
Abstract
This paper analyses whether a multi-scale representation of geographical context based on statistical aggregates computed for individualised neighbourhoods can lead to improved estimates of neighbourhood effect. Our study group consists of individuals born in 1980 that have lived in Sweden since 1995 and we analyse the effect of neighbourhood context at age 15 on educational outcome at age 30 controlling for parental background. A new piece of software, Equipop, was used to compute the socio-economic composition of neighbourhoods centred on individual residential locations and ranging in scale from including the nearest 12 to the nearest 25,600 neighbours. Our results indicate that context measures based on fixed geographical sub-divisions can lead to an underestimation of neighbourhood effects. A multi-scalar representation of geographical context also makes it easier to estimate how neighbourhood effects vary across different demographic groups. This indicates that scale-sensitive measures of geographical context could help to re-invigorate the neighbourhood effects literature.
Introduction
In 2012, two books with strikingly different ideas about the role of neighbourhood processes in urban development were published. On the one hand, Robert Sampson’s Great American City: Chicago and the Enduring Neighborhood Effect, argued that neighbourhood processes are of fundamental importance for the working of a modern city. On the other hand, Neighbourhood Effects Research: New Perspectives, edited by Van Ham et al. (2012), essentially argued that neighbourhood effect studies are at an impasse and that further progress will require both radical rethinking of theories, and changes in research methodology. Together, these two books reflect the current state of neighbourhood effect studies. They bear witness to the continuing interest in neighbourhood effects, but they also make it clear that this is a field characterised by considerable controversy.
One possible reason for the controversy is that in spite of a strong theoretical argument – backed up by considerable qualitative evidence – there is mixed quantitative evidence for an influence of neighbourhood context on life outcomes. This discrepancy is clearly frustrating.
In this paper, we will argue that one reason for the lack of clear-cut results could be problems associated with the measurement of neighbourhood context. Up to now the main approach in this field of study has been to measure context using aggregate values for administratively defined areas. This implies that neighbourhood effect studies have, to a considerable degree, ignored the argument put forward by Openshaw (1984) and others that such aggregate measures will be plagued by indeterminacy. Certainly researchers have been aware that their measures have been far from perfect (see e.g. Putnam, 2007), but there seems to have been a widespread belief that values that have been aggregated using fixed areal units can serve as good approximation, given a lack of feasible alternatives. Statistical theory, however, says that measurement errors in explanatory variables will have strong negative effects on one’s ability to obtain good estimates of the parameters of a statistical model. Therefore, it is possible that disappointing results in neighbourhood effect studies are simply a reflection of weakness in the empirical design (Galster, 2008; Sampson et al., 2002).
The solution that we propose in this paper is to measure neighbourhood context using aggregates for individualised, egocentric neighbourhoods. These neighbourhoods will be constructed as buffers around the residential location of the individuals under study in such a way that the buffer for each location will include the same number of nearest neighbours. In this way, the modifiable areal unit problem will be circumvented since the measurement of context will become independent of any statistically given areal subdivision. In addition to addressing the modifiable areal unit problem, such individualised, egocentric neighbourhoods also offer a possible way to handle another challenge for contextual measurement: the problem of uncertain geographic context discussed by Kwan (2012). More specifically, individualised neighbourhoods based on buffers with different population counts can be used to obtain contextual measures for different neighbourhood scales.
The question we will address in this paper is how educational achievement at adult age is influenced by the neighbourhood context in early youth. We will use Swedish register data, and our basic design is similar to that used by Andersson (2004), Andersson and Subramanian (2006), Bygren and Szulkin (2010) and Sundlöf (2008). However, whereas these studies use aggregates for fixed geographical sub-divisions to measure context, we take advantage of the availability of individual level data with geo-coordinates to construct aggregates for individualised neighbourhoods with fixed population counts. A similar approach to contextual measurement has previously been used by Bolster et al. (2007), Chaix et al. (2005) and Macallister et al. (2001). In our case we used the Equipop software developed by John Östh to extract contextual information from geo-coded, individual level register data (Östh et al., 2014). With Equipop it is easy to obtain aggregate information for neighbourhoods that vary in scale, with scale measured by the population count. Neighbourhoods can be defined to include only a handful of individuals, but it is also possible to compute aggregates for neighbourhoods with population counts similar to those of medium-sized cities. This flexibility forces researchers to explicitly consider at which geographical scale different neighbourhood effects are likely to operate.
Studies measuring contextual/neighbourhood effects (Ainsworth, 2002; Andersson, 2004; Andersson and Subramanian, 2006; Crane, 1991; Evans et al., 2003; Immergluck, 1998; Ludwig, 1999; South et al., 2003) share a concern for data quality and an interest in determining if contextual effects are significant for the specified outcomes. However, there is less agreement about the mechanisms behind such contextual effects (Galster, 2012; Galster and Santiago, 2006).
Different mediating processes discussed among researchers include social control, collective socialisation, social capital, and institutional characteristics (see Ainsworth, 2002; and Galster, 2007). However, what is not discussed at length is how such contextual/neighbourhood effect mechanisms and processes work at different geographical scales (Andersson and Musterd, 2010; Östh et al., 2014). We believe our multi-scalar approach to contextual measurement can stimulate interest in theories about how scale is important for contextual effects.
Consider, first, neighbourhood level social control; that is, the monitoring and sanctioning of deviant behaviour of youths and others. If there are fewer adults around and if they do not spend time with youths, youths may shape their own norms (Ainsworth, 2002). Here it could be argued that small-scale environments can be of special importance. Adult monitoring is stronger for pre-school children who play in local streets and playgrounds (see Jacobs, 1993). Likewise, children in lower primary school will typically gather in the vicinity of local schools with relatively restricted catchment areas. In Sweden, an average primary school is attended by 82 children in grades 1–3 (Swedish National Agency for Education, 2013).
Consider, second, the scale at which collective socialisation could be thought to influence ideas and traditions of education among children and adolescents. Collective socialisation is a process in which youths are exposed to role models among adults, and adapt to those models to varying degrees. The importance of such role models has been questioned (Joseph et al., 2007) but in relation to educational aspiration one could imagine a context wherein homework and studying are not seen as the ‘coolest’ things. Or the opposite: a neighbourhood where homework and reading were taken seriously by most parents and children. To the extent that attitudes towards education are formed in early youth, the spatial scale of such influence could be less restricted than the space in which smaller children move. Using Swedish data, Andersson and Subramanian (2006), for example, show effects for administrative areas with on average 970 individuals as influencing years of education.
Third, it can also be argued that social capital or social networks that exist in a given community (Putnam, 1993) will be found on a larger scale than social control. Children and adolescents living in advantaged neighbourhoods are more likely to be exposed to helpful social networks. In advantaged neighbourhoods, children are also more likely to meet adults who can provide positive recourses in the form of information (or job opportunities, help with advanced homework etc.). If information about educational opportunities, encouragement and support become more important for the educational decisions of individuals when they are in upper secondary school this would allow contextual influences from environments that are more extended than those that have importance for children in primary school.
Fourth, it can be argued that neighbourhood processes that are linked to institutional mechanisms operate at scales that, in the Swedish context, can transcend local neighbourhoods and can encompass an entire urban district or an entire non-metropolitan municipality. Such institutional mechanisms are discussed by a number of authors (Ainsworth, 2002; Galster and Santiago, 2006; Sampson et al., 2002) and relate, for example, to the quality of institutions and the availability of institutions such as health centres, schools, universities, hospitals and job centres (for a discussion of school effects see e.g. Brännström, 2008; Östh et al., 2013; Sellstrom and Bremberg, 2006; Sykes and Musterd, 2011).
Clearly, the above discussion gives support to Sampson’s (2012) argument that there is a need for spatial flexibility when it comes to measuring contextual influences. According to Sampson, what is required is not a ‘search for the “best” or “correct” operational definition of neighbourhood’ (Sampson, 2012). Instead, in his view:
there are multiple scales of ecological influence and possibilities for constructing measures, ranging from micro level street blocks (or street corners) to block groups to neighbourhood clusters to community areas of political and organizational importance to spatial ‘regimes’ and cross-cutting networks that connect far-flung areas of the city. (2012: 361–362)
Based on this argument, we propose an approach to contextual measurement that explicitly allows for multiple scales of influence. This is achieved by computing aggregate values for individualised neighbourhoods of 12 different sizes ranging from very small to large. Compared to traditional measures this gives a richer and more composite description of the socio-spatial environment of individuals. Below we will demonstrate that estimates of neighbourhood effects based on this more composite description will be greater than those obtained with traditional measures based on fixed areal subdivisions.
It can, however, be questioned whether neighbourhood effects is an appropriate term for describing the influence of environmental factors that are measured for such a broad range of geographical scales. Can the term neighbourhood be used both for an area that encompasses the 12 nearest neighbours and areas that include the 25,600 nearest neighbours? Given that Equipop computes aggregate statistics for areas defined using population counts, the term neighbour effect could be used. However, in this paper we will use, interchangeably, the well-established concepts of neighbourhood effects and contextual effects.
Empirical design, data and methods
The purpose of the empirical study presented below is to test if contextual measurements based on individualised neighbourhoods can lead to improved estimates of neighbourhood effects. The outcome variable will be educational achievement at age 30 for a cohort born in 1980, and we will analyse the effect of neighbourhood exposure during the age range of 14–18 years. Moreover, we will use two sets of contextual data: one set based on individualised neighbourhoods ranging in scale from areas including the 12 nearest neighbours to areas including the 25,600 nearest neighbours, and, to enable a comparison, one set based on aggregates for fixed geographical subdivisions, the Swedish SAMS areas. For both these data sets we will use the same socio-economic indicators, described below in Table 1. The data originate from PLACE, a database delivered by Statistics Sweden located at Uppsala University.
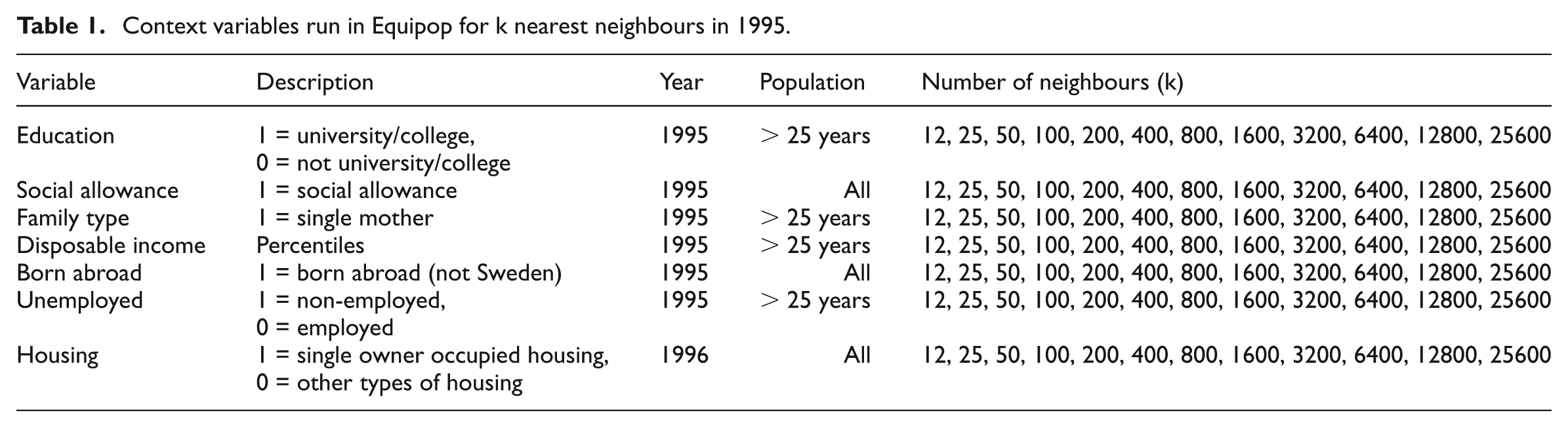
Context variables run in Equipop for k nearest neighbours in 1995.
In the contextual effect estimations we will not, however, use statistical aggregates obtained for individualised neighbourhood and SAMS areas directly. Instead we will use factor scores resulting from a factor analysis carried out separately for the SAMS-based and individualised-neighbourhood based data. With this setup, our claim that the individualised neighbourhood provides a better basis for contextual analysis can be evaluated by comparing the estimates for SAMS-based and individualised-neighbourhood-based context measures.
Individual level, cohort and household data
To be included in our study individuals had to have stayed in the same geographical location between the ages of 14 and 18 years. This non-mobility criterion, which reduced the sample by 15%, was imposed in order to ensure that they have been affected by the same surroundings during the exposure period. Individuals with missing data on parental background have also been excluded. Of 102,592 individuals born in 1980, 74,649 individuals are included in our final sample.
Excluding movers had some effect on the composition of the sample since movers have a higher share of unemployed, lower educated, foreign-born, low income, and visible minority parents. The dependent variable of education was measured by the existence of a university or university college degree, as shown in Table 2 below.
Individual level variables.

To account for individual level influence on educational achievement our statistical model will include six indicators of parental background: visible minority parents, foreign-born parents, parents with tertiary education, parents with social allowance, non-employed parents, and parents’ disposable income in the top decile of parental incomes. In addition, we include an indicator for gender and for living in a single mother household. Descriptive statistics for these variables are given in Table 2.
Contextual measurement
With respect to the use of individual background variables the empirical design of this study is conventional. This is not the case, though, with our approach to context measurement. Here, instead, our study introduces two important novelties: first, and most importantly, we introduce contextual measures that are based on individually defined and scalable neighbourhoods. Second, we introduce a factor-analysis based representation of the spatial variation in a socio-demographic context as a means to manage the wealth of information resulting from scalability. Last in this section, and as means of comparing this work with earlier studies, we present the often used Swedish areal division of so called SAMS areas.
Individually defined and scalable neighbourhood
We measure neighbourhood population compositions using individual centred neighbourhoods of fixed population size. Thus, we have used register data containing information of individual residential location to compute contextual variables based on the population composition among an individual’s nearest 12, 25, 50, 100, 200, 400, 800, 1600, 3200, 6400, 12,800, and 25,600 neighbours for 1995 (for the population older than 25 years and the total population, depending on variables) (see Table 1) (Östh et al., 2014).
Traditional measures of segregation such as the isolation index are strongly dependent on the size of the statistical units for which the segregation index has been computed (Malmberg et al., 2011). In the Equipop software, the individualised neighbourhoods are obtained by expanding a circular buffer around each residential location until the population encircled by the buffer corresponds to the population threshold chosen. When this threshold is reached, the program computes aggregate statistics on a selected socio-economic variable for the encircled population.
Equipop requires that the input data are geocoded on a detailed level. We have used data from the PLACE database of Uppsala University. These data contain register-based, individual level data for the population in Sweden from 1990 to 2010 with geocodes of the residential location by 100 metre squares. From these data, seven different socio-demographic indicators have been extracted and used as input for Equipop (see Table 1).
SAMS areas as context
The residential differentiation according to the Small Area Market Statistics, SAMS, classification scheme is a national subdivision in homogenous residential areas (more than 9000). SAMS was developed by Statistics Sweden in collaboration with the municipalities, and is a social division according to building characteristics and tenure form. Originally, for publicity purposes and municipal planning, SAMS was formed to include a certain target group. Some SAMS areas are uninhabited, and accordingly the number of inhabitants and sizes of SAMS vary. Our study makes use of 7704 SAMS areas which vary in population size between 1 and 207 individuals.
Factor-analysis based representation of contextual variation: individualised neighbourhoods
With seven different socio-demographic indicators and 12 different levels of neighbourhood scale we obtain a total of 84 different contextual variables. Clearly, such a large number of contextual variables cannot be included, without problems, as explanatory variables in a regression of educational achievement. Moreover, many of the indicators are strongly correlated, for example, contextual indicators based on the same socio-economic indicator but computed for different neighbourhood sizes. In order to make the analysis manageable we have subjected the contextual indicators to a factor analysis that compresses the 84 original indicators to 10 orthogonal factors that jointly capture more than 79% of the original variation. The factor analysis was based on covariances, and the number of principal components to be rotated was selected based on them having eigenvalues higher than one. The factors were rotated using the varimax method.
Some factors influence a small number of neighbours (k) as contextual variables, and other factors influence a large number of neighbours. This result of the factor analysis is clearly of interest since it provides an opportunity to analyse the scale dependence of contextual effects.
Figure 1 shows diagrams of what the different factors represent. This interpretation is important since we are going to include factor scores as explanatory variables in the logistic regression of educational achievement. Without an interpretation of the different factors it will be difficult to interpret the regression results. Our interpretation of the factors is given below.
Factor 1
Factor 2
Factor 3
Factor 4
Factor 5
Factor 6
Factor 7
Factor 8
Factor 9
Factor 10

Factors and loadings. (To reduce clutter, these graphs only show factors that for at least one k-level have a loading higher than 0.2 or lower than −0.2.).
Factor-analysis based representation of contextual variation: fixed geographical sub-divisions
The seven variables aggregated using SAMS areas are not as strongly correlated as the contextual variables resulting from using individualised neighbourhoods, but to allow a clear-cut comparison we apply factor analysis on these variables too. In this case only three factors are needed in order to account for 80% of the variation in the original variables. Factor 1 has high loadings for share of foreign-born, share with social benefit, and single mother share. Factor 2 has high loadings for single house share and high disposable income. Finally, Factor 3 has high loadings for high disposable income and share of people with tertiary education.
Results
Below we present the estimates of four logit models with university education in 2010 as the dependent variable. Model 1 uses only individual level variables. Model 2 adds contextual variables based on individualised neighbourhoods to the individual level variables. Model 3 is similar to model 2 but uses context variables based on administrative units, SAMS areas. Finally, model 4 is based on model 2 but adds individual-contextual interaction variables.
Model comparison
As explained below, the individual level variables including parental characteristics are most important for predicting educational achievements.
The first logistic regression (model 1) shows the strongest individual level effects for university education for adolescents with university-educated parents, and for girls (see Table 3). Significant but negative effects are found for adolescents with parents receiving social allowances and those with non-employed parents as well as those with single mothers. These results are supported by earlier research on Swedish data (Andersson and Subramanian, 2006). Model 2 includes both individual as well as contextual level variables. Here too university-educated parents are strongly and positively associated with an adolescents’ university education in 2010. Also comparable with the model including individual level variables only, are negative effects from non-employed parents and parents receiving social allowances. In addition, being a girl or a boy strongly affects the likelihood of having a later university education. Finally for models 3 and 4, results from individual level variables are generally the same; having parents with university education, and whether one was a boy or a girl, are important factors in determining whether adolescents achieve a university education.
Individual level and contextual effects on educational achievement in 2010, model estimates.

Turning now to the contextual effect estimates we begin by comparing the log likelihood values across our four models. The most important finding here is that the use of a multi-scalar measurement of context based on individualised neighbourhoods results in a drastic increase in estimated context effects on adolescents’ educational achievements compared to the standard approach based on fixed geographical sub-divisions. This can be seen by comparing the full model log-likelihood values (see Table 3, bottom) for models 3 (SAMS-based context) and model 2 (Equipop), multi-scalar context.
Compared to model 1 with individual level variables, the contextual level variables in model 2 add 273 to the full model log likelihood (see Table 3). Also taking into account that model 2 has more parameters than model 3, this addition is larger than an increase of 73, the result obtained using context measures based on SAMS areas (Busemeyer and Wang, 2000: 176). A likely explanation for the larger effect-size estimated for model 2 is that multi-scalar contextual measures provide a better representation of how socio-spatial conditions of relevance for individual educational careers vary between locations. If this is true, our finding of a larger effect size compared to a traditional approach based on SAMS areas aggregates is what should be expected.
Contextual factors
As shown from ChiSquares in Table 3, model 2, it is the first three contextual factors that have the largest effect on educational achievement. The strongest effects are found for Factor 1 Elite areas. This large effect of growing up in an area with a high proportion of individuals with university education, high disposable income, and few non-employed fits with the idea that individuals’ life choices are influenced by the choices of their peers and by norms that are present in their residential context.
The elite areas are important in all counts of closest neighbours, from 12 closest up to the city scale of 25,600 closest neighbours. At the lowest scale this can be explained by collective socialisation processes and social control. At the city scale (25,600 neighbours) we suggest that institutional mechanisms such as the availability of universities, public role models and local newspapers are important in shaping the educational outcome.
Factor 3 Foreign-born, Factor 4 Marginal nearby, and Factor 5 Marginal intermediate all have parameter estimates that are negative, with a large ChiSquare for Factor 3 in particular. These three factors are all associated with a high proportion of foreign-born residents and a high proportion of households receiving a social allowance. Factor 4 and Factor 5 in addition are associated with a high proportion of single mothers and a low proportion of single-family housing. Factor 3 is associated with high loadings across all neighbourhood scales, Factor 4 has high loadings only for large scale neighbourhoods, and Factor 5 mainly for small- and medium-sized neighbourhoods. One reason for the negative effects of these factors on the probability of having a university education at age 30 could be that a high presence of marginal groups has negative effects on the school achievements (Sykes and Kuyper, 2009).
Table 3 reports a positive parameter estimate for Factor 6 Single family housing. But judging from the ChiSquare, this effect is significant but not strong in comparison to the effects of Factor 1, Factor 2 and Factor 3. A similar effect was reported earlier by Andersson (2004). Bramley and Karley (2007) have also reported positive effects of home-ownership on educational achievement, and they provide a discussion of possible mechanisms for this positive effect.
The effect of Factor 2 Low employment in adjacent areas is about half as strong as the effect of Factor 1. Moreover, the effect of growing up with low employment rates in adjacent areas is to increase the likelihood of getting a university degree by age 30. Other estimates that go in the same direction (but are much weaker) are obtained for Factor 8 Low employment medium scale and Factor 9 Marginal medium scale.
One explanation is that the positive effect on having a university education at age 30 from high values for Factor 2 is not the result of effects on aspiration but instead the results of differences in opportunity structure. In 1995, when our study cohort was 15 years of age, unemployment rates were still high in the aftermath of the early 1990s economic crisis in Sweden. This situation may have stimulated students in regions of high unemployment to consider academic studies as a more secure path to employment than a non-academic career. On the other hand, students living in regions with low unemployment and high labour demand may have been able to secure employment without the need for costly academic studies. The opportunity structure explanation is supported by the fact that Factor 2 is associated with high levels of non-employment, not in students’ close neighbourhood but mainly in neighbourhoods of up to 25,600 people. In contrast, the effect of a low level of employment in the close neighbourhood is negative (but weak), as shown by the estimate for Factor 7 Low employment small-scale.
Finally, the estimate for Factor 10 Non-academic elite is negative, a fact that is associated with high income but not with high levels of education of parents. This corroborates the view that high income per se does not imply that you have strong norms concerning the values of education in the Swedish case.
Interactions
In Table 3 we present model 4 where the projected effects for some of the contextual variables have been allowed to depend on the gender and parental education of the students. The analysis shows that the strength of the contextual effects varies according to gender and parental education.
The strongest effect of Factor 1 Elite areas is found for men with university-educated parents. The effect is weaker for women with university-educated parents. This is a group that, irrespective of context, has a high propensity to attain a university degree. But the effect is even weaker for men with parents lacking a university degree. This group, thus, is less influenced by an elite environment. One interpretation of this pattern is that elite areas can help to tip the balance for groups that are willing to consider the idea of a university education. This fits with the fact that women with parents lacking a university degree also experience a relatively strong effect of growing up in an elite area.
A tipping-the-balance pattern is also true for Factor 3 Foreign-born. Again men with university-educated parents experience the strongest effect of context, here with a clear negative effect on the probability of achieving a university degree. And again it is women with parents lacking a university degree that experience the second strongest negative effect of a high proportion of foreign-born residents in the neighbourhood. For men with parents lacking a university degree, local context as measured by Factor 3 is of smaller importance.
However, for men with parents lacking a university degree Factor 2 Low employment in adjacent areas plays an important role. Indeed, the effect of Factor 2 is much stronger for this group than for any other group. This can be seen as favouring the opportunity structure argument for the positive effect of low local employment levels on the probability of getting a university education. The idea would be that the risk of becoming unemployed after school could help young men to overcome barriers to higher education that are linked to their gender and to parental education.
A multilevel approach
To further analyse the finding of larger contextual effects we tested the same data in a multilevel model. The multilevel approach is common in neighbourhood effect literature because it offers a way of analysing data in hierarchical structures, for example, individuals in neighbourhoods, in municipalities, in counties and so on. The results can thereafter be interpreted as variance explained at different geographical levels. In this particular analysis the individuals in the 1980s cohort constitute the individual level, and the SAMS areas constitute the second, contextual level (7704 areas). Because the individualised neighbourhoods are flexible in size they could not be used as a hierarchical level in the model. Instead, mean values from Equipop over SAMS areas were used.
In an empty model, no explanatory variables included, the unexplained variance of educational achievements for the 1980s cohort was 5.8% at the contextual level. The rest of the variance in educational achievement was attributed to the individual level. The level of variance of around 5% is found in other Swedish studies using multilevel approaches (Andersson and Subramanian, 2006; Bergsten, 2010), and in a study of the Oslo region a larger contextual level variance of 15% was found (Brattbakk and Wessel, 2013). Furthermore, studies in other contexts, such as the United States, show higher contextual level proportions of variance for different outcomes. Thus, it is commonly believed that the welfare state regimes produce more equal societies with lower contextual effects (Sampson, 2012).
When we included individual level variables to explain university education in 2010 the contextual level variance was reduced to 2%. This remaining unexplained variance at the contextual level was then to be tested with both SAMS area variables and the individualised neighbourhoods/factors (as means) to try to reduce the unexplained variance. Not only the log likelihood test above, but this test also showed individualised neighbourhoods to be a better measure of context; it could explain more variance than the SAMS areas. Of the remaining unexplained variance at the contextual level the multi-scalar contextual measure captured 35% whereas the SAMS-based contextual measure captured 8%. As stated above we consider the multi-scalar measures from Equipop efficient in showing what neighbourhood effects are expected to be.
Because of the seemingly low remaining variance at the contextual level it is worth describing actual consequences in terms of the difference in the shares of individuals that achieved a university education in 2010 (see Table 4). Note that for individuals living in the lowest 10th percentile of elite area factor loadings, 45.6% were obtaining university education. This is significant when compared to elite areas with the highest factor loadings (90th percentile), where 72.3% had obtained a university education at 30 years of age. The difference of 26 percentage points should not be neglected as a contextual effect.
Area description, effect on proportion obtaining a university education.
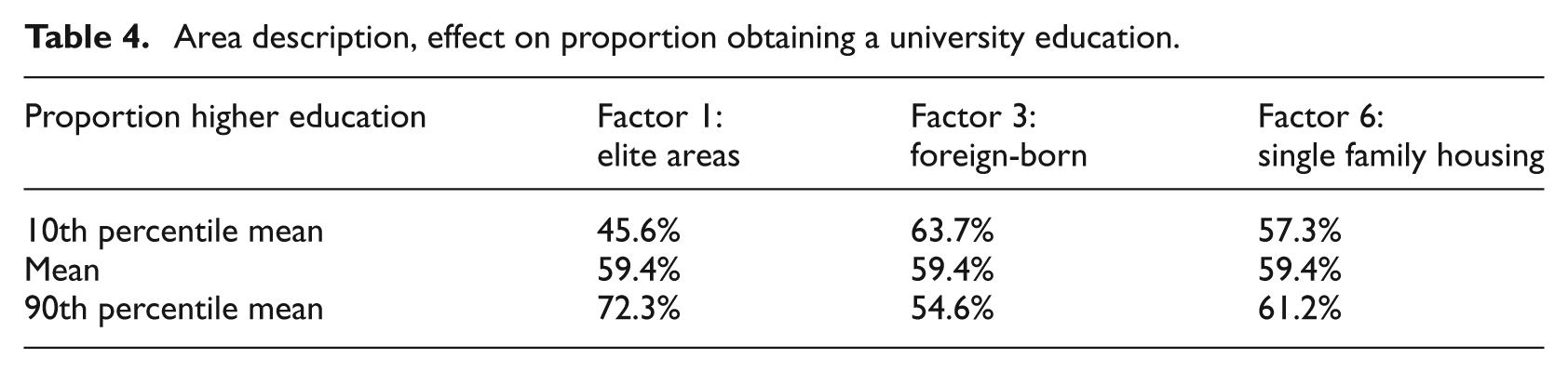
Factor 3, including foreign-born and to some extent parents with social allowances, has a negative association with university education. As a consequence, in areas with low Factor 3 loadings (lowest 10th percentile), 63.7% obtained a university education. Adolescents living in areas highly loaded with Factor 3 had a 9 percentage points lower probability of becoming university-educated. As for the Factor 6 describing loadings of single family housing, the difference between the least loaded 10th percentile’s proportions compared to the highest 90th percentile was smaller.
Concluding discussion
In recent years, increasing criticism has been directed at the methods used in neighbourhood effect studies and it has even been questioned if such methods exist at all (Hedman, 2011). Criticism has touched on: the stability of effects over time, the use of cross-sectional studies, and the fact that measured effects are quite small or non-existent (Brännström, 2004; Hedman, 2011). In the same vein, different groups of inhabitants in a neighbourhood might be influenced differently, which has not been researched sufficiently (Andersson and Musterd, 2010; Bergsten, 2010; Galster et al., 2010; Sykes and Kuyper, 2009). The policy of mixing the population and mixing housing (tenure forms) has been criticised for not being an effective policy against segregation because neighbourhood effects are not satisfactorily assessed.
But there are several reasons that neighbourhood effects still remain a large research area and a matter of political interest and debate. One reason is that qualitative research, as well as lived experiences, show people that there is greater importance to where they have been growing up than has been proved scientifically. A second reason is that inequality of outcomes in, for example, education due to where adolescents live is against the expectations and goals set by welfare states and against national policies of education. In the US, for example, segregated schools were declared unconstitutional because of their detrimental effect on educational equality (Brown v. Board of Education, 1954; Clark, 1987; Coleman, 1966). A third reason is that mixing residential areas and schools is a direct policy and planning measure that is in constant debate. Mixing strategies are questioned and need scientific support if continued in (especially) times of economic crisis (Galster, 2007; Holmqvist and Bergsten, 2009).
In this paper we have used Swedish register data to analyse contextual effects on educational achievement for a cohort born in 1980. For this cohort, neighbourhood exposure was measured in 1995 (at age 15) and educational achievement was assessed in 2010 (at age 30). An important innovation in this study is that context is not measured using aggregate values for statistical areas. Instead, we have used statistics computed for individualised neighbourhoods that have been expanded to include between 12 and 25,600 nearest neighbours. With this method – which departs significantly from the standard approach – we have obtained results that in many ways improve those obtained in earlier studies.
Our first finding is that the strength of the estimated contextual effects increases when statistics based on scalable individualised neighbourhoods are used to measure context. Compared to traditional, area-based measures the effect is about three times stronger. These stronger effects are also tested with a multilevel approach.
Second, the stronger overall effect allows us to get significant estimates for several contextual indicators when they are used simultaneously in the same model. To avoid problems of multicollinearity, earlier studies of contextual effect on educational achievement have often included only one contextual variable per model. However, using individualised neighbourhoods of varying size makes it possible to capture context at different scale levels: variation in the composition of the 50 nearest neighbours, variation in the composition of the 100 nearest neighbours, and so on. This increases the amount of contextual variation that is used to estimate contextual effects, and with increased variance in the explanatory variables the problem of multicollinearity can be reduced. Hence, we have been able to show that high levels of education, low levels of marginality, and a dominance of single family housing in the neighbourhood all have separate, positive effects on educational achievement.
Third, the use of individualised neighbourhoods has allowed us to explore how contextual effects are linked to scale. Most important here is the unexpected finding that low employment levels among the 1000+ nearest neighbours can have a positive effect on educational achievement.
Fourth, stronger overall contextual effects have allowed the estimation of interaction effects. Here our results indicate that the effects of a specific neighbourhood context can be of great importance for one group but less important for a different group. As we see it, this finding provides a strong rationale for a new generation of neighbourhood effect studies that focus less on diffuse overall neighbourhood effects and more on how specific circumstances influence different groups.
Taken together, we would claim that the findings presented above suggest that a revised methodology that takes advantage of the possibilities offered by the use of multi-scalar approach would not only provide neighbourhood effect studies with a new lease of life, but would also help to make neighbourhood effect studies a more central concern for social science research in general. The results thus support Sampson’s claim of no ‘correct’ or ‘best’ way of measuring contextual effects and that one should instead strive for measurements at multiple scales (Sampson, 2012: 361–362). Last but not least, as measures develop, theories have to develop too. To explain multi-scalar contextual effects further studies of different mediating mechanisms are needed along the lines we have outlined in this paper.
Footnotes
Acknowledgements
The authors thank Professor George Galster, Wayne State University, Detroit for his reading and comments at an early stage of the work. The Equipop software used for computing contextual variables based on individualised neighbourhoods was developed by John Östh, Uppsala University.
Funding
This research was supported by the Stockholm University Linnaeus Center on Social Policy and Family Dynamics in Europe, SPaDE (grant number 349-2007-8701), of the Swedish Research Council.