
Abstract
Mandarin classifiers are a complex system, but little is known about how Mandarin-speaking children manage to learn the system. Based on the extant literature, we explored potential factors influencing the comprehension and production of Mandarin shape classifiers, including classifier-based semantic categorization and errors pertaining to the semantic strategies, input frequency of classifier-noun combinations, and vocabulary knowledge. In total, 138 typically developing monolingual Mandarin-speaking children between ages 4;1 and 6;5 completed an object categorization task, shape classifier comprehension and production tasks, and a vocabulary test. The results showed that classifier-based categorization did not significantly relate to classifier knowledge, but children’s comprehension errors were mostly selecting an object that is perceptually similar to the target object. Estimated input frequency of classifier-noun combinations was significantly related to classifier comprehension, and there was differential accuracy for different classifier-noun combinations, which may indicate item-by-item learning of individual classifier-noun pairings. Mandarin-speaking children may take a combined approach by sorting semantic features for different classifiers and learning individual classifier-noun combinations. The interplay of the two approaches can be very complex and should be further investigated in future studies. Vocabulary knowledge was significantly related to classifier comprehension and production, indicating common traits between classifier learning and noun learning.
Keywords
Background
Mandarin as a classifier language
Mandarin is a classifier language that requires a classifier to be placed between a number and a noun for the purpose of quantification. A classifier is obligatory in the ‘numeral+classifier+noun’ construction. The majority of Mandarin classifiers are noun classifiers (Erbaugh, 2006). The choice of a classifier is related to the semantic properties of an entity with which it co-occurs (e.g. animacy, shape, function, size; Allan, 1977; C. Li & Thompson, 1981). For example, ‘条tiáo’ is a shape classifier that is typically paired with long, narrow, and flexible objects (Chien et al., 2003). In examples (1), (2) and (3), ‘条tiáo’ is used with snake, rope, and necklace which share these semantic properties.
(1) 两 条 蛇 liǎng tiáo shé two classifier-tiao snake two snakes (2) 三 条 绳子 sān tiáo shéngzi three classifier-tiao rope three ropes (3) 四 条 项链 sì tiáo xiàngliàn four classifier-tiao necklace four necklaces
The pairing of a classifier and an object is usually not a strict one-to-one mapping. For example, ‘根gēn’ is a semantically similar classifier that can be paired with some objects that are paired with ‘条tiáo’. ‘根gēn’ may be paired with rope in (2) and necklace in (3) but not snake in (1), and these are accepted as conventions by native speakers of Mandarin. In addition to specific classifiers, there is a general classifier ‘个gè’ illustrated in (4) which is more frequently used than specific classifiers (Erbaugh, 1986).
(4) 一 个 人 yí gè rén one classifier-ge person one person
Erbaugh’s (2006) classification scheme of Mandarin classifiers captured the range of classifier meanings. 1 She identified the following five types of classifiers: measure classifiers (一公里路one kilometer of road), collective classifiers (一扎啤酒 one bundle of beer), kind classifier (一种水果 one type of fruit), event classifiers (一场电影 one performance of movie), and sortal classifiers (一条蛇 one tiáo snake). She pointed out that perhaps every language has the vocabulary to express concepts of measure, collection, kind, and event, but not sort. For example, English measure words are similar to Mandarin measure classifiers, which represent length, weight, or volume (e.g. 两磅苹果two pounds of apples, 三升水three liters of water). However, sortal classifiers, which mainly focus on shape and size, are a strikingly distinctive linguistic feature in Mandarin that is not commonly present in non-classifier languages. Sortal classifiers in Mandarin provide unique insights into the semantic organization of nouns by Mandarin speakers (Zhang & Schmitt, 1998). Also, sortal classifiers appear to be more prototypical than other types of classifiers for native speakers of Mandarin. When native Mandarin-speaking adults were asked to list as many classifiers as they could, they listed mostly sortal classifiers (Chien et al., 2003). In this study, we focused on sortal classifiers that encode semantic features of shape or size. In the following, we refer to the classifiers as shape classifiers.
Classifier comprehension and production
Previous studies consistently revealed age-related changes in classifier comprehension and production among Mandarin-speaking children. In three cross-sectional studies (Chien et al., 2003; Li et al., 2010; Sera et al., 2013), Mandarin-speaking children participated in a forced-choice object or picture-selection task, which was used to examine classifier comprehension. Among the three objects or pictures (e.g. wallet, snake, schoolbag), only one (i.e. snake) could be paired with the target classifier (e.g. 条tiáo) in a carrier phrase (e.g. 米老鼠说他想要一条something. Mickey Mouse says that he wants one tiáo something.). Results showed that comprehension accuracy increased as an effect of age. While 2-year-old children were below chance on most specific classifiers tested, the 6-year-old children achieved over 80% accuracy.
One limitation of these studies was the lack of manipulation of object or picture distractors in each test trial. In some trials, the distractors were perceptually similar (e.g. pencil, tree) to target objects (e.g. rope), while in other trials, distractors were perceptually distinct (e.g. wallet, schoolbag) from target objects (e.g. snake). As shape classifiers relate to perceptual properties, this potentially resulted in varied difficulty levels regarding different semantic relatedness (here, perceptual similarities) across different test trials.
Abilities to produce appropriate specific classifiers emerged later than abilities in comprehension (Fang, 1985; Ying et al., 1983). Using a counting task, children were presented with pictures depicting sets of objects in different quantities. Classifiers are obligatory in the ‘numeral+classifier+noun’ construction when used in the act of counting. In Ying et al. (1983), the 4-year-olds achieved only 17% accuracy. These young children widely overgeneralized the general classifier ‘个gè’ to occasions when specific classifiers should be used. Between the ages of 5 and 6, accuracy increased to around 60%, but children produced some inappropriate classifier-noun pairings. For example, the classifier ‘辆liàng’ should be paired with cars but not planes and ships, but some children used it for all vehicles. By age 7, children’s production accuracy reached more than 80%, indicating improved but not perfect mastery. Although Ying et al. (1983) and Fang (1985) provided some examples of children’s errors, the studies did not include an analysis of errors that could inform us on children’s distinctions of semantic properties for different classifiers, especially the influence of semantic relatedness.
Potential influential factors of classifier learning
The above studies highlight the developmental sequence of classifiers and illustrate that classifiers are acquired over an extended period of time. It is not surprising that children demonstrate age-related changes in the comprehension and production of specific classifiers. However, based on the findings to date, factors influencing classifier knowledge among Mandarin-speaking children are not apparent. As the Mandarin classifier system is challenging for Mandarin-speaking children, it is important to understand the foundational and fundamental question of how they manage to learn the complex system. On the basis of the limited literature, we intended to explore the following potential influential factors.
Classifier-based semantic categorization
Humans organize words that share similar semantic representations (Markman & Hutchinson, 1984). The words hands and gloves go together, as they are thematically related. The words cat, dog, and rabbit can be grouped together, as they are taxonomically related. A unique kind of word categorization that may be formed by Mandarin speakers is based on shared classifiers (e.g. Imai et al., 2010; Zhang & Schmitt, 1998). Erbaugh (2006) regarded ‘classifiers as a system of noun categorization’ (p. 3). In order to learn classifiers, children may need to extract core semantic properties among objects that are paired with the same classifier. Since we focused on shape classifiers in this study, the semantic properties were related to perceptual features. For example, ‘条tiáo’ is paired with snake, fish, tie, necklace, and rope, and children may summarize and synthesize the shared perceptual features among these objects (i.e. long, narrow, and flexible), and encode them in the classifier ‘条tiáo’.
Age may interact with semantic categorization skills. In Uchida and Imai (1999), a classifier learning task was conducted in Japanese-speaking 4- and 5-year-olds. The researchers taught two real Japanese classifiers, 2 and the children were assigned to one of three learning conditions: rule-explicitly-given (i.e. rules of the two classifiers were explicitly taught), exemplars-only (i.e. only exemplars of the two classifiers were displayed), and control (i.e. no training was provided). A post-test was administered to test comprehension immediately after the training. The two age groups both performed at floor on the control condition and at ceiling on the rule-explicitly-given condition. 3 However, for the exemplar-only condition, children at age 4 were below chance accurate, while 5-year-old children were over 70% accurate. The authors speculated that the accuracy gap between children ages 4 and 5 was related to the improved ability to categorize and synthesize classifier-based semantic properties.
Sera et al. (2013) found that the learning of classifiers had an influence on children’s object categorization preference. The researchers tested 48 Mandarin-speaking and 48 English-speaking children ages at 3, 5, and 7 years old on the categorization of objects to understand the kinds of information children used to classify objects. In the experiment, a picture depicting one object was shown to children (e.g. snake). Then, the experimenter presented two pictures and asked children to select one from the two that was more similar to the first picture. One object shared the same classifier ‘条tiáo’ with the initial picture (e.g. rope), and the other object was related taxonomically (e.g. rabbit). The results showed that Mandarin-speaking children made classifier-based selections in more than 70% of opportunities, whereas English-speaking children made classifier-based and taxonomy-based selections equally often. Importantly, the researchers measured classifier comprehension among these Mandarin-speaking children and found that probability of categorizing objects by classifiers was significantly higher in children who demonstrated better classifier comprehension.
A caveat concerning the reliability of this finding should be noted. In data analysis, the Mandarin-speaking children were divided into two groups based on their comprehension accuracy (i.e. a group that knew the targeted classifiers and a group that did not know the targeted classifiers). For each group, they were further categorized into a group categorizing by shape and a group not categorizing by shape. The researchers used arbitrary cutoffs to decide who should go into each group. By converting the numerical data to nominal data and organized the counts in different cells, a Chi-Squared test was employed to examine the relationship. Due to low values in some cells, only 3- and 5-year-old children’s data were used. Therefore, the postulated relationship was based on data from 32 children, a relatively small sample size. It is unclear why a correlation test for numerical data (e.g. Pearson’s correlation) was not used to directly examine the correlation between classifier comprehension accuracy and percentage of shape-based choices in the categorization task. Given that this is a potential flaw of data analysis in Sera et al. (2013) and that Uchida and Imai (1999) only provided a speculation without presenting evidence for the correlation, semantic categorization as a learning mechanism of classifier learning warrants further investigation.
Error patterns related to semantic strategies
There is varied semantic distance among different Mandarin classifiers. Some classifiers are semantically similar with subtle distinguishing semantic properties. For example, ‘片piàn’ and ‘面miàn’ may be semantically similar classifiers that are paired with flat objects. A fine-grained difference between them is that ‘片piàn’ is typically paired with flat thin objects (e.g. leaf), whereas ‘面miàn’ emphasizes the flat and smooth surface (e.g. wall; Li et al., 2010). Some classifiers are semantically distant. For example, ‘片piàn’ is semantically distinct from ‘条tiáo’, as ‘条tiáo’ is paired with long objects.
Semantic distance has been found to affect Mandarin-speaking children’s classifier comprehension. In an error detection task, Mandarin-speaking children were asked to determine whether a puppet’s uses of classifiers were correct (Uchida & Imai, 1999). Four nouns were paired with the same classifier (e.g. 条tiáo): a typical target object (e.g. worm), a nontypical target object (e.g. eel), a perceptually similar but non-target object (e.g. lizard), and a perceptually distant and non-target object (e.g. car). The results showed that children demonstrated the poorest performance on identifying the pairings of classifiers and perceptually similar but non-target objects as wrong uses, and judgments on the other three types of pairings were more accurate. This appears to indicate the use of semantic strategies by children. It may be challenging for them to categorize objects with similar perceptual features and match them to the correct classifiers.
In production, Salehuddin and Winskel (2009) found that Malay-speaking children commonly substituted a target classifier using a classifier with only one distinguishing semantic feature. For instance, a predominant substitution for ‘keping’ (2D, +rigid) was ‘helai’ (2D, –rigid). Since Malay does not have a general classifier to be used as a default, Malay-speaking children used specific classifiers in substitutions. Different from Malay, Mandarin has the general classifier ‘个gè’. As a classifier is obligatory in the classifier construction, Mandarin-speaking children may use the general classifier more predominantly as substitutions than specific classifiers.
The above two studies (i.e. Salehuddin & Winskel, 2009; Uchida & Imai, 1999) emphasize the usage of semantic strategies in the comprehension and production of classifiers. A common error pattern is to match a classifier with a perceptually similar but non-target object. To learn the full use of classifiers, children need to make more fine-grained distinctions among classifiers with similar semantic properties. While the two studies stress the role of semantic strategies in classifier comprehension and production, they also draw attention to that classifiers cannot be fully learned through semantic rule abstraction. Children need input from the environment to learn different parings of classifier and noun, especially the conventional pairings that may not align well with semantic categorization. Therefore, input frequency should be considered as an influential factor of classifier learning.
Frequency of classifier input
In addition to Uchida and Imai (1999) and Salehuddin and Winskel (2009), Li et al. (2010) also mentioned that semantic strategies alone were insufficient to support classifier acquisition. Children need to have adequate exposure or receive explicit instructions to learn classifiers from their language learning environment (Ying et al., 1983). It is widely accepted that language acquisition is frequency sensitive (Ambridge et al., 2015), and frequency effects have been found in a wide range of linguistic domains, vocabulary (Weisleder & Fernald, 2013), inflectional morphology (Theakston et al., 2005), and multiclause sentences (Huttenlocher et al., 2002) to name a few. Frequency may not be the only factor of the acquisition of language features, and it may interact with other relevant factors to influence acquisition, for example, phonotactic probability, neighborhood density (e.g. Edwards et al., 2004; Storkel et al., 2006).
Salehuddin and Winskel (2009) estimated input frequency of nine Malay classifiers using a corpus of 150,000 words that were collected in a range of situations (e.g. children’s television programs, storybooks). The results showed a significant positive relationship between production accuracy and frequency of classifiers in the corpus. Nevertheless, the authors noted that quantifying input frequency for real classifiers is difficult, and the corpus being used may not be fully representative of the actual linguistic environment for the group of children that participated in the study.
Vocabulary knowledge
The last factor we considered is children’s vocabulary knowledge. On one hand, many classifiers serve as nouns in Mandarin noun-noun compounds (Gao & Malt, 2009). For instance, ‘面miàn’ appears in multiple noun-noun compounds, which indicates the surface of something (e.g. 湖面 lake surface; 桌面 table surface), and the meaning of the noun ‘面miàn’ and the classifier ‘面miàn’ share the same semantic representations. A large vocabulary size, thus, may be related to better classifier knowledge. On the other hand, children may need to know different semantic properties before they can summarize and form a semantic category. In order to store and access words more efficiently, children with larger vocabulary may have a stronger need to categorize words and different semantic representations. Therefore, it is more likely for children with a larger vocabulary size to form semantic categories associated with different classifiers than children with a smaller vocabulary size.
Research goal and predictions
To gain a more in-depth understanding of how typically developing (TD) monolingual Mandarin-speaking children learn classifiers, we measured both the comprehension and production of classifiers as indices of learning outcomes. Similar to previous studies (e.g. Chien et al., 2003; Ying et al., 1983), we predicted that classifier comprehension would precede production. Based on the extant literature, we considered classifier-based categorization skills and possible errors relating to the semantic strategies. In addition to semantic strategies, we included input frequency of classifiers as a factor that could influence Mandarin-speaking children’s classifier knowledge. Vocabulary knowledge and age were also included as potential influential factors.
With regard to the role of classifier-based semantic categorization, we predicted that children with a stronger preference for classifier-based object categorization would demonstrate better performance on classifier comprehension and production than those demonstrating a weaker preference for classifier-based categorization (Kuo & Sera, 2009; Sera et al., 2013). There may be an interaction between categorization skills and age, as Uchida and Imai (1999) found that children at age 5 showed better classifier learning than children at age 4, which was suspected to be related to increased semantic categorization pertaining to classifiers.
Aligning with the semantic strategies, semantic distance among different classifiers may account for the error patterns in classifier comprehension and production (Salehuddin & Winskel, 2009; Uchida & Imai, 1999). In comprehension, if children make errors, they would be more likely to select an object that is paired with a classifier encoding perceptually similar features than an object that is paired with a classifier encoding perceptually distant features. In production, children would more likely substitute a target classifier using a classifier encoding perceptually similar features than a classifier encoding perceptually distant features. Alternatively, since Mandarin has a general classifier, a non-semantic strategy may be used. The general classifier ‘个gè’ may be predominantly used as a placeholder to replace specific classifiers, as the classifier construction requires a classifier (Ying et al., 1983).
Regarding the role of input frequency, in light of previous classifiers studies (e.g. Salehuddin & Winskel, 2009) and the frequency-sensitive nature of language acquisition in general (Ambridge et al., 2015), we predicted that input frequency of classifier-noun combinations estimated using corpus data would correlate with children’s performance on classifier comprehension and production. Although frequency effect has been discussed in previous literature, this is the first time the correlation was examined in Mandarin-speaking children.
We were also the first to examine the relationship between vocabulary size and classifier comprehension and production. Given the similarity in semantic representation between classifiers and other types of words, especially nouns, we predicted a positive correlation between the two.
As previous studies consistently showed age-related changes in Mandarin-speaking children’s classifier comprehension and production (e.g. Chien et al., 2003; Ying et al., 1983), we predicted the same in this study. Age was not a major focus of this study, and the age range was intended not to be very broad.
Method
Participants
We recruited 149 Mandarin-speaking children from two preschools in Beijing and one preschool in Nanjing, China. Ethical approval was granted by the fourth and fifth author’s institutes. The preschools informed parents and teachers about the study. Children between 4 and 6 years of age were encouraged to participate. If a parent was interested, he or she signed a consent form and completed a parent questionnaire. Each teacher signed a consent form to complete a teacher questionnaire.
The parent questionnaire included questions about children’s demographic information (e.g. birth date, sex, maternal education) and medical information pertaining to language impairment (i.e. hearing loss, Autism Spectrum Disorders, Cerebral Palsy, Down Syndrome, Williams Syndrome, other neurological or genetic disorders). None of the 149 children was reported to have any of these disorders.
As we only intended to include TD children, parents, and teachers evaluated children’s oral language performance to report on concerns of language impairment. To guide parents’ and teachers’ decisions of concern, we used the Inventory To Assess Language Knowledge (ITALK; Peña et al., 2018). The ITALK is a parent/teacher questionnaire with five questions in different areas of language, including vocabulary, speech, sentence length, grammar, and comprehension. The five questions were translated into Mandarin. To help the Chinese parents and teachers understand the questions, we replaced the English examples with Mandarin examples. For instance, for the question of grammar, we provided examples of Mandarin grammatical features (e.g. aspect markers, ‘bei’ construction), and asked parents and teachers to evaluate the frequency of accurate usage of these features. Based on the literature of child language development in Mandarin-speaking children (e.g. Hao et al., 2018; Li & To, 2017), these features are vulnerable areas. For each question, there was a 0–5 rating scale (0 represents the lowest performance and 5 represents the highest). If a parent or teacher expressed difficulties understanding the questions, experimenters provided them with explanations. Based on the rating of the ITALK, parents and teachers were asked if they had any concerns regarding the child’s language development. If there was a concern, they explained in more details the nature of their concerns.
We planned to include monolingual children. To learn about a child’s language experiences, we asked the parent to report any second language(s) that the child was learning, as well as the frequency and hours of second language training on a weekly basis. Parents also reported dialect usage at home by family members. In addition, the parent reported whether the child has recently lived in a foreign country for more than 3 months. These survey questions helped exclude children who had a relatively large amount of exposure to a language(s) other than Mandarin.
On the basis of the above questionnaires in parents and teachers, 11 children were removed for one of the following reasons: (1) There were concerns from either parents or teachers about the children’s oral language, as guided by the ITALK. Seven children were removed, and the concerns included ‘having difficulties with language comprehension’, ‘taking a long pause to organize a sentence before uttering the sentence’, ‘having difficulties with long sentence organization’, ‘repeating a sentence multiple times but could not express the meaning clearly’, ‘having a very small vocabulary compared to peers’, ‘having limited receptive skills, expressions, and attention’, and ‘having limited sentence organization skills’. Two parents reported that their children were very shy in front of strangers, and one parent reported that the child lacked confidence. Since these were not concerns about language but personality, we included the three children and regarded them as TD. (2) Based on parents’ responses on the survey questions about language experiences, two children were not regarded as monolingual Mandarin-speaking. One child had recently spent more than 3 months in the United States. The other child was reported to hear and use Cantonese all the time at home. There were multiple home dialects (e.g. Cantonese, Nanjing dialect, Beijing dialect, Shandong dialect, Anhui dialect). Cantonese was regarded as having most significant differences from Mandarin. Although most children were taking English language courses, they had at most 9 hours of English language training per week. (3) Two children did not complete all the tasks due to incompliance, and they were excluded from all analyses.
The final sample included 138 TD monolingual Mandarin-speaking children (72 boys and 66 girls). The mean age was 5;2 (year;month) (SD = 7.7 months), and the age range was 4;1 to 6;5. Maternal education was ranked: 1 indicated middle school or below, 2 indicated high school, 3 indicated associate degree, 4 indicated bachelor’s degree, and 5 indicated master’s degree or above. The average rank of maternal education was 4.1 (SD = 0.6), and the range was 2–5.
Materials and procedures
We tested children’s knowledge of six Mandarin shape classifiers using categorization, production, and comprehension tasks. The classifiers were selected to represent semantic features of different shapes (see Table 1). Five of the six shape classifiers were selected from Li et al. (2010), and we added another classifier (i.e. 粒 lì) to constitute the third pair of semantically related classifiers, as one of our aims was to study the influence of semantic relatedness. For each classifier, we drew two pictures depicting two real-life objects that are typically paired with the classifier.
Classifiers, corresponding semantic features, objects paired with the classifiers, input frequency of each classifier-noun combination in corpus.

We verified the acceptability of each classifier-noun combination in 17 native Mandarin-speaking adults residing in Beijing. They completed the comprehension test, a forced-choice picture-selection task (see Figure 3). Based on adults’ selections, at least 97% of the choices conformed to our planned accurate classifier-noun combinations. We intended to include a novel object condition (creating novel objects based on the perceptual features encoded in the classifiers) to control for children’s varied exposure to the range of nouns that could be paired with the same classifier. However, agreements on the pairing of ‘片piàn’ and the corresponding novel objects was low (i.e. both trials were at 53%). As the adult agreement was not reached, we excluded the novel object condition from this study.
In order to test the effect of frequency, input frequency of the 12 classifier-noun combinations was estimated using a 931,394-word corpus (Cheung & Chang, 2020a, 2020b; Erbaugh, 1992; Li & Zhou, 2015; Tardif, 1996; Zhou, 2001) from the Child Language Data Exchange System (CHILDES; Macwhinney, 2000). The corpus included caregiver-child interactions across a wide range of situations, including but not limited to having dinner, playing toys, watching television, cleaning up, talking and playing with neighbors, playing in a local amusement park, and reading books. Based on this corpus, we summed occurrences for each of the 12 classifier-noun combinations in caregivers’ language input (see Table 1).
Categorization task
Following Kuo and Sera (2009) and Sera et al. (2013), we asked children to identify objects by similarity. This was to understand if children were more likely to judge objects as similar when they were paired with the same classifier. Children were presented with a picture on top, and then asked to select a picture from two below (Figure 1). The instruction was ‘下面哪一张和上边这张更像? Which picture below is more similar to the above picture?’. One choice matched the top picture by representing an object sharing the same classifier but was not thematically or taxonomically related (e.g. pencil and bamboo). The other choice depicted an object that was thematically or taxonomically related but did not share the same classifier (e.g. pencil and eraser). Here, we intended to present a contrast of semantic categorization by classifiers which primarily encodes the perceptual features of objects, and by other types of non-perceptual semantic relations (see Table 2).
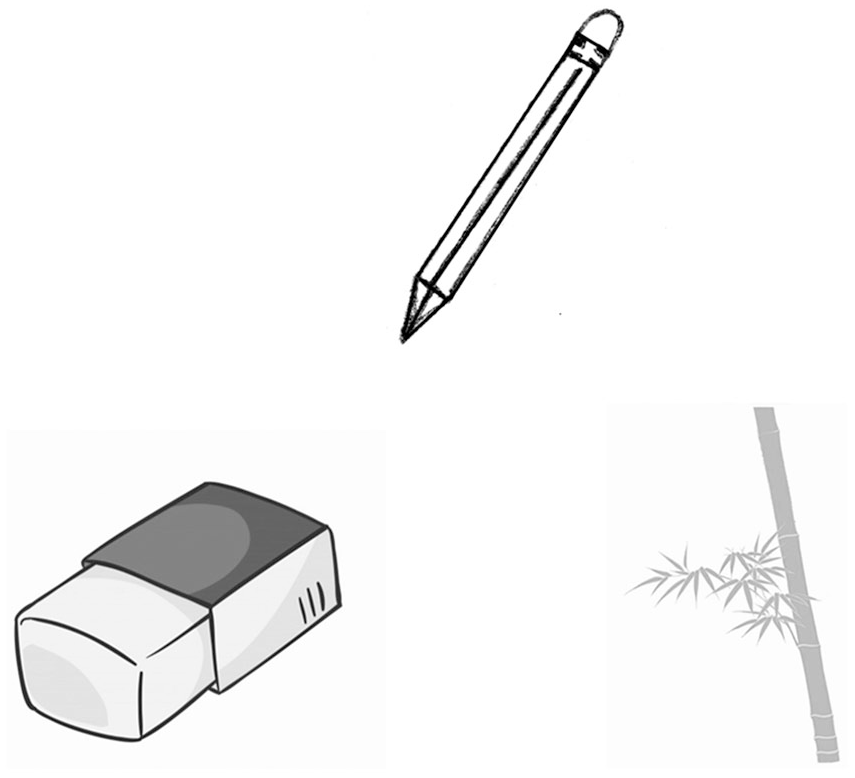
A sample trial of the categorization task.
Selections of objects in categorization task.
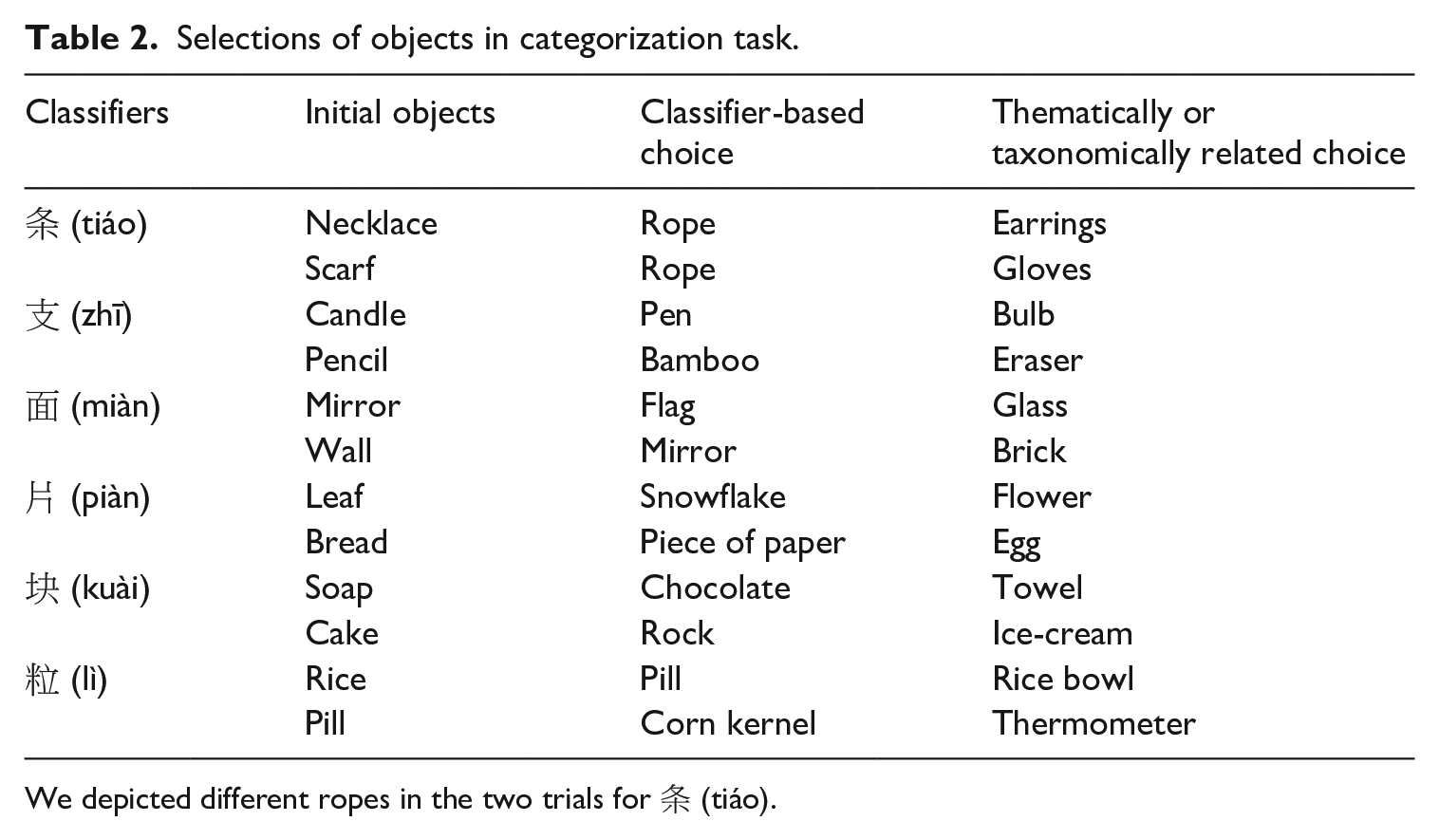
We depicted different ropes in the two trials for 条 (tiáo).
Each classifier was tested twice, and there were a total of 12 trials. The top pictures were the same pictures for the six classifiers as in the comprehension and production tests below. There were three practice trials to familiarize children with the task, and the pictures represented objects that could not be paired with any of the targeted classifiers. To ensure that children’s choices in this task were not primed by the experimenter’s usage of classifiers, the administration of the categorization task preceded the production and comprehension tasks. We created two forms, in which the 12 trials were randomly sequenced in two different orders. We used a response sheet to record children’s selections. Later, we coded the responses: if a child made a classifier-based selection, the response was coded as 1; otherwise, the response was coded as 0.
Production task
The next task we implemented was the classifier production task, in which children were asked to count the number of objects depicted in a picture. The number of objects ranged from 1 to 4 in a trial (see Figure 2 for an example). We created two forms with different sequences of the test trials in two random orders.

A sample trial of the production task.
Our production task included two practice trials and 12 test trials (two trials for each classifier). The experimenter provided three types of prompts to elicit responses in each trial: (1) Initially, ‘有多少?How many?’; (2) If the child only produced a number (e.g. 二 two), the experimenter prompted the child by asking ‘两什么?two what?’; (3) If the child only produced the noun (e.g. 围巾 scarf), the experimenter prompted the child by asking ‘多少围巾?How many scarfs?’. Note that all prompts were designed, so that no classifiers were modeled. We did not provide further prompts if the child omitted classifiers, once they had identified the number and target object (e.g. 两围巾 two scarfs). Classifier omission in the ‘numeral+classifier+noun’ construction is a type of error in children (Stokes & So, 1997).
Each child’s responses were recorded using an open response sheet, and the experimenter wrote down the exact responses during testing. All productions were audio recorded for reliability check, and a second experimenter listened to 20% of the recording and transcribed children’s responses independently. The two experimenters reached an agreement of 99%, and they had disagreement on one response. After listening to the recording again, the disagreement was resolved.
There was a two-step analysis for children’s responses in production. The first step was distinguishing acceptable alternatives and errors for the specific but non-target classifiers that children produced. We asked 42 native Mandarin-speaking adults to judge whether a usage was acceptable when presented with the corresponding picture stimulus. If more than half of the people accepted the usage of a specific classifier, it was regarded as an acceptable alternative. If more than half of the people did not accept the usage, it was considered as an error. Based on the results, acceptable alternatives of specific classifiers included ‘四块面包 four kuài bread’ for ‘四片面包 four piàn bread’, ‘两颗米 two kē rice’ for ‘两粒米 two lì rice’, ‘一串/根项链one chuàn/gēn necklace’ for ‘一条项链one tiáo necklace’, ‘一颗药 one kē pill’ for ‘一粒药 one lì pill’, ‘两道/座/块墙two dào/zuò/kuài wall’ for ‘两面墙two miàn wall’, ‘四根/杆铅笔 four gēn/gān pencil’ for ‘四支铅笔 four zhī pencil’, ‘三块/张镜子 three kuài/zhāng mirror’ for ‘三面镜子 three miàn mirror’, and ‘三根/盏蜡烛 three gēn/zhǎn candle’ for ‘三支蜡烛 three zhī candle’ (see Appendix 1 for more details about adult judgment). Altogether, there were 71 occurrences of acceptable alternative classifiers among the total 1656 occurrences. We scored children’s responses using a binary scoring system. Target classifiers and acceptable alternatives were coded as 1. The general classifier ‘个gè’, classifier omission, and specific classifiers that were deemed as errors based on adult judgment were scored as 0.
The second step was analyzing the classifier uses that were deemed as errors based on step one adult judgment, particularly semantically related and semantically unrelated substitution errors. We asked 73 Mandarin-speaking adults to judge whether children’s classifier errors (in total 31 occurrences) were semantically related or unrelated to the target classifiers. To avoid confusions with the acceptance judgment task described in the above paragraph, we removed the noun and replaced it with ‘something’. For example, the three errors for ‘四片面包’ (four piàn bread) included ‘四根面包’ (four gēn bread), ‘四支面包’ (four zhī bread), and ‘四张面包’ (four zhāng bread). We presented ‘四片something’ (‘four piàn something’) on top and asked these adults to judge whether the following three classifiers, including ‘四根something’ (four gēn something), ‘四支something’ (four zhī something), and ‘四张something’ (four zhāng something), were related to the target classifier on top in meaning. To potentially incorporate different semantic relations, there was no specified definition for semantic relatedness. Particularly, semantic relatedness was not defined as perceptual similarity, as some of the substitutions were not based on shape or size. Agreement was reached when more than half of the adults made the same judgment.
Comprehension task
A forced-choice picture-selection task was administered afterward to test children’s comprehension of the six classifiers. Semantic relatedness was manipulated in this task. The six classifiers included three pairs of semantically similar classifiers (Table 1). For example, in the pair of ‘条tiáo’ and ‘支zhī’, ‘条tiáo’ is typically used with long, narrow, and flexible objects, and ‘支zhī’ is typically used with long, narrow but rigid objects. On each test plate, the following three possible selections were provided on the basis of the semantic-relatedness (here, perceptual similarity): (1) an object that should be paired with the target classifier, (2) an object that should be paired with the classifier in the same semantic pair encoding similar perceptual features, and (3) an object that should be paired with a classifier in the other two semantic pairs with relatively distinct perceptual features. Figure 3 presents a sample test plate for ‘条tiáo’. The left (scarf) is the target. The middle (bread) is the distractor that should be paired with a semantically distant classifier ‘片piàn’. The right (candle) should be paired with ‘支zhī’, which is a semantically similar classifier to ‘条tiáo’. Scarf and candle are both long and narrow, but scarf is flexible, and candle is rigid. The position of the target object was controlled: 1/3 of the target objects appeared on the left, 1/3 appeared in the middle, and 1/3 appeared on the right. The other two objects were randomly positioned.

A Sample Test Plate of the Comprehension Task.
The test procedure was similar to Chien et al. (2003) and Li et al. (2010). Children were told that Mickey Mouse, a hand puppet from the United States, wanted to play a guessing game. However, Mickey Mouse could not speak much Mandarin but could speak good English. If Mickey Mouse did not know the name of an object, he would say he wanted ‘something’. In each trial, the child was asked to select an object that corresponded to the target classifier in a carrier phrase ‘米老鼠说他想要一CLASSIFIER something (Mickey Mouse says that he wants one CLASSIFIER something)’. There were two forms, in which the test trials were randomly sequenced into two different orders.
There were 12 trials, and each classifier was tested twice. Two practice trials were included in the beginning to familiarize children with the task, in which no target classifiers were included. All the children selected the correct pictures in the two practice trials, indicating that they understood the task. Children’s selections were recorded using response sheets. Later, correct selections were coded as 1 and incorrect selections were coded as 0. Incorrect selections were recorded using the sheet and analyzed in regard to the influence of semantic relatedness.
Vocabulary test
The final task we administered was a vocabulary test, the Mandarin Oral Vocabulary Screener (Sheng et al., in preparation). The test included 16 trials of picture selection for receptive vocabulary and 16 trials of picture naming for expressive vocabulary. All words included in the screener were nouns. The receptive vocabulary test had been administered in 580 Mandarin-speaking children, and the expressive vocabulary test had been given to 569 Mandarin-speaking children. Internal consistency was satisfactory for both the receptive vocabulary test (Cronbach’s alpha = .789) and the expressive vocabulary test (Cronbach’s alpha = .785), showing that the trials on these tasks were assessing the same skills (Henson, 2001). Among these children, 131 completed a sentence repetition task and the correlation with sentence repetition was significant, r(131) = .49, p < .001, providing evidence for external validity.
Each receptive vocabulary trial had four choices, and only one choice corresponded to the target word the experimenter verbalized. The experimenter used a response sheet to record children’s selections. Later, correct selections were coded as 1, and incorrect selections were coded as 0. The total score was the averaged accuracy of the 16 trials.
For expressive vocabulary, children were required to name objects depicted in pictures. Each trial had a list of acceptable answers, which were based on responses from 10 native Mandarin-speaking adults. The experimenter wrote down the exact responses using an open response sheet. The production was audio recorded, and a second researcher listened and transcribed 20% of children’s responses independently. An agreement of 99% was reached between the two researchers. One response was unintelligible, and the two researchers had different interpretations, but they agreed that the response was not a target response listed in the acceptable answers. Acceptable responses were coded as 1 and unacceptable responses were coded as 0. The total score was the averaged accuracy of the 16 trials.
Results
We displayed the demographic and descriptive data by age group in Table 3. Children below age 5 were grouped as the younger group, and children above age 5 were in the older group. This cutoff was selected to match Uchida and Imai (1999), in which the researchers compared classifier learning in Japanese-speaking children at 4- and 5-year-old. There was no significant difference in maternal education between the two age groups, t(136) = .82, p = .41. Children in the two locations, Beijing and Nanjing, did not differ in age, t(116.1) = 9.36, p = .13, and maternal education, t(136) = .92, p = .12.
Children’s demographic information by age group.

SD: standard deviation.
The younger group included children below age 5, and the older group included children above age 5. SD of age was displayed in month. Maternal education was ranked: 1 = middle school or below, 2 = high school, 3 = associate degree, 4 = bachelor’s degree, 5 = master’s degree or above.
Table 4 presents average accuracy, standard deviations, and ranges of the outcome measures in the two age groups, including classifier-based categorization preference, classifier production, classifier comprehension, receptive vocabulary, and expressive vocabulary. Accuracy on classifier comprehension was much higher than production accuracy in both age groups.
Average accuracy, standard deviations, and ranges of measures in the younger and older age group.
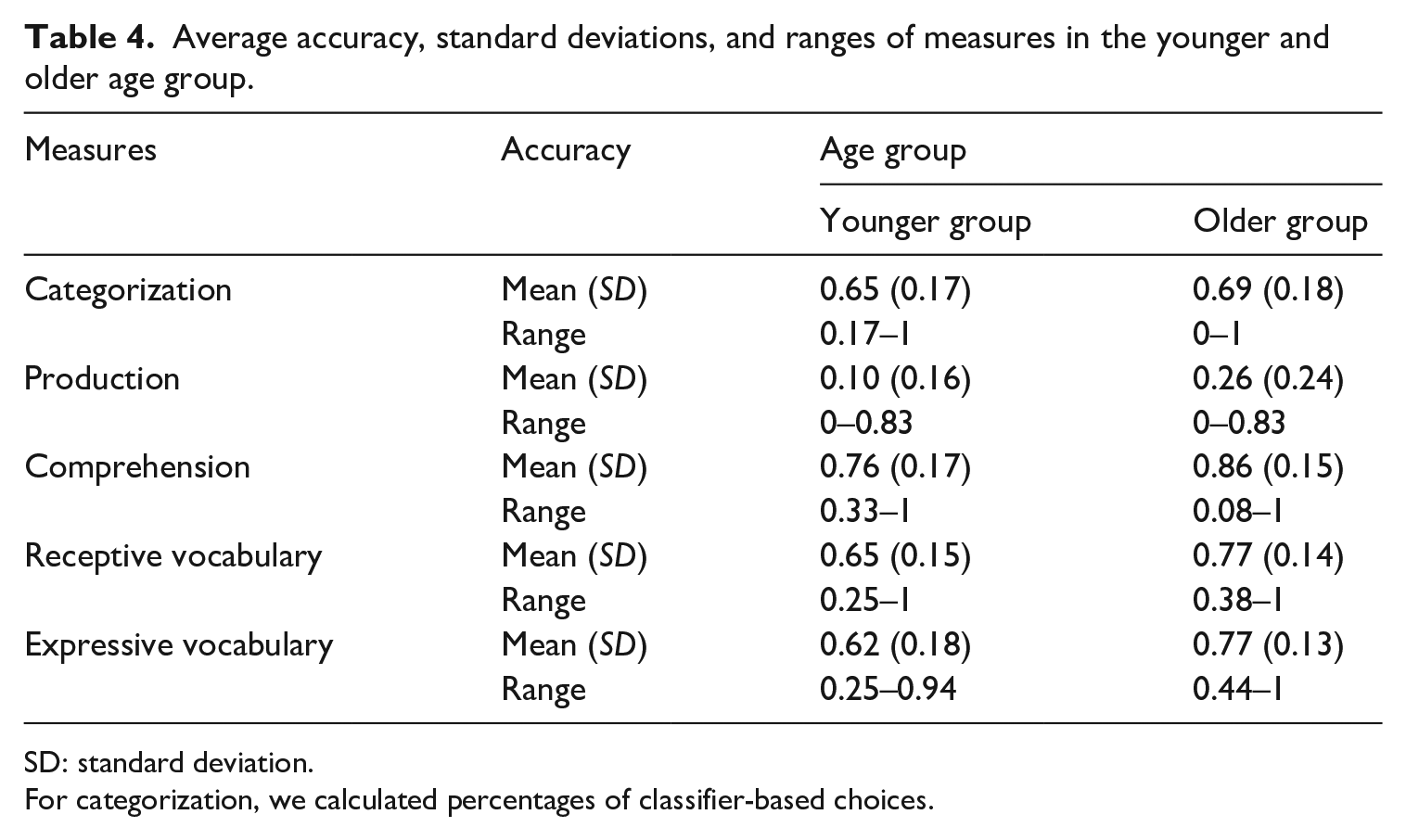
SD: standard deviation.
For categorization, we calculated percentages of classifier-based choices.
Production
We used a generalized linear mixed model for binary data to analyze results of production. Children’s accuracy on production was the dependent variable, which was entered as binary data (0 represented an incorrect choice and 1 represented a correct choice). Independent variables included categorization preference (percentage of classifier-based choices), age in month, overall vocabulary accuracy (averaged accuracy on receptive and expressive vocabulary tests), maternal education (1–5 indicated middle school or below to master’s or above), location (1 indicated Beijing and 2 indicated Nanjing). 4 As a previous study suggested that categorization skills may interact with age (Uchida & Imai, 1999), we included the two-way interaction between categorization preference and age.
We found two significant main effects. There was a main effect of vocabulary, F(1, 1647) = 16.76, p < .001. Children who scored higher in the vocabulary tests achieved better performance on the classifier production task. A significant main effect of maternal education was found, F(3, 1647) = 4.69, p = .003. Children whose mothers received a master’s or higher degree displayed higher production accuracy than children whose mothers received an associate degree, t(1647) = 2.67, p = .008, and children whose mothers received a bachelor’s degree, t(1647) = 3.50, p < .001. The sample only included one mother whose education was high school, and the other mothers achieved at least an associate degree.
There were two marginally significant main effects, including age, F(1, 1647) = 2.74, p = .09, and location, F(1, 1647) = 3.47, p = .06. Older children scored higher than younger children on the production task. For location, children in Nanjing achieved better production accuracy than children in Beijing. The main effect of categorization preference, F(1, 1647) = .06, p = .81, and the interaction between age and categorization, F(1, 1647) = .09, p = .76, were not significant.
Figure 4 presents production accuracy of each classifier. As each classifier was paired with two nouns, children may display different performance on the two trials of the same classifier. Thus, we examined the accuracy of each individual classifier-noun combination. As can be seen from Figure 5, there was a big accuracy discrepancy (0.25) between the two trials of ‘piàn’. Children were more likely to produce ‘piàn’ or an acceptable alternative when it was combined with leaf than bread. Regarding the classifier ‘zhī’, children tended to more accurately produce ‘zhi’ or an acceptable alternative when combined with pencil than with candle (discrepancy was 0.20). Children were also more likely to produce ‘miàn’ or an acceptable alternative when it was combined with wall than with mirror (discrepancy was 0.13). Accuracy differences between the two trials were relatively small for the other three classifiers.
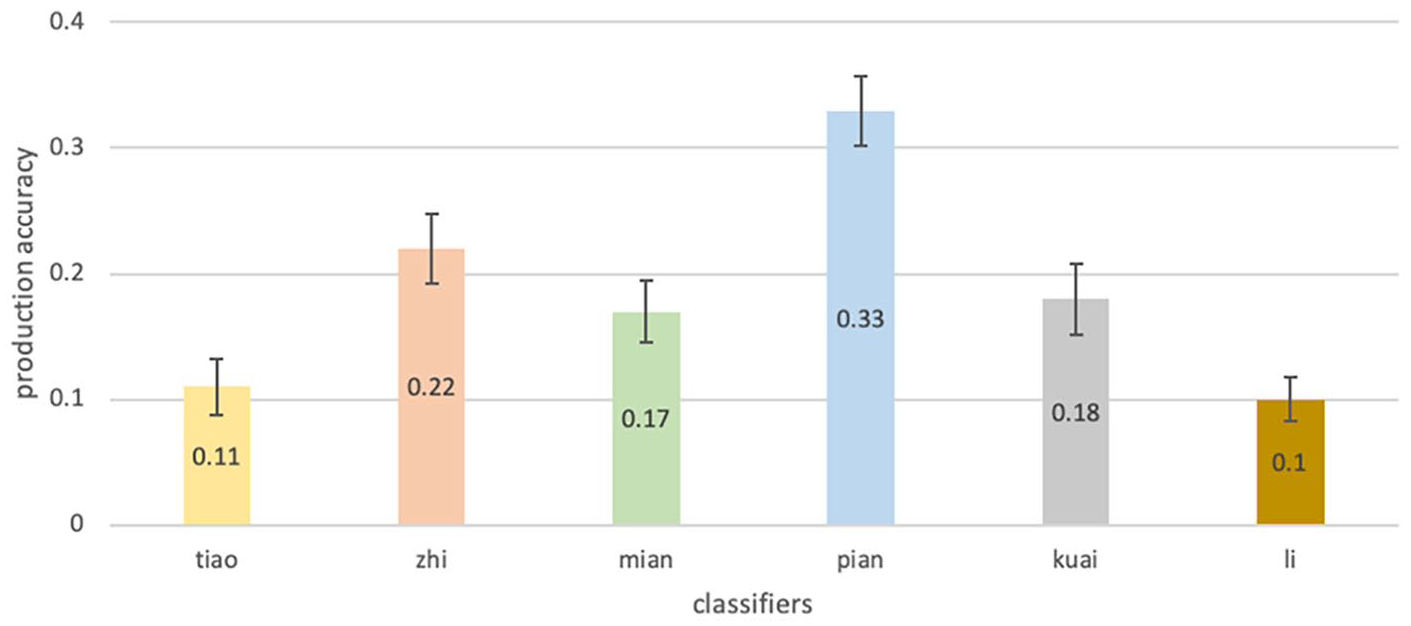
Production Accuracy of Individual Classifiers.
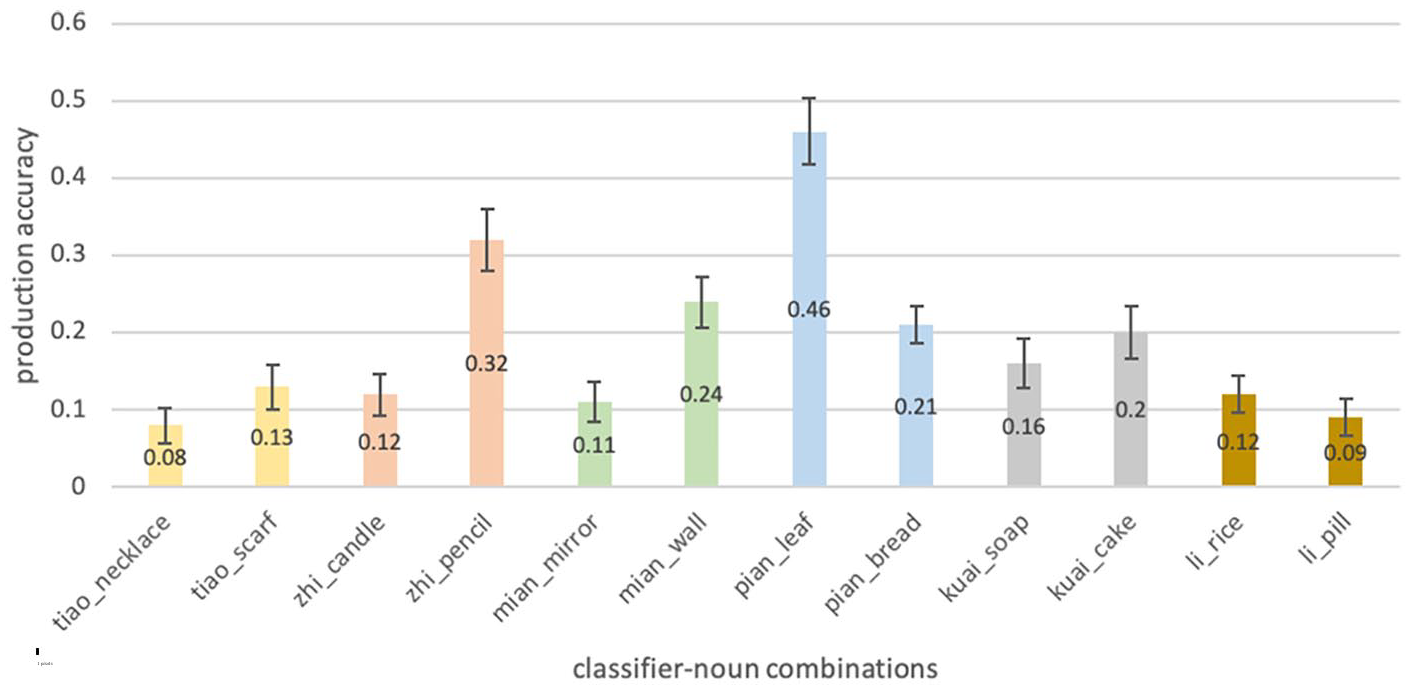
Production Accuracy of Individual Classifier-Noun Combination.
We used Spearman’s rank-order correlation test to measure the correlation between frequency of input estimated from the corpus and production accuracy for the targeted classifier-noun combinations. A correlation coefficient between 0 and 0.3 was considered a weak correlation, 0.3–0.7 moderate, and 0.7–1.0 strong. The correlation was weak and not significant, rs(12) = .04, p = .89. We excluded any acceptable alternative classifiers and only included the 12 targeted classifier-noun combinations for production accuracy, and the correlation was weak and still not significant, rs(12) = .06, p = .85.
Regarding the errors, there were 10 semantically related substitution errors. For example, some children used ‘张zhang’ for wall, whereas ‘张zhang’ is typically paired with paper. There were 21 semantically unrelated substitutions. For example, a child paired pencil with ‘块kuài’, which should be paired with cube-like objects. The majority of children’s production was using the general classifier ‘个gè’ to replace the target classifier. Among the 138 children, 41 children used ‘个gè’ exclusively, and they did not use any specific classifiers. There were three occurrences of classifier omission, in which two occurrences were from the same child, and the other occurrence was from another child. There were a few instances that children did not correctly identify the objects in the pictures (e.g. one child identified necklaces as matches) (see Table 5 for more details).
Occurrences and percentages of production types.
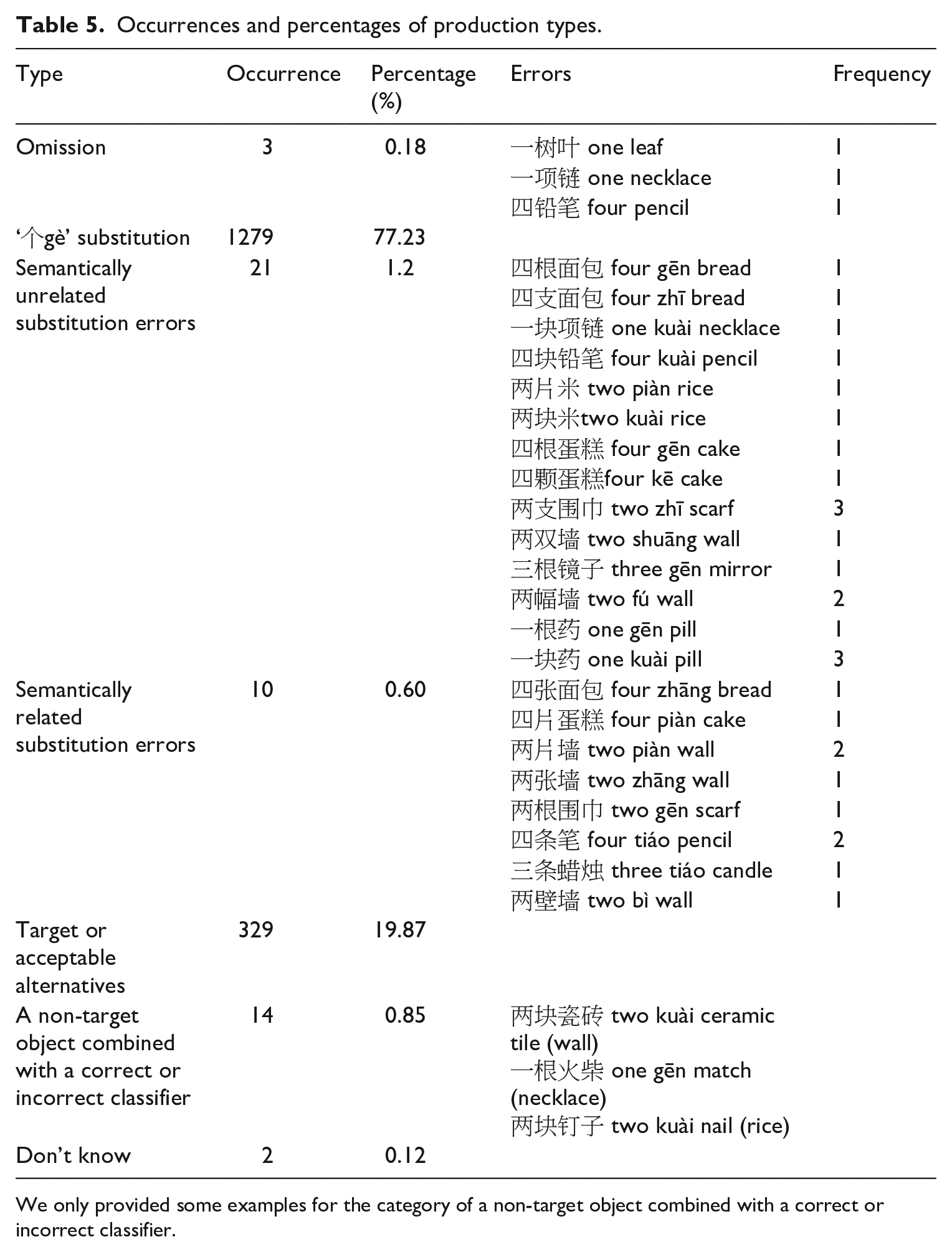
We only provided some examples for the category of a non-target object combined with a correct or incorrect classifier.
Comprehension
Results of the comprehension test were analyzed using a generalized linear mixed model for binary data. The dependent variable was accuracy on the comprehension test (0 indicated an incorrect response and 1 indicated a correct response). We entered categorization preference, age in month, the two-way interaction between categorization and age, overall vocabulary accuracy, and maternal education into the model. 5
The results showed only one significant main effect. Vocabulary was significantly related to children’s classifier comprehension, F(1, 1647) = 19.94, p < .001. Children with larger vocabulary tended to score higher in the classifier comprehension task. No significant main effects were found for categorization preference, F(1, 1647) = .08, p = .79; age, F(1, 1647) = 1.08, p = .29; the interaction between age and categorization, F(1, 1647) = .09, p = .76; and maternal education, F(3, 1647) = .06, p = .98.
We presented children’s accuracy on each classifier in Figure 6. In Figure 7, we presented comprehension accuracy for individual classifier-noun combinations. Accuracy differences between the two trials of the same classifier ranged from 0.01 to 0.12.

Comprehension Accuracy of Individual Classifiers.

Comprehension Accuracy of Individual Classifier-Noun Combinations.
We examined children’s errors in comprehension to see if perceptually similar selections were the dominant type of errors compared to perceptually distant selections. On average, 70.2% of errors children made were perceptually related, and the rest 29.8% of errors were perceptually distinct. We used Spearman’s rank-order correlation test to measure the correlation between frequency of input estimated from the corpus and comprehension accuracy for the 12 classifier-noun combinations. There was a strong and significant correlation, rs(12) = .74, p = .006.
Comprehension and production
Finally, we explored the correlation between comprehension and production accuracy. We intended to submit the data for Pearson’s correlation tests, but the data did not meet the assumption of normality. We then ranked the data and submitted it for a Spearman’s rho correlation test, which is non-parametric and does not assume normal distribution. There was a moderate and significant correlation between comprehension and production, rs(138) = .37, p < .001.
Overall, production appeared to be more challenging than comprehension. While the mean accuracy of comprehension was 0.81 (SD = 0.17, range = 0.08–1), production accuracy was only 0.18 (SD = 0.22, range = 0–0.83). The median for comprehension accuracy was 0.83 (i.e. 10 correct choices on the picture-selection task). The median for production accuracy was 0.08 (i.e. one correct production of a specific classifier on the counting task). To explore different comprehension-production patterns, we set medians of comprehension and production accuracy as cutoffs. See Figure 8 for the following four comprehension-production patterns: (1) high comprehension and high production, (2) high comprehension and low production, (3) low comprehension and high production, and (4) low comprehension and low production.
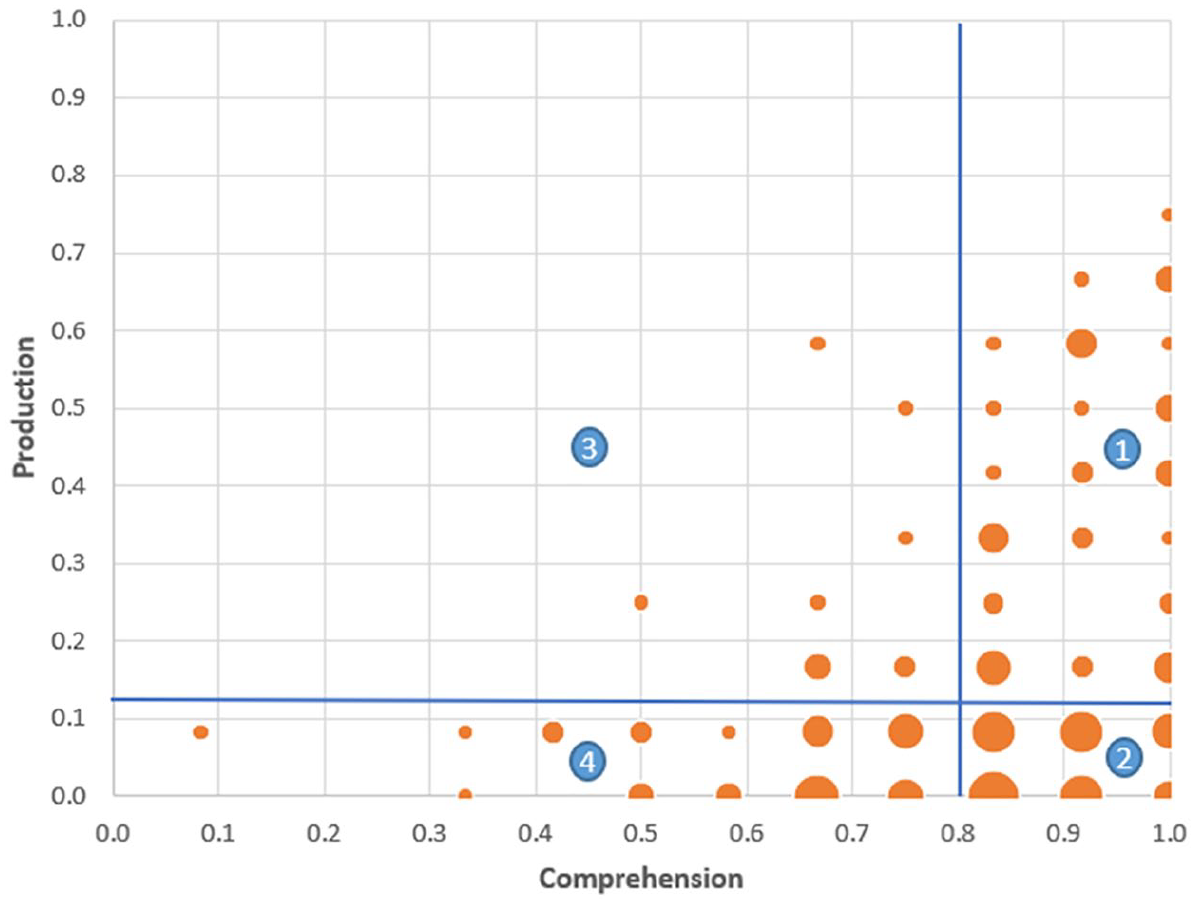
Bubble Plot for Comprehension-Production Accuracy Patterns.
Table 6 shows the descriptive data of the number of children, age, maternal education, vocabulary, categorization preference, comprehension accuracy, and production accuracy for the four patterns. The majority of children was categorized in patterns 1, 2, and 4, and only 10 children were grouped as pattern 3 which presents low comprehension and high production. To examine differences related to pattern groups, four ANOVAs were conducted. The independent variable was pattern group, and the dependent variables were age, maternal education, vocabulary, and classifier-based categorization preference. There was a main effect of age, F(3,134) = 16.98, p < .001. We conducted post hoc tests and used Bonferroni corrections to prevent Type I error. It was found that pattern 1 children were older than pattern 2 children, t(134) = 6.52, p < .001, and pattern 4 children, t(134) = 9.03, p < .001. There was also a main effect of vocabulary, F(3,134) = 18.03, p < .001. Post hoc tests with Bonferroni corrections showed that pattern 1 children scored higher than pattern 2 children, t(134) = .08, p = .01, and pattern 4 children, t(134) = .20, p < .001, and pattern 2 children scored higher than pattern 4 children, t(134) = .12, p < .001. There were no main effects of maternal education, F(3,134) = .83, p = .48, and classifier-based categorization preference, F(3,134) = 1.79, p = .15.
Characteristics of the four comprehension-production patterns.

SD: standard deviation.
Pattern 1 = high comprehension and high production, Pattern 2 = high comprehension and low production, Pattern 3 = low comprehension and high production, Pattern 4 = low comprehension and low production. The SDs of age were displayed in month. Maternal education was ranked: 1 = middle school or below; 2 = high school; 3 = associate degree; 4 = bachelor’s degree; 5 = master’s degree or above. For categorization, we calculated percentages of classifier-based choices.
Discussion
In order to understand how Mandarin-speaking children learn shape classifiers, we explored potential influential factors of the comprehension and production of shape classifiers among 138 Mandarin-speaking children. We investigated the influences of classifier-based semantic categorization strategies and associated errors, input frequency of classifier-noun combinations, and vocabulary knowledge. This study contributes to the literature with novel findings. For the first time, we found that vocabulary knowledge was significantly related to classifier knowledge, suggesting some common traits between classifier learning and noun learning. Also, we were the first to find that input frequency was significantly related to children’s comprehension of the classifier-noun pairings in Mandarin. Interestingly, maternal education and location (or dialect) appeared to relate to classifier production. Classifier-based semantic categorization, however, did not significantly relate to classifier comprehension and production. The dominant error in comprehension was pairing a classifier with an object that is perceptually similar to the target object. Below we expand our discussion.
Semantic strategies
We hypothesized that Mandarin-speaking children who preferred object categorization by shared classifiers would demonstrate more advanced classifier knowledge (Kuo & Sera, 2009; Sera et al., 2013). In the categorization task, we presented two types of semantic categorization choices on the basis of shared classifiers (e.g. pencil and bamboo) and taxonomic or thematic relations (e.g. pencil and eraser). Different from Sera et al. (2013), we found that classifier-based categorization was not significantly related to the comprehension of classifiers. Moreover, contrary to Uchida and Imai’s (1999) speculations, there was no significant interaction between age and classifier-based categorization skills.
As we have pointed out in the introduction, Sera et al.’s (2013) finding of a relationship between classifier knowledge and shape-based categorization skills suffered from a relatively small sample size (n = 32) and an unconventional and somewhat arbitrary analysis approach. To the best of our knowledge, Sera et al. (2013) is the only study that presented this relationship. Uchida and Imai (1999) did not test the correlation, and that classifier-based semantic categorization is a mechanism for classifier acquisition was just a speculation by the researchers. In our study, using a large sample size (n = 138), the hypothesis is not supported for both children’s receptive and expressive knowledge of shape classifiers. One possibility is that the semantic categorization may not be a predominant approach for Mandarin-speaking children to learn classifier. As we have found a significant correlation between input frequency and comprehension for classifier-noun combinations (discussed in more details below), frequency is likely more important for Mandarin classifier acquisition than semantic categorization. Another possibility is that the current categorization task may not be the best measure of classifier-based semantic categorization skills. The current task, adapted from Sera et al. (2013), presents two choices (classifier-based vs taxonomically/thematic-related) that are both reasonable. A classifier learning task may be a better measure, in which novel classifiers encoding different shapes will be presented. In order to learn the novel classifiers, children will need to distinguish and summarize different perceptual features for different novel classifiers.
Semantic distance or perceptual similarities among different classifiers appeared to have an influence on children’s pairing of classifier and object. In comprehension, a majority of children’s errors (i.e. 70.2%) was choosing an object that should be paired with a perceptually similar but non-target classifier, indicating that children made distinctions pertaining to perceptual features that were encoded in different shape classifiers. It is likely that detecting obvious semantic differences is easier and happens earlier in classifier development (e.g. long vs flat). It takes more effort and a longer time for Mandarin-speaking children to differentiate fine-grained semantic differences (e.g. long and flexible vs long and rigid). However, we cannot rule out the possibility that children’s overwhelming selections of non-target but semantically related objects were related to their exposure to these classifier-noun pairings in real life, for example, ‘一片镜子 one piàn mirror’, ‘一条蜡烛 one tiáo candle’. Although we originally planned a novel object condition, it was not included in this study, due to the low agreement on some testing items by native Mandarin speakers. Future studies may make continued efforts to create novel objects with adult agreement, which will help determine the plausibility of this possibility.
In production, most errors were using the general classifier ‘个gè’ to replace the specific target classifiers (i.e. 77.29%), which is consistent with the over-generalization of ‘个gè’ in previous studies (Tse et al., 2007; Ying et al., 1983). Given the dominant use of ‘个gè’ in the production task, future studies may consider using prompts to elicit specific classifiers if a child produces the general classifier. For example, a prompt can be ‘Mickey Mouse knows there is a better way to say one gè. It is one___’. In this study, some children may have used the general classifier as an easier way to respond to the counting questions. If such a prompt is used and children are pushed to produce specific classifiers, we may better distinguish whether children truly have difficulties with specific classifiers or they just find using the general classifier an easier response strategy. This may provide a more accurate picture of children’s expressive knowledge of specific classifiers.
Both semantically related (10 occurrences) and semantically unrelated specific classifier (21 occurrences) errors were infrequent. However, note that most of the 71 acceptable alternatives should be semantically related to the target classifiers. If we sum the acceptable alternatives and semantically related errors, the semantically related substitutions (81 occurrences) were about 5% among all productions, which was a higher percentage than the semantically unrelated substitutions (i.e. 1.2%).
Some of the production errors may indicate that some Mandarin-speaking children’s classifier uses are based on an overuse of semantic rules. For example, in production, some children paired wall with semantically related but non-target classifiers, including ‘张zhāng’ and ‘片piàn’. Note that ‘张zhāng’ should be paired with papers or bed, and ‘片piàn’ is typically paired with slices. To gain the knowledge about these conventions, children may need to receive didactic instructions about these conventional pairings in their Mandarin language classes. Reading may further reinforce classifier knowledge, as specific classifiers may more likely be included in literate language than in oral language.
Frequency effect and the learning of individual classifier-noun combinations
Frequency of input for classifier-noun combinations estimated from corpus data significantly correlated with the comprehension accuracy of these combinations, indicating that Mandarin-speaking children learn each pairing by hearing the usage from people around them. The more they are exposed to the usage of specific classifier-noun combinations in everyday language, the more they are able to identify and pair them receptively. This finding provides support for the frequency effect on the acquisition of linguistic features (e.g. Ambridge et al., 2015).
The correlation between input frequency and production accuracy for each classifier-noun combination, however, was not significant, even after removing acceptable alternatives and keeping only the targeted pairings when calculating production accuracy. One possible reason may be related to the setup of the production task, in which children were not prompted to provide a specific classifier. As we have noted, about one-third (41 out of 138) of the children used the general classifier ‘个gè’ exclusively in their responses. The children may have some knowledge of the appropriate specific classifiers but may not want to risk making errors. At the same time, using the general classifier may be a good enough answer for the counting questions. Again, future research should improve the production task by providing effective prompts in order to elicit specific classifier production.
Alternatively, the frequency effect in production may be better studied by creating novel classifiers and conducting a learning task, in which input frequency of novel classifiers can be easily manipulated, given that frequency of input may be hard to measure for real classifiers. However, as we have noted in the introduction, frequency cannot be treated as the only influential factor of language acquisition, and its influences should be evaluated with other relevant factors (e.g. Storkel et al., 2006). While the classifier comprehension accuracy may more directly reflect the influence of input frequency, classifier production performance may be affected by other factors. For example, children may need to have some prior successful experience with the production of a specific classifier-noun combination in real life before they can produce the combination in the experiment. Future research may also consider factors like phonotactic probability and neighborhood density to continue exploring the discrepancy between classifier comprehension and production pertaining to the frequency effect.
We found differential accuracy between the two classifier-noun pairs for the same classifiers in comprehension and production (Figures 5 and 7). Particularly, in production, the most striking accuracy gap is between the two trials of ‘片piàn’. While the accuracy of ‘piàn-leaf’ was 46%, the ‘piàn-bread’ accuracy was 21%. It is possible that the ‘piàn-leaf’ combination was frequently used at school in book reading or other class activities, resulting in higher frequency in children’s language input and more practice in production. Also, ‘piàn-leaf’ may have a one-to-one mapping, whereas ‘piàn-bread’ has many-to-one mapping (bread can be paired with multiple different classifiers depending on the shape of the bread like 片piàn, 块kuài and 根gēn). The accuracy gap between ‘zhī-pencil’ (32%) and ‘zhī-candle’ (12%) was also large. The pairing of zhī and pencil should be more frequent and familiar to children than the pairing of zhī and candle, given candles are typically not used in the school or home setting nowadays.
Children show better usage of certain classifier-noun combinations than others, suggesting that children may learn individual pairings from their language exposure in daily conversations or reading materials. As previous studies have proposed, language experiences and explicit instructions play an important role in the comprehension and production of Mandarin classifiers, in addition to semantic strategies (e.g. Li et al., 2010; Uchida & Imai, 1999; Ying et al., 1983). It is possible that the pairings that are more frequently heard and used in the child’s environment are better mastered than those that are less frequent in the environment. From our findings, it is likely that item-by-item learning from the language learning environment is the predominant approach, whereas semantic categorization is secondary. It is unclear how item-based learning and semantic strategies interact in classifier acquisition. It is also unclear when children mainly use semantic strategies or item-based learning based on the current findings. We speculate that there is a complex interplay between the two approaches, and the question should continue to be addressed in future studies.
Vocabulary
Vocabulary knowledge appeared to be a reliable index of classifier knowledge. Children who demonstrated better receptive and expressive knowledge of Mandarin nouns tended to achieve higher accuracy on Mandarin classifier comprehension and production. As mentioned in the introduction, many classifiers and concrete nouns share similar semantic properties. Thus, a larger vocabulary size can be positively related to better classifier knowledge. A larger vocabulary may also relate to more mature semantic organization skills, which may facilitate the organization of semantic properties for different classifiers.
Furthermore, the findings may indicate some similarities between the learning of shape classifiers and concrete nouns, both of which are heavily shape-based. A predominant tendency in noun learning is to extend a name to a novel object of a shared shape (e.g. Gershkoff-Stowe & Smith, 2004; Yee et al., 2012). It was also found that the awareness of shape categorization is a reliable early index of children’s noun learning. The majority of Mandarin classifiers has a cognitive base on shape (Zhang, 2007), and the six classifiers we included in this study are associated with different shapes.
Despite the similarities of classifier learning and noun learning, we want to note some differences between the two. The rate of acquisition is different. Noun production occurs early in infancy, which includes many concrete nouns referring to people, animals, or objects (Tardif et al., 2008). In our study, 4–6 years old Mandarin-speaking children’s average accuracy of specific classifier production was low at around 18%. Moreover, the semantic organization for classifiers appears to be more complex and unintuitive compared to the semantic organization for concrete nouns (Imai et al., 2010). ‘Long, narrow and flexible’ pertaining to ‘条tiáo’ is not a common combination of semantic properties.
Comprehension precedes production in classifier development
Consistent with previous findings (e.g. Chien et al., 2003; Ying et al., 1983), we found that comprehension preceded production in classifier development. We explored four comprehension-production patterns. While the ‘high comprehension high production’ group was on average 5;7 years of age, the ‘low comprehension low production’ group was almost 1 year younger at age 4;8 on average. It takes about 1 year for the younger children to be more competent in the comprehension and production of the shape classifiers. The accuracy gap for vocabulary between the two pattern groups was big, again indicating that vocabulary is a relevant factor of classifier comprehension and production. The ‘high comprehension low production’ and ‘low comprehension high production’ groups were similar in age and vocabulary knowledge, and both groups needed to develop classifier knowledge to reach the levels of the ‘high comprehension high production’ group. It is worth mentioning that comprehension accuracy is much higher than production accuracy across the four pattern groups, even for the ‘low comprehension high production’ group. The production of specific classifiers is likely more challenging than the comprehension of these classifiers. To make better comparisons between comprehension and production, future studies may make the two tasks more comparable. For example, a judgment task for comprehension (i.e. Mickey Mouse said ‘there are one tiáo necklace’. Is he right?) may be used to allow for a similar display of probe as the production task.
Maternal education and location
Maternal education was entered into the mixed models as a potential confound, and we found a significant correlation between maternal education and classifier production, but not comprehension. Mothers with higher education tend to have positive learning experiences, more knowledge and higher order thinking (Magnuson et al., 2009). When raising their children, they are more likely to carry higher expectations and thus provide richer learning environment, for example, more book reading activities (Davis-Kean, 2005). Also, mother–child interactions and mothers’ verbal responsiveness are found to be different between mothers receiving higher education and lower education. Highly educated mothers ask more questions and offer more feedback, rather than issuing many directions (Hoff-Ginsberg, 1998). As a result, children have more chances to practice different linguistic features and be reinforced or corrected by their mothers on their language production. Regarding classifier learning, in joint book reading activities, the highly educated mothers may require their children to repeat classifier-noun phrases or discuss quantity of objects which elicits specific classifier use by children. This provides increased opportunities for children to practice different specific classifiers, rather than just identifying and recognizing these classifiers. Moreover, instead of using the general classifier ‘个gè’, mothers with higher education may use specific classifiers more frequently when conversing with their children. The richer input of specific classifiers and the increased chances of practicing specific classifiers could have improved children’s performance on specific classifier production.
The marginal significant difference in production accuracy for the two locations is interesting and deserves more attention in future studies. Children from Nanjing achieved higher accuracy in the production of the shape classifiers than children from Beijing. Erbaugh (2006) documented some dialectal differences for classifier usage. Cantonese speakers use sortal classifiers more frequently than Mandarin speakers. While there is one sortal classifier use for every six nouns for Cantonese speakers, there is one sortal classifier for every 33 nouns for Mandarin speakers. Our findings seem to align with the dialectal differences. While children in Beijing were more cautious and refrained from using specific classifiers, children from Nanjing appeared to be more liberal and attempted more uses of specific classifiers which potentially resulted in higher accuracy in production as some alternative specific classifiers were accepted as correct usage.
Conclusion
In this study, we studied how Mandarin-speaking children learn shape classifiers by considering relevant factors including semantic strategies, frequency of input, and vocabulary knowledge. We are the first to find that input frequency of classifier-noun pairings was significantly related to the comprehension of the pairings among Mandarin-speaking children. In addition, children showed differential learning for different classifier-noun pairings, possibly as a result of differential exposure to the pairings. Classifier-based semantic categorization did not significantly relate to classifier comprehension and production. However, Mandarin-speaking children’s predominant error type in comprehension was to select a perceptual similar object to the target object. The results suggest that in order to learn classifiers Mandarin-speaking children may rely on classifier exposure from their language learning environment, as well as use semantic strategies. It is likely that item-based learning is the predominant approach, and semantic strategies are secondary for Mandarin classifier acquisition. We are also the first to find the significant positive correlation between classifier and vocabulary knowledge, which indicates that the two may share some common traits. Also, maternal education and dialectal differences were found to relate to children’s production of shape classifiers. The current findings warrant future studies to further explore approaches Mandarin-speaking children take to learn classifiers. This study only explored factors for the comprehension and production of shape classifiers. Future work should expand the exploration to other types of classifiers, for example, event classifiers, measure classifiers. Frequency should be closely measured to reflect amount of input for the targeted group of Mandarin-speaking children. Given that measuring the input of real classifiers is difficult, a learning task with invented classifiers is a sound way to manipulate children’s classifier input.
Footnotes
Appendix
Adult Mandarin native speakers’ acceptance of non-target specific classifier productions by children.

| Children’s production | Adult acceptance rate |
|---|---|
| 四根面包 four gēn bread | 0.09 |
| 四支面包 four zhī bread | 0.02 |
| 四张面包 four zhāng bread | 0.26 |
| 四块面包 four kuài bread | 0.98 |
| 两片米 two piàn rice | 0.07 |
| 两颗米 two kē rice | 0.95 |
| 两块米 two kuài rice | 0.05 |
| 一块项链 one kuài necklace | 0.02 |
| 一根项链 one gēn necklace | 0.81 |
| 一串项链 one chuàn necklace | 0.93 |
| 四片蛋糕 four piàn cake | 0.48 |
| 四根蛋糕 four gēn cake | 0 |
| 四颗蛋糕 four kē cake | 0.05 |
| 一根药 one gēn pill | 0.02 |
| 一块药 one kuài pill | 0.17 |
| 一颗药 one kē pill | 1 |
| 两座墙 two zuò wall | 0.52 |
| 两块墙 two kuài wall | 0.55 |
| 两双墙 two shuāng wall | 0 |
| 两壁墙 two bì wall | 0.33 |
| 两幅墙 two fú wall | 0.19 |
| 两片墙 two piàn wall | 0.31 |
| 两张墙 two zhāng wall | 0.31 |
| 两道墙 two dào wall | 0.83 |
| 两支围巾 two zhī scarf | 0.05 |
| 两根围巾 two gēn scarf | 0.45 |
| 四条笔 four tiáo pencil | 0.05 |
| 四杆铅笔 four gān pencil | 0.57 |
| 四块铅笔 four kuài pencil | 0 |
| 四根铅笔 four gēn pencil | 0.93 |
| 三根镜子 three gēn mirror | 0.02 |
| 三张镜子 three zhāng mirror | 0.59 |
| 三块镜子 three kuài mirror | 0.90 |
| 三盏蜡烛 three zhǎn candle | 0.62 |
| 三条蜡烛 three tiáo candle | 0.33 |
| 三根蜡烛 three gēn candle | 1 |
The native Mandarin-speaking adults were from 15 provinces, including Anhui, Beijing, Shandong, Sichuan, Shānxi, Neimenggu, Jiangsu, Hunan, Henan, Liaoning, Hebei, Gansu, Shanghai, Guizhou, and Shǎnxi.
Acknowledgements
The authors thank the preschools in Beijing and Nanjing for assisting participant recruitment. They are grateful for the children, parents, and teachers for volunteering to participate in this study. They appreciate the help of the research assistants from Tsinghua University and Nanjing Normal University. This manuscript has not been published previously. The authors do not have a financial interest in the materials or data presented in this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Part of the data collection was funded by Humanities and Social Sciences Project of the Chinese Ministry of Education (17YJAZH132) awarded to Li Zheng (PI) and Li Sheng (co-PI).