
Abstract
Fabric defect detection plays a crucial role in the production process of the textile industry. Vision-based inspection methods have emerged as an inevitable trend due to their lower labor costs and high detection efficiency. As the accuracy requirements for fabric defect detection, methods must not only identify and locate defects accurately but also describe the morphological features of the defects. This poses a challenge for the algorithm’s design, as it must consider both the semantic and texture information of the fabric. In this paper, we propose an end-to-end dual-path segmentation network called DPNet for fabric defect detection, which can extract and fuse both semantic and texture information to achieve high accuracy. The proposed framework consists of two paths: the semantic path, which has narrow but deep layers to obtain high-dimensional features, and the texture path, which has wide and dense layers to extract low-level details. To enhance the interaction between semantic and texture features, a crossed attention fusion module has been developed. Evaluations show that the proposed method outperforms other methods on different datasets in terms of mIoU, with results of 75.84% for Ngan and 70.69% for AITEX. In addition, we developed an inspection platform and tested the proposed method online. We found that it can achieve online detection at a speed of 40 m/min, making it well-suited for practical production environments.
Fabric defect detection is a crucial task in the textile industry’s production process, as the quality of the products directly impacts the economic efficiency and reputation of enterprises in the industry. 1 Manual visual inspection, being prone to inaccuracies, time consumption, and high costs 2 necessitates the exploration of alternative approaches to address these challenges.3,4 Among the commonly employed methods, machine-vision-based inspection is one of the most widely adopted approaches. 5
In the early stages of defect detection, hand-crafted feature extraction techniques were utilized. These techniques include statistical analysis,6–8 frequency domain analysis.9,10 model-based methods,11–13 and more. However, with advancements in the weaving process, the texture of different fabrics varies significantly, and the morphology of the defects becomes more complex. This increases the amount of semantic information in the fabric, which poses a limitation on the detection accuracy of these methods and also reduces the generalization performance, making their widespread application challenging.
In recent years, propelled by the rapid advancement of computer technology, deep learning models have been widely used in image classification,14–16 object detection,17–19 and image segmentation.20–24 These models, such as convolutional neural networks (CNNs), have proved to be particularly effective in automatically extracting suitable features according to the task requirements. By stacking a large number of convolutional kernels, down sampling layers and fully connected layers, deep networks can extract abstract semantic information to describe and distinguish different fabric textures and defects. However, despite enhancing the model’s generalization performance, deep learning models often overlook fabric texture information, which leads to a rough morphological description of the defect. In addition, the accuracy of deep learning models is mainly limited to the image or region level, making it challenging to obtain precise defect shapes and edge details.
The fabric defect detection task necessitates precise identification and localization of defects, as well as a detailed description of their morphological features for subsequent operations such as defect grading. Unlike typical detection tasks such as autonomous driving, which require a high level of semantic abstraction regarding the identified object, fabric surfaces often have similar or periodically changing patterns that are rich in texture information. Meanwhile, the fabric also carries a certain amount of semantic information due to the varying complexity of its texture and morphology of defects. Therefore, there is a need for a model that can consider both the texture and semantic information of the fabric.
To this end, we propose an end-to-end defect detection model with two distinct paths that can effectively combine texture and semantic features. The proposed method not only identifies the defect locations but also describes quantitative features, such as defect size and area, at the pixel level. The model architecture comprises two paths: the texture path, which employs dense connections to reuse the underlying features more frequently, increasing the weight of texture information in the decision; and the semantic path, which uses residual modules quickly to deepen the number of network layers and extract more semantic information. Moreover, we introduce a crossed attention fusion module to merge the two types of features effectively. To validate the effectiveness of our proposed method, we conducted several experiments on three different datasets separately.
The main contributions are as follows:
We propose a novel dual-path segmentation model for fabric detection that can extract both texture and semantic information from fabric for efficient detection of defects. To enable the interaction of various feature types and enhance the segmentation results, we introduce a crossed attention fusion module that can merge features effectively. We develop an online inspection platform and test our model in a real-world production setting. Our experimental results demonstrate that our method can achieve impressive results on different datasets and detect defects at a speed of 40 m/min, making it suitable for practical production environments.
Related works
According to the output form of results, fabric defect detection using deep learning can be classified into three approaches: classification, detection, and segmentation. Classification approaches have image-wise accuracy, while detection approaches have patch-wise accuracy. Segmentation approaches, on the other hand, offer pixel-wise accuracy.
Classification approaches regard the image as a whole and identify defects based on high-dimensional features extracted at the top-most part of the model. Jun et al. 25 proposed a two-stage method, consisting of local defect prediction in the first stage and global defect recognition in the second stage. Li et al. 26 proposed a structure comprising several micro-architectures that can help reduce the number of model parameters, whereas Liu et al. 27 used a modified VGG16 model to identify defects in fabric with complex texture. However, while classification approaches are effective at determining the presence of defects in an image, their accuracy is limited to the image level, which cannot meet the requirements of defect location in detection tasks. To address this limitation, some researchers have used the method of dividing images into small patches and inputting them into the model separately to achieve rough localizations of defects.28–30 However, this introduces a large number of repetitive operations and increases the time cost.
Detection approaches utilize bounding boxes to indicate the defect locations in fabric images.31–33 To improve accuracy and time efficiency, Zhao et al. 34 proposed a method based on a multi-scale convolutional neural network, while Peng et al 35 introduced prior anchor boxes and a feature pyramid structure in their model. Detection approaches are constrained by artificially set candidate frames, which limits their ability to describe the scale of defects accurately. Large defects may be identified as collections of small defects, while small defects may be disregarded or grouped with other nearby defects. Consequently, these approaches cannot provide a more detailed description of the defect boundaries, making it difficult to extract quantitative features such as measurements of defect size and area.
Segmentation approaches, as an end-to-end model, are capable of producing images that match the input image’s size, which allows for pixel-wise accuracy. This is more in line with human intuition and is more convenient for the subsequent extraction of quantitative features.36,37 Jing et al. 38 have reduced the complexity cost and model size of the network by introducing depth-wise separable convolution into the UNet model. Tao et al. 39 achieved defect segmentation using a cascaded self-encoder structure. Furthermore, segmentation approaches can handle input images of any size because they discard the final fully connected layers and introduce a fully convolutional network structure. When considering fabric defect detection as an image segmentation task, it is important to consider both texture and semantic information to obtain accurate segmentation results.
Proposed method
In this section, we present the dual-path segmentation network, as illustrated in Figure 1. The network extracts distinct features through the texture path and semantic path, and then merges them at the end (see Crossed attention fusion module) to obtain a more comprehensive feature representation. We will provide a detailed explanation of each module’s primary functions and design principles below.
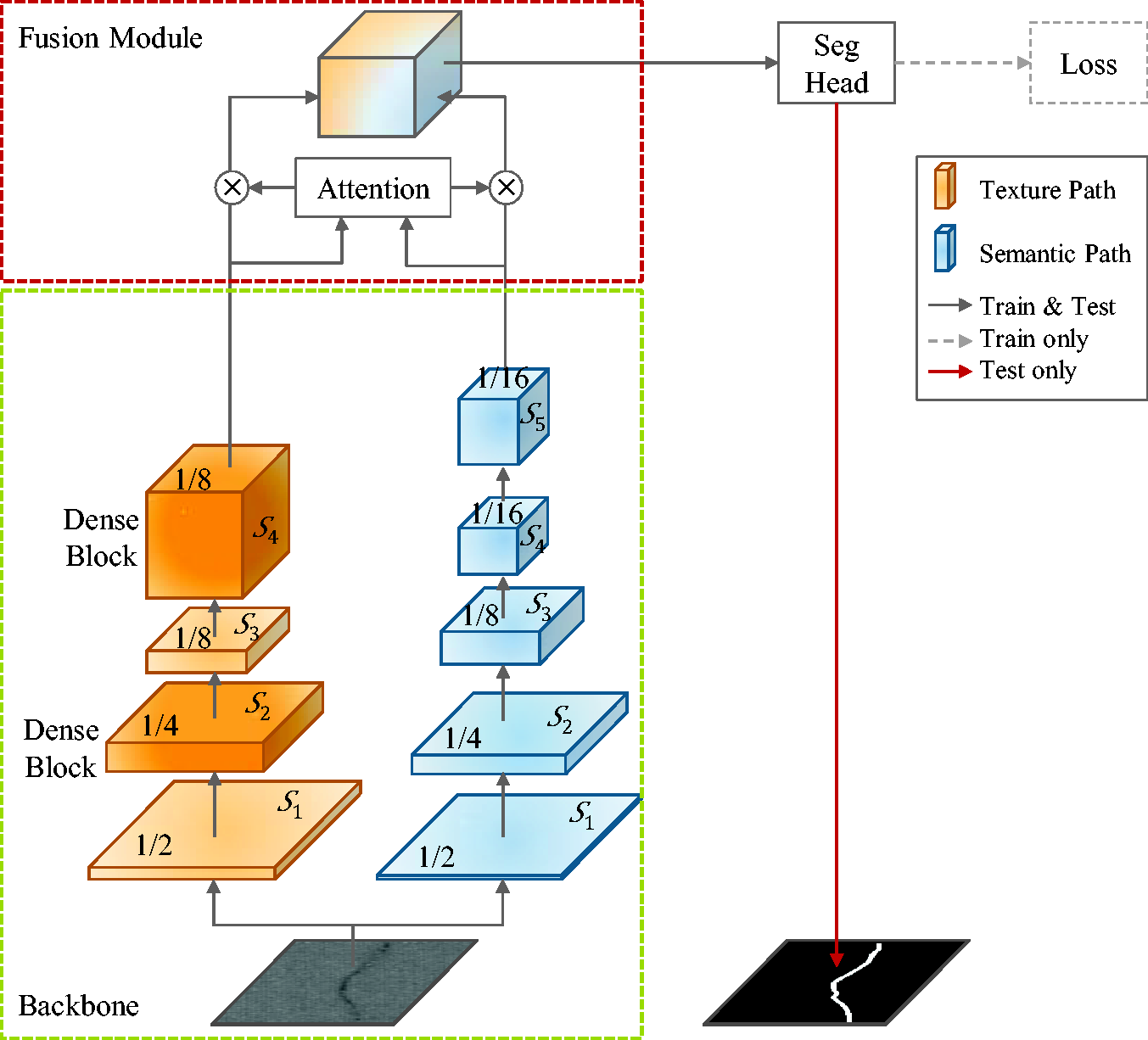
Pipeline of the proposed dual-path segmentation network. The architecture consists of two main components: the backbone network in the green dashed box, the fusion module in the red dashed box. The backbone network consists of the texture path (orange) and semantic path (blue). Each stage of the semantic or texture path is represented by
Texture path
Fabric inherently contains a plethora of textural information, primarily extracted by the network’s shallow layers. To encode richer textural features, the texture path has been devised with dense interconnections and ample width. The corresponding parameters have been tabulated in Table 1.
Details of texture path

Conv + BN + ReLU denotes convolutional operation followed by a batch normalization and a ReLU activation function.
Same convolution is introduced, in which the size of the feature map remains intact.
DB denotes the dense module.
AP is the average pooling layer.
The texture path is composed of four stages, and dense modules
40
are introduced in S2 and S4. The output feature map 
With an increase in the number of layers in dense modules, the shallow features are reused more frequently. For instance, for a dense module of depth
Semantic path
To achieve more precise distinction between defects and the background, the semantic path adopts a network structure with a higher number of layers. This design enables the model to expand its receptive field rapidly and capture more contextual information. The specific parameters are shown in Table 2. Some key modules in the semantic path are as follows:
Details of semantic path
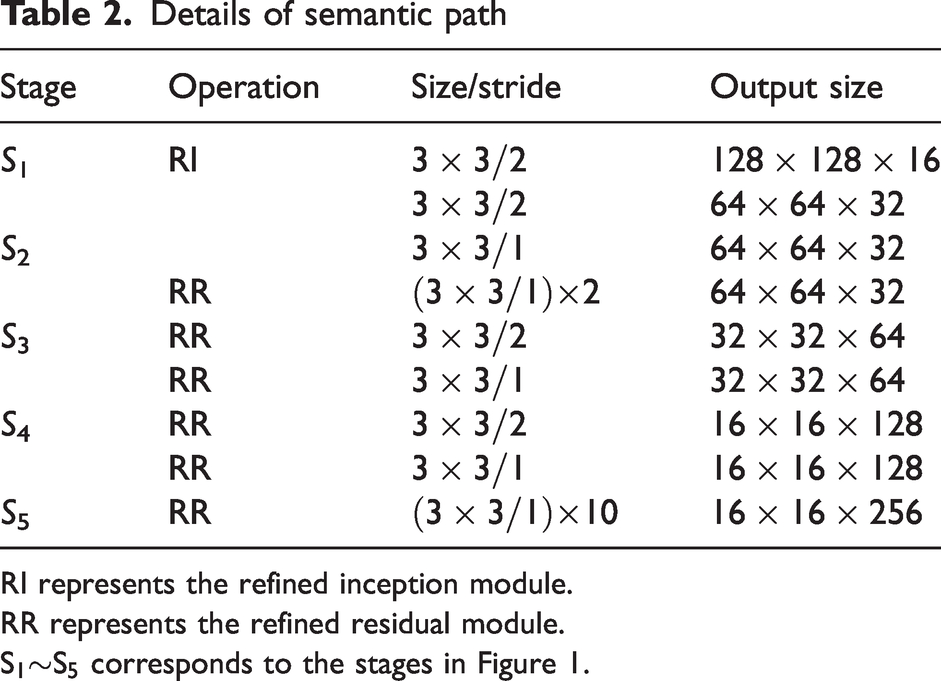
RI represents the refined inception module.
RR represents the refined residual module.
Refined inception module
Inspired by GoogleNet, 41 we adopt parallel pooling and convolutional operations to down sample and concatenate feature maps at the end. This approach does not impose excessive computational demands while mitigating the problem of information loss due to the decrease in resolution. The structure is illustrated in Figure 2.
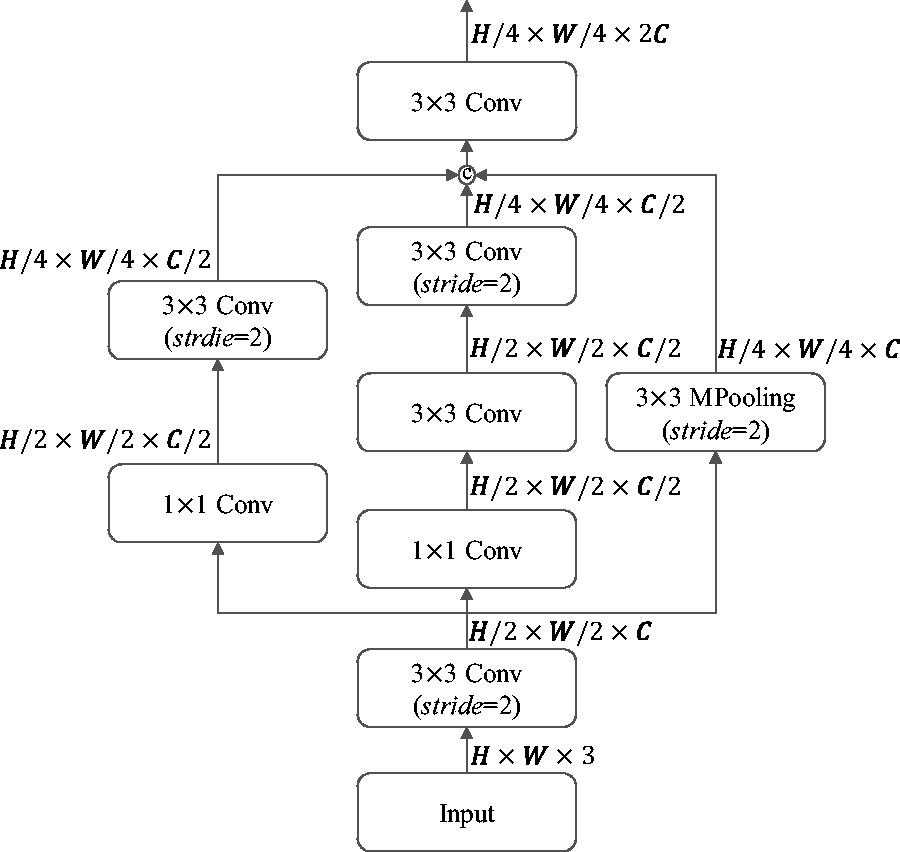
Details of refined inception module. Conv refers to the convolutional operation followed by a batch normalization and a ReLU activation function. MPooling is the max pooling layer.
Refined residual module
Given the limited number of channels in the feature maps of the semantic path, we draw inspiration from MobileNetv2
42
and design a refined residual module, as shown in Figure 3. First, we increase the input channels by a factor of 6, followed by the extraction of features by depth-wise separable convolution. We then append the squeeze and excitation (SE)
43
attention module to enhance the expression capability of the residual module for the features, as shown in Figure 3(c). The output y of SE is as follows:
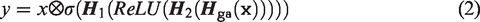
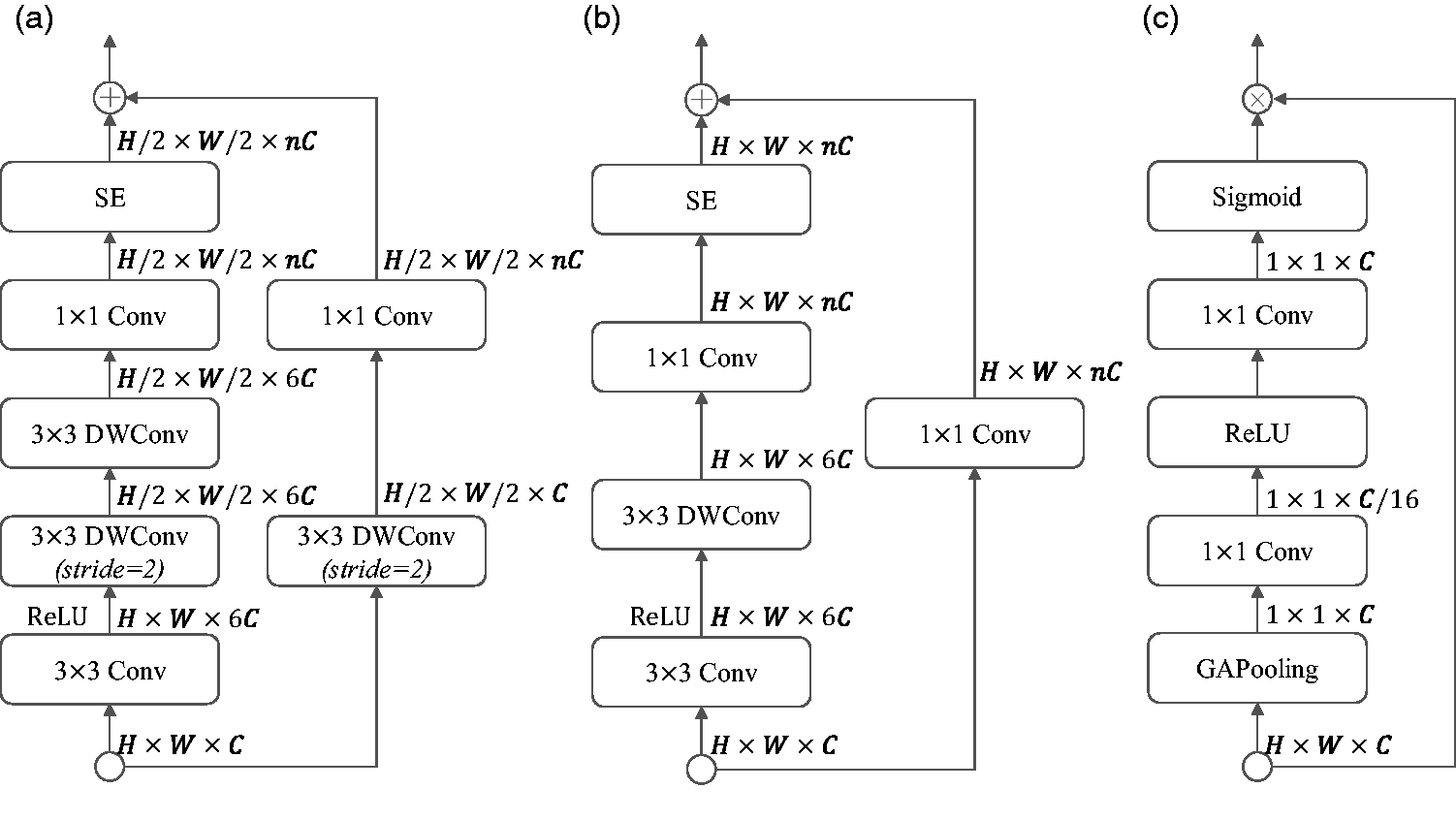
Details of refined residual module; (a) is used when the resolution of the output feature map is reduced; (b) is used when the input and output feature map resolutions are the same; (c) details of squeeze and excitation (SE) in (a) and (b). DWConv refers to the depth-wise convolution, and Conv refers to convolutional operation, which is followed by a batch normalization in (a) and (b). MPooling is the max pooling layer. GAPooling is the global average pooling layer. Sigmoid means the sigmoid activation function, and ReLU means the ReLU activation function.
Crossed attention fusion module
The texture path and semantic path represent complementary features. Combining the two through simple methods, such as pixel-wise summation or channel-wise concatenation, does not effectively enhance segmentation performance because it ignores the differences between the two information types.
Based on the analysis presented above, we propose a crossed attention fusion module to merge the complementary information from both paths, as shown in Figure 4. The channel attention block (CAB) guides the texture path from the channel dimension to distinguish the defects from the background better, while the spatial attention block (SAB) guides the semantic path from the spatial dimension to make a more detailed segmentation of the defect boundary. SAB and CAB are calculated as follows:
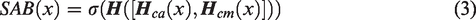
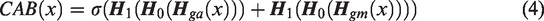
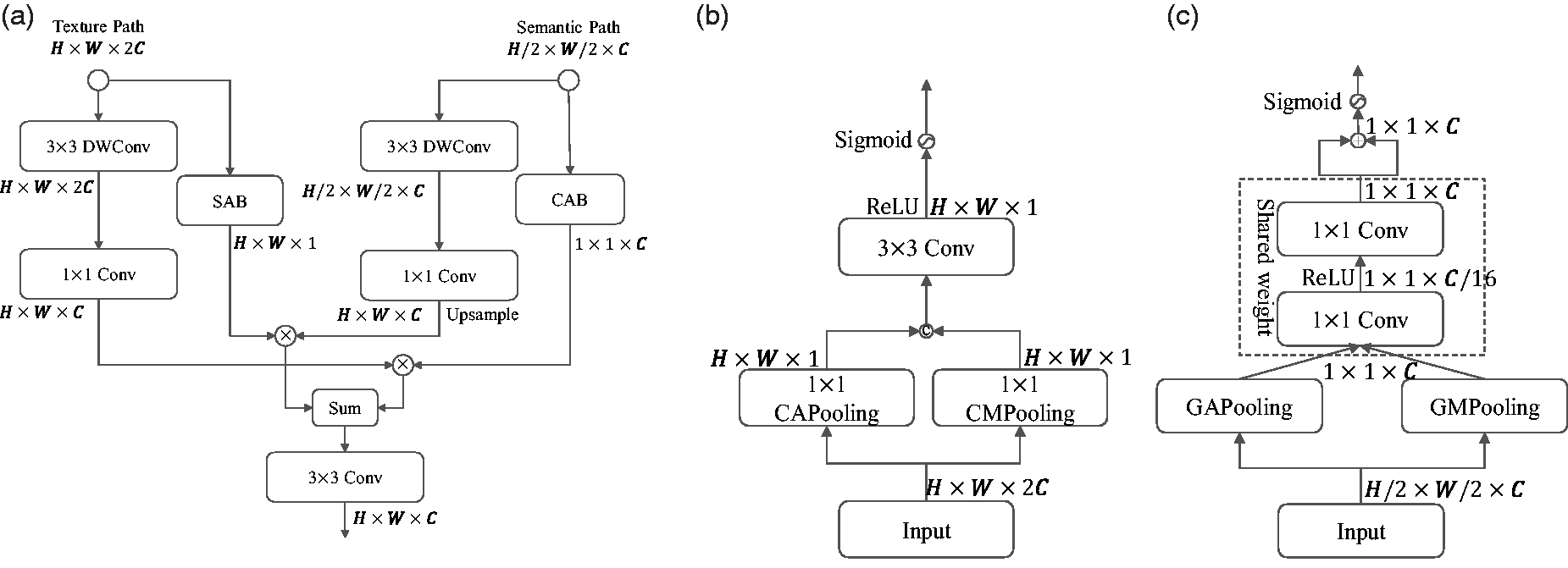
Details of crossed attention fusion module; (a) shows the overview of the crossed attention fusion module; (b) and (c) are the details of the spatial attention block (SAB) and channel attention block (CAB) structure. DWConv refers to the depth-wise convolution, and Conv refers to the convolutional operation, which is followed by a batch normalization in (a) and (b). APooling is the average pooling layer; GAPooling and GMPooling are the global average pooling layer and the global max pooling layer, respectively. CAPooling and CMPooling are the channel average pooling layer and the channel max pooling layer, respectively. Sigmoid means the Sigmoid activation function, and ReLU means the ReLU activation function;
Compared with simple combinations, this type of guided fusion allows for effective interaction between the two types of features and reduces the gap between them.
Segmentation head
The segmentation head integrates the characteristics and performs upsampling to match the input image dimensions using

Details of segmentation head Conv refers to the convolutional operation. BN is the batch normalization layer; ReLU means the ReLU activation function, and Upsample means bilinear interpolation.
Cross-entropy is employed as the loss function in this study, as displayed in equation (5):
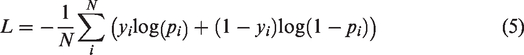
Experiments
In this section, we present the results of a series of experiments that evaluate the performance of our proposed method. First, we introduce the datasets and evaluation metrics that were utilized in the experiments and describe the implementation details. Next, we verify the effectiveness of each designed module of the proposed DPNet on the Ngan dataset. Finally, we compare the performance of our proposed DPNet with other deep learning algorithms, namely SegNet, 20 FCN, 21 PSPNet 44 and Deeplabv3+. 45 across different datasets.
Datasets and metrics
Datasets
We evaluated the performance of the proposed method on two different datasets, namely Ngan and AITEX.
Ngan
46
is provided by the Industrial Automation Research Laboratory, Department of Electrical and Electronic Engineering, the University of Hong Kong. The dataset consists of three different fabric structures of dot pattern, box pattern, and star pattern, each of which contains 26 images with five defect categories and 30 defect-free images. All images are in RGB and have a resolution of
AITEX
47
contains a total of 245 grayscale images of
Metrics
We apply the mean intersection of the union (mIoU) and the intersection of the union on the defect region (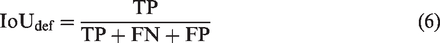
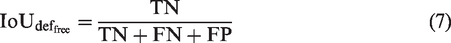


Schematic diagram of mIoU calculating on fabric; (a) marks the region of ground truth and detection result on the fabric and (b) reflects the relationship between ground truth and detection result, where TP is true positive, TN is true negative, FP is false positive, and FN is false negative.
Implementation details
Training
The parameters were initialized randomly from a Gaussian distribution. To optimize the parameters, we used the mini-batch stochastic gradient descent (SGD) with a batch size of 12. The momentum was set to 0.9 and the weight decay was
For data augmentation, we randomly cropped the input images to
Inference
To consider both accuracy and real-time in practical production environments, we did not apply inference tricks such as multiscale testing or multiscale cropping, which may improve accuracy but are time consuming. We set the batch size as 2. For offline testing, the input images were cropped into
Set-up
All experiments were built on the Pytorch1.8.1 deep-learning framework, and ran on Nvidia GeForce GTX 1660 devices.
Ablative studies
In this subsection, several ablative experiments are conducted on the Ngan dataset to assess different modules.
Ablation studies on individual path
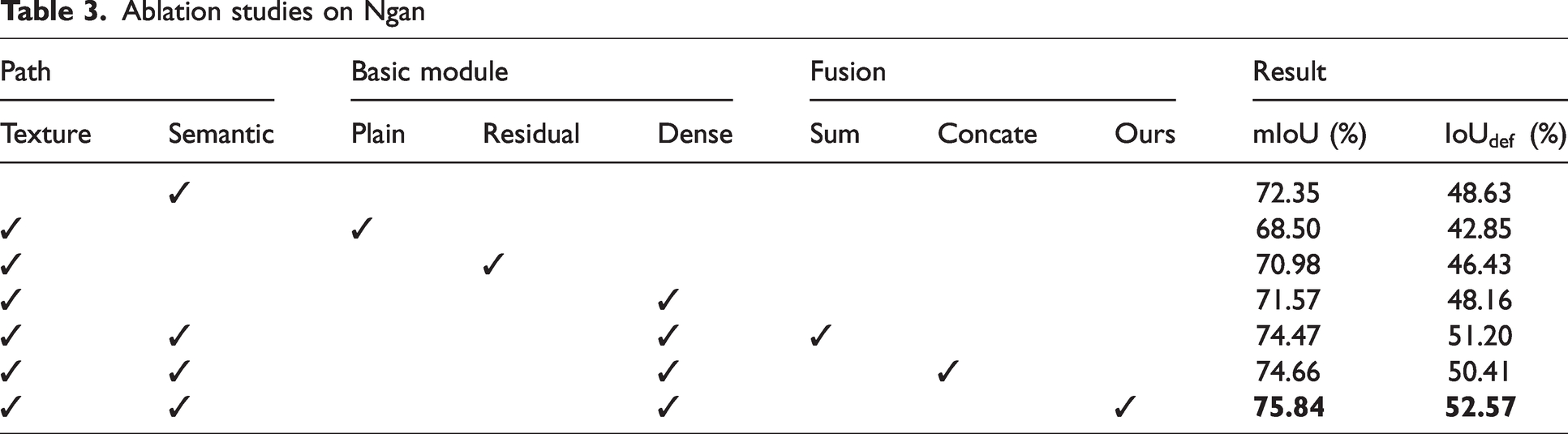
First, ablation studies were carried out on an individual path to explore the segmentation effect of texture path and semantic path. As evidenced by the first, fourth and fifth rows of Table 3, employing only simple fusion improves results by almost 3% compared with semantic or texture paths alone, suggesting that texture and semantic information are mutually complementary and essential in the defect detection task.
Ablation studies on Ngan
Ablation studies on basic module
The second, third and fourth rows of Table 3 demonstrate the impact of different basic modules in the texture path. We compared the dense module with the other two common convolution methods, the residual module and plain module, and found that the mIoU and
Ablation studies on feature fusion
We also analyzed the segmentation results using different fusion methods shown in Table 3. The proposed crossed attention fusion module achieved an mIoU of 75.84% and an
Accuracy analysis
To avoid sample imbalance, cropping was exclusively applied to the defect region, as defects are only observed in a portion of the image. The visualization of the detection results on Ngan and AITEX are shown in Figure 7 and Figure 8. More detailed metrics are shown in Table 4 and Table 5. It is apparent that fabric images possess a significant amount of texture information, thus models such as PSPNet that prioritize the semantic information of the images do not yield as accurate segmentation results as models such as FCN, which employ skip connections to supplement the texture information. While our proposed method still outperforms other methods in segmenting the boundary details of the defects, achieving mIou scores of up to 75.84% and 70.69%, respectively, it is noteworthy that skip connections represent a viable approach to supplementing texture information and will be explored further in the future.

Detection results of different methods on Ngan. White denotes defect region, while black denotes the defect-free region. (a) Original image. (b) DeepLabv3+. (c) FCN. (d) PSPNet. (e) SegNet. (f) DPNet and (g) Ground truth.

Detection results of different methods on AITEX. White denotes defect region, while black denotes defect-free region. (a) Original image. (b) DeepLabv3+. (c) FCN. (d) PSPNet. (e) SegNet. (f) DPNet and (g) Ground truth.
Evaluation metrics of different methods on Ngan

Evaluation metrics of different methods on AITEX

Discussion
Visualization of feature map
In this subsection, we aim to gain a deeper understanding of how different paths respond to various fabric features by visualizing the feature maps of the texture and semantic path outputs, 48 as shown in Figure 9. In particular, in Figure 9(b), we observe that the texture path is more sensitive to the texture pattern of the fabric and the edge details of the defects, whereas in Figure 9(c) the semantic path excels at identifying and locating the defect regions. By combining the features extracted from both paths using the proposed fusion module, the resulting class activation map in Figure 9(d) demonstrates that our method effectively integrates texture and semantic information to improve the overall segmentation results.

Grad class activation map (CAM) of DPNet model on the AITEX dataset. (a) Original image; (b) CAM on the texture path; (c) CAM on the semantic path and (d) CAM after fusion.
Online detection
In this subsection, we present the online testing results of our model. For image acquisition, we utilized two CMOS line-scan cameras specifically selected for their exceptional performance within our application. With their combined field of view spanning around 1 m, precisely suited for fabric widths of around 0.7 m, it ensured comprehensive coverage of the fabric surface. The final size of the captured images is 2048 × 256. Tunnel lighting was employed as the illumination. For uniform and minimally distorted image capture, an encoder was employed to trigger the camera capture based on the actual motion state of the fabric. As equipment shaking may affect image quality, we maintained independent installations for the camera and light source of the detection system, separate from the detection platform. The device configuration details are shown in Table 6.
Device configuration details

We created our own dataset, called warp knitted fabric (WKF), which consists of several rolls of defective warp-knitted cloth and 731 corresponding defective images collected from two factories in Fujian and Shanghai, over a period of 2 months. These images were captured using the prototype shown in Figure 10(b) and contain eight different types of defects, including broken yarns, hooked yarns, holes, knots, soiling and so on. A total of 1512 images were chosen as the final dataset samples after cropping and shifting. We first trained the model on this self-built dataset, and then used the model for online detection. The outcomes are illustrated in Figure 11, where it can be observed that the proposed method achieved satisfactory results with a detection rate of 40 m/min.
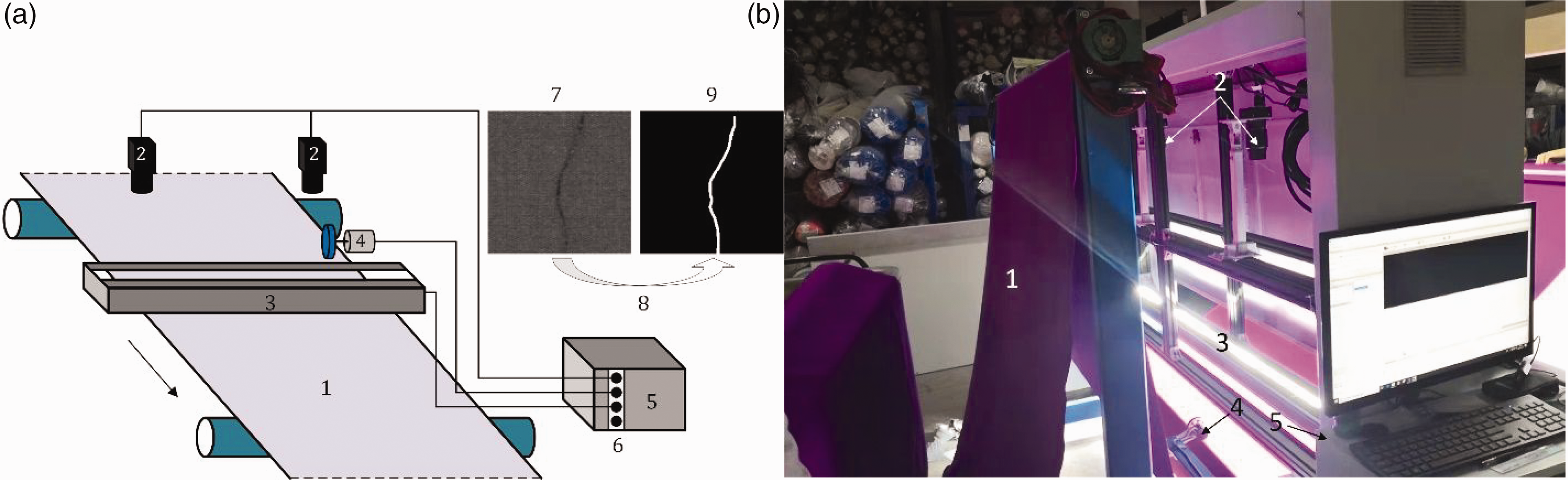
Automatic fabric defect detection platform; (a) shows the schematic diagram of the inspection platform; (b) shows the physical picture of the detection platform. The light source (3) provides a good lighting environment for the fabric (1). The movement of the fabric (1) drives the encoder (4) rotating, which triggers the camera (2) to capture images. The images (7) are transferred into the memory of the computer (5) through the frame grabber (6). While online detection, the images (7) are sent to the proposed model (8) to obtain the segmentation result (9).

Visualization of online detection. The first row is original images. The second row is the corresponding segmentation results. The third row is examples of quantitative feature extraction.
In addition, several examples of the extraction of quantitative features are depicted in Figure 11. We first segmented the connected components to determine the number of defects. Then, we calculated the defect area by quantifying the number of pixels within each connected component. Finally, we calculated the bounding rectangle using the contour coordinates and derived the length and width of the defects.
Conclusions
In this paper, we propose a novel dual-path model for fabric defect segmentation, thereby achieving outstanding accuracy at the pixel level, which renders it more conducive to subsequent quantitative feature extraction. The proposed model takes into account both texture and semantic information. We utilize dense connections effectively to reuse shallow features and amplify the significance of texture details in the decision-making process, while residual modules are employed rapidly to deepen the model and acquire semantic information. To achieve a more efficient integration of semantic and texture information, we have also devised a crossed attention fusion module.
Through comprehensive experiments conducted on various datasets, our proposed method exhibits impressive performance achieving an mIoU score of 75.84% on Ngan and 70.69% on AITEX. Furthermore, we have developed an automatic platform for fabric defect detection, capable of deploying our model for online testing. With a detection rate of 40 m/min, our system fulfils the demands of actual production requirements.
It is worth noting that the fabric defect dataset utilized in this study is small in terms of size, imposing limitations on the model’s performance. Therefore, we will focus more on the collection of fabric defect samples with the ultimate aim of creating a publicly accessible dataset for research purposes. Moreover, it is challenging to collect defective samples due to their rarity in production practice, whereas defect-free samples are abundantly available. In the future, we plan to concentrate on anomaly detection methods that train models using only defect-free samples.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of the article: This work was supported by the National Key Research and Development Project (grant number 2018YFB1308800).