
Abstract

I was looking at some regression results with a research assistant last week. The RA had been preparing administrative data from a jail, and I was interested in the correlates of returning to incarceration among those who were released. The big challenge in this analysis was simply cleaning up administrative records that were not generated for statistical analysis. Data cleaning had taken several months. We were eagerly awaiting these first regressions, and I wanted to look at basic demographic patterns: race and sex differences in reincarceration. The first regressions we ran also controlled for age, criminal offense, and county of jurisdiction. The initial output indicated that blacks were more likely to go back to jail than whites and that men were more likely to return to custody than women. Unexpectedly, the results indicated that older people were more likely to return to jail than younger people. This contradicted the age-crime curve, the universal finding that criminal offending declines with age. Hmm.
I asked the RA to pull up the coding of the age variable, but in the meantime I was thinking about why people older than 40 were more likely to return to incarceration than those in their 20s. Jails, more than prisons, incarcerate people who face a lot of social and economic insecurity. Problems of homelessness and mental illness are highly prevalent. Perhaps enduring needs for drug treatment and housing among older people explained their high rates of reincarceration. Just then, my RA announced that she had found the problem with the age code and fixed it. We fit the regression again. Now, the rate of reincarceration declined smoothly with age, just as expected.
A lot of data analysis looks like this. We begin with some intuitions about what patterns we will see in the data. But often, expectations are fairly weak, and if the data point in a different direction, we sort through an infinite catalog of post hoc explanations to make sense of the results. A lot of sociological data analysis does not involve the testing of a well-specified null hypothesis, but it is an iterative and inductive process of learning from data. Prior information is diffuse, and we readily invent explanations for unusual findings, at least for a few minutes in the privacy of our offices.
The article by Muñoz and Young (this volume, pp. 1–33) offers one approach to the problem of learning from data in a context with weak prior information. They consider model uncertainty in the familiar applied situation in which interest focuses on one predictor in a regression analysis, but the researcher is unsure which control variables to include in the model.
More formally, for a regression on the vector
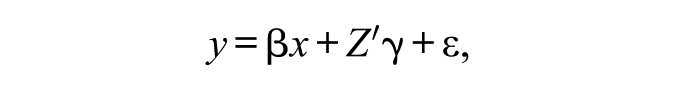
The authors address the problem of model uncertainty with a diagnostic in which all possible
The problem of model uncertainty is a fundamental applied challenge in quantitative sociology. The authors’ language of false positives is reminiscent of Bonferroni adjustments and the frequentist analysis of multiple independent comparisons, but the distinct problem of model uncertainty has been fully formalized from a Bayesian perspective. In the notation above, we have
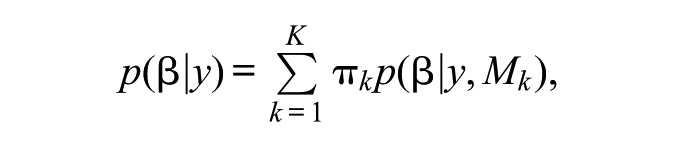
where
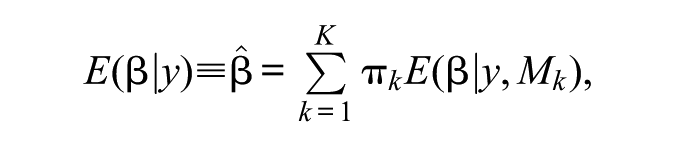
where
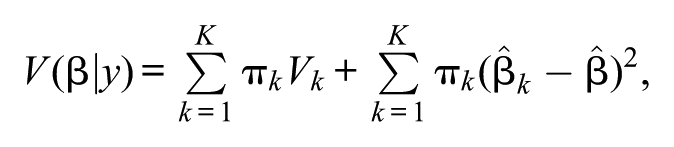
where
The Bayesian framework provides a few extensions to the analysis by Muñoz and Young. First, even when a model is robust according to the authors’ diagnostic, standard inference for a preferred model will still yield standard errors that are too small. This is because in the authors’ approach, once a model is judged to be robust, inference is conditional on a single preferred specification instead of averaging over all possible models. Second, the authors’ idea of a total standard error effectively places equal probability on every point in the model space, and the data themselves are not informative about the probability of each model; for Bayes, the data are informative about the probability of different models and greater weight is given to more probable models. Third, the instability of coefficients across models varies not just with sample size but also collinearity. The authors’ simulations illustrate some intuitions about model sensitivity and sample size, but only in the unrealistic situation where covariates are, on average, uncorrelated.
Nevertheless, drawing attention to the problem of model uncertainty, the pitfalls of uncalibrated data mining, and the inflation of nominal
Some readers may feel that the authors’ motivating example of inference about a treatment effect with observational data is anachronistic. Certainly, the limits of observational data for learning about causal effects are more widely understood now than in 1983, when Leamer was first taking the con out of econometrics. Indeed, the authors’ analyis of the job-training experiment illustrates how a strong experimental design can greatly reduce model uncertainty. In any case, the problem of statistical inference for which the issue of model uncertainty is relevant is distinct from the problem of inference about a causal effect.
The analysis of model uncertainty is one part of a larger methodology of data analysis that provides rules for learning from data, beyond estimation and inference for particular models. In the methodology of data analysis, I would also include the statistics of data visualization and exploration, outlier detection and other regression diagnostics, and more informal inquiries such as placebo tests and alternative codings of variables. For some methods, the objective is not statistical inference but description. Given a data description, other methods are concerned with sensitivity: assessing the dependence of a description on the specific set of observations and the underlying assumptions.
The problem of statistical inference can occupy an outsized place in quantitative sociology, where researchers work under conditions of radical model uncertainty—where even the age-crime curve can be doubted. In these settings, our largest contributions may involve making new observations with help from a rigorous research design, or developing new descriptions of secondary data.
Footnotes
Acknowledgements
I would like to thank Nate Wilmers, who provided comments on an earlier draft.