
Abstract
In this article, we develop a mixed-methods design that combines Bayesian regression with Bayesian process tracing. A fully Bayesian multimethod design allows one to include empirical knowledge at each stage of the analysis and to coherently transfer information from the quantitative to the qualitative analysis, and vice versa. We present a complete mixed-methods workflow explaining how this is accomplished and how to integrate both methods. It is demonstrated how to use the posterior highest density interval and the Bayes factor from the regression analysis to update the prior level of confidence about what mechanisms possibly connect the cause to the outcome. It is further shown how to choose cases for the qualitative analysis through posterior predictive sampling. We illustrate this approach with an empirical analysis of colonial development and compare it with alternative designs, including nested analysis and the Bayesian integration of qualitative and quantitative methods.
Keywords
Introduction
In the development of mixed-methods designs in political science, nested analysis marks an important contribution by overcoming the dichotomy between qualitative, small-n and quantitative, large-n studies that, prior to the early 2000s, was characteristic of political science research (Lieberman, 2005). The mixed-methods design covers the familiar
We contribute to the advancement of multimethod research by developing a Bayesian mixed-methods design that combines a Bayesian regression analysis with Bayesian process tracing. Our motivation is twofold. First, nested analysis is presented as “folk Bayesianism” by “introducing investigator knowledge to the world” (Lieberman, 2005). From a Bayesian perspective, its original frequentist formulation stops midway because one is not able to formally incorporate existing knowledge and transfer information from one design stage to the next. We show how Bayesianism allows one to include empirical knowledge at each stage of the analysis and to pass forward information from one stage to the next. We explain how Bayesian regression analysis can inform follow-up process tracing and how the qualitative insights gained can be linked back to the quantitative analysis. This allows one to turn “folk Bayesianism” into a formalized Bayesian framework that gives researchers the flexibility to combine regression analysis with formal, quantified process tracing, or informal process tracing that works with verbal classifiers such as “strongly in favor,” “moderately in favor,” and so on. Second, by following our proposed approach, researchers intending to perform Bayesian process tracing, which appears to become increasingly popular in empirical research, can seamlessly integrate it with a Bayesian regression.
The focus of the article is on the following four points. First, the Bayes factor for the regression estimate of
For the presentation of the Bayesian mixed-methods design, in the “Empirical Example: British Colonial Rule, State-Legal Capacity, and Development” section, we introduce an analysis of the development of former British colonies by Lange (2009) as the leading empirical example. We use this as a template for introducing the Bayesian workflow in “The Elements and Workflow of the Bayesian Design” section and illustrate the means by which Bayesian regression is integrated with process tracing in the “Illustration: British Rule and Colonial Development” section. In the Supplemental Appendix and“Illustration: British Rule and Colonial Development” section, we supplement the example with Monte Carlo simulations for a variety of parameter constellations. The “Comparison With Other Mixed-Methods Approaches” section clarifies the differences and commonalities of our Bayesian mixed-methods design with alternative mixed-method approaches. The final section concludes the article.
Empirical Example: British Colonial Rule, State-Legal Capacity, and Development
The leading empirical example is a study of the effects and mechanisms of the type of British rule on the socio-economic and political development of former British colonies (Lange, 2009). We introduce the theoretical argument to establish a basis for the following sections. Our primary aim is neither to make a contribution to this field of research nor to criticize it. Lange’s analysis is exemplary in following the standards set by Lieberman (2005). We discuss the design and the empirical strategy in the “Illustration: British Rule and Colonial Development” section.
On the macro level, the hypothesis is that more indirect British rule leads to worse socio-economic and political development than more direct British rule.
3
Direct rule is defined as the dismantling of existing institutions in the colony and the creation of new, bureaucratic-legal institutions run by colonial officials. Indirect rule follows a collaborative model that leaves the colony’s institutions intact in the periphery and complements them with British bureaucratic institutions in the center (Lange, 2009). In the following, we refer to the main independent variable
The negative effect of more indirect rule works through a mechanism having multiple components. Figure 1 summarizes the mechanism presented by Lange (2009). 4 First, more indirect rule produces weaker legal-administrative institutions throughout the country; second, it undermines inclusiveness because of a lack of regular interactions between the colonial state and society; and third, it weakens infrastructural power because of the absence of colonial officials and legal-administrative institutions throughout the country. A weaker bureaucracy and infrastructure further reduce inclusiveness. All three elements together represent a weakened legal-administrative capacity, which is why we refer to the mechanism in Figure 1 as the “legal-administrative capacity mechanism” or simply the ‘capacity mechanism'. By the end of this process, development is worse than in a more directly ruled colony where all relationships are reversed.
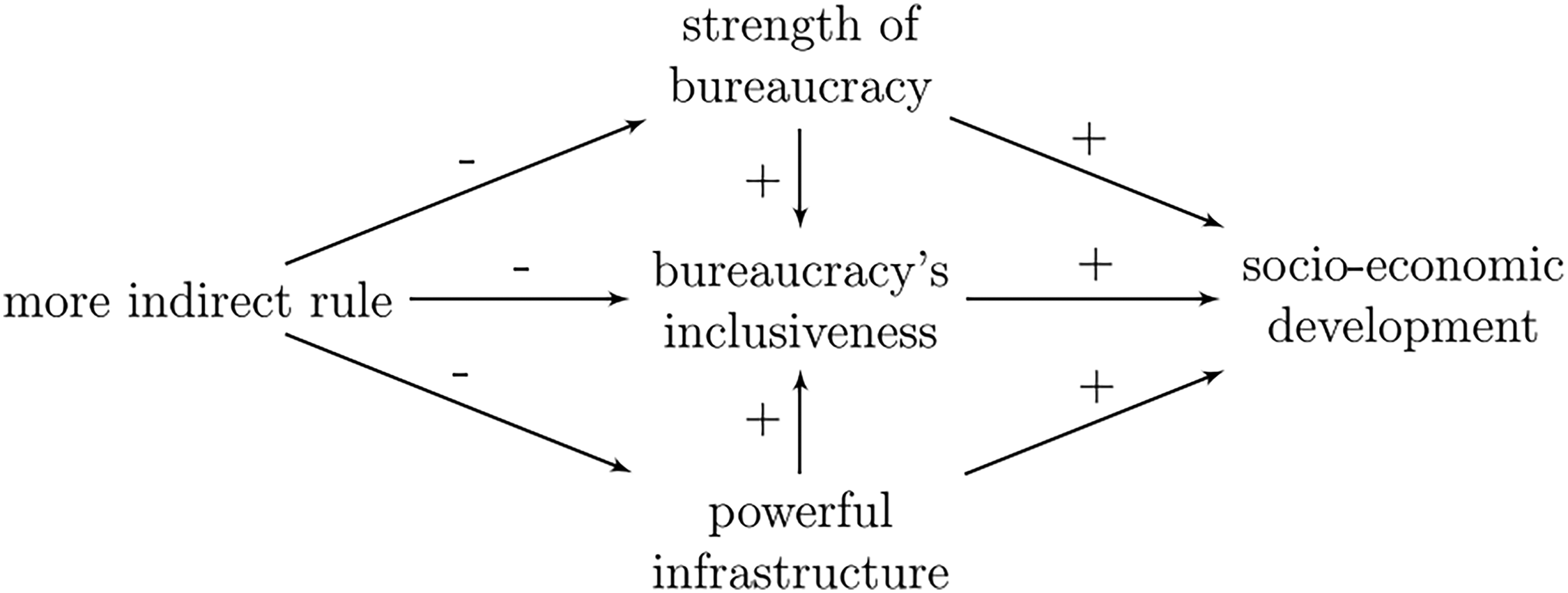
Theoretical model by Lange (2009).
For the purpose of presenting the Bayesian design, we introduce formal notations for the various elements of the theory and analysis (see for a summary of the formal notation Supplemental Appendix Section A). We generally refer to a parameter estimate in the quantitative analysis as
In a Bayesian analysis, we need a competing hypothesis because Bayesianism is inherently comparative. Based on colonialism research that was available when the analysis was done, one could have expected that more indirect rule would have a positive effect on development (see the “Illustration: British Rule and Colonial Development” section and Supplemental Appendix Section D.2).
Using this formalization, we can make the
The Elements and Workflow of the Bayesian Design
Mixed-methods research that combines a large-n and small-n method in this order has three interactive elements. We formulate these elements as questions that guide the discussion. First, what mechanism can one expect to be in place in process tracing based on the quantitative results? Second, how confident can one be that this mechanism is present and how many resources should we focus on collecting evidence for this mechanism and not others (on resources, Bennett, 2015)?
Comparison of Frequentist Analysis and Bayesian Design.

The stylized workflow in Figures 1 and 2 starts with a large-n analysis (as by Lieberman, 2005). The analysis can be implemented as a single-phase analysis, whereby each method is used once, or as a multiphase study with iterations of one or both methods. We discuss the Bayesian analysis as a multiphase design in which both methods inform each other in an iterative process. In the Concluding section, we briefly address designs starting with small-n research.

Procedure for Bayesian mixed-methods research starting with the quantitative analysis.
We introduce versions of Bayes’ theorem for the quantitative and qualitative analysis to lay the foundation for a detailed presentation of the design and workflow. Theorem 1 is used to make inferences about 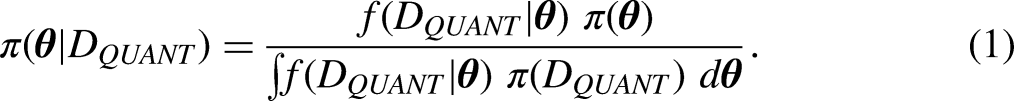
Theorem 2 presents the discrete version of Bayes’ theorem as it s used for process tracing (Abell, 2009; Beach and Pedersen 2019; Fairfield and Charman, 2017).
8
Following Lange’s argument, we use the negative mechanism 
Our focus will be on typical (well-predicted cases based on the regression estimates) and deviant cases (badly predicted cases). Our concern with these two types of cases follows the discussion of nested analysis (Lieberman, 2005). We do not deal with extreme cases (Galvin and Seawright, 2023; Seawright, 2016a) and pathway cases (Gerring, 2007; Weller and Barnes, 2016), or other types in this article. We made this decision for three reasons. First, the answer to the questions as to what type of case to choose and how to do so is independent of the answers to the first two questions. The relevance of large parts of our arguments does not depend on how one answers the third question. Second, nested analysis with its focus on typical and deviant cases has guided the implementation of many empirical mixed-methods studies that choose either typical or deviant cases, or a combination of the two (see Supplemental Appendix Section C.1). Following this review, extreme and pathway cases do not seem to be used formally in mixed-methods research so far. This makes a Bayesian procedure for typical and deviant cases seem more relevant for empirical multimethod research. 10 Third, we see no reason why extreme and pathway cases are fundamentally incompatible with a Bayesian template. We leave it to a follow-up study to explore how other types can be integrated into Bayesian mixed-methods designs. We discuss additional elements of the workflow in the Supplemental Appendix: the formulation of informative hypotheses (Stage 1); the specification and estimation of the regression model (transmission from Stage 1 to Stage 2); the consequences of process tracing insights for updating the mechanism-related priors and the entire analysis if one realizes a multiphase study (Stage 5).
Stage 2: How Probable Effects and Mechanisms Are Ex ante: The Priors
In Stage 1, one starts with the formulation of hypotheses about theoretically possible effects and mechanisms. In the second stage, one has to specify a prior distribution
The repertoire of strategies for the prior specification are the same in Bayesian multimethod research as in a standalone Bayesian regression and process tracing. First, the posterior of one empirical study is the prior of the next Bayesian study addressing the same research question (posterior passing, Brand et al., 2017). Second, one can use qualitative evidence for informed arguments about a plausible prior mean and variance. Third, this informal step can be formalized by relying on a structured evidence synthesis such as a meta-analysis or systematic reviews (van Grootel et al., 2020). Fourth, expert interviews can be used for prior elicitation. Regardless of the strategy one follows, which can possibly be in combination with other techniques, the rule of thumb is that the prior distribution for
The specification of the regression model and prior distributions are the foundation for estimating the model as an intermittent step between Stages 2 and 3. In Stage 3, we use the regression results for addressing the first two questions, where the order does not matter. The inferences that one makes in the two steps need to be evaluated together to determine what mechanism one can expect to be present with what level of confidence (3a), and how much of a difference in within-case evidence we can expect to observe between two cases (3b).
Stage 3a: How Much More Confident One Can Be in a Mechanism and With What Level: The Bayes Factor
The overall question of what the regression results imply for the level of confidence in the presence of a mechanism has two theoretical and two practical components that are all related to the forward-passing of information from the quantitative to the qualitative analysis. First, how much do the regression estimates for
We explain how one can address these four elements through a combined analysis of the Bayes factor (BF) and the credibility of the causal inferences about the effect of 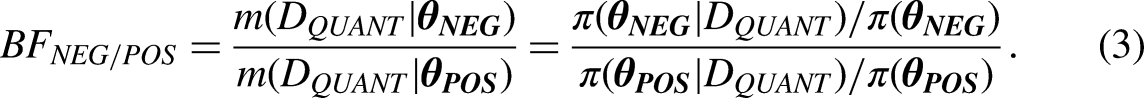
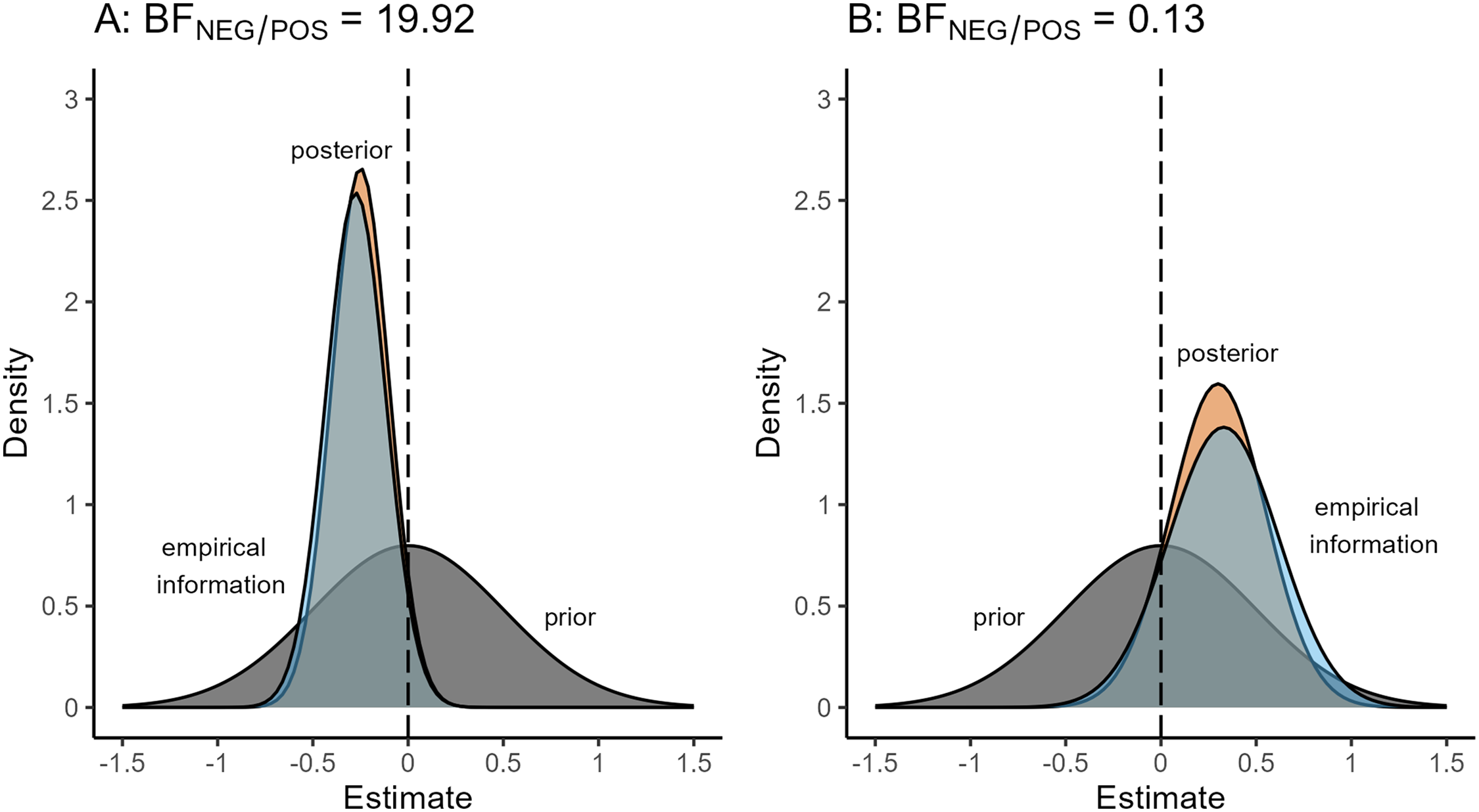
Strength of evidence for hypothetical pairs of prior and posterior distributions.
In Panel A of Figure 3, the likelihood function expresses a high level of confidence in a negative effect, with most support for an effect of
First, we use the BF to update the priors for the negative and positive mechanisms. When the BF strongly indicates a negative effect of the degree of indirect rule, one can take this result and plug it into the
If one theorizes that multiple mechanisms could underlie an effect in the same direction, the BF is not informative about which of these mechanisms is more likely to be present. This is not a shortcoming of the BF, but follows from a generic ambiguity concerning which mechanism or mechanisms support this effect. The possibility of multiple underlying mechanisms for the same type of effect is the reason that one does mixed-methods research and uses process tracing. 12
The natural follow-up question for a BF of 20 is: How much should one update the priors of the mechanism based on the BF? For Panel A of Figure 3, does a BF of 20 mean that we should update the prior of the negative mechanism by a factor of 20? We argue that the BF alone is insufficient for answering this question because it does not capture whether the effect of
This should be taken into account by factoring in the credibility of the quantitative causal inferences. The degree of credibility or trustworthiness of the inference that
The level of trust in the credibility of the quantitative causal inferences can be used as an adjustment or discount factor in the updating process for the qualitative priors.
14
For our example, it is plausible that the measure for “degree of indirect rule,” the share of customary court cases (Lange, 2009), exhibits systematic measurement error because the documentation of court cases could be more incomplete in more indirectly ruled colonies if they had weaker legal-administrative capacity. The possibility of systematic measurement error and, consequently, a biased estimator should decrease the level of trust in the causal interpretability of the estimate.
15
The consequence is that one increases the prior for the negative mechanism and reduces the prior for the positive mechanism less than a
The second implication of the BF concerns the question of how widely to “cast the net” in process tracing and be open for finding evidence for different mechanisms (Bennett, 2015). The more the BF favors a negative over a positive effect, the more process tracing should focus on
This use of the BF has implications for the distinction between a confirmatory, model-testing small-n analysis (mt-sna) and an exploratory, model-building analysis (mb-sna) that is salient in nested analysis (Lieberman, 2005). In the original formulation, a good model fit suggests adopting mt-sna focusing on one variable; an unsatisfactory fit requires the implementation of an exploratory mb-sna. In a Bayesian design, the BF as a continuous measure allows one to drop the crisp distinction and to decide about the approach based on the degree of confidence in finding evidence for
Stage 3b: What Strength of Process Evidence One Can Expect: The Posterior Highest Density Interval
The goal of process tracing is to find process observations that strongly support the presence of one mechanism and are unlikely to be collected under an alternative mechanism (Beach and Pedersen, 2019; Bennett, 2015). We show how one can use the posterior distribution for
We illustrate the role of the HDI in Figure 4, presenting three hypothetical posterior distributions. In each panel, the gray bar represents the 90% HDI. The HDI in Panel A of Figure 4 ranges from

Three hypothetical posterior distributions with 90% highest density interval (HDI) (I-axis varies).
For Panel A of Figure 4, a 90% probability that the effect is between
When one infers that the estimated effect of indirect rule is large and negative, the expectation would be that the increase in indirect rule causes a correspondingly large decrease in the school budget. This expectation builds on a proportionality assumption between the effect size of “degree of indirect rule” and the difference between the process evidence of two cases that vary in their degree of indirect rule. When one infers from a quantitative analysis that the effect is large and negative and plugs
The proportionality assumption is central to understanding how the HDI is related to the expected relative strength of process evidence. The relative strength of qualitative evidence is the ratio of the likelihood of one hypothesized mechanism to the likelihood of another mechanism. We refer to the likelihood ratio (LR) comparing the negative and positive mechanisms as 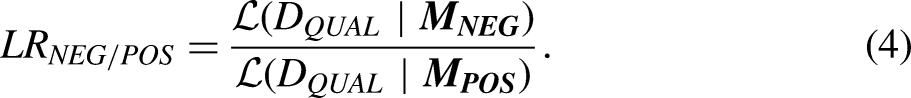
Panels B and C of Figure 4 present different HDIs to illustrate the implications of their location and width for the qualitative analysis. Compared to Panel A of Figure 4, the location of the HDI in Panel B of Figure 4 implies that the expected process evidence is weaker because the upper bound is much lower and the lower bound is practically indistinguishable from 0. Panel C of Figure 4 illustrates the importance of using the HDI instead of the point estimate. Based solely on the point estimate of
Stage 4: The Classification and Choice of Cases: Posterior Predictive Sampling
The third interactive element is the regression-based classification and choice of cases. The classification of cases as typical and deviant proceeds in four steps using posterior predictive sampling. First, one takes the posterior distribution
In the next step, classification is the basis for case selection. The choice of a single typical or deviant case should be guided by the research question. For a typical case, the interest could be the collection of evidence for high state-administrative capacity in a directly ruled colony or for low capacity in an indirectly ruled colony. For a single deviant case, one could select an overperforming case that did unexpectedly well or an underperformer that shows a poorer outcome than was predicted.
25
A comparative analysis of two typical cases follows the idea of a most-similar comparison wherein two typical cases differ in their degree of indirect rule and development and are similar on all other covariates. One should choose from the set of typical cases a diverse pair that maximizes the difference between
Illustration: British Rule and Colonial Development
Quantitative Analysis
The original analysis uses the share of customary court cases in a colony as a proxy for the form of British rule (Lange, 2009). A higher share of customary court cases represents more indirect British rule, which is hypothesized to have a negative effect on five outcomes: GDP per capita (2000, log); average school attainment (1995); infant mortality rate (2000) 27 ; aggregate quality of governance (1996–2005); and average level of democracy (1972–2005) (Lange, 2009). The five outcomes are alternative measures of development and are neither theoretically nor substantively important in themselves. We can exactly reproduce the frequentist estimates for the five original OLS models using the original data (see Supplemental Appendix Reproduction Material).
We have introduced the hypotheses on the negative effect and negative mechanism in the “Empirical Example” section (Step 1 of the workflow). In Stage 2, we must specify the priors for all variables in the regression model and the mechanisms. The use of five outcomes in the quantitative analysis allows us to implement posterior passing. Posterior passing means to pass forward information within the quantitative stage by using the posteriors of one regression analysis as the priors for the next (Brand et al., 2017). Posterior passing makes the most of the estimates of one analysis by conveying information from one model to the next. Posterior passing has two implications for the Bayesian regression. First, we only need to review existing research to specify the priors of the first model that we estimate because it produces priors for the second model, and so on. Second, a practical requirement is that we need to standardize all variables to estimate effects using a common scale.
We start posterior passing with the outcome “GDP/capita” and finish with the outcome “level of democracy.” “GDP/capita” is the first outcome because a review of colonialism research shows that it offers the most results on which to build. Our review is based on the literature that had been available at the time the original analysis was done (see Supplemental Appendix Section E.2). With regard to the form of rule, multiple studies have found that British rule had a positive effect on development and economic growth, as compared to French and Spanish colonial rule. This is indicative of a positive marginal effect of indirect rule because British colonies are consistently described as having been more indirectly ruled (Bernhard, Reenock, and Nordstrom, 2004; Brown, 2000; Grier, 1999: section 2). We use this evidence to specify a prior for the degree of indirect rule that expresses a moderate level of confidence in a positive effect with a mean of 0.1 and a standard deviation of 0.2.
28
The hypothesized capacity mechanism is tied to a negative effect of indirect rule. Based on the expectation that a positive effect is more likely than a negative effect, we assign an informally specified low prior
The reviewed research further indicates that two control variables (see Lange, 2009), latitude (Acemoglu, Johnson, and Robinson, 2001) and ethnic fractionalization (Bernhard, Reenock, and Nordstrom, 2004), have a negative effect on development. We assign a prior mean of
In the transition from Stages 2 to 3, we estimate each model with a normal likelihood function and conjugate normal priors using Hamiltonian Monte Carlo sampling (Gill, 2015: section 15.4). We begin with two separate Markov chains and check the results for convergence using the Gelman-Rubin diagnostic (Gill, 2015). For each model, the estimates are based on one chain and 10,000 posterior draws, from which we exclude the first 2,000 as warm-ups. We present the complete results for the final model in Supplemental Appendix Section E.4 and focus on the implications for the interactive elements of the design.
Implications of Estimates for Qualitative Analysis and Case Selection
We present the prior and posterior distributions for the final model that serves as the basis for Stages 3a and 3b (Figure 5). The 90% HDI ranges from

Prior and posterior distributions for degree of rule.
The BF shows that the quantitative data very strongly favor a negative over a positive effect with a natural log of the
Second and building on what we discussed in the “Stage 3a: How Much More Confident One Can be in a Mechanism and With What Level: The Bayes Factor” section, the share of customary court cases as the measure for degree of indirect rule might exhibit non-systematic and systematic measurement error. When we factor in these limitations, we find it appropriate to update the low prior
For the classification of cases in stage 4, we calculate 1,000 predicted outcome values and derive the 90% prediction interval (PI) for each case. 33 Figure 6 plots the mean predicted values and 90% PIs against the observed outcomes. The plot shows that 35 cases are classified as typical and that four cases are deviant. 34
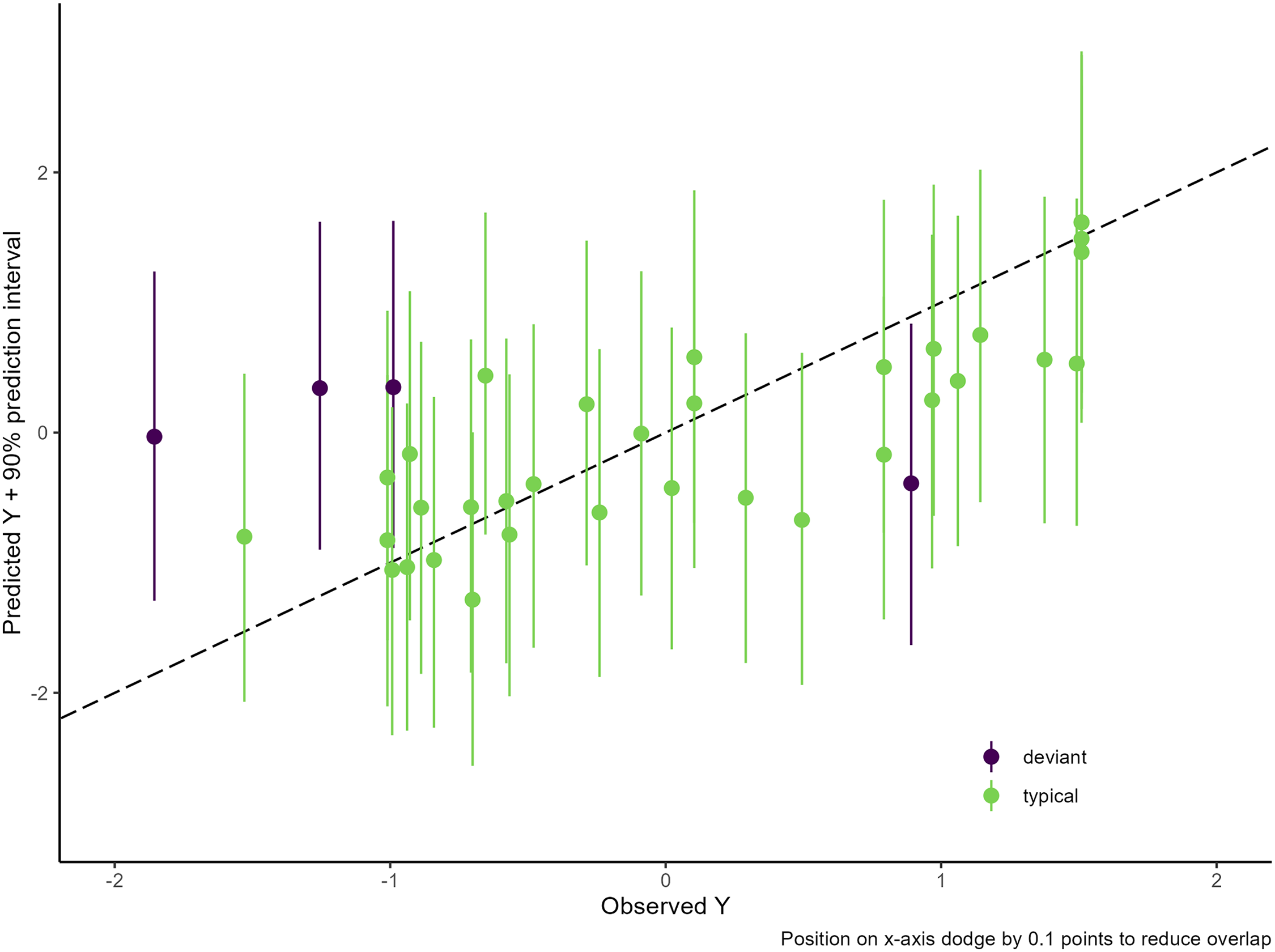
Predicted-versus-observed plot based on the final model.
Based on their classification, we choose cases for comparative process tracing following the idea of a most-similar design based on the calculation of their distances on the outcome, the degree of indirect rule and the set of controls.
35
For each pair of typical cases, we plot the difference in the level of democracy against the difference in the degree of indirect rule (Figure 7). The size of the marker symbols is proportional to the distance of the pair on all control variables in the regression analysis. There is no ideal pair of typical cases that combines the maximum distance in the degree of indirect rule and the level of democracy with a minimal distance on the controls.
36
If this holds, which depends on the data at hand, one has to decide whether to trade off a larger distance in

Similarity of pairs of typical cases.
The alternative is a comparison of Barbados with Malawi. The two countries differ in the degree of indirect rule (82) less than do Nigeria and the USA, but have a slightly larger difference on
Comparison with Other Mixed-Methods Approaches
Nested Analysis
We compare the quantitative-to-qualitative interaction between our design and a frequentist analysis to illustrate how the decisions and conclusions are made on a different basis and that, to some degree, the decisions differ substantively. In a nested analysis, for answering the question of what mechanism one can expect to be present and with what level of confidence, one would use the statistically significant, negative estimate of ‘degree of indirect rule'. The estimate is negative for all five outcomes, where one would not be able to implement posterior passing because this is not possible in a frequentist setup. This result would also lead us to expect that the negative mechanism is present, meaning that we would opt for mt-sna in a nested analysis and our Bayesian design. However, in a frequentist analysis, we would neither know how much more confident we can be nor what the updated level of confidence in the negative mechanism is because there is no conventional frequentist equivalent to the BF. The estimate for
For a comparison of the expected strength of process evidence (Stage 3b), Figure 8 presents the prior distribution for “degree of indirect rule” and the five posterior distributions next to the frequentist estimates. They are arranged from bottom to top in the order that we estimate them for posterior passing. For each outcome, the HDI is smaller than the corresponding confidence interval (CI), which is the frequentist equivalent to the HDI. For the final outcome, the CI ranges from
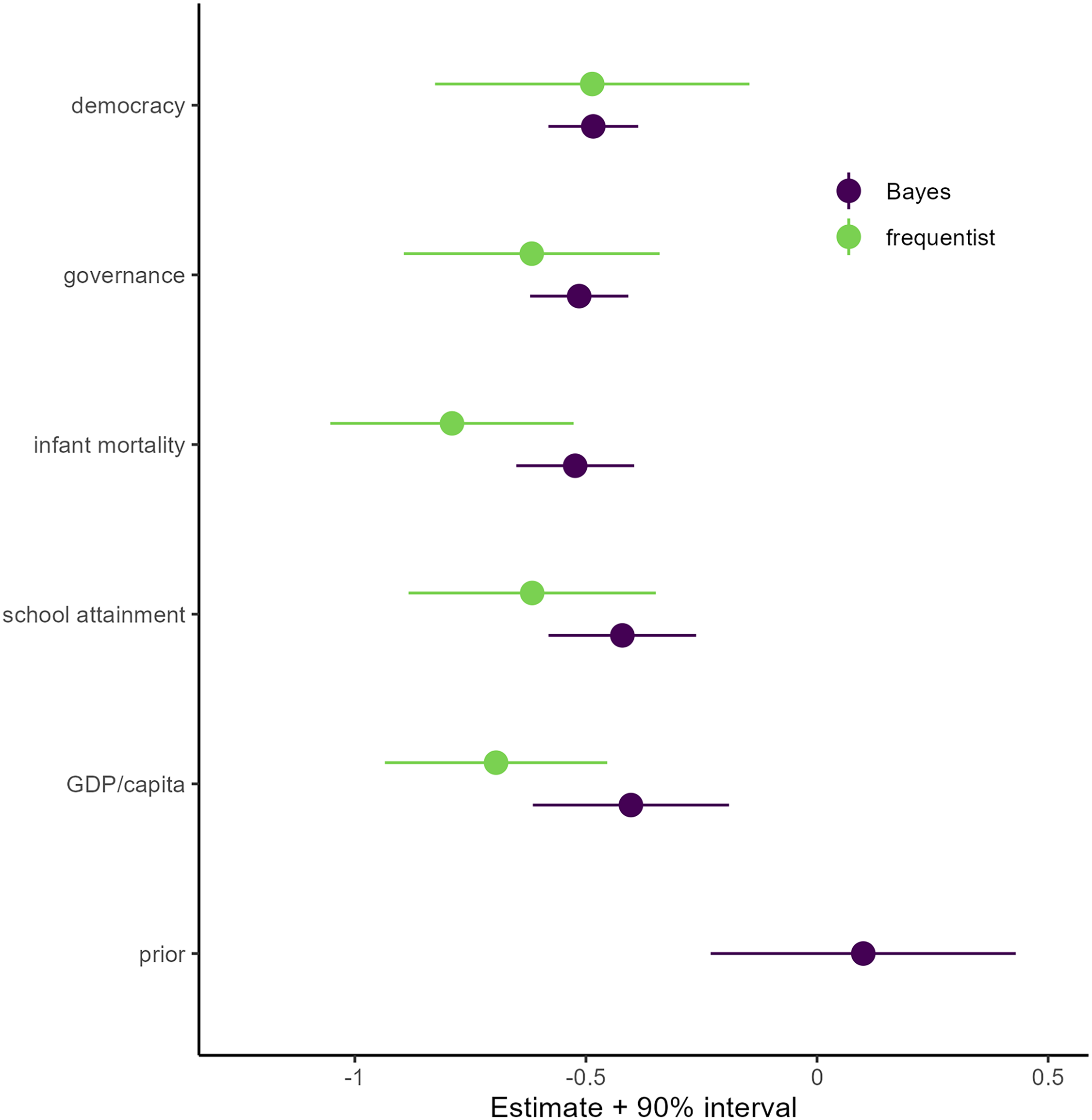
Estimates for effect of degree of rule.
For stage 4, we compare the classification of cases across all five models using the 90% PI (Figure 9). We focus on whether a case has the same status in nested analysis and a Bayesian analysis, as this step is fundamental for the choice of cases in the second step. The models are arranged from left to right in the order that we estimate them for posterior passing. The plots show that case classifications differ for four models out of five, whereas the number of cases that are classified differently is small for each model.
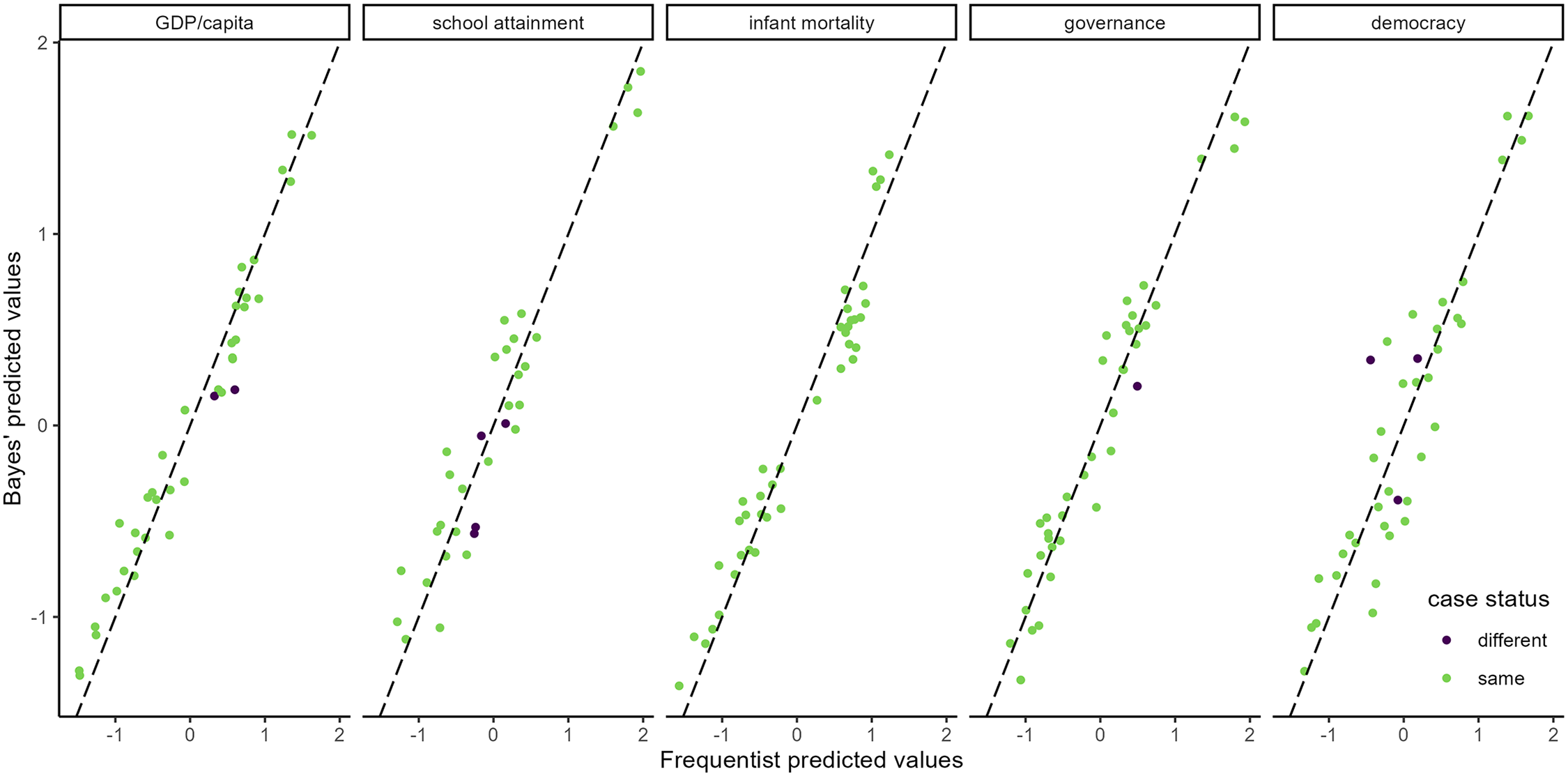
Comparison of case classification using 90% prediction intervals.
In summary, the illustrative comparison shows that the original frequentist analysis and a Bayesian analysis produce different quantitative results (beyond salient differences in their frequentist and Bayesian interpretation), which allows one to derive more informative expectations from the Bayesian regression estimates. The integration of quantitative and qualitative methods and sequential updating of priors are one advantage of the Bayesian design over the frequentist alternative. This means one should choose the Bayesian design when the goal is to quantify the uncertainty about what the possible direction of the effect and the underlying mechanisms are. We believe that the value of the Bayesian design is higher, the stronger the theory is that one can use to derive priors for the effect and mechanisms. This implies that the classic nested analysis may be preferable if theory is weak. In principle, one could work with flat priors in a Bayesian framework when theory is weak. However, one may still prefer the computationally and formally more lightweight frequentist approach to sharpen theory first and lay the basis for a follow-up Bayesian mixed-methods design.
We conclude the illustration by addressing two potential points of criticism. First, one might argue that the differences between a frequentist analysis and a Bayesian analysis are not large. Besides the fundamental differences in the interpretation of Bayesian and frequentist results, the similarities follow from the strong quantitative evidence for a negative effect of degree of indirect rule that dominates the prior information speaking for a positive effect. In Supplemental Appendix Section F, we present results of Monte Carlo simulations that show under what conditions a Bayesian analysis and nested analysis differ from each other in the interactive component of the design. The simulations show, first, that the differences in case classifications are the larger, the smaller the number of cases. Second, the results differ the more the prior information and information in the data diverge. Third, differences are larger whenthe weight of the prior information is larger, relative to the weight of the data. Of these three conditions, only one is met in our example because the sample size is small. The simulation results demonstrate that when all three conditions coincide, the differences between a Bayesian analysis and frequentist analysis are sizable.
Second, one might observe that the differences mainly derive from posterior passing, which is neither a necessary component of our design nor always available in a Bayesian mixed-methods study. The comparison of the Bayesian estimates with the results from the nested analysis show that they do not mainly follow from posterior passing. When one imagines that we only estimate one regression with GDP/capita as the outcome, the CI indicates an effect of indirect rule that is larger than the effect estimated with the HDI (CI:
Integrated Inferences and the Bayesian Integration of Quantitative and Qualitative Evidence
The Bayesian integration of quantitative and qualitative evidence (BIQQ) is an alternative approach that uses cross-case and within-case data (Humphreys and Jacobs, 2015, 2023). In its present form, BIQQ works with a small number of binary variables, including the treatment, and a binary outcome. Its key strength is the simultaneous updating of beliefs about the effect on the cross-case level and the mechanism on the within-case level, implying that BIQQ belongs to the class of simultaneous mixed-method designs. Given the constraint that one has to work with binary variables, this approach should be particularly attractive for integrated cross-case and within-case analyses in causal qualitative research.
The approach that we propose belongs to the group of sequential mixed-method designs. At a given stage of the analysis, one either updates quantitative or qualitative beliefs that are forwarded to the next part of the analysis. Our framework uses regression analysis for the estimation of treatment effects. This gives researchers the flexibility to choose the regression approach that is needed for the data structure at hand without the need to dichotomize variables. The chosen estimation approach only needs to give a researcher the opportunity to distinguish different types of cases using an appropriate criterion. What this criterion is depends on the types of approach; for OLS regression, it is the residual of a case and a criterion that guides case classification (Rohlfing and Starke, 2013). For generalized linear models with a logistic link function, one can calculate predicted probabilities for each case and compare them with the observed outcome to distinguish well-predicted from not-so-well predicted cases. Similar criteria can be devised for other estimation approaches such as event-history analysis and regressions for count data. This shows that BIQQ and our Bayesian mixed-methods design are not substitutes, but complement each other. They are alternative approaches that one can choose from depending on the research goal and the nature of the data at hand.
Conclusion
We proposed a design and procedure for the integration of Bayesian regression with process tracing. Our discussion has been guided by the idea of mixed-methods research that starts with a regression analysis. Future work on Bayesian mixed-methods research could develop a design that starts with Bayesian process tracing and performs the regression analysis as a second step. In this version of a Bayesian mixed-methods study, it would be crucial to work out how the qualitative results could inform the specification of prior distributions for the regression parameters. A Bayesian “process-tracing first” design along these lines would be a valuable addition to the Bayesian mixed-methods toolbox. A second possibility for further development is the exploration of how alternative types of cases such as extreme cases and pathway cases could be defined and chosen in a Bayesian analysis.
Supplemental Material
sj-png-1-smr-10.1177_00491241241295336 - Supplemental material for The Integration of Bayesian Regression Analysis and Bayesian Process Tracing in Mixed-Methods Research
Supplemental material, sj-png-1-smr-10.1177_00491241241295336 for The Integration of Bayesian Regression Analysis and Bayesian Process Tracing in Mixed-Methods Research by Lion Behrens and Ingo Rohlfing in Sociological Methods & Research
Footnotes
Authors’ Note
The reproduction material for the paper is available at https://doi.org/10.5281/zenodo.13745067. The appendix is available at ![]() .
.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Lion Behrens was supported by the German Research Foundation (DFG) via the SFB 884 on “The Political Economy of Reforms” (Project C7) and the University of Mannheim’s Graduate School of Economic and Social Sciences (GESS). Ingo Rohlfing has received funding from the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation program (grant agreement no. 638425). For research assistance, we are grateful to Dennis Bereslavskiy, Nancy Deyo and Michael Kemmerling. We are grateful to Matthew Lange for having shared his dataset with us.
Data Availability Statement
A README file, a codebook, R code and datasets generated and/or loaded and analyzed for the current study are available in a Zenodo repository (Behrens and Rohlfing, 2024).
Notes
Author Biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.