
Abstract
Lexical development is a key facet of later language development. To characterize the linguistic knowledge of school age children, performance in the written modality must also be considered. This study tracks the growth of written text-embedded lexicon in Catalan-speaking children and adolescents. Participants (N = 2161), aged from 5 to 16 years produced six different texts: a film explanation, a film recommendation, a joke telling and definitions of a noun, a verb and an adjective. The resultant corpus of 11,332 texts was analyzed using four distributional measures of lexical development: word length, lexical density, use of adjectives and nominalizations. Heylighen’s F-measure of level of text formality was also computed. Word length, use of adjectives and nominalizations were powerful indicators of lexical development. Text type and home language had an effect on these measures. Lexical density showed no clear developmental change, and did not vary by type of text. Heylighen’s F-measure was a weaker developmental indicator. Educational implications are discussed.
Keywords
Introduction
Children acquire most of the linguistic forms and constructions of their language very early on. However, they achieve proficiency and flexibility in the use of these forms in a wide range of communicative settings only after a long process of development, both in the spoken and written modalities (Berman, 2004). School age language exhibits an extended repertoire of linguistic items, categories and constructions as well as increasingly more efficient and explicit ways of representing the language and thinking about it (Berman, 2004, 2008; Berman & Ravid, 2008; Nippold, 1998; Ravid & Berman, 2010). Later language development has gained increasing attention from linguists and psycholinguists (Nippold, 2002; Tolchinsky, 2004). The current article focuses on the development of the written lexicon used by Catalan school children and adolescents − from 5 to 16 years of age– when producing different types of texts.
Lexical development is a key facet in later language development (Anglin, 1993; Nippold, 1998; Ravid, 2004a). Moreover, given the strong relationship between lexical command and grammatical development in the preschool years (Bates & Goodman, 1997) and from primary school to high school (Berman, 2008), the study of lexical development is critical for shedding light on language development beyond vocabulary acquisition.
Throughout schooling, the retrieval of words becomes faster and more accurate (Dockrell & Messer, 2004); lexical-conceptual diversity grows attuned to the characteristics of different semantic fields (Tolchinsky, Martí, & Llauradó, 2010). The use of derivational morphology expands, playing an important role in lexical enrichment (Anglin, 1993; Ravid & Schiff, 2006) and in the lexicon–syntax interface (Friedman & Novogrotsky, 2004; Ravid & Saban, 2008; Scott, 2004). A literate lexicon is built up through which abstract concepts and advanced figurative meanings are accessed, and complex verbal reasoning is enhanced (Peskin & Olson, 2004).
The lexical domain shows, in a unique manner, the ways in which context and cognition interact, as well as the changes in such interaction with development (Dockrell & Messer, 2004). Vocabulary development has been strongly related to cognitive development (as measured by intelligence tests; see Anderson & Freebody, 1981). Research on lexical development is also relevant for a number of educational reasons. Vocabulary knowledge predicts academic success (Cunningham & Stanovich, 1997; Leong & Ho, 2008) and explains individual variance in reading comprehension (Laufer & Nation, 1999; Leong & Ho, 2008). The frequency of use of nouns and verbs plays an important role in reading speed (Holmes, Stowe, & Cupples, 1989). Children with reading difficulties usually exhibit poorer command of vocabulary than their more skilled peers. Moreover, educational interventions on lexical aspects of language lead to progress in reading comprehension (Nation, Snowling, & Clarke, 2007).
The linguistic knowledge of school age children and adolescents can hardly be characterized without taking into account their performance in the written modality (Ravid & Tolchinsky, 2002; Tolchinsky, 2004). Increased exposure to and practice with the written modality influence major aspects of later language development. The speaker/writer moves from command of the writing system as a notational system to mastering the written language as a discourse style. The appearance of, for instance, low frequency syntactic structures (Jisa, 2004; Scott, 2004) and longer sentences in the written texts of school children (Nippold, 2002) promotes, in turn, greater flexibility in the choice between formal versus informal language registers (Jisa, 2004; Tolchinsky, 2004). Writing becomes the necessary platform without which the remarkable changes that occur at the lexical, morphosyntactic and discursive levels, all of which are key to the successful attainment of literacy, could hardly take place (Berman & Ravid, 2008; Cameron, Hunt, & Linton, 1988). That is why we focus on the development of the lexicon in the written modality.
In a previous study (Tolchinsky et al., 2010), we examined the production of written vocabularies in five semantic fields. Our findings revealed lexical developmental growth in both size and conceptual underpinning. Nevertheless, from the language-usage perspective adopted here (Bybee, 2007; Goldberg, 2005), linguistic forms must not be considered as abstract, isolated elements but rather in relation to how people use them in different kinds of texts (Berman, 2008; Berman & Verhoeven, 2002) and under the constraint of differing communicative circumstances, goals and audience. In other words, the genre-specific features that characterize language use have an impact on the selection of expressive devices and grammatical constructions in non-expert text production (Berman, 2005, 2007; Berman & Nir-Sagiv, 2007; Nir-Sagiv, Bar-Ilan, & Berman, 2008; Tolchinsky, 2004).
Throughout schooling, speakers/writers are meant to move from involved though scarcely informative and rather informal conversational productions on to detached, more accurate highly formal academic-like texts (Snow & Uccelli, 2009). Control over the level of text formality, a notion that can be associated with text register, involves the ability to adjust one’s use of linguistic forms in a variety of ways so as to suit the circumstances of their use. It is, therefore, an important feature of communicative competence (Jisa, 2004). Developmental changes embrace both local features/elements concerning lexical and syntactic choices and global features such as a text’s level of formality (Biber, 1995, 2007; Heylighen & Dewaele, 1999). In the current study, we focus on text-embedded lexical development as it is deployed in four different genres: narrative, argumentation, colloquial and definition. We examine lexical development by means of four distributional measures: word length, lexical density and presence of adjectives and nominalizations, considered to be suitable for the investigation of lexical development in a diversity of languages in addition to measuring the level of text formality.
Word length measured by the number of syllables per word is widely used in corpus linguistics research as a way of gauging lexical complexity (Riedemann, 1996; Wimmer & Altmann, 1996). It has been shown to be developmentally sensitive to literacy levels when measured by the number of letters per word in written language (Malvern, Richards, Chipere, & Duran, 2004). Longer words reflect both the advanced use of sophisticated, precise, low frequency terms (Biber, 1995) and an increased command of structurally complex derivatives (Anglin, 1993), a finding that was corroborated for a morphologically complex language such as Catalan (Cordero, 2002).
As content words convey the bulk of semantic content and propositional information, lexical density – a high proportion of content words relative to the total number of words – is considered to be a good indicator of textual richness and informativeness (Halliday, 1985; Malvern et al., 2004; Nir-Sagiv et al., 2008). Throughout schooling, the increasingly abstract and academic nature of school-based texts entails densely informative linguistic constructions with a complex hierarchical and varied syntactic architecture supported by rich lexical density (Berman & Ravid, 2008; Ravid & Berman, 2009; Ravid & Levie, 2010). Lexical density has been shown to be an indicator of school age children’s language development (Malvern et al., 2004; Strömqvist, Nordqvist, & Wengelin, 2004) and serves to distinguish between narrative and non-narrative usage (Nir-Sagiv et al., 2008; Ravid, 2004b). The usefulness of lexical density as a measure of lexical development remains debatable, however, and other developmental studies have not observed genre effects (Johanson, 2009), or differences by age between school age children and adults (Johanson, 2009). In another vein, Hyltenstam (1988) points out that lexical density may be not the best measure for lexical development in written productions in a second language (L2) as one can obtain a high density score with a small vocabulary. Thus, due to the scarcity of previous research on lexical development in languages typologically similar to Catalan, an additional benefit of this study will be to examine the suitability of the tested measures for cross-linguistic comparisons.
We avoided the more eschewed measure of lexical diversity, in addition to lexical density, and instead we used a syntactic category to characterize later language development. For English, Russian and Hebrew, the use of adjectives in written texts increases markedly as children move upwards in the school system to higher grades (Bar-Illan & Berman, 2007; Caselli et al., 1995). While children are aware of the informative value of adjectives in relation to nouns from early on, a full array of adjectival categories is far from present in 6-year-olds (Blodgett & Cooper, 1987). An improved command of school-based, nominally denser texts would thus entail a rich adjectival texture grounded in complex nominal syntactic structures. Hence, the size and makeup of the adjective category can be taken to constitute a yardstick for language ‘richness’. Such an increase has been suggested to coincide with the consolidation of an ‘advanced’, high-register, literate lexicon and its cognitive correlates (Dockrell & Messer, 2004) and has been shown to be indicative of language development in school age populations (Ravid, Levie, & Avivi-Ben Zvi, 2003).
Finally, specific, abstract concepts are progressively encoded by nominalizations, which can assist the writer in maintaining an impersonal tone and a detached stance and help to strengthen textual cohesion. Nominalizations require prior integrated knowledge in the domains of morphology, syntax and discourse, hence implying sophisticated morphologically complex lexical uses and, to some degree, constitute a feature of accomplished academic writing (Barata, 2010; Ravid &Avidor, 1998; Tyler & Nagy, 1989).
Due to increased experience with the written language and improved literacy levels, we predict school grade to be associated with all four measures. We expect that participants will gain in the ability to adjust to text-genre specific features and predict an effect of text type on the tested measures. In particular, we expect definition and explanation – both frequently practiced in academic settings – to be lexically denser, and to show a higher proportion of nominalizations, therefore yielding a higher word length average. In contrast, we expect more oral-like types of text such as joke telling and recommendation of a film to show less density, and to contain few morphologically complex words. The effect of the participants’ linguistic background on text-embedded lexical development will also be examined. To elaborate, in Catalonia, Catalan and Spanish are both official languages. Since all children use Catalan at school and Spanish is massively present both in the media and in social settings, one is unlikely to find a monolingual child or adolescent in either of the two languages. Rather, some degree of bilingualism, though unbalanced (Schlyter, 1993), is the norm. Due to a major surge of immigration over the past decade (3% in 2000 to 13% in 2008), an increasing percentage of children speak a language different from Catalan and Spanish at home. The linguistic background of Catalan school children is highly heterogeneous and the designation L1, L2 and so on does not correspond exactly to the ecological situations in which languages are acquired by children and adolescents nowadays. Our sample includes multilingual children some of whose home language coincides with the school language and others for whom this is not the case.
Indeed, both multilingual and monolingual learners face the same problem of mapping form and function to produce meaningful utterances based upon their language experiences (Ellis, 2002; Lieven & Tomasello, 2008). Certainly, phenomena like code switching and code mixing are restricted to multilingual speakers (Myers-Scotton, 1993; Poplack, 1987) but they are considered to be signs of a particular kind of linguistic competence rather than indications of a lack of proficiency (Gollan & Ferreira, 2009; Zentella, 1997). Multilingual development has not been proven to be detrimental to language development (Bialystok & Feng, 2010). However, when new languages are learned in formal contexts the amount of exposure and multiple motivational and individual factors may lead to important differences in the performance of multilingual learners (Gersten & Baker, 2000). It is reasonable to assume that the lexical uses of children and adolescents with differing home languages learning Catalan mostly at school and living in a multilingual environment will differ from their peers who, in spite of living in the same multilingual environment, have a home language that coincides with the school language. We therefore expect texts produced by participants who speak Catalan at home to be semantically richer, morphologically more complex and better adjusted to patterns of text formality than texts produced by children who do not speak Catalan at home, and whose use of Catalan is mostly restricted to school-based interactions.
Methodology
Participants
A cohort of 2161 children and adolescents took part in this study, aged from 5 to 16 years and distributed by school grade. At the time of the study they were attending 32 schools in the Catalan education system.
A sociolinguistic questionnaire was used to gather information on the participants’ sex, age, school grade, home language or languages, as well as how long they had been familiar with the Catalan language. Five different groups were established according to the participants’ self-declared home language: Catalan only (C); both Catalan and Spanish (CS); Spanish only (S); any language except Catalan or Spanish but familiarity with Catalan for more than 4 years (O>4); and any language except Catalan or Spanish at home and familiarity with Catalan for less than 4 years (O<4). It must be noted that the group of participants who speak neither Catalan nor Spanish at home is highly heterogeneous and includes speakers of Romance, Germanic, Slavic, Semitic, Austronesian and Sinotibetan languages. Table 1 shows the distribution of the participants by school grade and home language or languages.
Distribution of participants by school grade and home language.

Our sample reflects the current linguistic situation in Catalonia. Thus, 32% of the participants identified Catalan as their sole home language, 20% identified Spanish as their home language and a further 28% identified both Catalan and Spanish as their home languages. The home language of 16% of the participants was a language other than Catalan or Spanish. The remaining 4% of the sample did not provide a response regarding their home language and were not included in the analysis.
Tasks
Participants were instructed to produce six different types of texts: a film explanation, representing the narrative genre, following the instruction ‘think of a film or TV series that you like and tell us about it’; a film recommendation, accounting for the argumentative genre, with the instruction ‘think of a film or TV series that you like and recommend it to a friend’; the telling of a joke, accounting for the colloquial genre, following the instruction ‘think of a joke or funny story that you know and tell it’; and the definitions of three words (a noun, a verb and an adjective) ‘give a definition of’.
Text analysis
Tokens, types and lemmas (see below for definitions) were counted in order to explore overall text-embedded lexical growth, lexical diversity and conceptual underpinning in the texts. However, all analyses were performed at the token level (rather than type) since we were interested in actual usage patterns (Bybee, 2007; Goldberg, 1995).
Criteria for lexical characterization
Four distributional measures were applied to different dimensions of vocabulary: (1) word length, (2) lexical density, (3) use of nominalizations and (4) use of adjectives.
1. Word length was measured by number of letters per word.
2. Lexical density was measured as the proportion of words included under the grammatical categories noun, verb and adjective in relation to the total number of words in the text.
3. Nominalization refers to the process by which a noun is obtained from a verb (1) or an adjective (2). It can also be the outcome of a process of zero derivation by which a stem can be realized as a noun without involving any affixation (3).
(1) [satisfe(r)]v ‘to satisfy’→ [satisf + acció] ‘satisfaction’ (2) [brut] ‘dirty’→ [brut + ícia] ‘dirtiness’ (3) [cost] stem [cost]n ‘cost’
The measurement used was the proportion of nominalizations relative to the total number of words in the text.
4. Adjectives normally follow the noun in Catalan and are marked by gender and number, in agreement with the noun. They can be grouped into two classes according to their morphological complexity. The first class contains adjectives expressed by a root plus inflected gender and number (if necessary) (1). The second class is formed by a root plus one (or more than one) suffixed or/and prefixed morphemes plus inflected gender and number (if necessary). Participles are included in this group as, in Catalan, the characteristics of the participle morpheme are more derivational-like than inflectional-like (Mascaró, 1986) (2).
(1) [calb (root) + e (fem. gender) + s (plural number)] (2) [nacion (root) + al (suffixed morpheme) + (fem. gender) + s (plural number)]
The measurement used was the proportion of adjectives relative to the total number of words in the text.
Level of text formality
An index of formality was computed using Heylighen’s F-score (Heylighen & Dewaele, 1999):

Heylighen bases his measure on the frequencies of different word classes in a corpus. In his account, a high frequency of nouns, adjectives, prepositions and articles characterizes detached, accurate, highly formal texts whereas a high frequency of pronouns, verbs, adverbs and interjections are more like involved informal texts. Therefore, the higher the F value, the higher the level of text formality.
Procedure
Children performed the task in class groups. Texts were written by hand – in order to avoid possible graphic, spelling and textual deviations due to a lack of text processing skills. Both completion of the sociolinguistic questionnaire and text writing took place in the participants’ regular classrooms at the request of their usual Catalan language teachers. The teachers received training in text elicitation. The task did not last more than one class session. Sociolinguistic questionnaires were completed by the participants before they engaged in the text writing task. The task was carried out as part of their everyday school activities. A total of 11,332 texts was generated.
Text preparation
Three levels of linguistic units were established: lexical forms or tokens, that is the form as produced by participants; types, subsuming all the occurrences of a particular token; and lemmas, the canonical form of the word, that is, the form that represents all the word inflections (e.g., tense, number, gender), graphical and orthographical variants of the word. Graphical and orthographical variants were included given that the corpus was made up of non-normative texts.
The original version was written by hand and three new versions were produced from the original one: (1) an original version which reproduced the texts as they were written by participants without correcting spelling mistakes, (2) a normalized version which standardized orthography for conventional separation of words in written Catalan and (3) a labeled version in which words had been lemmatized and morphologically labeled (for an extended characterization of the corpus see Llauradó, Martí, & Tolchinsky, 2012).
Results
This section consists of four parts. First, we provide a general description of the corpus in quantitative terms regarding the number of texts by type of text. Second, we present quantitative results about the linguistic units in the corpus – tokens, types, lemmas and syntactic categories. Third, we approach the lexical configuration of the texts by means of the measures that were computed on these linguistic units (word length, lexical density, use of nominalizations and adjectives). Fourth, we show the results of applying an index of text formality.
A series of two-way ANOVAs, school grade (10) by home language (5) with repeated measures on type of text (6), were performed on the distribution of linguistic units (tokens, types and lemmas), the measures for characterizing the lexical composition of the texts and the level of text formality in order to determine the effect of school grade and home language as well as possible interactions on these dependent variables. The eta squared value (η2) is used to report the effect size of both the main effect and the interactions. The size effects of relevant pairwise comparisons are reported using Cohen’s d. An alpha level of .05 was used for all statistical tests. When the assumption of sphericity was found to be violated, degrees of freedom were corrected using Greenhouse–Geisser estimates.
General description of the corpus
There were 1830 definitions of a noun, 1820 definitions of a verb, 1829 definitions of an adjective, 2037 film explanations, 1955 film recommendations and 1861 joke telling texts. Of the 2161 participants, only 1385 participants produced all six required texts.
Linguistic units
The 11,332 texts yielded 207,028 tokens, of which 131,263 were types and were lemmatized into 113,160 different lemmas.
The growth of tokens, types and lemmas followed similar developmental patterns. School grade had a significant impact on the growth of each linguistic unit, F (9, 2161) = 28.129, p < .001, η2 = .13, F (9, 2161) = 39.057, p < .001, η2 = .14, and F (9, 2161) = 42.966, p < .001, η2 = .18, for tokens, types and lemmas, respectively. Bonferroni post-hoc comparisons revealed significant developmental gains between 1st and 3rd grade (d = 0.72; 0.74; 0.78 for tokens, types and lemmas, respectively), and 3rd and 5th (d = 0.85; 0.91; 0.93 for tokens, types and lemmas, respectively). An additional significant difference between 7th and 9th. grade reflected a decrease in the number of units (d = 0.30; 0.11; 0.11 for tokens, types and lemmas, respectively). Overall growth of tokens, types and lemmas between 6th and 10th grade proved to be moderately significant for both types (p = .039) and lemmas (p = .021) but not significant for tokens. Thus, the mean number of tokens, types and lemmas grows consistently up to 6th grade (11;6 mean group age) and then stagnates throughout secondary education, showing recovery only by 10th grade. By the end of compulsory schooling, growth of the conceptual underpinning of texts continues in the absence of a significant increase in text length.
It must be noted in Figure 1 that, while the total number of tokens equals the sum of tokens in each text, the total number of types and lemmas does not because repeated units are excluded from the count.
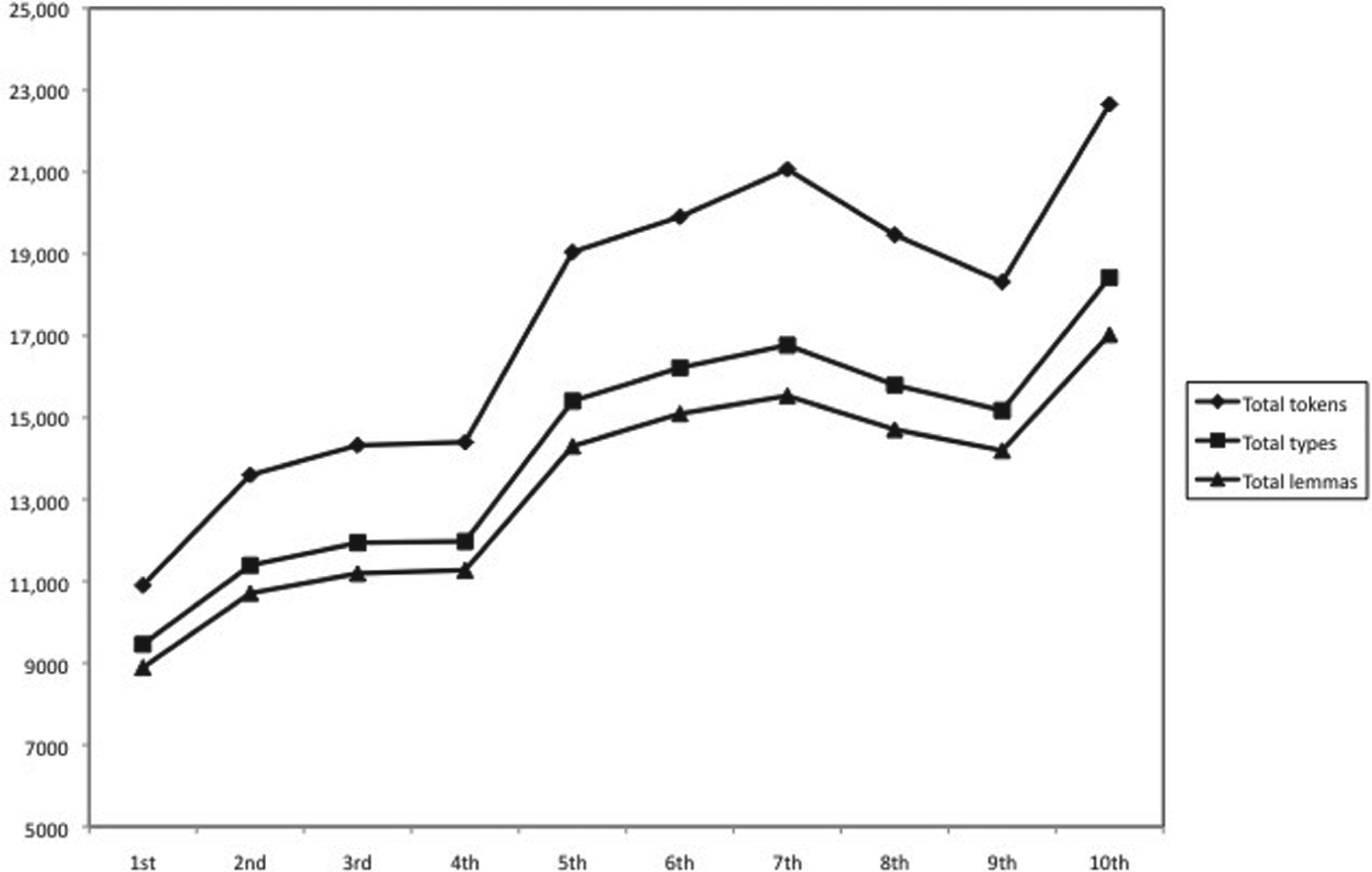
Plotted means of tokens, types and lemmas by school grade.
Type of text also had a significant impact on the increase in linguistic units, F (5, 2161) = 462.044, p < .001, η2 = .18, F (5, 2161) = 549.027, p < .001, η2 = .21 and F (5, 2161) = 549.514, p < .001, η2 = .21 for tokens, types and lemmas, respectively. For the three linguistic units, pairwise comparisons revealed significant contrasts between each type of definition and explanation of film and joke telling (d > 0.82), definitions and recommendation of a film (d > 0.32), and recommendations and both explanations and joke telling (d > 0.58).
Figure 2 shows that all types of text experience two marked increases, one between 4th and 6th grades, and a second one in 10th grade. Joke telling has an additional surge between 1st and 2nd grade and is the wordiest text up to 7th grade, then it is overcome by explanation of a film, the type of text that experiences the most pronounced increase in the number of tokens. Definitions experience rather mild overall growth throughout schooling. Their most pronounced surge happens between 4th and 6th grades, recommendations behave very much like definitions up to 4th grade and then experience a mild increase. This pattern of growth yielded a significant interaction between the type of text and school grade, F (45, 2161) = 6.955, p < .001, η2 = .04, F (45, 2161) = 8.603, p < .001, η2 = .04, F (45, 2161) = 5.529, p < .001, η2 = .07 for tokens, types and lemmas, respectively.

Mean number of tokens by school grade and text type.
Finally, home language had a significant impact on the three linguistic units, F (4, 2161) = 13.870, p < .001, η2 = .03, F (4, 2161) = 15.299, p < .001, η2 = .04, F (4, 2161) = 15.939, p < .001, η2 = .04 for tokens, types and lemmas, respectively. Bonferroni post-hoc analyses revealed significant contrasts between speakers of other languages with less than four years of experience of Catalan (O<4) participants (M = 70.20, SD = 46.50; M = 45.50, SD = 24.47; M = 39.46, SD = 19.87, for tokens, types and lemmas respectively) and both their Catalan-speaking (C) peers (M = 110.19, SD = 67.14; M = 67.99, SD = 34.03; M = 58.11, SD = 27.71 for tokens, types and lemmas, respectively) (d = 0.70) and Catalan and Spanish (CS) peers (M = 101.78, SD = 59.05; M = 64.28, SD = 30.28; M = 55.45, SD = 24.21 for tokens, types and lemmas, respectively) (d = 0.60), and between the Spanish-speaking (S) participants (M = 89.12, SD = 55.96; M = 57.35, SD = 29.61; M = 49.62, SD = 24.08), and both the Catalan-speaking (C) (d = 0.34) and the Catalan and Spanish (CS) (d = 0.22) groups. The Catalan-speaking (C) and the Catalan and Spanish (CS) participants consistently produced longer, more diverse texts than all the other groups. At the bottom end, the speakers of other languages with less than four years of Catalan (O<4) consistently produced the shortest, least diverse texts.
Lexical characterization of texts
Word length
Word length increased significantly with school grade, F (9, 2161) = 32.082, p < .001, η2 = .15 (see Figure 3). Bonferroni post-hoc analyses revealed significant developmental gains between 1st (M = 4.22, SD = 0.46) and 3rd grade (M = 4.35, SD = 0.34) (d = 0.34), 3rd and 6th grades (M = 4.51, SD = 0.31 ) (d = 0.71), and 6th and 10th grades (M = 4.73, SD = 0.34) (d = 0.68). Furthermore, we found significant differences by type of text, F (5, 2161) = 100.632, p < .001, η2 = .06. Pairwise comparisons revealed significant contrasts between joke telling (M = 3.34, SD = 0.25) and all other types of text (d > 0.54), and also between definition of a noun (M = 3.92, SD = 0.29) and definition of an adjective (M =3.67, SD = 0.27) (d = 0.92). An interaction was found between school grade and type of text, F (45, 2161) = 6.244, p < .001, η2 = .06.

Mean word length by school grade and text type.
Thus, from early school grades onwards, word length in definitions involves the use of long, low frequency, sophisticated (morphologically) complex words such as nominalized verbs, e.g., llegir: ensenyament de comprensió ‘to read: teaching of comprehension’. In contrast, word length decreases between 1st and 4th grades in explanations and recommendations of films possibly because they start off as almost a mere series of nouns with a lack of function words (prepositions, referential pronouns, etc.) which as a rule are shorter than content words, e.g., Los dibuxos (de) spider-man (i de) super- nan (i de) piratas del caibe ‘the cartoons (of) spider-man (and of) super-man (and of) pirates of the caribbean’ (words within brackets missing in the original). The omission of a written representation of such particles decreases sharply with age as children become better acquainted with uses of grammar, cohesive devices and other mechanisms necessary for text construction.
We also found a significant impact of home language on word length, F (4, 2161) = 3.976, p < .001, η2 = .02. C participants scored highest for word length (M = 3.77, SD = 0.14). They were followed by CS speakers (M = 3.73, SD = 0.13). Next, came the S speakers (M = 3.71, SD = 0.12). Finally the O>4 participants yielded the same mean word length as their O<4 peers (M = 3.68, SD = 0.27). However, only the contrast between C and O<4 participants was significant (d = 0.32).
Lexical density
Lexical density was significantly impacted by school grade, F (9, 2161) = 4.303, p < .001, η2 = .05 (see Figure 4). Bonferroni post-hoc analyses showed significant differences between 1st and 3rd grade (d = 0.6), and 3rd and 5th grade (d = 0.6). Type of text also had a significant impact on lexical density, F(5, 2161) = 67.442, p < .001, η2 = .04. Pairwise comparisons revealed significant contrasts between definitions of a noun and explanations, recommendations and joke telling (d > 0.80), between definitions of adjectives and explanations and recommendations and joke telling (d > 0.54), and between definitions of verbs and explanations and recommendations and joke telling (d > 0.40). The interaction between school grade and type of text was significant, F (45, 2161) = 2.619, p < .001, η2 = .01. Definitions were lexically denser than the other three types of text throughout schooling. Surprisingly, the findings suggest that young children produce denser texts than their older peers. In line with the findings for word length, there is evidence of a lack of full command of grammar by younger children, e.g., Quan (en

Mean lexical density by school grade and text type.
Lexical density was significantly affected by home language, F (4, 2161) = 3.138, p = .008, η2 = .02. Unexpectedly, O<4 participants produced the densest texts (M = 42.92 SD = 0.31). They were followed by C and CS participants, both groups producing equally dense texts (M = 42.24, SD = 0.20). Next, came O>4 speakers (M = 41.89, SD = 0.26). Finally, S participants yielded the least dense texts (M = 41.82, SD = 0.22). However, these contrasts were not significant.
Nominalizations
Participants produced a significantly higher proportion of nominalizations as they progressed through school grades, F (9, 2161) = 33.933, p < .001, η2 = .10 (see Figure 5). Post-hoc analyses revealed significant differences between 1st (M = 1.81, SD = 1.01) and 5th grade (M = 3.76, SD = 2.62) (d = 1.04), between 5th and 7th grade (M = 6.06, SD = 3.31) (d = 0.78), and between 7th and 10th grade (M = 7.55, SD = 3.52) (d = 0.44).
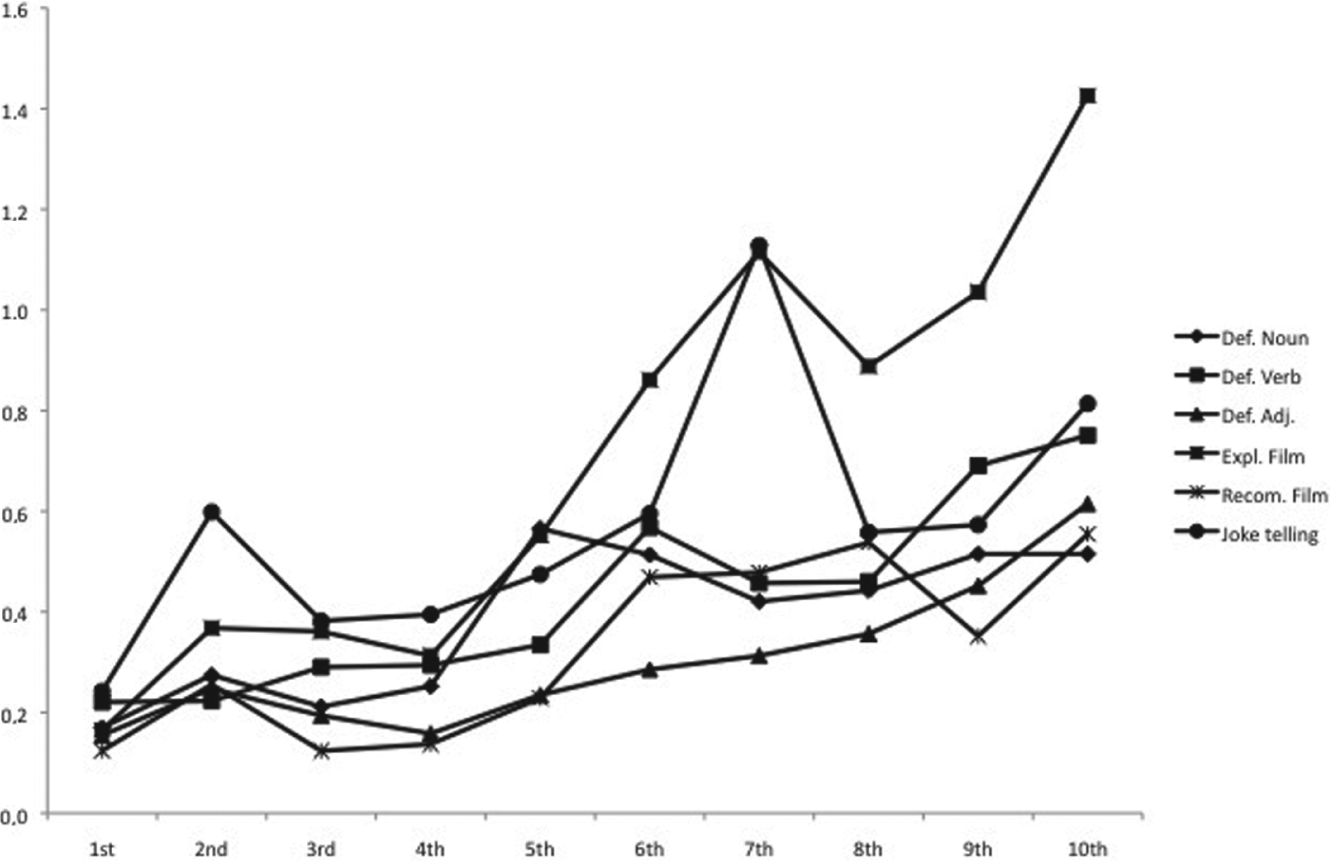
Mean proportion of nominalizations by school grade and text type.
The use of nominalizations was also significantly affected by type of text, F (5, 2161) = 57.397, p < .001, η2 = .04, and pairwise comparisons showed significant contrasts between definitions of adjectives and all other types of text (d > 0.30), between explanations and all the other types of text (d > 0.47), and between joke telling and all other types of text (d > 0.46). Explanation of a film showed the highest mean number of nominalizations (M = 7.00, SD = 3.00) and definition of an adjective showed the lowest mean number (M =2.78, SD =1.50).
Type of text had an additional effect: it was determinant in the distribution of complex versus non-complex nominalizations. Thus, definitions provided a fertile context for rich complex nominalizations, e.g., pau ‘peace’: amistat, confiança ‘friendship, trustfulness’; in contrast, recommendations of a film/TV series promoted the use of a rather basic, colloquial vocabulary, and also allowed for the presence of imported anglicisms, e.g., (…) L’advertiria també que no es deixi ‘menjar el coco’ perquè en aquest món hi ha molt de ‘marketing’ ‘(…) I would also warn him not to let himself be fooled because this field is full of marketing’. Table 2 shows the ratio of complex/non-complex nominalizations by type of text.
Ratio of complex/non-complex nominalizations by type of text.
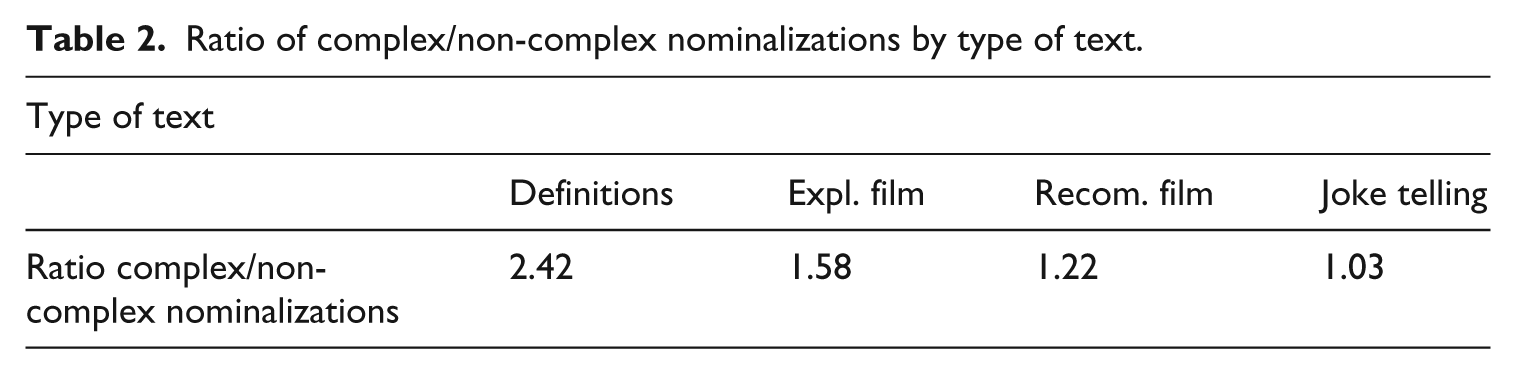
Taken together, these findings suggest that definition tasks foster the greatest use of morphologically complex vocabulary. It appears that the less school-based the type of text is the less likely participants are to use sophisticated vocabulary.
A significant interaction between school grade and type of text was also found, F (45, 2161) = 2.581, p < .001, η2 = .02. The use of nominalizations increases in every type of text. Joke telling starts off as the type of text containing the highest number of nominalizations but, in 5th grade, it is overtaken by film explanations, which from then on surpasses all other types of texts. Film recommendations and the definition of verbs obtain the poorest results up to 4th grade, but by 10th grade it is the definition of nouns that yields the lowest mean use of nominalizations.
We found a marginally significant effect of home language on the use of nominalizations, F (4, 2161) = 8.678, p = .048, η2 = .06. Post-hoc Bonferroni analyses revealed significant contrasts between the O<4 (M = 3.98, SD = 3.10) and both C (M = 5.57, SD = 1.90) (d = 0.63) and SC (M = 4.65, SD = 2.00) (d = 0.26). We found an additional significant contrast between the S group (M = 3.80, SD = 2.10) and their C peers (d = 0.88).
Adjectives
The relative proportion of syntactic categories varied within each school grade. Only adjectives (and conjunctions) showed a steady increase. Adjectives grew from 3% of the total number of tokens produced by participants in 1st grade to 9% in 10th grade.
We found a significant effect of school grade, F (9, 2161) = 28.899, p < .001, η2 = .11. The use of adjectives increases significantly throughout schooling (see Figure 6). Bonferroni post-hoc analyses revealed significant differences between 1st (M = 3.37, SD = 3.2) and 3rd grade (M = 4.71, SD = 2.9) (d = 0.44), 3rd and 5th grade (M = 6.12, SD = 2.8) (d = 0.49), 5th and 7th grade (M = 7.76, SD = 3.4) (d = 0.53), and 7th and 10th grade (M = 9.32, SD = 3.6) (d = 0.45). We observed a significant effect of type of text, F (5, 2161) = 126.863, p < .001, η2 = .11. Pairwise comparisons revealed significant contrasts between definitions of a verb and all other types of text (d > 0.82), between joke telling and all other types of text (d > 0.54) and between recommendations and all the other types of text (d > 0.35). In sum, four types of text: recommendation of a film (M = 9.97, SD = 2.7), definition of adjectives (M = 7.52, SD = 2.2), film explanations (M = 7.05, SD = 3.0) and definition of nouns (M = 6.66, SD = 2.4), favor the use of adjectives more than joke telling (M = 4.92, SD = 2.4) and the definition of verbs (M = 2.30, SD = 1.3).
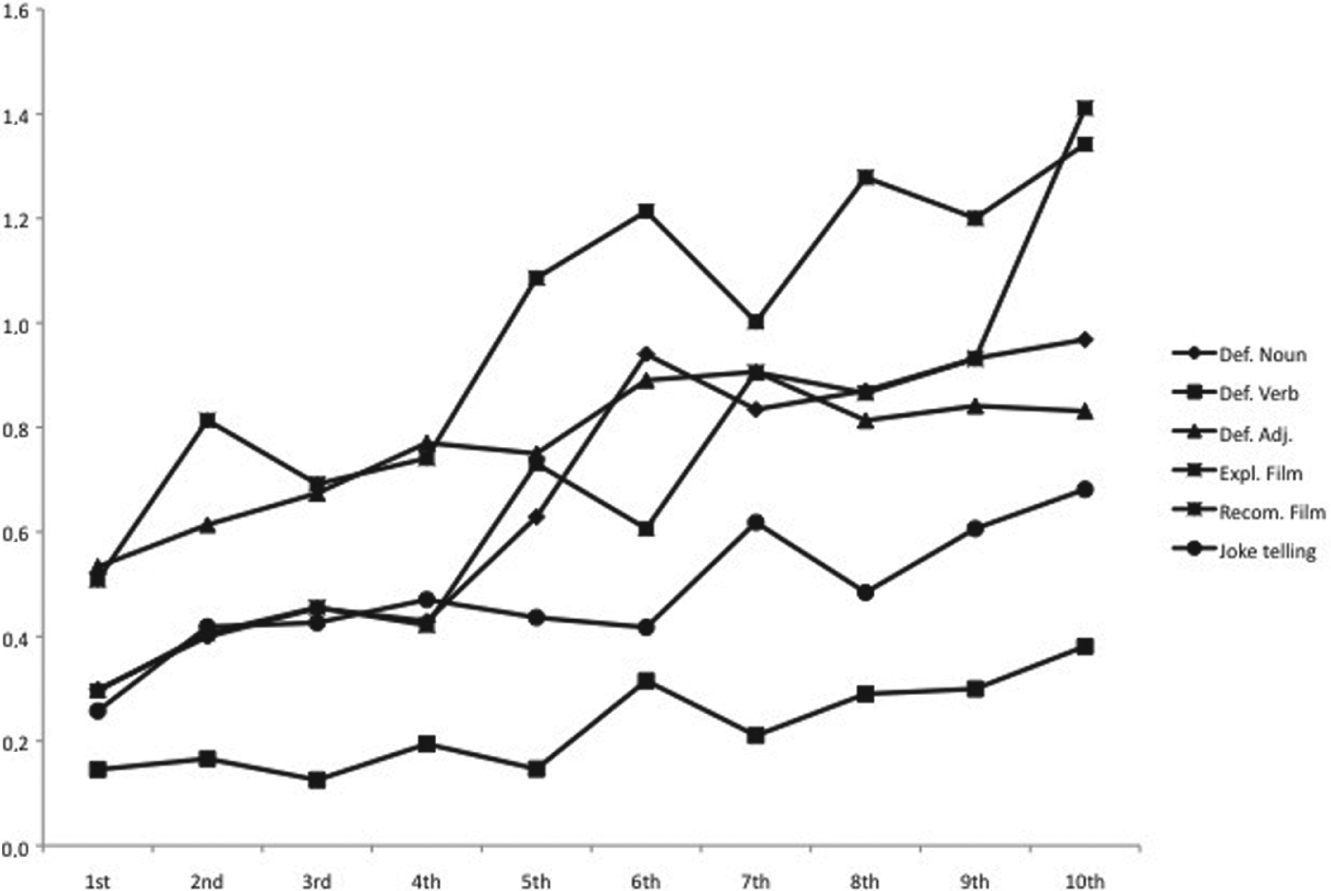
Mean proportion of adjectives by school grade and text type.
Type of text has an additional effect: it was related to the distribution of complex versus non-complex adjectives (see Table 3). For instance, definitions provided participants with the opportunity to produce sophisticated complex adjectives, e.g., fastigós ‘nasty’: esser viu despreciable ‘despicable living being’. In contrast, joke telling tended to foster the use of more basic kind of adjectives, e.g., Un acudit
Ratio of complex/non-complex adjectives by type of text.

Thus, the two types of texts most frequently practiced at school – definitions (here taken together) and explanations – appear to provide the context for the use of morphologically complex adjectives. In contrast, less school-based, more oral like texts tend to contain non-complex, i.e., more basic, kinds of adjectives.
A significant interaction was observed between school grade and type of text, F (45, 2161) = 3.493, p < .001, η2 = .06. Specifically, three types of text: definition of a noun, film recommendation and film explanation undergo a clear boost in the mean number of adjectives in 4th grade (film explanation also shows a second burst in 9th grade). Definition of a verb and joke telling fall behind the other types of text but also evidence an overall increase in adjective use. In contrast, data on the definition of adjectives indicates a more consistent pattern of use throughout the age range studied here.
Home language had a significant effect on the use of adjectives, F (4, 2161) = 8.519, p < .001, η2 = .02. Post-hoc Bonferroni analyses revealed a significant contrast, between S speakers (M = 5.8, SD = 2.0) and both C (M = 7.5, SD = 2.0) and CS (M = 6.6, SD = 2.1) (d > 0.40). O<4 (M = 0.56, SD = 0.03) speakers produced fewer adjectives than any of the other groups, though this difference was not significant.
In sum, word length, the use of nominalizations and the use of adjectives showed a developmental increase in all types of texts. In contrast, lexical density showed neither a clear developmental pattern nor consistent distributional particularities by type of text. In other words, measures determined by the proportion of content words over the total number of words (lexical density) do not seem to account for developmental changes or genre differentiation. In contrast, measures specifically related to the characteristics of the lexical pieces (length, the use of nominalizations and syntactic category) were better suited to characterize genre-specific developmental patterns.
Level of text formality
Results show significant differences by school grade, F (9, 2161) = 6.992, p < .001, η2 = .03, and type of text, F (5, 2161) = 163.162, p < .001, η2 = .07. Post-hoc analysis revealed significant differences between recommendation of a film and all the other types of text (d > 0.40), while definitions of a noun contrasted with every other text except explanations (d > 0.60).
We also found a significant interaction between school grade and type of text, F (45, 2161) = 3.594, p < .001, η2 = .01. Thus, we observed a developmental increase in text formality for definitions (of nouns, verbs, and adjectives). However, the formality of film explanations and recommendations and joke telling appear to decrease with age. This decrease was, however, far from linear and was characterized by marked ups and downs. From 5th grade on, the definition of nouns and film explanation showed higher levels of formality than other types of text. The recommendation of a film consistently yielded lower levels of text formality. Home language had no significant effect on the level of formality, F(4, 2161) = 1.988, p = .077. Figure 7 shows the mean F-level of text formality by school grade and text type.
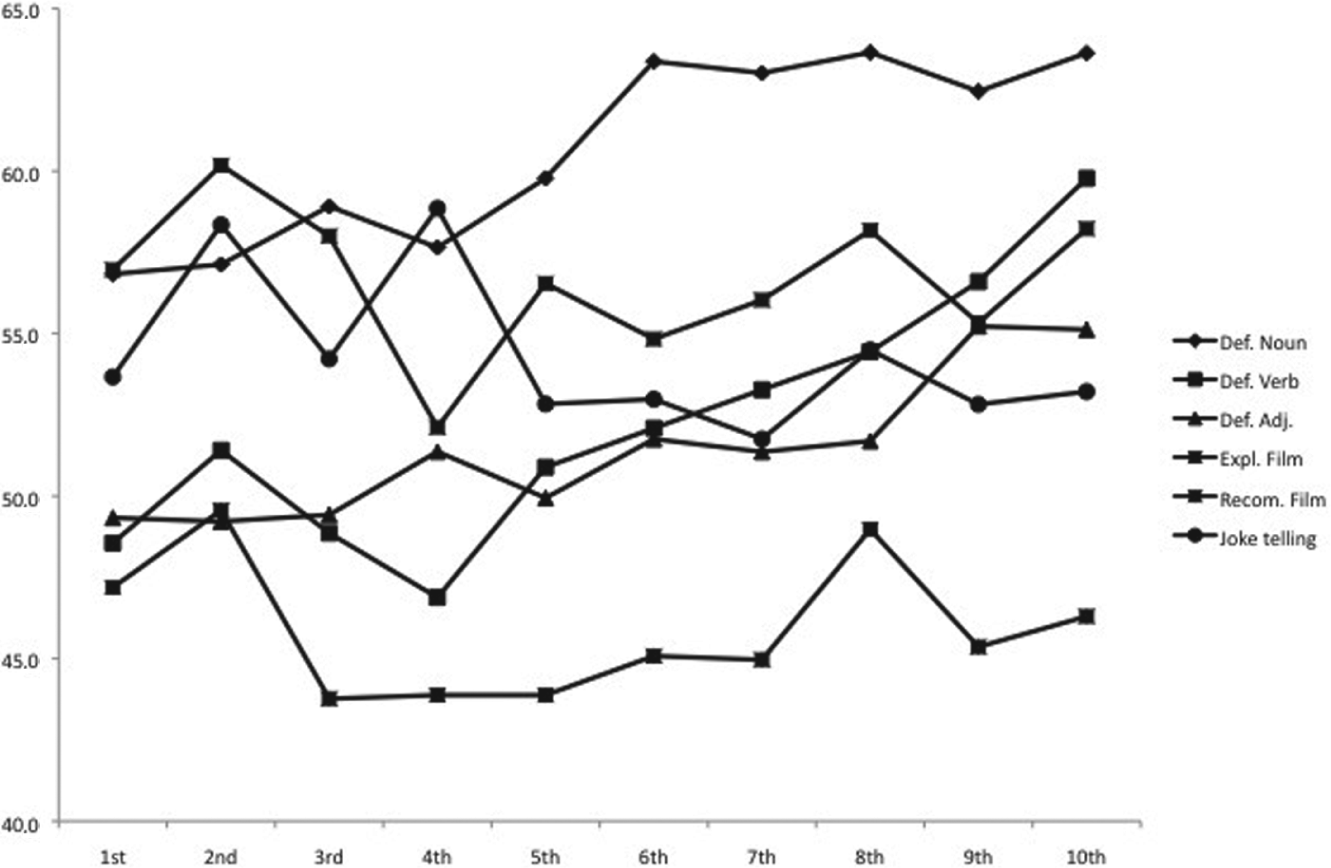
Mean F-level of text formality by school grade and text type.
Discussion
We have tracked changes in the breadth and token/characterization of the written lexicon of Catalan students from different home language background, from childhood to adolescence. The study offers four main findings. First, text-embedded lexicon increases notably throughout compulsory schooling, both behaviorally and conceptually. Second, text-embedded lexical development can be assessed by a number of measures of lexical usage. Word length, lexical density and the use of nominalizations and adjectives have been used as criteria to discriminate text-embedded lexical usage both developmentally and by genre (Johanson, 2009; Nir-Sagiv, 2005; Ravid, 2004a, 2004b). Our results support the suitability of word length, the use of nominalizations and the use of adjectives for assessing developmental lexical usage. As for lexical density, our results are less clear. We suggest that both the characteristics of the tasks and the typological characteristics of Catalan may underlie the lack of sensitivity of this measure. Third, Heylighen’s F-measure of the level of text formality is more reliable for assessing genre differences than for assessing developmental changes. Lastly, text-embedded lexical usage is somewhat sensitive to participants’ home language and familiarity with Catalan. In the following, we elaborate on each of these findings and discuss a number of the linguistic and educational implications.
Regarding lexical increase, 10th graders produced three times as many tokens as their 1st grade peers. The observed differences also affect the growth of types and lemmas. However, while the size of the lexicon (measured in tokens) did not differ significantly from 6th grade on, by age 16 their lexicon had a greater diversity and a deeper conceptual underpinning as shown by the fact that the mean number of types and lemmas continued to increase. However, further research is needed in order to examine whether such patterns continue beyond compulsory schooling.
School children’s text-embedded lexical usage is sensitive to communicative purposes and circumstances. With age and increased experience with the written language, participants produce texts that are both more informative and better adjusted to genre-specific features, affecting text length and lexical quality. In terms of length, joke telling is the first type of text to experience a marked increase in the number of tokens (by 2nd grade). This is most likely due to the combination of an initial command of writing and the reproductive, rather than productive, nature of this type of text. Next comes the narrative genre, as indexed by the explanation of a film, which shows two marked bursts, one between 4th and 6th grades and a second one at 10th grade when it becomes the wordiest type of text. The fact that narrative is the most intensively practiced genre at school may partly account for this finding. The argumentative genre, represented here by the recommendation of a film, evidences a text length burst at 4th grade, once command over the notational aspects of writing is presumably achieved and children write for increasingly different purposes. Also, age 10 (5th grade) was found to be a turning point in light of the proposal that ‘explanatory discourse’ (Blum-Kulka, 2010) allows for background, shared information and sources of knowledge (Goetz & Shatz, 2000). Finally, the data on definitions suggest a burst in the number of tokens around 4th and 5th grades – overlapping with instruction in formal definitions at school. Although definitions, whether of nouns, verbs or adjectives, are systematically the least wordy texts, there are, nonetheless, relevant differences between them. The definition of nouns is the wordiest type of definition followed by the definition of verbs and the definition of adjectives. This may be a consequence of the fact that the definition of nouns is progressively attuned to the canonical definitional pattern whereas the definition of verbs is resolved in most cases by simpler constructions of the sort córrer: que va molt depressa ‘to run: that he/she goes very fast’ and the definition of adjectives by the even more concise method of using a synonym, bo: bondadós ‘good: gentle’.
With respect to the application of the four distributional measures, our results indicate that word length, nominalization use and adjective use are the most powerful measures of text-embedded lexical usage in Catalan. Developmental changes in word length showed different patterns by type of text. For instance, it increases steadily throughout schooling in definitions, a task that even very young children take as a markedly school-based task requiring specific text structure and high level vocabulary. In contrast, it decreases between 1st and 4th grades in film explanation and recommendation, both tasks allowing for a more relaxed tone involving colloquial language and showing a relatively frequent omission of the written representation of mandatory function words. Later on, the use of increasingly sophisticated vocabulary and of more accurate morphology reverses this tendency causing word length to increase. As for joke telling, it consistently yields the shortest mean word length, possibly due to its oral-like lack of morphosyntactic complexity, and an abundance of interjections and other attention prompts. Word length in this type of text experiences no remarkable developmental changes most likely due to its reproductive character.
Next, we focus on the use of nominalizations in the texts. This was affected by both school grade and, to a lesser extent, type of text. A marked increase starts at 4th grade and continues up to 6th or 7th grade. Then, except for definitions of verbs, it decreases in all types of text during secondary school but gains new momentum by 10th grade, especially for explanations of films. This result does not support our initial predictions. We had hypothesized that the more academic-like the texts (i.e., definition) the higher the number of nominalizations. While the pattern used for definitions of nouns (super-ordinate + relative clause) appeared to foster the use of nominalizations, the pattern used for either definitions of verbs (that + simple clause) or adjectives (synonym) did not. However, a qualitative view that distinguishes between the use of morphologically complex versus non-complex nominalizations would suggest few differences between definitions and film explanations, on the one hand, and film recommendation and joke telling, on the other hand. In other words, our two academic-like texts favored the use of morphological complexity more than the other two types of texts of a more oral-like nature which accommodate more colloquial and less complex lexical choices.
Distribution of the text-embedded lexicon by grammatical category revealed that the verb category was the most used at each school grade while the adjective was the least used (interjections are dismissed here, as their percentage of use is hardly significant). In line with other studies showing the relevant growth of adjectives in later language development, adjectives (and prepositions) were the only syntactic categories that underwent a sustained increase by school grade in their percentages of use relative to other syntactic categories. Type of text also affected the use of adjectives, though not as markedly as school grade. This was particularly evident from 4th grade on, when four types of text: recommendation of a film, explanation of a film, definition of nouns and definition of adjectives, experienced a marked growth in the use of adjectives. Thus, when recommending a film, participants move from using oral-like formulae such as inviting a friend to watch the film together, to qualifying the recommended film, elaborating on plot description and their personal impressions upon watching it.
Similarly, film explanation grows from an action-based narration in the lower levels to including more in-depth elaboration of both characters and events. The definition of nouns also fosters the use of adjectives, as children gain command of the canonical definitional structure. Finally, when defining adjectives, children naturally provide synonymous adjectives from very early school grades. Definition of verbs and joke telling account for a less pronounced developmental increase in adjective use. In line with nominalizations, type of text had an impact on the distribution of adjectives by morphological complexity. Thus, the two types of texts most marked as academic-like – definitions and film explanations – concentrate higher ratios of morphologically complex adjectives. In contrast, less school-based types of text such as film recommendations and joke telling foster the use of basic morphologically simple adjectives. This characterization by morphological complexity leaves out semantic aspects (Boleda, 2006; Ravid & Avidor, 1998) that may well contribute interesting information in the processes studied here, and thus should be taken into account in future research.
The computation of lexical density yielded no clear developmental pattern, though we did find some distributional differences by type of text. Unlike other studies in which lexical density showed critical developmental differences (Nir-Sagiv et al., 2008) or at least a tendency to increase with age, we found no clear increase between 1st and 10th grade. Importantly, our sample did not include adults, the subgroup that most markedly yields an age effect for lexical density (Johanson, 2009). Also, lexical density has been tested as a measure of lexical development in studies focusing on different languages (English mostly, but also Hebrew, French and Swedish) and considerations that it could be language dependent have been suggested before (Johanson, 2009). Consistent with this argument, in Catalan, attainment of a full command of required mandatory use of function words is an important goal of school-based tasks. Consequently, short texts still showing faltering language uses written by young children might be denser than longer, more proficient texts written by their older peers.
A somewhat clearer picture arises regarding the distribution of lexical density by type of text. In line with some previous research (Nir-Sagiv et al., 2008) and in contrast to other studies that suggest limited effects of type of text on lexical density (Johanson, 2009), we found that throughout schooling definitions obtain higher scores of lexical density than film explanations and recommendations and joke telling. In other words, when producing markedly academic-like texts (definitions), participants tend to use more informative, denser language than when (re)producing more oral-like texts such as joke telling and, to a certain extent, film recommendations and film explanations. Thus, lexical density does not appear to be a reliable developmental indicator of texts written in Catalan from childhood to adolescence. Further research focusing on the use of syntactic structures in our corpus may shed light on developmental change in the use of function words that may overcome the shortcomings of this measure.
Third, we found level of text formality to be more clearly affected by type of text than by age. Only definitions, and particularly definitions of nouns, showed signs of a developmental pattern. Definition is a clear exponent of academic-like text and the development of definitional skills is well documented in the literature. It is worth noting that, despite the similarity in the magnitude of increase for the three types of definitions, the definition of nouns starts out with a higher F-score than the other two types of definitions and remains the highest. This should not surprise us, since the definition of nouns, that is, of referential entities, is commonplace in children’s interactions and also we would argue is the most practiced in school. Level of text formality for film explanation and recommendation and joke telling showed no developmental trend. It exhibited only a small overall increase in film explanations and actually decreased in film recommendations and joke telling.
A plausible interpretation of the above findings may be that, unlike definitions, both recommendation and joke telling have an oral-like, informal nature. While this would explain why these two types of text scored lower on the level of text formality, it does not necessarily imply an overall decrease. However, while Heylighen and Dewaele (1999) argue that the high frequency of pronouns reduces the level of the text formality, as we have pointed out above, the appropriate deployment of a full range of pronouns is characteristic of text formality in Catalan. Importantly, it has been argued elsewhere (Teddiman, 2009) that while the F-score works extremely well in genre discrimination − and indeed our results attest a greater effect of text type − it fares less well at accommodating internal makeup differences of the lexical categories upon which it is based. In future research, the corpus-driven oriented exploration of the intra-category frequency distribution of the use of different pronouns, for instance, may produce more enlightening results. Furthermore, we will pursue the issue of the level of text formality by adding syntactic markers. The inseparability of lexicon and syntax has been established for word production tasks (Tolchinsky et al., 2010). Pursuing this issue by addressing it in text-embedded lexical usage is therefore of relevance in order to obtain a clearer picture regarding the ways lexicon and syntax interact in the use of language in different communicative contexts.
Finally, our results attest to some effect of home language on every text-embedded lexical measure tested here. Participants who identified Catalan either as their sole home language or as their shared home language along with Spanish scored systematically higher than all other groups, implying that the extended opportunity for using the language (at least orally) for a wide variety of communicative purposes and circumstances affects performance in text writing. In contrast, participants who spoke another language or languages at home but not Catalan or Spanish and who have known Catalan for less than four years consistently obtained the poorest results. The exception was lexical density. This may have been due to the fact that these individuals produced the densest texts, which we would argue was at least partially due to their lack of full command of the language as evidenced by their erratic use of function words. These findings also suggest that lexical density may not be a suitable measure of text-embedded lexical development when studying both young and far-from-native-like speakers/writers. Interestingly, participants who speak another language other than Catalan and Spanish at home but who have known Catalan for more than four years score considerably better and, in fact, slightly overtake participants who only speak Spanish at home. This would support the view that multilingualism does not harm language development or interfere with academic performance.
Implications
Our findings have a number of linguistic and educational implications. First, whereas word length, the use of nominalizations and the use of adjectives gain validity as measures of text-embedded lexical usage, there is some doubt as to the reliability of lexical density. Further research on the lexical density of written texts in typologically distinct languages is needed in order to establish the true power of this measure to cross-linguistically assess written texts. Second, by including data on non-narratives, this study makes a contribution to developmental studies, which, with some notable exceptions (Nippold, 1998; Scinto, 1986; Scott & Windsor, 2000), have traditionally been more focused on the narrative/expository division. Here, we have included joke telling and film recommendation, two types of texts that remain underexplored so far. As we expected, joke telling yields a less marked developmental pattern than its counterparts. Notably, the number of tokens and word length (both strong developmental measures) show an increase with age but do so at a lower rate than in other types of texts. As for film recommendations, they serve here as ‘explanation’ in the sense used by Blum-Kulka (2010), because they afford an opportunity for the justification of one’s arguments. Our results suggest that the recommendation of films is a genre that particularly fosters the use of adjectives, more so than the explanation of films. Thus, we expand the widely held conception that narratives are the most natural setting for the occurrence of adjectives to include argumentative genres. It is also interesting to note that writing down the recommendation of a film appears to allow for a wide range of register distinctions, from very spoken-like texts, e.g., he!! as de veure vendela!! no tu pots perdre!! ho fan al dilluns i el dimart!! ho fan a les 10 i 10 o a les 10 i 1/2. ‘Hey!! You must watch it!! You can’t miss it!! It’s on Mondays and Tuesdays!! It’s on at 10:10 or 10:30’ to other, far more distant, informative, written-like language, e.g., Es una sèrie molt entringuda i divertida on la barreja d’humor, drama, amor acció, sarcasme i ironia són constants i molt bé combinats. ‘It is a very entertaining, funny TV movie where humor, drama, love, action, sarcasm, and irony are constantly mixed up and very well balanced.’ The notable effect of type of text on most of the measures tested here provides evidence of the importance of assessment of lexical development in text-embedded contexts.
As for the educational implications, our findings highlight the relevance of providing extended opportunities for practice in a wide variety of genres as part of the school curriculum. To the best of our knowledge, this is not always the case in Catalan schools especially before 4th grade, since children are kept focused on the notational aspects of writing. The fact that we have found the 4th grade to be a clear turning point regarding participants’ ability to adjust to genre-specific requirements reopens the debate as to the importance of giving young children ample opportunities to gain command of the writing system by producing authentically motivated pieces of text.
The existence of this corpus, which is publicly accessible at http://clic.ub.edu/cesca, enables psycholinguists and educationalists to obtain an updated picture of the state of the Catalan language as it is used in writing by children attending compulsory education from childhood to adolescence.
Footnotes
Funding
This research received no specific grant from any funding agency in the public, commercial, or not-for-profit sectors.