
Abstract
In this corpus study, it is asked whether young children speaking European French build their early syntax around grammatical or lexical words. Specifically, the study examines the relationship of grammatical and lexical words in three types of syntactic structures (determiner–noun, pronoun–verb and subject pronoun–verb). The corpus included 315 samples from children aged 24–48 months, a period of rapid growth in grammatical morphology and syntax. The results of a series of stepwise multiple regression analyses indicate that prepositions and auxiliaries explain the unique variance in determiner–noun and determiners and prepositions explain the unique variance in pronoun–verb and subject pronoun–verb combinations better than lexical categories. All these strong predictors support the view that grammatical words guide and facilitate syntactic knowledge. Early grammar is based not on a lexicon but on basic grammatical relationships that young children build gradually, making use of the formal distributional properties of their native language.
Introduction
The issue of whether young children build their early syntax around grammatical or lexical words from their target language is still debated. On one hand, the construction of syntactic structures has been argued as being too complex and too idiosyncratic to be acquired by infants on the sole basis of the sentences they hear. In this view, syntactic acquisition relies on innate constraints (Fisher, 2002; Gleitman, 1990; Lidz, Waxman, & Freedman, 2003; Naigles, 1990, 2002). The child’s construction of early syntactic structures would be similar in kind to the adult’s and would become functional as he/she learns words to fill the syntactic categories. On the other hand, constructivists argue that children start without syntax. Their first utterances are limited to specific word strings, produced by rote. Infants construct lexical categories such as ‘noun’ and ‘verb’ and learn the specific syntactic computations of their mother tongue by generalizing from these fixed utterances, using their general learning capacities and social skills (Lieven, Behrens, Speares, & Tomasello, 2003; Tomasello, 2000; Tomasello & Abbot-Smith, 2002). This can only happen once a ‘critical mass of exemplars’ has been reached, at around 3 years of age. In French, this difference between the noun and the verb categories has been confirmed by Paradis, Crago, and Genesee (2006) who demonstrated that monolingual and bilingual French-speaking 3-year-olds produced more determiners than object pronouns, despite the fact that the forms of the two functional categories and the position with regard to nouns and verbs are exactly the same (e.g. ‘la porte’ (the door) vs ‘il/elle la porte’ (he/she brings it). Thordardottir (2005) followed the lexical and syntactic development of Quebec French- and English-speaking children from age 1;9 to 3;11 and reported normative information about the development of grammatical inflections. She looked at the type of errors produced by children and showed that fewer errors and omissions occurred in samples of French-speaking children than English-speaking children. She also demonstrated that whereas English children tended to develop larger vocabulary sizes, French-speaking children produced longer mean lengths of utterance (MLUs). The use of auxiliary and modal verbs appears later than noun grammaticalization (Bassano, 2000).
The productive use of grammatical words in early syntax has played a central role in this debate. For infants and toddlers, learning syntax involves simple and complex relationships like dependencies between words and their morphological properties as well as non-adjacent dependencies across phrase boundaries. They acquire syntax with a restricted set of utterances extracted from their language input (Ninio, 2011). They make use of the formal distributional properties of their native language and build a generalized knowledge of grammar very early on. Language input not only influences the generalization of construction schemas (Bybee, 2010) but also makes it easier to store the word forms and word sequences (Croft & Cruse, 2004).
Another reason related to this debate is the way that syntactic categories occur in a sentence. Although grammatical categories have traditionally been thought not to be cognitively processed by infants and toddlers, experiments in perception have demonstrated that infants are sensitive to early grammar (Gerken & McIntosh, 1993; Hallé, Durand, & de Boysson-Bardies, 2008; Shi & Gauthier, 2005; Shi, Werker, & Cutler, 2006). Young children have grammatical knowledge of their mother tongue by the end of their first year and already associate articles with nouns before the age of 18 months (Höhle, Weissenborn, Kiefer, Schulz, & Schmitz, 2004; Melançon & Shi, 2015; Shi & Melançon, 2010). Studies also show that they associate pronouns with verbs by the age of 18 months (Cauvet et al., 2014) and can exploit the syntactic context of a new word to infer its syntactic category by the age of 2 years (Bernal, Lidz, Millotte, & Christophe, 2007). Very early on, French children are able to distinguish appropriate grammatical categories – a definite article for nouns, a third person subject pronoun for verbs or even to recognize nonword forms produced in noun or verb syntactic contexts e.g. ‘la coupile va conduire’ (the nonword will drive) (Van Heugten & Shi, 2009) or ‘regarde! elle dase’ (Look! she nonword) (Bernal et al., 2007).
The syntactic structures that specify the relationships within and across grammatical words might be considered the building blocks of the sentence in which lexical words providing the basic content (car, table, dog, put, etc.) are inserted. Nouns frequently have a referential function whereas verbs have a predicative function referring to meanings related to sensory experiences, cognitive events or mental states. In contrast, given their highly predictable distribution, grammatical words might provide the formal architecture or the skeleton of the sentences (e.g. determiners, prepositions and pronouns).
The way in which young children easily succeed in extracting word form classes from the speech they hear in their daily experience and the role that grammatical words play in syntactic development are not fully understood. French is an excellent test case to explore this issue because grammatical words show a certain morphological richness. Bound morphemes are inflected for gender (masculine or feminine) and number (singular or plural). Most of them mark gender, number and person information (e.g. case information for pronouns), resulting in a wide variety of words within these classes. For instance, the four types of determiners and the eight types of pronouns reflect use in different syntactic contexts. The determiners include three demonstratives ‘ce’ (this) ‘cet/cette’ (this) ‘ces’ (those); four generalized determiners ‘quelque’ (any), ‘quelle’ (which), ‘quel’ (what), ‘chaque’ (each); 13 types of possessives ‘sa’ (her), ‘son’ (his), ‘ma’ (my), ‘mon’ (my), ‘leur’ (their), ‘ton/ta’ (your), ‘ses’ (their), ‘mes’ (my), ‘notre’, ‘nos’ (our), ‘votre’, ‘tes’, ‘vos’ (your); and six definite/indefinite articles ‘la, le, les, l’ ’ (the), ‘un, une’ (a). The eight types of pronouns include subject, object, relative, interrogative, reflexive, demonstrative, indefinite and a specific pronoun with the ‘y’ (it). Young children speaking French might learn to encode formal grammatical agreements such as gender when they acquire determiner–noun combinations, e.g. ‘la voiture’ (the car) vs ‘le bébé’ (the baby), or might learn to encode case and tense markers when they acquire subject pronoun–verb combinations, e.g. ‘il va prendre sa voiture’ (he is go-ing to take his car) vs ‘elle va prendre sa voiture’ (she is go-ing to take her car). Agreement categories like gender, number and/or person are considered to be very easy for native French learners. Between 24 and 48 months, most typically developing children speaking French have mastered all the basic morphological inflections, function words and syntactic structures of their native language. Distributional and correlational analyses between syntactic categories produced by children and adults suggest that children’s word combinations are adultlike (Parisse & Le Normand, 2000b, 2001). Young French children are even able to retrieve the meaning of homophonous words, which in adult language are either nouns or verbs, e.g. ‘une ferme/je ferme’ (a farm/I close) (Veneziano & Parisse, 2017).
In this corpus study, we ask whether young children speaking European French build their early syntax around grammatical or lexical words and which type of information guides their use of grammatical words. Specifically, we examine the relationship of grammatical words in three types of syntactic structures (determiner–noun, pronoun–verb and subject pronoun–verb) because these structures are considered to be the building blocks of early syntax. Given that all pronouns including subject pronouns tends to precede the verb and are related to morphological features for case, agreement, number and tense, for our analysis subject pronoun–verb combinations are separated from all other pronoun–verb combinations. The main reason is to examine the morphosyntactic strategies for encoding and decoding different types of pronouns in several syntactic contexts. It is expected that pronoun–verb and subject pronoun–verb will encode and decode word order and morphological features similarly.
The corpus included 315 samples from children aged 24–48 months, a period of rapid growth in grammatical morphology and syntax. We hypothesize that children make use of the formal distributional properties of their native language and build a generalized knowledge of grammar very early on. If early grammar is guided by high-frequency words and morphemes, by phonological saliency and by the regularities of the target language, we can predict that determiner–noun, pronoun–verb and subject pronoun–verb will be more strongly associated with grammatical words than with lexical words. If this is the case, then grammatical words and not lexical words should be considered the building blocks of early syntax.
Method
Participants
The participants in this study were 315 typically developing children (146 girls and 169 boys) ranging in age from 2 to 4 years. Participants were recruited from homes and nurseries in the Paris area, France. Inclusion criteria were (1) passing an auditory screening test, (2) scoring in the normal range on an age-appropriate nonverbal cognitive test (Symbolic Play Test; Lowe & Costello, 1976) and (3) being a French native speaker. The participants’ sociocultural level was also assessed using the classification developed by Desrosières, Goy, and Thévenot (1983), taking into account the family income, the father’s occupation and the mother’s level of education.
Data collection, recording, transcription and sampling procedure
Data were obtained using a 20-minute spontaneous speech sampling method. Each child was individually video-recorded with his or her mother and two female experimenters during the same play context: five figurines (two adult-sized, two child-sized and one baby), one dog, 11 pieces of furniture (two tables, four chairs, two armchairs and three beds) and three figurative objects (stairs with a mobile door, a garage with a sliding door, and a front door bell).
Transcriptions were orthographically made in accordance with the CHAT format (MacWhinney, 2000, https://childes.talkbank.org). After tagging all utterances with the French MOR program (Le Normand, Moreno-Torres, Parisse, & Dellatolas, 2013; Le Normand, Parisse, & Cohen, 2008; Parisse & Le Normand, 2000a), the type/token frequency list of syntactic categories was extracted from the corpus. A fra.cut script for KidEval with the output directly to spreadsheets was used to make the type/token frequency for the three types of syntactic structures investigated (determiner–noun, pronoun–verb and subject pronoun–verb). To avoid any ambiguities about the definition of a category, the tagging quality of the present corpus was checked by hand and averaged 97%. The coding was checked by a research assistant using the Grevisse manual (Grevisse & Goosse, 2011) and discussed until complete agreement was reached. The trained raters were blind to group membership and the inter-rating agreement of the transcribed material was 95%.
Results
The token frequency of the first 100 words listed in Table 1 revealed that all syntactic categories were used. We note that four grammatical categories were productively used with the highest frequencies: (1) subject pronouns, (2) auxiliaries ETRE (BE), (3) determiner articles and (4) demonstrative pronouns.
Token frequency of the first 100 words from the French corpus.

The following CHILDES coding for tense markers was used: -INF = infinitive form, -PP = past tense, -IMP&2s = second person singular imperative, -IMP&3s = third person singular imperative, &PRES&2s = second person singular present, &PRES&3s = third person singular present, &PRES&2p = second person plural present, &PRES&3p = third person plural present.
The description of the token/type frequency by syntactic categories with illustrative examples is presented in Table 2. Grammatical words included modals and auxiliaries, four types of determiners, eight types of pronouns and 30 types of prepositions. Lexical words included nouns, verbs, adjectives and three types of adverbs. Overall, 99,358 word-tokens were used as independent variables in this study.
Token/type frequency by syntactic categories (99,358 tokens/1739 types).

Determiners, b Pronouns, c Auxiliaries and modals, d Adverbs.
The description of token frequency by type of syntactic structure (determiner–noun, pronoun–verb and subject pronoun–verb) is reported in Table 3. Overall, 35,767 word-tokens were used as dependent variables in this study.
Token frequency by syntactic structure used in this corpus study (35,767 tokens).

To investigate the contribution of grammatical or lexical words in three types of syntactic structures (determiner–noun, pronoun–verb, subject pronoun–verb), a series of stepwise multiple regression analyses was performed with the R statistical package (http://www.R-project.org).
Predictors of determiner–noun combinations
Two categories of grammatical words (prepositions and auxiliaries) and three categories of lexical words (adjectives, adverbs and verbs) were entered in a first regression analysis as the independent variables to predict determiner–noun combinations. As can be seen in Table 4 and Figure 1, prepositions were found to be the best predictor (r = .89, p < .001) explaining 79% of the variance, F (1, 314) = 1157.3, p < .001. The final step in the regression confirms that prepositions and auxiliaries remain significant in the model even when the three categories of lexical words (adjectives, adverbs and verbs) were included. Adjectives, adverbs and verbs were not longer significant and only reach 83% of the variance. In order to control for the variance shared by the five predictors, the squared semi-partial correlation coefficient (‘partial r2’) for each predictor was computed, indicating that the two categories of grammatical words (prepositions and auxiliaries) explain the unique variance in determiner–noun better than the three lexical categories (partial r2 = .212 and .130 respectively).
Stepwise multiple regression analysis predicting determiner–noun combinations.

ns p > .05, * p < .05, ** p < .01, *** p < .001.
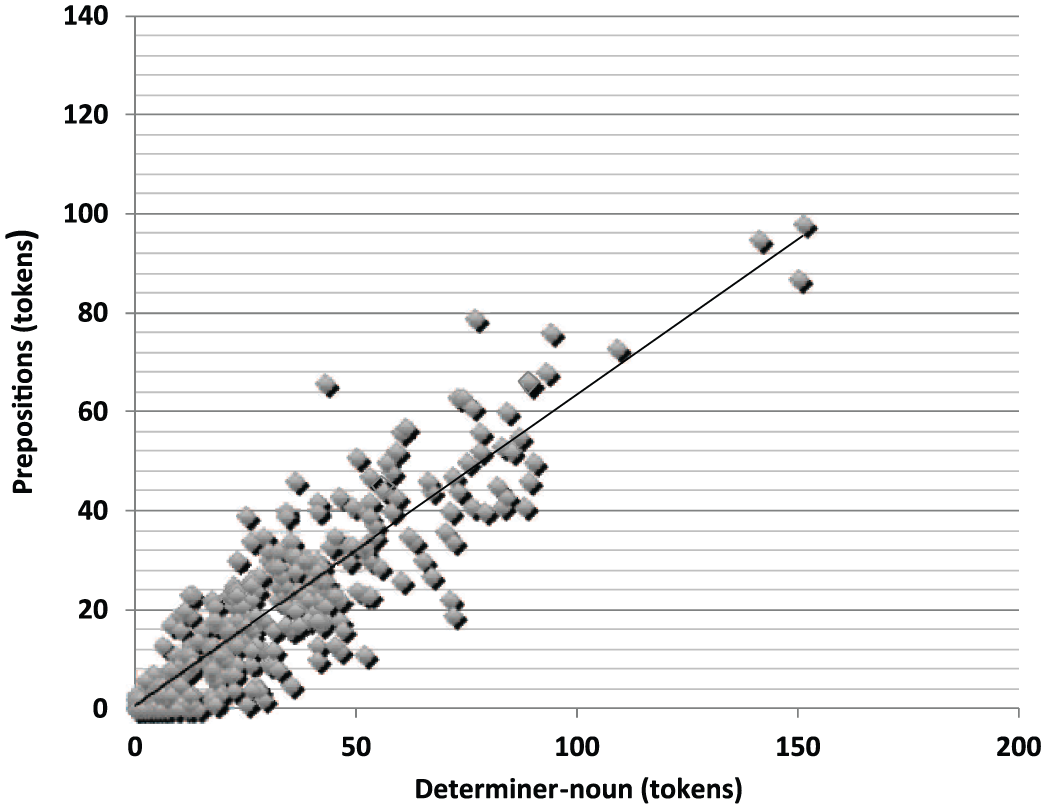
Scatter plot between prepositions and determiner–noun (r = .89).
Predictors of pronoun–verb combinations
Two categories of grammatical words (prepositions and determiners) and three categories of lexical words (nouns, adjectives and adverbs) were entered in a second regression analysis as the independent variables to predict pronoun–verb combinations. As can be seen in Table 5 and Figure 2, determiners were the strongest predictor (r = .86, p < .001), explaining 74% of the variance, F (1, 314) = 887.5, p < .001. The final step in the regression shows that determiners and prepositions remain significant, F (5, 314) = 199.7, p < .001, even when nouns, adjectives and adverbs were included in the model. Nouns, adjectives and adverbs were no longer significant and only reach 76% of the variance. The squared semi-partial correlation coefficient for each predictor indicates that the two categories of grammatical words (determiners and prepositions) explain the unique variance in pronoun–verb better than the three lexical categories (partial r2 = .166 and .081 respectively).
Stepwise multiple regression analysis predicting pronoun–verb combinations.

ns p > .05, * p < .05, ** p < .01, *** p < .001.

Scatter plot between determiners and pronoun–verb (r = .86).
Predictors of subject pronoun–verb combinations
The same set of grammatical words (prepositions and determiners) and the same set of lexical words (nouns, adjectives, adverbs) were entered in this third regression analysis as the independent variables to predict subject pronoun–verb combinations. As can be seen in Table 6 and Figure 3, determiners were again the strongest predictor (r = .86, p < .001) explaining 73% of the variance, F (1, 314) = 847.5, p < .001. The final step in the regression shows that determiners, prepositions and adverbs remain significant, F (5, 314) = 256.4, p < .001, even when nouns and adjectives were included in the model. Nouns and adjectives were no longer significant and only reach 80% of the variance. The squared semi-partial correlation coefficient for each predictor indicates that the two categories of grammatical words (determiners and prepositions) and one category of lexical word (adverb) explain the variance in subject pronoun–verb (partial r2 = .142 for determiners and prepositions and .136 for adverbs), suggesting a relatively flexible word order for adverb.
Stepwise multiple regression analysis predicting subject pronoun–verb combinations.

ns p > .05, * p < .05, ** p < .01, *** p < .001.
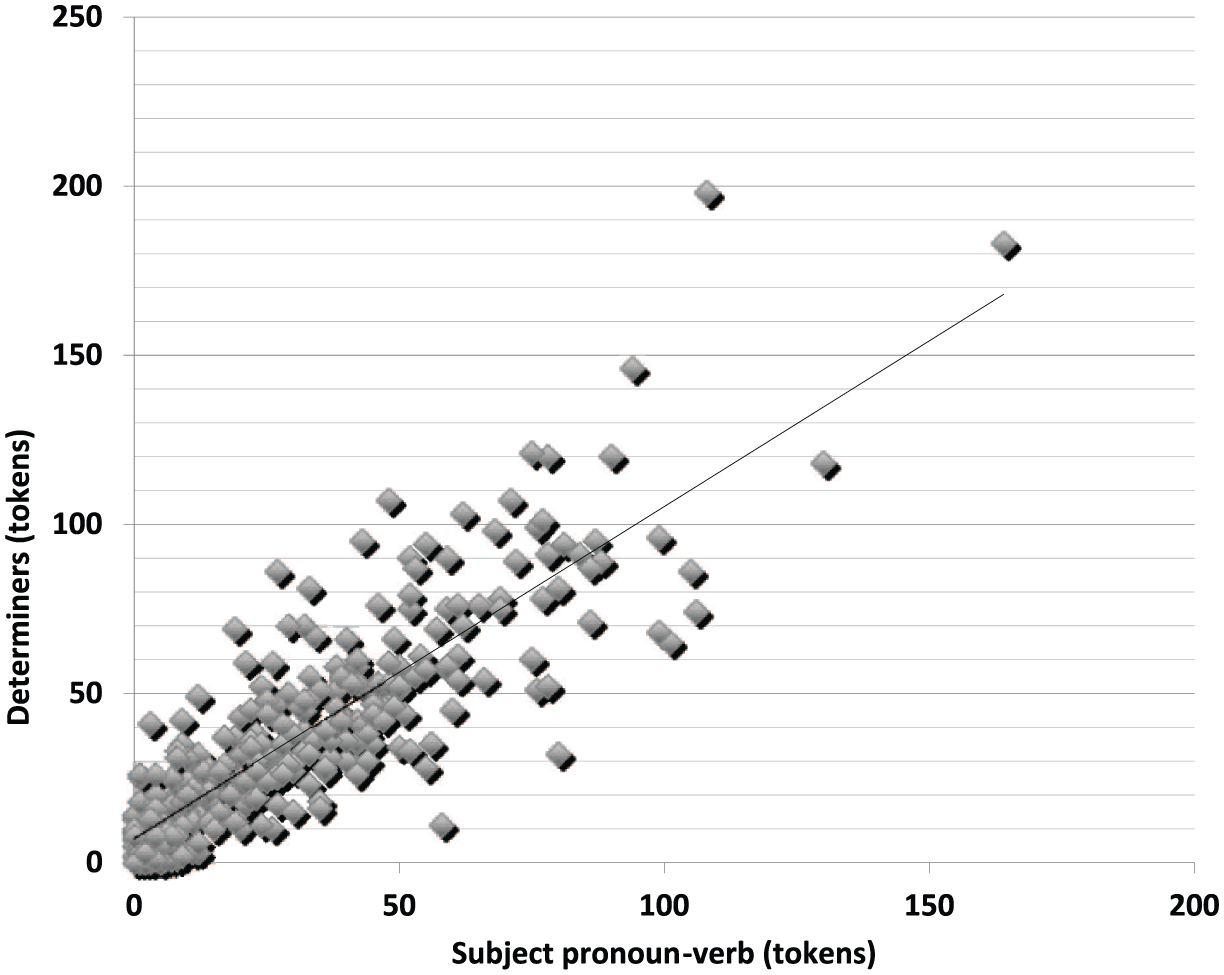
Scatter plot between determiners and subject pronoun–verb (r = .85).
Discussion
In this corpus study, we asked whether young children speaking European French build their early syntax around grammatical or lexical words. Specifically, we examined the relationship of grammatical words in three types of syntactic structures (determiner–noun, pronoun–verb and subject pronoun–verb). The results indicate two strong independent predictors: prepositions explain 79% of the variance in determiner–noun and determiners explain 74% of the variance in pronoun–verb and 73% of the variance in personal subject pronoun–verb. These findings support the view that grammatical words guide and facilitate syntactic knowledge. Early grammar is not based on a lexicon but on basic grammatical relationships that children build gradually, making use of the formal distributional properties of their native language.
This first finding that prepositions predict determiner–noun provides evidence that prepositions are an important predictor to build grammatical relations in different syntactic contexts. The most frequent prepositions found in our corpus (6510 tokens and 32 types) relating to determiner–noun indicate local and global regularities involved in learning grammatical relationships. At the local level, i.e. in immediate syntactic contexts, the use of prepositions preceding the types of determiners exposes the child to the grammatical relationships of both case and gender such as ‘dans la’ (in the) 498 tokens, ‘dans le’ (in the) 348 tokens, ‘à la’ (to the) 191 tokens, and ‘de la’ (from the) 184 tokens. It is important to note that the feminine gender was more frequently used than the masculine gender in our corpus. This supports the salient property of gender agreements in young French learners. The speech sound ‘a’ is more phonological salient than the speech sound ‘e’ (Tranel, 1987). These local regularities, in which prepositions belong to the same grammatical category, suggest that this simple indicator is sufficient to build a generalized knowledge of grammatical relationships. At the more global level, i.e. beyond two co-occurrences, the productive use of prepositions reflects more complex grammatical relationships, which are also highly predictable, e.g. ‘la voiture dans le garage’ (the car in the garage).
A second major finding of this corpus study is the role played by determiners (11,611 tokens and 26 types in our corpus) to build a generalized knowledge of grammatical relationships involving both pronoun–verb and subject pronoun–verb. This is not surprising because determiners and pronouns carry low meaning, which makes their grammatical relationships easier to learn, particularly demonstrative pronouns preceding multiple determiners such as ‘c’est le, c’est la, c’est un, c’est une’ (this is the, this is a), relative pronouns with a flexible word order such as ‘où il est? il est où?’ (where is it?) and specific pronouns with the expression ‘y’ preceding multiple determiners such as ‘y’a le, y’a la, y’a un, y’a une’ (it has the, it has a). These three frequent types of pronouns contribute to build multiple grammatical relationships with multiple determiners.
Two features of determiners could be advanced to explain this prediction. First, all determiners are independent words. Second, they are function words that are prosodically constrained very early on and whose distribution is very limited. Studies of French-speaking children suggest an important role for rhythmic preferences. Before the age of 2, French children prefer to insert fillers or ‘proto-articles’ in front of monosyllabic nouns in order to achieve an iambic rhythm of a weak syllable followed by a strong one, which is a dominant rhythm in the input (Bassano et al., 2013; Demuth & Tremblay, 2008; Veneziano & Sinclair, 2000). These ‘proto-articles’ provide important information of syntactic knowledge in the prenominal and preverbal position showing not only the distributional regularities of syntactic categories but also the increasing length in the phonological structure of children’s language (Veneziano, 2017). The evidence that young children learn syntax on the basis of grammatical words such as determiners and prepositions suggests that it is directly related to a constellation of phonological, morphological and syntactic properties of the native language.
Another reason to explain the strong relationship of determiners to pronoun–verb and subject pronoun–verb combinations is that they are linked to the development of the verbal system: all pronouns including subject pronouns encode and decode word order and obligatory markers similarly for case, agreement, number and tenses. They mark the person correctly, use all pronouns including subject pronouns appropriately, especially first, second and third person markers.
These two findings are in line with other studies that emphasize the role of grammatical words and morphemes in syntactic structures. When young children put words together, their processing of syntactic structures is surprisingly robust. This depends on both the distributional regularities of syntactic categories and on the properties of the native language.
For example, in German language similarly to French, Szagun and Schramm (2018) showed that multiple determiners have morphosyntactic features which make them very easy to learn: they are extremely frequent and have a highly predictable distribution. Determiners in German are highly frequent and restricted in their distribution to placement within the context of a noun. Such distributional regularities are readily learned by children and constitute their early generalized syntactic knowledge. Both the input directed to the child and the child’s ability to process that input are likely to impact the child’s syntactic development (Morgan, Meier, & Newport, 1987; Ninio, 2011; Szagun & Schramm, 2018; Xanthos et al., 2011).
The two results of this corpus study also confirm our previous findings showing that the best predictors of syntactic development measured by global regularities like mean length of utterance (MLU) are grammatical words and not lexical words. Subject pronouns, determiners and prepositions were considered to be the three best predictors explaining more than 50% of the MLU variance and, when taken together, accounting for 73% of the MLU variance, sufficient to determine early syntax (Le Normand et al., 2013).
Although lexical words were productively used in the first 100 words of the corpus, e.g. ‘voiture’ (car) 898 tokens, ‘mettre’ (put) 569 tokens, ‘petit’ (small) 460 tokens, these words did not predict the three types of syntactic structures examined. These results provide evidence that syntax cannot be deduced from the lexical categories of nouns, verbs and adjectives but from grammatical categories. Young children exploit distributional regularities to build different syntactic structures, which in turn provide them with a basic cognitive architecture to master adult syntax. Grammatical words guide and facilitate the distributional regularities of the sentence into which lexical words are inserted. This suggests that young French children generalize the regularities of their native language on the basis of form rather than meaning.
The role of grammatical words found in this corpus study may depend on the particular language being explored, which is defined either as an analytic language with limited inflections or as a synthetic language with rich inflections, derivations and compounds. It is plausible that Turkish with flexible word order, Cantonese with an extensive set of function words (classifiers, prepositions, particles, suffixes, negations, pronouns and aspect markers), or Russian with rich gender inflections but no determiners might give different patterns of results. Further cross-linguistic studies should be carried out to generalize our findings as a language-independent phenomenon. If our results are replicated, they should be explained by cross-linguistic accounts of syntactic development. Furthermore, our findings also confirm the interest of multiple regression analyses to explore syntactic development and open up the possibility of carrying out similar analyses on other syntactic structures with more dense corpora.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.