
Abstract
The large and growing body of neighbourhood effect studies has almost exclusively neglected individuals’ particular residential histories. Yet, former residential neighbourhoods are likely to have lingering effects beyond those of the current one and are dependent on exposure times and number of moves. This paper tests to what extent this blind spot induced a misestimation of neighbourhood effects for individuals with differential residential histories. Ultimately, we develop a methodological framework for studying the temporal dynamics of neighbourhood effects, capable of dealing with residential histories (moving behaviour, the passage of time and temporal exposure to different neighbourhoods). We apply cross-classified multi-level models (residents nested in current and former neighbourhoods) to analyse longitudinal individual-level population data from Dutch Statistics, covering fine-grained measures of residential histories. Our systematic comparison to conventional models reveals the necessity of including a temporal dimension: our models reveal an overestimation of the effect of the current neighbourhood by 16–30%, and an underestimation of the total body of neighbourhood effects by at least 13–24%. Our results show that neighbourhood effects are lingering, long-lasting and structural and also cannot be confined to a single point in time.
Introduction
Over the past decades, researchers on both sides of the Atlantic have found evidence that the neighbourhood of residence affects residents’ socioeconomic life opportunities (e.g. Cotter, 2002; Van Ham and Manley, 2010). Supposedly, residents living in disadvantaged neighbourhoods lack positive role models and resourceful social contacts in the neighbourhood (Friedrichs et al., 2003). The neighbourhood effects field has made progress in using longitudinal data (Andersson et al., 2007; Musterd et al., 2003) and dealing with self-selection bias (Van Ham and Manley, 2010).
Yet, despite methodological innovations, neighbourhood effects continue to be misestimated. This misestimation is caused by neglecting the temporal dimension (persistence, timing, duration) behind neighbourhood exposure. Scholars have almost exclusively focused on the resident’s current neighbourhood, even though the influence of this neighbourhood should theoretically vary with the individual’s residential history. After all, residents who only lived in a neighbourhood for a short period of time are less exposed to potential neighbourhood effects (Galster, 2012; Musterd et al., 2012a). Moreover, residents are likely to continue to be influenced by their previous neighbourhood, for instance as a result of lingering effects of previous socialisation or by sustaining social ties with former neighbours (Hedman, 2011). As movers are thus exposed to different neighbourhoods at the same time, it is necessary to include the residential neighbourhood history in the analysis (Hedman, 2011: 509–511; Hedman et al., 2013).
Although integrating the temporality and duration of exposure is key to understanding the persistence of neighbourhood effects over an individual’s life course (Sharkey and Faber, 2014), only a limited number of studies have given attention to this temporal dimension (for a comprehensive review see Hedman et al., 2013; see also Musterd et al., 2012a; Quillian, 2003; van Ham et al., 2014). Nevertheless, there is a widely echoed call in the literature for a theoretical and methodological framework to model the temporality of neighbourhood effects (Galster, 2008; Hedman, 2011; Musterd et al., 2012a). Such a model would be relevant to scholars as well as policy makers:
It is important to know more about possible impacts of timing, duration, and cumulative exposure and the durability of these impacts, because of academic interest in building stronger theory, and because policy makers are searching for interventions that will promote the most efficacious neighbourhood environment for human well-being. (Musterd et al., 2012a: 606)
The present study will take up this challenge and pull apart the impact of the current and earlier residential neighbourhoods. We assess to what extent the impact of the current and previous neighbourhoods is dependent on the residential histories (number of moves, time elapsed since moving out, length of residence).
The aim of our study is threefold. First, we aim to introduce the long-requested theoretical and methodological framework to model the temporal dimension of lingering neighbourhood effects for the adult working population and their conditionality on neighbourhood exposure. Second, we aim to illustrate how current and lingering neighbourhood effects can be modelled through cross-classified multi-level models (with individuals nested in current and former neighbourhoods) using longitudinal individual-level population data. Third, we aim to scrutinise how the conventional, deficient models of neighbourhood effects prevalent in the literature bias the estimated neighbourhood effects. This study teases out to what extent implicit methodological decisions are at the root of the lack of consensus among neighbourhood effect studies. 1 We systematically compare estimates from conventional models that are widely used in the literature to our temporal-dynamics models. 2
The Netherlands form an excellent case to study the effects of residential history on individuals’ current socioeconomic status. First, in terms of socioeconomic status, Dutch residential neighbourhoods are less strongly segregated than other European countries and the neighbourhoods are very heterogeneous, particularly compared with the USA. This difference is due to ubiquitous social housing, welfare distribution programmes and interventions in deprived neighbourhoods (De Vries, 2005; Musterd et al., 2006). Consequently, moving histories tend to show more variation in both frequency and direction of residential mobility. Second, income distribution in the Netherlands is relatively egalitarian, especially compared with the USA. To the extent that this study finds that the impact of the current neighbourhood tends to be misestimated in conventional models, these misestimations are thus likely to be smaller in the Dutch case than in less egalitarian countries. This implies that our test on neighbourhood effects is rather conservative. Finally, the Dutch Social Statistical Database offers unique longitudinal individual-level population data. It allows us to examine records of different addresses of residence (residence spells) for the adult working population (21–55 years of age, excluding those that were students in 1999) and their socioeconomic status over the course of our period of analysis (observation period 1995/1999–2011). This enables us to pull apart influences of the current neighbourhood from lingering effects of previous neighbourhoods and deal with self-selection (selective residential mobility) bias.
Our analyses provide a range of theoretically and methodologically relevant outcomes. First, we illustrate the degree to which alternative modelling procedures yield different estimates of neighbourhood effects. We find strong empirical evidence that neighbourhood effects are misestimated in conventional models, owing to the invalid assumption that the residential environment of residents is static. On the one hand, models that solely assess the impact of residents’ current neighbourhood but do not distinguish between movers and non-movers – i.e. the bulk of the literature – overestimate the impact of the current neighbourhood. On the other hand, models that solely assess the impact of residents’ current neighbourhood through an exclusive focus on non-movers underestimate that neighbourhood effect. Once we model residents’ current and previous neighbourhoods of residence simultaneously, we find that the previous neighbourhood(s) still have a statistically detrimental effect on residents’ current income.
Second, we provide a basic framework for a much-needed life-course perspective. The more frequently a resident has moved, the lower the impact of the current neighbourhood of residence. Lingering effects of former residential neighbourhoods also fade the more often a resident moves. Concurrently, for these movers the effect of the current neighbourhood is stronger if they lived there for a longer period of time. Residents that only moved once tend to be more strongly influenced by the previous neighbourhood, when they lived there for longer a period of time.
All in all, this study shows the theoretical and methodological necessity to model the lingering effects of former residential neighbourhoods for the adult working-age population.
Theoretical grounds for a temporal dimension of neighbourhood effects
Neighbourhood effect estimation dealing with temporality
Many studies have related neighbourhood composition to individual socioeconomic outcomes in the American (Cotter, 2002; Weinberg et al., 2004) and European context (Andersson et al., 2007; Musterd et al., 2003; Van Ham and Manley, 2010). Yet, most studies in this line of research estimated what Hedman et al. (2013: 2) described as ‘instantaneous effects of single point-in-time measurements’ of the current neighbourhood on individual outcomes, regardless of residents’ individual neighbourhood histories. Evidently, this modelling strategy need not reflect a theoretical assumption that only the current neighbourhood matters. Rather, data limitations made it scientific practice to simplify residential histories to single point-in-time measures. However, the consequences of this common modelling strategy ought to be tested.
Few studies tried to deal with the temporality of neighbourhood effects among the adult population. First, a range of studies focused on non-movers only, believing them to be exposed to the neighbourhood for a sufficient amount of time to be influenced by it (Bergsten, 2010; Galster et al., 2008; Kauppinen et al., 2011; Musterd et al., 2012b). Yet, a serious downside of such non-mover analyses is that the income change of movers is more progressive than for non-movers and that social climbers that move out of a neighbourhood are therefore ignored (as acknowledged by Musterd et al., 2012b).
A second group of studies – two, to be precise – included actual exposure time for the adult working-age population to more than one neighbourhood. The one paper to include the exposure time to poverty neighbourhoods over a long period for adults is that by Hedman and colleagues (2013). The authors find that cumulative exposure to neighbourhood deprivation after leaving the parental home has a positive effect on income, while remaining in this type of neighbourhoods in subsequent years has clear negative effects. The first finding is merely a reflection of the start of a housing career in relatively deprived neighbourhoods of people who simultaneously enter and advance on the labour market (Hedman et al., 2013: 16). The second finding is in line with the study by Musterd et al. (2012a) who also find that neighbourhood effects persist after years for adults, even though they do decay. Recent continuous and cumulative exposure to a low-income neighbourhood has more impact on the resident’s income than episodic or lagged exposure to the neighbourhood.
There are some downsides to this approach, however. Both studies fall short of modelling the unique impact of former neighbourhoods, as they lack a fine-grained measure of residential histories. The study by Musterd et al. (2012a) limits exposure time to only four years that are lagged in time (as discussed by Hedman et al., 2013: 3). Our study expands this time span to more than a decade, to allow for a more encompassing view of residential histories. The study by Hedman et al. (2013) does allow a more complete temporal scale, but narrows the residential history to three different cumulative exposure variables (exposure to a poverty neighbourhood between 1991 and 1996, between 1997 and 2002, and between 2003 and 2007). Rather than studying the cumulative effect of subsequent neighbourhoods, our study separates the influence of these different contexts in detail to understand the temporal dynamics of neighbourhood effects. We also include a continuous neighbourhood deprivation scale, rather than the dichotomous variable on exposure to poverty concentration neighbourhoods as employed by Hedman et al. (2013).
Finally, there has been no agreement on what constitutes a change. Hedman et al. (2013) only allow for change after an actual residential move, whereas Musterd et al. (2012a) only assess the change in the neighbourhood’s socioeconomic composition, not actual moves. Our study follows Hedman et al. (2013) by focusing only on changes in neighbourhood composition due to residents’ actual moves, but extends the temporal framework by including the number of moves, the exposure times to all unique neighbourhoods of residence, and the time elapsed since leaving the previous neighbourhood of residence. Building on these more recent attempts to account for the temporal dimension, we thus propose a third model that incorporates lingering effects of previous neighbourhoods, including a more detailed residential history of individuals.
Mechanisms to explain (lingering) neighbourhood effects
Many scholars allocated the neighbourhood effects on residents’ socioeconomic outcomes to social-interactive mechanisms (Galster, 2012: 41), most notably socialisation (exposure to attitudes, values and behaviours of neighbours) and the resources embedded in social networks in the neighbourhood (Friedrichs et al., 2003; Galster, 2012; Galster et al., 2010). These mechanisms depend on interactions between neighbours (Van Ham and Manley, 2012: 9) and residents only become acquainted with their neighbours after a certain length of residence in the neighbourhood (Hedman, 2011; Van Ham and Manley, 2012).
In this perspective, moving is an important life-course event (Sampson, 2012). A clear distinction between movers and non-movers accounts for the diverse moving experiences and exposure times to the neighbourhood of residents (Hedman, 2011). To the extent that ties with the former neighbourhood are kept – for instance through (ir)regular visits – influences from the previous neighbourhood will still continue after the move. People’s experiences are not wiped clean once they have left their former residential neighbourhood, and may even linger on. Neighbourhoods are constantly changing environments with a flux of changing social ties, networks and interactions (Tienda, 1991). While neighbourhood characteristics generally hardly change over time (Hedman et al., 2013), the subjective context evolves as networks break down and other former residents also leave. Therefore, we expect a decaying effect of former residential neighbourhoods with time as residence spells move further into the past.
There are rivalling mechanisms that might also explain neighbourhood effects, such as environmental mechanisms (exposure to violence and the physical state of buildings), geographical mechanisms (proximity to jobs and local political authorities) and institutional mechanisms (stigmatisation and local institutional resources) (Galster, 2012). Generally, the influence of environmental mechanisms, geographical mechanisms and institutional mechanisms are expected to be less of an influence after the move. Yet, one could expect a scarring effect of having previously resided in a deteriorated, stigmatised neighbourhood that has been detached from the local labour market.
Ultimately, although this paper cannot test them directly, various mechanisms suggest that former residential neighbourhoods are likely to have lingering effects later in life. This reinforces the need to model the effect of previous neighbourhoods. We expect that the previous neighbourhoods of residence still have an effect on an individual’s current socioeconomic status.
Conditionality of (lingering) neighbourhood effects
Neighbourhood effects, both of the current and previous neighbourhood of residence, are not likely to be unconditional. A first temporal conditionality has been recognised in earlier studies. For neighbourhood effects to occur, residents need to be exposed to their neighbourhood (Galster, 2008), most notably by residing there for an extended period of time. Kasarda and Janowitz (1974: 334) emphasise that ‘[…] neither social class nor stage in life-cycle are as powerful or consistent in affecting local social bonds as is length of residence’. Musterd et al. (2012a: 607) find that ‘those who are exposed only briefly to an environment that is trying to reshape their behaviours will experience little if any effect from it compared with those who are exposed to the same socializing environment for a longer period of time’ and ‘some minimum duration of exposure to this new context will be required before new local social networks will produce any measurable differences in job-related information conveyed by them’.
The implications of this finding should be extended to previous neighbourhood(s): Residents who only lived in neighbourhoods for a short time span may not have been sufficiently exposed to continue to be affected even after they leave that neighbourhood. The impact of this earlier socialisation thus depends on the length of residence: The longer the exposure time, the stronger neighbourhood effects will be on residents’ subsequent income. In the words of Hedman and colleagues (2013: 5): ‘A longer stay in a poor neighbourhood where social norms prevail which are less supportive of regular employment might lead to lower income, whereas a brief period in such a neighbourhood is likely not to be sufficient to lead to different behaviours or beliefs’.
In sum, subsequently residing in deprived areas brings about long-lasting negative socialisation effects which are detrimental for a resident’s socioeconomic outcomes. We expect that the effects of the current and previous neighbourhoods will be stronger for individuals who have lived there for a longer period of time.
Yet, concurrent to the line of reasoning that it takes time for social ties to be built after one moves into a neighbourhood, it takes time for social ties to erode once one moves out. Evidently, the activity of moving out of a neighbourhood is likely to disrupt ties with (former) neighbours, but it is not evident that those ties are eradicated completely after moving. Especially in the short run former neighbours might be likely to keep in contact, even though such ties will become more difficult to maintain, will be replaced with newly established ties, and therefore will ultimately erode. Hence, even lingering neighbourhood effects are likely to fade with time: the effects of the previous neighbourhood(s) of residence will be stronger for individuals who lived there more recently (both in terms of time elapsed and of number of moves since).
Lingering neighbourhood effects and model estimation
In analyses of pooled data (i.e. of data that cover movers and non-movers, that do not distinguish between former residence, number of moves and length of residence, and therefore model direct effects of the current neighbourhood), we expect this data set-up to have a direct impact on the estimation, as the effects of former neighbourhood(s) are simply not included in the analyses. On the one hand, it follows that the role of the current neighbourhood of residence in affecting its residents’ socioeconomic status is thus overestimated in analyses of pooled data, as part of the effect in these types of analysis is attributable to the former neighbourhood of residence. On the other hand, the total body of possible neighbourhood effects is underestimated as an individual is often exposed to more than one neighbourhood over their life course.
H1. The estimated effect of the current residential neighbourhood on residents’ socioeconomic status is smaller in models that incorporate the potential effects of one or more former residential neighbourhood(s).
The alternative model in the literature, which focuses exclusively on non-movers to pinpoint potential neighbourhood effects, only shows a selective part of the whole range of potential neighbourhood effects. It limits itself to the current neighbourhood and to non-movers.
On the one hand, we can expect weaker neighbourhood effects once we include movers, as non-movers are exposed to the neighbourhood for a longer period of time and therefore more likely to be impacted by their neighbourhood. This line of reasoning suggests, however, that non-movers actually have a choice. An alternative hypothesis is that neighbourhood effects for non-movers largely reflect self-selection, as they lack the resources to move and in general have a lower income (Musterd et al., 2012b), so that once we include movers, neighbourhood effects are thus stronger. This leads to two contrasting hypotheses:
H2a. Compared with models of non-movers, models that incorporate effects of former residential neighbourhood find weaker effects of the current residential neighbourhood on residents’ socioeconomic status.
H2b. Compared with models of non-movers, models that incorporate effects of former residential neighbourhood find stronger effects of the current residential neighbourhood on residents’ socioeconomic status.
Data, measures and methods
Data register files
This paper explores the degree to which alternative modelling procedures – analysis of instantaneous effects in pooled data, analysis of non-movers, and analyses that takes into account residential neighbourhood histories – yield different estimates of neighbourhood effects. This comparison requires multiple analyses of a single, individual-level longitudinal population data set. These data should cover full information on both the previous neighbourhood(s) of residence and the current neighbourhood of residence, so that we can model residents as being nested within both the current neighbourhood and the previous neighbourhood simultaneously. The Social Statistical Database as made available by Statistics Netherlands meets these requirements.
This database is an individual-level longitudinal data file that covers the entire population of the Netherlands (1995–2011). In order to improve the modelling speed we have drawn a perfect random sample of 5% of the total population that was ever registered in the Netherlands from 1995 onwards. We refined our sample to individuals – both men and women – that are born between 1956 and 1974 (between 21 and 55 years old in 1995–2011), whose employment histories were further bookended by not being a student in 1999, and by being active on the labour market in 2011, and who had no missings on the key variables during their residential histories. This leaves us with a sample size of 158,377 individuals. 3
Description of variables
Time-variant and time-invariant individual-level variables
Each individual is allowed to have up to five residence spells; timing and duration characteristics are included for each residence spell. 4 The dependent variable in our model is personal income, measured statically at one point in time, i.e. at the end of the last residence spell in 2011 (measured in euros). 5 This income variable combines income on a yearly basis from work (earned wages of the employed and the profits for the self-employed) and also includes transfers from social security benefits, funds and alimonies minus the premiums for income insurance. This variable will be centred for the analysis. As we carefully build up our analyses, later models control for residents’ income at the start of their current residence spell.
We also control for year of birth, gender, nationality and household status (four dummies: single, couple with and without children and single parent and interactions of these dummies with gender) at the end of the last residence spell. Variables that we do allow to change for each residence spell are the neighbourhood deprivation index, the length of residence, the years elapsed until the end of 2011 since leaving the neighbourhood (for previous residence spells only) and for individuals with five addresses or more we include their residential mobility (number of addresses). Data on educational attainment are not yet available as education is not registered for the entire population.
Neighbourhood-level variables
The neighbourhood is operationalised as the area delineated and operationalised by Statistics Netherlands, with an average size of about 1500 residents. We created a population-based standardised index of neighbourhood deprivation for each neighbourhood for the year 2011. An alternative modelling strategy would have us focus on the effects of previous neighbourhood as they were at the time when residents left to test for lingering effects of previous socialisation. We have two main reasons to focus on the neighbourhood information from 2011.
Theoretically, the lingering effect is more about sustained socialisation and interaction effects (such as contacts with the former neighbours) beyond past conditions (that should be captured by controlling for income when entering the current neighbourhood). The 2011 context is not necessarily the same as the context as it was when the respondent left the neighbourhood (see section ‘Mechanisms to explain (lingering) neighbourhood effects’), but we account for this by testing the decaying effect of the former residential neighbourhoods over time.
Methodologically, the alternative model strategy would lead to nesting issues in our cross-classified model. Each respondent would then have unique contexts (depending on their time of leaving). If we had to account for the dependence of neighbourhood composition at time t0 and that very same neighbourhood’s composition at times t−1 and t−2, we ought to have added yet another level of analysis on top of our cross-classified model. This was unfeasible.
The neighbourhood deprivation index contains socioeconomic dimensions that represent various domains of opportunity structures, resources and stratification in the neighbourhood. The factorability of the following five items (measured in the year 2011) was examined among 7632 neighbourhoods: (1) the average personal income per income recipient; (2) the average personal income per resident; (3) percentage of income recipients with income less than or equal to the 40-percentage point of the national income distribution; (4) percentage of income recipients with income equal to or greater than the 80-percentage point of the national income distribution (5) number of welfare benefits per 1000 households. The correlations between each pair of items ranged from 0.451 to 0.932. The internal consistency for the index was examined using Cronbach’s alpha based on standardised items, which was high (0.921). The Kaiser-Meyer-Olkin postfactor measure of sampling adequacy was 0.81, suggesting an adequate factorability. Using principal component analysis (unrotated) only one component is estimated which explains 77% of the variance and the eigenvalue of this component is 3.86. The index of neighbourhood deprivation is standardised and included in the model as a continuous independent variable. 6
Descriptive statistics
The main data set of 158,377 individuals is employed for the first model, combining the analysis of movers and non-movers for their most recent address. As explained, we also estimate models on non-movers and residents that lived on two, three, four and five (or more) addresses. Table 1 provides descriptive statistics for each sub data set. 7 The distinct differences between individuals with dissimilar residential trajectories stresses the importance of explicitly taking this into account when comparing alternative models and estimating conditional neighbourhood effects.
Descriptives of each subsample.

Modelling strategy
To investigate the consequences of the models that ignore individual residential neighbourhood histories on the estimation of neighbourhood effects, we take on two different modelling strategies. In the first step of our analysis, we replicate the existing methodological approach by estimating two conventional two-level models with individuals nested within the current neighbourhood of residence. The first model is estimated on a sample of both movers and non-movers combined and ignoring residential histories (cf. Andersson et al., 2007; Musterd et al., 2003; Van Ham and Manley, 2010). The second model is estimated on a sample of non-movers (cf. Musterd et al., 2012b). As we do not account for the previous neighbourhood(s), these models are not cross-classified. These conventional random intercept two-level models (model 1 and model 2 in Tables 2 and 3) function as reference points to uncover misestimations in previous studies.
Random intercepts model of impact of exposure to deprived neighbourhoods on personal income in 2011 with various individual residential histories.
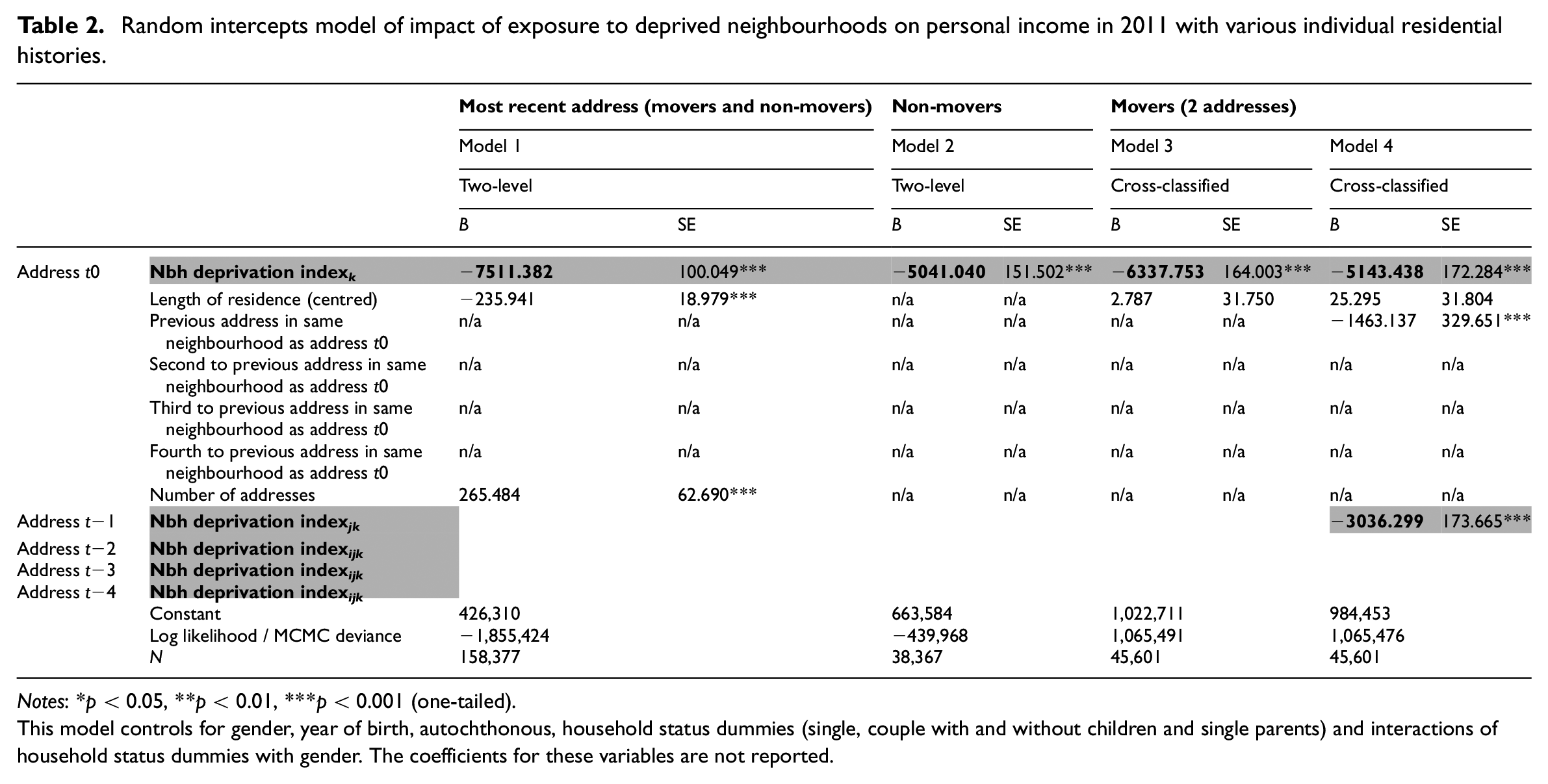
Notes: *p < 0.05, **p < 0.01, ***p < 0.001 (one-tailed).
This model controls for gender, year of birth, autochthonous, household status dummies (single, couple with and without children and single parents) and interactions of household status dummies with gender. The coefficients for these variables are not reported.

Notes: *p < 0.05, **p < 0.01, ***p < 0.001 (one-tailed).
This model controls for gender, year of birth, autochthonous, household status dummies (single, couple with and without children and single parents) and interactions of household status dummies with gender. The coefficients for these variables are not reported.
Random intercepts model of impact of exposure to deprived neighbourhoods on personal income in 2011 (controlled for income at start residence spell) with various individual residential histories.
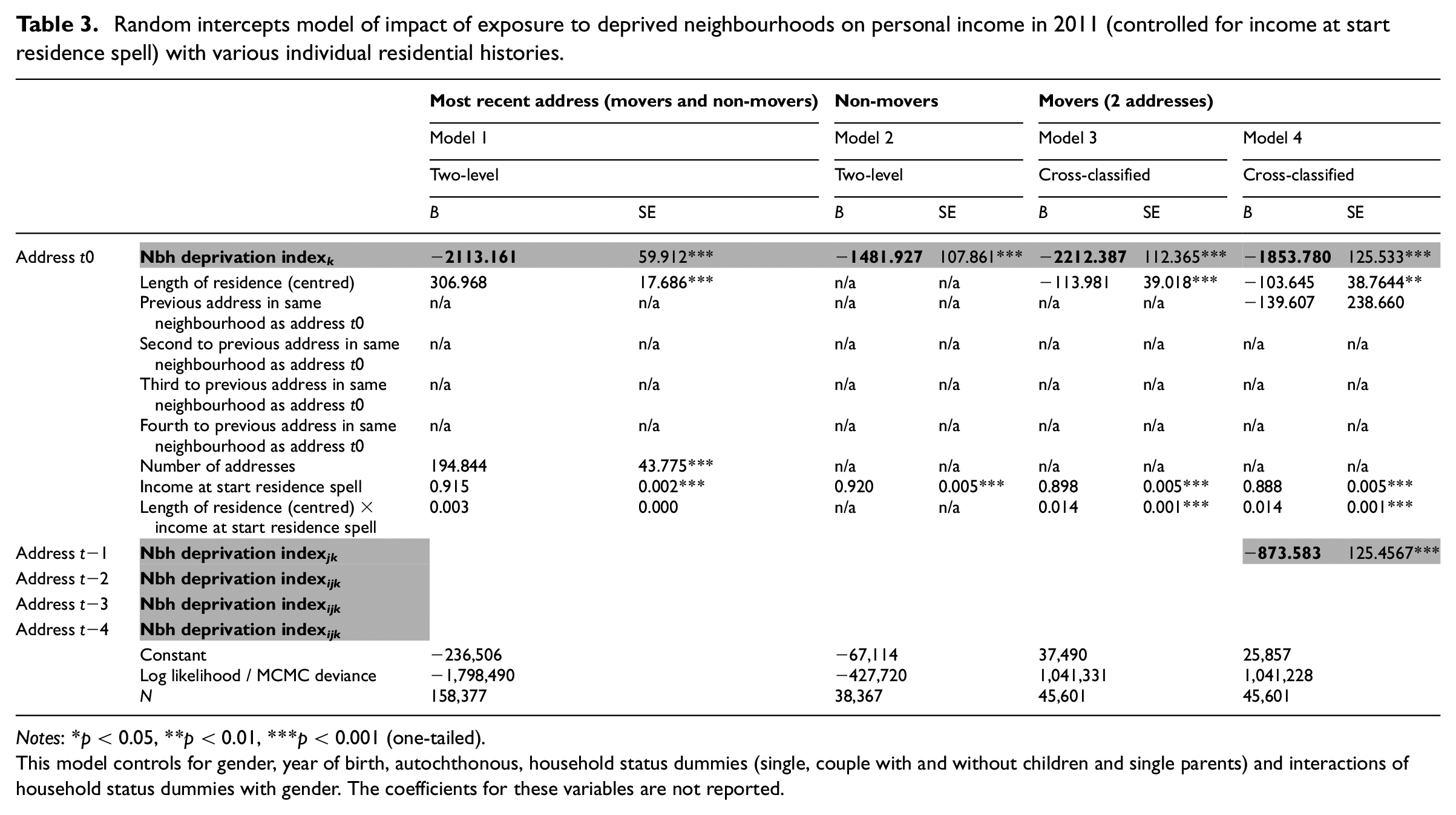
Notes: *p < 0.05, **p < 0.01, ***p < 0.001 (one-tailed).
This model controls for gender, year of birth, autochthonous, household status dummies (single, couple with and without children and single parents) and interactions of household status dummies with gender. The coefficients for these variables are not reported.
Notes: *p < 0.05, **p < 0.01, ***p < 0.001 (one-tailed).
This model controls for gender, year of birth, autochthonous, household status dummies (single, couple with and without children and single parents) and interactions of household status dummies with gender. The coefficients for these variables are not reported.
In the second step of our analysis, we take into account both the previous neighbourhood(s) of residence and the current neighbourhood of residence. We model multiple contexts simultaneously, even though these contexts themselves are not nested in each other. For that purpose, cross-classified multilevel models are the most appropriate technique. 8 It allows us to estimate the effects of functionally different contexts (i.e. current and former neighbourhoods) simultaneously. Although the very same neighbourhoods constitute the contexts at the higher levels of analysis, these contexts are functionally different to the respondents (as we separate current and former place of residence) and theoretically expected to induce different effects. Separating these effects is crucial to test assumptions behind potentially underspecified models (Fielding and Goldstein, 2006). 9 Cross-classified models are computationally very demanding to estimate. To avoid numerical and memory problems, we estimate our models in MLWin using the more efficient MCMC Bayesian estimation method with a IGLS estimation prior as propagated by Browne et al. (2001). As these cross-classified models rapidly become too complex to estimate, we only model the current and the immediately previous neighbourhood at higher levels of analysis. The second-last, third-last and fourth-last neighbourhood for residents with respectively three, four or five addresses are included as individual-level characteristics. While this has no consequences for the effect size, the standard errors of the effects of these specific contexts are underestimated. Nevertheless, we incorporate them in our analyses to see how the inclusion of these effects affects the other estimates. The cross-classified model we consider for the individual i can be represented as follows (Rasbash et al., 2009):

where yi (jk) is the income in 2011 of respondent i from the (jk)th former neighbourhood/current neighbourhood combination; β1xijk is the effect of an individual-level characteristic of respondent i; β2zjk is the effect of a neighbourhood-level characteristic of the current (k) and former neighbourhood (j) cross-nested; β3zk is the effect of a neighbourhood-level characteristic of current neighbourhood k; β4xijk is the effect of neighbourhood-level characteristics for the second-last, third-last and fourth-last neighbourhood of residents (which are included as an individual-level characteristic of respondent i); u0k represents the variation in the intercept across the current neighbourhood of residence; u0j represents the variation in the intercept across former neighbourhood of residence; and εi (jk) is the remaining variation within individuals.
We build up eight cross-classified models of individuals nested in the current and former residential neighbourhood, namely those estimated on a subsample of respondents who lived at precisely two addresses (3–4), on a subsample of respondents who lived at precisely three addresses (5–6), on a subsample of respondents who lived at precisely four addresses (7–8), and a subsample of respondents who lived at five or more addresses, controlled for the number of addresses (9–10). For each subsample, we first model only the current neighbourhood effect and then add the neighbourhood effect(s) of the previous neighbourhood(s) of residence in the second step. 10 As these models fix the number of addresses and moves, our outcomes are not dependent on residential instability.
In the build-up to our data set and models, we have made some major choices regarding what constitutes a residential move and our population of study. To further substantiate our findings, we performed multiple robustness checks on our core model. We will elaborate on this in section ‘Robustness checks’.
Results
Baseline models
Table 2 shows that regardless of the length of residence, living in a neighbourhood with a high deprivation index has a statistically significant negative effect on an individual’s income. In other words, there is a substantive loss in income: one point rise in the deprivation index means a loss of a few thousand euros in yearly income. It also shows a large difference in the effect depending on our subsample and modelling strategy, however. Model 1 pools together movers and non-movers, neglecting residential mobility and lingering neighbourhood effects. By comparison, model 2 focuses on the non-movers only and shows a much lower estimation of the neighbourhood effect.
Models 3–10 are the three-level cross-classified models for residents that lived at two, three, four and five (or more) addresses. What is apparent from these models is that an exclusive focus on the current residential neighbourhood overestimates that neighbourhood effect. When all the previous neighbourhoods of residence are taken into account, the effect of the current neighbourhood drops (as shown in models 4, 6, 8 and 10). Having lived in a neighbourhood with a high deprivation index has a statistically significant detrimental effect on an individual’s current income. The impact of the composition of the immediately preceding neighbourhood is more than half the size of the impact of the current neighbourhood. This suggests that there are relevant lingering effects from the previous residential neighbourhood. The second-last, third-last and fourth-last neighbourhood for residents with respectively three, four or five addresses also have some impact, albeit less strong than the last neighbourhood.
Table 3 illustrates the effects for models that are able to control for this type of self-selection effect and explicitly controls for the income of residents at the start of their most current residence spell. 11 Although the neighbourhood effects are much smaller than in Table 2, the same pattern is observable. Regardless of the income at the start of the residence spell and length of residence, living in a neighbourhood with a high deprivation index has a statistically significant negative effect on individuals’ income. When the last neighbourhoods of residence are taken into account, the effect of the current neighbourhood diminishes substantially: having lived in a neighbourhood with a high deprivation index before the current address still has a statistically significant detrimental effect. Including the previous residence spell reveals an overestimation of the current neighbourhood by 16 (model 3–4) up to 30% (model 7–8). Once we control for self-selection, the second-last, third-last and fourth-last neighbourhood for residents with three, four or five addresses no longer have a substantive, significant negative impact. Still, the lingering effects from the previous residential neighbourhood show an underestimation of the total body of neighbourhood effects by 13% (model 9–10) up to 24% (model 7–8).
The comparison of residents with two to five (or more) addresses also indicates that the impact of the current neighbourhood of residence diminishes with the frequency with which residents have moved. This supports the first hypothesis: models that incorporate effects of former residential neighbourhoods find weaker effects of the current residential neighbourhood on residents’ socioeconomic status. Similarly, we find support for hypothesis 2b: models that solely focusing on non-movers underestimates neighbourhood effects, models that incorporate effects of former residential neighbourhoods find stronger neighbourhood effects. Thus, the previous neighbourhood(s) of residence still have an effect on an individual’s current socioeconomic status.
The temporal conditionality of neighbourhood effects
The lingering effects are not likely to be unconditional upon the individual’s residential history. Tables 4 and 5 build on Table 3 by introducing conditional neighbourhood effects. 12 Table 4 interacts the effect of the current neighbourhood of residence with the amount of time spent in this neighbourhood. 13 For residents with three, four or five addresses the neighbourhood effects of the current neighbourhood are stronger for individuals who have lived there for a longer period of time. This is not found for individuals with only two addresses. 14
Random intercepts model of impact of exposure to current neighbourhood in interaction with length of residence in current neighbourhood on personal income in 2011 (controlled for income at start residence spell) with various individual residential histories.
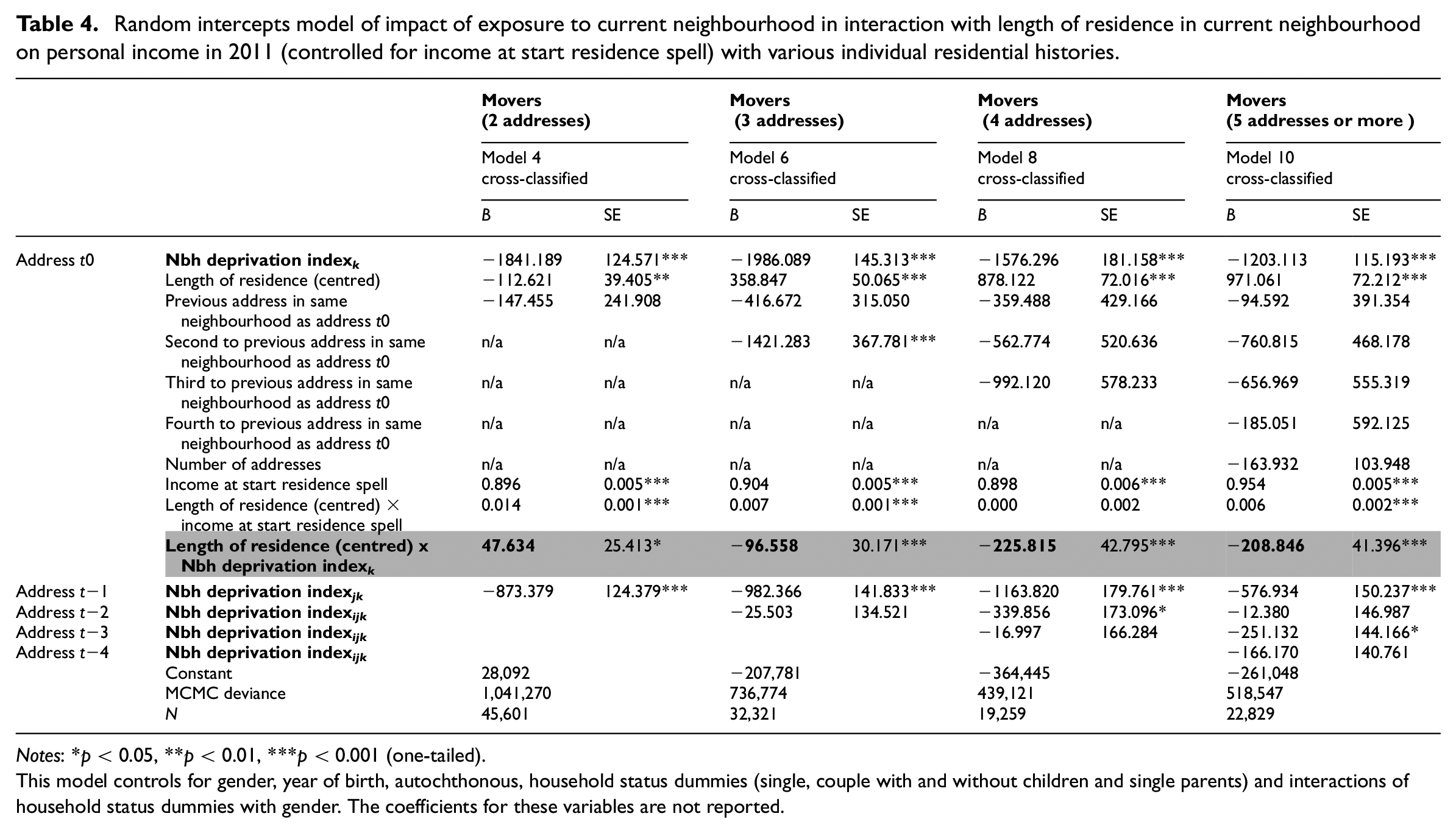
Notes: *p < 0.05, **p < 0.01, ***p < 0.001 (one-tailed).
This model controls for gender, year of birth, autochthonous, household status dummies (single, couple with and without children and single parents) and interactions of household status dummies with gender. The coefficients for these variables are not reported.
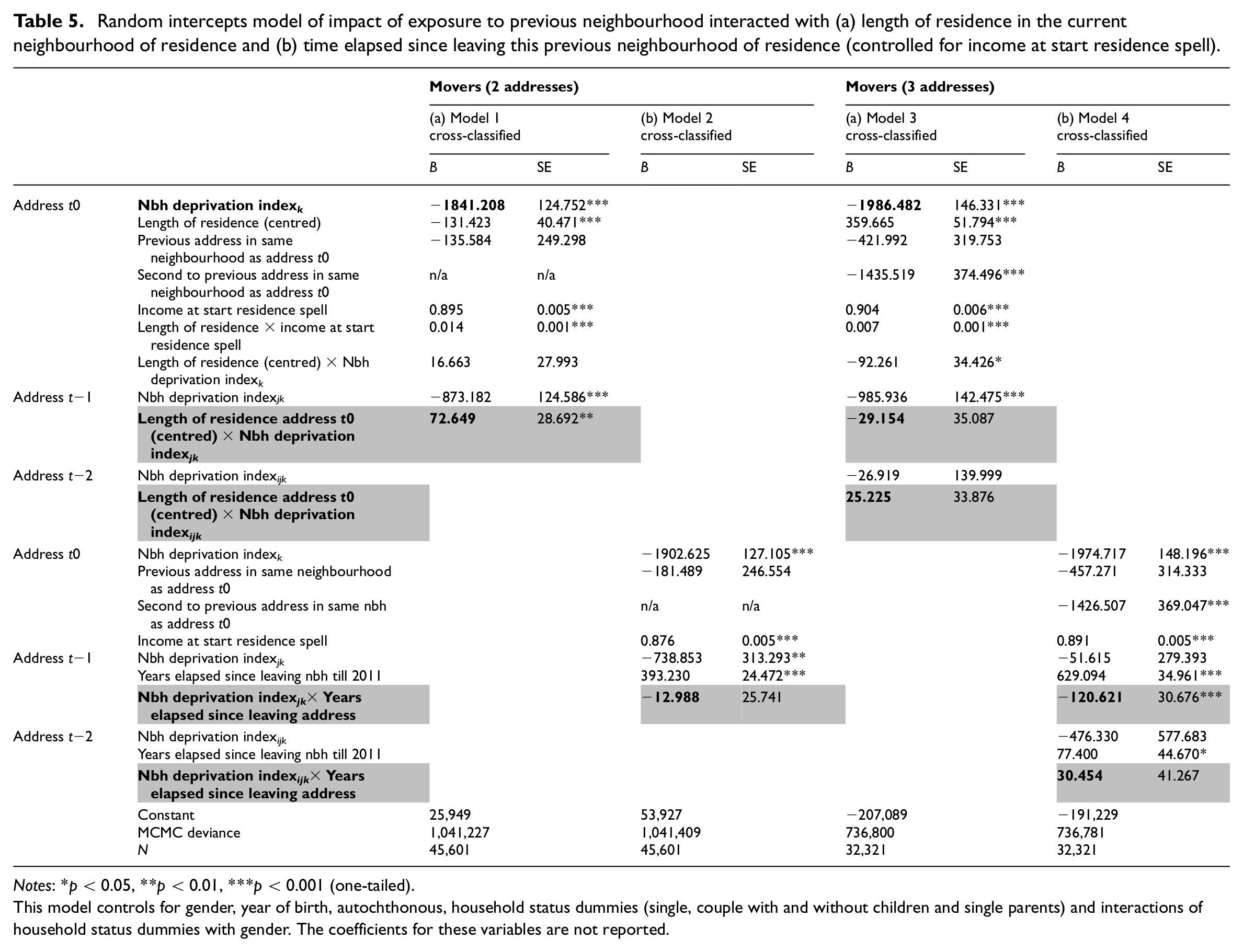
Random intercepts model of impact of exposure to previous neighbourhood interacted with (a) length of residence in the current neighbourhood of residence and (b) time elapsed since leaving this previous neighbourhood of residence (controlled for income at start residence spell).
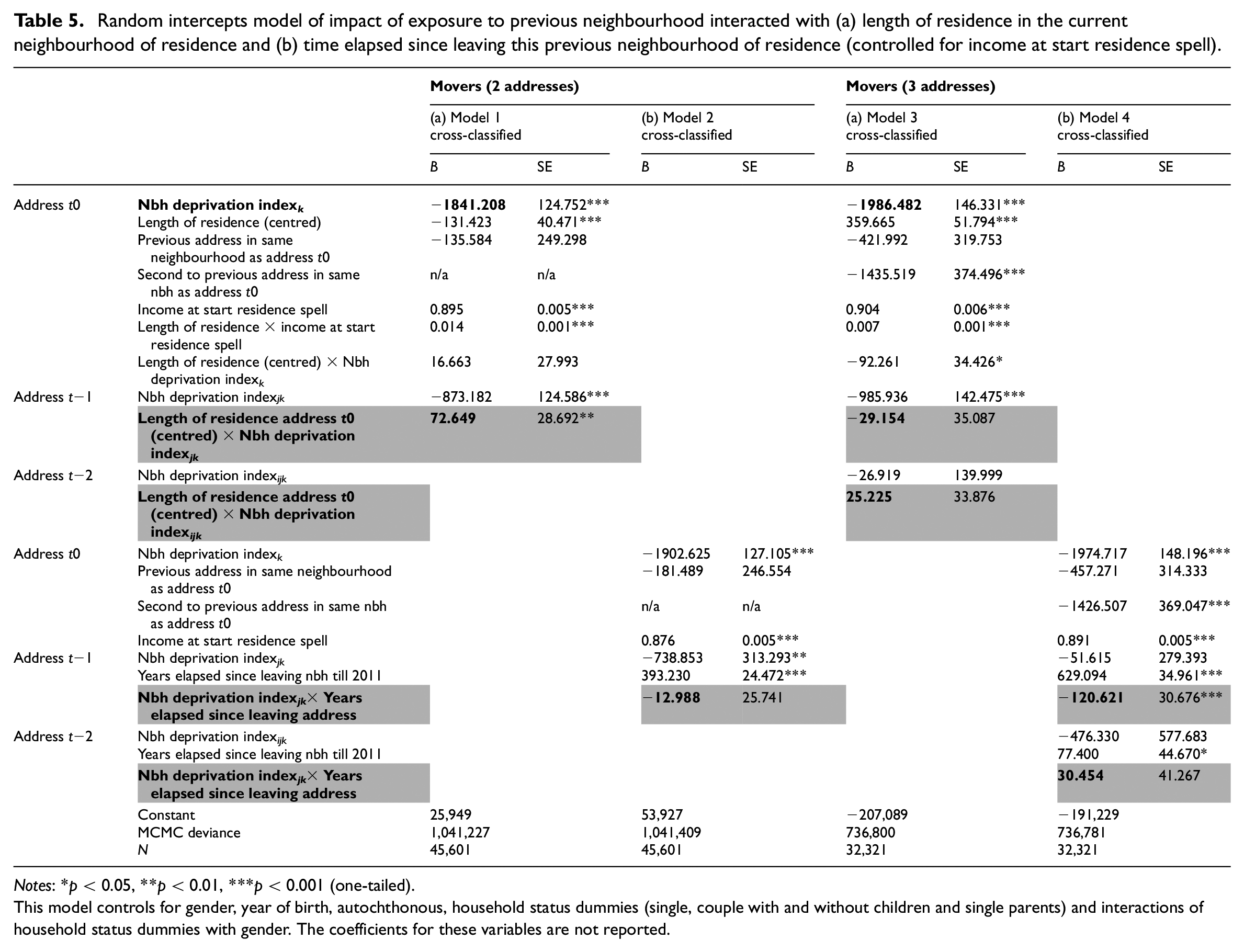
Notes: *p < 0.05, **p < 0.01, ***p < 0.001 (one-tailed).
This model controls for gender, year of birth, autochthonous, household status dummies (single, couple with and without children and single parents) and interactions of household status dummies with gender. The coefficients for these variables are not reported.
Are the lingering neighbourhood effects also conditional upon the temporality of the residential histories? Table 5 focuses only on individuals with two or three addresses, given that we found no significant effects of residential neighbourhoods further in the past. Table 5a (model 1) shows that for individuals that only moved once (have two addresses), the effect of the previous neighbourhood grows weaker with the time they lived at the current address. 15 Table 5b shows that, contrary to our expectations, for individuals with three addresses (model 4) the lingering neighbourhood effect of the previous neighbourhood is stronger rather than weaker when individuals have lived there further in the past. 16
Robustness checks
Our analyses suggest the necessity of including an individual’s residential history in the estimation of neighbourhood effects. In this section, we test the robustness of our models to some choices that were behind our core models (Table 3, model 3–4).
The first choice concerns what constitutes a move: in our models a residential move is any move between addresses, including those within a single neighbourhood. To verify the robustness of our results, we distinguished the data set in movers that move within and those that have moved beyond the neighbourhood (both in a split-run and via interaction models). We find that this distinction does not substantially affect our findings: the impact of the former residence spell is somewhat (but not significantly) weaker among those who moved within the same neighbourhood than among those who moved between different neighbourhoods.
The second main choice concerns our data selection. We have drawn a perfect random sample of 5% of the total population ever registered in the Netherlands from 1995 onwards. To test the robustness of our findings, we split our original sample in half and re-ran our models models to find highly similar results.
We had refined our sample to individuals who had an income above zero over the course of 2011 (excluding individuals with debts and/or without income) and that were active on the labour market in its broadest meanings. We re-estimated our core models on dataets (1) with males only, (2) without self-employed individuals, (3) with yearly income capped at 100,000 euros, and (4) without individuals from the most and least affluent neighbourhoods (1.5 standard deviation above and below the neighbourhood population mean). In all of these analyses the direction and significance of neighbourhood effects are highly similar to our main models. Most importantly, all our substantive conclusions concerning the lingering neighbourhood effects hold. 17 Regardless of data selection, residential histories matter.
Conclusions
This study conducted a systematic comparison of neighbourhood effects with alternative modelling procedures taking into account residential neighbourhood histories. We found strong evidence that conventional models of neighbourhood effects overestimate the impact of the current residential neighbourhood. Previous neighbourhood(s) have a statistically detrimental effect on residents’ current income beyond their current neighbourhood of residence, even when we control for the level of income when these residents entered their current neighbourhood. Inclusion of these lingering effects of previous neighbourhoods in our models has significant and substantive consequences for the estimated impact of the current neighbourhood in models that are conventionally used in this literature. Compared with common cross-sectional studies, the inclusion of lingering neighbourhood effects diminishes the estimated impact of the current neighbourhood. By contrast, compared with studies that focus solely on non-movers, the inclusion of lingering neighbourhood effects shows a stronger impact of the current neighbourhood.
Methodologically, our findings imply that scholars should be aware that conventional models of neighbourhood effects that neglect residential histories lead to a serious bias of the estimates. The impact of the current neighbourhood is overestimated (16–30%); the impact of the whole body of (current and former) neighbourhood is strongly underestimated (by 13–24%). This study stresses the need for a methodological framework that better isolates current and former neighbourhood effects. This framework should include the previous neighbourhood(s) of residence, the moving behaviour, the passage of time and the temporal exposure to different neighbourhoods. Cross-classified, multilevel models provide such a framework.
Theoretically, these findings suggest that residents are exposed to different neighbourhoods at the same time. People continue to be affected by their previous residential neighbourhoods even after the move (as theorised by Hedman, 2011). Although these lingering neighbourhood effects tend to fade the more often individuals move, they are rather persistent and last even beyond the level of income residents’ have at the start of their current residential spell. These effects might be induced by long-lasting socialisation (that stay with residents in subsequent years), continuing social networks, or a scarring effect of poor labour market histories. Ultimately, though, this study is unable to isolate the mechanisms behind the effects we find. Future studies should aim at identifying these mechanisms, for example by enriching the register data with social network survey data.
From this it follows that scholars should widen the scope of their studies beyond the current neighbourhood of residence, and recognise that individual selection into and exposure to more neighbourhoods is part of a larger structure of social and spatial inequalities. Residentially mobile individuals are continuously embedded in social and spatial structures. As neighbourhood conditions influence residents’ incentives and – as this study illustrates – resources that are at the basis of subsequent decisions to move in or out of any neighbourhood, the phenomenon of selection bias itself is a form of neighbourhood effect. Such neighbourhood effects are not constrained to one neighbourhood or to a single point in time. Rather, they cross the borders of the current residential neighbourhood and point to larger temporal and spatial (dis)advantages for residents. On the contrary, one could also argue that continuing to live in disadvantaged neighbourhoods may not only be the cause, but also another indicator of (pre-existing) individual deprivation (Bailey, 2012). Nevertheless, it seems that scholarly research has underestimated the extent to which socially spatial stratified settings breed structural (dis)advantages (Sampson, 2012).
Footnotes
Acknowledgements
The authors would like to thank Matthijs Kalmijn, Herman van de Werfhorst, Sako Musterd and Cody Hochstenbach for their helpful comments on an earlier version of this paper.
Funding
This work was supported by The Netherlands Organization for Scientific Research (NWO) by a Research Talent grant to Emily M Miltenburg (grant number 406-11-038) and a VENI project to Tom WG van der Meer (grant number 311-99-015).