
Abstract
This study examined whether the reading passages in the new series of English-language textbooks for high-school students in Vietnam fostered reading comprehension and incidental vocabulary acquisition through reading by looking at four factors: the number of unfamiliar words in the texts, the importance of these words for text comprehension, the usefulness of contextual clues for interpreting the meanings of these words, and the frequency of these words within and across the texts. Results showed that most of the reading passages were overloaded with novel words and few of these words were important for text comprehension. Rarely did these words reoccur in the texts and the chance for successful lexical inferencing was extremely slim due to the paucity of useful contextual clues. These findings provide useful implications for both second language (L2) instructors and textbook writers inside and outside of this context.
Introduction
The relationship between second language (L2) vocabulary knowledge and reading comprehension is bidirectional. On the one hand, the more words L2 learners understand in a text (which is also known as their lexical coverage of that text), the more successfully they can interpret the input content. On the other hand, a sufficient level of text comprehension, in turn, puts them in a better position to decipher the meanings of novel words that occur in the text. Incidental vocabulary learning may happen on this premise. Research in this area consistently shows that these unfamiliar words are more prone to be learnt if they are important for reading comprehension (i.e. key words) (e.g. Elgort and Warren, 2014; Paribakht and Wesche, 1999), go with useful contextual clues for learners to infer the word meanings (i.e. quality of contextual clues for lexical inferencing) (e.g. Vidal, 2011; Webb, 2008), and reoccur in that text or a series of texts for a sufficient number of times (i.e. word repetition) (e.g. Pellicer-Sanchez and Schmitt, 2010; Webb and Chang, 2015). Thus, to foster learners’ content and vocabulary gain through L2 reading, textbook writers and instructors may need to give due attention to these factors.
An outstanding achievement that the Ministry of Education and Training of Vietnam has obtained through its National Foreign Languages Project 2020 is the development of the new series of English-language textbooks for general education. Although this series is highly appraised for its superiority to the former series in terms of the teaching content, the teaching method and the assessment practice, both teachers and learners in this context share the same view that there are too many new words in the reading texts, which, in turn impede learners’ text comprehension to a great extent. This study therefore aims to look at the lexical profiles of the reading texts in this series, with a special focus on those in the English-language textbooks for high-school students, to answer the question as to whether the influential factors mentioned above are taken into consideration during the process of textbook development.
Literature Review
The Role of L2 Vocabulary Knowledge in Reading Comprehension
Previous research shows a positive correlation between L2 vocabulary knowledge and reading comprehension. This holds true for both the breadth and the depth of vocabulary knowledge. Akase (2005), for example, found a coefficient of .44 (p < .01) and .47 (p < .01) for the correlation between the breadth and the depth of L2 vocabulary knowledge on one hand and reading comprehension on the other hand. Likewise, Qian (1999) also reported a coefficient of .78 (p < .05) and .82 (p < .05) for these two associations, respectively. While the relationship between the breadth of L2 vocabulary knowledge and reading comprehension is relatively consistent across studies in this area, that in the case of the depth of vocabulary knowledge appears to be less conclusive. In fact, the latter relationship is often found to be moderated by various factors including, learners’ L2 proficiency in general and their vocabulary size in particular (see Akase, 2005 for a more detailed account). It is, however, still clear from the above review that the more lexical knowledge L2 learners possess, the better text comprehension they tend to obtain from their reading process. Additionally, it is the breadth, but not the depth of their vocabulary knowledge that is a more reliable predictor of their reading ability. Therefore, the former is used as an indicator of learners’ L2 vocabulary repertoire in this study.
If L2 vocabulary knowledge has a significant role in reading comprehension, a pertinent question here is how large vocabulary knowledge learners need to foster unassisted reading. In fact, this question has captured the interest of many researchers from far and wide. Hu and Nation (2000), for instance, compared the level of L2 reading comprehension of a fiction text across three distinct thresholds of lexical coverage – 80%, 90%, and 95%. They found that only with the lexical coverage between 90% and 95% did some L2 readers cultivate sufficient understanding of that text, but most still failed to do so. Therefore, they suggested that L2 learners might need a 98% lexical coverage to facilitate their reading comprehension. Schmitt, Jiang and Grabe (2011) also examined the relationship between these two factors. Specifically, they compared how well 661 L2 learners with different lexical coverages ranging from 90% to 100% comprehended two academic texts. The results showed that the more words these learners knew in those texts, the better they understood the content. However, there was no particular vocabulary threshold, where their comprehension level significantly increased. Synthesizing previous research findings in this area, Laufer and Ravenhorst-Kalovski (2010) suggest a threshold of 95% and 98% respectively as a minimal and an optimal lexical coverage that guarantees success in L2 reading comprehension and incidental vocabulary learning through reading. In the present study, the former is used.
However, it should also be acknowledged that the studies above focussed too much on what L2 readers already knew, but not on what they were yet to know. A crucial question is what happens if the remaining 5% of running words in the text (which are generally assumed to be unknown to learners in prior research) are all crucial for text comprehension. In this case, those unfamiliar words might create a heavy learning burden for learners when they interpret the input content. Therefore, another factor that needs to be examined in the process of evaluating input comprehensibility is whether the novel words in a text are important for text comprehension or, in other words, whether they are key words in that passage.
Incidental Vocabulary Learning through Reading
An important added value of meaning-focussed L2 reading lessons is that they provide the opportunity for incidental vocabulary uptake. Previous research shows that L2 learners are able to make sizeable gains of new lexical knowledge through reading (e.g. Horst et al., 1998; Pigada and Schmitt, 2006; Waring and Takaki, 2003). Compared to listening, reading appears to be a better source of incidental vocabulary uptake (Vidal, 2011). This might be attributed to the challenging nature of real-time listening and L2 lexical segmentation while parsing connected speech. Therefore, it is of no surprise if teachers often resort to reading over and above listening as a platform for fostering incidental vocabulary acquisition. However, incidental L2 vocabulary learning through reading is moderated by many vocabulary- (and input-) related factors. Three factors that have been relatively well-researched to date include (a) whether unfamiliar words in a reading text are crucial for text comprehension (i.e. key words), (b) whether these words are accompanied by useful contextual clues for learners to interpret the word meanings (i.e. quality of contextual clues for lexical inferencing) and (c) whether these words reoccur in that text or a series of texts for a sufficient number of times (i.e. word repetition). In what follows, I shall discuss these factors in more detail.
Key words
One crucial condition for incidental vocabulary learning through reading to happen is that L2 learners need to notice the presence of unfamiliar words in a text as well as make effort to interpret the word meanings. Using a retrospective verbal report as the primary research tool in a classroom-based experiment, Paribakht and Wesche (1999) examined how L2 readers often dealt with novel words that occurred in a reading passage. They found that the readers had a tendency to focus more on an unfamiliar word if this word was important for text comprehension. Elgort and Warren (2014) gauged the size of incidental L2 vocabulary gain through reading and the predicting power of some variables for such gains, including, among others, whether novel words were also key words in the input materials. They found that this variable could predict vocabulary gains with a Beta coefficient of 1.54 (z = 3.95, p < .001). Thus, a novel word in a text stands a better chance of being acquired if it is important for text comprehension.
Quality of Contextual Clues for Lexical Inferencing
Haastrup (1991) was among the first to examine the association between the quality of contextual clues and the success rate of lexical inferencing in the context of L2 reading. She found that readers made use of both global and local understanding to interpret the meaning of a novel word. In addition, the quality of contextual clues strongly influenced the success rate of lexical inferencing. Specifically, explicit elaboration of word meaning in a reading text such as direct definition and description was more conducive to lexical inferencing than their implicit counterpart like apposition, paraphrase or parallelism. In a well-designed experiment, Webb (2008) compared the size of incidental L2 vocabulary gain from informative and less informative reading context. The former indeed brought about better lexical uptake, especially in the case of word-meaning gain. Likewise, Vidal (2011) also found that the quality of contextual clues explained 37% of the variation in the vocabulary gains that her L2 research participants made through academic reading. These studies altogether suggest that a novel word which goes with useful contextual clues for lexical inferencing is more likely to be acquired.
Word Repetition
Since Saragi, Nation and Meister (1978) first highlighted the importance of word repetition in incidental vocabulary learning through reading, there have been numerous studies further exploring the relationship between these two factors (e.g. Horst et al.,1998; Pellicer-Sanchez and Schmitt, 2010; Pigada and Schmitt, 2006; Webb and Chang, 2015). However, the effect sizes that word repetition has on incidental vocabulary learning widely vary from very negligible (e.g. r = .01, Horst, 2000) to relatively large (e.g. r = .69, Vidal, 2011). In order to generate a better picture of such effects, Uchihara, Webb and Yanagisawa (2019) carried out a systematic review of relevant correlational studies. After meta-analysing 45 effect sizes from 26 studies (N = 1,918), they found that word repetition exerted a medium effect size of .34 on incidental vocabulary learning through reading. Another crucial research line in this area is concerned with how often a novel word needs to reoccur in a text or a series of texts for incidental vocabulary learning to happen. Such studies are meaningful as they help us to make informed decisions about how to select and modify L2 reading materials. The findings, however, are rather inconsistent. For example, Rott (1999), Horst, Cobb and Meara (1998), Webb (2007), Elgort and Warren (2014) and Waring and Takaki (2003) respectively reported that L2 learners might need to reencounter a novel word 6, 8, 10, 12 and 20+ times for lexical uptake to be possible. In the present study, a threshold of 6 times is chosen as a minimum number of word occurrences that fosters learning.
The review above helps me to generate three key factors that are often found to facilitate reading comprehension and incidental vocabulary learning through reading. These factors will now be used as a basis to evaluate the extent to which the reading texts in the target English-language textbooks foster content and vocabulary gain in the present study.
The Present Study
Research Questions
This study is to examine the potential benefits of the reading passages in the English-language textbooks for high-school students in Vietnam for both content and vocabulary gain by weighing up the features of four word-/input-related factors, including (a) lexical coverage, (b) key words, (c) quality of contextual clues for lexical inferencing, and (d) word repetition. Specifically, it seeks the answers to the following research questions:
a) Do the target learners have at least a 95% lexical coverage of the main reading texts in the English-language textbooks for high-school students in Vietnam?
b) Are the remaining 5% of the word families in those texts important for text comprehension?
c) Do these unfamiliar word families co-occur with useful contextual clues for lexical inferencing?
d) Do these unfamiliar word families reoccur at least six times within or across those texts?
Research Participants
Research participants in this study were 422 high-school students recruited from the North (n = 154), the Centre (n = 127) and the South (n = 141) of Vietnam, from urban (n = 135), rural (n = 167) and mountainous areas (n = 120) as well as from Grade 10 (n = 140), Grade 11 (n = 141) and Grade 12 (n = 141). These students were selected from different geographical and socio-economic areas to enhance the representativeness of samples. To enter public high schools in Vietnam, students must have achieved English proficiency of A2 Level on the CEFR scale and they were expected to reach B1 Level after Grade 12.
To estimate their existing lexical knowledge, the updated Vocabulary Levels Test (VLT) developed and validated by Webb, Sasao and Ballance (2017) was used. This is a frequency-based vocabulary measure of receptive knowledge. It includes five levels with test items taken from the 1,000, 2,000, 3,000, 4,000 and 5,000 levels in Nation’s BNC/COCA word lists (2012). This test is generally deemed to provide a better measure of the breadth of lexical knowledge than Nation and Beglar’s Vocabulary Size Test (2007), thanks to a larger number of samples in each 1,000-word level. It is also superior to the Vocabulary Levels Test by Schmitt, Schmitt and Clapham (2001) in the regard that Webb, Sasao and Ballance (2017) also incorporated the 1,000 and the 4,000 level into the measure. Thus, using the updated VLT to gauge these students’ receptive vocabulary knowledge was the optimal option, at least, at the time I collected data for this study. Their VLT scores are summarized in Table 1.
VLT Scores (Maximum Score/Level = 30 Points).
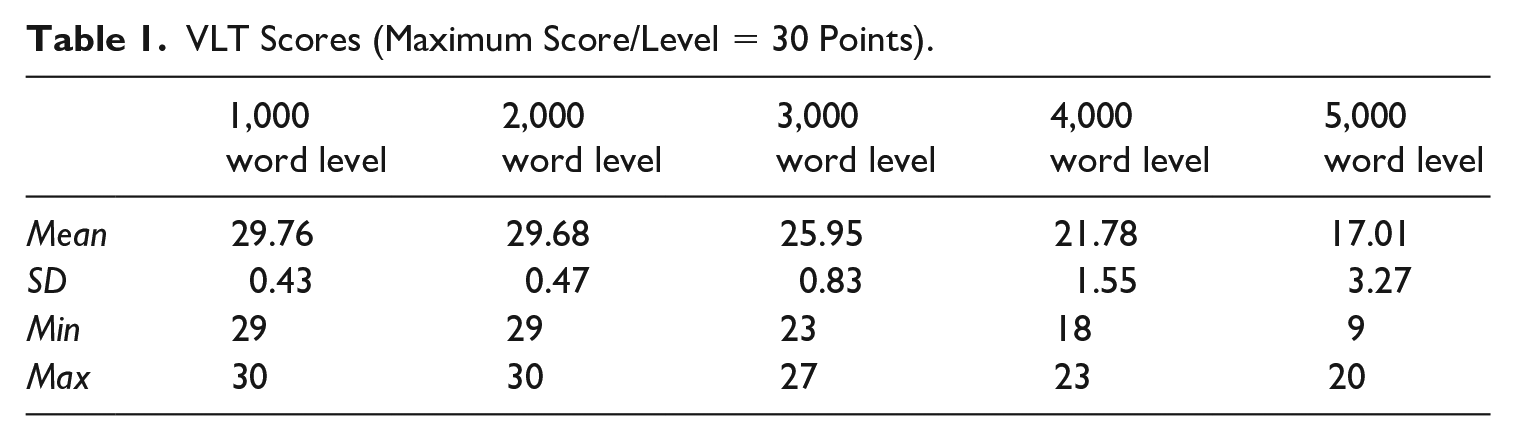
According to Webb, Sasao and Ballance’s guidance for interpreting the VLT scores (2017: 56), the mastery cut-off point for the 1,000, 2,000 and 3,000-word level was 29/30 points, while that in the case of the 4,000 and 5,000-word level was 24/30 points. Thus, these students were estimated to have a receptive knowledge of the first two 1,000-word lists in the BNC/COCA corpus. Of course, some of these students might have learnt word families which were less frequent than those in the two lists mentioned above. However, as their VLT scores showed that they only reached the mastery cut-off points for the first two 1,000-word lists, this level of lexical knowledge was selected as a basis for gauging their lexical coverage of the target reading texts.
Textbooks and Reading Passages
This new series of textbooks comprises Tieng Anh 10, Tieng Anh 11 and Tieng Anh 12 (also known respectively as the English Textbooks for Grades 10, 11 and 12), each of which consists of ten units. In each unit, there are six components: Getting Started, Language, Skills, Communication and Culture, Looking Back, and Project. Getting Started aims to present an overview of the whole unit. Language presents new language codes including Vocabulary, Grammar and Pronunciation. The Skills section helps students to establish and develop a wide range of micro-skills related to Listening, Speaking, Reading and Writing. Communication and Culture are first to provide students with socio-cultural knowledge and then guide them to integrate this knowledge into daily communication. Looking Back, as the name suggests, helps students to review what they have learnt in the preceding sections, while Project requires them to apply their acquired knowledge/skills to carry out of a real-life project as launching a go-green campaign or creating a brochure for a tourism attraction. After almost every three units, there is a review lesson in which students are given the opportunity to recycle their acquired knowledge/skills (those related to reading also included) in the preceding units.
With the above sequence, one might expect that the Vocabulary lesson under the Language section might introduce, at least, the forms and the meanings of novel words that occur in the upcoming reading passages in the Reading lesson. In this way, the number of new words that students need to process in these passages can be reduced. However, rarely do the words that students learn in the Vocabulary lesson reoccur in the reading texts, and therefore our expectation above is not met. Alternatively, the pre-reading stage can be used for the same purpose. However, all pre-reading activities in these textbooks are to activate students’ relevant schemata, but not to introduce the meanings of novel words in the reading texts. Neither do any glosses exist in the textbooks to offer students a quick check of the word meaning. Taken altogether, these textbooks, in the present form, provide a limited opportunity for students to reduce the quantity of novel words in the reading texts, thanks to deliberate learning prior to their actual reading process.
This series includes 30 main texts in the reading lessons and six extra texts in the review lessons. These texts are all used for meaning-focussed reading activities, which aim to develop students’ micro-skills such as skimming, scanning and/or lexical inferencing. The total number of running words in these texts is 8,358. After excluding the running words in the off-list (which are mainly proper nouns and high-frequent compound words and thus assumed to be already known to these students), this number shrinks to 8,062 tokens, with a total of 1412 word families.
Instrument and Procedure for Data Collection and Analysis
First, a frequency-based analysis of word families in the reading texts was carried out using the BNC-COCA 1-25k program in the Vocabprofilers of the Lextutor.ca website. The outcome from this analysis helped me to answer the first research question regarding the lexical coverage that the students in this context had for the reading texts. From this outcome, I could also detect the word families that were less frequent than those in the first two 1,000-word lists and thus likely unknown to these students (henceforth referred to as the novel word families, for short). Data related to the frequency of these novel word families could also be extracted from the above analysis, which in turn helped me to answer the final research question.
Subsequently, three experienced EFL teachers in Vietnam (one native speaker of English and two nonnative speakers) were invited to rate the importance of the novel word families for text comprehension on a dichotomous scale with 0 for ‘not important’ and 1 for ‘important’ as well as the usefulness of contextual clues for lexical inferencing on a four-point scale from 1 for ‘not useful’ to 4 ‘very useful’. The interrater reliability indices were all high with Pearson correlation coefficients of .92, .91, .91 (p < .001) and .86, .85, .83 (p < .01) in the case of the importance of the word families for text comprehension and the usefulness of contextual clues for lexical inferencing, respectively. The means of their rating outcomes were used as a basis to answer the second and the third research question above.
Findings
Lexical Coverage
According to their VLT scores, the students in this context were estimated to have a receptive knowledge of the first two 1,000-word lists in the BNC/COCA corpus. This level of lexical knowledge is now used as a threshold to gauge their lexical coverage of the reading texts. The results of this calculation are summarized in Table 2 for their lexical coverage of all reading texts combined (including both main and extra texts) and Table 3 for that of every single text (excluding extra texts).
Lexical Coverage of All Reading Texts Combined (N = 36).

Note: This table excludes all frequency-based 1,000-word lists whose word families do not occur in any reading texts.
Lexical Coverage of Every Single Text (in Percentage) (N = 30).
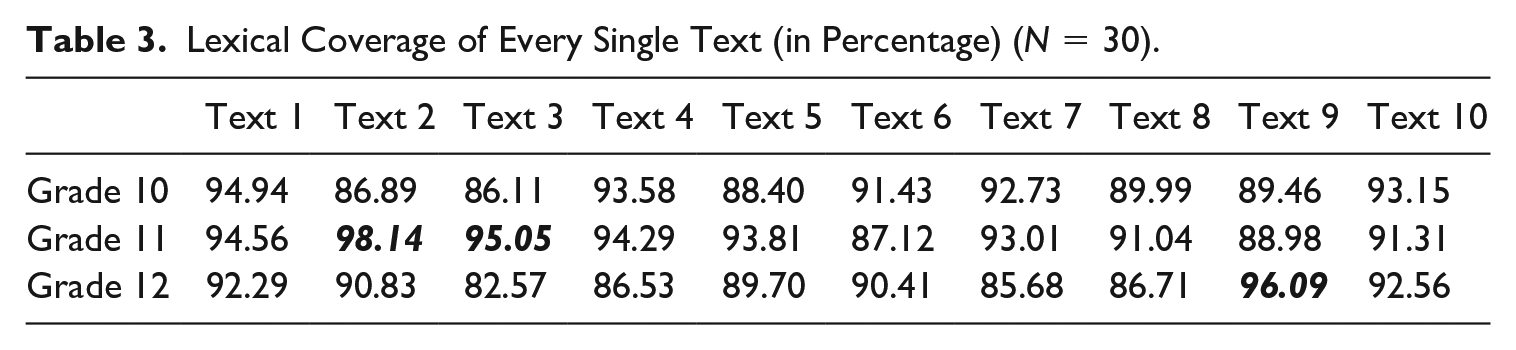
It is clear from the above table that with a receptive knowledge of the first two 1,000-word list in the BCN/COCA corpus, high-school students in Vietnam only had a coverage of 87.1% of all word families in the thirty-six reading texts. Combined with their knowledge of words in the off-list, which accounted for roughly 3.4% of all word families in those texts, the above lexical coverage went to 90.5%. In order to reach the 95% and the 98% coverage, these students needed to have a receptive knowledge of the first three and the first five 1,000-word lists, respectively. At the current lexical level, they might possibly find a sum of 410 word families unknown to them or an average of about 11 word families per text. Meanwhile, each reading text in this series of textbooks only included an average of around 40 word families (i.e. a total of 1412 word families for all 36 texts).
When it comes to their lexical coverage of every single text (excluding the extra ones), these students reached the 95% coverage for only three out of 30 reading texts (see
Key Words and Quality of Contextual Clues for Lexical Inferencing
The independent ratings of the three experienced EFL teachers indicated that there were merely 47 out of 410 novel word families (11.46%) which were important for interpreting the input content. Therefore, the chance for students to fasten their focus on these lexical items and attempt to infer the meanings of these words for the purpose of overall text comprehension was relatively limited. This, in turn, reduces the likelihood for incidental vocabulary learning to occur. However, it should also be clarified here that if the quantity of such novel word families is large, it may create another learning burden for L2 learners in terms of text comprehension.
Table 4 presents descriptive statistics for the outcome of the independent ratings by three raters regarding the usefulness of contextual clues for lexical inferencing.
Quality of Contextual Clues for Lexical Inferencing.

Their average rating outcome was relatively low, at 1.32/4 points (SD = 0.50). Thus, it appeared that the reading passages rarely provided useful contextual clues for the students to infer the meanings of the novel word families. It is not very difficult to locate specific examples in the reading passages that can demonstrate the finding above.
Soot comes from the incomplete combustion of coal, oil, wood and other fuels. In other words, diesel engines, vehicle exhaust pipes, farming machines, construction equipment, or simply fires in grills, fireplaces, and stoves are potential sources of soot. It appears in our daily life and can easily affect every one of us (Grade 12, Text 2, Soot).
The above paragraph is taken from the reading passage about Soot in Unit 3 of Tieng Anh 12. According to the Vocabprofilers program, the word ‘combustion’ belongs to List 7 in the 25 frequency-based 1000-word lists in the BNC-COCA corpus, which was therefore supposed to be novel to students. Even though the linking device ‘In other words’ in the second sentence suggested that this sentence might include some clues for students to interpret the meaning of ‘combustion’, such a clue was, in fact, really hard to find (even when students kept on reading the last sentence in the paragraph). Below is another example for this:
The ASEAN Charter came into force on 15 December 2008. It is the Constitution of ASEAN and the ten member states must act in accordance with it. After entering into force on December 15th 2008, the Charter has become a legal agreement among the ten ASEAN member states. Its main principles include respect for the member states’ independence and non-interference in their internal affairs (Grade 11, Text 5, ASEAN).
In this paragraph, the word ‘non-interference’ is classified into List 3 in the 25 frequency-based 1000-word lists in the BNC-COCA corpus, which was also deemed to be unknown to students. It is clear from the surrounding context that the meaning of ‘non-interference’ can be deciphered by using that of its neighboring word ‘independence’. However, the latter also belongs to List 3 and thus might be new to students.
Frequency of Novel Word Families
Table 5 presents the frequency of the novel word families in the target reading texts, together with the lists of the novel word families that reoccur at least six times within or across the reading texts.
Frequency of Novel Word Families (N = 410).

As can be seen from this table, the number of the novel word families that occurred at least six times in these texts was extremely small, merely at 17 out of 410 (roughly 4.2%). That in the case of the word families reoccurring at least 8, 10 and more than 10 times was even smaller, in that sequence, 10, 7 and 6 word families. Thus, the number of in-text occurrences of the novel word families in this series of textbooks was far lower than what previous research often suggests as optimal for incidental vocabulary learning.
Discussion and Implications
Regarding the first research question, with a receptive knowledge of the first two 1,000-word lists in the BNC-COCA corpus, high-school students in Vietnam were estimated to have a 95% lexical coverage for only three out of 30 reading texts in the new series of English-language textbooks (10%). Previous research shows that some L2 learners are still able to generate sufficient understanding of a L2 reading text merely with a lexical coverage of 90% (e.g. Hu and Nation, 2000; Schmitt et al., 2011). If we select the latter as a threshold that guarantees successful L2 text comprehension, these students still fail to reach this level for 12 out of the 30 reading passages (40%). Admittedly, many L2 learners can make use of their socio-cultural and/or discourse competence to compensate for their L2 vocabulary limitation. However, the low lexical coverages as reported above might lead to, at least, three possible problems. First, as these students have to struggle with a relatively large number of novel word families in each reading passage (i.e. about 11 out of 40 word families per text), it is very unlikely for them to cultivate sufficient understanding of that text. Such a struggle may also hinder them from forming and developing cognitive strategies (e.g. skimming or scanning) and meta-cognitive strategies (e.g. monitoring reading process or evaluating reading outcome) through reading as most of their mental resources have been invested in dealing with novel lexical items. Last but not least, when these students fail to generate a reasonable level of text comprehension, they might not obtain enough contextual clues to decipher the meanings of novel words occurring in those texts, either. Put differently, such a low lexical coverage can be detrimental to both L2 reading and vocabulary development.
As far as the second and the third research question are concerned, a vast majority of 88.54% of the novel word families in the reading passages were found to be unimportant for text comprehension. On the one hand, this might be good news to the students in this context as they could be able to cultivate sufficient understanding of those texts even without knowing these lexical items. On the other hand, this obviously deprived them of the opportunity to expand their lexical resources through meaning-focussed reading. Even if the novel word families above were crucial for text comprehension and thus attracted students’ attention for further processing, their lexical inferencing might not be likely to succeed due to the paucity of useful contextual clues. Of course, these students may also resort to their global understanding of the whole text for that purpose (Haastrup, 1991). However, the chance for these students to obtain sufficient understanding of that text was also slim, as already reported above. Since L2 vocabulary development cannot totally depend on deliberate and explicit instruction due to time constraints (Nation, 2013), incidental vocabulary learning deserves to have a place in a language course. However, the new series of English-language textbooks for high-school students in Vietnam provided a limited opportunity for such a learning process to occur, at least in the context of meaning-focussed reading lessons.
When it comes to the final research question, it is clear from the above report that the frequency of the novel word families in the reading texts could barely foster lexical uptake and retention. Specifically, only 17 out of 410 (roughly 4.2%) unfamiliar lexical items reoccurred at least six times in those texts. Of course, there is no specific number of in-text occurrences that guarantees incidental vocabulary uptake as L2 learners can infer word meaning using surrounding contextual clues (Webb, 2008). Again, this is not the case here, because the reading texts in the new series of English-language textbooks did not provide the students with useful contextual clues for lexical inferencing.
These findings suggest it is highly likely that high-school students in Vietnam might be overloaded by many new words in almost every reading lesson, but have few opportunities to reencounter and fine-tune their knowledge of those words further down their course of learning. Put differently, the lexical features of the reading texts neither fostered content nor vocabulary gain. These findings provide several implications for both L2 instructors and textbook writers.
Meantime, L2 instructors in Vietnam, might benefit from having relevant measures in place to reduce the number of novel words in reading texts before the textbooks are revised. One measure would be to pre-teach those lexical items if (a) the quantity of such items is small, ranging somewhere between five and seven words, and (b) most of these words are crucial for interpreting the input content. Previous research finds there are positive effects of pre-teaching vocabulary on both L2 reading and listening comprehension (Webb, 2009). When the number of these items is large (e.g. over 10) and most of them are not vital for text comprehension, providing L2 learners with a glossary of new words can be a more practical option. In fact, glossing is also found to foster both L2 reading comprehension and incidental vocabulary learning through reading (Elekaei et al., 2015). However, it should also be noted here that different types of glossing might create different effects on content and vocabulary gain, with inter-liner glossing faring far better than footnote, marginal and appendix glossing (see Elekaei, Faramarzi and Koosha, 2015 for a more detailed review). In addition, L1 and L2 glossing are equally effective in this regard.
On the part of textbook writers in Vietnam, the findings above might be helpful for their future revisions of the textbooks. First, lexical items that might be new to students need to be singled out and specially treated. In order to increase students’ lexical coverage of the reading texts, these items can be replaced by their higher-frequency synonyms or similar expressions. If textbook writers aim to maintain the authenticity of those texts, inter-liner glossing may be embedded into the reading passages. Second, it can also be a good idea to map the new words above to the course objectives. In case some of these lexical items belong to the learning targets, such words need to be typographically highlighted in the reading texts, accompanied by useful contextual clues for lexical inferencing and, if possible, reoccurred more often within or across the texts and in an increasingly longer interval (Nakata, 2015). Alternatively, the textbook writers can consider incorporating vocabulary pre-teaching activities before the main reading task in the textbooks or recommending L2 instructors to do so in the teacher books. Having L2 learners recycle those unfamiliar words in post-reading output tasks can also foster their word retention.
Conclusion
Taken altogether, there was little evidence that the main and extra reading passages in the new series of English-language textbooks for high-school students in Vietnam could foster both content and vocabulary gain. Specifically, most of those texts were overloaded with novel words. These words did not reoccur very often within or across the texts, and neither did they go with useful contextual clues for lexical inferencing. Most of these items were not crucial for text comprehension and therefore stood a limited chance of being incidentally acquired. Thus, the teachers and textbook writers in this context need to have relevant remedies to the above setbacks.
This cannot go without acknowledging the limitations of the present study. First, it might be better if the list of word families that were deemed to be novel to students based on the results of the Vocabprofilers program could be double-checked by students in this context. In addition, using the first two 1,000-word lists as a cut-off point to gauge the lexical coverage of these students as to the target reading texts failed to take their knowledge of some less frequent word families in the other word lists into account. Data from classroom observations focussing on the difficulties that English-language teachers and students in high schools in Vietnam often encountered while dealing with those reading passages might also help to triangulate the findings of this study. It is, however, still clear from the above findings that the reading passages in the new series of English-language textbooks for high-school students in Vietnam need to be substantially revised with a view to fostering both content and vocabulary gain.