
Abstract
Corpora are essential tools in the teaching of English as an international language (EIL). With the advent of high-powered computers, online corpora have been developed with the potential to transform how EIL is taught both inside and outside the classroom, since anyone with a mobile device and internet access can now take advantage of numerous corpora databases. But applying computer corpora to language pedagogy also requires teacher mediation; moreover, the issues involving the lack of corpus integration in either the EIL language classroom or teacher training programmes are both challenging and complex. Nonetheless, there is hope that empowering teachers with the necessary tools, skills, and knowledge in using online corpora will lead to the day when corpora resources and their use are no longer the exclusive preserve of researchers and reference material developers.
Keywords
Introduction
The advent of high-powered computers has led to significant developments in the study of language. The availability of computer technologies for storing language data in digital format and for accessing the data through a software interface for data analysis has generated great interest among researchers. Among these are researchers whose interest lies mainly in corpora and their potential for language teaching and learning. As a result, the prominence of corpus-based approaches in language education has been growing for several decades. In particular, the development of online corpora, paired with rapid changes in technology, has the potential to change how English as an international language (EIL) – in other words, the use of English by people of different language backgrounds to communicate – is both taught and learned inside and outside the classroom. Indeed, nowadays anyone with a mobile device (e.g. smartphone, laptop, or tablet) can access online corpora, which in turn has tremendous implications for their future use in language learning.
Important Developments in the Use of Corpora
The historical development, definitions, and types of corpora began with the Brown corpus in the 1960s and the first corpus-based dictionary for learners, Collins COBUILD English Language Dictionary, in the 1980s. Since those early days the use of corpora in linguistic research and language teaching has expanded with the improved availability and accessibility of sizable collections of language texts in electronic format. Corpus types (spoken, written, or a combination) range from general or reference (e.g. the British National Corpus) to specialized (e.g. the Michigan Corpus of Academic Spoken English, Hong Kong Engineering Corpus, or Hong Kong Corpus of Spoken English), parallel (same texts in different languages), or learner corpora (e.g. Cambridge Learner Corpus or International Corpus of Learner English), to monolingual or multilingual, and so on. All these types have been covered extensively in the literature (e.g. Flowerdew, 2012; Hoffmann, 2013). These developments have been further assisted by the software interface of concordancers for data analysis, most of which allow users to select key words or phrases, or even selecting speaker or transcript attributes (e.g. http://bit.ly/1Dzi1I4).
Nonetheless, attention to corpora and their use in helping researchers understand how language works, as well as the linking of insights from research to practical applications for teachers, have taken considerable time to develop. The same is true of the appreciation of corpora as a source and tool for language teaching and their direct use by teachers and learners in the classroom. Although since the early 1990s the field of English language teaching has witnessed growing interest in applying the findings of research on corpus linguistics to language pedagogy–easily seen at professional conferences and in the literature–to date the gap between research and practice in teaching English remains.
Yet promisingly, teaching-related concerns have recently begun influencing corpus-based research (Boulton, 2013; Römer, 2009). Other changes have begun having an effect. Rapid changes in technology, globalization, and the spread of English have added to developments in language teaching (Richards and Rodgers, 2014). Increased demand for speakers of English as a second or foreign language, growing immigration, and the internationalization of education have created a need for new language programmes and approaches. Further, important new developments have taken place in theories of language and of language learning, which typically inform pedagogical approaches and methods (Richards and Rodgers, 2014), as, for instance, audiolingualism was informed by the structuralist model of language and the underlying behaviourist learning theory. The impact of such changes in theories on approaches and methods has been well documented.
In particular, growing recognition in recent decades of the theories of psychologist Lev Vygotsky (1896–1934) in the field of second language education and changing perspectives on educational approaches have led to acknowledging the idea that language learners should be able to deal with issues not already present when learning the language. This approach stands in contrast with traditional approaches such as the grammar translation or audiolingual methods, where teachers teach learners how to produce and imitate language. This newer approach is also integral to the support of the underlying learning theory of corpus-based learning – namely, data-driven learning (Johns, 1994). In line with this theory, language learners are guided in using corpora or related materials first-hand to observe patterns in the language and to generalize about other forms and usages (Huang, 2016; O’Keeffe et al., 2007). Within this mode of learning, the learner plays an active role, the process is supported by teachers or peers, and the pedagogical materials reflect the learner’s emerging needs. Moreover, these materials are designed to provide activities allowing greater creativity and interaction based on solving problems instead of depending on fixed norms of information (Farr, 2008).
Major Uses of Corpora
Within corpus-based language pedagogy, most attention has been devoted to using corpora as sources of descriptive insights relevant to language teaching and as tools to directly improve learning and teaching processes and outcomes. In this respect, Leech (1997) was the first to notice an approaching convergence between teaching and language corpora, which he saw as developing along three foci; since his study, the field has indeed witnessed the manifestation of these foci, which in turn have relevance to teaching and learning in the EIL context. These foci are as follows:
1. The indirect use of corpora in teaching. This focus is evidenced in reference dictionaries and books (e.g. the Longman Grammar of Spoken and Written English, Longman Dictionary of Common Errors, Collins COBUILD Advanced Learner’s English Dictionary, Collins COBUILD Intermediate English Grammar and Practice, The Cambridge Advanced Learner’s Dictionary, Longman Dictionary of Contemporary English, Oxford Advanced Learner’s Dictionary, Oxford Collocations Dictionary for Students of English, Oxford’s Practical English Usage, and Macmillan English Dictionary), development of teaching materials (e.g. the Touchstone series, the PHaVE List, Academic Vocabulary Lists), and language testing (e.g. the University of Cambridge Local Examinations Syndicate).
2. The direct use of corpora in teaching. This focus concerns Fligelstone’s (1993) three-tiered model of teaching about (theoretically driven, teaching corpus linguistics as an academic subject), teaching to exploit (applied oriented, introducing students to ways to exploit corpora for learning purposes), and exploiting to teach (using a corpora-based approach to inform teaching).
3. The development of teaching-oriented corpora. This focus involves creating and using learner corpora in teaching, material development, and research. In classroom teaching, self-compiled student texts or large-scale learner corpora (e.g. Cambridge Learner Corpus) can be used to analyse linguistic deviations for teaching and learning purposes.
Nonetheless, despite these developments, there has been more indirect than direct use of corpora in language teaching, including the teaching of EIL. Unfortunately, corpora have yet to achieve mainstream status within the classroom (Breyer, 2009). Reasons for this include time limitations, lack of access to technology, programme requirements, insufficient language proficiency by learners, and inadequate expertise and skills needed by teachers to analyse and teach with corpora, factors that have all been pinpointed and discussed extensively in the literature.
With respect to reference publishing, on the other hand, the impact of corpora has been far-reaching, most notably in the development of learner dictionaries by Longman, Collins COBUILD, Oxford, Cambridge, and Macmillan. As Hunston said, ‘Even people who have never heard of a corpus are using the product of corpus-based investigation’ (2002: 96). Corpus-based learner dictionaries provide information based on both quantitative and qualitative data such as frequency, collocation, phraseology, and lexis in grammar; they also aim to provide definitions at the level of language that learners can understand, along with illustrative examples extracted from corpora. In the context of teaching EIL, where exposure to fluent speakers of different varieties of English may be limited, a corpus thus can serve as a source of evidence that complements both the intuitions of teachers who speak English as a first or additional language, and the notions of learners about the ways speakers and writers actually use the language.
In syllabus design and materials development, researchers have also critically examined syllabi and pedagogical materials for teaching English as a foreign language in relation to corpora. For example, Mindt (1996) compared non-corpus-based syllabi with corpus data and concluded that the order of grammatical items, such as modal verbs, future tense expressions, and conditional clauses, was not based on empirical evidence. Numerous researchers have suggested, however, that as teachers gain experience using corpora, they should begin to view the design of syllabi differently (Hunston, 2002). This trend can be witnessed in recent studies. For instance, Hajiyeva (2015) conducted a lexical analysis of university textbooks for English majors; Charles (2007, 2011) examined the corpus-aided, discourse-based activities of graduate students; and Poole (2016) implemented a corpus-based approach in an undergraduate composition course focusing on the study of rhetoric.
This emphasis on authenticity in language teaching and learning, especially in contexts where exposure to the target language is not readily available, has in turn led to developing corpus-based teaching materials such as the Touchstone series (McCarthy et al., 2005), which is based on the North American English subsection of the one-billion-word Cambridge International Corpus. These kinds of materials are designed to ensure that learners experience the ways people actually use the language. Moreover, as several scholars have pointed out, learning a second or foreign language involves ‘learning “explicit knowledge” with awareness’ (McEnery and Xiao, 2011: 368), which requires learners to be extensively exposed to language material – something that various general or specialized corpora can help provide. For teachers of EIL who want to use corpora for data-driven learning (John, 1991, 1994), however, the availability of a corpus that contains language from learners comparable to their learner group (e.g. level of proficiency, first language background, context of language use, or task type) may be an issue. For these teachers, creating a learner corpus (e.g. Mukherjee and Rohrbach, 2006) using anonymized data from their own groups of learners and publicly accessible tools such as Corpus Builder from lextutor.ca may be options for addressing the needs of their students.
The various corpus-based findings on lexical, grammatical, and discourse features are, moreover, helpful not only for learners but also for teachers, teacher trainees, and teacher trainers in deciding what to teach. Proponents of the lexical approach to language teaching emphasize, for example, teaching collocations and fabricated patterns and chunks, examining fixed and semi-fixed lexical expressions and their associated frequency and formality, and developing collocational knowledge (Sinclair and Renouf, 1988; Willis, 1990). As many have pointed out, this emphasis may aid in developing language fluency (e.g. Myles, 2005).
In the context of teacher training, corpora have also been used to train language teachers across different contexts. Conrad (1999) was among the first to point out the importance of corpus-based research for language teachers and suggested that teachers could benefit from taking a corpus-based approach by analysing lexico-grammatical patterns. Allan (2002), for example, reported on the ways corpus data are being used in Hong Kong to raise the language awareness of English teachers. O’Keeffe and Farr (2003) recommended that corpus linguistics be a component of language teachers’ education. More recently, Breyer (2009) presented a case study of student teachers in Germany who were introduced to corpus-based analysis and trained to teach with corpora. Finally, Farr (2008) evaluated the use of corpus-based instruction in a language teachers’ education programme in Ireland through a survey of student teachers that shed light on both the potential pedagogical benefits and challenges of using corpora.
These studies further suggest that the best place to introduce language teachers to teaching and learning with corpora is when they are receiving their initial teaching education owing to such matters as limitations of time, the availability and suitability of resources or training to teach with corpora and so on (Breyer, 2009). Findings in the aforementioned studies suggest that practitioners thinking about incorporating corpus-based instruction into teacher training must above all anticipate challenges regarding teacher trainees’ personal beliefs and preferred modes of instruction or learning. In particular, it is important that teachers be made aware of various local values when teaching EIL – such as those of the student, teacher, classroom practice, or institution – that could potentially conflict with data-driven learning or corpus-based instruction. Teachers whose own first language is not English may not feel comfortable or feel competent in the know-how needed to guide learners through corpus analysis. Because the approach encourages discovery and divergent learning among learners, who often pursue different paths of discovery in exploring language data, it may challenge the teachers’ beliefs about the traditional role of the teacher in the classroom. Such culture-related issues are far more entrenched than are the technical aspects of integrating corpora into teacher education courses in ways that equip teachers with the necessary training in corpus consultation and analysis.
Learner Corpora and Their Potential
Initially, the discussion in the literature on using corpora in the language classroom focused on corpora for English as a first language (e.g. Nesselhauf, 2004), as well as their role as a resource and tool in informing English language teaching either in general or for specific purposes. In recent years, however, the potential of learner corpora, which language learners began producing in the 1990s as texts collected on computers, has begun receiving greater attention (e.g. Flowerdew, 2012). The insights that learner corpora can provide through analysing the language production of certain groups of learners from particular language backgrounds with respect to the difficulties they face are invaluable in language teaching and learning. Such learner corpora include Longman Learners’ Corpus (10 million words of written language), the Cambridge International Corpus (20 million words from Cambridge exam scripts written by learners of English), and the International Corpus of Learner English (3 million words in the form of written essays by learners with various first languages). The appearance of such corpora means that corpus-based research on linguistic deviations for language learners in general or for a certain group of learners can now be compared. This comparison work in turn has informed the development of learner dictionaries (e.g. the Longman Dictionary of Common Errors). In the past decade, numerous studies have also used corpora to develop insights into the sequence of English language acquisition for learners of English and, from there, to draw out the pedagogical implications (e.g. Myles, 2005).
The growing discussion and research on World Englishes (see Hundt and Gut, 2012) and English as a lingua franca (ELF, a variety of English spoken among speakers whose mother tongue is a language other than English) has recognized the status of English as the language of international communication. Yet at the same time, this development has raised important questions about the ‘version’ of English and associated speaker norms that should be taught or learned, since most interactions that occur in English around the world are among English-as-an-additional-language speakers (Jenkins, 2006; Seidlhofer, 2005). Here learner corpora can be useful in examining the core features of successful communication between/among fluent speakers. A major example is VOICE (Vienna-Oxford International Corpus of English), a 1-million-word corpus of World Englishes, which provides transcripts of naturally spoken exchanges between experienced ELF speakers from many different first language backgrounds. Rather than restricting corpora to a local national language, using corpora such as those of VOICE is becoming crucial to the teaching of World Englishes and EIL, and thus deserves serious consideration when practitioners decide on pedagogic priorities in designing EIL courses and programmes (Flowerdew, 2012).
Despite the promises of learner corpora for language learning, however, their direct use by teachers in the classroom, as with other corpora types, remains rare, owing in part to their limited accessibility and the representativeness of the data gathered. Their importance, however, cannot be overlooked, especially if learners are to be taught English for use in local, national, or international contexts (e.g. Burns, 2005). Whatever the target standards, varieties of corpora have much to contribute, directly or indirectly, to the teaching of EIL. These varieties include those based on Kachru’s (1995) model of the Three Circles of English – namely, the Inner Circle (English as a first language), the Outer Circle (e.g. English as a second language), and the Expanding Circle (e.g. English as a foreign language) – and those designed specifically for ELF, consisting of different collections of language data (e.g. the International Corpus of English; see Sand, 2013).
In English-language testing, learner corpora (e.g. Cambridge Learner Corpus, Corpus of Young Learners English Speaking Tests) have also been used for various purposes (e.g. Ball and Wilson, 2002; Taylor, 2003). Among these are examining the distinctive elements in written output produced by users of English as a foreign or second language on the Cambridge English examinations, developing common measures to reflect different levels of ability, and producing wordlists for specific purposes for use in test materials.
Practical Applications at the Lexical, Phrasal, and Discourse Levels
Framed around Leech’s three foci, some practical examples are provided below to introduce practitioners to corpora-based instruction and illustrate their use.
The Indirect Use of Corpora in Teaching
Any of the above-listed dictionaries, which were developed with the help of corpora, can be easily incorporated into either teacher-training or learner-oriented activities. For example, type the word ‘advice’ in the search box of the Macmillan Dictionary (220 million words of written and spoken texts) to see the kinds of information the tool can provide: frequency (indicated by the number of stars), collocates, and phrases (see Figure 1); learner language (in the ‘Get it Right!’ section, which illustrates deviations from the learner corpora to facilitate error corrections; see Figure 2); and the ‘Expressing yourself’ section, which provides formulaic expressions for pragmatic usage in different ways of offering advice, accompanied by sample sentences from corpora (see Figure 3). The task can also include comparing the words ‘advice’ and ‘advise’.
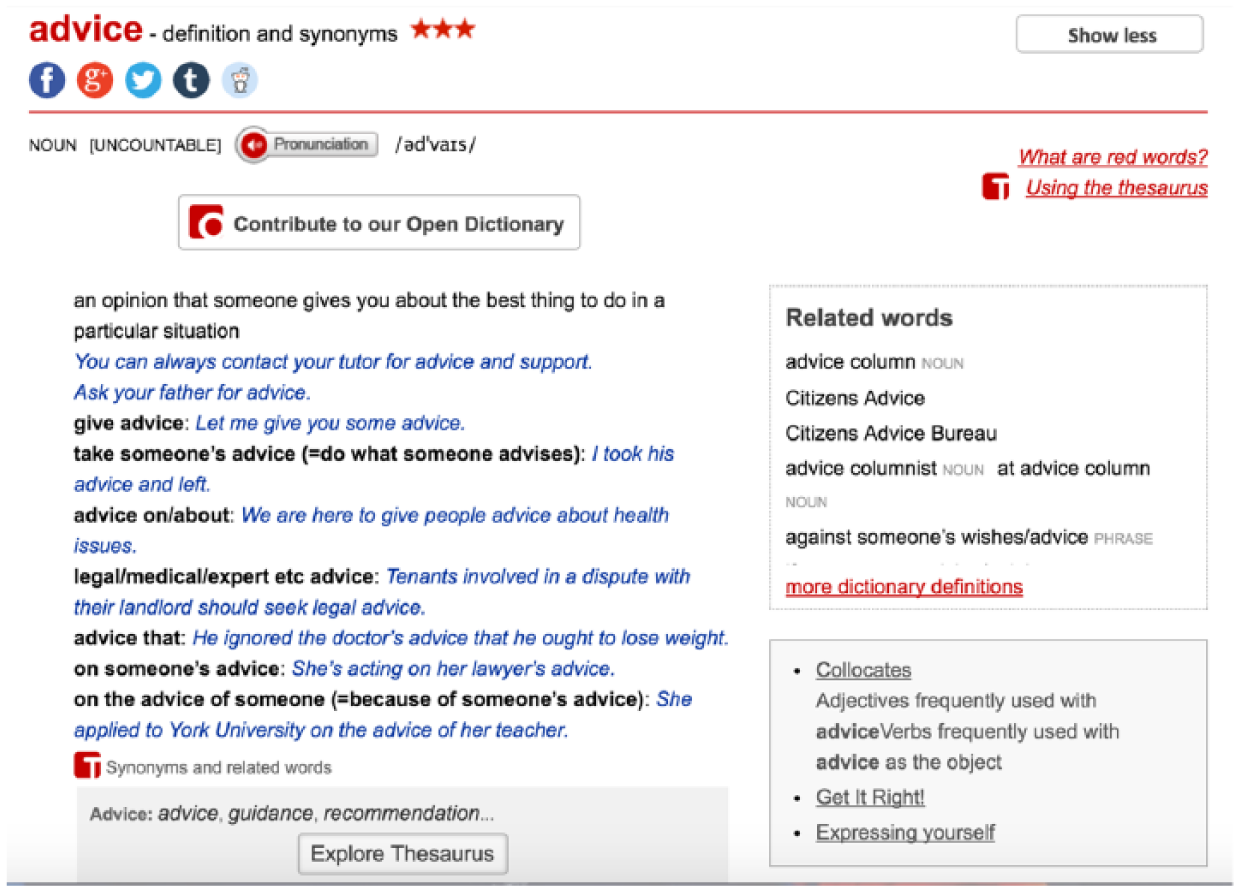
Sample search results for advice, using the Macmillan Dictionary.

The ‘Get it Right!’ section from the sample search of the word advice, using the Macmillan Dictionary.

The ‘Expressing yourself’ section from the sample search advice, using the Macmillan Dictionary.
Another example is the user-friendly PhaVE Dictionary (Garnier and Schmitt, 2015), which allows one to search the 150 most common phrasal verbs and their most common meanings. For example, Figure 4 illustrates the output for the phrasal verb ‘take off’, which includes its rank (#28), meanings (A, B, and C), and examples, along with a video example of the phrasal verb used in its most common meaning (meaning A).
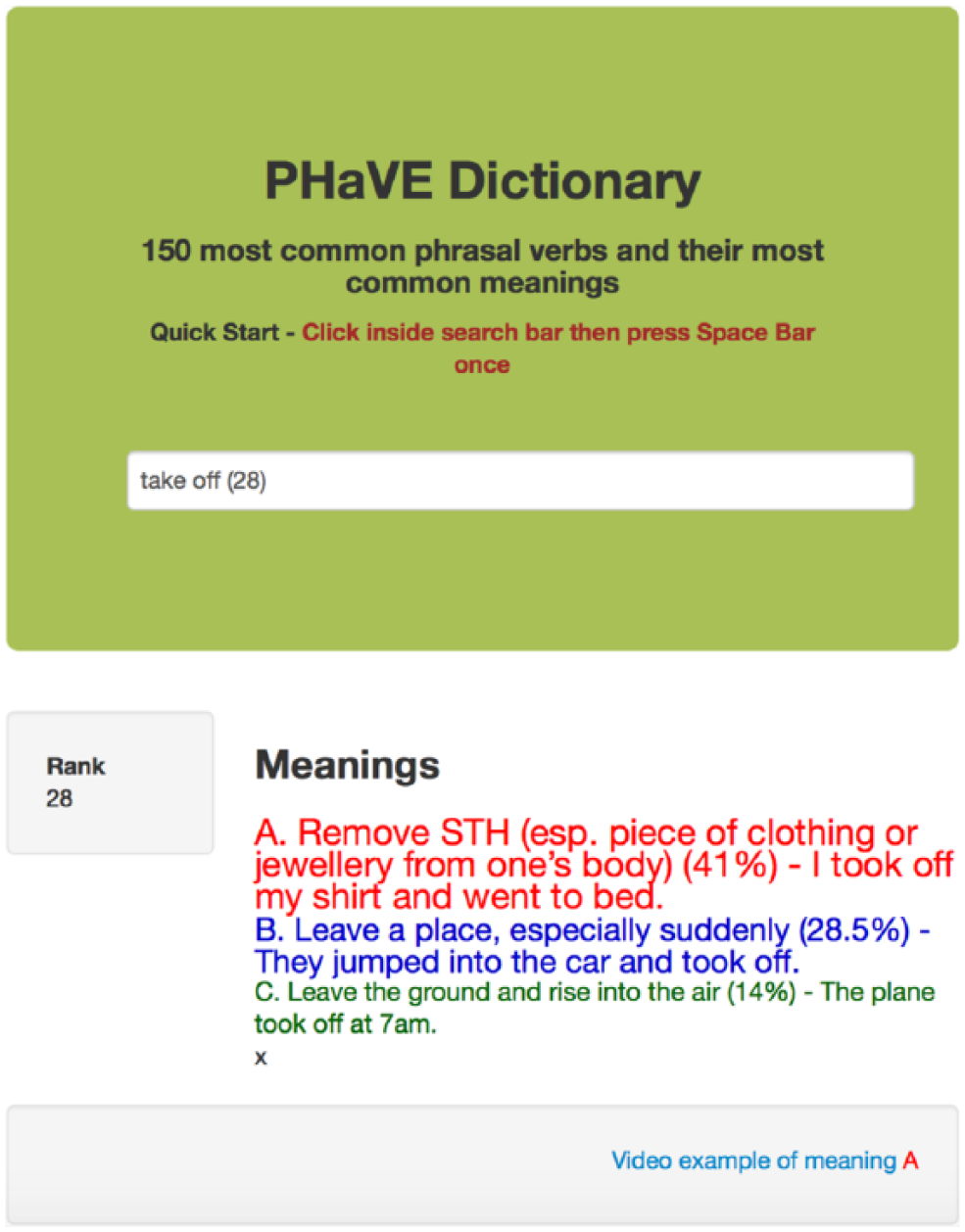
Sample output for take off generated by the PHaVE Dictionary.
The Direct Use of Corpora in Teaching
Various corpora-related articles or books (e.g. Bennett, 2010; Chamber et al., 2011; Liu and Lei, 2017; O’Keeffe et al., 2007; Reppen, 2010) have been written specifically for teachers and include plenty of corpus-based activities for the classroom involving the direct use of corpora.
At the lexical level, it is common to generate a word frequency list using
A sample text input using Lextutor’s Frequency tool (sample chapter from the MacMillan Graded Reader, intermediate level).
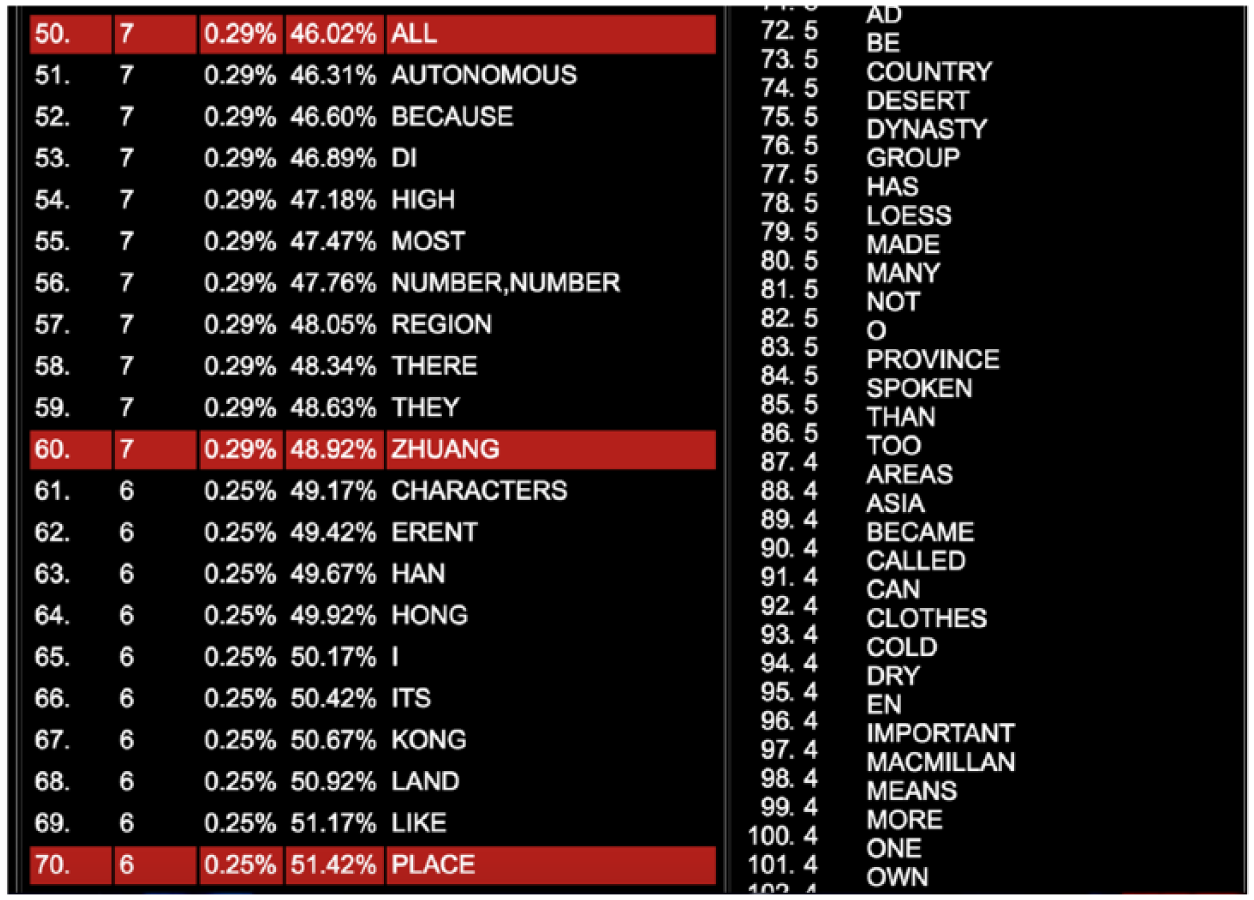
Output of word frequency list generated by Lextutor’s Frequency tool.

Sample concordance lines for autonomous in KWIC format from COCA.
In choosing suitable readings for classroom use in the EIL context, teachers can use news or featured articles published locally with cultural and linguistic relevance. The articles can be pasted into the Vocabprofilers to see the distribution by the classic four-way sorter (i.e. K1, first 1,000; K2, 1001-2000; AWL, academic; and Off-list words; see Figure 8), or by BNC-COCA (K1-K25 and Off-list) to determine whether a chosen article is suitable for specific learning purposes (e.g. intensive reading, development of fluency, or strategic development).
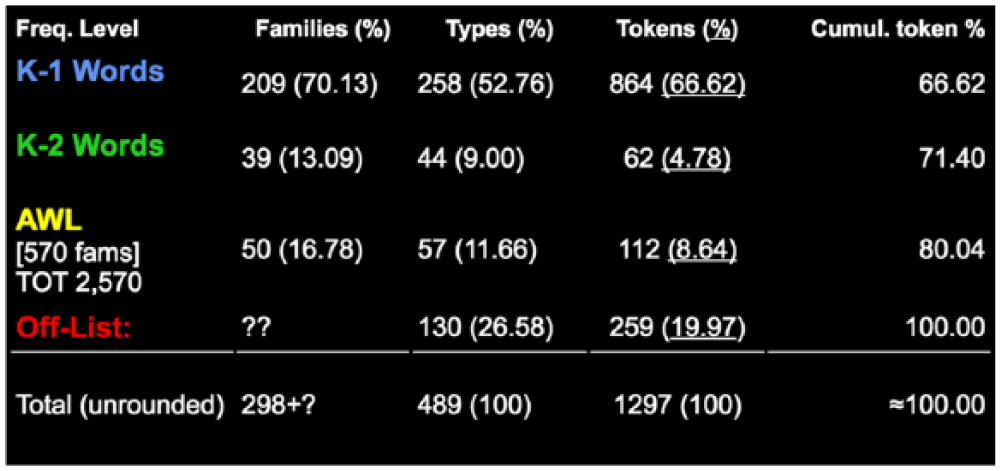
Sample vocabulary profile output using Lextutor’s Vocabprofilers.
For example, the output from a story on ‘Why ransomware is a big threat for computer users, and how to prevent [an] attack’ from the South Morning China Post website, obtained using the VocabProfilers, will generate the percentages of K-1, K-2, AWL, and Off-list words. Figure 9 shows the percentages of words falling into the first 1,000 (K1) all the way to the 21st 1,000. The off-list categories are highlighted in varying colours to more easily facilitate textual modifications (e.g. removing, simplifying, elaborating) using the ‘Edit-to-a-profile’ interface. Substantial research has suggested that for reading comprehension (for intensive reading, strategy use, and fluency practice), the amount of vocabulary necessary for learners to understand written texts is between 95% and 98% (Schmitt et al., 2011).
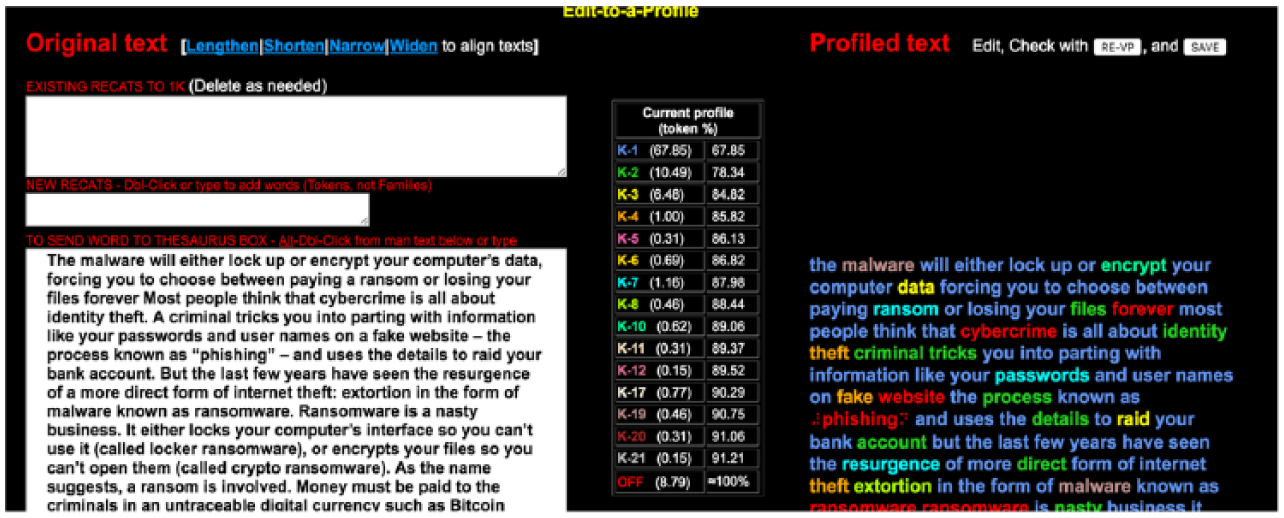
A sample lexical profiled text and editing interface.
At the phrasal level, one of the most common and easy ways to start exploring corpora is by using a concordancer to generate KWIC examples of how a chosen word or phrase is used in writing or speech in a specific communicative context. For example, keying in the phrase ‘look forward to’ in the Search String-Word(s) box will generate a frequency count of 3,889, with plenty of single examples per line, in KWIC format (see Figure 10). This promotes noticing and analysing the words that tend to follow the phrase (nouns, noun phrases, and gerunds) and their frequencies. Further, teachers or learners can key in the same phrase in VOICE (see Figure 11) or

Sample concordance lines for look forward to in KWIC format from COCA.
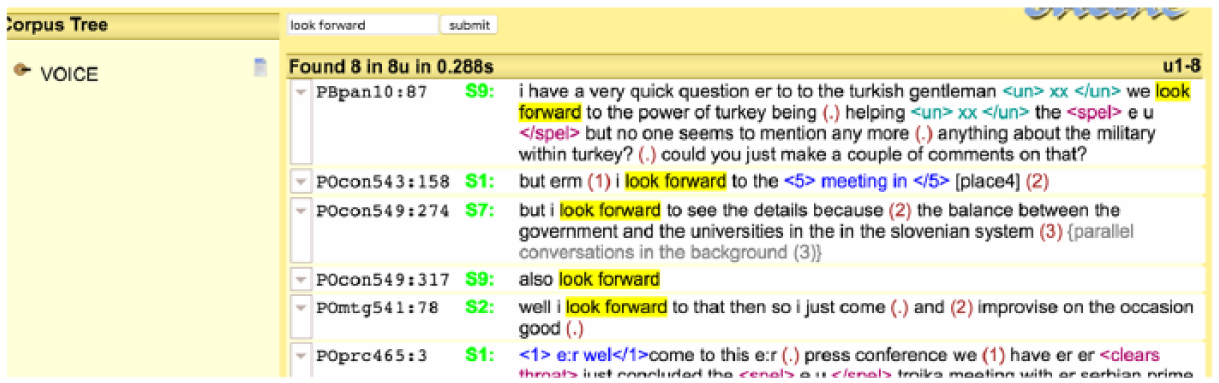
Sample concordance lines for look forward to in KWIC format from VOICE.

Sample concordance lines for look forward to in KWIC format from GloWbE.
The other way of teaching to exploit or exploiting to teach at the phrasal level involves using the tool
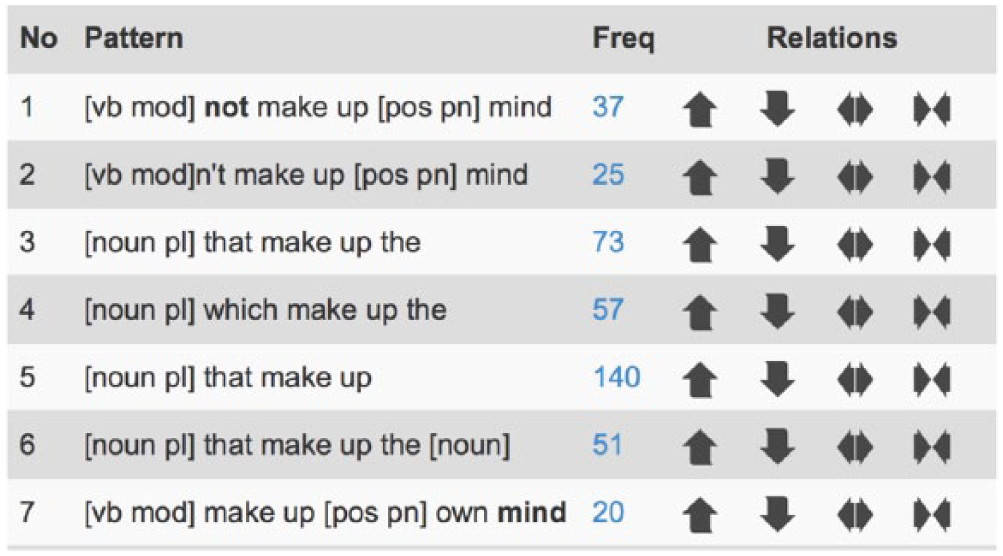
Sample output of linguistic patterns and frequency counts for make up, using StringNet.

Examples associated with [noun pl] that make up generated by StringNet.
At the discourse level, the examination of metadiscourse is an area to explore in the teaching of English for academic purposes. Teachers can refer students to Hyland’s models of metadiscourse, that is, ‘resources used to organize a discourse or the writer’s [or speaker’s] stance towards its content or the reader’ (cited in Hyland, 2004: 134) for concrete examples and linguistic markers that teachers and learners can use to examine different types of text. For example, the category of hedges (i.e. ‘withhold[ing] commitment to present propositional information categorically’) is often realized with markers such as might, perhaps, possible, may, would, could, appears, seems, think, as far as I know, and so on. Teachers may direct learners to examine the degree of certainty expressed by speakers or writers through corpora and to consider the ways in which the use of these linguistic devices in a specific article or transcript or a chosen selection of articles or transcripts strengthens or weakens an argument or claim. Further, learners may consider how the context of a communication may be at play. For instance, they can use
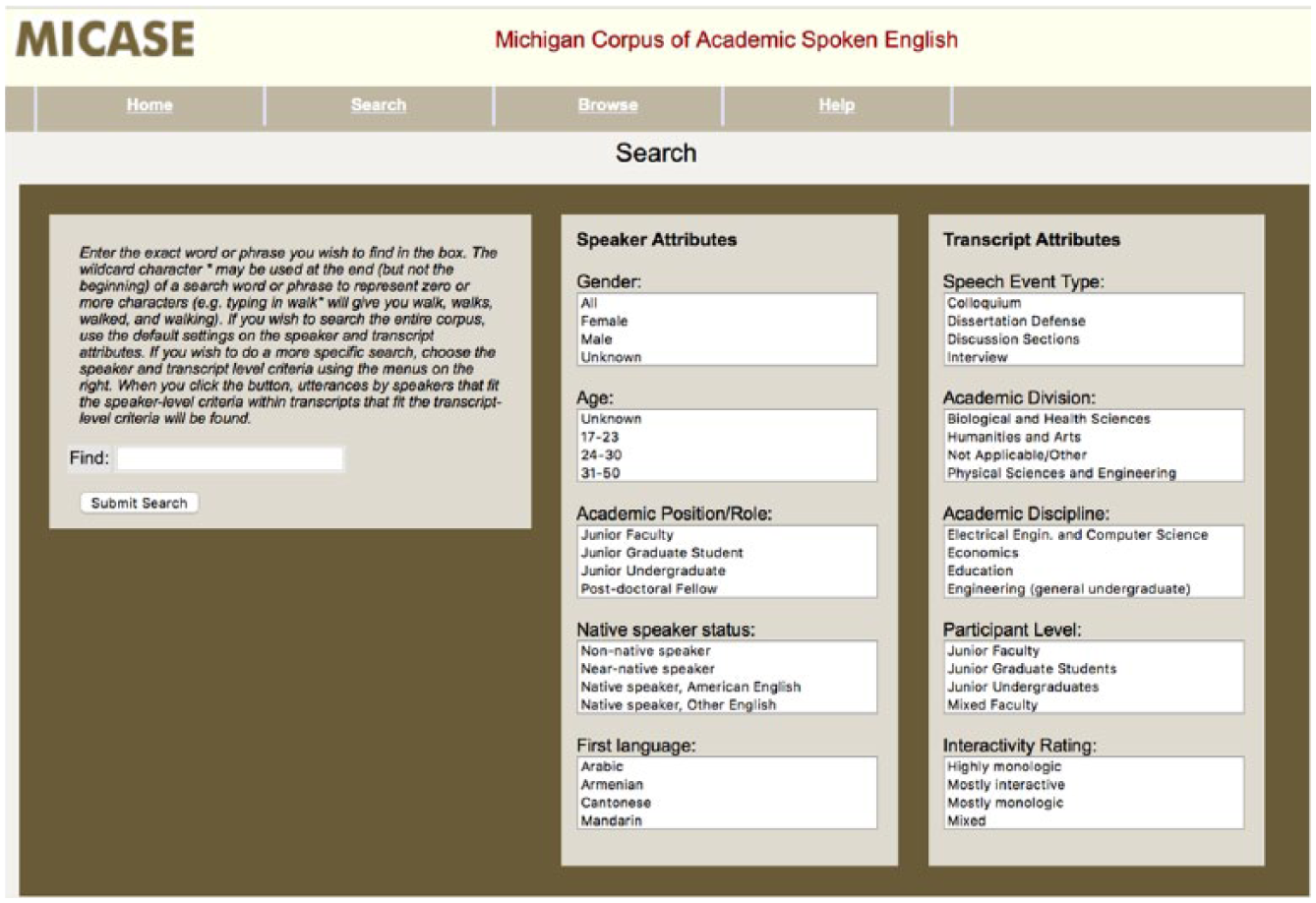
MICASE search attributes.

Sample search for the use of seem in the humanities and social sciences, using MICUSP.
The Development of Teaching-Oriented Corpora
Regarding the use of learner corpora, access to the International Corpus of Learner English version 2 is not open, which limits its use by teachers, learners, and material developers. In February 2016, however, it was announced that 4.5 million words of the Cambridge Learner Corpus, which consists of exam scripts written by students taking Cambridge exams globally, would be made available for public access (Cambridge Language Sciences, 2016). This opens up a possibility for teachers to create and use learner corpora in teaching, material development, and research. Another possibility is for teachers to self-compile corpora using texts or transcripts of students’ language production or a selection of texts for specific purposes; Lextutor’s text-tool
Current Emphases, Issues, and Challenges in Research and Theory
As noted by McEnery and Xiao, creating and using learner corpora in language teaching and research has been ‘one of the most exciting recent developments in corpus-based language studies’ (2011: 372). Flowerdew (2012) similarly observed that applying learner corpora to language pedagogy has been quite fruitful. This has been especially true in the development of the
To date, corpora have played a more salient role in their indirect than in their direct uses. Most work on the direct use of corpora in teaching has focused mainly on tertiary education, as numerous researchers have observed (e.g. Braun, 2007; Kaltenböck and Mehlmauer-Larcher, 2005; McEnery and Xiao, 2011). Until now, limited access to appropriate corpus sources, time constraints, and lack of training remain the principal issues preventing corpora from being used in general English language teaching or in teaching English as a second, foreign, or international language. Furthermore, integrating corpora at non-tertiary levels involves ‘the complementarity of corpus and curriculum content, the accessibility of the corpus for non-expert users and the mediation of the corpus in the pedagogical context’ (Braun, 2007: 326). Current research has clearly stressed that the key to integrating corpora systematically into the overall curriculum or their direct use by teachers lies in creating pedagogically driven corpora to meet instructional needs and curricular requirements. The research also points to the need to develop teachers’ knowledge and skills in corpus analysis and pedagogical mediation. The inductive nature of the data-driven learning approach necessarily involves time and requires both teachers and learners to be patient during the early stages of familiarization, which often involves trial and error. Clarifying expectations and encouraging openness to different learning pathways can go a long way in teachers’ endeavours to exploit corpora for teaching and in learners’ efforts to exploit them for learning.
In addition, the fact that the dominant corpora remain those based on Inner Circle standard varieties or first-language models of English has raised the issue of hegemony created by the international English language teaching industry (Flowerdew, 2012). Developing corpora that are culturally relevant for both direct and indirect applications is therefore critical. The financial backing to create sizable spoken corpora, a mode that is more difficult to collect but which tends to exhibit more distinctive features than written forms, is another challenge. Finally, promoting critical language awareness based on corpora, where learners are encouraged to compare features of different language varieties (e.g. by using
Given the growing attention to integrating corpus studies into language teacher training, it will be interesting to see whether more studies and projects will focus on doing so at the much-needed curricular level. Further, it will also be important to see whether that focus will be reflected in corpora assuming a more central role in the language classroom over the next decade through a rigorous evaluation of how teachers of EIL both learn and teach corpus-based activities.
Future Directions in Research, Theory, and Methodology
The widespread use of mobile devices and the increasing accessibility of various corpora types and their technologically enhanced quality are opening up new directions in research and methodology for different purposes with respect to teachers and learners. Boulton’s (2013) recent analysis of corpus-driven studies, as well as corpus-based research in language teaching and learning and teacher education, has revealed several areas for future work. For instance, in research and theory, the benefits that are often attributed to data-driven instruction (see Huang, 2016) require further empirical substantiation. The strongest theories are those that can be tested empirically, and the best applied activities are those that are scientifically based on the explanatory power of theories.
Methodologically, combining both a top-down (using the reference corpora of native English speakers) and a bottom-up (using learner corpora) approach in language teaching, along with the research on learner corpora discussed earlier, may lead to making informed decisions on developing pedagogically driven corpora, materials, and activities that account for the role of English and its sociolinguistic reality as an international language. This in turn would better address learning needs. Researchers may also strengthen the connection between findings and insights from corpus linguistics and language teaching and learning, a not unreasonable expectation based on the profiles of frequently cited researchers and their backgrounds in these areas (Boulton, 2013). The future also includes continuing to develop the various types of corpora discussed here as reference, teaching, and learning tools that may gradually transform both what is taught and how. The significant contributions made by corpus-based studies to the field of English language teaching, especially regarding lexical frequency, collocation, phraseology, and lexis in grammar, further point to the need for more attention to the textual and discourse levels (Boulton, 2013; Poole, 2016) and the potentially important pedagogical implications.
Given the shared view that successfully applying computer corpora to language pedagogy requires teacher mediation (Kaltenböck and Mehlmauer-Larcher, 2005), the key to making fundamental changes in language education will ultimately involve addressing the lack of corpus integration in either the EIL language classroom or teacher training programmes by finding ways to effectively integrate corpora beyond the tertiary level and in teacher education. Although the issues associated with using corpora in teaching EIL are complex and multidimensional, working on empowering teachers with the necessary tools, skills, and knowledge may well bring us closer to the day when corpora are no longer viewed as a resource mainly for researchers and reference material developers. Rather, both teachers and learners will be able to use corpora to complement or evaluate other sources of information (e.g. textbooks, reference grammars, dictionaries, or first-language speaker models) as well as learn directly from them.
Finally, Boulton’s (2013) analysis pointing to the increasing use of the web-as-corpus and Google-as-concordancer appears to be realizing Sinclair’s (2004) vision about the web becoming another rich source of language data available in the classroom. That, together with mobile technology, could ultimately transcend the teaching of EIL in any context. The field of English language teaching remains hopeful for the day hinted at by Fligelstone more than two decades ago, ‘where we can give the hoped-for response: “go to any of the labs, hit the icon which says ‘Corpus’ and follow the instructions on the screen”’ (1993: 101).
Footnotes
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.