
Abstract
In a recent contribution to Sociological Methods & Research, Baumgartner and Epple (B&E) employ Coincidence Analysis (CNA) to explain the outcome of the vote on the Swiss minaret initiative of 2009. Although the authors also present a substantive argument, their principal objective is to prove the superiority of CNA over Qualitative Comparative Analysis (QCA) due to the former’s capability of identifying causal chains in configurational data without resort to Quine–McCluskey (QMC) optimization, whereby logical contradictions are allegedly introduced into the latter’s minimization process that trivialize the results. In this methodological commentary, I demonstrate that CNA does not challenge QCA per se but merely seeks to find fault with QMC. However, the link between QCA and QMC has never been inextricable, and alternative algorithms not beset by the one-difference restriction B&E consider problematic have long been in use. Hence, it follows that CNA introduces a new algorithm but does not perforce offer a superior method. To support this argument, I showcase the untapped potential of QCA for identifying causal chains in data that even incorporate multivalent factors. In employing the eQMC algorithm, whose general approach to Boolean minimization resembles that of CNA in decisive parts, I extend the authors’ original analysis in several directions, without generating logical contradictions along the way. I conclude that future research should continue to explore the methodological implications of the issues which CNA’s introduction has raised for QCA. Ultimately, however, the integration of their individual strengths represents one of the most promising avenues for the further development of configurational comparative methods.
Keywords
Introduction
Qualitative Comparative Analysis (QCA) is a family of configurational comparative methods (CCMs) whose objective consists in the identification of causally relevant combinations of conditions with respect to some outcome by means of Boolean minimization. In a recent contribution to this journal, Baumgartner and Epple (B&E 2014) juxtapose QCA and Coincidence Analysis (CNA)—another CCM developed by Baumgartner (2009a, 2009b, 2013)—using data on the Swiss minaret initiative of 2009. The authors seek to prove CNA preferable to QCA due to the former’s capability of revealing chain structures behind the data without resort to Quine–McCluskey (QMC) optimization, whereby contradictory assumptions that allegedly trivialize results are inserted into the latter’s minimization process.
The objective of this commentary is to demonstrate that CNA does not challenge QCA per se, but only aims to find fault with QMC. However, various algorithms not relying on those of QMC’s components which B&E consider problematic have long been in use. To support this argument, I extend the authors’ original study by remodeling the data on the Swiss minaret vote as a causal chain with QCA, the first time in the literature the method will have been put to such use. I employ the enhanced Quine–McCluskey algorithm (eQMC) of the QCA package to this end, a procedure whose approach to minimization intriguingly resembles that of CNA in decisive aspects (Duş a and Thiem 2014; Thiem and Duş a 2013b). In this connection, I also illustrate how to exploit the untapped potential of QCA for discovering causal chains that include conditions from multivalent factors, yet another novelty whereby an unprecedented degree of analytical differentiation can be obtained.
The article proceeds as follows. First, I recapitulate B&E’s results; second, I address some of the methodological claims that undergird their argument; third and finally, I extend the authors’ analysis of the vote on the Swiss minaret initiative in three directions. Besides arguing against filters for sufficiency coverage, I reveal some minimal dependencies that have been missed in the original study. Most importantly, however, I show how data that incorporate even multivalent factors can be modeled with QCA as a causal chain. I conclude that CNA represents a tremendously important innovation that deserves more attention, but the mere existence of causal-chain structures provides no reason for impugning the suitability of QCA ab initio.
Summary of B&E’s CNA
Although the orientation of B&E’s article is methodological, their analysis provides the first empirical application of CNA. The authors are interested in the national vote on the Swiss minaret initiative of 2009, an event that caught significant attention because of its political explosiveness. After weeks of intense campaigning, 22 out of all 26 Swiss cantons approved a constitutional amendment that banned the construction of new minarets in the country.
Drawing on a number of explanations proffered in the wake of the vote, B&E investigate the dependencies among six bivalent factors on the cantonal level: the rate of old xenophobia (A: 1 high, 0 not high), the strength of left parties (L: 1 strong, 0 not strong), the share of the Serbian-, Croatian- or Albanian-speaking population (S: 1 high, 0 not high), the economic structure (T: 1 traditional, 0 not traditional), the rate of new xenophobia (X: 1 high, 0 not high), and the outcome of the vote on the initiative (M: 1 accepted, 0 rejected).
1
A causal ordering is imposed on these factors: Neither value of M can be a cause of any value of another factor; neither value of X can be the effect of any value of M; neither value of L or S can be the effect of any value of X or M; and neither value of A or T can be the effect of any value of another factor. The temporal relation

It says that the ban was accepted in cantons that had previously endorsed other xenophobic initiatives or that were characterized by a traditional economic structure. Cantons of the former type, with the exception of a single case, also lacked strong left parties and a traditional economic structure, or were home to a high share of native speakers of Serbian, Croatian, or Albanian.
Subsequently, the authors analyze the same data by means of QCA. They find that expression (1) is recovered, but, in the same breath, they point out that QCA has only been able to do so at the price of introducing logically contradictory assumptions, which trivializes this accomplishment. 3 B&E therefore conclude that CNA is preferable to QCA if causal-chain structures such as those found in their example exist.
Problems and Limitations
B&E seek to substantiate the claim that CNA trumps QCA by referring to QMC’s one-difference restriction—the repeated use of the fundamental Boolean-algebraic theorem
First, only four genuine variants of QCA exist, which are defined by specific set types. Both mvQCA (Cronqvist and Berg-Schlosser 2009; Thiem 2015) and fsQCA (Ragin 2008) are generalizations of csQCA on distinct dimensions, the former on the number of values that a crisp factor is allowed to take on, the second on an object’s degree of membership in each of the two sets constituted by the values of a bivalent factor. The fourth variant, generalized-set QCA, is based on the concept of the multivalent fuzzy-set factor, which integrates crisp multivalence with fuzzy bivalence (Thiem 2013, 2014b).
In contrast, TQCA, two-step QCA, and ESA-QCA are no “set-theoretic” variants of their own. TQCA is an enhancement of csQCA in which a set of auxiliary factors codify temporal order between substantive factors (Caren and Panofsky 2005; Ragin and Strand 2008). The idea of two-step QCA is to bifurcate the set of condition factors into a set of proximate and a set of remote factors so as to reduce the problem of limited diversity (Schneider and Wagemann 2006), and the primary goal of ESA is to break the algorithmic tie between simplifying assumptions on the one hand and different types of counterfactuals on the other in the derivation of parsimonious and intermediate solutions (Schneider and Wagemann 2013).
Second, the claim that all QCA variants employ QMC is incorrect. Minimization algorithms are not linked with QCA, but with particular software implementations. The fs/QCA program (Ragin and Davey 2014) and fuzzy for Stata (Longest and Vaisey 2008) use QMC with some modifications, the Tosmana software (Cronqvist 2011) employs a graph-based agent, the FSGoF program is, in fact, a fuzzified version of CNA for single outcomes (Eliason and Stryker 2009), and the QCA package for the R environment draws on eQMC (Duş a and Thiem 2015; Thiem and Duş a 2013a:512). 4
In point of fact, and most intriguingly from an algorithmic perspective, CNA and eQMC share a similar minimization logic but take exactly opposite routes. The former works incrementally by starting with the configurations according to
Besides claiming that QMC is intrinsic to QCA, B&E (p. 290) argue that “there are good reasons to impose lowest bounds at least for suf-coverage of whole solution formulas as well.” The problem that justifies this demand, they assert, lies in the existence of a potential host of confounding factors, whereby the risk of spurious dependencies increases. A call for high solution coverage, however, presupposes the overriding goal of the analysis to be the explanation of as many instances of the outcome as possible. Such a criterion stands on shaky ground. Suppose an educational evaluator was interested in whether an experimental high school reform had improved grades in a district or not. There may be many causes of academic success in school but as long as it can be plausibly ruled out that any other external conditions, even if causally relevant to high school success, were associated with any component of the experimental reform, gathering data on them in order to maximize the explained share of the outcome would not only be uneconomical but could induce even more problems.
Confounding cannot occur if a condition that is excluded from the analysis is not causally associated with the outcome, irrespective of whether it is causally associated with a condition that is included in the analysis. Nor can confounding occur if a condition that is excluded from the analysis is not simultaneously associated with the outcome and a causally relevant condition that is included in the analysis. The inclusion of a highly relevant condition may thus create more problems than if it had been left out when it is simultaneously associated with at least one other relevant condition that has been omitted from the analysis and at least one relevant condition that is included. Put differently, better-fitting models need not necessarily be more accurate than those with worse summary statistics.
Using QCA for Identifying Causal Chains
QCA has so far implicitly operated on the basis of what Baumgartner (2009a:72) refers to as the singularity, the independence, and the identifiability of causes and effects assumptions. The most noteworthy contribution of CNA to the literature on CCMs consists in the relaxation of these restrictions. In this section, I not only seek to confute B&E’s argument that QCA is unfit for this task, but I also show that the method can even already operate on such problems at a higher level of differentiation than CNA.
The extension of B&E’s original analysis comprises three elements: the identification of missed model components, the recalibration of M into a trivalent outcome factor whose calibration rests on empirical rather than theoretical criteria, and the analysis of all levels of each outcome factor supplied to
The minaret initiative data are not immune to this problem. For example, even though the canton of Jura has voted in favor of the ban unlike the canton of Neuenburg, their voting shares lie a mere 2 percentage points apart. In contrast, Jura and Appenzell Innerrhoden, the latter of which had the highest acceptance rate, show a difference of more than 20 percentage points, but both voted in favor of the ban. The originally bivalent factor M will thus be recalibrated empirically on the basis of the exact vote shares to incorporate three ranges. In addition, X will be made trivalent so as to include at least one such factor that is an element in both
The justification for the third part is that analyses for an outcome and its negation provide richer explanations for crisp-set data, and are indispensable controls with fuzzy-set data, for which simultaneous sufficiency relations may occur. Although it is impossible with crisp-set data to find some condition to be simultaneously sufficient for both the outcome and the negation of the outcome at reasonable levels, it seems expedient to provide a comprehensive outcome analysis, not least because a fuzzy-set version of CNA is in preparation (B&E:285). In summary, the new condition factor frame is given by
B&E (p. 290) set the cut-off for both sufficiency inclusion (
Solution and PI Details for Outcome Factors L and S.

Note: PI = prime implicant; Inc = inclusion; Covr = raw coverage; Covu = unique coverage; Out. = outcome.
The solutions for all three values of
Solution and Prime Implicant Details for Outcome Factor
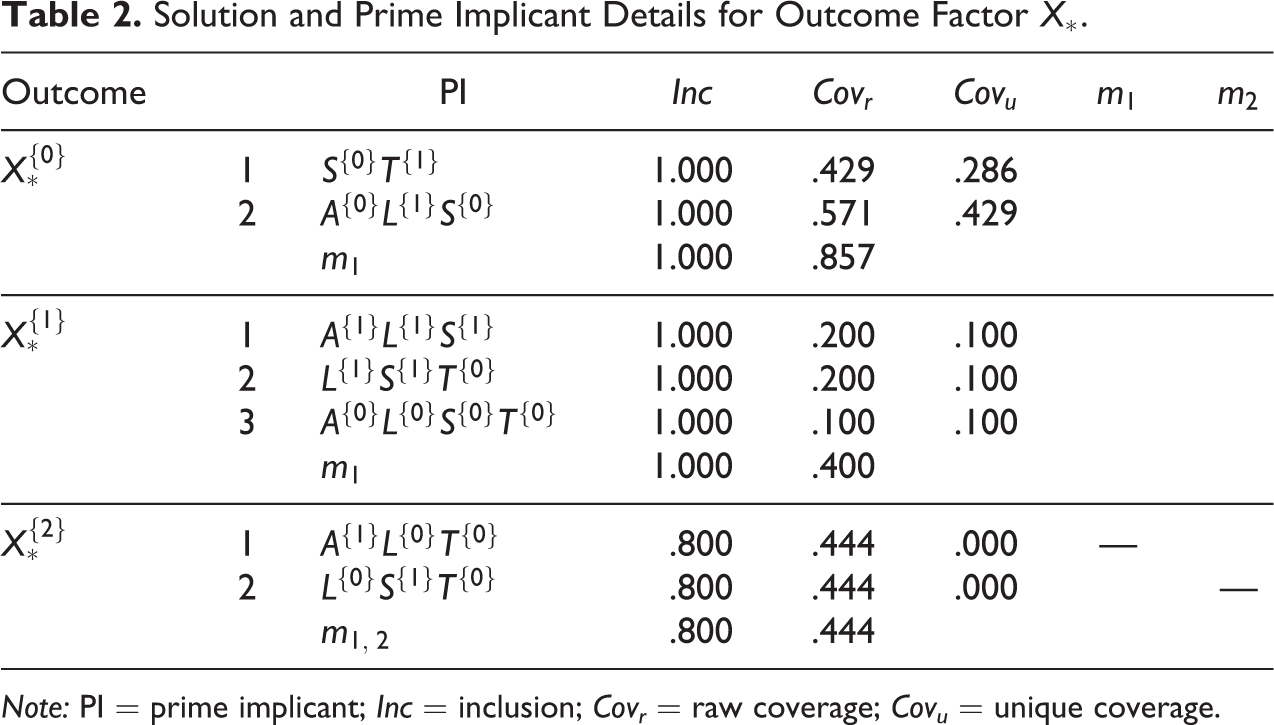
Note: PI = prime implicant; Inc = inclusion; Covr = raw coverage; Covu = unique coverage.
The solution details for the respective sets of cantons with a low and a high vote share are given in Table 3. While only four alternative models each with respect to outcomes
Solution and Prime Implicant Details for Outcome Factor
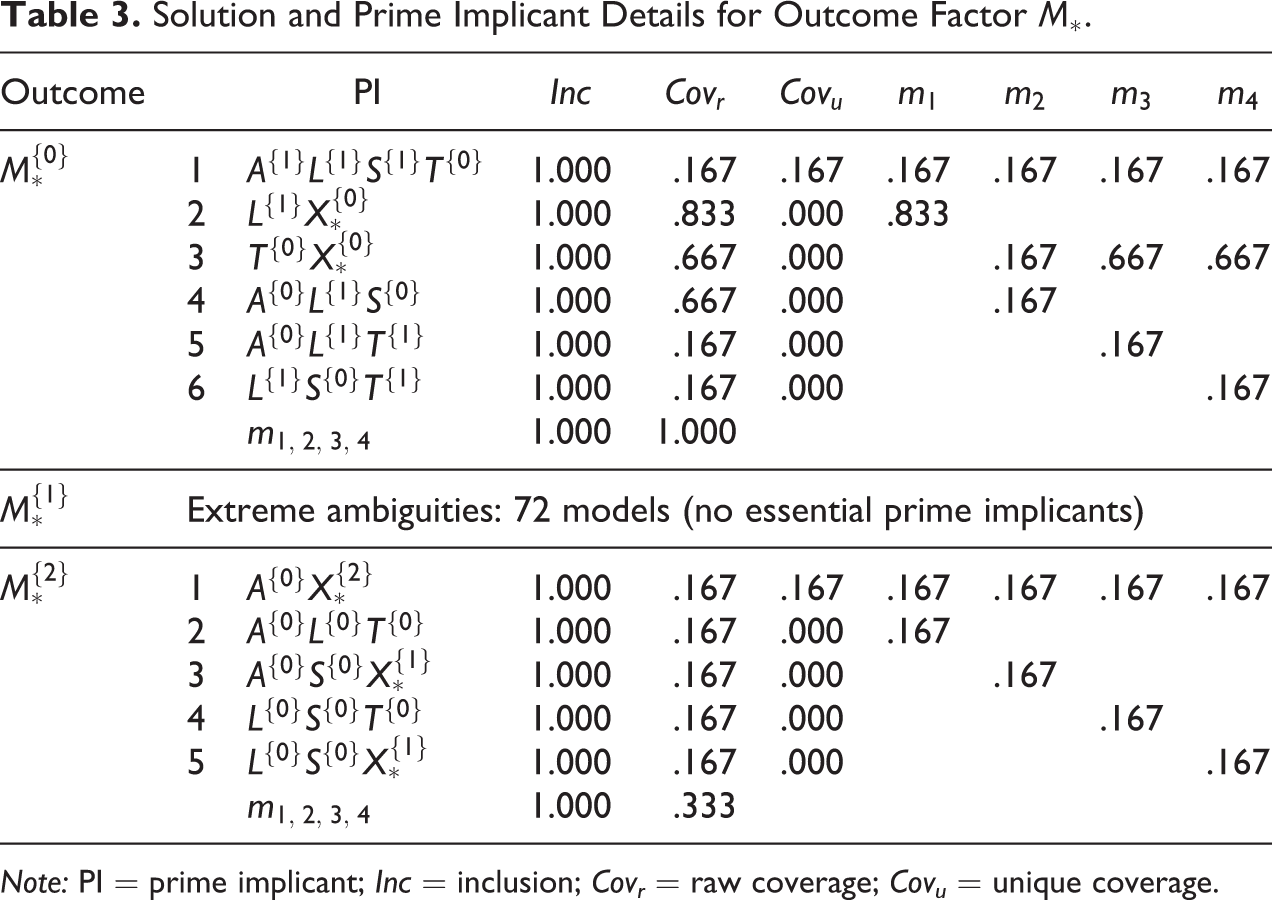
Note: PI = prime implicant; Inc = inclusion; Covr = raw coverage; Covu = unique coverage.
The solutions for
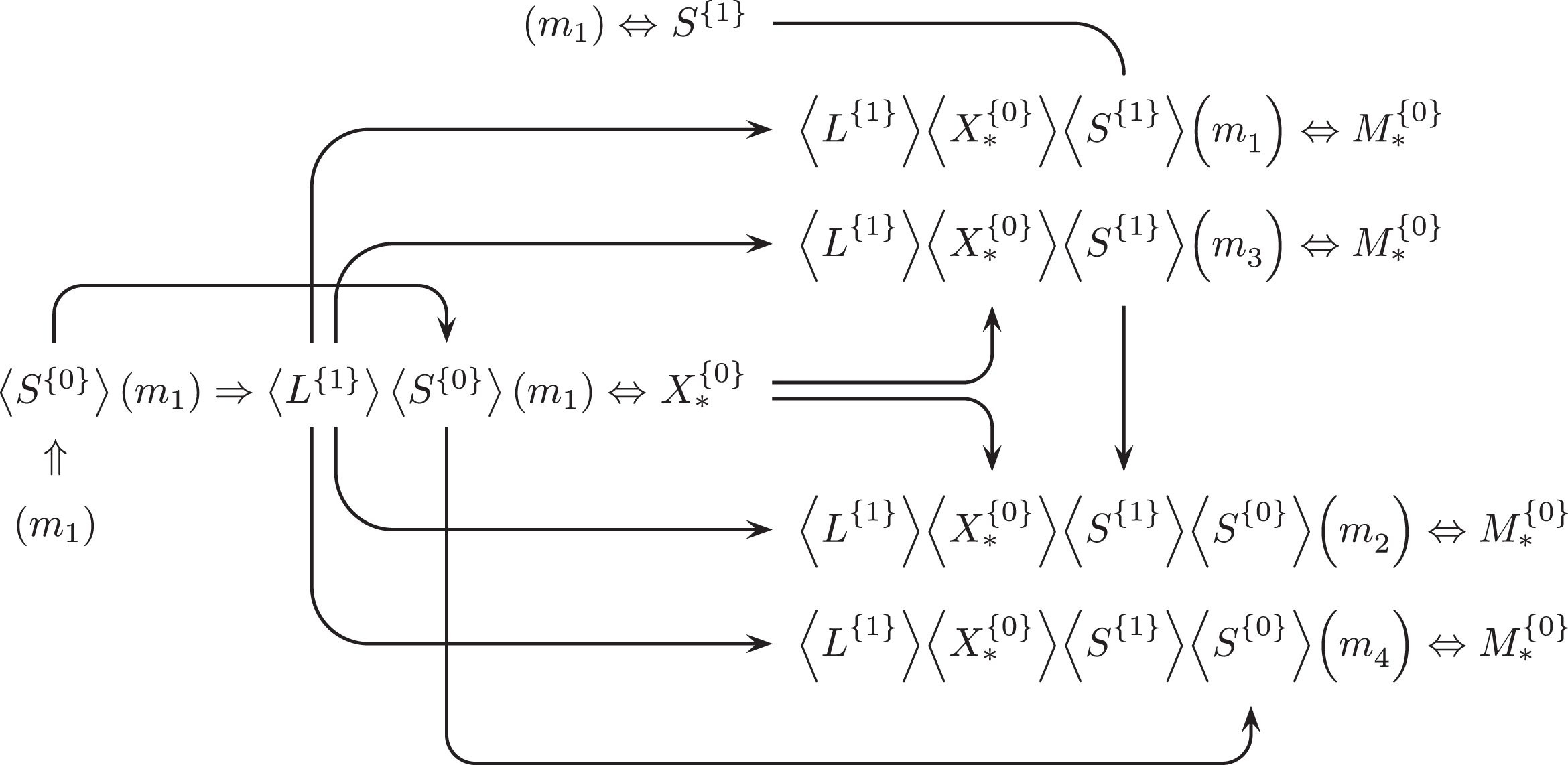
Reduced Causal-Chain Structure For Ultimate Outcome
As in B&E’s original study, the empirical interpretation of these results has to remain underdeveloped, but the main goal of this analysis was to illustrate how QCA can be used to study causal chains at an unprecedented degree of differentiation, without recourse to logical remainders. There is certainly no reason why CNA could not be enhanced with the possibility to process multivalent factors, which would only add to its potential, but at least as much potential continues to be unexploited in QCA.
Conclusions
CNA has enriched the toolkit of comparative researchers on several fronts. Most importantly, the concept of causal chains has so far been missing in QCA, although chain theories are omnipresent in the social sciences. However, this commentary has shown that QCA can be adapted to also discover causal chains, without the concurrent need to introduce logical contradictions along the way that allegedly trivialize results. CNA therefore only challenges QMC optimization rather than QCA as a family of techniques for processing different set types in the causally oriented analysis of configurational data.
In this regard, a decisive question that remains unaddressed by CNA to date is the following: If parsimonious QCA solutions for causal-chain structures derived by means of QMC optimization are trivialized because they require the introduction of logical contradictions, and if anything follows from such contradictions, why are these solutions not randomly different from those produced by CNA but usually match them one-to-one? The answer to this question will be crucial since it determines the extent to which CNA can defend its claim to superiority beyond algorithmic particularities.
CNA and QCA are much more closely related than has been acknowledged so far. Future research should continue to explore the methodological implications of the issues that the introduction of CNA has raised for QCA, but it should ultimately strive for an integration of the respective strengths of each so as to improve the technical foundations, and to further increase the empirical applicability, of configurational comparative methods across and beyond sociological research.
Footnotes
Acknowledgment
I thank Christopher Winship for having supported an open scientific debate on Qualitative Comparative Analysis in Sociological Methods & Research over the years, and the two anonymous reviewers for their comments on this particular article; but above all, I owe Michael Baumgartner a great debt of gratitude for the countless discussions we have had over the last years. I have benefited from every single one of them.
Declaration of Conflicting Interests
This article was submitted to this journal in December 2013. As of March 2014, Alrik Thiem has been employed as a post-doctoral researcher in the project “Coincidence Analysis”, which is funded by the Swiss National Science Foundation (award number PP00P1_144736/1) and led by Prof. Dr. Michael Baumgartner.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.