
Abstract
This study investigated the effect of the stressed word in Thai language on auditory event-related potential (aERP) in unattended conditions. We presented 30 healthy participants with monosyllabic Thai words consisting of either stressed or unstressed words. We instructed them not to attend to the sound stimuli, but rather to watch and memorize the contents of a silent natural documentary without subtitles. The two listening conditions consisted of 20% deviant stimuli (70 stressed and 70 unstressed words, respectively) and 80% standard stimuli (other 280 unstressed words) presented pseudorandomly and binaurally via a pair of earphones. Participants’ aERPs from the two conditions were evaluated by the mismatch negativity (MMN) component of aERP. The mismatch negativity amplitudes in the stressed word condition were significantly higher than those in the unstressed word condition, especially in frontal and left fronto-central brain areas. Therefore, these data show the role of the frontal and left fronto-central brain regions in auditory preattentive processing of stressed word perception among native Thai speakers. This is the first study demonstration that stressed meaningful monosyllable words in tonal language facilitate word perception in this preattentive stage. This result has implications for developing clinical tests evaluating preattentive speech perception.
Introduction
Languages are classified into tonal and nontonal (Duanmu, 2004), with tonal languages (commonly found in Africa, East Asia, and Mexico) characterized by the use of distinctive tone patterns (differences in pitch or frequency) to differentiate word meaning (Yip, 2002). In Thai, a tonal language, five lexical tones use five different sound frequencies to indicate five different meanings. For example, “Khā” is a mid-tone word meaning “stick,” and “K¯h`̀ā” is a falling tone word meaning “galangal” (Honbolygó, Csépe, & Ragó, 2004; Kaan, Barkley, Bao, & Wayland, 2008). Nontonal languages do not use pitch variation for differentiating word meaning but, instead, use syllable stress and so are called “stress languages” (e.g., English and German; Fry, 1958; Kaan et al., 2008). In English, there are two stress patterns: lexical stress (or “syllable stress” within a word) and sentence stress (or “word stress” within a sentence). English language uses these stress patterns to distinguish meaning and voice quality to express emotion in speech communication. The variation in frequency in both tonal and stress languages is called “suprasegment” or speech prosody (Chandrasekaran, Krishnan, & Gandour, 2007; Honbolygó et al., 2004; Zora, 2011).
Lexical or syllable stress is defined as prosody dominating only a small number of words at the word level (Waibel, 1988). For examples, two-syllable English words, “PREsent” stressed in the first syllable, is a noun meaning “a gift,” whereas “preSENT” stressed in the second syllable, is a verb meaning “to show” or “to display.” Terken (1991) noted that the prosody, in this case, was the dominating linguistic unit (syllable), expressed so as to distinguish it from the other syllables in the word. The stressed syllable has four forms consisting of length, volume, frequency (pitch), and voice quality (Fry, 1958), each related to four physical properties of a word—duration, intensity, fundamental frequency, and timbre of speech, respectively. A previous study showed that syllable stress could be used to identify the word (Norris, McQueen, Cutler, & Butterfield, 1997). The stressed syllable of a word has higher fundamental frequency (f0), intensity, and longer duration than unstressed syllables. Lexical stress affects speech perception because of the greater acoustic reliability of stressed syllables. When the lexical stress pattern of two-syllable words was shifted, research participants’ reaction times to correctly stressed words were significantly faster than their reaction times to incorrectly stressed words (Zora, 2011), suggesting that word recognition is poorer when a word is incorrectly stressed. Previous studies of the effect of syllabic stress on speech perception in Finnish and English include those by Ylinen, Strelnikov, Huotilainen, and Näätänen (2009) and Zora (2011). However, in stress language research, there have been no studies of the effect of monosyllabic stress on meaningful words compared with the same words pronounced without monosyllabic stress. As noted earlier, in contrast to word stress, sentence stress depends on monosyllabic stress and constitutes sentence prosody in which one word is the dominating word within a sentence. For example, “I bet YOU win” stresses the third word, and “I bet you WIN” stresses the fourth word, with each emphasis associated with a different sentence meaning. The first sentence emphasizes that it is “YOU,” not other people who will win, while the second sentence emphasizes that you will “win,” rather than “lose.”
This study sought to clarify correlations found within relevant previous studies and to investigate the effects of prosody features, such as pitch, rhythm, and stress. We proposed to investigate prosody features within Thai language. While many previous electrophysiological studies have measured brain functioning in speech processing, our research design intended to apply auditory event-related potential (aERP; Pilling, 2009; Polich, 1996), normally correlated with the time-course of sound events to demonstrate the dominant brain response to the sound stimulus. The event-related potential (ERP) property is shown in high temporal resolution but low spatial resolution. The voltage response to spoken language is called “language-related components” (Steinhauer & Connolly, 2008), and there are many different components, such as P100, N100, P200, mismatch negativity (MMN), N200, P300, N400, and P600. Each component represents different brain processing in each period (Sur & Sinha, 2009). The potentials resulting from language-related components reflect the brain processing response to the sound features of speech at the preattentive stage (as an MMN) and at the attentive stage (as P300). During the period of 270 – 310 ms, phonological mapping negativity represents word expectation (prelexical expectations; Connolly, Phillips, & Forbes, 1995). At the period of 350 – 450 ms, the N400 represents sound comprehension. Previous studies analyzing relative clause and grammatical validity generate left-lateralized anterior negativity at approximately 100 – 500 ms (Friederici, Pfeifer, & Hahne, 1993; Kaan & Swaab, 2003). Written language elicits P600 at approximately 500 – 1,000 ms (Hagoort, 1993; Osterhout, Holcomb, & Swinney, 1994).
Many prior studies of preattentive sound discrimination brain processing have used aERP (Jemel, Achenbach, Müller, Röpcke, & Oades, 2002; Näätänen, Pakarinen, Rinne, & Takegata, 2004; Rinne et al., 1999). Preattentive processing involves a subconscious accumulation of information from the environment (Atienza, Cantero, & Escera, 2001), and these were investigations on sound discrimination when participants were paying no attention to the sound stimulus (unattended condition) and were not responding with button pressing, also known as the passive oddball paradigm. The brain activity elicited in the preattentive stage was the MMN component of aERP—the subcomponent of N200 which was the anterior cortical distribution evoked while ignoring any deviant stimulus (Patel & Azzam, 2005). The MMN component is calculated by subtracting aERP components elicited by standard stimuli from the aERP components elicited by deviant stimuli. MMN generated by supratemporal and frontal processing was found at 100 – 250 ms in the fronto-central scalp areas (Fz; Jemel et al., 2002; Näätänen et al., 2004; Rinne et al., 1999). Thus, MMN can now be used as an index of sensory (echoic) memory, preattentive processing, sound features discrimination, spectral envelope perception, brain plasticity, and language training effects (Kujala, Tervaniemi, & Schröger, 2007; Stoody, Saoji, & Atcherson, 2011; White & Stuart, 2011).
Previous aERP studies on prosody features of nontonal language focused on lexical stress perception in the preattentive stage of Finnish, English, and other languages. In Finnish, stressing the second syllable led to greater MMN when compared with stressing the first syllable of disyllables, and most words in Finnish were normally stressed in the first syllable. Thus, the unfamiliar stress pattern might show the high MMN component and might increase spoken word recognition (Ylinen et al., 2009). In English, lexical stress perception in disyllables was studied using verbs (stressing on the second syllable) as standard stimuli and, for deviant stimuli, there were three types of disyllabic words, including words containing different frequency, different intensity, and different frequency and intensity. Research findings were that deviant stimuli stress perception was characterized by first syllable, versus second syllable stress, on all three types of disyllabic words—higher frequency, higher intensity, and higher frequency and intensity. Words containing different frequencies and intensity (higher frequency and intensity on the first syllable) elicited a higher MMN component than those elicited by other deviant stimuli, indicating that integrating of frequency and intensity might efficiently cue lexical stress perception (Zora, 2011).
Previous ERP studies on prosody features of tonal language, especially lexical tones perception in the preattentive stage, have focused on the languages of Cantonese (Tsang, Jia, Huang, & Chen, 2011), Chinese (Chandrasekaran et al., 2007), and Thai (Kaan, Wayland, Bao, & Barkley, 2007; Sittiprapaporn, 2002). Tsang et al. (2011) reported that six lexical tones are used in Cantonese, and their study examined the effects of different pitch height using height-large difference (Tone T6/T1) and height-small difference (Tone T6/T3) stimuli. They examined the effects of different pitch contour using contour-early difference (Tone T1/T2) and contour-late difference (Tone T6/T2). They discovered that height-large difference (between Tone 6 and Tone 1) elicited larger MMN amplitude than contour-early difference (T1/T2) did. However, there was no difference between MMN amplitudes elicited by the height-small difference (T6/T3) and contour-late difference (T6/T2). The difference of pitch height tone between T6 and T1 was larger when compared with that between T1 and T2, leading to a larger MMN component in T6/T1 (Tsang et al., 2011).
In Mandarin Chinese, researchers used four lexical tones and studied the different effects on lexical tones perception in preattentive stage of three lexical tones (T1, T2, and T3) by comparing T2 and T3 (T2/T3) and T1 and T3 (T1/T3). High-rising contour T2 was standard in T2/T3, and high standard T1 was standard in T1/T3. These researchers reported that T1/T3 elicited a larger MMN component and more varied pitch, when compared with T2/T3, resulting in a greater MMN component in T1/T3 (Chandrasekaran et al., 2007).
One study (Kaan et al., 2007) investigated Thai lexical tone perception in native Thai speakers in the preattentive stage and used the low-falling and high-rising tones as deviant stimuli (infrequent stimulus) and the mid tone as standard stimuli (frequent stimulus). These researchers found that MMN was larger in the low-falling versus high-rising tone with deviant stimuli. This result might be caused by the comparatively different frequencies between low-falling and mid tones; a higher frequency was evident when comparing high and mid tone. These characteristics led to higher MMN amplitude in the low-falling mid tones. However, another study on Thai nonword lexical tone discrimination in the preattentive stage found that the MMN amplitudes of consonant, vowel (segmental phonological units) were left lateralized, whereas lexical tones (suprasegmental phonological units) were right lateralized (Sittiprapaporn, 2002).
Pichitpornchai and Arunphalungsanti (2016) investigated the effects of spoken Thai word durations on brain recognition processing evaluated by aERP and reaction time in a recognition task. This study found that performance accuracy and P300 amplitude were higher for target words with long versus short durations, suggesting that longer than normal word duration can facilitate word processing and recognition. This research differed from the present study in that the earlier study evaluated only the word durations of prosody features on speech recognition in the attentive stage while we evaluated the effects of stressed word in preattentive perception.
Finally, a previous pilot study examined prosody features in Thai language and found that unfamiliar stressed words increased the amplitudes of N200 or N2a components, and that theta and delta wave (electroencephalogram [EEG]) powers were generated frontally in preattentive processing (Arunphalungsanti & Pichitpornchai, 2016). These researchers evaluated only one manipulated stimulus condition consisting of stressed words randomly presented with unstressed words and compared aERP (N200) and EEG elicited from stressed and unstressed words. The researchers’ methodology differed from this study in that the earlier study investigated two stimuli conditions consisting of (a) stressed deviant word and (b) unstressed deviant word. In the first condition, stressed deviant words were randomly presented along with unstressed standard words. For the second condition, unstressed deviant words (the same word list used in the stressed deviant word but pronounced in an unstressed manner) were randomly presented with unstressed standard words. In this pilot study, the comparison was evaluated using MMN defined by subtracting the standard stimuli aERP from the target stimuli aERP.
Through this complex literature review, we concluded that, in neither tonal nor nontonal languages have there been prior studies on stressed and unstressed conditions of the same monosyllable words with regard to their effects on brain-based word perceptions in the preattentive stage. We sought to address this gap in the research literature by evaluating speech perception through the mismatch negativity component of aERP, hypothesizing that Thai words spoken in a stressed words condition (SWC) would result in larger MMN amplitudes and shorter latencies than those spoken in an unstressed words condition (UWC).
Method
Participants
We recruited 30 right-handed participants with a normal hearing threshold (15 women, 15 men; aged 20−30 years) from among graduate students of the Faculty of Medicine Siriraj Hospital, Mahidol University. No participants had any history or presence of neurological illness, drug addiction, musical training, language-related disorders, and neuromuscular disorder of hands and fingers. Prior to the experiment, each participant gave written informed consent, and the research protocol was approved by the ethics committee of the Siriraj Institutional Review Board, Faculty of Medicine Siriraj Hospital, Mahidol University (Certificate of Approval number: Si314/2013).
Stimuli Preparation
Voice stimuli were verbalized by a female adult Thai native speaker (aged 35 years) and recorded within the Educational Technology studio, Faculty of Medicine Siriraj Hospital. Audio files were adjusted to an intensity level of 60 – 80 decibels of sound pressure level (dB SPL), and word durations were adjusted to 560 – 700 ms with Adobe audition software (Adobe Systems Inc., USA). Word stimuli were Thai monosyllabic neutral words with mid tone in Thai lexical tones. A neutral word is a word heard or seen in emotionally indifferent feelings (Dara, Monetta, & Pell, 2008). A single word was recorded twice, once as a stressed word and once as an unstressed word. A stressed word was pronounced in higher fundamental frequency, higher intensity, and longer duration, whereas an unstressed word was pronounced in normal fundamental frequency, intensity, and duration.
The stressed and unstressed words’ frequency (Hz), intensity (dB), and duration (ms) were analyzed and averaged. The means (M) and standard deviations (SD) of the stressed words components were (a) frequency M = 182.76, SD = 16.67 Hz; (b) intensity M=76.95, SD = 2.10 dB; and (c) duration M = 656.82, SD = 41.47 ms; and those of the unstressed words were (a) frequency M = 173.22, SD = 13.32 Hz; (b) intensity M = 74.19, SD = 1.56 dB; and (c) duration M = 606.37, SD = 43.76 ms. All three components – frequency, intensity, and duration – of stressed words, were significantly higher than those of unstressed words: t(69) = 13.67, 15.94, and 12.02, respectively, p < .05. The effect sizes were larger for higher mean differences in all three components (Cohen’s effect size values d = 0.63, 1.49, and 1.18, respectively). The stimuli were adjusted to 80 and 60 dB in stressed and unstressed words, respectively; and the interstimulus interval was 2,000 ms. The voice stimuli were sequenced and coded by the Stim2 software (Compumedics Neuroscan, USA; Arunphalungsanti & Pichitpornchai, 2016). The stimulus words were arranged into two passive oddball conditions. The first condition was the SWC, comprising 70 stressed words (20% deviant stimuli) and 280 unstressed words (80% standard stimuli); and the second condition was the UWC, comprising 70 unstressed words (the same words as stressed words mention previously but pronounced in the unstressed condition; 20% deviant stimuli) and 280 unstressed words (80% standard stimuli).
Experimental Procedure
Participants sat 60 centimeters in front of a 20-inch. computer screen, and they were asked to avoid eye blinking or head movements. The two passive oddball conditions of stimuli (stressed and unstressed conditions) were presented binaurally via a pair of earphones, and their order was counterbalanced. In each condition, deviant and standard stimuli were presented pseudorandomly with a silent period of 2,000 ms (Figure 1). Each condition took about 15 minutes and there was a 5-minute break before continuing to the test for the second condition. Participants were instructed not to attend to the sound stimuli, but, instead, to watch the silent nature documentary without subtitles. The EEG data were recorded throughout both conditions. After the experiment, participants were asked to answer five multiple choice questions (four choices for each question) in a questionnaire asking about the content of the documentary to test their attention, and data from participants with correct answers less than 90% would be discarded. The percentage of correct answers was higher than 90% in both SWC (M = 93.33, SD = 1.99%) and UWC (M = 94.67, SD = 1.90%), and there was no statistical difference between the percentage of correct answers of the two conditions: t(29) = −0.57, p > .05. Therefore, none of the data were discarded. These data indicated that the participants paid equal and sufficient attention to the details of silent documentary movies and ignored the voice stimuli in both conditions, as the protocol advised.
The stimulus presentation in stressed word and unstressed word conditions. EEGs were recorded throughout the experiment (about 2600 ms/stimuli × 350 stimuli = about 15 minutes). Gray box: deviant stimuli, Black box: standard stimuli. EEG = electroencephalogram.
EEG Recording
EEGs were recorded with the Neuroscan and Quick cap with 32 channels (Ag/Ag-Cl electrode; Compumedics Neuroscan, USA). Electrodes were attached on the participant’s scalp according to the international 10–20 system connected to the headbox of the SynAmps amplifier. The following 32 electrode positions were used: Fp1, Fp2, Fz, F3, F4, F7, F8, FCz, FC3, FC4, FT7, FT8, Cz, C3, C4, CPz, CP3, CP4, TP7, TP8, Pz, P3, P4, P7, P8, Oz, O1, O2, T7, T8, A1, and A2. The configuration of electrode positions was predefined according to the SynAmps Digital. The montage was referenced to both mastoid processes. Electrode impedance was kept below 10 kΩ. High-pass (1 Hz) and low-pass (30 Hz) filters were used. Horizontal and vertical electrooculograms were recorded and any trials with voltage above 100 mV were removed to avoid artifacts.
Data Analysis
EEG data were averaged, and ERPs were obtained by deleting EEG epochs that started 100 ms before stimulus onset and ended 600 ms after onset. The interval from −100 to 0 ms was used as a baseline correction for all electrode sites. Trials containing eye movements and muscle artifacts were excluded. The accepted trials of both conditions were classified into two types (standard and deviant stimuli) and averaged. The averaged ERP contained at least 80% accepted trials. The MMN was obtained by standard stimuli ERP subtracting from deviant stimuli ERP. Finally, ERP data were averaged across participants to obtain the grand average ERP.
Data were presented as Ms and SDs. Independent paired t tests were calculated to compare the behavioral data (percentage of correct answers of the questionnaires) and ERP data (peak amplitudes and latencies of MMN components from 12 electrode sites (F3, Fz, F4, FC3, FCz, FC4, CP3, CPz, CP4, P3, Pz, and P4) for comparing the effect of SWC and UWC. Paired t tests were used to compare the effect of electrode sites between the anterior (Fz) and posterior (Pz) midline electrode sites, and between left and right corresponding electrode sites (F3 and F4, FC3 and FC4, CP3 and CP4, and P3 and P4). Statistical significance was set at p < .05. The normality of data was tested by Kolmogorov–Smirnov test.
Results
MMN Component Analysis
The normality of the data regarding SWC and UWC was tested by Kolmogorov–Smirnov test and found to be normally distributed. Amplitudes and latencies of the MMN components were analyzed and compared both in between- and within-groups conditions. In the comparison between SWC and UWC, the MMN amplitudes evoked by the SWC were statistically significantly higher than those evoked by the UWC at all 12 electrode sites (F3, Fz, F4, FC3, FCz, FC4, CP3, CPz, CP4, P3, Pz, and P4), t(29) = −3.06, −3.99, −3.69, −4.17, −4.72, −4.24, −3.05, −3.07, −2.76, −3.16, −3.12, and −2.59, respectively (p < .05). Cohen’s effect size values (d) were 0.83, 0.88, 0.85, 1.01, 1.08, 0.95, 0.74, 0.79, 0.54, 0.76, 0.64, and 0.61, respectively. The larger effect sizes indicated higher difference in MMN amplitudes elicited from stressed words and unstressed words at all 12 electrode sites. Figure 2 demonstrates the grand average MMN waveforms in both conditions elicited at the 12 electrode sites.
Grand average waveforms of MMN components elicited by deviant stimuli subtracted by those elicited by standard stimuli in SWC and UWC at the F3, Fz, F4,FC3,FCz, FC4, CP3, CPz, CP4, P3,Pz, and P4 electrode sites. MMN = mismatch negativity; SWC = stressed word condition; UWC = unstressed word condition.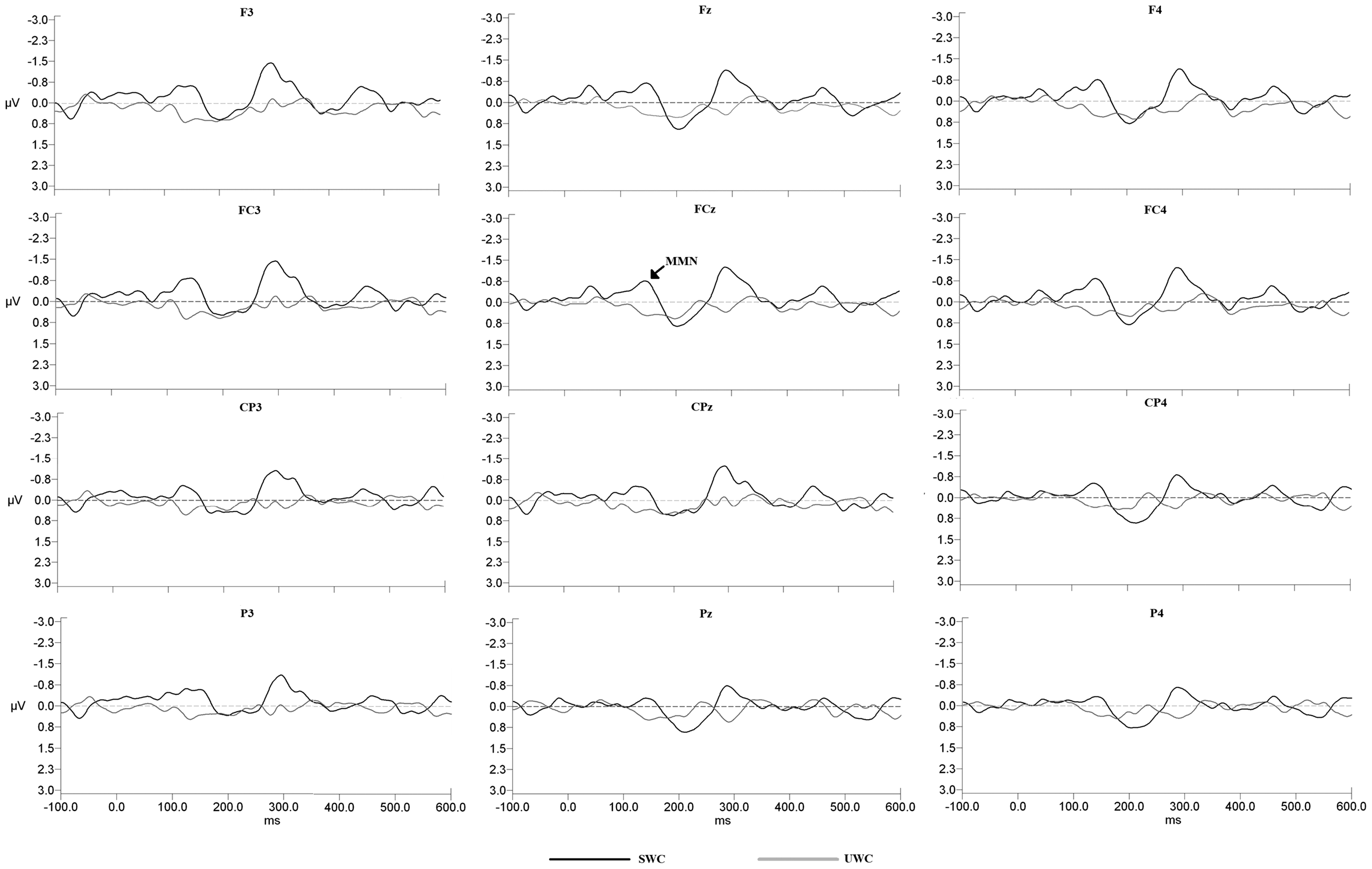
In the within-groups condition comparison, the mean MMN amplitude of the SWC elicited at the Fz electrode site (anterior electrode site) was significantly larger than that at the Pz electrode site (posterior electrode site; M = −1.27, SD = 0.89 µV, and M = −0.96, SD = 0.63 µV, respectively; t(29) = −2.28, p < .05; see Figure 3(a)). The effect sizes were moderate for different MMN amplitudes between Fz and Pz electrode sites (d = 0.40). Moreover, MMN amplitude elicited at the FC3 electrode site (left anterior hemisphere) was significantly larger than that of FC4 electrode site (right anterior hemisphere; M = −1.61, SD = 1.12 µV, and M = −1.32, SD = 0.78 µV, respectively; t(29) = −1.67, p < .05; see Figure 3(b)). The effect sizes were moderate for different MMN amplitudes between FC3 and FC4 electrode sites (d = 0.30). The results indicated that the stressed word processing was highly processed in the frontal and at the left fronto-central areas. There was no significant difference between the MMN latencies elicited from SWC and UWC at any of the 12 electrode sites (F3, Fz, F4, FC3, FCz, FC4, CP3, CPz, CP4, P3, Pz, and P4) of which t(29) = −0.15, −1.84, −1.36, −0.54, −1.82, −1.97, −2.66, −0.95, 0.39, −1.46, −1.59, and 0.02, respectively, p > .05.
Grand average waveforms of MMN components elicited by deviant stimuli subtracted by those elicited by standard stimuli in stressed word condition. (a) Fz and Pz (anterior and posterior electrode sites, respectively). (b) FC3 and FC4 (left anterior and right anterior electrode sites, respectively). MMN = mismatch negativity.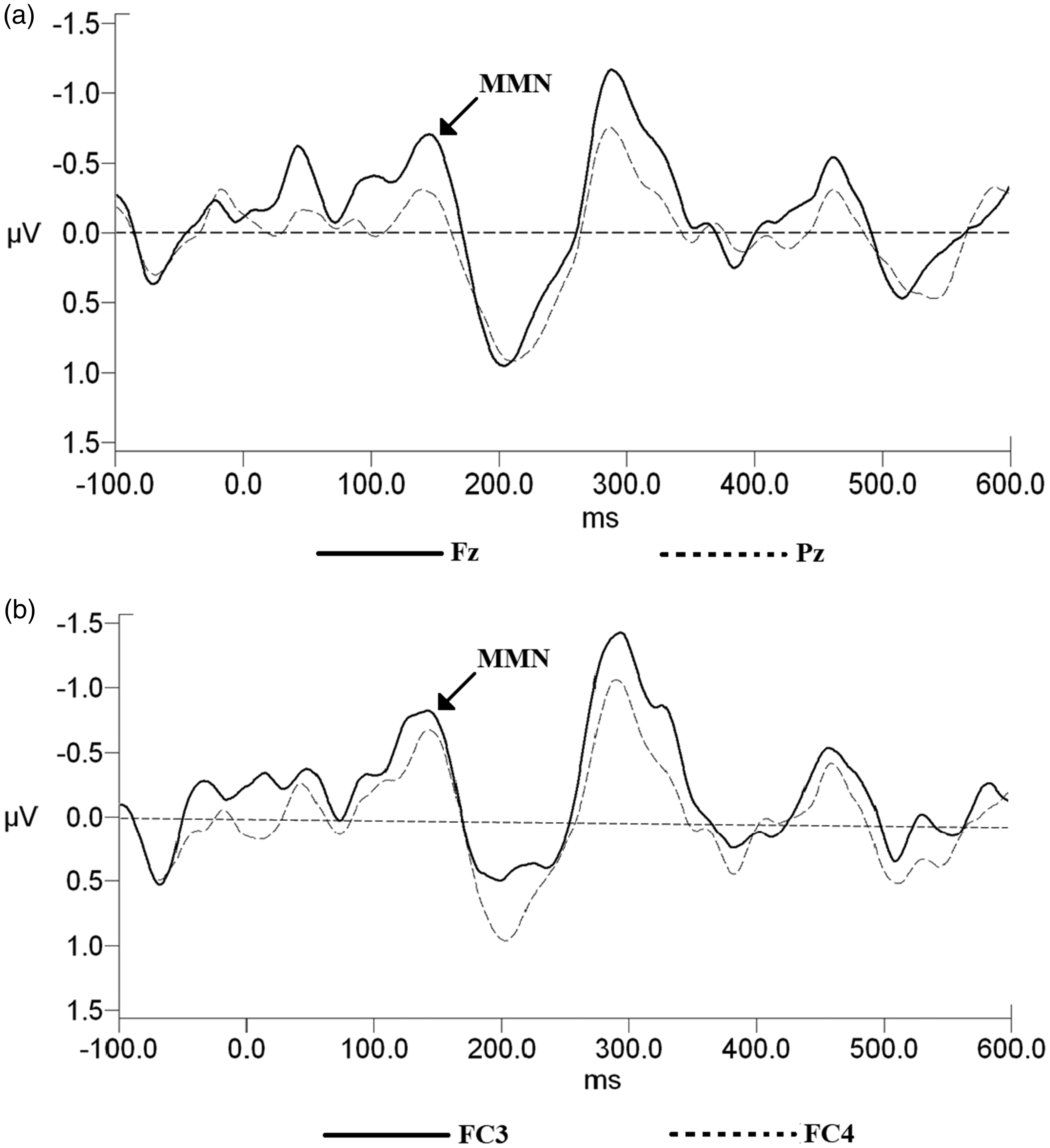
Discussion
This study provided electrophysiological evidence of the effects of stressed words in native Thai speakers on word perception in the brain as evaluated with MMN from aERP. On test questions presented to them, participants demonstrated good knowledge of its content (correct scores of >90%) and therefore good attention to a silent documentary movie presented in both SWC and UWC. Thus, participants followed instructions not to attend to the voice stimuli, and the effect of voice stimuli on aERP can be considered as an under unattended or a preattentive condition (Näätänen, Gaillard, & Mäntysalo, 1978; Näätänen et al., 2004).
This study revealed that MMN amplitude was larger in the SWC than in the UWC. These data implied that it was the frequency and intensity (spectral) contrast of the SWC that accounted for this finding (Stoody et al., 2011; White & Stuart, 2011). In addition, the longer word durations of stressed words in this study might have played an important role in eliciting larger MMNs. Consistent with prior findings that the MMN component was mostly evident in fronto-central areas at 100 to 250 ms (Jemel et al., 2002; Näätänen et al., 2004; Rinne et al., 1999), we found that, in the SWC, MMN amplitude was more prominent at frontal (Fz) and left fronto-central (FC3) areas than at parietal (Pz) and right fronto-central (FC4) areas, respectively. Thus, linguistic prosody processing was highly localized to the frontal region of the brain and lateralized to the left fronto-central area particularly. A previous study on Thai lexical tones (nonword) discrimination in the preattentive stage found that the MMN amplitudes of segmental phonological units (consonant, vowel) were left lateralized, whereas the suprasegmental (lexical tones) phonological units were right lateralized (Sittiprapaporn, 2002). Interestingly, however, this apparently contradictory finding, in a study without tonal changes, also found that stressed word discrimination at the preattentive stage was processed with left lateralization. These results implied that speech perception of stressed words in spoken Thai was similar to segmental processing. Stressed word speech might affect consonant and vowel sounds but not word meaning, leading to segmental processing and the left lateralized increased MMN component.
The left fronto-central focus of brain processing of stressed words in Thai speech is consistent with an functional magnetic resonance imaging study of brain activity elicited by selective attention to Chinese intonation (Gandour, 2000; Gandour, Dzemidzic, et al., 2003). Chinese speakers showed a left lateralized asymmetry in frontopolar or prefrontal regions compared with English speakers, indicating cross-language differences in linguistic processing of suprasegmental information (Gandour, Wong, et al., 2003). The functional roles of the prefrontal region are related to irrelevant information in the higher memory load in relationship to auditory selective attention (Sabri et al., 2014). Therefore, there is evidence here that the spoken Thai stressed word resulted, in the preattentive stage, in recruitment of left prefrontal brain regions, indicating asymmetrical brain processing for language under these conditions.
Several previous studies have also shown functionally and acoustically dependent brain asymmetry in nontonal language speakers. The general study of functionally dependent brain asymmetry found speech processing to be lateralized to the left hemisphere and musical processing lateralized to the right hemisphere (Tramo, 2001; Zatorre, Belin, & Penhune, 2002). Furthermore, acoustically dependent studies of brain asymmetry have reported that temporal (time-based) linguistic processing was left lateralized whereas spectral (pitch or frequency-based) linguistic processing was right lateralized (Okamoto, Stracke, Draganova, & Pantev, 2009; Schönwiesner, Rübsamen, & Von Cramon, 2005).
In our tonal Thai language study, we found stressed words to be processed in the left cerebral hemisphere, suggesting asymmetrical functional dependency in listening to Thai native speakers. Our findings were similar to those of nontonal language studies (Tramo, 2001; Zatorre et al., 2002), but a key difference was that in our study of native Thai speakers, there was higher pitch processing in the left hemisphere that was not evident in nontonal language speakers. Our results concerning pitch processing differences were consistent with the lexical and acoustic (nonspeech) pitch processing of Cantonese speakers who use a tonal language, as, in that study too pitch contrast elicited MMN with left lateralization (Gu, Zhang, Hu, & Zhao, 2013).
Among the limitations of this study, we used a female voice-over. The female voice is more complex and clearer than the male voice, because of gender differences in the length and shape of vocal cords and the larynx (Belin, Fecteau, & Bédard, 2004). Thus, further studies using a male voice for language stimuli are needed. Another possible limitation is that we investigated the effect of stressed monosyllabic word stimuli in an unattended condition, leaving open the question of whether stressed word stimuli would have the same effect in an attended condition.