
Abstract
The purpose of this study was to determine if children acquire grammatical case as a unified system or in a piecemeal fashion. In English language acquisition, many children make developmental errors in marking case on subject position pronouns (e.g., Me do it, Him like it). It is unknown whether children who produce pronoun case errors with first person pronouns also produce errors with third person pronouns. This finding would be expected if case were acquired uniformly across person through building a paradigm for an abstract case feature. Spontaneous pronoun case errors were collected from language samples of 43 typically developing toddlers at 21, 24, 27, 30, 33, and 36 months of age. A chi-square test was used to determine whether children were more likely to make both first and third person errors, indicating an association. The uniformity of the case marking system was further investigated by asking whether pronoun case errors in first and third person occurred at the same time using a Wilcoxon signed-ranks test. Most children treated case uniformly across person, producing both first and third person pronoun case errors or producing no case errors at all, resulting in a significant association. Additionally, errors were not significantly different in timing. The results of this investigation are compatible with the notion that children systematically extend case marking in a unified paradigm. Pronoun case is not acquired separately for each grammatical person in a piecemeal fashion.
Introduction
Young children characteristically produce pronoun case errors in which a non-subject pronoun is used in subject position (Me pick it up; Her want a bottle; Rispoli, 1994; Schütze & Wexler, 1996; Vainikka, 1993). In English, a case distinction between subjects and objects exists only for personal pronouns in the first person (i.e., I, we vs. me, us) and in the third person (i.e., he, she, they vs. him, her, them). Therefore, pronoun case errors in which a child substitutes an object form (i.e., accusative/dative case) for a subject form (i.e., nominative case) can only occur in the first and third persons (e.g., me for I; him for he). Errors in which subject forms (i.e., I, he, she, we, they) are used in contexts for possessive or object pronouns have been reported to occur far less frequently (Rispoli, 1998a; Tanz, 1974). Therefore, most researchers have focused on pronoun case errors in the subject position.
Case itself is a grammatical feature that systematically connects noun phrases in a clause to verbs, prepositions, and other nouns in the same clause based on their semantic roles (Blake, 2001; Haspelmath, 2002). For English pronouns, the four features and associated values that are represented are number (i.e., singular or plural), person (i.e., first, second, or third), gender (i.e., masculine, feminine, or neuter) and case (i.e., subject, object, or genitive). Pinker (1984) described grammatical features such as case as being organized in a mental paradigm. For children to correctly use adult grammatical distinctions, they must associate each feature with the values it can carry. Figure 1 illustrates the English pronoun paradigm with values for these four grammatical features intersecting. In the diagram, each box, or paradigm cell, represents the overlap of two or more of these features. For example, for the pronoun your, second person and genitive (i.e., possessive) case overlap. Pronouns with values for more features are more specific and are in smaller boxes. For example, the pronoun my also carries values for person and case as your does, but because it is only used for singular referents, it carries an additional feature, number. In the smallest boxes are the four pronouns that carry one value for each of the four features (i.e., he, him, his, and she).
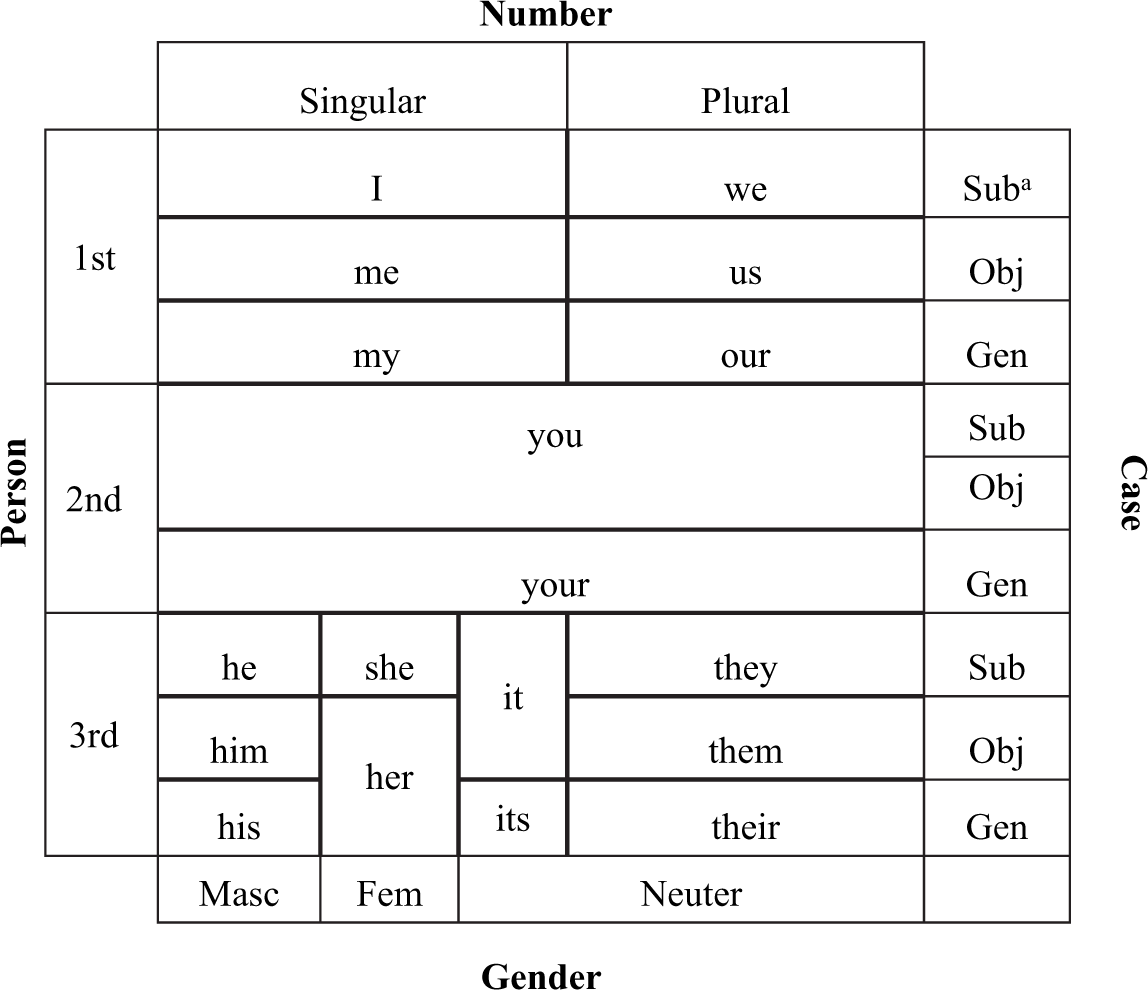
English personal pronoun paradigm.
The pronoun paradigm
A paradigm is a traditional way of representing grammatical information by depicting how sets of affixes are related. Pinker (1984) explained how a paradigm might be viewed developmentally. He drew a distinction between general and word specific paradigms. General paradigms represent classes of affixes that follow a regular pattern of inflection. The paradigm includes information regarding what grammatical features affixes carry. A general paradigm captures the ability of a mature, adult grammar to correctly deduce the inflected form of a new word based on previous experience with inflecting words of that lexical category. Rule formation allows the derivation of regularly inflected words. In a paradigm building view of language development, the end state for the child is a paradigm embodying knowledge of grammatical features. For features represented by affixes such as –ing, the child gains knowledge of what that affix encodes when it attaches to, or inflects, a stem. Innately available features are organized within a paradigm that is gradually built from experiences with input. The child extends these features, also called dimensions, across the paradigm (Pinker, 1984).
A word specific paradigm must be learned for irregular changes such as English pronoun inflection. A child’s errors can be seen as erroneously attempting to build a general paradigm for a particular subsystem in the grammar. A classic example is overregularization of past tense marking for irregularly inflected verbs (e.g., goed), resulting from an attempt to build a general paradigm for past tense. This type of error could also occur in the English pronoun system. For example, if a child mistakenly treats some or all of the phonetic material in me as indicating first person singular reference without recognizing the case feature, then me could be used as a subject or a possessive form (Rispoli, 1994, 2005). Because English personal pronouns are not regularly inflected, a child acquiring English eventually needs a word specific paradigm for each pronoun. If a child relies on a general paradigm, errors should arise across pronouns, collapsing multiple features. A child relying on a general paradigm or transitioning to a word specific paradigm might have a mental representation of me, you, him, her, and them extended over the roles of subject, object, and possessive. Utterances reflecting all of these word form choices are attested in children’s spontaneous sentences (e.g., This you purple fork; Here’s him tummy; Fitzgerald, 2014). A child with a partial paradigm with object cells filled in correctly might fill in unknown subject and possessive cells by overextending the object column. Then, the child must realize the attempt to create a general paradigm of pronouns has failed before considering additional dimensions one by one. With this discovery, a more appropriate and complete word specific paradigm can be created.
The construction of a general paradigm is adequate for languages with phonetic commonality across the pronoun paradigm. In agglutinating languages, strings of morphemes, each encoding a single meaning, affix to stems with common phonetic material. Each morpheme encodes only case, and separate morphemes carry information for other relevant features (e.g., number). Turkish is an agglutinating language in which each case (i.e., genitive, accusative, dative, locative, and ablative) is represented by a distinct monosyllabic morpheme attaching to a phonetically identical stem (i.e., ben/beni for I/me; biz/bizi for we/us, kim/kimi for who/whom; Kreider, 1954). On the other hand, in fusional languages, a single morpheme can signify multiple meanings such as in Spanish (e.g., –o signifies first person, singular number, and present tense) or in Russian (–l signifies singular number, masculine gender, and past tense; Mihaliček & Wilson, 2011). Mastery of inflectional systems takes less time for agglutinating languages than for fusional languages. A child acquiring a fusional grammatical subsystem has a more difficult task because two or more features must be considered at the same time. Children acquiring Turkish mark multiple cases correctly on pronouns and other pro-forms by age two (Slobin, 1982). By contrast, the correct marking of subject case appears to be particularly difficult in English acquisition. The acquisition of a paradigm embodying knowledge of English pronoun case marking is unlike a general stem + affix paradigm as in Turkish because in the English pronoun system, there is little phonetic similarity across pronoun forms in the first and third persons (Rispoli, 1994, 2005). Instead, the English pronoun paradigm is more similar to a paradigm from a fusional language. Specifically, although some English grammatical morphemes carry a single feature (e.g., –ed affixed to a verb encodes past tense, –s affixed to a noun encodes plural number), an English pronoun form can carry values for up to four features (i.e., person, number, gender, case).
The collapsing of many feature values onto a single morpheme is not the only challenge in acquiring English case marking. Case is marked in numerous other languages that are typologically different from English. One key way that case marking differs between English and other languages is that case is only distinct on personal pronouns. Many other languages such as German, Polish, and Russian additionally mark case on nouns, determiners, and adjectives (Draye, 2002). A second difference is that English case marking is limited to nominative, genitive, accusative, and dative, with the latter two sharing identical forms for direct and indirect objects. Other languages, such as Finnish, Hungarian, and Russian, distinguish additional cases such as instrumental or ablative (Corbett, 2008; Onikki-Rantajääskö, 2006). They may also have different markers for a single case such as the Polish genitive having three forms depending on the class of noun being marked (Dabrowska, 2001). A final typological difference is that languages vary regarding which case serves as the default and under what conditions it is used. In adult English, the accusative case is the default case. Identifying the default case for a language is necessary in studying children’s case errors because children typically substitute the default form for other cases (Eisenbeiss, Bartke, & Clahsen, 2006).
Another potential challenge in acquiring English is the subject–object distinction, which might be difficult to detect because pronoun subjects and objects are less phonetically distinct than in other languages. Pelham (2011) contrasted the phonetic similarities of the English personal pronoun you, used for both subjects and objects with the phonetically distinct German pronouns du (you nominative), dich (you accusative), and dir (you dative). Pelham found that 62.3% of pronouns spoken to English acquiring children were ambiguous (i.e., same subject and object phonetic form) compared to only 9.7% for German acquiring children. Pelham concluded that these data explained why children acquiring English produce pronoun case errors whereas children acquiring German tend not to. Wisman Weil and Leonard (2017) found support for Pelham’s (2011) hypothesis. When toddlers were primed by imitating sentences containing it and you as subjects and objects, they were more likely to subsequently produce pronoun case errors on he and she targets than when they were primed by imitating sentences containing phonetically distinct subject and object pronouns.
Children’s experience with the highly frequent child-directed subjects you and it might delay the correct use of the case-marked subject pronouns by obscuring the subject–object case distinction in English (Li & Shirai, 2000; MacWhinney, 2000). Despite hearing the least specified pronouns (i.e., I, you) more frequently (recall Figure 1), children must still come to use number, person, gender, and case distinctions correctly for the four most specific forms, i.e., he, him, his, and she. Adult input may place children at a disadvantage for using case correctly given that the least specified pronouns such as you are more common in child-directed speech than the most specified pronouns such as he and she.
In summary, the challenges for a child in using English subject pronouns correctly are as follows. First, morphemes carrying case represent other feature values that must be tracked simultaneously (i.e., number, person, gender). Second, subject case marking occurs on only some personal pronouns and not on other noun phrases, so children acquiring English have limited experience making adjustments based on case distinctions. Additionally, the default case in English is the accusative, which aligns with objects; therefore, the default form should not appear in subject position. Finally, English pronoun subjects have different phonetic forms than objects and these forms must be matched to the semantic roles subjects and objects play in sentences.
A unified system or piecemeal acquisition
An open question in the field of psycholinguistics is whether case errors propagate, originating in one pronoun and expanding to other pronouns. Propagation of this type is plausible if children approach the acquisition of case with the expectation of a general paradigm (Pelham, 2011; Pinker, 1984; Rispoli, 1994; Wisman Weil & Leonard, 2017). Alternatively, children might acquire overt case distinctions in a piecemeal, item-based fashion, learning each pronoun’s forms with no apparent carry-over from one pronoun to another. This is the alternative emphasized in a usage-based approach to the acquisition of pronoun case (Kirjavainen, Theakston, & Lieven, 2009; Lieven, 2014). In the first alternative, when a child does not fully understand the conditions of case marking and is using an overly general paradigm, case errors could be made on any pronominal subject regardless of person, number, or gender. If the child uses one case, the default accusative, then accusative pronouns will be used in subject position for both first and third person (e.g., me for I and him for he). Furthermore, children who make errors on first person pronouns would be expected to make errors on third person pronouns at the same time, so temporally overlapping errors would be observed. Then, once an overt case distinction is learned for one pronoun, case distinctions will be extended to other pronouns (i.e., I, we, he, she, they). That is, regardless of person (i.e., first or third), correct case would be applied with the child using distinct subject and object forms where appropriate. In the second alternative, case is acquired in a piecemeal fashion. If a child has difficulty with the overt marking of case on one pronoun, there is no a priori reason to expect difficulty with other pronouns. In short, pronoun case errors could be isolated to individual pronouns. Following the logic of Kirjavainen et al. (2009), a child who errs in producing me for I has no proclivity to extend the error pattern to other pronouns in the paradigm, namely he, she and they. Additionally, a child might never err in the first person pronoun and incongruously exhibit errors in third person pronouns de novo.
Previous studies have not addressed whether children who produce case errors make them in both the first person and third person. Hence, the question of whether case is acquired as a unified system or in a piecemeal fashion has not been investigated. Additionally, the extant literature has not reported whether errors on first and third person pronoun targets are made at the same point in development. Often, this was because methodologies used cross-sectional sampling or collapsed across different types of errors. Previous studies have not been able to address these questions because they have not examined first person and third person pronoun case errors in the same group of children in a large longitudinal study. To address whether a relationship exists between first and third person pronoun case errors, it is necessary to examine the developmental period when children attempt personal pronouns in both first and third person sentences.
Previous studies of young children spontaneously producing first person pronoun case errors have reported errors occurring between 20 and 33 months of age (Budwig, 1989; Kirjavainen et al., 2009; Schütze & Wexler, 1996; Vainikka, 1993). Third person pronoun case errors have been observed in an older age range, between 22 and 43 months (Huxley, 1970; Schütze & Wexler, 1996; Tanz, 1974; Vainikka, 1993; Wexler, Schütze, & Rice, 1998). Oftentimes studies of third person error collapsed data across participants; however, data from studies that report errors by participant age suggest that third person errors begin for nearly all children by 35 months of age (Loeb & Leonard, 1991; Moore, 1995; Pine, Rowland, Lieven, & Theakston, 2005; Rispoli, 1994, 2005). Many studies of first person error did not also study third person error. As a result of the focus on just one person, it has not been possible to tell if an association exists between first and third person developmental pronoun case errors.
The current study asked two research questions. The first was whether an association existed between first person case errors and third person case errors with most children producing both or neither. An association would be consistent with a unified acquisition of case with errors reflecting erroneous extension of case across a general paradigm. The lack of an association would point to piecemeal acquisition with case errors reflecting difficulty with individual pronoun forms, acquired one at a time. If an association existed, the second research question asked whether first person case errors overlapped in timing with third person errors or if the timing of errors was significantly different. Overlapping errors would be consistent with unified acquisition of a paradigm.
Method
Participants
Participants in the study were 43 typically developing toddlers (i.e., 22 boys, 21 girls). They were selected from an existing longitudinal database of spontaneous language samples from 58 toddlers interacting with their primary caregivers (Rispoli & Hadley, 2013). Recruitment and screening procedures were previously described in Hadley, Rispoli, Holt, Fitzgerald, and Bahnsen (2014). Longitudinal data were collected at approximately 21, 24, 27, 30, 33, and 36 months for each child. For the current study, 15 of the original 58 toddlers were excluded. Children were excluded if they did not pass the communication domain of the Ages and Stages Questionnaire (ASQ, Bricker & Squires, 1999) at 21 or 24 months or if they were referred for speech-language pathology services any time during the original study. Children were also excluded if they had low language status (i.e., below the 10th percentile) at 30 months based on either the vocabulary checklist or grammatical complexity portions of the MacArthur–Bates Communicative Development Inventories as reported by parents (CDI; Fenson et al., 2007). Lastly, children with low intelligibility were excluded because transcribers needed to be certain which subject pronoun forms children were attempting. Five children were excluded for referral to speech-language pathology services, and nine were excluded for low scores on the ASQ or CDI or for low intelligibility. One child was excluded due to attrition (i.e., completed only the 21-month measurement point).
Of the 43 participants who met the criteria for the current study, 38 children had 1-hour language samples at each measurement point between 21 and 36 months. Two children’s 36-month language samples were 30 min long, and three children participated in the study from 21 to 30 months. The average Mean Length of Utterance (MLU) at 30 months of age was in the typical range (N = 43, M = 2.90, SD = .68, range = 1.58–4.62; cf. Miller & Chapman, 1981). The average Number of Different Words (NDW) at 30 months was 138 words (SD = 40.4, range = 62–244).
Children were primarily from college-educated families. Mothers’ highest educational levels attained were less than high school (n = 1), high school (n = 2), associate’s degree or some college (n = 6), bachelor’s degree (n = 21), and advanced degree (n = 13). Children were reported by their parents to be White (n = 38), Black (n = 3), or biracial, i.e., White/Black, (n = 2). One child was also reported to be Hispanic. All families spoke only Standard American English.
Procedures
Language sampling procedures were previously described in Hadley et al. (2014). A 1-hour language sample was collected at each measurement point. Children and their primary caregivers visited a lab playroom furnished with a standard set of age appropriate toys (e.g., blocks, baby dolls, Mr. Potato Head, bubbles). Caregivers were instructed to play with their children as they would at home for 30 min. After 30 min of caregiver–child play, an examiner joined the caregiver and child for an additional 30 min of play and introduced toys as the topic of conversation to create opportunities for children to talk about third person referents.
All language samples were transcribed by a trained research assistant (RA) using Systematic Analysis of Language Transcripts (SALT, Miller & Iglesias, 2010). When possible, the examiner who interacted with the child transcribed the sample. Transcribers used video recordings for context when needed to interpret child utterances.
Measures
Sentence contexts
Before categorizing each child as either making pronoun case errors or not making errors, it was necessary to establish that contexts for subject pronouns were present. This step prevented misclassifying a child’s language sample as error-free when there was no opportunity for error. To identify opportunity for first person error, transcripts were explored for the following: a correct use of I as in (1), a first person pronoun case error with me or my used for I as in (2), or any uses of the child’s own name as a sentence subject (i.e., transcribed as Cname) as in (3).
(1) C I reach it. (GTP06G, 21 months)
(2) C Me blow bubbles. (GTP10G, 27 months)
C My want that. (GTP51G, 27 months)
(3) C Cname have to open it. (GTP49G, 24 months)
Sentence contexts for producing a third person pronoun case error were more varied. Samples with third person sentences with pronoun or noun subjects could establish sufficient opportunity for third person error. To identify third person sentence contexts, and thus opportunity for third person error, transcripts were first explored for he, she, they, him, her, them in the subject position of a sentence as in examples (4) and (5). If none of these pronouns were observed in subject position, a sample could be identified as having the opportunity for a third person error when children produced five or more unique third person sentences. Unique third person sentences were operationalized as different combinations of third person subjects and predicates as in (6). Five different combinations could be established with five different third person subjects, the same subject with five different predicates, or any combination.
(4) C He’s hungry. (GTP38G, 27 months)
C He sitting.
(5) C Her want a bottle. (GTP58G, 24 months)
C Her taking a shirt off.
(6) C No, baa|sheep eat. (GTP22B, 24 months)
C Lion eat.
C Horsie alldone.
C Ducky sit there.
C It fall.
Presence of error
The primary measure was the presence of pronoun case errors across the 15-month sampling period. This categorical variable was selected for its potential to examine the relatedness of first and third person case errors that might not occur at the same age. A large degree of individual variation exists in rate of grammatical development during the ages sampled, including variation in the number and type of sentences that children produce (Hadley et al., 2014). Given this variation, choosing a single measurement point to identify error could have underestimated how many children ever produce errors during this stage of language development by misclassifying children whose errors occurred outside of the single measurement point. By using a categorical variable, presence of error, the potential relationship between first and third person errors could be investigated more readily across time. The categorical variable also avoided the challenges of using percent accuracy, or error rate, which is complicated by variability in the number of opportunities to produce error (Balason & Dollaghan, 2002).
All pronoun case errors in spontaneous, complete and fully intelligible child utterances were previously coded by trained RAs. Pronoun case errors in the subject position of sentences were the focus of this study, specifically object forms (i.e., me, us, him, her, them) as in (7) and genitive determiner forms and pronouns (e.g., my, his, hers) as in (8). Pronouns were considered to be in subject position if they occurred before a lexical verb, copula, auxiliary, modal or an obligatory context for any of these. Pronoun subjects were identified in declaratives, in inversion, in negation, and in elliptical contexts. Discourse was used as needed for elliptical uses to confirm that pronouns were used in subject position.
(7) C Me gonna get her milk. (GTP45G, 33 months)
C Him need play with us. (GTP51G, 33 months)
C Her want a bottle. (GTP58G, 24 months)
C Where them go? (GTP26B, 27 months)
(8) C My make him. (GTP49G, 21 months)
Pronoun case errors that were not in subject position were not analyzed. Examples included object forms used to mark possession (e.g., This where him shoe go) and rare instances of subject forms used incorrectly in object position (e.g., I want she sit). Children were not observed to use third person pronouns for self-reference (e.g., him for I; he for I).
All transcripts were searched for I, me, my, mine, we, us, our, ours, he, him, his, she, her, hers, they, them to identify both pronoun case errors in subject position and correct uses of subject pronouns. This step additionally identified any case errors in non-subject position for exclusion and confirmed that no case errors had been missed in the original coding. Including all measurement points for this search identified which children produced any subject pronoun case errors between 21 and 36 months of age.
Once presence of error was determined for each child for both first person and third person errors, the child was assigned to one of four categories based on the presence of error. The categories were children who produced: no errors, first person errors only, third person errors only, or both first and third person errors. These four combinations accounted for all participants.
The last measures, age of onset and age of last observed error, provided empirical data for the age when children began and resolved first and third person pronoun case errors. Age of onset was defined as the first measurement point at which a pronoun case error was observed. Plural forms (i.e., us, them) were not included because they were expected to emerge later than singular forms. Age of onset was determined for all children who made any case errors. The age at which children ceased producing pronoun case errors was based on the earliest measurement point in which errors were no longer observed. Means, standard deviations, and ranges were determined for the age at initial appearance and final appearance of errors for both first person and third person.
Reliability
Transcribers completed 20 hours of training. Transcribers were required to transcribe words and morphemes at 80% agreement for three consecutive training transcripts before transcribing actual data. After the first transcriber completed the transcription of each language sample, a second RA completed a consensus pass of all child and adult utterances. The consensus transcriber removed any words in disagreement and changed those segments to unintelligible but could not add or change words or morphemes. A third RA confirmed any additions or changes before being added to transcripts.
Reliability for the coding of pronoun case errors was also completed through consensus procedures. All error codes in the archival transcripts were confirmed by the first author for the current study. Error codes were found using the explore multiple transcripts function in SALT to confirm the utterance contained a subject pronoun case error. Additionally, all utterances containing a personal pronoun but no error code were extracted to check that they did not contain a subject pronoun case error. Changes were made as needed.
Analyses
The primary analysis was conducted to determine whether an association existed between first person and third person pronoun case errors. After each child was classified as producing only first person errors, only third person errors, both first and third person errors, or neither type of error, these frequencies were entered into the cells of a contingency table. The presence of an association was then determined with a chi-square test using these values.
The next analysis was conducted to determine whether errors overlapped in developmental time or occurred sequentially. Only children who made both singular first and third person errors were included in overlap analyses. The overlap analysis asked whether there was a difference in the age at which first person errors resolved and third person errors began. This analysis used a Wilcoxon signed-ranks test to determine the significance of the number of children whose errors overlapped.
Results
Because pronoun case errors cannot arise until children produce sentences with opportunities for pronominal subjects, these opportunities were identified first. About half of the children produced first person sentences at the first measurement point, 21 months (i.e., 25 of 43 children). Most children at 24 months (i.e., 38 of 43) and all children at 27 months had an opportunity to produce a first person pronoun case error. The opportunity to produce third person pronoun case error came later for most children (i.e., 5 third person sentences or one third person case-marked pronoun). At 21 months, 10 of 43 children had sufficient opportunity to produce a third person error. At 24 months, 32 of 43 children did, and at 27 months all children did.
Next, age of onset for first and third person errors was determined for children who produced pronoun case errors. The mean age of onset of first person singular error was 26.4 months (n = 30, SD = 3.73, range = 21–36). The mean age of onset for third person singular error was 29.5 months (n = 28, SD = 2.95, range = 21–36). The onset of first person error was primarily observed at 24 and 27 months. In contrast, the onset of third person errors was more commonly observed at 27 or 30 months. Half of the children who produced first person errors made their initial error before 27 months. The median value for initial third person errors was 30 months.
The age of last observed error was determined for children producing each type of error. One child was lost to attrition before errors in either person had ceased. Therefore, age of last observed first person error was determined for 29 of the 30 children who produced a first person error, and age of last observed third person error was observed for 27 of the 28 children who produced a third person error. The mean age of last observed first person error was 29.07 (SD = 4.17), a value nearly 3 months older than the mean age of onset. The mean age of last observed third person error was 33.33 months (SD = 3.66). Third person error was observed in the final measurement points for most of the children who produced third person error, so third person errors may persist until a later age.
The final measure was presence of error. Children produced both first and third person pronoun case errors, and both types of error were observed to some degree at every measurement point. Of the 43 children, 35 children (i.e., 81%) were observed to produce a pronoun case error between the ages of 21 and 36 months. The majority of children who produced first person error also produced third person error (i.e., 23 of 30; 76.6%). Of the 28 children who produced a third person error, only five lacked first person error (i.e., 17.9%). Figure 2 displays by measurement point the number of children producing first person, third person or both pronoun case errors. The peak age for both types of error was 30 months. At 30 months, children were especially likely to make errors across gender or number. All children who produced a them for they error also made a singular her or him error, or both. The general trend was to make third person pronoun case errors in multiple gender and number combinations. Of the 30 children who made first person errors, 20 made errors using either my for I (n = 8) or me for I (n = 12) compared to only 10 who produced both.
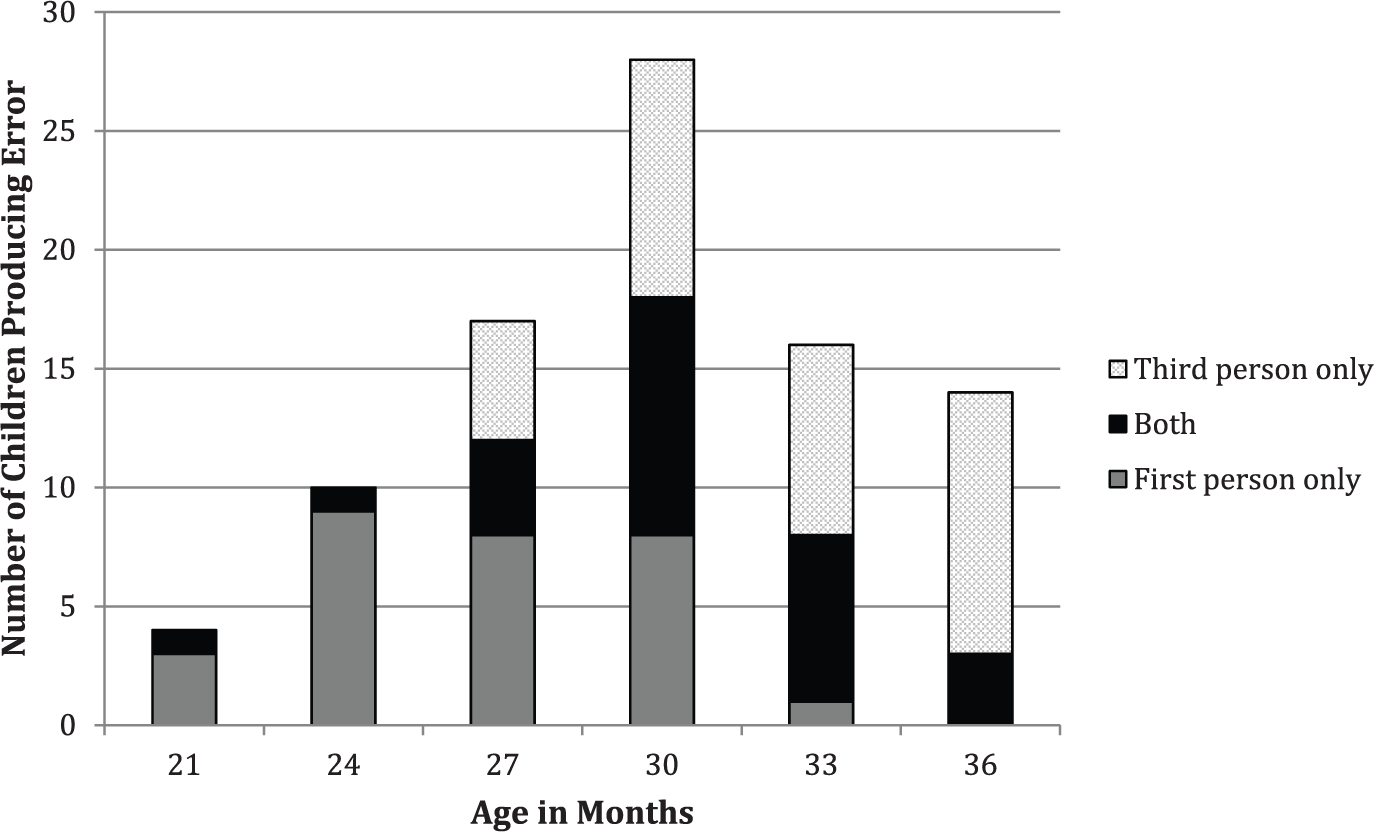
Number of children producing pronoun case errors by measurement point.
The primary research question focused on whether there was an association between the presence of first person and third person pronoun case errors. The purpose of the association analysis was to determine if case is acquired as a unified system or in a piecemeal fashion. Recall all participants demonstrated sufficient opportunity to produce pronoun case errors. Collapsing across all measurement points, children were classified as making only first person pronoun case errors (n = 7), only third person pronoun case errors (n = 5), both first and third person errors (n = 23), and neither (n = 8) (see Table 1). A chi-square test of independence was performed to examine the relationship between the presence of first person pronoun case error and the presence of third person pronoun case error. The association between these variables was significant, χ2(1, N = 43) = 4.27, p = .04, indicating the likelihood of co-occurrence for the two errors was significantly greater than would occur by chance.
Contingency table with frequencies of children by type of pronoun case error produced across 15 months, N = 43.

The second analysis tested whether first person errors overlapped with third person errors for children who produced both. Children who made both first and third person singular errors (n = 22) were entered into a Wilcoxon signed-ranks test. Each child contributed a pair of values derived from their age in months at the end of first person error (i.e., Xa) and their age at the onset of third person error (i.e., Xb). The absolute difference was taken for each pair (e.g., |30–33| = 3) and ties in which the two ages were the same were omitted from the calculation. The remaining differences were ranked from smallest to largest and assigned as positive when Xa – Xb > 0 and negative when Xa – Xb < 0. The ranks were summed to determine the test statistic (Lowry, 2014). A positive rank indicated that first person errors continued past the onset of third person errors (i.e., overlap). Negative ranks represented cases in which first person errors ended before third person errors began (i.e., no overlap). The Wilcoxon signed-ranks test resulted in nine ties and ns/r = 13, or 13 signed ranks. Seven ranks were positive and six were negative. Collectively, 16 of 22 children demonstrated overlap between first and third person errors in the same sample (i.e., 9 ties and 7 positive ranks). The Wilcoxon test indicated that there was no significant difference in the end of first person errors and the onset of third person errors, z = –.12, p = .90.
Discussion
Association between first and third person errors
The goal of this study was to determine whether an association existed between children’s first person and third person pronoun case errors. An association would suggest that children initially approach case as a system through a general paradigm that cuts across person (and number) (Pelham, 2011; Pinker, 1984; Rispoli, 1994; Wisman Weil & Leonard, 2017). Pronoun case errors represent difficulty in establishing the place of the nominative vs. accusative distinction within this general paradigm. The lack of an association would indicate that pronoun forms are learned individually in a piecemeal fashion with specific pronouns learned one by one as emphasized by a usage-based approach (Kirjavainen et al., 2009; Lieven, 2014). If a general paradigm existed, most children should treat case marking for first and third person pronoun subjects alike. If pronouns were instead learned individually, then it would be possible for errors to exist for only one person (i.e., first or third).
Evidence for a case system was found in the association between first and third person pronoun case errors. The majority of children in this study (i.e., 72%) treated case similarly for first person and third person by producing case errors in both persons (i.e., 53%) or neither (i.e., 19%). Children were more likely to produce first and third person pronoun case errors than to make errors in just one person. They were also more likely to produce singular and plural errors than to make errors in just one number. Additionally, they were more likely to produce masculine and feminine third person errors than to make errors in just one gender. These outcomes are consistent with the interpretation that children attempt to build a general paradigm with a unified case system. The novel methodology of categorizing children by presence of error revealed that children tended to make errors across multiple features in the pronoun paradigm providing evidence that their attempts at producing pronouns were generated from a general paradigm. Thus, the association between first and third person errors is consistent with the notion of abstract grammatical features being arranged in a general mental paradigm, which the child uses in approaching the learning of personal pronouns (Pinker, 1984; Rispoli, 2005, 2009). Thus, we can say that the child approaches the acquisition of personal pronouns in a consistent manner, often choosing the accusative form by default. However, because the English pronoun case system is irregular with little phonetic material in common across pronouns, children must learn that additional word specific paradigms are necessary. Children who produced both first and third person errors (n = 23) can be seen as not having fully learned these word specific paradigms and the overt distinctions between subject and object word forms in these individual, word specific paradigms.
Patterns in the data reflected that more complex parts of the paradigm took longer to acquire. Recall that the third person singular pronouns he, she, him, his, are the four pronouns that are only ever used for intersections of four grammatical features (see Figure 1). In the current study, children still struggled with correct use of he and she as subjects at 33 and 36 months of age, while at the same time, they were mastering the pronoun I, which encodes fewer grammatical features. This finding is congruent with the cross-linguistic differences between fusional and agglutinating languages reported by Slobin (1982). Children tended to produce her for she errors for a longer duration than they produced other errors. This finding may be predictable from Pinker’s (1984) claim that incorrect irregular forms take longer to replace in the paradigm with correct forms when they are homonymous with another form in the paradigm, as her is (i.e., used for both object and genitive).
The current study explored the potential for overlapping first and third person errors by tracking both types of error over multiple measurement points. Overlap analyses were an alternative way to investigate the existence of a unified case system. The Wilcoxon signed-ranks test indicated that the null hypothesis, that errors overlapped, could not be rejected. For most children, during the time that their acquisition of case was incomplete, they produced errors in both the first and third person. The association discovered in the primary analysis provides evidence for unity in the child’s approach to overt case marking, because errors occurred at the same time. Since children treated case systematically, third person errors began before case had been acquired for the first person. It appears that difficulties with first person overt case marking carried over to third person pronouns. Taken as a whole, the relationships between first and third person pronoun case errors fail to support the possibility of piecemeal acquisition. If children learned each of the different pronoun forms individually, there would be no predictability to the progression of their errors.
Input and the origin of pronoun case error
Early attempts at explaining the origin of these errors focused on factors internal to the child, whether semantic, pragmatic or formal (Budwig, 1989; Rispoli, 1994; Schütze & Wexler, 1996). However, more recent attempts at explaining the origin of pronoun case error have shifted their focus to input (Kirjavainen et al., 2009; Pelham, 2011). Although our findings do not directly speak to the question of the origin of pronoun case errors, they are more congruent with Pelham’s (2011) Input Ambiguity Hypothesis in which the lack of subject–object distinction in the most frequently encountered parts of the English pronoun paradigm (i.e., you, it) is generalized to less frequent pronouns that have overt case distinctions. Children’s tendency in the present study to make both first and third person errors or neither type of error supports Pelham’s proposal that when children make case errors, they are blind to the subject–object case distinction generally and not just for one pronoun. We also know that children’s experience with I in input far exceeds their experience with she and he (Li & Shirai, 2000; MacWhinney, 2000). This might help explain a general developmental ordering, in which opportunity for first person pronoun case error arises earlier and is numerically more frequent than opportunity for third person error. However, this difference in frequency explains neither the finding of association, nor the overlap in the timing of error.
In another frequency-based approach to pronoun case error, Kirjavainen et al. (2009) propose that me for I substitution is related to the frequency of verb me verb (e.g., let me do it) sequences in the input. But, their hypothesis cannot explain why children tend to generalize their treatment of first person subjects to third person subjects. Nor can their approach explain a long-standing observation in the history of child language, namely that children also make my for I substitutions (Budwig, 1989; Rispoli, 1998b). The explanation proffered by Kirjavainen et al. fails to anticipate the systematic nature of the progression and extent of these errors.
Limitations and future directions
In interpreting our results, we should bear in mind several limitations of the current study. The sampling interval of 3 months used in this study limits the interpretation of its results. Errors were more likely to be caught for children with slower rates of development who made errors over at least a few months. The 3-month sampling interval may have missed errors for faster developing children who were only observed to produce one type of error, or no error whatsoever. In general, when using spontaneous language samples as a data source, there is a trade-off between sampling density and the number of participants. Although the 3-month sampling interval was appropriate for characterizing longitudinal change in the acquisition of tense and agreement in the original study, a monthly sampling interval would have been better for capturing pronoun case error. Denser sampling may have detected errors for the faster children between measurement points. Denser sampling might also have improved the precision in estimating age of last first person error and age of onset for third person error. However, even with the 3-month interval, an association with overlapping pronoun case errors was still detected. This finding may have been strengthened by any additional children observed to produce pronoun case errors through denser sampling. Future studies would benefit from denser sampling given the ephemeral nature of pronoun case errors for some children.
To have a comprehensive view of how case is acquired, cross-linguistic data should be examined. However, languages differ substantially regarding which lexical categories require case marking, which cases are distinguished, and which cases serve as a default (Corbett, 2008; Draye, 2002). Cross-linguistic validation of the presence of an association would require identifying another language that marks case on personal pronouns, distinguishes subjects from objects through case marking, and has nominative–accusative alignment paired with accusative as the default case.
Our study did not include a measure of pronoun gender errors. We recognize that children occasionally confused the conventional gender associated with toys such as baby dolls and Mr. Potato Head, which were among the toys in our laboratory playroom. If a child did produce a gender error in referencing one of these toys, we would not have been able to distinguish whether the error was caused by a misunderstanding of the gender of the toy, or a systemic reduction of the gender dimension in the third person pronoun paradigm. Loeb and Leonard (1991) acknowledged this challenge in classifying gender errors accurately (p. 345). At this juncture, we cannot say how gender errors might relate to the association we found between first and third person. A future study could investigate the propagation of pronoun errors across other features such as gender and number.
We also wish to note that there is a rich history of research that examines the development of self-reference in language development. Complicating our understanding of the development of self-reference is the fact that in child-directed speech, parents may use mommy, daddy, and the child’s name for first and second person reference, often varying between these proper nouns and first and second person pronouns (Bamberg, Budwig, & Kaplan, 1991; Conti-Ramsden, 1989; Oshima-Takane & Derat, 1996). The phenomenon appears in multiple languages, but English is exceptional in having extensive pronoun case error as a hallmark developmental error (Hyams, 2008). It appears to us that the specific typology of English and its exceptional marking of case only on pronouns plays a greater role in the origin of these errors than does the replacement of pronouns by nouns. However, the fact is investigations into the development of self-reference and pronoun case errors seldom overlap. The studies in which they do, do not report pronoun case errors in third person pronouns (Smiley, Chang, & Allhoff, 2011; Smiley & Johnson, 2006). Future studies that report data on the development of self-reference and pronoun case errors across the entire personal pronoun paradigm would be relevant to the question raised in this article, which is how pronoun case errors propagate through the personal pronouns. Such futures studies would indeed make a valuable contribution.
There remain many open questions with regard to pronoun case errors. One aspect that needs to be explored in greater detail is what brings about an end to the errors. One explanation for why errors cease is that a maturational constraint on the checking of multiple features is lifted from the child by maturation, thus enabling the consistent assignment of case (Wexler, 1998). We should note that some of the children in this study appeared to resolve their first person error before their third person errors resolved. Thus, resolution in the first person singular pronoun is possible while the error lingers elsewhere in the personal pronoun paradigm. Some form of experience, as opposed to pure maturation, may be involved in the extinction of these errors. It is also possible that parents provide negative feedback for these errors (Bohannon & Stanowicz, 1988). Although monitoring parent reactions to their children’s errors was beyond the scope of the present study, it is a relevant topic for future research.
Conclusions
This study investigated whether children apply knowledge of case to all subject pronouns uniformly or learn the subject–object distinction separately for each pronoun. In this study, making pronoun case errors was rather commonplace with the majority of children producing pronoun case errors between 21 and 36 months of age. Furthermore, these children were more likely to treat case in the same way regardless of the person of the pronoun. This uniformity in case marking is interpreted as support for a unified case system. Children’s overlapping errors in first and third person are taken as evidence that when children do not fully understand the conditions of case marking, case errors will arise across the general pronoun paradigm.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was based on Colleen Fitzgerald’s dissertation, which was supported, in part, by the Graduate College at the University of Illinois. Data collection and analyses were funded by NSF BCS-0822513 awarded to Matthew Rispoli and Pamela Hadley.