
Abstract
Simple, fast and effective fiber identification can help consumers purchase their desired apparel and help the industry conduct large-scale textile testing. This paper presents a transformer architecture incorporating convolutions to recognize fibers in textile surface images, which meets the above requirements. Firstly, a convolution operation is performed on textile images to pick up overlapping patches as tokens and the linear projections in transformer encoders are replaced by depth-wise separable convolutions to extract the fiber representations. Secondly, the multi-head cross-attention module enables each label embedding to be compared with features at each spatial location to locate and pool the corresponding fiber characteristics. Finally, a simplified asymmetric loss is introduced to further purify the extracted fiber features. Experiments demonstrate that the proposed approach provides a significant improvement in fiber identification accuracy over both state-of-the-art multi-label classification frameworks and fiber identification architectures.
Keywords
With the pursuit of a high quality of life, consumers are increasingly concerned about the comfort and functionality of garments, such as skin-friendliness, wicking properties and sun protection.1–3 The attributes of apparel are closely associated with the types of raw fibers. 4 , 5 Clothes of 100% cotton have superior softness, moisture absorption and skin-friendliness, yet are prone to wrinkling. Clothing of 100% polyester provides excellent durability, sun protection and drapability, but poor water vapor permeability. Fabrics with various mixing ratios of cotton and polyester fibers have different properties. 6 , 7 Therefore, simple and efficient identification of textile components can help consumers get their desired products.
The most common fiber identification methods are burning fibers, testing solubility, the staining test, microscope observation and photo discrimination.8–11 They are widely used by various research units and fiber identification institutions because of their high accuracy in specific environments. All of these techniques, however, necessitate tearing textiles to collect fiber samples. In addition, they have drawbacks such as long testing times, high appraisal environmental requirements, strong human impact and an inability to conduct large-scale rapid fiber recognition.
12
,
13
For these reasons, a considerable number of textiles are marketed with components that do not match their labels, putting consumers’ interests at risk.
14
Hence, non-destructive technologies for quick fiber classification, such as infrared spectroscopy and image recognition, have been developed.
15
,
16
The former classifies fibers by analyzing the spectrogram produced by the fibers’ absorption of infrared energy. Infrared spectroscopy necessitates prior knowledge of the types of garment fibers to be tested, and the cost of owning such equipment is very high, so this method is only employed by research institutes and customs. The latter identifies fibers with photographs taken directly on the textile surfaces by magnifiers or high-definition cameras. This image identification method without tearing the fabric and extracting the fibers to make samples is becoming a new research interest. Kampouris et al.
16
collected a dataset of nine different classes of garment surfaces with portable photometric stereo sensors and distinguished fibers in single-component apparel images. Feng et al.
13
built a textile surface image dataset with 50
Many powerful multi-label classification schemes have emerged in recent years that may help identify textile fibers. CNNs and recurrent neural networks (RNNs) jointly characterize semantic label dependencies and image-label correlations, 19 , 20 graph convolutional networks (GCNs) model correlations between multiple labels21–23 and transformers tackle complex dependencies between image features and target labels.24–26 However, the large intra-type and small inter-type variations of apparel fibers 16 seriously affect previous models’ performances. Moreover, various curling, entanglements and overlapping between fibers as well as the small sample size make fiber classification more challenging. There are numerous efforts 18 , 27 , 28 to improve models’ representation capabilities by combining CNNs with transformers in various ways to exploit the advantages of CNNs in collecting local information and transformers in capturing long-range dependencies. Peng et al. 29 extracted fiber picture features with a transformer encoder and near-infrared spectrogram feature with a CNN and classified five types of fibers.
A fiber identification framework that incorporates convolution into the transformer architecture is proposed. Firstly, overlapping patches are obtained by convolutional operations on the input textile images or feature maps with strides different from patch sizes. These patches are flattened into token sequences, which are reshaped back into two-dimensional (2D) token maps after layer normalization.
30
This not only extracts local information about fibers in the image but also gradually decreases the feature resolution (i.e., token number) while increasing the feature dimension (i.e., token width) across stages. On the token maps, the
Proposed approach
This work aims to identify fibers from textile surface images with challenges such as bending, overlapping and entanglement between fibers. Since only the physical mixing and intertwining of fibers occurs in the process of making fibers into fabrics, their properties are usually retained. Cotton fibers are flat and ribbon-like, with irregular twists around the axis.
33
Rayon fibers have longitudinal straight grooves with bright lusters after dyeing.
34
Animal hair fibers are all curly and scaly, but there are some subtle differences among various hair types. For example, wool scales are irregularly shaped into tiles or oblique rings, while cashmere scales are arranged in circles. In addition, compared with wool scales, cashmere scales are more evenly arranged, less dense and have wider scale spacing. By mining these unique visual properties, the proposed architecture can significantly improve fiber recognition performance, even with the small sample size and imbalanced sample problems. As shown in Figure 1, transformer encoders fused with convolutions are employed to extract fiber spatial representations and transformer decoders to adaptively decode various types of fiber characteristics. Convolutions extract overlapping patch embeddings as tokens, which can prevent the information loss of 2D spatial features that appear in non-overlapping patches,
35
thus preserving substantial nuanced information about fine fibers, such as wool scale patterns. DWSCs
31
instead of linear projections to gain

Illustration of the proposed fiber identification framework: (a) fiber spatial feature extraction module; (b) textile composition unmixing module; (c) the convolutional encoder and (d) the transformer decoder without masks. DWSC: depth-wise separable convolution.
Fiber feature extraction
The fiber feature extraction architecture is a hierarchical transformer encoder incorporating convolution, which consists of three stages, as shown in Figure 1(a). Given a garment image
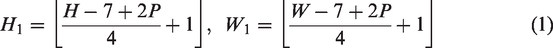
Tokens are normalized by layer normalization
30
and then reshaped back into 2D feature maps
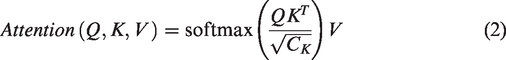

Fiber composition unmixing
Fiber classification will be carried out in the transformer decoder, as shown in Figure 1(b). The output spatial features


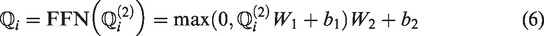
Finally, the queried feature vectors

Loss function
Although the types of fibers can be well discriminated through cross-attention operation in transformer decoders, the imbalanced fiber characteristics in mixed fabrics and the small sample size problems may interfere with fiber differentiation. To overcome the above issues, a simplified asymmetric loss function 38 is introduced, which works remarkably well at alleviating the long-tail data distribution in multi-label classification and performs excellently in experiments.
There are
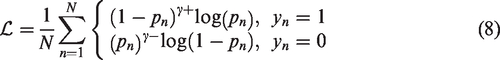
In experiments, the hyperparameters γ+ and γ− were set to 0 and 1, respectively, by default. The loss of each sample in the training dataset is averaged to compute the total loss.
Experimental details
Dataset
To increase the diversity of samples in the study, some photos were taken from randomly purchased clothes and masks from online or brick-and-mortar stores, while more photos were captured in the field during visits to numerous fashion stores with magnifiers and mobile devices. Figure 2 depicts the process for photographing the garment surfaces. Firstly, as shown in Figure 2, a commercially available optical magnifier (about US$50) with a magnification of 200

The equipment and sampling procedure: (a) a magnifier; (b) objective lens with a diameter of 2 mm surrounded by eight light-emitting diodes and (c) example of a magnifier connected to a smartphone via Wi-Fi for photographing textile fibers.
Some samples taken from different directions: (a) frontside images of a knitted fabric with 100% wool; (b), (c) frontside and backside images of a woven fabric with 91% cotton, 8% polyester and 1% spandex; (d) backside images of a non-woven material with 100% polypropylene.
Some 24,125 images of 78 textile categories made of 28 types of fibers were collected, where fabrics composed of the same types of fibers in different mixing ratios belong to one category (e.g., textiles with the composition of cotton 75% and rayon 25% are in the same category as fabrics with the composition of cotton 40% and rayon 60%). The statistical distribution of samples is depicted in Figure 4, which highlights the significant imbalances in various types of fibers and textile categories.

Statistical information on the collected textile dataset: (a) statistics of the type of fibers in each sample; (b) occurrence frequency of each type of fiber in all textile samples and (c) textile sample number for each textile category.
There are 8.32% single-component textiles, 34.47% two-component textiles, 46.51% three-component textiles, 7.96% four-component textiles and 2.74% other-component textiles, while some components in multi-component textiles are less than 5%. In addition, the number of different types of fibers and textile categories varies greatly, and even some types of fibers or textile categories appear in only a few dozen garment images. The types of fibers in Figure 4(b) are acetate, alpaca, acrylic, bamboo fiber, camel hair, cashmere, cotton, cuprammonium, hemp, kapok fiber, linen, lyocell, milk fiber, modal, nylon, polyester, polyethylene, polylactic acid, polypropylene, rabbit hair, ramie, rayon, silk, soybean, spandex, vinylon, wool and yak hair.
Evaluation metrics
The fiber identification performance of various frameworks was evaluated with the mean average precision (mAP), per-class precision (CP), recall (CR) and F1-measure (CF1) and the overall precision (OP), recall (OR) and F1-measure (OF1). These metrics are calculated as follows:
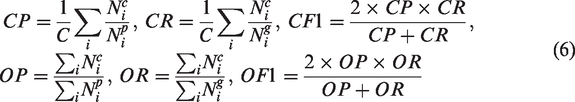
Experimental setup
For all experiments, the input textile surface images were resized to 320
Results and discussion
Results of fiber identification
The proposed approach was compared with the three frameworks specifically for identifying fibers in garment surface images 13 , 17 , 29 and the state-of-the-art multi-label classification methods, including GCN-based models 23 , 40 , 41 and transformer-based models. 18 , 24 , 25
As shown in Figure 4, the types of fibers in the collected dataset are remarkably imbalanced. To mitigate the challenges of imbalanced fibers and small sample sizes, only fabric images with more than 5% composition and from at least 10 different textiles were identified in experiments. Table 1 shows the fiber identification results of various architectures for 22 types of fibers in textile surface images at 200
Comparison of state-of-the-art multi-label image classification models on the collected textile dataset; the best results are shown in bold

mAP: mean average precision; CP: per-class precision; CR: recall; CF1: F1-measure; OP: overall precision; OR: overall recall; OF1: overall F1-measure.
The occurrence frequency of fiber types in the new dataset is shown in Figure 5(a), which has eliminated fibers from less than 10 textiles and those with less than 5% composition. Fiber types from 1 to 22 are alpaca, acrylic, bamboo fiber, camel hair, cashmere, cotton, hemp, kapok fiber, linen, lyocell, modal, nylon, polyester, polylactic acid, polypropylene, rabbit hair, ramie, rayon, silk, spandex, wool, and yak hair. The per-type precision and the per-type recall of the presented framework on the new dataset are depicted in Figure 5(b), which illustrates that the proposed approach performs excellently even on types of fibers with small sample sizes. The pink circles mark the types of fibers with small sample sizes (i.e., those with less than 500 samples). Blue squares mark the three types of fibers with the lowest F1 values, and red triangles mark the three types of fibers with the highest F1 values. In addition, the red triangles denote the top three F1 values and the blue squares denote the bottom three F1 values. Type 16 (rabbit hair), type 17 (ramie) and type 21 (wool) with higher F1 values are natural fibers with unique visual characteristics, while type 10 (lyocell fiber), type 11 (modal fiber) and type 19 (spandex) with lower F1 values are man-made fibers. Lyocell fibers (type 10) with smooth surfaces and modal fibers (type 11) with grooves are identified with interference from polyester fibers (type 13) and rayon fibers (type 18), respectively, which have similar surface characteristics and relatively massive fiber data sizes. The worst-performing spandex fiber (type 19), due to its greater elasticity (elongation up to 700%), is mostly used in textiles covered by other fibers, 42 , 43 which makes its recognition more challenging.
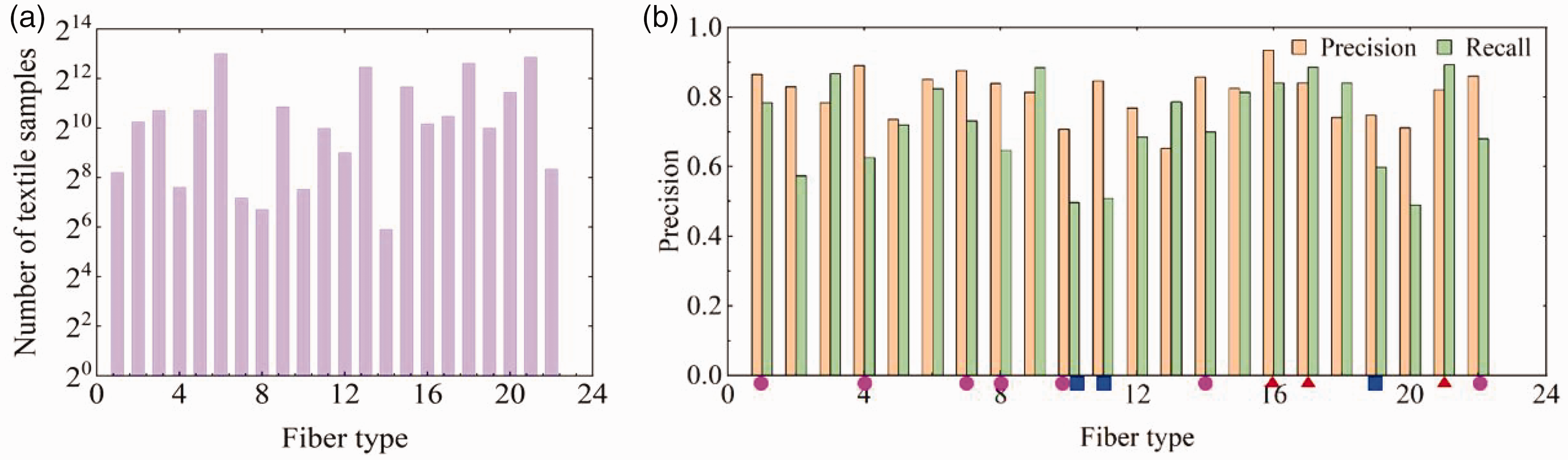
Performance of the presented method on each type of fiber in the collected textile dataset: (a) occurrence frequency of each fiber type in the new dataset and (b) the per-type precision and recall of the proposed method (color online only).
Ablation study
Ablation experiments were carried out on the textile surface dataset to evaluate the contribution of each component in the proposed framework to fiber identification. The framework consists of the CvT network to extract fiber features from garment images, the transformer decoder to localize and pool fiber features for each label and the simplified asymmetric loss function to further purify the extracted fiber representations.
Firstly, the performance of different backbones for extracting fiber features was compared, that is, replacing only the fiber feature extraction backbone in the architecture without changing the other components. The new framework with various fiber feature extractors will be retrained, and their classification results are shown in Table 2. As a fiber feature extractor, CvT-w24, which incorporates convolutions into the transformer architecture, outperforms both the convolutional network (ResNet 101) and the transformer framework (Swin-L) because the CvT is able to take better care of local and global information in identifying slender fibers.
Performance comparison of the proposed architecture with different fiber feature extractors

mAP: mean average precision; CP: per-class precision; CR: recall; CF1: F1-measure; OP: overall precision; OR: overall recall; OF1: overall F1-measure.
Then, ablation experiments were performed on other components with CvT-w24 as the fiber feature extractor, as shown in Table 3. The Dec represents that the multi-head cross-attention module in the transformer decoder is utilized to match label embeddings and fiber representations, while ASL means that a simplified asymmetric loss function is employed to purify the fiber features. The baseline has a 0.8% improvement in mAP accuracy due to ASL, indicating that the ASL helps to purify the extracted fiber representation. The mAP accuracy of fiber recognition with the Dec in the baseline is substantially improved by 3.2%, while the mAP of the proposed method is improved by 3.7% compared to that of the baseline. The above results prove the practicality of the strategy to differentiate different types of fibers in an image by exploiting the multi-head cross-attention mechanism in transformer decoders, which allows each label to adaptively locate fiber features and pool the desired features. Figure 6 illustrates the test loss curves of the framework with different components. The loss of the proposed method decreases faster than those of the other approaches, and the loss curve of the method is steadier than that of baseline (CvT-w24), which further validates the effectiveness of the multi-head cross-attention (Dec) and ASL.
Ablation study for different components
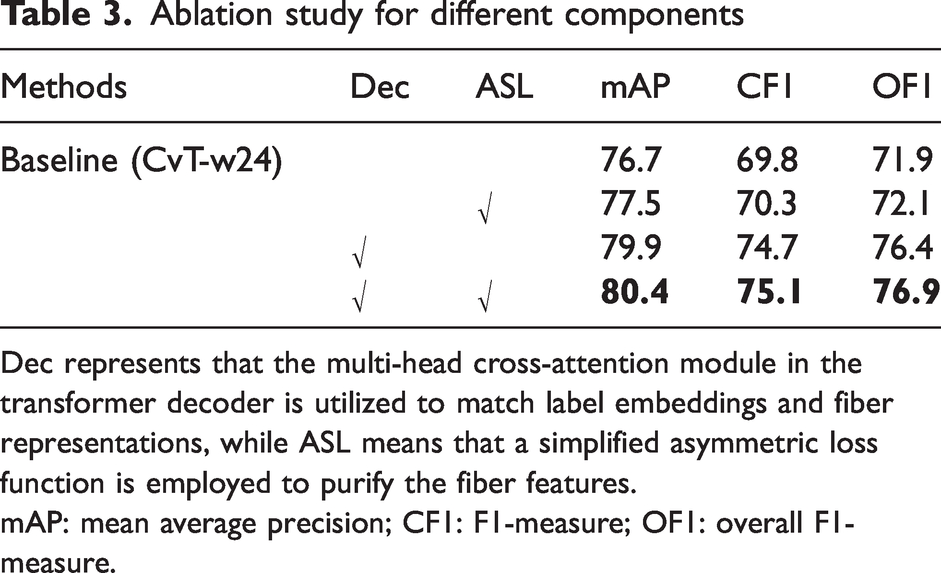
Dec represents that the multi-head cross-attention module in the transformer decoder is utilized to match label embeddings and fiber representations, while ASL means that a simplified asymmetric loss function is employed to purify the fiber features.
mAP: mean average precision; CF1: F1-measure; OF1: overall F1-measure.

Test loss curves of presented architecture with different components. Dec represents that the multi-head cross-attention module in the transformer decoder is utilized to match label embeddings and fiber representations, while ASL means that a simplified asymmetric loss function is employed to purify the fiber features.
Visualization of attention maps
The top five attention windows of some cross-attention maps in the last layer of the architecture were visualized and three of them were zoomed in for a better observation of fiber characteristics, as shown in Figure 7. The ground truth labels (queries) for raw textile images are displayed in the text above the images. These windows showed that the presented framework could approximately locate the unique properties of fibers, such as the scales of wool, the smooth surface of polypropylene and the twists of cotton. This proved the effectiveness of the presented fiber identification approach, which incorporated convolutions into the transformer encoder to extract features of slender fibers and employed the multi-head cross-attention mechanism in transformer decoders to locate and pool the desired characteristics for each label embedding.

Visualization of some samples.
Conclusions
This paper presents a textile fiber identification framework that incorporates convolutions into the transformer architecture to identify multiple types of fibers at once by just processing textile surface images. Experiments demonstrate that input tokens of overlapping images and DWSC instead of linear projection in the transformer encoder can extract richer fiber characteristics, and the multi-head cross-attention module in the transformer decoder can effectively let each label embedding query the presence of fiber type labels and pool type-related fiber features. The proposed method enables the simple, fast and effective automatic identification of fibers without damaging the fabric, which is of significant importance for improving productivity and production efficiency in the textile industry. Firstly, it identifies fibers without tearing the fabric or using chemical reagents, thereby saving resources and eliminating environmental impact. Secondly, the recognition algorithm automatically extracts fiber features from fabric surface images and performs fiber classification, reducing the need for manual operations and the occurrence of human errors. Thirdly, it can instantly recognize the fibers in the captured fabric surface photos, significantly minimizing the time required for fiber testing. Fourthly, it can discriminate various types of fibers in the fabric at once, which improves the efficiency of fiber discrimination. Finally, it has excellent versatility in the textile industry, such as for real-time fiber identification for ordinary consumers purchasing textiles, automatic detection of fabric defects in textile fabrication by textile manufacturers and large-scale fiber composition classification for customs or textile testing companies.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The Fundamental Research Funds for the Central Universities (No. 2232023Y-01), the National Natural Science Foundation of China (Grant No. 61972081), and the Natural Science Foundation of Shanghai (Grant No. 22ZR1400200).