
Abstract
Across six studies, we validated a new measure of helpful and hurtful behaviors, the Tangram Help/Hurt Task. Studies 1 to 3 provided cross-sectional correlational convergent and discriminant validity evidence for the Tangram Task using college-based and adult online samples. Study 4 revealed that previously validated empathy primes increase helpful behaviors on the Tangram Task. Studies 5 and 6 revealed that previously validated provocation manipulations increase hurtful behaviors on the Tangram Task. The effects of various experimental manipulations on the Tangram Task were similar to or larger than on other established indices of helpful and hurtful behaviors. In addition, motivation items in all studies indicate that tangram choices are indeed associated with the intent of helping and hurting. We discuss the advantages and limitations of the Tangram Help/Hurt Task relative to established measures of helpful and hurtful behaviors.
The importance of measuring aggressive and prosocial behaviors in the laboratory is paramount for understanding such complex social behaviors. Anderson and Bushman (1997) discovered remarkable consistency in the size and direction of various effect sizes for aggression-based findings in the laboratory and in the “real-world.” This suggests that laboratory-based studies of aggressive behavior are generalizable to outside the laboratory and further exemplify why developing and validating high-quality measures of aggressive (and prosocial) behavior are important. The current research presents six studies that examined the validity of a laboratory-based tool designed to measure aggressive and prosocial behaviors simultaneously: the Tangram Help/Hurt Task.
Conceptually, prosocial and aggressive behaviors appear to be opposites, one involving behavior that helps another person, the other involving behavior that harms another person. Theoretically, they share the very important feature of being largely defined by intent rather than actual outcome (e.g., Anderson & Bushman, 2002; Batson, 2014; Malle, 2011). For this reason, perhaps, the psychological processes underlying both types of behavior may be very similar, involving both fairly automatic (impulsive) perception–decision–action sequences as well as more resource-intensive controlled sequences. Indeed, Hirsh, Galinsky, and Zhong (2011) suggested that the common factor behind seemingly contradictory prosocial and antisocial outcomes is a disinhibited state characterized by reduced response conflict. This state of disinhibition influences the most salient response in a given context based on either trait tendencies or strong social cues (Hirsh et al., 2011). In addition, Graziano and Habashi (2010) provided an excellent theoretical integration of the similar processes underlying prejudice (which is strongly aligned to outgroup aggression) and prosocial behavior. Although testing various theoretical aspects of this integration is beyond the scope of the present article, and word limits preclude further theoretical discussion, it is important to note that our studies include tests of the underlying motivation or intent for both aggressive and prosocial behavior. Furthermore, we believe that the Tangram Task will aid researchers interested in testing and refining these recent theoretical advances.
Assessing Aggressive and Prosocial Behavior
Aggressive Behavior
Myriad techniques exist to measure aggressive behavior. Popular methods include self-report measures of behavioral tendencies (e.g., Buss & Perry, 1992), and similar tendency reports by others (peer [Walder, Abelson, Eron, Banta, & Laulicht, 1961], teacher’s [Huesmann, Eron, Guerra, & Crawshaw, 1994], and parent’s [Achenbach & Edelbrock, 1983]). Although such measures are important to answering important research questions, they may be less suited to reliably measure laboratory-based state aggressive behaviors in certain situations. 1 Indeed, Anderson et al. (2010) argued that one criteria for best practice laboratory experimentation (in video game violence research specifically) includes not using trait-based measures to assess aggressive behavior after an experimental manipulation, because of their lack of sensitivity to short-term changes in goals and intentions.
Several laboratory measures have been used to validly and reliably assess aggressive behavior (see Bushman & Anderson, 1998, for review). Although these measures are not without criticism (Ritter & Eslea, 2005; Tedeschi & Quigley, 1996), a variety of empirical approaches have established their internal and external validity (e.g., Anderson & Bushman, 1997; Carlson, Marcus-Newhall, & Miller, 1989; Giancola & Chermack, 1998; Giancola & Parrott, 2008). Common examples include the Buss Aggression Machine (e.g., Buss, 1961), Competitive Reaction Time Task (e.g., Bushman, 1995; Taylor, Gammon, & Capasso, 1976), hot-sauce allocation (e.g., McGregor et al., 1998), point subtraction aggression paradigm (e.g., Cherek, 1981), ratings of an experimenter that have bearing on re-appointment (e.g., Pedersen, Gonzales, & Miller, 2000; Twenge, Baumeister, Tice, & Stucke, 2001), hand in ice-water (Pedersen et al., 2000), and others. Using such measures, researchers have uncovered and substantiated several important theoretical claims regarding aggression effects. Indeed, research reveals that aggressive behavior is affected by (a) violent media (e.g., Anderson et al., 2010), (b) provocation (e.g., Bettencourt & Miller, 1996), (c) reminders of our own death (e.g., McGregor et al., 1998), (d) presentation of aggressive primes (e.g., Berkowitz & LePage, 1967), and other situational factors (see Anderson & Bushman, 2002, for review).
Prosocial Behavior
Although several trait-based and observational methods exist for assessing prosocial behavior, fewer laboratory-based measures exist. Typical laboratory measures of prosocial behavior include amount of money donated to charity (e.g., van Baaren, Holland, Kawakami, & van Knippenberg, 2004), number of pencils (or other materials) picked up after they spill (e.g., MaCrae & Johnston, 1998), monetary transfers in an economic decision-making game (e.g., Piff, Kraus, Cote, Cheng, & Keltner, 2010), willingness to help a distressed person (e.g., Mikulincer, Shaver, Gillath, & Nitzberg, 2005), and others. Using such measures, research has shown that prosocial behaviors are affected by (a) presentation of pictures of religious symbols (e.g., Shariff & Norenzayan, 2007), (b) prosocial video games (e.g., Greitemeyer & Osswald, 2010), (c) being assisted in a difficult task by another (e.g., Bartlett & DeSteno, 2006), (d) secure attachment primes (e.g., Mikulincer et al., 2005), and others.
Aggressive and Prosocial Behavior
Despite the use of the aforementioned measures to assess aggressive behavior or prosocial behavior, these measures do not allow researchers to measure both aggressive and prosocial behavior simultaneously, which may be theoretically important in certain contexts. Indeed, researchers cannot equate a lack of aggressive (or prosocial) behavior using any of the aforementioned tasks as a prosocial (or aggressive) response. Although helpful and hurtful behaviors are conceptually distinct, they often are inversely related—especially in short-term real-world contexts. For example, when people engage in a hurtful behavior toward a target person, they seldom simultaneously engage in helpful behavior toward that same target. Of course, specific types of aggressive behavior (e.g., instrumental aggression) may involve harming another with an overarching prosocial goal. Consider, for example, an individual pushing an attacker away from a loved one. In this example, the act is consistent with our understanding of aggression (against the attacker), but the overall goal is likely primarily prosocial. Therefore, it may be important to measure aggressive and prosocial behaviors simultaneously to get more insights into such complex social behaviors. However, there is a paucity of research validating behavioral assessments of both types of social behavior simultaneously. Indeed, we are aware of only two laboratory-based tasks designed to measure both types of behavior. Each is discussed in detail below.
The first measure is called the Help/Hurt button (Liebert & Baron, 1972). Originally designed to assess how violent television images influence children’s aggressive and prosocial behavior, this measure places children in front of a wooden box with two buttons labeled Help and Hurt. Participants are told that the buttons will make a task easier or harder for another ostensible child. For example, Gadow, Sprafkin, and Grayson (1990) told children that another (fictitious) child was steering a remote controlled boat. Pressing the Help button would allow the partner to steer the boat with ease, whereas pressing the Hurt button would make the steering wheel cold, making the “partner’s” hand hurt, and steering the boat very difficult. Results showed a significant positive correlation between Hurt scores and trait aggression (assessed by parent ratings) for those exposed to an aggressive cartoon.
The Help/Hurt measure has several clear advantages. First, this measure can assess both helping and hurting simultaneously. Second, the instructions and apparatus are amenable to change. For instance, Liebert and Baron (1972) used a similar measure; however, pressing the Hurt button made it difficult for another child to turn a handle, whereas pressing the Help button made this task easier. Third, the cover story is easily understandable for children, and research has used this measure in both emotionally disturbed and learning disabled children (e.g., Sprafkin & Gadow, 2001). However, several limitations dampen the enthusiasm for using the Help/Hurt button measure. First, this measure has only been validated with children and in lab settings, making it potentially inappropriate to use with college-aged or online samples. Second, the primary dependent measure is the length of time the Help or Hurt button is pressed, rather than the decision to choose helping or hurting behavior. Finally, and perhaps most importantly, there is no third non-aggressive, non-prosocial option. In other words, participants either help or hurt the fictitious partner without substantial alternatives.
Another laboratory-based measure that allows researchers to assess aggression and prosocial behavior is the selection of aversive versus pleasant pictures for another hypothetical participant to view (Mussweiler & Förster, 2000). In this task, participants assign 10 of 30 pictures (10 pleasant, 10 neutral, 10 unpleasant) to another participant to view. The advantage of this task is that it allows for a neutral option. The disadvantage is that it cannot be administered with children as the aversive images are quite unpleasant (e.g., picture of a rotting animal corpse). Furthermore, it is unclear to what extent responses on this task are associated with trait aggression and prosocialness as no published studies have documented this.
To maximize the advantages of many of these paradigms while minimizing the disadvantages, we created a laboratory-based measure of aggressive and prosocial behavior called the Tangram Help/Hurt Task. Participants are told that they will interact with another participant on a puzzle task. Furthermore, participants are instructed that (a) they are to select 11 (out of a possible 30) puzzles of varying difficulty for the ostensible participant to complete, and (b) if the other participant completes 10 of these puzzles in 10 min, then this other participant wins a prize (e.g., gift certificate). The 30 puzzles are pre-classified into easy, medium, and hard, 10 puzzles per difficulty level, based on prior studies. Helpful and hurtful scores are calculated based on the number of easy and hard puzzles assigned to the other participant. A detailed discussion of the advantages of this Tangram Task is presented after our empirical studies of its validity.
Overview of the Current Research
This article reports six studies that tested the convergent and discriminant validity of the Tangram Help/Hurt Task. Studies 1 to 3 used a cross-sectional correlational design to test the relations between scores on the Tangram Help/Hurt Task and other validated self-report measures of aggressive and prosocial personality in college-based and adult online samples. Study 4 primed participants with empathy (or not), an experimental procedure known to influence prosocial behavior. Studies 5 and 6 experimentally manipulated provocation (or not), a factor known to influence aggression. Additional measures of helpful and hurtful behaviors were included in Studies 4 through 6 for comparison with the Tangram Task.
Studies 1 to 3: Cross-Sectional Tests of the Help/Hurt Tangram Task
Studies 1 to 3 tested the convergent and discriminant validity of the Tangram Help/Hurt Task. Specifically, Study 1 tested the association between trait measures of aggression and prosocialness and tangram choices. Study 2 tested the association between trait empathy, perspective taking, state hostility, prosocialness, aggression, and tangram choices. Study 3 tested the association between tangram choices, trait neuroticism, sensation seeking, agreeableness, and control aggression schemas. Study 3 also provided evidence for discriminant validity by testing the association between tangram choices, social desirability, emotional regulation, achievement motivation, and participants’ perceptions of tangram difficulty. These constructs allowed us to test alternative explanations of participants’ tangram choices. Motivations for tangram assignment were assessed in all three studies.
Participants
Study 1
A total of 166 participants from a Midwestern University participated for course credit. Four participants indicated they were suspicious about the presence of another participant during the debriefing and were excluded from the analyses, leaving 87 females and 75 males (Mage = 19.59 years; SD = 1.96).
Study 2
A total of 200 participants completed the survey on Amazon MTurk for monetary compensation. Twenty-one participants were unable to view the tangram instruction video due to problems with their video or audio player. Two participants indicated that they did not understand the Tangram Help/Hurt Task after watching the online instructional video. Of the remaining 177 participants, 73 were female, 101 were male, and 3 unidentified (Mage = 33.40 years, SD = 10.84).
Study 3
A total of 160 participants completed the survey online through Amazon MTurk for monetary compensation. Fourteen participants indicated that they did not believe that the tangrams were assigned to another participant and were excluded from the analysis. Of the remaining 146 participants, 71 were female and 75 were male (Mage = 36.05 years; SD = 12.84).
Materials
Table 1 lists the descriptive statistics for all measures used in Studies 1 to 3. It also shows which measures were included in each study.
Means, Standard Deviations, and Alphas for All Measures Used in Studies 1 to 3.
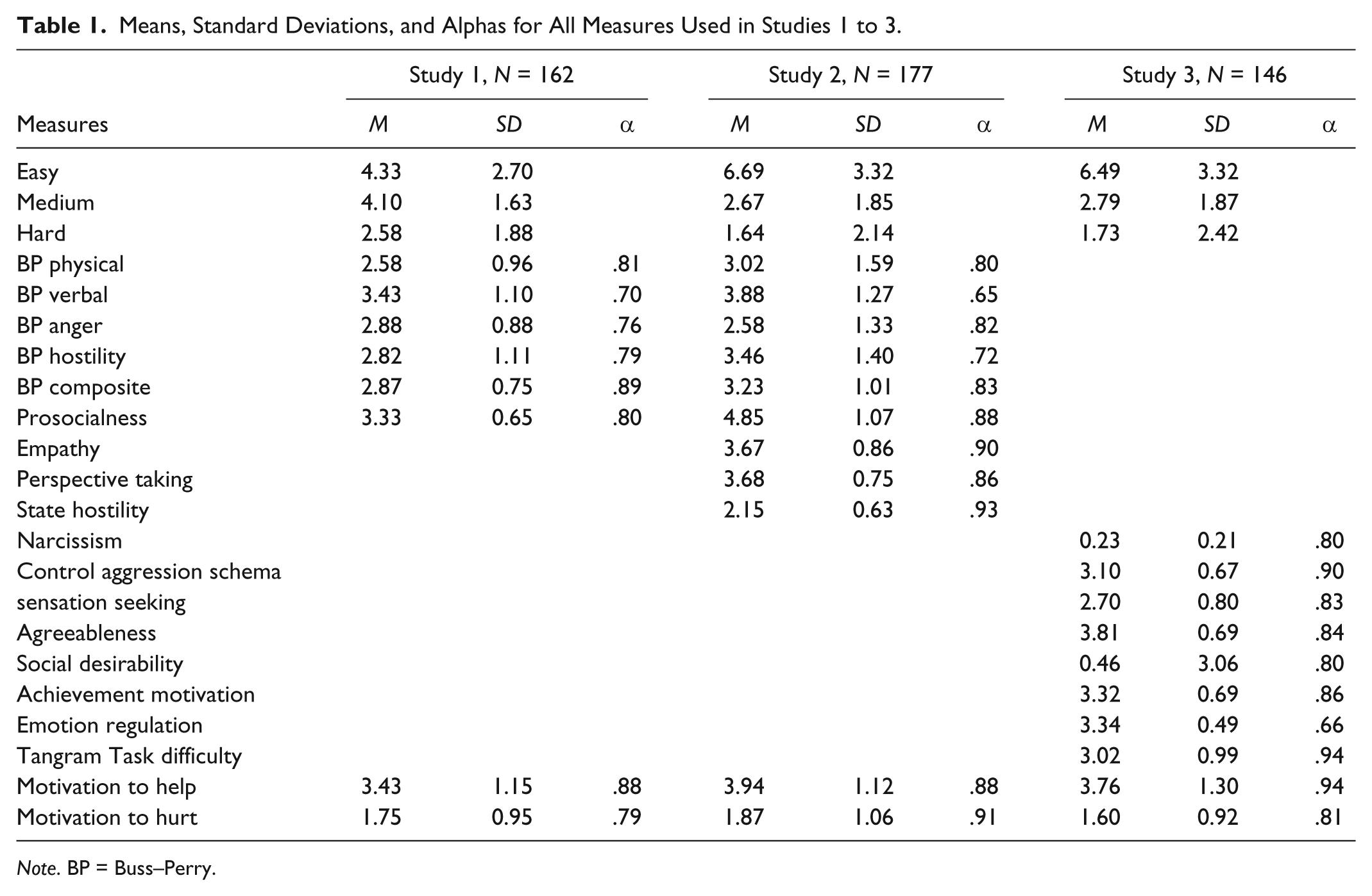
Note. BP = Buss–Perry.
Tangram Help/Hurt Task
Tangrams are based on seven differently shaped plastic pieces (e.g., small square, large triangle) used to form a specified outlined shape. Figure 1 displays the standard seven pieces. Participants first view the outline shape and then use the Tangram pieces to create the target shape. We selected 30 tangrams and assigned them to easy, medium, and hard difficulty levels, based on the number of pieces required to complete a particular tangram shape and on pilot testing. Easy tangrams can be completed using one to three tangram pieces, medium shapes can be completed using four to six pieces, and hard shapes require all seven pieces. 2 This tangram assignment table (see the appendix) was used by participants to assign 11 tangrams to the “other participant,” and was supposedly used by the “other participant” to assign 11 puzzles for the participant to complete within the 10-min time limit.

Tangram pieces.
Tangram assignment motivation
Participants indicated their agreement with two statements assessing their motivation to help (e.g., I wanted to help the other participant win the prize) and two assessing motivation to hurt (e.g., I wanted to make it difficult for the other participant to win the prize) on a 1 (strongly disagree) to 5 (strongly agree) scale.
Measures Assessing Convergent Validity
Trait aggression, state hostility, sensation seeking, narcissism, and control aggression schemas have been associated with aggressive behaviors in the previous literature (Anderson & Bushman, 2002; Joireman, Anderson, & Strathman, 2003; Warburton, 2007). Similarly, trait prosocialness, empathy, perspective taking, and agreeableness have been associated with prosocial behaviors (Dovidio, Piliavin, Schroeder, & Penner, 2006; Graziano, Habashi, Sheese, & Tobin, 2007). Thus, we expected these trait measures to correlate with helping and hurting scores on the Tangram Task.
Trait aggression
Trait aggression was assessed through the 29-item Buss–Perry Aggression Questionnaire (BPAQ; Buss & Perry, 1992) in Study 1 and the 12-item brief measure (Webster et al., 2014) in Study 2. Participants indicated agreement with statements (e.g., “If somebody hits me, I hit back”) on a 1 (extremely uncharacteristic of me) to 5 (extremely characteristic of me) scale.
Trait prosocialness
Trait prosocialness was assessed through the 14-item Prosocial Personality Battery (Penner, Fritzsche, Craiger, & Freifeld, 1995) in Study 1 and a 10-item brief measure (Prot et al., 2014) in Study 2. Participants indicated how often they engaged in each of the behaviors specified (e.g., “I have done volunteer work for a charity”) on a 1 (never) to 5 (very often) scale.
Trait empathy and perspective taking
Trait empathy and perspective taking were assessed using the Interpersonal Reactivity Index (Davis, 1983). Participants indicated their agreement with statements on a 1 (does not describe me well) to 5 (describes me very well) rating scale. Examples of perspective-taking items included, “I sometimes try to understand my friends better by imagining how things look from their perspective,” and “I believe that there are two sides to every question and try to look at them both.” Examples of empathy items included, “I often have tender, concerned feelings for people less fortunate than me,” and “Sometimes I don’t feel very sorry for other people when they are having problems” (reverse-scored).
State hostility
We used a shortened version of the State Hostility Scale (Anderson, Deuser, & DeNeve, 1995). Participants indicated the extent to which they currently feel various antisocial (12-items) and prosocial (10-items) emotions (e.g., “I feel furious,” “I feel happy”) using a 1 (strongly disagree) to 5 (strongly agree) scale. 3
Sensation seeking
Participants indicated their agreement with eight statements (e.g., “I would like to try bungee jumping”) on a 1 (strongly disagree) to 5 (strongly agree) scale (Hoyle, Stephenson, Palmgreen, Lorch, & Donohew, 2002).
Narcissism
Participants read 16 pairs of statements and selected the option that best represents them within each pair (e.g., “I like to be the center of attention”). Narcissistic options were coded as 1 and non-narcissistic options were coded as 0 (Ames, Rose, & Anderson, 2006).
Agreeableness
Agreeableness was assessed with nine statements (e.g., “I see myself as someone who likes to cooperate with others”) on a 1 (strongly disagree) to 5 (strongly agree) scale (John & Srivastava, 1999).
Control aggression schemas
Control aggression schemas were assessed using Warburton’s (2007) scale. Participants indicated their agreement with 35 statements (e.g., “The world belongs to those who can dominate others”) on a 1 (completely untrue) to 6 (completely true) scale. Three items negatively correlated with other items and were removed.
Measures Assessing Discriminant Validity
It is possible that tangram choices are influenced by participants’ perception of Tangram Task difficulty, social desirability concerns, achievement motivation, and/or emotion regulation.
Perception of Tangram Task difficulty
Four statements assessed the extent to which participants’ perceived the Tangram Task to be difficult (e.g., “The Tangram Task seems hard”) on a 1 (strongly disagree) to 5 (strongly agree) scale in Study 3.
Social desirability
Participants indicated whether each of the 11 statements (e.g., “I’m always willing to admit it when I make a mistake”) was true/false in describing them (Reynolds, 1982). Socially desirable responses were coded as 1 and other responses were coded as 0.
Achievement motivation
Participants rated their agreement with 10 statements (e.g., “I am appealed by situations allowing me to test my abilities”) on a 1 (strongly disagree) to 5 (strongly agree) scale (Lang & Fries, 2006).
Emotional regulation
Participants rated their agreement with 10 statements (e.g., “I control my emotions by not expressing them”) on a 1 (strongly disagree) to 5 (strongly agree) scale (Gross & John, 2003).
Overall Procedure
All participants completed an informed consent and were told that they would be completing a puzzle task with another participant. Participants received standardized tangram instructions in person in Study 1 and online through a video in Studies 2 to 3. Participants practiced solving tangrams with a practice packet in Study 1 and saw examples of tangrams being solved by an experimenter through a video in Studies 2 and 3. Next, participants answered trait measures specific to each study (see Table 1). Next, they chose 11 tangrams to assign the other participant either by circling with a pen/pencil (Study 1) or clicking (Studies 2 and 3) directly on the tangram assignment table (see the appendix). Then, participants completed questions assessing their motivation for tangram assignment and demographic information. Next, participants were asked questions about the study using open-ended questions designed to assess suspicion. Finally, participants were debriefed, thanked, and dismissed.
Results
Preliminary analyses
We propose two ways of scoring the Tangram Task depending on the researcher’s goals: (a) separate helping and hurting scores, and (b) an overall tangram difference score. Importantly, all studies included analyses using both scoring techniques.
Separate helping and hurting scores
Researchers interested in assessing helpful and hurtful behaviors can compute two separate, but inversely related, scores using the Tangram Task. Because the task includes 10 puzzles per difficulty level and required 11 choices, participants have to pick from at least two categories. It is possible for someone to pick 10 medium tangrams and 1 easy (or hard) tangram to complete the 11 required. However, this individual is not necessarily intending to help (or harm) the other participant, because the other participant needed to complete only 10 tangrams to win the gift certificate. Thus, “helping” was operationally defined as the number of easy puzzles greater than 1. Similarly, “hurting” was defined as the number of hard puzzles greater than 1. 4
Note that although helping and hurting scores are inversely related using this scoring method; they are not necessarily incompatible with each other. For example, an individual may decide to assign two easy, seven medium, and two hard puzzles in which case their helping and hurting scores would be 1 and 1, respectively. Another individual may decide to assign two easy, two medium, and seven hard puzzles in which case their helping and hurting scores would be 1 and 6, respectively. Although both of these individuals have the same helping score, the latter is clearly intending to hurt the other participant’s chances of winning by assigning them a greater number of harder puzzles, whereas, the former is not necessarily intending to hurt or help the other participant.
Difference score
Researchers interested in assessing to what extent an individual is more likely to be helpful versus hurtful can compute a difference score using the Tangram Task. The difference score was computed by subtracting the hurting score from the helping score (defined earlier). Thus, higher numbers represent a tendency to be helpful whereas lower numbers represent a tendency to be hurtful.
Studies 1 to 3 General Findings
Table 2 reports the zero-order correlations for all measures. Several general findings emerge (see Table 2). First, the helping, hurting, and the overall tangram scores were (necessarily) highly intercorrelated. Second, participant sex was unrelated to tangram scores. This obviates the need to control for sex in other more substantive analyses. Third, motivations to help and hurt the “other participant” were strongly and consistently related to the tangram scores in exactly the expected pattern. Fourth, among the Buss–Perry trait aggression subscales, the tangram scores were consistently associated with physical aggression, anger, and hostility, and were least associated with verbal aggression. Fifth, the tangram scores correlated with other individual difference variables with which they should correlate (convergent validity) and yielded weak and/or essentially zero correlations with variables that one would hope that they would not be related (discriminant validity). Specifically, trait aggressiveness was consistently and modestly positively correlated with the hurting scores, across all three relevant samples, rs = .27 to .30, using the Buss–Perry composite score. Helping score consistently correlated positively with trait prosocialness, rs = .18 to .24. Similarly, both empathy and perspective taking correlated positively with helping and negatively with hurting.
Zero-Order Correlations of Tangram Scores With Other Measures Used in Studies 1 to 3.
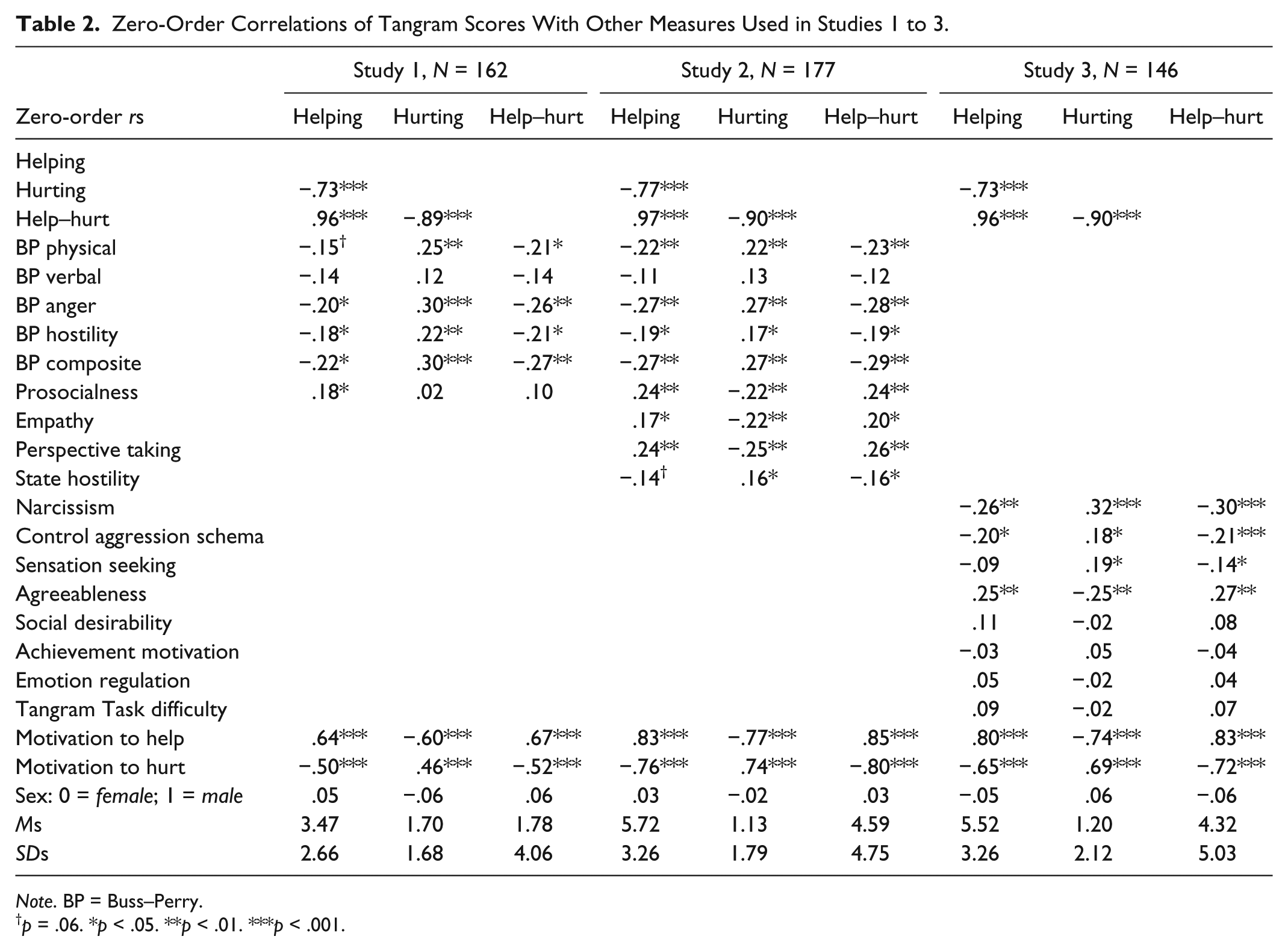
Note. BP = Buss–Perry.
p = .06. *p < .05. **p < .01. ***p < .001.
Studies 1 to 3 Specific Findings
Beyond these general findings, there were several important distinctions. First, Study 1 used a college sample, whereas Studies 2 and 3 used an online MTurk sample. Second, though helping was positively associated with prosocialness in Studies 1 and 2, hurting was significantly negatively associated with prosocialness only in Study 2. Whether this is the result of differences in the prosocialness measures or the samples is unclear, but also is not terribly important for present purposes. Third, state hostility (Study 2) was negatively associated with helping and positively associated with hurting scores. Fourth, Study 3 yielded very small nonsignificant associations between the tangram scores and social desirability, achievement motivation, emotion regulation, and perception of Tangram Task difficulty, thereby providing evidence of discriminant validity. Study 3 also yielded theoretically expected correlations between tangram scores and narcissism, control aggression schema, agreeableness, and sensation seeking.
Regression analyses were conducted in Studies 1 to 2 to test the effects of trait aggression (prosocialness) on hurting (helping) after controlling for helping (hurting). In Study 1, trait aggression was significantly related to hurting even after controlling for helping, t(1, 158) = 2.91, p < .01, b = 0.27, 95% confidence interval, CI = [0.09, 0.45]. Similarly, trait prosocial behavior significantly predicted helping while controlling for hurting, t(1, 158) = 4.39, p < .001, b = 0.60, 95% CI = [0.33, 0.87]. In Study 2, trait aggression (prosocialness) was positively associated with hurting, b = 0.11 (helping, b = 0.21) while controlling for hurting (helping) but not significantly.
Summary of the Correlational Studies
In sum, the three correlational studies provide strong convergent and discriminantly validity evidence for the Tangram Task. These results suggest that the Tangram Task is a valid assessment of both, prosocial and aggressive behaviors.
Study 4: Empathy Prime Effect on the Tangram Task
Study 4 tested the effects of a validated empathy manipulation on the Tangram Task. Pre-experimental measures of trait aggression and trait prosocialness were assessed. In addition, we explored whether the effect of the empathy-inducing prime on tangram choices is influenced by participant mood by including an assessment of state hostility. Finally, to compare the effects of the experimental manipulation on the Tangram Task as well as an established measure of helpfulness, participants made a recommendation for additional monetary compensation for the other participant.
Method
Participants
A total of 312 participants completed the study online through Amazon MTurk. Forty participants indicated that they did not believe that there was another participant in this experiment. 5 Suspicion rate did not vary significantly by condition, p > .20. These participants were excluded from the main analyses. Of the remaining 272 participants, 154 were female, 113 were male, and 5 unidentified (Mage = 35.58 years, SD = 12.21).
Materials
Helping and hurting scores were assessed by the Tangram Help/Hurt Task used in previous studies. In addition, we included measures of trait prosocial behavior from Study 1, tangram assignment motivations, trait aggression, state hostility, and demographics from Study 2.
Priming manipulation
Participants read an essay written by another ostensible participant describing something important that happened to them recently. Participants in the empathy-inducing condition read about a same-sex participant describing their recent break-up from a serious relationship. Participants in the neutral condition read about a same-sex participant describing their recent weekend in which they hung out with friends. The essays were of approximately the same length. This manipulation has been successfully used in the past to prime prosocial behavior (Batson, Klein, Highberger, & Shaw, 1995; DeWall & Baumeister, 2006).
Monetary reward for the other participant
As an additional assessment of helpful behavior, we asked participants how much to pay the other participant in addition to the amount specified for this research study. Participants moved a slider scale that ranged from $0 to $10.00.
Procedure
After completing an online informed consent, participants were told that the goal of the study is to understand how people interact with each other based on writing styles. Participants received standardized tangram instructions through a video, and indicated whether they understood the task. Next, participants wrote a brief essay about something important that happened to them recently and were told that they would read a similar essay written by “the other participant.” Participants then completed demographic, trait aggression, and trait prosocial behavior items. Next, participants were randomly assigned to read either an empathy-inducing or neutral essay from “the other participant.” After reading the essay, participants assigned 11 tangrams to that “other” participant. Then, participants completed the post-experimental questionnaires assessing their motivation for tangram assignment, state hostility, and recommendation for additional monetary compensation for the other participant. Finally, participants answered an open-ended question about any thoughts they had about the other participant, were debriefed, and thanked.
Results
Preliminary analyses
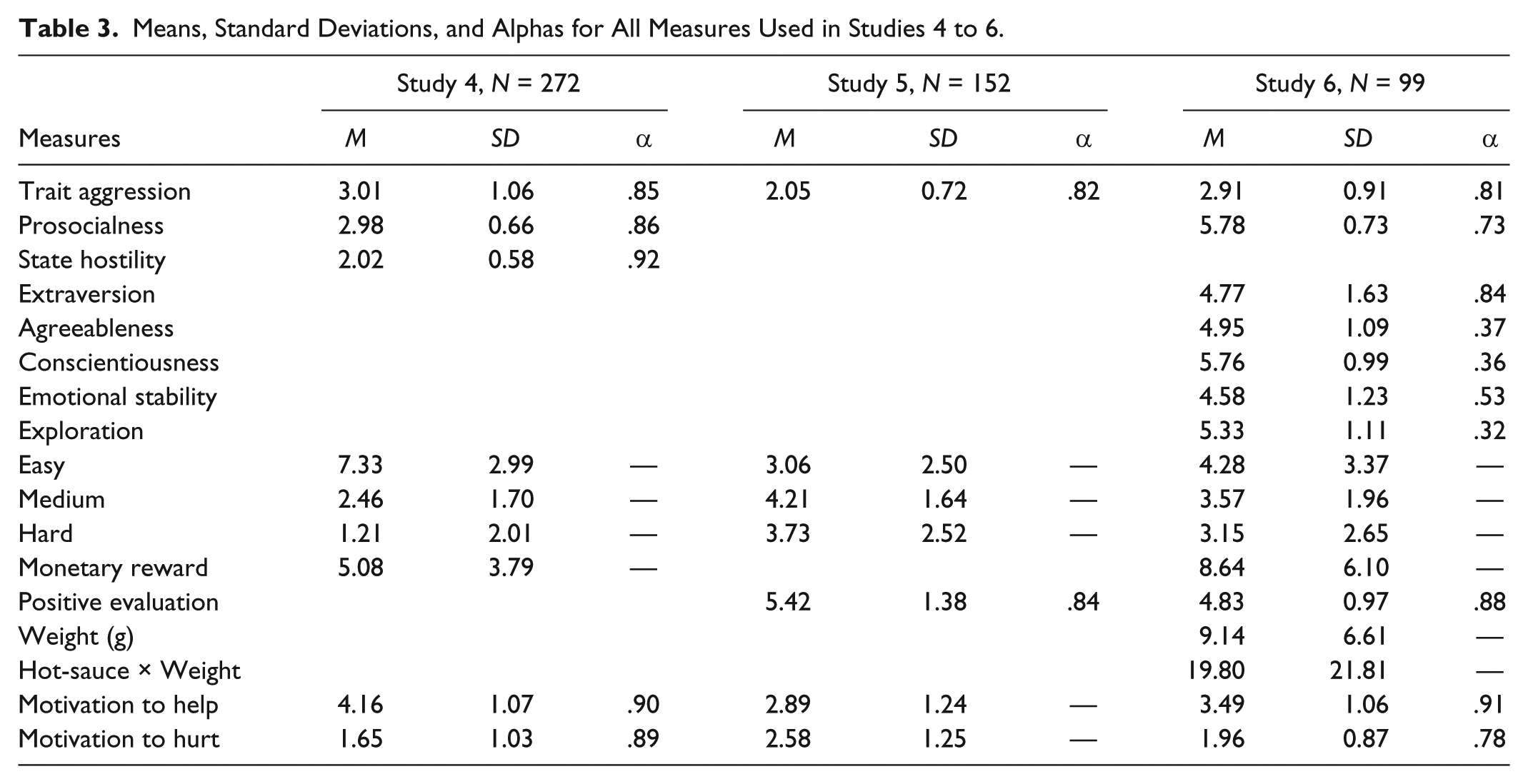
Means, standard deviations, and correlations among the six post-experimental measures are provided in Tables 3 and 4. As seen in Table 4, the usual pattern of correlations occurred for the three tangram and two motivation measures. Furthermore, monetary reward correlated positively with helping behavior and motivation, and negatively with hurting motivation.
Means, Standard Deviations, and Alphas for All Measures Used in Studies 4 to 6.
Zero-Order Correlations Between Tangram Scores and Other Outcome Measures Used in Studies 4 to 6.
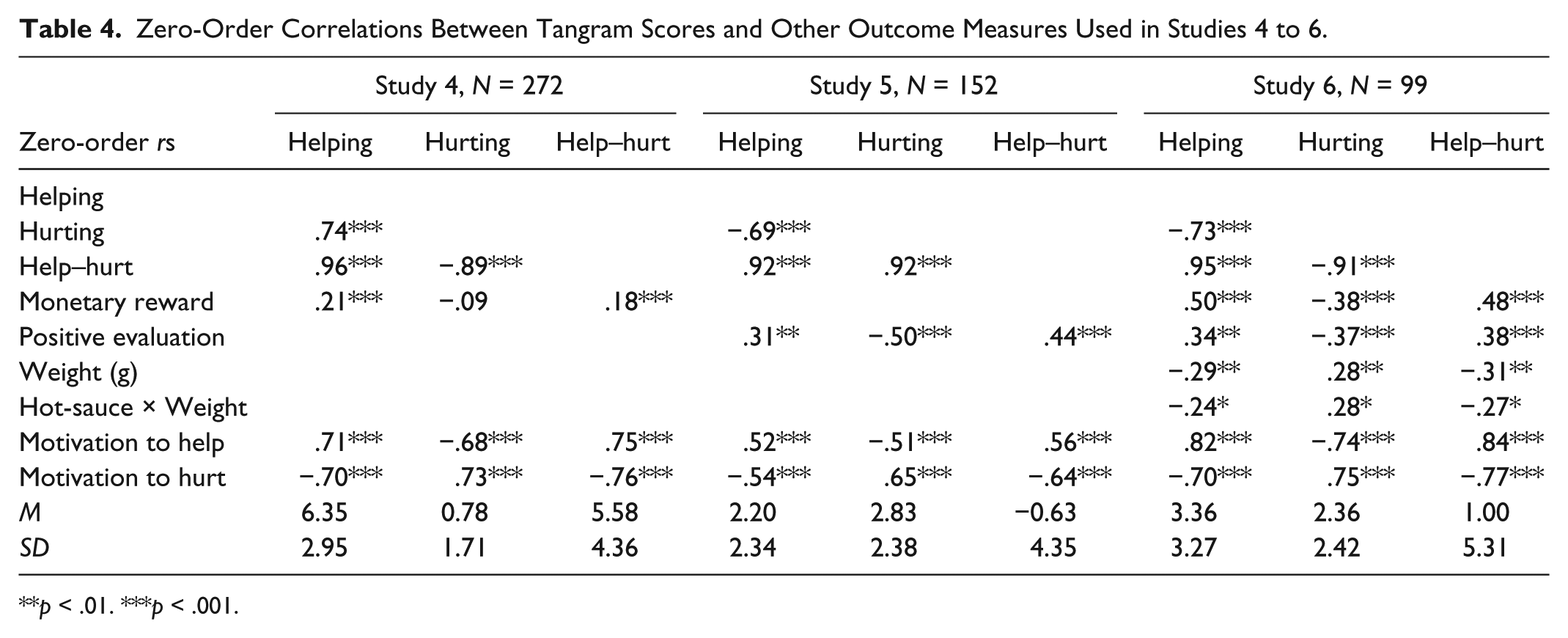
p < .01. ***p < .001.
For each pre-experimental measure and demographic variable, we tested the main effect and two-way interaction with condition in separate ANCOVAs for helping, hurting, and the difference score. Trait aggression, participant age, and sex yielded significant effects and thus were included as covariates in the main analyses; all other measures were dropped. 6
A one-way (condition: empathy-inducing/neutral) ANOVA revealed that condition did not significantly influence state hostility, F < 1.00, p > .10, and thus it was dropped from the main analyses.
Main analyses
Difference score
A one-way (condition: empathy-inducing/neutral) ANCOVA with trait aggression, participant sex, and age as covariates revealed a significant effect of condition, F(1, 262) = 11.57, p < .01, d = 0.42,
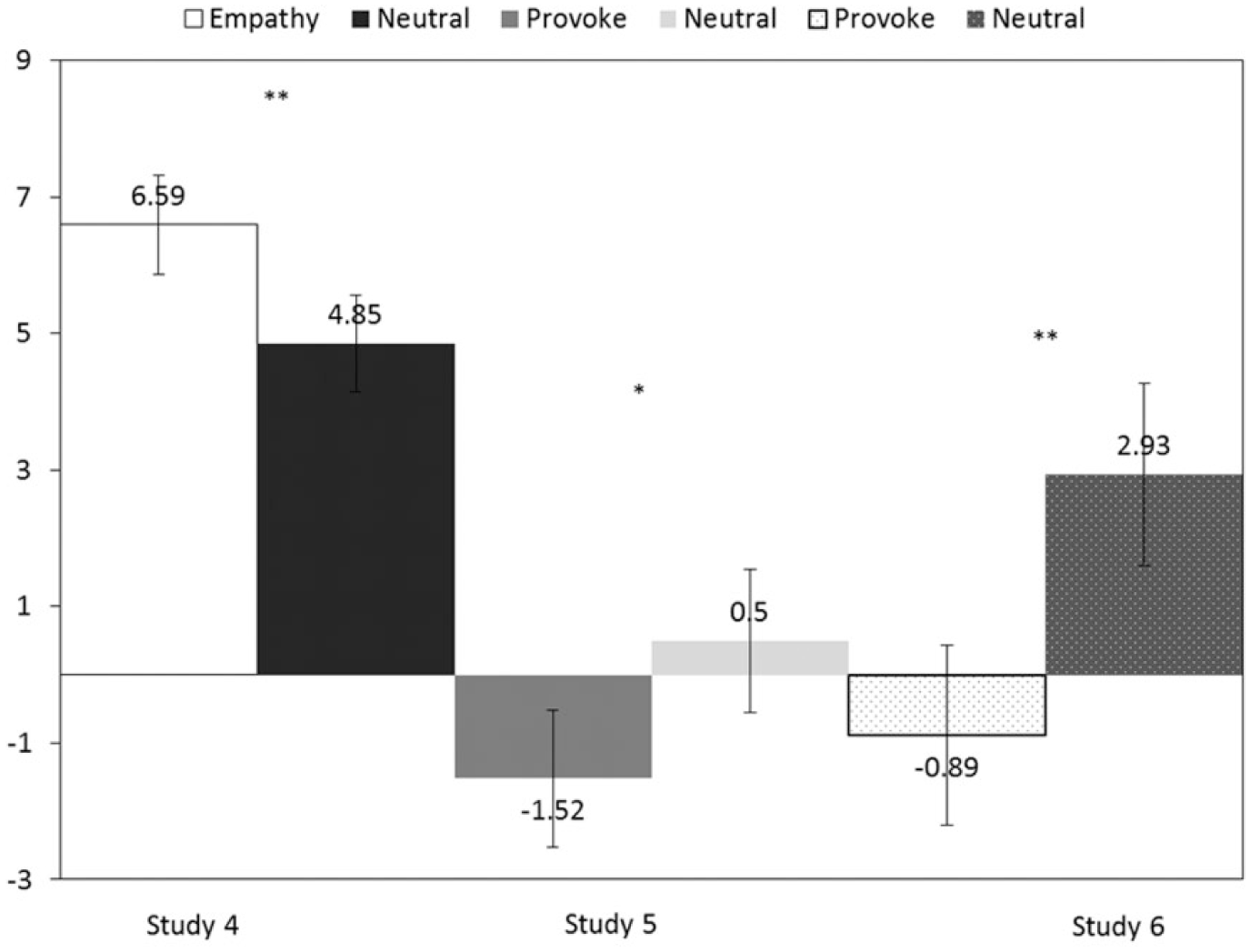
Difference score as a function of experimental manipulations in Studies 4 to 6.
Separate helping and hurting scores
As shown in Figure 3, participants in the empathy condition were more helpful than participants in the neutral condition (Ms = 7.03 and 5.88, 95% CIs = [6.54, 7.51] and [5.40, 6.37], respectively), F(1, 262) = 10.98, p < .01, d = 0.41,
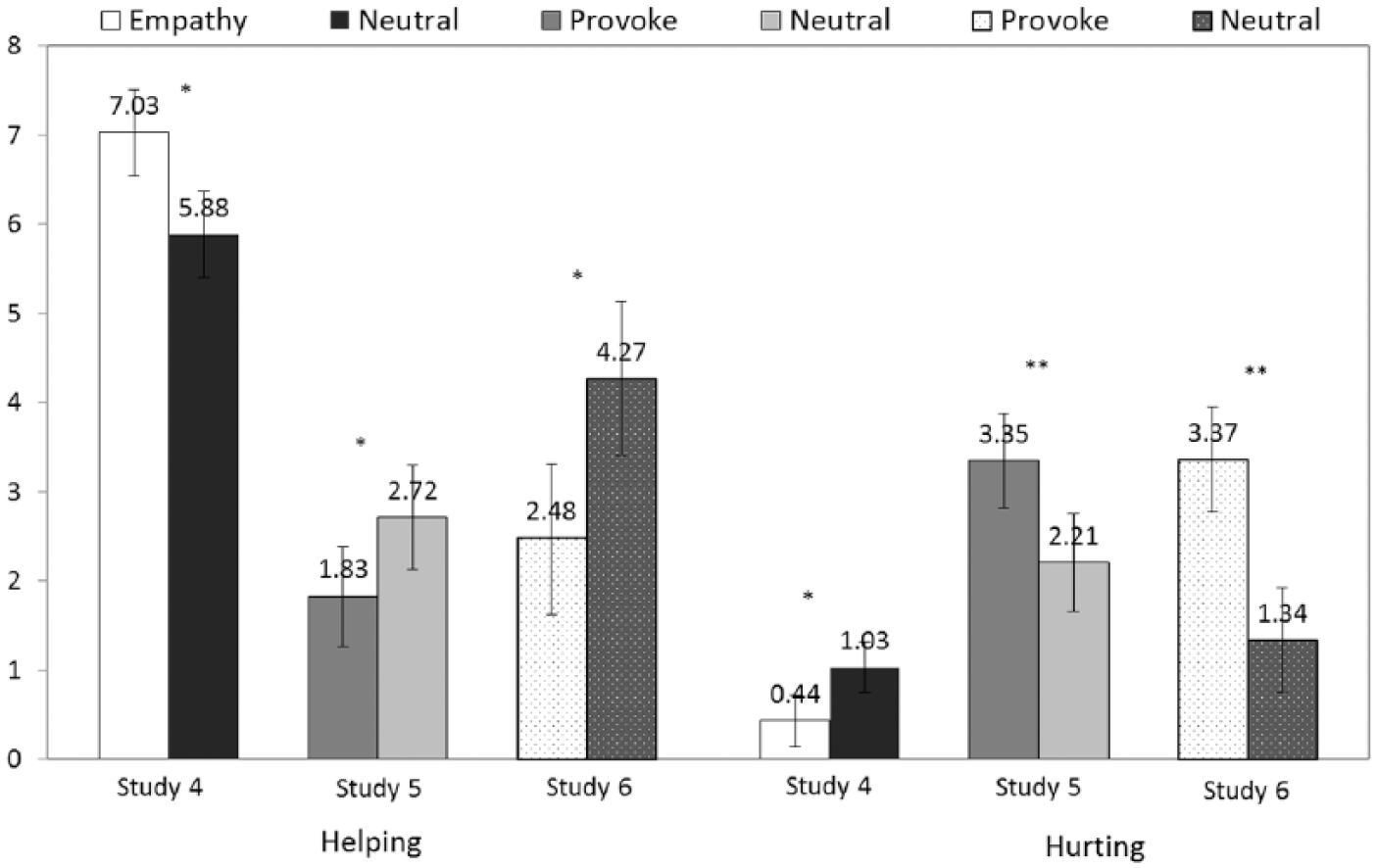
Helpful and hurtful behavior as a function of experimental manipulations in Studies 4 to 6.
In addition, participant sex influenced helping, F(1, 262) = 5.67, p < .05, d = 0.29,
Monetary reward recommendation
A one-way (condition: empathy-inducing/neutral) ANOVA revealed a significant effect of condition, F(1, 270) = 11.42, p < .01, d = 0.41,
In sum, an empathy-inducing prime known to increase prosocial behavior increased helping as assessed by the Tangram Task. Importantly, these effects were found using both scoring methods. These effects cannot be attributed to changes in mood as the prime did not influence state hostility.
Study 5: Provocation Effect on the Tangram Task
Study 5 tested whether a provocation manipulation that is known to increase aggressive behavior would influence hurting behavior as assessed by the Tangram Task. Participants also evaluated the other participant on several theoretically relevant dimensions.
Method
Participants
One hundred fifty-two students from a large Midwestern University participated in this experiment for course credit. Fifteen were rated as suspicious based on debriefing questions, so their data were deleted. Suspicion did not vary significantly by condition, p > .20. Of the remaining 137 participants, 59 were male, 72 female, and 6 unidentified. The mean age was 19.60 (SD = 2.15) years.
Materials
Helping and hurting were assessed through the Tangram Help/Hurt Task. Demographics were assessed using the same items as in previous studies. Due to time constraints, only the physical aggression subscale of the BPAQ scale was measured pre-experimentally. Helpful and hurtful intention/motivation for tangram assignment were assessed using one item each (e.g., “I wanted to help [make it difficult for] the other participant to win the prize”).
Provocation
Participants wrote an essay on the topic of abortion. They were led to believe that their essay would be evaluated by another participant through written feedback. Similarly, they were told that they would evaluate the other participant’s essay and give them feedback. Participants in the provocation condition received negative feedback on all dimensions, whereas those in the neutral condition received average feedback on all dimensions. This manipulation is known to increase aggression (Bushman & Baumeister, 1998).
Evaluation
Participants rated their agreement with 11 statements about the other participant (e.g., “The other participant is competent,” “The other participant is fair and reasonable”) using a 1 (strongly disagree) to 10 (strongly agree) scale. Similar items have been used in previous research (Pedersen et al., 2000; Twenge et al., 2001).
Procedure
After consenting, participants were told that we are interested in understanding the relationship between participants’ writing style, impressions of others, and performance on a puzzle task. Participants received standard tangram instructions and then completed the physical trait aggression scale. Next, participants wrote an essay either supporting or opposing abortion (their choice). When participants finished writing, they were given the essay ostensibly written by the other participant and were asked to evaluate it. Next, they received the other participants’ supposed essay evaluation—the experimental manipulation of provocation. Next, they chose 11 tangrams to assign the other participant, and then evaluated that person on 11 dimensions. Then, participants completed demographics items and were probed for suspicion before being thanked and fully debriefed.
Results
Preliminary analyses
Means and standard deviations for the tangram scores are provided in Tables 3 and 4. As displayed in Table 4, all three tangram scores were significantly related to motivation items and to evaluations of the other participant. The same strategy as Study 4 was used to determine which covariates to include in the main analyses. Trait aggression yielded significant effects on helping, hurting, and the difference score and thus was included in the main analyses.
Main analyses
Difference score
A one-way (condition: provocation/neutral) ANCOVA with physical aggression as a covariate revealed a significant effect of condition, F(1, 127) = 7.72, p < .05, d = 0.49,
Separate helping and hurting scores
Provoked participants scored higher on hurting than participants in the neutral condition (Ms = 3.35 and 2.21, 95% CIs = [2.82, 3.88] and [1.66, 2.76], respectively), F(1, 127) = 8.73, p < .01, d = 0.52,
Evaluation of the other participant
As expected, participants in the neutral, relative to provoked, condition gave the other participant more positive evaluations, Ms = 5.99; 4.89, F(1, 129) = 24.48, p < .001, d = 0.87,
Comparison of hurting indices
To test whether the experimental manipulation influenced the hurting scores from the Tangram Task differently than the evaluation for the other participant, a 2 (condition: provocation/neutral) × 2 (outcome: hurting score from the Tangram Task/evaluation) mixed ANOVA was conducted with outcome as the within-subjects factor. In these analyses, we reverse-scored the positive evaluation items, so higher scores represent negative evaluations of the other participant. In addition, both outcomes were standardized. As expected, the condition effect was significant, F(1, 129) = 19.51, p < .01. In addition, the Condition × Outcome interaction was significant, F(1, 129) = 4.49, p < .05. Simple effects analyses revealed that the condition effect on negative evaluations was significantly stronger than on hurting scores assesses through the Tangram Task, Fs(1, 129) = 24.58, 6.90, ps < .05, ds = .87; .46,
Study 6: Provocation Effect on the Hot-Sauce and Tangram Tasks
Study 6 tested and compared the effects of a provocation manipulation on the Tangram, other participant evaluation, and Hot-Sauce Tasks. Pre-experimental measures of trait aggression, trait prosocialness, and the 10-item personality inventory were included to provide additional convergent and discriminant validity evidence for the Tangram Task.
Method
Participants
A total of 104 students from a large Midwestern University participated in this experiment for course credit. Five were rated as suspicious based on debriefing questions; their data were deleted. Suspicion did not vary significantly by condition, p > .10. Of the remaining 99 participants, 9 were male, 90 female. 8 The mean age was 19.10 (SD = 0.61) years.
Materials
Table 2 includes the means, standard deviations, and alphas for all measures.
Pre-experimental measures
Trait aggression, trait prosocialness, and demographics were assessed as in Study 3. Personality was assessed using the Ten-Item Personality Inventory (TIPI; Gosling, Rentfrow, & Swann, 2003). The TIPI contains two items designed to assess each of the Big Five personality traits (i.e., extraversion, agreeableness, conscientiousness, emotional stability, and exploration).
Experimental manipulation
Provocation
The provocation method was the same as in Study 5, except the essay topic was affirmative action instead of abortion.
Outcome measures
Tangram Task
Helping and hurting scores were assessed through the Tangram Help/Hurt Task used in previous studies.
Hot-Sauce Task
The Hot-Sauce Task was administered based on the procedure described by McGregor et al. (1998). We assessed two indices, the weight in grams of the hot-sauce assigned to the other participant (McGregor et al., 1998), and the product of the hotness of the sauce selected and the weight in grams (C. Barlett, Branch, Rodeheffer, & Harris, 2009).
Evaluation and monetary reward
Participants rated their agreement with statements describing the other participant as intelligent, skillful, competent, kind, and warm on a 1 (strongly disagree) to 5 (strongly agree) scale (Pedersen et al., 2000; Twenge et al., 2001). Additional items assessed the extent to which they liked the other participant and would want to work with them again. Finally, participants were told that at times, we reward research participants with a monetary reward for their outstanding performance. Participants made a recommendation of how much money the other participant should get in addition to the credit they were receiving on a continuous scale ($0-$20.00).
Procedure
After completing informed consent, participants were told that we were interested in understanding how people interact with someone they do not know. Participants were told that they will complete writing, puzzle, and food tasks. Regarding the food task, participants were told that today all participants are randomly assigned to taste a food sample from the dry or spicy category. Participants were told that both participants will assign a food sample from one of these categories to the other participant and will be informed of the other participants’ food preferences. Next, they rated their food preferences. After that, participants received standard Tangram Task instructions and completed pre-experimental measures. Next, participants wrote an essay either supporting or opposing affirmative action (their choice). After submitting their essay, participants were told that the other participant has not yet completed their essay and thus were asked to answer demographic questions meanwhile. Next, they were given the essay ostensibly written by the other participant and were asked to evaluate it. Next, they received the other participants’ supposed essay evaluation—the experimental manipulation of provocation. Next, they completed the Tangram and Hot-Sauce Tasks. The order of these two tasks was counterbalanced across participants. Next, they tasted the food sample assigned to them, evaluated the food sample, and evaluated the other participant on seven dimensions. Finally, participants were asked questions assessing their suspicion of the experiment, thanked, and fully debriefed.
Results
Preliminary analyses
Tables 3 and 4 present the means, standard deviations, and correlations among the outcome measures. As can be seen, the usual pattern of correlations occurred for the three tangram and two motivation measures. In addition, the weight of hot-sauce, the product of hot-sauce number and weight, the evaluation, and the monetary reward scores correlated with Tangram Task scores and the motivation measures as they theoretically should, providing further convergent validity evidence.
The same strategy as in Studies 4 to 6 was used to determine which covariates to include in the main analyses. Only trait prosocialness yielded significant effects, so others were dropped from main analyses.
Main analyses
Difference score
A one-way (condition: provocation/neutral) ANCOVA with trait prosocialness as a covariate revealed a significant effect of essay condition, F(1, 96) = 16.35, p < .01, d = 0.83,
Separate helping and hurting scores
As shown in Figure 3, provoked participants scored higher on hurting than participants in the neutral condition (Ms = 3.37 and 1.34, 95% CIs = [2.78, 3.95] and [0.75, 1.93], respectively), F(1, 96) = 23.12, p < .001, d = 0.98,
Hot-Sauce Task
Recall that there were two indices, the weight in grams of the hot-sauce assigned to the other participant and the product of the hot-sauce selected and the weight in grams. Two one-way (condition: provocation/neutral) ANCOVAs with trait prosocialness as a covariate revealed a significant effect of condition on both the weight and the Weight × Hot-sauce product, Fs(1, 96) = 9.71, 4.84, ps < .05, ds = .64. 0.45,
Evaluation
A one-way (condition: provocation/neutral) ANCOVA with trait prosocialness as a covariate revealed a significant effect of condition, F(1, 95) = 38.21, p < .001, d = 1.27,
Monetary reward
A one-way (condition: provocation/neutral) ANCOVA with trait prosocialness as a covariate revealed a significant effect of condition, F(1, 95) = 18.54, p < .001, d = 0.88,
Correlations across outcomes
As shown in Table 4, the tangram measures correlated appropriately with the monetary reward, evaluation, and hot-sauce measures, providing further validation.
Effect sizes across outcomes
Figure 4 displays the effect sizes of the essay manipulation on the multiple outcomes assessed in this study. Indices of hurtfulness from the Tangram Task (hurt score and difference score) were more sensitive to the provocation manipulation than the indices of hurtfulness from the Hot-Sauce Task (weight in grams and Weight × Hot-sauce product). However, the positive evaluation and monetary reward measures were more sensitive to the provocation manipulation than the Tangram Task and the hot-sauce indices. We suspect that the latter two measures reflect more accurate assessments of behaviors, whereas, the former two measures represent cognitive and affective constructs that are generally more sensitive to priming methods.
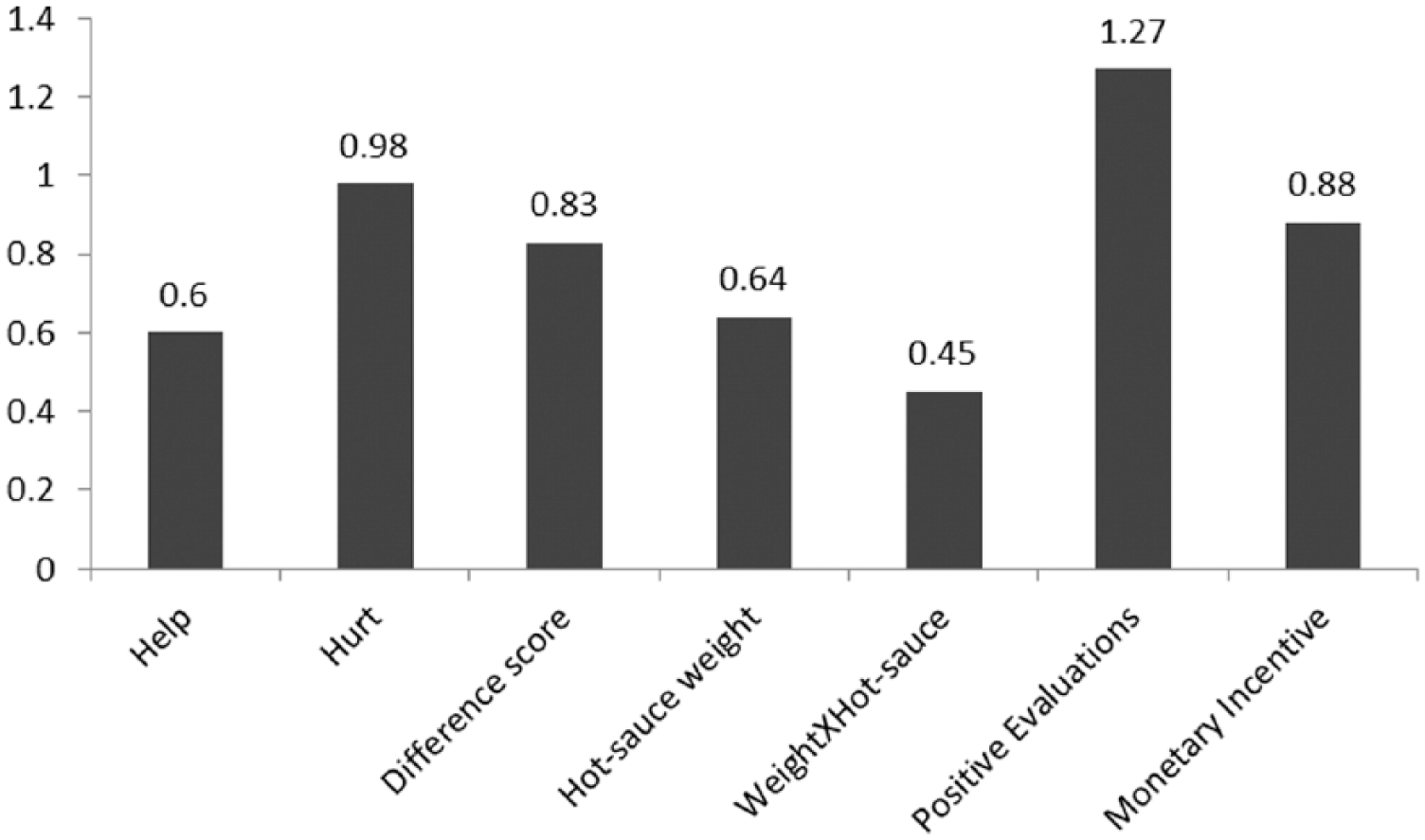
Cohen’s d effect sizes reflecting the effect of provocation on all outcomes in Study 6.
Comparison of hurting indices
We tested the effect of essay condition on aggression as assessed by the Tangram (hurting score) and Hot-Sauce (weight) tasks. Both outcomes were standardized in this analysis. A 2 (condition: provocation/neutral) × 2 (task: tangram/hot-sauce) mixed ANOVA was conducted with task as the within-subjects factor. As expected, the condition effect was significant, F(1, 97) = 24.51, p < .001, d = 1.01,
In sum, provocation increased hurting and decreased helping behavior as assessed by the Tangram Task. Once again, this effect was reliable for both scoring methods. The Tangram Task was more sensitive to the provocation manipulation than the Hot-Sauce Task but not as sensitive as the evaluation and monetary reward outcomes. Finally, the correlations between the pre-experimental measures and the helping and hurting scores assessed through the Tangram Task were comparable in size and direction with those observed with other established assessments of helpfulness and hurtfulness.
Discussion
The Present Studies
The primary goal of this research was to introduce and validate the Tangram Task as a measure of helping and hurting behaviors. Studies 1 to 3 provide convergent and discriminant validity evidence for the task using college-aged and adult samples through correlational designs. Across these three studies, helpful and hurtful scores were significantly correlated with established trait assessments of aggression, prosocialness, empathy, perspective taking, state hostility, narcissism, agreeableness, and control aggression schemas. Specific to trait aggression, it is important to note that hurting behavior on the Tangram Task was more strongly related with the physical, anger, and hostile subscales of the BPAQ, relative to the verbal subscale. In addition, tangram choices were not influenced by social desirability, achievement motivation, emotion regulation, sex of participant, or perception of the Tangram Task difficulty.
Experimental evidence from Study 4 validated the Tangram Task for use in studies priming prosocial behavior. Studies 5 and 6 validated the Tangram Task for studies of provocation effects on aggression. Additional indices of helpfulness and hurtfulness included in Studies 4 (monetary reward), 5 (evaluation of other participant), and 6 (Hot-Sauce Task, evaluation of other participant, and monetary reward) significantly correlated with scores on the Tangram Task. The effects of the manipulations on the Tangram Task were comparable and in some cases more sensitive than established indices of helpful and hurtful behaviors (i.e., monetary reward and Hot-Sauce Tasks). Conversely, evaluations of the other participant (in Studies 5 and 6) were more sensitive to the experimental manipulations than the Tangram Task. This may be due to the former representing an attitude, which is generally more sensitive to priming manipulations, and the latter representing a behavior. Note that the correlations observed between the pre-experimental trait measures and the Tangram Task were also similar in direction and size to those observed for established measures of prosocial and aggressive behaviors (see Supplemental Material analyses for these tables).
Finally, the intention/motivation assessments in all studies provided evidence that the assignment of harder puzzles was motivated by a desire to hurt (and not help) the other participant, whereas, the assignment of easier puzzles was motivated by a desire to help (and not hurt) the other participant. These consistent findings across multiple designs and methods provide further evidence of the key role played by intentions in both prosocial and antisocial domains (e.g., Graziano & Habashi, 2010).
Related Studies
In addition to the present six studies, we know of at least five additional experiments that have used the Tangram Task. In an intergroup context, Saleem et al. (under review: Study 3) found that participants primed with secure attachment chose more easy tangrams for outgroup members than did those in the neutral condition. Another experimental study (C. P. Barlett & Anderson, 2011, Study 1) revealed that the number of hard tangrams selected for another participant was highest for participants who were both (a) previously provoked, and (b) who had not been given any mitigating information concerning the provocation, relative to participants who either did receive mitigating information after the provocation, or who were unprovoked. Thus, in addition to provocation, the Tangram Task is sensitive to re-appraisal manipulations.
Experimental evidence from Gentile et al. (2009, Study 3) found that college-aged participants randomly assigned to play a prosocial video game selected significantly more easy tangram puzzles for the “other” person to solve, relative to participants who played a neutral video game. Conversely, participants in the violent video game condition selected significantly more hard tangrams, relative to those who had played a neutral video game. These video game results were further replicated using the Tangram Task with children 9 to 14 years of age (Saleem, Anderson, & Gentile, 2012).
The Tangram Help/Hurt Task has several advantages over other established measures of helpful and hurtful behaviors. First, the Tangram Task allows simultaneous assessment of helping and hurting behavior. Although these two scores are negatively correlated, by assessing them in the same paradigm at the same time, researchers can use regression techniques to assess the unique and shared variances with correlational and experimental variables, and could even assess changes in helping/hurting choices over time to examine the roles of automatic and controlled processes (cf. Graziano & Habashi, 2010). Second, researchers have the flexibility to evaluate what kind of scoring method is appropriate for their particular research design. For some studies, it may be appropriate to use a simple overall difference score. For other studies, it may be more appropriate to have separate help and hurt scores. Indeed, in some studies it might make sense to use even stronger adjustments to what constitutes clear evidence of helpful and hurtful intent. For example, counting only the number of hard tangram selections greater than 2 or 3, and assigning zeros to participants who chose 0, 1, or 2 hard tangrams, would further reduce the correlation between the “help” and “hurt” scores and providence evidence for extreme forms of aggression. Third, the Tangram Task includes a medium category, allowing for a response that is neither aggressive nor prosocial response (a common criticism levied against other validated aggression measures; see Ritter & Eslea, 2005). Fourth, tangrams can easily be used with adults and children. One can adjust the difficulty of the task for different populations by selecting a different set of tangrams or by setting different time limits. Fifth, the cover story and various materials used are easily amenable to change, therefore allowing use in a diverse array of studies. Sixth, the Tangram Help/Hurt Task relies on simple count data compatible with paper or computer-based administration, and does not require fancy timing equipment. Indeed, it is easily administered in online studies. Seventh, because the Tangram Task inherently involves puzzle completion and assignment, task instructions should easily translate into other languages allowing this measure to be used cross-culturally. Finally, the Tangram Task could easily be used as a provocation stimulus or a success/failure manipulation by assigning mostly easy/hard puzzles from another ostensible participant.
Limitations
It also is important to note several limitations of the Tangram Help/Hurt Task. First, all the studies reported in this article reveal a strong negative correlation between the helping and hurting scores, when used separately. Individuals who score high on helpfulness by selecting a greater number of easy puzzles will score low on hurtfulness, and vice versa. Indeed, even after using our “greater than 1” scoring procedure, the correlation between the helpful and hurtful scores remained high. This concern can be addressed in several ways: (a) ignoring the medium category for the analyses, thus reducing interdependence; (b) using the number of easy and difficult puzzles greater than 1 instead of raw scores so that participants can obtain a score of 0 on both helpfulness and hurtfulness; (c) entering both helpful and hurtful scores as a within-subjects factor in analyses; (d) using a difference score (helpful score-hurtful score); and (e) using regression procedures to examine the effects of an independent variable of either helping or hurting, while statistically controlling for the other tangram score. Finally, one can further reduce the correlation between helpful and hurtful scores by setting more extreme rules for what counts as helpful or hurtful behavior.
A second limitation identified by the present studies is that the correlations between relevant trait measures and tangram choices are small to moderate (rs = .17-.32). This is common throughout social psychology, especially when using college student samples that have relatively restricted range, relative to other samples (e.g., Kalmoe, 2015). For online MTurk samples, the online setting may have induced greater suspicion regarding the presence of another participant who was involved in the experiment at the same time as the participant. Two other possible contributors to the small magnitude of the correlations are (a) the fact that general trait measures usually do not predict specific behaviors very strongly, and (b) the reported correlations did not adjust for unreliability of the trait measures, or of the Tangram Task itself. In short, obtained correlations support the convergent validity predictions for this task, and are likely as good as convergent validity correlations for most other brief laboratory style measures of aggressive behavior.
Third, though we established discriminant validity for the Tangram Task using assessments of social desirability, achievement motivation, emotion regulation, and perception of Tangram Task difficulty, other constructs may relate to the Tangram Task. Future research can address these concerns.
Future research also could compare the convergent validity of the Tangram Help/Hurt Task with additional aggressive and prosocial behavioral measures such as competitive reaction time task (Bushman, 1995), prisoner’s dilemma task (Rapoport & Chammah, 1965), and intention to volunteer or donate to charities (Twenge, Baumeister, DeWall, Ciarocco, & Bartels, 2007). In addition, it is important to assess whether experimental manipulations of aggressive and prosocial cognitions influence choices on the Tangram Help/Hurt Task. Finally, the Tangram Help/Hurt Task should be used with different samples that have diverse demographic characteristics to better understand its generalizability.
Artificial, laboratory-based aggression paradigms like the Tangram Task are not necessarily designed to capture the full essence, nuances, and contextual complexity of “real-world” aggression. Rather, the primary goal of most laboratory research is the development of theories designed to explain underlying processes and mechanisms, it is these theoretical principles that one wishes to generalize, not the specific characteristics of the sample, setting, manipulation, or measure. (Anderson & Bushman, 1997, p. 22)
We encourage other researchers to use the Tangram Help/Hurt Task to explore its conceptual and methodological advantages and limitations.
Footnotes
Appendix
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.