
Abstract
Rank-order relational data, in which each actor ranks other actors according to some criterion, often arise from sociometric measurements of judgment or preference. The authors propose a general framework for representing such data, define a class of exponential-family models for rank-order relational structure, and derive sufficient statistics for interdependent ordinal judgments that do not require the assumption of comparability across raters. These statistics allow estimation of effects for a variety of plausible mechanisms governing rank structure, both in a cross-sectional context and evolving over time. The authors apply this framework to model the evolution of liking judgments in an acquaintance process and to model recall of relative volume of interpersonal interaction among members of a technology education program.
Keywords
1. Introduction
Rank-order sociometric data, in which each actor in a network ranks other actors according to some criterion, have a long history in the social sciences. Among many other instances, Sampson (1968) famously asked each of 18 novitiates in a monastery to rank his three most liked novitiates among the other 17; Newcomb (1961) measured evolving rankings of one another by 17 men living in fraternity-style housing over the course of a semester; and, more recently, Wave I of the National Longitudinal Study of Adolescent Health asked high school students to list, in order, up to five male and up to five female friends (Harris et al. 2003). Although many network processes (e.g., diffusion, brokerage, exchange) are only sensibly posited for networks with categorical- or ratio-scale relationship states, many others, particularly those involving personal preferences (e.g., liking, advice seeking), are much more readily represented ordinally and, indeed, may not even have interval, ratio, or categorical meaning across raters. This can be true even when data are not collected in an explicitly ordinal fashion. For instance, Johnson, Boster, and Palinkas (2003) asked personnel in an isolated environment (the Amundsen-Scott South Pole Station) to rate their degree of interaction with one another on a scale ranging from 0 to 10, with 0 indicating no interaction and 10 indicating a “great deal” of interaction. Although it is reasonable to assume that such ratings are ordinally coherent within rater (e.g., if Bob rates Sally below Jill, then Bob regards himself as interacting more with Jill than with Sally), such ratings cannot be compared across raters: if Bob rates his interaction with Jill at 4, and Sally rates her interaction with Jill at 6, we have no basis for concluding that Sally’s interaction with Jill is stronger than Bob’s. Such interaction rating data are thus “local” to the rater and must be analyzed in a manner that avoids cross-rater comparisons.
The most common approach taken to analyzing rank-valued network data in current practice is to dichotomize ranks into binary ties, defining a tie to be present if a given ego had ranked a given alter above a certain cutoff and absent otherwise. Many methods of dichotomizing have been proposed. For instance, cutoffs have been set at a particular rank (such as top five) (e.g., Arabie, Boorman, and Levitt 1978; Breiger, Boorman, and Arabie 1975; Harris et al. 2003; Pattison 1982; Wasserman 1980; White, Boorman, and Breiger 1976), set at a particular quantile (such as top 50 percent) (Krackhardt and Handcock 2007), or found adaptively (Doreian et al. 1996). Another common approach is to focus on rank correlations and on treating ranks on an additive scale (Newcomb 1956; Nakao and Romney 1993).
These approaches come with significant limitations. Dichotomizing ties requires a threshold point to be selected, inevitably discarding information and possibly introducing biases (Thomas and Blitzstein 2011), while methods such as rank correlation are limited to simple comparisons and cannot, for example, be used to examine the strength of one social factor after controlling for the effects of another. More importantly, these techniques implicitly assume that tie values can be equated across raters, an assumption that is often unjustified. When the presence of an
Modeling frameworks explicitly designed for rank-order data would address these limitations, but to date work on model-based approaches to rank-order network data has been very limited. Gormley and Murphy (2008), for instance, used a generalization of the Plackett-Luce model (Plackett 1975) in a latent position framework to model what can be viewed as a bipartite rank-order network of affiliations from voters to candidates in Irish proportional representation through the single transferable vote elections. Null models for comparison of rank-order (or otherwise valued) data structures were developed by Hubert (1987), and model-based extensions of this approach for comparison of multiple structures were introduced by Butts (2007b). (See also related work on null hypothesis testing in a network regression context, such as that of Krackhardt 1987 and Dekker, Krackhardt, and Snijders 2007.) This latter work is focused on modeling degrees of correspondence between relational structures, and it does not attempt to model the internal properties of rank-valued networks themselves. This second problem is the focus of the present article.
For modeling of internal network structure, exponential-family random graph models (ERGMs) or
Building on this work, Krivitsky (2012) formulated a generalized framework for exponential-family models on networks whose ties have values (categorical or otherwise) and introduced Markov-chain Monte Carlo (MCMC) methods for simulation and maximum likelihood inference in this more general case. The Krivitsky formulation provides a basis for generalizing to models of the kind we consider here, but it retains the assumption of “absolute” edge values that have a constant meaning across raters. In this paper, we develop ERGMs for “locally” ordinal relational data in which ratings cannot be directly compared across subjects; we focus on the foundational case of complete rankings but introduce model terms that can be used with more general models (such as those for partial orders). In Section 2, we discuss representation of ordinal relational data and introduce the probabilistic framework for exponential-family models for them. In Section 3, we describe statistics that can be used to model common network properties within this framework. Two applications of this framework are demonstrated in Section 4, and some extensions of the framework are discussed in Section 5. Additional details involved in simulation and inference on these models are provided in Appendix A.
2. Exponential-Family Framework for Ordinal Relational Data
2.1. Actors, Rankings, and Comparisons
We begin this section by defining notation for representation of ordinal relational data and by establishing basic principles for using such data in a manner that respects their intrinsic measurement properties.
Consider a set of n actors, N, whom we index as
As discussed in the introduction, our data consist of observations in which each actor (ego)
A simple example of a ranking structure is provided in Figure 1, in which actor

Ego
In general, we make few assumptions regarding
We will, furthermore, focus on the case in which the ego does not report a ranking for self and where the set of egos is the same as the set of alters (e.g., people ranking other people who rank them in turn, as opposed to consumers ranking brands or other objects), so relation
Rankings are not assumed to be comparable across egos: for each ego i, we may only say that one alter is “
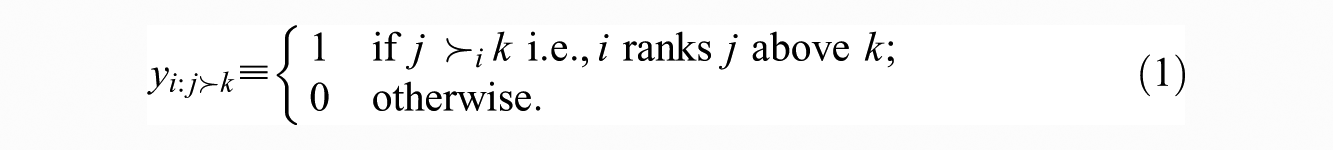
This represents the basic distinction that can be unequivocally made from locally ordinal data. As we shall see in Section 3, being limited to such statements does not prevent us from specifying a very rich class of models.
2.2. Representations of Ordinal Networks
We make use of two numerical representations of the observed networks of rankings, which we illustrate on toy networks with
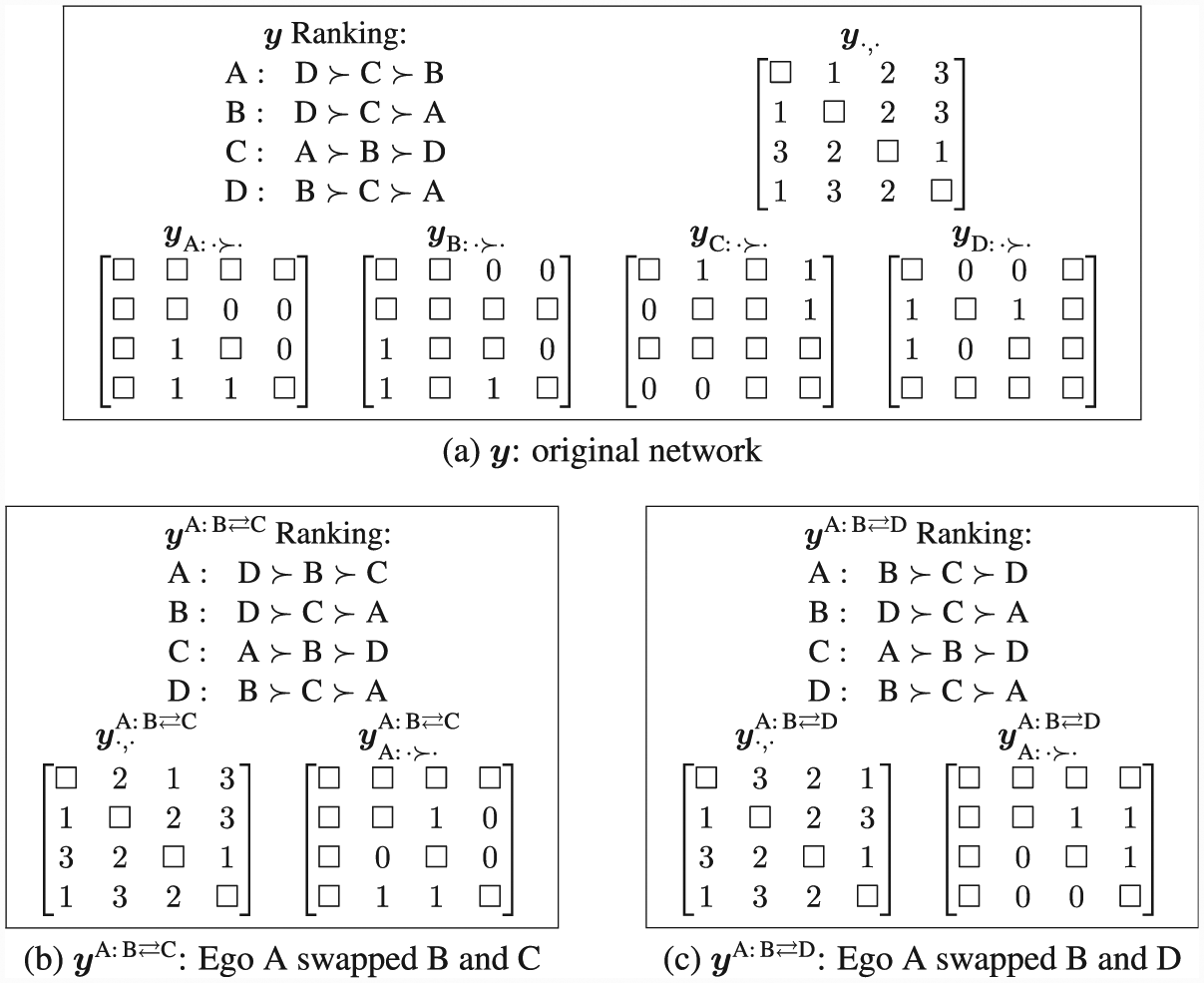
Representations of complete rankings

Representations of idiosyncratic ordering structures for
First, a network of a complete or a weak ordering
Second, we may represent the comparisons reported by an ego i, or implied by i’s ranking, in a binary
As we have noted, because the framework itself requires relatively few assumptions regarding
2.3. Model Formulation and Specification for ERGMs for Compete Rankings
Krivitsky (2012) suggested that a sample space of complete rankings of every actor in a network by every other actor can be represented by a directed network with no self-loops, whose set of observed relations

Again, this representation is slightly misleading in that elements of
Taking the set defined by equation (2) as our sample space, we can specify an exponential family for rank-order networks by defining a sufficient statistic

with the normalizing factor
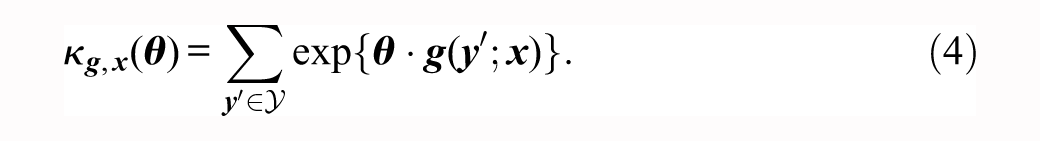
This is an exact parallel to the more familiar ERGMs for dichotomous data (e.g., Wasserman and Pattison 1996). For notational convenience, we will drop
3. Terms and Parameters for Ordinal Relational Data
We now introduce and discuss a variety of sufficient statistics
3.1. Interpreting Model Terms Using “Promotion” Statistics
For binary ERGMs, Snijders et al. (2006), Hunter, Handcock, et al. (2008), and others have used change statistics or change scores, the effect on the model of a toggling of a tie—an atomic change in the binary network structure—to aid in interpreting the model terms. For complete ordering data, an ego changing the ranking of one alter necessarily changes the ranking of at least one other, and the atomic change—one that affects the fewest alters—is to swap the rankings of two who are adjacently ranked. We thus use the effect of having ego i“promote” a promotable alter
Let
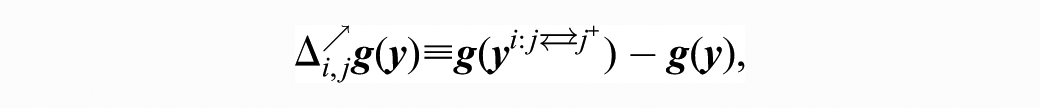
that is, the change in
Analogously to change scores, the promotion statistic emerges when considering the conditional probability of an ego i ranking an alter j over alter
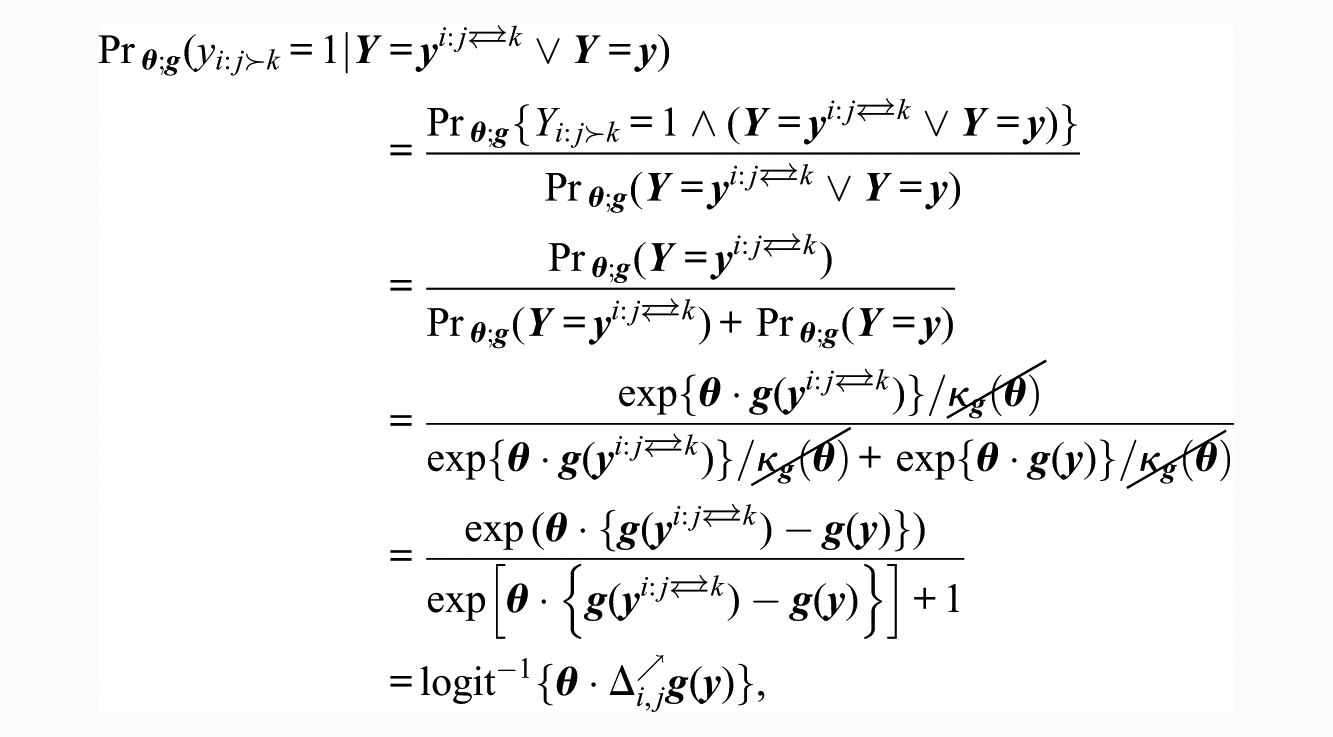
because, by construction,
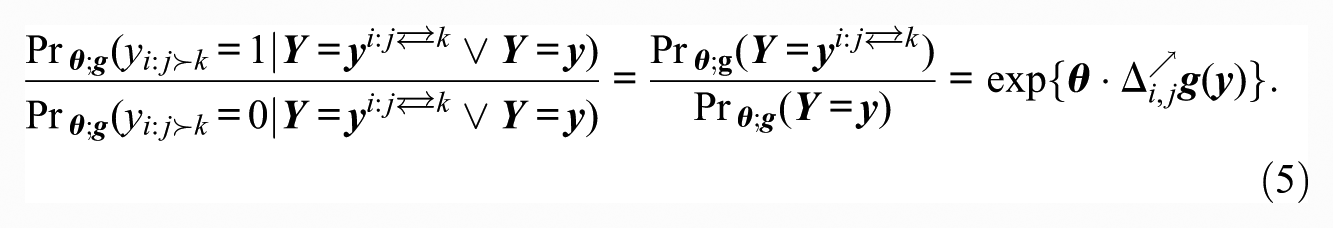
In this, the promotion statistic also reflects the conditional dependence structure of the model: if its form for a particular
Note that promotion statistics are mainly useful for complete orderings: if the ordering is partial, it is possible for i to promote j without demoting
3.2. Terms for Exogenous Covariates
We begin our quorum of substantively useful statistics by considering “exogenous” factors: those factors that would influence rankings by an ego i in a manner that is independent (in the probabilistic sense) of the rankings of all other egos
3.2.1. Attractiveness/Popularity Effects
For assessments of attractiveness, liking, and status, it is likely that egos’ rankings will be influenced by some relatively stable (and exogenous) tendencies of particular alters to be rated more highly than others. For instance, assessments of physical attractiveness tend to be broadly consistent within a given cultural context, and such assessments correlate positively with physical attributes and performance characteristics (e.g., subtleties of dress and speech) that are usually difficult to alter over short time scales (Morse et al. 1974; Webster and Driskell 1983). Thus, we have the emic notion that some persons “are attractive,” with the attribution regarded as a fixed trait of the person being assessed; while the reality is less trivial, stable factors governing attractiveness are sufficiently important that we may wish to capture them where possible. In other settings, institutionalized status characteristics (e.g., group membership, formal social roles) or the like may have similar effects (Berger, Cohen, and Zelditch 1972; Berger et al. 1977).
Regardless of source, we can treat these effects directly by positing some covariate vector
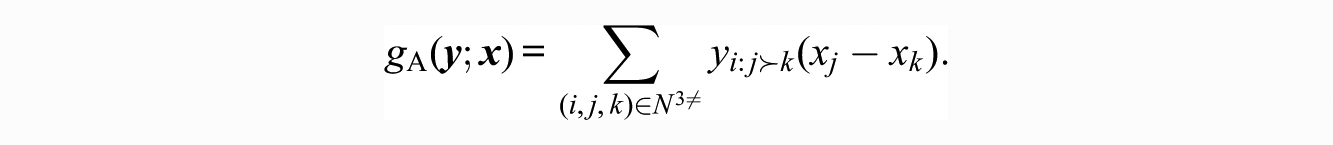
This statistic simply indexes the tendency for those with higher values on x to be ranked more highly than those with lower values. The promotion statistic associated with the above is
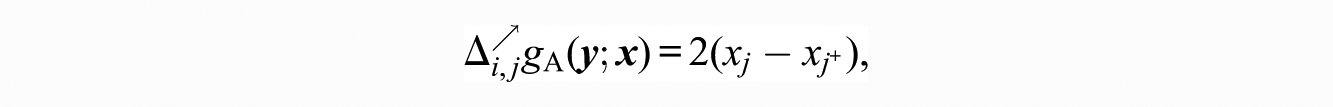
that is, twice the difference between the attractiveness of j and the actor over whom j may be promoted. Therefore, the multiplicative effect of this term on the odds (equation 5) of j’s being ranked over
This coefficient of 2 appears in many of the promotion statistics proposed, because every promotion of j over
As expressed,
3.2.2. Difference/Similarity Effects
Just as we may posit a differential tendency to “win” ranking contests overall, we may also posit that each actor i has exogenous characteristic

where
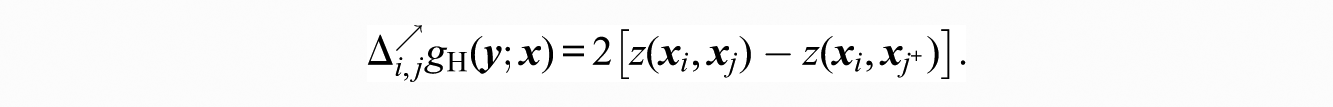
As with attractiveness, difference effects can be based either on observed covariates or on latent quantities.
3.2.3. Dyadic Covariates
We can extend the above logic to general dyadic covariates. For instance, we may consider a case in which a within-context ranking is made by actors having ongoing social relationships; we might expect, then, that actors engaged in positive long-term relationships would tend to give preference to their partners within the specific rating context. Statistics for this behavior can be produced in this way:
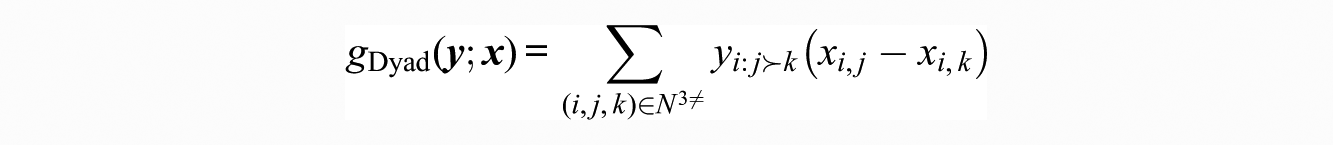
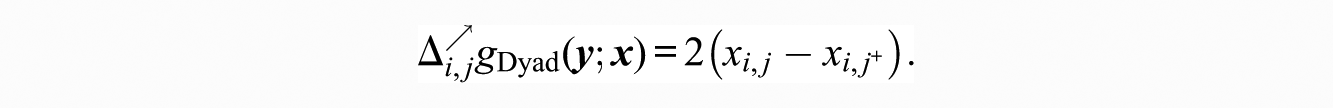
Of course, the cases of attractiveness and difference described above are simply special cases of dyadic covariates, with particular structure imposed. (Notably, the matrix permutation family of Butts 2007b has a somewhat similar structure.)
3.2.4. Comparison Covariates
Finally, in the framework of pairwise comparison, the most general exogenous covariate form assigns a weight to each pairwise comparison by each ego:
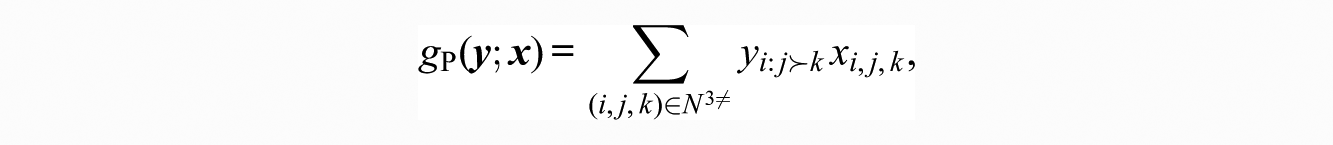
for some
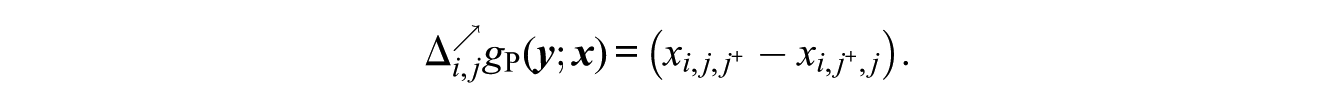
This statistic has all other exogenous statistics as special cases.
3.3. Terms for Endogenous Mechanisms
We now turn to factors that are endogenous in the sense that, unlike exogenous factors, their effect on the rankings by Ego i does depend on rankings by other egos
3.3.1. Global Conformity
In many settings in which an ego is able to observe or infer the rankings of others, there is reason to presume that this will influence ego, so that he or she will tend to bring his or her own rankings into conformance with the rankings of others. This is certainly true in dominance or status rankings, for which there is considerable evidence that individuals can and do infer status ordering from observation of third-party judgments (e.g., see Anderson et al. 2006); this synchronization may even be explicit, as in certain types of gossip (wherein two or more parties “compare notes” on the relative status of their peers) (Dunbar 1997). The status of influence for relations such as relative liking is less clear but still plausible: an ego may take an alter’s evaluations of the relative merits of other alters into account in assessing his or her own preferences, just as one can be influenced in one’s judgment of the merits of food, art, or other experiential goods by the evaluations of others (Bordieu 1968). Finally, the mutual observability of rankings may produce in some settings a form of “conformity pressure” (e.g., Asch 1951), such that those displaying deviant rankings anticipate (and are possibly exposed to) sanction. The importance of influence processes in such settings is well documented.
To formalize influence in the ranking context, we must note that four elements are involved: an ego’s assessment of two alters (say, j and k), and the assessment of those same alters by a distinct third party (say,
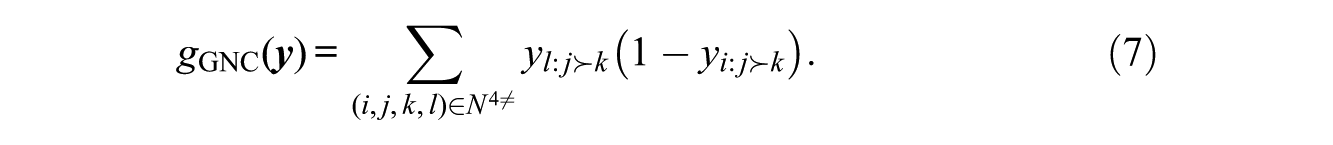
The promotion statistic for nonconformity can be derived by observing that when i promotes j over
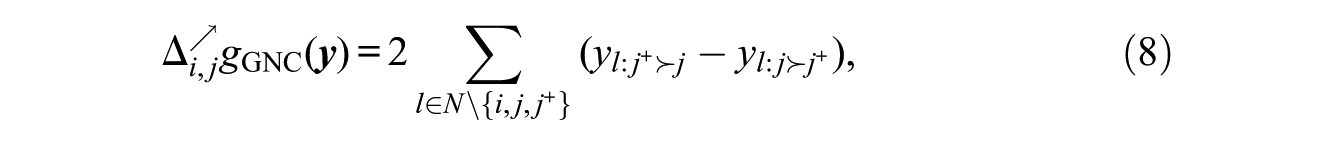
a “vote” among the ls as to the relative ranking of j and
Unlike the promotion statistics of the terms for exogenous mechanisms, this one is a summation. This is unsurprising, because it reflects the dependence among the egos that it induces: whereas before promotion statistics did not depend on
It should be noted that this form of influence and the random attractiveness effect, mentioned in Section 3.2.1, can both explain the same network feature: both heterogeneity in attractiveness and social influence induce an agreement in rankings, and the latter may be considered a marginal representation of the former, in a manner similar to that of a within-group correlation as a marginal reflection of a (conditional) random effects linear model.
3.3.2. Local Conformity
For global nonconformity
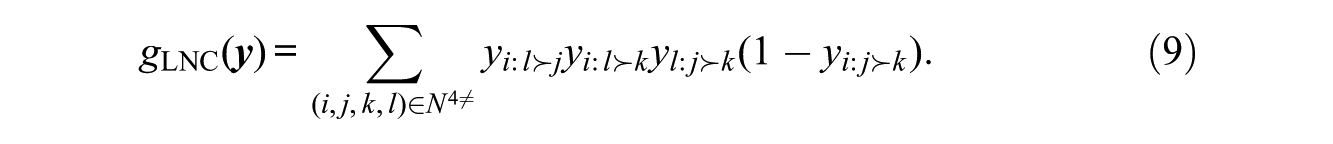
The atomic effects for this statistic are somewhat complex:
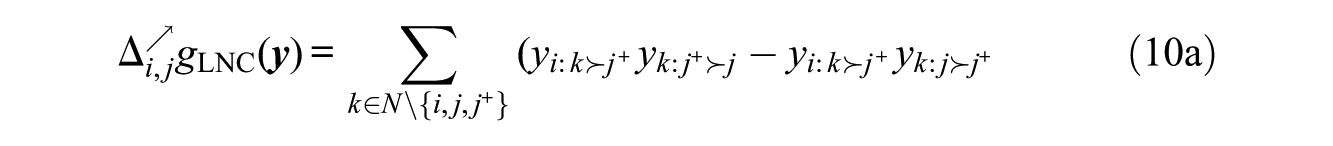
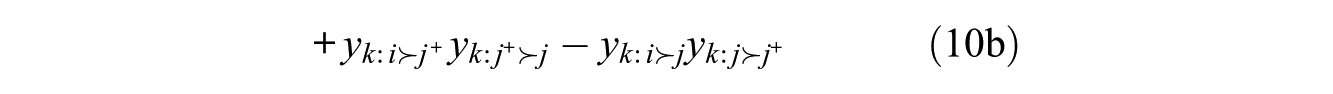
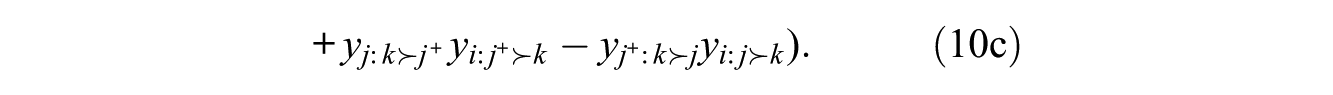
They have, however, a meaningful interpretation. The two terms in line 10a represent the effect of i’s bringing his or her ordering of j and
This promotion statistic is also unusual among the others in that it does not have the coefficient of 2 first discussed in Section 3.2.1. In this case, it serves to underscore that the indicators
3.3.3. Deference Aversion
Influence, as defined above, deals with the mutual adjustment among raters regarding their relative assessments of third parties. When ego is a party to the rating in question, the situation becomes more complex. By assumption, ego does not explicitly self-rate; thus, ego cannot adjust toward alter’s impression of him or her. In many settings, however, another mechanism may be active that will make alter’s ranking of ego salient for ego’s ranking of alter. In particular, consider the case in which higher rankings are associated with positive evaluation, such that being ranked below others is aversive. Moreover, let us assume that ego infers his or her own status via an implicit transitivity mechanism, such that if alter l ranks j above ego (i) and ego ranks l above j, then ego is for social purposes ranking himself or herself below l. Under such circumstances, deference aversion may lead ego to resist ranking l above j.
To capture this notion with a statistic, we propose the following:
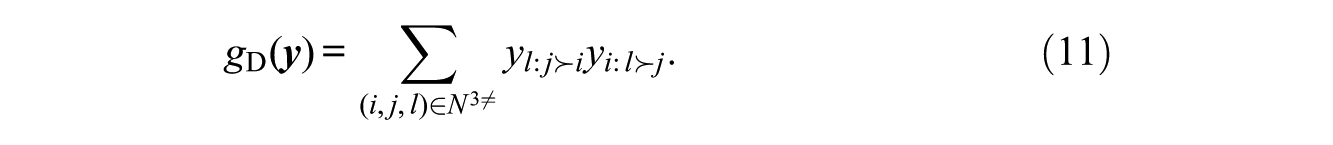
We expect this statistic to be suppressed when deference aversion is present. The promotion statistic is incremented if
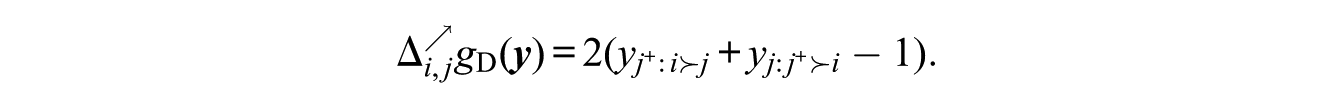
It is interesting to note that the principal effect of suppressing this statistic is actually to bring ego’s rankings in line with those of alter, somewhat akin to the reciprocity or mutuality in binary relations. Specifically, if there are r persons ranked by alter as being above ego, then ego will also tend to rank those same r persons as being above alter. Where a total order is present, ego and alter will thus tend to give each other the same rank (and, indeed, to agree on those persons having higher ranks). Of course, applying this logic to all pairs suggests pressure toward equality, which is impossible to achieve in the total order case (but not necessarily for others). Even in the case of total orders, however, considerable variation in
3.4. Consistency across Settings
When ranking the same alters among multiple settings—across time or across rubrics—there is reason to expect that ego will tend to exhibit consistency in alter ratings. Across time, this is an exogenous effect, because earlier rankings cannot be influenced by later rankings. Across rubrics, it may be endogenous. Here we assume two rating structures,
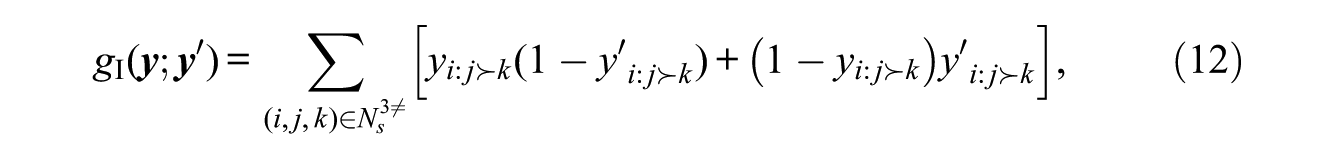
with the promotion statistic being simply
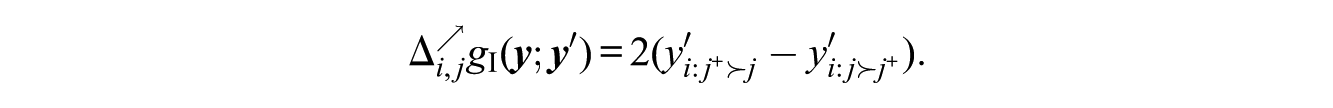
Because
Statistic (12) treats all disagreements between
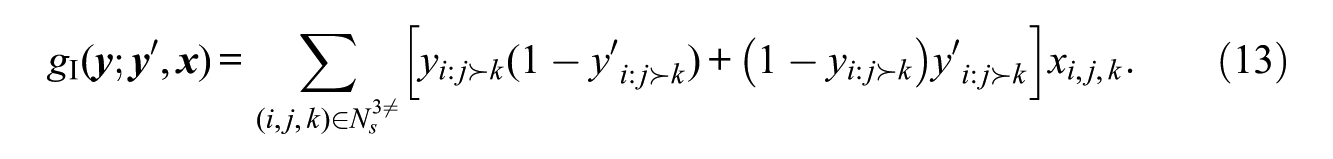
Note that
These statistics are used extensively in the example in Section 4.2, in which they are used to examine the accuracy of informants’ self-reported interaction frequencies.
4. Examples
4.1. Dynamics of the Acquaintance Process
From 1953 to 1956, a research group led by Theodore Newcomb (1961) conducted an experimental study of acquaintance and friendship formation. In each of the two study years, 17 men attending the University of Michigan—all transfer students with no prior acquaintance among them—were recruited to live in off-campus fraternity-style housing. Demographic, attitudinal, and sociometric information was collected about the subjects. In particular, in the second year, at each of 15 weekly time points (with week 9 being missing), each participant was asked to rate all other participants on “favorableness of feeling,” with ratings forced to be distinct and converted to ranks (pp. 32–34). These data represent an example of longitudinal data of complete ranks, and the data from the second year of the study in particular have been used to study the formation of interpersonal relationships by Newcomb (1956), Breiger et al. (1975), White et al. (1976), Arabie et al. (1978), Wasserman (1980), Pattison (1982), Nakao and Romney (1993), Doreian et al. (1996), Krackhardt and Handcock (2007), and many others.
We use ERGMs for rank-order data to study this network, examining the social forces relevant to its structure and its evolution over time. We take two distinct approaches: (1) cross-sectional, in which each time point’s network structure is modeled on its own, and (2) dynamic, in which each time point but the first is effectively modeled as a change from the previous time point’s rankings.
4.1.1. Cross-sectional Analysis
Demographic data, including age, religion, and political views of the subjects, were gathered. Also, within the house, the subjects were assigned to rooms, spread over two floors of the house—three one-occupant rooms, four two-occupant rooms, and two three-occupant rooms (Newcomb 1961:67–68). Furthermore, although some subjects were assigned to rooms at random, others were assigned with an aim to maximize (for some rooms) and minimize (for other rooms) the roommates’ compatibility as understood by the researchers (pp. 216–20). If available, all of these factors could be used as predictors in our modeling framework via terms introduced in Section 3.2. Sadly, to our best knowledge, none of these elements of the Newcomb data survive, leaving us to focus on endogenous effects (although the “birds of a feather or friend of a friend” [Goodreau et al. 2008a] caveat applies). For each of the 15 networks, we model deference aversion—via
We report the maximum likelihood estimates for each of the terms over time in Table 1 and plot them in Figure 4. Deference aversion is significant (the coefficient on the deference statistic is negative) throughout the evolution of rankings, starting with the first point of observation. This is consistent with the finding of Newcomb (1956), Doreian et al. (1996), and others that “friendships are reciprocated immediately.” Our analysis, however, suggests deepening deference aversion over time, not reaching its ultimate magnitude until week 4 or 7. (Informally, the estimated Kendall’s rank correlation between the parameter estimate and week number is
Results for Cross-sectional Analysis of Newcomb’s Data
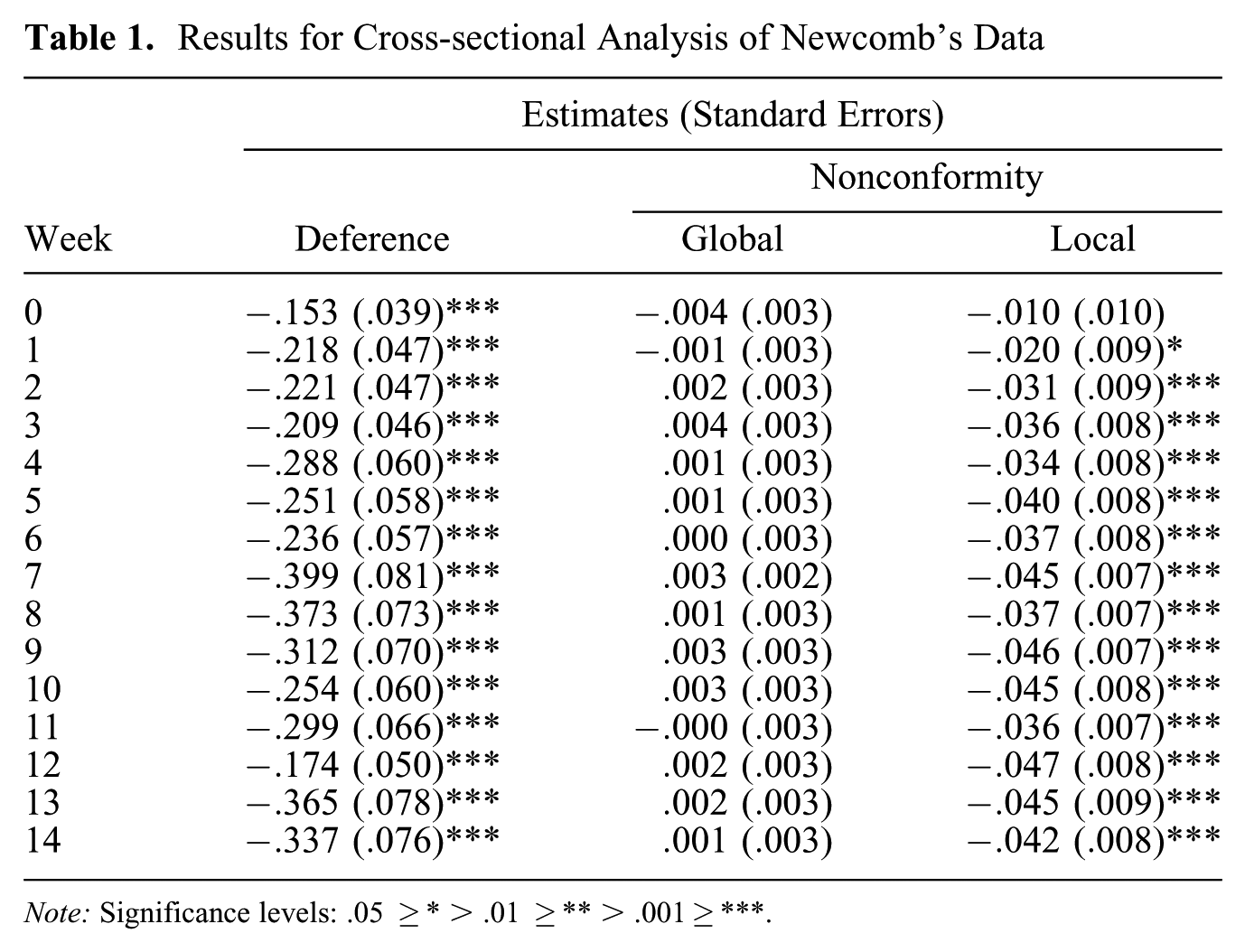
Note: Significance levels: .05 ≥* > .01 ≥** > .001≥***.

Estimated coefficients for the cross-sectional model fit to each week’s rankings in Newcomb’s fraternity. Error bars are at 95 percent confidence.
The local nonconformity term is also significant for all but the first observation point, although its effects seem to emerge more gradually than those of deference aversion (Kendall’s
In the presence of the local nonconformity term, the global nonconformity term is not significant: there does not appear to be a significant overall consensus in ratings, although Newcomb (1956) reported that three specific subjects were generally disliked by everyone, including one another, so perhaps failing to detect this is a result of lack of power and presence of the local nonconformity term. Notably, the estimated correlation between the local and global nonconformity parameters (within each week’s fit) is strongly negative and consistent (
4.1.2. Dynamic Analysis
We now turn to modeling the evolution of the rankings over time. For our dynamic analysis, we use a simple Markov formulation similar to those of Krackhardt and Handcock (2007) and Hanneke, Fu, and Xing (2010):
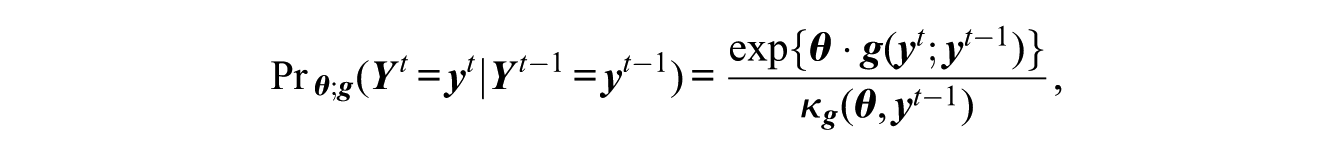
having the normalizing constant
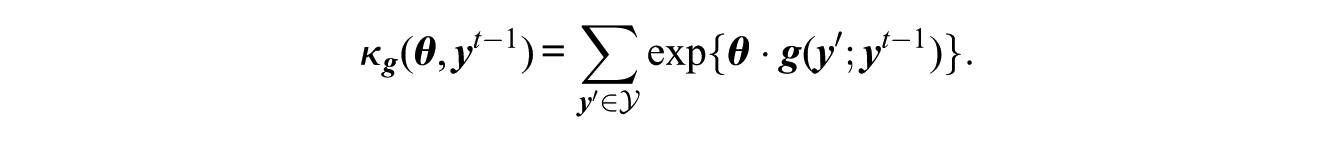
For each of the 14 transitions between successive networks, in addition to the three terms used in the cross-sectional analysis, we model inconsistency over time via
Because we seek to examine the strengths of the factors over time, we use time-varying parameters (although Krivitsky and Handcock [2014] showed that the approach of Hunter and Handcock [2006] can be applied to series of networks or transitions as well). Week 9 rankings were not reported. Because of this, for week 10, we fit the parameters for transition from week 8.
The maximum likelihood estimates for each transition are reported in Table 2 and visualized in Figure 5. The estimates for the transition from week 8 to week 10 do not appear to be qualitatively different from those for nearby transitions. In particular, inconsistency does not appear to be higher over this particular two-week period.
Results for Dynamic Analysis of Newcomb’s Data
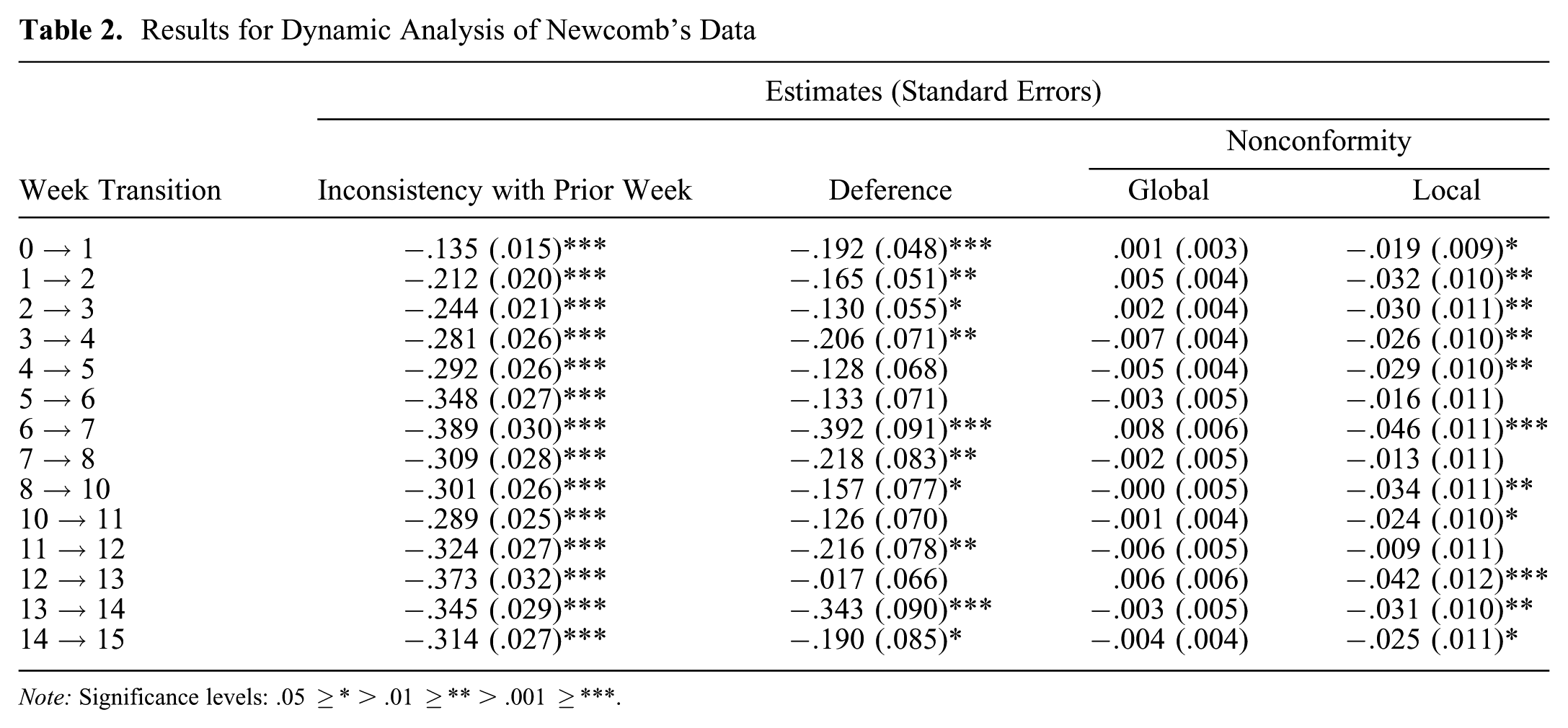
Note: Significance levels: .05 ≥* > .01 ≥** > .001 ≥***.
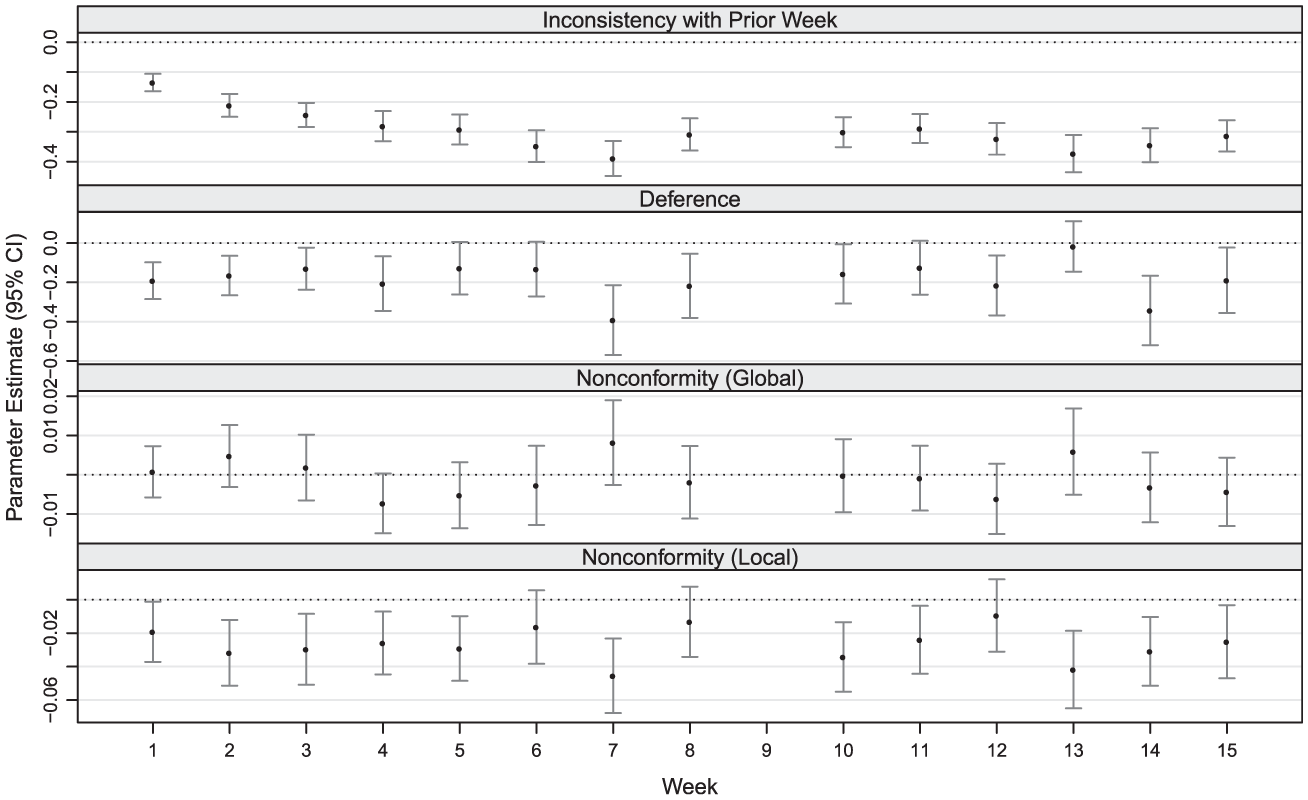
Estimated coefficients for the longitudinal model fit to each week’s rankings in Newcomb’s fraternity. Error bars are at 95 percent confidence.
The clear downward trend (
In contrast to the cross-sectional analysis, neither deference nor local nonconformity appears to have a significant monotone trend over time (both correlations have
4.2. Informant Accuracy
In the late 1970s, Bernard et al. (1984) conducted a series of studies to assess the accuracy of retrospective sociometric surveys of several types. In each study, respondents in a social network—deaf teletype users; amateur radio operators; office workers at a firm; students in a fraternity; and faculty members, graduate students, and staff members in an academic program—had their social interactions observed or recorded and were asked, in retrospect, to indicate others in their network with whom they interacted, allowing recalled and observed network structures to be compared. In the latter study, conducted in a graduate program in technology education at West Virginia University, the 34 subjects had the frequency of their interactions recorded by a team of observers over the course of a week, and then each subject was asked to provide a complete ranking of the other subjects on “most to least communication that week” (Bernard and Killworth 1977). This produced a complete ranking, suitable for analysis using our methods.
4.2.1. Modeling Inconsistency
In this application, we use models with sufficient statistics of the form of equations (12) and (13) to assess factors that appear to affect accuracy of rankings. Let
For notational convenience, we re-express equations (3) and (13) as
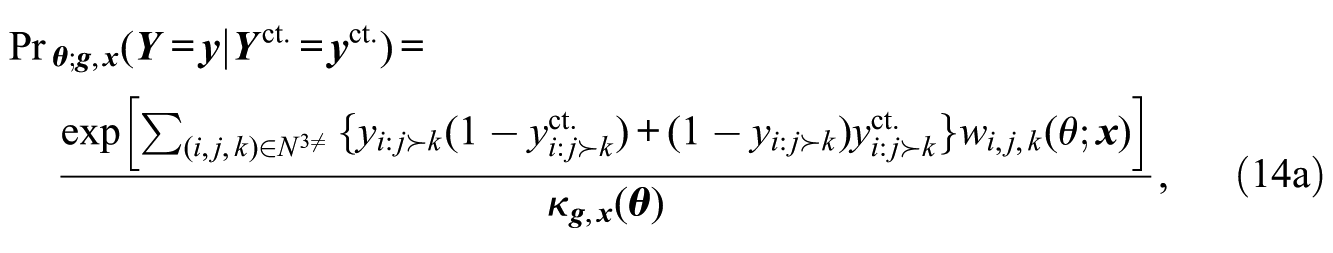
where

for covariate
Because there are ties among the observed interaction frequencies (i.e., where
For convenience, let
4.2.2. Effect of Frequency of Interaction
The first question we address is whether the magnitude of the difference in the frequency of interaction affects the accuracy. That is, if i’s frequency of interaction with j differs from i’s frequency of interactions with k by more than i’s frequency of interaction with j differs from i’s frequency of interaction with l, is i more likely to rank j and k accurately than j and l?
To answer this, we begin by fitting a simple model with two covariates:
Effect of Frequency of Interaction on Reporting Inaccuracy

Note: Significance levels: .05 ≥* > .01 ≥** > .001≥***.
We also fit a similar model in which we replace frequency difference with frequency rank difference:
4.2.3. Effect of Salience
The second question that we address is whether the accuracy of reported ranking is affected by the positions of those being ranked. Can an ego i better discern the ranking of those with whom he or she interacts the most? Is he or she more accurate at the extremes?
To answer this, we fit a model for inconsistency that is a quadratic polynomial in rank values. More concretely, in the form of equation (14),
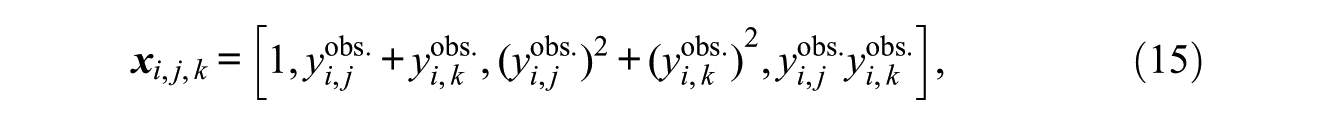
inducing a model in which the inconsistency of reported with observed is modeled as a second-degree polynomial function of the observed ranks of the alters being compared; and this function is symmetric for these two alters. The statistics in equation (15) represent baseline inconsistency, the linear effect of the ranks of the alters being compared, their quadratic effect, and their interaction effect, respectively.
In fitting this model, we found that it suffers from collinearity, which impedes inference; so to improve its numeric conditioning, we fit an equivalent model, using rescaled and centered quantiles, evaluating
We report results from this fit in Table 4. All four covariates appear to be highly significant. Somewhat surprisingly, the higher ranked alters appear to have slightly higher inconsistency between observed and reported. However, the negative coefficient on the quadratic term suggests that the middle ranks are reported with the least accuracy of all. We show the predicted inconsistency weight
The Effects of Alter Positions on Reporting Inaccuracy

Note: Significance levels: .05 ≥* > .01 ≥** > .001≥***.

Predicted effect of alter positions on reporting inaccuracy.
5. Discussion
As befits the long history of ordinal data analysis in the social sciences, many extensions and applications of the present framework are possible. Here, we briefly discuss two such directions: (1) the extension of the current framework to “bipartite” rank data and (2) the use of our framework in settings that imply particular kinds of ordinal constraints (e.g., partial orders, semi-orders, and incompletely observed total orders).
5.1. Extension to “Bipartite” Rank Data
Although our focus here has been on the classic sociometric setting in which a group of individuals is asked to rank each other with respect to some dimension (e.g., liking), our modeling framework can easily accommodate other cases as well. One such setting is the case of “bipartite” rank data, in which members of a given group are asked to rank a set of objects not including the group members themselves. Examples of such data include preference rankings of political candidates, organizations, or policy positions; ordinal judgments regarding physical objects or perceptual stimuli; liking or other rankings of nongroup members, and so on. Although such data are widely analyzed throughout the social sciences using traditional techniques, the contribution of our approach is the ability to model interdependence among raters in a natural way. For instance, the global conformity statistic of Section 3.3.1 can be used to capture a general tendency of group members to converge on a common rating of a set of objects; likewise, the consistency effects of Section 3.4 have the same meaning in the “bipartite” setting as in a standard sociometric setting. The exogenous effects of Section 3.2.1 can be used to capture differences in the net attractiveness of objects to members of the rating group, and dyadic covariates (Section 3.2.3) can be used to measure effects related to the tendency of particular raters or subgroups of raters to give higher/lower ratings to particular objects. On the other hand, statistics that depend upon the ratings by the object (e.g., local conformity) are clearly meaningless in a bipartite context, and should not be used.
The bipartite case suggests certain statistics that may prove especially useful for assessing influence in structured groups. For instance, consider the case in which our set of raters,

To the extent that adjacent actors influence each other to form similar views of the object set,
Simulation and estimation for bipartite rank data requires modifying the support of the associated model to include only the observable ranks, and eliminating impermissible rating triads from the proposals in Algorithm A1 in Appendix A.2. These are straightforward changes to the base implementation and are not discussed in detail here.

5.2. Considerations Relating to Types of Orderings
It should be noted that in our development, we focus on the case of orderings that are defined from the psychological process in question, rather than data that are ordinal simply due to limitations in measurement (such as count or continuous data observed only as ranks). Although the present framework may in some cases be useful for such data (e.g., to avoid having to model the count distribution), the assumptions involved—for example, in the choice of sufficient statistics (and their interpretation)—may be quite different.
Although we have focused on complete orderings, the above distinction gains further importance when considering partial orderings: the case of partial orderings being a property of underlying psychological phenomena is substantively different from the case of incomplete orderings arising from measurement itself. A well-known example of the latter is a frequently used sociometric survey design that asks each ego to rank his or her top k alters with respect to some criterion (liking, interaction frequency, etc.). Cases of unobserved ranking are better handled by means of a latent variable framework in which a probability distribution is placed on the complete data, and in which likelihood is assessed via the marginalization of the complete data conditional on that observed. (Plackett-Luce models for top-k ranking data [Plackett 1975] do this implicitly.) Such a strategy has been used in the traditional ERGM framework by Handcock and Gile (2010), and can be employed here as well.
In contrast, orderings in which the alters may be substantively tied or incomparable with one another pose different challenges. A close examination of Sampson’s (1968) data reveals that some of the novitiates were in fact recorded assigning equal ranks to some of those they nominated, and these would be substantively tied in an underlying partial ordering. Tied ratings in data like those of Johnson et al. (2003) could be interpreted either way: either that the scale of 0 to 10 was not sufficiently granular to encode small differences in degrees of interaction, meaning that which one of the tied alters was actually higher is unobserved, or that an ego’s choice to rate two alters equally means that their degrees of interaction were substantively the same.
In the complete ordering case, there exists a distribution of rank orderings that is unambiguously uniform and can thus serve as the baseline distribution (reference measure) for the exponential family (e.g., see Barndorff-Nielsen 1978:115–16). In the partially ordered case, there is no natural baseline that is unambiguously uniform. For example, an ego may rank all
Despite our focus on complete orderings, our techniques can (with appropriate choice of reference measure) be generalized to the weaker case: all of the model statistics that we present in Section 3 can be applied to partially ordered network data without modification, because they only make references to the network of interest through the indicator
6. Conclusion
Rank-order data are a cornerstone of sociometric measurement, but principled treatment of such data in an interpersonal context poses significant statistical challenges. Here, we have shown how statistical exponential families may be used to generalize the now well-known ERGM framework to the rank-order case. We have also introduced a corresponding set of sufficient statistics that are appropriate for use when only within-ego ordinal judgments are psychologically meaningful, a restriction that is important when modeling such data. As with conventional ERGMs, a wide range of statistics may be posited to capture alternative psychological and social mechanisms; the ability to evaluate and compare competing models on the basis of such distinct alternatives is one of the strengths of the statistical approach.
In our assumption that the network must be modeled through
Finally, we note that development of ERGMs for rank-order data opens the way to a rich family of novel statistical models for phenomena such as interdependent choice behavior in group context and social influence on preferences. Particularly because of their suitability for data collected in observational settings, rank-order ERGMs provide a useful tool for considering both new and classic problems in social psychology and the study of decision making.
Footnotes
Appendix A
Appendix B
Acknowledgements
We wish to thank David Krackhardt for helpful discussions.
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Research was supported by the Portuguese Foundation for Science and Technology Ciência 2009 Program (Krivitsky), U.S. Office of Naval Research award N000140811015 (Butts and Krivitsky), U.S. Army Research Office award W911NF-14-1-0552 (Butts), and National Institutes of Health award 1R01HD068395-01 (Krivitsky). Computation and simulations were performed on a computing cluster partially funded by a Eunice Kennedy Shriver National Institute of Child Health and Human Development research infrastructure grant (R24HD042828), to the Center for Studies in Demography and Ecology at the University of Washington (Krivitsky). No products by these institutions were discussed or alluded to.
Notes
Author Biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.