
Abstract

Qualitative comparative analysis (QCA) opens up two new forms of knowledge: (1) knowing about alternative pathways to one outcome (equifinality) and (2) perceiving nuances of necessary cause and sufficient cause. Several misunderstandings of QCA occur in the article by Lucas and Szatrowski (this volume, pp. 1–79). First, there are minor problems with expressions. Second, there are differences between their philosophy of science (arguments 1, 2, and 3 below) and a realist approach. Third, they misinterpret what was meant by sufficient and necessary cause (arguments 4 and 5 below).
The minor problems with expressions arise in sections 2.2 and 3. In section 2.2, the authors define consistency, but here they miss out on two key points. First, they neglect to say that this particular measure of consistency is a measure of sufficiency of cause, not of necessary cause. 1 Second, they ignore the way that the consistency level exists for each possible configuration of characteristics. A configuration can be shown in one row of a truth table, with n1 = 28, n2 = 17 within a larger sample of 155, and so on (see Byrne 2009:262). Using QCA’s definition of “consistency,” we can discern more about the pattern of causality than one might initially expect. This learning is possible whether N overall is 155, or just 39, or thousands of cases. The essential task is to simplify and rank the list of configurations (Ragin 2001, 2006).
In section 3, the discussion of “determinism” is also confusing, lacking a clear statement of what is meant by determinism. What is needed is a clear ontological position. Realism offers a clear position: Realists would say that causes are real, but each one is often obstructed or mediated by contextual factors (Byrne 2002).
Overall, partly as a result of their lack of ontological clarity, Lucas and Szatrowski understate the user-friendliness of the QCA method. Several arguments come to mind.
Argument 1: Investigators Have Purposes and Theories
Scholars such as Rihoux and Grimm (2006) and Snow and Cress (2000) who invoke QCA are serious experts with deep knowledge of their subjects. These investigators make sure their interpretations conform to the reality, and inevitably they produce situated knowledge (Smith 1998).
By suggesting that we mine data sets to find an optimal model or “solution,” Lucas and Szatrowski have neglected the links people draw between funders, scholars, users, and readers of research (Flyvbjerg 2001). Even given these links, any new knowledge must also still be true to reality (Byrne 1999, 2002). There may be more than one practically adequate interpretation (sic, Sayer 1992:69–70). The evidence might support more than one interpretation. The idea of “validating the method” (section 4 in Lucas and Szatrowski) is not consistent with realism (Sayer 1992). Each author instead needs to draw out valid claims after doing the research. In QCA, therefore, the “parsimonious,” intermediate, and complex solutions to a simplified data table can help us develop warranted arguments (Fisher 1988, 2001). The “results” do not simply constitute those arguments (Olsen and Morgan 2005). QCA is an accessible, systematic, transparent medium for presenting case-study research.
In reviewing the paper, I took results based on Table 9 (p. 30) of Lucas and Szatrowski and made sure the fuzzy-set QCA software replicated them. It did. (The software is by Ragin et al. 2006.) The issue is interpretation.
Argument 2: There Is Epistemological Grounding for QCA-based Findings and QCA Procedures
Deeper issues also arise because I claim that knowledge about a particular configuration can be a valid contribution to sociological knowledge. Knowledge need not be about one universal model for a whole social domain. Knowledge claims are constrained by the data gathered and marshaled to support them. Knowledge is grounded by making reference to the real world (Olsen 2012). Thus, the argument using artificial data in section 4 is poorly constructed. It does not refute QCA, because no background knowledge can be obtained: these data do not reflect reality.
Argument 3: Data Are Traces of the Real
Realist scholars have asserted that epistemology is always flavored by ontological presuppositions or assertions (Sayer 1992). It is important for social theorists to tease out and name the different types of causal mechanisms as if they were separate, because they are different in their nature. These essential features of social causes are in turn contingent on events and structures in social history. Realism is not deterministic. Ragin’s (2006, 2008) work is more like Byrne’s realism. Ragin uses ontological elements similar to those listed by Sayer (1992:24–28, 93–98), and his work is unlike Mahoney’s (2000) approach (section 3). The trope that the QCA “solution” offers “recipes” does not do justice to the complexity of society or the types of real objects being studied. Perhaps the choice of the word recipe is unfortunate. Realists develop warranted arguments. In sections 3 and 4, the paper does not do justice to the seriousness of many QCA authors’ applied contributions. The randomly distributed error term found in simulation equation (1) (p. 12) shows a lack of understanding of a depth ontology. It also shows a preference for an artificially constructed data world that is unlike the real world. Among realists, this is sometimes called “idealism” (meaning a focus on ideal types or ideas, not on reality).
Argument 4: Patterns That Suggest Sufficiency Deserve to Be Noticed
Equifinality (two pathways to one outcome) has been recognized in other methods. These include structural equation modeling (SEM) and interaction effects in regression. Similar to QCA, one pathway may be active in one group of cases and another pathway in a different overlapping set of cases. There are limits to this analogy. Notably, SEM is always carried out in a random-sampling context. Another key difference is how the “errors” are treated: In QCA there are no “error” terms, but in SEM the model structure and its goodness of fit are absolutely central to the method. In this sense, QCA as presented by Ragin is mainly about causal models.
In QCA, the left- and right-hand-side deviations away from the diagonal line in the X-Y space mean entirely different things. The upper-left triangle reflects “sufficient cause of X for Y,” and the lower-right triangle reflects the X factor’s being a “necessary cause of Y.” If X is necessary, it can usually not also be sufficient, since necessity and sufficiency relations are converses of each other.
Suppose we begin by testing the interaction X1*X2. Suppose X1 and X2 are crisp, and Y is a fuzzy set. (X1 and X2 are a configuration; * means “and” here.) For sufficiency, the effect of X1*X2 could be discerned by counting the relative prevalence of three possible situations:
Cases with X1 and X2, and Y1 high
Cases with X1 and X2 absent and Y1 low
Cases with X1 and X2 absent and Y1 high (nevertheless).
Y1 may also have been caused by something other than X1 and X2 combined. Figure 1 illustrates.
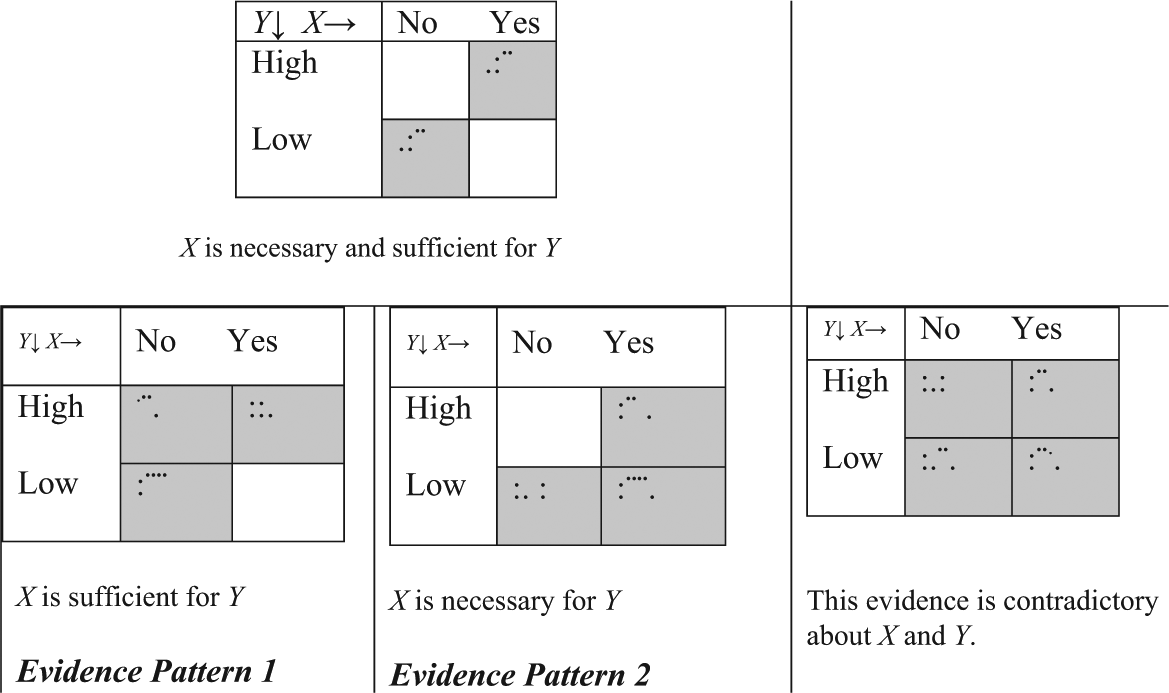
Four patterns and their interpretation in qualitative comparative analysis.
In evidence pattern 1, each time a case appears in the bottom right cell, it contradicts the hypothesis that X is sufficient for Y. Using a mixture of crisp- and fuzzy-set memberships, we have empirically discerned sufficient configurations using data on slum dwellers in Chennai (Harriss-White et al. forthcoming; Olsen et al. 2010).
Argument 5: Mechanisms that Operate as Necessary Causes Operate Independently of each other and in Tandem
A wholly different evidence pattern occurs where the data instead support the claim that X1*X2 is necessary for Y (Ragin 2008, 2009). Finding necessity within a configuration that is sufficient 2 is different from finding necessity overall. This distinction is not highlighted in the paper by Lucas and Szatrowski. Their Table 4 should be clearly labeled as “sufficiency consistency,” and their addition of a “noncausal” factor should be noted as artificial. If a real factor had raised all the levels of consistency (for sufficiency), we would then explore what aspect of it bore this causal mechanism. We would explore its nature and then develop a better theory that integrated this causal mechanism.
Conclusions
On the basis of the preceding arguments, this critique of QCA does not seem well founded. Lucas and Szatrowski created an artificial data set by a data-generating process that mimicked random error (their equation 1) rather than mimicking a mix of “necessary,” “sufficient,” and INUS relations. They have ignored a key fact about asymmetry in the data. Variation in one direction supports the claim of necessity, but variation in the other direction supports the converse claim of sufficiency. The attempt to rebut QCA needs to assume the strongest possible underlying presuppositions for QCA (Fisher 2001). The best foundation is to assume complexity of the underlying social relations. These data and the “solutions” (Tables 4–6) do not reflect in a naturalistic way any underlying social relations. As a result of ignoring complexity and the role of theory, the rebuttals are unconvincing. Replication studies can attempt to refute researchers’ findings, but they need to make reference to the real world, not to purely numerical patterns.