
Abstract
This article aims to clarify fundamental aspects of the process of assigning fuzzy scores to conditions based on family resemblance (FR) structures by considering prototype and set theories. Prototype theory and set theory consider FR structures from two different angles. Specifically, set theory links the conceptualization of FR to the idea of sufficient and INUS (Insufficient but Necessary part of a condition, which is itself Unnecessary but Sufficient for the result) sets. In contrast, concept membership in prototype theory is strictly linked to the notion of similarity (or resemblance) in relation to the prototype, which is the anchor of the ideational content of the concept. After an introductive section where I elucidate set-theoretic and prototypical aspects of concept formation, I individuate the axiomatic properties that identify the principles of transforming FR structures into fuzzy sets. Finally, I propose an algorithm based on the power mean that is able to operationalize FR structures considering both set-theoretic and prototype theory perspectives.
Concepts have a polysemic nature (Gerring and Barresi 2003), making them complicated to define homogeneously. Concepts can be structured in different ways and, in addition to the classic view of categorization (e.g., Murphy 2004), there are other typologies of conceptual structures such as family resemblance (FR; Rosch and Mervis 1975; Wittgenstein 1953) and radial category (Collier and Mahon 1993; Lakoff 1982). Such conceptual typologies have been defined and employed in different ways by set-theoretic and cognitive scientists. Set-theoretic scholars mainly operationalize all typologies of concepts through the principle of compositionality, which frames the concept into parts. Each part is then transformed into sets that are aggregated according to specific set-theoretic rules. Meanwhile, cognitive scientists mainly operationalize concept typologies through the principle of typicality, which defines items of a concept according to their distance to a typical central case (Hampton and Jönsson 2012).
Many criticisms of set theory are based on the operationalization of the principle of typicality (Furhmann 1991). On the one hand, according to set-theoretic scholars, it is sufficient to transform any component of a concept into fuzzy sets (Furhmann 1991). This would presumably allow one to individuate the distance from a central to a peripheral case in agreement with the principle of typicality. On the other hand, fuzzy sets are widely criticized by cognitive scientists (Lakoff 2014; Osherson and Smith 1981) due to the rigidity of the aggregation process concerning linguistic hedges (Johnson-Laird 1983). According to cognitive scientists, fuzzy sets cannot represent concepts because they do not correctly describe the actual representativeness relationship (e.g., Kamp and Partee 1995; Lakoff 2014; Osherson and Smith 1981; Roth and Mervis 1983). The main issue is linked to the aggregation strategies employed to aggregate fuzzy sets that are rooted within the Boolean logic of conjunction and disjunction. These logics sharply define membership and conceptual boundaries (Roth and Mervis 1983).
In this article, I agree with cognitive scientists concerning the inefficiency of the Boolean strategy of aggregation. As reported below, Boolean operators have a binary understanding of membership that is inconsistent with the principle of typicality.
As it is possible to comprehend from the debate between cognitive and set-theoretic scholars, the core problem of translating concepts into sets is not linked to fuzzification strategies; rather, it is linked to aggregation strategies. In social science, the discussion on conceptual structures and aggregation strategies is very basic (e.g., Goertz and Mahoney 2013, Quaranta 2013) because it is still linked to the classic Boolean operators of conjunction, disjunction, and negation that have been largely criticized for more than 40 years by cognitive scientists. As pointed out by Smithson (2016:178-79), most researchers using fuzzy set theory concentrated their effort on the issues of measurement, inference, and data analysis and paid little or no attention to the original Zadehian question of set operations. As described by Smithson (2016), this issue has been swept under the carpet in most applications throughout the human sciences. Instead, set operations can be considered as the core of fuzzy theory and are important in social sciences because they will ultimately allow one to represent social reality without loss of information.
In this article, I examine set aggregation issues. The main target is identifying an operator capable of aggregating fuzzy sets considering conceptual structures rooted in prototype theory, such as FR and radial category. In the first part of this article, I provide a general overview of concept structures. Next, I summarize the FR from a set-theoretic perspective and explain the difficulties of operationalizing FR in set theory in relation to a prototypical approach. This introductive section provides important information on FR principles in set theory and prototype theory that is then used to extrapolate a series of axiomatic properties able to identify fundamental principles of transforming FR structures into fuzzy sets. Then, I develop and illustrate the aggregation algorithm and apply it to Skocpol’s (1979) study on social revolution. This example will provide clarification on the importance of having a performant algorithm in order to (i) aggregate scores without losing essential information, (ii) distinguish cases according to their distance to a central idea, and (iii) accurately identify set relationships of sufficiency and necessity between variables. The proposed algorithm ultimately allows one to match the numeric scores with the content of the original source.
Finally, as discussed in the Conclusion section, this algorithm’s accuracy has important implications for describing and analyzing social phenomena considering set theory. In this respect, it allows one to produce results that accurately reflect the complexity of social reality, clearly identify relationships of sufficiency and necessity, and clarify case selection for a more in-depth qualitative research. Therefore, its application is wide across different analytical techniques that employ fuzzy sets as a tool of data analysis. This, for example, includes concept measurement and operationalization (e.g., Smithson and Oden 1999; Treub 2013), comparative configurational methods—such as qualitative comparative analysis (QCA; Ragin 2000), coincidence analysis (CNA; Baumgartenr and Ambühl 2018), fuzzy set case studies (Mikkelsen 2015), case selection in set-theoretic multimethod research (MMR; e.g., Mikelsen 2017; Rohlfing and Schneider 2013, 2018, Schneider and Rohlfing 2013)—or operational analysis such as multiple criteria decision-making analysis (MCDM; e.g., Kaya et al. 2019).
As a premise, I would like to point out that the focus of this article is not to provide an empirical sense of FR in social science. I rely on existing literature (e.g., Barrenechea and Castillo 2018; Goertz 2006; Goertz and Mahoney 2005) that have already made strong arguments on the importance of such conceptual structures in the empirical analysis.
Concepts and Theory of Concepts
There are at least three ways to describe concepts: the classical concept, the FR concept, and the radial category concept.
Classical Concepts and Set Theory
Classical concepts are rooted in the classical theory of concepts that can be traced back to Aristotle who identifies concepts by their essential attributes (e.g., Smith and Medin 1981). According to the classical view, concepts have some fundamental characteristics in common that determine their membership status (Medin 1989:1470). The classical view suggests that all categories have defining features necessary to establish the membership of a case in a particular category. In this respect, concepts are structured as lists of common elements, attributes, or features necessary for category membership and, collectively, sufficient to determine the category membership (Medin 1989:1470).
Hence, the classical view refers to concepts as a collection of fundamental elements that should be present (and not absent) to define an item. This view suits set theory, which employs binary Boolean operators to aggregated sets. Set theory can easily operationalize the binary membership system of classic concepts by establishing the presence or the absence of necessary and jointly sufficient attributes that define the ontological architecture of a concept.
The classical view of the concept is widely used in social science and has already been analyzed in relation to set theory by Goertz and Mahoney (2005), Smithson and Verkuilen (2006), and Veri (2020).
FR and Prototype Theory
FR concepts can be conceived as a network of overlapping and crisscrossing similarities (Wittgenstein 1953:66). This idea was formalized into prototype theory by Rosch (1973), who proposed prototypical categories as graded structures of overlapping information linked together by relationships of similarities (Rosch 1999). According to Rosch and Mervis (1975), not only the items that share the most attributes to the prototype belong to FR but also the items that share a few (or any) attributes with the members of a contrasting category.
The FR is the core idea behind prototype theory, as concept formation is strictly linked to the notion of similarity (or resemblance) in relation to the prototype (Rosch, 1999). The prototype is the best observable example of a specific category, and it anchors the ideational content of the concept. Membership is defined by a grading approach. Therefore, a case is either a good or a bad example of the category because its resemblance to the category’s prototype is high or low, respectively (Rosch 1999:65-71).
Lakoff (1987) reformulates the idea of prototype into radial category structures. In this formulation, categories are radially structured around a central category (Lakoff 1987:379). A radially structured category does not possess a precise and unique representation. Both central and noncentral categories have their representation, and there are different properties between the central and noncentral categories. In radial categories, the degree of similarity is determined by various elements radiating out from a prototypical central point; such a central point provides a model around which the less central members of the category are clustered (Lakoff 1987).
FR in Set Theory
Set theory provides some models to prescribe FR and radial category structures. In set theory, FR and radial categories are conceptualized by considering Collier and Mahon’s (1993) understanding of FR based on the possible matching of nonnecessary attributes within a concept. Such an approach is employed by Barrenechea and Castillo (2018) to explain FR in relation to set theory. Specifically, Barrenechea and Castillo (2018) identify three different subtypes of FR.
The first subtype refers to the INUS 1 structure (insufficient but nonredundant components of a combination of conditions that are unnecessary but sufficient for an outcome structure). This idea is based on the m of n rule; where n refers to the total number of a condition’s attributes and m to the number of attributes that are needed for a case to be considered a member of a concept (Barrenechea and Castillo 2018). Essentially, a case CS requires m attributes to be a member of the concept family CF, which is characterized by n number of attributes. The second subtype of FR refers to the individually sufficient structure (Barrenechea and Castillo 2018). This structure is a specific formulation of the m of n rule in which m = 1.
These two typologies of FR are based on the same conceptual structure characterized by the absence of necessary attributes. The third typology of FR is the mixed structure concept in which necessary attributes are combined with nonessential attributes. However, the mixed approach results are very similar to the INUS structures in which there is at least one element that is constant toward the conceptual structure.
A similar approach to Barrenachea and Castillo’s mixed structure was employed by Quaranta (2013), who attempted to formalize the radial category by considering a combination of sufficient attributes that are linked to individually necessary but insufficient and nondefinitional attributes.
The Tension Between Set Theory and Prototype Theory
The key point that differentiates prototype theory and set theory is its logical foundation, which refers to two different algebraic systems and two different concept formation principles.
Set theory, as pointed out by Hampton and Jönsson (2012), follows the so-called principle of compositionality, which framed the concept into parts: The content of a complex concept is determined by the contents of its parts and their mode combination. The compositionality principle implies a formal and categorical dimension of concept that defines the concept through the composition of sufficient and/or necessary attributes. This principle can be operationalized using Boolean algebra, which enables one to aggregate each attribute according to the subset/superset relationship pattern and the criteria of presence and absence of attributes.
Prototype theory is mainly linked to the principle of typicality. As explained by Hampton and Jönsson (2012), “a prototype is a structured set of descriptive properties that captures what a cluster of items of some category typically have in common and what differentiates them from other kinds of things.” Hence, the idea of compositionality in prototype theory is not rejected because concepts are still conceived as an aggregation of attributes or clusters of items (e.g., Kamp and Partee 1995). However, in prototype theory, the principle of compositionality is not set theoretic but gradual. In this respect, the degree of similarity of a case to the prototype plays the dominant role in determining the case’s membership to a specific family. Concepts are connected to a prototype though a linear dimensional space that can be translated into a linear algebraic system that enables the treatment of a category in terms of graded distances from a prototypical central point.
The different logical foundations between prototype theory and set theory have been perceived as conflicting by cognitive scientists. Specifically, cognitive scientists consider set theory unsuitable to capture the essence of the FR or radial category. According to them, sets are not able to correctly describe typicality in different categories given their binary structure that categorizes objects according to a clear membership status (e.g., Kamp and Partee 1995; Lakoff 2014; Osherson and Smith 1981; Roth and Mervis 1983). Hence, set theory and prototypical categorization are considered mutually exclusive because a concept’s attribute in set theory is operationalized in terms of dual membership structure and aggregated through Boolean binary operators of conjunction, disjunction, and exclusion (Osherson and Smith 1981:338). This binary nature of set-theoretic items produces clear-cut boundaries of presence and absence that contrast with the prototypical vision of FR and radial categories (Rosch 1999).
Conversely, set-theoretic scholars accuse cognitive scientists of not fully grasping the potential of set theory by systematically operationalizing gradualness through fuzzy set structures and compensatory operators such as t-norms or t-conorms (e.g., Belohlavek et al. 2002). In this respect, fuzzy sets might appear to be a valid alternative to aggregate FR in accordance with set theory and prototype theory (Zadeh 1982) because fuzzy sets allow for differences in degree and deal with the principle of gradualness.
In social sciences, the debate on transforming concepts into fuzzy sets to express gradualness is well developed (e.g., Basurto and Speer 2012; De Block and Vis 2018; Ragin et al. 2007; Smithson 2016; Toth et al. 2017; Verkuilen 2005). Generally, as also pointed out by Verkuilen (2005), it is possible to individuate a direct strategy for assigning fuzzy membership scores and an indirect strategy that employs either statistic models or techniques of mapping variables to transform data into fuzzy membership values. While these strategies of assigning fuzzy membership to data offer significant attempts to translate gradualness into mono-dimensional items, they do not provide solutions to translate gradualness into more complex structures such as concepts based on FR.
In this respect, the debate on complex fuzzification of conceptual structures is underdeveloped and confined to classic Boolean aggregation strategy (based on Zadeh-AND, Zadeh-OR, and Zadeh-NOT; e.g., Goertz and Mahoney 2005; Quaranta 2012; Treub 2013). As also discussed by cognitive scientists, Boolean strategies of aggregation only provide the possibility of membership or nonmembership without a gradual transition in-between. Strictly speaking, Boolean operators satisfy rules that are not shared by linear algebra, such as the absorption power of OR and AND operators (Dubois and Prade 2000). Absorption properties do not allow a trade-off between different attribute scores; the entire membership would, therefore, be determined by one single attribute in accordance with the sole principle of compositionality pointed out above. As a consequence, these rules generate rigid and fixed fuzzy thresholds that do not provide information about the similarity of cases in relation to a prototype. Essentially, the in-use aggregation strategies do not prevent loss of information. If we use a heuristic example, the existent strategy of aggregation of fuzzy score would consider a medieval throne as a prototypical example of the house furniture in the same vein as a kitchen chair because a throne is the same as a kitchen chair in that it is a seat with four legs and a back. However, no one would expect to find a medieval throne at IKEA.
Principles of FR, Conceptualization, and Operators
The core element of FR is the principle of typicality, which can be defined as the degree of similarity of a case, CS, to a central case of a family, CF. Similarity has different meanings in set and prototype theory. In set theory, typicality is encompassed in the principle of compositionality, while in prototypes, it is related to a metric-like understanding of the conceptual structures.
Set-theoretic Compositionality and Typicality
Set-theoretic typicality is defined by the compositionality principle, which establishes the minimum number of attributes, m, of the set of central attributes, n, that a case, CS, should have to belong to the same family of a central case, CF. The higher the number of CS attributes shared with a CF case, the higher the degree of typicality will be.
Figure 1 displays the relationship between compositionality and typicality in set theory. The central case in the family CF is the point of intersection of each family attribute (
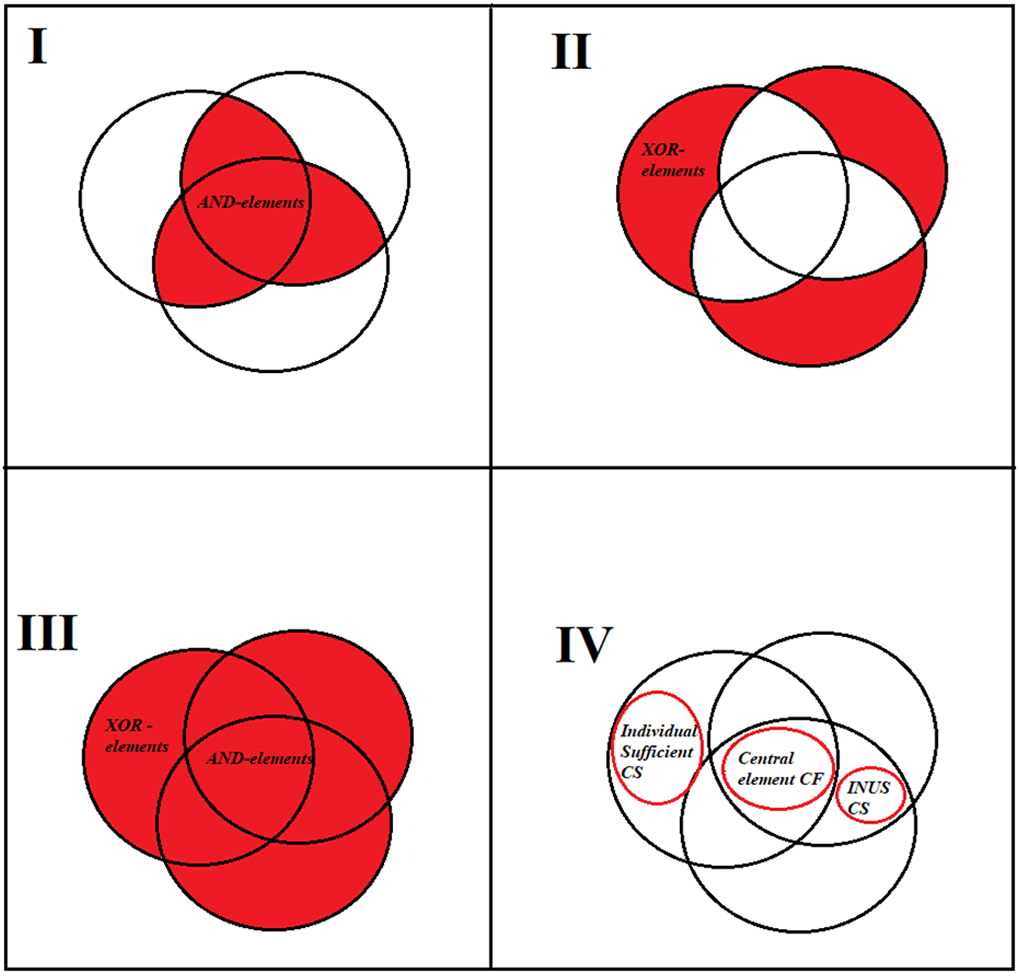
Boolean representation of the principle of similarity.
In Boolean terms, a central case of a CF family is defined as the intersection of all attributes

Each

Furthermore, as illustrated by the second quadrant of Figure 1, the subtraction between the set of attributes that characterize CF (

In Boolean terms, the attributes of exclusive disjunction (
Essentially, the typicality in set-theoretic terms is determined by the cardinality of AND-attributes or the total number of
Table 1 contains an example of the importance of the cardinality of AND-attributes and XOR-attributes to determine similarity and dissimilarity from a set-theoretic point of view. In this respect,
Set Theoretic Similarity (m = 1, n = 4)—Hypothetical Example 1.

Therefore, considering the following central case, CF:
A random case

As a result, the INUS structure is only a variation of the individually sufficient structure in which the attribute m > 1. Essentially, FR substructures can be merged and generalized into one single structure.
Prototypical Compositionality and Typicality
In prototype theory, concept descriptive attributes are defined into a metric-like understanding of space: The closer the score of a CS case is to the prototype score, the closer it will be to its prototypical term in the CF family. However, as also argued by the promoters of prototype theory (e.g., Rosch 1999), typicality does not exclude compositionality. This means that the peripheral CS case and the central CF case are both composed of an aggregation of attributes, as indicated in Figure 2.
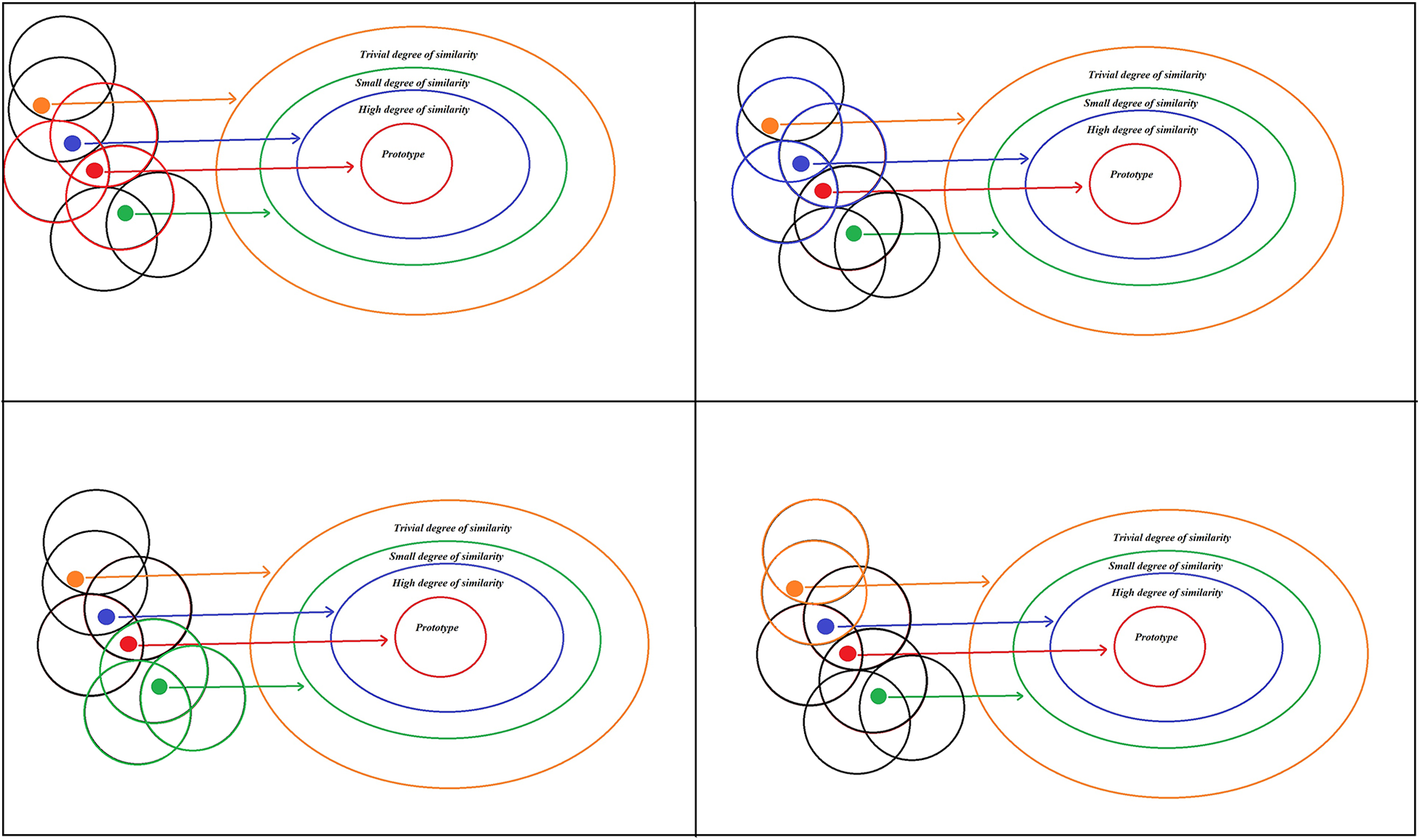
Similarity—typicality and compositionality.
As displayed in Figure 2, the similarity in prototype theory refers to both principles of typicality and compositionality. In relation to the compositionality principle, the central CF case is the one that conforms with the highest number of AND-attributes related to its family, while the empirical CS case belongs to the same family of CF when they share at least one attribute. As in Figure 2, each case is inserted in a network of attributes that are somehow connected together. Cases are related to a central CF case (in red) by the overlapping and crisscross pattern of attributes. However, a case can belong to other families at the same time and be connected to other cases that might be trivial to the conceptual family under investigation by a researcher. As displayed in Figure 2, the blue case belongs to the same family as the case in orange and the case in red, despite the case in orange not being a part of the red case’s family.
The prototypical typicality would be determined by the gradient membership values of both the AND-attributes and the XOR-attributes of a CS case and a central CF case. This is because, as pointed out by Rosch and Mervis (1975), a case belongs to a family of a prototypical case whenever its attributes overlap those of the prototype, and it has the least number of attributes with categories outside the family.
From a set-theoretic perspective, by looking at Table 2, it is possible to observe that the cases that refer to the
Set-theoretic Similarity−Hypothetical Example 2.

However, within cases that have
The AND- and XOR-attributes are central in establishing the similarity between CS and CF. For cases that are inside the CF set, the AND-attributes are more important in establishing similarity: The more AND-attributes with high fuzzy scores appear, the shorter the distance between CS and CF would be. In contrast, the XOR-attributes are more important in determining dissimilarity between CS and CF: The more XOR-attributes with low fuzzy scores appear, the larger the distance between CS and CF would be.
Aggregation Function
The aggregation function f(x) should be able to extrapolate the minimum distance between the empirical CS case and the central CF case in terms of linear distance and by considering the m of n rule.

In the circumstance where a case does not fulfill the m of n rule, a second aggregation function, h, is needed to serve as the complement of the aggregation function established above.

The functions under our investigation should simultaneously satisfy set-theoretic space based on the compositionality principle of the m of n rule and the prototypical characterization of typicality. The principle of typicality implies a linear compensatory function that should enable values ranking. The compensation power of such a function should tend toward the highest value of the attribute
Tversky (1977) provides a definition of similarity that is particularly adaptable to both prototype theory and set-theoretic logic. Tversky proposed an increasing function of common features between two objects and a decreasing function of not common features between the two analyzed objects. According to Tversky (1977:330), the similarity function s(x) is defined as follows:

This function can be employed to define the similarity between a CS case and a central CF case. In this respect, the similarity would be determined by the intersection of the common features of the central CF and the CS case as well as the differences between the features of CF and CS. Essentially, as emphasized by Tversky and Gati (1978:79), similarity includes the features that belong to both CF and CS and the features that only CS and not CF have and vice versa.
Considering the prototype CF and the empirical case CS as cases defined by the set of attributes cf and cs:

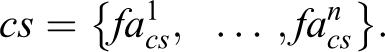
The Tversky matching function between CF and CS can be defined as follows:
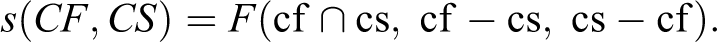
The similarity increases within
The Tversky formulation can be related to the set-theoretic formulation of AND- and XOR-attributes:
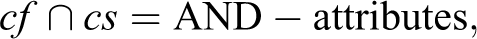
and

The intersection
Function Properties
The function that defines the similarity between CS and CF should have a series of properties to fulfill compositionality and typicality principles.
First, the function should fulfill strong compensatory properties to operationalize the principle of prototypical typicality. In other words, each case’s
Second, the function should integrate the principle of compositionality. Such a principle refers to the minimum number of m
Considering:

then

If the minimum number m of attributes is reached, the case is considered a member of the CF set, while if the number of m attributes is not reached, the case is outside the CF set. The minimality principle can be expressed in terms of frequency between m and n. The number of m attributes refers to the cardinality of m in the CF set or that the frequency of the m attributes is determined in advance by the researcher and expressed in natural numbers ℕ:
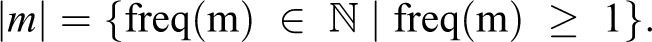
However, in principle, it is sufficient to have at least one m attribute that belongs to the same CF category. Therefore, the
Weighted Operator
The m of n rule principle of compositionality should be considered in Tversky’s similarity function. This would be possible by introducing weights to Tversky’s similarity function for each AND and XOR-attribute.
When weights are applied to a similarity function, the following equation is generated:

The values θ and α are the relative weights of components of similarity
The compensatory power of the f and h functions should be linked to the requirement of similarity established above.
The maximum weight
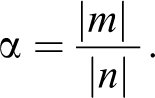
The
The lowest possible frequency ratio for a CS case to belong to a family of CF would be the case of |m| =1, then:

A low
A low
Subsequently, the weight that should be assigned to each score can be decided whether we have a function f or a function h. For cases that satisfy the m of n requirement, we apply the function f. In this case, the greater weight
Operator Formula
The operator formula must fulfill typicality properties. In this respect, each attribute
Any averaging operators with positive compensatory properties are found in the family of the generalized mean. The generalized mean coincides with the power mean (PM; Dubois and Prade 2000:165) and is defined as follows:

According to fuzzy logic literature, PM operators belong to the p-norm functions. These operators can rank decisions, mimic human intuition, compute with words, or imitate the human preference process (e.g., Hong et al. 2007; Mendel and Wu 2010; Rickard, Aisbett, and Yager 2015; Rickard et al. 2013, 2011; Wang and Luo 2009). In summary, p-norm operators are appropriate for human reasoning processes that also include FR concept schemes.
The PM is the general operator in which the weights explained above should be implemented.
Doing so produces a weighted power mean (WPM).

where,


The denominator
Indeed, in relation to the principle of typicality, a case
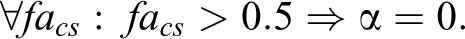
Then,
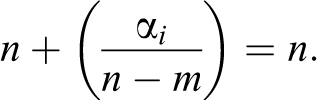
While whenever a
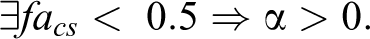
Then,

When the value
In relation to the principle of typicality, the denominator implements the m of n rules through the value derived by
Considering cf∩cs=AND-attributes and cs-cf and cf-cs=XOR-attributes, we can simplify the formula as follows:
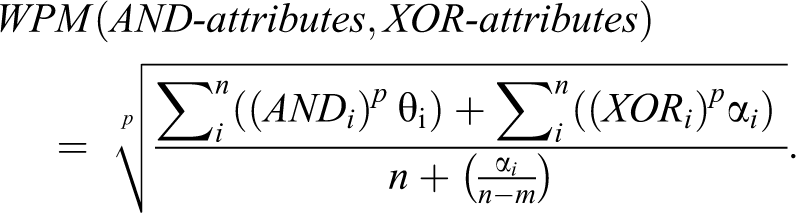
Meanwhile, the computation of the cases outside the prototype set should follow the logical negation operator of WPM. This function reverses the meaning of its operand by assigning more relative weight to smaller numbers.
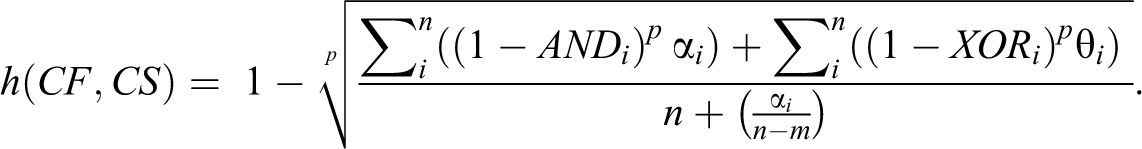
This technique inverts the central tendency data to the smaller number in the nonmembership set instead of the highest number in the membership set.
As summarized in the flowchart presented in Figure 3, the algorithm is flexible toward four different circumstances. In this respect, it is possible to have four different scenarios: Whenever every Whenever every Whenever there is at least one Whenever there is at least one
These four circumstances also cover INUS and single sufficient FR.

WPM algorithm and circumstances.
Calculation of the Power-p
The power-p should not be too high or too low. The higher the power-p is, the higher the compensatory power of the WPM operator will be. However, as pointed out by Dyckhoff and Pedrycz (1983:146), the WPM with p = ∞ corresponds to the MAX value (Zadeh-OR). With a p that is too high, the operationalization of the typicality principle would not be possible. Essentially, by using an operator with a compensatory power that is too high, identifying the internal differences in degree between cases becomes more difficult because all the results tend toward the MAX score.
In contrast, the lower the power-p is, the lower the compensatory power of the WPM operator will be. An operator with low compensatory power tends to produce false-negative results given low compensatory power does not allow the principle of typicality to be fulfilled.
False-negative scores can be avoided through a WPM with a relatively moderate power-p value.
False-negative scores are tested in the following two extreme circumstances:
The first refers to an individually sufficient FR and an infinite number of attributes:

and

The second refers to the INUS structure of FR in which:

and

False-negative and False-positive Results in Individually Sufficient FR
False-negative results are observed in both extreme circumstances described above.
As displayed in Table 3, in relation to the scenario of individually sufficient FR in which m = 1 and n = ∞, a power-p value > 35 is required to significantly reduce false-negative results in the presence of one AND-attribute = 0.51 and infinite XOR-attributes = 0.
Power-p Values in m = 1 and n > 2.
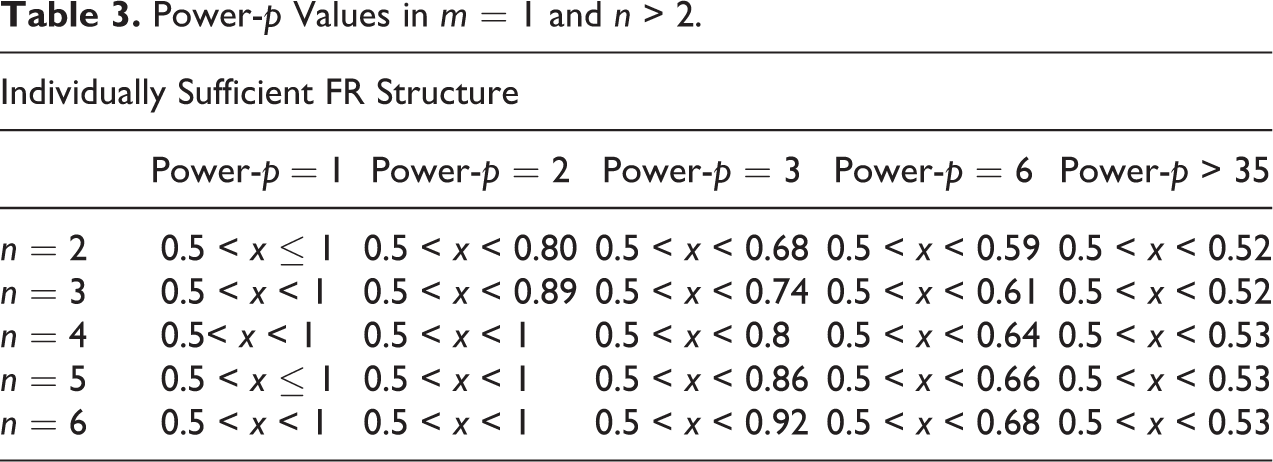
Unfortunately, a power value > 35 is too high to individuate similarity between cases easily.
However, it is important to point out that the value of ∞ attributes is extreme, and it refers to an implausible circumstance. In practice, a prototypical concept would be formed by four or five attributes.
In general, the researcher should decide the score depending on the minimum fuzzy score >0.5 and considers applying a relatively small power p-value to clearly observe similarity and dissimilarity between CS and CF. As displayed in Table 3, in a more likely circumstance of 2 ≤ n ≤ 6, false-negative scores can be avoided with power-p from 6.
In relation to false-positive results, the individually sufficient FR presents no risk because of the idempotency property of the h function, which is applied to cases that do not satisfy the m of n requirements. In individually sufficient FR, the m of n rule is not applied whenever no attributes are >0.5. In this circumstance, the maximum score will be =0.5 or the maximum score that XOR-attributes can have.
False-negative Results in INUS FR
In relation to the second extreme scenario of INUS FR, false-negative results are mainly generated when a concept has a reduced number of attributes.
As displayed in Table 4, in the extreme circumstance of m = n − 1, a power-p value = 6 is sufficient to avoid false-negative results in the presence of AND-attributes >0.5 and XOR-attributes = 0.
Power-p Value in m = n − 1 and n > 2.

In light of such concerns, both false-negative and false-positive scores can be avoided with a power-p value between 3 and 6 for most cases. To establish the power-p value, the researcher should first individuate the minimum score value > 0.5. If this score is > 0.6 (as, e.g., often used in QCA), a power-p value of 3 is sufficient to avoid the risk of having false negative and false positive scores.
Empirical Example
The algorithm presented in this article can be employed for either INUS or individually sufficient FR. To demonstrate its performance, I have applied the algorithm to the example from Goertz and Mahoney’s (2005; from now G&M) discussion of Skocpol’s (1979) social revolution study through the perspective of two-level theories using fuzzy sets case study. In the Online Appendix (which can be found at http://smr.sagepub.com/supplemental/), it is possible to have a practical guide of the calculation in R.
G&M rediscuss the Skocpol study according to their two-level theory approach. They argue that Skocpol’s famous study can be restructured according to a basic-level and a secondary-level theory. As proposed by G&M (2005), the basic-level theory refers to the causation level of a theory or the variables that have a causal relationship with an outcome, while the second-level theory refers to variables that are not central to the casual relationship but are ontologically linked to the basic level variables (pp. 258-64). In other words, secondary-level variables are elements that constitute basic-level phenomena (Goertz and Mahoney, 2005:498).
G&M (2005) apply their two-level theories to Skocpol’s famous study, States and Social Revolutions, arguing that the basic level of the social revolution outcome is the Boolean conjunction of the variables State Breakdown and Peasant Revolt. These two conditions refer to a secondary level of variables. Specifically, State Breakdown is considered as an FR concept defined as (i) international pressure, (ii) dominant-class leverage, and (iii) agrarian backwardness, while the variable Peasant Revolt is an FR concept composed of the secondary-level variables: (i) Peasant Autonomy and (ii) Landlord Vulnerable.
As argued by G&M (2005:512), in addition to the causal variables that lead to social revolution, the outcome itself is definable by three elements that are linked together in terms of FR: (i) class-based revolts from below, (ii) rapid and basic transformation of state structures, and (iii) rapid and basic transformation of class structures. Although Skocpol (1979:33) considered these three elements as necessary and jointly sufficient, G&M (2005:5252-526) argue that such elements are structured as an FR concept given Skocpol only chose cases that are somehow similar for her analysis.
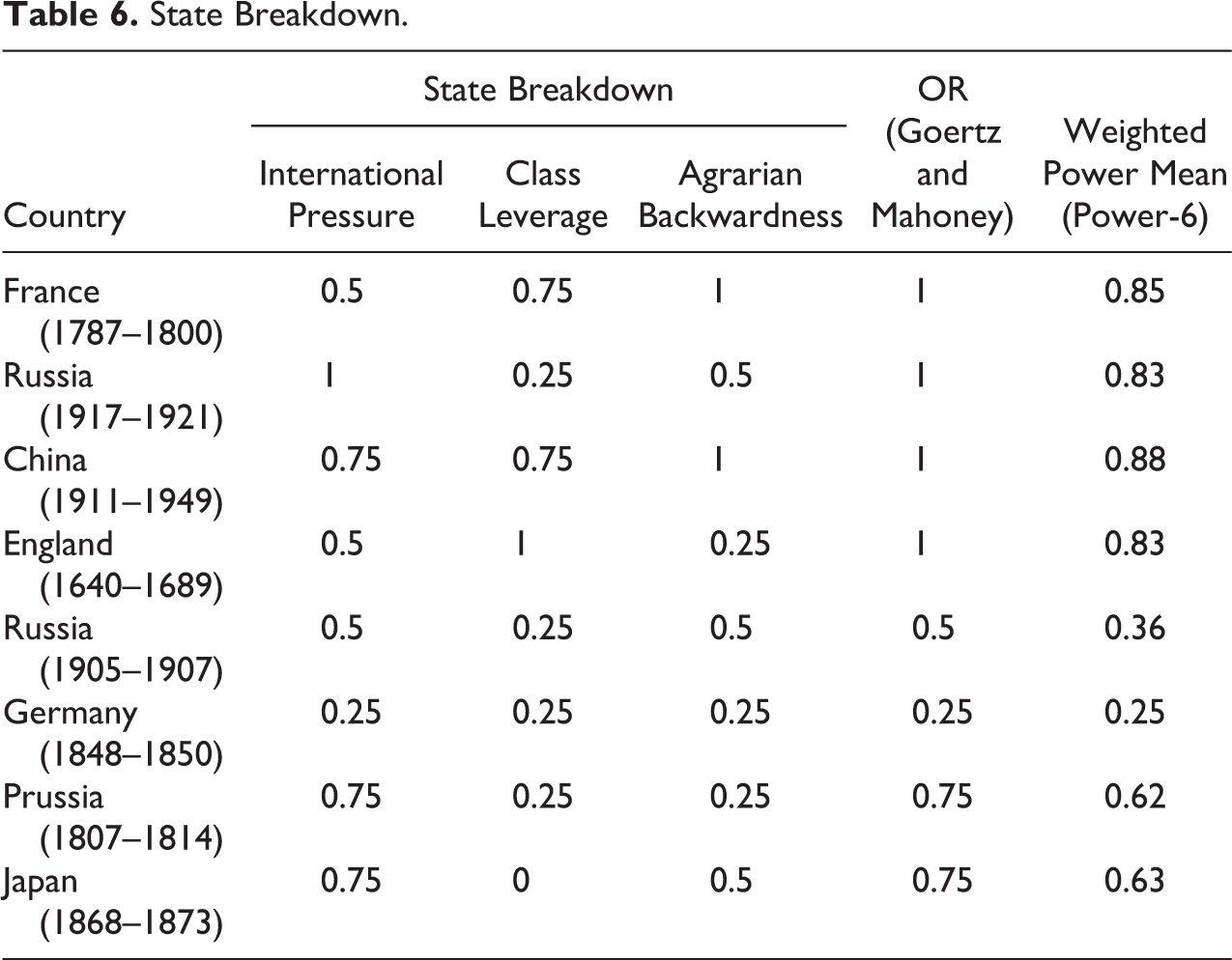
To be consistent with G&M’s arguments and demonstrate the differences between the proposed algorithm and the existing way of aggregating fuzzy sets, I retain their fuzzy scores and their conceptual structure operationalization. According to G&M, each of the variables that compose the basic-level variables State Breakdown and Peasant Revolt is individually sufficient (Tables 5 and 6). As a result, these variables refer to the individually sufficient typology and therefore follow the m of n requirement of m = 1. The operationalization of Social revolution outcome (Table 7) will follow an INUS FR structure (m = 2 and n = 3) because G&M employ a min(sum) operator that implies a trade-off between each element of the variable, while Skocpol considers these elements from a classic conceptual ontology. In this respect, an INUS FR is the closest operationalization of both G&M and Skocpol’s understanding of Social revolution.
Peasant Revolt.

State Breakdown.
Outcome Social Revolution.

As displayed in Tables 5 and 6, the proposed aggregation strategy generates a more diverse range of scores compared to the Zadeh-OR aggregation proposed by G&M. This example also highlights the fact that the Zadeh-OR lacks descriptive qualities and is, therefore, unable to identify similarities between a case and its prototype. This inability is due to the axiomatic absorption property of the Zadeh-OR (Dubois and Prade 1980:15), in which the highest degree of implication between
In this respect, the score resulting from the WPM aggregation better fits Skocpol’s narrative of Peasant Revolt and State Breakdown. As for the example in Peasant Revolts, the lower score for France in relation to Russia is due to peasants’ economic and political autonomy being more limited with regard to communal land-use and a higher level of struggle against seigneuries for agrarian rights (Skocpol 1979:120) than is the case for Russia where the peasants had the right of self-government under the supervision of bureaucratic agents of the Imperial State (Skockpol 1979:132). Although small, such differences allow differentiation of cases and variables without losing information during the aggregation process.
It is possible to observe from Table 8 that the operationalization proposed in this article better fits Skocpol’s narrative of social revolution. This is important given the goal of the algorithm of aggregate variables and attributes is not to lose information from the source of transformation. In this respect, Skocpol’s original argument is intact despite G&M’s reformulation into fuzzy sets.
State Breakdown AND Peasant Revolt Versus Social Revolution.
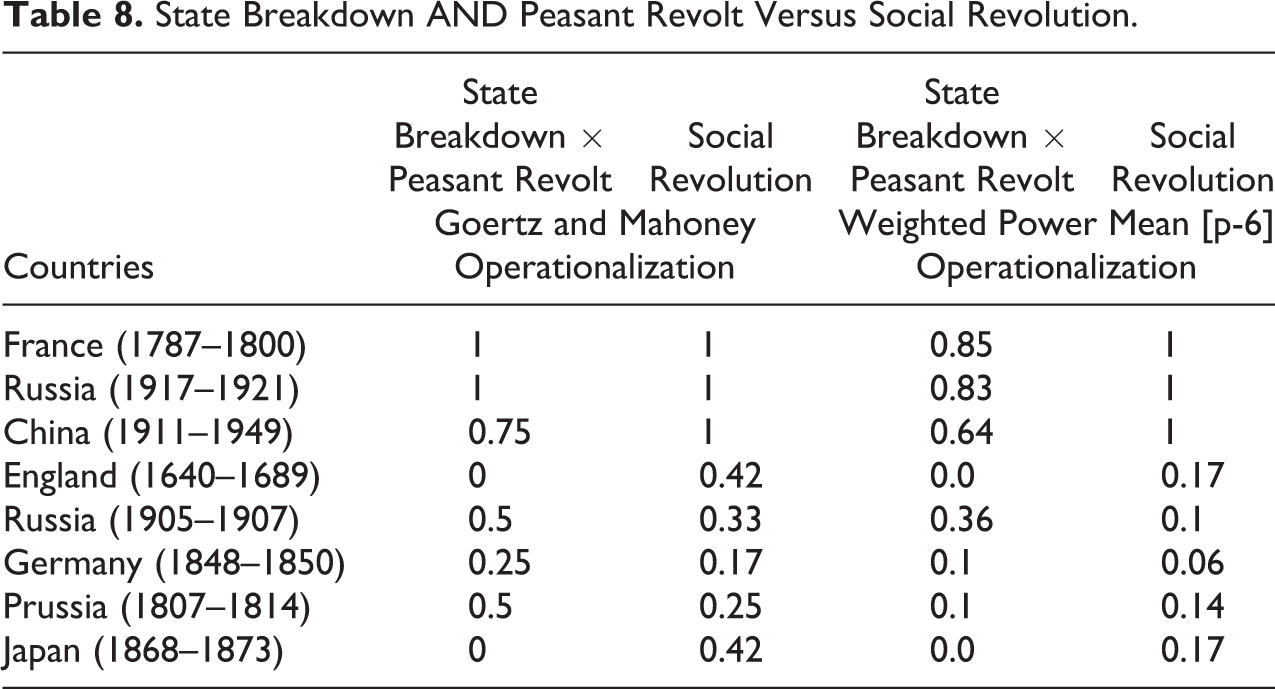
Additional evidence of the algorithm’s performance can be observed in the close relationship between the predicted value of the outcome of Social Revolution and the resultant score from the conjunction of the variables State Breakdown AND Peasant Revolt. Generally, the data through the WPM algorithm are closely related and indicate a clear relationship of sufficiency between the variables State Breakdown AND Peasant Revolt with the Social Revolution outcome. This is observable given the conjunction of the two conditions is almost always in a subset relationship with the outcome of interest. This becomes evident whenever we compare the final result based on G&M’s operationalizations and the proposed algorithm operationalization.
The resultant scores from G&M’s analysis are quite approximate in relation to the historical accounts. This is visible in the scores relative to Russia (1905–1911) and Prussia, in which the G&M operationalization of the variable’s score coincides with the point of maximum ambiguity, 0.5. G&M argue that such a high score indicates a prerevolutionary state in both Russia and Prussia. However, the ambiguity of 0.5 remains difficult to interpret, given a 0.5 score represents indifference between two poles. Notwithstanding the score ambiguity, it is also difficult to agree with G&M’s arguments on Prussia. Indeed, while it is possible to agree that the Russian revolts in 1905 were a prelude of the Russian social revolution in 1917, it is difficult to label the case of Prussia as a pre (or potential) revolutionary state given no social revolution occurs in Prussia or Germany in later years.
In this respect, the WPM operationalization of the variables clearly provides an answer that fits with Russia’s prerevolutionary state in 1905–1911 (with a score of 0.36) and the nonrevolutionary state of Prussia (with a score of 0.1). The WPM results also correspond with Skocpol’s account of Prussian revolts, which is not considered a proto-social revolution. In this respect, Skocpol pointed out that the Prussian regime adapted speedily to international exigencies through reforms instituted from above by autocratic political authorities (Skocpol 1979:110).
Such clarity is also reflected in the cases of England and Japan. Both cases score low in the outcome (i.e., 0.17), which contrasts with the relatively high score proposed by G&M (0.42). Essentially, while G&M oddly consider both England and Japan to almost fit in the family of social revolutionary cases, the WPM score highlights the fact that the basic conditions for social revolution in England and Japan were not satisfied. This is consistent with the Skocpol observations, which emphasize a lack of transformation of class structures or class revolts in both cases.
A final observation can be made in relation to the relationship of sufficiency. The algorithm proposed in this article clearly provides information in relation to sufficient relationships between variables and the outcome. In this respect, the causally relevant variables Peasant Revolt and State Breakdown are almost always in a subset relationship with the outcome Social Revolution.
Conclusion
In social science, the aggregation of FR is quite compelling, especially in relation to set theory, because of the apparent incompatibility between set theory and prototype theory. Here, I have proposed a weighted compensatory operator that demonstrates that sets can assume metric-like shape and therefore resolve the apparent tension between prototype and set theories.
This algorithm is particularly useful for all the approaches currently used in social science, which employ fuzzy sets as a tool of analysis. As pointed out through the empirical example, this algorithm has some crucial implications concerning concepts operationalization and data analysis. These implications can be summarized considering three perspectives: (i) the perspective of concept description, (ii) the perspective of data analysis, and (iii) the perspective of case selection.
From a descriptive perspective, this algorithm enhances the accuracy of data operationalization within FR concepts. This, as exemplified above, is particularly useful for transforming data by retaining all the original information. More broadly, the algorithm allows one to operationalize concepts and constructs into values with both gradual and cutoff membership that are often characterized by a lack of uniformity and formalization. In this respect, WPM allows one to rank cases according to their membership status and their differences in degree. Therefore, WPM can be employed for index building as intended by Treub (2013) or for ranking cases in relation to a prototype to establish which cases better fit criteria of evaluation as in MCDM (e.g., Kaya et al. 2019).
From an analytical perspective, the algorithm enhances the accuracy of the analysis because the input data resulting from the algorithmic aggregation are more precise than aggregation strategies currently used. Precise data input allows one to identify relationships of necessity and sufficiency with a certain degree of confidence, as shown in the empirical example above. This is also valid for other methods that employ fuzzy sets such as QCA (Ragin 2000) or CNA (Baumgartner and Ambühl 2018).
Finally, from a case selection perspective, the fine-grained scores produced by this algorithm allow one to enhance case selection after QCA for MMR. In MMR, cases are selected after QCA analysis in order to operate a case-based analysis such as process tracing (PT; e.g., Beach and Pedersen 2013; Blatter and Haverland 2012) with the target to individuate mechanisms linking conditions to outcomes (e.g., Mikkelsen 2017; Rohlfing and Schneider 2013, 2018). As already highlighted by Veri (2020), in MMR, a fined-grained score membership would allow one to identify typical cases accurately, deviant cases in consistency, deviant cases in coverage or irrelevant cases according to the original data source. Schneider and Rohlfing (2013) emphasize that having fined-grained information enclosed in fuzzy-sets membership scores is essential to provide additional leverage for selecting the most typical and most deviant cases. Through an operator that loses information during the aggregation process, such as the OR or the min(sum) operators, researchers might select a case that is not the best example of its category. Therefore, they might produce an approximate qualitative analysis.
In contrast, the WPM algorithm correctly identifies the most typical cases or the most deviant cases because it successfully retains the information enclosed in the original source. This allows the researcher to search for causal mechanisms between conditions by considering the most prototypical and/or the most deviant cases. Ultimately, the reliability of PT results will also be enhanced.
Supplemental Material
Supplemental Material, sj-csv-1-smr-10.1177_0049124120986196 - Transforming Family Resemblance Concepts into Fuzzy Sets
Supplemental Material, sj-csv-1-smr-10.1177_0049124120986196 for Transforming Family Resemblance Concepts into Fuzzy Sets by Francesco Veri in Sociological Methods & Research
Supplemental Material
Supplemental Material, sj-r-1-smr-10.1177_0049124120986196 - Transforming Family Resemblance Concepts into Fuzzy Sets
Supplemental Material, sj-r-1-smr-10.1177_0049124120986196 for Transforming Family Resemblance Concepts into Fuzzy Sets by Francesco Veri in Sociological Methods & Research
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
Note
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.