
Abstract
This article provides preliminary validity evidence for the shorter Mandarin version of the Vocabulary Size Test (VST) under the content aspect, technical quality, substantive and generalizability aspect of Messick’s (1995) construct validity framework. The shorter version with 177 Chinese university students in three proficiency levels indicates that the test enjoys a high level of validity both from the perspective of classical test theory and item response theory. A one-way ANOVA and detailed statistics of Rasch analyses demonstrate that the test could effectively distinguish learners from different proficiency levels. The first eight levels of the VST generally display an ascending difficulty continuum except that some loan words in the seventh and the eighth level prove to be problematic in assessing Chinese learners’ vocabulary size accurately. The generalizability aspect of construct validity is demonstrated in that there is no item bias for learners of the same proficiency group in terms of gender. Compared with the results of other studies either on monolingual or bilingual version, this research attempts to justify the appropriateness of the Mandarin version and calls for cautious applications of the test instrument on Chinese learners.
Introduction
The diagnostic and guiding nature of language testing has long been recognized in the field of second language acquisition. Consequently developing language testing tools with high validity and reliability has been the ultimate goal language testers seek to achieve. A great number of scholars not only proposed the principles for test design, but also devised a series of vocabulary test batteries. These test instruments, for example, the Vocabulary Levels Test (Nation, 1983, 1990), the Eurocentres Vocabulary Test (Meara and Buxton, 1987; Meara and Jones, 1990), and the Vocabulary Size Test (Nation and Beglar, 2007) have been used either in a placement test or as a measure of learners’ vocabulary size, and manifested to be applicable vocabulary assessment tools both for native and non-native speakers. This article reports on attempt to validate the shorter Mandarin version of the VST within Messick’s (1995) construct validation framework.
The Vocabulary Size Test
The Vocabulary Size Test is designed by Nation (2006) (available at http://www.victoria.ac.nz/lals/staff/paul-nation/nation.aspx) to provide a reliable, accurate and comprehensive measure of both first and second language learners’ written receptive vocabulary size. The test samples 10 items each from the first 1000 to the 14th 1000-word families of English from the British National Corpus. There are also a total of 140 items arranged according to the frequency level because it is generally assumed that the frequency level is related to the probability of knowing the words at that level. Under Read and Chapelle’s (2001) framework, the test is discrete, selective, relatively context-independent and is presented in a multiple-choice format which aims to control item difficulty level, enhance reliability and ease the scoring process (Nation and Beglar, 2007). The test measures knowledge of written word form, the form-meaning connection, and to a smaller degree concept knowledge. The total score is to be multiplied by 100 to obtain learners’ total receptive vocabulary size. Apart from its monolingual version, a number of bilingual versions have been developed including Russian, Korean, Vietnamese, Mandarin, Japanese and Persian.
Beglar (2010) provided comprehensive validity evidence by combining Messick’s (1989,1995) framework with the framework proposed by the Medical Outcomes Trust Scientific Advisory Committee (1995). First, it can be used with learners from a wide range of proficiency levels. Second, it measures what it is supposed to measure. In other words, it shows a high degree of psychometric unidimensionality. Third, it distinguishes between learners of different proficiency levels, has a range of item difficulties related to the frequency level of the tested words, and clearly distinguishes several different levels of vocabulary knowledge so that learners’ vocabulary growth over time could be measured. Lastly, it performs consistently and reliably, even though test circumstances may change. The comparison between male and female subjects and different versions of the test all produce a Rasch reliability measure of around .96. The test exhibits other features such as easy operation including scoring and interpretation of scores and efficient administration as well.
With respect to its bilingual versions, Nguyen and Nation (2011) designed a Vietnamese version and found that a bilingual version performed in much the same way as the monolingual test, distinguishing learners of different proficiency levels and returning lower scores at later levels of the test. The bilingual test is a feasible alternative to the more challenging and time-consuming monolingual one because it usually avoids complexities such as grammatical knowledge as well as reading skills. They suggest that learners should take every level of the test, otherwise there would be a considerable underestimation of learners’ vocabulary size. Karami (2012) developed a Persian version and indicated that bilingual versions could be more efficient than the monolingual version. Factor analysis revealed that a single construct, presumably word knowledge, is underlying the test. The hypothesized difficulty order is realized in the test and clusters of 1000 word levels provide more meaningful difficulty levels as they are less susceptible to idiosyncrasies at each 1000 level. He further calls for careful administration of the whole test which would lead to a more valid estimate of learners’ vocabulary size.
VST Studies in China
In China, researchers not only made great efforts to introduce the test instrument (Zhang, 2014; Zhu, 2009; Zhang, 2006) and validate the Mandarin version but also attempted to discover the relationship between vocabulary size and other language skills (Fu and Shan, 2014).
The validity study on the Mandarin version (Wang and Fan, 2011) found that the test could measure learners’ receptive vocabulary effectively but words from the seventh to the 14th frequency level could not distinguish between intermediate and high level students significantly. In addition, the Mandarin version appeared to be more suitable to low level students while bilingual and monolingual versions made no difference to intermediate and high level students. Wang (2012) compared the monolingual and bilingual Mandarin version and identified the 6000 word frequency level in monolingual version to be the best instrument in analyzing the relationship between vocabulary size and second language proficiency level. Linear regression demonstrated that there was a rather significant relationship between vocabulary size and listening, reading and writing skills. Wang (2014) examined the predictability of vocabulary size, as measured by the VST, on learners’ language proficiency levels. Results demonstrated a rather moderate correlation between vocabulary size and scores of College English Test (CET, a nationwide English proficiency test) Band 4 and no correlation between vocabulary size and the scores of CET Band 6. Tan and Yin (2015) investigated the vocabulary size of non-English majors by applying the Mandarin version. The students’ vocabulary size steadily increased from 3945 to 4128 and to 4972 in three continuous terms. Post-hoc results showed that there was no significant difference on vocabulary size between the first and the second term but there was significant difference between the first and the third term and between the second and the third term.
In general, Chinese scholars have explored vigorously and elucidated the test instrument. However, there are some limitations coupled with the research. First, the validity of the instrument is not verified at the preliminary stage of the research. Researchers directly adopted the monolingual or the bilingual version without testifying its appropriateness on Chinese learners. The huge population of Chinese learners, their unique learning experience and special learning environment may all affect the degree of suitability of the test. As the Chinese proverb goes, a handy tool makes a handy man. The guarantee on the validity of the instrument is the prerequisite for a convincing research result. Researchers need to adopt, adapt and develop an instrument in order to maximize the quality and effectiveness of the test. Second, the instrument was not in accordance with the purpose in some research. The purpose of the VST is to examine the vocabulary knowledge required for reading, thus it provides little indication of how well these words could be used in speaking, listening and writing (Nation, 2012). If the test is manipulated to investigate learners’ listening skills, it definitely goes against its design purpose and will not demonstrate a high relationship between receptive vocabulary size and other language skills except reading. Third, previous studies aiming at investigating receptive vocabulary size were conducted within the framework of Classical Test Theory (CTT). CTT has some limitations, for example, the test item difficulty and discriminability are sample-dependent; the observed and true test scores are test-dependent; it mistakenly assumes equal measurement errors for all examinees (Alagumalai and Curtis, 2005). Therefore there is an urgent need to demonstrate the degree of appropriateness of the VST on Chinese learners.
This research aims to demonstrate the validity of the Mandarin version of the VST. Validity is whether ‘a test really measures what it purports to measure’ (Kelly, 1927: 14). From this simple definition evolved different types of validity, namely content validity, construct validity, concurrent validity and predictive validity etc. (Angoff, 1988; Davies, 1990; Gregory, 2005). Validity becomes multifaceted but these types of classification are not alternatives but complementary aspects of an evidential basis for test interpretation (Weir, 2010). Messick (1995) put forward his unified concept and identified six aspects of construct validity including content, substantive, structural, generalizability, external and consequential validity. These function as general validity criteria or standards for all educational and psychological measurement. This article will examine the validity of the Mandarin version of the VST mainly within Messick’s (1995) construct validity framework.
The task will also be approached from the perspective of item response theory (IRT). IRT includes a range of probabilistic models that enables researchers to describe the relationship between a test taker’s ability level and the probability of his correct response to any individual item (Lord, 1980; Shultz and Whitney, 2005). It has found tremendous use in computer adaptive testing and developing performance tests. The detailed information the model provides has proved to be helpful for constructing and rigorously testing the psychometric properties of a measuring instrument. This study uses the one-parameter logistic model, also known as the Rasch model, which is based on the assumption that there is only one parameter apart from person ability that determines what the response is, namely item difficulty (Rasch, 1960). Psychometric properties, including item reliability, person reliability, data-model fit statistics and bias size are examined by Facets (3.71.4). SPSS is applied to estimate the consistency of the test and demonstrate complementary roles of CTT and IRT in test score interpretation.
Research Questions
This research aims to answer four questions:
Could the shorter Mandarin version of the VST effectively distinguish learners of different proficiency levels?
Do the items in different frequency levels display a reasonable distribution and form fair difficulty continuum?
Do the items in each frequency level conform to the difficulty level presented in the word list of College English Curriculum Requirement (2007)?
Does the shorter Mandarin version of display item bias in terms of gender?
Participants
Three groups of participants in Jiangsu University of Science and Technology are involved in the study with 35 English majors and 142 non-English majors. They are: (1) seniors of English majors who are considered as a high level group with 4 males and 31 females (n=35); (2) sophomores majoring in electronics with 37 males and 55 females (n=92); (3) freshmen majoring in international business with 37 males and 13 females (n=50). Their ages vary from 19 to 24. The test was given to group 2 and group 3 one week after the nationwide CET Band 4 exam and their English proficiency levels are represented by the CET Band 4 scores (Table 1). Independent sample t-tests show that the t-value between the two groups is -4.083(p<.000) which means the proficiency level of the two groups is significantly different. The participants were fully informed of the test purpose and were familiar with the test format.
CET Results for Group 2 and Group 3.

Instrument
This study adopted the bilingual Mandarin version of the VST in which a stem is in English and the four choices are presented in Chinese. An example from the fourth 1000 word frequency level is shown here:
candid: Please be candid.
a. 小心的
b. 表示同情的
c. 公平的
d. 直率的
Test takers are required to select the best translation of each word from four choices. Because a majority of the participants are non-English majors (n=142), the test items are checked against the word list in the College English Curriculum Requirement (CECR) (2007). The standard for recommended vocabulary in CECR is 4795 words. Results from comparison show that words from the ninth to the 14th frequency levels in the VST are far beyond the demand of CECR (2007). Wang and Fan (2011) demonstrate that items from the seventh to the 14th frequency levels display no significant difference in differentiating high and intermediate students and so the first eight levels of the VST were chosen and formed as the shorter Mandarin version. A pilot study was carried out in order to identify some translation problems. An informal interview afterwards confirmed these problems and three translations were revised to avoid ambiguities.
The following are the revised items with the original choice in brackets.
yoghurt (7000–10): This yoghurt is disgusting d. 呕吐物(榅桲)
marrow (8000–6): This is the marrow. d. 亭子(增加工资)
cube (5000–6): I need one more cube. c. 茶杯(缸子)
Choice D in yoghurt was changed into 呕吐物(meaning something vomited) because the original expression was a term unfamiliar to the subjects. Choice D in marrow was changed into 亭子(meaning pavilion) because the original causes an apparent subject-verb conflict. Choice C in cube was changed into 茶杯(meaning cup) in that the original consists of a dialect which causes some ambiguities in Chinese. All the participants finish the revised version in class within 20 minutes.
Results and Discussion
Could the shorter Mandarin version effectively distinguish learners of different proficiency levels?
The content aspect of construct validity includes evidence of content relevance, representativeness, and technical quality (Messick, 1995: 6). ‘A key issue to the content aspect is to determine the knowledge, skills, attitudes, motives and other attributes to be revealed by a task’ (Messick, 1995:17). The current research endeavours to investigate whether there are a sufficient number of items in the test to distinguish learners of different proficiency levels. The descriptive statistics for test-takers are presented in Table 2. The mean scores of the high, mid and low group are 53.94, 45.88 and 40.28 respectively, with a S.D of 6.51, 5.38 and 5.45. The maximum score is 67, whereas the minimum is 30. The standard deviation of the high level group is the largest, indicating high variability of score difference among subjects.
Descriptive Statistics for Three Groups.

To determine whether the differences among the three groups were statistically significant, a one-way ANOVA was carried out. The F ratio for the total score of the test between groups was F(2,176)=60.359, (p<.05) (Table 3), which indicated significant difference among the three groups. To identify the exact differences among the three proficiency levels, post-hoc comparisons were performed (Table 4). The difference between high level group and low level group was the greatest (Mean difference=13.662, 95%CI=−16.60,−10.72, p⩽.05). The mean difference between the high level group and mid level group was 8.062 (95%CI=5.41,10.71, p⩽.05) and the mean difference between the mid level and low level group was 5.60 (95%CI=−7.94,−3.25, p⩽.05). Generally, the results support the fact that the 80 items could discriminate individuals of different proficiency levels.
The Results of One-way ANOVA of Group Differences.

Post-hoc Tests for Group Differences.

The mean difference is significant at the 0.05 level.
Compared with CTT, IRT aims to investigate the underlying trait of both examinees and items and project them on the same scale according to their ability or level of difficulty (Masters, 2005). The reliability of the test is reflected by the separation index and the separation ratio which describes the amount of variability in the measured elements. The reliability of the separation index for each facet is a proportion ranging between 0 and 1.0, while the separation ratio ranges from 1.0 to infinity (Linacre, 1998).
It can be seen from Table 5 that the mean ability for examinees was .58 (with a standard deviation of .63) and their ability range was from -.80 to 2.54. The person separation index was 1.89, which suggests the scores of the vocabulary test were reliable to separate them into different levels of ability. The separation strata was 2.85 indicating the subjects could be roughly divided into three level groups, thus conforming to group categories of the research. The chi-square of 756.5 was significant at p<.00 and therefore demonstrated significant difference between groups. Based on the analyses from CTT and IRT, a conclusion may be drawn that the shorter Mandarin version could effectively distinguish learners from different proficiency levels. Under Messick’s (1995) construct validity framework, this confirms that the number of items is sufficient to demonstrate its content relevance.
Examinee Measurement Report (N=177).

Do the items in different frequency levels display a reasonable distribution and fair difficulty continuum?
In Messick’s (1995:17) opinion, ‘it is not sufficient merely to select tasks that are relevant to the construct domain…the assessment should assemble tasks that are representative of the domain in some sense’. The criterion for representativeness is whether the item hierarchy shows sufficient spread. Under IRT, the item difficulty ranges from -4.76 to 2.92 (with a standard deviation of 2.01) with a mean difficulty of -.07 showing a good spread of item difficulty (Table 6). The standard errors indicate the precision of item measures. The smaller the errors, the more precise the estimates. The standard error values within 0.3 or even 0.5 is generally considered acceptable (Green, 2013: 169). The standard error of .34 bore a witness to a rather precise estimate. The item reliability of .97 with a fixed chi-square of 3609.3 (p<.00) and a high separation ratio (5.80) demonstrated that task difficulties were clearly and reliably separated along the continuum. The item strata statistics (8.06) indicated the number of artistically distinct strata of item difficulty (Wright and Masters, 2002). This finding confirms that the difficulty of the items representing the empirical item hierarchy varies greatly (showing nearly eight statistically distinct levels). Thus this version can be applied to estimate learners with different levels of written receptive vocabulary and provides sufficient numbers of strata to measure learners’ vocabulary size.
Items Measurement Report (N=80).
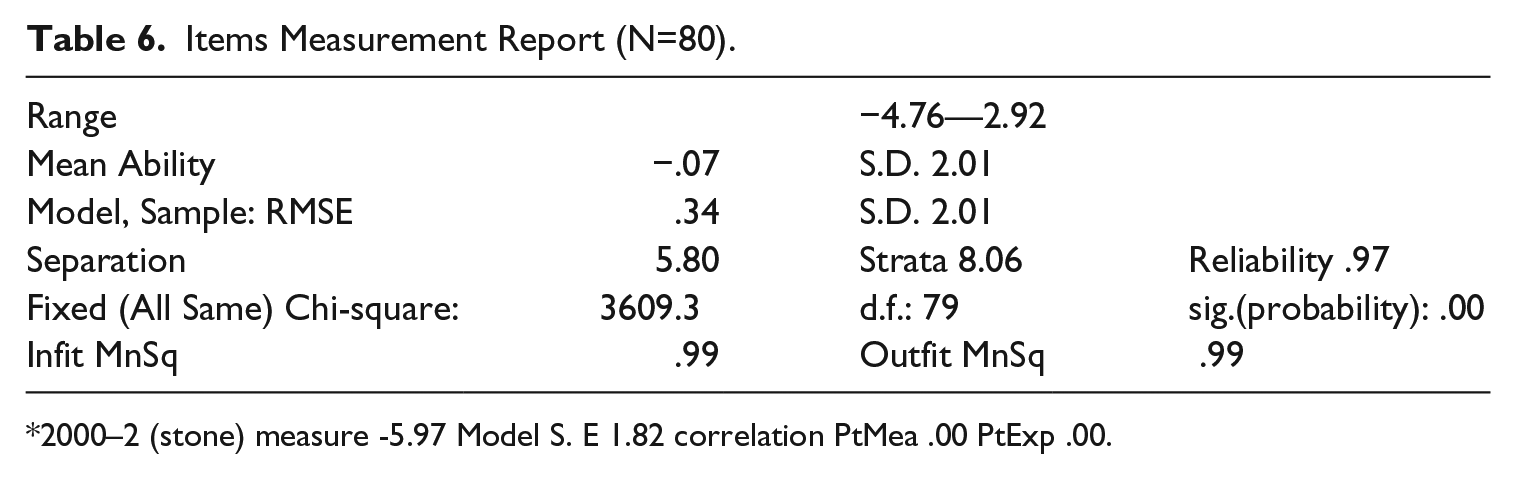
2000–2 (stone) measure -5.97 Model S. E 1.82 correlation PtMea .00 PtExp .00.
One aspect of content validity is its technical quality (Messick, 1995), which was evaluated by inspecting standardized item weighted mean square fit statistics. The fit statistics reflected by Infit mean square (Mnsq) and Outfit Mnsq help to identify misfitting items. The ideal value of Infit Mnsq and Outfit Mnsq is 1.00 (Bond and Fox, 2007; Wright and Linacre, 1994). The fit statistics of Infit MnSq of .99 and the Outfit MnSq of .99 in this study indicate a perfect construct validity except one item. Item 2000-2 (stone) displayed a logit measure of -5.97 which may suggest that this item is rather unchallenging for Chinese learners. This result is different from other studies (Beglar, 2012; Nguyen and Nation, 2011; Karami, 2012) and it might be a unique characteristic displayed by Chinese learners. The difference may be explained by comparing choices in both versions. The four choices in the monolingual version are: hard thing; kind of chair; soft thing on the floor; part of a tree while the Mandarin version for the four choices are stone, special kind of chair; cushion; branch. Apparently the Mandarin version is rather straightforward for Chinese learners. The other reason may be associated with Chinese learners’ special learning experience. This word appears in the Oxford Junior English textbook (2009) for year seven. When Chinese learners start learning English in junior schools, rote learning is the dominant vocabulary learning strategy. In such a learning environment, the word stone is presented to learners repeatedly either in spelling or pronunciation so that it could be remembered permanently, but this remains to be explored in future studies.
Beglar (2010) found that basis (1000-10) displayed underfit to the Rasch model (Infit Mnsq=2.05, Infit Zstd=6.4) which was judged if the standardized fit value is >2.00. While in the current study, the word basis displayed good fit statistics (Infit Mnsq=1.18, Infit Zstd=1.6). This again could be explained by the difference between the two versions. In the monolingual one, the two choices answer and main part could have a strong distracting effect while the choices in the Mandarin version are uncomplicated. This indirectly confirms Karami’s (2012: 55) research that ‘complex grammatical knowledge as well as good reading skills are required on the part of the test-takers to get the item right in the monolingual version’.
Do the items in each frequency level conform to the difficulty level presented in the word list of College English Curriculum Requirement (2007)?
Messick (1995:16) referred to substantive aspect of content validity as ‘theoretical rationales for the observed consistencies in test response, including process models and task performance, along with empirical evidence that the theoretical processes are actually engaged by respondents in the assessment tasks’. This aspect was investigated by determining whether the item difficulty ascends in the hypothesized order. The items in the VST are based on their frequency levels in the BNC and it is hypothesized that word frequency could be an indicator of the probability that an individual would encounter a word in an authentic communicative context (Beglar, 2010: 108). This study investigated the difficulty continuum by calculating the mean scores for each frequency level (Table 7).
Descriptive Statistics for Each 1000 Frequency Level.
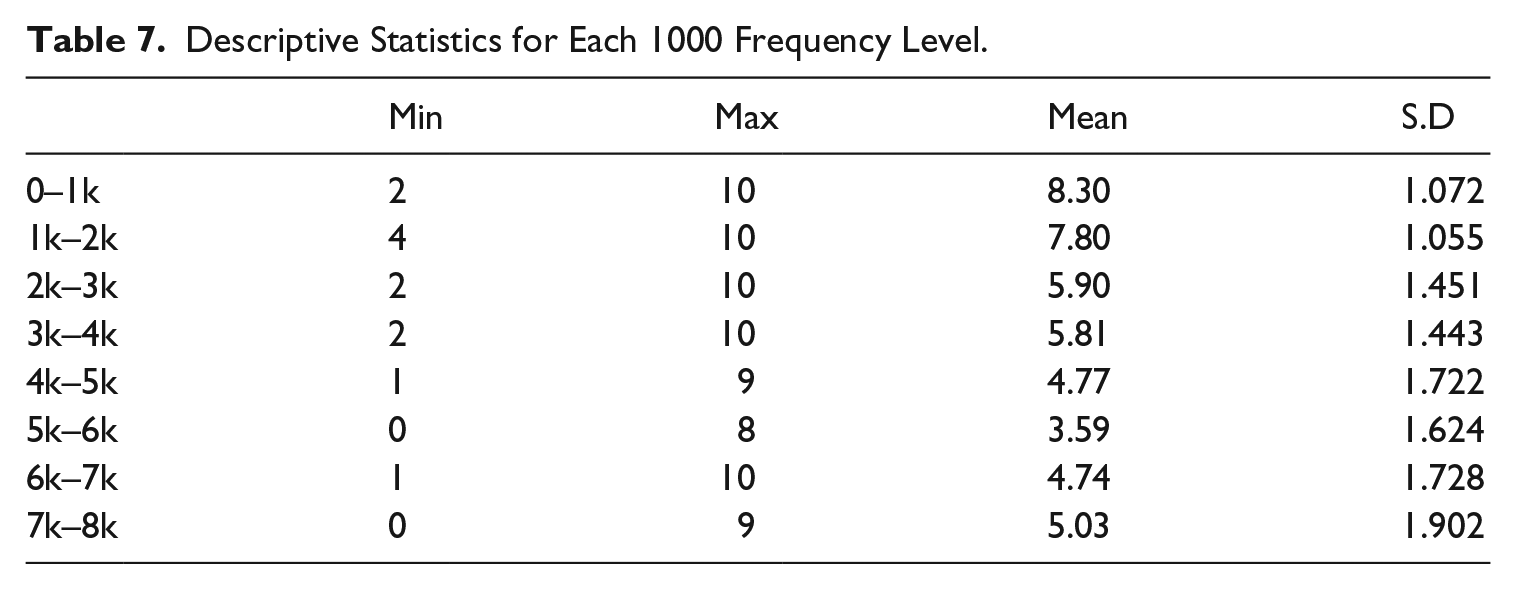
The mean scores from the first frequency level to the sixth frequency levels descends from 8.30 to 3.59, and then it increases slightly in the last two levels. This means the difficulty level does not rigorously follow a declining pattern. A Friedman test was performed showing the statistics of Chi-square with 391.838 (p<.000), thus demonstrating the significant difference of each frequency level. The fluctuation at the seventh and eighth level is apparently associated with loan words, namely palette, kindergarten, cabaret. Karami’s research displayed a similar trend. He argues that ‘despite the existence of some idiosyncrasies in the difficulty order, it is clear that there is a rough order of difficulty to the frequency levels. It may be more apt to compare the performance of the examinees on clusters of levels rather than the individual levels themselves’ (Karami, 2012: 62).
Since 142 subjects are non-English majors, the difficulty level of the 80 items was checked against the word list in CECR (2007). CECR lays down the foundation for vocabulary teaching for non-English majors in all Chinese universities and colleges. Given the huge population of students, the widespread locations and different levels of universities, it is hardly possible to apply a universal criterion for college English teaching all over China. Therefore CECR divides students into three levels: basic, intermediate and high level. The recommended receptive vocabulary for each level is 4795, 6395 and 7675 respectively. The distribution of 80 items in CECR is presented in Figure 1.
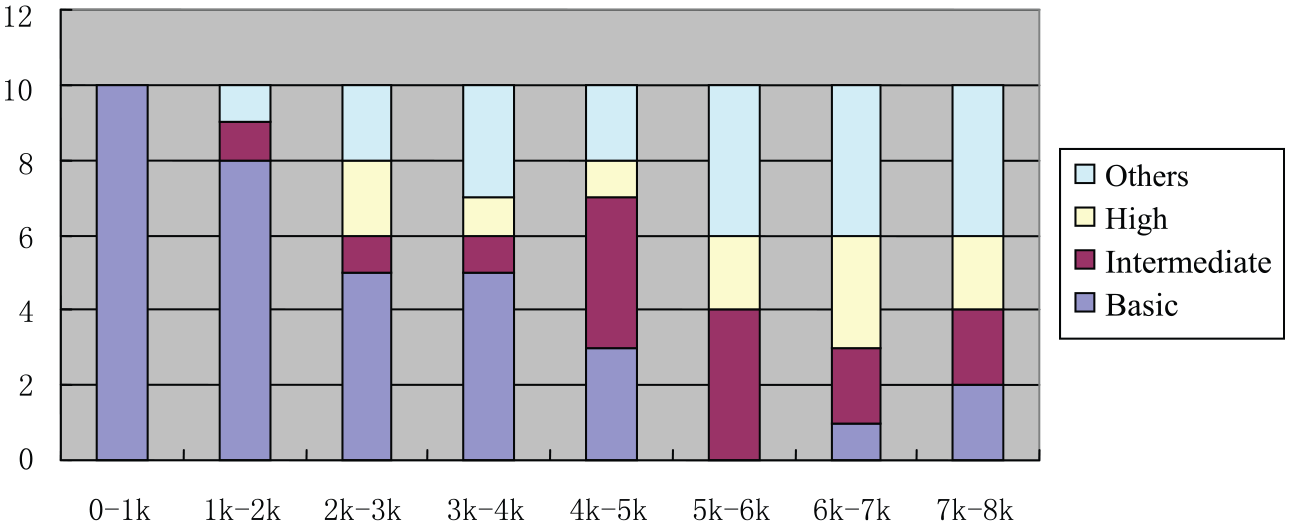
Distribution of 80 Items in College English Curriculum Requirement.
Words from the first six frequency levels in the VST which are classified as basic level in CECR show a declining pattern, while in the seventh and eighth frequency levels, three words (yoghurt, kindergarten, authentic) are listed in basic level and four words (olive, bloc, eclipse, locust) are grouped as intermediate level. Figure 1 shows some discrepancies on difficulty levels between the VST and CECR, but this does not affect the estimate of vocabulary size as a whole. The item difficulty index from Rasch analyses for kindergarten (logit=−2.50, S.E=.34), olive (logit=−.75,S.E=.18) and authentic (logit=−.20,S.E=.17) show that the three words are not difficult for Chinese learners. This could be attributable to Chinese learners’ learning experience. For example, the pronunciation of the word kindergarten has some connection with the word garden so that learners could form natural phonological associations. The word olive is common either in association with a kitchen or in advertisements, so Chinese learners are not in a shortage of linguistic input with regard to these two words. By comparing the VST and CECR, we may draw a tentative conclusion that the items in the seventh and eighth frequency level in the VST do not conform exactly to the difficulty level of CECR (2007). Therefore, it is not valid enough to have an accurate estimate of Chinese learners on this level. Nation (2012) explains that loanwords or cognates in the learner’s first language are not removed from the test because they are a legitimate part of a learner’s second language vocabulary size. This statement is reasonable, however, Chinese learners do seem to display some inconsistent results on the seventh and eighth level because of these loan words. Therefore, words in these two levels should be singled out cautiously in order to obtain accurate pictures of Chinese learners’ vocabulary size.
This finding could be utilized to explain the research result of Wang (2014) who found a moderate correlation between vocabulary size and CET Band 4 and no correlation between vocabulary size and CET Band 6. His explanation was that a large vocabulary size as well as a good command of the depth of vocabulary knowledge were necessary to obtain a higher score in Band 6. This is plausible on the surface, but the weak predictability of VST on CET Band 6 may lie in the inappropriateness of some items from the seventh to the eighth frequency level. If these two frequency levels are improved, their predictability on CET Band 6 scores might be enhanced.
Does the shorter Mandarin version of the VST display item bias in terms of gender?
Messick (1995: 11) stated that ‘the generalizability aspect examines the extent to which score properties and interpretations generalize to and across population groups, settings and tasks’. This means when male and female subjects display roughly the same probabilities of answering the items correctly, the validity of the test could be reassured. Since the gender proportion in the high level group and the low level group varies greatly, with predominantly females in the high level group (31 out of 35) and mostly males in the low level group (37 out of 50), the mid level group with 37 males and 55 females was investigated to determine the gender bias. Descriptive statistics were obtained with a mean score of 45.02 (with a standard deviation of 5.38) for males and a mean score of 46.45 (with a standard deviation of 5.36) for females. Independent sample t-tests were conducted and showed that when equal variances assumed, F ratio was .295 (p=.588), which means there was no significant difference between male and female subjects in this group. From a validity perspective, the interpretation of scores could be generalized across male and female subjects within the same proficiency level. In addition, a bias size in the Rasch model was generated by testing differential item functioning (DIF) for the interaction between each item and gender. Magnitude of bias size indicates whether the item is harder or easier for gender subgroup compared with overall item difficulty measure. Although bias-interaction analyses across gender and items showed different bias sizes, they did not differ significantly among males and females in the mid level group. So it was concluded the items display a high degree of generalizability within Messick’s (1995) construct validity framework.
Conclusion
Based on Messick’s (1995) construct validity framework, this article provides some validity evidence on the shorter Mandarin version of the VST from its content aspect, technical quality, substantive and generalizability aspect. In general, this version could be utilized to differentiate learners effectively based on the results of ANOVA and measurement reports of Rasch analyses. Since the recommended vocabulary for advanced learners in Chinese universities is 7675 words in CECR (2007), this research proves that 80 items are sufficient to investigate the vocabulary size of non-English majors in China. It would be cost effective and time saving when we take the huge population of Chinese EFL learners into consideration. Second, the first six frequency levels display a reasonable distribution of difficulty level and a fair difficulty continuum. By comparing the difficulty level of items with the word list in CECR (2007), a tentative conclusion is drawn that some words, especially loan words from the seventh and the eighth frequency level prove to be problematic for an accurate estimate of Chinese learners’ receptive vocabulary size. Indirect evidence shows the Mandarin version seems to be more straightforward than the monolingual one because the wording on the choices are less distracting and easier to understand. Third, there is no item bias within the same proficiency group concerning gender difference. Item stone (2000-2) with its extremely low logit scale suggests the item is undemanding and this phenomenon was probably unique to Chinese learners because of their special learning experience and learning strategy.
This study sheds some light on the applicability of the VST on Chinese learners and aims to improve the test instrument in order to assess the vocabulary size of Chinese learners precisely. Future studies may be expected to include more subjects and participants undertaking the whole test, so that a more accurate picture of the test could be obtained. At present, researchers in China have not reached a consensus on how to measure the written receptive vocabulary size effectively and we are looking forward to more empirical projects on vocabulary research with varieties of test designs and diversities of research results.
Supplemental Material
10.1177_0033688216639761_Supplementary – Supplemental material for Validation of the Mandarin Version of the Vocabulary Size Test
Supplemental material, 10.1177_0033688216639761_Supplementary for Validation of the Mandarin Version of the Vocabulary Size Test by Ping Zhao and Xiaoli Ji in RELC Journal
Footnotes
Funding
This work was supported by the 7th Chinese Foreign Language Education Fund [ZGWYJYJJ2014A32] and Jiangsu Social Sciences Fund [2013SJB74008].
Supplemental material
Supplemental material is available for this article online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.