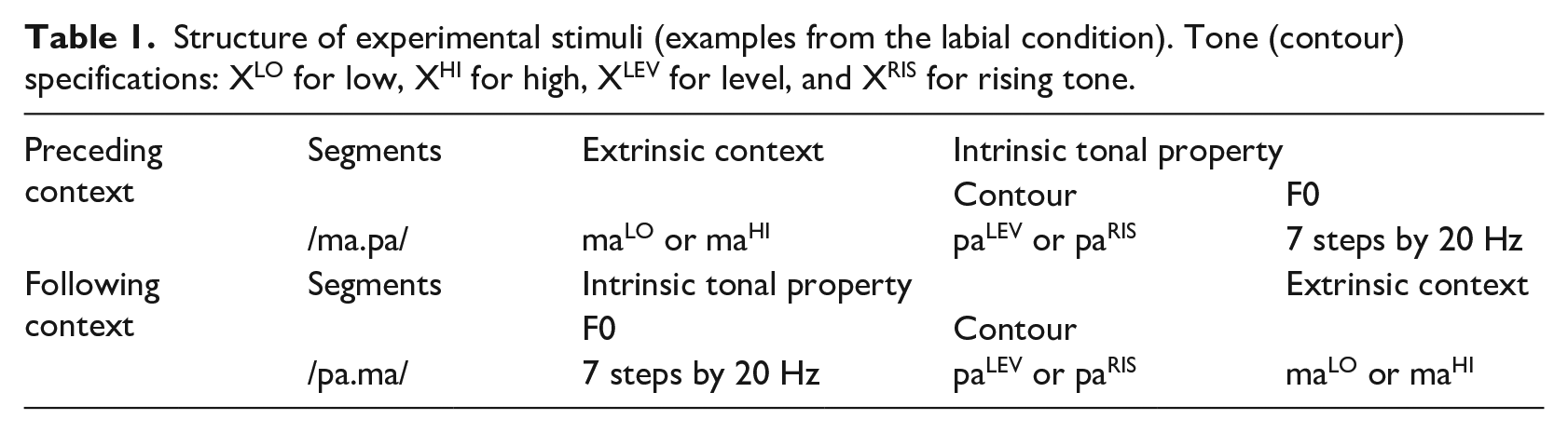
For the intrinsic tone properties, the target syllables were also varied in F0 at vowel onset by 20 Hz in seven steps. This particular F0 interval is comparable to the values adopted in previous studies (Kim, 2004; Lee et al., 2013; Schertz et al., 2015). The original tone contours, level or rising, were retained by raising or lowering the entire F0 contour so that the effects of F0 and tone contour could be assessed independently. This manipulation replicates a previous study which showed that an increase in F0 led to more fortis responses, with learners being significantly more sensitive to the F0 variable than naïve listeners (Lee-Kim, 2020). The addition of intrinsic F0 properties in this study was expected to contribute another piece of empirical evidence for learners’ greater sensitivity to F0 cues. Table 1 summarizes the structure of the experimental stimuli.
Structure of experimental stimuli (examples from the labial condition). Tone (contour) specifications: XLO for low, XHI for high, XLEV for level, and XRIS for rising tone.
The recordings were made by a female Mandarin native speaker aged 40 who was born and had lived in Beijing until she moved to Korea nine years prior to becoming an instructor of Mandarin Chinese. To guide the recording, Hanyu Pinyin (Chinese phonetic alphabets) along with Chinese characters were presented on a computer screen, whenever available, to ease the reading of semantically non-sense words (e.g., 妈拔 mā.bá [ma55.pa35]). All possible tone combinations were applied to a single segmental string, and the speaker repeated the list three times. The recordings were made in a sound-attenuated booth using a Zoom H4 recorder connected to a Shure SM58 microphone at a sampling rate of 22 kHz with 16-bit resolution.
For word-medial stops, two context syllables (e.g., ma55 vs. ma21) and two target syllables (e.g., pa55 vs. pa35) were chosen based on clarity and cut from the disyllabic words. They were then spliced together to create four baseline stimuli: maLOpaLEV, maHIpaLEV, maLOpaRIS, and maHIpaRIS in Praat 6.0.26 (Boersma & Weenink, 2017). In doing so, syllables with the same segmental and tonal specifications had the same physical properties. The same procedure was implemented for word-initial stops. Additionally, some minor manipulations were performed to control irrelevant phonetic cues. Vowel duration was manipulated to be 350 ms for both context and target syllables using the PSOLA synthesis function in Praat. Stop closure duration was set to be 90 ms, a value that could be ambiguous between lenis and fortis for Korean listeners (closure duration: M(fortis) = 140 ms vs. M(lenis) = 56 ms (Han, 1996); see Silva (1992) for similar values). RMS intensity was first normalized for entire words using a Praat script, and then the maximum intensity of the target vowel was further manipulated to be 65 dB for all baseline words.
The pitch range and contour were slightly manipulated for the two context tones. For the high tone context, the F0 value from the midpoint of the vowel to the part closer to the targets was flattened to be 280 Hz using the pitch synchronous overlap and add (PSOLA) algorithm in Praat due to a small F0 fluctuation in the original token. The particular F0 values for the stimuli used in this study were chosen based on the natural pitch range of the talker. The F0 of the disyllabic words produced by the talker was as high as 360 Hz at the onset of high-falling Tone 4 and as low as 150 Hz at the onset of mid-rising Tone 2. Given this F0 range, caution was taken during digital manipulation to ensure the resulting stimuli would sound natural. For example, 280 Hz was chosen for high context tone so that the offset of the rising target tone would fall within the talker’s natural F0 range (280 Hz (onset F0) + 80 Hz (the extent of F0 rise) = 360 Hz (offset F0)) (Figure 4, right). Also, the lowering of F0 to 160 Hz for the target level tone did not introduce any distortion to the signal (Figure 4, left).
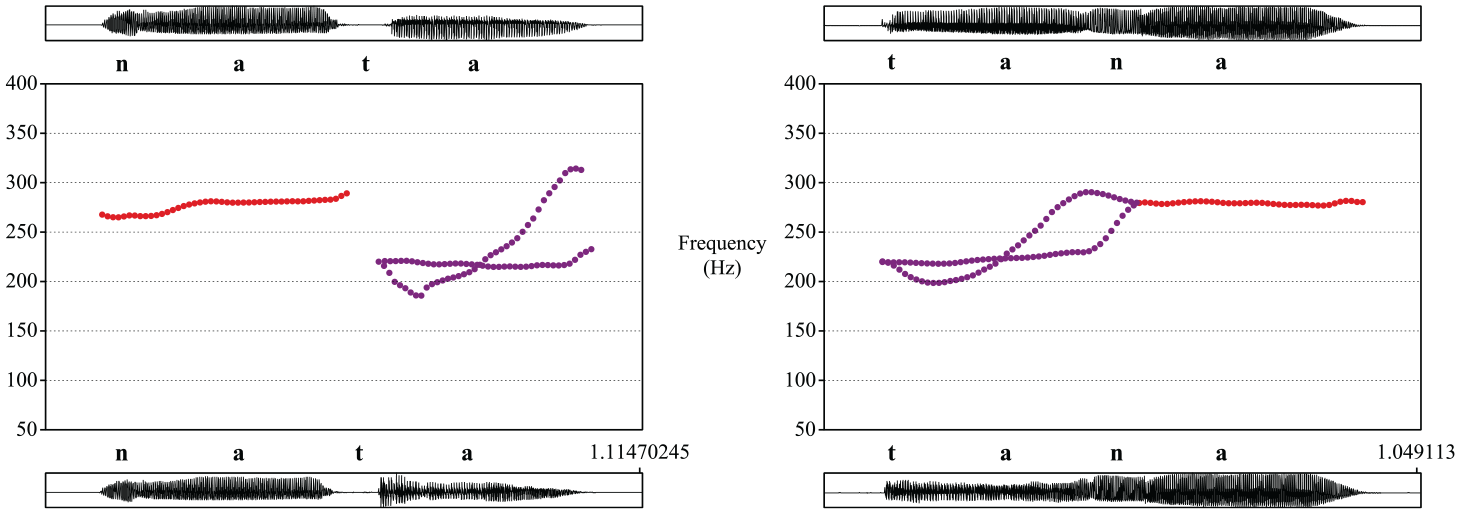
For the low tone context, the shape of the Mandarin Tone 3 contour differed based on word position: low(-falling) word-initially (Figure 2, left, blue line) and low-dipping word-finally (Figure 2, right, blue line). Nevertheless, no further manipulations were made of the Tone 3 F0 contour because the low F0 in the middle caused the signal to become creaky (Belotel-Grenié & Grenié, 1994; Chao, 1956; Kuang, 2017). The significant F0 dipping of the word-final low tone enhanced the physical distance from the corresponding high tone, and therefore a context effect, if any, should be greater for the following context. On the contrary, the results showed the opposite, and this variation in Tone 3 seemed to contribute little to the listeners’ interpretation of extrinsic context. Besides, the vowel offset of the word-initial low tone and vowel onset of the word-final low tone were set to be around 150 to 160 Hz. The F0 contour of the medial nasals was interpolated between the F0 of the offset of the first vowel and that of the second vowel’s onset.

Examples of context tones (i.e., low (blue line) vs. high (red line)), for a target stop with a mid-level F0 contour. Waveforms of word-medial stops [maHI.pa] (top) and [maLO.pa] (bottom) with a preceding context (left) and those of word-initial stops [pa.maHI] (top) and [pa.maLO] (bottom) with a following context (right).
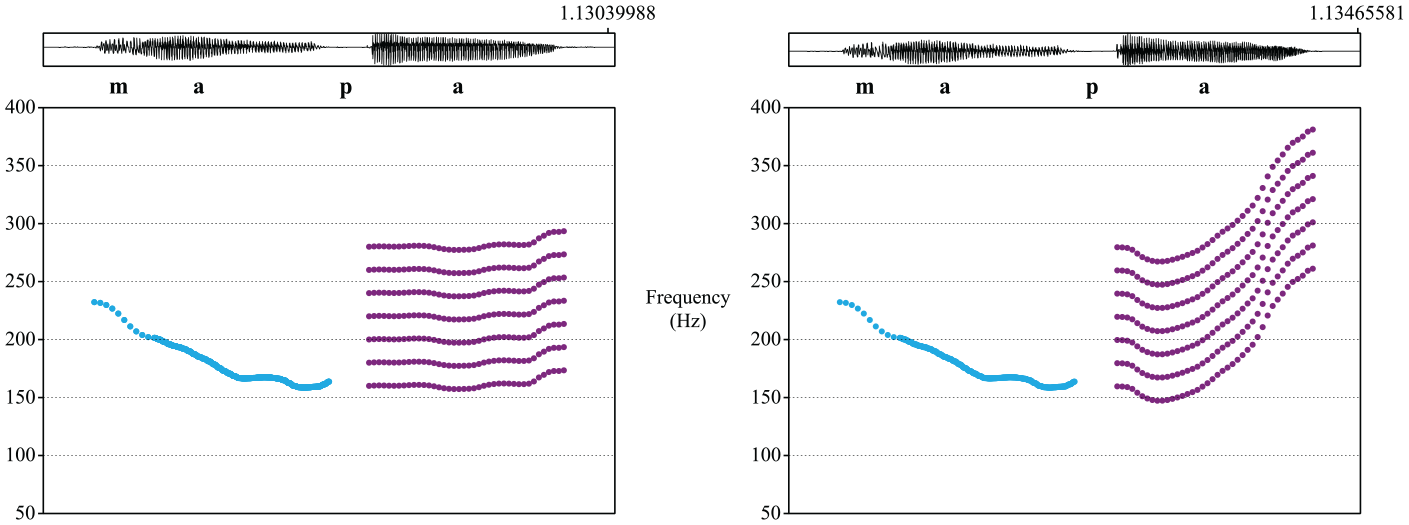
Next, the syllable containing target stops carried either a level or a rising tone (Figure 3). The F0 offset of the rising tone was higher than its onset F0 by around 80 Hz. There was no a priori assumption about how much rise in F0 would be sufficient for the F0 trajectory to be perceived as a rising contour. This particular value was chosen because it created an unambiguously salient rising tone and digital manipulation did not create unnatural sounding tokens given the talker’s natural F0 range.
Examples of target tone contours in the high tone context (red line) and waveforms: level (purple line, corresponding waveforms on the top) versus rising (purple line, corresponding waveforms on the bottom), for word-medial (left) and word-initial stops (right) both in a high preceding and following context, respectively.
Lastly, the F0 values were raised or lowered by 20 Hz using the PSOLA function in Praat, resulting in seven different target syllables with F0 ranging from 160 to 280 Hz (Figure 4). The F0 endpoint of the rising tone was as high as 360 Hz which sounded natural given the speaker’s wide F0 range.
Examples of the F0 manipulation of the stimuli for word-medial stops [maLO.
2.3 Procedure
Participants were tested in two separate sessions, one for word-medial stops and the other for word-initial stops, with at least a five-day span between sessions. The order of the experiment was randomized between participants. Experiments were carried out in a quiet classroom or in a sound-attenuated booth at the Phonetics Laboratories at Seoul National University using AKG-K240 MKII headphones connected to ACER Swift 5 laptop computers.
Each block contained a randomized set of 56 stimuli with all combinations of the experimental variables, 2 Contexts (High vs. Low) * 2 Contours (Level vs. Rising) * 7 F0 steps * 2 Place of Articulations [POAs] (Labial vs. Coronal). In the experiment session, the block was repeated five times with randomization of stimuli each time. The participants took part in two-alternatives forced-choice (2-AFC) identification tasks run in ePrime. In each trial, a fixation mark appeared in the center of the screen while a nonce word was played. After the sound was completed, two numbered words in Korean orthography were vertically presented on the screen, for example, 1. 마바 ([ma
As an anecdote, many learners reported in their post-experiment briefing that they did not recognize the source language of the stimuli and expressed surprise when informed that the language materials were based on Mandarin Chinese. This is presumably because the stimuli carried quite distinct tonal patterns from Mandarin Chinese after substantial digital manipulation. This suggests that the learners, as well as naïve Korean listeners, have treated the stimuli as unknown novel sounds and participants have utilized their sensitivity to individual phonetic cues maximally to give coherent judgments of stop categories. This is considered to be positive for the purpose of the present study because the learners were unlikely to have benefitted from familiar sounds, if any.
3 Results
Response time (RT) data were not analyzed in this study, but participants’ responses were fast overall: mean RTs were 439 ms (SD = 398) and 431 ms (SD = 426) for word-medial stops and word-initial stops, respectively. Missing responses were extremely rare; three participants missed one response each for word-medial stops, and another three participants missed up to three responses each for word-initial stops.
To analyze the results of the binary responses, a mixed-effects logistic regression model was fitted to the data using the glmer function in the lme4 package (Bates & Maechler, 2015) in R v.3.2.2 (R Development Core Team, 2016). Two separate models were fitted to the data for word-medial and word-initial stops. The dependent variable was the participants’ judgment of the stop stimuli as fortis (coded as “1”) or as lenis (coded as “0”). Each model included fixed effects for CONTEXT (2 levels: High = -1 vs. Low = 1), CONTOUR (2 levels: Level = -1 vs. Rising = 1), F0STEP (7 levels: -3, -2, -1, 0, 1, 2, 3, reflecting the seven-step F0 continuum) and L2EXP (2 levels: Naïve = -1 vs. Learners = 1). All categorical variables were contrast coded manually so that the weight of each level summed to 0 (Davis, 2010). Both models included random intercepts for SUBJECT and POA (place of articulation of the target consonants: labial vs. coronal) as well as by-subject random slopes for CONTEXT and CONTOUR.
Along with those main effects, critical interaction terms were also included in the statistical model. First, a three-way interaction was included between CONTEXT, CONTOUR, and L2EXP. The primary variable of the experiment, CONTEXT, aimed to test whether the neighboring tone would have a contrastive effect on stop perception. However, the degree to which this context effect is borne out may be dependent on the intrinsic tonal properties of the target stops (i.e., the level or rising contours). The interaction between CONTEXT and CONTOUR, therefore, will help establish a potential interaction between extrinsic and intrinsic tonal properties on stop perception. These variables may be further modulated by linguistic experience, however. The two groups of Korean listeners may show differential patterns regarding the interaction of the two factors; if so, this will be demonstrated by significant three-way interactions. An interaction between F0STEP and L2EXP was also considered. Target stops beginning with higher F0 values have been reported to elicit more fortis responses. A significant F0STEP-L2EXP interaction would indicate that linguistic experience may lead Korean listeners to use F0 cues differently in stop identification. There was no a priori prediction that F0 would interact with other predictors, and only the two-way interaction was included in the model.
3.1 Perception of word-medial stops with preceding low/high tone context
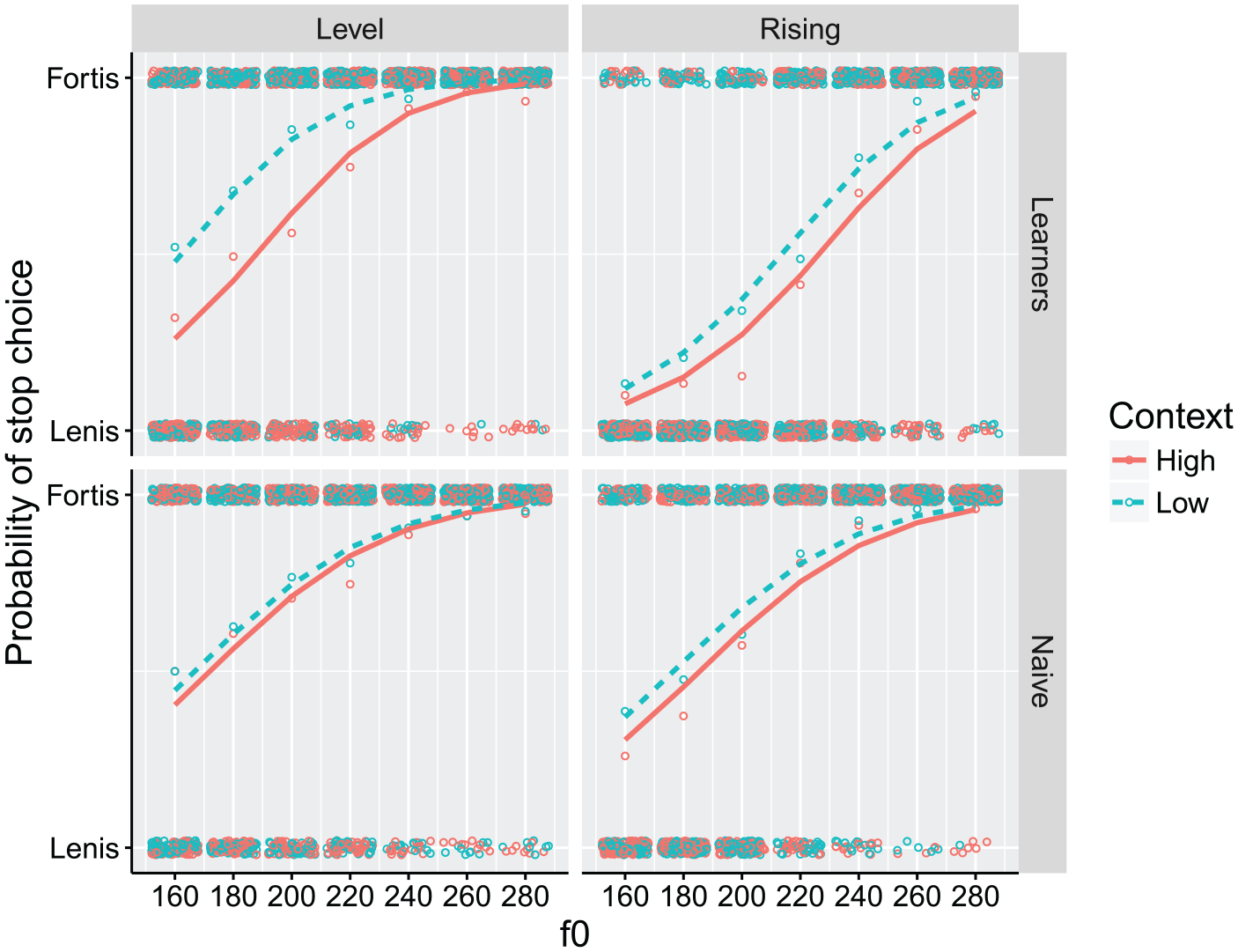
Figure 5 plots predicted response curves drawn from the regression model and actual mean data (circles) for stop judgments as a function of F0 and preceding tone contexts. The data are plotted separately for contour types and for language experience. A summary of the logistic statistical analysis is presented in Table 2.

Predicted logit curves and actual mean values (circles) for the identification of word-medial stops /ma.
Summary of the mixed-effects logistic regression model predicting word-medial stop perception (fortis: 1, lenis: 0) with preceding context. Formula: fortis choice ~ CONTEXT*CONTOUR* L2EXP + F0STEP*L2EXP + (1+CONTEXT+CONTOUR|SUBJECT) + (1|PoA), family = “binomial”. Significant results are highlighted in bold.
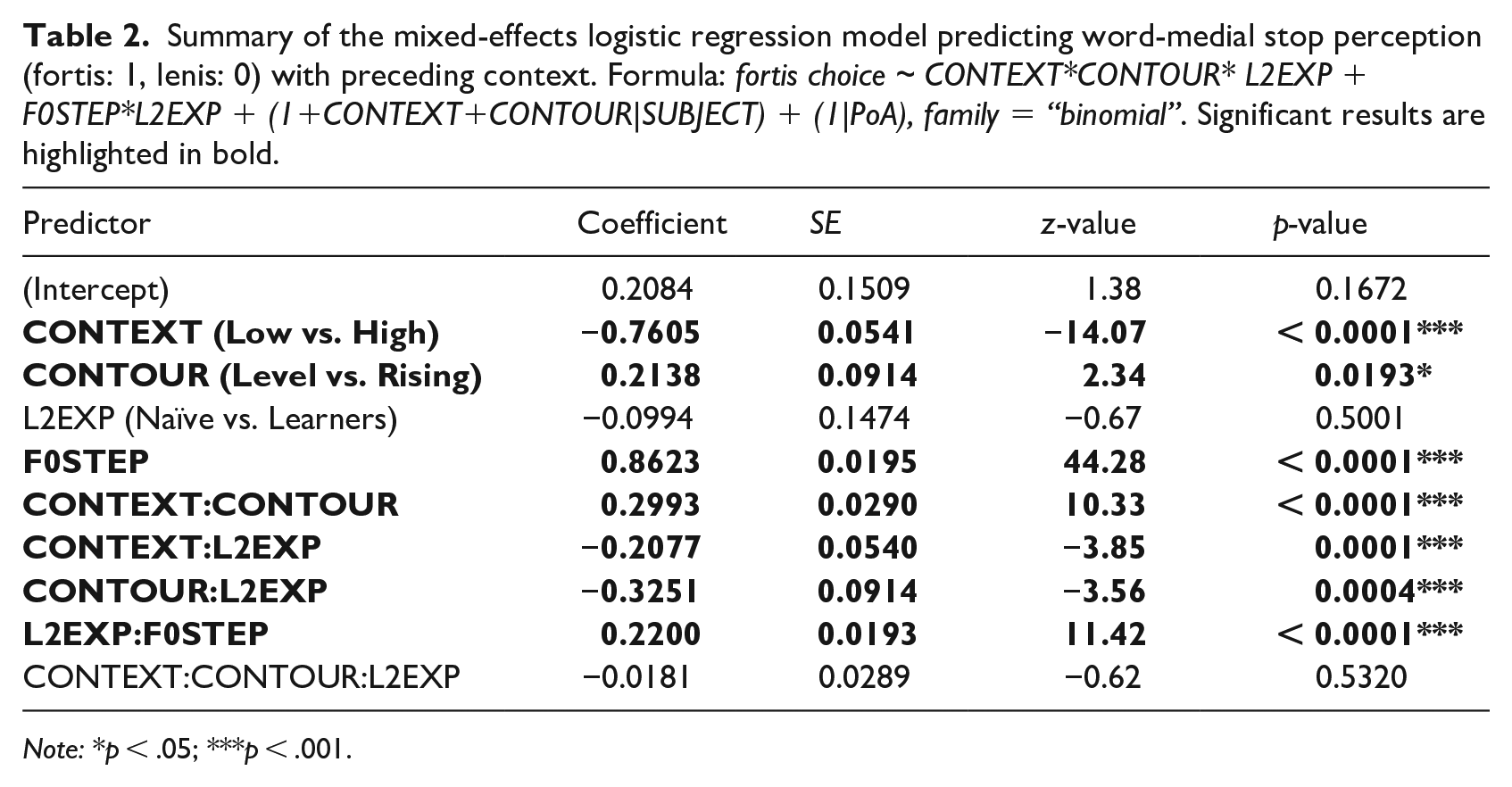
Note: *p < .05; ***p < .001.
Overall, participants’ responses were distributed quite evenly between lenis and fortis judgments for word-medial stops, fortis responses: M (naïve) = 55% vs. M (learners) = 51%. This is in contrast with the results of word-initial stop perception (discussed below) which demonstrated a preference for fortis responses in both groups. This asymmetry seems to be attributed to the differences in primary phonetic cues for stops in different word positions. While short VOTs trigger a strong fortis bias in a word-initial position (Kim, 2004; Lee et al., 2013), other phonetic cues such as closure duration emerge as salient cues in a word-medial position (Han, 1996; Silva, 1992). The particular design of this experiment, namely closure duration set to be neutral, seems to have made both choices, lenis versus fortis, equally likely.
The predictor CONTEXT was motivated to evaluate the effect of extrinsic context on stop perception. The analysis showed that fortis judgments were made significantly more often when stop stimuli appeared in the low (64%) than in the high tone context (42%). In Figure 5, the diverging curves in blue dashed and red solid (low and high tone context, respectively) and their relative positioning, namely low-context curves being placed consistently above high-context curves across all conditions, clearly reflect this tendency. This finding confirms the general contrastive effect of neighboring tone on stop perception: when following a low tone context, the F0 at the vowel onset is perceived as higher, providing positive evidence for a fortis stop. In contrast, when following a high tone context, a physically identical stop stimulus is more often perceived as lenis due to the perceptual lowering of the onset F0. In particular, the large deviation between the curves even for the naïve listeners with no prior training in tone languages clearly demonstrates the pervasiveness of the contrastive nature of speech processing.
However, that is not to say that the context effect is not modulated by one’s linguistic experience, as shown by the significant CONTEXT-L2EXP interaction. This is illustrated by Figure 5 (right), in particular, in which the two curves representing different contexts deviate to a greater degree for the learners than for naïve listeners. The data confirms this trend: overall, there is a greater difference between the fortis judgements made by the learners (63% in low tone context; 40% in high tone context) than between those made by the naïve listeners (64% in low tone context; 46% in high tone context). This result highlights the role of linguistic experience in auditory processing such that the generally autonomous contrastive tone perception could be further strengthened by linguistic training in relevant phonetic cues.
The CONTEXT-CONTOUR interaction also reached statistical significance, indicating an interplay between extrinsic and intrinsic tone properties. The hypothesis was that the reliance on the extrinsic context of a syllable carrying a rising contour would be smaller due to its dynamic intrinsic F0 property. A simple level tone contour, in contrast, was hypothesized to elicit greater reliance on the extrinsic context. From Figure 5, it is apparent that the deviation of the curves is much larger in the level contour (left) than in the rising contour (right). In the level contour, the average fortis judgments was 64% in the low tone context versus 35% in the high tone context, but such a big difference was not observed for the rising tone condition (63% in the low tone context vs. 51% in the high tone context). However, this pattern is shown to be independent of linguistic experience as evidenced by the lack of a three-way interaction CONTEXT-CONTOUR-L2EXP.
Next, F0STEP, another intrinsic tonal property, elicited strong veridical responses: listeners made significantly more fortis responses as the F0 of the stimuli increased. This effect is clearly shown in positive slopes in all panels in Figure 5. This variable encodes differences in F0 values that varied from low to high on a seven-step scale. High F0 values at the vowel onset are well-established acoustic features of fortis stops in Korean, whereas low onset F0 values signal lenis stops (e.g., Cho et al., 2002; Kagaya, 1974), and this distribution of phonetic cues in the listeners’ native language was actively used to interpret the experimental stimuli. This effect is quite robust and is a consistent finding across studies (Lee-Kim, 2020).
The effect of intrinsic tonal properties is, again, shown to be enhanced by linguistic experience as indicated by the significant interaction between F0STEP and L2EXP. As evident in Figure 5, the slopes of the curves are different between the two groups of participants; those in the upper panels (learners) demonstrate steeper slopes than those in the bottom panels (naïve), which suggests a stronger effect of F0 for the stop judgment for the learners than for the naïve listeners. Along with the findings of extrinsic context, this result showed that the learners’ sensitivity to F0 cues broadly influences how tonal properties of the speech signal are interpreted and facilitate coherent stop perception.
3.2 Perception of word-initial stops with the following low/high tone context
Figure 6 plots predicted response curves along with actual mean data. The results of the logistic regression analysis are summarized in Table 3.
Predicted logit curves and actual mean values (circles) for the identification of word-initial stops /
Summary of the mixed-effects logistic regression model predicting word-initial stop perception (fortis: 1, lenis: 0) with following context. Formula: fortis choice ~ CONTEXT*CONTOUR* L2EXP + F0STEP*L2EXP + (1+CONTEXT+CONTOUR|SUBJECT) + (1|PoA), family = “binomial”. Significant results are highlighted in bold.
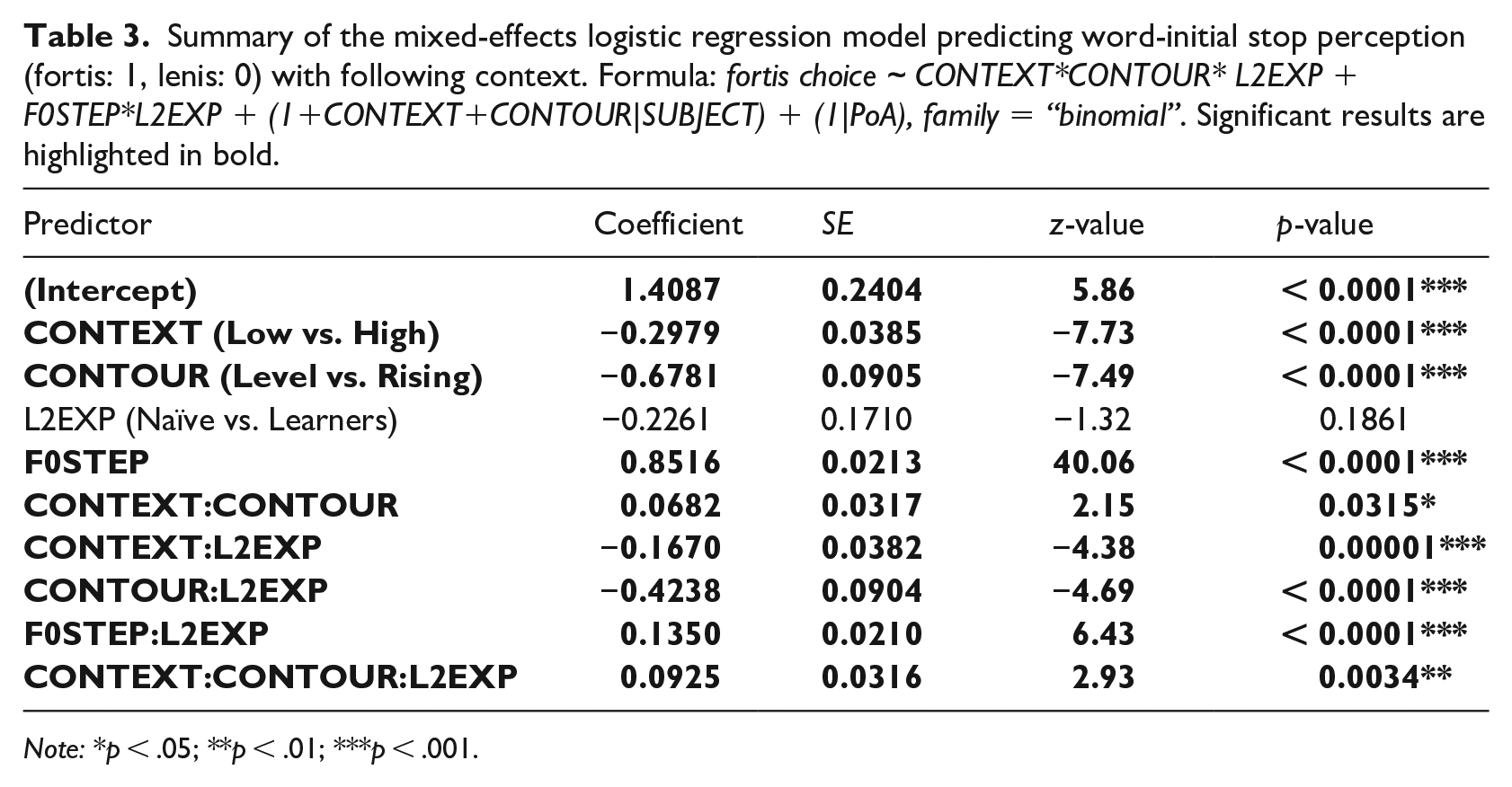
Note: *p < .05; **p < .01; ***p < .001.
For word-initial stops, listeners gave more fortis than lenis responses (fortis responses: M (naïve) = 75% vs. M (learners) = 64%). As opposed to the responses for word-medial stops which were evenly distributed between fortis and lenis, those for word-initial stops are biased toward fortis stops. Given the similarity in VOT between Korean fortis and Mandarin unaspirated stops, the listeners’ fortis bias seems to stem from the heavy perceptual weight given to VOT for word-initial stops (e.g., Kim, 2004; Lee et al., 2013). Despite the bias for the fortis perception in word-initial position, however, the separation of the curves informed by extrinsic context is still observed, albeit to a smaller degree.
Despite small deviations between context curves in Figure 6, the main effect of CONTEXT, as well as its interaction with L2EXP, reached statistical significance in the same direction: overall listeners gave more fortis responses in the low tone context (73%) than in the high tone context (66%), but this propensity was more clearly pronounced for the learners than for the naïve listeners. In Figure 6, the curves from the low tone context (blue dashed) are generally above those from the high tone context (red solid), and comparatively greater deviations are observed in the learners’ responses. This result confirms that extrinsic context effects are contrastive in both directions: both preceding and following tone contexts elicit contrastive effects.
While the CONTEXT-CONTOUR interaction also reached statistical significance in the same direction, the level of statistical significance was much smaller in the following context, p = 0.0314, compared to the preceding context, p < 0.0001. This was also reflected in the magnitude of coefficient values drawn from the two models, β (following) = -0.0682 versus β (preceding) = -0.2993. Furthermore, Figure 6 reveals that the level tone’s greater reliance on extrinsic context is observed for the learners, but such a trend is absent for the naïve listeners. This is reflected in the significant three-way interaction CONTEXT-CONTOUR-L2EXP. In order to ascertain the source of this interaction, separate logistic regressions were performed, one for the learners and the other for the naïve listeners. The predictor L2EXP was removed from the statistical model, while the structure of fixed and random effects remained the same. Focusing on the CONTEXT-CONTOUR interaction, the learners’ data revealed a significant interaction effect, β = -0.1561, SE = 0.0453, p < 0.001, but those of naïve listeners did not, β = 0.0323, SE = 0.0417, p = 0.439. Taken together, the results indicate that the magnitude of the overall context effect is much smaller for word-initial stop perception to the degree that the contour-based asymmetry is no longer observed for the naïve listeners. Nevertheless, the learners consistently showed an asymmetry in the same direction with word-medial stop perception, albeit to a smaller degree.
Next, as in word-medial stop perception, F0STEP was a significant predictor for the initial stops—the higher the F0, the more fortis responses. Unlike the CONTEXT predictor, F0 in the following context was as strong a predictor as in the preceding context, β (preceding) = 0.8623 versus β (following) = 0.8516. This pattern was again more strongly pronounced for the learners than for the naïve listeners as shown in the significant F0STEP-L2EXP interaction as in the steeper slopes in Figure 6, regardless of contour type. Along with the greater extrinsic context effects for the learners, their greater sensitivity to the intrinsic tonal properties, once again, provides supporting evidence for their general sensitivity to F0 cues and its broad application to stop perception.
One peculiarity of the results of this experiment is that the effect of CONTOUR was particularly strong, β = -0.6781, compared to 0.2138 for the preceding context; listeners gave significantly more fortis responses in the level (77%) than in the rising contour (61%) condition. Further, the significant CONTOUR-L2EXP interaction indicates that this tendency was more prominent for the learners than for the naïve listeners. From Figure 6, it can be observed that this contour-dependent asymmetry can be attributed to the significantly more lenis judgments especially in the initial portion of the response curves for the rising contour condition. Some conjectures about the source of this pattern are provided in the discussion section.
3.3 Comparison of effect sizes between preceding and following context
The deviation of the context curves is noticeably larger in the preceding (Figure 5) than in the following context (Figure 6). This is also, in part, hinted at by the large difference in the coefficient values of CONTEXT in the two regression models, β (preceding) = 0.7605 versus β (following) = 0.2979. In order to verify the observation more directly, this section reorganizes the results of the two experiments by computing the differences of proportion of fortis responses in the high and low tone contexts. The computation was performed on each individual speaker, and their distribution is presented in Figure 7. For objective assessments, a mixed-effect regression model was fitted against proportion differences of fortis responses with DIRECTION (2 levels: Preceding = 1 vs. Following = -1), CONTOUR (2 levels: Level = -1 vs. Rising = 1), L2EXP (2 levels: Naïve = -1 vs. Learners = 1), and their interaction as fixed effects. The model also included random intercept for SUBJECT and by-subject random slopes for DIRECTION and CONTOUR. The results of the statistical analysis are summarized in Table 4.
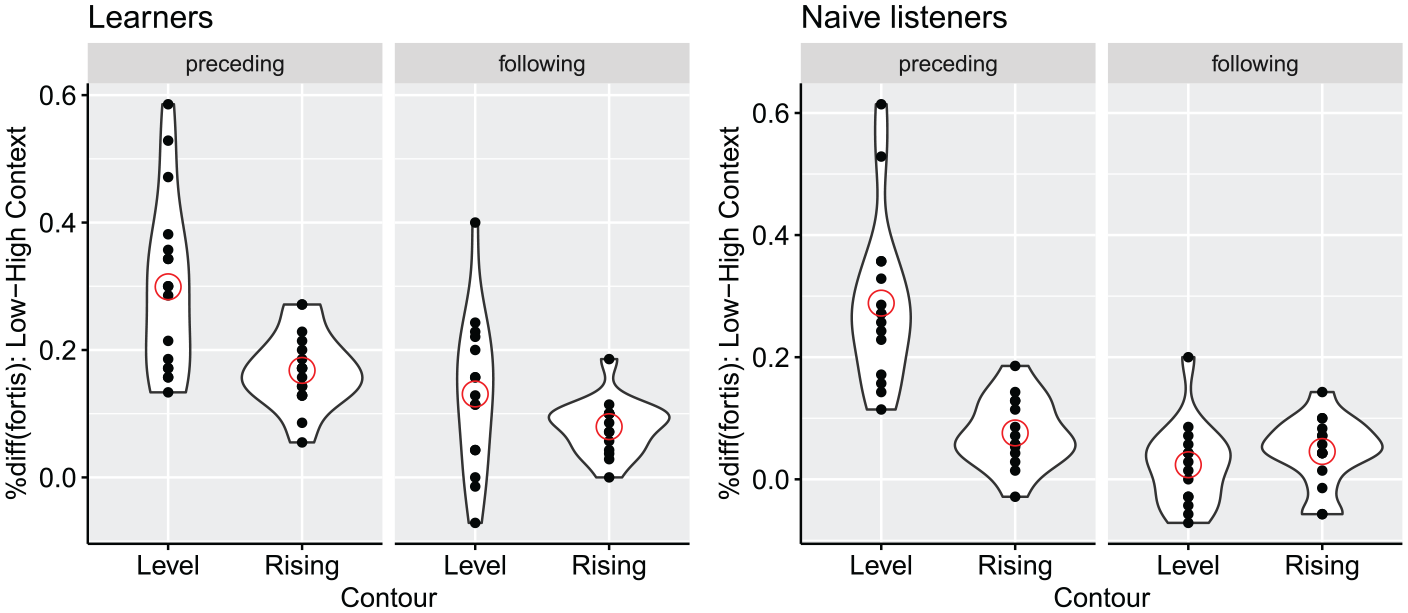
Violin plots of the size of context effects in preceding and following context further divided by tone contour. Individual speakers’ data are represented by small filled circles and the mean values are indicated by red outlined circles.
Summary of the mixed-effects regression model predicting effect sizes of extrinsic tonal context. Formula: %Difference ~ DIRECTION *CONTOUR*L2EXP + (1+ DIRECTION +CONTOUR | SUBJECT). Significant results are highlighted in bold.
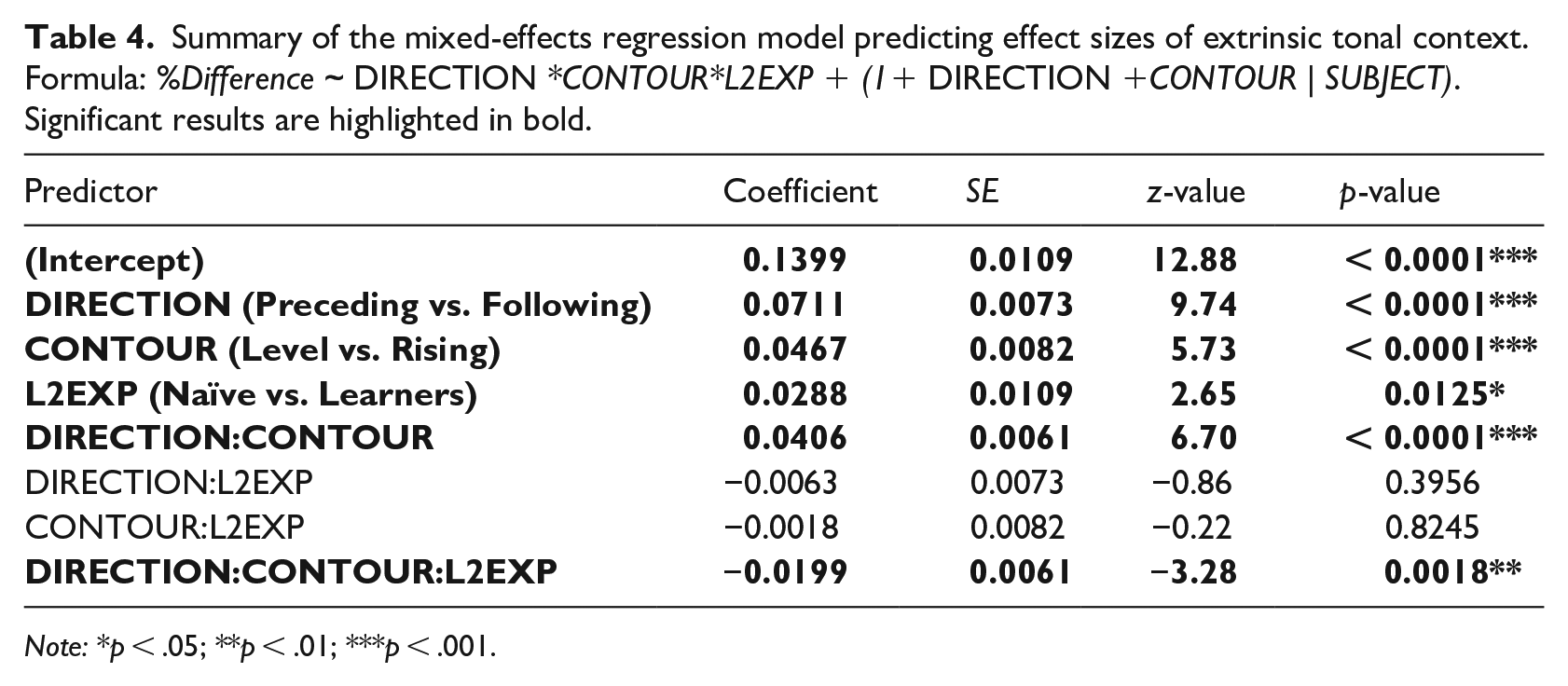
Note: *p < .05; **p < .01; ***p < .001.
Most importantly, DIRECTION was a significant predictor (β = 0.0711, SE = 0.0073, p < 0.0001), confirming that the context effect was greater for the preceding than for the following context. This pattern held true regardless of linguistic experience, as indicated by the non-significant DIRECTION-L2EXP interaction, β = -0.0063, SE = 0.0073, p = 0.3956.
In addition, CONTOUR was shown to be a significant predictor for the magnitude of context effects, confirming the finding that level contours tended to elicit greater reliance on extrinsic tonal context than rising contours did. This pattern was comparable between the two groups of listeners as shown by the non-significant interaction between CONTOUR and L2EXP. However, when DIRECTION was taken into account, this general tendency diminished; for the learners, level contours elicited greater extrinsic context effects than did rising contours for both directions; however, this pattern was only observed for the preceding context for the naïve listeners. This complex interplay was reflected in the significant three-way interaction for DIRECTION-CONTOUR-L2EXP, β = -0.0199, SE = 0.0061, p = 0.0018.
4 Discussion
The literature on context effects has centered on two distinct phenomena: tone normalization and compensation for segmental coarticulation. The former has focused on the suprasegmental contrast in lexical tone processing, while the latter has delved into perceptual contrasts in segmental distinctions. Drawing on the recent findings from the two lines of studies, the present study explored a case where a contrastive effect of neighboring tones may be further integrated to give rise to a systematic asymmetry in stop perception. In two experiments varying the direction of context, the target stops which varied between level and rising contours were located next to either high or low context tones. Robust contrast effects of extrinsic context were found for both directions such that participants gave more lenis responses in the high tone context and more fortis responses in the low tone context, regardless of linguistic experience. The results were in part in accordance with the characteristics of tone normalization in that both directions of context elicited contrastive effects. However, unlike previous studies, the effect of preceding tone context was much stronger than the following one, suggesting that the laryngeal stop distinctions are not entirely accounted for solely by the principles of tone normalization. Further, there was a clear interaction between contour and context, suggesting that listeners relied less on extrinsic tonal properties when the target carried a rising tone with dynamic intrinsic F0 characteristics. Interestingly, naïve listeners without prior exposure to tone languages and experienced learners patterned similarly, indicating that the context effects arise, by and large, independent of linguistic experience. Below, details of the findings are discussed in depth along with their implications for the theories of context effects in speech perception.
4.1 Directionality and the size of context effects
Previous studies on tone normalization have reported consistent and robust contrast effects of neighboring tones from both directions; segmental contrasts, on the other hand, have been found to be direction-sensitive—only the preceding context consistently triggers contrastive perception (Rysling et al., 2019; Sjerps et al., 2018). The key to the qualitative difference may reside in the differential temporal window of processing. The processing of tone may take place with some delay, enabling the incorporation of information from the following as well as the preceding context (Cutler & Chen, 1997), while segmental processing is relatively instantaneous, perhaps with some influence from the preceding context.
The present study testing segmental distinctions stemming from extrinsic tonal context presents a rather unique case in that while principles of tone normalization predict bidirectional contrast effects, the ultimate decision needs to be made over a segment which may be direction-sensitive. The results were unambiguous: both directions yielded clear contrast effects consistent with the characteristics of tone normalization. This result suggests that the segmental decision is, to some extent, open to the information from the following context as well. The assimilatory effect of following segments (e.g., more /e/ perception before /t/ than before /p/) reported by Rysling et al. (2019), in fact, indicates that segmental perception takes place through an integration of the preceding context as well as the immediately following context.
Nevertheless, the results are not entirely consistent with the findings of previous tone normalization studies, though some conditioning effects from the segmental status of the target sound are still observed. While a larger effect of the following context than the preceding one has been reported (Francis et al., 2006; Sjerps et al., 2018; Wong & Diehl, 2003), the results of the present study revealed the opposite trend. As Figures 5 and 6 show, the response curves diverge to a greater degree for the preceding than for the following context, which was confirmed by the statistical analysis on the size of context effects (Figure 7). Although the following tone context has been incorporated into initial stop perception, the effect is minimal, presumably due to the relative insignificance of the following context for the segmental decision.
In addition, the position-dependent cue distribution of Korean stops might be another contributing factor to the observed asymmetry. Previous perception studies have shown that Korean listeners identify word-initial stop stimuli with short VOTs as fortis regardless of onset F0 values (Kim, 2004; Lee et al., 2013). Given the short VOTs of the stimuli used in this experiment, the perception of initial stops is likely to be biased toward fortis stops. This is, in fact, reflected in Figure 6 in which the response curves have an upward trend (toward more fortis judgments) compared to those in Figure 5. This is in part reflected in the mean statistics of fortis responses: M(medial) = 53% versus M(initial) = 70%. With a strong fortis bias for initial stops, listeners are less likely to choose lenis stops unless other cues have overridden the bias. In contrast, VOT is demoted in the word-medial position as closure duration emerges as the primary cue for stop distinction. In the present study, closure duration was set to a neutral value in order to minimize the effect of irrelevant phonetic cues for stop perception. With the demotion of VOT cues and the neutral closure duration, the medial position might have been more susceptible to the influence of the extrinsic tonal context for stop perception.
It is not possible to assess the independent contribution of the above two factors to the directional asymmetry. However, it is likely that the asymmetry resulted from a combinatory effect of the two. Due to the nature of segmental processing, the following context is likely to be less influential than the preceding one. Focusing more on the intrinsic segmental features then, the short VOTs, a salient phonetic cue for fortis stops in an initial position, may have driven the strong bias toward fortis perception and hence smaller extrinsic effects.
4.2 Interplay between extrinsic and intrinsic tones
The results of the present study have confirmed an unambiguous effect of intrinsic tone contour on the degree of contextual tone effects. The reliance on extrinsic context was considerably larger for the level than for the rising tone as indicated by the larger divergence between response curves in the level tone condition (Figure 5). This held true for the following context, at least in the case of the learners; despite small context effects, the contour-asymmetry was still consistently observed. This is in line with previous findings that perception of contour tones indeed relies on extrinsic context as well (Huang & Holt, 2009; Moore & Jongman, 1997). However, this study confirmed the intuition, straightforward but yet to be verified, that extrinsic properties are not as essential for contour tone processing, presumably due to their rich and dynamic intrinsic F0 representation. Still, it is important to note that this and other studies have taken rising contours to represent the entire class of contour tones, but it is crucial to test other contours (e.g., falling contours) to obtain further empirical support.
One may wonder whether the contour-driven asymmetry in the context effect results from the acoustic characteristics of the stops in L1 Korean. That is, Korean lenis stops are associated with a low F0 at the vowel onset, and fortis stops with a high F0 (Cho et al., 2002; Cho & Keating, 2001; Kagaya, 1974), which might have biased stop judgments toward lenis for rising contours and fortis for level contours. However, the empirical findings in this study contradict this possibility. Focusing on the preceding context, as in previous studies (Huang & Holt, 2009; Moore & Jongman, 1997), the two groups of listeners in this study behaved differently with respect to contour shape: learners tended to make more lenis judgments for rising contours, while naïve listeners favored fortis in the same condition (Figure 5). This is, in fact, reflected in the statistical results in Table 2 wherein the interaction CONTOUR-L2EXP was shown to be significant, β = -0.3251, SE = 0.0914, p = 0.0004. This indicates that contour shape did not particularly bias Korean listeners’ judgments in one way or the other. Therefore, the fact that the level contour elicited significantly larger context effects than the rising contour suggests that the context sensitivity modulated by intrinsic contour is likely a genuine perceptual bias.
While the preference for lenis judgements when the stops were carried by rising contours was not consistently observed for the naïve listeners, learners tended to be consistent across the two directions of contexts. This tendency was slight in the preceding context (Figure 5) and more clearly pronounced in the following context (Figure 6). One possibility is that the stimuli created based on physically different base tokens may have carried distinct voice quality. In Mandarin, Tone 1 (high-level) is typically associated with low H1-H2, while Tone 2 (mid-rising) with high H1-H2 (Kuang, 2017). On the other hand, Korean lenis stops are characterized by high H1-H2 and fortis stops by low H1-H2 (Cho et al., 2002; Lee & Jongman, 2012). Taken together, it is plausible that level contours modeled on Mandarin Tone 1 may have biased responses toward fortis perception, while rising contours modeled on Mandarin Tone 2 biased listeners toward lenis perception. However, this scenario does not hold given the acoustic properties of the stimuli used in the experiment. First, focusing on the learners’ performance in the following context condition (upper panel in Figure 6), a clear preference for lenis stops in the rising contour was observed when the extrinsic context tone was low (blue dashed lines), even though H1-H2 values of the target tones were not significantly different (bottom left panel in Figure 1). Second, rising contours indeed had significantly higher H1-H2 values than level contours when the extrinsic context tone was high (bottom right panel in Figure 1), but the separation of the two response curves (red solid lines) was not as large as that in the other condition. The voice quality in the experimental stimuli, therefore, cannot account for the connection between contour shape and stop judgments by the learners.
Rather, the rising tone contour itself may have induced a perceptual contrast such that the initial portion of the F0 frequency may have been perceived as even lower, providing positive evidence for lenis stops, due to the contrast with the subsequent high F0 frequency. In a study of tone normalization, Zhang, Ding, and Lee (2018) found that a rising tone with the same offset F0 as a level tone elicited significantly more low tone perception for the following target syllable. The authors conjectured that the offset of the rising tone might be perceived as higher than that of the level tone, leading to more low tone perception for the following target. For the learners, who were familiar with dynamic F0 change in lexical tones, the dynamic F0 frequency change for the rising tone may trigger an interesting internal contrast effect such that the onset F0 is perceived as lower due to the contrast with the high F0 offset, and conversely, the offset is perceived as higher due to the contrast with the preceding low F0 onset. However, this speculation must be verified by testing a falling contour tone which is predicted to show the opposite trend, namely being perceived as having a higher onset F0 compared to a level tone with the same onset value. While this is beyond the scope of the current study, it is hoped that follow-up studies could take on this issue to draw a fuller picture of the sources of the contour-driven perceptual bias.
4.3 Context effects and linguistic experience
Participants of the present study were drawn from two groups of native speakers of Seoul Korean, one with experience in a tonal second language (i.e., Mandarin Chinese) and the other with no such experience. Overall, the two groups responded similarly to the experimental variables. Both groups utilized F0STEP, an intrinsic tone property, for stop perception, as predicted. The higher F0 values led to more fortis responses for both groups. More interestingly, stop distinctions were driven by extrinsic context for both groups: more fortis responses were given in the low tone context than in the high tone context. What is more, a contour-dependent asymmetry was attested regardless of linguistic experience: a more significant context effect was observed for the level than for the rising tone condition for word-medial stop perception. The parallel between the two groups lends support for the non-language-specific nature of the contrastive context effects.
The results showed that tone normalization arises from general cognitive processing that does not require prior knowledge of lexical tone. This is in accordance with previous studies of coarticulatory compensation which show that contrast effects are not contingent on explicit knowledge or particular phonological representations of pertinent sounds (Mann, 1980; Viswanathan et al., 2010). As demonstrated in Mann (1986), Japanese speakers were able to show compensation for coarticulation for the alga-arda experiments even when they could not tell the differences between /al/ and /ar/ in isolation. Similarly, naïve Korean listeners are likely to have difficulty identifying isolated tones, but they could still show the contour-dependent asymmetry and context-driven contrast effects. While previous studies have made this point on the basis of segmental contrasts, the present study adds another piece of empirical evidence to the literature. Like segmental contrasts, tonal context effects are also generally independent of prior experience.
One might wonder if the observed pattern can be attributed to the recent sound change in Seoul Korean wherein F0 cues have emerged as a critical phonetic cue for stop distinctions, overriding the once-reliable VOT cues (Kang, 2014; Silva, 2006). However, this cue reversal in Korean is limited to the aspirated and lenis contrasts only in the domain-initial position. The aspirated stops have undergone a remarkable reduction in aspiration, neutralizing the original differences in VOT between aspirated and lenis stops. The absence of the VOT cue in the initial position has been replaced by once-redundant F0 cues. However, there is still a large difference in VOT between lenis (long VOT) and fortis stops (short VOT), and the F0 cue is considered to be secondary at best. When VOT is kept extremely short, Korean listeners identify a stop primarily as fortis, regardless of varying F0 values (Lee et al., 2013).
When other phonetic cues are controlled and not varied as in the current study, however, the redundant F0 cues appear to be actively employed for the lenis-fortis distinction. In both experiments, F0STEP turned out to be a strong predictor of stop judgments. This may be the baseline performance by Korean listeners in general, informed by F0 as the secondary cue for stop categorization. However, the existing phonetic cue in Korean cannot fully explain the extrinsic context effect observed in the present study. For one thing, although the overall sensitivity to F0 cues could still be beneficial, the role of F0 cues is limited to the domain-initial position in Korean, while the large context effect was rather observed in the word-medial position in this study. Second, extrinsic context effects appear to be independent of the processing of intrinsic tonal cues. This is evidenced by the naïve listeners’ performance for the initial stop identification. They were able to use F0STEP for the categorization of initial stops, but they did not show significant context effects in that condition.
Despite global similarities, it should be noted that the two groups differed in terms of the magnitude of responses to the conditioning factors. Learners were more sensitive to the intrinsic tonal property, F0STEP. Learners also showed stronger extrinsic context and tone contour effects than naïve listeners. Intuitively, this could be attributed to the learners’ sensitivity to F0 cues acquired through training in Mandarin Chinese lexical tones. This is a strong possibility, as previous studies have shown L2 learners do indeed acquire a higher sensitivity to F0 cues (e.g., Franciset al., 2008; Guion & Pederson, 2007; Qin & Jongman, 2015). In Guion and Pederson (2007), for example, English-speaking advanced learners of Mandarin Chinese could attend to dynamic F0 changes as well as F0 height on par with native speakers of Mandarin, while naïve English listeners could attend only to F0 height. Qin and Jongman (2015) have also shown that English-speaking learners of Mandarin generally outperformed monolingual Mandarin native speakers in the perception of lexical tones in Cantonese. These examples certainly demonstrate that the acquisition of a second tonal language is beneficial for the tonal distinctions in general.
However, a higher sensitivity to F0 cues through tonal L2 experience may be too broad to explain all the patterns obtained in the present study. Recall that learners demonstrated the context effect in both directions, while naïve listeners generally failed to show the effect for the following context. Given the large effect of extrinsic tone context for the preceding tones for the naïve listeners, the nearly categorical absence of a context effect for the following tones is somewhat surprising. One conjecture is that the knowledge of tonal second language may involve parsing the tonal domains during processing. The learners seem to have acquired the ability to apply a wider scope for the processing of the consecutive tones; the information of the following tones is systematically incorporated into the processing of the preceding tones. This delayed processing of tonal information has been reported to be vital for tone language speakers (Cutler & Chen, 1997; Ye & Connine, 1999), and learners might also have acquired this structural knowledge of tone domains, which enables context effects in both directions. Without experience in tone languages, however, naïve listeners may be limited to simply processing the immediately available tones. The preceding context seems to present a different situation, however. The first tone precedes the second one, and at the time of processing the second tone, the information of the first tone would be readily available. This temporal precedence of the preceding tone is likely to enable naïve listeners, as well as learners, to process two consecutive tones altogether and show contrastive context effects.
Taken together, tone normalization, by and large, does not necessarily require prior experience in or knowledge of lexical tones, echoing the general findings in the studies of compensation for coarticulation. Contrastive context effects seem to be best represented as universal characteristics of cognitive processing. Under these general principles, however, specifics could still be further shaped by ones’ linguistic experience with their native sound system or second language experience, which may enhance certain contrast effects.
5 Conclusion
This study examined the ways in which various characteristics of tones exert complex but systematic influence on the perception of neighboring stops. Global effects of extrinsic tonal context were evident regardless of linguistic experience. Korean listeners with and without knowledge of Mandarin Chinese showed large bidirectional contrastive effects of extrinsic contexts which were then integrated to give rise to a systematic asymmetry in laryngeal distinctions of stops. Such contrast effects were more clearly observed for the level than for the contour tone, suggesting that simple intrinsic F0 characteristics of a level tone trigger a greater reliance on extrinsic tonal properties. This pattern again held true regardless of one’s language background. On top of those global effects of extrinsic context, however, it was shown that minor details of stop perception were further modulated by specific linguistic experience. The learners’ acquired sensitivity to F0 cues was pervasive, driving larger effects of all F0 variables, including both intrinsic and extrinsic cues to stop identification. Taken together, extrinsic context effects of tone were shown to be contrastive in the auditory domain, reflecting broad cognitive biases. However, generalizations arising from linguistic experience may further refine the ways in which perceptual contrasts manifest their effects.
Footnotes
Acknowledgements
I would like to thank Hyoju Kim and Yeonmee Kim for help with data collection and Hannah Parsamehr for her careful editing of the manuscript. I also thank audiences at the NCTU Phon Brown Bag, the Linguistic Society of America, Hanyang International Symposium on Phonetics and Cognitive Sicences of Language, and the Korean Society of Chinese Studies. I acknowledge the Editor and reviewers of Language and Speech for their constructive comments, which led to substantial improvements to the manuscript.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by a research grant MOST107-2410-H-009-016-MY3 from Ministry of Science and Technology, Taiwan.