
Abstract
The impossibility of uniquely estimating all of the age, period, and cohort coefficients in age-period-cohort multiple classification (APCMC) models without imposing a constraint on the model is widely recognized. The problem results from a linear dependency in the design matrix, and this dependency involves the linear trends of age effects, period effects, and cohort effects. This article critiques the use of fit statistics to assess the overall importance of the effects of ages, periods, and cohorts in APCMC models. In particular, one proposed strategy to avoid the APCMC model identification problem is to test to see if including only two of the factors in a model (e.g., ages and cohorts) produces a fit that is not significantly different statistically from a model that includes all three factors. If the third factor (in this example periods) does not account for a statistically significant amount of variance, this strategy suggests that one should use the model with only the two factors. This is consistent with model selection approaches. The two-factor model is identified and produces estimates of the individual effects of ages and cohorts. There is, however, a fundamental problem with this approach when used with APCMC models. That problem results from the complete confounding of the linear effects of the three factors.
1. Introduction
For decades, researchers have known that it is not possible to separate the effects of ages, periods, and cohorts in a straightforward manner since they are intrinsically confounded (Mason et al. 1973; Schaie 1965). Schaie (1965), Mason et al. (1973), and other researchers consider a particular parameterization of this problem: the age-period-cohort multiple classification (APCMC) model. In this parameterization, each of the ages, periods, and cohorts are coded categorically (with a single category for each of these factors serving as reference categories). I will focus on this parameterization, which is widely used in the literature.
The most popular solution to this confounding problem (identification problem) places a single constraint on a model that contains all three factors; for example, the first age-group coefficient equals the second age-group coefficient or the linear trend for the period coefficients is zero. The single just-identifying constraint produces a solution for the age, period, and cohort coefficients under the constraint. 1 Unfortunately, there is an infinite number of these solutions that fits the data equally well, and these solutions can differ considerably depending on the constraint used. Only if the constraint is consistent with the age, period, and cohort parameters that generated the data will the coefficients under the constraint be unbiased estimates of the data-generating parameters. When using this method, we should use theory/substantive knowledge to set a constraint that is more likely to be close to the parameters that generated the data. 2
The incremental factor fit strategy, which is the focus of this article, does not depend on theory/substantive knowledge. It eliminates one of the factors (ages, periods, or cohorts) if that factor does not make the model fit significantly better statistically when added to a model containing the other two factors. In the ordinary least squares (OLS) situation, we could compute
The same rationale is used for generalized linear models (GLM), although the criterion differs. Typically, one would calculate the likelihood ratio chi-square:
These incremental fit tests, using OLS or GLM, are employed by many authors working in the APC tradition; for example, see Clayton and Schifflers (1987b); Greenberg and Larkin (1985); Hall, Mairesse, and Turner (2005); Phillips (2014); Shahpar and Li (1999); and Yang and Land (2013). Working with just two of the factors identifies what otherwise (without a constraint) would be an unidentified model. 6
2. Incremental Fit Tests of Factors in APCMC Models
Although it is known that the linear trends of the categorical effect coefficients for ages, periods, and cohorts are linearly dependent (Holford 1983; Luo 2013; O’Brien 2011b), the implications of this dependence are often overlooked when it comes to employing incremental fit tests for the overall importance of ages, periods, and cohorts. Recently Yang and colleagues (Yang et al. 2008; Yang, Fu, and Land 2004; Yang and Land 2013) suggested that such tests should be conducted before deciding to use the intrinsic estimator (IE). Yang and Land (2013:107) state:
One way to select among models is to conduct model fit tests of whether all three of the A, P, and C effects are present and should be simultaneously estimated (e.g., see Mason and Smith 1985). That is, analysts should successively estimate models with A, P, C, AP, AC, PC, and APC sets of effect coefficients and examine the corresponding model fit statistics for improvement as additional sets of combinations of coefficients are added. This gives a sense of the relative importance of A, P, C, effects and the best models that summarize the trends in the observed data.
They conclude: “We reiterate that imposition of a full APC model on data when a reduced model fits the data equally well or better constitutes a model misspecification and should be avoided” (Yang and Land 2013:109).
Yang, Land, and colleagues are not alone in advocating the incremental fit tests for the two- and three-factor models. Clayton and Schifflers (1987a, 1987b) in epidemiology and Hall et al. (2005) in economics provide two other prominent examples. As noted previously, many other authors have used this approach to identify APCMC models.
The problem with such solutions derives from the confounding of the linear trends of the three factors: age, period, and cohort. To explain the operational meaning of linear trends in the APCMC context, I use the age-factor as an example. To obtain the linear trend for ages, regress the age effect coefficients (based on one of the just-identifying constrained solutions) from the youngest to the oldest age group on
Explicit and Estimated Model

Table 1 uses
3. The APCMC Problem
The APCMC problem is well known. The individual coefficients for ages, periods, and cohorts are linearly dependent, and therefore, unique estimates of these coefficients are not estimable. The problem is that the linear effects of any two of the three factors (age, period, and cohort) are linearly related to the third (Clayton and Schifflers 1987b; Holford 1983; O’Brien 2014, 2015a; Smith 2004). Models that contain each of these factors are not identified, and the matrix of independent variables does not have an inverse. This is the case whether these factors are linearly coded or whether they are coded using categorical variables. I focus on the situation in which the ages, periods, and cohorts are categorically coded (the APCMC model) since this is the most common situation, but I note the linear coding situation next.
3.1. Linear Confounding with Linear Coding
The confounding for the linearly coded variables is easy to describe. If we code age from the youngest age to the oldest age as
3.2. Linear Confounding with Categorical Coding
Categorical coding of the three factors is far more common in APC analysis. I denote the APCMC model with categorical coding as
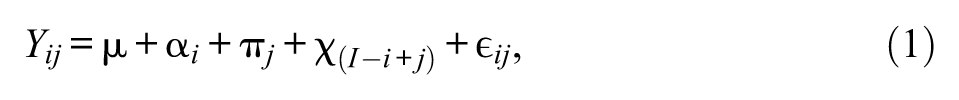
where
For concreteness, Table 2 shows the linear coding in a 4 by 5 age-period table. The linear coding for ages is 1 to 4 on the rows; the linear coding of periods is coded as 1 to 5 on the columns. Using this linear coding and (
Relationships between the Linear Effects of Ages, Periods, and Cohorts*
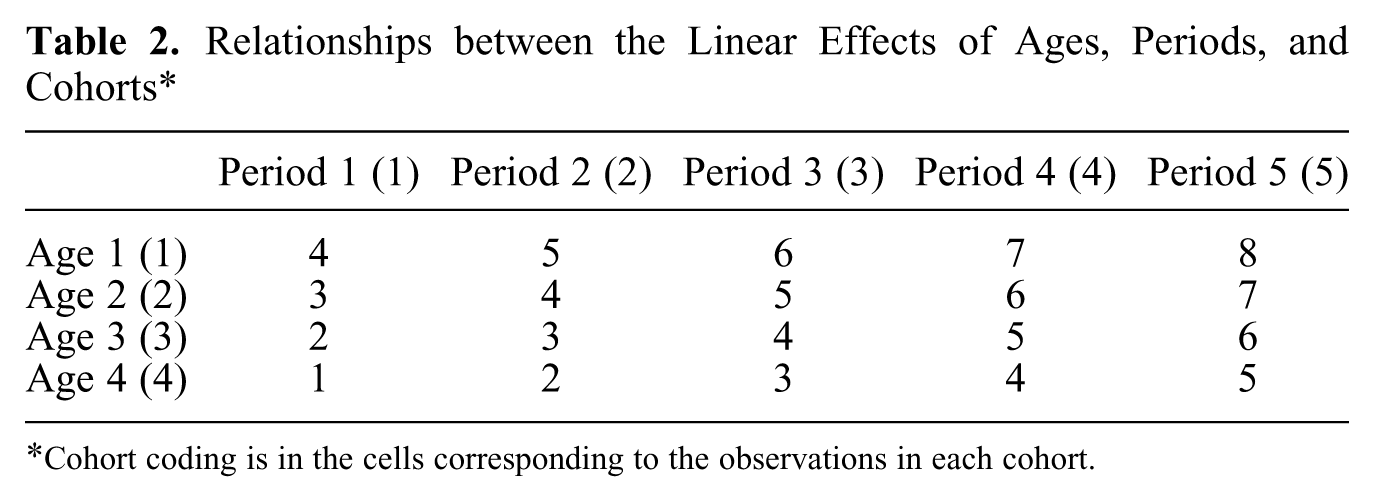
Cohort coding is in the cells corresponding to the observations in each cohort.
4. Relationships between the Linear Trends for Ages, Periods, and Cohorts
Although different constrained solutions can lead to very different estimates of the age, period, and cohort coefficients, the linear trends for ages, periods, and cohorts for different solutions are systematically related. Rodgers (1982:782) shows that the linear trends of the age-effects, period-effects, and cohort-effects are related to each other in the following straightforward manner (presented using my own notation):
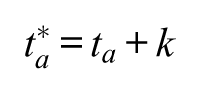
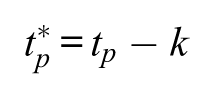

Interpreting the first equation,
I focus in the following on two situations. Leaving one of the three factors out of the model is the situation most commonly found in the literature. The other is to constrain the trend of one of the factors to be zero, which is a just-identifying constraint and does follow equation 2 exactly. With categorical coding, the linear trends are similar using either strategy; but, as noted previously, they are not exactly the same. Intuitively, imagine that the trend of periods for the data-generating process is
The relationships between the slopes of the three factors described in equation 2 provide insight into what happens when we drop one of the factors from the APC model.
The left-out factor’s effects are constrained to be zero, both its linear trend effects and the effects of its deviations from the linear trend.
When the model contains just two factors, those two factors take credit for their own linear trend effects, their effects that involve deviations from their linear trends, and they take credit for the linear trend effects of the third (left-out) factor.
Since the other two factors get credit for any linear trend effects in the data-generating process due to the left-out factor, this may make the two factors appear to be statistically significant even if their contribution to the data-generating process is not.
When the third factor is added to the two-factor model to determine whether it accounts for addition variance in the dependent variable, any variance due to its linear trend has already been “controlled for,” and the third factor will not get credit for any effects due to its linear trend.
With the test for incremental variance, only effects that are associated with the third factor’s deviations from its linear trend will be attributed to it.
Leaving the third factor out of the model based on its incremental fit not being statistically significant will too often eliminate a substantively important factor. This elimination affects the coefficient estimates of the two factors in the model.
This unique variance associated with the third factor is an estimable function (O’Brien 2014); it is the same no matter which just-identifying constraint is applied to the three-factor model. The increment in
5. Regression Procedures and Linear Trends for Ages, Periods, and Cohorts
The main purpose of this section is to provide a greater intuitive understanding of these relationships: Researchers typically have not (and will not) run these regressions while conducting their research (except for 1 below). I use cohort as an example of the “third” or left-out factor. The analogous procedures can be used with periods or ages as the left-out factor and with any GLM procedure.
Run an OLS regression with any single just-identifying constraint to calculate
Run a regression with just the age and period factors (categorically coded variables) and calculate
The difference between the
The F-test for the statistical significance of
There is a difference between leaving a factor out of the equation (then it is constrained to have no effect on the solution either from its linear trend or deviations around its linear trend) and constraining the linear trend to be zero. In the latter case, the linear trend effect is zero, but the deviations from the linear trend are allowed to account for variance in the dependent variable. In both cases, however, any linear effect in the factor is absorbed by the other two factors.
6. Discussion
One feature of the APC problem is nearly universally recognized: the impossibility of estimating a model with all three of these factors simultaneously in the model unless some sort of constraint is placed on the model to identify it. Placing a constraint on the model results in a specific set of estimates for the age, period, and cohort effects; a different constraint results in a different set of estimates. Only if the constraint is consistent with the parameters that generated the outcome variables will the solutions under the constraint be an unbiased estimate of those parameters. In fixed models, those constraints are explicit, and in mixed models (Bell and Jones 2014; O’Brien, Hudson, and Stockard 2008; Yang and Land 2006), the constraint is embedded in the model. The linear trends of ages, periods, and cohorts are linearly dependent, and this creates the APC identification problem, while the deviations around the linear trend of these factors are identified/estimable (Clayton and Schifflers 1987a, 1987b; Holford 1983; O’Brien 2014).
What is less well understood are the implications of the complete confounding (linear dependency) of the linear trends estimates of ages, periods, and cohorts on results that compare three-factor and two-factor models. For the categorically coded APC models that drop one of the factors from the model, any linear trend in the dropped out factor is absorbed by the other two factors. The two-factor model takes credit for any linear trend of the effects in the third factor. When the linear trend in the third factor is constrained to zero (rather than dropped from the model), the relationship between the effect of this constraint on the linear trend in the third factor and the linear trends in the other two factors is exact, as shown in equation 2. These insights explain specific shifts between the coefficients of the APCMC model when different factors are dropped from the model and show that the test for incremental variance should not be used as a criterion for dropping a factor from the model. The incremental fit test in the APCMC context is an atheoretical test that is likely to lead to a misspecified model.
What is the researcher to do? The following strategies are not a panacea, but they can provide valuable information about the age, period, and cohort effects.
Estimable functions do not depend on the constraint used to identify the APCMC model. Some examples of estimable functions are the second differences of age effects, period effects, and cohort effects: deviations of age effects from the linear trend in the age effects, deviations of period effects from linear trends in the period effects, and deviations of cohort effects from linear trends in the cohort effects and the variance accounted for by the three-factor model. Each of these estimable functions (and others) tells us something about the age, period, and cohort effects (O’Brien 2014).
Factor characteristic models can be used to estimate the effects of ages, periods, and cohorts. For example, we can categorically code ages and periods and code cohorts using a proxy variable such as the proportion of the cohort that was born out of wedlock or the relative size of the birth cohort. The effectiveness of this approach depends in part on how well the characteristics capture the effects of cohorts on the dependent variable (O’Brien 2000).
We can use a just-identifying constraint but should make sure the constraint is based on theory and/or substantive knowledge. The rationale is that if the theory and/or substantive knowledge are nearly correct and the constraint is based on these, then the constraint is more likely consistent with the data-generating parameters. If the constraint is approximately consistent with the data-generating parameters, it should provide an approximately unbiased estimate of those parameters. Using multiple approaches that reach similar conclusions will build confidence that the analysis may be getting at the data-generating parameters (O’Brien 2015a).