
Abstract
Research on automatic stereotyping is dominated by the idea that automatic stereotyping reflects the activation of (group–trait) associations. In two preregistered experiments (total N = 391), we tested predictions derived from an alternative perspective that suggests that automatic stereotyping is the result of the activation of propositional representations that, unlike associations, can encode relational information and have truth values. Experiment 1 found that automatic stereotyping is sensitive to the validity of information about pairs of traits and groups. Experiment 2 showed that automatic stereotyping is sensitive to the specific relations (e.g., whether a particular group is more or less friendly than a reference person) between pairs of traits and groups. Interestingly, both experiments found a weaker influence of validity/relational information on automatic stereotyping than on non-automatic stereotyping. We discuss the implications of these findings for research on automatic stereotyping.
Keywords
Within every society, there are widely shared beliefs about the characteristics of social groups and their members (Ashmore & Del Boca, 1981). These societal stereotypes influence, among other things, which demographic groups are more likely to be arrested (Spencer et al., 2016), the kinds of medical treatment members of those groups receive (Moskowitz et al., 2012), and the kinds of jobs members of those groups are offered (Koch et al., 2015).
From a cognitive perspective, societal stereotypes are typically construed as stereotype representations at the mental level. Activation of these representations results in stereotyping, that is, behaving in line with these stereotypes (see De Houwer, Gawronski, & Barnes-Holmes, 2013 for a similar conceptualization in the domain of attitudes). Stereotypes are usually distinguished from evaluations; whereas evaluations vary along a positive–negative continuum, stereotypes involve nonvalenced semantic content (Amodio & Ratner, 2011; Greenwald et al., 2002). In the last two decades, researchers have started to study automatic stereotyping. 1 Automatic stereotyping can be defined broadly as a behavior (a stereotypic response) that is emitted under suboptimal conditions (De Houwer, 2019; De Houwer, Barnes-Holmes, & Moors, 2013; De Houwer et al., 2020). Conditions that are typically considered to be suboptimal include those in which there is limited time to respond, where people are engaged simultaneously in other demanding tasks, or where people do not have the explicit goal to engage in stereotyping (see Moors, 2016, and De Houwer et al., 2009, for more details). Whereas non-automatic stereotyping is typically measured by directly asking people under optimal conditions about what they think and do, automatic stereotyping is usually measured with indirect (implicit) measures, which attempt to capture this information under sub-optimal conditions. For example, one of the main measures of automatic stereotyping is the Implicit Association Test (IAT; Greenwald et al., 1998) which requires participants to respond quickly (i.e., participants are instructed to respond as quickly as possible) and fosters conditions where stereotyping responses will be emitted unintentionally (i.e., participants are not asked to make a stereotypic response or to report their stereotypes).
The prevailing view on automatic stereotypes for decades has been that stereotype representations are mental associations (e.g., women-emotional), and that automatic stereotyping reflects the activation of these associations (e.g., Blair et al., 2001; Devine, 1989; Greenwald et al., 2002; Kawakami et al., 2017). For example, Devine (1989) argued that stereotypes are a “well-learned set of associations. . . that [are] automatically activated in the presence of a member (or symbolic equivalent) of the target group” (p. 6). Greenwald et al. (2002) defined stereotypes as “the association of a social group concept with one or more (nonvalenced) attribute concepts” (p. 5) and argued that stereotyping measured with indirect measures, such as the IAT, reflect the activation of these associations.
The dominance of associative theorizing on automatic stereotyping, however, does not align well with the fact that societal stereotypes typically involve relational beliefs about the characteristics of members of certain groups (e.g., Hilton & Von Hippel, 1996). The relational nature of societal stereotypes can be illustrated by the distinction between descriptive stereotypes (e.g., “women are emotional”) and prescriptive stereotypes (e.g., “woman should be emotional”; e.g., Burgess & Borgida, 1999), a distinction that can only be drawn in terms of relational terms (e.g., “are” vs. “should be”). Importantly, initial research suggests that evidence for this distinction can be also found under sub-optimal conditions, that is, at the level of automatic stereotyping (Cummins & De Houwer, 2019).
In the current research, we suggest an alternative perspective on automatic stereotyping: that stereotype representations are propositions, and that automatic stereotyping results from the activation of propositions, not associations. Propositional representations differ from associative representations in two key ways: (a) they encode relational information (i.e., they specify how stimuli are related) and (b) they have a truth value (i.e., they can be evaluated as being true or false). Indeed, propositional perspectives on social psychological phenomena have already shown promise elsewhere, such as in the context of automatic evaluation (De Houwer, 2014; De Houwer et al., 2020). This perspective on automatic evaluation has recently challenged the dominant associative perspective which purports that automatic evaluation reflects the activation of associations between a target and a valence concept (e.g., a Bob–positive association mediates the evaluation of Bob; Gawronski & Bodenhausen, 2006). According to a propositional perspective, automatic evaluation reflects the automatic activation of propositional representations (e.g., “Bob is a good person”; De Houwer, 2014). Critically, this novel propositional perspective has inspired investigation into a host of new findings which do not follow readily from the associative perspective (see De Houwer et al., 2020, for a review).
Similar to the context of automatic evaluation, the propositional perspective also offers new predictions in the context of automatic stereotyping. First, because propositions (e.g., “women are emotional”) have a truth value, a propositional perspective predicts a sensitivity of automatic stereotyping to validity information. Second, because propositions specify the relation between the two concepts (e.g., group and trait), a propositional perspective predicts a sensitivity of automatic stereotyping to the relation between groups and traits.
The question of whether automatic stereotyping is sensitive to relational and validity information is highly important. As part of their everyday lives, people cannot help being exposed to information about social groups. However, not all of the information people are exposed to is true or accurate. We are often exposed to false or inaccurate information about social groups in the media and through speculation and gossip (e.g., Martin et al., 2014). From the propositional perspective, this leads to the question: will automatic stereotyping be influenced by information about social groups even when a person knows that this information is invalid? Furthermore, information given to us about members of social groups is almost always relational in nature. For example, we can learn that members of a social group are related to hostility because they are usually suffering as a result of it, or because they usually cause hostility (Andreychik & Gill, 2012). This leads to a further question: will automatic stereotyping be influenced by the specific relation between social groups and traits? Except for a few limited studies (described in the following), these questions have not been explored in the past in the context of automatic stereotyping.
Before we discuss the initial base of evidence for a propositional perspective of automatic stereotyping, we would like to emphasize two things. First, our goal with the present research is not to prove which of the perspectives (associative vs. propositional) to automatic stereotypes is correct. From a similar debate in the domain of automatic evaluation we know that even for findings that confirm the predictions of propositional models, it will often be possible to devise alternative explanations in terms of associations, and vice versa (De Houwer et al., 2020). Our goal here is to use the generative power of the idea that automatic stereotyping results from activation of propositional representations in order to formulate new and interesting research questions (e.g., is automatic stereotyping sensitive to validity information?) that were hardly investigated before. Importantly, the answers to these can be later used to constrain different theoretical models of automatic stereotyping.
Second, we can draw from the fact that the propositional perspective has already inspired a substantial amount of research on automatic evaluation (for a review see De Houwer et al., 2020). We hope that the present research is the start of a similarly informative line of research on automatic stereotyping. Supporting the predictions of the propositional perspective, research has accumulated evidence that automatic evaluation can be sensitive to relational and validity information (e.g., Moran et al., 2015, 2017; Peters & Gawronski, 2011). However, the fact that automatic evaluation has shown sensitivity to relational and validity information does not necessarily mean that the same pattern will be observed for automatic stereotyping. Debate around the nature of the link between automatic evaluation and automatic stereotyping is still on-going, with some suggesting a weak relation between them (Amodio & Devine, 2006; Amodio & Ratner, 2011; Cunningham et al., 2004; Rudman & Goodwin, 2004; Sabin et al., 2008) and others suggesting a strong relation (Kurdi et al., 2019; Phills et al., 2020). It is therefore important to elaborate on a propositional account of automatic stereotyping, to better understand the nature of its relationship to automatic evaluation.
We are aware of one published study that found sensitivity of a new developed automatic stereotyping measure (Truth Misattribution Procedure; TMP) to relational information (Cummins & De Houwer, 2019). There is some evidence suggesting that automatic stereotyping can be sensitive to validity information. Jabold (2020) investigated the effect of crime reports on criminal stereotyping of novel groups, and whether stereotyping is updated when new crime statistics negate the initial learned information (i.e., suggesting that the initial crime reports are invalid). Results indicated that automatic stereotyping was sensitive to the validity of the initial stereotypic information. In addition, Rubinstein et al. (2018) tested whether race stereotypes (e.g., Black people are less intelligent than White people) or individuating information (e.g., SAT scores) influence the automatic stereotyping of individuals as intelligent or not. When valid individuating information contradicted the race stereotypes, automatic stereotyping reflected only the individuating information. However, both these studies confounded stereotyping with evaluations. Jabold (2020) examined stereotyping against criminals versus lawful people, which are groups that clearly differ in valence. Rubinstein et al. (2018) focused on stereotypes about intelligent versus stupid people, a distinction that is also confounded with valence. Hence, it is unclear if these previous studies provide evidence supporting sensitivity to validity information of automatic stereotyping or merely automatic evaluation.
The Current Research
In the present research, we tested whether automatic stereotyping is sensitive to validity information and relational information. As in previous research on stereotyping (e.g., Crawford et al., 2002; Dotsch et al., 2013; Phills et al., 2020; Sherman, 1996; Smith & Zarate, 1990), we simulated automatic stereotyping processes in the lab by presenting information about the traits of novel groups. Experiment 1 tested whether automatic stereotyping of novel groups was influenced by the validity of the information presented. We asked participants to form impressions of two novel groups, each paired with verbal descriptions that imply that one group is warm and the other group is competent. We then informed half of the participants that the information had accidentally been mixed up and that the traits attributed to one group were actually about the other group, and vice versa. We tested whether automatic stereotyping (measured with the IAT) was sensitive to this validity information, or whether it reflected only the initial pairing. Experiment 2 tested whether automatic stereotyping was sensitive to the relational content of the information provided. We described two groups in relational terms (e.g., Group A is less friendly than Lisa, Group B is more friendly than Lisa) and then informed half of the participants that, accidentally, the words “more than” and “less than” had been mixed-up. We then tested whether automatic stereotyping reflected this relational information. Unlike in previous research, we took two steps to ensure that any results we find would be the result of stereotyping rather than evaluations. First, we used only positively valanced traits (warm and competent) in the manipulations and stereotyping measures. Second, we also measured participants’ (automatic) evaluations of the novel groups and controlled for their influence in our analyses. 2
All experiments were preregistered (see links in the following), and no file-drawered studies exist. Deviations from the preregistered plan are specified within the manuscript. We report all data exclusions, manipulations, measures, and how we determined our sample sizes (Simmons et al., 2012). Participants in all experiments were recruited online via the Prolific Academic website (https://prolific.ac). Each experiment took 15 min to complete and all participants were paid £1.60. In all experiments, we planned to collect data from 270 participants to have 95% power to find a between-participants effect of medium size (
Experiment 1
In Experiment 1, to test whether automatic stereotyping was sensitive to validity information, we adopted a “mix-up” manipulation that was used in previous research to test the effect of validity information on automatic evaluation (Gregg et al., 2006; Moran et al., 2017). Informing participants of such a “mix-up” in trait–group pairing implies that the initial pairing between each group and trait was invalid and needed to be updated. If we found evidence of such updating in the performances of participants, this would imply that their automatic stereotyping responses were reflective of the validity of the previous pairing between the groups and the traits, which would therefore provide evidence that automatic stereotyping is sensitive to validity information.
Method
Participants
The preregistration of Experiment 1 is available at osf.io/5pbry/. A total of 270 participants completed the study. The preregistered data exclusion involved removing participants who (a) did not fully complete all questions and tasks (1%), (b) had more than 10% trials in the IAT faster than 300 ms (9%), or (c) made at least one error on the comprehension questions (17.7%, Table 1 summarizes the exclusion according to this criterion as a function of experimental condition). The final sample included 200 participants (55% women, Mage = 33.53, SD = 11.70).
Exclusions (%) Based on Errors on the Comprehension Questions as a Function of the Experimental Condition in Experiments 1 and 2.
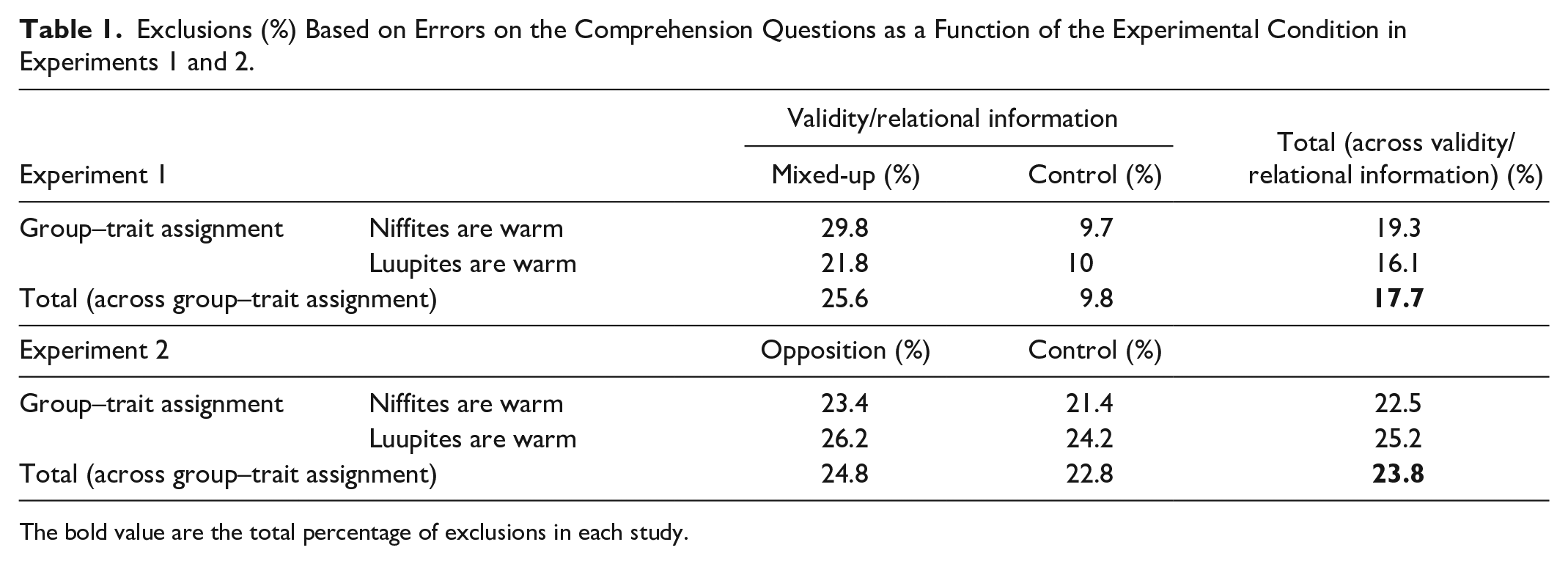
The bold value are the total percentage of exclusions in each study.
Materials and procedure
The full procedure, instructions, and materials of Experiments 1 and 2 are explained in detail in the online supplement. Participants were asked to imagine that they were planning to travel to an exotic island where two tribes (called “Niffites” and “Luupites”) live. They were told that Lisa, who has already visited this island and met these two tribes, would provide them with information about those groups. Participants were asked to learn this information and form an impression of each of the tribes. Then, we presented descriptions of the two tribes in three blocks. Each block consisted of four descriptions of each tribe, one at the time, for 4 s, in random order. The descriptions implied that one group was warm, and the other competent (see Table 2). After exposure to the descriptions, participants in the mixed-up condition were informed that, after Lisa provided the information about the tribes, she realized that she had mixed up the two tribes: everything she had told them about the Niffites was really about the Luupites, and everything she had told them about the Luupites was actually about the Niffites. Participants were asked to correct their impression of the tribes based on this new information. Participants in the control condition did not read this information.
Descriptions Presented in Experiment 1.

Note. All the traits used to represent the “warm” and “competent” categories were adopted from previous studies that used these traits to represent these two categories (Carlsson & Björklund, 2010; Fiske et al., 2002, 2007).
Next, all participants completed measures of automatic and self-reported stereotyping. All participants completed the automatic measure first. To measure automatic stereotyping, we used a seven-block IAT (Nosek et al., 2005). “Niffites” and “Luupites” were the target categories and “Warm” and “Competent” were the attribute categories (Table 3 details the items for each category). In two of the IAT’s critical blocks, “Niffites” and “Warm” shared the same response key, and in the other two critical blocks, “Luupites” and “Warm” shared the same response key. The D2 algorithm was used to create stereotyping IAT scores (Greenwald et al., 2003). We computed these scores such that positive scores indicated stereotypes in line with the initial information (median split-half reliability r = .70, 95% CI [.63, .76] 3 ). To measure self-reported stereotyping, we asked participants, in two questions, how much they associated the traits “warm” and “competent” with Niffites versus Luupites (with a 7-point Likert-type scale for responses: 1 = Much more strongly with Niffites, 4 = Equally strongly with Niffites and Luupites, 7 = Much more strongly with Luupites). Self-reported stereotyping scores were calculated by recoding the scale to -3 to +3, reversing the scores for the “competent” item and then averaging the scores of the two questions, such that positive scores indicate stereotypes in line with the initial information (Cronbach’s Alpha = .96).
Items used for each category in the IAT in Experiments 1-2.
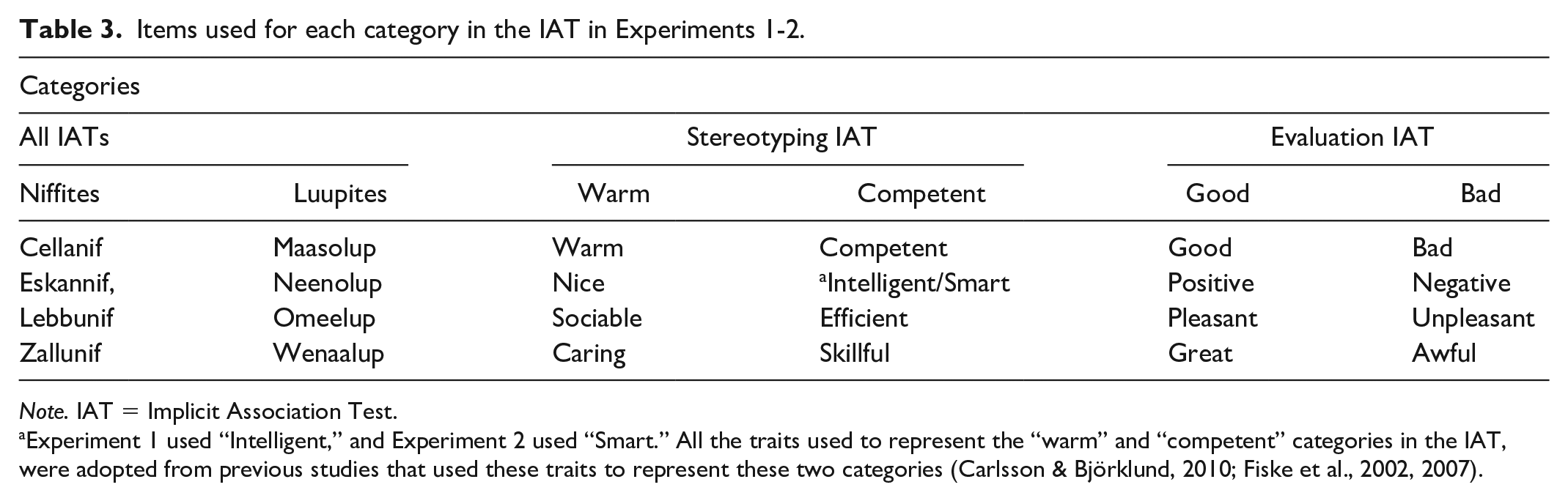
Note. IAT = Implicit Association Test.
Experiment 1 used “Intelligent,” and Experiment 2 used “Smart.” All the traits used to represent the “warm” and “competent” categories in the IAT, were adopted from previous studies that used these traits to represent these two categories (Carlsson & Björklund, 2010; Fiske et al., 2002, 2007).
Next, we assessed participants’ comprehension of the information provided about the two tribes. For each tribe, participants were asked to indicate the best-fitting description of the Niffites and Luupites from a series of options, including options which categorized them as warm/competent. Participants who responded incorrectly to one of these questions (based on both the initial information and the mixed-up information) were excluded from the analyses. 4
Finally, participants completed automatic and self-reported evaluation measures. All participants completed the automatic measure first. To measure automatic evaluation, we used the IAT, which was similar to the stereotyping IAT, except that we replaced the “Warm” and “Competent” categories with “Good” and “Bad” (see Table 2). To measure self-reported evaluation, participants rated on four different questions how positive or negative, and how good or bad, Niffites and Luupites were (with a 9-point Likert-type scale for response: −4 = very bad/very negative; +4 = very good/very positive). For both evaluation measures, scores were computed to reflect a preference for Niffites over Luupites (IAT: r = .61, 95% CI = [.51, .68], ratings: α = .94).
Design
The main independent variable was validity information (mixed-up vs. control). We counterbalanced, between participants, the group–trait assignment (Niffites are warm vs. Luupites are warm), the stereotyping IAT’s block order (Niffites-Warm/Luupites-Competent first vs. Luupites-Warm/Niffites-Competent first) and the evaluation IAT’s block order (Niffites-Positive/Luupites-Negative first vs. Luupites-Positive/Niffites-Negative first).
Results
For both the automatic and self-reported stereotyping measures, we tested whether the stereotyping scores were predicted by the validity condition (mixed-up vs. control). For the analysis of automatic stereotyping, we controlled for group–trait assignment, stereotyping IAT block order, and their interactions (with each other and with validity condition), and for the IAT evaluation score.
5
The full results of the analysis are detailed in Table 4. Importantly, the IAT stereotyping scores were predicted by validity condition, F(1, 191) = 34.35, p < .001,
Full ANOVA Results for IAT and Self-Reported Stereotyping Scores in Experiments 1 and 2.
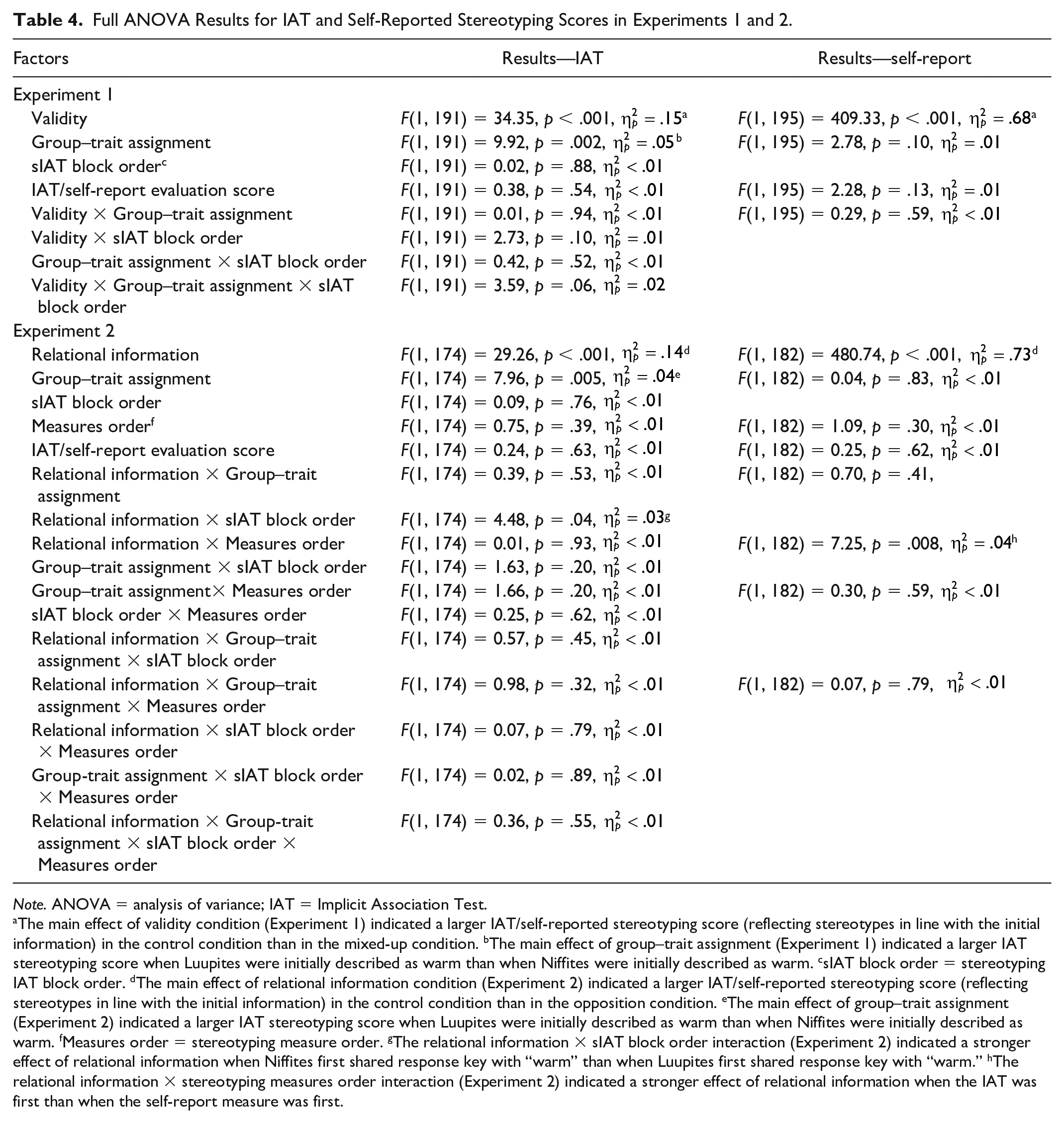
Note. ANOVA = analysis of variance; IAT = Implicit Association Test.
The main effect of validity condition (Experiment 1) indicated a larger IAT/self-reported stereotyping score (reflecting stereotypes in line with the initial information) in the control condition than in the mixed-up condition. bThe main effect of group–trait assignment (Experiment 1) indicated a larger IAT stereotyping score when Luupites were initially described as warm than when Niffites were initially described as warm. csIAT block order = stereotyping IAT block order. dThe main effect of relational information condition (Experiment 2) indicated a larger IAT/self-reported stereotyping score (reflecting stereotypes in line with the initial information) in the control condition than in the opposition condition. eThe main effect of group–trait assignment (Experiment 2) indicated a larger IAT stereotyping score when Luupites were initially described as warm than when Niffites were initially described as warm. fMeasures order = stereotyping measure order. gThe relational information × sIAT block order interaction (Experiment 2) indicated a stronger effect of relational information when Niffites first shared response key with “warm” than when Luupites first shared response key with “warm.” hThe relational information × stereotyping measures order interaction (Experiment 2) indicated a stronger effect of relational information when the IAT was first than when the self-report measure was first.
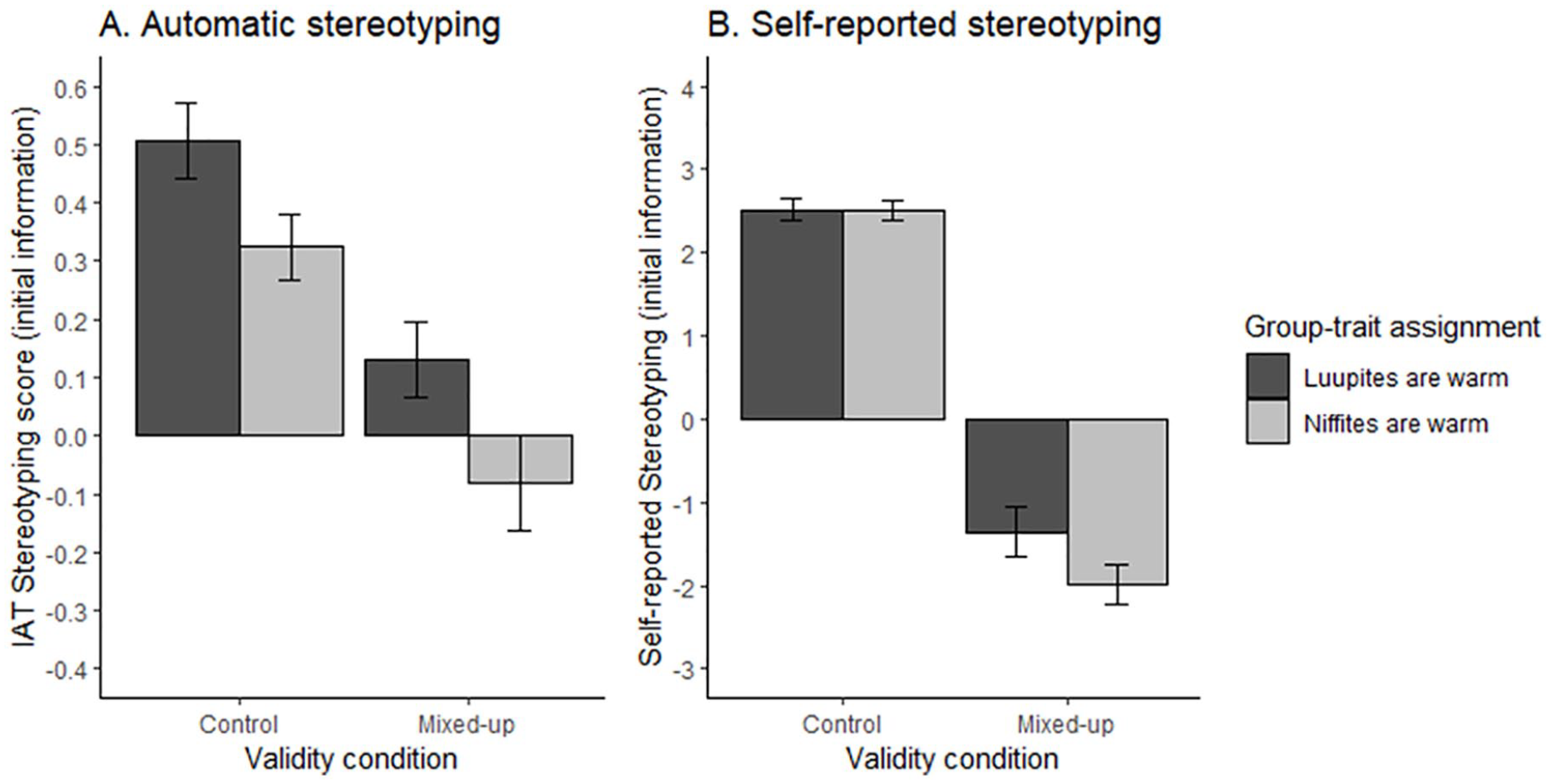
Experiment 1: Stereotyping scores (reflecting stereotypes in line with the initial information) as a function of validity condition (control vs. mixed-up) and group-trait assignment (Niffites are warm vs. Luupites are warm).
For the self-reported stereotyping analysis, we controlled for group-trait assignment, its interaction with validity condition, and the self-reported evaluation of the groups. Self-reported stereotyping scores were predicted by validity condition, F(1, 195) = 409.33, p < .001,
Direct comparison between self-reported and IAT stereotyping effects. 7
To directly compare the effects of validity on the automatic versus self-reported stereotyping measures, we first computed stereotyping scores that reflected a “Niffites are Warm/Luupites are competent” stereotype, and standardized these scores. Next, we recoded these scores to reflect stereotyping in line with the initial information. We submitted the standardized scores to a 2 (Measure type) × 2 (validity condition) × 2 (group–trait assignment) × 2 (stereotyping IAT block order) mixed ANOVA with measure type as the only within-participants factor. Table 5 summarizes the full results of the ANOVA. Importantly, the interaction between validity and measure type was significant, F(1, 192) = 46.02, p < .001,
Full ANOVA Results for the Direct Comparison of IAT and Self-Reported Stereotyping Scores in Experiment 1 and 2.

Note. ANOVA = analysis of variance; IAT = Implicit Association Test.
The main effect of measure type (Experiments 1 and 2) indicated overall stronger stereotyping effects (reflecting stereotypes in line with the initial information) for automatic stereotyping measures than for self-reported stereotyping measures. bCondition = validity information in Experiment 1, relational information in Experiment 2. cThe main effect of validity condition (Experiment 1) indicated a larger stereotyping score in the control condition than in the mixed-up condition. dThe main effect of relational information condition (Experiment 2) indicated a larger stereotyping score in the control condition than in the opposition condition. esIAT block order = stereotyping IAT block order. fMeasures order = stereotyping measure order. gThe interaction between measure type and validity condition (Experiment 1) indicated a larger effect of validity on self-report stereotyping than on automatic stereotyping. hThe interaction between measure type and relational information condition (Experiment 2) indicated a larger effect of relational information on self-report stereotyping than on automatic stereotyping. iThe relational information × Stereotyping IAT block order interaction (Experiment 2) was not further analyzed due to complexity and lack of theoretical interest. jThe Validity × Group–trait assignment × Stereotyping IAT block order three-way interaction (Experiment 1) was not further analyzed due to complexity and lack of theoretical interest.
Discussion
Experiment 1 showed that automatic stereotyping was sensitive to validity information. Automatic stereotyping scores, reflecting stereotypes in line with the initial information provided, were larger in the control condition (valid) than in the mixed-up (invalid) condition. Although we did not observe a full reversal in the mixed-up condition, the validity of information still exerted a clear influence over responding, leading to effects not significantly different from zero when the pairings of the groups and the traits were described as invalid. Interestingly, a direct comparison reveled a larger effect of validity on self-reported than on automatic stereotyping, although the fixed order of the two measures limits the interpretation of these results. In Experiment 2, we moved to test another prediction of the propositional perspective: that automatic stereotyping is sensitive to relational information.
Experiment 2
To test whether automatic stereotyping was sensitive to relational information, in Experiment 2, we used a manipulation that required participants to use information about the specific relation between the two groups (Niffites and Luupites) and traits (warm and competent) to form accurate stereotypes about them. Specifically, instead of describing the traits of the groups in absolute terms (e.g., Niffites are helpful), the traits of Niffites and Luupites were described in relational terms (e.g., Niffites are more helpful and less confident than Lisa, who is a warm and competent person). We then informed half of the participants that, accidentally, the words “more than” and “less than” were mixed-up. This manipulation resembles the validity manipulation of Experiment 1. However, to correctly update the stereotypes of the groups based on the new information, participants would need to account for the initial relational information. Therefore, an indication of an update would imply that the representation of the groups included relational information, and would therefore provide evidence that automatic stereotyping is sensitive to relational information.
Method
Participants
The preregistration of Experiment 2 is available at osf.io/rczwn/. In all, 270 participants completed the study. The preregistered data exclusions involved removing participants who (a) did not fully complete all questions and tasks (1.5%), (b) had more than 10% trials in the IAT faster than 300 ms (5.5%), or (c) made at least one error on the comprehension questions (23.8%, see Table 1 for exclusion rate as a function of experimental condition). The final sample included 191 participants (53% women, Mage = 29.56, SD = 9.48).
Materials, procedure and design
The materials, procedure and design were similar to those of Experiment 1, except for the following changes. First, unlike Experiment 1 in which the traits of the groups were described in absolute terms, the traits of Niffites and Luupites were described in relational terms. Specifically, in one condition, Niffites were described as warmer and less competent than Lisa and Luupites were described as less warm and more competent than Lisa. In the second condition, Niffites were described as less warm and more competent than Lisa and Luupites were described as warmer and less competent than Lisa (see Table 6). All participants were informed, before the exposure to the descriptions, that Lisa is generally considered to be a warm and competent person. In two blocks, we presented eight descriptions of each group, one at a time for 4s, in random order (16 descriptions in each block). 10 Second, instead of the validity manipulation, we used a relational information manipulation. Specifically, after the exposure to the descriptions, participants in the opposition condition were informed that Lisa had mixed up the words “less than” and “more than” in her descriptions of the Niffites and Luupites. In other words, all the traits that Niffites were described as having less than Lisa, they actually have more than Lisa. All the traits that Niffites were described as having more than Lisa, they actually have less than Lisa. All the traits that Luupites were described as having less than Lisa, they actually have more than Lisa. And, all the traits that Luupites were described as having more than Lisa, they actually have less than Lisa. Participants in the control condition did not read this information. Third, we counterbalanced the order of the automatic and self-reported stereotyping measures, as well as the order of the automatic and self-reported evaluation measures (the stereotyping measures were always administered first). Fourth, opposite to Experiment 1, to keep the structure of the descriptions similar, the trait “intelligent” was used in the learning (“more intelligent” instead of “more smart”) and the trait “smart” was used in the IAT. Fifth, because the response options of the comprehension measure in Experiment 1 did not fit the descriptions used in Experiment 2, we used different response options (i.e., “They are warm,” “They are competent,” “They are tall” and “I don’t remember”). Finally, to simplify the design of the experiment, for the evaluation IAT we used only one block order (Luupites-Positive/Niffites-Negative first). Automatic and self-reported stereotyping scores were calculated such that positive scores indicated stereotypes in line with the initial information (IAT: r = .65, 95% CI = [.56, .72], ratings: α = .94). Automatic and self-reported evaluation scores were computed to reflect a preference for Niffites over Luupites (IAT: r = .65, 95% CI = [.57, .72], ratings: α = .88).
Descriptions Presented in Experiment 2.

Results
For both the IAT and self-reported stereotyping, we tested whether the stereotyping scores were predicted by the relational information condition (opposition vs. control). For the IAT analysis, we controlled for group–trait assignment, stereotyping measures order, stereotyping IAT block order, and their interactions (with each other and with the relational information condition) and for IAT evaluation scores.
11
The full results of the analysis are detailed in Table 4. Importantly, the IAT stereotyping scores were predicted by the relational information condition, F(1, 174) = 29.26, p < .001,
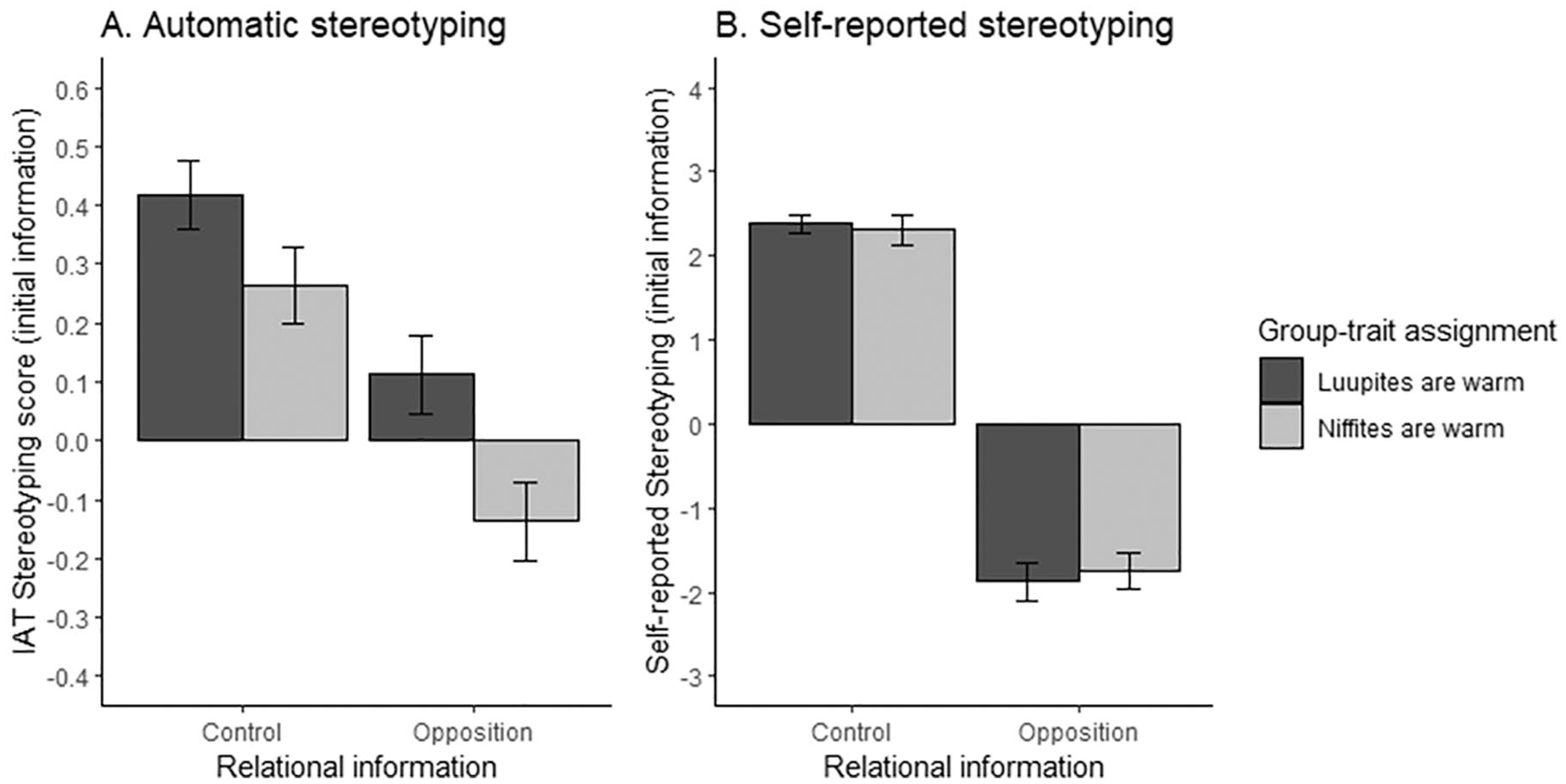
Experiment 2: Stereotyping scores (reflecting stereotypes in line with the initial information) as a function of relational information condition (control vs. opposition) and group–trait assignment (Niffites are warm vs. Luupites are warm).
Direct comparison between self-reported and IAT stereotyping effects
Standardized scores were computed as in Experiment 1. We submitted these standardized scores to a 2 (Measure type) × 2 (relational information condition) × 2 (group–trait assignment) × 2 (stereotyping measures order) × 2 (stereotyping IAT block order) mixed ANOVA with measure type as the only within-participants factor. Table 5 summarizes the results of the ANOVA. Importantly, the interaction between relational information and measure type was significant, (1, 175) = 38.26, p < .001,
Discussion
The results of Experiment 2 exhibited an impact of relational information on automatic stereotyping. Automatic stereotyping scores, reflecting stereotypes in line with the initial information provided to participants, were larger in the control condition than in the opposition condition. As with Experiment 1, we did not observe a full reversal in the opposition condition, but relational information still exerted a clear influence over responding, leading to IAT effects not significantly different from zero when participants learned that the words “less than” and “more than” had been mixed up. A direct comparison between the two stereotyping measures, which were counterbalanced in Experiment 2, revealed a greater effect of relational information on self-reported than on automatic stereotyping.
General Discussion
In two experiments, we tested predictions derived from a propositional perspective on automatic stereotyping. We tested if automatic stereotyping was sensitive to two components that are characteristic of propositional representations: truth value (validity) and relational information. Experiment 1 found that automatic (and self-reported) stereotyping of novel groups was influenced by validity information. Two novel groups were paired with warm or competent traits. Then, some participants learned that the pairings did not provide valid information for inferring that the groups possess the traits that were paired with them. The results revealed less stereotyping in line with the pairing when the pairing was described as invalid. In addition, the validity manipulation had a stronger effect on self-reported than on automatic stereotyping.
Experiment 2 found that automatic (and self-reported) stereotyping was also sensitive to relational information. In this experiment, we described the two groups in relational terms. One group was described as warmer and less competent than Lisa (a very warm and competent person). The other group was described as less warm and more competent than Lisa. Then, we added a manipulation that required participants to use the encoded relational information about the tribes to update the stereotypes about them. Specifically, we informed half of the participants that the words “more than” and “less than” were mixed-up. The results revealed less stereotyping in line with the initial information when the words “more than” and “less than” were mixed-up. As in Experiment 1, the relational information manipulation had a stronger effect on self-reported than on automatic stereotyping.
Importantly, in all experiments, we controlled for evaluation by (a) using only positive traits in our manipulations and measures of stereotyping and (b) measuring the evaluations of the groups and controlling for their influence in the analyses. Because of this, we can safely argue that the present results speak to automatic stereotyping rather than automatic evaluation.
Implications for Research on Automatic Stereotyping
The present research results have three levels of implications: adding new knowledge about moderators of automatic stereotyping, providing constraints on cognitive theories of automatic stereotyping, and providing new ideas for applied interventions used to fight the negative consequences of automatic stereotyping. First, the present results contribute to our understanding of factors that determine how and when exposure to information affects automatic stereotyping. Overall, our results indicate that automatic stereotyping takes into account the validity and relational nature of information that pairs social groups and traits. In both experiments the invalid/opposition relation conditions did not lead to a full reversal in stereotyping, but rather led to the absence of statistical difference of the stereotyping effects from zero. The lack of full reversal is compatible with what had been usually found for the effects of manipulations of validity and relational information on automatic evaluation (e.g., Moran & Bar-Anan, 2020; Moran et al., 2015; Wyer, 2016; Zanon et al., 2012). Despite the lack of full reversal, the results from both of our experiments indicated that automatic stereotyping can be impacted by relational and validity information.
Second, although the present research was not designed to prove that a specific model of automatic stereotyping is correct, our results can help to constrain cognitive theories of automatic stereotyping. Research on automatic stereotyping has flourished in the last two decades (e.g., Blair et al., 2001; Nosek et al., 2009). However, the vast majority of this research has relied on an associative theoretical perspective. In the present research, we adopted an alternative propositional perspective. Importantly, a propositional perspective of automatic stereotyping has merit because it allows researchers to conceptualize new questions about the fundamental nature of automatic stereotyping (see Kuhn, 1970, for a treatment on how theories may constrain the questions scientists ask). In our paper, we focused on questions about validity and relational information. Our results demonstrate that validity and relational information can in fact have a substantial impact of automatic stereotyping.
It is important to note that none of the existing models for automatic stereotyping can easily explain the whole set of the current research findings. The propositional perspective clearly predicts the sensitivity of automatic stereotyping to validity and relational information. However, it is less clear what the propositional perspective predicts with regard to the relative impact of that information on automatic versus non-automatic stereotyping. It can provide a post hoc explanation for the findings that validity and relational information had a weaker influence on automatic than on non-automatic stereotyping by assuming that (a) both automatic and self-reported stereotyping are influenced by propositions and (b) under sub-optimal conditions (i.e., automatic stereotyping) there is less control regarding which propositions influence stereotyping. For example, the learning in Experiment 1 could have led to the formation of the propositions “Niffites were paired with warm traits” and “Niffites are really competent.” When people have ample time and opportunity to consider which proposition to use in their response, it is plausible to assume that they will give more weight to the latter proposition. However, when processing conditions are suboptimal there is less control of which of the propositions will influence performance. Importantly, however, the propositional perspective does not provide clear predictions regarding the exact conditions under which different propositions will influence automatic stereotyping.
Similarly, models that rely on an associative theoretical perspective also cannot fully explain the current set of results. For example, the Associative-Propositional Evaluation (APE) model (Gawronski & Bodenhausen, 2006) assumes that automatic evaluation is mainly influenced by the activation of associations between an object and valence, regardless of the validity of these associations. However, this model also assumes that validity can sometimes have an indirect effect on automatic evaluation when the inference from the validity information affects self-reported evaluation, which may then lead to the creation of new associations that reflect the inferred valence. Applying the assumptions of the APE model to automatic stereotyping, the results of Experiment 1 (a lack of full reversal in the invalid condition for automatic stereotyping, and a full reversal for self-reported stereotyping) can be interpreted as evidence for an indirect effect of validity information on automatic stereotyping. Importantly, however, the APE model does not provide clear predictions regarding the exact conditions under which validity will have an indirect effect on automatic stereotyping.
The full set of findings of the current research not only raise questions about current accounts of automatic stereotyping but also inspire future research and theories on this topic. Any future model of stereotyping should be able to account for (a) why automatic stereotyping is sensitive to relational and validity information, (b) why automatic stereotyping in some cases is not completely corrected by relational and validity information, and (c) why validity and relational information have a stronger effect on self-reported than on automatic stereotyping.
Third, we believe that adopting a propositional perspective of automatic stereotyping could help to improve current interventions used to fight the negative consequences of automatic stereotyping. Most current interventions in this regard are conceptualized from an associative perspective (e.g., Dasgupta & Asgari, 2004; Johnson et al., 2018). However, the propositional perspective uniquely predicts new and important ways in which we can maximize the effectiveness of these interventions. For example, a popular intervention to reduce automatic stereotyping is exposure to a counter-stereotypic individual (e.g., a successful female scientist; Dasgupta & Asgari, 2004; Stout et al., 2011). The idea is that this exposure creates new associations linking the target group with the counter-stereotypic attributes. However, a propositional perspective can inform us that simply presenting such counter-stereotypic individual may not necessarily be sufficient to achieve this change: factors like validity (e.g., the extent to which one believes that the counter-stereotypic example is valid) and relational information will have a critical impact on what effect this presentation might have. These factors should therefore be considered in-depth to optimize the effectiveness of such an intervention.
One limitation of the present research is that we used a limited set of stimuli (i.e., fictitious social groups as targets) and traits (i.e., warm and competent), and a specific sample (Prolific participants). Future research should extend the present research by examining the sensitivity of automatic stereotyping to validity and relational information with different stimuli, contexts, and samples. Moreover, the present research used only one type of automatic stereotyping measure (the IAT). It is possible that the observed sensitivity of automatic stereotyping to validity and relational information is due to specific properties of the IAT and does not transfer to other automatic stereotyping measures. Future research could extend this line of research by using different automatic measures such as the Semantic Misattribution Procedure (SMP; Ye & Gawronski, 2018).
In addition to extending the present research results, future research could also use the assumptions of the propositional perspective of automatic stereotyping to generate new research questions. For example, future research could test if, as in the case of automatic evaluation, verbal instructions are sufficient to form and change automatic stereotyping (Kurdi & Banaji, 2017), and if automatic stereotyping is also sensitive to diagnosticity (Cone & Ferguson, 2015) and believability (Cone et al., 2019). Finally, as we already highlighted, the present research was not designed to prove that a specific model of automatic stereotyping is correct. Future research could be designed to directly compare competing predictions of different theoretical models. Overall, the present research highlights the value of considering a propositional perspective in the context of automatic stereotyping.
Supplemental Material
sj-docx-1-psp-10.1177_01461672211024121 – Supplemental material for Examining Automatic Stereotyping From a Propositional Perspective: Is Automatic Stereotyping Sensitive to Relational and Validity Information?
Supplemental material, sj-docx-1-psp-10.1177_01461672211024121 for Examining Automatic Stereotyping From a Propositional Perspective: Is Automatic Stereotyping Sensitive to Relational and Validity Information? by Tal Moran, Jamie Cummins and Jan De Houwer in Personality and Social Psychology Bulletin
Footnotes
Authors’ Note
The materials, data, and analysis scripts of the whole project are available at the Open Science Framework (osf.io/c8kyb/).
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship and/or publication of this article: This manuscript is supported by Ghent University under grant BOF16/MET_V/002.
Supplemental Material
Supplemental material is available online with this article.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.