
Abstract
This study aimed to investigate specific associations between structural and acoustic characteristics of infant-directed (ID) speech and word recognition. Thirty Italian-acquiring children and their mothers were tested when the children were 1;3. Children’s word recognition was measured with the looking-while-listening task. Maternal ID speech was recorded during a mother–child interaction session and analyzed in terms of amount of speech, lexical and syntactic complexity, positional salience of nouns and verbs, high pitch and variation, and temporal characteristics. The analyses revealed that final syllable length positively predicts children’s accuracy in word recognition whereas the use of verbs in the utterance-final position has an adverse effect on children’s performance. Several of the expected associations between ID speech features and children’s word recognition skills, however, were not significant. Taken together, these findings suggest that only specific structural and acoustic properties of ID speech can facilitate word recognition in children, thereby fostering their ability to extrapolate sound patterns from the stream and map them with their referents.
Introduction
Research in the last few decades has demonstrated that language development is a product of dynamic interactions between the infant’s internal mechanisms and the social context (Hoff, 2006). From birth, infants show sensitivity to human speech; newborns exhibit early preferences for specific types of voices, such as the maternal voice (Kisilevsky et al., 2003), specific languages (Moon, Cooper, & Fifer, 1993), and linguistic sounds (Moon, Lagercrantz, & Kuhl, 2013). During their first years of life, infants also display a set of pattern-finding skills that help them to extrapolate information and regularities of sound patterns, such as transitional probabilities between syllable pairs, from their linguistic environment (Tomasello, 2005). This set of domain-general biases contributes to establishing several developmental skills, such as the process of attunement to the sounds of their native language, speech segmentation, and mapping between words and referents.
Although infants’ abilities are fundamental and sophisticated, their social environments represent a crucial source of support for their language acquisition process. In speaking with infants and children, parents use a particular linguistic register that is different compared to when they communicate with adults. The speech addressed to infants (ID speech; 1 infant-directed speech) is primarily characterized by short syntactically simple sentences and a simplified, redundant lexicon (Soderstrom, 2007). In regard to acoustic and prosodic features, high overall pitch, wide pitch ranges, and slower speech rate are some of the aspects that differentiate ID speech from adult-directed (AD) speech (Albin & Echols, 1996; Kitamura, Thanavishuth, Burnham, & Luksaneeyanawin, 2002; Ko & Soderstrom, 2013). ID speech features are thought to serve various functions in the infant language acquisition process. For instance, specific intonation aspects, such as the use of heightened pitch, are effective in maintaining and engaging infant attention and in allowing mother–infant communication of emotional content (Trainor, Austin, & Desjardins, 2000; Werker & McLeod, 1989). Similarly, ID speech lexical content, syntactic structure, and prosodic properties provide the inexperienced learner with a simplified amount of information about language itself (Hoff & Naigles, 2002).
A large number of studies on ID speech specifically relate to the influence of quantitative, lexical, and syntactic aspects of maternal verbal input on children’s lexical and morpho-syntactic development (Hoff & Naigles, 2002; Rowe, 2008; Soderstrom, 2007). Nevertheless, the role of verbal input in promoting language acquisition is evident well before infants are able to utter their first words (see review by Cristia, 2013). Several studies have documented that infants prefer to listen to ID speech over AD speech very early in life. For instance, both two-day-old newborns and one-month-old infants are able to process prosodic aspects of linguistic input, and they are more engaged by speech in which prosodic features are exaggerated (Cooper & Aslin, 1990; Fernald & Kuhl, 1987). Later in development, the clarity of maternal ID speech at a phonetic level, in terms of the degree of the expansion of vowel space, affects speech perception skills in infants aged 0;6–1;0 (Liu, Kuhl, & Tsao, 2003). Additional studies have documented that prosodic modifications in ID speech also influence infants’ speech stream segmentation. Thiessen, Hill, and Saffran (2005) tested infants aged 0;6.15–0;8.15 with respect to ID speech versus AD speech in a preferential listening paradigm. ID speech and AD speech sentences differed only in terms of intonation contours (e.g., average F0 was 292 Hz for ID speech and 230 Hz for AD speech); thus they were identical in grammatical structure and word order. Infants were only able to segment ID speech and showed no ability to discriminate words uttered in an AD speech modality. Similar conclusions are drawn by Hirsh-Pasek et al. (1987). The authors collected samples of ID speech and modified them into two versions. In the first version (coincident), they inserted pauses at the boundaries between two clauses as normally occurs in ID speech (Broen, 1972). In the second version (non-coincident), pauses were placed between words within a clause. Seven-month-old infants tested in the two conditions with a head turn preference procedure displayed a listening preference for the coincident version, which was interpreted as sensitivity to the presence of prosodic markers between clausal units. These findings suggest that not only are ID speech acoustic and prosodic proprieties preferred by infants but they also play a crucial role in facilitating the process of attuning to particular language sounds and in supporting speech segmentation.
After children accomplish the task of speech segmentation, they develop the ability to map between words and their referents (i.e., word comprehension). Compared to the research on children’s language production, limited attention has been devoted to the study of early language comprehension, due to the difficulty in investigating this ability in infancy (Bates, 1993). However, the development of the Intermodal Preferential Looking Paradigm (IPLP) by Golinkoff, Hirsh-Pasek, Cauley, and Gordon (1987) and the more recent looking-while-listening (LWL) procedure (Fernald, Pinto, Swingley, Weinberg, & McRoberts, 1998) has stimulated a growth in studies on this topic, providing findings on how children’s language processing skills develop during the first three years of life (Fernald & Marchman, 2012; Fernald, Perfors, & Marchman, 2006). Both IPLP and LWL are intermodal looking preference procedures where the infant, seated on a parent’s lap, is contemporaneously presented with visual and linguistic stimuli (Golinkoff, Ma, Song, & Hirsh-Pasek, 2013). The visual stimuli are normally displayed on two screens or on a large monitor with a split screen. The linguistic material – which is presented through a loudspeaker system – only matches one of the images or scenes displayed on the screens. Infants’ gaze behavior towards the stimuli is videotaped and successively coded offline. The typical IPLP studies use total looking fixation time towards the linguistic matching scene/image (target) as a measure of infant language comprehension while the LWL procedures also offer data on the time course of infant gaze behavior, providing several insights on infants’ speech processing.
Recently, researchers have begun to investigate whether the qualities or the amount of early language experience can influence the efficacy of language processing in young children. Hurtado, Marchman, and Fernald (2008) provided the first evidence that children’s individual differences in speech processing are related to the quality and amount of input to which they are exposed. Specifically, maternal word types, word tokens and mean length of utterance (MLU), as observed in a mother–child interaction session at the age of 1;6, predicted children’s word recognition abilities six months later, even after controlling for the child’s speech processing efficacy as assessed on an LWL task at 1;6. Weisleder and Fernald (2013) expanded these findings by documenting that children who were more exposed to child-directed speech at 1;7, as calculated by all-day recordings at home, were more rapid and accurate on the LWL word recognition task. Song, Demuth, and Morgan (2010) investigated the relationships between ID speech prosodic properties and children’s word recognition skills on an IPLP task. They presented children aged 1;7 with ID speech stimuli (e.g., Where’s the ball?) in which speaking rate, vowel hyper-articulation, and pitch range are altered. Children’s word recognition skills were improved by stimuli characterized by slow speaking rate and vowel hyper-articulation but were not affected by the extent of pitch range. The authors concluded that only the ID speech modifications that are linguistically relevant in English, such as speech rate and vowel hyper-articulation, influence children’s ability to map word stimuli to their referents, whereas the alteration of pitch range constitutes only an attentional cue to speech.
The principal aim of the current study is to extend the reported findings by investigating how several characteristics of infant-directed speech concurrently relate to infants’ emerging skills in lexical processing. Given the previous findings, both structural and prosodic aspects of ID speech are considered. In this study, ID speech properties are assessed during a mother–infant semi-structured play session at the age of 1;3. At the same age, we investigate infants’ online lexical recognition abilities using an LWL task (Fernald et al., 2006). In order to control for significant delays in vocabulary acquisition, infants’ language abilities are also assessed by the administration of the Italian version of the McArthur–Bates CDI (Fenson et al., 1994). The rationale for investigating this particular age is that at this stage of language development, children are still learning new words, specifically nouns and routine words, with an associationist mechanism (Nazzi & Bertoncini, 2003), so that their principal task is to segment the speech stream, isolate the verbal labels, and associate them with their external referents. Thus, we expect that infants at this age would benefit from a maternal verbal input that is rich and stimulating but at the same time easy to segment.
Given this information, specific hypotheses were tested. Considering the conclusions reported in the literature (Song et al., 2010), we expected that the ID speech characteristics that contribute to simplifying maternal utterances and word intelligibility, such as slow speech rate and marked final syllable lengthening (FSL), and positional salience, would be associated with infants’ lexical processing abilities. Moreover, even if a high pitch variation and the use of utterances characterized by modulated pitch contours are not considered as linguistically relevant cues, these characteristics are determinant in engaging infants’ attention towards their linguistic environment and could support their language processing skills (Spinelli, Fasolo, & Mesman, 2017).
Finally, considering the works by Hurtado et al. (2008) and Weisleder and Fernald (2013), in which the quality and quantity of caregivers’ speech at 18–19 months predicted children’s efficiency in word recognition at 24 months, we hypothesize that significant positive associations exist between the amount and complexity of ID speech and infants’ word recognition abilities. In particular, we suggest that a large amount of input would provide infants with multiple exposure to different types of the same words, thus simplifying their isolation in the speech stream.
Method
Participants
Participants included 30 healthy full-term children, 14 girls and 16 boys, aged 1;3 (M age = 1;3.15, range = 1;2.26–1;4.07), who were recruited to participate in the study via a written invitation that was sent to parents based on birth records provided by neighboring cities. All participating children were raised in monolingual Italian families. Mothers’ ages ranged from 26 to 42 years with a mean age of 35.52 years (SD = 3.44). Maternal levels of education ranged from lower secondary school to the highest educational levels, as follows: 3.33% lower secondary school, 16.7% upper secondary school, 50% master’s degrees, 30% postgraduate degrees. All parents were informed about the general aim of the study and signed a consent form to participate in the research project.
Procedure
Mother–child dyads participated in an evaluation session that lasted approximately one hour at the Department of Psychology at Milano-Bicocca University. Children first participated in a word recognition task, the looking-while-listening procedure. After a brief break, mother–child dyads participated in a video-recorded semi-structured play session. During the session, mothers were asked to play freely with their children as they would at home using various toys (illustrated books, a toy farm, and a baby-doll with its meal set) that were selected with the specific aim of stimulating communicative exchanges between the mothers and their children.
Speech processing
In the LWL procedure (Fernald et al., 1998) children are presented with pairs of images while hearing sentences naming one of the depicted pictures. Because children tend to look at a familiar object when named, looking longer at the named picture (target) rather than at the unnamed picture (distractor) is considered a measure of word recognition.
Speech and visual stimuli
The speech stimuli selected for the task consisted of prerecorded sentences containing a target word embedded in a carrier phrase. Highly familiar words were chosen from the Words and Gestures form of the questionnaire ‘Il Primo Vocabolario del Bambino’ (Caselli & Casadio, 1995), the Italian version of the McArthur–Bates CDI (Fenson et al., 1994). A female native Italian speaker recorded, in a soundproof booth, various tokens of each stimulus as if she was addressing a toddler, matching them closely in intonation contour. The candidate stimuli were then recorded and normalized in intensity using the software Audition 1.5. Two researchers then selected the best token of each stimulus based on its duration and intonation contour. Target words were preceded by the carrier phrase, ‘Hey, where’s the [target word]?’ (Ehi, dov’è il/la [target word]), which lasted 950 ms. Stimuli were matched in pairs based on word duration (M = 573.75; SD = 74.77), grammatical gender, and the animate or inanimate nature of the objects depicted. The following four stimuli pairs were used: ball–shoe (palla–scarpa), pacifier–juice (ciuccio–succo), apple–hand (mela–mano), doggie–baby (cane–bimbo). Visual stimuli were digitalized photographs that represented the stimuli pairs. The two objects of each pair were presented at the extreme sides of a cyan blue background and were comparable in terms of brightness, size, and dimension (1600*900 pixels).
Apparatus
The LWL task was conducted in a 1.5 × 2 m Amplifon soundproof booth. During the task, the child, seated on the mother’s lap in a swivel chair, faced a 26.3 inch computer monitor at a 40 cm distance. The seat height was regulated so the monitor was always at the eye level of the child. Speech stimuli were presented at a constant level of 60 db with a 2.1 JBL creature III system located below the monitor. During the testing session, mothers were asked to listen to music using a pair of Sennheiser HD 280 PRO headphones to avoid influencing the children’s responses. A Sony video camera, placed above the monitor, was used to capture the child’s eye and head movements. The video camera and the monitor were connected to a PC located outside the booth where a researcher controlled the experiment presentation with MATLAB.
Procedure
The testing session began with a familiarization period during which parents and children were made comfortable and acquainted with the laboratory environment. At the beginning of the test session, the lights inside the booth were dimmed and an animated cartoon with a child playing with soap bubbles was displayed on the monitor. When the child’s attention was engaged in the animated cartoon, the experimental session began. Each trial began with a white display, then the pair of images was presented in silence for 2 s prior to the speech stimuli presentation and then continued to be displayed for 2 s following the audio offset. Picture pairs were presented six times for a total of 24 trials. In the six trials of each pair, the single picture (e.g., ball) was presented an equal number of times as a target (i.e., it was named in the speech stimulus) and as a distractor. If the child was inattentive during trials, the animated cartoon was presented to get her or his attention back to the task. The entire experimental session lasted approximately four to five minutes. The order of trial presentation was based on the considerations raised by Fernald, Zangl, Portillo, and Marchman (2008). In particular, the side of the screen where the target object appeared was counterbalanced so that target images were at the right extreme of the monitor in half of the trials. Furthermore, target images did not appear at the same side of the monitor for more than three consecutive trials. These options allowed the child’s eye directions to be controlled, and fixation times were not associated with the position of the image on the monitor or with a preference towards a specific image.
Coding and measures
Recorded experimental sessions were analyzed by trained observers who used the Observer XT software. The observers, blind to trial type and side of the target picture, coded the sessions without sound. In each trial, coding began with the onset of the target word and ended at the offset of the trial itself. Observers coded the child’s gaze frame by frame (40 ms) and noted, for every frame, if it was on the right picture, on the left picture, at the center of the monitor, or away from the monitor. At the end of the coding, details on trial type and side of the target picture were matched to the sequential data of child’s gaze behavior. As established by the study of Fernald et al. (2006), only shifts occurring within the 300 to 1800 ms window from target word onset were considered informative of infants’ speech processing abilities. The use of this particular time window allows both those gaze behaviors that occur too early, likely by chance, from the onset of the target word, and the long latencies that are unlikely responses to the target word to be left out of the analyses. Therefore, for each trial, the total cumulative amount of time the child spent fixating on the target or the distractor during the 300 to 1800 ms window following target word onset was first measured. Mean looking times towards the target pictures and towards distractor pictures were also computed. Accuracy was then calculated as the proportion of time the child spent fixating on the target picture compared to the total time spent fixating on both images. Trials were excluded when the child spent more than 50% of the 300 to 1800 ms time window not looking at either the target or the distractor images. In our study, accuracy is based on M = 22.7 trials per participant (range = 10–24 trials). Finally, considering the child’s gaze position at the frame corresponding with the onset of the target word, trials were classified into target-initial trials, distractor-initial trials, and off/center-monitor-initial trials. Thus, considering only distractor-initial trials (M = 10 trials; range = 3–13 trials), in which the child’s correct response is to shift her or his gaze towards the target image, a reaction time (RT) measure was calculated that represented the time the child needed to shift her or his gaze from the distractor image to the target image.
Parental report measures of children’s lexical development
Parents were asked to complete and then return by mail the Words and Gestures form from the ‘Il Primo Vocabolario del Bambino’ questionnaire (Caselli & Casadio, 1995). Of the 30 questionnaires, 29 were returned. A measure of receptive vocabulary (CDI-r; the total number of words the child understands) and a measure of expressive vocabulary (CDI-e; the total number of words the child understands and says) were calculated for each child.
Mothers’ speech
Mother–child observational play sessions lasted, on average, 17.21 minutes (SD = 1.30) and were video-recorded using a set of three Sony HD cameras. The audio portion was captured with an Ecler Mixer using a shotgun Sennheiser microphone hidden in a pendant lamp. Maternal utterances directed to the children were transcribed into the CHAT (CHILDES system) format (MacWhinney, 2000) by a trained observer. Onomatopoeic sounds, interjections, and incomplete or unintelligible words in maternal input were excluded from the analyses. An utterance, defined as any sequence of talk followed by silence or a pause or as an understandable change in the conversational turn, was considered the basic unit of transcription for maternal speech.
Structural characteristics
Various indices of linguistic amount and complexity were calculated using CLAN programs. The syntactic complexity of maternal utterances was measured by computing the mean length of utterance (MLU), i.e., the ratio of words to utterance, using the MLU program. Vocabulary diversity in maternal talk was analyzed by means of the VOCD program (McKee, Malvern, & Richards, 2000), which provides a measure (D) that, in addition to controlling for the total amount of speech produced, provides a less biased measure of lexical complexity than the type/token ratio (TTR) and word types. Finally, considering that play sessions were not fixed-length, maternal word tokens per minute were calculated as a measure of maternal amount of speech.
Prosodic characteristics
Given the specific aims of the study, prosodic features of child-directed speech were also analyzed. For each mother, 40% of the utterances directed to the children were randomly selected from the transcriptions. Again, utterances including fragmented speech or non-semantic material were excluded from the analyses. A total number of 2350 utterances (containing 8740 words and 14,647 syllables) were considered with an average of 78.3 utterances per mother–child dyad. Speech analyses were conducted using the PRAAT software (Boersma & Weenink, 2005). The following acoustic measures that define the general acoustic and prosodic characteristics of the mothers’ speech were calculated:
Mean F0 pitch, F0 maximum (F0max) and F0 minimum (F0min) as automatically calculated by PRAAT (Boersma & Weenink, 2005);
The logarithmic difference between the highest and the lowest F0 values in the utterance, measured in semitones, as a pitch range measure 2 (Collier, 1990);
Speech rate as syllables per second;
Non-final syllable (nFS) length: mean duration in ms of the utterances’ non-final syllables;
Final syllable (FS) length: mean duration in ms of the utterances’ final syllables.
Positional salience
For each utterance the lexical category of the final word was also identified, and utterances were then classified into utterances ending with a noun, a verb, or a word belonging to a different lexical class.
FSL distribution
Based on this latter classification, we looked at the nouns, verbs, and other category words (i.e., adjectives, adverbs, conjunctions) in utterance-final position in which the final syllable was lengthened compared to the non-final syllables of the utterance. The final syllable was considered lengthened if its duration exceeded at least 20% of the mean duration of the utterance’s non-final syllables. The proportional frequency of nouns, verbs, and other lexical elements in which the final syllable was lengthened was calculated based on the total number of utterances ending with a noun, a verb, or a word belonging to a different lexical class, respectively.
Reliability
Inter-rater agreement analyses were conducted. Acoustic and pitch measures of 50% of the utterances of 12 mothers in the study were re-scored by a second coder. High and statistically significant Pearson correlations were identified in the calculations of speech rate (r = .77), FS length (r = .94), mean F0 (r = .94), F0max (r = .83), and F0min (r = .86) performed by the two coders.
Results
Children’s word recognition skills and vocabulary measures
Descriptive statistics for children’s word recognition and vocabulary measures are reported in Table 1. Children’s vocabulary measures were compared to the normative data retrieved from Caselli and Casadio (1995) using a one-sample t-test. Children’s CDI-e results were similar to the normative population (M = 16; SD = 17), t(28) = 0.91, p = .368, while their CDI-r results were marginally wider (M = 141; SD = 71), t(28) = 1.84, p = .077). With respect to accuracy on the word recognition task, the descriptive statistics showed that, on average, children’s identification of the target pictures was above chance level (M = 0.59; SD = 0.09). A paired t-test confirmed that children’s mean looking time towards the target pictures (M = 0.82; SD = 0.14) was significantly higher than mean looking time to the distractor pictures (M = 0.56; SD = 0.12), t(29) = −5.9, p < .001, d = 1.07. RT times extensively varied among children, with, on average, participants needing approximately one second to shift their gaze in the direction of the correct target picture. Accuracy and RT measures were uncorrelated (r = .02; p = .923).
Means, standard deviations, and range for children’s word recognition and vocabulary measures.
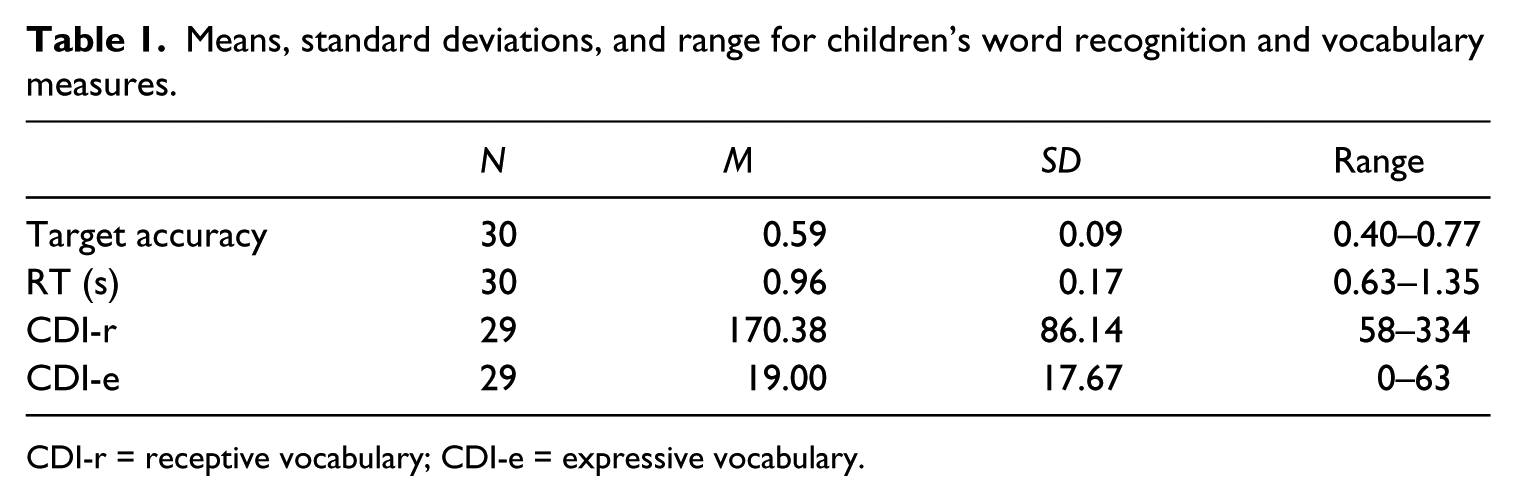
CDI-r = receptive vocabulary; CDI-e = expressive vocabulary.
Maternal talk: structural and prosodic features
Table 2 summarizes the structural and prosodic characteristics of maternal speech directed to the children in the sample.
Means, standard deviations, and range of the structural and prosodic characteristics of maternal verbal input (n = 30).
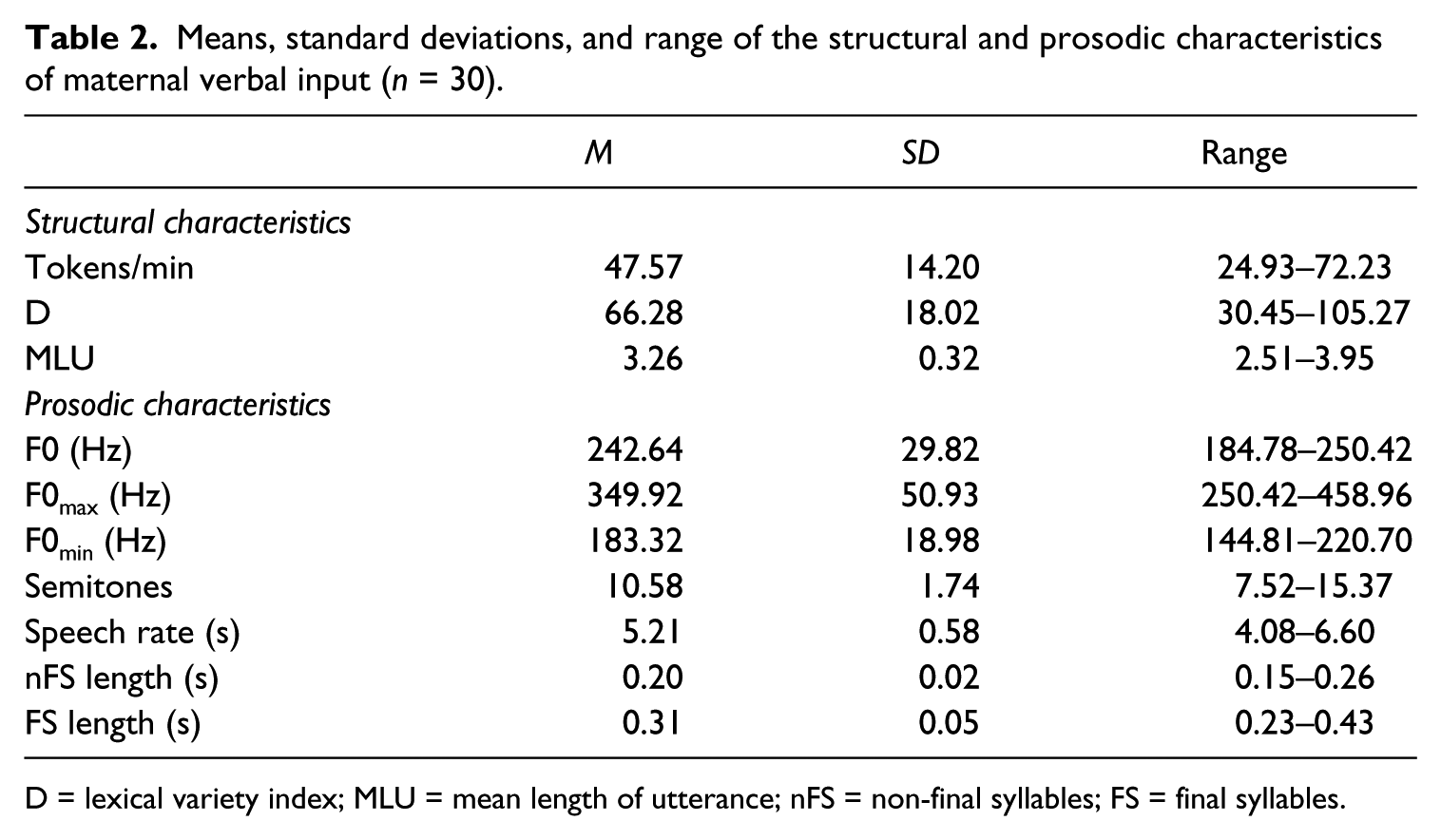
D = lexical variety index; MLU = mean length of utterance; nFS = non-final syllables; FS = final syllables.
The descriptive statistics showed considerable variation in quantity, lexical diversity, and syntactic complexity of maternal input as well as in pitch height and range. Table 2 also includes maternal measures of speech rate, non-final, and final syllable length. Mothers lengthened the duration of final syllables more than non-final syllables, t(29) = −16.71, p < .001, d = 3.05.
In addition, a further analysis was conducted to understand which lexical element was more likely to be in the utterance’s final position. The descriptive statistics of the utterances ending with a noun, verb, or another lexical element are reported in Table 3.
Means, standard deviations, and range of the distribution of lexical elements in utterance-final position and of final syllable lengthening (FSL) distribution (n = 30).
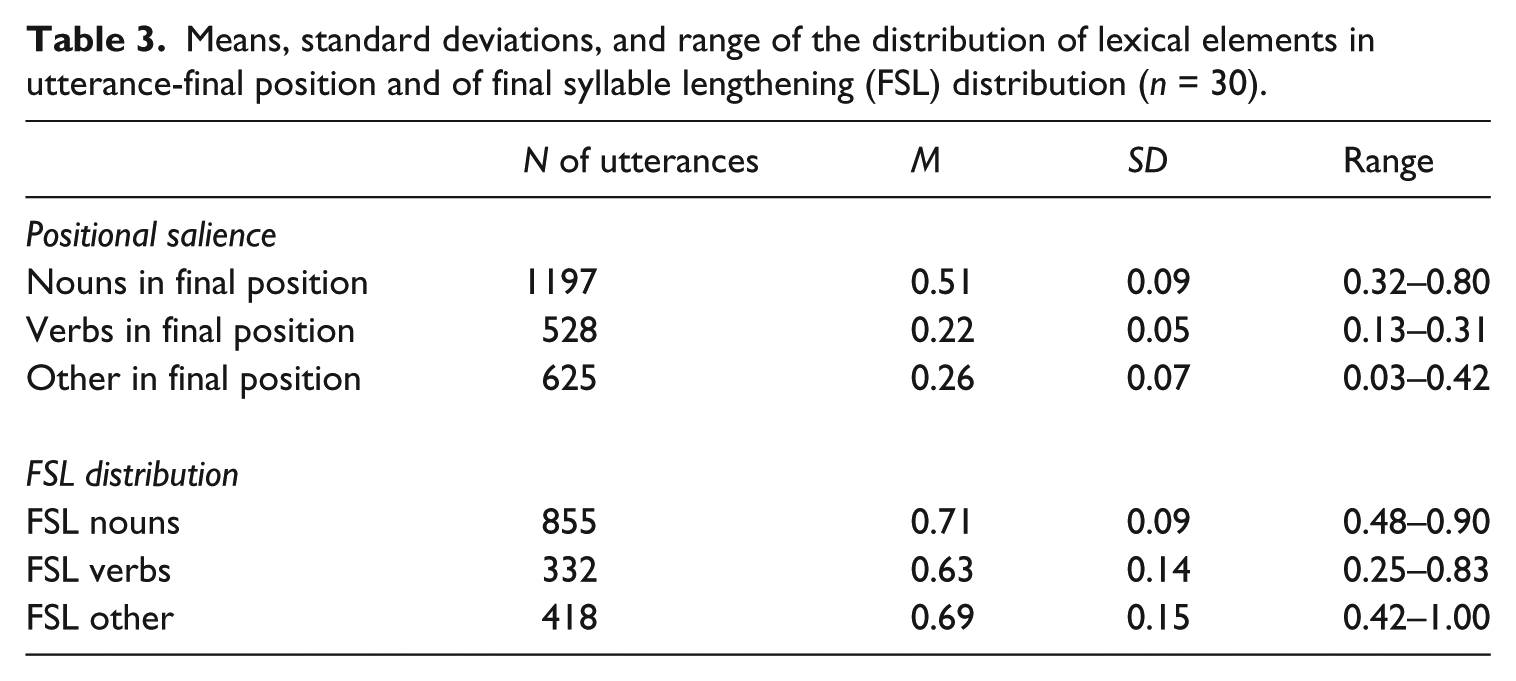
A one-way repeated measures ANOVA (Word in final position: Nouns, Verbs, Other) yielded a significant main effect, F(2,58) = 89.79, p < .001, partial η2 = .76. A post hoc Bonferroni test was conducted for multiple comparison. Results revealed that mothers used more nouns than verbs (p < .001) and other lexical elements (p < .001) in the final position, and verbs were more likely to be in the final position than other category words (Other: p = .026; Nouns: p < .001). Finally, another one-way repeated measures ANOVA (FSL: Nouns, Verbs, Other) was conducted to evaluate which lexical category in the final position was more likely to be marked with final syllable lengthening (see Table 3 for descriptive statistics). Again, a main effect was found, F(2,58) = 4.03, p = .023, partial η2 = .12. Bonferroni post hoc comparison showed that nouns in the final position were more often marked with FS lengthening than verbs (p = .012). No other significant differences were found.
Associations between maternal talk and children’s word recognition
A series of correlation analyses between children’s word recognition accuracy (target accuracy) and RT and selected structural and prosodic characteristics of maternal verbal input was conducted. Results are reported in Table 4. F0max and F0min were excluded because the difference in semitones between them was used as a measure of maternal pitch variation.
Pearson’s correlations between measures of maternal ID speech and children’s speech processing (n = 30) and vocabulary (n = 29) measures.
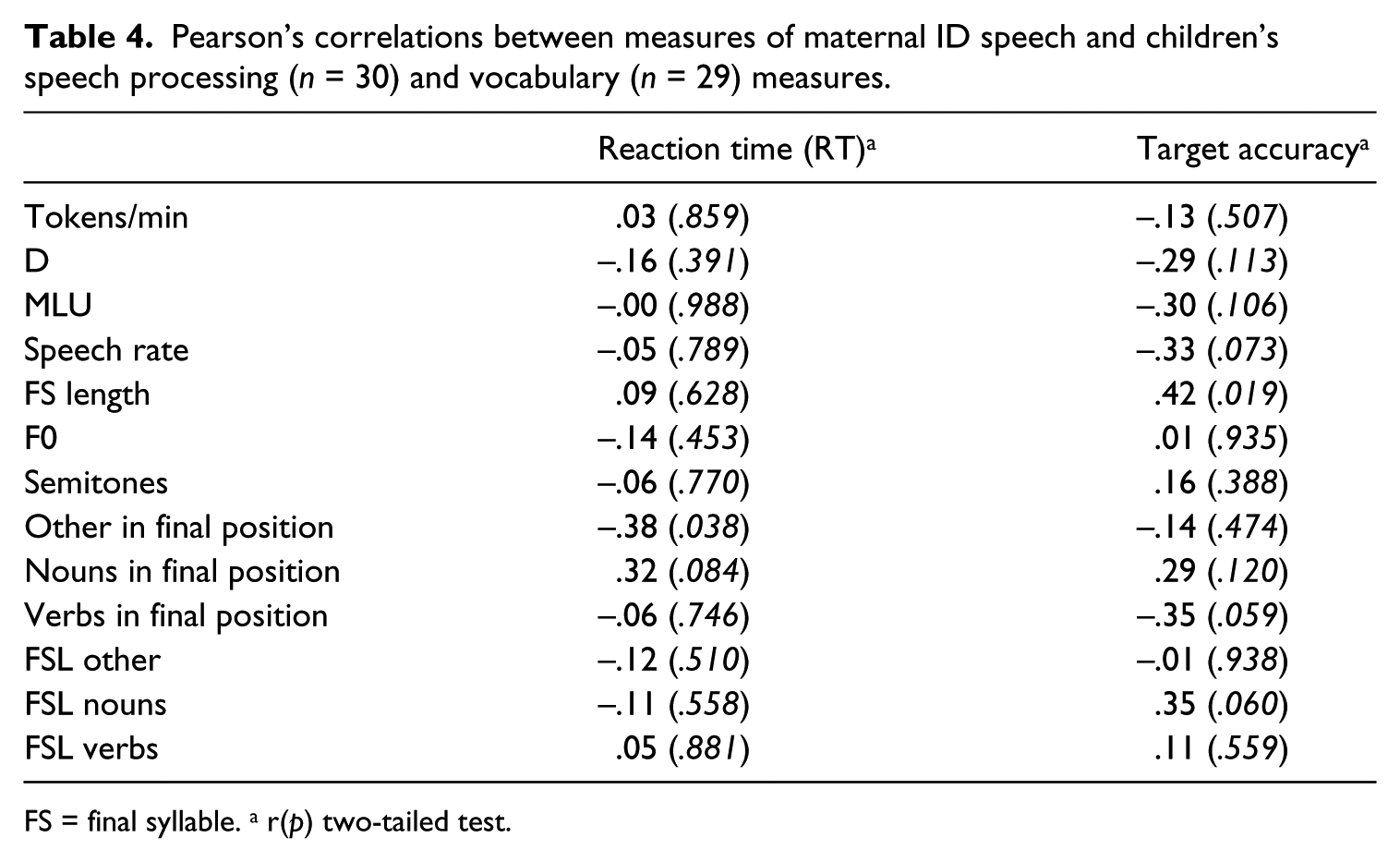
FS = final syllable. a r(p) two-tailed test.
As reported in Table 4, results showed that a longer duration of the utterance-final syllables was positively associated with children’s accuracy in word recognition. Figure 1 illustrates a scatter plot of this correlation.
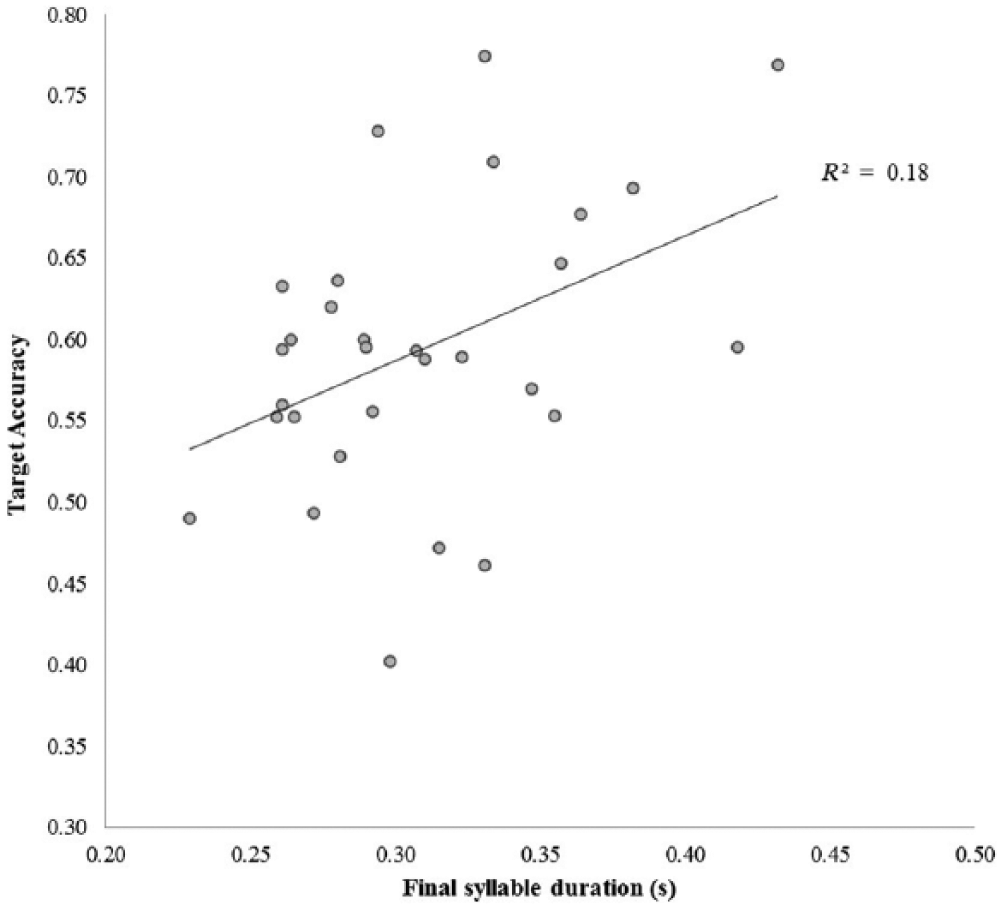
Correlation between target accuracy and final syllable duration (n = 30).
More specifically, a wider use of final syllable lengthening of nouns in the final utterance position was, even if marginally, positively associated with children’s accuracy in word recognition. Furthermore, significant results also emerged when investigating the distribution of lexical class in the final utterance position and its associations with children’s linguistic measures. In particular, the use of verbs in the final position of utterances was negatively associated, although not quite significant, with target accuracy. Moreover, greater use of adjectives, adverbs, or conjunctions in maternal utterance-final position was associated with shorter RT on the word recognition task. Finally, the maternal speaking rate, measured as the number of syllables per second, was negatively correlated with children’s accuracy on the LWL task. Measures related to the amount of speech directed to children and measures of lexical and syntactic complexity of maternal verbal utterances were not correlated with children’s word recognition. Similar results were found for the measures concerning the intonation of maternal utterances, showing no significant associations between maternal high pitch and pitch variation and children’s accuracy and RT.
In light of the results of the previous correlation analyses, the specific contribution of the characteristics of maternal speech in accounting for the children’s differences in accuracy on the LWL task was investigated with a regression analysis. Using target accuracy as the dependent variable, final syllable length, use of verbs in the final position, maternal speech rate, and FSL on nouns were all entered into the model as predictors using a stepwise approach. The model, F(2,27) = 5.56, p = .009, explained 29% of the variance, with FS length (β = .41, p = .017) and verbs in the final position (β = –.33, p = .049) as significant predictors of children’s accuracy on the word recognition task. Speech rate (β = .26, p = .379) and FSL on nouns (β = .31, p = .128) were not significant predictors.
Discussion
The aim of the present work was to investigate how differences in various aspects of maternal verbal input directed towards children are related to differences in children’s language processing skills. Two major contributions of this study deserve emphasis. First, the present study is one of the first to address the role of ID speech prosodic and temporal features in relation to the ability to map between words and their referents. Previous studies have principally explored the association between these features and speech segmentation abilities and documented how intonation and temporal aspects of ID speech facilitate this. Furthermore, this study investigates the role of several characteristics of maternal verbal interactive style, such as structural, prosodic, and acoustic features, during an early stage of language comprehension development, whereas other works, such as those conducted by Hurtado et al. (2008) and Weisleder and Fernald (2013), analyzed the period following children’s vocabulary spurt.
In consideration of previous research findings and theory, specific associations between several aspects of maternal ID speech and children’s word recognition ability were tested. Our findings failed to fully support the study hypotheses. In contrast with our expectations, the amount, variety, and complexity of maternal ID speech were uncorrelated with children’s performances in the word recognition task. Both Hurtado et al. (2008) and Weisleder and Fernald (2013) found that structural aspects of parental verbal input, such as MLU and lexical diversity, foster children’s language processing skills during the second year of life. Accordingly, the lack of significant associations among these measures in our sample could be explained by the age of our participants. At 1;3, immediately before the vocabulary spurt phenomenon, children are still acquiring new words using an associationist mechanism, whereas, on average, a few months later they learn up to nine new words a day using a referential mode of lexical acquisition (Nazzi & Bertoncini, 2003). Thus, if children can benefit from clear and intelligible verbal input during the first phase, i.e., around the onset of the vocabulary spurt, then they can take advantage of rich verbal input both in terms of amount and diversity. In other words, as recently proposed by Newman, Rowe, and Bernstein Ratner (2015), specific features of the input could serve children’s language acquisition during particular stages of the development and could be ineffective in others.
In a similar vein, considering the lack of significant associations between pitch variables and children’s performance on the LWL task, it could be suggested – as also indicated by Song et al. (2010) – that the exaggeration and modulation of pitch in maternal verbal input mainly serve attentional and emotional functions and are unrelated to child-specific language processing abilities. One recent meta-analysis provides some corroboration of these latter suggestions. By investigating 15 studies, Spinelli et al. (2017) find that prototypical ID speech prosody is associated with more infant attention and better prelinguistic and linguistic skills, with a greater effect on prelinguistic outcomes. The authors conclude that for children at a preverbal stage, the prosody of maternal speech could be more salient that linguistic aspects of the input; later on, from the end of the first year, children will rely more on linguistic features of speech.
In this light, our results highlighted the presence of specific ID features that resulted in association with children’s word recognition. Our main findings are twofold. First, our analyses highlight several modifications in the maternal speech directed to children that may enhance speech intelligibility. In the first place, maternal utterances were significantly marked by the lengthening of final syllables. This phenomenon, which is well described in the work by Fisher and Tokura (1996), represents one of the more significant acoustic cues in speech segmentation. Studies on spontaneous maternal speech directed to preverbal infants consistently document exaggerated utterance-final syllable lengthening (Albin & Echols, 1996; Bernstein-Ratner, 1996). With regard to the Italian language, D’Odorico and Jacob (2006) examined the maternal speech directed to 20-month-old children with typical language development and late-talking toddlers. They reported that FSL occurs in maternal speech independently from children’s linguistic development. The elongation of the final syllable in an utterance provides young children with fundamental information about the boundaries between units of speech, anticipating phrase and clause pauses. This phenomenon could serve to enhance the acoustic salience of both syntactic and lexical units of speech (Fernald & Mazzie, 1991). Moreover, further analyses emphasize that, in our sample, mothers significantly placed nouns more than verbs or other lexical elements in utterance-final position and that these nouns were more likely to be marked with final syllable lengthening compared to other lexical categories. Fernald, McRoberts, and Swingley (2001) demonstrated that at 1;3, infants are able to identify familiar words when occurring at the end of the utterances but failed to recognize familiar words embedded in the middle of utterances. Fernald and Mazzie (1991) documented that mothers consistently arrange focused words in utterance-final position when reading to their infants aged 1;2, whereas in reading for adults, the position of these words is variable. Thus, positioning nouns at the end of the utterances could have a perceptual advantage for language-learning infants at a lexical level. Moreover, mothers not only highlight utterance boundaries by marking them with final syllable lengthening, but they also significantly emphasize nouns in utterance-final positions, which likely fosters the mapping between words and their referents.
Accordingly, the second main finding of the study regards the identification of significant associations between these aspects of ID speech and children’s abilities regarding word recognition. According to the results of the regression analysis, maternal elongation of utterance-final syllables and the distribution of verbs at the end of utterances were the only predictors of children’s gaze time towards target images. Specifically, while the exaggeration of final syllable length enhanced children’s accuracy in word recognition, the use of verbs in the final position of utterances had an adverse effect on task performance. As previously stated, final syllable lengthening is broadly thought to play a fundamental role in facilitating speech segmentation, which then promotes children’s language development (Albin & Echols, 1996; Fisher & Tokura, 1996). It is important to note that even if this association is widely hypothesized, the present study is the first to empirically test the relationship between FS lengthening and children’s word recognition abilities.
Furthermore, positioning verbs at the end of the utterances revealed a negative effect on children’s word recognition accuracy. This association should be considered in light of the specific stage of language acquisition of the children participating in the study and the distinctive characteristics of their native language. When compared with English-acquiring children, Italian children demonstrate a similar noun bias in the early phases of vocabulary acquisition (Caselli & Casadio, 1995). Several authors (Choi & Gopnik, 1995; Tardif, 1996) raised the hypothesis that the presence or the absence of a noun bias in children’s early vocabularies would be determined by certain aspects of maternal verbal input, assuming that emphasizing lexical categories in utterance-final position contributes to early vocabulary acquisition. Later studies (Camaioni & Longobardi, 2001; Tardif, Shatz, & Naigles, 1997) document that when addressing children in their second year of life (from 1;4 to 1;11), Italian mothers emphasize nouns in the utterance-final position more often than verbs. In two recent studies, Longobardi and collaborators (Longobardi, Rossi-Arnaud, Spataro, Putnick, & Bornstein, 2015; Longobardi, Spataro, Putnick, & Bornstein, 2016) report that at 1;4, the percentage of nouns in maternal input both in the initial and the final utterance positions predicts children’s production of nouns at 1;8 and at 2;0. Conversely, in the same study, children’s verb growth was negatively related to the percentage of verbs in utterance-final position and positively predicted by the percentage of verb types occurring in the utterance-initial position. Thus, the conclusion drawn from the present data is that, at this stage of child language development, the maternal use of verbs instead of nouns in utterance-final positions leads to a premature emphasis on a grammatical class that is far from the focus of children’s language acquisition process and thus is detrimental to the processes of early word recognition and production.
With respect to children’s word processing speed, a different result emerged, thus indicating that children’s reaction time was enhanced by the maternal use of adjectives, adverbs, and conjunctions in utterance-final position (Other in final position). This latter finding contrasts with the previous conclusions drawn on the negative effect of verbs in final position on LWL accuracy. A possible explanation for this discrepant result may lie in methodological aspects. In a longitudinal LWL study, Fernald et al. (2006) find that between 1;3 and 1;6, the variance in children’s response speed is wide and unstable. At the same time, our data indicate substantial independence between accuracy and RT measures. From our findings and Fernald et al.’s (2006) conclusions, it could be hypothesized that at the onset of word recognition, processing speed would represent a less reliable measure than accuracy for capturing children’s performances.
Before closing the discussion, two relevant limitations of our study design deserve mention. First, the cross-sectional nature of the study did not allow us to conclude that specific characteristics of maternal speech, such as FS lengthening, directly promote children’s efficacy in word recognition. In this context, it would be worthwhile to investigate the associations between ID speech features and children’s word processing skills from a longitudinal perspective by considering how the exposure to specific aspects of the input can promote the development of these skills. Furthermore, maternal education in the sample was unbalanced, with 80% of the mothers in the sample having at least a master’s degree. The skewness of maternal education distribution in our sample requires caution in the generalization of our findings as differences in socioeconomic status (SES) are strongly associated with variation in children language outcomes (Fernald, Marchman, & Weisleder, 2013; Rowe, 2008).
To conclude, our findings provide evidence that a maternal emphasis on words, and especially nouns, in utterance-final position is associated with better word recognition in children aged 1;3. At the same time, data failed to corroborate the hypothesis that structural characteristics of the input such as the number of word tokens and lexical variability and voice prosody would be positively related with children’s lexical processing. As claimed by Golinkoff, Can, Soderstrom, and Hirsh-Pasek (2015), what can be useful for children at certain points of language development could change as they crack the code and they develop and acquire new competences and knowledge.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.