
Abstract
The comprehension of constituent questions is an important topic for language acquisition research and for applications in the diagnosis of language impairment. This article presents the results of a study investigating the comprehension of different types of questions by 5-year-old, typically developing children across 19 European countries, 18 different languages, and 7 language (sub-)families. The study investigated the effects of two factors on question formation: (a) whether the question contains a simple interrogative word like ‘who’ or a complex one like ‘which princess’, and (b) whether the question word was related to the sentential subject or object position of the verb. The findings show that there is considerable variation among languages, but the two factors mentioned consistently affect children’s performance. The cross-linguistic variation shows that three linguistic factors facilitate children’s understanding of questions: having overt case morphology, having a single lexical item for both ‘who’ and ‘which’, and the use of synthetic verbal forms.
Introduction
Research in language acquisition is most frequently conducted with a focus on one or two particular languages. Such research has led to many interesting findings, including differences between languages. But studies designed only for one or two languages are often not the best way to address questions of how specific properties of the target language affect the acquisition process. The reason is that such studies often need to be adjusted in non-trivial ways before they can be carried out for a different language, which makes it impossible to compare the results across studies. Recently, a number of works have appeared that compare a larger sample of languages (Armon-Lotem et al., 2016; Katsos et al., 2012; Tribushinina et al., 2013; Varlokosta et al., 2016; Xanthos et al., 2011) within a single study. These studies have addressed passives, quantification, pronouns, inflection, and adjectives. The study we report is the first to target constituent questions for a larger sample of languages.
The understanding of constituent questions represents an important area of investigation in language acquisition studies (Thornton, 1990; van der Lely & Battell, 2003; van der Lely & Pinker, 2014, among others). The interest in this area is both theoretical and practical. The theoretical interest derives from the fact that questions are distinguished from declarative sentences in many languages by word order. Most prominently, the questioned constituent occupies an initial position in English and most other European languages. Especially interesting is that, as a consequence, the order of subject and object in a question can deviate from the canonical order of the two arguments. Consider for example the English object question in (1). The grammatical object is who, but in (1) it occupies the initial position and therefore precedes the subject the fairies. But the canonical order of subject and object in a declarative is the reverse: The fairies are catching the queen. Much research starting with Chomsky (1957) has argued that who in (1) is related to the post-verbal position. We specifically assume an account of (1) involving a movement transformation, though we hasten to acknowledge that approaches involving coindexation, copying, and structure sharing instead of movement also exist and our study was not designed to distinguish between these different theoretical analyses of adult grammar.

Movement relations are a central interest in theoretical syntax, but also important for many related fields. The study of movement relations in child grammar has provided important evidence for theorists to rely on. Acquisition research has corroborated theoretical syntax with the finding that children find object questions like (1) more difficult to understand than subject questions such as (2) (Seidl, Hollich, & Jusczyk, 2003; van der Lely & Battell, 2003, and others). 1
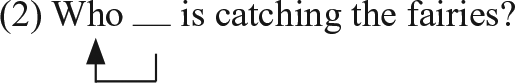
A difference in difficulty between (1) and (2) is predicted by syntactic theories that assume that who and the verbal argument position in (1) must be related in some way. Because the relationship between object who in (1) and its argument position is longer than that between subject who and its argument position, (1) is predicted to be more difficult since the wh-phrase who must be held in memory for longer. In this study, we provide further evidence for this prediction of syntactic theory.
We address two further theoretical issues. The first is how the properties of the moved phrase and the subject affect child success at understanding object questions across different languages. To do this, we compare who with which- phrases like which princess relating to both subject and object positions. This comparison also allows us to address the proposal by Adani, van der Lely, Forgiarini, and Guasti (2010), Friedmann, Belletti, and Rizzi (2009), Guasti, Branchini, and Arosio (2012), and others, that the difficulty of object movement in children is caused by a difference between adults and children in the syntactic principle Relativized Minimality (Rizzi, 1990, 2004, 2013) or related conditions such as the Minimal Link Condition (Chomsky, 1995). The Relativized Minimality account predicts that the difficulty of object extraction as in (1) should depend on properties of the moved object phrase, as we discuss below. The proposal is controversial (Goodluck, 2010; Varlokosta, Nerantzini, & Papadopoulou, 2015), and some of the original studies claiming to support it worked with very small sample sizes (15 and 22 participants in Avrutin, 2000; Friedmann et al., 2009 respectively), so it is important to have new, stronger evidence to evaluate the proposal.
Second, we investigate how sensitive children are to different cues that indicate that the fronted phrase is to be related to the object position. In English, the differences between (1) and (2) are verbal agreement and the position of verb relative to the object. But languages differ in the number of disambiguation cues they use. Consider for comparison the Serbian subject and object question in (3a) and (3b). Serbian differs in two ways from English: Case marking on the initial interrogative pronoun (and also on the other noun phrase in the sentence) distinguishes between the subject and object questions, while the word order of the verb and the other argument does not. Some work has already shown that different disambiguating factors affect children’s performance differently (Adani et al., 2010; Arosio, Yatsushiro, Forgiarini, & Guasti, 2011; Guasti, Stavrakaki, & Arosio, 2012; Varlokosta et al., 2015), but no study has yet compared more than two languages.
(3) SERBIAN a. Ko gura princeze? who.NOM push.3SG princesse.ACC.PL.FEM ‘Who is pushing the princesses?’ b. Koga guraju princeze? who.ACC push.3PL princess.NOM.PL.FEM ‘Who are the princesses pushing?’
Our study is also of practical importance for the diagnosis of atypical child language in Europe. Several studies have established that understanding of object questions as well as similar structures (e.g. object relative clauses) is impaired in specific language impairment (SLI, van der Lely & Battell, 2003 and others). For this reason, several diagnostic tests for SLI employ structures such as object questions (e.g. the GAPS test, Gardner, Froud, McClelland, & van der Lely, 2006; van der Lely, Gardner, McClelland, & Froud, 2007) or object relative clauses (e.g. the TROG test, Bishop, 2003). But the test designs are primarily based on research on English. At the same time, researchers and practitioners have in some cases created adaptations of the tests for other languages. For many languages with fewer speakers than English, such an adaptation of the fruits of the research on English can be an effective strategy to meet a demand for language diagnostics. But the strategy carries a risk if we do not know how the individual properties of a specific language affect the acquisition process and interact with language impairment. It could be, for example, that the presence of case marking in Serbian changes how sensitive question understanding tests are to SLI. In this study, we investigate the influence of grammatical variation on the understanding of questions in typical 5-year-olds across Europe.
Methods
Design
The two factors investigated within each language were whether the wh-phrase is simple (in English, who) or complex (in English, e.g. which princess) and whether it is the subject or object argument of the verb. This leads to a 2 × 2 design and we created six items for each of the four conditions. Sample items in English are shown in (4). All English items and sample items for all 18 languages are presented in the Appendix.

The lexical material used was selected to make it possible to translate the items into the 18 languages under study without introducing confounds for the cross-linguistic comparison. In particular, we avoided items that would be ambiguous in one of the target languages in a relevant way. Such an ambiguous translation would have arisen, for example, if we had used items with a singular definite as illustrated by German (5). (5) is globally ambiguous between the subject question and the object question interpretation, which are distinguished in English by the position of the verb.
(5) Welche Frau schiebt die Prinzessin? which woman pushes the princess ‘Which lady is pushing the princess?’ / ‘Which lady is the princess pushing?’
With the plural definite, verbal agreement disambiguates between the two interpretations as shown in (6). When the verb has singular agreement only the subject question interpretation is possible, and with plural agreement only the object question interpretation. All items with two lexical nouns like (4b) and (4d) contained a number contrast. Namely, the fronted question phrase was singular, and the other argument of the verb was marked plural. Because of the number contrast, verbal agreement for number could serve as a cue as to whether a subject or object interpretation was correct at least in these items (i.e. those of the complex condition).
(6) a. Welche Frau schiebt die Prinzessinen? which woman push.SG the princesses ‘Which lady is pushing the princesses?’ b. Welche Frau schieben die Prinzessinen? which woman push.PL the princesses ‘Which lady are the princesses pushing?’
Furthermore, we ensured that the items were uniform in each language with respect to morphological marking for case and gender, and verb complexity. We chose lexical nouns that are morphologically marked as the same gender in all languages; namely, feminine in languages with masculine, feminine, and neuter gender, and as common gender in languages with only common and neuter gender. The six nouns we used are princess, queen, granny, lady, fairy, and dancer in English. Furthermore six verbal actions were chosen so that two criteria would be satisfied for all 18 languages involved. The first criterion was that the actions could be described by a monomorphemic verb root in all 18 languages. The second criterion was that all six verbs exhibit uniform case properties within each of the languages. Since languages such as Finnish and Lithuanian exhibit a rich case system, we made sure that in all examples the case marking of the object arguments was identical. The six verbs used are push, pull, wash, catch, feed, and scratch in English. In some languages, the verb for tickle was used instead of the one for scratch.
The items were created simultaneously in the 18 languages in this study: Estonian, Finnish, Maltese, Hebrew, Greek (both Standard and Cypriot), Lithuanian, Croatian, Serbian, Polish, English, German, Dutch, Danish, French, Italian, European Portuguese, and Romanian. 2 For each language, we used a general, natural way of asking constituent questions, but within each language the same pattern was used consistently for all items of the same type. The Appendix presents a set of four sample items for each language. In addition to the different cues (word order, case, agreement), variation between languages exists in at least three other respects: first, whether a synthetic or analytic verb form is used, as illustrated by the contrast between the analytic English progressive forms like is pushing in (4) and the synthetic Serbian present tense form like gura (‘push’) in (3); second, whether a cleft structure was used for the question in the European Portuguese example (7); and third, whether the object questions used a clitic pronoun doubling an argument as in French (8).
(7) Quem é que está a puxar as senhoras? who is-3SG that is-3SG at pulling the-PL ladies-PL? lit. ‘Who is (it) that is pulling the ladies?’ (‘Who is pulling the ladies?’) (8) Qui les grands-mères grattent-elles? who the grand-mother.PL scratch-they ‘Who do the grannies (they) scratch?’
Children’s understanding of the questions was tested in a picture choice task. The same pictures were used for all 19 test sites. The samples in Figure 1 illustrate this aspect of the task. In addition to the target picture three alternative pictures were shown as choices corresponding to three different types of misunderstandings. Specifically, these were: (1) A number error picture corresponding to the question where the number of the non-questioned argument is singular rather than plural as in (9b). Note that, in object questions children committing a number error also ignore number agreement on the verb which Johnson, de Villiers, and Seymour (2005) show that 5-year-olds are sensitive to in other cases. (2) A reversal error picture corresponding to the question where the grammatical roles of subject and object are switched as in (9c). Because the subject and object phrases also differ in number, the reversal error entails also an error on the number agreement of the verb, but not the number marking on the nominals. (3) A semantic verb error corresponding to a question where verb is different from the verb in the actual question as in (9d).
(9) a. actual question: Who are the queens washing? b. number error: Who is the queen washing? c. reversal error: Who is washing the queens? d. semantic verb error: Who are the queens chasing?

Sample picture choice displays for items 15 on the left and 19 on the right. For item 15, the four possible responses correspond to positions as follows: ‘CORRECT’ is top left, ‘REVERSAL ERROR’ is bottom left, ‘NUMBER ERROR’ is bottom right, and ‘SEMANTIC VERB ERROR’ is top right. For item 19, the correspondence is: ‘CORRECT’ is top right, ‘REVERSAL ERROR’ is bottom left, ‘NUMBER ERROR’ is top left, and ‘ SEMANTIC VERB ERROR’ is bottom right.
At each test site, all items were recorded by a native speaker of the local variety of the target language. Two versions of the experiment were created as a Microsoft PowerPoint presentation. The two versions only differed with respect to the order of the experimental items, and we refer to them as order A and B in the following. The experiment included three initial slides as part of the instructions to the child. The first slide introduced all the six types of characters involved in the slides. The second and third slides were practice items. The experiment was presented to the participants on a laptop computer using the internal speakers of the laptop. Participants were asked to indicate their answer to the question by a hand gesture, which was recorded by the experimenter. The results were then coded at each site in an anonymized format and collected centrally for the analysis.
Participants
Both children and adults participated in the experiment. The 392 child participants were tested in 19 different countries with 18 different languages. The age range was 4;10 to 6;0. The number of child participants and language, age, and gender information at the individual test sites is shown in Table 1.
Overview of country and language distribution of 392 child participants.
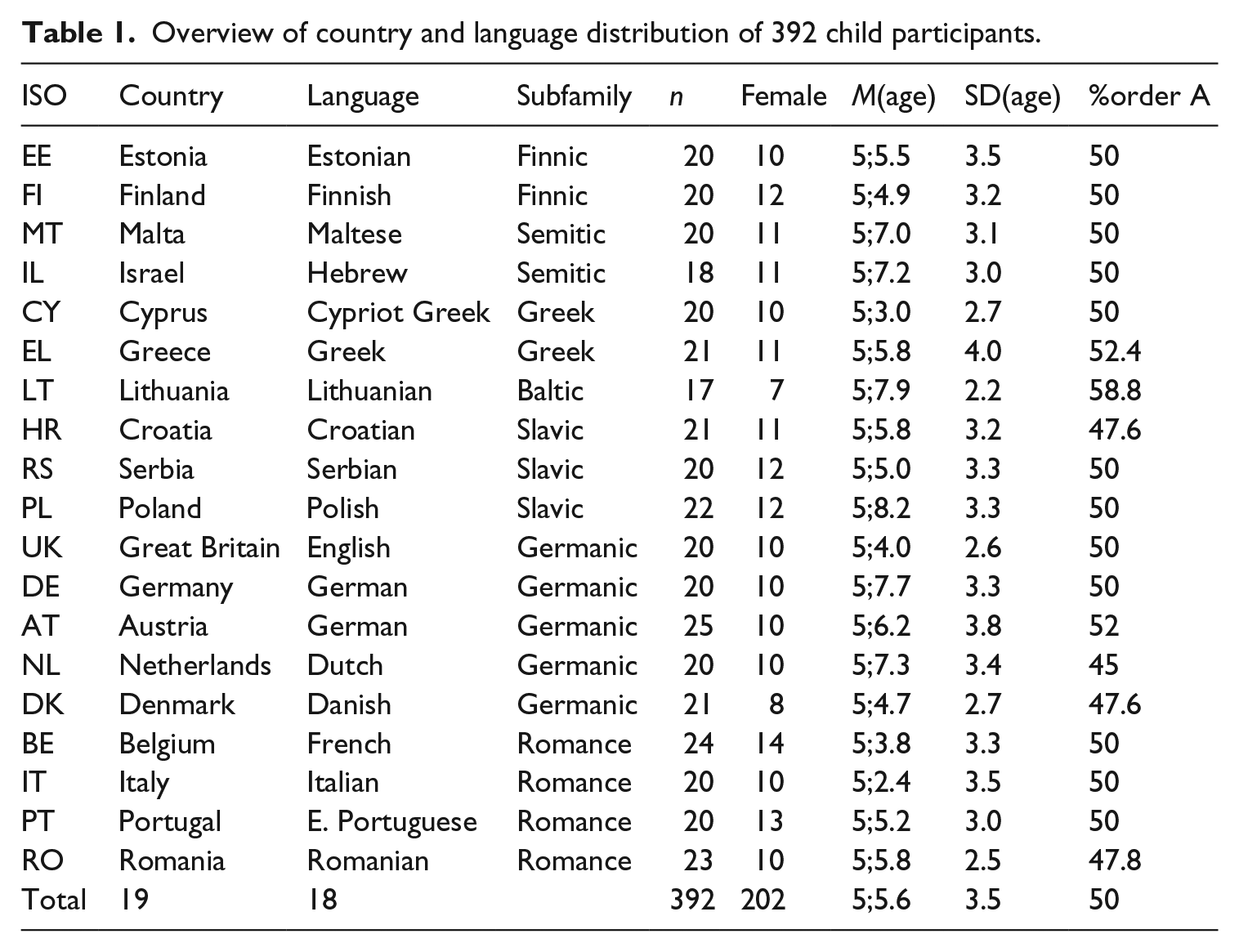
In the following, we frequently use the two letter ISO country codes shown in the first column of Table 1. The number of child participants varied between 17 (Lithuania and Israel) and 25 (Austria). In each country at least 7 children of either gender participated. The mean age of children differed by almost 6 months between the youngest (Italy) and the oldest (Poland) group. The age differences are in part explained by the variation in school entry age across the European countries and whether our collaborating educational institution was a pre-school or a primary school. In the statistical analysis, we therefore include age as a factor of the analysis to differentiate the effects of age and language. Finally, order A and order B of the list of test sentences are close to balanced in each country with a 58.8 : 41.2 balance in Lithuania the furthest away from the ideal 50:50 balance. In addition to the children, 59 adults (38 females, 21 males) participated in the study in 6 countries. The number of adult participants by country was 10 Estonia, 11 Croatia, 10 Lithuania, 10 Malta, 5 Netherlands, and 13 Poland. Unfortunately it wasn’t possible to obtain adult data from all 18 languages in this study, but we still found the adult data useful to exclude five problematic items.
Linguistic factors
To capture the effects of cross-linguistic variation, we coded specific linguistic properties that varied across the languages in our sample. The eight linguistic factors that we included in the cross-linguistic analysis are agreement (agr), word order (wo), distinctive case morphology (case), one wh-marker (1wh), cleft structure (clf), synthetic verb form (syV), clitic doubling (ClD), and subject pro drop (pro). The values of the eight factors are shown in the Table 2, and we explain in more detail in the following how we arrived at these value. All factors are binary at the item level. The symbol ⚫ in Table 2 indicates that the factor is true for all items of the language, the symbol ⚪ indicates the opposite. The symbol ☉ indicates that the items of the respective language are not uniform with respect to the factor, e.g. simple wh-phrases in some cases differ from complex wh-phrases. The items used in Germany and Austria were identical in the written form, so there is only one column for these two countries. The voice recordings for the two countries were different though, to match the local pronunciation.
Table of linguistic factors considered in the analysis.

Consider in more detail the eight factors represented in the table in the order given. Agreement (agr) represents whether number agreement of the verb is distinct for the subject questions and object questions, and thus could serve as cue to understand the question correctly. In two languages (Italian and Dutch) agreement is the only cue. Dutch is unusual: The Dutch equivalent of English *‘Who are singing?’ is grammatical if the expected answer is a plurality. As a consequence, the Dutch translation of the object question given in (10) outside of a specific situation is ambiguous between a subject and an object question interpretation. In the experimental situations, however, it was always disambiguated to a subject question interpretation by the fact that none of the four pictures matched the object question interpretation. Since the agreement marking itself does not disambiguate (10) syntactically, the factor agreement was false for Dutch who questions. But Dutch complex singular wh-phrases such as welke prinses (‘which princess’) are disambiguated by number agreement of the verb. This is represented by ☉ in Table 2.
(10) Wie trekken de prinses-sen? who pull.3PL the princess-PL ‘Who is pulling the princesses?’ / ‘Who are the princesses pulling?’
In Danish, we used question structures where verbal agreement does not distinguish between subject and object questions.
Word order (wo) indicates whether the order of the main verb and the definite noun phrase distinguishes between the subject and object questions. In our sample verb-medial (SVO) languages like English (see example (4)) have the entry ⚫ here, while the entry for verb-final (SOV) languages like German (see example (5)) is ⚪. 3 Case (case) captures whether there is overt case marking that distinguishes between subject and object questions. The table entry for English here is ⚪ because the form of the wh is always who or which. 4 Serbian as shown in (3) is a language with case morphology. The entry for German is ☉ because the simple wh-forms wer vs wen in German show case morphology, but the complex forms in the feminine gender do not. 5
The factor 1wh indicates whether the simple and complex wh-phrases use the same morpheme or two different ones. The entry for English is ⚪ because the morphemes who and which are distinct. But in Finnish, the simple wh-word kuka (‘who’) is exactly the same as the form used for complex wh-phrases such as kuka keiju (‘which fairy’). In Greek and Cypriot Greek the two forms are not exactly identical as used in the examples, but this is because the simple form pjos (‘who’/‘which.M’) corresponds to the masculine singular agreement while the feminine form pja (‘which.F’) is used as part of the complex phrases. The factor clf (cleft) indicates whether the question used had the structure of a cleft (see the Portuguese (7) above). In French, the subject questions used a cleft structure, but not the object questions. The factor syV (synthetic verb form) shows whether the verb form consisted of a single (inflected) verb or involved auxiliaries. In English, the use of the progressive forms is/are pushing is represented by the ⚫ entry in the table. The factor ClD (clitic doubling) indicates whether any argument phrase in the question was doubled by a pronoun (see (8) above). In Romanian, clitic doubling is optional with simple wh-phrases and obligatory with complex (D-linked) wh-phrases. We used clitic doubling only with the latter, hence the table entry ☉. Finally the factor pro indicates whether the language in question permits the omission of subject pronouns (i.e. the pro drop parameter of Chomsky, 1981). For example, in English omission of she from ‘She is sneezing.’ is ungrammatical, and it has the entry ⚪. None of our experimental items contained a subject pronoun, so a possible effect of factor pro would have to be a language level effect. Glossed sample items for all 18 languages are provided in the Appendix.
Statistical analysis
Statistical analyses were performed using R (R Core Team, 2012) and mixed logit models (Bates et al., 2015) for each response type. We used a stepwise forward inclusion procedure, starting with the null model with only the random factors Subject and Item. We then added one potential predictor at a time and compared the model with the predictor against the one without it using a χ2-test (Jaeger, 2008). We first tested whether presentation position or the verb used would significantly improve model fit. Then the fixed factors age (in months), argument type, wh-type, case, agr, and wo were considered in this order in all analyses. For the analysis of correct responses, we furthermore introduced the other five linguistic factors from Table 2 in the order 1wh, clf, syV, ClD, and pro. In all the models, the reference category for the predictor Argument type is object questions, for Wh-type is which-phrase, and for the linguistic factors of Table 2 the value marked ⚪ in the table. Both first-level effects and interactions between the fixed-effect factors were examined. Thus, we established which factors contributed significantly to the model’s fit. Based on z values (Wald statistics), we obtained an estimation of the statistical significance of each predictor in the model.
Mixed logit models do not provide an intuitive measure of effect sizes but the coefficients we report are the log of the odds-ratio due to the predictor (Hosmer, Lemeshow, & Sturdivant, 2013, Ch. 3, and others). For example, the coefficient 0.544 for predictor Wh-type in Table 3 shows that the odds of a correct response are exp(0.544) = 1.723 times higher for simple than for complex wh-phrases. For reader convenience, we report in Table 3 also individual percent correct ratios (ind %cr) for the presence/absence of the significant predictors of correctness as an intuitive measure. These values have no direct interpretation in our multifactorial model, but provide an intuitive measure of the effects of the predictors. Take the predictor Wh-type in Table 3 as an example: the individual probabilities correspond to odds of 644 : 366 = 1.760 and 513 : 487 = 1.053 and the ratio of these two odds, 1.671. This value is similar to the exponent of the coefficient of the logit model for Wh-type, 1.723, but because the logit model takes into account other factors the two values are not identical.
Summary of the fixed effects in the mixed logit models for children for correct responses.

Note. Random effects for participants and items had SD of 0.64 and 0.31, respectively.
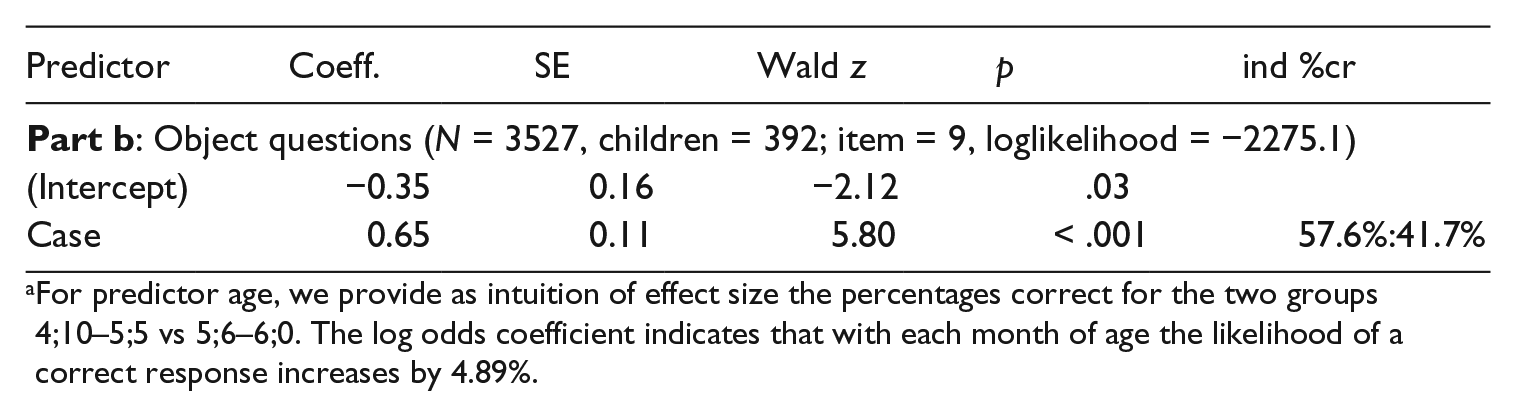
For predictor age, we provide as intuition of effect size the percentages correct for the two groups 4;10–5;5 vs 5;6–6;0. The log odds coefficient indicates that with each month of age the likelihood of a correct response increases by 4.89%.
Results
We obtained 24 responses per subject. Items 4, 10, 13, 16, and 22 were excluded from the further analysis for the following reasons: Items 4, 10, 16, and 22 used the verb catch and required a distinction between a picture depicting pull and one depicting catch. They showed adult semantic verb error rates up to 35.6%. Item 13 showed an even higher rate (40.7%) of semantic verb errors in the adult results. After these exclusions, the number of correct responses by adults was 96.8% (MT 94.9%, LT 100%, HR 95%, PL 98.5%, NL 89.8%).
In the following, we analyze the data from 392 children on the 19 remaining items, which amounts to 7446 responses because two responses are missing. Figures 2 and 3 show the frequency of the four possible responses across the 19 sites. Figure 2 compares the subject questions with the object questions. There are two languages where the object questions elicited more correct responses than the subject questions, namely, Hebrew and Polish. At the other 17 sites, subject questions elicited more correct responses with the greatest difference in Dutch. The number of reversal errors also shows an interesting pattern since it is higher for object questions than for subject questions at all 19 sites.

Comparison of subject (red) vs object (blue) questions across 19 countries. Correspondences: Dark red/blue – correct; light red/blue – number error; dark grey – reversal error; light grey – semantic verb error.

Comparison of simple (red) vs complex (blue) questions for 19 countries. Correspondences: as in Figure 2.
Figure 3 displays the same data as Figure 2, but as a comparison between simple and complex questions. The number of correct responses for simple questions is higher than for complex questions across all 19 countries. But the effect of the factor simple vs complex seems to vary less across languages than that of subject vs object. For more detailed findings, we proceed to the statistical analysis.
In the first model we computed, Correct response was the dependent variable. Following the stepwise inclusion procedure described above, we first verified that neither the presentation position of an item nor the verb used were significant factors. Of the other fixed factors, the following factors contributed significant information and were included in this order where we show the significance of improvement in model fit for each step: Age [χ2(1) = 14.08, p < .001], Argument type [χ2(1) = 6.18, p = .01], Wh-type [χ2(1) = 11.55, p < .001], and Case [χ2(1) = 10.11, p < .01]. An interaction Argument type × Case was also significant [χ2(1) = 43.07, p < .001]. Part a of Table 3 indicates that the probability of correct responses increases with age; it also increases from object to subject questions (positive coefficient, 0.93), from complex to simple questions, from questions lacking morphological Case to questions with morphological Case. To unpack the interaction (Sentence type × Case), we ran separate analyses for subject and object questions. Case provided significant information in object questions [χ2(1) = 36.58, p < .001]: object questions with Case were better understood than object questions without Case. This is illustrated in Table 3, Part b. The probability of correct responses increases from object questions without Case to object questions with Case. Word order (wo) was also found to significantly contribute to model fit [χ2(1) = 10.83, p < .001]. Finally, two further linguistic factors contributed significantly: 1wh [χ2(1) = 31.11, p < .001] and syV [χ2(1) = 10.51, p < .002]. Table 3 shows that the probability of a correct response increases if words for who and which are identical and if the questions used a synthetic verb form. In the model we had thus arrived at, the factor wo did not contribute a significant effect anymore, and we verified that the fit of a model not including wo as a predictor did not fit significantly worse than the one that included wo [χ2(1) = 0.64, p = .42]. Hence the final model we report below excludes wo.
As discussed above, column ‘ind %cr’ of Table 3 shows the individual ratio of correct response percentages as an intuitive measure of effect size. For the factors Argument type and Case that also interact with each other, the picture is more complicated. For the significant interaction between Argument type subject and Case the corresponding probabilities are a 2 × 2 matrix with the following values: Argument type subject with Case morphology, 63.4%, without Case, 62.2%, object with Case: 57.6%, and object without Case: 41.7%. Table 4 shows the individual % correct ratios for the factors that were not significant predictors of correct responses.
Individual percent correct for non-significant factors.

The ratio reported excludes subject questions since clitic doubling only occurred with object questions in our sample.
Notable about Table 4 is that the last three non-significant factors exhibit ratios more extreme than some of the significant predictors. But note that all three also correlate strongly with some of the significant predictors as can be seen in Table 2. Specifically, clf in French and ClD in both French and Romanian correlate with Argument type. Factor pro matches factor Case for 15.5 out of 18 languages, 6 and Case exhibits an individual ratio more skewed than pro. To verify that including Case rather than pro as a factor in the model is justified, we first compared the significance of the two at the step of the inclusion procedure where Case was added, but in both cases the significance was so great that the software we used showed no difference. We then computed a model including factor pro in addition to the predictors of the model described in Table 3. Since we found pro was not a significant predictor, while Case remained a significant predictor, we decided to report the model including Case. Factor pro also matches factor 1wh for 13 out of 18 languages, but 1wh exhibits an individual ratio more skewed than pro too. To further confirm that inclusion of 1wh over pro yields a better model, we compared the two at the step of the inclusion procedure at which we tested 1wh. Including pro instead at this point also would improve model fit, but the significance of the improvement was much lower [χ2(1) = 6.37, p = .012 for pro vs χ2(1) = 31.1, p < .001 for 1wh].
In the error analysis, we did not consider the linguistic factors other than Case, Agreement (agr), and Word order (wo) because we had no specific hypothesis for these. Children made three different types of errors: Reverse, Number, and Semantic errors. In the second model with Reverse response as the dependent variable in Table 5, the following factors contributed significant information and were included: Argument type [χ2(1) = 34.96, p < .001], Wh-type [χ2(1) = 5.09, p < .05], Case [χ2(1) = 36.30, p < .001], and wo [χ2(1) = 55.22, p < .001]. The interactions Argument type × Case [χ2(1) = 29.76, p < .001], Argument type × wo [χ2(1) = 47.83, p < .001], Wh-type × wo [χ2(1) = 8.23, p < .01], and Case × wo [χ2(1) = 22.20, p < .001] were significant. To unpack the first two interactions we ran separate analyses for subject and object questions and found that Case and wo mattered only for object questions. The probability of making a Reverse error decreases from object questions without Case to object questions with Case, and from object questions with –wo to object questions with +wo, as evident in Table 5 part b. Then, we ran separate analysis for wo. Predictor Argument type was significant for both +wo and –wo languages shown in parts c and d of Table 5. Subject questions were less likely to receive a Reverse response in both language types, but the effect was weaker in +wo languages. Wh-type was only significant for –wo languages, where Simple questions were less likely to receive Reverse responses. Case, however, only was significant for +wo languages, where the combined absence of wo and Case saw more Reverse responses.
Summary of the fixed effects in the mixed logit models for children for Reverse responses.

Note. Random effects for participants and items had SD of 0.73 and 0.29, respectively.

Note. Random effects for participants and items had SD of 1.02 and 0.0001, respectively.

Note. Random effects for participants and items had SD of 0.64 and 0.29, respectively.

Note. Random effects for participants and items had SD of 0.77 and 0.31, respectively.
In the third model with Number response as the dependent variable in Table 6, the following factors contributed significant information and were included: Age [χ2(1) = 14.29, p < .001], Argument type [χ2(1) = 7.58, p < .01], Wh-type [χ2(1) = 5.72, p < .05], and wo [χ2(1) = 8.77, p < .01]. The interactions Argument type × wo [χ2(1) = 7.98, p < .01] and Wh-type × wo [χ2(1) = 3.99, p < .05] were also significant. To unpack them, we ran separate analyses for +wo and –wo languages. The two predictors Argument type and Wh-type were only significant in –wo languages. Specifically, subject questions received more Number Error responses than object questions, and simple wh-phrases received more Number Error responses than complex wh-phrases in –wo languages as evident in part b of Table 6.
Summary of the fixed effects in the mixed logit models for children for Number Error responses.

Note. Random effects for participants and items had SD of 0.61 and 0.24, respectively.

Note. Random effects for participants and items had SD of 0.67 and 0.31, respectively.
In the fourth model, with Verb Semantic Error response as the dependent variable, only Case was a significant predictor [χ2(1) = 12.06, p < .001]. As Table 7 shows, more Verb Semantic Errors occurred in +Case questions than –Case questions.
Summary of the fixed effects in the mixed logit model for children for Verb Semantic Error responses (N= 7446, children = 392, items = 19, loglikelihood = −1051.1).

Discussion
Our results from 18 different languages show that there is substantial variation, but also some uniformity across languages in the understanding of questions by 5-year-olds. For all 18 languages in the study, we found that object questions elicit more reversal errors than subject questions, i.e. errors where children mix up the grammatical roles of subject and object. This result also corroborates many earlier findings, starting with Thornton (1990), that object questions are more difficult for children than subject questions. Moreover, in our data the percentage of correct responses exhibits a similar pattern, but not quite as universal. Only Hebrew and Polish children gave more correct responses to object questions than to subject questions. We think that the effect of argument type on correct responses may be a little weaker than on reverse responses because in our design the number error response could only be given by children who assigned the argument roles correctly. Since the statistical analysis indicates that argument type is a significant predictor of correct response, we think the reverse result from Hebrew and Polish is due to random variation, and would not expect it to hold up in further testing. Our result for argument type is expected because of the structural properties of the languages in our sample, which was determined by funding constraints rather than scientific considerations. Specifically, all languages in our sample had two important structural characteristics: (1) the most frequent word order in declaratives places the subject (S) in front of the object (O) (either SVO or SOV), and (2) in questions the wh-phrase is fronted to the left periphery of its clause. Therefore, subject questions corresponded in all languages of our sample with the most frequent order of subject and object, while the order of object questions was the reverse of that. There are therefore several factors that could make object questions more difficult for children than subject questions. For example, the deviation from the most frequent word order could be the reason. But the reason might also be that the length of the dependency between the wh-phrase and its trace position (e.g. 0 words between wh-phrase and trace in English (11a), but 4 in (11b)) is longer for object questions. Or the reason could be that specifically the presence of the subject in the movement path of the object interferes with syntactic movement of the object for some children.

The second finding true of all 18 languages is that more correct responses are given to questions with a simple who phrase than to questions with a complex which phrase (see Figure 3). This finding corroborates earlier results by Avrutin (2000) and Goodluck (2010). Avrutin and Goodluck discuss this finding in terms of the semantic property of D-linking (Pesetsky, 1987). Our cross-linguistic data indicate that another factor is relevant too. Namely, we found that the factor 1wh, indicating morphological identity of the words for who and which in a language, predicts higher rates of correct responses. This finding suggests that children speaking a language like English are less familiar with the word which than the word who, while in languages like Finnish where kuka is the word for both who and which this difficulty does not arise. But, the semantic factor D-linking seems to be also relevant since we consistently find better performance on who questions even in the 10 languages that are like Finnish in this respect. In sum, the two universal patterns are for the most part expected, the effect of the identity of who and which is novel.
We now come to predictors of the variation. We found three language-specific factors that predicted a greater probability of correct response: the presence of over case marking on the moved phrase, whether there is only a single morpheme for both who and which in the language mentioned in the previous paragraph already, and whether the verb form used is synthetic.
Furthermore, we showed that some other plausible linguistic factors were not significant predictors: whether a cleft structure was used or not, whether a pronoun doubling the wh-phrase was used or not, and whether the language allowed subject pronoun to be omitted. For clefts and pronoun doubling, our data set only included two languages each that had the phenomenon, so these may warrant further testing. Of the significant predictors, syV was not considered in any previous studies. The four languages with the auxiliary show little commonality though: in English and Portuguese, the auxiliary exhibits number agreement, but in Maltese and Danish it does not, and only in Maltese is the main verb marked for agreement. We think nevertheless that English children may benefit from the early presence of the number agreement cue in examples starting with who is/are… when determining the question interpretation, and Portuguese may be similar. Note that these two languages show markedly better comprehension than all other languages that lack relevant case morphology.
A closer look at the other factors of variation we found is particularly interesting from the perspective of the Relativized Minimality proposal of Grillo (2009), Rizzi (2004, 2013), and Friedmann et al. (2009). Relativized minimality proposes that the interpretability of movement of a phrase depends on relationships between the syntactic features of any intervening phrase (i.e. c-commanded by the moved phrase and c-commanding the trace) and those of the moving phrase. Generally, a match of some or all features of the two relevant phrases is assumed to cause interference. To apply this to our data, consider the configuration in (12) where the feature set of the object wh-phrase is X (X1 for who, X2 for which) and that of the subject is Y. Relativized minimality predicts that the interpretability of the two kinds of object questions depends on the relation of X and Y.
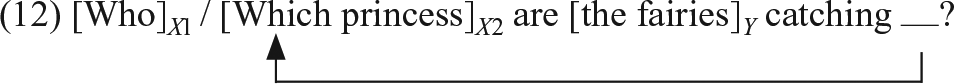
We can use our data to deduce for which specific features there is an effect of relativized minimality. This test relies on the fact that the subject questions we tested never violate relativized minimality. Therefore any difference we found between the simple and complex subject questions must be the effect of other properties; e.g. the difficulty of accessing which in the lexicon and the D-linked status of which that we mentioned above. Any effect of relativized minimality therefore must be visible as an interaction with argument type: for example, a difference between the two object questions, but no corresponding difference between the subject questions. The features that have been implicated in relativized minimality in other studies are NP (Friedmann et al., 2009), case (Arosio, Guasti, & Stucchi, 2011; Arosio, Yatsushiro, et al., 2011; Guasti, Stavrakaki, & Arosio, 2012; Varlokosta et al., 2015), number (Adani et al., 2010), and gender (Adani et al., 2010). In our study, gender was not tested, 7 but the features NP, case, and (indirectly) number were relevant. For case, we found an interaction with argument type in the direction predicted by relativized minimality – children are more likely to comprehend object questions if the overt case marking is present. For NP, however, we did not find the interaction predicted by relativized minimality. The parameter +NP corresponds in our data to the Wh-type = Complex for the which questions, and –NP corresponds to the who questions. The presence of an interaction for case and the absence of one for NP is also visually apparent in Figure 4: only for case is the difference between the +Case and –Case probabilities greater for objects than for subjects.

Box plots of mean % correct per language showing the Case-Argument type (Cs: Case, S: Subject, O: Object) interaction on the left and the absence of a NP-Argument type interaction on the right.
While the effect of case is consistent with the earlier findings mentioned above, the absence of an effect for NP differs from findings reported in the literature, with the exception of Goodluck (2010). Since our study with 392 children is more powerful than previous studies (Friedmann et al., 2009 report data from 22 children in their subexperiment 5), the effect found in previous studies should have also been detected in ours. We can think of three possible reasons for the discrepant results: (1) differences in the design especially with respect to number, (2) the effect is restricted to specific populations and languages, and (3) the result reported by Friedmann et al. (2009) is a false positive. Consider first a relevant design difference: as one reviewer points out, our experimental items all involved a number contrast between the singular wh-phrase and a plural in the other argument position. Adani et al. (2010) have argued that a number difference can ameliorate a relativized minimality effect, so the number difference may override any effect of the NP feature in our data. A remaining problem with this proposal, though, is that our data show that the effect of case cannot be overridden by a number difference in the same way. This is not predicted by the theory assumed by Friedmann et al. (2009), which is stated in terms of subset/superset relations of feature sets, since the difference in number features should block any subset relationship. To accommodate our data, we could instead assume that the number feature subcategorizes the NP feature as represented by ±NP±PL and that number of features in the intersection of the two feature sets correlates with their interpretability. While this is not implausible, other explanations of the discrepancy should also be considered at this point. Second, it might be that the NP effect is restricted to some languages or age groups – Friedmann et al. (2009) tested only 4-year-olds speaking Hebrew. We therefore tested the data from all 19 sites individually for an interaction using a logistic regression with the three factors Wh-type, Argument type, and their interaction. But, we found that the interaction was significant at no site. 8 Hence, our data show it to be unlikely that only some languages are subject to intervention by the feature NP in object questions. The difference in age, however, may be the cause of the difference in findings. Finally, a third possibility for the discrepancy between our result and Friedmann et al.’s (2009) may be that their result is a false positive, as Goodluck (2010) suggests. Friedmann et al. (2009) tested only 22 children and furthermore only report pairwise t-tests of the number of correct responses per subject in the statistical analysis of their data. Since t-tests assume normal distributions, their use may lead to false positives if applied to categorical and count data (Jaeger, 2008 and others). When we compute a non-parametric statistic, the χ2-test, for the counts of ‘No. of participants of 22 who performed above chance’ of Friedmann et al.’s (2009) table 6, our analysis shows a substantial risk that the result may indeed be a false positive [χ2(1) = 2.2, p = .14]. 9 At this point, our data cannot decide between the three explanations for the discrepancy, but we hope future research will resolve the question.
In the analysis of reverse responses in Table 5, we also found effects of Argument type, Wh-type, Case, and the interaction of Argument type × Case, each in the opposite direction compared to the analysis of correct responses. This is expected because of the complementarity between the two types of response. But in addition, word order (wo) was a significant predictor of reverse responses, individually and also in pairwise interaction with Wh-type, Argument type, and Case. 10 As a single factor disambiguation by word order led to fewer reverse responses, which is expected since children are sensitive to word order from a young age (Seidl et al., 2003). The reason that we do not find a complementary relationship in the case of correct responses seems to be that children in +wo languages give more number errors (see Table 6). The three interactions involving word order are more interesting. First consider why the effect of argument type is stronger in –wo languages. We hypothesize that this is due to a general preference for a subject question interpretation by children. The absence of evidence from word order would then cause children to be more likely to misinterpret object questions than subject questions. Second, we find that, only in –wo languages, reversal errors are less likely in questions with case marking on the wh-phrase than in questions without case marking. This indicates that case and word order are both good cues for the children to avoid reversal errors, but that their effects are not additive, and one of the two cues suffices. Finally, consider our finding that who questions are less likely than which questions to receive an erroneous reverse response in the +wo languages but not in the –wo languages. This effect suggests that subjects indeed intervene for movement of which phrases in +wo languages, but that in –wo languages there is a way of bypassing the intervening subject. Bypassing of the subject may be not directly related to the wo factor, but instead to word order flexibility. Specifically, several of the –wo languages (all three Slavic languages, German, Dutch; e.g. Cinque & Kayne, 2005), and only one +wo language (Portuguese, Costa, 2004) have been shown to allow a type movement referred to as scrambling that may place the object to the left of the subject even when the object is not a wh-phrase. Furthermore, Greek (Alexiadou, 1999) and Italian (Burzio, 1986) exhibit word order variation similar to scrambling. Scrambling or another movement of the object may circumvent subject intervention derivationally as shown in (13) (vs (12) above) if scrambling itself is not subject to relativized minimality. Then after the application of scrambling, the subject does not intervene with wh movement.

Next consider our data for number errors. Our results provide further evidence for the finding that children often understand plural forms to be compatible with singular reference (Sauerland, Anderssen, & Yatsushiro, 2005; Tieu, Bill, Romoli, & Crain, 2014). That the relationship between number errors depends on other properties of question and the language is, however, unexpected by these proposals. But note that the design of our items has the consequence that children could only commit a number error if they assign the argument roles correctly. Therefore we expect that factors that positively predict reversal errors should negatively predict number errors and vice versa. This predicted correlation is what we find for Argument type, word order and their interaction. This leaves the effect of Wh-type and its interaction with word order to be explained: Why do fewer number errors occur with who phrases than with which phrases and why would that effect be stronger in –wo languages? Since both effects are only weakly significant, we leave this question for future research. Finally, the positive effect of case on the occurrence of verb semantic errors is equally surprising to us. It may indicate that the presence of case morphology leads children to pay less attention to the verbal form.
In this article, we do not report more detailed analyses of the data from specific languages involved for reasons of space. But some of these have already been completed by contributors to this article (CY: Varnava & Grohmann, 2014; NL: Metz, van Hout, & van der Lely, 2012; Metz, van Hout, & van der Lely, 2010; Schouwenaars, van Hout, & Hendriks, 2012; Strangmann, Slomp, & van Hout, 2014), and we hope that further analyses will be undertaken.
Conclusion
Large-scale language comparisons in language acquisition research offer a way to quickly identify language-specific factors that help or hinder the acquisition process. In our study of constituent question understanding in 5-year-olds for 18 languages spoken in Europe and Israel, we found evidence for three language-specific properties that help children to understand questions and, in the first case, also specifically object questions: the presence of overt case morphology, the lack of two distinct words for who and which, and the use of synthetic verb forms. The latter two of these three had not been detected in earlier work on the matter. Additional effects, especially of word order variation across languages, were found in the error analysis.
In the introduction we mentioned that object movement structures are frequently used for the diagnosis of SLI, mostly on the basis of research on English. Do our results validate this approach? The answer is a qualified yes, but with some caution added. Our results show that at least across the languages with the structural characteristics of SOV or SVO word order and movement in questions there are some general commonalities in the acquisition profile – object questions are generally more likely to receive the reverse interpretation than subject questions. This makes it plausible that object questions or other object movement structures can be used for SLI-diagnosis in these languages. At the same time, our results show that there is also variation in the acquisition of object questions due to properties of the language and that English has at least two properties –the absence of morphological case and that it uses two different morphemes, who and which, to ask for animates – that make questions and specifically object questions difficult for a child to interpret correctly. Therefore any use of object extraction structures for diagnostic purposes needs to be accompanied by further research into the acquisition process in that language.
This type of result has great potential value to European society because object movement structures are implicated in the diagnosis and therapy of atypical child language (Adani, Forgiarini, Guasti, & Van der Lely, 2014; Friedmann & Novogrodsky, 2011; Levy & Friedmann, 2009; van der Lely & Battell, 2003; van der Lely & Pinker, 2014, see also the Introduction). We believe that the economic potential of first language acquisition research is widely underestimated – language acquisition research could contribute as much to European economy as the entire agricultural sector. Here is how we arrive at this estimate. Consider first that first language acquisition is crucial for later educational and economic success. In modern society, individuals with unmet speech, language, and communication needs (SLCNs) cannot contribute to their fullest potential to the overall well-being. The lost economic potential is likely enormous. For the UK, Bercow (2008) cites an estimate of the damage of unmet SLCNs in 2008 of £26 billion when British GDP was £1,682 billion (see also Hartshorne, 2006; Law, Zeng, Lindsay, & Beecham, 2012). The British figure represents about 1.5% of the annual gross domestic product (GDP). For the United States, Ruben (2000) provides an even higher estimate relative to GDP, namely US$154.3 to US$186 billion, i.e. 1.6–1.9% of 1999 GDP of US$9.661 trillion. Similar statistics are unfortunately not available for other European countries as far as we know, but we perceive the UK to be a leader for the diagnosis and therapy of SLCNs within Europe, especially because many more different diagnostic tools and procedures are available for English than for all other languages. So, an annual damage of about 1.5% GDP due to unmet SLCNs across all European countries represents in our view a conservative estimate. In countries such as Britain and Germany, this loss of GDP represents roughly three times the contribution the entire agricultural sector makes to GDP. For the European Union as a whole it amounts to an annual sum lost of over 210 billion euros based on the 2014 GDP figure, which is roughly in line with the GDP contribution of European agriculture.
SLI is the most prevalent SLCN with 7% of an age cohort affected (Bishop, 2010). It is realistic that SLI accounts for the major share of the cost too: 1.5% of GDP would correspond to slightly more than 20% of the GDP contribution from the share of the population affected with SLI. At the same time, Bishop (2010) reports that far less research on SLI is published than on most other neurodevelopmental disorders. One factor Bishop identifies as holding back research on SLI is the lack of a critical mass of researchers. We believe one important means to increase the critical mass is to link researchers working on different languages. Indeed, the two most prevalent disorders that Bishop’s analysis shows as under-researched affect primarily language, namely SLI and speech sound disorder. Since disorders that affect language differ at least superficially across languages (Clahsen, Bartke, & Göllner, 1997; Leonard, 2014, and others), it is more difficult to compare research results for different languages. Part of the goal of the research reported here is to contribute to a basis for future cross-linguistic research on typical and atypical language acquisition in Europe. We think such cross-linguistic research is of growing importance, especially as migration within and to Europe contributes to the creation of multilingual societies. Finally, we hope our research facilitates practitioners spreading best practice across the boundaries between different European linguistic communities.
Footnotes
Appendix
Acknowledgements
We dedicate this article to the memory of Heather K. J. van der Lely. We would much prefer if she could have still been the lead author of the article: she designed the study and as vice-chair of COST Action A33 led its execution up to a presentation of preliminary results at the 2010 final conference of the action in London. We remain grateful to Heather for this and the many other contributions she made to all of our careers and lives. We thank also Paul Richens, who made relevant files from Heather’s computer available to us.
We thank the many researchers and research assistants who provided technical assistance to this project, namely Sanne Berends (NL), Mechthild Bernhard (DE), Joana Cerejeira (PT), Ane Knüppel (DK), Helen Kõrgesaar (EE), Franziska Krüger (DE), Maria Lobo (PT), Vasiliki Marcopoulou (GR), Michaela Nerantzini (GR), Lisa Raithel (DE), Stavroula Stavrakaki (GR), Alma Veenstra (NL), and John Weston (UK). We are especially grateful to the many children who participated in this research and their parents and care-givers. Finally, we thank the audiences at the 2015 GALA conference, the University of Leiden, and Boğaziçi University, the two anonymous reviewers, Jesse Snedeker, and the two editors, Kevin Durkin and Chloe Marshall, for their many helpful suggestions.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: We thankfully acknowledge the funding for COST Action A33 (chair: U. Sauerland, vice-chair H. K. J. van der Lely) that made it possible to coordinate the research reported here. Furthermore the research was supported in part by the following grants: UK, IT, DE, RO, LT, and BE: European Union, CLAD 135295-LLP-2007- UK-KA1SCR; NL, DE, IT: Netherlands Organization for Scientific Research (NWO), grant 236-78-001; AT: Austrian Science Fund (FWF), grant P 20464-G15; DE: German Research Council (DFG), grant SA 925/1-4, Bundesministerium für Bildung und Forschung (BMBF), grant 01UG1411; Danish Agency for Science and Technology and Innovation (FKK), grant 09-063957; FI: Academy of Finland; PL: Polish Ministry of Science and Higher Education, grant 809/N-COST/2010/0, Faculty of Psychology University of Warsaw, grant BST No. 1445/2009; and RS: Serbian Ministry for Education, Science and Technological Development, Project ON179033.