
Abstract
Many children with autism spectrum disorder (ASD) do not have symbolic play skills. One type of symbolic play involves playing with imaginary objects, in which a child displays play actions without actual objects. The purpose of this study was to evaluate the effects of video modeling on the acquisition, maintenance, and generalization of playing with imaginary objects in young children with ASD. Three male Chinese children (aged 4–5 years) with ASD participated in this study. A multiple-probe across three behaviors design was used. The results indicated that video modeling was effective in establishing and maintaining target symbolic play behaviors for the three children. Generalization to untaught imaginary play activities occurred in all three children.
Play constitutes most daily activities in early childhood. Symbolic play involves play behaviors that are not consistent with reality in some way and generally emerges at approximately 18 months of age in typically developing children (McCune, 2010). The ability to demonstrate symbolic play is considered one of the most important milestones in child development (Copple et al., 2009) due to its correlation to the development of language (McCune, 1995; Orr & Geva, 2015) and adaptive behavior in late childhood (Weinberger & Starkey, 1994).
With core deficits in repetitive behavior patterns or restricted activities, many children with autism spectrum disorder (ASD) often engage in inappropriate toy play and do not demonstrate symbolic play (Baron-Cohen, 1987; Charman et al., 1997; Jarrold, 2003). The lack of symbolic play skills may limit a child’s opportunities to engage in interactive activities with other children, potentially interfering with developing adequate social relations in childhood or limiting the educational benefits in inclusive settings (Barton & Pavilanis, 2012; Schreibman & Charlo-Christy, 1998). Despite the complexity involved in symbolic play, children with ASD can acquire such skills through systematically planned intervention (Barton, 2015; Kasari et al., 2006; Lee, Feng, et al., 2019a; Lee et al., 2019b; MacManus et al., 2015; Stahmer, 1995).
The play activities observed in typically developing children are diverse and often complex. Leslie (1987) distinguished functional play and symbolic play. Functional play refers to playing with an object with its typical function while symbolic play involves playing with an object with an unusual function, assigning absent properties to that object, and imagining a missing object. Barton (2010) further differentiated functional play with pretense (e.g., pretending to drink water from an empty cup) and functional play without pretense (e.g., rolling a ball). Pretend play and symbolic play are sometimes used interchangeably (e.g., Lang et al., 2009). In the present study, symbolic play is used specifically to refer to three types of play activities, including object substitutions, assigning absent attributes, and imaginary objects (Barton & Wolery, 2008; Leslie, 1987). Although children often engage in multiple types of play activities at once, each type of symbolic play involves unique behavioral processes and requires a different set of skills in a child’s repertoire to engage in such play activities. Therefore, it is necessary to analyze the behavioral processes and develop specific intervention procedures based on the analysis. This approach will not only increase the likelihood of success for a given intervention but also provide guidance for practitioners to customize intervention plans based on each child’s skill sets and specific deficits in play behaviors.
Research has shown that children with ASD and other developmental disabilities can acquire symbolic play skills via naturalistic intervention (Stahmer, 1995), discrete trials combined with naturalistic instructions (Kasari et al., 2006), systematic prompts (Barton, 2015; Qiu et al., 2019), and intraverbal training (Lee, Feng, et al., 2019a; Lee et al., 2019b). However, Stahmer (1995) did not describe enough procedural details to allow replications. In the studies conducted by Barton (2015), Kasari et al. (2006), and Qiu et al. (2019), the results did not specify which type of symbolic play behaviors were improved by the given intervention. Therefore, it remains unknown whether the naturalistic strategies and systematic prompts used in their studies were effective in increasing all types of symbolic play or only a particular type of play behavior. As discussed, each type of symbolic play is complex and requires specific instructions. It is also necessary to assess existing play skills in a child’s repertoire to determine his/her strengths and weaknesses for individualized intervention. Developing specific procedures for each type of symbolic play will also facilitate replications of interventions in various settings.
Lee et al. (2019a) analyzed the behavioral processes involved in object-substitution symbolic play and used intraverbal training with picture prompts that effectively increased this type of symbolic play behavior with the emergence of novel responses in young children with ASD. The intraverbal training consisted of the instructor presenting an object and asking the child to demonstrate a play action that was not the object’s typical function. However, generalization of object-substitution symbolic play using untaught objects were not evaluated. Lee et al. (2019b) taught children with ASD to play with imaginary objects using an intraverbal training procedure incorporated with the prompt hierarchy, consisting of instructor modeling, verbal instructions, and physical assistance. In their procedure, the instructor suggested a play activity with guided questions but did not use any actual objects for the play activity (e.g., “Let’s draw some pictures! I have a pen and paper for you (no real objects),” “What are you doing?” “What are you drawing?”). The results indicated that play responses for the target imaginary play activities were increased, but generalization to untaught play activities only occurred in one of the three children. Both the studies included play skills assessments for each type of symbolic play behavior and indicated that functional play skills were required for the acquisition of symbolic play skills.
Playing with imaginary objects refers to the demonstration of play activities without using any actual objects (Barton, 2010; Barton & Wolery, 2008; Leslie, 1987). Such play activities are similar to what we see in pantomime. The behavioral processes involved in playing with imaginary objects may be related to the notion of conditioned seeing (Skinner, 1953, 1957), in which the occurrence of a particular behavior in the absence of a visual stimulus is a result of the association between that visual stimulus and the behavior in the past. Skinner suggested that the responses resulting from conditioned seeing are potentially respondent in nature – for example, when a person hears the word “snake” and a startle response is elicited even though a snake is not present. Further, Lee et al. (2019b) postulated that the notion of conditioned seeing observed in children’s acquisition of naming (Horne & Lowe, 1996) closely resemble children’s play activities involving imaginary objects. For example, the phenomenon of conditioned seeing is demonstrated when a child with naming capacity emits a tact response (e.g., swimming) along with its associated responses (e.g., a swimming action) without seeing the visual stimulus (e.g., a swimming pool). Such demonstrations of conditioned seeing are similar to what is observed in children’s playing activities with imaginary objects. That said, children’s play activities come from their experiences and learning that has occurred in their environment. Further, Shanman (2013) measured conditioned seeing via drawing responses and found a correlation between conditioned seeing and naming, suggesting that conditioned seeing can be acquired via the process of operant conditioning. As conditioned seeing is closely related to imagining objects in play behavior, it is logical to present relevant visual stimuli in the intervention.
A relevant type of visual stimuli is video modeling, an intervention option involving visual and audio presentations. Video modeling is an evidence-based practice that effectively teaches complex behaviors to individuals with ASD without the need for external reinforcement to maintain participation (National Autism Center, 2010; Wong et al., 2015). Although research has documented that video modeling is effective in increasing pretend play in children with ASD, the pretend play activities involving verbal statements and play actions may or may not contain the symbolic play activities referred to in this study. For example, the play scenarios in Boudreau and D’Entremont (2010) included symbolic play activities (e.g., taking a toy puppy and saying, “puppy sick”) and functional play activities with or without pretense (e.g., driving a truck, “Vroom;” making the rock fall, “crashhhhh”). Similar play activities with miniature figurines are effectively taught using video modeling (Dueñas et al., 2019; Lydon et al., 2011; MacManus et al., 2015), and yet, improvements in specific types of symbolic play behavior are not reported. Thus, it is not clear whether video modeling increases functional play, a specific type of symbolic play, or all types of symbolic play in children with ASD.
Previous research has demonstrated that video modeling promotes generalized play behaviors across stimuli, settings, and persons (Boudreau & D’Entremont, 2010; Charlop-Christy et al., 2000; Dueñas et al., 2019; MacDonald et al., 2005, 2009). However, research also indicates that after video modeling intervention, generalization of play skills to new toys was limited to stimuli sharing similar physical characteristics (Paterson & Arco, 2007), and generalization to unmodeled actions or unscripted verbalizations only occurred at a low level (D’Ateno et al., 2003). Researchers further reported that generalization to novel stimuli and responses was improved when multiple exemplar training (Dupere et al., 2013) or matrix training (Dauphin et al., 2004; MacManus et al., 2015) was included along with video modeling. Therefore, it is important to consider generalization in video-based instruction by including various play actions and verbal descriptions. Additionally, assessments of readiness for video-based instruction may be conducted to ensure children’s success (Burke, 2009; MacDonald et al., 2015).
Given the importance of symbolic play in child development and limited research in interventions for specific symbolic play behavior, this study attempted to extend the literature by using video modeling to increase a specific type of symbolic play—imaginary objects—in young children with ASD. The effects of video modeling on the acquisition, maintenance, and generalization of playing with imaginary objects were evaluated. The analysis of the behavioral processes involved in such play behavior suggests the relevance of conditioned seeing. Therefore, video-based instruction presenting visual modeled actions was used in this study. Incorporating multiple exemplars with variations of the given tasks in video models is fundamental to increasing response diversity and to programming for generalization. The child was required to verbalize his/her play actions in order to increase the use of descriptive gestures and make imaginary play activities more interactive with others. The following research questions are addressed: (a) to what extent does video modeling increase the acquisition of target imaginary play activities? (b) to what extent does video modeling maintain the acquired imaginary play activities? and (c) to what extent does video modeling increase the generalization to untaught imaginary play activities for the three children with ASD?
Method
Participants
To be included in this study, a participant must (a) have an ASD diagnosis; (b) be aged between 4 and 7 years; (c) have play-related goals in his/her curricular plan; (d) have a language level above 18 months, assessed by the Chinese version of the Verbal Behavior Milestones Assessment and Placement Program (VB-MAPP; Huang & Li, 2017; Sundberg, 2008); (e) have readiness for video-based instruction as suggested by Burke (2009) and MacDonald et al. (2015); and (f) have functional play skills but did not symbolic play, as assessed with the Developmentally-based Behavior Assessment for Children with Autism (DBACA; Feng & Sun, 2017). The participants were recruited from an inclusive preschool in northeast China. Based on their records, they were diagnosed with ASD by pediatricians using the criteria of the Diagnostic and Statistical Manual of Mental Disorders (DSM-5; American Psychiatric Association, 2013). The Chinese versions of the standardized assessments reported herein were validated with Chinese samples.
Cheng was a 4-year-old boy on the autism spectrum who attended the preschool full time (8 hr per day, 5 days per week). His IQ score was 93 (average intelligence), measured by the Chinese version of the Wechsler Preschool and Primary Scale of Intelligence-Revised (WPPSI-R; Wechsler, 1989; Zhang, 2009). His score on the Chinese version of the Childhood Autism Rating Scale (CARS; Li et al., 2005; Lu et al., 2004; Schopler et al., 2002) was 31, indicating mild to moderate autism symptoms. His adaptive behavior composite score, measured by the Chinese version of the Vineland Adaptive Behavior Scale-2nd edition, Parent Rating Form (VABS-II; Sparrow et al., 2005; Wei, 2016), was 83, indicating a moderately low level of adaptive functioning. Cheng’s verbal behavior skills level was between Level 2 (18–30 months) and Level 3 (30–48 months). He had relatively strong skills in tact, intraverbal skills, listener behavior, reading, and math, and relatively weak skills in mand and socialization. He could mand for preferred items/activities when they were not present; tact at least 200 common objects and actions; answer at least 25 “What” questions and at least 12 “Who” and “Where” questions; display direction-following skills in group activities; and spontaneously tact at least 10 of these items by function, feature, and class. He demonstrated generalized imitation skills involving objects after watching the videos.
Tian was 5 years old and attended the same preschool full time. His WPPSI-R IQ (score: 87) was below the normal range. His VABS-II adaptive behavior composite score was 62, indicating that his adaptive functioning was at a low level. His score on the CARS was 33, in the category of mild to moderate autism. His VB-MAPP assessment indicated that his verbal skills were also between Levels 2 and 3, except for listener behavior and socialization. He could mand for preferred items, tact more than 200 common items and actions, and responded to at least 25 “What” questions. He could follow three-step directions; select at least 25 items by function, feature, and class; count up to 5 items; read his name; and, engage in listening when being read to. He also demonstrated generalized imitation after viewing the actions shown in videos. However, he could not sit in a group without disruptive behavior for more than 5 min, although he was observed to make eye contact with other children during group activities.
Dong attended the preschool for 4 hr in the morning and received eclectic therapy for 3.5 hr in the afternoon in an early intervention center. He was 5 years old at the time of the study. His WPPSI IQ score was 73 (borderline intelligence), and his VABS-2 score was 54, indicating a low level of adaptive functioning. He had a score of 36 on the CARS, placing him in the range of mild to moderate autism. His verbal skills assessed by the VB-MAPP were between Level 2 and Level 3. He could spontaneously mand for preferred items/activities; tact at least 200 common items/actions; follow two-step directions; select at least 25 common items based on function, feature, and class; complete 25 WH-questions; sit in a group for more than 10 min; and, watch other children during group activities. However, he did not respond to or initiate interactions with his peers. He also imitated actions involving objects demonstrated in videos.
Setting and Material
Intervention sessions for Cheng and Dong were held in the living room of their homes, with their family members present in other rooms. The child and the instructor sat on the couch with a table in front of them. Intervention sessions for Tian took place in a room of the university-affiliated research center without the presence of other people. This room was approximately 3 m × 2 m × 2.5 m in size, with a table, two chairs, and a computer desk in the corner. The child and the instructor sat at the table during sessions. The generalization setting for all three children was in a carpeted playroom of the research center with toys on the shelves within the child’s reach, a table and chairs in the corner, and the presence of two to three other children and graduate students.
Video models included an 8-year-old typically developing boy and a female adult. Each instructional goal contained six to eight sequenced steps for the task, and each step was demonstrated by the two models with a pantomime action and a corresponding verbal description. In the videos, no actual object was used for instructional goals in Stage 1, and a doll was used in Stage 2. Three different versions of task analyses for each instructional goal were demonstrated across the two models to increase response variability. See Tables 1 and 2 for sample scripts and modeled pantomime actions used in Stage 1 and Stage 2 of the intervention. The instructor used a laptop computer to show the videos during sessions. Each video lasted for approximately 28 to 40 seconds. No real objects were used in the Stage 1 probe and intervention sessions; two child dolls (a boy and a girl) were used in the Stage 2 probe and intervention sessions. Additionally, four different stuffed animals (Peppa pig, a panda, a monkey, and a giraffe) were used to evaluate generalization goals in Stage 2.
Scripts for Goal 3 (cleaning) in Stage 1 Intervention.

Scripts for Goal 1 (Haircut for Dolls) in Stage 2 Intervention.

Experimental Design
A multiple-probe across three behaviors (Gast et al., 2018) was used to examine the relationship between video modeling and the acquisition, maintenance, and generalization of playing with imaginary objects. Baseline probe trials were conducted for all instructional and generalization goals. Once a stable baseline was established for Goal 1, video modeling was introduced. When Goal 1 reached six scripted steps in two probe trials, Goal 2 entered the intervention condition, and Goal 3 followed the same pattern. The intervention was completed when the child demonstrated 100% accuracy for all scripted steps in each goal in three consecutive probe trials.
Follow-up trials for instructional and generalization goals were probed immediately after the criterion was reached for each instructional goal and at 2 weeks, 4 weeks, and 12 weeks following the completion of the intervention.
Definition of Dependent Variables
The dependent variable was the number of correct steps in instructional and generalization goals. The correct steps of the instructional goals consisted of scripted and unscripted steps. Each correct step was defined as the child providing a verbal description (e.g., “I wash my face”) and its corresponding motor action (e.g., holding hands up with palms facing towards the face and moving them in circular motions). An incorrect step was defined as the child providing only a verbal description without a motor action or vice versa, or, a verbal description that did not match the motor action (e.g., a verbal description of “washing face” with an action of “turning on tap water”). Each correct scripted step was defined as the child providing a motor action along with a corresponding verbal description that matched the step in one of the video models. Each unscripted step was defined as the child providing a motor action along with a corresponding verbal description that involved a new motor action or a new detail that was not modeled in the videos. For example, if the script was “I wash my face,” the response “washing face” was coded as scripted, but the response “I rinse my hands and face” or “I rub soap on my face” was coded as unscripted.
Pre-experimental Assessments
Play skills assessments
The children’s play skills in functional play and symbolic play with imaginary objects were assessed using the items listed in the DBACA. The DBACA is a semi-structured assessment that evaluates children’s abilities in language, self-help, communication, and social domains. The field tests were conducted with Chinese-speaking children from 2 to 12 years of age in Taiwan. It demonstrated content validity with two experts in developmental psychology, and the average inter-scorer agreement was 92% (90–100%). The procedure for assessing functional play was described by Lee et al. (2019). Demonstrations of functional play skills were required to proceed to the assessment of imagining objects.
The procedure of assessing symbolic play with imaginary objects is described as follows. The first imaginary object was an apple. Without the presence of an actual apple, the assessor faced both hands upward, saying, “Here is an apple. I’m eating the apple,” and then opened and closed her mouth as if she were eating an apple. The assessor then told the child, “Now it’s your turn” and waited for 10 s for the child to respond. The second imaginary object was reading a book. The assessor moved one of her hands from one side to another two to three times, pretending to turn the pages of a book and read. The assessor then said, “I’m reading a book,” asked the child to respond (i.e., “It’s your turn”), and waited for 10 s. The third imaginary object was driving a car. The assessor held up both hands, making a turning action two to three times as if she were turning a steering wheel, saying, “I’m driving.” The assessment was completed after the child responded to the third imaginary object or after 10 s of no response.
An instance of playing with imaginary objects was defined as the child demonstrating a pantomime action of an activity with verbal descriptions that are different from the assessor’s demonstration. If the child only described a different activity (e.g., “I’m drinking”) without the corresponding actions, the assessor would ask the child to perform the actions (e.g., “Show me what you just said”). If the child only performed a play action without a verbal description, the assessor would ask for a verbal description (e.g., “What are you doing?”). If the child provided a verbal description that matched the actions, or vice versa, it was coded as a correct response. If the child imitated the assessor’s response, displayed irrelevant responses or no response, it was coded as an incorrect response. A “0” was scored if a child responded incorrectly to all three imaginary objects. If the child responded correctly for one or two imaginary objects, this item was scored a “1.” The child had to respond correctly to all three imaginary objects to obtain a score of “2.” Children who scored a “0” on this item were invited to participate in this study.
Assessments for readiness of video-based instruction
To assess each child’s readiness for video-based instruction, the assessor (a) read storybooks for at least 5 min to the child; (b) gave six one-step directions; (c) asked the child repeat six two- to three-word phrases heard; (d) asked the child to point to five body parts; (e) asked the child three basic social questions; and, (f) showed the child videos containing six gross motor actions and six actions with objects for the child to imitate (Burke, 2009; MacDonald et al., 2015). All three participants demonstrated these skills with 100% accuracy during the assessment.
Goal selection
The selection of instructional goals and generalization goals was based on observations of play activities of typically developing children in a kindergarten. The chained responses for each instructional goal included in the video modeling were collected from three different child models in the kindergarten. Each generalization goal was selected based on its relevance to each instructional goal or to routine daily activities. Generalization goals were also play activities appearing in the observations of children’s free play.
The categorization of goals in the two stages of intervention was based on the three levels of agents suggested by Lifter et al. (1993): self as agent, child as agent, and doll as agent. Goals in Stage 1 intervention involved self as agent (the child performs actions towards himself); goals in Stage 2 intervention involved child as agent (the child performs actions towards a figure). Stage 1 instructional goals included washing one’s face (generalization goal: dressing up), eating a meal (generalization goal: cleaning up the table after a meal), and cleaning up the desk and floor (generalization goal: packing a backpack for camping). Stage 2 instructional goals were giving a haircut to a doll (generalization goal: feeding a stuffed animal), taking care of a sick doll (generalization goal: putting a stuffed animal to bed), and bathing a doll (generalization goal: dressing up a stuffed animal).
Procedure
The procedure in the two stages of the intervention was identical, except the children were provided with a doll or stuffed animal in Stage 2.
Probe trials across conditions
The probe trials for the instructional and generalization goals were conducted in the same manner. Probe trials of instructional goals were conducted across baseline, intervention, and follow-up conditions in the intervention setting. Probe trials of generalization goals were conducted in baseline and follow-up conditions in the generalization setting.
A probe trial of the instructional goal was conducted before the intervention session of the day in the intervention condition. Each probe trial was conducted in the following manner. Step 1: The instructor delivered the antecedents and waited 10 s for the child to respond. For example, the instructor said, “Let’s play a pretend game. I don’t know how to wash my face, and I want you to show and tell me how to do it. Here is a sink (drawing a sink with an index finger), a tap (drawing a tap), a towel (drawing a towel), and the facial soap (drawing a soap).” Step 2: If the child responded, the instructor watched attentively with smiles and imitated the child’s motions until the child finished all the steps. The instructor provided descriptive praise for each correct step (e.g., “It is great that you showed and told me how to turn on the tap water to rinse”). The incorrect steps were ignored. If the child did not respond within 10 s, the trial ended. The instructor provided positive comments at the end of each trial (e.g., “I like the way you are listening” or “This is fun”).
If the child displayed self-injurious behavior or aggression for more than 3 min, the instructor notified the parent for assistance, and the session was terminated. If the child emitted repetitive behaviors or stereotyped speech, the instructor ignored such behaviors and continued the session. If the child attempted to leave, the instructor first gave a verbal direction (e.g., “Come back here”) and waited 5 s for the child to respond. If the child did not come back within 5 s, the instructor provided physical assistance. The children did not display any of these problem behaviors throughout the study.
Intervention
The instructor was a graduate student in her second year of the master’s program in special education. Each intervention session (8–15 min) consisted of six instructional trials with six versions of the videos for each play activity presented randomly. Each instructional trial was conducted in the same manner as a probe trial described above, except one additional step was added before Step 1. In this additional step, the instructor invited the child to watch a video and presented a video on a laptop computer (e.g., “Let’s watch a video showing you a pretend game”). Steps 1 and 2 in a probe trial then followed. The consequences for correct (i.e., praise) and incorrect (i.e., ignore) responses were the same as in a probe trial. One intervention session was conducted per day, with three to four sessions per week. The intervention for both stages took approximately 6 to 8 weeks for completion.
Social Validity
A questionnaire for parents and a questionnaire for children were developed to assess social validity regarding the acceptability, feasibility, and satisfaction of the intervention. The questionnaires were administered after the two stages of the intervention were completed. The parents’ questionnaire contained 15 items, including intervention acceptability (Items 1–5), feasibility (Items 6–11), satisfaction (Items 12–15), and an open-ended question for suggestions or sharing experiences. The acceptability questions included the appropriateness of the content, the use of video modeling, the child’s learning needs, the one-on-one format, and whether the instruction was suitable to Chinese culture. The feasibility questions included frequency, location, duration, time of weekly sessions, transportation, and whether additional financial costs were reasonable to manage. The satisfaction questions consisted of parents’ satisfaction with their child’s overall progress in play skills, the results of the instruction, whether they would recommend this intervention to other parents, and whether they perceived that their children liked the instruction. Each item was rated on a 5-point Likert scale (1 = strongly dissatisfied or disagree to 5 = strongly satisfied or agree).
The children’s version of the questionnaire consisted of five questions (i.e., Do you like the instructor? Do you like to watch the videos? Did you learn the pretend games? Do you want the instructor to come in the future? Do you want to invite other kids to play with us? Why or why not?). The instructor asked each child the questions and recorded their responses.
Procedural Fidelity and Interobserver Agreement
All probe and instructional sessions were videotaped to assess procedural fidelity and interobserver agreement. Two graduate students naïve to the purpose of the study were trained to evaluate procedural fidelity and interobserver agreement (IOA) by watching the videotapes of the recorded sessions. The assessors independently checked the accuracy of each step implemented in each probe trial and instructional trial. The assessors also recorded the child’s responses for each probe trial to assess IOA. See the description of each step of a probe trial under
Procedural fidelity was assessed for 40% to 50% of the intervention sessions and 40% to 50% of probe trials for instructional and generalization goals across conditions. The percentage of procedural integrity was obtained by dividing the number of accurate steps in the intervention by the total number of steps and multiplying by 100. In Stage 1 intervention, the average procedural fidelity for instructional sessions was 96% (90%–100%), 98.8% (90%–100%), and 100% for Cheng, Tian, and Dong, respectively. The average procedural fidelity for probe trials of instructional and generalization goals across conditions was 97.5% (87.5%–100%) for Cheng and 100% for Tian, and Dong. In Stage 2 intervention, the average of the procedural fidelity for instructional trials was 100% for Cheng and Tian and 96.3% (90%–100%) for Dong. The average fidelity for probe trials, including instructional and generalization goals, was 100% for all three children.
Point-to-point IOA was assessed for 40%–50% of the probe sessions across conditions for each child. The formula of point-to-point IOA was as follows: the number of agreements ÷ total the number of agreements and disagreements × 100. In Stage 1 intervention, the IOA of scripted responses averaged 100% for Cheng, 96.4% (85.7%–100%) for Tian, and 97.6% (85.7%–100%) for Dong. The IOA of unscripted responses averaged 100% for all three children. In Stage 2 intervention, the IOA of scripted responses averaged 100% for Cheng and Tian and 97.5% (83.3%–100%) for Dong. The IOA of unscripted responses averaged 100% for all three children.
Results
Stage 1 Intervention
Figures 1–3 depict the number of scripted and unscripted steps for instructional goals and the number of correct responses for generalization goals in probe trials across conditions in Stage 1 intervention for Cheng, Tian, and Dong, respectively.
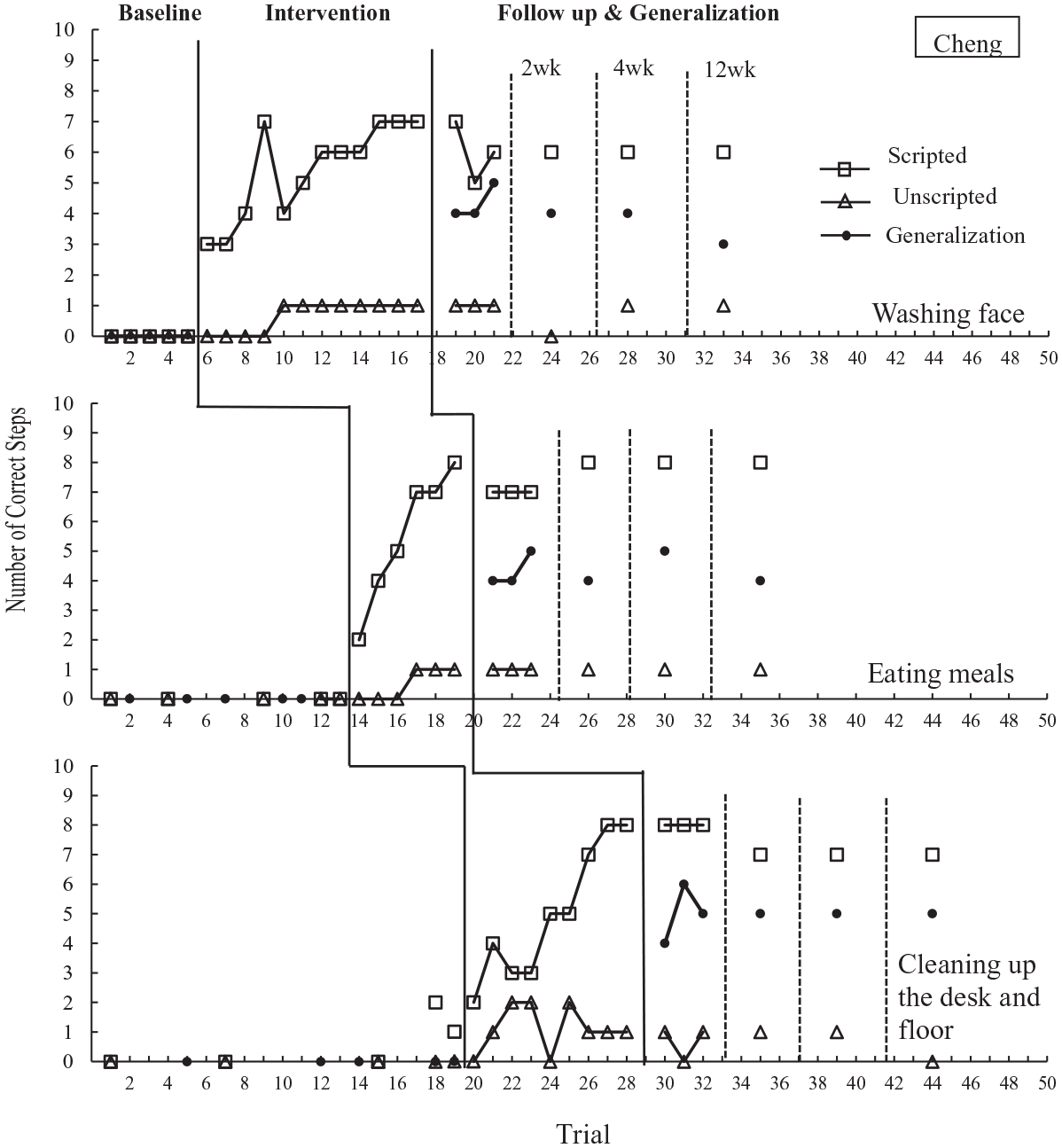
Number of correct scripted and unscripted steps of instructional goals and generalization goals during probe sessions across conditions in stage 1 intervention for Cheng.

Number of correct scripted and unscripted steps of instructional goals and generalization goals during probe sessions across conditions in stage 1 intervention for Tian.
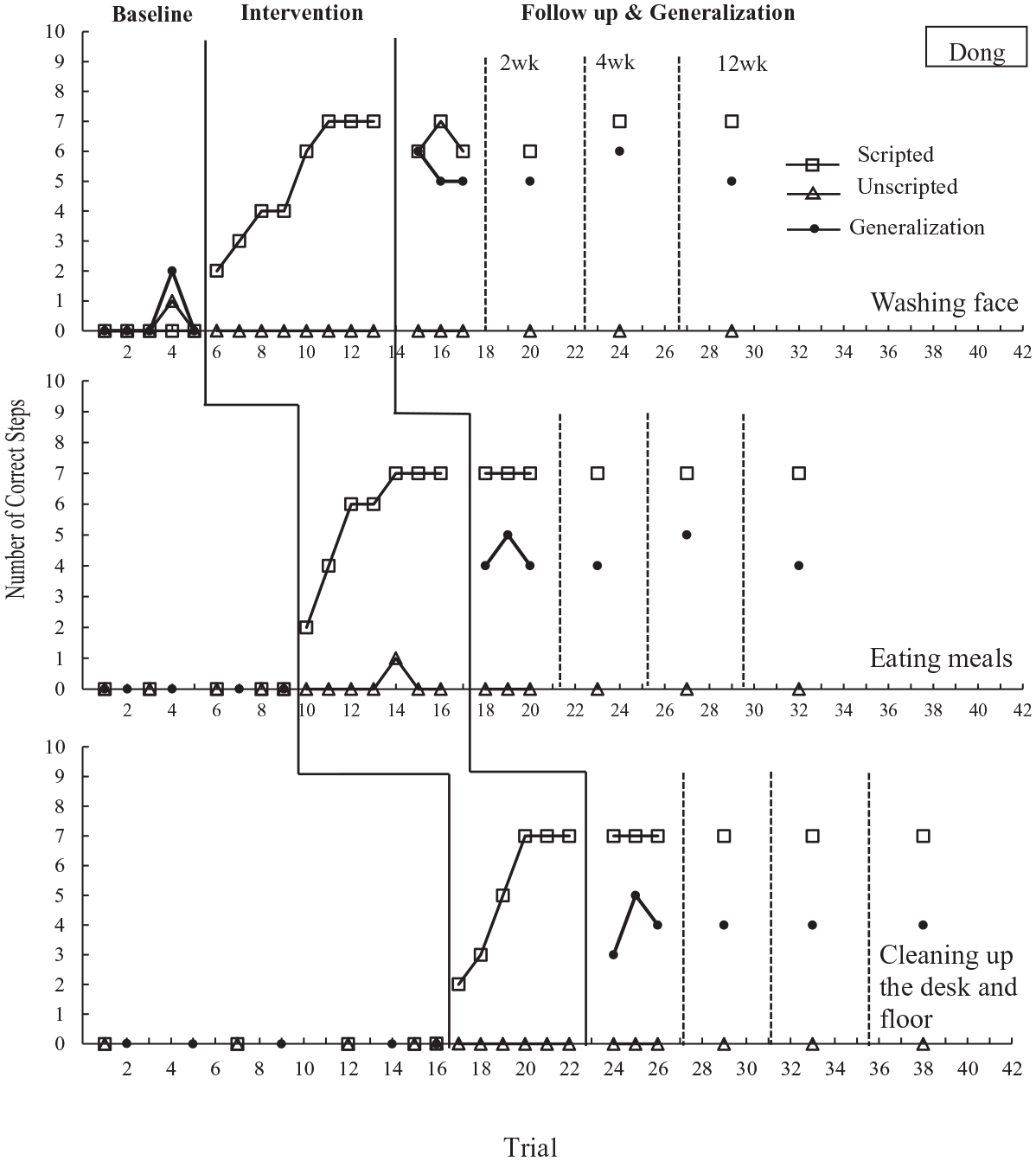
Number of correct scripted and unscripted steps of instructional goals and generalization goals during probe sessions across conditions in stage 1 intervention for Dong.
Instructional goals
Overall, all three children had zero or a low level of correct responses for the three instructional goals at baseline. When video modeling was introduced, the correct responses immediately increased to a slightly high level with a gradual ascending trend toward criterion for these goals (Cheng Goal 1: scripted M = 5.4, range 3–7, unscripted M = 0.7, range 0–1; Goal 2: scripted M = 5.5, range 2–8, unscripted M = 0.5, range 0–1; Goal 3: scripted M = 5, range 2–8, unscripted M = 1.1, range 0–2; Tian Goal 1: scripted M = 6.2, range 4–7, unscripted M = 0.2, range = 0–1, Goal 2: scripted M = 6.4, range 5–7, unscripted M = 0.2, range 0–1; Goal 3: scripted M = 5.8, range 3–8, unscripted M = 0.3, range 0–1; Dong Goal 1: scripted M = 5, range 2–7, unscripted M = 0, range 0–0, Goal 2 scripted M = 5.6, unscripted M = 0.1, range 0–1, Goal 3: scripted M = 5.2, range 2–7, unscripted M = 0, range 0–0). Each child maintained the acquired goals at a high level immediately following the completion of the intervention and in all follow-up probe sessions. No overlapping data were observed between baseline and intervention conditions as well as between baseline and follow-up conditions. The only exception was that Cheng had one overlapping data point between baseline and intervention conditions for Goal 3.
Generalization goals
All children’s correct responses to generalization goals also displayed a similar pattern. Their correct responses were at a low level at baseline, except Tian’s first generalization goal (M = 2.8, range 2–3). After acquiring the instructional goals, the correct responses for generalization goals increased to a relatively high level (Cheng Goal 1: M = 4.3, range 4–5, Goal 2: M = 4.3, range 4–5, Goal 3: M = 5, range 4–6; Tian Goal 1: M = 6.3, range 5–7, Goal 2 M = 4.7, range 4–5, Goal 3: M = 4, range 4–4; Dong Goal 1: M = 5.3, range 5–6, Goal 2: M = 4.3, range 4–5, Goal 3: M = 4, range 3–5). They also maintained these goals at the same level for 12 weeks. No data overlap was observed between baseline and follow-up conditions.
Stage 2 Intervention
Figures 4–6 depict the number of scripted and unscripted responses for instructional goals and the number of correct responses for generalization goals in probe trials across conditions for Cheng, Tian, and Dong, respectively.

Number of correct scripted and unscripted steps of instructional goals and generalization goals during probe sessions across conditions in stage 2 intervention for Cheng.
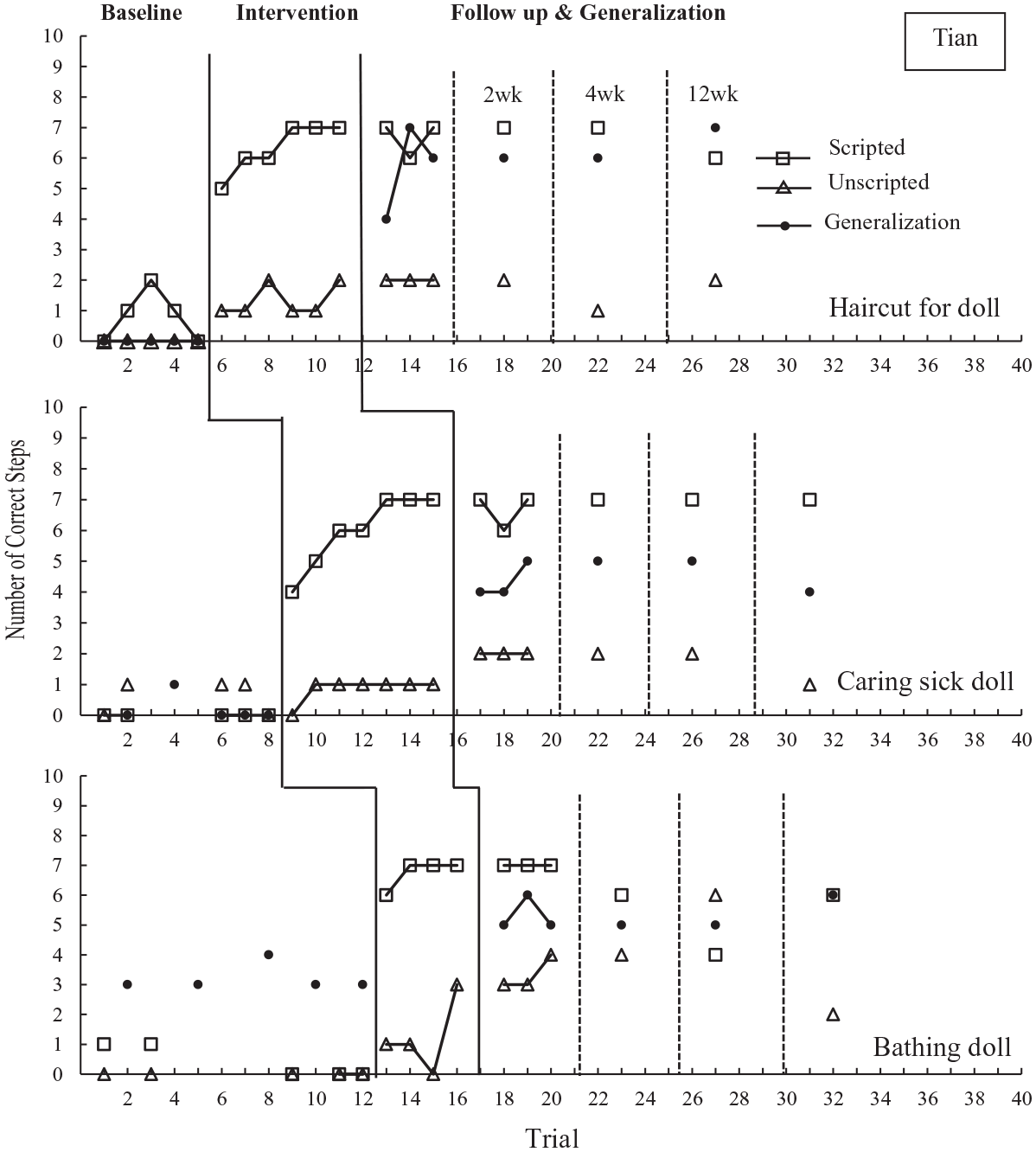
Number of correct scripted and unscripted steps of instructional goals and generalization goals during probe sessions across conditions in stage 2 intervention for Tian.

Number of correct scripted and unscripted steps of instructional goals and generalization goals during probe sessions across conditions in stage 2 intervention for Dong.
Instructional goals
At baseline, all children displayed a relatively low level of correct responses for the three goals. Their correct responses increased immediately after video models were introduced and gradually ascended toward criterion (Cheng Goal 1: scripted M = 6, range 4–7, unscripted M = 0, range 0–0, Goal 2: scripted M = 6.6, unscripted M = 0, range 0–0, Goal 3: scripted M = 6.5, range 4–8, unscripted M = 0.2, range 0–1; Tian Goal 1: scripted M = 6.3, range 5–7, unscripted M = 1.3, range 1–2; Goal 2: scripted M = 6, range 4–7, unscripted M = 0.9, range 0–1, Goal 3: scripted M = 6.8, range 6–7, unscripted M = 1.3, range 0–3; Dong Goal 1: scripted M = 5.4, range −7, unscripted M = 0.1, range 0–1, Goal 2: scripted M = 5.4, range 2–7, unscripted M = 0, range 0–0, Goal 3: scripted M = 5.4, range 2–7, unscripted M = 2.8, range 2–4), without data overlapping between the intervention and baseline conditions. All children maintained the acquired goals at the same level for 12 weeks following the intervention.
Generalization goals
All children displayed a similar data pattern for generalization goals. They provided a relatively low level of correct responses at baseline and increased to either a middle or high level following the intervention (Cheng Goal 1: M = 4, range 4–4, Goal 2: M = 5.3, range 5–6, Goal 3: M = 4, range 4–4; Tian Goal 1: M = 5.7, range 4–7, Goal 2: M = 4.3, range 4–5, Goal 3: M = 5.3, range 5–6; Dong Goal 1: M = 5.7, range 5–7, Goal 2: M = 4.3, range 4–5, Goal 3: M = 6, range 6–6) and maintained at the same level for 12 weeks. The exceptions included Cheng’s second generalization goal and Tian’s third generalization goal, where the correct responses only increased slightly, compared to the baseline data (Cheng Goal 2: M = 1.8, range 1–3; Tian Goal 3: M = 3.2, range 3–4). No data overlap was observed for generalization goals between baseline and follow up conditions.
Social Validity
One parent for each child responded to the parent questionnaire. The average of their ratings was 4.73 (SD = 0.57) on intervention acceptability, 4.61 (SD = 0.49) on feasibility, and 4.27 (SD = 0.77) on satisfaction. All three parents provided responses to the open-ended question. Cheng’s mother perceived that Cheng’s social initiations improved after the completion of the study. For example, when Cheng saw a commercial advertisement for cell phones, he initiated a conversation by asking, “Mom, what is the model of your cell?” His mother recommended continuing this intervention and enriching it with instruction in social communication (e.g., teaching children to express their feelings). Tian’s mother reported that she noticed that Tian engaged in more interactive and complex imaginary play at home. She shared that he invited his dad to play pretend activities at home, and he had never done such activities before. She suggested that we could incorporate teaching emotional management with video modeling, as Tian experienced some emotional difficulties. Dong’s mother also responded positively and suggested for us to expand video-based instruction to promote children’s independence in daily living activities and task completion.
All three children’s responses to the questionnaire were positive. They liked the instructor, the videos, and the pretend play activities. If the instruction were to be continued, they wanted to participate and invite other children to join them.
Discussion
The purpose of this study was to evaluate the effects of video modeling on the acquisition, maintenance, and generalization of playing with imaginary objects in children with ASD. The results of the study indicated that video modeling was effective in increasing the number of correct responses in playing with imaginary objects for all three children. The number of unscripted responses emerged at a low level. Generalization to untaught imaginary play activities occurred for all children. All children’s performance was maintained at a relatively high level for 12 weeks following the intervention. The results of this study extended the literature by using video modeling to improve symbolic play behavior involving imaginary objects for children with ASD.
The notion of conditioned seeing supports that visual presentations involved in video modeling are key to facilitating the acquisition of the target imaginary play activities with complex chained responses. It is possible that visual demonstrations of these activities via video modeling connected with the child’s relevant daily experiences, which made play activities with imaginary objects more likely to occur. The maintenance effect after the video modeling intervention was probably due to the child’s experiences in the daily activities occurring in the natural environment. With video modeling, the children learned to play with imaginary objects without going through intraverbal training, instructor live modeling, verbal instructions, or prompts as described by Lee et al. (2019b).
The results of the study also provided evidence to support the generalization effects of video modeling to untaught imaginary play activities. In this study, multiple exemplar instruction, including three different versions of scripts across two models (a total of six versions of videos for each activity), was used to promote generalization. Although the children’s unscripted verbal and motor responses were at low levels, all children provided some varied unscripted responses of these goals in intervention and follow-up conditions. Generalization to untaught goals was evidenced by the fact that all children’s verbal and motor responses to these goals occurred at a relatively high level after the completion of the intervention compared to their baseline performance. This finding is consistent with the generalization effect reported in Dupere et al. (2013), where different toy stimuli were incorporated in the video modeling intervention, and the acquired play behavior was generalized to new toys thereafter without instruction. In addition to multiple scripts and models in the videos, the pre-experimental assessments of specific play skills were helpful in determining the appropriateness of the intervention to each child, which in turn made generalization more likely to occur.
The strengths of this study included the assessment of each child’s prerequisite skills to receive video modeling instruction, the assessment of each child’s functional and symbolic play skills, and the variations of video models for each instructional goal. The assessment of perquisite skills for video-based instruction is important to ensure children’s success in learning complex play behavior from video modeling. The assessment of specific play skills serves as a basis for determining the adequacy of the instructional goals. The variation of video models, scripts, and motor actions not only promotes engagement in instruction but also generalization to untaught imaginary play activities. Video modeling is relatively easy to implement without requiring instructor models or relying on assistive prompts as described in Lee et al. (2019b).
The limitations of this study included using verbal direction presented as an antecedent to initiate symbolic play, potential confounding variables resulting in the increase of target play behavior at baseline, and the lack of evaluations of children’s play behavior in free play settings. Although verbal antecedents may increase target play responses, it inevitably served as prompts for the play responses. Play should take place under naturally occurring antecedents initiated by the child, peers, or other individuals in appropriate contexts rather than a verbal direction. It is possible to replace the verbal direction with a different, non-target imaginary play activity (e.g., pretending to play tennis without actual objects) as an antecedent to initiate a spontaneous play action.
The increase in correct responses occurred at baseline (e.g., Stage 1, Goal 3 for Cheng; Stage 2 all goals for all three children) may be explained by (a) the reinforcement delivered contingent upon correct responses, (b) the covariation resulting from the mastery of previous goals, and (c) each child’s previous experiences or familiarity with the goals. Reinforcement for correct responses was provided at baseline to avoid suppression of correct responses and to isolate the effect of video modeling under the intervention condition. At the same time, reinforcement alone can possibly increase the number of correct responses. It is also possible that the increase was related to the mastery of previous goals, as the children’s baseline performances in Stage 2 were consistently higher than those of Stage 1. Therefore, after acquiring skills for playing with imaginary objects in several activities, the covariation to subsequent untaught goals may occur. Additionally, the goals were related to daily activities and could be familiar to the children. Although familiarity with these activities may affect children’s performances, the increase at baseline was maintained at a relatively stable level without reaching mastery criterion, suggesting that video modeling was in effect.
This study highlighted an important steppingstone to fostering play behavior involving imaginary objects for young children with ASD. Requiring the children to provide a verbal description along with a play action may not be natural, as shown in typically developing children’s imaginary play activities. On the other hand, verbalizing the actions provides an opportunity for the children to use descriptive gestures and is an important component in shaping the target play behavior to be more interactive with others in the future. However, whether the intervention changed the children’s engagement in symbolic play activities with their peers was not evaluated. The next step is to ensure that the children incorporate imaginary play in interactions with their peers. Therefore, it is important for future research to include peer interactions in video models and evaluate the effects on children’s spontaneous symbolic play behavior and interactions with peers in natural play settings.
The results of this study have important implications for teaching complex play behavior to children with ASD. Video modeling is an effective approach to establish and maintain play behavior involving imaginary objects in children with ASD. Incorporating multiple exemplars in video modeling promotes generalization to new imaginary play activities without additional prompts or instructions. Video modeling is a relatively easy and reliable way to establish or increase play behavior using imaginary objects for children with ASD.
Footnotes
Author Note
Gabrielle T. Lee is Assistant Professor at the Faculty of Education, Western University, London, Canada
Xiaoyi Hu is Associate Professor in the Department of Special Education at Beijing Normal University, Beijing, China
YanHong Liu is Associate Profesor in the Department of Special Education at Beijing Normal University, Beijing, China
Yuan Ren is a Teacher of Special Education in Long Yuan School, Nanshan District, Shenzhen, Guangdong, China
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by Beijing Education Science Plan Fund 13th Five-year 2018 Key Research Fund CAEA18082 (PI: Xiaoyi Hu).