
Abstract
Mass adoption of advanced information technologies is fueling a need for public servants with the skills to manage data-driven public agencies. Public employees typically acquire data skills through graduate research methods courses, which focus primarily on research design and statistical analysis. What data skills are currently taught, and what content should Master of Public Administration (MPA) programs include in their research method courses? We categorized research method course content in 52 syllabi from 31 MPA programs to understand how data skills are taught in public administration. We find that most graduate programs rely on research methods more suited for academic and policy research while lacking the data skills needed to modernize public agencies. Informed by these results, this work presents the Data Science Literacy Framework as a guide for assessing and planning curriculum within MPA programs.
Introduction
Public agencies are increasingly reliant on and inundated by large volumes of complex, continuously created data known as Big Data (Secundo et al., 2017). Public sector professionals need new data skills to effectively use Big Data to inform decision-making (Secundo et al., 2017; Mergel, 2016). Collecting, cleaning, managing, and deriving meaning from data are quickly becoming necessary skills, while traditional research methods and inferential statistics are becoming less valuable (Baumer, 2015; Cobb, 2015). Consequently, educators must consider revising existing research methods curriculum and teaching students’ data skills to ensure relevance (Miller, 2014). What data skills are currently taught, and what content should Master of Public Administration (MPA) programs include in their research method courses?
There is a clear need for practitioners with data science skills in the public sector (Secundo et al., 2017). Using data effectively requires that employees possess data and computational skills, but there are few practical paths for MPA students to acquire them. Public Administration (PA) programs are ill-equipped to offer data science courses because faculty often lack computational training, and the prohibitive technicality of data science makes adding it as a non-focal point of curricula difficult. Data science programs housed in computer science and statistics departments are available at many universities but are largely inaccessible and irrelevant to PA students due to burdensome pre-requisites and pedagogical approaches tailored almost exclusively to private sector applications (Kleinschmit, 2019; Cobb, 2015).
To create a foundation for teaching data skills within PA, we first assess what skills are currently taught. We conducted a content analysis of 52 research method syllabi from 31 MPA programs in the United States to accomplish this goal. Course content is then classified using a typology of data skills, the Data Science Literacy Framework (DSLF), which provides data science and data literacy content for research method instructors to consider including in their courses. The strengths and weaknesses of PA data education is evaluated through this classification system while offering prescriptive guidance for incorporating data competencies throughout research methods sequences.
This work begins with a discussion of the data skills gap, then considers how data science and literacy address the gap but are incomplete individually. Next, the DSLF and its domains are outlined and explained. Following the presentation of the DSLF, the methodology and results sections detail the analytical approach and findings, then the manuscript concludes with a discussion of potential revisions to MPA research method curricula.
The data skills gap
There is a considerable difference between the data skills public sector employees have and the data skills public organizations need resulting in a data skills gap (Chinien and Boutin 2011). City managers identified the lack of data skills (i.e., internal capacity and technical expertise) as significant barriers to adopting and implementing smart city technologies (ICMA and Smart Cities Council, 2016). Additionally, among a survey of federal managers, 96% of respondents perceived a discernible data skills gap at their agencies, identifying a lack of adequate training, cultural norms surrounding technology, data accessibility issues, and budget restraint as challenges (Fiorenza, 2016). Other research suggests management is partially to blame as a “lack of executive understanding” was cited by 37% of public organization leaders as an obstacle to the effective use of data to achieve goals and mandates (Mullich, 2013).
The evidence of data skills gaps within public agencies mirror similar findings in other professional disciplines, such as healthcare administration. Dolezel and McLeod (2021) posit that labor pipeline issues, such as high educational requirements for data science practitioners and a shortage of academics with data science teaching skills, contribute to these gaps. This work addresses pipeline issues by examining how data skills are taught within MPA programs and provides guidance for upskilling practitioners and assessing academic curriculum development.
In statistics curricula, the transition to teaching data skills over inferential statistics is underway due to the growth of computational resources, the size of datasets, and the volume of non-experimental/observational data available for analysis (Cobb, 2015; Kaplan, 2018). There is a new emphasis on “thinking with data” (Baumer, 2015) through the development of data habits of mind, or DH (Finzer, 2013). DH refers to how experience creating, formatting, managing, analyzing, and applying data allows individuals to reflexively identify potential issues and generate solutions before starting a data-centric project (Baumer, 2015; Finzer, 2013; Zhu et al., 2013). To develop students' DH, applied statistics curricula are moving away from theory and mathematical notation and towards computational skills, visualization, and data collection, cleaning, and management (Baumer, 2015; Bryan and Wickham, 2017; Asamoah et al., 2020).
As part of its Grand Challenges in Public Administration initiative, the US-based National Academy of Public Administration identified the need to revise and expand curricula to address the challenge of managing technological change (Gerton and Mitchell, 2019). The acquisition of data skills is critical to successfully implementing technological change (Secundo et al., 2017), but PA programs are not responding effectively. Graduates of elite institutions that house many existing public data science programs pursue careers outside the typical government agencies that employ MPA graduates (Kleinschmit, 2019), such as state and local governments. Most data science courses are inaccessible to many students due to prohibitive pre-requisites in computer science and mathematics curriculums. Currently, few academic programs in PA offer courses in this area.
Research method courses are the most appropriate context to teach data skills in MPA program, as these courses are offered in most NASPAA-accredited MPA programs (Morçöl et al., 2020). Updating statistics curricula in MPA programs aligns well with PA scholarship, suggesting there is too much emphasis on topics that practitioners do not value (Henderson and Chetkovich, 2014). PA scholars have previously explored changes through modified approaches to teaching research design (Engbers, 2016; Fitzpatrick, 2000), an increased emphasis on qualitative and mixed methods (Morçöl and Ivanova, 2010), embedding research skills throughout a curriculum (Gunn, 2017), and an openness to teach program evaluation and management science methods in place of statistics (Aristigueta and Raffel, 2001; Horne, 2008). However, a scholarly gap remains that addresses the appropriate content of PA research method sequences, explicitly identifies what is taught, and articulates how to develop DH and data skills within these courses. The following sections discuss how data science and data literacy provide principles essential to addressing the data skills gap but are inadequate in isolation.
Data science
Data science—the extraction of knowledge and insight from raw data (Provost and Fawcett, 2013) culminating in a data product (Cao, 2017)—is the interdisciplinary study of data (Cao, 2017), enabled by the growth of computational power over the last few decades. By combining computational skills and statistical theory (Cleveland, 2001; Donoho, 2017), data scientists capture, curate, and analyze data (Provost and Fawcett, 2013) that they could not process using previous generations of information technology. The primary feature distinguishing data science from statistics is “computing with data” (Cleveland, 2001). Increases in computational power enabled the analysis of non-structured data such as text, photos, video, and sound (Donoho, 2017), new forms of data visualization (Bell et al., 2009), and data products powered by advances in predictive analytics (Cao, 2017).
The purpose of data science is to enable new forms of scientific discovery (Bell et al., 2009; Mergel, 2016), actionable knowledge (Dorr et al., 2015), and organizational learning (Jennex and Bartczak, 2013). These goals are reached through a data product—a tangible deliverable driven or enabled by data (Cao, 2017). Data products can range from software applications and decision-support dashboards to traditional deliverables like policy reports and program evaluations.
Although some view data science solely as an analytical domain (Hernán et al., 2019), the broader discipline is engaged with the process required to turn data into insight (Provost and Fawcett, 2013; Donoho, 2017). Computing enables the capture of massive amounts of real-time data in previously unavailable formats. Once captured, data are curated through validation and archiving processes. Only after curation can they be analyzed to extract value. Donoho (2017) outlines the six greater data science activities encompassing the scope of data science: (1) data gathering, preparation, and exploration; (2) data representation and transformation; (3) computing with data; (4) visualization and presentation; (5) modeling; and (6) science about data science. These activities emphasize applied data scientists' interdisciplinary and computationally intensive skillset and are the best examples of a data science skills framework.
Data literacy
Although the sophistication of data science can be intimidating, data literacy offers an accessible, but limited approach to data skill acquisition. Broadly, data literacy is the ability to comprehend and utilize data to improve and inform decisions (Mandinach and Gummer, 2013). More specifically, Ridsdale et al. (2015) outline five knowledge areas of data literacy from a systematic literature review: conceptual understanding, collection, management, evaluation, and organizational application. An educational approach grounded in data literacy emphasizes the development of non-analytical data skills (Overton and Kleinschmit, 2021). In contrast, data science education emphasizes advanced analytical methodologies at the expense of non-analytical data skills.
Unlike data science that assumes a level of skill sophistication, the skills that make an individual data literate change across disciplines (Carlson and Johnston, 2015; Overton and Kleinschmit, 2021). The skills required in the private sector differ from those needed in the public sector. Consequently, subfields within public affairs require specific skills grounded in the problems and data products of each subfield. Data literacy is context-specific and can be anchored to the needs of public organizations.
The Data Science Literacy Framework
Data science and data literacy are individually flawed as guides for data skill development. Data science emphasizes a broad range of computational and statistical skills used to actualize a data product. Its technical sophistication prevents it from being widely applicable or accessible to MPA students. Data literacy emphasizes non-analytical skills taught at a variety of sophistication levels and customized for the specific needs of a discipline. Yet, it lacks data science’s emphasis on computational skills and data products necessary to guide systematic skill development. Both approaches lack overarching or systematic goals and organizing principles, preventing easy identification of relevant skills. A framework is needed that synthesizes these approaches to guide the teaching of data skills in the public sector.
The DSLF is a framework that is adaptable to the different needs of practitioners because it grounds the identification and breadth of data skills in a field agnostic sequence of discrete, non-overlapping data tasks that turn unquantified phenomena into a data product called the Data Task domain (Overton and Kleinschmit, 2021). It synthesizes (1) data science and data literacy approaches to skill development and (2) relevant data skills from data science, data literacy, and statistical pedagogy scholarship but is not limited to any specific substantive area. Since there is a lack of PA-specific scholarship identifying data skills most relevant to public managers, the competencies and skills identified in the DSLF represent competencies in data science, applied statistics, and data literacy that are likely beneficial for public managers. Still, their efficacy in the public sector lacks definitive empirical support. Therefore, the skills and competencies in the DSLF are data skills that are probably valuable to practitioners, but additional study is required to confirm the value of data skills to MPA students and PA professionals. Further, the sequence of data tasks contextualizes the relevance of data skills within the data science process and focuses skill development on a predominant goal—creating a data product. Centering skill development on the data tasks required to create a data product provides educators the flexibility to determine the appropriate sophistication levels of essential data skills.
The DSLF emphasizes practical data skills needed to actualize a data product over the development of traditional inferential statistical skills reflecting the larger trends in statistical and data science pedagogy (Baumer, 2015; Cobb, 2015; Kaplan, 2018). Non-analytical data tasks that precede and follow an analysis are crucial because they ultimately determine the quality of an analysis and results, which influences decisions. The reprioritization of skill development, including an emphasis on computational skills, is needed to prepare public servants for an increasingly data-driven public sector.
PA programs must develop a student’s ability to think with data and develop DH. Data skill development around data tasks and a data product supports DH by contextualizing data skills in a broader framework. DH are developed through experience, which allows students to gain an intuitive understanding of how one data task affects other data tasks. By organizing data skills around data tasks, instructors can identify and target different steps of the data science process to help students gain proficiency. Even limited exposure to data skills can be put into the context of the broader sequence of data tasks allowing for the development of broader DH from narrow data-skill experience. For example, suppose an intern collects and cleans census data passed to a manager for a report. In that case, the intern with the broadest DH will most likely identify missing data and data structure issues before the project progresses.
The DSLF categorizes data skills into four domains: one task-oriented domain and three support-oriented domains. The Data Task domain organizes skills into seven discrete steps needed to turn real-world phenomena into insight. The three support-oriented domains—Computation, Statistical, and Application and Systems Integration Knowledge (ASIK)—organize skills that interface with (1) two or more steps in the Data Task domain or (2) the other macro-domains. For example, the computational skill of programming enables and informs multiple steps in the Data Task domain and cannot be categorized as a discrete data task. Figure 1 lists all DSLF domains and competencies. DSLF domains and competencies.
Proposed DSLF modules.
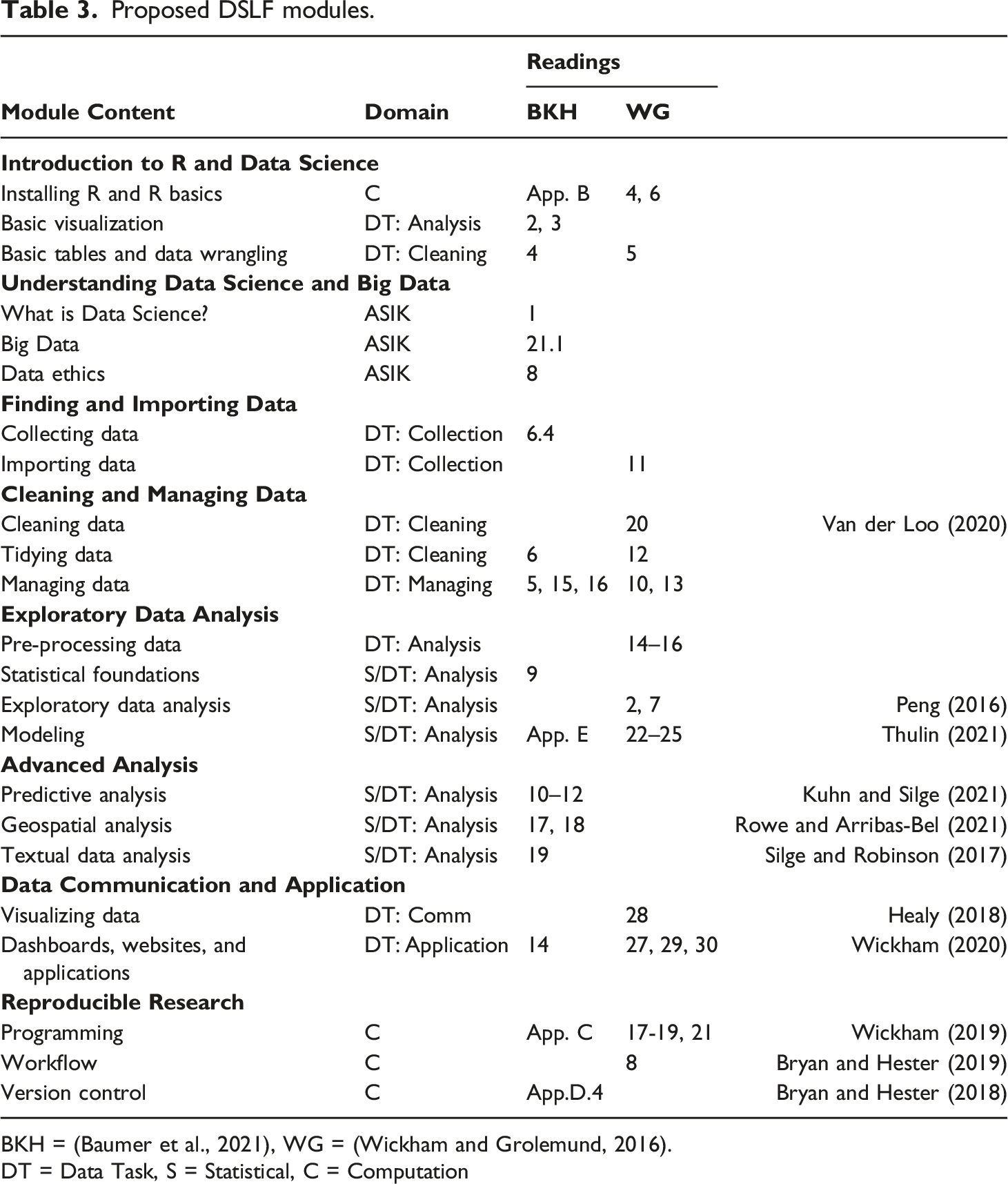
BKH = (Baumer et al., 2021), WG = (Wickham and Grolemund, 2016).
DT = Data Task, S = Statistical, C = Computation
Data Task Domain
The Data Task domain comprises seven discrete tasks—data generation, collection, cleaning, management, analysis, communication, and application. This sequencing represents the capture, curation, analysis, and production of a data product, starting with quantifying real-world phenomena. The first step is generation, where real-world phenomena are quantified into captured data or digital exhaust. Knowing how and why data are generated is a routinely overlooked aspect of data science and essential for ensuring instrument design and validity.
Data collection is the process of identifying, locating, and acquiring data. The explosion of Big Data has made secondary data widely available in easily accessible data repositories and understanding how to find and extract resources from these repositories is crucial. Beyond repositories, data can be collected using various methods, including APIs, web scraping, point and click downloads, and compilation of individual observations into a single collection of machine-readable formats.
Cleaning is the process of quality controlling and organizing raw data to create a “tidy” dataset. Quality control is conducted to identify, flag, and remove problematic errors or artifacts in addition to addressing outliers (Zhu et al., 2013). Tidying is a data preparation guideline to help structure data to aid in the ease of visualization, transformation, and analysis, where each variable is a unique column, each observation is a unique row, and each type of observable unit forms a table (Wickham, 2014). Data cleaning is a time-consuming task for practitioners, so much so that it often comprises the primary responsibility of those in data roles (Buttrey and Whitaker, 2017).
Data management in the DSLF framework involves three broad tasks: data description, curation, and relating. Description involves appropriately assigning formats to variables, data dictionaries, and generating metadata. Curation is the cataloging and storage of data to promote security, privacy, and reusability. Relating refers to merging disparate clean datasets through some standard key or variable (Wickham and Grolemund, 2016). Management results in the secure storage of structured and organized information in electronic repositories known as databases, which are contextualized through the addition of metadata to data.
The analysis step involves pre-analysis data transformation, data analysis, and evaluation of models. It is not limited to inferential analysis but also considers exploratory, optimization, and mechanistic calculation, to name a few. The DSLF conceptualizes analysis as a broader task than traditional research methods courses that focus on inferential statistics. The analysis task concludes with the interpretation of the results.
After an analysis, the results then must be communicated effectively and accurately to others. Communication of data requires synthesis and distillation of complex relationships with precision and clarity. Data’s oral and verbal communication are increasingly gaining recognition as vital skills (Ridsdale et al., 2015; Diggle, 2015). Visualization is a device for communicating results extracted from data, enhancing understanding, increasing engagement, and improving co-production (Metze, 2020). Data visualization for communication requires knowledge of statistics, graphic design, typography, and color theory.
The final step, Application, refers to the completion of a data product. Data products include software applications, dashboards, and policy reports. They can be built from a variety of this framework’s previous steps, though most integrate models from the analysis phase into communication elements like infographics in program evaluation reports. Identifying a field’s data products will guide the identification of relevant data skills.
Computational knowledge
Working with data requires a foundation of computational skills (Nolan and Lang, 2010) aided by computer hardware, software, and computational thinking that evolves with advancements in technology (Overton and Kleinschmit, 2021). Unlike the Data Task domain, computational competencies are not discrete skills that fit into any single data task but facilitate every step in the domain. The primary competencies include programming, literate programming, workflow, and version control using a software platform like R or Python. 1
Programming is “the ability to write and manipulate computer code,” and in the context of data science, involves understanding the syntax of a programming language (Winslow, 1996). Programming can significantly improve analysis by automating data collection, visualization, and dissemination. Query languages, such as SQL, improve data collection, cleaning, and management and assist with scaling analysis for computationally intensive datasets. Literate programming combines “plain English” descriptions with chunks of code in a programming language (Knuth, 1984). Reproducible research is an extension of literate programming, where charts, tables, and visuals are interspersed with the code that generates the analysis. Workflow refers to both organization of digital projects through macro-file management systems and code organization within a script (Stodden and Miguez, 2014). Version control is a digitized way of tracking changes to code and programs during software development (Cetinkaya-Rundel and Ellison, 2020) to improve collaboration and transparency of scripted analyses.
Statistical knowledge
The rise of data science has undeniably changed the practice and pedagogy of statistics (Donoho, 2017). Although the traditional emphasis on statistical methods is ill-suited for a data-rich world, statistical thinking provides a philosophy for identifying and understanding uncertainty and data structure (Diggle, 2015; Weihs and Ickstadt, 2018). The growth of computing power and subsequently data science has shifted the burden of calculation from statistics to computers (Cobb 2015; Wild and Pfannkuch, 1999), yet statistics remains relevant through statistical thinking that informs multiple data tasks and the whole of the inquiry process (Diggle, 2015).
The statistics domain contains two competencies: inquiry and modeling. Inquiry uses statistical thinking from “problem formulation to conclusions” on data to model uncertainty and understand the world (Wild and Pfannkuch, 1999: p.223). Modeling skills and competencies include mathematically representing, describing, predicting, and explaining real-world phenomena divided into two categories: stochastic and predictive modeling (Donoho, 2017). Stochastic modeling refers to inferential statistical methods where the data generating process is known or assumed (Donoho, 2017; Diggle, 2015). Predictive or algorithmic modeling aims to maximize prediction over inference using supervised or unsupervised methods. Predictive modeling can also be integrated with traditional public service tools like decision trees manifesting into new techniques that improve their reliability, such as random forest models.
Applications and system integration knowledge
The ASIK domain complements the computational and statistical knowledge underlying data science but is independently necessary to develop public data science as its own field of practice. Unlike generalized, context-agnostic approaches to data skill development, PA will benefit from delineating its own body of scholarship that meshes data technology and common public agency tasks. Data science in the public sector is practical beyond traditional managerial decision-making and strategic policy analysis. To be effective public data users, administrators need broader knowledge about data, computing, and its application (Banerjee et al., 2015). The emergence of city information offices and chief data officers facilitates everyday operational uses of data in public organizations (Young, 2020). Tools like dashboards can integrate data streams across public organizations, improve oversight, and provide a comprehensive picture of organizational performance. They can also be implemented at a smaller scale within organizations to improve public service delivery (Rogge et al., 2017).
ASIK constitutes the skills and knowledge required to apply and integrate data science to public agencies' operational environment and data. The public data sphere invites an understanding of data’s legal and ethical implications, cybersecurity risks and mitigation strategies, government accountability facilitated through open-data policies, and the integration of information systems in policy and administrative decision-making. The successful utilization of data science hinges on understanding public problems and how data science mitigates or exacerbates these problems. The “publicness” of PA necessitates understanding how data affects agency ethics, statutory compliance, budgeting and procurement, data security, privacy, and civic engagement. Additionally, ASIK involves modernizing existing practices within administrative agencies, such as performance measurement and program evaluation, to reflect efficiencies gained from data skills. However, these competencies are not exhaustive, unlike the previous DSLF domains. This ambiguity is purposeful as PA has not developed enough PA-specific data science skills and concerns to identify the range of potential ASIK subcategories, but this is an area of future inquiry that will be in part guided by the emergence of other analytics and informatics-driven subfields.
Methods
To study what data skills are currently taught in MPA methods curricula, syllabi from core research method courses were reviewed. We collected a sample of 52 syllabi from 31 MPA programs from the Spring 2019 and Fall 2020 semesters using a request for syllabi issued to the Journal of Public Affairs Education listserv and through a similar request via the journal's Twitter account. Course topics were determined from the manifest content in the description of weekly topics in syllabi schedules. Weekly content was also assigned a topic category within a DSLF domain area, if appropriate, to provide further detail on course content coverage. By assessing course content covered each week, we approximate what topics were covered and how much time was spent on each. In addition, we recorded the required statistical software to understand if computational domain competencies could be taught given software restrictions.
Weekly course content topics were recorded, and DSLF domains and specific topics within a domain were coded a 1 if the domain was covered, 0 otherwise. We deductively developed a hierarchical classification coding scheme (i.e., the domains and associated topics discussed previously while outlining the DSLF). Course titles and, if available, descriptions of weekly topics were coded into domains. If the information in the syllabus was too vague to extract content topics, the assigned readings were referenced. Weeks that did not cover course material like introductory, test, or project presentation weeks were not recorded.
Fourteen programs required two or more methods courses, while 17 programs required only one. We received syllabi from two separate instructors across five different courses and calculated the average value of the summary statistics for our analysis. Of the sampled programs, nine are housed in Carnegie R1 institutions, six in Carnegie R2 institutions, and sixteen are housed in institutions that are not Carnegie ranked.
One drawback of convenience sampling methods like the one used in this study is that the sample is not representative of the population. To evaluate the sample’s representativeness, we created bootstrap confidence intervals of program rankings from our sample and the total population of 2022 US News Public Affairs program rankings. For our sample, the average program ranking was ranked 111 (one program was not ranked), and our bootstrap confidence interval was 85 to 139, whereas the total population’s bootstrap confidence interval was 128 to 146. This result suggests that our sample is skewed towards higher-ranking programs compared to the larger population of PA programs. Though we cannot say with any absolute certainty how this biases the results, it is reasonable to assume that higher ranking programs are more likely to teach courses reflecting innovative curriculum due to increased access to resources and leading research faculty. If our results are biased, they are most likely biased towards overestimating the current level of data science skills taught in research method courses.
Our approach has limitations that are important to outline before the presentation of results. First, we did not consider avenues outside of research method courses for data skill acquisition in MPA programs. These skills may be taught or supplemented in electives or possibly other core classes. We focused our analysis on research method sequences as (1) these courses are a logical home for these skills, (2) we could make a reasonable comparison across programs because of the universal use of research methods courses, and (3) data science and statistical pedagogy suggest approaching research methods education differently. Second, we only include MPA programs located in the United States. The findings are likely to apply to programs outside the United States because research methods training is not as country specific as other areas of public administration education. Still, our analysis cannot support this claim with a high level of certainty.
Results
Results.
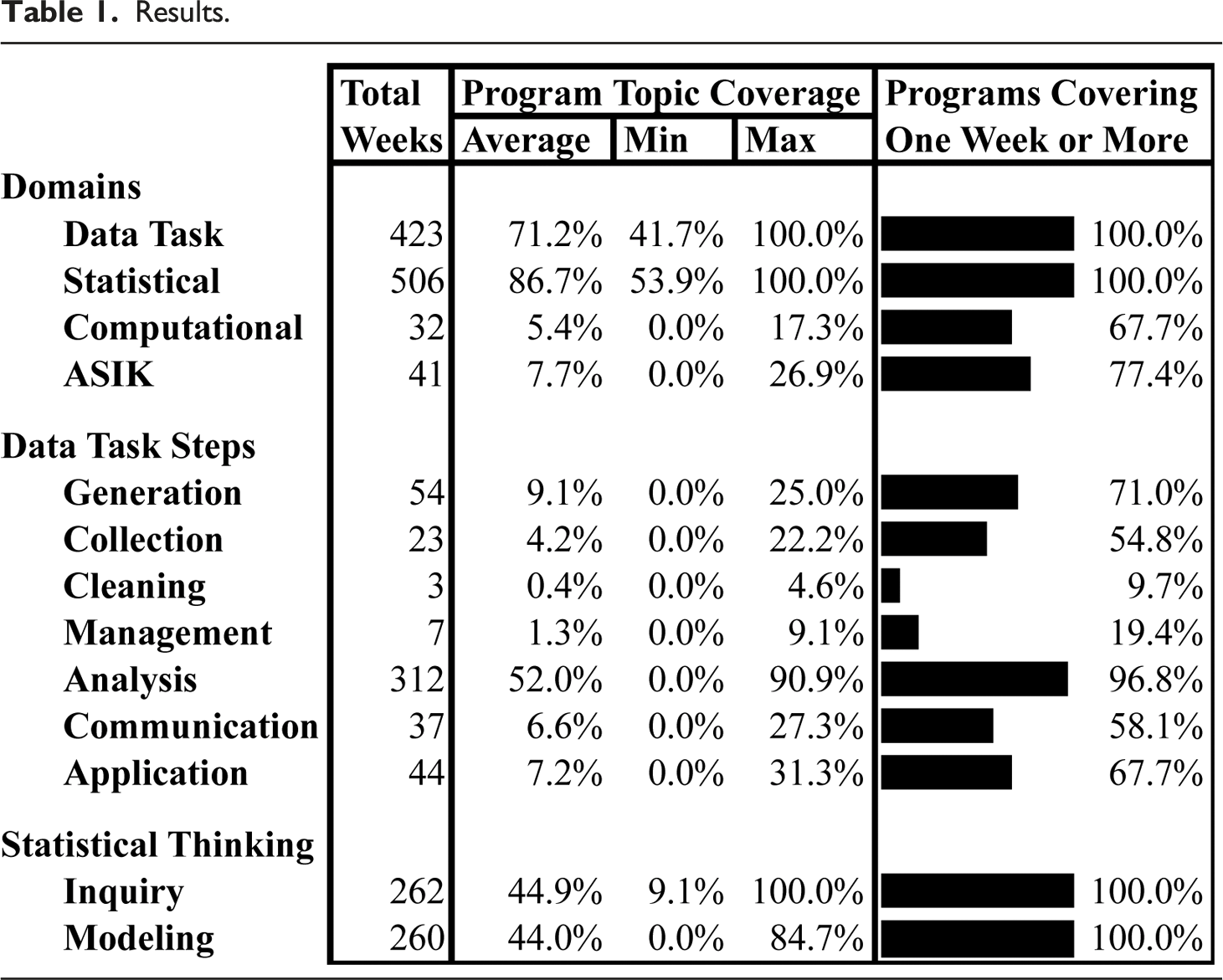
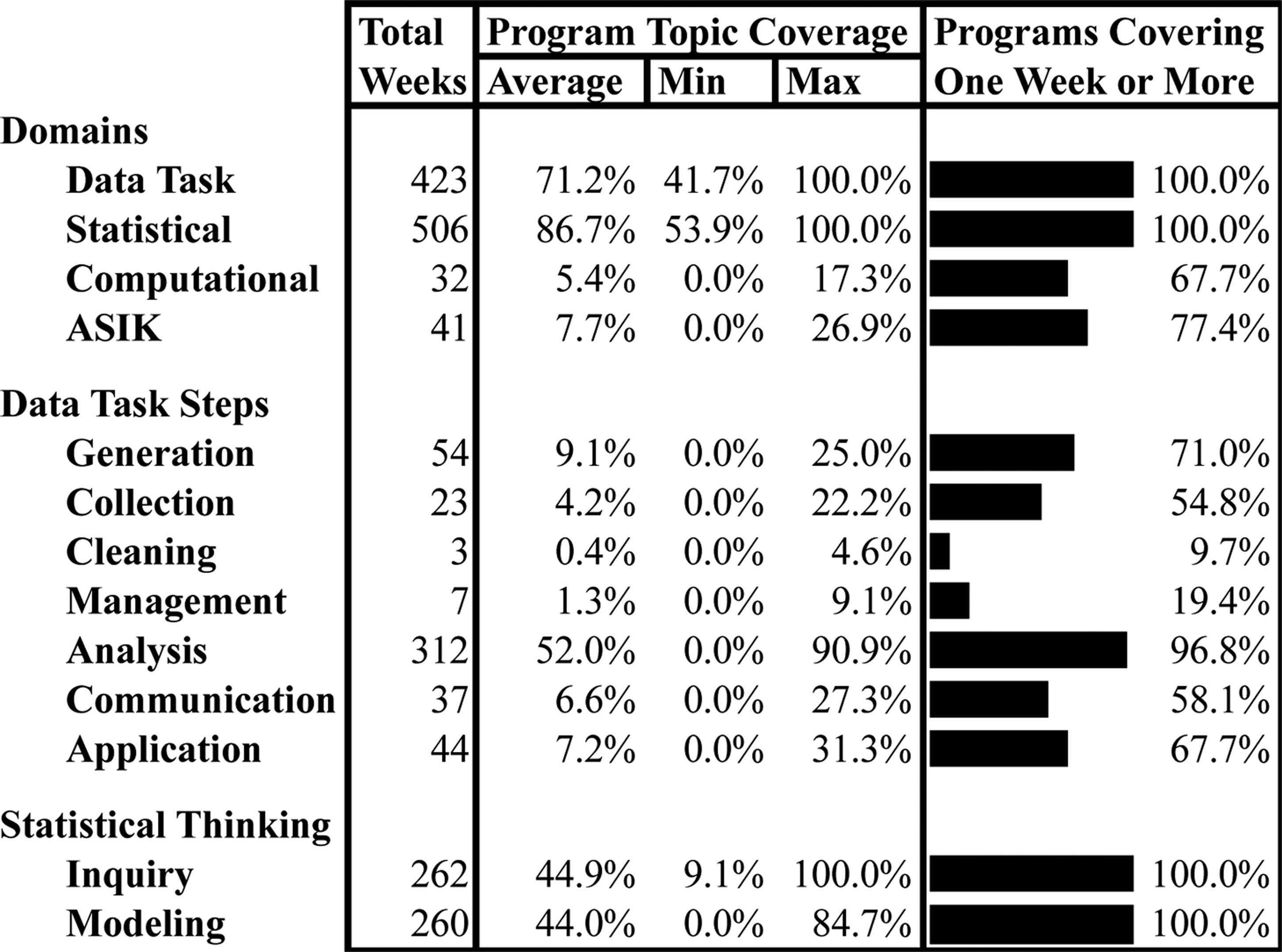
Data Analysis saw a wide range of subject coverage and included data transformation (8 weeks), descriptive analysis (88 weeks), basic analysis (104 weeks), regression (69 weeks), and 54 weeks of other types of analyses, which were categorized using Rethemeyer and Helbig’s (2005) classification of statistical skills. Other analysis tasks included qualitative data analysis, time series, maximum likelihood analysis, factor analysis, and managerial methods like cost-benefit analysis. Data Generation, which comprised the second largest Data Task topic, were entirely survey design and qualitative method content such as conducting interviews and focus groups. Data Application topics were the next most frequent topic covered. Twenty-four weeks covered writing basic and applied research papers, fourteen covered policy analysis/program evaluation, and seven were spent covering performance management and decision-making from data. The next most frequent Data Task topic, Data Communication, covered writing (16 weeks) and visualizing (18 weeks) data. Twenty-three total weeks were spent on Data Collection and addressed where and how to find secondary data such as census data. Finally, Data Management and Cleaning were covered the fewest times out of our sample. Some of this is likely a biproduct of what the DSLF considers data cleaning and management. These tasks seldom intersect with traditional approaches to statistical analysis as they are primarily aspects of data curation.
Statistical domain tasks were coded into one of two categories—statistical inquiry or statistical modeling. Research method sequences taught a statistical inquiry or modeling topic in 45% and 44% of weeks covering content accordingly. Of the weeks coded as covering a statistical inquiry topic, programs spent an average of 7% of weeks covering quantitative, 5% qualitative, and 1% mixed methods approaches to inquiry. The other statistical inquiry topics were general research design topics and not specific to quantitative or qualitative inquiry.
The computational domain is largely absent in the research methods curriculum. Most computational topics consisted of introductions to software and coding and manipulating variables. Interestingly, Big Data was a featured subject for 4 weeks across three programs, suggesting that the topic is growing more salient in research method curriculum.
Software.


Finally, the ASIK domain constituted a limited amount of attention in research method sequences and primarily constituted research ethics (76% of all ASIK weeks). Four different courses across ten total weeks covered research in specific public policy contexts, though seven of the ten weeks occurred in one course.
Discussion
The purpose of this article is to identify the data skills currently taught and make recommendations about potential topics to consider adding, removing, emphasizing, and deemphasizing in MPA research method curricula. Our analysis suggests that most MPA research method courses cover traditional statistical inference topics focusing on inferential statistical methodology, research design, and writing research papers. However, they neglect important DSLF competencies such as computational skills, data cleaning, management, visualization for communication, and non-inferential analytical methodologies. Simply put, research methods courses are not covering data skills from either data science or data literacy as outlined in the DSLF. We cannot say with certainty that either the current traditional inferential or DSLF research method curricula develops desired data skills for PA practitioners because no direct studies assess either’s importance to practitioners. The DSLF outlines an array of data skills that could be—and likely are—relevant to PA professionals and presents an alternative to traditional inferential topics. Using the DSLF as a guide, the following MPA research methods curricular revisions should be considered. (1) Reconsider the amount of time devoted to traditional inferential statistical methods.
Our findings suggest that traditional inferential statistics are the primary analytical methodology taught to MPA students in their research methods courses. Traditional inferential techniques are useful but applied statistical pedagogy scholarship suggests that the methods taught in MPA programs do not match the current data-rich and computation-intensive environment (Cobb, 2015). These new methods place a greater premium on using large samples, messy data, multivariate modeling and analysis, data visualization, and simulation over common inferential topics like hypothesis testing and t-tests (Cobb, 2015; Kaplan, 2018). By deemphasizing traditional inferential topics, instructors can include modules on non-inferential analytical methods that are likely more relevant to public sector practitioners than inferential statistics such as predictive analytics that dominate data science programs (Asamoah et al., 2020; Donoho, 2017), spatial analysis (Ferrandino, 2014), program evaluation, time series, textual, exploratory, and managerial science in their research method courses (Aristigueta and Raffel, 2001; Horne, 2008). (2) Reconsider the amount of time devoted to research design and research papers.
Instructors in our sample spent a considerable amount of time covering research design (averaging 45% of all topics covered in a program) and research papers (54.5% of all Data Task Application content). Formulating a research project helps students become informed consumers of research (Fitzpatrick 2000), guides analytical inquiry, and prepares students for doctoral programs. However, there have been calls to decrease the time spent on research design topics (Desai, 2008) because Masters-level alumni working in government do not use and value research design skills (Henderson and Chetkovich, 2014).
The current emphasis on research design and research papers in MPA research methods curricula comes at the expense of alternative approaches to inquiry and data products that are likely more germane for practitioners. First, instructors wanting to devote less instructional time to research design can consider using simpler frameworks to guide inquiry like the problem, plan, data, analysis, and conclusion approach (Wild and Pfannkuch, 1999). Second, data products like program evaluations, memos, white papers, and dashboards should be strongly considered in lieu of research papers. (3) Consider devoting more time to teaching data collection, cleaning, and management.
Our results indicate that little time, if any, was dedicated to data cleaning, management, and teaching newer data collection methods such as web-scraping or using APIs. Real-world analysis works with messy data requiring these skills (Bryan and Wickham, 2017). Using messy data forces students to clean and manage that data, providing opportunities to address problems often encountered on the job. Embedding these skills early in a methods curriculum and emphasizing them often gives students experience and confidence, ultimately helping them develop DH (Baumer, 2015). (4) Consider devoting more time to teaching data visualization for communication.
Data visualization is essential for developing DH (Finzer, 2013), considered a crucial part of modern statistics education (Kaplan, 2018), valued as a useful skill by MPA graduates (Henderson and Chetkovich, 2014), and a powerful tool for communicating insights that can increase public participation and engagement (Metze, 2020). Though 14 different programs included data visualization content, this content primarily supported exploratory visualization rather than visualization for communication. One useful approach is introducing visualization early in the research method curriculum (Kaplan, 2018; Wickham and Grolemund, 2016). Providing this exposure will help students understand the information that can be derived from data, the value of using statistical software, and most importantly, it gives them the skills to build on throughout the research method curriculum and into their careers (Çetinkaya-Rundel and Ellison, 2020). Visualization can also be extended past the statistical realm, including geospatial analysis. (5) Consider devoting more time to developing student computational skills using R or Python.
The computational skills taught in our sample were basic introductions to software, data transformation, and exploratory visualization. Computational skills facilitate data collection, cleaning, management, analysis, visualization, and enable new applications like dashboards and mobile apps. Plus, computational skills permit the collection and analysis of unique data forms such as spatial, text, audio, and visual.
Most programs used Excel as their preferred software. Excel is a useful and ubiquitous program, but one that has substantial limitations. In fact, using Excel during the pandemic resulted in avoidable data problems (Tesi, 2020). A current best practice is to assign an open-source (i.e., free) software platform, either R or Python (Asamoah et al., 2020) that functions both as a statistical analysis platform and integrated programming environment. Teaching a few lines of code is easier to communicate than the equivalent in a point-and-click program like SPSS. These open-source programs also facilitate a range of computational skill development that Excel does not. The primary advantage of using R or Python is not that it enables new types of analysis (which they do) or visualizations (they do that too), but that data cleaning, management, and analysis become reproducible. Data cleaning and management with scripts can be verified and even shared with the public to enhance transparency and provide options for co-production. The advantages are numerous and something research method instructors should strongly consider. (6) Consider devoting additional time to qualitative data generation, data applications in the public sector, and data ethics.
Using the DSLF as a guide for evaluating the method curriculum in MPA programs suggests that aspects of our field’s curricular approach should be applauded. There is a great deal of focus on data generation—mostly from qualitative research content—and collection. However, both subjects can and should be modernized to include more computationally intensive methods. In addition, data application in the form of research papers, performance measurement systems, and program evaluations is a core piece of many courses. The inclusion of data applications puts research topics in the context of an overarching data product, which ultimately helps develop DH that potentially connects data generation (beginning), application (end), and the steps in between. Finally, most programs cover research ethics—a fundamental concern of the digital age moving forward. Research ethics can and should be expanded to consider data ethics emphasizing data governance, privacy (Mergel, 2016), ownership (Hand, 2018), and behavioral design (Verhulsdonck and Shalamova, 2020).
Conclusion
The growth of data and computational power have the potential to revolutionize the public sector. To leverage these resources, the field must address the data skills gap in the profession, starting with critically evaluating the relevance of our research method curriculum. Our research indicates that most content in research method classes in US-based MPA programs emphasizes traditional research methods topics and inferential statistics. Unfortunately, this content is unlikely to prepare MPA students for the challenges of the digital age and does not aid in the development of DH. The DSLF provides a framework for understanding the breadth of data science and literacy skills and identifying competencies that should be considered in research method curricula to promote DH. Our analysis also highlights the absence of empirical PA studies identifying the data skills public managers need. Future research is required to identify the most advantageous data science skills for professional public managers, optimal training paths to acquire these skills and should examine research methods courses in MPA programs based outside of the US.
MPA programs will face challenges as they modernize their methods curriculum. One of the most significant issues is a lack of faculty and instructors with the knowledge and skillset to teach computational and data science skills. Instructors will need time to develop courses and data skills appropriate for MPA programs. One important insight from the DSLF is that faculty and students do not need to become experts of sophisticated methods because there is value in “basic” skills and competencies across all four domains. These skills also need to be taught to the current public sector workforce. Public organizations are unlikely to realize what a data science-literate workforce can accomplish if leaders lack data science literacy.
The rapid evolution of information technology presents many challenges to public agencies. A concerted effort to develop data skills provides is a clear path to building a foundation for addressing the challenges of the digital age. Public sector organizations need a workforce that can harness data for the public good. The DSLF guides what skills and competencies are needed.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Note
Proposed Modules
We have designed example modules using the DSLF. This list is not intended to be exhaustive or a complete research methods syllabus. However, it is intended to supplement current research method courses. The readings mostly come from Baumer et al. (2021) and Wickham and Grolemund (2016), but three other resources are needed, and eight additional books are intended for instructors. All readings are free and available online.