
Abstract
Case studies appear prominently in political science, sociology, and other social science fields. A scholar employing a case study research design in an effort to estimate causal effects must confront the question, how should cases be selected for analysis? This question is important because the results derived from a case study research program ultimately and unavoidably rely on the criteria used to select the cases. While the matter of case selection is at the forefront of research on case study design, an analytical framework that can address it in a comprehensive way has yet to be produced. We develop such a framework and use it to evaluate nine common case selection methods. Our simulation-based results show that the methods of simple random sampling, influential case selection, and diverse case selection generally outperform other common methods. And, when a research design mandates that only a very small number of cases, say one or two, be selected in the course of a research program, the very simple method of sampling from the largest cell of a 2 × 2 table is competitive with other, more complicated, case selection methods. We show as well that a number of common case selection strategies work well only in idiosyncratic situations, and we argue that these methods should be abandoned in favor of the more powerful and robust case selection methods that our analytical framework identifies.
Introduction
Case study analysis is one of the more prominent research methods in empirical social science. One can readily find case studies in areas dominated by qualitative modes of inquiry, and within political science case studies are relatively common in the fields of comparative politics and international relations. A simple JSTOR 1 search (on December 6, 2012) for the terms “case study,” “case-study,” “case studies,” or “case-studies” in the full text of articles in the American Political Science Review (APSR) from 1998 to 2007 returns 108 results. Similar JSTOR searches for other methodological terms yield the following: “regression,” 210 hits; “probit,” 84 hits; “instrumental variables” or “instrumental variable,” 33 hits; “field experiment,” eight hits. Nearly 11 APSR articles per year make some mention of case studies, and this is a larger number than that for all the other terms above save “regression.”
Performing a similar analysis on the holdings of a journal that specializes in comparative and international politics suggests an even greater role for the case study method. A JSTOR search (on December 6, 2012) for the terms “case study,” “case-study,” “case studies,” or “case-studies” in the full text of articles in World Politics from 1997 to 2006 returns 64 results. Similar JSTOR searches for other methodological terms yield the following: “regression,” 70 hits; “probit,” 17 hits; “instrumental variables” or “instrumental variable,” nine hits; “field experiment,” three hits. The point to take from this is that case study methods are commonly used in political science, particular among scholars of comparative and international politics.
A key question—arguably the key question—faced by scholars pursuing case studies is that pertaining to case selection criteria. Namely, a scholar carrying out a case study must confront the question, what criteria should he or she use to choose his or her case or a set of cases for analysis? Should, for example, a case for analysis be picked on the basis of being representative of a large set of possible cases? Or, should a case be chosen because it is distinctly nonrepresentative? Relatedly, should a case study researcher use deterministic rules to select cases—by, say, choosing cases that are guaranteed to be different along some notable dimensions—or should case selection include a stochastic element?
Decisions regarding case selection rules must be made early on in a research program, and these decisions can have a profound effect on the ultimate quality of said program. Indeed, the conclusions of a case study analysis are, by construction, valid only to the extent that the case or cases used to support them are chosen in a compelling way, compelling suitably defined.
How might one know if the criteria for case selection employed in a case study research program are adequate or effective and what precisely might such a characterization mean? Different researchers employ case study analysis to achieve different goals, 2 and as such, the efficacy of any particular rule for case selection must be evaluated in terms of its ability to achieve a particular research objective. The specific research goal that we consider in this article is inference about the effects of causes. By inference, we mean the use of data from a fixed number of cases to make claims about a larger set of cases. We use the terminology effects of causes in the manner of Holland (1986). Holland makes a useful analytic distinction between questions about effects of causes and questions about causes of effects. The former questions take forms similar to, “What is the effect of enrollment in a particular test prep course (relative to no test prep) on SAT scores?” The latter questions take forms similar to “Why do some students do better on the SAT than other students?” While both types of questions can be interesting, Holland and others have argued that questions about effects of causes (“What’s the effect of test prep on test scores?”) are narrower and thus easier to answer in a credible way than are questions about causes of effects (“Why do some students do better on the test than others?”). Further, many would argue that methods for producing credible answers to questions about effects of causes are well understood and relatively uncontroversial, whereas methods for producing credible answers to questions about causes of effects are less well developed and more controversial. For these reasons, throughout this article, we focus on inference about the effects of causes.
To assess the efficacy of various case selection methods with respect to this goal, we develop an analytical framework that can be used to evaluate case selection methods, and we then apply the framework to common case selection rules that scholars have historically used to select cases for research. These rules are described by Seawright and Gerring in Chapter 5 of Gerring (2006) 3 ; see also Seawright and Gerring (2008). We note that methods similar to those considered by Seawright and Gerring have been discussed by other researchers as well. We comment shortly on these methods, but for the moment, it suffices to say that Seawright and Gerring’s exploration of case study methods constitutes a current and comprehensive study of this research methodology, as it appears in empirical political science.
The case selection methods that we explore here are found primarily in qualitative research designs. Such designs typically have small sample sizes, say, ten observations or fewer. Nonetheless, our framework for analysis should not be thought of as a framework that pertains only to qualitative research. Indeed, rather than focusing on “case selection criteria,” we could have chosen to focus instead on “observation selection criteria” or “unit selection criteria.” Nothing would have changed analytically had we relied on the latter terms, but we use the former exclusively because of the prevalence of case studies in small n, qualitative research designs. While at times in what follows we refer explicitly to qualitative research, we note that our findings have little (or one might even say nothing) to do with precisely how a researcher studies a case once it is chosen for analysis. As we will make clear shortly, we do assume that a researcher can formulate particular counterfactual claims about the cases chosen for detailed study, but we are agnostic as to methods by which those claims are generated. Our framework is a general one that can be used to study the effectiveness of selecting some cases (or units) for more extensive, in-depth examination when the goal is to infer the effect of a cause, and we turn to it now.
A Framework for Causal Inference and Case Selection
While much attention has been paid to case study methodology in recent years, there is at present no general mathematical framework for thinking about how case studies can help improve the quality of causal inferences. Similarly, while many practitioners of case study methodology acknowledge a fundamental role for counterfactuals in what they do (see inter alia Fearon 1991; Ferguson 1999; Hawthorn 1993; Lebow 2000; Levy 2008), these same researchers have not attempted to place their methodologies within an explicitly counterfactual causal model such as proposed by Neyman, with Iwaszkiewicz, and Kolodziejczyk (1935), Rubin (1974, 1978), Robins (1986), and Pearl (1995, 2000; but see Sekhon 2004). We attempt to bridge these gaps, and the remainder of this section details our attempt to place case study research within an explicitly counterfactual causal framework. The benefit of this approach is that—to the extent that our account of case study research is persuasive—case selection methods can be evaluated according to standard statistical criteria such as bias, root mean square error (RMSE), and variance reduction, at least with respect to our stated research goal of inferring effects of causes. Without reference to standard measures like these, it is difficult if not impossible to evaluate whether a given case election technique “works.”
The Basics
Consider the situation where a researcher observes the value of a dichotomous causal variable along with the value of a dichotomous outcome variable for each unit in a sample from some well-defined population. By “causal variable,” we mean here a variable that could plausibly be a cause of the outcome in question. Some readers may find it more convenient to think of what we are calling a causal variable as a “treatment variable.”
We let i = 1,…N index sample units,
To fix ideas and make our notation concrete, we introduce data from Licklider (1995) on method of civil war termination and war resumption (see Table 1). The causal question of interest implicit in this table is whether negotiated settlements (X = 1) decrease the likelihood of war resumption (Y = 0) relative to what occurs when military victory ends a war (X = 0). 4
Relationship Between Method of Civil War Termination and War After Termination Among “Identity Civil Wars.”

Note: Each entry is the number of cases in that category. Data from Table 2 of Licklider (1995).
Throughout this article, we assume that it is possible for a researcher to sample units from the population of interest (or to collect data from the entire population of interest) and classify the selected units on the basis of their values of the causal variable Xi and outcome variable Yi of interest. In other words, we assume that a researcher in her research program of interest can construct a 2 × 2 table similar to Table 1.
Even with a table akin to Table 1, one cannot directly identify causal effects. Simply put, this is because of the possibility of confounding bias or what is often called omitted variable bias. For example, one might observe in a 2 × 2 table of Xi and Yi that when Xi =1, one tends to also see that Yi = 1. One cannot conclude from this that a unit’s treatment status, that is, Xi = 1, leads to success, that is Yi = 1, because a third—and unobserved—variable might be a cause of both Xi and Yi .
We adopt the notation Yi
(Xi
= 0) and Yi
(Xi
= 1) to denote the value of unit is outcome variable if Xi
is set equal to 0 and 1, respectively, by an outside intervention that leaves all preintervention variables unchanged. Yi
(Xi
= 0) and Yi
(Xi
= 1) are referred to as potential outcomes, or, in some cases, counterfactual outcomes, and we write 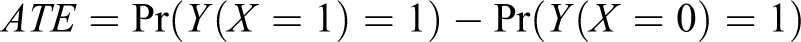
can be written in terms of the above probabilities.
5
Note that
The assumptions typically employed to estimate
Yi
(Xi
= 0) and Yi
(Xi
= 1) do not depend on the realized values of any variables in units other than unit i.
Yi
(Xi
= x) = yi
if Xi
= x. In words, the observed outcome for case i takes the same value as the potential outcome under the scenario, where the causal variable is set equal to its observed value by outside intervention. The implication is that we get to observe the value of the potential outcome Yi
(Xi
= x) when the observed value of Xi
is x.
The first assumption is commonly referred to as conditional ignorability of treatment assignment, no unmeasured confounding, and/or selection on observables. The latter two assumptions make up what is commonly referred to as the stable unit treatment value assumption (SUTVA). These assumptions, or close cousins thereof, are the starting point for nearly all principled attempts to infer causal effects from observed data, including analyses based on regression, matching, and inverse propensity score weighting. Our analysis in this article is no exception.
In typical applications, one attempts to define
Conceiving of
Possible Patterns of Potential Outcomes and Coarsest General Confounding Variable.
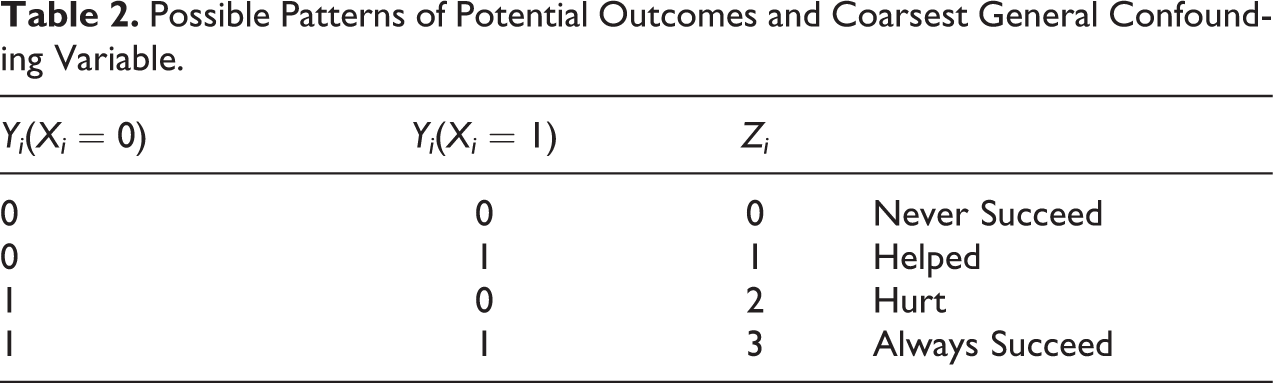
A unit i for which Zi = 0 has a value of Ui which implies that Yi will always be equal to 0 regardless of the (possibly counterfactual) value of Xi . We say such a unit is a “never succeeder.” If Zi = 1, then in contrast, we say that unit i is “helped” by treatment because its potential outcome under X = 1 is equal to 1 (success), while its potential outcome under X = 0 is 0 (failure). If, though, unit i has Zi = 2, we say that i is “hurt” by treatment because its potential outcome under X = 1 is equal to 0 (failure), while its potential outcome under X = 0 is 1 (success). Finally, if Zi = 3, then we say that i is an “always succeeder” because its value of Ui is such that Yi will always equal 1, regardless of the (possibly counterfactual) value of Xi .
To help with intuition, consider the example we invoked earlier regarding the effect of war termination via negotiated settlement on war continuation. Suppose that a qualitative researcher is interested in the case of Paraguay in 1947. Licklider codes this as a case with a military victory and no recurrence of the same war, that is, Xi = 0 and Yi = 1. After evaluating and weighing the myriad factors which, within the detailed context of the particular case of Paraguay in 1947, contribute both to type of war termination and to continuation of conflict, our hypothetical researcher concludes that this conflict would not have resumed regardless of whether the conflict ended (as it did) in military victory or (as it could have) in a negotiated settlement. 7 Making a counterfactual claim like this is something that many researchers, particularly historians and scholars of international relations, often do; see Fearon (1991); Hawthorn (1993); Ferguson (1999); Lebow (2000); and Levy (2008). The key piece of intuition that we want to convey at this point is that this counterfactual claim is exactly equivalent to the claim in our terminology that Zi is known for Paraguay in 1947 and that in fact Zi is equal to 3 (Paraguay in 1947 is an “always succeeder”). Indeed, any counterfactual claim about the value of the outcome variable in a world where the causal variable X took a different value than its observed value is equivalent to a claim about the value of Zi for the case in question.
Since Z is defined in terms of the value of the potential outcome pairs, it is clear that conditional ignorability of treatment assignment (assumption 1) holds, given Z. We assume that (Xi
, Yi
, Zi
) for all i are independent replicates from some joint distribution PXYZ
. This means that each case i, which is characterized by treatment Xi
, outcome Yi
, and confounder Zi
, is drawn from a common distribution. This is consistent with a scenario where xi
, yi
, and zi
take constant values for each unit i and (xi
, yi
, zi
) triples are sampled from the population of interest. If PXYZ
were known, then one could write 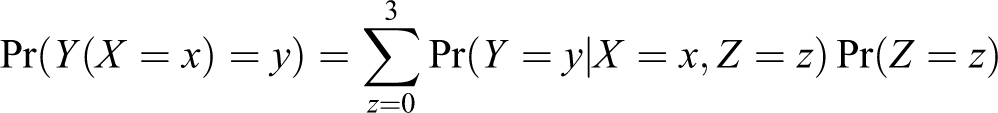
where the probabilities on the right-hand side of the equation above can be calculated directly from PXYZ .
Thus, if either
In what follows, we let
Case Selection for Causal Effect Estimation
So far we have assumed that (xi , yi , zi ) triples are randomly drawn from a common distribution. The researcher gets to observe (xi , yi ) for each i (meaning, treatment, and outcome status for each observation i) but, at least initially, is unable to observe the confounding variable zi . This gives rise to a two-way table of X and Y that has been effectively marginalized over Z. The aforementioned Table 1 is an example of this.
Nevertheless, the true table of interest for causal inference is the 2 × 2 ×4 table of (X, Y, Z ) values, that is, the table that includes the confounder Z and is not marginalized over it. While it might seem that there is no information in the observed 2 × 2 (X, Y ) table about the unobserved (X, Y, Z ) table of interest, this is not correct. To see why this is the case, note that conditioning on Xi = xi and Yi = yi reduces the set of logically possible values of zi to two elements. For instance, all of the 19 cases in the (X = 0, Y = 1) cell of Table 1 are either Hurt (Z = 2) or Always Succeed (Z = 3) units. We know this is true because, since Y = 1 in this cell, observations i in this cell cannot be Never Succeed Units or Helped Units, as they would then not have Yi = 1. We exploit this ability to partially identify the conditional distribution of Z, given X and Y, in what follows.
After this initial sampling of N units has taken place and the (X, Y ) table has been filled out, we allow the researcher to select Q of N initially sampled units for additional inspection. We introduce the variable Si to indicate whether unit i was selected for additional inspection (Si = 1) or not (Si = 0). As noted previously, we are agnostic as to the methods used to study a particular case once it is selected for additional inspection, but we do assume that if case i is selected for additional inspection (Si = 1), then the value of the confounder Zi is perfectly observed. This second round of case selection and inspection gives rise to a partially observed 2 × 2 × 4 × 2 table for (X, Y, Z, S).
Let Cxyzs
denote the number of cases with X = x, Y = y, Z = z, and S = s. At some points below, we will want to denote cell frequencies that have been summed over some margins of the 2 × 2 × 4 × 2 table. The notation we use here replaces an alphabetic subscript with a + to denote summation over the replaced variable. For instance,
We formalize case selection procedure as follows. Let Q denote the total number of cases to be selected for analysis and let t = 1,…Q index the sequence of selections. Let 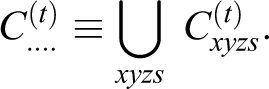
In the results that follow, we allow the probability that unit i is selected for analysis at time t
Our probability model for (X, Y, Z ) features two sets of parameters—θ and ψ. θ governs the multinomial distribution for (X, Y ) marginalized over Z, and ψ controls a series of binomial distributions for Z that are defined conditionally on X and Y. θ captures the descriptive association between X and Y, whereas ψ captures information that is purely causal (how the potential outcomes vary, given X and Y ). Table 3 provides details and interpretations of these parameters.
Interpretation of Parameters in the Model for (X, Y, Z ).
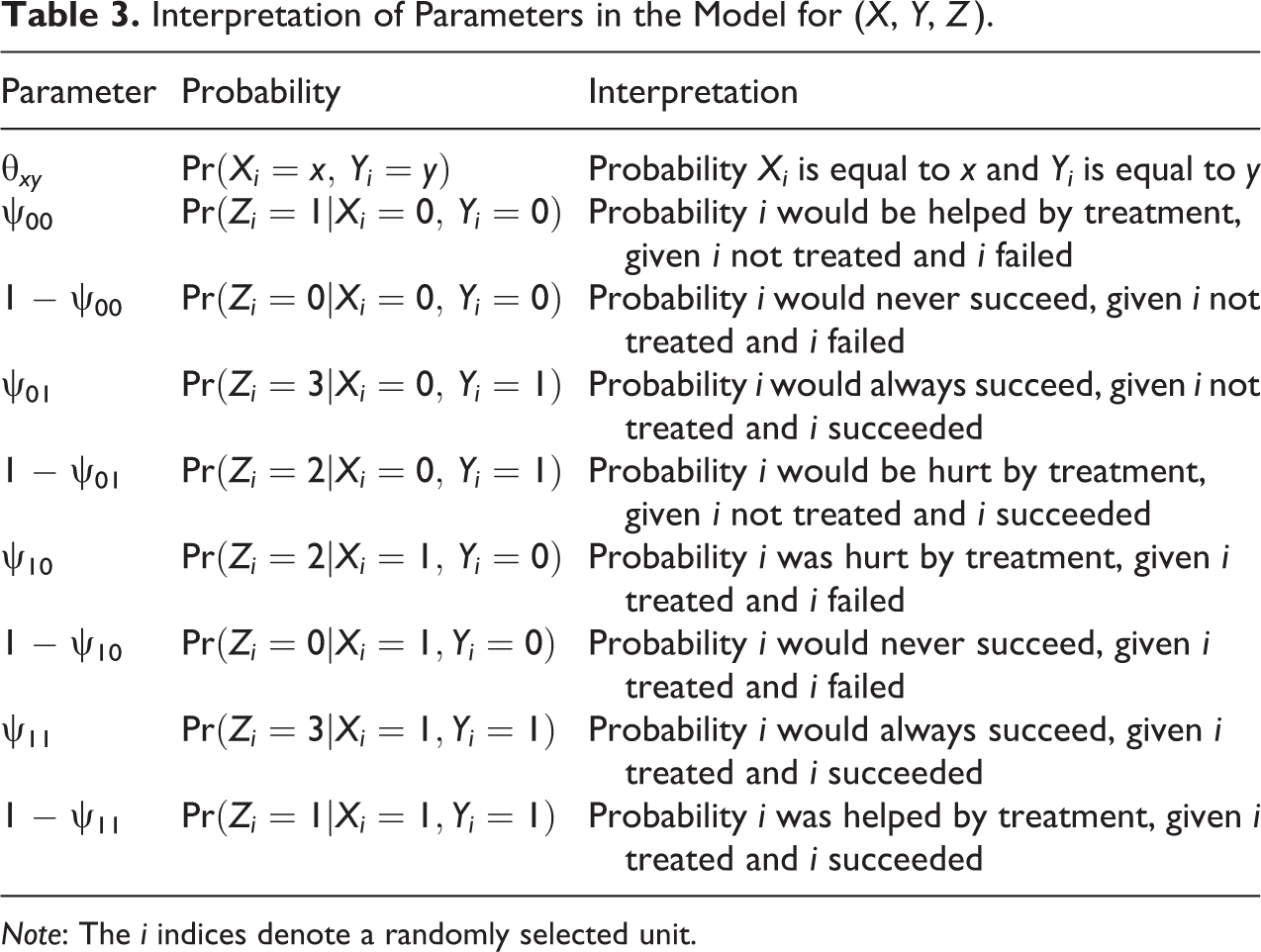
Note: The i indices denote a randomly selected unit.
Before writing out the posterior distribution for our parameters of interest, it is useful to introduce the notation 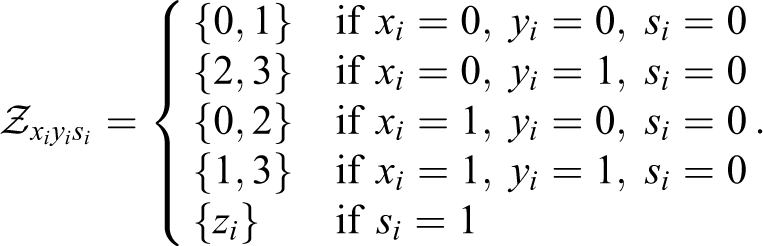
Now we can write the posterior distribution of θ and ψ as: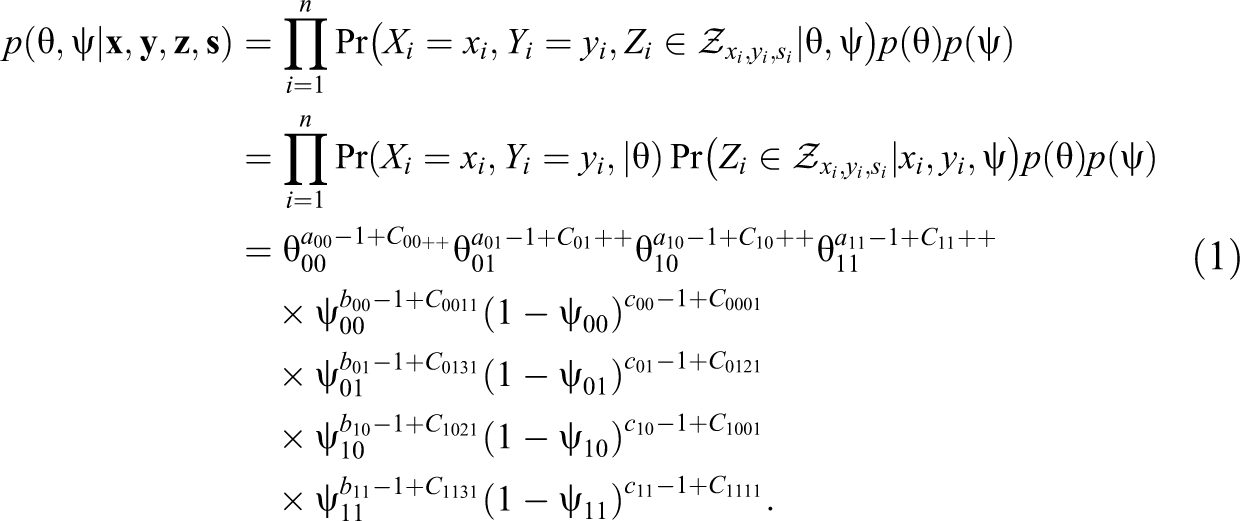
Note we assume that, a priori,
If ψ is known, we can write the average treatment effect as: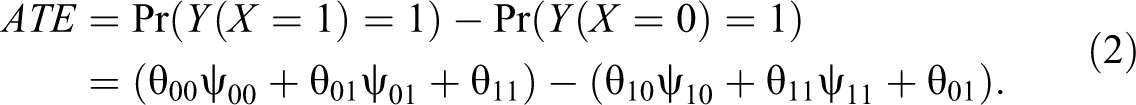
This will be valid regardless of the pattern of confounding, but it does require knowledge of ψ (and SUTVA). In what follows, we choose to look at case selection as a way to learn about the conditional probability distribution of Z, given X and Y (i.e., ψ) and hence infer ATE. Bayesian inference for
Case Selection Methods
The analysis in Case Selection for Causal Effect Estimation subsection is predicated on knowing the realized values of Zi for some (small) subset of units. Having noted this, we now attempt to operationalize a number of methods of case selection that have appeared in the qualitative methodology literature. The methods of case selection that we consider here are largely derived from the methods discussed in Gerring (2006) and Seawright and Gerring (2008). While it is not always unambiguously clear how, within the analytical framework of this article, to operationalize a particular case selection technique, we have tried to remain as faithful as possible to the spirit of Gerring’s suggestions. Nonetheless, it is important to be clear up front that our results and conclusions deal only with our very specific implementations of various case selection mechanisms. Thus, our conclusions about, say, influential case selection only apply to our specific implementation of this method and not to other case selection methods that might be referred to as influential case selection methods. We also emphasize that we evaluate these case selection methods in reference to their performance as part of a research strategy designed to infer effects of causes.
Although not necessarily advocated by Gerring, we include simple random sampling as a case selection technique. This is primarily for purposes of comparison. Random sampling provides a natural set of benchmarks for other case selection techniques, and in the remainder of this section, we discuss our implementation of the latter.
Typical Case Selection
Gerring (2006) writes: In order for a focused case study to provide insight into a broader phenomenon, it must be representative of a broader set of cases. It is in this context that one may speak of a typical-case approach to case selection. The typical case exemplifies what is considered to be a typical set of values, given some general understanding of the phenomenon (p. 91).
And he goes on to state: When a case falls close to the regression line, its typicality will be just below zero. When a case falls far from the regression line, its typicality will be far below zero. Typical cases have small residuals. (p. 94)
We operationalize Gerring’s typical case method of case selection in two ways. The first way, which we refer to as typical case selection, works as follows.
Note that the log odds ratio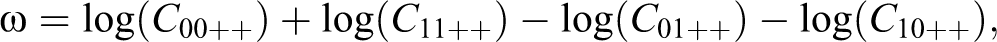
for a given (X, Y ) table contains information about the association between X and Y. In particular, if ω > 0, then there is a positive association between X and Y, if ω < 0, there is a negative association. If there is a positive association, that is, ω > 0, then we randomly sample cases for additional analysis from the main diagonal cells (X = 0, Y = 0) and (X = 1, Y = 1) with selection probabilities proportional to C 00++ and C 11++, respectively. If the association in the table is negative, we sample from the (X = 0, Y = 1) and (X = 1, Y = 0) cells with selection probabilities proportional to C 01++ and C 10++, respectively. This sampling protocol captures the essence of Gerring’s description of typical cases as lying close to the regression line.
A second way to define a typical case is to posit that such a case falls within the largest cell of an (X, Y ) table. For instance, if C 00++ > C 10++ > C 01++ > C 11++, then we would take a random sample of observations from the (X = 0, Y = 0) cell of the table for analysis. We refer to this method as largest cell selection.
Diverse Case Selection
Gerring (2006) writes: A second case-selection strategy has as its primary objective the achievement of maximum variance along relevant dimensions. I refer to this as a diverse case method. For obvious reasons, this method requires the selection of a set of cases—at minimum, two—that are intended to represent the full range of values characterizing X
1, Y, or some X
1/Y relationship.
In the present context, we take this to mean that cases should be selected for analysis in such a way that keeps the total number of cases selected from each of the four cells of the (X, Y ) table as close to equal as possible. In our notation, this means that cases must be selected, so that C 00+1 ≈ C 01+1 ≈ C 10+1 ≈ C 11+1 with as many as possible of the equalities holding exactly.
We use the following sequential sampling method to achieve this goal. As stated previously, let Q denote the total number of cases to be selected for analysis, and let t = 1,…Q index the sequence of selections. When t = 1, 5, 9, …, pick one of the four cells of the (X, Y ) table with equal probability and randomly sample an observation from that cell. When t = 2, 6, 10, …, pick one of the three cells that was not sampled from iteration t − 1 with equal probability and randomly sample an observation from that cell. When t = 3, 7, 11, …, randomly pick one of the two cells that was not sampled from iteration t − 1or t − 2 with equal probability and sample an observation from that cell. When t = 4, 8, 12, …, randomly sample an observation from the cell that was not sampled from iteration t − 1, t − 2, or t − 3.
We call the method described previously as diverse case selection. Note that this way of operationalizing diverse case selection remains well defined for values of Q that are not evenly divisible by 4—including Q = 1. This is useful when we move on to a comparison of various case selection methods later in the article.
Extreme Case Selection
Gerring (2006) writes: The extreme-case method selects a case because of its extreme value on an independent or dependent variable of interest…An extreme value is an observation that lies far away from the mean of a given distribution…For a dichotomous variable (present/absent), I understand extreme to mean unusual. If most cases are positive along a given dimension, then a negative case constitutes and extreme case. If most cases are negative, then a positive case constitutes an extreme case…It is the rareness of the value that makes a case valuable, in this context, not its positive or negative value (pp. 101-2).
We chose to operationalize this case selection method by randomly sampling observations from the smallest cell of the (X, Y ) table. Thus, if C 10++ < C 11++ < C 01++ < C 00++, we would randomly sample observations that have X = 1 and Y = 0. We refer to this selection method as extreme case selection.
Deviant Case Selection
Gerring (2006) writes: The deviant-case method selects the case(s) that, by reference to some general understanding of a topic (either a specific theory or common sense), demonstrates a surprising value…The important point is that deviantness can only be assessed relative to the general (quantitative or qualitative) model employed…In statistical terms, deviant-case selection is the opposite of typical-case selection. Where a typical case lies as close as possible to the prediction of a formal, mathematical representation of the hypothesis at hand, a deviant case lies as far as possible from that prediction…Deviance ranges from 0, for cases exactly on the regression line, to a theoretical limit of infinity. Researchers will usually be interested in selecting from the cases with the highest overall estimated deviance (pp. 105-7).
Since Gerring views deviant case selection as the opposite of typical case selection, we operationalize our version of deviant case selection accordingly. As stated previously, the log odds ratio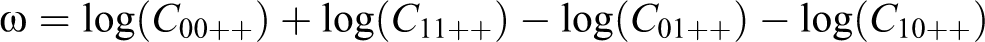
is calculated for a given (X, Y ) table. As we discussed earlier, ω > 0 implies a positive association between X and Y, and ω < 0 implies a negative association. If there is a positive association, deviant case selection would have us randomly sample cases for additional analysis from the off diagonal cells (X = 0, Y = 1) and (X = 1, Y = 0) with selection probabilities proportional to C 01++ and C 10++, respectively. On the other hand, if the association in the table is negative, we sample from the (X = 0, Y = 0) and (X = 1, Y = 1) cells with selection probabilities proportional to C 00++ and C 11++, respectively.
Influential Case Selection
Gerring’s discussion of what he terms influential case selection is cast largely in terms of analogies to linear regression. While such ideas do not translate cleanly to the present context, we interpret Gerring’s discussion of this case selection method to be primarily concerned with selecting cases that minimize the sampling variability of one’s estimator—much as one would do under optimal model-based sampling designs; for example, see Glynn et al. (2008). Accordingly, we chose to define influential case selection as a case selection procedure that is part of a Bayesian decision problem whose goal is to minimize the posterior variance of the quantity of interest, here ATE.
Within the framework of this article, we operationalize influential case selection with the following adaptive sampling procedure. Once again, let t = 1,…Q index the sequence of case selection decisions. Let 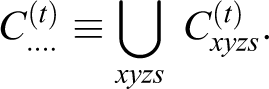
Define: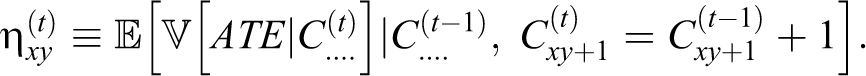
In words,
Crucial (Most) Case Selection
Close reading of Gerring (2006) suggests that his crucial (most) case selection method depends on strong prior knowledge of the counterfactual outcomes of units. In our opinion, case selection methods that require accurate prior knowledge of the potential outcomes of units in order to work well are hard to rationalize—if one knows the potential outcomes of units, then one does not need to do any case selection to infer average causal effects.
Nonetheless, we have attempted to operationalize a case selection method that corresponds with a simple understanding of Gerring’s crucial case selection method, specifically what is written in table 5.1 of his book. Suppose
To be clear, we do not think that this case selection technique is what Gerring is discussing in the text of his 2006 book. Nonetheless, this does seem to loosely correspond to what is printed in table 5.1, and it is conceivable that some researchers would pursue similar case selection strategies in actual research situations. For instance, principle 1 of Goertz (2008) would have one look solely among the cases with Y = 1. While Goertz explicitly argues against random selection, his focus on examining cases with only a single Y-value is similar in spirit to our crucial (most) method (and the crucial (least) method discussed immediately below).
Crucial (Least) Case Selection
The same caveat that applies to our crucial (most) case selection method applies to what Gerring refers to as crucial (least) case selection. We operationalize crucial (least) case selection as follows. Suppose
Case Selection via Simple Random Sampling
We also look at the properties of simple random sampling when applied to the problem at hand. This selection method can be conducted in the following way. First, randomly choose cell (X = x, Y = y) of the 2 × 2 table with probability proportional to Cxy ++ for x = 0, 1 and y = 0, 1. Then randomly select a unit from this cell (with equal probability).
General Comments
All the case selection methods discussed previously are forms of (possibly stratified and possibly adaptive) random sampling. The only way that nonrandom sampling methods will perform well is if a researcher has a great deal of background knowledge about the distribution of potential outcomes of interest (the ψ parameter). However, methods that require accurate prior knowledge about potential outcomes to perform well do not require any case selection to be done at all since accurate knowledge of ψ and θ is sufficient to accurately infer ATE.
Monte Carlo Experiments
To evaluate the nine methods of case selection discussed previously across a variety of plausible scenarios, we conduct 12 Monte Carlo experiments. These 12 experiments vary the degree to which the elements of
Each of the 12 Monte Carlo experiments was conducted in the following fashion. 1. Set θ00, θ01, θ10, θ11, ψ00, ψ01, ψ10, ψ11, first-stage sample size N, and second-stage sample size Q. Also, choose a case selection method. 2. For m = 1,…, M
Randomly generate Cxyz
+ from the appropriate distribution, given the fixed values of Sample Q cases for analysis using the case selection method chosen in step 1. The z values for these units become observed. Using the data generated in steps 2(a) and 2(b), calculate the posterior distribution of (θ, ψ) and then use this information to calculate and summarize the implied posterior distribution for ATE. Save the ATE posterior summaries. 3. Summarize the performance of the case selection method under study over the M data sets to which it was applied.
Our results are based on N = 10,000, M = 1,000, and
Summary of Monte Carlo Experiments.
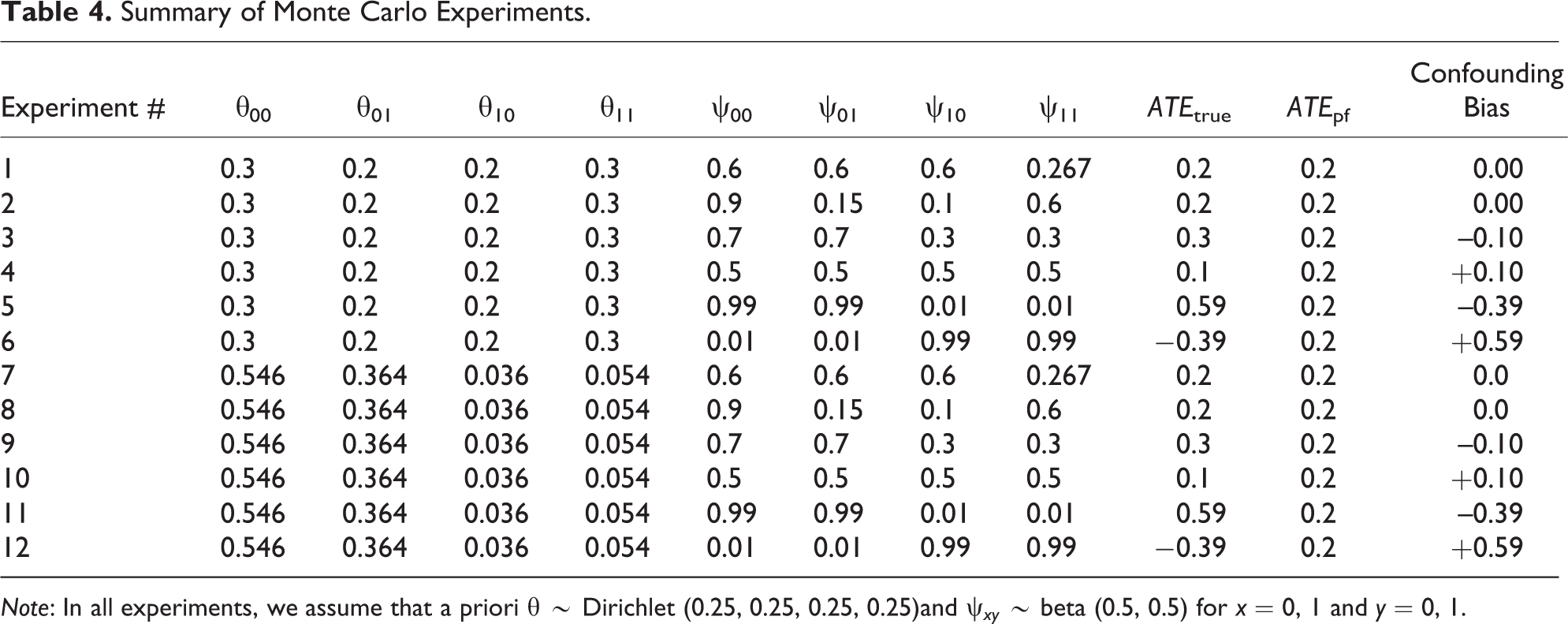
Note: In all experiments, we assume that a priori
We look at four quantities to gauge the performance of the case selection schemes under study: bias, frequentist RMSE, posterior variance, and posterior RMSE. Let Dm
denote all of the prior parameters and observed data from Monte Carlo replication m and 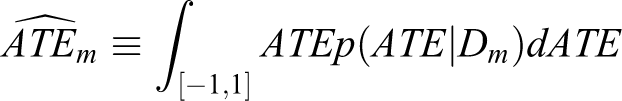
denote the posterior mean of ATE in the mth Monte Carlo replication under a particular case selection scheme.
Traditional frequentist criteria of bias and RMSE are defined as: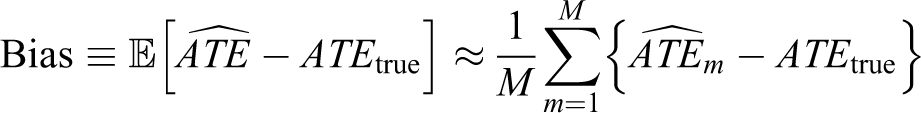
and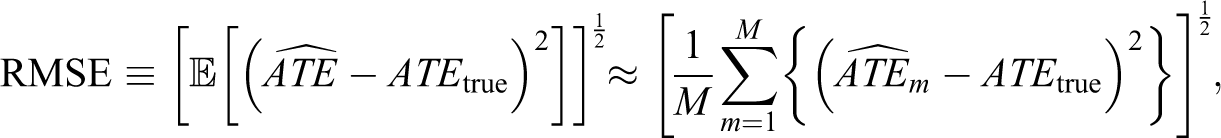
where the last terms give the Monte Carlo estimates of these quantities. Criteria with more of a Bayesian flavor include the posterior variance of ATE: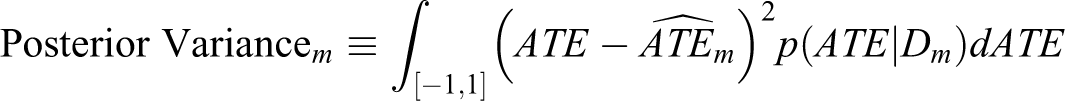
and the posterior RMSE: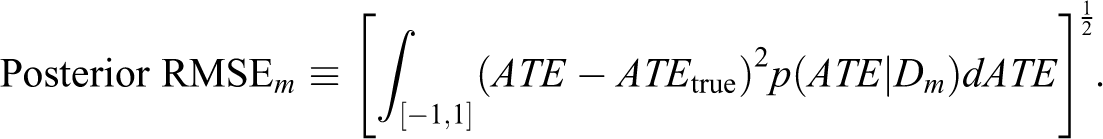
Note that these quantities are defined for an individual Monte Carlo replication m. In what follows, we will look at the distribution of these quantities over all M Monte Carlo replications
In a perfect world, a case selection technique will have bias close to 0 and low RMSE, posterior variance, and posterior RMSE. This statement provides absolute standards for a case selection method. Selection methods can also be compared to each other, as we show subsequently.
Bias
Figures 1 and 2 display the biases of the various case selection methods across the different data-generating processes and sample sizes. When confounding is absent and the (X, Y ) cells are of similar size (experiments 1 and 2), then all methods perform similarly with a slight edge going to typical case selection, diverse case selection, influential case selection, and simple random sampling. However, when the (X, Y ) cells are not of similar size and the prior for ψ is not close to the true value of ψ (experiment 8), then methods other than typical case selection, influential case selection, or simple random sampling do poorly—in some cases increasingly poorly as the sample size gets large. With moderate or severe confounding, methods other than typical case selection, influential case selection, or simple random sampling also do poorly. Again the disparity in performance between these methods and the others grows as the sample size gets larger.
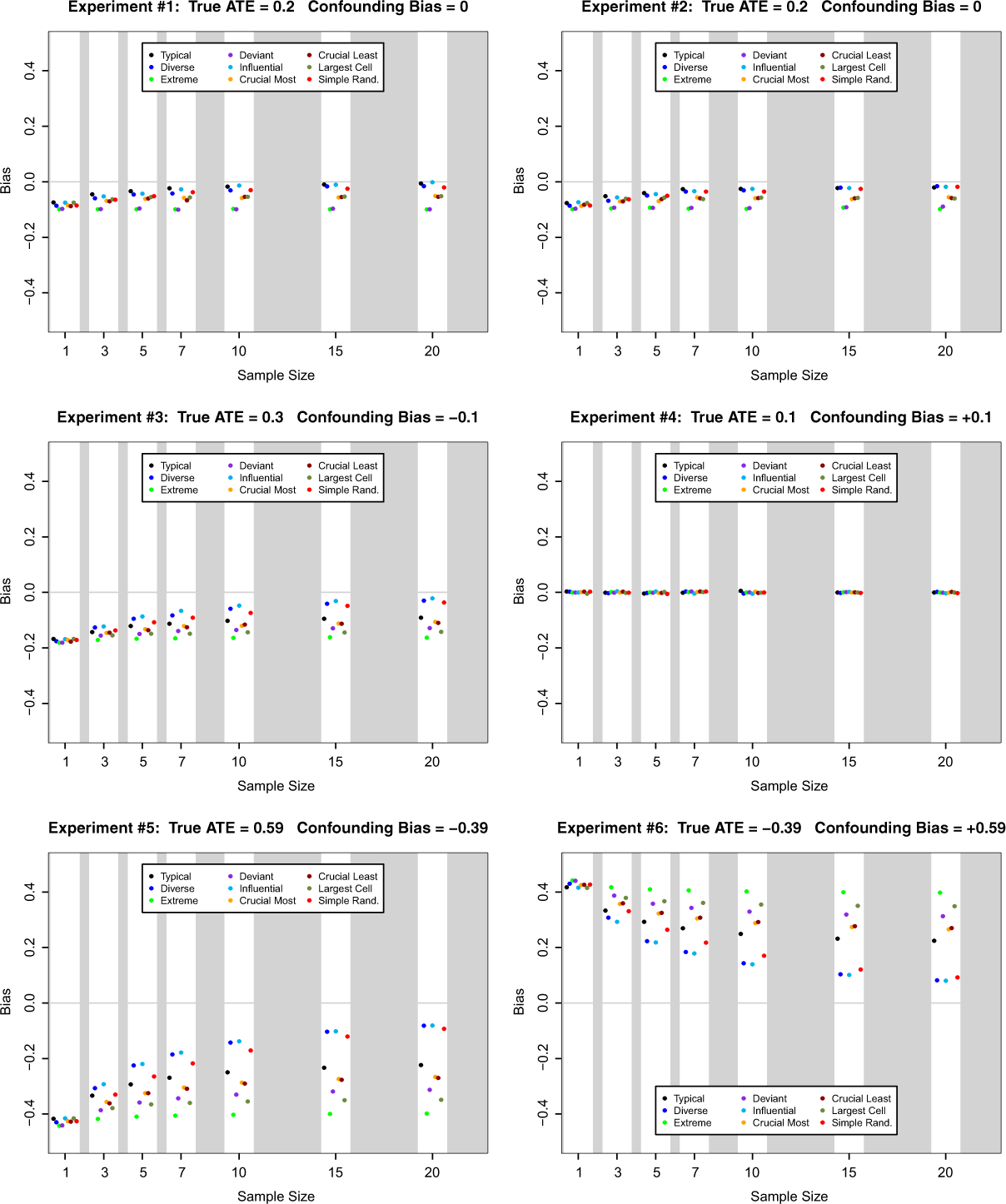
Bias of posterior mean estimator of ATE for nine case selection schemes and seven sample sizes in Monte Carlo experiments 1 through 6. Here the cells of the (X, Y ) table are relatively balanced with θ00 = 0.3, θ01 = 0.2, θ10 = 0.2, and θ11 = 0.3.
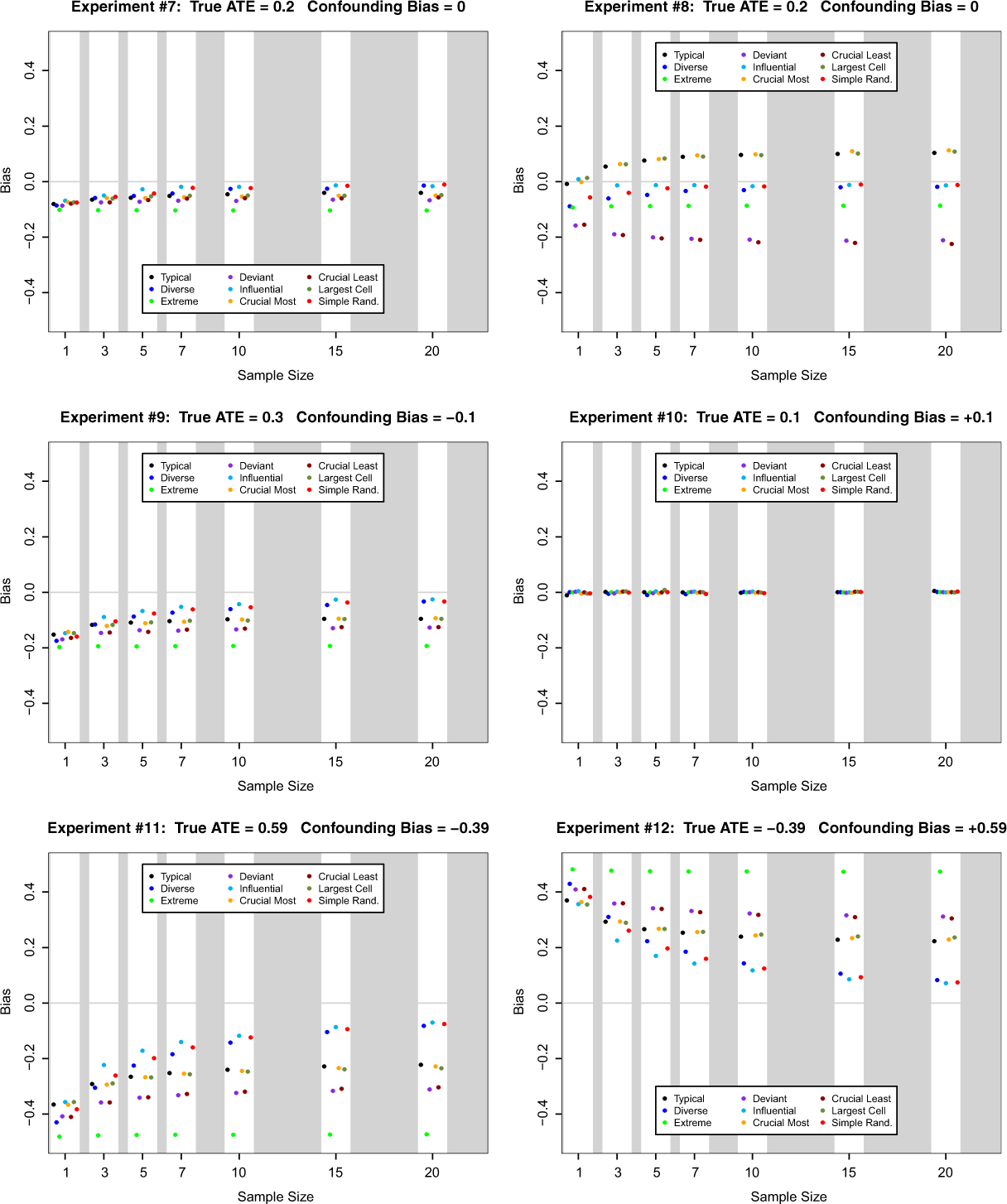
Bias of posterior mean estimator of ATE for nine case selection schemes and seven sample sizes in Monte Carlo experiments 7 through 12. Here the cells of the (X, Y ) table are relatively unbalanced with θ00 = 0.546, θ01 = 0.364, θ10 = 0.036, and θ11 = 0.054.
It is worth noting that for relatively small sample sizes of 3 and 5, influential case selection exhibits noticeably less bias than other methods. However, it is also worth noting that simple random sampling—often maligned as inappropriate for small-Q (qualitative) case study research—has lower bias than most other case selection methods. Of course, many would argue that this is not surprising and that the real reason for not using simple random sampling is its relatively high variance and high RMSE. We examine the accuracy of this belief subsequently. Finally, we note that bias is low for all case selection methods in experiments 4 and 10 because the prior distribution used in the experiments is (coincidentally) centered on the true value of ATE.
RMSE
Figures 3 and 4 display the RMSE of the various case selection methods across the various Monte Carlo experiments. For the experiments in which confounding is either moderate or absent, no sampling scheme dominates in terms of RMSE. Our hypothesis for why this is the case is that frequentist RMSE looks only at the sampling distribution of our point estimator (here the posterior mean) and this will depend heavily on the prior. For instance, RMSE is low for case selection methods that select cases from small (X, Y ) cells in experiments 4 and 10 because the prior distribution used in the experiments is (coincidentally) centered on the true value of ATE. Sampling in a way that does little to change the posterior from the prior will only have good properties when, as is the case in these experiments, the prior is centered on the truth.

Root mean square error (RMSE) of posterior mean estimator of ATE for nine case selection schemes and seven sample sizes in Monte Carlo experiments 1 through 6. Here the cells of the (X, Y ) table are relatively balanced with θ00 = 0.3, θ01 = 0.2, θ10 = 0.2, and θ11 = 0.3.
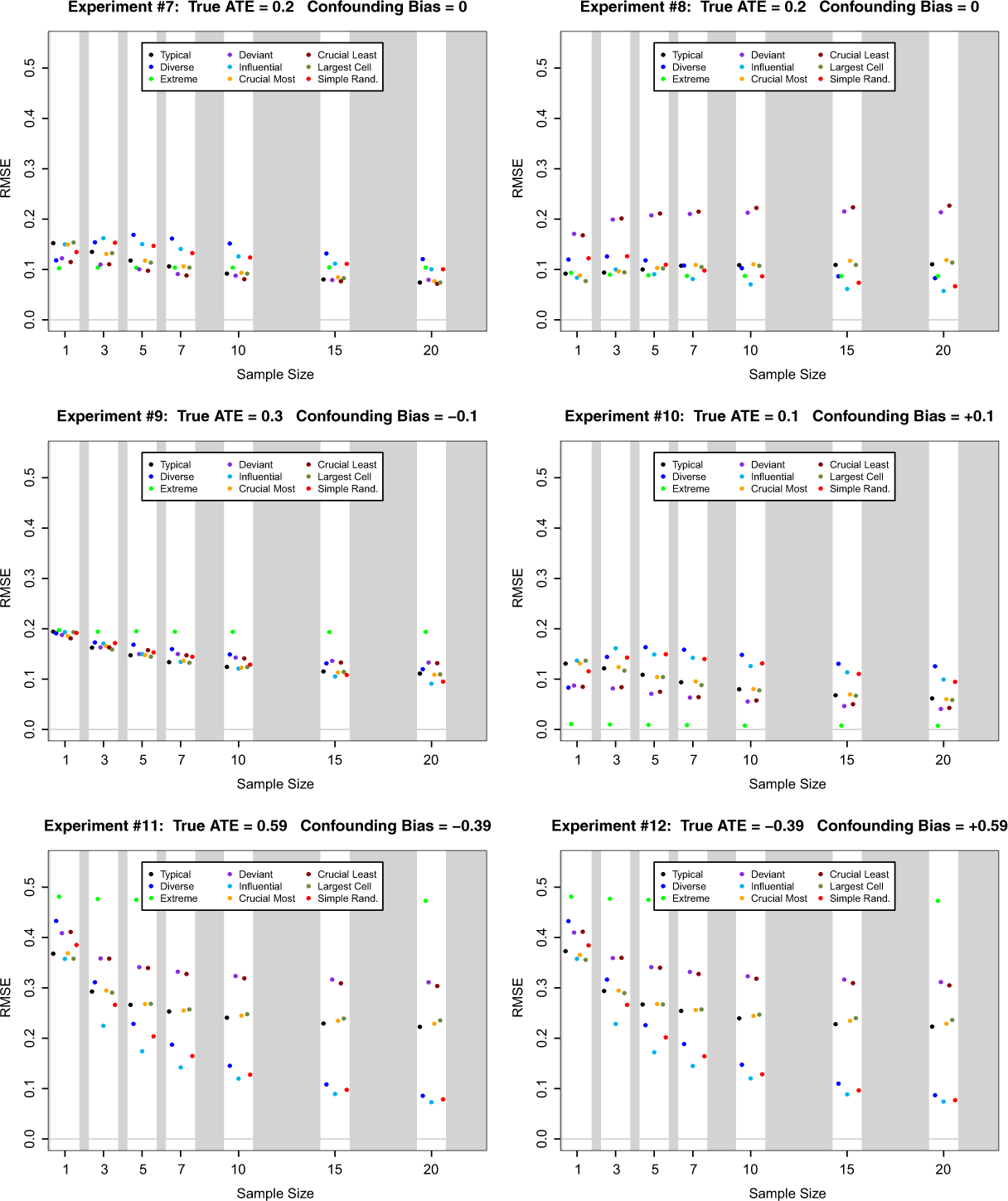
Root mean square error (RMSE) of posterior mean estimator of ATE for nine case selection schemes and seven sample sizes in Monte Carlo experiments 7 through 12. Here the cells of the (X, Y ) table are relatively unbalanced with θ00 = 0.546, θ01 = 0.364, θ10 = 0.036, and θ11 = 0.054.
When the degree of confounding becomes severe (experiments 5, 6, 11, and 12) a clearer picture emerges. With similarly sized (X, Y ) cells (experiments 5 and 6) and moderate sample sizes (Q = 3, 5, 7), both diverse and influential case selection perform much better than the alternatives. In these situations, simple random sampling becomes increasingly attractive as Q gets larger. With very different (X, Y ) cell sizes, (experiments 11 and 12), and moderate sample sizes (Q = 3, 5, 7), influential case selection performs better than the alternatives, with simple random sampling coming in second. Diverse case selection closes the gap as Q gets larger. In situations with severe confounding, the case selection methods that focus on relatively unpopulated (X, Y ) cells do extremely poorly in terms of RMSE.
Posterior Variance
Figures 5 and 6 summarize the distribution of the posterior variance of ATE for the various sampling schemes, sample sizes, and data-generating processes. While the posterior variance is of limited interest in its own right (a certain case selection method might often produce low posterior variance but be very far from the truth), it does allow us to see which case selection methods produce the largest changes from prior to posterior. In some sense, this is a measure of how much learning has occurred under a particular case selection scheme.
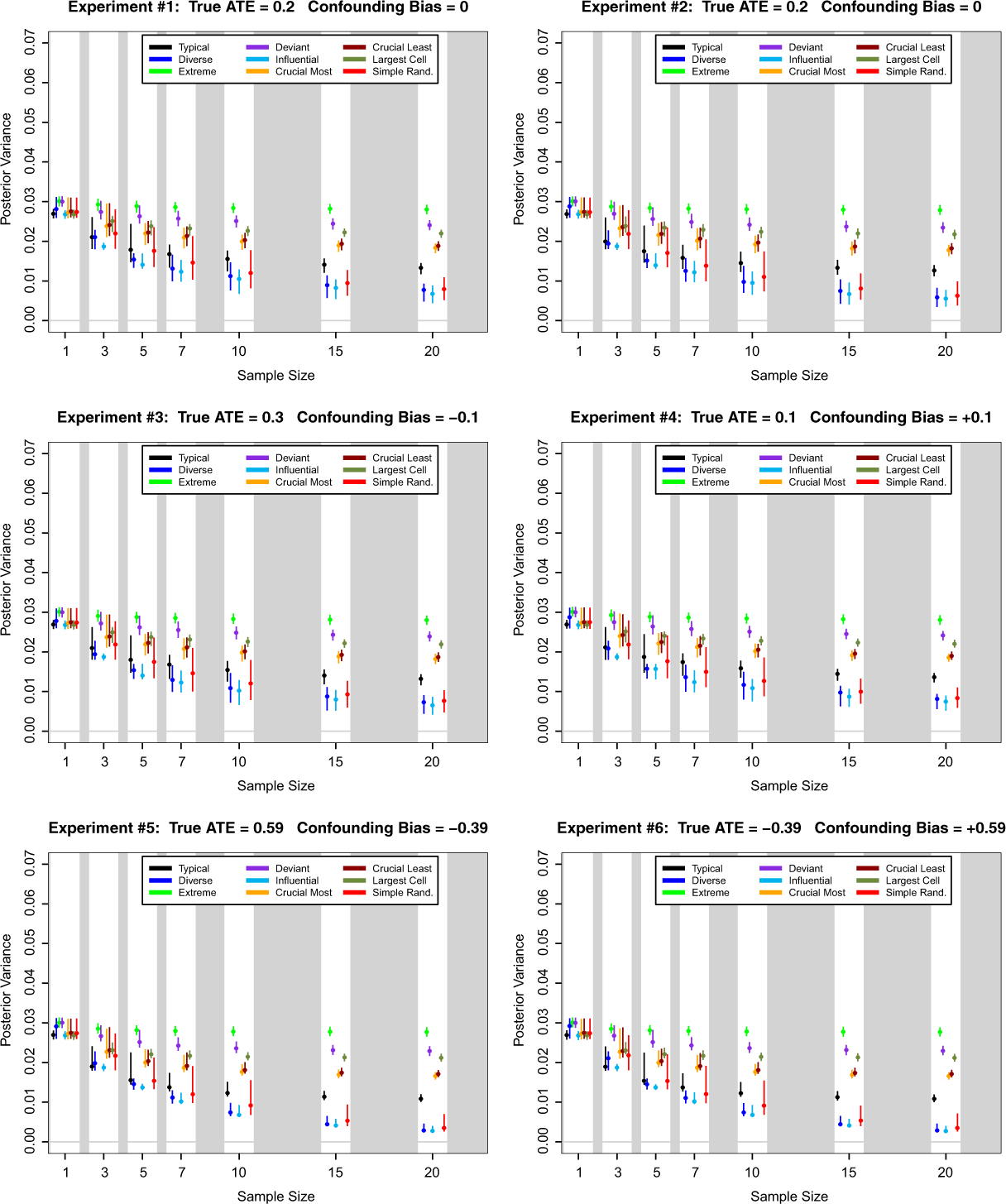
Posterior variance of ATE for nine case selection schemes and seven sample sizes in Monte Carlo experiments 1 through 6. Here the cells of the (X, Y ) table are relatively balanced with θ00 = 0.3, θ01 = 0.2, θ10 = 0.2, and θ11 = 0.3. Dots are median values over 1,000 simulations and line segments are central 95 percent regions.
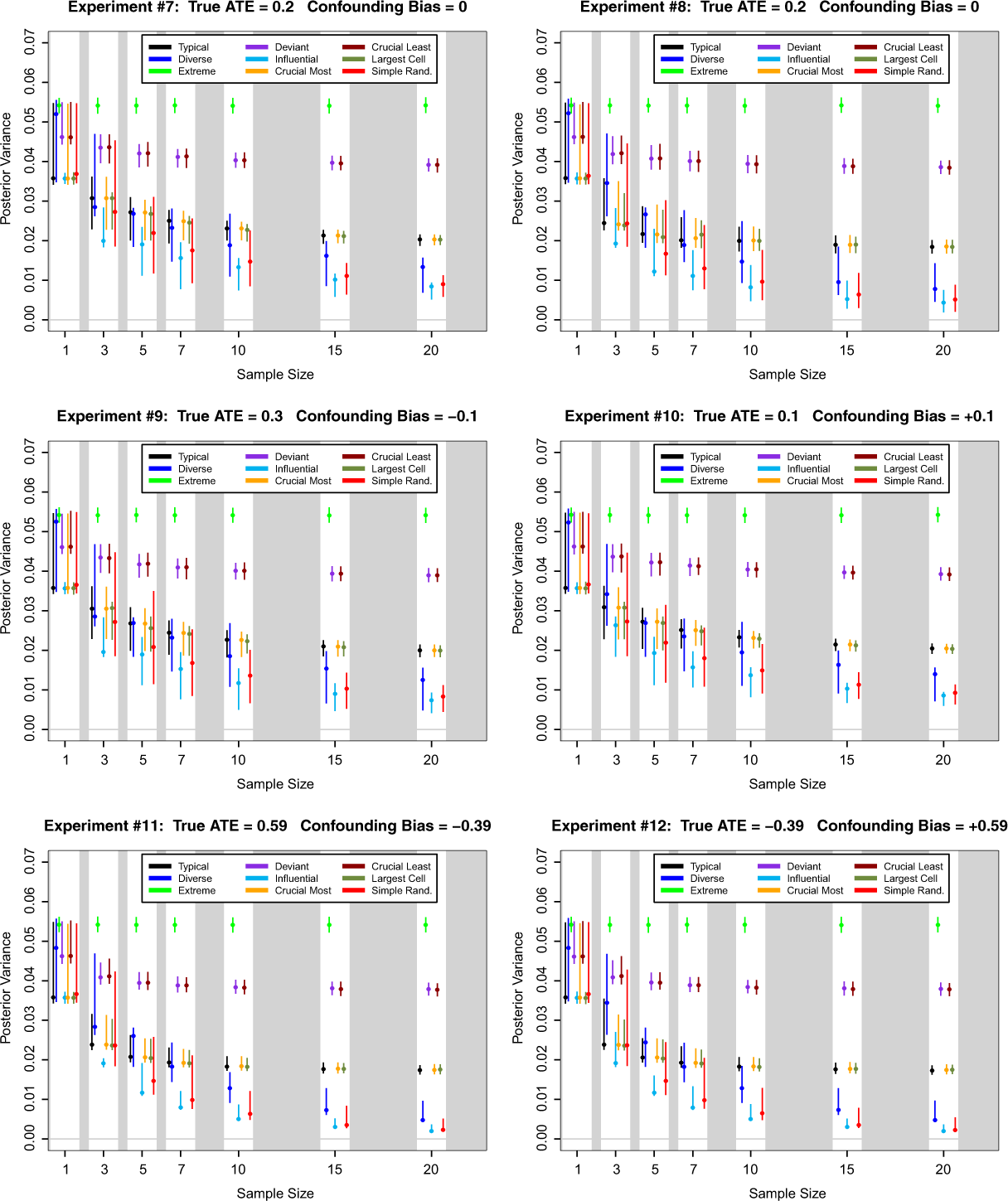
Posterior variance of ATE for nine case selection schemes and seven sample sizes in Monte Carlo experiments 7 through 12. Here the cells of the (X, Y ) table are relatively unbalanced with θ00 = 0.546, θ01 = 0.364, θ10 = 0.036, and θ11 = 0.054. Dots are median values over 1,000 simulations and line segments are central 95 percent regions.
The results here are quite unambiguous—influential case selection does the most to shrink the posterior variance of ATE. This is true across all values of Q in all the Monte Carlo experiments. This should not be too surprising since our operationalization of influential case selection was designed to minimize posterior variance of ATE. Nevertheless, it is instructive to see how much better influential case selection is in this regard than other case selection methods. It is also very interesting to note that simple random sampling also fares quite well in terms of posterior variance. This is the case even with fairly moderate sample sizes (Q = 5, 7). It thus seems that some of the concerns regarding the assumed high variance of simple random sampling with moderate sample sizes are misplaced.
Posterior RMSE
Figures 7 and 8 summarize across Monte Carlo experiments the distribution of the posterior RMSE for the nine sampling schemes under study. In many ways, low posterior RMSE is of most relevance to applied researchers, as it measures how close the entire posterior distribution is to the truth rather than just the proximity of a point estimator to the truth.
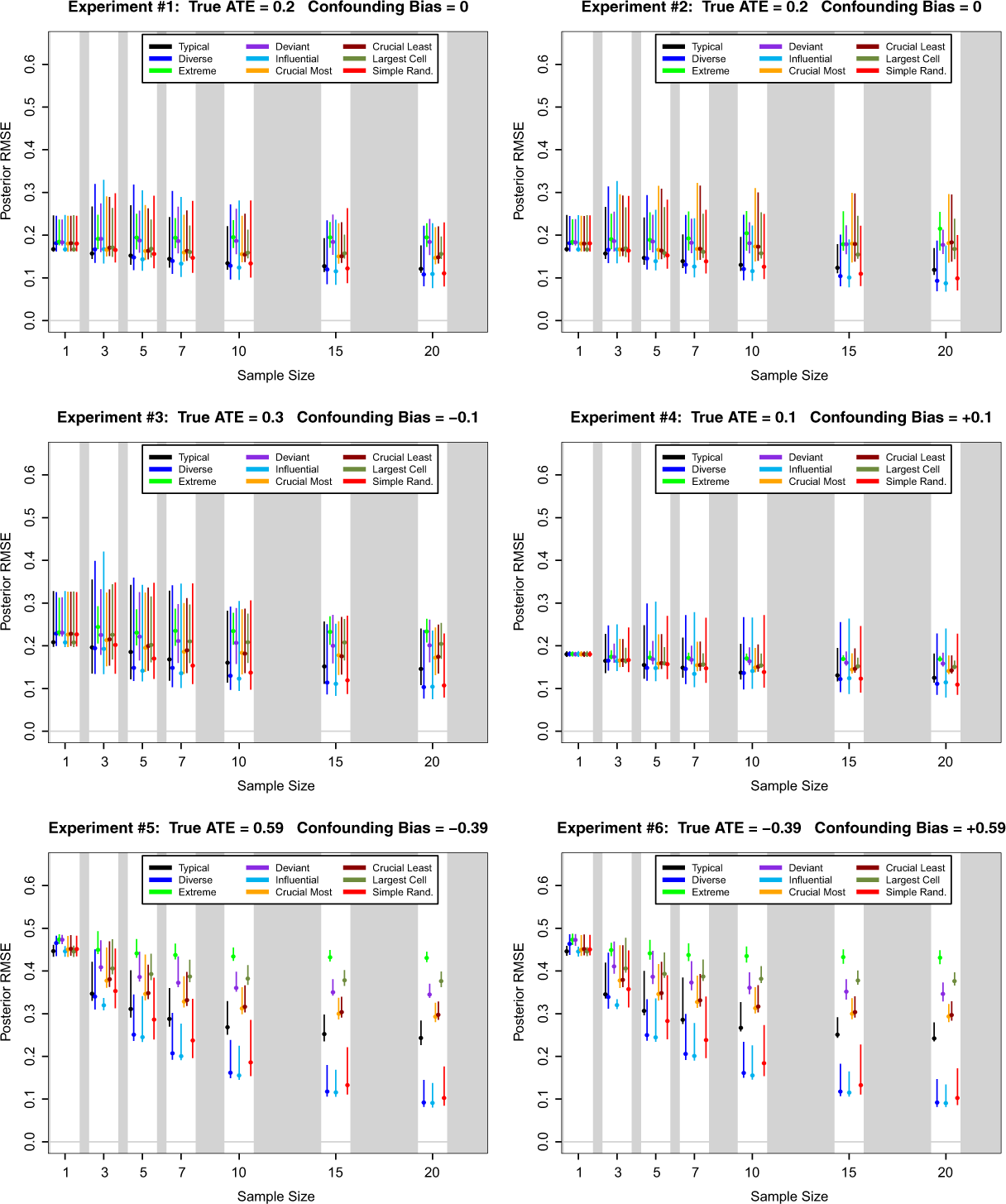
Posterior root mean square error (RMSE) of ATE for nine case selection schemes and seven sample sizes in Monte Carlo experiments 1 through 6. Here the cells of the (X, Y ) table are relatively balanced with θ00 = 0.3, θ01 = 0.2, θ10 = 0.2, and θ11 = 0.3. Dots are median values over 1,000 simulations and line segments are central 95 percent regions.
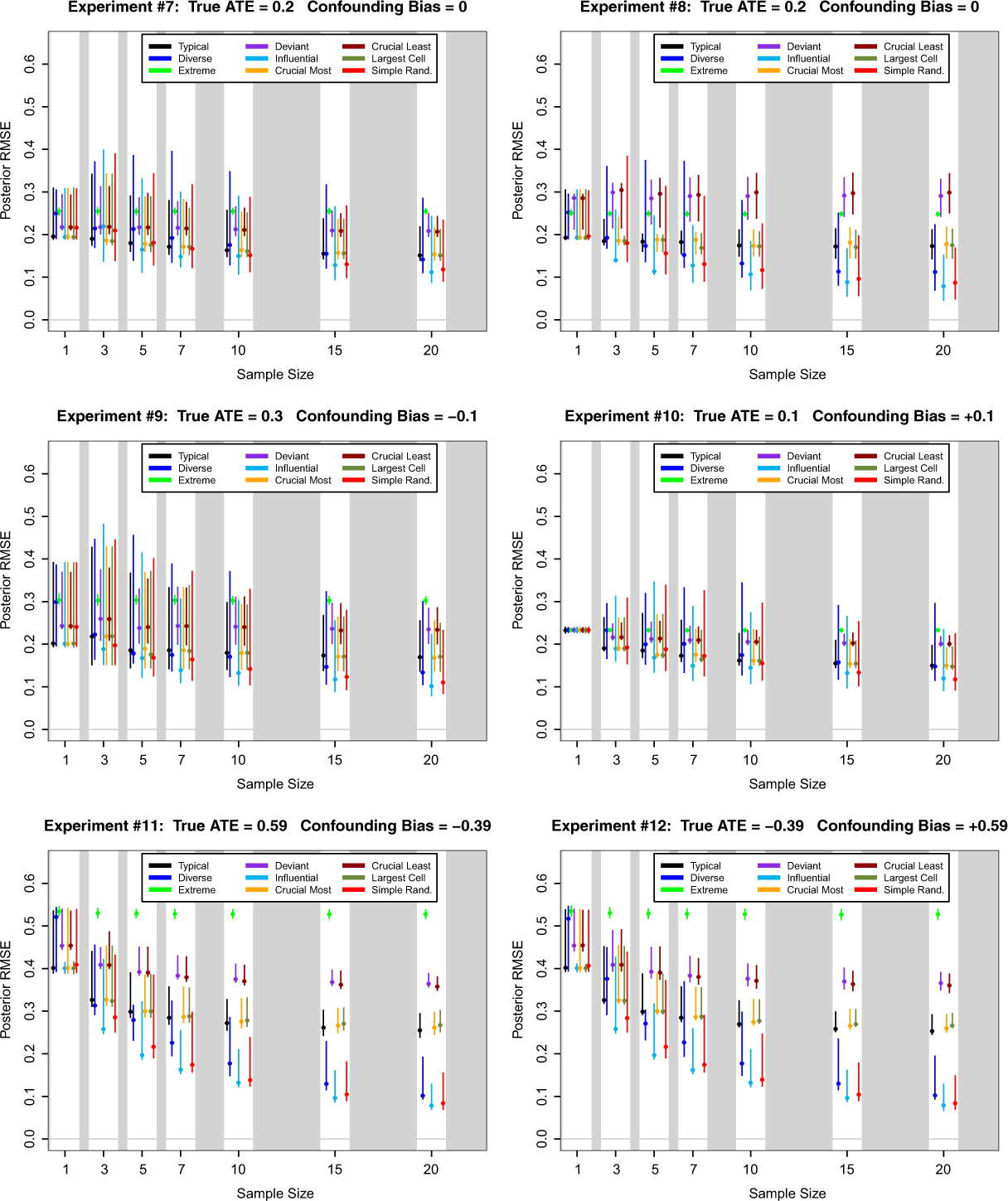
Posterior root mean square error (RMSE) of ATE for nine case selection schemes and seven sample sizes in Monte Carlo experiments 7 through 12. Here the cells of the (X, Y ) table are relatively unbalanced with θ00 = 0.546, θ01 = 0.364, θ10 = 0.036, and θ11 = 0.054. Dots are median values over 1,000 simulations and line segments are central 95 percent regions.
Once again, influential case selection emerges as the dominant case selection method. This is true across sample sizes and Monte Carlo experiments. The gains to using influential case selection are greatest when there is severe confounding and moderate to small sample sizes. When the (X, Y ) cells are of roughly equal size, diverse case selection does nearly as well as influential case selection. When the (X, Y ) cells are of very different sizes, then simple random sampling is second best. However, the largest posterior RMSE that one might see under simple random sampling can be noticeably higher than the largest posterior RMSE under influential case selection. Finally, it is worth noting that extreme case selection always does quite poorly when judged in terms of posterior RMSE. Based on these simulation results, it seems prudent to recommend that extreme case selection should not be used if the goal is to infer population-level average causal effects.
Summary of Monte Carlo Results
The message that applied researchers should take from our simulations is that our implementation of influential case selection is stronger on more criteria across more types of data-generating processes than other case selection methods. Influential case selection appears to be the best way to select cases if the goal of such case selection is to infer population-level average causal effects. Our implementation of diverse case selection and simple random sampling also fare quite well. Given that these latter methods are easier to implement that influential case selection, there is some argument for preferring these methods in certain situations. The fact that simple random sampling outperforms most methods of case selection—even when sample size is as small as 5 or 7—should be news to many (qualitative) researchers who assert that simple random sampling should only be used with relatively large, say Q > 20, sample sizes. Finally, if one can only choose a very small number of cases, say fewer than three, for case analysis, then the very simple method of randomly choosing cases from the largest cell of the 2 × 2 (X, Y ) table (largest cell case selection) is extremely competitive with other, more complicated, cases selection strategies.
The simulation results also set forth some clear messages about which case selection methods should always be avoided. Our implementation of extreme case selection always does extremely poorly unless one is lucky enough to know the answer (and encode this in one’s prior distribution) before the analysis begins. Similarly, deviant case selection and crucial (least) case selection generally fare quite poorly. The commonality shared by all three of these case selection methods is a focus on sparsely populated cells in the 2 × 2 (X, Y ) table. From a purely statistical sampling perspective, focusing attention on cases that are not representative of the population as a whole will usually lead to a huge waste of resources. While such cases may be useful for exploratory analysis and/or theory construction, the amount of information they can provide about population-level average causal effects is, by definition, limited.
Conclusion
Case study methodology is widely used by empirical social scientists, especially by qualitative researchers in the subfields of political science known as comparative politics and international relations. The fundamental issue involved with this methodology is how one should choose cases for detailed analysis. While a great deal has been written about case selection, there is still widespread disagreement regarding which case selection technique is optimal and in what circumstances. We believe that part of the reason for this lack of agreement stems from the lack of a rigorous counterfactual causal framework for case study research, and with this dearth in mind, we have provided such a framework.
We have used our framework to evaluate a number of prominent case selection methods that have been discussed at length by Seawright and Gerring. Our results suggest that our implementation of influential case selection is generally to be preferred over the other case selection methods under study. We also find that deviant case selection works quite well and that, contrary to conventional wisdom, simple random sampling performs well relative to most other case selection methods as long as a moderate number (say five or more) of cases are to be selected for case study analysis. Our findings have clear implications for how applied researchers should select cases for analysis, and extending our analytical approach to additional case selection techniques will help shed light on the best techniques in a variety of research situations. That said, we again emphasize that our results only speak directly to our stated goal of inferring effects of causes.
Footnotes
Acknowledgment
We thank Oliver Bevan, Adam Glynn, and Gary King for helpful conversations and the National Science Foundation (grants BCS 05-27513 and SES 07-51834) for research support. The authors are listed in alphabetic order.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Kevin Quinn. National Science Foundation (grants BCS 05-27513 and SES 07-51834).