
Abstract
Conventional model selection evaluates models on their ability to represent data accurately, ignoring their dependence on theoretical and methodological assumptions. Drawing on the concept of underdetermination from the philosophy of science, the author argues that uncritical use of methodological assumptions can pose a problem for effective inference. By ignoring the plausibility of assumptions, existing techniques select models that are poor representations of theory and are thus suboptimal for inference. To address this problem, the author proposes a new paradigm for inference-oriented model selection that evaluates models on the basis of a trade-off between model fit and model plausibility. By comparing the fits of sequentially nested models, it is possible to derive an empirical lower bound for the subjective plausibility of assumptions. To demonstrate the effectiveness of this approach, the method is applied to models of the relationship between cultural tastes and network composition.
1. Introduction
Existing techniques of model selection evaluate models on their ability to accurately represent data (Burnham and Anderson 2002), but they do not explicitly account for how modeling is dependent on underlying theories (Elwert and Winship 2014). Moreover, this practice ignores the fact that a purely empirical justification for models is fundamentally impossible (Hume [1748] 1993; Sober 2002). This theory-agnostic approach to models is at odds with the ultimate goal of empirical research: evaluating and making inferences about theoretical statements (Merton 1996).
In this article, I first investigate how the intractable philosophical problem of underdetermination relates to statistical models (Duhem 1906; Quine 1953; Sober 2002). Specifically, I argue that methodological assumptions can never be fully supported by either theory or data (Blalock 1979; Lieberson 1985). The use of models with external, and somewhat arbitrary, assumptions is thus a problem for making inferences about theory from models (Collins 1984; Turner 1987; Wedeking 1976). This means that simpler models, having more assumptions, are less well suited to making inferences about theory, than marginally more complex models.
Second, though this philosophical problem cannot be eliminated, I argue that it can be managed in practice (Laudan 1990) by selecting models using both theory and data. I suggest that model-based inference can be improved by incorporating theoretical judgments about the plausibility of assumptions. In contrast to the use of priors in Bayesian techniques (Raftery 1995), assessing model plausibility at the level of assumptions creates a bias toward models with fewer assumptions and more complexity. Just as empirically oriented model selection attempts to find a balance between bias and variance in model estimates, inferentially oriented model selection must choose between additional assumptions and additional model complexity. In short, the advantages of models should be weighed against the subsequent “loss of realism” (Arrow 1952). By considering both simultaneously, empirical data can help evaluate the theoretical plausibility of modeling assumptions.
For example, suppose I am studying the relationship between education and a specific cultural taste, X, proposing that more education should lead to greater affinity for X. A simple model could use a linear representation:

This model includes simplifying assumptions that (1) only formal education matters, (2) all forms of formal education have the same effect, and (3) the effect of each additional year is the same. All of these methodological assumptions are compatible with the theory, but none follow directly from it. If I find that the coefficient β is significantly greater than zero, I could attribute this to my hypothesis being correct. However, a skeptic could also propose that one of the assumptions is wrong and that the model does not support my hypothesis because (1) other forms of education also matter, (2) different types of education have different effects, or (3) there is variation in the effect of an extra year of education. The more simplifying assumptions I impose on my model, the more such objections there could be.
Suppose now that I want to justify my inclusion of assumption (3) specifically. Decisions such as this one are underdetermined in that there is not enough information in my theory or in the data to fully determine whether this assumption should be included. A purely empirical approach to justification would compare my model with another model with a weaker assumption that allows the effect to change, 1 for example, Probability of liking X = β(Years of schooling) +β(Squared years of schooling). I would want to show that my original model has a better value for a given model selection metric, such as the Akaike information criterion (AIC). However, the skeptic could still argue that an alternative metric prefers a different model or that the theoretical support for a changing effect precludes the consideration of the simpler model altogether. In contrast, a purely theoretical justification could argue that the assumption is plausible because it does not conflict with my theory, and there is no evidence that years of schooling have different effects. Skeptics may of course disagree on how plausible that is.
In general, we can say that the assumption is better supported (1) the more plausible it is given my theory and (2) the more it improves the AIC. However, these two justifications are not always compatible with each other, as when a theoretically supported model has worse fit to the data. In such cases, there is no existing way to adjudicate between support from subjective plausibility and differences in the AIC.
In this article I develop a method for making decisions about theoretical plausibility and empirical support. In Section 2 I explain the problem of underdetermination and how it applies to statistical modeling. In Section 3 I show that the need for external assumptions transforms the standard logic of model selection and presents problems for inference. In Section 4 I derive a mode of model selection that aims to minimize the inferential problems caused by assumptions. In Section 5 I demonstrate this method in practice by applying it to the case of cultural tastes and network composition. In Section 6 I present a discussion of the findings. Section 7 concludes the article.
2. Underdetermination of Theory and Method
The underdetermination of theory by observation is a fundamental philosophical problem for empirical research. Simply put, underdetermination is the condition where the information available is insufficient for determining what we should believe (Laudan 1990). All theoretical statements are underdetermined in that they rely on a large set of auxiliary assumptions to define terms, operationalize concepts, and specify implicit relationships (Quine 1953). Homans (1967) called these supporting assumptions “nonoperating definitions” and “orienting statements.” In sociology, terms such as role, culture, and socialization are commonly used without explicit definitions, relying instead on a common understanding with the reader. Auxiliary assumptions themselves depend on further auxiliary assumptions, leading to a vast web of implicated statements that are difficult, if not impossible, to explicate (Quine 1953). Because of this dependence on external and largely implicit assumptions, theories cannot make empirically testable predictions on their own and thus cannot be supported solely via empiricism 2 (Duhem 1906).
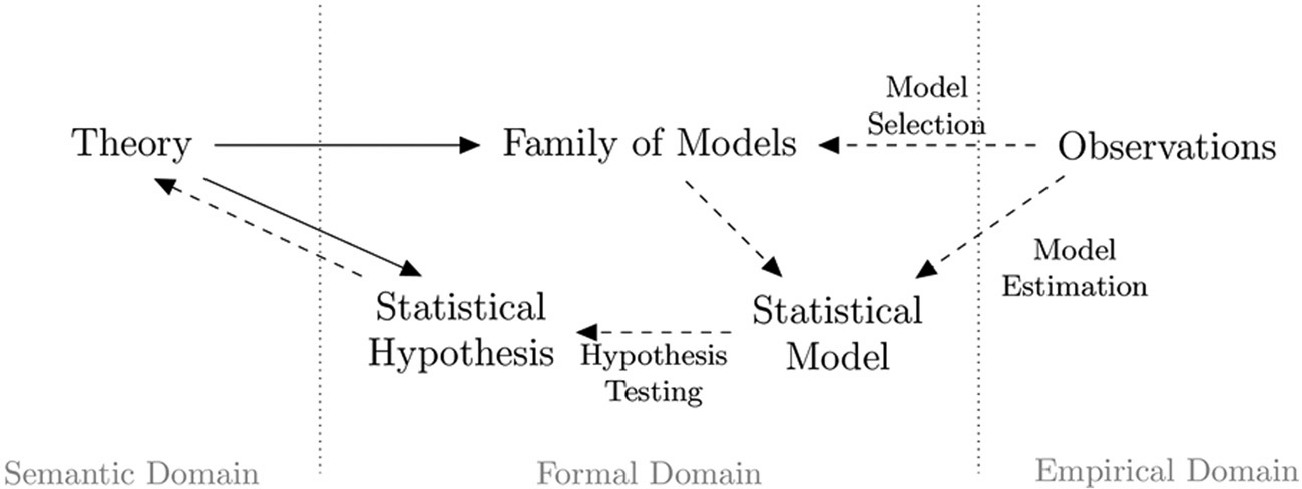
The problem of underdetermination appears in many forms. The most common formulation (Quine 1953) presents scientific research as a contrast of a conceptual domain (theory and assumptions) against an empirical domain (real-world observations). Hypotheses cannot be directly related to observations. Instead, to formulate and test empirical predictions, we impose a theoretical framework formed in the combination with auxiliary assumptions.
In this way, the underdetermination shown in Figure 1 presents a problem for falsification. The hypothesis can be evaluated only in the presence of auxiliary assumptions, never on its own. When disconfirming observations are encountered, they can be interpreted either as a failure of the hypothesis or as a failure of one of the many auxiliary assumptions. This indeterminacy created by auxiliary assumptions means we can never fully falsify a theory with observations, a problem known as holistic underdetermination. A related problem, known as contrastive underdetermination, asserts that observation is also insufficient for conclusively supporting one theory over another. For any given body of evidence, there may be multiple explanations that are logically consistent with the data and thus empirically equivalent.

Quinian underdetermination model of research.
2.1. Underdetermination of Models
When it comes to statistical models, social science tends to treat underdetermination and modeling as two separate problems. The problem of underdetermination is framed largely in terms of the uncertainty in model specification (Western 1996; Young and Holsteen 2017). For any given set of data, there is an infinite number of equations that can represent the data perfectly (Forster and Sober 1994). In this respect, the problem of empirically equivalent models is not at all hypothetical but occurs with every set of data. The best fitting model may change with the availability of additional data, but there will always be an infinite number of equations that fit equally well.
Model selection metrics can distinguish between these empirical equivalents, but only by imposing additional assumptions about how models should be evaluated (Sober 2002). For example, the AIC selects between models by prioritizing expected predictive accuracy (Akaike 1974), while the Bayesian information criterion (BIC) maximizes posterior likelihood (Schwarz 1978). There are substantive differences among the AIC, BIC, and other selection metrics, but there is no a priori justification for choosing one over the other (Forster 2000; Sober 2002; Wasserman 2010). The principle on which model selection is based is itself an auxiliary assumption. However, unlike the philosophical problems, the problems of model selection are framed as relating to statistical representation, not inference about theory.
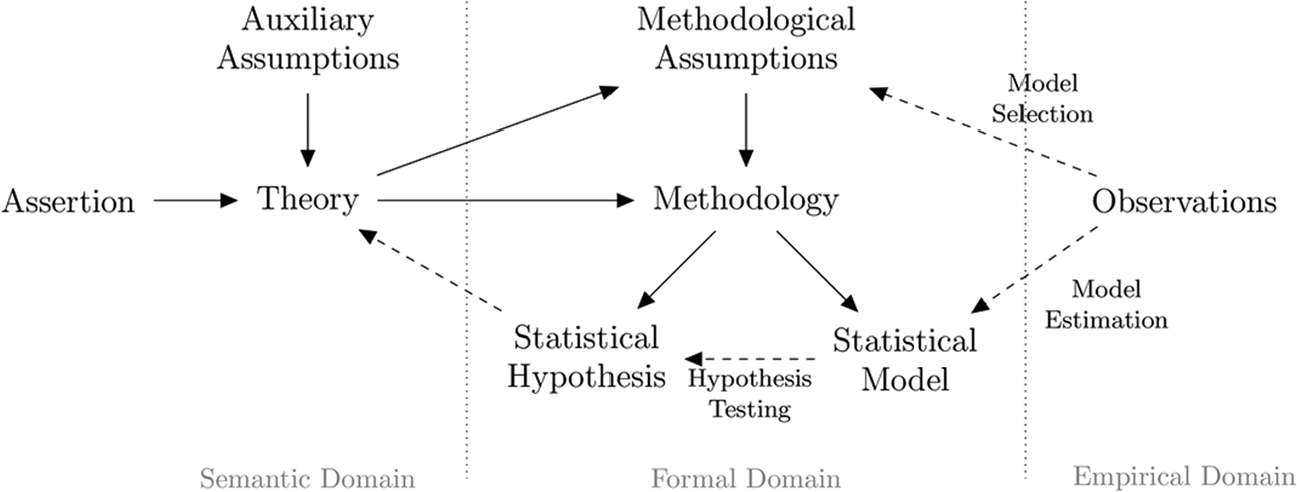
Figure 2 outlines this conventional mode of statistical inference in sociology, following the hypothetico-deductive framework (Cox and Hinkley [1979] 1996; Hempel 1965). Theories described conceptually are converted into a formal hypothesis that can be tested with statistical methods (Blalock 1979:107). Observations are used to select the most appropriate model and to estimate parameters within the model. The outcome of a hypothesis test can then provide information about the validity of the initial theory. In this view, statistical models mediate between data and theory. Models help reduce a large number of observations into a more synthetic and testable observation. This liminal role means that formal models contain both empirical and semantic content (Fararo 1997; Lazarsfeld 1958).
Statistical model of research.
Unfortunately, the added assumptions necessary for abstraction into statistical models also create a barrier between semantic statements of theory and empirical data (Blalock 1979:14). This separation is seen by some as specifically invalidating quantitative research. Turner (1987) argued that underdetermination of models, particularly with respect to the theory-data linkage, makes quantitative methods unable to inform grand social theory or theories of the middle range. To Collins (1984), the presence of these assumptions means that we should treat statistics as an entirely separate theory, rather than a method.
Others see the separation between theory and method as a welcome division of responsibilities. Blalock (1979:7) argued that theoretical concerns lie outside the domain of methods and that statistics enters only in the analysis stage of the research process. A common justification for ignoring the auxiliary assumptions on which models are based is that they consist of statistics and conventional practices with established foundations and thus constitute unproblematic background knowledge (Collins 1984; Lakatos 1976). Statistical knowledge is neither part of the research question nor open to falsification. Put more simply, we assume the model is correct and move on. In the same way, theorists are generally content to ignore methodological concerns. For example, in his taxonomy of the meaning of “theory,” Abend (2008) left out methodological concerns altogether. 3
2.2. Methodological Underdetermination
A third view of underdetermination looks at the assumptions used in relating theory and method, combining the previous two views. Duhem’s (1906) original formulation of the problem of underdetermination was primarily focused on the problem of assumptions in indirect measurements translating sense impressions (e.g., the height of mercury in a glass tube, the number of people selecting a given answer on a survey) into a seemingly unrelated measurement (e.g., temperature, aggregate opinions). In contrast to auxiliary assumptions that pervade every statement (Quine 1953), this type of assumption mediates between the domain of theory and observations, contributing to the theory-ladenness of observations (Hanson 1958).
Figure 3 illustrates this Duhemian perspective on underdetermination. The formal domain of statistics is determined by theory, by data, and by methodological assumptions. This perspective contains elements of Blalock’s idea that methods cannot be reduced to theory, Collins’s (1984) observations that statistical methods rely on external theoretical considerations (i.e., statistics), and Turner’s (1987) criticism that this poses an inferential problem.
Model of underdetermined statistical research. Solid arrows indicate logical implications; dotted arrows indicate empirical relations.
Why is it then that these statistical assumptions should not be considered unproblematic background knowledge? There is certainly good reason to treat rigorous statistical and mathematical foundations as part of the unproblematic “hard core” of our theory (Lakatos 1976). Yet statistical models are not simply extensions of mathematical logic. They correspond to a specific theory. There is no justification for treating the assumptions “there is no interaction between A and B” or “educational attainment is linearly related to parental educational attainment” the same as the law of large numbers or the central limit theorem. The focal theory under consideration is implicated in the formulation of the model or family of models, the identification of functional form, and the determination of independent, dependent, and control variables. Even estimation and inference techniques need not be considered inviolable (Collins 1984). Underdetermined statistical inference thus provides an altogether different picture of the relations among concepts, observations, and formal representations of both.
This framework highlights the inverse problem as well: models are also underdetermined by theory. For any given theory, there is generally more than one model that can adequately test it. As Collins (1984) argued, the assumptions necessary for formalization are distinct from the assumptions relied on by the focal theory. This is evident in the way a theory can produce identifiable predictions without any reference to method. 4 The assumptions required for forming theoretical predictions are generally insufficient for uniquely determining a mathematical model (Cicourel 1964).
2.3. Methodological Discrepancies
Overall, this unified framework identifies three sources of methodological discrepancy between observation and theory: implicit, empirical, and methodological. Implicit discrepancies are impossible to resolve. As Quine (1953) identified, auxiliary assumptions always create differences between the original hypothesis and the theory that gets tested. In contrast, empirical discrepancies, typically described as errors between the data and the predictions of a statistical model, can be effectively minimized with proper model selection.
The introduction of methodological assumptions into inference allows a third type of discrepancy, methodological discrepancies, which are differences between theory and observation created by imposing methodological assumptions. These are similar to implicit discrepancies in that they are impossible to remove entirely, but like empirical discrepancies they may be effectively modified through proper model selection.
There are three benefits to considering methodological discrepancies separately. First, unlike theoretical assumptions, methodological assumptions have been largely (though incompletely) explicated and scrutinized. This enables researchers to identify the necessity and effect of many methodological assumptions. It is not only possible but practical to vary assumptions.
Second, methodological assumptions are only partially dependent on theory, relying on a separate hard core of statistical knowledge we need not worry about testing. This creates some freedom to choose methodological assumptions to improve inferences about a theory without affecting its substance (Blalock 1979). Third, distinguishing implicit and methodological discrepancies allows us to bracket larger philosophical problems surrounding underdetermination. If methodological assumptions are distinct, then we can consider ways of improving methodological problems, without falling into the larger philosophical rabbit hole presented by holistic underdetermination.
3. The Effects of Methodological Assumptions
To account for methodological discrepancies, the process of model selection must be reevaluated in two respects. First, the assumptions used in models can no longer be considered neutral but are themselves an inferential problem. Second, models do not exist solely for representation but exist also (and perhaps primarily) for inference. The role of models in the scientific process is not just to fit the data but to provide a test for the focal theory.
The necessities of formalization have led researchers to view statistical models as simplifications of theory (Arrow 1952). However, to make simpler models, theories are augmented with assumptions that define, limit, and clarify key components in the theory. Thus, models are only a conceptual simplification of theory. The inclusion of additional assumptions means that models represent a logical complication of theory. If we model the assertion “education has a positive effect on income” as

we assume the effect of education is constant. Statistically, we are measuring only the average unit increase in income with a unit increase in education, while theoretically, we are asserting “education has a positive effect on income”and “the effect of education is constant.” The model no longer represents only the theory it was derived from but also the operationalizations and modeling decisions present in the statistical assumptions.
To demonstrate this more formally, consider how assumptions influence hypothesis testing. Following Popper (1959), empirical falsification of a hypothesis occurs when a hypothesis H predicts an observable phenomenon O and then indicates something else (¬O). Wedeking (1976) stated this in formal deterministic logic as

From a statistical perspective, we infer support for the alternative hypothesis H1 by falsifying a null hypothesis

Transition from the semantic domain to the formal domain is complicated by the presence of assumptions. The null hypothesis that we actually test is not the inverse of the original semantic hypothesis H. Moving into the formal domain means that the statistical alternative hypothesis (H1) and the statistical null hypothesis (

Observations inconsistent with the null hypothesis do not exclusively support the asserted hypothesis. Instead, they could also suggest that the modeling assumptions are wrong or the theoretical framework is wrong. It will be expedient to assume a general acceptance of the theoretical framework T. A rejection of the null hypothesis then implies we can believe H if we also believe M (
Because there are no well-defined prior probabilities for theories, I use the term plausibility for these subjectively determined probability-like quantities. The plausibility of the model provides a lower bound for the plausibility of the hypothesis. To help maximize the ability for a rejection of the null hypothesis to support the theory, we can maximize the plausibility of the model.
Naturally, the practice of statistical hypothesis testing offers less certainty than the simplicity provided by formal logic. The combination of statistical indeterminacy and the subjective quality of plausibility judgments introduces considerable uncertainty into the decision to accept or reject the hypothesis. One final modification can make this criterion more practical. Because the model is assumed to be a set of assumptions, the model plausibility can be written in terms of individual assumptions:

The more plausible each individual assumption is, the less likely are false rejections. A corollary to this is that as the new assumptions are included, the total set of assumptions necessarily becomes less plausible, reducing the lower bound on the plausibility of the hypothesis.
3.1. Methodological Assumptions as Restrictions
Up to this point, I have treated the methodological assumption as any statement added to the theoretical framework. From a semantic perspective, there is considerable ambiguity in what constitutes a methodological assumption or what it would mean to not include a given assumption. Methodological assumptions can be easily reframed as their opposite. Consider the example of an inclusion assumption compared with an exclusion assumption, which is typically framed as “Z has an effect on Y” versus “Z does not have an effect on Y.” If the variable Z is not explicitly considered in the theory, both statements appear to be logical complications and the decision to frame a modeling assumption as an inclusion or exclusion appears symmetric and arbitrary.
To resolve this ambiguity, it is useful to return to the original problem of underdetermination: observations cannot be meaningfully applied to theory without additional assumptions. Our data are too detailed to be directly compared with theoretical abstractions (Quine 1953). From the perspective of modeling, this initial condition is like having a model that is extremely overfit, reproducing the data exactly and using all degrees of freedom. In contrast, an extremely underfit model will likely not represent observations accurately, but it has the advantage of higher abstraction. It follows that the least restrictive model best approximates the original empirical problem, making it the logical starting point. We can also infer a rough directionality in statistical assumptions: adding methodological assumptions has the effect of decreasing detail in the model and providing more abstraction. 6
Returning to the example of inclusion and exclusion assumptions, consider two models:
Consider now a second pair of models that vary the degrees of freedom:
In the same way, reducing the degrees of freedom in a model, via restrictive assumptions, restricts the set of observations these models can accommodate. Given two nested models, the model with fewer degrees of freedom will be a priori less probable than its counterpart with more degrees of freedom (Forster and Sober 1994). As Table 1 shows, methodological assumptions of many types can be used to construct similar nested pairs of restricted and relaxed models.
Restricted and Relaxed Examples of Methodological Assumptions

On the basis of this reasoning, I will treat methodological assumptions as restrictive assumptions that simplify the model. This convention parallels Popper’s (1959) reasoning that more restrictive theories correspond to simpler models in that they are both less probable and thus more falsifiable. This convention also has an intuitive interpretation with respect to the standard extremes of underfitting versus overfitting. Models that are overfit in the standard statistical sense include too many parameters, capturing some of the noise at the expense of real relationships. Such models have too few assumptions and are positioned too close to the theory to be effective representations. From an underdetermination perspective, such models are overfit both in a statistical sense and in a theoretical sense. Similarly, models with too few parameters and thus too many simplifying assumptions end up statistically and theoretically underfit.
4. Measuring Methodological Discrepancy
As discussed above, the plausibility of a methodological assumption is directly related to the degree to which it supports inference. To improve model fit with respect to both theory testing and data, rather than just the data, it is necessary to find a trade-off between the utility of the assumption (in terms of model fit) and the damage it does (in terms of inferential complexity). However, there is no a priori criterion for determining exactly where this position lies. Because the formal domain is a combination of semantic and empirical content, the process of determining this balance will require both empirical evidence and theoretic considerations. Theory must be weighed relative to the data. Section 4.1 outlines a method for joining the two domains and a process for making underdetermined modeling decisions.
4.1. Inferential Information Criterion
This trade-off can be found by combining the goal of conventional model selection—that is, maximizing the likelihood of the model given the data (
I derive a metric for this trade-off by extending Akaike’s framework to theoretical predictive accuracy. Let
The optimum model then is the set of assumptions that maximizes the likelihood of the theory, or equivalently

The first term is a measure of the overall plausibility of the model as composed of assumptions. The second term is simply the log likelihood of the model. Importantly, the first term is evaluated relative to the theory and is consequently more subjective, while the second term is evaluated relative to the data and can be determined empirically.
Following Akaike (1974), it can be shown that the model that maximizes the second term in expectation corresponds with the one that minimizes AIC. From this we can derive a composite metric I call the inferential information criterion (IIC), which combines plausibility with AIC (details shown in the Appendix):

It follows from the impossibility of articulating all assumptions that the probability of the model given the theory cannot be determined exactly. As a result, this measure is useful only in terms of relative values. Using the assumptions made above about nested models, we can say that

This can be used to form the trade-off between predictive accuracy (Sober 2002) and the incremental plausibility of the model. Setting

which can be understood as the minimum plausibility necessary to justify assumption i’s contribution to model fit. The plausibility of an assumption is judged conditional on the previous assumptions and the theoretical framework, meaning that its plausibility may change if it is tested in the context of a different model. Models that contradict the theory or a previously incorporated assumption will have zero plausibility.
Given the proper assumptions (see the Appendix), this expression for plausibility can be related to the likelihood ratio of the two models (Burnham and Anderson 2002:74) and can be coerced into a mathematical form similar to a Bayes factor (Raftery 1996).
Assumptions that increase model fit will reduce the AIC, making ΔAIC negative and letting
Assumptions that decrease model fit (
This criterion can be converted into a model selection process consisting of three steps. First, enumerate all methodological assumptions in a starting model to the extent possible, including variable selection, functional form, error distributions, and so forth. Second, assign an order (or multiple orders) to these assumptions, taking care to ensure that models are estimable at all points. This will likely produce models not originally conceived or intended by the researchers. Third, sequentially estimate the model for each partial set of assumptions and evaluate the AIC and minimum plausibility threshold.
As defined above, adding methodological assumptions will decrease model complexity as measured in degrees of freedom (Sober 2002). This notion can be made useful for other modeling approaches where the parameters are not easily identified, like nonparametric regressions and random effects models, by generalizing away from simply the number of parameters. The most common way of inferring degrees of freedom is using the trace of the “hat” matrix (Hastie and Tibshirani 1986; Vaida and Blanchard 2005).
As the number of parameters changes, empirical support (as inversely measured by the AIC) should increase as the model nears the most parsimonious version and then decrease as it becomes oversimplified. Theoretical support should strictly decrease with the number of simplifying assumptions. Consequently, the combination of empirical support and theoretical support should reach a maximum just short of the most parsimonious model. Thus, whereas a conventional model selection process would be like ball rolling around a U-shaped bowl and finding the minimum, an inferential model selection process would be more like a ball that sticks to the side of the bowl, stopping short of the observable minimum.
4.2. Scope Conditions
There are three primary scope conditions for determining whether an assumption’s plausibility threshold can be estimated in this way. The first set of scope conditions arises from plausibility thresholds being estimated by conditioning on theory. Models are useful only to the extent that they are appropriate to test the theory under consideration. A model that fits the data quite well but cannot relate to the given theory may be excellent in terms of model fit but will not be useful for inference. Practically speaking, this condition formalizes what researchers already do informally. Models must incorporate every methodological assumption or core relationship that is implicated in the theory. 9 If the theory suggests that X is related to Y, then the model should not assume that X is unrelated to Y. It follows that the prime candidates for evaluating plausibility are relationships that the theory allows but does not require. This may include the type of relationship between dependent variables and independent variables (e.g., linear, nonlinear, nonparametric), complex interactions between variables, the inclusion or exclusion of control variables, and error assumptions.
Second, like the majority of selection techniques, the IIC is conditional on the data. This conditioning restricts comparisons to models fit on the same data. Transformations of the dependent variable will affect the baseline of the AIC, making comparison impossible. Operations on independent variables are allowable, provided they maintain the nestedness of models. For example, a linear equation
Third, plausibility thresholds cannot be determined for identification assumptions or estimation methods. Models must be able to be estimated from data. Removing identification assumptions prevents the model evaluation and limits the ability to construct nested pairs of models with different identification strategies (Manski 1995). 10 Moreover, the specific set of identification assumptions to be used, particularly in the case of whether a variable is treated as exogenous or endogenous, is largely determined by theory (Elwert and Winship 2014:47). The expected data generation process should inform decisions about whether variables are treated as confounding or colliders. Including such variables may increase model fit, while simultaneously undermining inference by inducing spurious correlations (Elwert and Winship 2014).
Given the nature of auxiliary assumptions, it is important to note that this approach to methodological discrepancies may not hold for all types of methodological assumptions. However, because the IIC is essentially a variation on AIC, it can be usefully applied to justify decisions between models in which the AIC and other conventional modeling approaches are already used.
5. Selecting Models of Cultural Conversion
To better illustrate how this mode of model selection works in practice, I apply this approach to Lizardo’s (2006) analysis of the effects of cultural practices on the composition of social networks. Lizardo argued that social networks act as a mechanism for Bourdieu’s ([1986] 2001) conversion of cultural capital into social capital. More specifically, because highbrow cultural tastes (such as literature, poetry, classical music, opera, and attending museums) are less common, they provide access to elite social circles, forming a barrier between individuals with and without highbrow tastes. Thus, according to Lizardo, taste in highbrow cultural forms should translate into more strong interpersonal ties, as measured in number of confidants, and fewer weak interpersonal ties, as measured by the number of people that respondents associate with who are not confidants. Conversely, popular cultural tastes (such as movies and pop music) should translate into fewer strong interpersonal ties and more weak interpersonal ties. This reasoning leads to Lizardo’s two hypotheses: (H1) “Highbrow culture taste leads to a denser network of strong ties” and (H2) “popular culture taste leads to a denser network of weak ties” (p. 786).
Lizardo supports this argument with multiple analyses of General Social Survey data. He begins by using log-linear models to demonstrate that class background affects network composition via cultural taste. Next, he refines these log-linear models to analyze the relations between numbers of strong and weak ties and the amounts of highbrow and lowbrow cultural consumption. Finally, Lizardo isolates the effect of culture on network composition using Poisson regression, an instrumental variable that controls for socioeconomic and demographic factors.
The section below replicates Lizardo’s second log-linear analysis, focusing on model selection. Log-linear models are a fitting test case for model selection because (1) the inferential logic of log-linear analysis hinges on model fit, rather than parameter estimates and (2) the hierarchical nature of model terms make the ordering of modeling assumptions more straightforward, simplifying the discussion of model variations.
This case in particular is useful because Lizardo (2006) uses log-linear models within a model selection framework, rather using them to directly test a hypothesis (cf. Weeden and Grusky 2005). This example demonstrates the role of theoretical evaluation of assumption plausibility, how plausibility is contingent on model context, and how this approach to model selection can alter the interpretation of results. My goal with this replication is not to disprove or contradict the results or the hypotheses in Lizardo. However, applying inferential model selection does suggest a different model than Lizardo’s method and consequently proposes a different theoretical interpretation than the one Lizardo provides.
5.1. Replication
Here I discuss the data and methods in Lizardo (2006) only as they pertain to the second analysis. Data were taken from the 2002 General Social Survey (Smith et al. 2018), which contains a social network and social support module and a culture module.
Cultural taste was measured by five questions that asked whether respondents had, in the past 12 months, (1) seen a movie in a theater; (2) gone to a live performance of popular music, like rock, country, or rap; (3) visited an art museum or gallery; (4) read novels, short stories, poems, or plays; or (5) went to a classical music or opera performance. A composite popular culture indicator (P) was constructed from the movie and popular music questions according to whether respondents reported 0, 1, or 2 activities. A composite high culture indicator (H) was constructed from the art, reading, and classical and opera music questions according to whether respondents reported 0, 1, or 2 or more activities.
Network composition was measured using two questions asking (1) how many friends and relatives respondents keep in contact with at least once a year and (2) how many contacts they feel close enough to discuss personal or important problems with. The number of strong ties (S) was operationalized using the latter question and split into three levels according to whether the reported 3 or fewer, 4 to 10, or 11 or more such contacts. The number of weak ties (W) was operationalized as the difference between the responses to the first and second question, that is, the number of contacts respondents do not feel really close to. This measure was split into three levels according to whether respondents reported 10 or fewer, 11 to 25, or 26 or more contacts.
Lizardo tested the relations between these four variables (H, P, W, S) using log-linear models. The saturated model (HPSW) includes a parameter for all 16 possible terms and interactions and uses all 81 (3 × 3 × 3 × 3) degrees of freedom:

Model variations can be produced by constraining any of these terms to be zero. Lizardo constrained his investigation to first- and second-order terms. These models were evaluated on the basis of their BIC and the similarity of their predictions to the observed data, which is implicitly a proxy for the saturated model. On the basis of these criteria, Lizardo selected the model (HP)(SW)(HS)(PW), containing four second-order terms. This model assumes that seven terms have no effect: the four-way interaction HPSW; the four three-way interactions HPS, HPW, HSW, and PSW; and two of the six two-way interactions HW and PS.
Given Lizardo’s argument about the relationships between the four concepts, we can assume that every model must include at least the four first-order terms λH, λP, λS, and λW. The plausibility of each of the assumptions between this model and the saturated model will be explored by sequentially adding assumptions to the saturated model (which reproduces the data perfectly). Table 2 provides one such sequence of models, formed by gradient descent. Beginning with the saturated model, each successive model was determined by considering the models formed by constraining one remaining parameter to be zero and selecting the model that reduces AIC the most.
Model Specifications, Fit Statistics, and Minimum Plausibility

Note: AIC = Akaike information criterion.
5.2. Inferential Model Selection
Which model should be selected? Table 2 also shows the modeling assumptions that change between successive models, AIC, change in AIC, and the corresponding plausibility threshold of each change. The solid line in Figure 4 provides a visual representation of how the AIC changes through this sequence. The minimum AIC is found in model 7, which includes five of the six two-way interactions. This is also the minimum across all models as found by exhaustive search of all model specifications. The constant decrease in AIC from model 1 to model 7 shows that none of the constituent assumptions can be deemed impossibly implausible.

Akaike information criterion (AIC) (a) and change in AIC (b) by model selection step for three different model orderings. The solid line shows models selected by gradient descent. The short-dashed line shows models ordered by gradient descent except at step 6. The long-dashed line shows one model ordering leading to Lizardo’s (2006) preferred model (indicated with a triangle). Circles show models discussed in the text.
The least plausible assumption (p = 0.235) is the assumption added between models 5 and 6 that the there is no three-way interaction between high culture, popular culture, and strong ties. To determine whether this assumption should be accepted or rejected, we must consider it in the context of the theory. Although Lizardo does not explicitly rely on any three-way relations, he does not also assert that they do not exist. From the lack of an explicit interaction term in the Poisson regression, we could infer that Lizardo’s theory treats high and popular culture to be separate causal influences on tie formation (Lizardo 2006:798). Under such an interpretation, this assumption should be accepted. However, it would also be reasonable to suggest that no interaction between high culture, popular culture, and strong ties is not a very plausible assumption. From Lizardo’s theory, a correlation between high culture and popular culture could be induced from their sharing a common cause, that is, socioeconomic status (p. 793). In this case, the assumption should be rejected, and model 5 (HPS)(HW)(PW)(SW) should be selected as the final model.
5.3. Assumption Orderings
Although gradient descent is a practical approach in this case, other modeling approaches may not have as constrained a search space or permit exhaustive evaluation of all models. It is useful to consider the effects of the ordering of assumptions because the plausibility of each additional assumption is conditional on the current model. The plausibility of an assumption is likely to change when it is added to one model rather than another.
Table 3 shows the model fit metrics and plausibility for one reordering of the modeling assumptions. This specific reordering produces different models at steps 6 and 7. The associated AIC and change in AIC are shown in Figure 4 by the short-dashed line. Two features of this sequence are important. First, the AIC decreases all the way to model 8, suggesting that every assumption is at least somewhat plausible. Thus, unlike the previous sequence of models, this sequence provides some justification for model 8.
Model Specifications, Fit Statistics, and Minimum Plausibility for Alternative Model Sequences
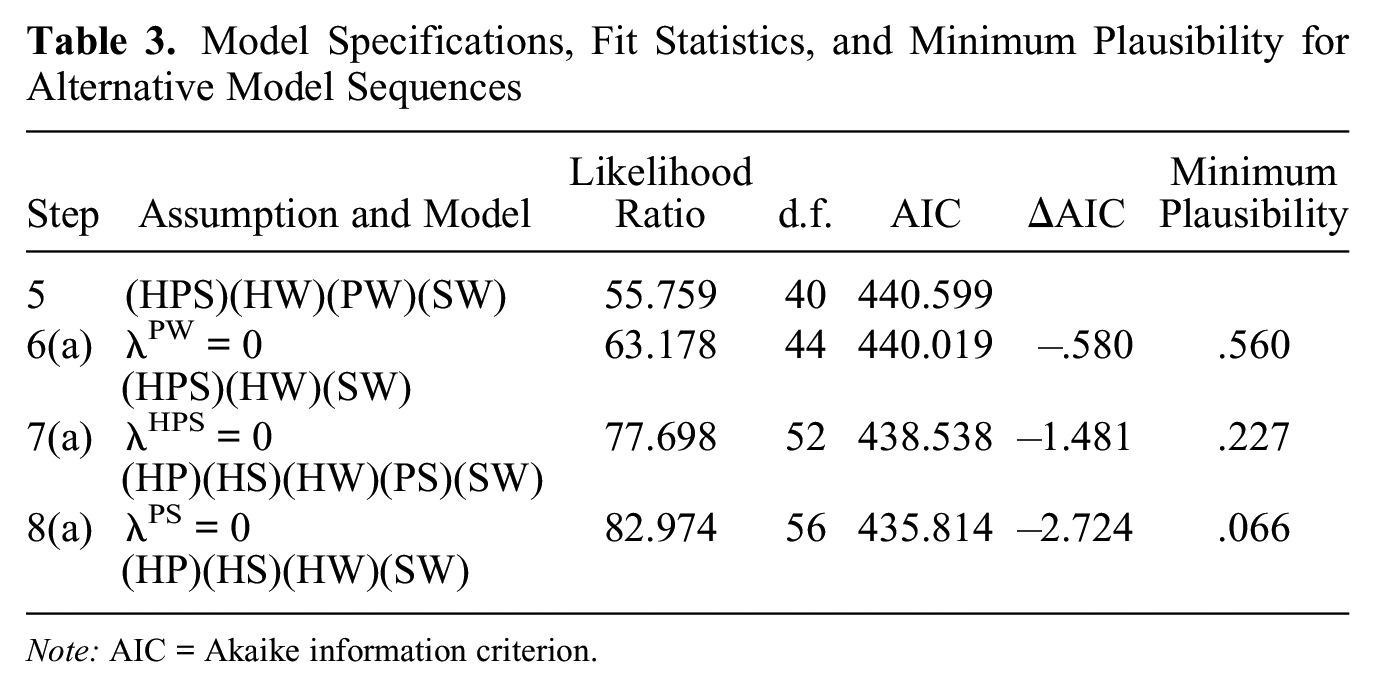
Note: AIC = Akaike information criterion.
Second, the assumption of no association between popular culture and weak ties, which was previously impossibly implausible, now has a reasonable, though high, plausibility threshold. Although under the previous sequence the λPW = 0 assumption would need to be rejected, this sequence opens the possibility of accepting it. This high plausibility on this assumption also offers the possibility of rejecting it and accepting model 5.
5.4. Evaluating Lizardo’s Model
These two sequences of models do not touch on the model (HP)(HS)(PW)(SW) preferred by Lizardo (2006:794). To evaluate how this model would fare under the proposed method, I constructed a third sequence of models by working backward from Lizardo’s model with the intention of forming a sequence of plausible assumptions. One such sequence is shown in Table 4 and as the long-dashed line in Figure 4.
Model Specifications, Fit Statistics, and Minimum Plausibility for Alternative Model Sequences
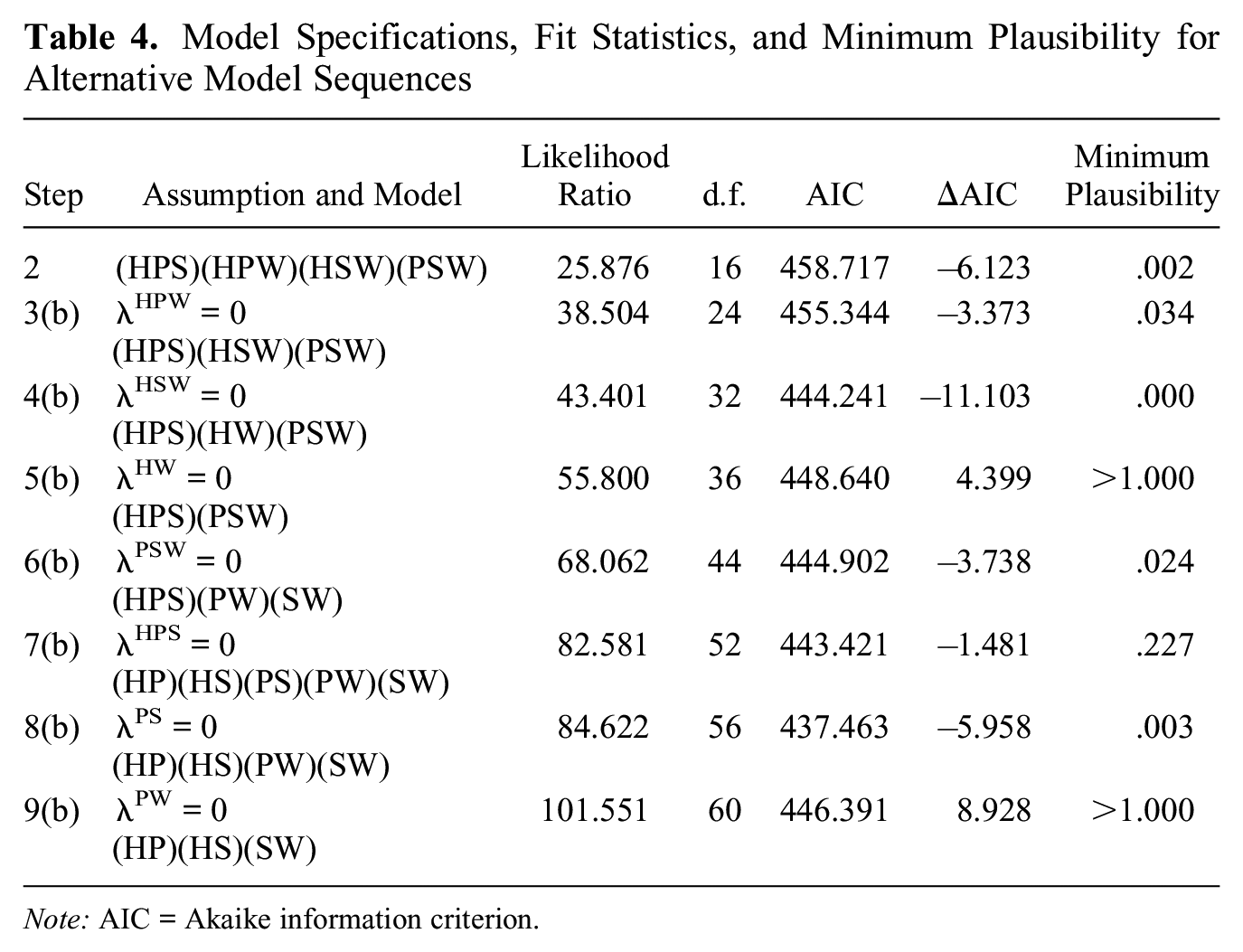
Note: AIC = Akaike information criterion.
Unlike the previous two model sequences, this sequence does not have consistently declining AICs. Instead, the assumption of no association between high culture and weak ties is considered to be impossibly implausible given the model (HPS)(HW)(PSW) in step 5(b). On the basis of this sequence and the implausibility of a key assumption, Lizardo’s model would not be a viable model. However, as just shown, this may change with model context and assumption ordering.
To test this more rigorously, I compared every model with the λHW = 0 assumption with the same model without the assumption and calculated the difference in the AIC. The distribution of the resulting 40 models is shown in Figure 5, alongside similar distributions for the other two-way associations. The results show that the λHW = 0 assumption increases the AIC in every model configuration and thus is always impossibly implausible. In this respect, the sequence of models shown in Table 4 is characteristic of every sequence leading to Lizardo’s preferred model. Three other two-way associations, SW, HP, and HS are similarly unable to be constrained to 0 in any model. Each of these is included in Lizardo’s preferred model. The plausibility of the remaining two two-way associations, PW and PS, is contingent on the proper model context, as discussed above.

Changes in Akaike information criterion (AIC) when each second-order term is added to a model. Box-and-whisker plots show the distribution over models of every possible combination of second- and third-order terms (N = 40), excluding the focal term and including all first-order terms.
5.5. Effects on Inference
Does this process make a substantive difference in the inferences we draw about the theory? The preceding analysis has shown that the preferred model contains assumptions that cannot be supported by the data. Similarly, any selected model should include two-way associations between SW, HP, HS, and HW. Of the three plausible models indicated by the first two sequences above (steps 5, 7, and 8 in Table 2), only model 8 omits an association between popular culture and weak ties that would contradict Lizardo’s hypothesis 2, and even this selection would need to be based on a theoretical determination that the λPW = 0 assumption is more implausible than plausible (p = 0.580). Models 5 and 7 differ on the associations HPS and PS.
Although these models differ from Lizardo’s simple hypotheses that associate high culture with strong ties and popular culture with weak ties, they are consistent with the larger theoretical framework that cultural forms are significantly associated with network composition. An observed three-way association between high culture, popular culture, and strong ties is also consistent with the idea that socioeconomic status is a common cause of tastes for high and popular culture. The omission of socioeconomic status from these models creates a spurious correlation.
In sum, model selection through these means could be interpreted as inconsistent with Lizardo’s hypotheses, but only to the extent that they are insufficient descriptions of the larger theoretical framework. This interpretation is equally consistent with the results from the subsequent regression analysis, which demonstrates the significant effects of the two types of culture on both strong and weak ties.
6. Discussion
Although underdetermination is widely accepted as a philosophical problem for science, there is considerable debate over whether underdetermination poses a practical problem for knowledge production (Grünbaum 1976; cf. Laudan 1965, 1990; Okasha 2000; Wedeking 1976). Put plainly, this debate asks whether unspecified assumptions can really limit or distort knowledge production. Some have suggested that underdetermination fundamentally undermines the scientific process (Quine 1953), with radical views suggesting that underdetermination is proof that scientific knowledge is inherently subjective, a product of social construction, and no more valid than other forms of knowledge (Barnes 1974; Bloor 1991). Laudan (1990) dismissed such views, pointing out that the possibility of multiple equally well supported theories does not imply that they exist.
In the same way, in this article I have argued that underdetermination is a philosophical problem for model selection, but that there are ways in which this problem can be practically addressed. Specifically, I have argued that models should be selected not simply on the basis of their empirical support but also on their effect on inference within theoretical framework. Balancing the plausibility of the theory with model fit should result in models that are better supported by the data and are better reflections of the theories they test. This reasoning follows directly from the logic in statistical models of research after accounting for underdetermination.
Addressing this problem requires including subjective judgments about the plausibility of each hypothesis. To be clear, this process does not increase the role of subjective judgments over typical research practice. The same judgments are integral to the research process but are excluded by conventional model selection. This approach simply makes assumptions more apparent, their inclusion or exclusion more empirically grounded, and the selected model more defensible.
Using this method of selecting models could have two possible effects. The ideal outcome is that the selected model is no different than the one chosen with conventional methods. Because this method relies heavily on the AIC, I would consider this a likely outcome in most cases. Similarly, even if all assumptions are deemed acceptable, analysis of this sort should still push modelers to consider new combinations of assumptions, possibly resulting in a better fitting model in conventional terms.
The second outcome is that researchers may decide that some assumptions do not offer sufficient improvement in model fit to justify their inclusion. This will have the predictable effect of making models more complex and having lower, but also more plausible, measures of model fit. This penalty will be offset by more conservative tests and more reliable theories.
6.1. Comparison with Other Model Selection Methods
It is worth briefly summarizing how this mode of model selection relates to existing model selection techniques. The primary difference between this and conventional techniques is that inferential model selection provides a means of justifying modeling decisions, rather than prescribing a criterion of the best model (such as “minimizing AIC” or “maximizing posterior probability”). Justification of models is post hoc, incorporating theory and data simultaneously. Many common techniques, such as the AIC, the BIC, and cross-validation, evaluate models with only the data (Akaike 1974; Schwarz 1978), leaving the influence of theory to the often underscrutinized selection of candidate models.
In contrast, Bayesian model selection (Raftery 1995) makes judgments about methodological assumptions explicit by requiring that each candidate model be assigned a prior probability. Unfortunately, the complexity of assigning a specific prior probability to each model has made it common practice to assume noninformative priors 11 (Kass and Wasserman 1996), eliminating this advantage altogether. Inferential model selection simplifies this problem by not requiring a specific prior probability, only requiring the plausibility of an assumption to be determined above or below the threshold. This reduces the complexity of subjective judgments and makes the connection between judgments and the selected model more transparent.
The second principal difference is that this method is sequential and includes a directional bias. Most modes of model selection, including frequentist and Bayesian techniques, optimize a single model selection metric that incorporates the desired trade-off between accuracy and simplicity in one quantity. In relation to selection via Bayes factors (Raftery 1995), the proposed method has a similar mathematical form on the basis of pairwise comparisons (see Appendix). Inferential model selection is distinct in that it requires different levels of evidence depending on the relative complexity of the two methods involved. It treats complexity-decreasing changes differently than complexity-increasing changes. A new model that decreases the AIC could be favored if it decreases model complexity (has more assumptions), but it will definitely be accepted if it increases model complexity (has fewer assumptions).
Bayesian model averaging (Hoeting et al. 1999) and similar ensemble techniques sidestep the model selection problem altogether, while still producing accurate predictions. This comes at the cost of relying on contrasting sets of methodological assumptions to varying extents, making them difficult to interpret analytically. A distinct take on using multiple models is found in the model uncertainty analysis, of Young (2009) and Young and Holsteen (2017), which is in many respects a complementary technique. This approach looks at whether and to what extent parameter values are sensitive to changes in model specification and identifies assumptions that require special consideration. It aims to solve a similar problem of inference by coming at it from the perspective of parameters, rather than models. The primary difference between the model uncertainty and this method is that Young requires the specification of the focal relationship to remain constant: parameters must be comparable. Because inferential model selection results in justification of a single model, it permits inferences about relationships that are measured with one, two, or more parameters, that is, parametrically or nonparametrically.
6.2. Parsimony
Quantitative discussions of parsimony—the simplest way to represent observed data—have tended to equate statistical modeling with theorizing (Forster and Sober 1994; Sober 2002). For sociology and most other social sciences, this equivalence will not hold (Turner 1987). From the perspective of underdetermination, a simple theory cannot be considered one that produces a simple model. In fact, because simple models entail the most assumptions, they represent the most complex theories.
Inferential model selection suggests a different perspective on the virtues of the AIC versus the BIC as model selection metrics. Supporters of the BIC often argue that it selects the more parsimonious model because it imposes a higher penalty on the number of parameters in a model. However, this also means that the BIC imposes a lower penalty on assumptions, meaning that assumptions are held to a lower standard of plausibility than they would be under the AIC. Consequently, the BIC favors greater discrepancy from the theory.
6.3. Underdetermination in Qualitative Research
Finally, although the arguments presented above are oriented toward statistical modeling, there is nothing peculiar to quantitative research in the logic of the arguments. The same inferential logic can be applied qualitative research. Quantitative and qualitative research both aim to take observations and organize them in such a way as to provide evidence for a theoretical conclusion. The difference lies in the nature of the empirical data and how it is marshaled to support the theory. It has been argued that this difference lies in the dramatic simplification of experience that occurs in the translation from phenomenon to number (Mills 1961:56). Although true, the difference is one of degree, not of quality. Qualitative sociology, like all observations requires simplification. Nor is the difference as Collins (1984) described it, that statistical work entails an additional theory, premised on assumptions. Qualitative research is equally built on assumptions. As Biernacki (2012) recently argued, the transmutation of meaningful data into meaningful analyses via coding (or other systems) necessarily imports auxiliary assumptions into the relation.
In his attack on quantitative methods, Turner (1987) misunderstood the fundamental feature of underdetermination as somehow more problematic for quantitative sociology than it is for qualitative sociology:
There are no relations of implication, no logical relations, which hold or can hold between general theoretical claims . . . and the values of correlations and regressions derived in causal models or multiple regression analyses. They depend on ordering, completeness and independence assumptions which are a priori in the sense that they are logically independent of, and cannot be warranted by, any results derived within the model. (p. 180)
This statement would be equally true if “correlations” and “regressions” were to be replaced with “historical documents,”“‘interview responses,” and “ethnographic observations,” and “models” and “analyses” were to be replaced with “frameworks,” “interpretations,” or “perspectives.” Neither approach can escape from the fundamental philosophical problem of observations being insufficient to justify a theoretical concept.
7. Conclusions
Model underdetermination remains a fact of empirical research. The process proposed here cannot solve the problem of modeling assumptions, but it can serve as a tool for justifying decisions. Modeling and hypothesis testing can be made more rigorous and more effective by acknowledging and addressing underdetermination, rather than by ignoring it.
A larger problem is that sociological research tends to underscrutinize models in general. By limiting itself to a narrow class of models and largely ignoring model fit, such research is burdened with unnecessary simplifying assumptions, and observations are coerced into overly reductive patterns. Consequently, existing research practices select models that are poor reflections of their theory and poor fits to the data. This need not be the case. Underdetermination should provoke us to select more complex models that better describe our data and provide more reliable theoretical inference.
Footnotes
Appendix
Acknowledgements
I am grateful for helpful comments from Jonah Stuart Brundage, Jacob Habinek, Sameer Srivastava, three anonymous reviewers, and the participants at the American Sociological Association Methodology Section’s 2016 Mid-Year Methods Meeting.
Funding
This research was supported by NASA grant NNX15AM26G.