
Abstract
Studies in different languages have identified a broadcast speaking style, a particular manner that broadcasters have of reading news. This speaking style is characterized by an emphatic intonation with a fast speech rate easily recognizable by listeners. Some authors have stated that messages in this style are not positively perceived by listeners, as it is repetitive and regular, but there is no empirical data to support this conclusion, nor has the style been analyzed with physiological measures. The physiological approach has some advantages, such as a more objective assessment and real-time evaluation. Therefore, this study aims to analyze the effectiveness, adequacy, and physiological response of this broadcast style compared to a narrative pattern. We combined self-report with physiological measures. Fifty-six participants listened to six news pieces in both styles and with two voices, male and female. They had to rate the effectiveness and adequacy of the news while we measured their physiological responses (heart rate and electrodermal activity). The results showed that news conveyed through the broadcast style elicited less cognitive resource allocation and emotional arousal than the narrative pattern, but there were no significant differences in self-report evaluations.
When we listen to the news on radio or television, we can notice that journalists use a standard characteristic speaking style. Cotter (1993) has defined it as the “broadcast news register.” This speaking manner is characterized by a repetitive and emphatic sing-song pattern with a fast speech rate. This particular style has become familiar to us. Proof of this is that some studies have shown that listeners can easily recognize it. Escudero et al. (2017) conducted a study where participants were asked to recognize the speaking style in the news delivered by journalists using either the typical broadcast pattern or a more natural narrative style. 72% of the listeners correctly identified the radio journalists. In the context of advertising, Medrado et al. (2005) found that listeners were more accurate when identifying an advertising text narrated by professionals than by nonprofessional voiceovers. The authors concluded that listeners could recognize the voiceover style thanks to its particular intonation, cadence, and rhythm. Finally, in a recent study, Gasser et al. (2019) found that listeners could correctly distinguish newscasters from conversational speech 58% of the time based on prosody alone. Prosody can be defined as the set of voice features that we use when talking, formed by elements such as intonation, accent, speech rate, or loudness (Den Ouden et al., 2009; Wells, 2007). These features are considered supra-segmental linguistic elements, as they affect units that are superior to phonemes and words.
The broadcast speaking style is so well-defined that common patterns have been found across different countries and languages, even though prosody is strongly linked to the language. Every language has its own phonological system in which different features such as intonation or speech rate are different. For example, Pellegrino et al. (2011) reported different rates depending on the language. However, the news speaking style seems to prevail over the language itself (Iivonen et al., 1995). A similar pattern has been found in Australian English (Price, 2008), Swedish (Strangert, 2005), Portuguese (Castro et al., 2010), Russian (Oleinik, 2006), Spanish (Rodero Antón, 2013), Polish (Francuz, 2010), or Cantonese (Mok et al., 2014), to cite some examples.
However, it is unclear to what extent the broadcasting speaking style is effective in conveying information. The studies that have specifically analyzed this distinctive prosody pattern have examined it from a linguistic perspective. Research on the style’s effectiveness for information processing is scarce and primarily limited to descriptive studies, with no experimental data corroborating the conclusions. This limitation poses a critical problem, as optimal presentation skills and a good voice are crucial for radio and television stations (Purdey, 2000). Prosody is a very complex speech feature that rarely is explained rigorously in communication courses. The instructions about prosody usually are vague with expressions such as “you have to be dynamic,” “try not to be monotonous,” or “vary your tone.” This lack of training causes junior broadcasters to imitate the senior journalists’ style, thus perpetuating this broadcast pattern (Escudero et al., 2017). An underlying problem is that there are very few communication studies that have looked at prosody in different formats. In consequence, as Nissen et al. (2020) have pointed out, this literature gap means that the media industry has to rely on ambiguous instruction techniques that might not be appropriate to train future professionals. For these reasons, more research is needed to help train new broadcasters effectively and adequately, which is a contribution of this study.
As far as we know, this study is the first to test the effects of the broadcast style on listeners empirically. In addition to self-reported evaluations, this research uses physiological measures to examine how the prosody style used in the news might affect automatic aspects of message processing, specifically cognitive resource allocation, measured with heart rate, and sympathetic arousal or emotional activation, measured with electrodermal activity. A main advantage of psychophysiological measures over self-report is that they directly tap on automatic responses to the message in real-time. On the other hand, self-reported variables are more susceptible to bias because they depend on conscious decision-making by the participant, they are rarely time-locked to the stimuli, and highly reliant on memory retrieval, which is more easily influenced by attitudes and beliefs (Potter & Bolls, 2012).
Given that most people use different news outlets to keep themselves informed and that this information is conveyed by voices using the broadcast style, it is essential to know whether it is adequate for information processing. As a follow-up on the study by Escudero et al. (2017), where the purpose was simply to test if participants could accurately recognize the radio style as such, we will compare the broadcast style to a narrative pattern, examining the perceived effectiveness and adequacy of these different patterns as well as their impact on the individuals’ automatic responses to message processing. Compared to the regular and emphatic intonation of the broadcast style, the narrative style is a more expressive and natural way to speak. This pattern is characterized by a more varied intonation, moderate pitch inflections, and a more reduced speech rate, which should sound more like interpreted reading. Therefore, the goal of this study is to compare two different speaking styles, the typical and most common broadcast style (BS) and a narrative style (NS), more similar to reading a story, to determine which one elicits higher resource allocation, a stronger emotional response, and is perceived as more effective and adequate. The contribution of this study will be twofold. First, it aims to make a theoretical contribution to the study of speech processing in the specific context of broadcast news prosody. Second, our findings may have practical implications for the media industry by recommending what style is more effective for conveying the news.
In the next sections, we define and characterize the broadcast style to then study the differences with the narrative pattern.
Prosody Characteristics of the Broadcast Style
The particular speaking style that broadcasters use when conveying news comprises a group of prosody elements. In this study, we will focus on intonation and speech rate. In media, loudness is not an essential feature as broadcasters always use a microphone. Hence, volume levels change minimally and do not have a significant expressive meaning, while accent, especially prominence, is included in intonation as pitch variation.
Intonation
In prosody, intonation is the group of tone variations produced in speech (Gussenhoven, 2004; Wells, 2007). These tone or pitch variations form the intonation curve, what Wells (2007) calls “the melody of speech.” Intonation conveys distinctive, affective, and pragmatic information that plays a vital role in understanding the spoken discourse (Globerson et al., 2013; Gussenhoven, 2004; Hammerschmidt & Jürgens, 2007). As pitch variations are acoustic changes, intonation is also one of the most salient and noticeable features for a listener (Perrachione et al., 2013). Therefore, it is a central feature in auditory perception and essential to message processing (Cutler et al., 1997).
There are two kinds of pitch variations in intonation: pitch level and pitch range (Gussenhoven, 2004). Pitch level is the average tone in the intonation curve, while pitch range is the difference between the highest and the lowest pitch level and shows the tone variability throughout the intonation curve. Thus, while pitch level is a static measure (the mean of all the tones), pitch range shows the variability of intonation. As pitch range represents the variation, it is a more precise measure to define intonation. For this reason, we will mainly focus on pitch range in this study.
Related to intonation, some studies have characterized the prosodic characteristics of the broadcast style used by radio and television journalists. Cotter (1993) defined the newscasters’ style as having higher pitch and higher variability than normal conversation. Diniz (2002) compared professional and nonprofessional voiceovers and characterized the professional voiceover style as having an upward and downward intonation, high pitch level, and emphatic elements. Medrado et al. (2005) observed that professionals use a higher pitch than nonprofessionals. Strangert (2005) analyzed the television newscasters’ style and concluded that these professionals employ a high pitch level. Grawunder et al. (2008) reached a similar conclusion in the context of German news, pointing out that newscasters and reporters use a distinctive style characterized by significant pitch variation and a broad pitch range. A circumflex and emphatic intonation (up and down continuous movements at regular intervals) at the beginning, in the middle, and at the end of the sentences was detected as predominant in another study looking at television newscasting (Rodero, 2006). Similar conclusions were obtained by Price (2008), who characterized the style as exhibiting hyper accentuation, exaggerated pitch, and abuse of pitch prominence, that is, as an emphatic style with abrupt pitch variations and accents. In the same line, Francuz (2010), in an analysis of television news, showed that newscasters tend to use many rhetorical accents. Similarly, De La-Mota and Rodero (2012) examined radio news bulletins and concluded that broadcasters use an emphatic style with circumflex intonation. The same circumflex pattern was also identified by García-Riverón and Marrero (2017) and Gasser et al. (2019). This intonation generates a regular and constant melody with a compressed pitch range (Cotter, 1993; McGregor & Palethorpe, 2008; Nihalani & Lin, 1998). A study examining 24 radio news bulletins confirmed the presence of a regular intonation with an abundance of circumflex contours sustained by a high pitch level (Rodero Antón, 2013). Mok et al. (2014) added greater pitch variability to these elements when they compared newscasters with students reading aloud. Finally, Nissen et al. (2020) compared broadcasters with the general population and found that professionals exhibit an elevated mean pitch, more pitch variability, and a wider range. In sum, a large body of research has characterized the prosodic style typically used by news broadcasters as having a high pitch level and regular and emphatic intonation.
Speech Rate
Speech rate, a suprasegmental linguistic feature like intonation, is determined by both pauses and speaking rate. It can be defined as the rhythm or pace that a speaker uses when speaking, and it is usually measured in words per minute (wpm) or syllables per minute (Martins et al., 2007). This study will focus on speech rate alone quantified in words per minute, not on pauses. Greenwald et al. (2000) have estimated the regular speaking rate in adults ranging between 110 and 175 wpm. In general, the media problem (news and advertising) is that the speech rate tends to be fast and has short pauses (Castro et al., 2010; Cotter, 1993). For instance, Shevchenko and Uglova (2006) registered an average speech rate for English TV news at 207 wpm, Mok et al. (2014) found a fast speech rate in Cantonese news, Castro et al. (2010) in Portuguese newscasters, and Finkelstein and Amir (2013) in Hebrew professional radio.
In brief, newscasters use a regular and emphatic intonation, compressed pitch range, and high pitch combined with a fast speech rate. This prosody pattern has likely become the industry standard because it is not monotonous, and it might help grab the listeners’ attention (Gasser et al., 2019). As Wheatley claimed a long time ago: “the inappropriate emotional intonation, perhaps, springs from the desire to put a great deal of expression into one’s speech” (1949, p. 213). However, at the same time, broadcasters aim to sound natural and objective, as their role is to convey information impartially. In fact, naturalness is one of the characteristics highly valued in a speaker (De Waele et al., 2019). This apparently contradictory goal of being neutral but also appealing (Cotter, 1993) could be why the speaking style has been described as “strange” (Oleinik, 2006). Some authors have suggested that listeners perceive it negatively due to the repetitive and regular intonation and fast speech rate (Bolinger, 1998; Francuz, 2010; Nihalani & Lin, 1998; Price, 2008; Rodero Antón, 2013; Strangert, 2005).
We evaluate perception in this study by measuring the effectiveness and adequacy of the news conveyed through the different styles. We think that these two variables can indicate the success of a performance. Effectiveness can be defined as the efficacy of the style and adequacy as the adaptation of the style to the news format. Previous studies that have used these two factors have shown that an expanded pitch range with more varied intonation (Rodero et al., 2017) and a moderate speech rate (Rodero, 2020) are perceived as more effective and adequate. Therefore, based on the literature, our first hypothesis is that the news conveyed in BS will be perceived as less effective and adequate than the messages delivered with NS, using expanded pitch range, varied intonation, and slower pace.
H1. The news conveyed in BS, compared to NS, will be perceived as less effective and less adequate.
Prosody Processing
Some authors have underlined the importance of prosody features in the cognitive processing of messages (Hirschberg & Pierrehumbert, 1986; Levi & Pisoni, 2007). Fraundorf et al. (2010) found that listeners use pitch accenting and pitch range differences to encode and update discourse information suggesting that these features facilitate memory and recall. Along with intonation, speech rate also plays an essential role in the processing of information. If this pace is not optimal (e.g., very fast), listeners can struggle to understand the messages. This is particularly important in media such as radio or television, where the audience has to understand the message at first exposure.
This study draws from the Limited Capacity Model of Motivated Mediated Message Processing (LC4MP; Lang, 2017) to conceptualize prosody as a structural feature that influences information processing. LC4MP maintains that cognitive resources for processing a message can be allocated in either a controlled or automatic way. Processes that use automatic resources do not require excessive effort and attention and are unconscious, while controlled resources are more effortful and conscious. The so-called orienting response, a rapid and automatic reaction to a novel stimulus in the environment, is one of the mechanisms involved in the automatic allocation of resources for processing messages (Bradley, 2009; Lang, 1990). As it has been shown by research under the LC4MP, structural features such as voice changes, pitch range, or speech rate, among others, can elicit more body activation (arousal) and an orienting response affecting automatic resource allocation (Lang, 2000, 2006; Potter, 2000; Potter et al., 2008, 2019; Rodero, 2020; Rodero et al., 2017). First, these structural features can cause higher activation of the sympathetic nervous system or more arousal. This variable can be measured with electrodermal activity or skin conductance, which is the measure that we use in this research. As our human cognitive system has limited resources, this automatic reaction is crucial to catch the listeners’ attention in the context of time-dependent media messages such as broadcast news. This orienting response can be measured as a decrease or slowing down in heart rate activity, which is the method used in this study. Thus, heart rate deceleration can indicate more automatic allocation of resources to process the message and, thus, more attention. The present study proposes that different prosody combinations, as structural features, may produce an orienting response, facilitate automatic resource allocation for the message, and increase arousal. The acoustic changes produced by pitch and speed variations could orient the listener’s attention and raise their physiological arousal.
Only a few studies have analyzed the effect of prosody on information processing using psychophysiological measures. Rodero et al. (2017) compared commercials with different pitch range models: homogeneous low or high pitch and expanded high-low or low-high pitch. They found that ads with expanded pitch range, and therefore, more variation (especially those with a high-low range), exhibited higher sympathetic nervous system activation and better recall and recognition of the information. Considering those findings, the BS condition used in the present study was designed to have a compressed pitch range or regular intonation, characteristics of the broadcasting style used in the news. In contrast, the NS condition was designed to have an expanded pitch range with varied intonation. We expect that the higher acoustic variation and irregularity of the NS, reflected in the expanded pitch range, will cause greater physiological arousal and an orienting response, allocating more cognitive resources than the BS. These acoustic changes can act like claims of attention that could help keep the listeners engaged. In contrast, the broadcast pattern is less varied, repetitive, and regular. Consequently, BS is far from being a novel stimulus that causes orienting responses.
Regarding speech rate and drawing from LC4MP, Rodero (2016) conducted a study to analyze different speaking rates in audio commercials (150, 170, 190, 210, and 230 wpm). Rodero found that commercials between 170 and 190 wpm had the highest recognition level and were considered easier to understand. In a more recent study also looking at speech rate in audio advertising but using psychophysiological responses, Rodero (2020) showed that 180 wpm was the optimal speech rate. The ads at this rate, compared to those in 160 and 200 wpm, were evaluated more positively and led to higher attention and autonomic arousal activation. A rate of 180 wpm was faster than normal conversation and, therefore, sufficiently dynamic to catch the listener’s attention and elicit a greater emotional response. At the same time, 180 wpm was not too fast to avoid affecting recall. On the contrary, the faster speech rate in this study, 200 wpm, was dynamic, but its excessive speed dampened attention and arousal in the listeners, and hindered their recall.
Building upon that research, the BS condition in this study was recorded at a rate of 200 wpm while the NS condition was recorded at 175 wpm, closer to the optimal pace. We expect that the NS’s moderate but dynamic speech rate will grab more listener’s attention and elicit high body activation than the fast BS style, as the second one will be the hardest to follow for listeners. Along with this, as we suggested in H1 that the news conveyed in BS will be perceived as less effective and adequate, we can infer that this more negative perception will lead to catch less attention and elicit less arousal. Therefore, based on the literature about intonation and speech rate, we posit the following hypotheses:
H2. The news conveyed in BS, compared to NS, will elicit less cognitive resource allocation, as indicated by more cardiac acceleration.
H3. The news conveyed in BS, compared to NS, will elicit less emotional arousal, as indicated by a lower skin conductance level.
Methodology
Design
The study employed a 2 (prosody condition: narrative style and broadcast style) by 6 (news messages) by 2 (speaker: male and female) mixed design. The purpose of the six news messages was to allow for repeated measurements of the effect of prosody while avoiding making participants listen to the same content twice. All news messages were recorded in both prosody conditions and by both speakers. Participants heard all news messages in either the male or the female voice, but the presentation of this factor was nested within the prosody condition so that they heard half of the messages in each style. There were four presentation blocks to which participants were randomly assigned. The presentation blocks were counterbalanced so that each news message across the four blocks fulfilled the following criteria: (1) each news message was presented in both prosody conditions the same number of times; (2) each news message appeared in the first half and second half of the series the same number of times; and (3) no news message appeared twice in the same position. Additionally, the prosody condition was alternated so that participants did not listen to two consecutive news messages in the same style.
Participants
Fifty-six voluntary participants aged 18 to 22 (M = 19.77, SD = 1.03; 20 males) took part in this study in exchange for course credit. All participants were undergraduate students at a large university in the Midwestern United States. 47 participants (84% of the sample) reported that English was their primary language. Due to technical issues during data collection, the physiological data of the first six participants had to be discarded, so the total amount of participants for the physiological analyses was 50 (17 males).
Stimuli
The stimuli of this experiment were composed of six different news stories. The news, taken from different radio and television stations of national coverage, was real but not recent. Of the six messages, two were political news, two were society news, one was culture, and the last one was the forecast, following a news bulletin’s typical structure. We adjusted the length to 60 words for each news piece and removed complicated words or expressions. Then we conducted a pretest with these news pieces to ensure that they were simple and understandable. Twenty participants rated on a 5-point scale if each message was easy (1) or difficult to understand (5). All the news pieces were considered easy to understand and they did not significantly differ from each other (F(5,15) = 1.72, p = .135; M = 2.10; SD = .80).
Then, two professional broadcasters (radio newscasters), male and female, recorded both versions in a professional studio with optimal acoustic conditions. A male and a female broadcaster were chosen so that any potential finding regarding prosody style would be relevant to broadcasters of both genders. Both broadcasters spoke with a Standard American English accent. Each broadcaster recorded six news in the BS and six in the NS condition (12 by speaker, 24 in total). Both newscasters had low-pitched voices (male: 110 Hz; female: 180 Hz), as this kind of voice has shown to be more pleasant (Klofstad, 2016; Tigue et al., 2012) and the most common in broadcasting (Gasser et al., 2019; Medrado et al., 2005). The instruction for recording the BS condition was to simply read the news as they professionally did every day for their job. The recording of the NS presented more difficulties because the two broadcasters were accustomed to using the BS style. They were asked to read the news as if they were stories, in a narrative style with a more paused speed, trying to make sense of the words and main ideas and avoiding a regular or monotonous intonation. We had to train the radio broadcasters until the final recordings sounded natural.
We performed an acoustic analysis of the recordings to test that there were differences between the two styles. This analysis was carried out with Praat (Boersma & Weenink, 2021). The two conditions differed in three main prosody features, pitch level, pitch range, and speech rate. The values of intonation are shown in semitones (above 100 Hz), as semitones are more significant in studying intonation than absolute pitch in Hz (Nootebom, 1997) and moderate gender effects (Traunmüller & Eriksson, 1995). Women have higher-pitched voices than men due to the anatomy of the vocal cords: smaller and thinner than men (Latinus & Taylor, 2012). Women also use a more varied and expressive intonation than men; thus, their pitch range usually is higher (Berryman-Fink & Wilcox, 1983; Haan & van Heuven, 1999). For these reasons, we will show the results differentiated by the speakers.
In the BS style, the pitch range was expanded while it was compressed in the NS. In the analysis, the general pitch range was higher in the NS (19.18 semitones) than in the BS (14.32 semitones) with significant differences, F(1, 23) = 5.38, p = .030. The female broadcaster had a higher pitch range in the NS (23.33 ST) compared to BS (18.94 ST), with significant differences (F(1, 11) = 6.20, p = .032). The male speaker also had a higher pitch range in the NS (15.02 ST) than in BS (9.71 ST), with significant differences (F(1, 11) = 39.85, p < .001).
The general pitch level was slightly higher in BS (7.42 ST) than in NS (5.04 ST), with no significant differences (F(1, 23) = 2.34, p = .140). However, the differences were clear among styles for speakers. The male speaker’s pitch level was higher in BS (3.75 ST) than NS (1.44 ST), with significant differences (F(1, 11) = 171.16, p < .001). In the female speaker, BS (11.09 ST) also was higher than in NS (8.63 ST), with significant differences (F(1, 11) = 597.18, p < .001).
Finally, in the BS news, broadcasters used a more emphatic style than the smoother NS style. We measured the number of highest pitch prominences in both patterns: more than 7.03 ST in the male voice and 12.05 ST in the female voice. Therefore, the differences between the two styles were acoustically perceptible. There was an average of 15 peaks in each message in the BS while, in the NS, there were 8.9, with significant differences, F(1, 11) = 57.52, p < .001. The sing-song regular or circumflex intonation was easily perceived in the BS with continuous pitch prominences or peaks that produced the regular melody while, in the NS condition, the intonation did not maintain a regular sing-song pattern.
In sum, there were clear acoustic differences between both styles that characterized the NS as more moderate and expressive than the more emphatic BS. Figure 1 shows an example of the intonation in the different styles and both speakers.

Intonation styles.
The other notable difference between the two styles was speech rate. According to the main characteristics of the broadcast news style, BS news pieces were faster than news in the NS. All the news pieces in BS spanned an average of 18 seconds, while in the NS condition, they were an average of 21 seconds despite the word count being the same. The news was conveyed at a rate of 200 wpm in BS, while NS’s speech rate was 175 wpm.
Once all the messages were recorded, six radio professionals acted as informants for this study in the radio station where we recorded the messages. All of them subjectively agreed that the styles were different and represented the different patterns.
For data collection, the audio messages and the questionnaires were presented with MediaLab. Psychophysiological measures were recorded with BioPac and Acqknowledge. Physiological data were recorded at a sampling rate of 2,000 Hz. Data cleaning was performed in Acqknowledge, and data transformation and analysis were performed with R version 4.0.2.
Procedure
All procedures were pre-approved by the Institutional Review Board. After providing informed consent, subjects were individually conducted to a room with a partition separating the researcher and the participant’s space, both furnished with a table and a chair. After explaining the procedure, the researcher proceeded to place the sensors for physiological measurements. Prior to placing the ECG electrodes, the skin on the interior side of both forearms was cleaned with an alcohol pad and moisturized with a conductance gel. Two disposable pre-gelled ECG electrodes were placed on the interior side of the forearm and wrist of their non-dominant hand, and a third one was placed on the wrist of their dominant hand. After cleaning the skin on the palm of their non-dominant hand with a tissue soaked in distilled water, two pre-gelled EDA electrodes were placed on the hand’s hypothenar eminence. Then, the researcher left the participant’s partition, and the participant was instructed to start the experiment. Participants heard the six audio messages in one of four order presentations, in either a male or a female voice. The sound was presented via peripheral speakers at a comfortable, medium level of loudness kept constant across all participants. After each message, they were first asked to evaluate it using several Likert scales described below. At the end of the experiment, they were asked to answer some demographic questions, and after that, participants were thanked and dismissed.
Dependent and Independent Variables
Self-reported measures: Adequacy and effectiveness
Ten 7-point Likert scales were used to test the impact of prosody on the perception of the speaker. The items were obtained and adapted from a study on radio commercials comparing different styles in terms of adequacy and effectiveness (Rodero et al., 2013). Prompted by the question “to what extent did you think the news piece conveyed through this voice was. . .”, participants were asked to rate how correct, appropriate, comprehensible, intelligible, credible (adequacy), as well as how clear, natural, pleasant, dynamic, and persuasive (effectiveness) they found the speaker’s voice. In all scales, the leftmost bubble was marked with a description for the corresponding negative perception (e.g., “incorrect,” “little credible”) and the rightmost bubble was marked with a description for the corresponding positive perception (e.g., “correct,” “credible”). Principal component analysis with varimax rotation was used as a starting point. The two-factor model explained 57% of the variance, while a three-factor model only added 4% more variance explained. Following Rodero et al. (2013), we kept the two-factor model as representative of the adequacy and effectiveness constructs. Confirmatory Factor Analysis (CFA) revealed that the original, theoretically motivated model with five items under each factor had poor fit (χ2/df = 215.602/34, p < .001, RMSEA = .125, CFI = .908). An optimal model was found where the adequacy factor comprised how correct, appropriate, comprehensible, intelligible, credible, and clear the speaker was, whereas the effectiveness factor comprised how natural, dynamic, and persuasive the speaker was (χ2/df = 108.36/26, p < .001, RMSEA = .096, CFI = .952). The item “pleasant” was dropped because it loaded equally on both factors, and removing it improved model fit. Two final dependent variables, adequacy (M = 27.42, SD = 5.41), and effectiveness (M = 7.29, SD = 2.43), were created by calculating a weighted sum from the standardized coefficients. Higher values in adequacy and effectiveness would indicate a more positive evaluation.
Cognitive resource allocation
Heart rate is commonly used to measure cognitive resource allocation during message processing (Potter & Bolls, 2012). As attention to external stimuli increases, heart rate decelerates, and conversely, disengagement from message processing would lead to increased heart rate over time (Wise, 2017). Electrocardiogram (ECG) was used to measure the heart’s electrical activity during message exposure, at a sample rate of 2,000 Hz. QRS-complexes were automatically identified with an algorithm, and a researcher visually inspected them to manually correct missing or misidentified QRS-complexes. Using the software Ackqnowledge’s pre-defined algorithms, the distance between R-peaks was converted into tonic Heart Rate (HR) and averaged across 1-second intervals for the analysis.
Emotional arousal
Electrodermal activity (EDA) is commonly used in media psychology as a measure of sympathetic system activation, an indicator of emotional arousal (Potter & Bolls, 2012). EDA was recorded in microsiemens (μS) at 2,000 Hz on the subjects’ non-dominant hand during message exposure. Skin conductance level (SCL) was calculated as a continuous measure of sympathetic system activation by averaging the raw EDA values at 1-second intervals. Higher SCL in one condition would suggest a stronger emotional response to the message.
Covariates
To control for potential variability of the emotional impact across the different messages, three emotional 7-point Likert scales were used: an arousal scale, ranging from “1: Not at all aroused” to “7: Extremely aroused”; a negativity scale ranging from “1: Not at all negative, unhappy, annoyed” to “7: Extremely negative, unhappy, annoyed”; and a positivity scale ranging from “1: Not at all positive, happy, pleased” to “7: Extremely positive, happy, pleased”. The valence scale was computed by subtracting the negativity score from the positivity score for a given subject and message. Additionally, to control for potential effects of the participants’ gender on the physiological and self-reported variables, participants were asked to self-report their gender as male, female or other.
Data Transformation
Physiological signals are susceptible to significant subject-to-subject variability. To mitigate this issue, the raw data was transformed into change scores by subtracting the value of the second prior to message onset from each datapoint for that subject and message. Additionally, physiological signals often show nonlinear trends, so both HR and SCL were plotted and fitted before data analysis to assess their linearity over time. Visual inspection suggested possible quadratic trends in both the HR and SCL signals, so quadratic terms were included in all psychophysiological models. All categorical variables (i.e., prosody condition, speaker, and participant gender) were sum-to-zero coded to facilitate interpretation of the results. The time variable was scaled by subtracting the mean and dividing it by the standard deviation. Since the two conditions varied slightly in length (NS = 21 s, BS = 18 s), only the first 18 seconds of each message were included in the analysis to avoid issues related to data points systematically missing for only one of the conditions.
Analytic Procedure
All the measures used in this study were analyzed using a multilevel modeling approach. Unlike other methods typically used to analyze repeated measures (e.g., ANOVA), this technique allows modeling of randomly missing data, a common issue in physiological recording, and more importantly, it can partition variance from more than one grouping variable, in this case, subjects and stimuli. All multilevel analyses were performed with the R package “Lme4” (Bates et al., 2015) and were based on an unstructured covariance matrix. Given that participant and news message were fully crossed with each other in our experimental design (i.e., every participant was exposed to every news message), we chose cross-classified multilevel modeling as the most appropriate analytical strategy, so our analyses included separate random intercepts for subject and news message. As pointed out by Judd et al. (2012), cross-classified models support the generalization of any findings beyond the subjects and stimuli sampled in the study.
Before running the analyses, we explored potential order effects on the dependent measures by testing the effect of the presentation group of the subject (a categorical variable representing the four presentation blocks). Presentation group did not significantly predict any of the dependent variables, so it was not included in any of the models.
All multilevel analyses started with a maximal model (Barr et al., 2013), which included random slopes for both subject and news message for all predictors of interest, as well as of their interactions. The predictors of no theoretical interest (i.e., speaker, participant gender, message arousal, and message valence) were not included in the random structure and were left as main effects to control any confounding effects. The model selection followed a data-driven strategy to find an optimal model (Bates et al., 2015). The maximal model was often degenerate due to overparameterization, so model selection was performed following a backward, “best path” iterative selection. Parameters of the random structure were removed in order of complexity and attending to how much variance they explained in the variance-covariance matrix of random effects. Interaction terms, followed by variables reflecting higher level polynomials (e.g., quadratic time over linear time), were removed first. When a term was removed, the model was re-estimated, and a likelihood ratio test was used to compare if any differences in AIC with the previous model were significant. The new model was kept if there was no significant reduction in model fit. If a model was found that offered the best fit (i.e., any further removals of random terms significantly decreased its fit) but was still degenerate, terms were continued to be removed until a stable model was found. Once a stable model was found, terms in the random structure were further removed if they did not add to model fit. The “sjPlot” R package was used to visualize interactions and diagnose the models’ compliance with the assumptions of MLM. When post hoc tests were needed, they were tested post hoc with the emmeans and emtrends functions of the “emmeans” R package.
Results
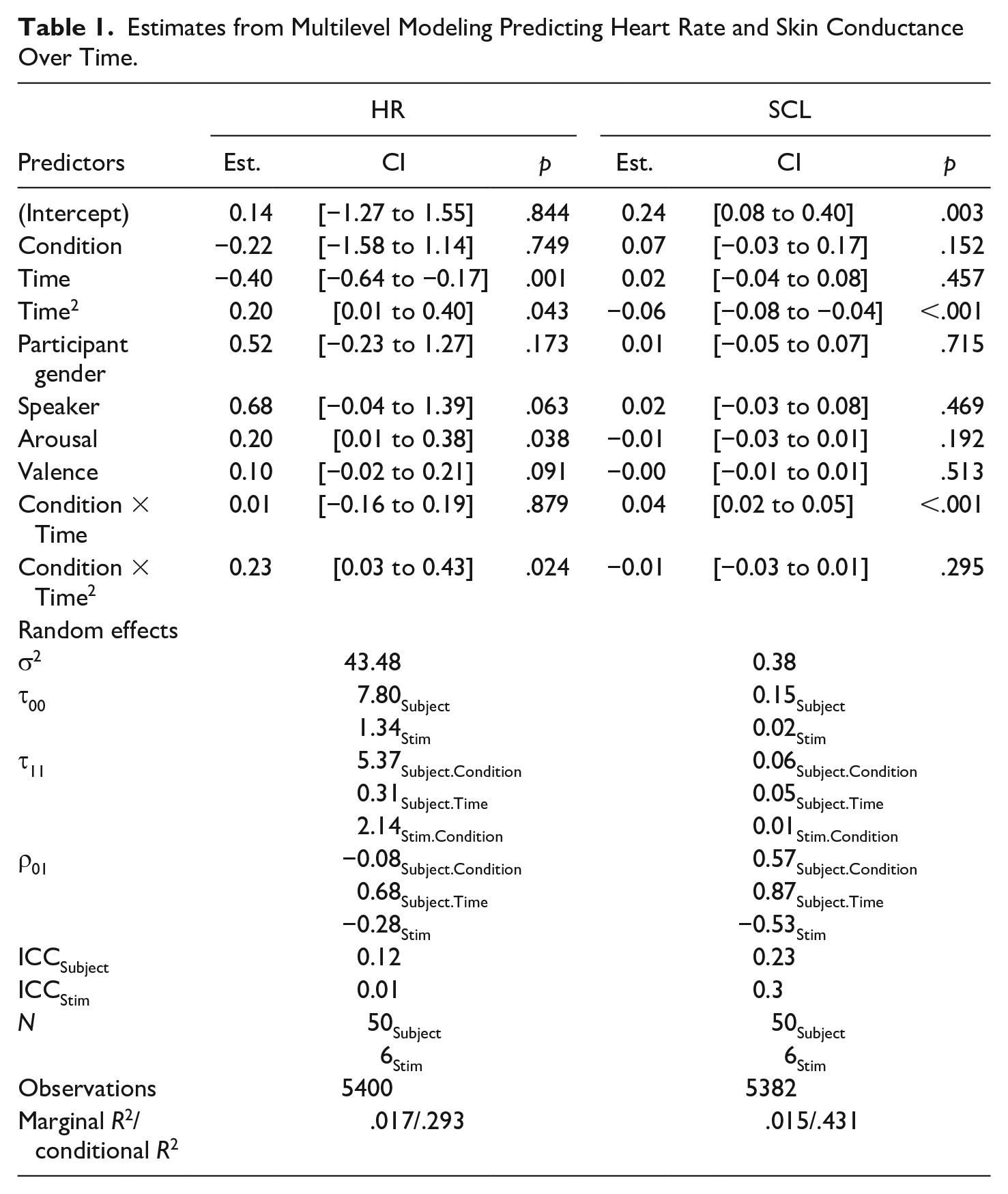
Parameter estimates from all the multilevel models can be seen in Table 1. Figure 2 presents the effect of condition on the physiological data plotted over time.
Estimates from Multilevel Modeling Predicting Heart Rate and Skin Conductance Over Time.

Heart Rate and Skin Conductance Levels.
Control Variables
Speaker and participant gender did not significantly predict any of the dependent variables (see supplementary code for statistics). Message arousal had a significant main effect on HR (b = 0.19, t(3437.57) = 2.07, p = .038), on adequacy (b = 1.07, t(208.42) = 6.43, p < .0001), and on effectiveness (b = .51, t(235.95) = 6.39, p < .0001), but not on SCL (p = .19). More arousing messages exhibited faster HR, that is, less cognitive resource allocation, and they were evaluated more positively. Message valence had a main effect on adequacy (b = 0.48, t(25.21) = 5.55, p < .0001) and on effectiveness (b = .18, t(31.91) = 4.13, p < .001), but not on the physiological variables (HR: p = .09; SCL: p = .51). Participants who felt more positive or less negative after listening to the news message evaluated the speaker more positively.
Hypothesis Testing
Hypothesis 1 predicted that the news conveyed in BS would be perceived as less effective and adequate than the messages delivered with NS. Model selection for the adequacy measure resulted in an optimal model with only a subject and news message random intercept, but no random slopes. This model revealed that prosody condition did not have an effect on the perception of adequacy of the speaker (b = .009, t(279.86) = .047, p = .96). The optimal model for the effectiveness measure resulted in a model with random slopes for prosody condition on both intercepts. This model also revealed no effect of prosody condition on the perceived effectiveness of the speaker (b = −.043, t(235.95) = −.15, p = .88). Thus, H1 was not supported.
Hypothesis 2 predicted the news conveyed in BS, compared to NS, would elicit less cognitive resource allocation, as indicated by more cardiac acceleration. This hypothesis was tested with a cross-classified model with random intercepts for both subject and news message, condition random slopes for both random intercepts, and a time random slope for subject (see Table 1). The main effect of prosody condition on HR was not significant (p = .75) but there was an interaction between condition and the quadratic time term (b = 0.22, t(5236.6) = 2.26, p = .024). Post hoc comparisons of the time trends revealed that the effect of quadratic time was different across the two prosody conditions (b = −0.45, t(5237) = −2.26, p = .02). Specifically, there was an effect of quadratic time on HR for the NS condition (b = 0.43, p = .003) but not for the BS condition, (b = −0.02, p = .86). As it can be seen in the left panel of Figure 2, heart rate for messages in NS followed a U-shaped deceleratory trend characteristic of an orienting response (Potter, 2000). Thus, in support of H2, the BS condition led to less cognitive resource allocation than the NS condition, as shown by HR deceleration over time.
Hypothesis 3 predicted that the news conveyed in BS, compared to NS, would elicit less emotional arousal, as indicated by a lower skin conductance level. The random effect structure that was found to be optimal for the SCL analysis was the same as for the HR analysis, that is, a cross-classified model with random intercepts for both subject and news message, prosody condition random slopes for both intercepts, and a time slope for the subject intercept (see Table 1). The multilevel analysis revealed no main effect of condition on SCL (p = .17), but a significant interaction between condition and linear time (b = 0.038, t(5221.03) = 4.57, p < .0001). As shown in the right panel of Figure 2, messages in both prosody conditions exhibited a similar rise in SCL following message onset, but SCL started decaying after peaking for the BS condition, while for the NS condition, SCL stayed high throughout the message. A post hoc comparison between the time slopes of the two conditions confirmed that they were significantly different from each other (b = −0.076, t(5221) = −4.57, p < .0001). Thus, H3 was supported, with messages in the BS exhibiting lower SCL than the NS, indicative of a less intense emotional response.
Discussion
The goal of this study was to compare two different speaking styles, the typical and most common broadcast style (BS) and a narrative style (NS), more similar to telling a story, to determine which one was the most effective, adequate, and elicited more cognitive resource allocation and emotional arousal when listening to news messages.
The self-report results showed no significant differences in the effectiveness and adequacy, but the narrative style elicited greater cognitive resource allocation and emotional arousal, as indicated by a more pronounced cardiac deceleration and higher electrodermal activity. Thus, the self-report data did not coincide with the physiological response. At a conscious level, participants considered both styles equally effective and adequate, but their automatic bodily response suggested a more attentive and stronger emotional response to the narrative style over the broadcast pattern. Both styles were perceived as equally positive, but this perception does not have an equivalent physiological response. There were some prosody elements in the NS that improved attention and arousal compared to the BS.
Regarding the self-report findings, messages in both styles were evaluated as positive (more than five in 7-point scales), so the two types of prosody did not significantly differ from each other. A possible explanation is that the listeners’ familiarity with the broadcast style counterbalanced or canceled out the narrative style’s benefits. Although some authors have described the broadcasting style as inappropriate or strange (Bolinger, 1998; Francuz, 2010; Nihalani & Lin, 1998; Oleinik, 2006; Rodero Antón, 2013; Strangert, 1991; Wheatley, 1949), it is undeniably the standard in the industry. The broadcasting style is a commonplace way to convey the news, widespread across countries and languages (Castro et al., 2010; Francuz, 2010; Mok et al., 2014; Oleinik, 2006; Price, 2008; Rodero Antón, 2013; Strangert, 2005), so it has become a very recognizable pattern by listeners (Escudero et al., 2017; Gasser et al., 2019; Medrado et al., 2005). It is important to note that the audience does not listen to different features (e.g., intonation or speech rate) in an isolated way but all together in a defined style. For this reason, in this research, we analyzed styles and not the different parameters. Consequently, we suggest that participants could have automatically identified the broadcast pattern as a news style and that this familiarity might have played a role in their evaluation, in contrast to previous studies that have examined the prosody parameters independently. Drawing from the Heuristic Systematic Model of Information Processing (HSM) (Chaiken, 1980), they could have used a heuristic kind of processing based on this simple rule, learned and stored in memory to rapidly evaluate and process the news content. Listeners have learned to recognize this style and rapidly associate it with the news, applying effortless processing (Lang, 2017). In other words, the familiarity of the pattern could have done that, by association with professional broadcasting, they found it an effective and adequate way to deliver the information.
Additionally, the broadcast style is dynamic, characterized by high pitch, emphatic intonation, and fast speech rate, configured to be appealing and catch the listeners’ attention (Cotter, 1993; Gasser et al., 2019). Given its positive evaluation, we can suggest that this goal was somehow achieved in this study. However, the broadcast style also has a repetitive pattern and compressed pitch range that has been shown to be negatively perceived (Rodero Antón, 2013). It is possible that, had the news messages been longer (and therefore more tiresome), or had participants been exposed solely to one of the two styles, instead of both conditions, the self-report evaluations would have been more negative for messages in the broadcast style than what we found.
In any case, despite it being more strongly associated with broadcast news, people did not evaluate this style more positively overall, so the narrative style must have also had some advantages that led to an equally positive evaluation. One of its main strengths is that it adjusts the prosody features to the content, making sense of the information. More than using a mechanical way to speak reading news, the narrative style tries to tell the stories and explain the information. Instead of relying on a regular and overemphatic intonation, this style changes depending on the type of information transmitted. Therefore, it sounds more natural, although also possibly more unexpected in the context of broadcast news. Another advantage is that this pattern uses an expanded pitch range and a slower speech rate, prosody characteristics that have been shown to be beneficial for cognitive processing (Rodero, 2020; Rodero et al., 2017). For the aforementioned reasons, when it came to listeners engaging in conscious evaluation, the narrative style managed to fare equally well as the more familiar broadcast style.
In contrast, the results of the psychophysiological analyses draw a much clearer picture. On the one hand, the broadcast style’s prosody configuration, with a repetitive pattern, compressed pitch range, and fast speech rate, lost participants’ attention throughout the news pieces and led to significantly lower emotional arousal than the narrative pattern. This result is logical considering that this prosody configuration was regular, which could have easily caused fatigue in the listeners. Additionally, the faster speech rate would have increased the difficulty of being engaged and maintaining attention throughout the message. Lastly, this style was not unexpected or new for participants, so novelty did not additionally facilitate automatic resource allocation and emotional arousal, while it could have played a role in the narrative style.
On the other hand, the narrative style elicited more cognitive resource allocation and emotional arousal than the broadcast style, as indicated by a more pronounced cardiac deceleration and higher electrodermal activity. These findings are likely due to two factors: its prosody configuration and its novelty level. First, the pattern of the narrative style had an expanded pitch range, with no repetitive intonation movements and moderate use of emphasis, so it was effective in grabbing the listeners’ attention, according to research conducted in advertising (Rodero et al., 2017). Unlike the broadcast style, pitch variations in the narrative style molded to the message’s content, avoiding a regular pattern, which helped maintain the listeners’ attention throughout the message. Additionally, the moderate speech rate was likely another contributor to easier cognitive processing (Rodero, 2020). Along with prosody configuration, another critical factor in interpreting the physiological results is the fact that the narrative style is not habitual in the news. Novelty could have played a decisive role in triggering an orienting response, eliciting more cognitive resource allocation and higher emotional activation (Lang, 2000, 2006; Potter, 2000; Potter et al., 2008). Thus, the narrative style’s prosodic configuration facilitated greater engagement of listeners with the message than the broadcast style, as shown by higher attention and stronger emotional response.
In sum, we can conclude that the narrative style achieved an optimal result, as it offered a significant advantage in terms of automatic responses (shown in the physiological results), while it was not detrimental to the listener’s conscious experience, as shown by its positive evaluation in self-reported measures. Thus, our findings suggest that the narrative style can be appealing but natural at the same time, unlike the broadcast pattern that some authors have described as “strange.”
As a laboratory study, this research has some limitations. One is the variety of prosody features that could have acted simultaneously in each news recording. Prosody is formed by a variety of factors operating at the same time. As a dynamic phenomenon, it is hard to handle all the elements, as some authors have assumed (Calhoun, 2010). Although we have controlled the main features such as intonation and speech rate, other factors may have impacted the results. Also, the fact that participants listened to the two conditions alternated with each other (BS-NS-BS-NS. . .) could have, on the one hand, lessened the negative impact of the broadcast style’s repetitive effect, and on the other hand, reinforced the positive effect of the narrative pattern thanks to its novelty in broadcast news. Further research using a between-subject design could look into each condition’s effects separately to rule out novelty effects. Another limitation is that we only tested two voices, male and female. However, it should be noted that there were no significant main effects of speaker for any of the measures. Future research should add more kinds of voices. Moreover, we only tested two styles. Therefore, future research should examine more styles, with a between-subject design and prosody patterns more divergent from the broadcast model. Lastly, the focus in this study was exclusively on attention, physiological emotion, and message perception. Future research should test if prosody style affects other psychological dimensions.
This study has made two significant contributions. The first one is to show that prosody changes in the delivery of broadcast news can alter listeners’ physiological responses, suggesting an impact both on their cognitive and emotional processing. Secondly, these findings may have practical implications for the media industry. As this study has shown, a more natural prosody configuration such as the narrative style employed here can have important advantages over the repetitive broadcast pattern. We suggest that newscasters and broadcast stations could benefit from moderating or reducing the emphatic style commonplace in news broadcasting. Moreover, the narrative pattern could be particularly suitable for other new forms of audio communication. A straightforward application would be using the narrative pattern in informative or documentary podcasts, where the focus is on delivering factual information. This new style could make these podcasts sound more contemporary and different from traditional news. However, the most appropriate application of this style could be creative messages, such as fiction podcasts and, especially, audiobooks. These expressive formats are narrative in essence. Therefore, they need a natural style adequate for narrating stories. All these recommendations can be very useful for training journalists.
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.