
Abstract
Tourism companies increasingly adopt artificial intelligence (AI) tools to enhance their efficiency and customer service, but doing so introduces new risks that can affect customer–provider relationships. This study examines generative AI performance (success vs. failure) by distinguishing between regular service mistakes (e.g., context-based inaccuracies) and hallucinations (illogical or fabricated information). Two experimental studies, carried out with travel agencies, compare AI versus human employee performance on the task of providing travel choices. Service failures reduce loyalty and positive word-of-mouth (WOM) intentions, while increasing negative WOM intentions, and these effects are stronger for human employees, such that customers react more intensely to human than to AI failures. Yet in addition, customers react particularly negatively to AI hallucinations. Hallucinations thus must be carefully prevented, because they substantially increase negative WOM and erode customer loyalty. Transparent communications about AI limitations can help mitigate these relational and reputational risks.
Keywords
Introduction
Since the launch of ChatGPT in late 2022, implementations of generative artificial intelligence (AI) have spread across many sectors, reflecting its potential to increase productivity and profoundly transform business operations. The percentage of businesses across sectors that report organizational uses of AI doubles yearly (McKinsey & Company, 2024), suggesting that companies are effectively overcoming hesitations about introducing generative AI to create value, particularly in marketing and sales (McKinsey & Company, 2024).
In the global tourism industry for example, AI-enabled solutions help firms develop content (N. Fan et al., 2026), plan trips (Hrankai & Mak, 2026; Kang et al., 2026), retain customers (H. Fan et al., 2024), and forecast demand (Yu & Schwartz, 2006; Y. Zhang et al., 2021), as well as increase their efficiency. For example, the Iberostar Hotel group leveraged AI tools to reduce food waste, resulting in a 27% cost saving (WTTC, 2024). In turn, projections suggest that AI could add up to $800 billion in additional value to the global tourism industry by 2030 (Manyika et al., 2022), while also supporting an efficiency- and responsibility-focused paradigm shift in tourism management (UN Tourism, 2024). When companies in the tourism sector adopt generative AI agents as alternatives/complements to traditional, employee-based agents (Rojewska, 2024), the AI agents provide customers with personalized advice and additional features, such as the ability to download flight and hotel reservations and share inspirational photos (e.g., MindTrip, Wanderlog).
Yet AI systems are not without flaws. Some mistakes are humorous, as when a Microsoft AI generated a travel guide that suggested the Ottawa Food Bank’s warehouse was a must-see attraction (CBC News, 2023). But AI also has been implicated in two plane crashes (The New York Times, 2019), and when AI algorithms in social media promote information cocoons and polarization, they can create biases in tourists’ destination choices (G. I. Huang et al., 2025). Calls to implement generative AI responsibly (e.g., The Guardian, 2024) arise from accusations that it provides bad advice and incorrect prices, causes unnecessary wait times, and leads to unsatisfactory customer experiences (Christensen et al., 2025). Thus, tourism companies face a dilemma, regarding whether to integrate AI tools into their operations, given the risks involved and their mandate to take a responsible approach that avoids causing harm to customers. Highlighting the difficulty of this decision, 70% of European accommodation businesses had refused to adopt AI systems as of 2023 (Statista, 2024). In general then, the benefits of AI implementation (Ameen et al., 2025; M.-H. Huang & Rust, 2024) must be measured against the risks and ethical concerns it raises (Carvalho & Ivanov, 2024; Flavián et al., 2024).
One pertinent risk associated with the implementation of generative AI is the potential for service failures, especially in the form of inaccurate responses, which 73% of practitioners in one survey cite as their biggest concern (Thomson Reuters, 2025). When Air Canada’s generative AI chatbot quoted an incorrect fare, the airline had to pay more than US$800 to the affected passenger (The Guardian, 2024). In addition, AI hallucinations have emerged as a novel, underexplored phenomenon, with potentially harmful consequences for customers and tourism companies (Christensen et al., 2025; Hwang & Jeong, 2025). The false and/or incorrect information produced through AI hallucinations increases companies’ risks of poor decisions, reputational damage, regulatory sanctions, and missed opportunities (Deloitte, 2025). In customer-oriented travel advice services in particular, hallucinations generally entail incorrect, but potentially true, responses that customers might believe, representing “a potentially huge problem for the tourism industry” (Christensen et al., 2025, p. 545).
Although the errors caused by companies’ uses of generative AI represent a major concern (Carvalho & Ivanov, 2024; Dogru et al., 2025), research has yet to establish customers’ perceptions of tourism companies’ adoption of generative AI and the influence of AI-related service failures (including hallucinations) on the customer–provider relationship and travel companies’ reputations. Some studies address earlier AI technologies, such as service robots, which produce very different service encounters and customer experiences (Becker et al., 2023; Pitardi et al., 2024). Reflecting AI’s strong text and speech analysis capabilities, another stream of research deals with its potential for achieving recovery following a service failure (Liu & Xu, 2023; Tan et al., 2025). Among limited research on generative AI failures, most investigations include direct users of ChatGPT (Christensen et al., 2025; J. H. Kim et al., 2024), rather than customers who suffer failures when service providers, such as tourism companies, adopt the tools, as is the focus of the present study. In addition, scarce research into AI hallucinations indicates that they negatively affect customer satisfaction and service evaluations (Song et al., 2025), which leads customers to discontinue using the AI, particularly if the AI agent does not apologize (H. Kim et al., 2025).
Thus, though prior studies are informative, research has not provided a meaningful comparison of AI travel agents with human agents, distinguished between failures caused by hallucinations versus other types of mistakes, or analyzed the implications in relation to customers’ word of mouth (WOM) or the companies’ reputations. Reflecting these identified gaps, the current research aims to address the following research questions:
How do the service outcomes (success vs. failure) when consumers interact with AI travel agents versus human travel agents influence their loyalty, positive WOM, and negative WOM intentions?
Do customers react differently (in terms of loyalty, positive WOM, and negative WOM) to (a) failures perpetrated by AI agents versus human travel agents and (b) when faced with hallucinations versus regular mistakes?
To what extent does perceived service fulfillment mediate these effects?
Answering these questions establishes several contributions to this emerging and underdeveloped research field. First, we review scant research on AI failure and hallucinations to provide a clear conceptualization of AI hallucinations and identify reasons they occur. Second, our research focuses explicitly on customers’ reactions when travel agencies adopt generative AI travel agents and thus moves beyond previous research that deals with users of AI services managed by developers (e.g., ChatGPT, Shin et al., 2025). Third, in recognition of the current state of generative AI, the current research outlines customers’ differential responses to the service performance of travel agencies that provide human services and those that have shifted to generative AI agents. Fourth, to address some of the novel challenges faced by the industry, we compare hallucinations with regular mistakes made by AI or human travel agents, an aspect that has been ignored in prior literature dealing with AI hallucinations. Fifth, our research explores the consequences for travel agencies, in terms of customers’ intentions to be loyal to the firm and to engage in positive and negative WOM. This approach goes beyond previous research that disregarded the impact of failures on companies’ reputations.
This article concludes with a thought-provoking discussion, based on the findings, of customers’ tolerance of failure in the age of AI. That discussion, and indeed this whole article, aims to encourage scholars and practitioners to address and better understand the challenging phenomena of generative AI failures and hallucinations.
Literature Review
Generative AI Failures
Unlike predictive AI, which focuses on algorithms that use consumer data and that can be tracked (e.g., personalized cross-selling offerings by Amazon, movie recommendation system by Netflix), generative AI can create new content based on available information, through a “black box” process that emulates human capabilities (Hermann & Puntoni, 2024). Generative AI systems deliver outstanding performance for certain tasks, such as responding promptly to online customer complaints in hospitality settings (scoring higher than human employees in attentiveness, timeliness, redress, and apology, though not on consistency; Koc et al., 2023). Generative AI tools also provide good conversational services, because they use large language models fed by domain-specific and domain-general information. However, because AI lacks feelings and empathy (M.-H. Huang & Rust, 2021; Ling et al., 2025), it frequently fails when relational and affective aspects are pertinent. For example, generative AI companion apps sometimes fail to respond adequately to distress (De Freitas et al., 2024), and they may become addictive (Marriott & Pitardi, 2024).
Growing interest in generative AI has led to a better understanding of the service failures associated with this novel technology (see Table 1). Because of their roots in language models trained on vast amounts of data, these tools tend to be inherently overconfident in their answers (Hermann & Puntoni, 2024), leading them to provide incorrect or fabricated answers that sound coherent. Recent literature has started to analyze and categorize the many and diverse flaws of generative AI (Sun et al., 2024; R. W. Zhang et al., 2024) and cites AI hallucinations as the most outstanding failure (Christensen et al., 2025). Most discussions of AI failures focus on consumers’ direct uses of ChatGPT (J. H. Kim et al., 2024; J. H. Kim, Kim, Kim, & Kim, 2023) and suggest that, despite its efficiency, ChatGPT provides poor quality or even unethical information, filled with biased responses or data that can raise privacy concerns (J. H. Kim, Kim, Kim, & Kim, 2023). Research into AI hallucinations also shows that customers react negatively to these failures (H. Kim et al., 2025; Song et al., 2025) and that forewarning them about the potential risks can limit its harmful consequences (Hwang & Jeong, 2025). Nevertheless, further, intensive, and comparative analyses are needed to better understand this phenomenon in tourism settings.
Literature Review: Previous Findings on Generative AI Failures and Hallucinations.
AI Hallucinations
Some initial conceptualizations seek to define the “AI hallucination” phenomenon, as a type of error made by large language models when they “create responses that appear plausible but are nonsensical or incorrect” (Hwang & Jeong, 2025, p. 284). Notably, some scholars argue that the term hallucination, which is generally applied to psychiatric patients, should not be assigned to AI, because doing so inappropriately humanizes the technological agents (Maleki et al., 2024); a more precise term might be “AI fabrication.” It is also worth clarifying that an AI hallucination is not a lie, because it is not a conscious fabrication of fake or misleading content, and generative AI has no conscience or desire to misinform. Christensen et al. (2025: 548) gather informal definitions of AI hallucination proposed by scholars and practitioners that describe the errors as “untruths or half-truths” (Brameier et al., 2023) and “inaccurate, implausible or wholly made-up outputs” (Pophal, 2023). Maleki et al. (2024) also indicate that previous research has described AI hallucinations as “confabulation,” “delusion,” “falsification,” and “fabrication.” Accordingly, we define AI hallucinations as a type of generative AI error that creates plausible content that deviates from factual accuracy and faithfulness to the knowledge source, making it misleading and nonsensical. The most paradigmatic AI hallucination is a factual contradiction, such that the generative AI responds with a fact that sounds plausible but is nonsense and totally wrong (IBM Technology, 2023). In addition to factual hallucinations (H. Kim et al., 2025), logic hallucinations result from a lack of coherence between the customer’s prompts and the system’s response or between sentences in a response.
Concerns about generative AI hallucinations also affect academia, and some published scientific articles have been found to include fake references (Table 1). This phenomenon is particularly alarming in health research, where a recent study determined that 16% of cited articles lack a DOI, suggesting they may have been fabricated (Athaluri et al., 2023). Aljamaan et al. (2024) developed a Reference Hallucination Score to address this problem. Generative AI hallucinations in the courtroom (CNBC, 2023) have led to a low but growing number of lawyers in the United States, Canada, and United Kingdom being sanctioned for using “false extracts” and “AI-generated fake cases” in trials (MK Legal Consultancy, 2024).
Generative AI large language models create hallucinations for several reasons. Large language models require months of training, so data quality is fundamental. As is the case with online sources, training data are not 100% accurate and do not cover all the topics demanded by generative AI users, but generative AI must generalize its responses based on its “knowledge.” Similar to Don Quixote after reading too many chivalric novels, AI seemingly tries to address these challenges by fitting them into what it has previously learned. In addition, generative AI involves trade-offs between the complex large language models’ generation methods (beam search, maximum likelihoods, sampling) and writing objectives (e.g., fluency, creativity), which occasionally result in incoherent responses (IBM Technology, 2023).
However, hallucinations are not the only way that generative AI can fail. Other, regular mistakes are common, as may arise from contextual or external factors, similar to errors made by human agents. For example, if a user does not specify a context, large language models might make incorrect assumptions about contextual variables not specified in the input prompt (e.g., Is the customer an adult? Is it a leisure trip?). Similarly, generative AI may misinterpret instructions or information (e.g., when describing the content of an image), fail to provide complete information, or be unable to adapt to novel situations or changing temporal circumstances (Song et al., 2025). It is difficult to establish the limits of generative AI hallucinations though (see Table 1), such that authors often refer to similar failures as mistakes (J. H. Kim, et al., 2024; J. H. Kim, Kim, Kim, & Kim, 2023) or hallucinations (Christensen et al., 2025; H. Kim & Lee, 2024).
Theoretical Rationale and Hypotheses Development
Distinguishing Between Service Success and Service Failure
Expectation confirmation theory (Oliver, 1980) predicts that customers’ satisfaction and behavioral reactions are significantly shaped by the alignment between their expectations and actual service outcomes. When customers experience successful service outcomes, they evaluate service performance favorably and develop a sense of trust in the service provider (Oliver, 1980). To the extent that customers perceive that an outcome meets their expectations of reliable and consistent performance, they are more likely to be loyal to that service provider. Complementarily, justice theory (Blodgett et al., 1997) suggests that service breakdowns due to a lack of distributive (outcomes), procedural (processes), or interactional (treatment) justice have immediate and detrimental consequences for customer–company relationships. A service failure implies the inability of the firm to meet promised standards, which decreases satisfaction and trust and increases negative behavioral responses, such as switching intentions and negative WOM (Bitner et al., 1990; Tax et al., 1998). If travel agencies provide valuable travel advice and support to their customers on their trips, it increases their satisfaction and loyalty to the company (Grissemann & Stokburger-Sauer, 2012), whereas an unkept promise undermines the psychological contract customers develop with tourism providers, thereby decreasing their willingness to stay loyal or recommend the service, as well as leading them to develop negative affect and engage in negative WOM (Hemthong et al., 2025).
Previous research has shown that positive disconfirmation (i.e., performance exceeds expectations) leads to increased positive WOM (e.g., Anderson, 1998). Positive WOM is driven by people’s desire to help others make better decisions, reinforce their own positive tourism experiences (Munar & Jacobsen, 2014), and be seen in a positive light by others (Belanche, Casaló, et al., 2025). In contrast, when service performance fails to meet customers’ expectations or they sense that a service outcome is unfair, they likely express their dissatisfaction through negative WOM. Longitudinal studies confirm that customers create significantly more negative WOM when they experience service failures in hotels (Maxham III & Netemeyer, 2002). Recent research involving Thai four- and five-star hotels indicates that a lack of perceived justice leads customers to engage in negative WOM, whereas perceived justice motivates them to remain silent or engage in positive WOM (Hemthong et al., 2025). Thus, when customers see service outcomes as successful and fair, they have no reason to complain, which reduces negative WOM and encourages the dissemination of positive WOM. We propose the following hypothesis:
Customers develop different perceptions and behaviors, depending on whether they are interacting with a human employee or an AI-enabled agent (Belanche et al., 2020; Rapp et al., 2021). The theory of mind (ToM, Premack & Woodruff, 1978; see also Apperly, 2010) indicates that they attribute mental states (e.g., beliefs, intentions, knowledge) to other people. When customers evaluate a service outcome after interacting with a human employee, they take into account the employee’s thoughts and feelings, which they do not do when interacting with computers/AI-enabled agents (Belanche et al., 2020; Bitner et al., 1990). Customers assume that human employees have a social perspective and that they share some common ground, such as empathy and shared knowledge (Krämer et al., 2012), whereas they see AI-enabled systems as lacking human reasoning and judgment (Nadarzynski et al., 2019). Thus, customers are more likely to attribute superior, human-like qualities to human employees, which naturally prompt them to develop higher expectations of these employees, in terms of their mutual understanding and ability to provide good service and personalization. Justice theory reinforces this expectation-driven asymmetry, with the prediction that customers evaluate service encounters and outcomes on the basis of their perceptions of fairness, responsibility, and controllability (Bitner et al., 1990; Tax et al., 1998). Because customers attribute higher agency, intentionality, and control over their actions to human agents, their failures may be judged as more blameworthy and less acceptable than equivalent failures perpetrated by AI agents (Belanche et al., 2020).
In addition, when expectations about human employees are met or exceeded, customers experience higher satisfaction, leading to increased loyalty and positive WOM (Parasuraman et al., 1988). Conversely, when these expectations go unmet, their disappointment is greater, resulting in lower loyalty and negative WOM (Bitner et al., 1990). In particular, customers develop higher expectations of human employee–driven service outcomes, because they believe that human behavior is heterogeneous and non-standardized (e.g., sometimes delightful, sometimes dreadful) (Bitner et al., 1990). In contrast, their expectations are lower for AI-enabled systems, because they believe that technological agents have less capacity for learning and adaptation, so they often expect inferior service outcomes (Belanche et al., 2020). In this regard, consumers may regard AI systems as mechanical response tools, rather than sentient agents, so they start with lower expectations that ultimately prompt them to respond more neutrally to success and failure. Consequently, our second hypothesis predicts:
Perceived service quality is based on the comparison between the customer’s expectations and the company’s actual service performance (Parasuraman et al., 1988). The ES-QUAL framework (Parasuraman et al., 2005: 220) defines service fulfillment as “the extent to which [the company’s] promises about order delivery and item availability are fulfilled.” In turn, service fulfillment has been described as the strongest predictor of customer satisfaction, quality, and loyalty in e-commerce settings (Annaraud & Berezina, 2020; Ding et al., 2011; Wolfinbarger & Gilly, 2003). It can be defined as “the process that ensures services are available to customers efficiently” and has been linked to improved operational efficiency and implementation times (e.g., applying automation), as well as to creating a satisfactory customer experience (Britto, 2024, p. 1).
Companies must fulfill customers’ needs to meet their service outcome expectations. For example, customers value companies that adapt their services to external market changes and/or to meet their time-saving expectations, such that it results in higher customer loyalty and affective commitment (Davis-Sramek et al., 2008). Consistent with notions of procedural and distributive justice in justice theory (Hemthong et al., 2025), when customers feel that a company’s service has fulfilled its promises and successfully met their needs, they are more likely to return to and recommend the service to others, through positive WOM (Zeithaml et al., 1996). Similarly, in AI-enabled tourism services, customers’ perceptions of service fulfillment should be positive if performance meets their expectations, which will create good customer experiences and evoke higher intentions to continue using these AI tools (A. Huang et al., 2024). Poor service performance instead will prompt perceptions of low levels of service fulfillment, which is linked to negative emotions, complaining behaviors (Hemthong et al., 2025; Tax et al., 1998), reduced customer loyalty, and increased negative WOM. Consequently, we hypothesize:
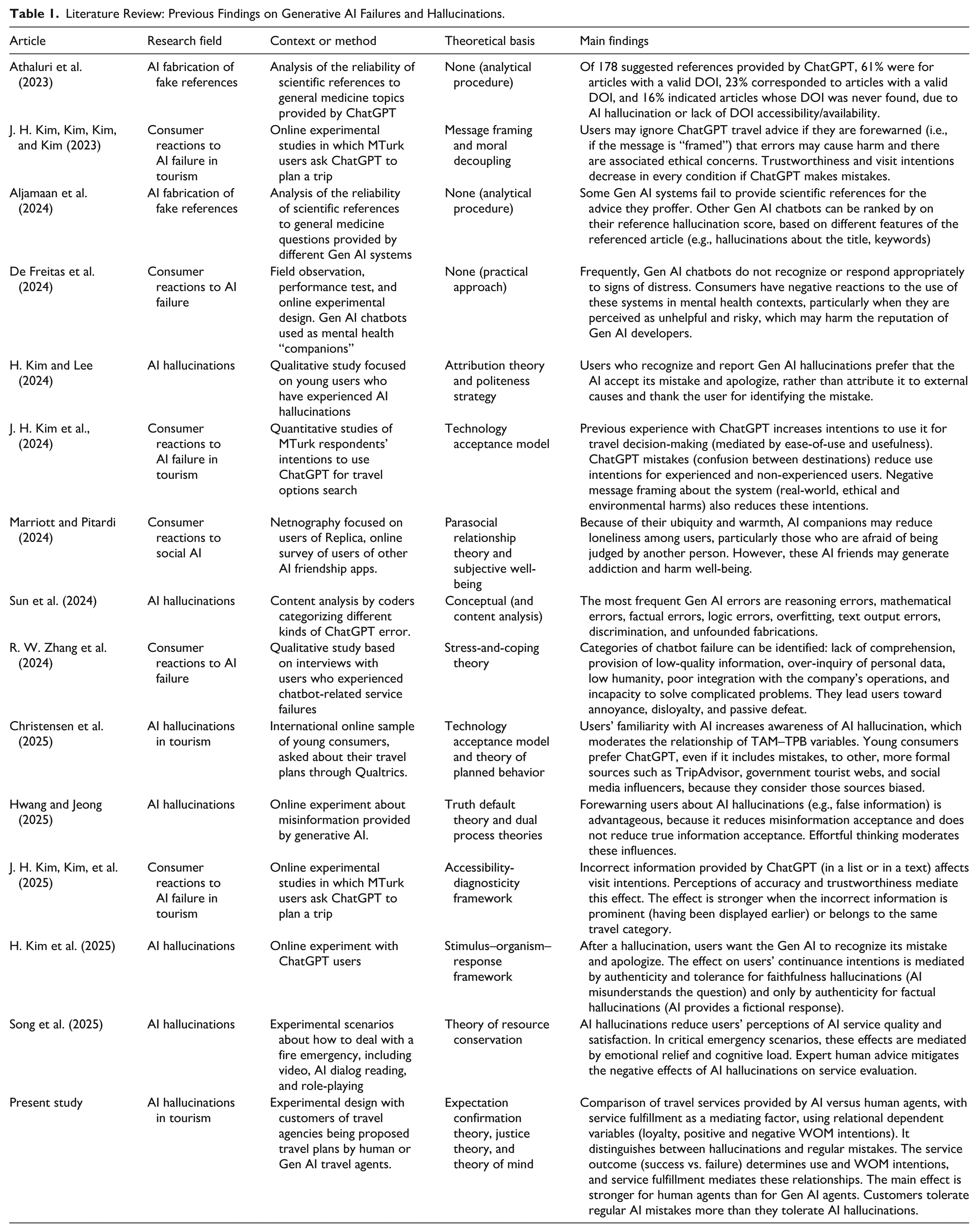
In summary, we propose that the relationships that distinguish between service success and service failure, which we test in Study 1, are as depicted in Figure 1.
Proposed relationships (Study 1).
Distinguishing Between Regular Mistakes and Hallucinations
As explained in the literature review section, whether tourism companies use generative AI tools or human employees, they suffer service failures. Because of the novelty and technological focus of the hallucination concept, service failure research has not yet addressed the distinction between regular mistakes and hallucinations though. Customers might regard some failures in tourism services as regular mistakes that travel agents might make because they are not paying enough attention to the task (e.g., not checking opening hours) or because they ignore environmental changes (e.g., weather). Previous studies into failure severity have suggested that regular mistakes, even when they lead to unsatisfactory outcomes, often seem minor to customers (e.g., no towels in the hotel room; Weun et al., 2004) and easily reparable (e.g., incorrect order in a restaurant; Roschk & Gelbrich, 2014). In contrast, hallucinations are factual and/or logical errors (H. Kim et al., 2025), such as informing customers that they can sleep in a restaurant that does not have guest rooms or recommending a ferry route that does not exist (Travel Weekly, 2024). Applying the rationales of expectation-disconfirmation theory and status quo bias (Samuelson & Zeckhauser, 1988), when customers encounter a regular mistake, they experience moderate disconfirmation, because they regard the error as falling within the familiar range of service system imperfections. Responses featuring hallucinations, which contain fabricated information that appears plausible yet is incorrect, instead represent a severe violation of expectations, because they are qualitatively different from conventional human or system errors. Thus, hallucinations might be considered equivalent to severe failures identified in prior literature (unavailable or unclean hotel room, Weun et al., 2004) or as irreparable mistakes (e.g., unavailable meal, Roschk & Gelbrich, 2014).
Relevant literature repeatedly affirms that customers react more negatively to severe failures than to minor failures. In particular, service failure literature suggests that customers exhibit extreme reactions when critical incidents occur during service provision (Bitner et al., 1990). Customers tend to avoid future contacts with firms after severe failures, even if the service recovery was successful (Roschk & Gelbrich, 2014; Weun et al., 2004). Previous research also indicates that customers’ tolerance of severe failures is limited, which has negative impacts on companies (Hoffman et al., 2016; Weun et al., 2004). When critical failures occur, customers engage in negative WOM and tend to be disloyal to the company (Weun et al., 2004). In this regard, recent evidence related to AI hallucinations reveals that customers react more negatively when AI agents fabricate information than when they misinterpret information the customer provides (H. Kim et al., 2025). If customers identify responses as including fallacies or as illogical, they likely develop very negative perceptions, leading to dramatically negative reactions. Thus, we propose the following:
Previous literature also suggests that customers form an overall evaluation of services that is based on both the service failure type and agents’ capabilities (Bitner et al., 1990). Hospitality service customers consider AI agents to be less skilled than human agents (Belanche et al., 2020; J. H. Kim, Kim, et al., 2025). Based on attribution theory (Weiner, 1979) and the theory of mind (Premack & Woodruff, 1978), Belanche et al. (2020) determine that customers, after suffering from a serious failure carried out by a service agent (e.g., assigned a hotel room occupied by another guest), might continue to rely on the responsible human service agent, but not an autonomous agent. Customers assume the human agent learns from their errors and will try to avoid committing them in the future, whereas autonomous agents lack a mind and empathy, and consequently, they might continue to make mistakes over time. Users who employ ChatGPT for AI travel recommendations assume that generative AI “may occasionally generate incorrect information” (H. Kim et al., 2025, p. 3); they worry more that generative AI is a source of misinformation (J. H. Kim, Kim, et al., 2025). In particular, customers distrust and reject generative AI systems that cause failures the agent cannot explain (H. Kim & Lee, 2024), as is the case with AI hallucinations. This rationale is supported by research into AI in other contexts, such that financial services’ customers avoid using algorithm-based advisors to a greater extent than they do human advisors after verifying that the advisor is causing them to lose money (Dietvorst et al., 2015).
Theoretical insights into status quo violations (Samuelson & Zeckhauser, 1988) reinforce this argument. When evaluating new technologies, customers compare their performance with that of an existing service baseline. The status quo sets a standard for what constitutes an “acceptable” level of error in service contexts. Regular mistakes are seen in the context of this standard, because they resemble the errors that humans or traditional systems might make. In contrast, AI hallucinations represent a category of failure that falls short of the status quo, violating the attributes that define AI’s value proposition (e.g., precision, logic, reliability). For instance, U.S. lawyers who used fictitious AI-generated cases in court suffered irreparable reputational damage, were accused of fraud, and were fined for “abandoning their responsibilities” (CNBC, 2023; MK Legal Consultancy, 2024). Thus, the harm seems greater in an AI (vs. human) context if it is attributable to a hallucination, rather than to a regular mistake, whereas this distinction is less important when a human agent fails. Consistent with status quo bias (Samuelson & Zeckhauser, 1988), this downside comparison arising from AI hallucinations should strengthen negative behavioral responses toward the AI agent. We formally propose:
Practitioners are alarmed by the possibility of hallucinations arising when generative AI agents interact with customers and the risk of subsequent, detrimental consequences for their companies (Robinson, 2024). As the technology consulting firm Gartner (2024) noted, hallucinations create major complications for companies for several reasons. First, generative AI presents information with a veneer of authenticity, which prompts customers to over-rely on it. Second, customers do not see the failure risk as limited to the inadequate behavior of any one human agent but instead conclude that all the company’s generative AI tools may make errors. Third, because of their believability, generative AI hallucinations could cause serious harm to customers without being questioned by any human agent, as would be the case with dangerous advice about how to repair a product. If a response by a generative AI system includes hallucinations, customers tend to feel confused and frustrated and begin to question the professionalism of the firm, which can erode the brand’s reputation. Therefore, AI hallucinations can have long-lasting repercussions, such as lowering customers’ perceptions of the firm’s competence and reliability, ultimately reducing their loyalty (Robinson, 2024). Previous evidence of generative AI hallucinations indicates that the harm involves the service provider’s reputation, because it gives the AI system responsibilities that should be assumed by an employee (CNBC, 2023; MK Legal Consultancy, 2024). These failures reduce customers’ perceptions of the company’s ability to fulfill its service promises. This conclusion is consistent with previous findings in service automation contexts that suggest customers attribute severe failures caused by a human agent to that agent but blame the company when the failure is caused by an AI agent (Belanche et al., 2020).
Customers have certain expectations about service fulfillment when contracting with a travel agency, which will be left unfulfilled if its advice includes hallucinations. False or illogical responses could lead customers to believe that the firm is not competent, in that it does not meet the required standards to provide a travel advice service. The resulting status quo violation (Samuelson & Zeckhauser, 1988) likely causes the customer to have negative reactions toward the firm. As practitioners have suggested, this type of failure negatively affects customers’ perceptions of the firm’s capabilities, which undermines their loyalty and the brand’s reputation (Gartner, 2024; Robinson, 2024). Thus, applying confirmation of expectations theory (Oliver, 1980) to our research context, we hypothesize:
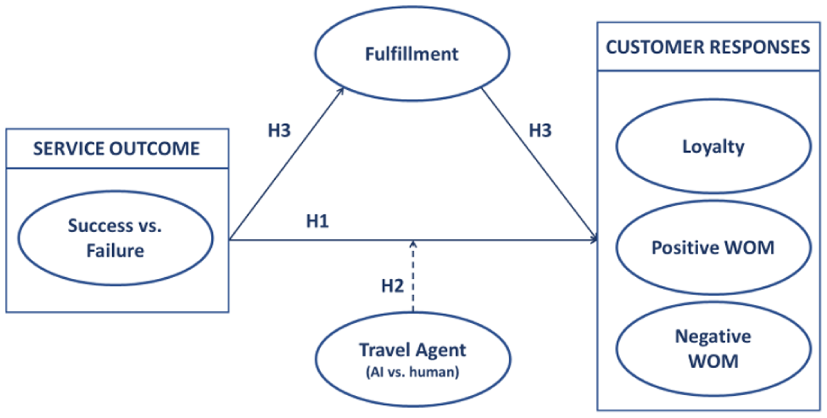
The proposed relationships for distinguishing between regular mistakes and hallucinations, as we will test in Study 2, are depicted in Figure 2.
Proposed relationships (Study 2).
Study 1
Methodology and Data Collection
To test H1–H3, we developed a two-factor, between-subjects experimental design, in which we manipulate travel agent type (human vs. generative AI) and the outcome of the service (success vs. failure). The experimental participants were instructed to contact a travel agency to plan their trip to a foreign city for their next holiday. The travel agent providing the service was either a human or a generative AI system. The agent requested information, for example, about when the participant expected to travel, for how many days, the budget available, and their preferred tourism activities. The agent then provided a recommendation based on these needs. Next, we described the outcome of the service. In the “success” situation, everything (an outdoor dinner in a restaurant and visits to museums proposed by the agent) was as expected and fulfilled the consumer’s demands. In the “failure” situation, the proposed visits to museums and the outdoor dinner could not take place, so consumers’ expectations were unfulfilled. The scenarios are fully set out in Table A1.
The experiment was conducted online, among members of a reputable online panel of U.S. consumers (paid for their participation). We explained the scientific purpose of the experiment to the participants and gave them data protection advice, following which they provided explicit informed consent. Thereafter, they were exposed randomly to one of four scenarios, and then they completed the research questionnaire. The questionnaire used multi-item Likert-type scales (ranging from 1 = “completely disagree” to 7 = “completely agree”) to measure the variables of the research model. The scales were adapted from previously validated scales in previous literature: loyalty intentions (Algesheimer et al., 2005), fulfillment of expectations (Belanche et al., 2014), and positive WOM and negative WOM (Alexandrov et al., 2013). Following previous literature, positive WOM and negative WOM were conceptualized and measured as distinct constructs, rather than as opposite endpoints of a single continuum, because they can have different antecedents and independent nomological networks, such that a decrease in positive WOM is not necessarily related to an increase in negative WOM (Hemthong et al., 2025; Talwar et al., 2021). In addition, a semantic differential item (Osgood, 1964) checked participants’ perceptions about the outcome of the service (1 = “failure,” 5 = “success”; Belanche et al., 2020), and a dichotomous item (human vs. generative AI) was used as an attention check to ensure that the participants correctly identified the travel agent type providing the service. Finally, the perceived realism of the situation was evaluated following Bagozzi et al. (2016). The scales are set out in Table A2.
The assignment process guaranteed a minimum of 55 participants per scenario. This value is much higher than the minimum of 25 observations per cell proposed in prior literature (e.g., Seltman, 2018). In addition, an a priori power analysis was conducted using G*Power v3.1.7 (Faul et al., 2007, 2009) for sample size estimation. With a significance criterion of α = .05 and power = 0.8 (Cohen, 1988), the minimum sample size needed is 179 for the analyses of variance (ANOVAs) and 72 for the multivariate analyses of variance (MANOVAs). Our sample size is thus appropriate, in that we collected data from 232 participants who correctly answered the attention check. The sample had the following socio-demographic characteristics: gender (49.57% women, 49.57% men, and 0.86% prefer not to disclose), age (21.98% < 30 years; 25.43% 30–39 years; 25.86% 40–49 years; 21.98% 50–59 years; 4.74% > 59 years), and education (80.17% university studies, 18.53% secondary/high school, and 1.29% up to primary school).
Manipulation Checks
Before testing the hypotheses, we checked that our manipulations worked as expected. First, participants exposed to the failure scenarios perceived the outcome of the service as being much more negative than those assigned to the success scenarios (MFailure = 1.44, MSuccess = 4.79, t = 42.267, p < .01). Second, all the participants correctly identified that their travel advice was provided by a human or a generative AI travel agent, depending on the assigned scenario. A t-test also confirmed the suitability of the scenarios in terms of perceived reality, in that participants perceived them as significantly more realistic than the midpoint of the scale at 4 (M = 5.42, t = 16.900, p < .01).
Results
First, we checked that the Cronbach’s alpha values were greater than the recommended value of 0.7 (Nunnally, 1978) for the dependent measures: loyalty intentions (α = .987), fulfillment of expectations (α = .975), positive WOM intentions (α = .992), and negative WOM intentions (α = .969).
Second, we undertook a MANOVA to evaluate the multivariate effect of the independent variables on the model’s dependent variables. As expected, the results revealed a significant multivariate effect for service outcome (Wilks’ λ = .168; F (3, 226) = 372.926, p < .01), suggesting differences in the dependent variables (i.e., loyalty, positive WOM, and negative WOM intentions) according to whether the service outcome was a failure or a success. Similarly, the interaction between the service outcome and the travel agent type exerted a significant multivariate effect (Wilks’ λ = 0.919; F (3, 226) = 6.648, p < .01), which suggests that the effects of service outcome on the dependent variables are reinforced when the service is provided by a human agent (cf. AI agent). Finally, travel agent type did not exert a multivariate direct effect on the dependent variables (Wilks’ λ = .997; F (3, 226) = 0.228, p > .1).
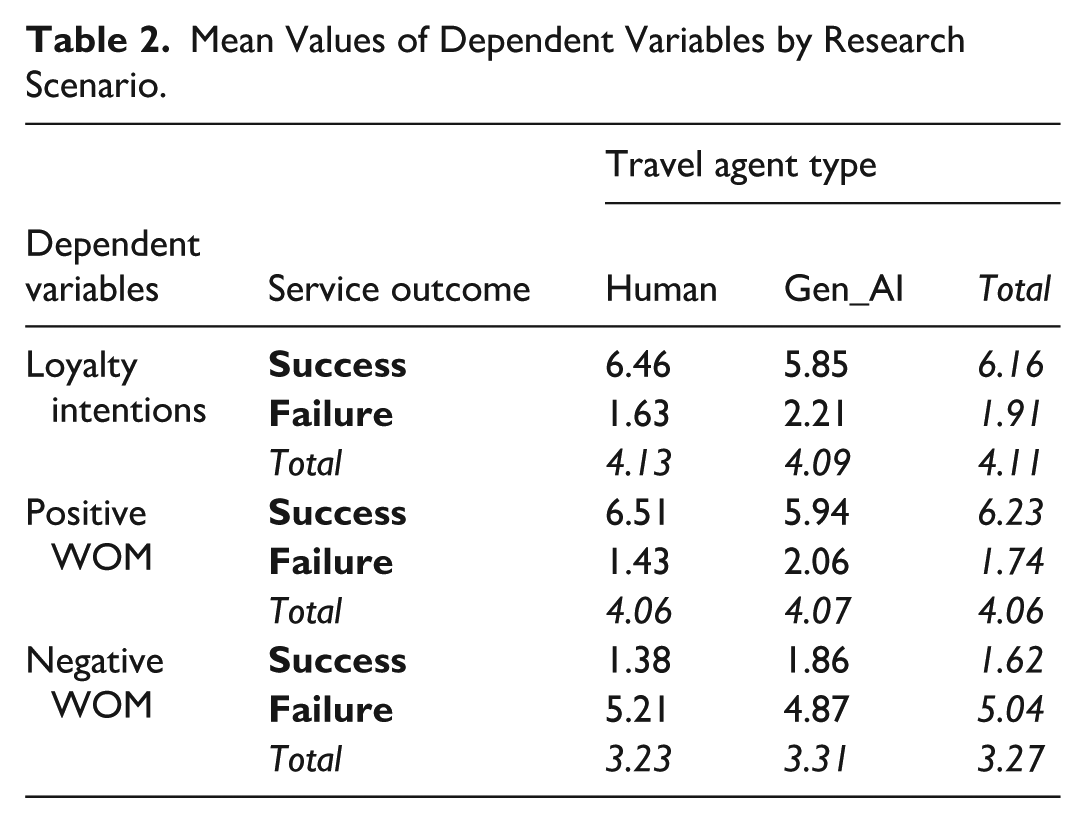
Third, three ANOVAs, each with two factors (service outcome and travel agent type), provide tests of H1 and H2. Positive WOM, negative WOM, and loyalty intentions were the dependent variables (Table 2 shows the mean values of these variables by scenario). In support of H1a, H1b, and H1c, greater loyalty intentions (F = 834.012, p < .01), positive WOM intentions (F = 1,091.184, p < .01), and less negative WOM intentions (F = 315.493, p < .01) were observed when the service outcome was successful. This influence is reinforced—for loyalty intentions (F = 16.820, p < .01), positive WOM intentions (F =19.886, p < .01), and negative WOM intentions (F = 4.466, p < .05)—when the travel agent is a human rather than generative AI. These interaction effects support H2 (Figure 3). The direct influence of travel agent type on loyalty (F = 0.014, p > .1), positive WOM (F = 0.049, p > .1), and negative WOM intentions (F = 0.129, p > .1) is non-significant.
Mean Values of Dependent Variables by Research Scenario.
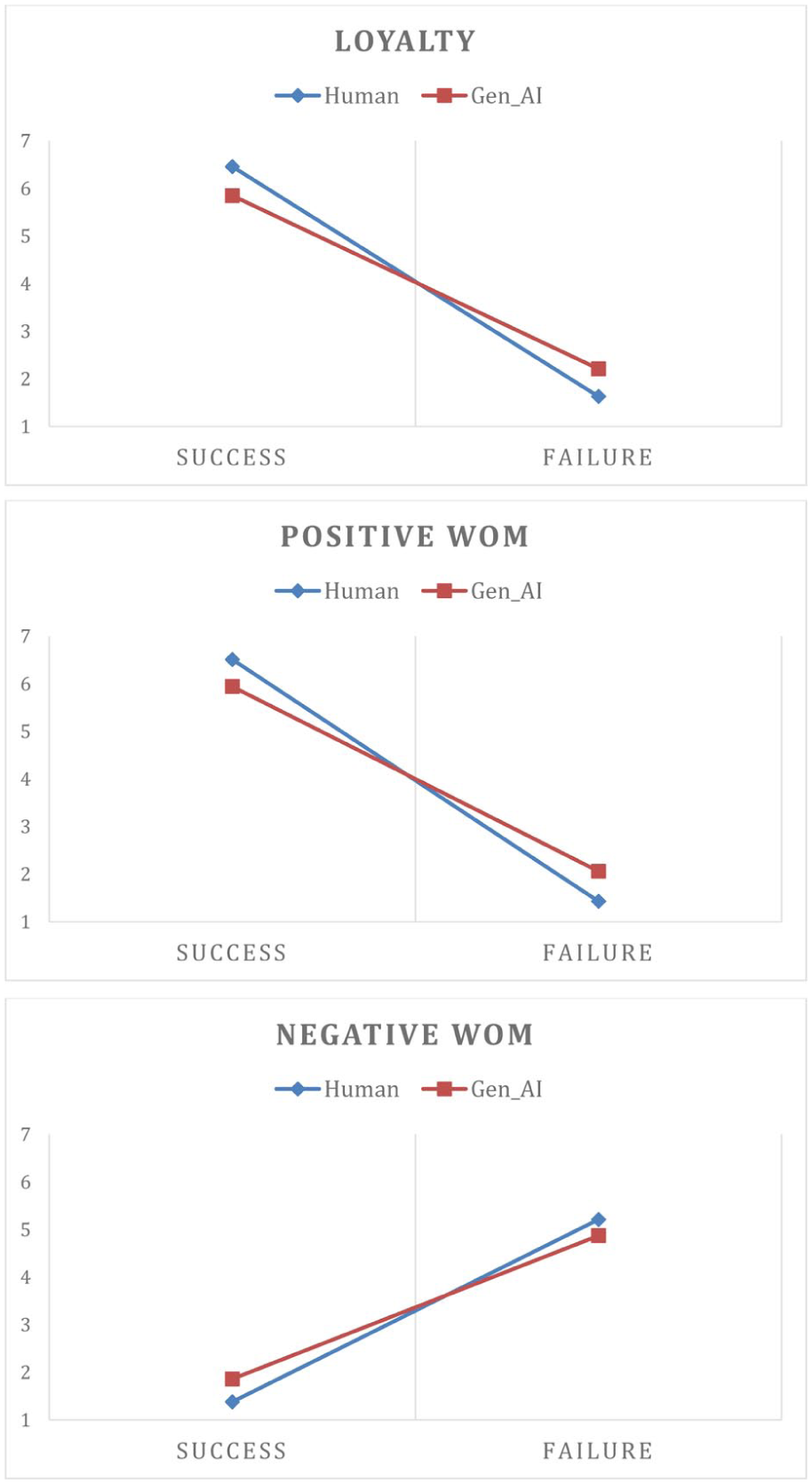
Interaction effects (H2).
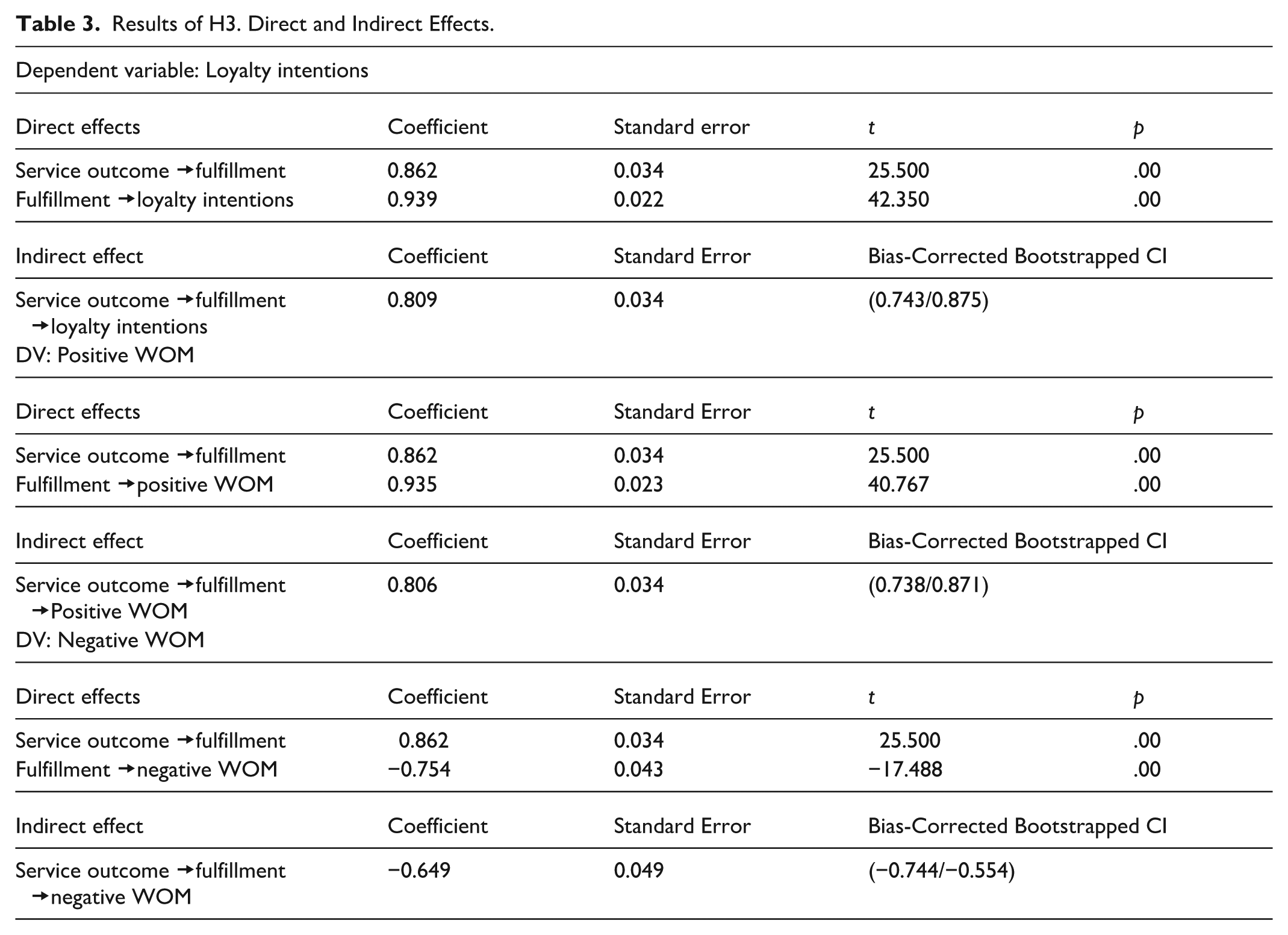
Fourth, the mediation effect proposed in H3 was tested using PROCESS (Hayes, 2022), a regression-based modeling tool that is widely used in social, business, and health sciences. It allows researchers to analyze indirect, total, moderating, and conditional effects simultaneously, using ordinary least squares regression. In addition, PROCESS supports the analysis of dichotomous independent variables and moderators (Hayes, 2025) and is especially appropriate for testing specific mediation and moderation hypotheses and in analyses where key predictors have been experimentally manipulated, as in our case. Specifically, three regressions were undertaken, one for each dependent variable. Service outcome serves as the first independent variable; service fulfillment as a mediator; and loyalty, positive WOM, and negative WOM intentions as dependent variables. Then we introduced travel agent type as a moderator. As Table 3 indicates, the service outcome (1 = “success,” 0 = “failure”) had a positive effect on expectation fulfillment (β = .862, p < .01). In the success scenario, the service meets consumers’ expectations to a greater extent, whereas in the failure scenario, the service fails to meet these expectations. Expectation fulfillment had a positive effect on loyalty (β = .939, p < .01) and positive WOM intentions (β = .935, p < .01) and a negative effect on negative WOM intentions (β = −.754, p < .01). We also note an indirect effect of the service outcome on the dependent variables, through fulfillment (loyalty intention: β’ = .809, Confidence Intervals [0.743/0.875]; positive WOM: β’ = .806 [0.738/0.871]; negative WOM: β’ = −.649 [−0.744/−0.554]). Thus, H3 receives support, and higher (lower) loyalty and positive WOM, along with higher (lower) negative WOM, arise when the service outcome is a success (failure).
Results of H3. Direct and Indirect Effects.
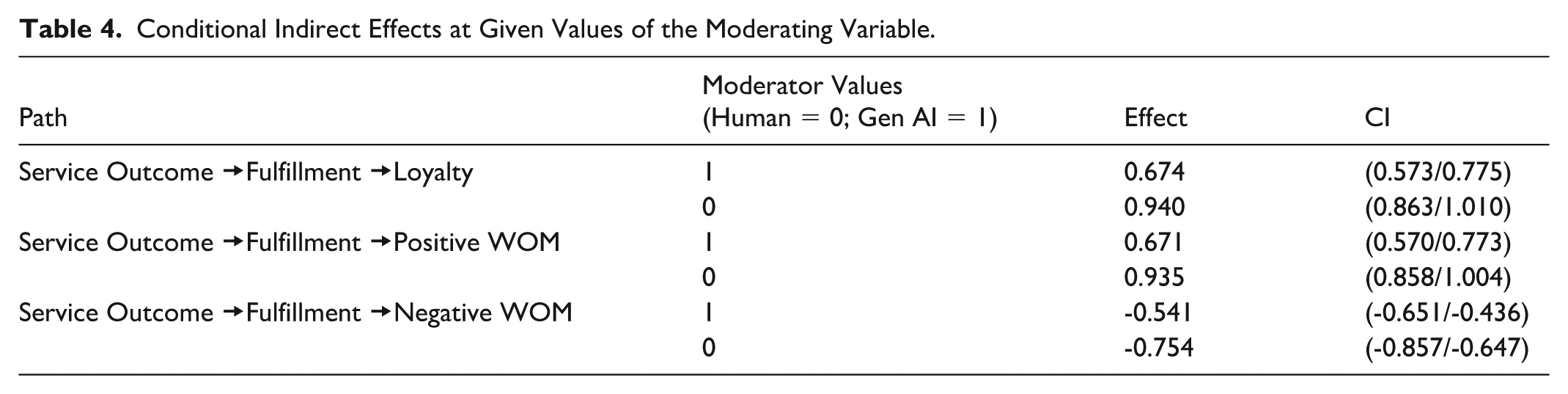
To better understand the moderating role of travel agent type in the indirect effect, we analyzed the conditional effects at given values of the moderating variable (Preacher et al., 2007). Specifically, as can be seen in Table 4, the indirect effects of service outcome via fulfillment were more extreme when the travel agent was human (coded as 0) rather than generative AI (coded as 1) for all the dependent variables: loyalty intentions (βHuman = .940, βGen_AI = .674), positive WOM intentions (βHuman = .935, βGen_AI = .671), and negative WOM intentions (βHuman = −.754, βGen_AI = −.541).
Conditional Indirect Effects at Given Values of the Moderating Variable.
Study 2
Methodology and Data Collection
To test H4–H6, we focused on service failure outcomes, using a 2 × 2 between-subjects experimental design in which we manipulated the travel agent type providing the service (human vs. generative AI) and failure type (hallucination vs. regular mistake). As in Study 1, the participants read about a situation in which they had to contact a travel agency to plan their next holiday trip to a foreign city, and they provided the same information to the agent. The agent was either a human or a generative AI system; it provided recommendations based on the participants’ needs. Next, we described the negative outcome, that is, whether it was caused by a regular mistake or a hallucination. The regular mistakes were a planned visit to a museum that had to be voided, because it was closed at that time of the year, and the proposed dinner could not take place because the restaurant needed to be pre-booked (which the agent failed to mention). For simplicity, the term “regular mistake” was used in this condition to refer to errors not based on hallucinations, such that they resulted in service failures but did not feature fabricated or illogical responses. They might be attributed to a variety of causes, such as if the user prompted the system with outdated information. The hallucination scenario instead featured information about a visit to a museum that did not actually exist, and the restaurant did not have an outdoor dining facility (which the customer had specified). These kinds of hallucinations correspond, respectively, to the categories of factual hallucinations (generating false information, H. Kim et al., 2025) and logical hallucinations (If a = b and b = c, then a ≠ c; Dang et al., 2025). The scenarios are set out in Table A3.
The experiment was conducted online, following the same procedure as in Study 1. The participants were informed about the scientific purpose of the study and data protection, and after giving their explicit informed consent, they were randomly assigned to one of the four scenarios. They completed the research questionnaire, which used the same scales as in Study 1 for positive WOM, negative WOM, loyalty, fulfillment of expectations, service outcome, perceived realism, and travel agent type providing the service. In addition, we developed a scale to evaluate perceived hallucination, drawing on items from Christensen et al.'s (2025) AI hallucination potential scale (see Table A2).
We collected data from 225 participants who correctly answered the travel agent type attention check, obtaining a minimum of 54 per scenario. Again, the sample size is appropriate, according to the criteria used in Study 1. The final sample had the following socio-demographic characteristics: gender (51.11% men, 48% women, and 0.89% prefer not to disclose), age (22.22% < 30 years; 23.11% 30–39 years; 20.44% 40–49 years; 25.33% 50–59 years; 8.89% > 59 years), and education (81.78% university studies, 17.78% secondary/high school, and 0.44% up to primary school).
Manipulation Checks
Before testing the hypotheses, we evaluated whether our manipulations worked as expected. Participants exposed to the hallucination scenarios scored the service outcome as higher on the hallucination scale than those assigned to the regular mistake scenarios (MHallucination = 3.46, MRegular_Mistake = 2.30, t = 7.485, p < .01). However, the service outcome was perceived as equally negative in both scenarios (MHallucination = 1.31, MRegular_Mistake = 1.50, t = 1.906, p > .05). That is, the outcome was perceived as a failure (and not as a success) in both the regular mistake and hallucination scenarios. Similarly, all participants correctly remembered the type of travel agent (human vs. generative AI) who provided the service in the scenario to which they had been assigned. A t-test confirmed the suitability of the scenarios too, such that they were perceived as significantly more realistic than the midpoint of the scale at 4 (M = 4.92, t = 10.507, p < .01). No significant differences in perceived realism were observed across scenarios (MHuman_Regular_Mistake = 4.85; MHuman_Hallucination = 4.75; MGenAI_Regular_Mistake = 5.07; MGenAI_Hallucination = 5.05), based on travel agent type (F = 2.206, p > .1), failure type (F = 0.098, p > .1), or interaction effect (F = 0.041, p > .1).
Results
We checked that the Cronbach’s alpha values for our measures (perceived hallucination [α = .768], loyalty intentions [α = .926], fulfillment of expectations [α = .899], positive WOM intentions [α = .973], negative WOM intentions [α = .934]) exceeded the cut-off value of .7 (Nunnally, 1978). With a MANOVA, we evaluated the multivariate effects of the independent variables (failure and travel agent types) on the dependent variables. As expected, the MANOVA results revealed a significant multivariate effect of failure type (Wilks’ λ = .946; F (3, 222) = 4.212, p < .01), indicating differences in the dependent variables (i.e., loyalty intentions, positive WOM intentions, and negative WOM intentions), according to whether the failure was caused by an AI hallucination or a regular mistake. Similarly, the interaction between failure type and travel agent type exerted a significant multivariate effect (Wilks’ λ = .957; F (3, 222) = 3.330, p < .05), which suggests that the effects of failure type on the dependent variables is greater when the service is provided by an AI agent rather than a human. Finally, travel agent type did not exert a multivariate direct effect on the dependent variables (Wilks’ λ = .992; F (3, 222) = 0.574, p > .1), which mirrors the results of Study 1.
Subsequently, three ANOVAs, each with two factors (failure type and travel agent type), were performed to test H4 and H5, with loyalty, positive WOM, and negative WOM intentions as the dependent variables (Table 5 contains the mean values by scenario). In support of H4a and H4c, we observe lower loyalty intentions (F = 5.232, p < .05) and greater negative WOM (F = 7.041, p < .01) when the failure was a hallucination rather than a regular mistake. The differences in positive WOM (H4b) were as expected (i.e., lower for hallucination scenarios), but they were only marginally significant (F = 3.061, p < .1). This influence was greater for loyalty intentions (F = 8.821, p < .01), positive WOM (F =12.215, p < .01), and marginally for negative WOM (F = 3.044, p < .1) when the travel agent was generative AI (cf. human). These interaction effects support H5 (Figure 4). The direct influence of travel agent type on loyalty intentions (F = 0.000, p > .1), positive WOM intentions (F = 0.277, p > .1), and negative WOM intentions (F = 0.052, p > .1) was non-significant, consistent with the Study 1 results.
Mean Values of Dependent Variables by Research Scenario.
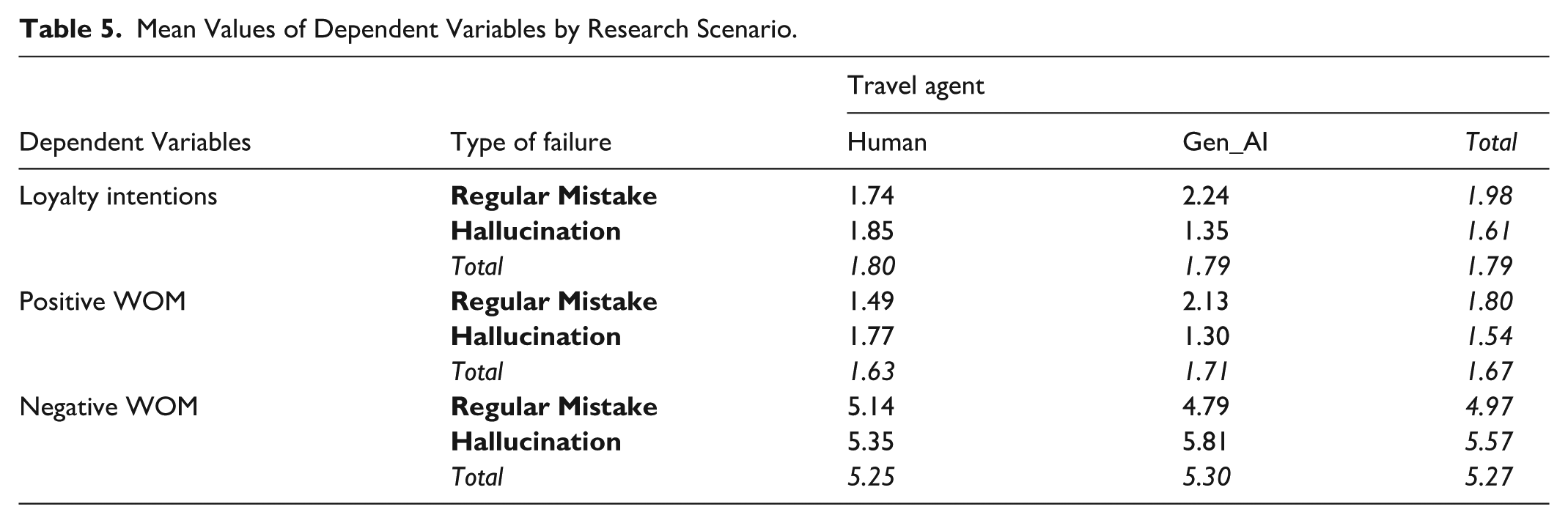
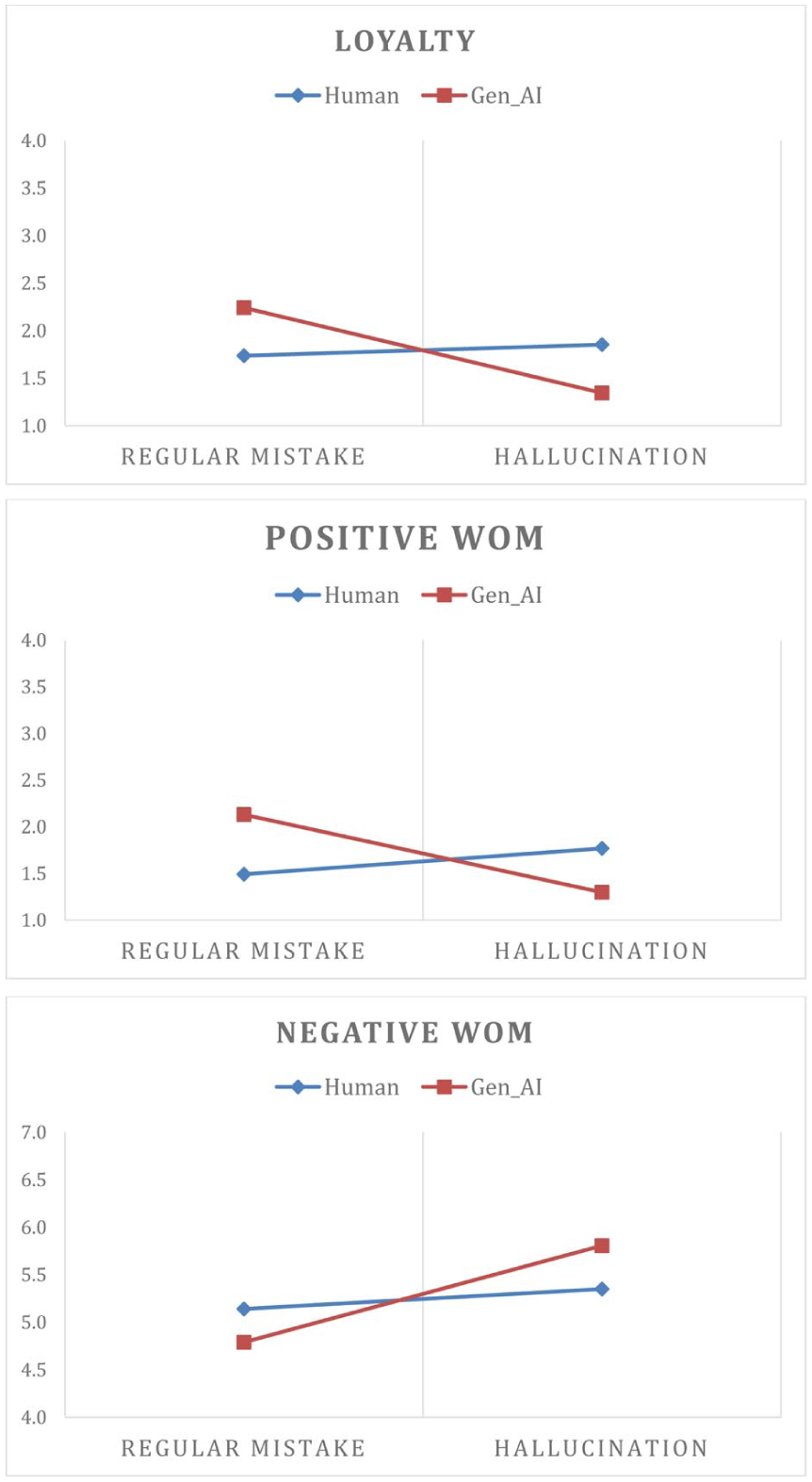
Interaction effects (H5).
Finally, the mediation effect proposed in H6 was tested using the PROCESS model (Hayes, 2022). Failure type served as the independent variable, fulfillment was the mediator, and loyalty intentions, positive WOM intentions, and negative WOM intentions provided the dependent variables. Travel agent type was introduced as a moderator. As Table 6 indicates, failure type (1 = “hallucination,” 0 = “regular mistake”) had a negative effect on expectation fulfillment (β = −.191, p < .05). Fulfillment exerted a positive effect on loyalty intentions (β = .117, p < .05) and positive WOM intentions (β = .105, p < .05). Although its influence on negative WOM intentions was negative (β = −.079, p > .1), as expected, it was non-significant. We observed an indirect effect of failure type on the dependent variables, through fulfillment, for loyalty intentions (β’ = −.022 [-.054/−0.001]). The value was very close to the threshold, but it was not observed for positive WOM intentions (β’ = −.020 [−0.049/0.001]) or negative WOM intentions (β’ = .015 [−0.002/0.043]). Thus, H6 receives partial support.
Results of H6: Direct and Indirect Effects.
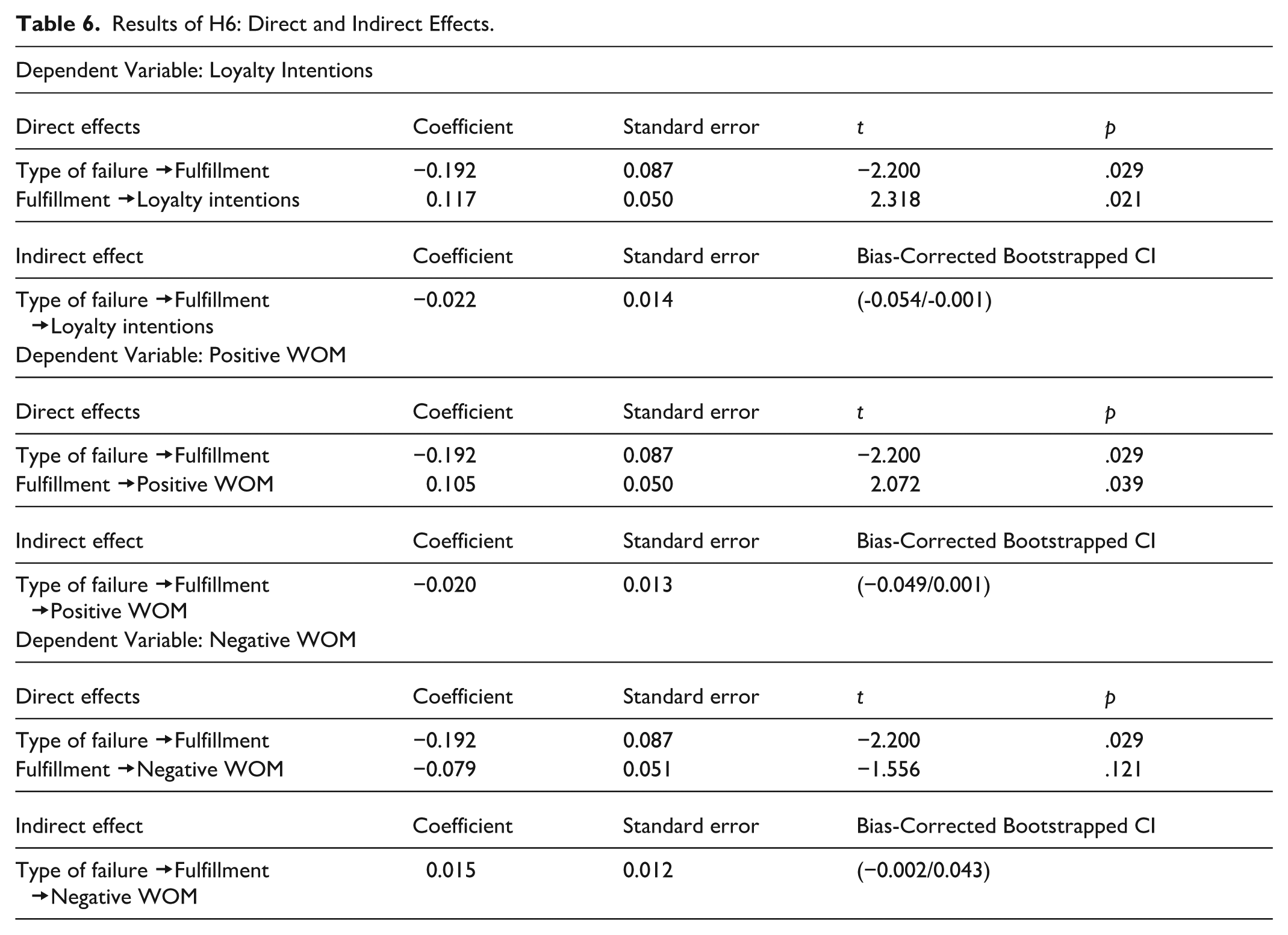
To clarify the moderating role of travel agent type in the indirect effect, we also analyzed the conditional effects at given values of the moderating variable (Preacher et al., 2007). As the results in Table 7 reveal, the indirect effects of failure type via expectation fulfillment were significant when the travel agent was generative AI, but not when the agent was human, for both loyalty intentions (βHuman = .005; βGen_AI = −.051) and positive WOM intentions (βHuman = 0.004; βGen_AI = -0.046). For negative WOM intentions, the indirect effect (mediated by service fulfillment) was non-significant, but it was greater for AI than for human travel agents AI (βHuman = −.003; βGen_AI = .035). Thus, our results suggest that failure type does not affect the dependent variables when the travel agent is human. However, when it is a generative AI agent, hallucinations evoke more negative consumer reactions. Consumers seem to tolerate regular mistakes made by AI systems more than they do AI hallucinations.
Conditional Indirect Effects at Values of the Moderator.

Discussion
Although generative AI improves efficiency, its potential drawbacks must be carefully considered (G. I. Huang et al., 2025; WTTC, 2024). Companies in the tourism sector remain hesitant to adopt generative AI systems, because AI-related errors could have significant consequences for their relationships with their customers (Gartner, 2024; Statista, 2024). The present study advances previous work on AI failures and AI hallucinations (e.g., H. Kim et al., 2025; Song et al., 2025) and thereby makes several contributions. In particular, it focuses on customers of travel agencies that use generative AI agents, instead of direct users of ChatGPT; establishes a comparative analysis of customers’ responses to generative AI versus human travel agents; compares hallucinations and regular mistakes committed by travel agents; analyzes service fulfillment as a mediating factor; and addresses the consequences of failures that go beyond customer loyalty to include company reputation considerations (positive and negative WOM).
With a paradigmatic example of generative AI implementation in tourism services (Casaló et al., 2025; J. H. Kim et al., 2024), we conducted two studies to compare customers’ perceptions and behavioral intentions toward travel agencies that use human versus generative AI travel agents. The findings from the first study indicated that customers react more positively to service successes and more negatively to service failures when the service is performed by a human agent rather than by an AI agent. However, the second study revealed that, even if customers tend to be more tolerant of regular mistakes by generative AI agents than by human agents, their reactions are more negative when the AI-generated travel advice contains hallucinations, which helps answer our second research question. In both experimental studies, customers’ perceptions of service fulfillment emerge as a mediating factor that helps explain the effects of service performance on their intentions to remain loyal to the firm and engage in positive or negative WOM (third research question). Both studies also affirm that failures and agent types affect customers’ loyalty intentions and travel agencies’ reputations, in terms of their intentions to engage in positive and negative WOM. In theoretical and managerial discussions, we elaborate on these findings, their contributions to research, and their implications for practice.
Theoretical Implications
This article contributes to services management literature pertaining to tourism. It corroborates the main postulates of expectation confirmation theory (Oliver, 1980) in the novel research field of generative AI. As Study 1 confirmed, a successful service outcome that meets customers’ expectations enhances their loyalty and positive WOM intentions, while reducing their negative WOM intentions. In contrast, when such expectations are unmet because the service fails, customers become less loyal and reduce their positive WOM intentions, but their intentions to engage in negative WOM increase. These findings support previous research into generative AI, particularly if it performs tasks successfully or avoids human errors (e.g., responding to customers’ online hotel reviews, Koc et al., 2023). In an extension of previous findings, we show that this effect is moderated by travel agent type: Customers react more strongly to service performance when they interact with a human employee than with a generative AI travel agent. The theoretical rationale for this moderating effect is rooted in the theory of mind (Premack & Woodruff, 1978; see also Apperly, 2010). Customers attribute mental states and a social perspective to other people (thoughts, intentions, feelings, common ground, empathy), such that service provided by a person is perceived as more heterogeneous, and more clearly linked to the abilities and efforts of that person, than when the service is provided by a generative AI agent. Consequently, and in line with classic research on critical service encounters (e.g., Bitner et al., 1990), customers react more positively or negatively to interactions with human employees, based on whether the interaction results in success or failure, than to interactions involving a more homogeneous and abstract generative AI agent. This finding aligns with previous research into the introduction of technology in tourism services, which identified stronger reactions to service performance by frontline human concierges than to service robots (Belanche et al., 2020).
Another key contribution stems from our conceptualization and analysis of AI hallucinations, a phenomenon in which AI generates responses that appear plausible but actually are nonsensical (Hwang & Jeong, 2025). Our literature review explains the causes of hallucinations and identifies some critical consequences (e.g., academic reference fabrications in health research; Aljamaan et al., 2024; De Freitas et al., 2024). In addition, we offer a review of previous insights into AI failures and the still scarce, but growing, stream of research into AI hallucinations (Table 1). This literature review helps delineate the scope and deepen understanding of AI hallucinations for tourism research and also reveals some research gaps that this article has sought to address.
Study 2, focused on travel agent service failures, distinguishes between hallucinations (e.g., the museum never existed) and regular mistakes (e.g., the museum is closed today). As theoretically predicted, and consistent with a status quo violation rationale (Samuelson & Zeckhauser, 1988), the results reveal that customers have stronger negative reactions to hallucinations than to regular mistakes, such that hallucinations reduce loyalty and positive WOM and increase customers’ negative WOM, to a greater extent than regular mistakes. This finding aligns with previous tourism literature that distinguishes minor mistakes from severe or irreparable failures (Roschk & Gelbrich, 2014; Weun et al., 2004), suggesting that customers consider hallucinations to be severe failures that threaten the customer–provider relationship. This finding also is consistent with evidence of the serious reputational consequences faced by firms that have used generative AI featuring hallucinations, as widely reported in the media (CBC News, 2023; CNBC, 2023) and legally punished (MK Legal Consultancy, 2024).
The moderating effect of service agent type also is significant, offering further in-depth understanding of the main effect. In comparison with regular mistakes, travel advice that includes hallucinations provokes stronger negative reactions toward generative AI travel agents than toward human travel agents. Whereas regular mistakes by a human agent affect customers’ responses more than regular mistakes by generative AI, the opposite is true for hallucination-related failures. Customers react more negatively to AI hallucinations than to regular AI mistakes because they perceive the latter as expected and usual (Christensen et al., 2025). This finding is consistent with recent research in the field, indicating that customers have a lower tolerance toward AI factual hallucinations (H. Kim et al., 2025).
The stronger negative reaction to generative AI hallucinations also seems to suggest the presence of a form of rejection of the underlying technology following a severe failure, and of the companies that use the systems, which has important implications for companies. Our findings show that generative AI hallucinations can damage loyalty and positive WOM, but their intense impacts on negative WOM suggest a broader societal concern. Perhaps this damage relates to consumers’ perceptions that AI is being used to mislead them and to create and spread fake news (Belanche, Ibáñez-Sánche, et al., 2025; Hwang & Jeong, 2025). This insight contributes to literature on customer reactions to service innovation in tourism, which highlights the need to prevent AI systems from committing critical failures that can have harmful consequences for the customer–provider relationship and company reputations.
Both studies identify service fulfillment as a mediator of the relationship between service outcomes and customers’ responses. As established in service research literature (e.g., Parasuraman et al., 1988, 2005), fulfillment represents the firm’s ability to execute processes that ensure that efficient service is provided as promised. The Study 1 results indicate that successful travel agent performance leads to greater perceptions of fulfillment, which positively influences customer loyalty and positive WOM intentions, while reducing negative WOM intentions. In contrast, travel advice that results in service failures triggers negative experiences, leading to a decline in service fulfillment perceptions (i.e., perception of the firm as inefficient) that in turn reduces loyalty and positive WOM intentions while increasing negative WOM intentions. Additional analyses reveal that this mediation effect is stronger when customers interact with human agents rather than generative AI travel agents, in line with our proposed moderating effect. The findings also are consistent with evidence that customers attribute responsibility to companies after service failures (Belanche et al., 2020), and also demand professional human oversight or intervention (Kopalle et al., 2024) in responses provided by travel agents, particularly when they involve negative service outcomes.
The results of Study 2 partially support the hypothesized mediating effect, in that service fulfillment mediates the effect of hallucinations (vs. regular mistakes) on customers’ reactions toward the firm. This effect is significant for customers’ loyalty but not for their WOM intentions, suggesting that positive and negative WOM may be motivated by factors other than the company’s fulfillment of its promises, such as positive/negative emotions (Hemthong et al., 2025) or social impressions (Belanche, Casaló, et al., 2025). In further analyses, the mediating factor is particularly significant when the failure is committed by a generative AI travel agent, not a human. This finding resonates with classic findings that customers evaluate service encounters with employees holistically (e.g., personal treatment, emotions, fairness), not based solely on the level of service fulfillment (Bitner et al., 1990; Blodgett et al., 1997). In contrast, the analyses support our prediction that customers perceive a lack of professionalism and an abrogation of responsibility by companies that use generative AI that present hallucinations, which can cause considerable harm to their reputations (Belanche, Ibáñez-Sánche, et al., 2025; CNBC, 2023; MK Legal Consultancy, 2024). This issue, along with practical recommendations for practitioners, is further explored in the managerial implications section.
Managerial Implications
Deploying generative AI systems for customer-facing tasks can lead to service failures, with significant consequences. Not all AI-related failures are perceived equally by customers though, and some may pose substantial reputational and relational risks if not properly managed. Managers should recognize that AI hallucinations constitute a qualitatively different and more severe form of service failure than regular mistakes: They are perceived as unacceptable failures that strongly undermine loyalty and positive WOM and that trigger negative WOM. From a managerial perspective, preventing hallucinations should be a top strategic and operational priority. Travel agencies should invest in robust AI control mechanisms, such as using combinations of internal and external data for system training, continuous content validation, and systematic testing of AI outputs in realistic service scenarios. These controls should continuously monitor and update generative AI responses, with particular attention paid to hallucinations (Taplin, 2024).
In a complementary way, tourism companies should carefully manage customers’ expectations of AI capabilities. Firms that implicitly position their AI systems as flawless and/or superior to human agents may amplify customers’ negative reactions when service failures occur, particularly if they are based on hallucinations. Companies should issue clear communications and disclaimers about the roles, limitations, and scope of their AI tools, along with detailed transparency policies, and then invite customers to verify information provided by their AI with a human agent, to calibrate their expectations and mitigate the negative consequences of disconfirmation. Companies also should be able to adjust their parameters (e.g., level of accuracy) to align their outputs with the specific needs of the sector. For example, coherence, rigor, politeness, and consumer satisfaction are critical in the tourism industry (as opposed to other features, such as conciseness), so they should be configured to minimize the harmful consequences of AI mistakes and hallucinations. Increasing transparency about the nature of AI mistakes and employing multi-shot prompting (i.e., gradually refining and improving responses) can be effective strategies for adapting to customers’ expectations and reducing hallucinations and their potential negative consequences (IBM Technology, 2023). This view aligns with previous research that suggests generative AI is transforming tourism companies’ service operations through the provision of more dynamic, real-time responses to inquiries, which enhances their customer service (Buhalis & Sinarta, 2019; Koc et al., 2023). In addition, AI-related innovations offer multiple ways to enhance this dynamic transformation of tourism services. For example, online trip planners (e.g., MindTrip, Wanderlog) represent a business opportunity, in that they offer customers travel plans but also provide added AI features, such as the ability to view and share pictures posted by other travelers, which influences customers’ decision-making.
Our research suggests that AI hallucinations strongly affect companies’ reputations and, particularly, prompt negative WOM. Thus, travel agencies using AI-enabled systems to interact with their customers run a significant reputational risk. Negative WOM can spread rapidly in digital environments and may have long-lasting effects on consumer trust and the credibility of tourism services (Hemthong et al., 2025). YouTube users employed words such as “hallucinations, “lie,” and “fake” when describing messages containing AI hallucinations (Mohanna & Basiouni, 2024). In addition to preventing AI hallucinations, companies should develop AI-specific service recovery protocols, including immediate acknowledgments of errors, clear explanations, and rapid escalation to human support. Previous research also suggests that apologies (H. Kim et al., 2025) and human expert advice (Song et al., 2025) can partially mitigate negative customer reactions.
Finally, our research indicates the value of employees and human–human interactions for delivering travel services. Customers’ reactions are more extreme when both successful and failed service performances are attributed to a human agent rather than to a generative AI agent. Therefore, employees and the “human touch” continue to play a crucial role in customer–company interactions (Bitner et al., 1990). In addition, customers react negatively to AI hallucinations, holding firms especially responsible for deploying unreliable AI systems and violating the status quo, which suggests that human oversight remains essential, particularly when AI recommendations fail. If a generative AI failure compromises service fulfillment, it elicits negative customer reactions toward companies, so incorporating human oversight to verify information inputs and outputs can help ensure that customers provide clear, specific prompts to generative AI tools while also enabling the system to interpret them more accurately, as a human would (IBM Technology, 2023). This approach would involve training AI systems to understand aspects that human employees easily infer, but that AI cannot because it lacks reasoning, as well as to develop an inherent understanding of what is being said and human experience (Belanche et al., 2024; Hermann & Puntoni, 2024). Tourism companies might consider hybrid service models, in which generative AI supports human employees rather than fully replaces them, and human employees oversee AI operations. To ensure a positive and satisfactory customer experience, human and AI capabilities should be carefully balanced in tourism service interactions, leveraging AI’s scalability while maintaining human oversight, reasoning, and empathy (Kopalle et al., 2024; Song et al., 2025).
Limitations and Further Research Directions
The limitations of this research open new avenues for continued studies, particularly by scholars interested in the application of generative AI tools in the tourism sector. First, we conducted two experimental studies in the United States, with participants recruited from a reputable online panel. Despite the valuable insights obtained from these experiments, further research should examine generative AI failures in real-world settings, such as with case studies employing qualitative methodologies. The human–agent hallucination scenario in Study 2 offered good internal validity, but it might not reflect real business practices. Further research should be conducted to distinguish between human and AI failure types, which may become interrelated in human–technology collaborative teams.
Second, large language models that power generative AI systems continue to evolve, as do the failures they produce. We did not distinguish different AI hallucination types but hope that future studies will investigate its various forms (e.g., logical, factual; Song et al., 2025), as well as how travel companies and other service providers might address them to prevent negative customer reactions. In addition, as technology advances, AI hallucinations could (and should) disappear. A longitudinal study might analyze the types of responses used by generative AI and how customers’ perceptions of, or adaptation to, AI failures evolve over time. In this regard, previous research suggests that young consumers seeking travel advice increasingly shift from online browsers to generative AI tools such as ChatGPT, even while they acknowledge that AI-generated information may contain errors (Christensen et al., 2025).
Third, we address this issue implicitly in the discussion, but an ethical question requires further attention: AI systems provide advice without reasoning or being aware of the implications. This lack of consciousness may lead to dramatic consequences, for commercial relationships but also for people’s lives (e.g., AI hallucinations falsely accusing people of crimes; Noyb, 2025). Although AI systems increasingly incorporate human-like features (Casaló et al., 2025), they still lack causal and abstract reasoning (Hermann & Puntoni, 2024). Research should explore customers’ perceptions of AI hallucinations from a broader ethical perspective to contribute to ongoing debates about the implications of generative AI-driven decision-making.
Supplemental Material
sj-docx-1-jtr-10.1177_00472875261456334 – Supplemental material for When AI Fails: The Impacts of Hallucinations and Service Errors on Customer Loyalty and Word of Mouth
Supplemental material, sj-docx-1-jtr-10.1177_00472875261456334 for When AI Fails: The Impacts of Hallucinations and Service Errors on Customer Loyalty and Word of Mouth by Daniel Belanche, Luis V. Casaló and Carlos Flavián in Journal of Travel Research
Footnotes
Appendix
Study 2 Research Scenarios.
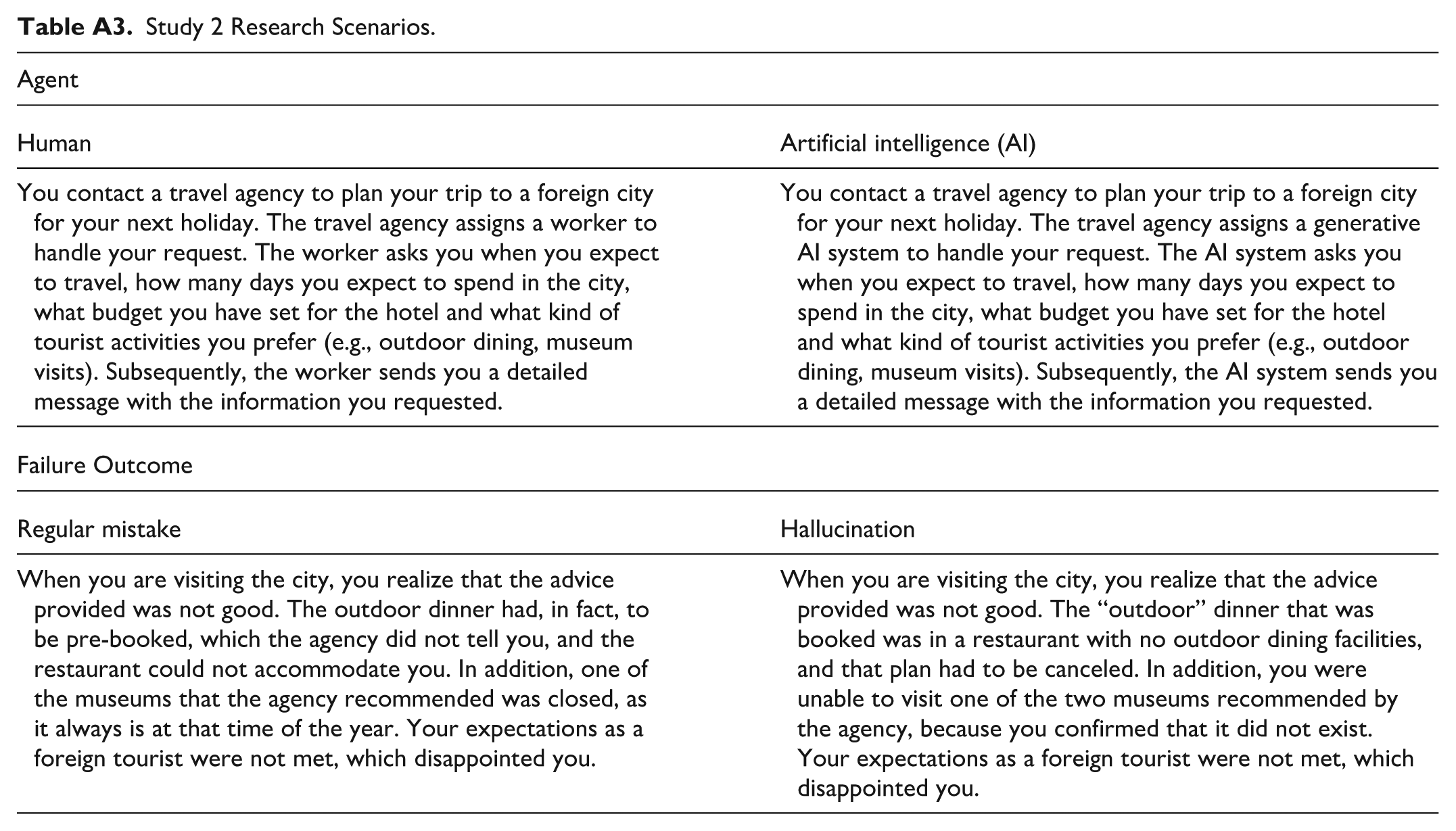
| Agent | |
|---|---|
| Human | Artificial intelligence (AI) |
| You contact a travel agency to plan your trip to a foreign city for your next holiday. The travel agency assigns a worker to handle your request. The worker asks you when you expect to travel, how many days you expect to spend in the city, what budget you have set for the hotel and what kind of tourist activities you prefer (e.g., outdoor dining, museum visits). Subsequently, the worker sends you a detailed message with the information you requested. | You contact a travel agency to plan your trip to a foreign city for your next holiday. The travel agency assigns a generative AI system to handle your request. The AI system asks you when you expect to travel, how many days you expect to spend in the city, what budget you have set for the hotel and what kind of tourist activities you prefer (e.g., outdoor dining, museum visits). Subsequently, the AI system sends you a detailed message with the information you requested. |
| Failure Outcome | |
| Regular mistake | Hallucination |
| When you are visiting the city, you realize that the advice provided was not good. The outdoor dinner had, in fact, to be pre-booked, which the agency did not tell you, and the restaurant could not accommodate you. In addition, one of the museums that the agency recommended was closed, as it always is at that time of the year. Your expectations as a foreign tourist were not met, which disappointed you. | When you are visiting the city, you realize that the advice provided was not good. The “outdoor” dinner that was booked was in a restaurant with no outdoor dining facilities, and that plan had to be canceled. In addition, you were unable to visit one of the two museums recommended by the agency, because you confirmed that it did not exist. Your expectations as a foreign tourist were not met, which disappointed you. |
Ethical Considerations
Following the instructions of the ethical code for social sciences research approved by the University of Zaragoza Management Team (6.8/2018), before participating in the research, participants were provided with information on the scientific purpose of the study and data protection, and they gave their explicit informed consent.
Author Contributions
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by the European Social Fund and the Government of Aragon (Group “METODO” S20_23R), and by the grant PID2024-158196OA-I00 funded by MICIU/AEI/10.13039/501100011033 and ERDF/EU.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
Data available from the corresponding author upon reasonable request.
Supplemental Material
Supplemental material for this article is available online.
Author Biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.