
Abstract
The Karlson–Holm–Breen (KHB) method has rapidly become popular as a way of separating the impact of confounding from rescaling when comparing conditional and unconditional parameter estimates in nonlinear probability models such as the logit and probit. In this note, we show that the same estimates can be obtained in a somewhat different way to that advanced by Karlson, Holm, and Breen in their original article and implemented in the user-written Stata command khb. While the KHB method and this revised KHB method both work by holding constant the residual variance of the model, the revised method makes comparisons across multiple nested models easier than the original method.
Sociologist and other social scientist routinely compare coefficients across same-sample nested models. For instance, when sociologists want to investigate how much of the association between a variable of interest, X, and an outcome, Y, is mediated through a third variable, Z, they often first fit a model with Y as the dependent variable and X as the predictor. Then, they fit another model that adds Z as a control variable. The coefficient for X from this model is compared with the corresponding coefficient from the first model. The difference between the two is then taken as a measure of how far the relationship between X and Y is mediated by Z.
If the models used are linear (estimated by, e.g., ordinary least squares [OLS]), this procedure is unproblematic, but this is not so for nonlinear models such as the logit, probit, multinomial logit, or ordered logit, which would often be used if the outcome, Y, were categorical or ordinal. Because nonlinear models are noncollapsible over confounders (or mediators), the change in the coefficient of the independent variable of interest is not solely driven by mediating or confounding by the added variables; part of the change is due to change in the residual variance of the models. The more variables that are included in a nonlinear probability model, the smaller the residual variance, and because the variance and mean are not separately identified in these models, change in the residual variance also affects the coefficient estimates. One consequence of this is that, even if a variable unrelated to X is added to the model, the coefficient of X will change. 1
Several methods have been suggested to separate this so-called rescaling effect from the true degree of confounding or mediation. They include Y-standardization, average marginal effects, and, more recently, the Karlson–Holm–Breen (KHB) method. The KHB method compares the regression coefficients for the variable of interest X from two models. One includes X and the mediators/confounders, Z (which may be a single variable or a vector), and one includes X and a residualized version of Z. The Z variables are residualized with respect to X. Both models have the same predictive power and hence the same residual variance, but the residualized Z are uncorrelated with X, and so a comparison of coefficients of the independent variable of interest across these models reveals the true impact of mediation/confounding on the coefficient for X.
In this article, we present a simple method to obtain exactly the same measure of confounding/mediation, using the latent index (i.e., the estimated linear predictor) from a nonlinear probability model. We show that this approach allows the researcher to infer the amount of mediation/confounding through simple linear regression analyses. We illustrate it with an example using the ordered logit model.
Method
We begin by defining the following latent linear regression models:

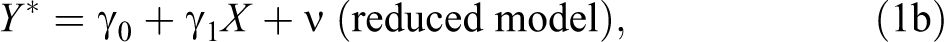
where
We observe the binary indicator, Y, defined in terms of the unobserved
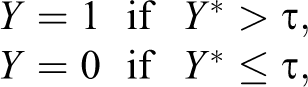
with
The nonlinear regressions corresponding to the latent linear models are


where
The KHB method works by residualizing the mediator/confounder, Z, by regressing it on X using OLS, and then another nonlinear model is estimated:

where

where u is an error term assumed to be independent of X and Z. Karlson, Holm, and Breen (2012) show that
The revised method presented here recovers the same ratio but in an easier way. Define V as the linear predictor (latent index) from equation (2a), that is,

Next, we fit two OLS models, using V as the dependent variable:


Equation (6a) has no error term because it is saturated: It fits the data perfectly.
Karlson et al. (2012) proved that the KHB method recovers the ratio

Thus, we need to show that the revised method, using equations (6a) and (6b), recovers the same ratio: That is, we need to show that
For all coefficients, we know that
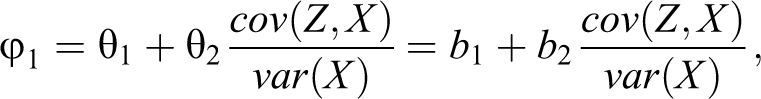
and this yields
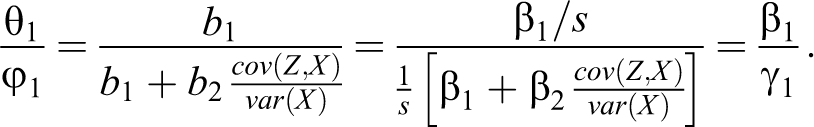
This method returns exactly the same ratio estimates of confounding or mediation as the KHB method, and these are equal to the true ratio in the underlying latent variable model in equations (1a) and (1b).
Comparing the Revised Method With the Original KHB
The method proposed here requires the following steps: fit the full model, including X and all other predictors of Y, as a logit or other nonlinear probability model; save the latent index from this model; and taking the latent index as the dependent variable, use OLS models (with and without the mediators/confounders), to estimate the extent of mediation or confounding.
The steps for the original KHB method are: regress the confounder on the independent variable of interest, obtain the predicted values from this regression, fit the full model, and fit the reduced model, controlling for the predicted values.
At first sight, it may seem that both methods are equally convenient, but suppose we wanted to introduce meditating or confounding variables sequentially (i.e., through successive models, starting with a model including Z 1, followed by a model including Z 1 and Z 2, and so on) to see where the coefficient of X changed most. In this case, the method presented here would be more convenient because it would not require any extra steps other than an additional OLS regression including both Z 1 and Z 2. Using the KHB method, however, we would need to residualize both of these, using separate regressions. As the number of mediators or confounders whose impact we want to assess increases, so does the computational advantage of the new method.
Standard Errors
Karlson et al. (2012:295-96) developed a Z-test for whether the conditional and unconditional effects of X are equal (this is labeled Zc ). It is a test of whether the coefficient of X is changed by true confounding or mediation, net of the effect of rescaling. In our notation, this test would be written as:

This is equivalent to a test of the significance of the product

Karlson et al. (2012) use the delta method to derive the standard error of
As an alternative, the bootstrap is a fast and convenient way of obtaining standard errors (the analytical standard errors based on the delta method can be cumbersome to calculate without specialized software).
2
Another advantage of using the bootstrap for estimating standard errors is that one can easily compute standard errors of differences of coefficients, that is, of indirect effects, or of ratios of coefficients such as the percentage mediated. In this case, we would often care about our estimate of the ratio
Example: Parental Income and Support for Redistribution
To illustrate how our method works, we examine potential mediators of the association between parental income and individuals’ stated support for redistribution in the United States using the 1987, 1993, 1994, 2008, and 2010 waves of the General Social Survey. The final sample after listwise deletion is 3,603.
The outcome variable is the respondents’ response to a question about whether the government should reduce income differentials and has five ordered response categories: strongly disagree, disagree, neither, agree, and strongly agree. The main predictor variable is the respondent’s parents’ income when the respondent was 16 years old. We recode this variable into three levels: below average, at average, and above average. As mediators we include socioeconomic and sociodemographic characteristics of the respondent: the respondent’s income grouped into 12 income bins (which we use as a continuous covariate), the respondent’s years of schooling, the respondent’s occupational prestige score (2010 scoring on a 100-point scale), the marital status of the respondent (married, widowed, divorced, separated, and never married), and the respondent’s region of residence (New England, Middle Atlantic, East North Central, West North Central, South Atlantic, East South Central, West South Central, Mountain, and Pacific). In addition to these variables, we control all models for survey year fixed effects and the respondent’s age to balance the sample on these characteristics.
Table 1 shows the estimated association, using ordered logit models, between parental income and a respondent’s support for government action to reduce income differentials. The gross or unmediated association in model 1 (M1) suggests that respondents born to affluent parents less often support redistribution (as defined here). Introducing respondent characteristics as mediators leads to a decline in the effect of parental income across the models, particularly across the first three. For example, the coefficient for above-average parental income declines by 24.7 percent from M1 (−.673) to model M3 (−.507).
Ordered Logit Models Regressing Support for Redistribution on Parental and Respondent Characteristics.
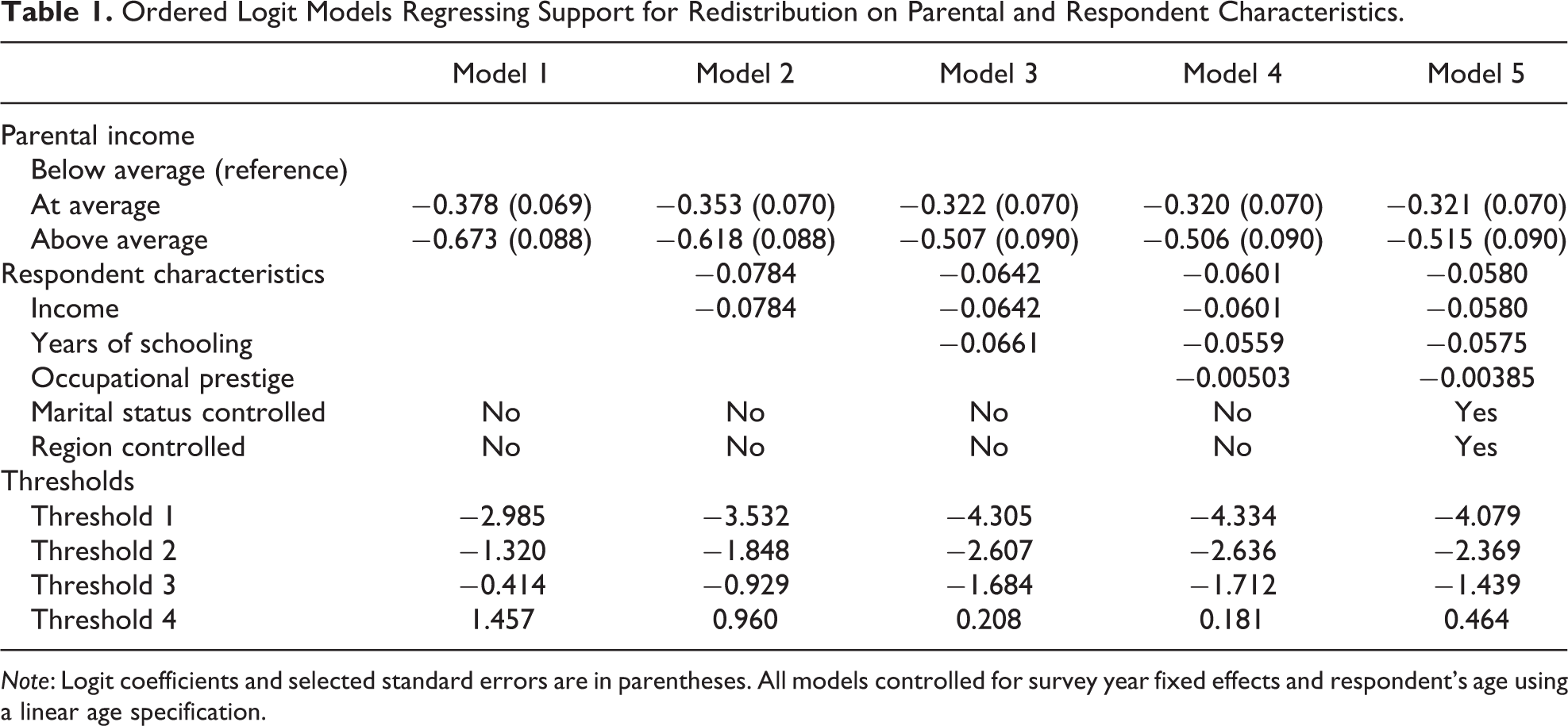
Note: Logit coefficients and selected standard errors are in parentheses. All models controlled for survey year fixed effects and respondent’s age using a linear age specification.
Rescaling may influence comparisons of the effect of parental income across these same-sample nested models. Therefore, in Table 2, we report the corresponding estimates using the revised KHB approach detailed in this article. It appears that, in fact, changes in the coefficients are not substantively driven by rescaling: The rescaling effect is negligible, as can be seen by comparing the gross association in the first columns in Tables 1 and 2. For example, the coefficient for above-average parental income declines by 26.2 percent from M1 (−.693) to M3 (−.511). This relative decline is slightly larger than the one reported in Table 1 but would not lead to meaningfully different conclusions about the degree to which respondent attainment explains or mediates the association between parental income and support for redistribution.
Rescaled Logit Models Using Linear Predictor Method, Regressing Support for Redistribution on Parental and Respondent Characteristics.

Note: Logit coefficients measured on the scale of the full model and selected bootstrapped standard errors are in parentheses (500 replications). All models controlled for survey year fixed effects and respondent’s age using a linear age specification.
The standard errors for the coefficients for parental income reported in Table 2 are estimated using the bootstrap. In Table 3, we give an example and we report our Stata code for the bootstrap loop in the Online Appendix. We report estimates of the indirect effects and the corresponding percentage mediated involving M1, M2 and M3 in Table 2. We find that all indirect effects are statistically significant at conventional levels, suggesting that the respondent’s socioeconomic attainment is a significant mediator of the association between parental income and support for redistribution. Adding the respondent’s income to M2 reduces the effects by about 8 percent and 10 percent for respondents whose parents were at the average income and respondents whose parents exceeded the average income, respectively. Further adding respondent’s years of schooling results in about 17 percent and 26 percent mediated, respectively. Also, the incremental mediation by respondent’s years of schooling over and above that by the portion mediated by respondent’s income is about 9 percent and 19 percent, respectively. All of these mediation percentages are statistically significant at conventional significance levels, again supporting the conclusion that a respondent’s socioeconomic characteristics explain some, but not all, of the association.
Selected Indirect Effects and Percent Mediated of Parental Income Effect on Support for Redistribution.
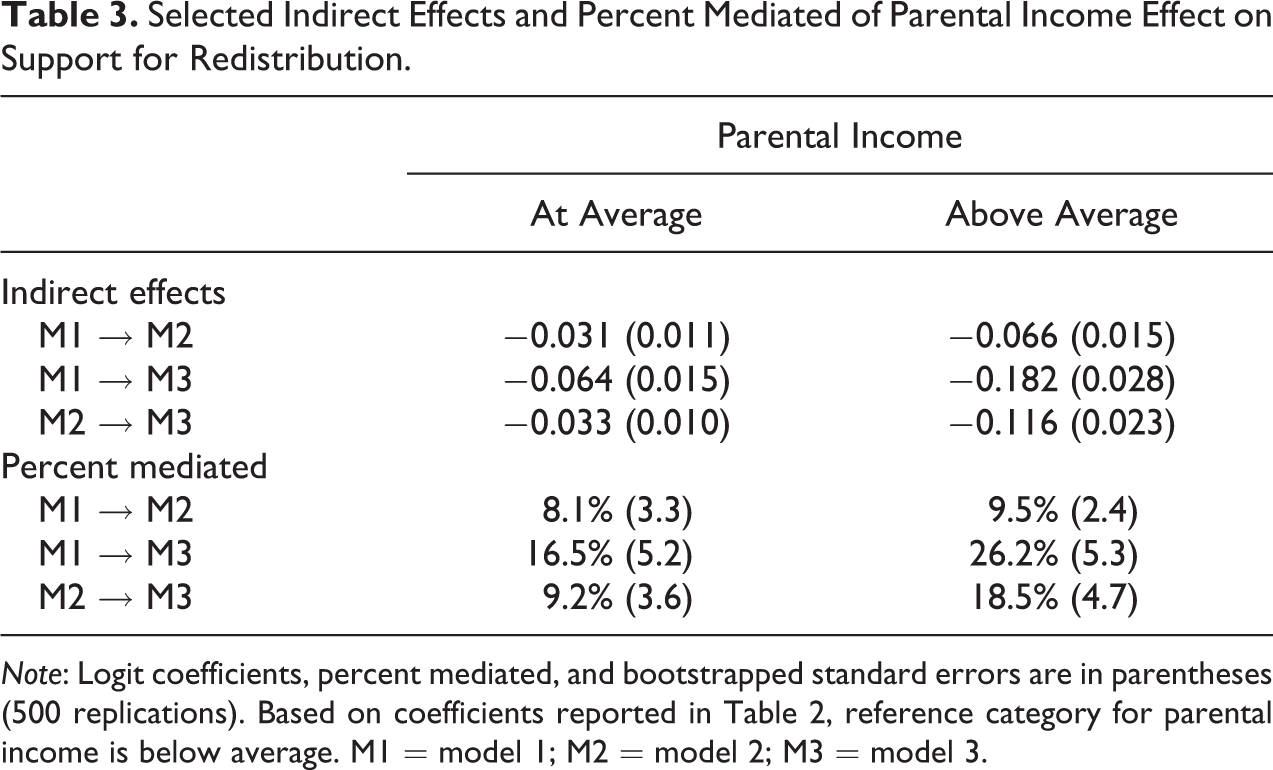
Note: Logit coefficients, percent mediated, and bootstrapped standard errors are in parentheses (500 replications). Based on coefficients reported in Table 2, reference category for parental income is below average. M1 = model 1; M2 = model 2; M3 = model 3.
Conclusion
The KHB method has rapidly become popular. In this note, we have provided, and illustrated, a reformulation of the method, which, we believe, is simpler to implement than that used in the original paper and implemented in the Stata program, khb, 4 Kohler, Karlson, and Holm (2011). It has particular advantages when we want to consider how the association between a categorical or ordered outcome and a predictor variable of interest changes when we add several mediators or confounders sequentially
Supplemental Material
Online_Appendix - A Note on a Reformulation of the KHB Method
Online_Appendix for A Note on a Reformulation of the KHB Method by Richard Breen, Kristian Bernt Karlson and Anders Holm in Sociological Methods & Research
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.