
Abstract
Contemporary society demands from individuals new and relevant literacies that go beyond the basics of reading and writing. Furthermore, texts now appear less confined to a single semiotic resource. The proliferation of different forms of communication like visuals, among others, encourages people to use literacy in multiple modalities. Nevertheless, not all individuals are capable of understanding and producing information in modalities other than the usual linguistic texts, and teachers are not exempt in this phenomenon. Ironically, school curricula burden teachers with the demand to develop visually literate learners even though most teachers themselves were not formally trained for visual literacy and visual grammar. Consequently, this study sought to identify and describe the processing strategies and the sources of information that teachers, as ESL readers, deliberately use when they make sense from multimodal still visuals. The think-aloud method, as an introspective procedure, was used to collect, analyze, and code 42 sets of verbal protocols from 14 teacher-respondents who read three different multimodal still visuals in three sectional rounds. Results reveal four integrated categories or themes of comprehension processes that teachers used when making sense of the visual stimuli. These are (a) anticipation or preparation; (b) sampling; (c) deepening; and (d) regulation. As regards to the sources of information they use in building meaning, a dismal number of verbal protocols manifest that the majority of the teachers do not use all the elements of the visual grammar and they lack the ability to integrate reader-based, text-based, and context-based sources of information in order to establish a closer match between their meaning and the intended meaning of the multimodal still visuals. Ultimately, the paper provides a theoretical model which can serve as basis for teacher development with regard to visual literacy in an ESL context and offers future directions in multimodal language learning and teaching.
Keywords
Introduction
Communication appears to be one of the most complex areas of human interest, where philosophers, logicians, and scholars spend a great deal of effort in order to explain its phenomenon. Alternatively, lay people seem to perceive it as a simple process of conveying ideas to another and/or receiving ideas from another through the macro-skills of listening, speaking, reading, and writing. Interestingly, communication, in its seemingly fluid occurrence to humans, does not come as easy as laymen would put it.
One important area in the study of human communication is the reading process. Much has been discovered in this domain, establishing that reading is a process of interaction between the text, the reader, and the context (Dechant, 1991; Gunning, 2003; Stanovich, 2000; Wallace, 1993; Weaver, 1994). Nonetheless, there is still a dearth of information regarding visual reading needed to institute a cohesive theory of visual literacy.
Conceivably, at this point, it is important to see literacy in its broadest sense and, consequently, observe visual literacy as one of its rightful domains. Literacy, traditionally referred to as the ability to read and write, has long been one of the supreme and paramount goals of schooling or education. Nevertheless, the dynamic changes brought about by technological developments, the increasing perspective about individual differences, the proliferation of ideological divides, the abundance of alternative modalities in communication, and the other correlates of change and development, put the traditional definition of literacy into a state of inexorable modification or redefinition.
Hirsch (1988) recognizes and implicitly suggests that what has been an acceptable view of literacy in the 1950s is no longer acceptable in the late 1980s. This is, in all probability, due to society’s expanding view of what it is to be literate. Furthermore, this implies that if changes remained constant about the views of literacy after the 1980s, it is not surprising to understand that the current view of literacy has expanded even more, accommodating different kinds of “literacies,” such as academic literacy, cultural literacy, document literacy, computer literacy, scientific literacy, media literacy, functional literacy, and visual literacy, among others.
The growing number of literature specifying the multiple areas or, rather, specific names of literacy implies that there is also a growing acceptance of advocating the need to develop citizens who should be empowered with these “literacies.” Not surprisingly, Venezky et al. (1990) made an attempt to rationalize why there is a need to specify the definition of literacy based on its local use and context. They believe that the creation of a definition of literacy may be helpful for policymakers when they need to determine the necessity for literacy efforts and when they require outcomes of specific policies to be evaluated. Consequently, teachers and other education specialists are driven to respond to these policies. Furthermore, the specific “literacies” drive them to reexamine their teaching cognition. These eventually cause them to somehow modify their pedagogical or instructional practices as well.
One of the specific “literacies” that continuously gains attention from researchers is “visual literacy” (Avgerinou and Pettersson, 2011; Begoray, 2001; Brill et al., 2007; Flynt and Brozo, 2010; Gaede, 2000; Harrison, 2003; McTigue and Flowers, 2011; Markovits et al., 2006; Santas and Eaker, 2009; Seglem and Witte, 2009; Yeh and Lohr, 2010). The emergence of the term is probably due to the obvious extra-abundance of materials, which are more visual than printed. These visuals may take the form of motion visuals or still visuals.
Consequently, if one is to respond to the need to develop citizens who are also visually literate and not only basically literate, one has to have a comprehensive view of the nature of the visual reading process, with emphasis on the variables of the different reading domains, which interact during the active search for meaning.
Avgerinou and Pettersson (2011) implicitly recognize that the field of visual literacy is still in the process of establishing its firm ground as a legitimate discipline. Nevertheless, they have attempted to establish a cohesive theory of visual literacy. Consequently, in order to advance a solid and secure theory of visual literacy, this study provides its contribution to the ever-growing knowledge about visual reading processes, especially on multimodal still visuals.
A great extent of information has also been established with regard to the cognitive processes in general, but there is still a scarcity of knowledge about the behavioral manifestations of readers in their cognition of visuals, especially when the elements of the visuals they are reading are only relatively universal, if not universal at all. Furthermore, while evidences from literature and studies provide lenses where visual reading can be understood, much of these works possess orientations involving first language (L1) visual reading; hence, they are studied in the framework of the natives’ culture. To put this further, Scollon and Scollon (2003) recognize that much of the studies and literature about visuals and semiotics are observed using L1 orientation. This implies that the arena is open for studies using orientations from viewers, readers, or visual producers reading, writing, or printing visuals written in their second language.
Additionally, a number of local evidences in the Philippines about reading processes and variables are concentrated on studies involving primary and secondary education learners and college students—such as that of Tatlonghari (1999), Navas (2005), and Gutierrez (2002)—but rarely on the professionals who provide these learners with the literacy itself (Gutierrez, 2013). In reality, Borg (2006) asserts that the study of teachers’ beliefs, practices, and other psychological paradigms, which he calls as “teacher cognition,” is relatively new or young as a field of inquiry. He puts forward the idea that there is a need to look into teachers’ cognition so as to establish a stronger understanding of what it means to be a teacher—more importantly, a literacy teacher and more specifically, a visual literacy teacher.
Research Purpose
The evidences cited earlier show what is currently known about the reading process and its domains—that reading is an interactive process of meaning-making between the text (a semiotic sign), the reader (who possesses cognitive and social experiences), and the context (the relevant situation where connections between the reader and the text are linked). However, these studies show limitations on (a) linguistic texts and rarely on visual texts, specifically on multimodal still visuals which contain linguistic (digital) and non-linguistic (analog) entries; (b) limitations on mother-tongue or first language (L1) reading and rarely on second language (L2) reading of multimodal still visuals; and, finally, (c) limitations on the use of respondents comprising learners at the primary education to learners at the tertiary level and rarely on in-service teachers.
Consequently, this research sought to identify and describe the comprehension processing strategies of 14 elementary teachers as ESL readers of multimodal still visuals.
Specifically, it attempted to attain the following objectives:
1) describe the comprehension processes the respondents use while reading;
2) identify the sources of information they use to construct meaning of the visual stimuli; and
3) describe how these sources influence how they make sense of the visual stimuli.
Ultimately, the results of the study are expected to inform the development of teachers’ content knowledge and pedagogical content knowledge with regard to visual literacy development.
Related Literature
Issues on Language in Images
While visuals may be treated as “language,” it is also interesting to note that there seems to be an opposition to this belief. Mansell (1999) puts forward the major differences between language in linguistic texts and language in images. He contends that an image cannot be equivalent to language because an image cannot set the borders of its aspects so as to formally separate what seemingly constitutes a linguistic property of an image. He further advances that language is disjoint and digital, while images are analog. Moreover, he claims that whatever seems to be a part of the whole image, which may be separated as a disjoint member, cannot totally exist independent of the whole, therefore, images cannot be broken down into parts.
This problematic situation in semiotics poses an area of confusion in the systematic study of signs or representations related to visual communication. Nevertheless, to reconcile these opposing views, it is creditable to consider the paradigm used by Kress and van Leeuwen (1996) regarding the premeditation or intentionality of visual images. Scollon and Scollon (2003), citing Kress and van Leeuwen (1996), articulate that it would be harder to understand pictures that depict accidental snapshots of something happening in the world outside the designer’s studio and outside the image frame due to the fact that the production of the image is not premeditated. This implies that accidental snapshots may mean nothing more than what the picture literally portrays. Therefore, in this sense, the image may not be treated as language that communicates. Nevertheless, if one is viewing an image, which is deliberately made to communicate, it may be treated as language because the elements of this image are purposely chosen to communicate what it is supposed to convey.
Veritably, visual images, in order to be considered as language or “discourse”,” must be produced or printed with the aim of intentional communication (Avgerinou and Pettersson, 2011; Scollon and Scollon, 2003) so that meanings may emerge from different sources and that meanings may be confirmed. However, due to the problematic analog nature of images, it is harder to achieve a common shared meaning of images, especially when the image creator’s presupposition of his or her viewer does not match the real viewer’s frame of mind in viewing, perceiving, or understanding things. Nevertheless, it is interesting to note that Kress and van Leeuwen (1996) offer a way to establish a grammar of visual design—something that communicators may want to consider using so that the reading and production of visuals will generate a common ground for meanings to be collectively validated by the community that uses them. One has to be forewarned, however, that the images in the framework of Kress and van Leeuwen’s visual semiotics only include that which is made for the purpose of communication and not just some random snapshots of everyday phenomena (Scollon and Scollon, 2003).
On Visual Literacy and Visual Thinking
Avgerinou and Pettersson (2011) identified five major components or domains under the Visual Literacy Theory they wish to establish. These components include visual perception, visual language, visual learning, visual thinking, and visual communication. Building on available literature and studies, they were able to institute a considerable amount of evidences to ascertain that visual language exists. Nevertheless, they implicitly manifest that there is dearth of information or studies about the other four domains. In response, this study attempts to contribute to the domain of visual thinking in the context of teachers as ESL readers of multimodal still visuals.
The framework of this study, as seen in Figure 1, reflects the interactive view of reading where comprehension is believed to be established through the interaction of three different domains in the reading process. These domains include the reader, the text, and the context. To establish the relevance of these domains in the current study, the domains are hereby referred to as: (a) ESL reader; (b) visual text; and (c) visual context.
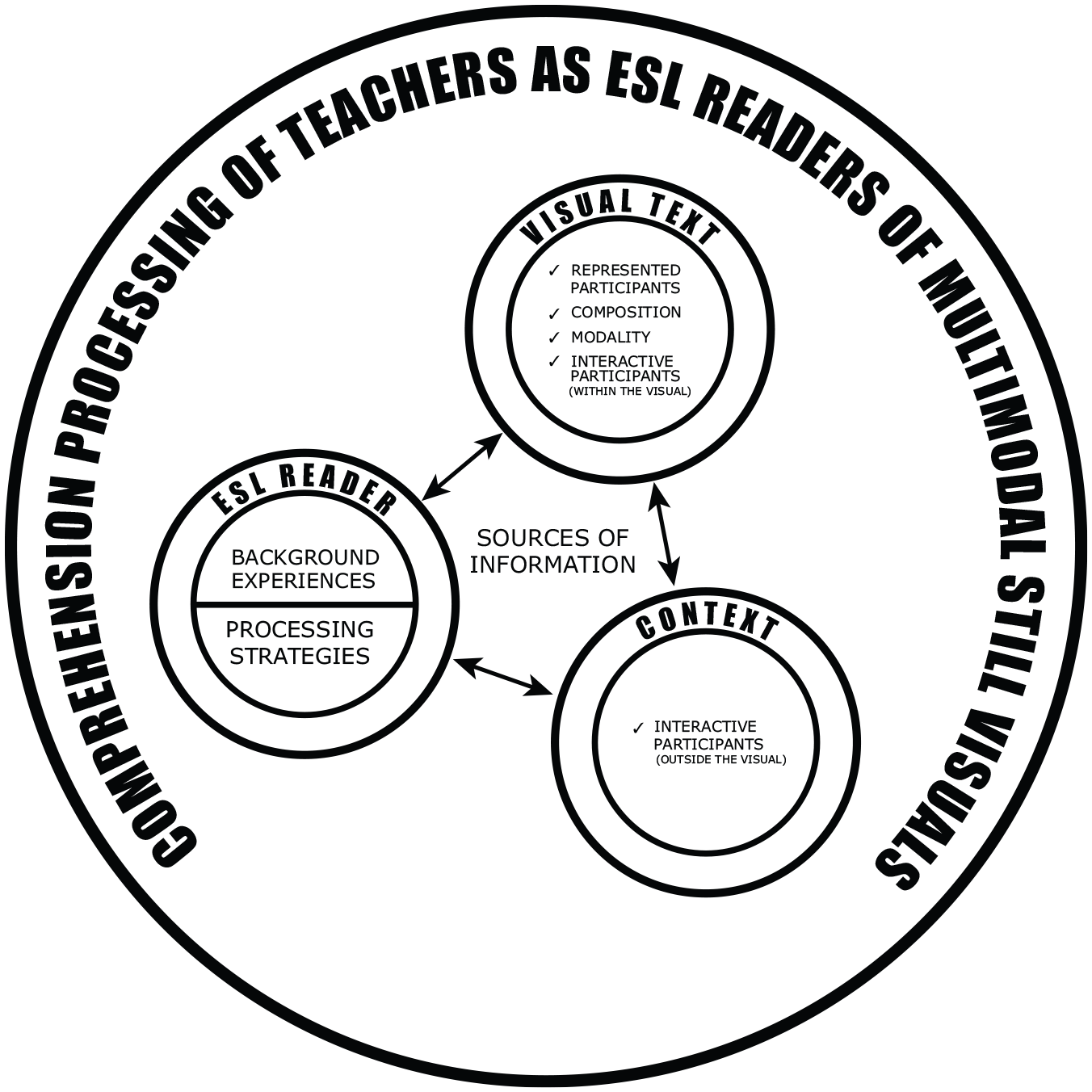
Conceptual framework on comprehension processing of multimodal still visuals.
In the domain of the ESL reader, it is believed that the reader possesses background knowledge which includes his or her personal and social experiences and observations (Wallace, 1993; Weaver, 1994). This implies that he or she brings with him or her the cognitive, affective, and social resources he or she has in order to interact with the text. Furthermore, the ESL reader possesses processing strategies in order to establish the meaning of the visual text.
In the domain of the visual text, there are different elements that can be used by the reader to build meaning. The text-based participants that are reflected inside this domain come from the “visual grammar” established by Kress and van Leeuwen (2006). These are the “represented participants,” “composition,” “modality,” and “interactive participants.” It can be observed, however, that in the domain of the context, the element “interactive participants” also appears. This is due to the dual nature of the element “interactive participants.”
According to Kress and van Leeuwen (1996, 2006) and Scollon and Scollon (2003), the element of “interactive participants” includes: (a) the relationship between the visual entries; (b) the relationship between the visual author and the visual entries; and (c) the relationship between the visual reader and the visual entries. In other words, the “interactive participants” which are explicitly manifested in the visual text are text-based sources of information while the “interactive participants” beyond what the visual text explicitly shows are the context-based sources of information. It only goes to suggest that when one builds meaning of multimodal still visuals, it is important to go beyond what the visual texts explicitly convey.
Visual readers need to consider the context which is established when one recognizes and uses the “interactive participants” outside the visual material. It does not suggest, however, that the “interactive participants” outside the visual material could readily be perceived by the reader without due consideration to the “interactive participants” within the visual material. The visual reader should perceive the context based on what is cued by the other elements of the visual grammar. This suggests that the visual reader should simultaneously perceive and deliberately use, through the processing strategies he or she possesses, the visual text and the visual context in addition to his or her background experiences, in order to establish the intended meaning of the multimodal still visuals.
Therefore, in relation to the current study, the interaction of the comprehension processing strategies and the different sources of information which are reader-based, text-based, and context-based will build a clearer view of the comprehension processing of the teachers as ESL readers of multimodal still visuals.
Methodology
Research Design
The study employed qualitative methodology, specifically the grounded theory design. The researchers attempted to establish a theoretical model by using multiple stages of data collection and analyzed the data to establish patterns and continuously refined them to establish the interrelationship of categories of information (Strauss and Corbin, 1990 as cited in Creswell, 1994 and Merriam, 2002).
Participant Selection
Initially, the researchers purposively included all 20 teachers, whose mother tongue is Ilocano and whose second languages include English, from a central elementary school in the Philippines to compose the population of the study. Nevertheless, during the actual data-collection, only 16 teachers were present because the rest were required to attend a conference. During the profiling of the respondents, one teacher did not fit the criteria set for the study because she had Filipino as her first language. Hence, she was eliminated from the pool of respondents. Another respondent was also eliminated because prior to the think-aloud procedures she reported that she was feverish. The researchers decided to take her out of the pool of respondents due to this extraneous variable that could affect the validity of the results. For humanitarian purposes, however, the researchers allowed them to still participate so that they would not feel isolated from the rest of the respondents. Their data in the profiling and the verbal protocols gathered from them were eventually taken out of the pool of data for presentation and analysis. Ultimately, the total number of respondents was composed of 14 elementary teachers who fit the criteria mentioned earlier.
Such purposive selection of respondents is made due to the following grounds: (a) There is the need to elicit authentic L1 or mother tongue verbal protocols from the respondents when they process the still visuals. This is made due to the idea that in processing texts, the reader may think in his or her mother tongue even if the text he or she is reading is written or printed in the second language (Nuttall, 1982). This process of eliciting their responses even in their L1 ensures that the comprehension processes that the subjects exhibit through their verbal protocols reflect the more genuine reactions they make toward the stimuli. Furthermore, one of the researchers is capable and competent to capture and transliterate the authentic responses that the subjects reveal due to his facility of understanding and utilizing the L1 of the respondents; (b) The selected school (locale) serves as a melting pot of students and teachers coming from 34 villages and some other proximal towns surrounding the area. It serves as the largest central elementary school of the town in terms of the number of faculty members. This purposive selection increases the probable representation of teachers coming from the different villages and from other proximal towns; (c) In the Philippine context, elementary school teachers attended their initial teacher education as a generalist, which is contrary to what the secondary school teachers underwent. This experiential characteristic of the elementary teachers makes them apposite as respondents of the study due to their exposure to a more general body of content knowledge. The explicit reservation to using high school teachers in the study puts forward the assumption that the responses they possibly will manifest may be influenced by their strong attachment to a specialization, which could possibly limit the possible range of knowledge they may use when interpreting or reading the visual images. The selection of the elementary teachers ascertains that the responses they make come from an assortment of sources of information and are not only limited to a concentration of schemata in a particular content specialization.
Ultimately, the teacher-respondents group is composed of 13 female and one male. The youngest participants were around the ages of 21–25 years, while the oldest participants were around 51–55 years. A majority of the respondents possessed postgraduate units and had been teaching for around 1–5 years, while some participants have been teaching for up to three decades.
Data Collection and Coding Procedures
Through think-aloud method, verbal protocols were collected using three different multimodal still visuals shown to the teacher-respondents. The protocols captured through audiovisual recording were subsequently analyzed and coded in three sectional rounds. Prior to the analysis of the data, the verbal protocols were manually transcribed and transliterated by one of the researchers. However, to ascertain the validity of the transcription and the translation, member-checking was conducted. This was done by bringing the transcripts back to the respondents for them to check if the transcription and translations matched the processes they had as they read the stimulus materials.
During the first round of data-collection, every teacher-respondent thought-aloud from a multimodal still image. 1 The verbal protocols gathered from this round constitute the data for open coding. The same procedures were done for the second round but with a different text, which is a multimodal still cartoon. The verbal protocols from this round and the initial codes from the first round make up the data for the axial coding. In this round, the codes developed were combined with compatible codes that were present from the first round. Hence, the researchers were able to develop named categories. Ultimately, similar to the first and second rounds of data collection, verbal protocols were gathered from the teacher-respondents for the purpose of selective coding. During this round, the teacher-respondents thought aloud from a multimodal still graph. Consequently, the codes developed in this round were analyzed for goodness of fit with the named categories that were developed in the second round of coding. Subsequent to the analysis, the researchers were able to establish the integrated categories.
Therefore, from 14 teacher-respondents who thought aloud from three different multimodal still visuals, the researchers were able to collect a total of 42 different sets of verbal protocols and these became the bases for the establishment of the comprehension processing strategies that the teacher-respondents used in comprehending multimodal still visuals. With regard to the sources of information that the teacher-respondents used to build meaning from the visual stimuli, their verbal protocols were analyzed for organic unity based on the visual grammar offered by Kress and van Leeuwen (1996, 2006).
After unpacking the processing strategies and the sources of information that the teachers used to construct meaning from the multimodal still visuals, the researchers were able to establish a grounded theory on the comprehension processing of teachers as ESL readers of multimodal still visuals.
Results and Discussion
Building on the numerous codes that emerged from the 42 different sets of verbal protocols gathered and analyzed from the three rounds of data collection 2 , there were 27 “named categories” of processing strategies, namely: preparation, participant sampling, affective reaction, translanguaging, integration, information dissection, inferencing, interpretation, inquiry, giving opinion, prediction, elaboration, schema activation, schema building, monitoring, information affirmation, evaluation, cognitive repair, intermission, summarizing, termination, determining importance, scanning, reconstruction, reflection, hypothesizing, and making conclusions. These “named categories” eventually established the four “integrated categories” of processing strategies that teacher-respondents used to make sense of the multimodal still visuals.
A part of Figure 2 visually summarizes the results with regard to the first objective of the study, which is to describe the comprehension processes the respondents use while reading. The processes include anticipation, sampling, deepening, and regulation. These processes are reflective of the processing strategies they use which are hereby categorized as: anticipation strategies, sampling strategies, deepening strategies, and regulatory strategies.
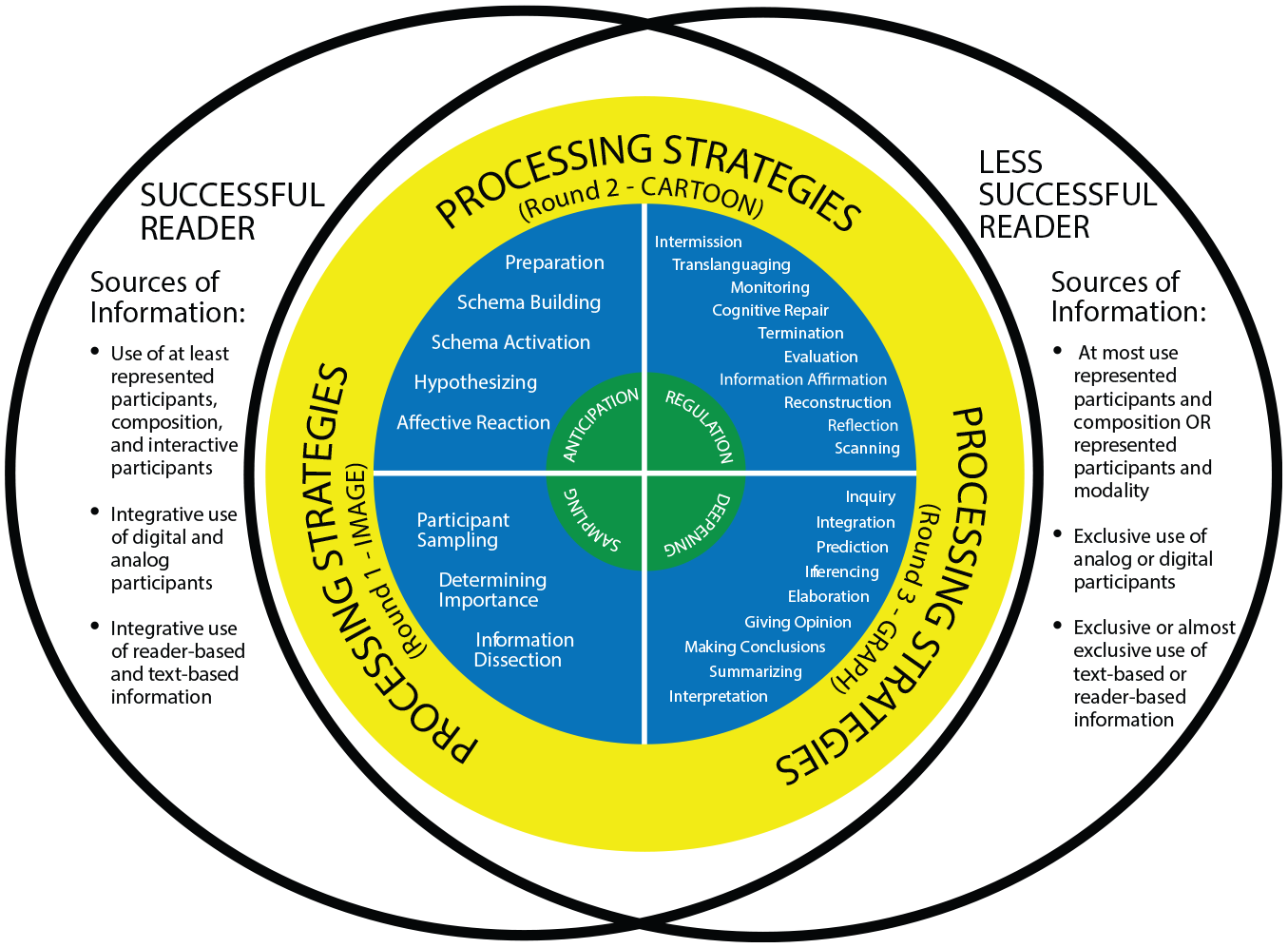
A theoretical model on the comprehension processing of teachers as ESL readers of multimodal still visuals.
The “anticipation strategies” include preparation, schema activation, schema building, hypothesizing, and affective reaction. Preparation is where the respondents expressed readiness to process the text. It also includes overviewing, skimming, and scanning. Schema activation is where the respondents attempted to retrieve information from background knowledge. Schema building is where the subjects used prior knowledge of word-meanings and concepts and where the respondents restated textual information in their own words. Hypothesizing is where the respondents generated an initial hypothesis about the content of the visual materials or summarized what was gained from previewing the visual text. Affective reaction is where the subjects expressed feelings of surprise, disbelief, and other emotional responses toward the stimuli. Affective reaction approximates the “feeler” stance by Navas (2005).
It can be inferred from the grouping of these strategies that they are mostly used as pre-reading strategies. However, in the protocols, schema and affect, as variables in comprehending multimodal still visuals, play a significant role across the different phases of reading, ranging from the pre-reading phase to post-reading phase.
“Sampling strategies” comprise the deliberate use of participant sampling where the respondents decoded the digital and the analog participants of the visual material. This forwards that the respondents recognized the linguistic entries and the non-linguistic entries in the text. Participant sampling equates to “decoding” in the context of reading linguistic texts.
The sampling strategies also include determining importance, where the respondents identified keywords, concepts, and critical information believed to be important. Sampling also includes information dissection, where the respondents deconstructed or broke down the textual information into parts in order to make sense of the visuals.
It only goes to imply that the grouping of participant sampling, determining importance, and information dissection into one general comprehension processing, i.e. sampling, shows the process where the reading of multimodal still visuals is also greatly influenced by text-driven processing. It only goes to provide more evidence that reading or comprehension is a bidirectional interaction of reader-based and text-based factors and not just unidirectional processing.
The “deepening strategies” involve inquiry, where the respondents asked questions to clarify, to retrieve relevant information from background knowledge, to unify information, to challenge text, or to express skepticism over the content of the stimulus visuals. Furthermore, this set of strategies allowed the readers to do inferencing, predicting, giving opinion, and making conclusions. Part of this set of strategies is integration, where the respondents connected textual information with background knowledge and also with other textual information. In addition, this set of strategies includes elaboration, where the teacher-respondents substantiated meanings that they have established by drawing examples from their personal and social experiences and observations. Moreover, this set also includes interpretation, where the respondents explained the signification of a visual participant or explained the function of a visual participant in relation to the purpose of the visual designer. Ultimately, this set of strategies involves summarizing, where the respondents unified all information into one organic or cohesive unit of meaning.
The “regulatory strategies” comprise monitoring, where the respondents expressed non-understanding, expressed awareness of the lack of relevant knowledge, expressed that a visual participant is misrecognized or misdecoded, expressed that a conflict exists between textual information and background knowledge, and recognized a mismatch between personal expectation and the message of the visual material. Furthermore, this set of strategies also consists of cognitive repair, where the respondents repeated or restated selected ideas to help retain information in working memory, corrected a misrecognized visual participant, reread visual participants to integrate the relationship of information, reread to check understanding of visual composition, regressed to fix-up frustration to provide meaning, regressed to access another source of information, asked information from an external authority, attempted to explain textual input, attempted to elaborate, and reread to clarify. Moreover, this set also includes information affirmation, where the respondents expressed agreement with a visual participant or expressed agreement between prior knowledge and digital participants.
Additionally, when the respondents identified possible areas of difficulty posed by the visual material, when they suggested improvement of textual information, and when they recognized instability of meanings that may be generated, they clearly demonstrated evaluation.
Moreover, the set involves accessing language resources or translanguaging, where respondents used their L1 in addition to their L2s in order to make sense of the visual material. This supports the idea proposed by Nutall (1982) where she forwards that readers process texts in their L1 even when they read texts written in their L2.
“Regulatory strategies” also has scanning, where the respondents looked for text-based information in order to answer self-imposed questions. Reflection was also manifested by the respondents. This is where they expressed insight after self-questioning and where they explicitly paused to generate insight from portions of the visual materials or from the whole visual material itself. The buying of time in order to allow oneself to process more of the visual texts demonstrates the strategy of intermission that the respondents used as reflected in their protocols. Another strategy they manifested under this set is reconstruction. This is where they changed their responses to the visual text or rebuilt their initial understanding of the visual materials or rebuilt their initial inferences. Finally, when the respondents were done with the task of reading the visual materials, they demonstrated the strategy of termination.
With regard to the second and third objectives of the study, which are to identify the sources of information that the teacher-respondents used to construct meaning of the visual stimuli and to describe how these sources influenced how they made sense of the visual stimuli, only seven out of the 42 sets of verbal protocols were able to manifest a closer match of meaning with the intended meaning of the visual stimuli based on the visual grammar of Kress and van Leeuwen (1996, 2006). This forwards that 35 out of the 42 sets of verbal protocols only manifested a partial match of meaning in contrast to the intention of the visual author.
The more successful teacher-respondents, who reflect the seven organically unified and successful verbal protocols, equally used and integrated reader-based and text-based sources of information and used at least the “represented participants,” “composition,” and “interactive participants” in order to establish the intended meaning of the multimodal still visuals. On the other hand, the less successful teacher-respondents, who reflect the 35 unsuccessful verbal protocols, used reader-based and text-based sources of information but failed to integrate them. Furthermore, the less successful reader-respondents relied exclusively on the use of either analog or digital participants, and they mostly based their processing on their recognition and use of either “represented participants” and “composition” alone or “represented participants” and “modality” alone. They were not able to recognize and use “interactive participants” to be able to build meaning and establish the intended message of the visual materials.
The findings above affirm earlier literature stating that reading or making meaning in texts required the integration of schemata and that reading should be processed in a bidirectional and not a unidirectional manner (Dechant, 1991; Gunning, 2003; Stanovich, 2000; Wallace, 1993; Weaver, 1994). This implies that for reading texts, whether they are linguistic texts or multimodal visuals, readers should capitalize on different sources of information. In the case of reading multimodal still visuals, the knowledge of the visual grammar or visual social semiotics offered by Kress and van Leeuwen (1996, 2006), and further explained by Scollon and Scollon (2003), will help visual readers to make sense of the real intentions of the multimodal still visuals.
Figure 2 summarizes the theoretical model that reflects the comprehension processing of the elementary teachers as ESL readers of the multimodal still visuals.
It is worthy to note that, in this model, it appears that both successful and unsuccessful teacher-respondents use all four comprehension processing strategies, which may be contrary to what is known in the literature about the difference of strategy use by proficient and less proficient readers (Gutierrez, 2002). Nevertheless, it may be safe to assume at this point that because they are educators who mostly possess relatively long experiences in teaching and have postgraduate units in education, most likely, they have already developed a repertoire of mature and deliberate comprehension strategies because of the nature of their profession which is to model excellent learning habits.
The unsuccessful comprehension of the visual materials now rests upon the extent of the (in)capability of the teacher-respondents with regard to recognizing different sources of information. Additionally, it also rests upon the extent of their (in)ability to integrate relevant schema with other textual and contextual sources in order to arrive at an organically unified meaning. The unsuccessful meaning-making manifested in the verbal protocols of the respondents reflects the argument of Markovits et al. (2006) stating that teachers are not usually exposed to systematic trainings that develop their visual cognition abilities.
Conclusions and Future Directions
Comparable with the processes of reading linguistic texts, the comprehension processing of multimodal still visuals manifest that reading or comprehension is affirmatively an active process of constructing or building meaning. It is evidently seen in the study that the elementary teachers as ESL readers of multimodal still visuals actively go through the processes of anticipation, sampling, deepening, and regulation using deliberate strategies in order to make sense of the visual stimuli. Furthermore, the study forwards that successful ESL reading of multimodal still visuals rely on the interaction of both text-based and reader-based sources of information. The text-based information should essentially include the digital and analog “represented participants,” “composition,” and “modality.” The successful signification of these three text-based information are greatly driven by relevant personal, cognitive, affective, and social experiences. The match of meaning between the visual’s author and the visual’s reader rely heavily on the latter’s recognition and use of the “interactive participants,” which serve as the context of the visual reading process.
It only goes to say that in reading multimodal still visuals, it is essential for a reader to use text-based information, reader-based information, and context in order to establish the intended meaning of the said reading materials. In other words, the more a reader uses all the elements of the visual grammar in interaction with his or her relevant schemata, the closer the reader is to the establishment of the intended meaning of the multimodal still visuals.
In light of this conclusion, it is recommended that teachers should be deliberately trained with regard to reading and teaching multimodal still visuals. This implies that teachers need to have exposure to systematic pre-service and in-service preparation with regard to using the four general processes that readers undergo as they make sense of such visual stimuli. Additionally, explicit training as regards to the different sources of information that visual readers can use to comprehend the visual material such as relevant schema, “represented participants,” “composition,” “modality,” and “interactive participants” should be ascertained or included in the teacher education curricula. In other words, teacher education programs should allot at least one general course for visual literacy and one pedagogical or methods course for the teaching of visual literacy.
Given the assumption that teachers are trained with these four general comprehension processes and these sources of information via the general course and the methods course, they are then expected to employ content and strategy instruction when they teach their students how to comprehend multimodal still visuals, especially when the learners are also ESL readers of multimodal still visuals.
Other investigators may want to replicate the study with other elementary teachers in other locales or by using high school and college educators. Additionally, since this qualitative research is limited to the 14 teacher-respondents, such replication studies are needed for the purpose of stronger generalizability. Other researchers with inclinations to quantitative research may also want to conduct true experimental investigations comparing the effects of strategy instruction in visual literacy using the framework established in this study against conventional literacy instruction programs. Ultimately, other researchers and curriculum developers may want to develop and validate content and performance standards or competencies that compel the production of competent teachers of visual literacy and competent instructional designers of multimodal still visual technologies.
Footnotes
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by dissertation grants obtained from the Philippines’ Commission on Higher Education and from the Philippine Normal University Professional Development Incentive Program.