
Abstract
An experiment examined how veracity, modality, and experimenter sanctioning of deception influenced credibility assessments made by professionals who conducted interviews face-to-face (FtF) or by video conference (VC). Participants (N = 243) completed a trivia game with a confederate who encouraged cheating. Some lies were sanctioned by the experimenter and others were unsanctioned. The professional interviewers educed a high number of confessions in the sanctioned (58%) and unsanctioned (79%) lie conditions. Overall accuracy of the interviewers ranged from 45% to 67%. Interviewers were more accurate when judging veracity FtF than in VC. Those in the deceptive VC conditions (especially sanctioned liars) were rated by interviewers as more dominant, involved, relaxed, and active than those in the FtF condition, revealing that modality affected deceivers’ demeanor.
Credibility assessment is so critical to the process of communication that the construct of credibility occupies a vaulted position in the communication discipline. Sizing up another’s credibility is an elemental component of all interpersonal interactions and especially professional encounters such as employment interviews, fraud inquiries, or criminal investigations. Central to credibility are judgments related to another’s character, dependability, and truthfulness. Thus the assessment of credibility implicitly includes a determination of whether another is being deceptive or not.
In today’s increasingly mediated interactions, a common concern is whether modalities that foster more favorable credibility assessment, such as those that allow for visual cues like videoconferencing or FtF, may simultaneously impair deception detection even though they offer more cues for the detector (see Burgoon, Stoner, Bonito, & Dunbar, 2003). The research examining the effects of computer-mediated communication (CMC) on deception detection has largely explored media such as synchronous, text-based chat or audio-only interaction but with conflicting results. Some researchers have concluded that CMC (e.g., chat) reduces assessment capability (e.g., Giordano, Stoner, Brouer, & George, 2007), whereas others have concluded that audio-only forms of CMC actually enhance assessment capability relative to either text or video-only modalities (Bond & DePaulo, 2006). Because CMC technology has improved so substantially and multimodal formats such as videoconferencing (VC) are now far more common, this investigation revisited the role of CMC in a deception detection task to assess whether mediated communication alters how deception is performed and is detected.
The investigation focused on VC, which is the medium most likely to be favored in professional settings because of the potential of mediated interviews to maximize interviewer efficiency, reduce travel time and fatigue, and reduce the need for interviewers at innumerable locations. When the costs of potential deception are high (e.g., in criminal interviews or security screening), the need for accurate credibility assessment and deception detection is particularly acute. Professionals must not only distinguish truthful statements from fabrications and uncover relevant evasions or omissions but must also properly attribute credibility to individuals who are in fact honest and trustworthy. Given that local, national, and global threats to security are adding an increasing burden on professional, physically present interviewers who conduct credibility assessment interviews, it becomes increasingly relevant to test whether new technologies such as VC enable the same or better credibility assessment and deception detection by professional interviewers than do typical FtF interviews.
Our decision to use professional judges as confederates was motivated by another concern in the deception literature—the lack of high-stakes, consequential circumstances under which deceptions are produced and veracity assessments are rendered (see, for example, Frank & Feeley, 2003). The vast majority of published research in the deception arena has been based on samples of undergraduate students participating as either message senders or message judges for extra credit or small financial incentives. It is questionable whether deceits produced under benign conditions or judgments rendered by naïve, untrained individuals with no vested interest in the credibility assessment process generalize to those for whom the assessment of veracity is of paramount importance. This investigation sought to elevate the ecological validity of this research by creating conditions more equivalent to those faced by perpetrators of consequential deception and those regularly charged with ferreting out the truth.
To frame our inquiry, we drew upon interpersonal deception theory (IDT; Buller & Burgoon, 1996; Burgoon & Buller, 2008), which postulates that deception and its detection vary as a function of interactivity. Interactive modalities are ones that foster the greatest degree of contingent, interdependent, synchronous, participatory, information-rich, and individuated communication (Burgoon et al., 1999, 2000). FtF communication is considered more interactive than VC because not only are visual, auditory, and verbal channels engaged but so are visceral and sometimes even tactile senses. Moreover, FtF includes two other related features of interactivity: nonmediation and propinquity (or geographical proximity). People who interact FtF experience greater sensory immersion, immediacy, relational connection, and psychological closeness than those who are geographically separated and must interact through some medium (Burgoon et al., 1999, 2002). VC affords qualities of sensory richness, engagement, and psychological immediacy more so than other forms of CMC but not to the same extent as FtF. The question of interest is whether VC, as a form of CMC, is like the double-edged sword of communication that simultaneously fosters trust but undermines detection of deception (Burgoon et al., 2000; Dunbar, Ramirez, & Burgoon, 2003) or that creates more psychological detachment that actually aids deception detection. To address this question, we tested whether professional interviewers would be subject to the same positivity biases and leniency errors as found in past investigations with naïve participants under FtF communication (Burgoon et al., 2000) and the influence of VC on the accuracy of professional interviewers’ assessments.
Theoretical Rationale and Hypotheses
Interpersonal Deception Theory
Several features of IDT (Burgoon & Buller, 2008) framed the current experiment. First, IDT describes deception as a goal-based exchange between a sender and receiver in which deceptive senders attempt to perpetrate their deceit successfully without detection and receivers attempt to gauge sender credibility. Throughout the interaction, deceivers are thought to surreptitiously attune to signs of receiver suspicion and, within the scope of their skill set, to adapt to any signs of receiver incredulity (Burgoon & Levine, 2010). The modality of communication becomes relevant to the extent that it moderates awareness and adaptation.
Second, IDT postulates that both deceiver and receiver will display intentional (strategic) and unintentional (nonstrategic) behaviors as they attempt to simultaneously manage the interaction and their own self-presentations. Strategic behaviors are purposeful attempts to manipulate the interaction in pursuit of an interactant’s goals. Both truthful and deceptive interviewees should be inclined to “put their best face forward,” but modality may again influence the interaction process by moderating how well people manage their self-presentations. Deceivers, for example, may take a “fight” or “flight” approach to deception by choosing either offensive maneuvers such as actively justifying their deceptive stance or adopting more defensive maneuvers such as dodging a probing question (Burgoon, Buller, Guerrero, & Afifi, 1996), depending on which is more manageable and potentially successful under the modality in use.
Third, and particularly germane to the importance of modality, IDT maintains that communication patterns during deceptive episodes are influenced by the degree of interactivity present in the communication context. Under normal, “cooperative” discourse conditions (see Grice, 1989), greater interactivity fosters (among other things) more coordinated, synchronized, involved communication patterns that cement a sense of similarity, responsiveness, understanding, connectedness, and “pseudo relationship” between conversational partners (Burgoon, Buller, & Floyd, 2001). Whereas engagement and enmeshment are hallmarks of unmediated FtF interaction, mediated forms of communication like VC may interfere with the ability to create a normal, synchronous interaction rhythm with seamless turn-taking that undergirds the creation of rapport and mutuality at least in the span of a single interaction.
The relevance to credibility assessment is threefold. To the extent that FtF communication affords a more involved, expressive, pleasant, relaxed dyadic communication pattern with more rapport and mutuality than mediated communication, it should promote a generalized truth bias and favorable credibility assessments (Burgoon, Blair, & Strom, 2008; Burgoon et al., 1999). Mediated communication also reduces the number of sensory channels through which messages are exchanged (Daft & Lengel, 1984, 1986; Ramirez & Burgoon, 2004). When judging deception, such channel constraints can have opposing effects. Mediation may create psychological detachment and shift the interviewer’s perspective from participant to observer (Burgoon et al., 2001; Dunbar et al., 2003), thereby ironically producing a more objective assessment that permits better detection of deceit. Alternatively, mediation may impede interviewers’ detection efforts because the available telltale deception indicators are limited (Carlson, George, Burgoon, Adkins, & White, 2004; Hancock, Curry, Goorha, & Woodworth, 2008). Empirical findings have shown that deception detectors are more accurate in richer CMC modalities like audio conferencing than leaner ones like synchronous chat (Burgoon et al., 2003; Giordano et al., 2007). However, more is not necessarily better: people are less accurate judging visible than audible lies (Bond & DePaulo, 2006), possibly because judges are easily distracted by visual media and the stereotypical deception cues that are more prominent in them. In the same vein, Schweitzer, Brodt, and Croson (2002) found that adding video to teleconference negotiations increased trust by receivers, which is beneficial when all parties have benign motives but detrimental if they have ulterior motives or are deceitful.
Thus modality exerts a significant influence on the sending and receiving of deceptive messages. From the standpoint of the sender, it might seem that deceivers could utilize VC to their benefit through selective self-presentation minus the close scrutiny of FtF interaction while still capitalizing on the availability of feedback in VC to discern skepticism and adapt to it.
From the standpoint of the receiver, VC might provide judges offsetting objectivity that would aid their detection. However, VC occupies a smaller portion of a viewer’s visual field than does a copresent human. As the camera generally only captures the face and head, hidden from view are nonverbal signals displayed by other parts of the body. The focus on the face may overemphasize the more honest-looking facial expressions and downplay postural shifts, gestures, or foot and leg movements that may be more revealing than the face (DePaulo et al., 2003). Thus VC could disadvantage receivers by focusing attention on those facial features that senders are most careful to compose and eliminate the ones in the limbs and trunk that are least likely to be monitored and managed by senders (Dunbar & Jensen, 2011). Comparatively, and consistent with the IDT assumption that receivers are not passive but instead can also communicate strategically to achieve their own ends, the FtF modality may benefit skilled professional interviewers, who, unlike untrained and inexperienced student interviewers and judges, may establish a sense of rapport that creates psychological pressure toward disclosing information and confessing (Inbau, Reid, Buckley, & Jayne, 2001). Coming face-to-face with a highly skilled interviewer may cause liars discomfort and their communication may betray less self-assurance than if interviewed by the same interviewer “at a distance” via VC. Marett and George (2013) found that deceivers committed more lies under CMC than FtF, presumably because they felt less scrutiny and/or connection with targets in the former condition. In an interview context, deceivers may feel less secure in their ability to convey credibility when seated opposite a seasoned professional examiner than when that examiner is just an image on a computer screen.
Given the countervailing forces and predictions, we tested a nondirectional hypothesis regarding the effects of modality and deception on credibility and deception detection.
Hypothesis 1 (H1): Modality interacts with deception to affect (a) detection accuracy and (b) credibility assessment by professional interviewers.
The second hypothesis assessed whether the combined effects of modality and veracity on judgments can be explained by differential communication patterns.
Hypothesis 2 (H2): VC affects interviewers’ perceptions of deceivers’ and truth-tellers’ (a) general expressivity (i.e. dominance, activation, involvement, and pleasantness) and (b) tension relative to FtF.
Experimenter Sanctioning
We have noted that one objective of this investigation was to elevate ecological validity. A common criticism of deception research is the significant gulf that exists between sanctioned deception studied in controlled experiments and actual deception probed by professional interviewers (Frank & Feeley, 2003). Sanctioned lies are ones in which researchers give participants permission or instruction to lie, whereas unsanctioned lies are ones in which participants deceive without explicit instruction or permission. Despite early expressions of skepticism that laboratory experiments using only sanctioned lies could generalize to operational environments because they lack the high stakes of “real-world” environments (Feeley & deTurck, 1998; Miller & Stiff, 1992), the majority of deception research continues to rely on sanctioned deception as a method for establishing ground truth, preferring to randomly assign subjects to conditions rather than allow them to choose their own condition by allowing them to use unsanctioned lies. Results from research comparing sanctioned to unsanctioned lies has been mixed: Early research by Feeley (1996) found no difference in involvement or nervousness for sanctioned and unsanctioned deceivers but later, Feeley and deTurck (1998) found that unsanctioned deceivers appeared more confident and less nervous than sanctioned ones. More recently, Sporer and Schwandt (2007) found in their meta-analysis that unsanctioned deceivers smiled more than sanctioned deceivers, suggesting greater poise and relaxation although they also caution that their results are based on a very limited number of studies.
Essentially, there are two different assumptions made in the research literature regarding whether experimenter sanctioning will make deceivers more or less detectable. On the one hand, some research suggests that because sanctioned liars have not chosen to lie, they can blame the experimenter for their wrongdoing and experience less guilt than unsanctioned liars. The lack of affect, positive or negative, and the confidence of sanctioned deceivers could make them appear more believable than unsanctioned deceivers (Burgoon & Dunbar, 2000). The very fact that sanctioned liars know something their partner does not (such as the purpose of the experiment) can also empower them and make them appear more credible (Dunbar et al., 2012). This may explain why Feeley and deTurck (1998) had 8 participants who confessed to cheating in their experiment in the unsanctioned lie condition (or about 22%), whereas no participant in the sanctioned lie condition confessed.
On the other hand, Levine, Shaw, and Shulman (2010) argue that unsanctioned liars, by virtue of the fact that they have chosen to lie, will lie more readily when they believe they are skilled liars or have honest demeanors that make them more difficult to detect. They suggested that only good liars will self-select into the deception condition in experiments in which they have a choice, thereby making them difficult to detect because of their confidence or dominance. Given that Serota, Levine, and Boster (2010) argue that there are few “prolific” liars, it is possible that the majority of sanctioned deceivers would experience negative emotions (specifically guilt and shame), which impair their communicative fluency, expressiveness, relaxation, and assertiveness and make them more detectable than unsanctioned liars.
Both of these explanations rest on the assumption made by many deception theories, including leakage theory (Ekman & Friesen, 1969), the four-factor theory (Zuckerman, DePaulo, & Rosenthal, 1981), and IDT (Burgoon & Buller, 2008), that negative affect experienced by deceivers such as the guilt and shame associated with violating conversational norms through deception can be a pivotal factor influencing how deception is manifested and detected. Some have argued that sanctioned liars experience less guilt because they hold the experimenter responsible for their lies while others have argued that unsanctioned liars experience less guilt because they are skilled or experienced liars who have excused themselves for lying long ago. This reasoning has yet to be tested because guilt has not been measured directly nor have confession rates been compared very often between sanctioned and unsanctioned lies. We measured guilt and confessions in the current experiment so that we could test this recurrent conjecture:
Hypothesis 3 (H3): Sanctioned deceivers (a) experience less guilt and (b) confess less often than unsanctioned deceivers.
Hypothesis 4 (H4): Sanctioned deceivers are judged as (a) more credible and (b) are detected less accurately than unsanctioned ones.
Method
Overview
Our experiment follows the model of previous experiments (Feeley & deTurck, 1998; Levine et al., 2010) in which participants engage in a problem-solving task (a trivia game in our case), are encouraged to cheat on the task by a research confederate, and then are interviewed about their participation in the cheating afterward. However, our version also differs from previous ones in several ways. For example, Levine et al. (2010) noted several shortcomings of their investigation that may have attenuated their effects:
(a) the brief duration of the questions and answers (the majority were under 20 seconds), (b) that the questioning was by a young graduate student rather than by a professional interrogator, (c) that the question content was held constant across interviewees, and (d) that the judges were untrained undergraduate students. By implication, extended interviews by experienced interrogators free to pursue suspicious answers might yield even higher accuracy rates than current values. Thus, past research showing poor performance from experts may not generalize to all interrogative situations. Usually, of course, experts in deception detection studies do not get to ask their own questions (for a notable exception, see Hartwig, Granhag, Stromwall, & Vrij, 2004, p. 225).
Our investigation was designed to address all of these shortcomings. We employed professional examiners with extensive training and interviewing experience, created a longer battery of interview questions and permitted the interviewers to incorporate follow-up questions as they deemed necessary, a design change that created more natural and ecologically valid interviewing conditions. As a result of these changes, the interviews were also much longer 1 than the Levine et al. (2010) studies, giving the professionals richer data upon which to base their judgments and allowing more natural conversations to unfold. Unlike the graduate student interviewers in the Levine studies and the randomly selected undergraduate participants selected to be interviewers in the Feeley and deTurck (1998) experiment, our interviewers also participated in the interview planning process and proposed questions they wanted included in the standardized list. Finally, whereas Levine et al.’s studies utilized undergraduate judges to make assessments after viewing video recordings of the interview sometime after the interviews took place; our judges participated in the interview itself and made their judgments immediately following the interview. All these changes, along with the addition of the VC modality that had not been tested in previous cheating experiments, were undertaken in an effort to improve validity and make the experimental setting more involving for participants.
Participants
Participants were undergraduate students (N = 251) recruited from the entire campus of a large Midwestern university via a mass email for a study in “communication and teamwork.” The participants came from at least 60 different major fields of study. Eight participants were excluded from the analysis due to technical errors, failure to follow instructions, or withdrawal after the debriefing, resulting in a final sample of 243 individuals (83 males, 159 females, and one nonresponse). The ethnicity of the participants included 168 Whites, 23 African Americans, 19 Asians, 14 others, 10 Native Americans, 6 Latin Americans, and 2 participants who declined to report their ethnicity. Education averaged 15 years (SD = 1.35). All procedures were approved by the host University’s Institutional Review Board.
Experimental Setting and Procedure
Participants reported to a research laboratory consisting of six rooms: a reception area, two rooms where participants completed pre- and postmeasures on laptop computers and were later debriefed, one room where the confederate, posing as a participant, was stationed with a laptop computer and where the trivia game took place, one room with a laptop computer equipped with Skype for VC, and one room, equipped with three cameras and a laptop for interviewers to record their assessments, where FtF interviews were conducted.
After completing preinteraction questionnaires, which included demographic information and some bogus teamwork questions, participants were told they would join their partner (the confederate) in an adjoining room where he or she had also just completed questionnaires. Participants were left alone with confederates and told to work together as a team to answer eight difficult trivia questions taken from the original Genus version of Trivial Pursuit. Participants were informed that each correct answer was worth US$5 for a total of US$40 and that the minimum they could earn in the experiment was US$20. The questions had to be answered in 5 minutes; a timer was set to add further “time press.”
Confederate partners were 6 students (3 males and 3 females, 5 undergraduates and 1 graduate student) who trained and practiced for 1 hour on their roles in the experiment. The confederates were instructed to initiate cheating in the two deception conditions (described below) by waiting until the last interaction minute to suggest looking up answers to the trivia questions using the Google search engine. In order to ensure that a large enough sample of subjects cheated, the confederates were instructed to cheat even if the participant objected to the cheating. There was only one laptop in the room, so confederates encouraged participants either to look up the answers or write them down so participants would feel they were a party to the cheating. A survey completed by the confederates after the trivia game was used to confirm the participant’s willingness to cheat in the two cheating conditions. It asked, “Did the participant go along with the cheating?” Confederates then described how the participant responded to the suggested cheating. Results indicated that participants went along with it willingly (participated in the cheating or even suggested it themselves before the confederate did) 61% of the time. Of those who objected to the cheating, none withdrew from the experiment or alerted the experimenter that cheating had occurred immediately following the trivia game when they were in the unsanctioned condition. They were also no more likely to confess to the cheating during the interview if they were an unwilling cheater (69% of the willing cheaters confessed but 66% of the unwilling cheaters also confessed).
The qualitative descriptions of events reported by the confederates were coded independently by two of the authors on a 5-point scale ranging from 1 (strong disapproval of the cheating) to 5 (strong approval of the cheating). The coder independently rated the statements and then discussed the discrepancies until 100% agreement was reached. Among all cheaters, 31.6% expressed strong disapproval 2 (sometimes even physically trying to close the browser or refusing to record answers) and another 15.2% expressed mild disapproval (frequently showing reluctance but rarely trying to stop the confederate). Another 25.3% showed mild approval such as in this confederate report: “He never condoned cheating but in the end he wrote down the answers while I searched the next question on Google.” Finally, 24.1% demonstrated strong approval, sometimes even suggesting the cheating before the confederate did or initiating a search on their own cell phones while the confederate used the computer. Only 3.8% appeared indifferent about the cheating to the confederate.
After the trivia game, participants were told they were going to be interviewed separately about their teamwork strategies used during the game. The interviewers (two females and two males) were professional interviewers who were provided by the Department of Defense. All were certified polygraph examiners who had extensive training in interviewing and credibility assessment and had professional experience ranging from 4 to 30 years. Interviewers were furnished the protocol in advance of the experiment and conducted practice sessions prior to the conduct of the actual experiment. They also made suggestions for questions to be included in the study prior to the first interviewer’s arrival. The first interviewer was monitored through a one-way window by the researchers and received feedback throughout the course of his interviews. The three subsequent interviewers reviewed recordings of the first interviewer and were asked to tailor their own style to that of the first interviewer in order to ensure consistency across all the interviews.
During the interview, the interviewers asked 13 standard questions (see Table 1), some of which were adapted from previous cheating experiments. Interviewers were allowed to ask follow-up questions and probe for further information. At the conclusion of the interview, interviewers and interviewees were separated to complete postmeasures. Interviewers assessed the truthfulness, credibility, and communication of the participant. Participants completed postinterview questionnaires rating their own performance, were debriefed, and received payment for their participation. The debriefing informed them that they participated with a confederate who either supplied correct answers in the truth condition or encouraged them to cheat during the deception conditions. After reading and signing the debriefing form, participants were given the opportunity to withdraw from the experiment and have their data removed from analysis. Two participants did so; their data were removed.
Interview Protocol Questions.

Experimental Design
A 3 (Veracity: truth, sanctioned lie, unsanctioned lie) by 2 (Modality: FtF, VC) experimental design was employed. 3 Participants were randomly assigned to veracity conditions when they arrived at the laboratory. Because it was not practical to move the interviewers to a different location with every interview, participants were randomly assigned to their modality conditions in blocks while ensuring that blocks were dispersed evenly among interviewers, various times of day, and days of the week. Interviewers were blind to the veracity condition.
Veracity conditions
In both lie conditions, the confederate suggested looking up the correct responses to the trivia questions and proceeded to do so with or without the cooperation of the participant. They were instructed to use Google to search for two of the answers in the last minute of their time (although in rare cases when the participants suggested cheating before the last minute, they may have Googled more than two answers). In the sanctioned lie condition, just before the time expired, the lab assistant opened the door and “caught” them cheating. The lab assistant informed them that because they were cheating they could not earn any money for correct answers over the US$20 minimum for the study but that they could earn an extra US$20 if they convinced the interviewer that they had not cheated. They were explicitly told to lie and that this was acceptable in the context of the experiment. The unsanctioned lie condition was identical to the sanctioned lie condition except the lab assistant did not catch them cheating and they were taken directly to the interview with the interviewer. They were told they could earn a US$20 bonus if the interviewer found them to be “credible” in their answers but were not told the content or purpose of the interview. In the truthful condition, the confederates did not initiate cheating but instead supplied the team with at least two answers to the trivia questions so that every participant would obtain at least two correct answers. The confederates were instructed to say “I know this one” so that the participants would feel confident about at least two of the answers. Truthful participants were also told they could earn the US$20 bonus for appearing credible.
Modality
Participants were interviewed either FtF or via Skype, an Internet-based VC program. In the FtF condition, participants sat directly across from the interviewer in an experiment room with three video cameras that recorded the interview for later analysis. A lab assistant turned on the three cameras, announced the participant number and left the room. In the VC condition, the participant and interviewer were in separate rooms, each equipped with a laptop. Lab assistants provided brief instructions regarding Skype for participants who were unfamiliar with it. The lab assistant informed the interviewer by phone that the participant was ready to begin; the interviewer initiated the video conference. The video and audio for both the participant and the interviewer were recorded.
Measures
Interviewer judgments
After the interview, interviewers rated interviewees on measures of truthfulness, believability, credibility, and trustworthiness on single-item unipolar scales ranging from 0 (not at all) to 10 (completely). As these four judgments were highly correlated with each other (ranging from r = .83 to .91), we created a composite variable called “credibility” based on these four judgments. A principal components analysis revealed only one component with eigen values greater than 1 that included all four variables and accounted for 89.46% of the variance. The credibility composite variable had a reliability of α = .96.
Interviewers also rated the participants’ dominance, involvement, tension, activation, and pleasantness on five 7-point semantic differential items including dominant-submissive, involved-uninvolved, tense-relaxed, active-passive, and pleasant-unpleasant. These variables were all significantly correlated with one another (ranging from r = .15 to .78, with tension negatively related to the other three). A principal components analysis revealed only one component that included all five variables with eigen values greater than 1.0 and accounted for 54.31% of the variance. However, tension had a low factor loading (–.43) and so was not combined with the other three variables. A composite variable called “expressivity” was created that included dominance, involvement, activation, and pleasantness (α = .80) and tension was retained as a separate measure.
Interviewers also recorded their belief that the interviewee had cheated and whether or not the interviewee confessed, using two dichotomous (yes/no) items: “Did this participant cheat?” and “Did the person confess to cheating?” Accuracy of interviewer judgments of truthfulness ratings followed the method advocated by Burgoon, Buller, Ebesu, and Rockwell (1994). It was calculated as the absolute difference between the participant’s self-reported truthfulness and the interviewer’s judgment of truthfulness. Inasmuch as deceivers often deceive by shading the truth, equivocating or concealing relevant information rather than lying outright, their reported truthfulness or deceit may vary along a continuum. Receivers who detect these variations should be given credit for their accuracy. Creating difference scores between interviewee reported truthfulness and interviewer assessment is far more sensitive to receiver awareness of less-than-candid answers without having to declare them outright lies and is supported by meta-analytic results showing greater receiver accuracy than use of dichotomous scales (Bond & DePaulo, 2006). Such measurement also satisfies requirements for interval measurement as compared to binary yes/no judgments for each answer. This method yielded a single truthfulness difference score for each interview. Although single-item measures are typically not ideal, they were used in this case to reduce interviewer fatigue since they completed the survey after every participant and interviewed several participants a day. The interviewers were fully trained on the meaning of each item by the authors, and verbal examples were provided for each item.
Participant self-reports
Interviewees and interviewers both used the same unipolar scales to gauge truthfulness and believability. Ratings ranged from 0 (not at all) to 10 (completely). Participants also rated the interviewer’s communication style (i.e., dominance, pleasantness, ease) with items similar to the ones used by the interviewer.
Three items measured the participant’s comfort level with using VC (i.e., Skype) as a form of communication on a 7-point Likert-type scale (α = .85; M = 5.11, SD = 1.47).
The State Shame and Guilt Scale (Marschall, Saftner, & Tangney, 1994) was used to assess the level of guilt felt by participants for lying to the interviewer. After the interview, the participants were asked to rate how they felt “at that moment.” The scale, comprised of 15 Likert-type items, included “I feel proud” (reverse-coded) and “I feel like I am a bad person” (α = .94; M = 2.46, SD = 1.16).
Results
Manipulation Checks
A first check examined whether the four interviewers differed in their performance according to the judgments made by the participants. Although all were experienced examiners who had conducted numerous interviews in the field, the fourth interviewer was near retirement and was about 20 to 30 years older than the other three. Not surprisingly, in comparing the participants’ ratings of interviewer dominance, a one-way ANOVA revealed a significant difference by interviewer, F(3, 238) = 14.44, p < .001, η2 = .15. Post hoc Tukey’s HSD tests confirmed (p < .001) our suspicions that the fourth interviewer was seen as more dominant than the other three interviewers. All other comparisons were not significant.
In addition, a coder examined the transcripts of the interviews and manually counted the number of follow-up questions for each of the 13 main questions found in Table 1, including questions and also commands by the interviewers such as “tell me more,” to create a tally of how many follow-up questions/commands followed each main question. An analysis of the number of follow-ups also revealed differences among the interviewers. Interviewer No. 1 averaged .68 to 5.29 follow-ups per question, (overall M = 2.73; SD = 2.57), Interviewer No. 2 averaged .05 to 2.67 follow-ups per question (overall M = 1.07; SD = .95), Interviewer No. 3 averaged .17 to 3.70 follow-ups per question (overall M = .98; SD = 1.25) and Interviewer No. 4 averaged 1.98 to 5.11 (overall M = 3.73; SD = 3.69). A one-way ANOVA for interviewer on the total number of follow-ups was significant F(3, 223) = 98.21, p < .001, η2 = .57. A Tukey post hoc test revealed that Interviewer No. 1 and No.4 differed significantly from the other three interviewers at the .001 level. Because of these differences, the interviewer variable was included as a blocking factor in the analyses.
A second manipulation check tested whether participants self-reported that they were more truthful in the noncheating condition than the two cheating conditions. A one-way ANOVA revealed a significant difference by veracity condition F(2, 239) = 12.39, p < .001, η2 = .09. However, a significant number of participants confessed to the cheating or at least implicated their partner in cheating in both the sanctioned lie (57.5%) and the unsanctioned lie (77.8%) conditions. When those who confessed were eliminated, those in the no-cheating (truth) condition rated themselves significantly more truthful (M = 9.74, SD = 1.07) than those in the sanctioned (M = 6.41, SD = 3.23) or the unsanctioned lie condition (M = 7.67, SD = 2.85). Post hoc Tukey’s HSD tests confirmed that all three conditions were significantly different from one another at the .01 level. Thus the truth-deception manipulation was successful. It should be noted, however, that even in the lie conditions, participants rated their responses above the midpoint of the scale, indicating a fair degree of truthfulness in their answers, doubtless due to only a portion of the interview asking about cheating.
Analysis Plan
To reduce the number of tests being conducted and control for multicollinearity among dependent variables, unless otherwise stated, the hypotheses and research question were tested with a single MANOVA that included the interviewer blocking variable, modality (FtF or VC), and veracity (truth, sanctioned lie, or unsanctioned lie) as the independent variables. The dependent variables were interviewer accuracy, interviewer confidence, interviewer judgments of interviewee credibility, expressivity and tension; and interviewee self-reported guiltiness. Those who confessed were excluded from the analysis unless otherwise noted.
The multivariate test of the MANOVA revealed significant main effects for modality Pillai’s Trace = .17, F(5, 117) = 4.62, p = .001, η2 = .16 and veracity Pillai’s Trace = .36, F(10, 234) = 5.60, p <.001, η2 = .19, and a significant modality by veracity interaction Pillai’s Trace = .17, F(10, 234) = 2.26, p = .02, η2 = .09. The interviewer blocking variable was also significant Pillai’s Trace = .41, F(15, 357) = 3.87, p < .001, η2 = .14. Box’s Test of Equality of Covariance Matrices indicated that covariance matrices were different across groups, F(165, 4539.05) = 425.22, p < .001. Therefore Pillai’s Trace was used to analyze the multivariate tests (Meyers, Gamst, & Guarino, 2006). Furthermore, Levene’s Test of Error Variances indicated that there were significant differences in error variance for guilt, F(22, 107) = 2.615, p = .001, the credibility composite, F(22, 107) = 2.03, p = .009 and truth accuracy, F(22, 107) = 2.85, p < .001. Therefore, variance was not assumed to be equal in any comparisons of means and this often resulted in fractional degrees of freedom in mean comparison tests.
Hypothesis Tests
H1a predicted that modality and veracity influence detection accuracy. Results revealed a significant modality main effect on accuracy F(1, 129) = 4.04, p = .04, η2 = .03, such that interviewers were more accurate in the FtF modality (M difference = 2.99, SD = 2.28) than the VC modality (M difference = 4.08, SD = 2.86). However, the hypothesized modality by veracity interaction effect was not significant F(2, 129) = .75, p = .47, η2 = .01. Professional interviewers correctly classified participants as truth-tellers or deceivers 59% of the time overall but 53.8% of the time in the VC condition and 63.4% of the time in the FtF condition (accuracy rates by veracity condition can be found in Table 2), further demonstrating greater difficulty correctly assessing credibility in the VC than the FtF modality. Table 3 demonstrates that the interviewers were differentially affected by the modality, some finding it easier to assess deceptiveness and extract conditions in VC and some finding it more difficult.
Interviewer Accuracy Scores in Correctly Judging Nonconfessors and Confessors, by Interviewer.
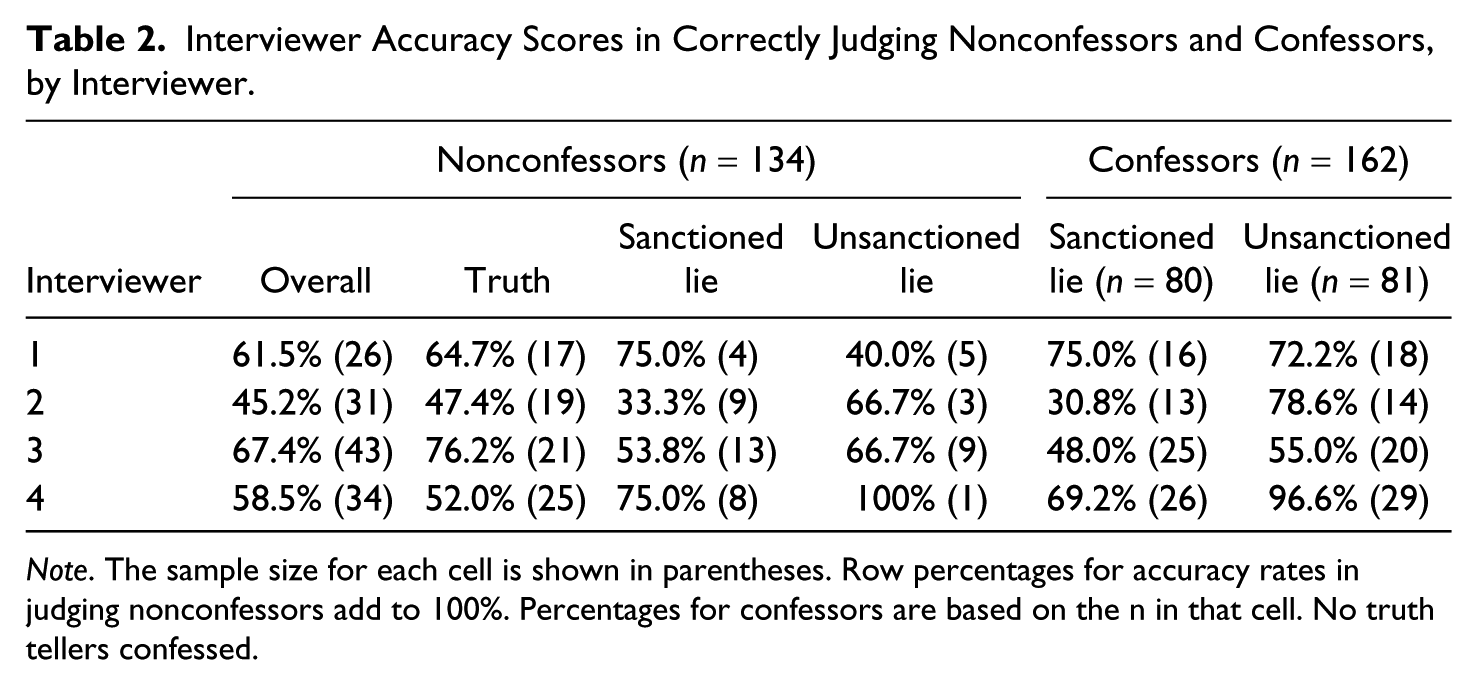
Note. The sample size for each cell is shown in parentheses. Row percentages for accuracy rates in judging nonconfessors add to 100%. Percentages for confessors are based on the n in that cell. No truth tellers confessed.
Accuracy Scores and Confession Rates by Interviewer and Modality.
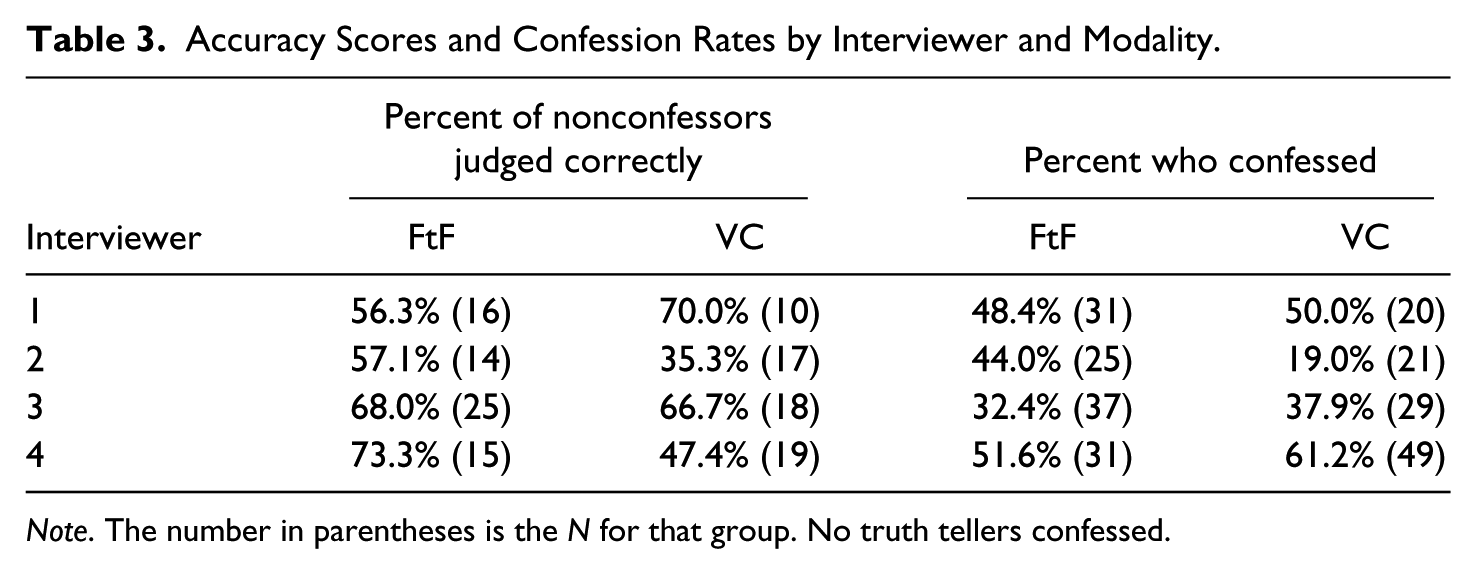
Note. The number in parentheses is the N for that group. No truth tellers confessed.
H1b predicted that modality interacts with deception to affect the credibility assessment of the interviewers. The veracity by modality interaction approached significance on the credibility composite variable F(2, 129) = 2.46, p = .09, η2 = .03, and there was no modality main effect F(1, 129) = .24, p = .62, η2= .002. Interviewers saw FtF truth-tellers as most credible but, in the VC condition, there was very little variance across conditions, indicating that interviewers were unable to make clear differentiation between truth and deceit.
H2 predicted that VC would affect interviewers’ perceptions of (a) expressivity and (b) tension relative to FtF. As predicted, main effects emerged for modality on interviewee expressivity F(1, 129) = 7.86, p = .006, η2= .04 and tension F(1, 129) = 8.99, p = .003, η2= .06. However these main effects were overridden by a significant modality by veracity interaction on expressivity F(2, 124) = 6.95, p < .001, η2= .07, and a near-significant interaction on tension F(2, 124) = 2.65, p = .07, η2 = .04. Differences in modality were evident in the deception conditions and not the truth condition. In the truth condition, there was no difference between FtF and VC for either expressiveness t(74.56) = −.49, p = .81 or tension t(77.76) = .06, p = .95 but in the sanctioned lie condition, there was a difference between FtF and VC for both expressiveness t(30.38) = −2.89, p = .001 and tension t(26.46) = 2.55, p = .02. In the unsanctioned lie condition, there was a significant difference between FtF and VC on tension t(15.71) = 3.03, p = .009 but not expressiveness t(10.18) = −1.36, p = .20 (see Means in Table 4 and patterns in Figures 1 and 2). Truth-tellers were seen by interviewers as significantly more expressive than either sanctioned or unsanctioned deceivers (see means in Table 5), and unsanctioned deceivers were seen by interviewers as more tense than truth-tellers.
Means and Standard Deviations for Interviewer Social Judgments by Modality With Confessors Excluded.
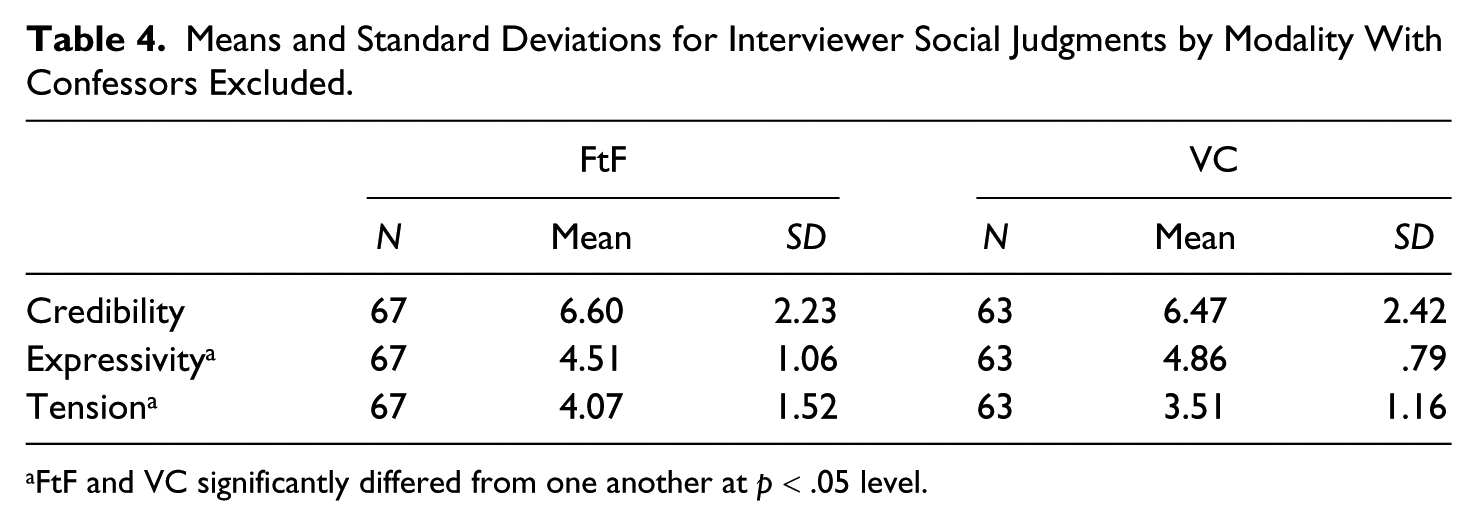
FtF and VC significantly differed from one another at p < .05 level.
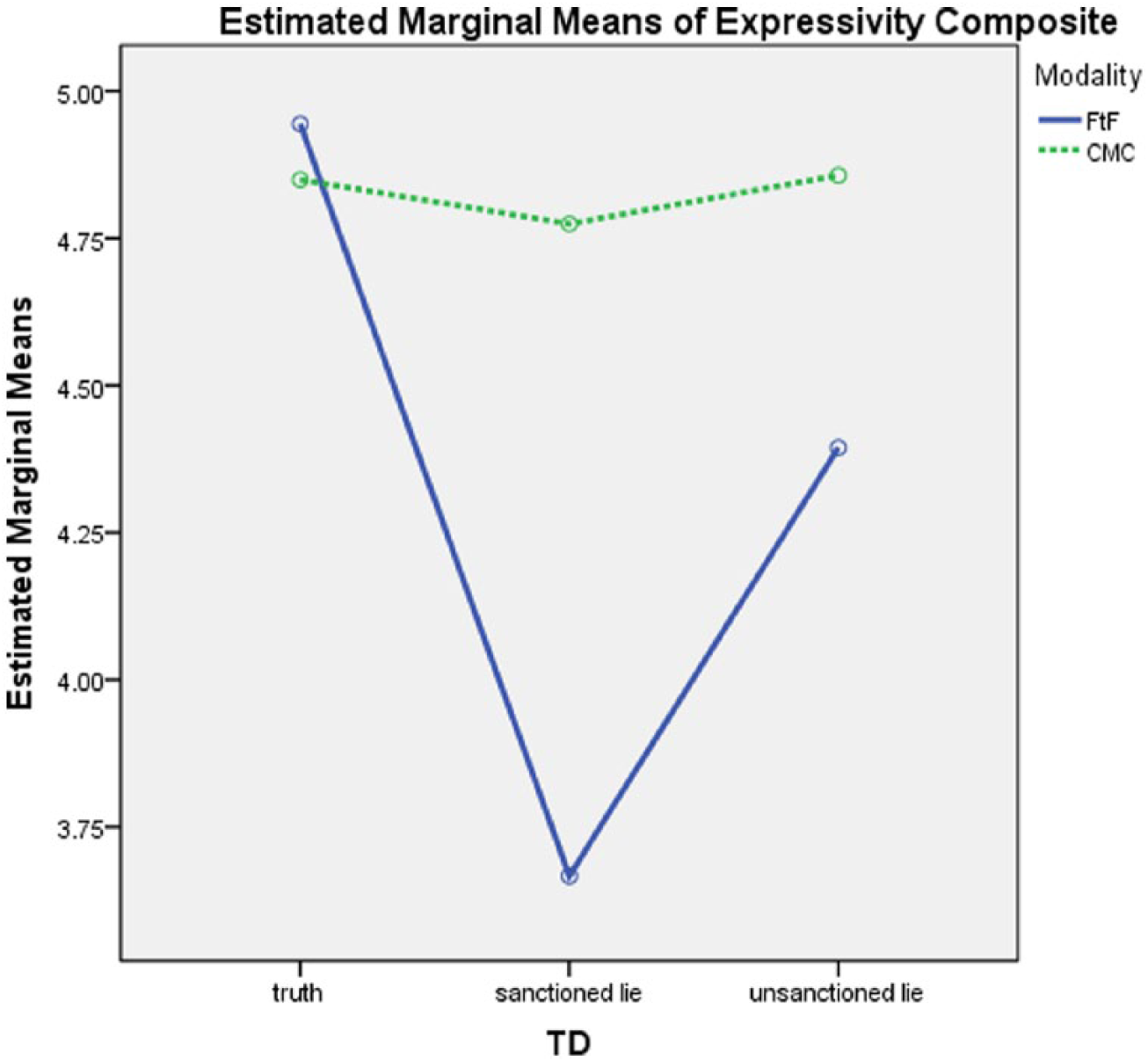
Means for the expressivity composite of interviewer ratings for Modality × Veracity interaction.
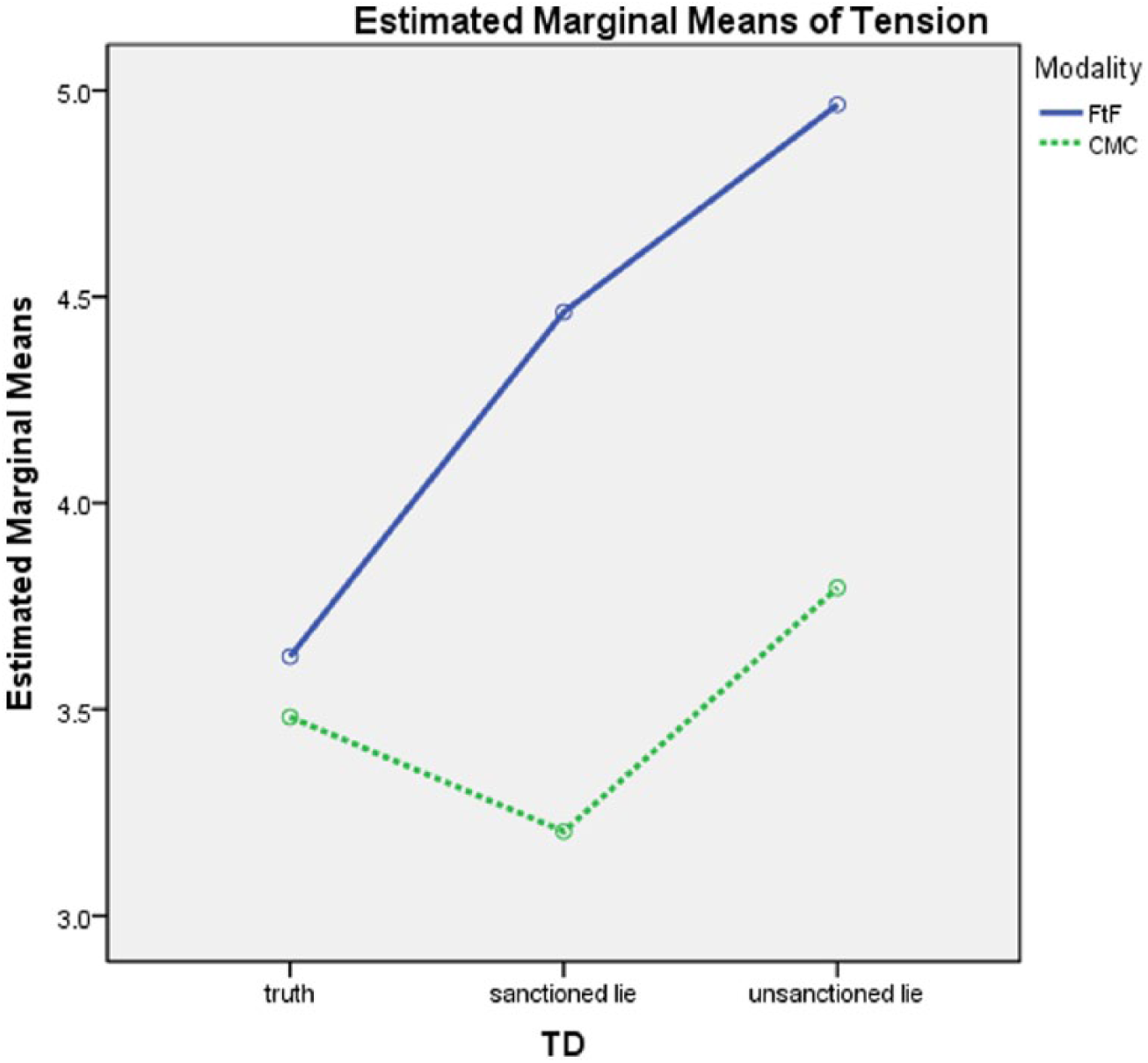
Means for interviewer-rated tension for Modality × Veracity interaction.
Means and Standard Deviations for Veracity Conditions With Confessors Excluded.
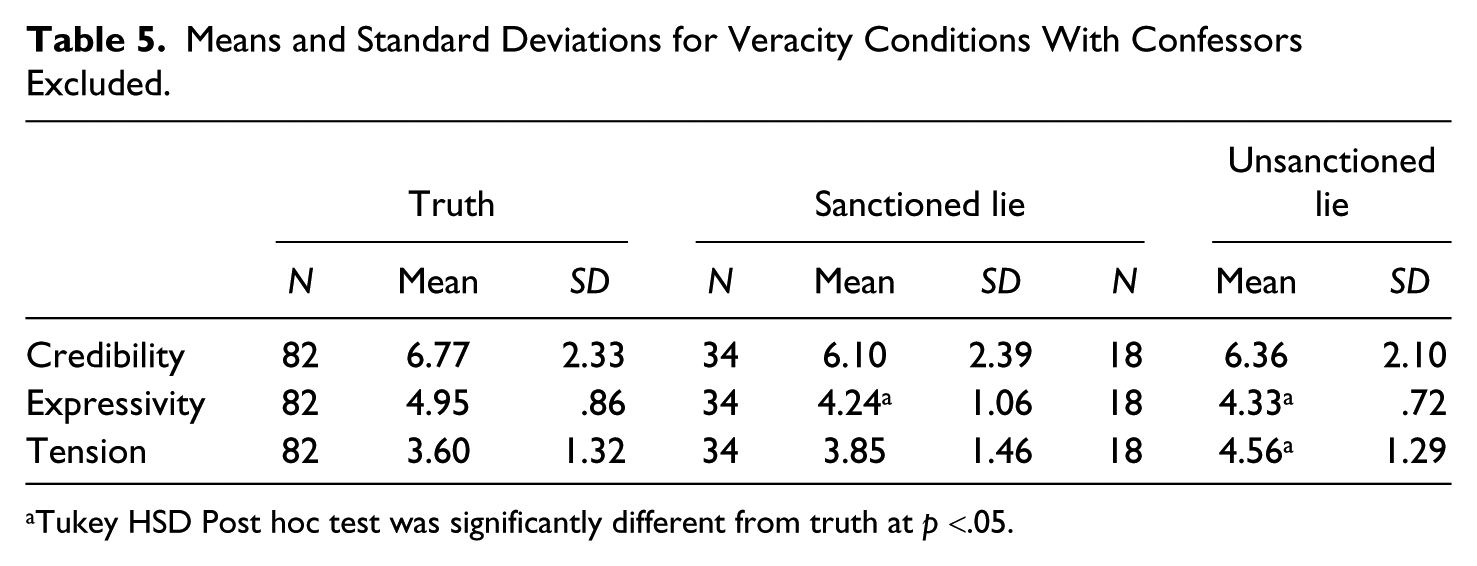
Tukey HSD Post hoc test was significantly different from truth at p <.05.
H3a predicted that whether or not the lie was sanctioned by the experimenter would have an effect on the guilt experienced by the participants. The results revealed a significant main effect for veracity condition for guilt/shame F(2, 129) = 25.17, p < .001, η2 = .27. The means revealed that truth tellers experienced the least guilt (M = 1.80, SD = .65), while sanctioned deceivers (M = 3.11, SD = 1.18) and unsanctioned deceivers (M = 2.71, SD = 1.18) experienced more guilt than truth tellers. Tukey post hoc tests revealed significant differences at the .001 level between truth-tellers and both sanctioned and unsanctioned deceivers but the difference between sanctioned and unsanctioned deceivers was not significant (p = .25). Thus the hypothesis that unsanctioned liars would experience more guilt than sanctioned ones was not supported. In addition, while self-reported guilt was not associated with the interviewer’s perception of the participants’ credibility, whether or not the participant confessed, or the accuracy of the interviewers’ judgments, it was associated with the interviewer’s judgments of the expressivity of the participants r(132) = −.40, p < .001. The more the participant experienced guilt, the less expressive he or she appeared to the interviewer even though it was not affected by the sanctioning of the deception.
The prediction made by H3b that sanctioning of the lie would affect the propensity of cheaters to confess was tested with a binary logistic regression with participant confession (yes or no) as the dependent variable and the interviewer blocking variable, modality, and veracity conditions as the predictor variables. Since no truth-tellers falsely confessed, we eliminated truth-tellers from this analysis. The omnibus test was significant, χ2(3, N = 161) = 9.38, p = .03, and only veracity condition emerged as a significant predictor of confessions: B = .97, Exp (B) = 2.63, p = .01. Only 57.5% of sanctioned deceivers confessed, whereas 77.8% of unsanctioned deceivers confessed. Thus H3b was supported.
H4a predicted that sanctioned liars would be seen as more credible than unsanctioned ones. The veracity condition main effect for the credibility composite variable was not significant F(2, 124) = 1.83, p = .17, η2 = .02. The results of H1b reported earlier revealed a near-significant veracity × modality main effect (p = .09) with credibility ratings the lowest in the sanctioned, rather than the unsanctioned, condition, especially in FtF (see Figure 1) but a t test on the FtF condition revealed this difference was not significant t(25.99) = 1.11, p = .28. Thus H4a was not supported.
H4b predicted that sanctioned liars would be more difficult to detect than unsanctioned liars. Confessors were eliminated from this analysis because they would inflate the accuracy rates. The interviewers as a group correctly identified 59.8% of the truth-tellers, 55.9% of the sanctioned liars, and 61.1% of the unsanctioned liars. The MANOVA for detection accuracy revealed no main effect for veracity condition F(2, 129) = .25, p = .78, η2 = .002 (and as reported with H1a above, there was no Modality × Veracity interaction). Tukey post hoc tests revealed no significant differences between the means in the three veracity conditions at the .05 level. H4b was not supported.
Post Hoc Analyses
As a follow-up, because we had four interviewers with varying degrees of expertise and the manipulation check revealed some differences between them, we tested for differences between interviewers in terms of accuracy. An ANOVA with four levels of interviewer as the independent variable and truthfulness difference scores as the dependent variable revealed a significant main effect for interviewer F(3, 130) = 2.55, p = .05, η2 = .02. Overall, interviewer No. 3 was the most accurate but the condition also was a determining factor in interviewer accuracy. Accuracy scores ranged from 33.3% to 100%; this latter score was achieved by Interviewer No. 4 in the unsanctioned lie condition because he elicited a confession from all but one of the 29 participants he interviewed in that condition. Confession rates, also reported in Table 2 for each interviewer, also reveal a wide disparity in their ability to elicit confessions.
Discussion
Although modality of communication unquestionably affects how people interact with one another, few experiments have investigated the influence of modality on the process and outcomes of deceptive episodes. The current experiment was designed to explore not only how modality affects the perceptions and judgments of interviewers but also the experiences and behavior of interviewees. Results clearly demonstrate that modality alters interviewer judgments and must therefore be taken into account in predicting patterns of truthful and deceptive interactions.
Modality and Veracity Effects
Following IDT, we tested whether interactivity (operationalized through modality) affected the perceptions and judgments of professional interviewers. In terms of modality, even though we employed a relatively rich medium in VC, differences still emerged between FtF and CMC. Common wisdom holds that social presence between two communicators is lacking when operating in a lean modality (Carlson et al., 2004; Hancock et al., 2008). However, whether such presence aids or hinders credibility assessment and deception detection depends on whether the interaction is a deceptive or truthful one. When senders are truthful, the current results suggest that more credibility is engendered in FtF than VC interactions, but when senders are deceptive, not only is credibility lower in FtF interactions but is also substantially lower than in VC. This pattern implies that when speaking with professional interviewers, senders gain from FtF interaction when telling the truth, whereas receivers may gain from FtF interaction when senders are deceptive. This conclusion is borne out by the detection accuracy results: Interviewers were more accurate in judging truthfulness in FtF than in VC although the interviewers were not all affected by the modality in the same way. Whereas deceivers in past experiments profited from more interactive contexts (Burgoon et al., 1999, 2008), receivers (i.e., the professional interviewers) were the beneficiaries in the current context. Interactivity is thus a resource that can be leveraged by either senders or receivers. In the current case, the greater skill and experience of the interviewers vis á vis the interviewees allowed them to capitalize on the FtF modality to extract confessions or other diagnostic information that led them to accurately assess interviewee veracity. The fact that one interviewer was more accurate in the VC condition than the FtF condition (although he did not extract significantly more confessions in VC) is an interesting finding that deserves more attention from researchers in the future.
Two explanations for this finding merit discussion. First, in contrast to nonprofessional interviewers in other studies, the professional interviewers were not overwhelmed or inclined to a truth bias as a result of the greater sensory immersion of FtF. They may have benefited from being able to attune more closely to the uninhibited sensory and verbal details. The professional interviewers typically conduct interviews in a FtF setting and, as a result of their experience, are likely not easily swayed by FtF behaviors meant to convey credibility. In fact, their judgments of credibility were inversely related to their accuracy (r = −.69, p < .001), suggesting that higher accuracy was associated with lower assessments of the interviewee’s credibility. Conducting interviews via VC, however, was more challenging for interviewers because it was a significant departure from their professional experience and afforded them fewer sensory avenues from which to make judgments.
Second, the poorer detection under VC may have been a result of the differential communication patterns that were exhibited or perceived under FtF versus VC. Interviewees appeared less inhibited in the mediated condition. Their communicative demeanor was viewed as more expressive and less tense than in FtF, thus approximating the typical behavior of truth-tellers. In fact, the interaction effects displayed in Figures 1 and 2 clearly reveal that interviewers had more difficulty differentiating among the veracity conditions under VC than FtF interaction. The demeanor of VC interviewees was perceived as very similar across the truth and lie conditions; the main differences were observed within the FtF conditions. Interviewees telling unsanctioned FtF lies were less expressive than truth-tellers, suggestive of the “freeze” pattern common under high-stakes deception except that they were perceived as less tense than VC interviewees. Perhaps the unsanctioned deceivers, because of their self-presumed skill at deception (otherwise, they would not have chosen to lie) worked harder to present a credible front and were more successful. In addition, it appears that the psychological pressure of facing a copresent professional interviewer in the FtF interview “trumped” any benefit of interactivity for these interviewees. This notion was reinforced through several discussions with the interviewers, who expressed frustration at being physically separated from the interviewees. Regardless, the relationship between modality and credibility for deceivers is clearly complex and deserves more attention from researchers.
Sanctioning
IDT predicts that the affective experience (viz., fear, guilt, or shame) of participants affects their transparency or detectability. Despite earlier research suggesting few differences between sanctioned and unsanctioned deceivers (Feeley, 1996), other researchers have argued vociferously that the experimental setting must include unsanctioned lies in order to activate the guilt response of the participant (e.g., Levine et al., 2006). Although our research found little difference in the guilt experienced between sanctioned and unsanctioned liars and thus did not account for any differences between these two conditions, sanctioning of the lie did have an effect on the likelihood of confessions: Unsanctioned deceivers were far more likely to confess than were sanctioned deceivers. Without a difference in guilt, it is possible that these deceivers lied of their own volition and only continued to lie when they felt assured of success. Sanctioning occurred moments before the interview began, so it was unlikely that participants were able to mentally rehearse for their interviews, but the few moments when the sanctioned liars were being told to lie prior to the interview may have given them enough time to compose themselves and display a truthful demeanor during the interview. The high number of confessions (between 55% and 77% depending on sanctioning) was a good deal higher than in previous experiments and begs for further investigation of confessions. It is likely that, as Levine et al. (2010) speculated, the use of professional examiners who were given the freedom to ask their own questions was the critical difference. Upon reviewing recordings of the interviews, we noted that if there were inconsistencies or ambiguities in the responses from the participants, the interviewers would persistently probe until they were satisfied with the interviewees’ explanations. This technique trapped deceivers in their statements and frequently vindicated truth-tellers. These methods resulted in a greater proportion of confessions, especially with our most experienced interviewer, who elicited confessions from 28 out of 29 unsanctioned deceivers. The experience and training of the examiner was doubtless a factor inasmuch as the accuracy rates and the confession rates varied widely among the interviewers.
Although previous research has documented a lie bias of law enforcement professionals (Vrij & Mann, 2005), our professionals ranged in accuracy in the truth condition from 47.7% to 76.2%, suggesting variability in the degree to which they were lie biased. All of our professionals were polygraph experts who routinely conduct interviews in high security situations, but their differing field experiences and training may have played a role in the degree to which they were lie biased. Feeley and deTurck (1998) used as interviewers random participants recruited from their subject pool, and Levine et al. (2010) used a graduate student who did not deviate from her list of questions. The differences in confession rates across experiments underscores the value of using professionals to gain the most ecological validity and is a noteworthy advantage of the current experiment. The fact that we also had multiple interviewers and that there is variability among interviewers is also informative since it tells us that use of a single interviewer could yield very different results from one study to the next. Researchers should strive to include professionals and multiple interviewers when possible in their studies. Clearly, further study is needed that compares professionals to lay interviewers on the extent to which interviewer authority, training, and experience (both with interviewing and with a particular medium) influence interview outcomes.
Finally, we believe the use of random assignment to conditions, rather than allowing participants to self-select their own condition, is a crucial element in experimental design. Random assignment reduces many threats to the internal validity of the experiment (see Campbell & Stanley, 1963), which allows the researcher to be confident that other factors (such as a participant’s personality, mood, or a host of other variables unknown to the researcher) did not affect the assignment to experimental conditions. Many researchers in the deception literature have begun using unsanctioned deception whereby participants self-select into a condition through their decision to lie or not lie. While we understand that unsanctioned deception may be seen as achieving ecological validity, it comes at the expense of reduced internal validity, which is a threat to the generalizability of the experiment as well. In this experiment, we attempted find a balance between internal and external validity by not only randomly assigning participants to sanctioned or unsanctioned deceit conditions but also allowing the freedom to choose whether or not to lie, as demonstrated by the high confession rates discussed previously. Researchers who feel they must choose between unsanctioned lies that are not randomly assigned but may have greater external validity and sanctioned lies that are randomly assigned but have greater internal validity should consider including both conditions in their experiments. Like others before us (Feeley, 1996), our study demonstrated few differences between sanctioned and unsanctioned deception but the greater internal validity afforded by the random assignment to conditions suggests both types of deception conditions should be included.
Limitations
The professional interviewers were supplied by the U.S. government through a contact from our funding agency. Interviewers volunteered to be a part of the research out of their own interest, which limited our ability to choose the interviewers. One interviewer was from a different agency and was older than the others. Differences between his perceived dominance and that of the other three, and differences in the number of follow-ups used, led to the need to control for the effects of the interviewer in our analyses. In addition, the accuracy rates suggested that some of the interviewers were more truth biased and others were more lie biased. Although we controlled for the interviewer differences in the analyses, this represents a limitation, as perceptions of the most senior interviewer varied considerably from the other interviewers. However, the use of multiple seasoned interviewers also provides a glimpse of the variability that typically exists among “real-world” interviewers, variability that is masked when only a single interviewer is used in experimental research. The variability among interviewers bolsters the importance of investigating interviewer characteristics and their effects on interviewee reciprocity, detection accuracy, and confession rates as well as their comfort level using different modalities to detect deception.
Conclusion
As IDT predicts, the interactivity and resultant communication patterns of the participants—interviewer and interviewee alike—in a deceptive encounter affects whether or not the deception is detected and admitted. We arrived at this conclusion by creating high-stakes deception in a controlled experiment and using professional interviewers to produce ecologically valid findings. Our findings should inform efforts to detect deception whether interactions are mediated or in person and deception is sanctioned or unsanctioned. In light of these findings, we invite other researchers to continue this line of research by including professional interviewers in their experimental design and testing more than the FtF modality. In particular, we suggest that future research should examine the role that interviewer characteristics (e.g., experience, authority) affect interview outcomes.
Footnotes
Acknowledgements
The authors would like to thank their student research assistants, Abigail Allums, Kody Shipley, Justin Funk, Katie Fletcher, and Lauren Latimer, for their valuable help acting as confederates in this study.
Authors’ Note
A previous version of this article was presented at the 2010 National Communication Association annual convention in San Francisco, CA.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was funded by a grant from the Center for Information Technology Research, a National Science Foundation Industry/University Cooperative Research Center.