
Abstract

I am grateful to Professors Vassend and Weakliem for their comments on my paper (this volume, pp. 52–87) and its admittedly unusual approach to model selection and to the Sociological Methodology editors for the opportunity to respond. My goal here is not to defend the inferential information criterion (IIC) against all the points brought out by Vassend (this volume, pp. 91–97) and Weakliem (this volume, pp. 88–91). My paper aimed to (1) show how methodological assumptions interfere with inferences about theory and (2) develop a practical approach to minimize this interference. As an attempt at this latter goal, IIC is certain to have weaknesses and inconsistencies. Future work will be needed to identify and correct them. As such, I will limit my comments here to issues central to the overall argument. Specifically, I will address the likelihood maximization, Vassend’s Bayesian critique, the use of nested models, and the probabilistic interpretations of the Akaike information criterion (AIC).
However, before addressing the comments, it will be useful to articulate some of the implicit assumptions. IIC is intended as a method of justifying methodological assumptions in order to maximize consistency with both the proposed theory and observed data. As such, there is an obvious irony that any method of justifying assumptions is itself dependent upon assumptions.
Vassend is correct that the approach I take is not strictly frequentist, nor is it strictly Bayesian. This is because both perspectives contain a sharp separation of theory and method, not requiring statistical models to engage directly with the proposed theory, à la Blalock (1979). Still, I have assumed a vaguely frequentist perspective. I say “vaguely” because while my derivation makes use of many of the same assumptions that frequentists typically make, it also incorporates presuppositions and assumptions from the theoretical framework. More concretely, in selecting a model, I take theory as a given and data as stochastic. Models, being partially determined by the data and of uncertain relation to the theory, are also stochastic, which is a deviation from standard frequentist assumptions.
1. Likelihood Maximization
Both Vassend and Weakliem take issue with the goal of IIC—that is, maximizing the probability of the data and the model given the theory P(X, M|T). Combined with the assumption that theory and data are conditionally independent given the model, this quantity can be stated as P(X|M)P(M|T), which combines traditional maximum likelihood selection with selection based on consistency with theory. In contrast, Weakliem asserts that the goal should be to “represent the theory as accurately as possible,” which may be interpreted as P(M|T). Vassend states that the best model should have the highest likelihood given the data and the theory L(M|X, T) = P(X, T|M) or, from a Bayesian perspective, the highest posterior probability, P(M|X, T).
Since the proposed method is basically frequentist, I will focus on the first two suggestions. There are two reasons why I used the stated specification rather than one of the alternatives suggested by the commenters. First, since model selection is not a purely inductive exercise, theory must take precedence and be considered a given. Vassend’s proposal allows the theoretical framework to shift during model selection. Second, inferential model selection must attend to both theory and data. Weakliem’s proposal overlooks the empirical aspect of model selection, effectively proposing Vassend’s ideal selection criterion.
2. The Bayesian Critique
Based on his rejection of the starting point of IIC, Vassend applies a Bayesian perspective to interpret its performance. The motivating concern is important: Bayesian and frequentist model selection techniques often disagree. It is fitting then to evaluate how IIC will hold up from a Bayesian point of view. More broadly, it is equally important to consider how model selection aimed at justifying assumptions would look if it were derived from a Bayesian perspective. Though my approach is frequentist, there is nothing implicitly frequentist about analyzing the validity of assumptions. I find it likely that a Bayesian approach would turn out considerably different. As Vassend points out, Bayesian interpretations have difficulty with nested models as interdependencies between assumptions complicate the determination of priors.
In his analysis, Vassend shows that IIC approximates a “truer” ideal selection criterion (ISC). He shows this to be a trivial model selection criterion in that it always prefers more complex models. Vassend’s derivations are correct. ISC does reduce to a trivial selection process that favors the model with fewest assumptions. However, this does not imply that IIC is inconsistent. The premises of his reasoning are consistent only from a perspective that makes Bayesian assumptions.
The ISC relies on the posterior probability of the model given the theory and data, P(M|T, X). The assumption that the data are fixed conflicts with the basic frequentist assumption that the data are stochastic. Although Vassend’s derivation is correct, the expression he arrives at is not a meaningful statement under the original frequentist assumptions. The data are random; the model and its assumptions are chosen. The posterior probability of the model is impossible with an assumption about its prior probability, which would require a bounded model set, something a likelihood approach does not include. There could be an infinite number of models compatible with the theory. 1 By changing the foundational assumptions, he reaches a different and valid conclusion, though this validity does not apply under the original assumptions.
Vassend’s critique highlights the importance of analyzing and justifying assumptions in model selection but also in research more generally. Different assumptions lead to different conclusions. Given Bayesian assumptions, AIC is not a coherent model selection technique. Similarly, from a frequentist perspective, it makes little sense to assign prior probabilities to models. Each technique begins with different underlying assumptions. Swapping out the initial assumptions does not invalidate a conclusion, but it does simply shift the point of disagreement.
3. Nested Models
I agree with Vassend and Weakliem in their distaste for nested models. Model selection via nested models is highly restrictive and can produce ambiguous results. However, the effects of a specific assumption cannot be understood without accounting for the influence of other nonfocal and often implicit assumptions. Since nested models share the majority of assumptions in common, comparisons between nested models solve this problem effectively and reliably. Nesting models isolates the effects of an articulated assumption by suppressing the influence of nonfocal, irrelevant, or implicit assumptions, even when assumptions are interdependent. The more closely nested two models are, the fewer the assumptions that are included between them.
That being said, there are ways of relaxing this requirement. However, comparing less related models comes at the expense of interpretability, as I will show. A first approach would be to compare all models with one generalized model—that is, a model within which all others can be nested. Because they are nested, comparison between this baseline model and other candidate models will suppress the influence of other assumptions. However, plausibility thresholds will be determined for sets of assumptions collectively.
It is also possible to directly compare models that are not nested but are nested within a third model. Consider the simple case of two models, MA and MB, which are not nested within each other but are each nested within a third model, M0:
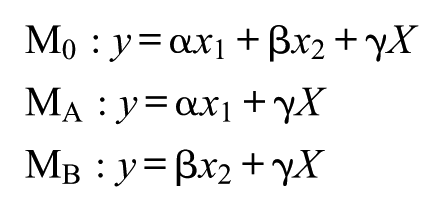
where X represents some set of variables shared in both models. Model A is Model 0 combined with the assumption that β = 0. Model B is Model 0 combined with the assumption that α = 0. Directly comparing Model A and Model B amounts to assessing the relative plausibility of these two assumptions. More specifically, it follows from IIC that the difference in AIC between Model A and Model B can be expressed directly as
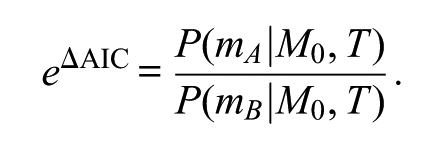
The AIC term for the generalized model cancels out, eliminating the need to evaluate it altogether. This expression provides a threshold for the plausibility ratio. Decisions from this expression are based not on whether Model A is more plausible than Model B but on the more difficult determination of whether the relative plausibility is higher or lower than the threshold. Deciding between the two models requires the comparison of two, rather than one, subjective judgments.
Both of these options are computationally easier but make decision making more difficult. Furthermore, I would argue that neither approach really helps to justify assumptions. In the first case, assumptions are evaluated collectively, obscuring the effects of specific assumptions. Decisions would be made about models relative to the general model but not between each other. In the second case, decisions are based on relative plausibilities, which really makes sense only if the two assumptions are mutually exclusive. It also will not distinguish two equally implausible assumptions from two equally plausible ones.
It should be noted that regardless of how models are compared, assumptions can be evaluated only when the model set includes a model not based on a particular assumption. For example, comparing varied combinations of predictors in a linear model will test only whether those predictors should be included. It will not test the assumption that predictors are, in fact, linear.
3. Probabilistic Model Selection
Weakliem points out that AIC can also be interpreted as a probabilistic mode of model selection (see Burnham and Anderson [2002:74] for a discussion). I agree that model selection can, and sometimes should, be interpreted as arriving at a probability distribution over models rather than as a single final model. I did not intend to suggest that the aims of IIC to select a single model is inaccurate, as Weakliem suggests. Every comparison is probabilistic or open to subjective evaluation. My reanalysis of Lizardo’s (2006) models showed that there are multiple models that could justifiably be used for inference. Nothing requires researchers to select a single model when multiple models could be justified.
There is one fundamental difference between the model likelihoods inferred from AIC and plausibilities based on IIC. Model likelihoods derived from AIC are determined in relation to the minimum AIC found in the model set. AIC treats all models equally. Any model in the model set may have the minimum AIC. Defining the minimum in this way makes the AIC differences positive by definition. In contrast, IIC is biased toward models with fewer assumptions. Comparisons are ordered. The baseline model is always the less restricted model, allowing differences in AIC to be both positive and negative. Whereas probabilistic model selection with AIC would allow more restricted models with higher AIC, IIC allows more restricted models only if they have a lower AIC.
4. Conclusion
In conclusion, I would like to reiterate and add to the point made by Weakliem. Model selection is a theoretical problem for the philosophy of social science, but unexamined and unjustified assumptions are also a practical problem for quantitative researchers. The method I have proposed is as susceptible to this problem as any. Regardless of whether they use a formal technique for incorporating theoretical considerations, statistical modelers should question whether their theory demands a “simple” statistical model. More complex models with fewer assumptions may serve their purposes as well or better.
Footnotes
Notes
Author Biography
An author biography can be found on page 87 of this volume.