
Abstract
It is shown that deviations of estimated from true values of item difficulty parameters, caused for example by item calibration errors, the neglect of randomness of item difficulty parameters, testlet effects, or rule-based item generation, can lead to systematic bias in point estimation of person parameters in the context of adaptive testing. This effect occurs even when the errors of the item difficulty parameters are themselves unbiased. Analytical calculations as well as simulation studies are discussed.
Keywords
As many computer-based methods are readily available nowadays, adaptive testing has become a popular and efficient testing method in psychometrics. The basic principle of an adaptive test can be shortly described as follows: An examinee is first given a few items to obtain a crude initial estimate of the person parameter. Then the next item is chosen so that it contributes maximally to the precision of the updated estimate obtained after the examinee has completed the item. Therefore, several item selection criteria have been developed, for example, the criterion of maximal Fisher information, which is probably the most commonly used in practice (van der Linden, 2010). Furthermore, a number of content- and test-specific constraints often have to be taken into account. The item selection process is iteratively repeated and terminates after a certain predefined number of items or when the estimate of the person parameter no longer changes significantly.
Item response theory (IRT) models are an essential element of adaptive testing, as they allow for an easy evaluation of the Fisher information for single items. A central feature of IRT models is that they have separate parameters to describe item and person characteristics. However, in this article it is shown that when the true item difficulty parameters of IRT models differ from the estimated ones, a systematic bias in the estimation of person parameters in adaptive testing arises, even when the errors of the difficulty parameters are unbiased.
Various sources of errors in item difficulty estimation are conceivable, four of which are discussed in the following section. Their effects will be demonstrated on person parameter estimation in adaptive testing analytically as well as by simulation studies with the Rasch, the two-parameter logistic (2PL), and the three-parameter logistic (3PL) models.
An already known phenomenon caused by imprecise item parameters in adaptive testing is the so-called capitalization on chance, which is described in more detail by van der Linden and Glas (2000). This effect is mainly due to the fact that an overestimation of the discrimination parameter leads to a disproportionate overestimation of the corresponding information function, which is a quadratic function of the discrimination. Hence, in many cases, the test algorithm prefers items with high-calibration errors. As a result, the accuracy of person parameter estimation is likely to be overestimated; however, no systematic bias is expected for the estimates themselves.
Sources of Variation in Item Difficulties
Deviations of the true item difficulty parameters from the estimated ones might be due to several reasons. Here four possible sources are briefly discussed, which are, depending on the specific testing situation, likely to contribute in varying degrees.
First, errors in the calibration of item parameters are generally not avoidable. In adaptive testing, a whole item pool rather than just a single test has to be calibrated. Furthermore, the items of the pool usually need to be replaced regularly to maintain item pool integrity. As calibrating new items is often expensive, the current trend is to minimize the size of the calibration sample (van der Linden, 2010), which in most cases leads to increased calibration errors. Errors in item calibration might therefore often be more predominant in adaptive testing than in linear testing.
Second, the neglect of person- or subgroup-specific differences in item difficulties might equally result in a misfit between true and estimated difficulty parameters. Item parameters are usually modeled as fixed effects. However, especially the item difficulty parameters might be slightly different for different individual persons. It is not unusual that when given two items, A and B, some people find Item A more difficult than Item B, whereas other people have more problems dealing with Item B than with Item A. Furthermore, when there are distinguishable subgroups of respondents, (mean) difficulty parameters might also vary across different groups (differential item functioning [DIF]; see Camilli & Shepard, 1994; Holland & Wainer, 1993; Osterlind & Everson, 2009; Zumbo, 2007). There are methods for detecting DIF, yet they are not always routinely applied. Also, they might only work when the differences are sufficiently large.
Although in classical IRT it is generally assumed that the difficulty of an item is not person or group dependent, it might therefore in many cases be more realistic to think of item difficulties as random parameters which differ across persons and/or groups (De Boeck, 2008; Rijmen & De Boeck, 2002). Assuming that in the calibration of (fixed) item parameters the means of these random effects are estimated, deviations from these means to the true person- or group-dependent item difficulty parameters are likely to occur.
Third, another source of variation in item difficulty parameters can arise within tests that comprise so-called testlets (Bradlow, Wainer, & Wang, 1999; Ip, 2010; Scott & Ip, 2002; Sireci, Thissen, & Wainer, 1991; Wainer, Bradlow, & Wang, 2007; Wainer & Kiely, 1987; Wang & Wilson, 2005). Testlets are subsets of items for which the assumption of local item independence might be violated. Often, items of the same testlet share a common stimulus (e.g., a reading passage or a table of numbers). In these situations, it can be assumed that the performance on the items not only depends on absolute values of item difficulties but also on how well the examinee is able to process the stimulus. In other words, true item difficulties are no longer fixed, but vary across persons, where the direction of the person-dependent shift of item difficulty is the same for all items that belong to the same testlet. Wainer et al. (2007) point out that testlets are especially useful in adaptive testing, as they can be conveniently used to meet additional constraints.
Fourth, deviations of true from estimated values of item difficulty in adaptive testing can also arise from rule-based item generation (Geerlings, Glas, & van der Linden, 2011; Holling, Bertling, & Zeuch, 2009). This technique can significantly improve test security, as the traditional item pool is replaced by an (ideally) infinite pool of items that can be generated by a computer algorithm. The main idea for rule-based item generation is that the items in the pool are nested in families, where items that belong to the same family share the same values of item parameters and can be generated according to certain rules (item cloning). However, as the items within a family actually differ from one another, it can be assumed that in practical applications, the assumption of equal item parameters of items within the same family holds only approximately, so that, at least to a certain extent, deviations of the true from the estimated (mean) item difficulty parameters can be expected (van der Linden, 2010).
Systematic Bias in Estimating Persons
In adaptive testing, deviations of estimated from true values of item difficulty parameters, caused, for example, by the sources described in the previous section can lead to systematic bias in point estimation of person parameters. When the errors of the item parameter estimates are unbiased, a systematic overestimation of the absolute values of person parameter estimates is expected, which generally increases with absolute values of true person parameters.
For the sake of simplicity, the following explanation of this phenomenon is based on the family of Rasch models and the criterion of maximal Fisher information because here the next item of an adaptive test is chosen so that its difficulty parameter coincides with the current estimate of the person parameter. This is the situation in which the systematic bias of person parameter estimation occurs in “pure form.” However, as for other models and other selection criteria, a difficulty parameter close to the current estimate is in most cases also advantageous, the effect will also be observable in much more general settings. This is demonstrated in the following section by simulation studies, where, next to the Rasch model, also the 2PL and 3PL models are evaluated.
To explain the effect of biased person parameter estimation in adaptive testing with imprecise difficulty parameters, assume that the distribution of the true difficulty parameters in the item pool has its maximum around 0 and constantly fewer items on the left and right tail, which is a reasonable assumption in most settings of adaptive testing. In an arbitrary step of the iterative test algorithm, let y be the current estimate of the person parameter, and assume that y is unequal to zero. Let U be a small interval containing y, so that an item is to be selected with estimated difficulty in U. Having assumed error variance in the (unbiased) estimation of basic parameters, U is likely to contain estimated difficulty parameters of items for which the true difficulty parameter is not in U. Let I1 and I2 denote two intervals of the same length d bordering on U to the left and right, where I1 is the one more remote from 0. Let A1 be the number of true difficulty parameters β in I1 so that the error ξ of β is of such a magnitude that
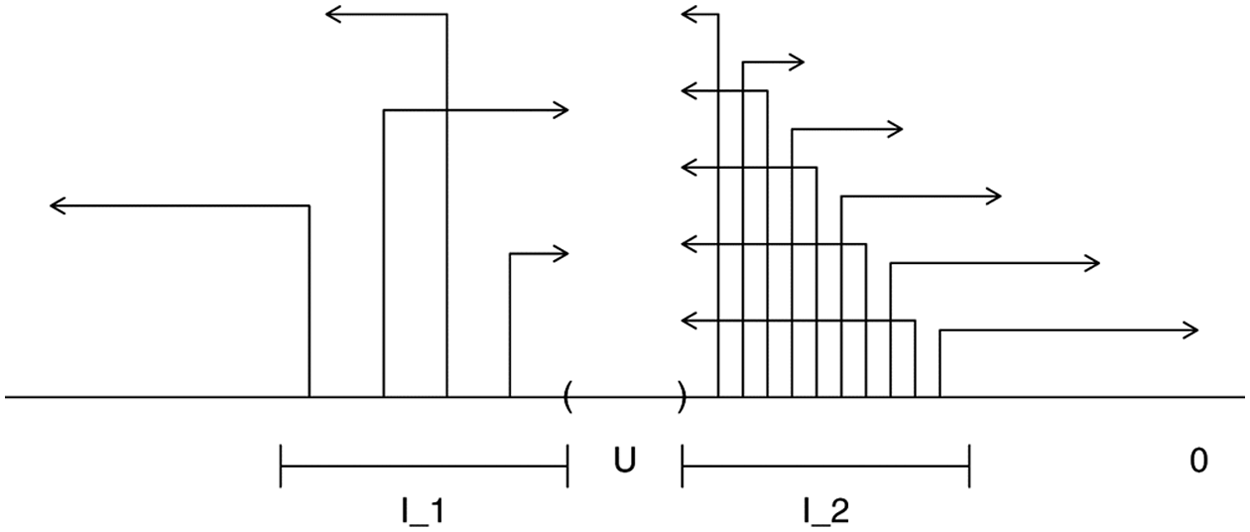
Effect of deviations of true from estimated values of item difficulty parameters on the estimation of person parameters in adaptive testing
For a person with a positive true person parameter, the algorithm will hence select items with overestimated difficulty parameters more often than items with underestimated difficulty. These items are easier to solve for the person than their difficulty estimates suggest, so the person parameter is systematically overestimated. The same reasoning holds for persons with negative true person parameters, which are therefore systematically underestimated.
An Asymptotic Formula of the Expected Bias
A formula is derived, which describes, as a function of the current estimate, the approximate expected value of the error term ξ when choosing an item whose estimated difficulty is supposed to match this current estimate. Therefore, the following assumptions were made:
Every item of the pool has a true difficulty parameter β that is estimated with an error term ξ; that is, the estimated difficulty of the item is
The density of the distribution of the true item difficulty parameters in the pool is given by
The density of the distribution of the error terms is given by
β and ξ are independent.
Let y be the current estimate of the person parameter. For
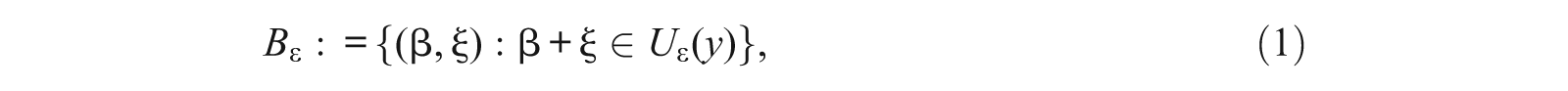
and the probability of this event is
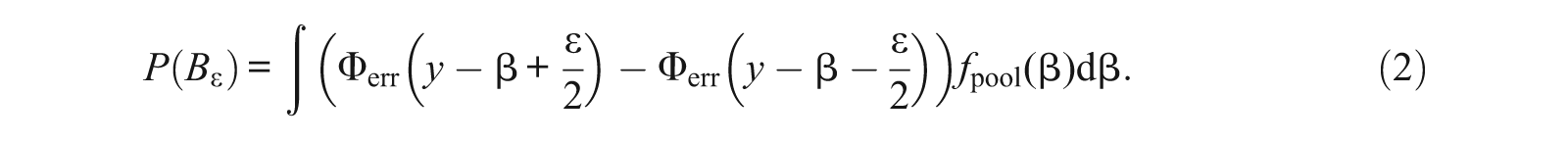
Let

For a given y, interest lies in
A density function of the conditional distribution of β given
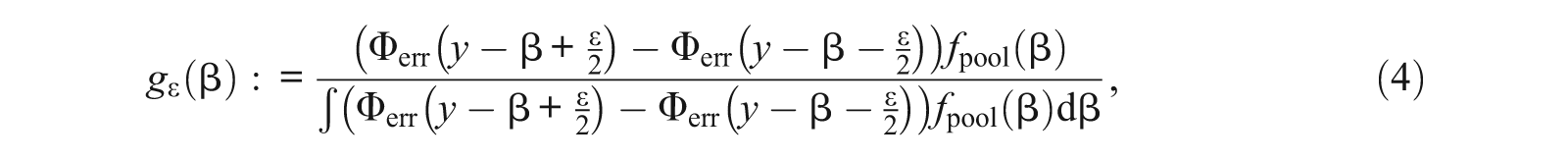
as for an arbitrary measurable
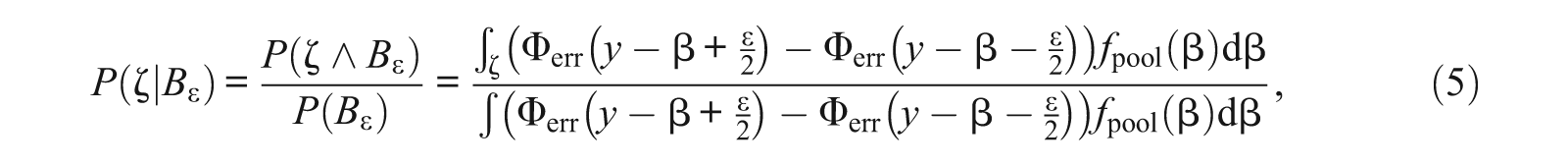
holds. Expanding the ratio in the expression for the density
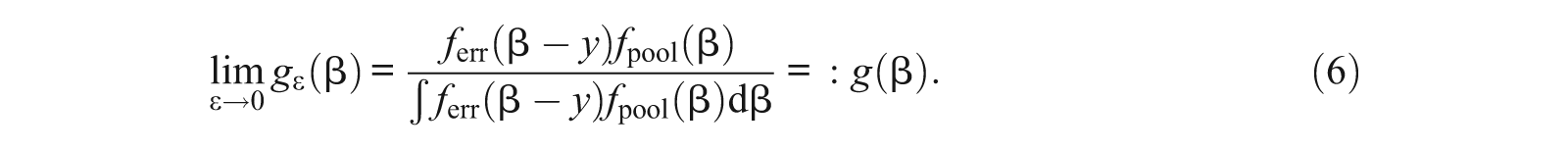
As

Equation 7 describes the expected value of the error term ξ of an item difficulty parameter as a function of y (note that g is also dependent on y), which is the value of the difficulty parameter that the next item is intended to have and which is commonly the value of the current estimate of the person parameter.
As the person parameter scale and the item difficulty scale coincide, the expected error term of the difficulty parameter for a given y can also be interpreted as the expected bias of the person parameter estimate when a person is only tested with items that are chosen so that their estimated difficulties equal y. In a real adaptive testing situation, y is supposed to change in each step of the iterative testing algorithm. However, it can be assumed that y will approximately alternate around the true value of the person parameter. Therefore, Equation 7 might nevertheless, for sufficiently large test lengths, give a good estimate of the expected bias of person parameter estimation when the true person parameter is y, as the expected bias is bigger for values of y whose absolute values extend the absolute value of the true person parameter and smaller for values of y whose absolute values are less than the absolute value of the true person parameter.
Figure 2 shows Equation 7 evaluated as a function of y under different assumptions of the true difficulty parameter distribution and the error term distribution. Increasing bias for growing error variances is clearly observable. Also, as expected, in the case of a skew normal distribution for the true item difficulties (compare Figure 3), the bias is larger when the gradient of this distribution is higher and lower when the gradient becomes smaller.

Expected bias as a function of y, as calculated in Equation 7
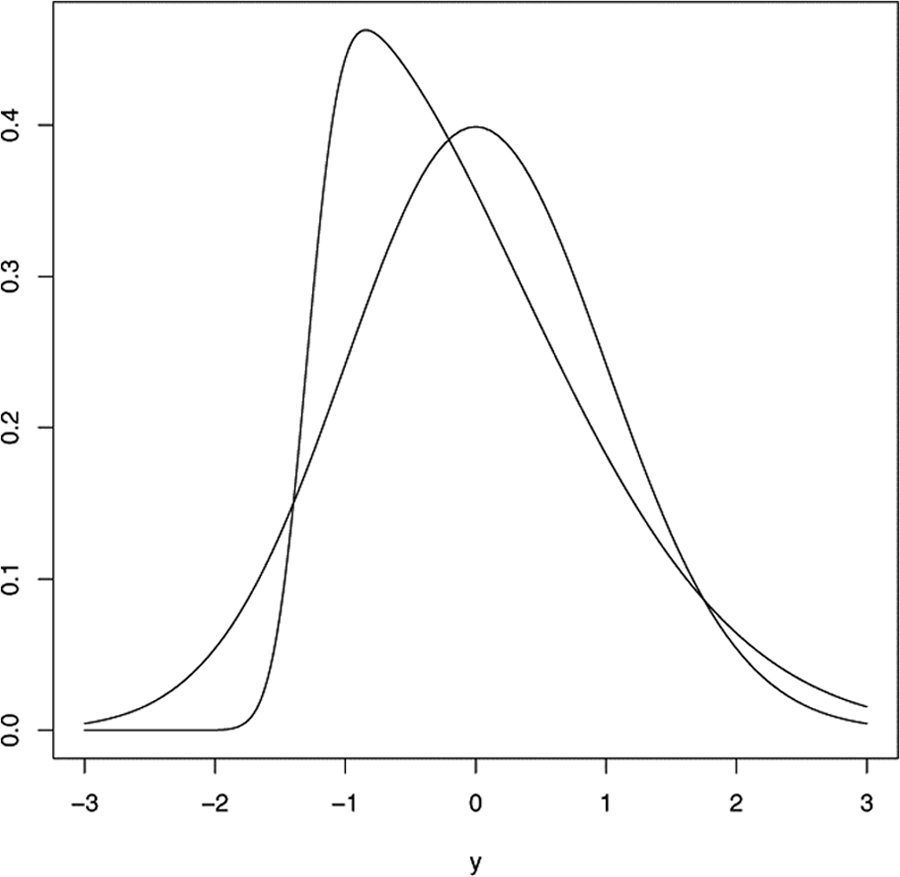
Standard normal distribution and skew normal distribution with shape = 8, scale ≈ 1.64, and location ≈ 1.30
Simulation Studies
Several simulation studies were conducted to study the effect of biased person parameter estimates caused by imprecise item parameters in different testing situations. These simulation studies investigated three models (Rasch, 2PL, and 3PL models), four estimators (maximum likelihood [ML], weighted maximum likelihood [WML; Warm, 1989] as well as expected a posteriori [EAP], and maximum a posteriori [MAP], both with normal priors), three variances of normally distributed error terms for the estimated item difficulty parameters (0.1, 0.25, 0.5), four test lengths (15, 30, 50, 100), and two sizes of item pools (500, 1,000). Item selection was based on the criterion of maximal Fisher information.
For each testing situation, 1,000 replications of testing five person parameters (−2, −1, 0, 1, 2) were made. For each run of these replications, true item difficulty parameters were randomly sampled from a standard normal distribution. For the 2PL and 3PL models, discrimination parameters were sampled from a lognormal distribution with location 0 and scale 0.2. Guessing parameters for the 3PL model were sampled from a uniform distribution on
Results
For each testing situation, the deviations of the estimated from the true person parameters were calculated. To obtain single numeric values representing the bias in person parameter estimation, an ordinary least squares (OLS) regression of the bias on the true
Slopes of Regressions of Mean Bias of
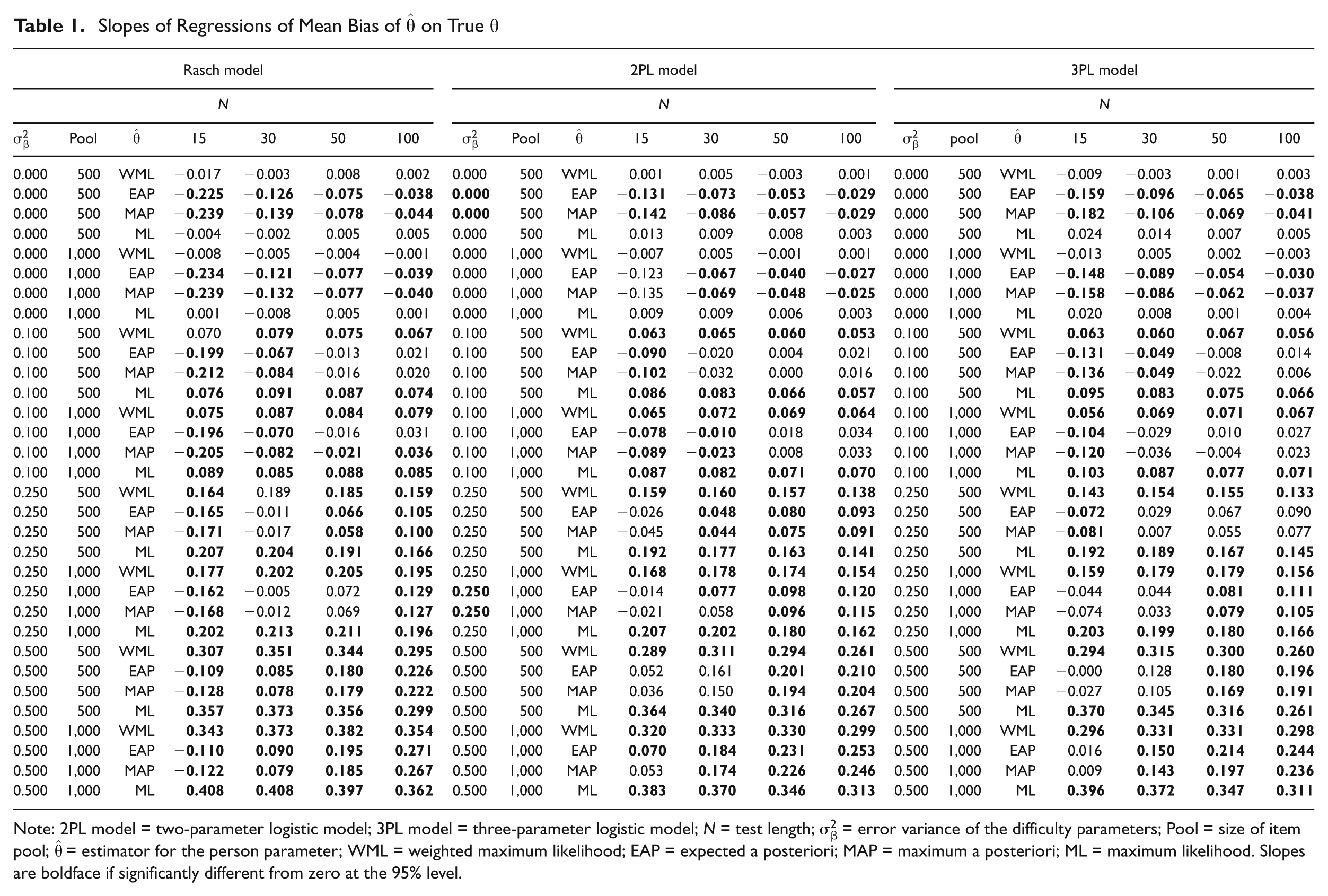
Note: 2PL model = two-parameter logistic model; 3PL model = three-parameter logistic model; N = test length;
To illustrate some of the results in more detail, Figures 4 to 7 show the deviations from true and estimated person parameters for some selected testing situations.

First three panels: Deviations of the estimated from the true person parameters for the four different estimators and the three different models. Lower right panel: Bias resulting from Bayesian MAP estimators for all three models.
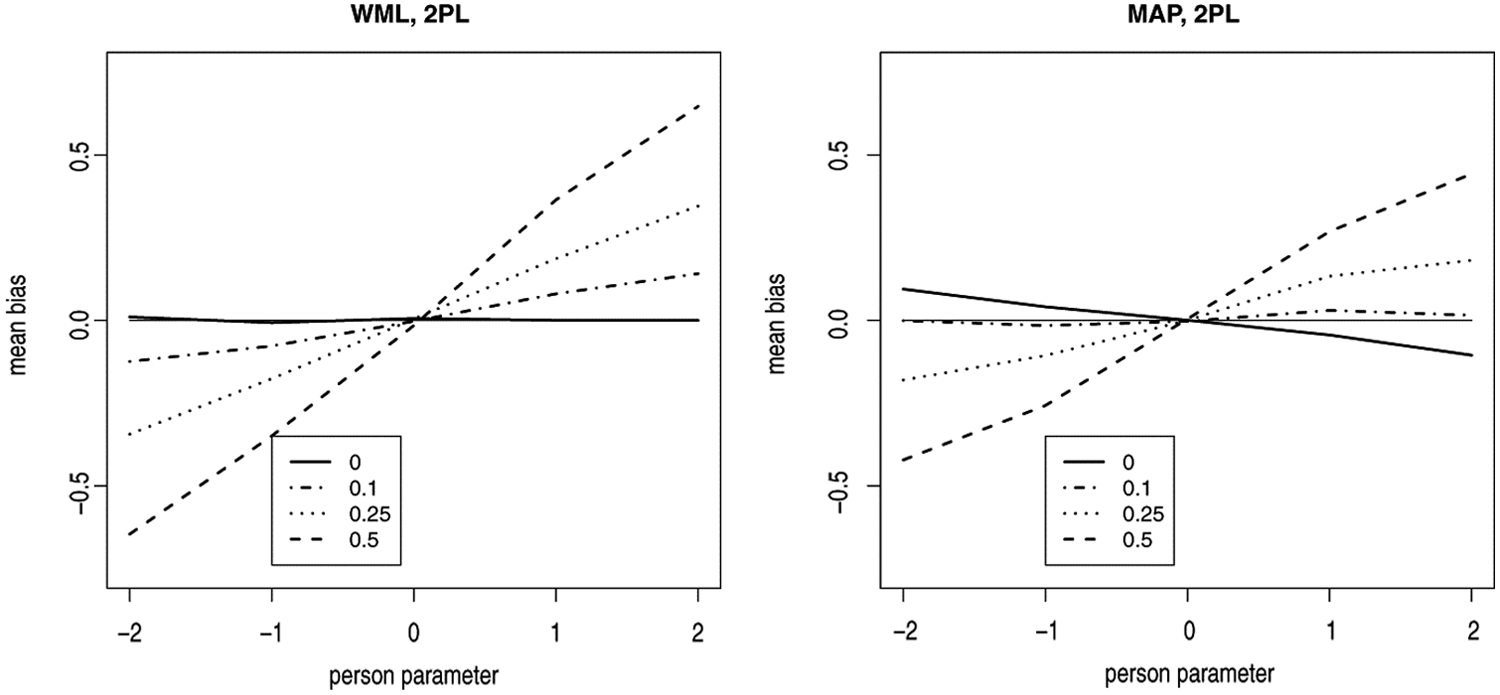
Deviations of the estimated from the true person parameters for different error variances of difficulty parameters.
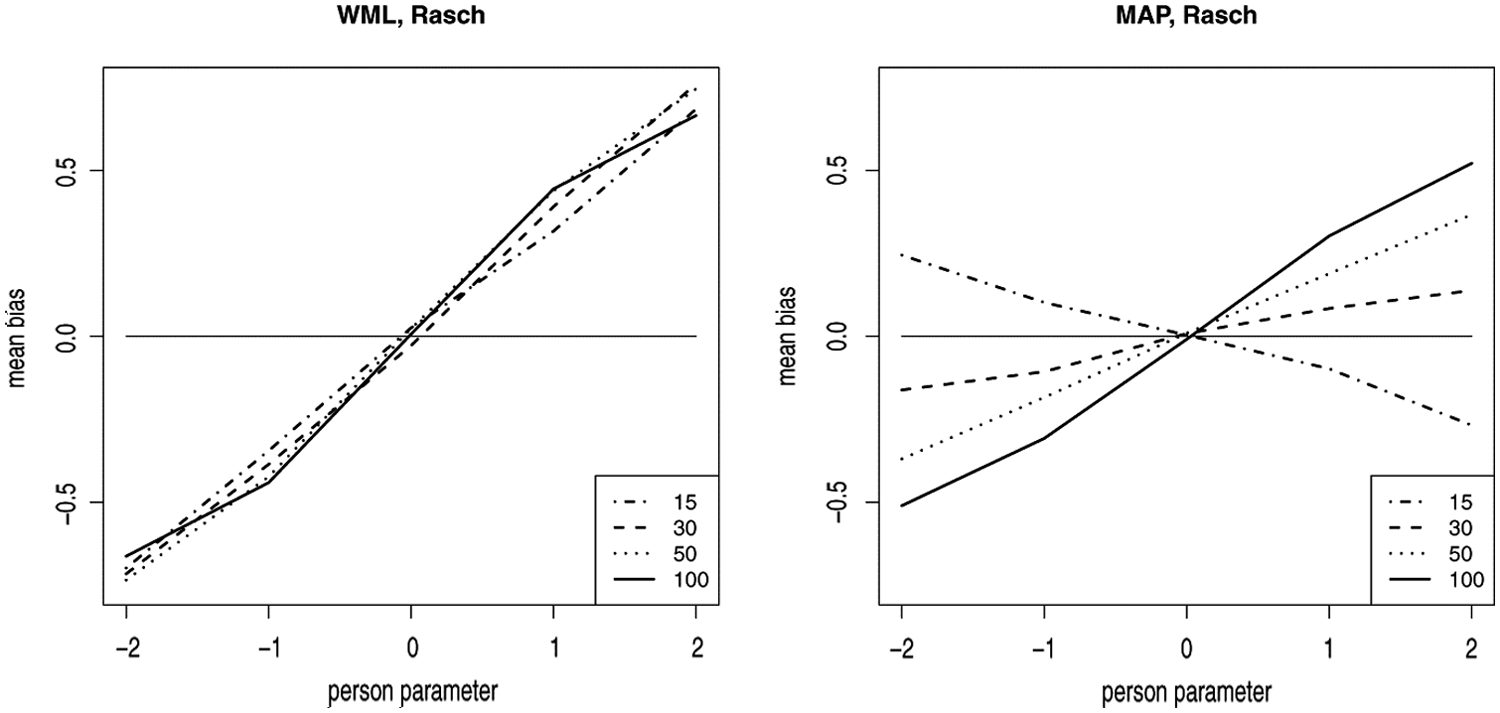
Deviations of the estimated from the true person parameters for test length varying from 15 to 100.
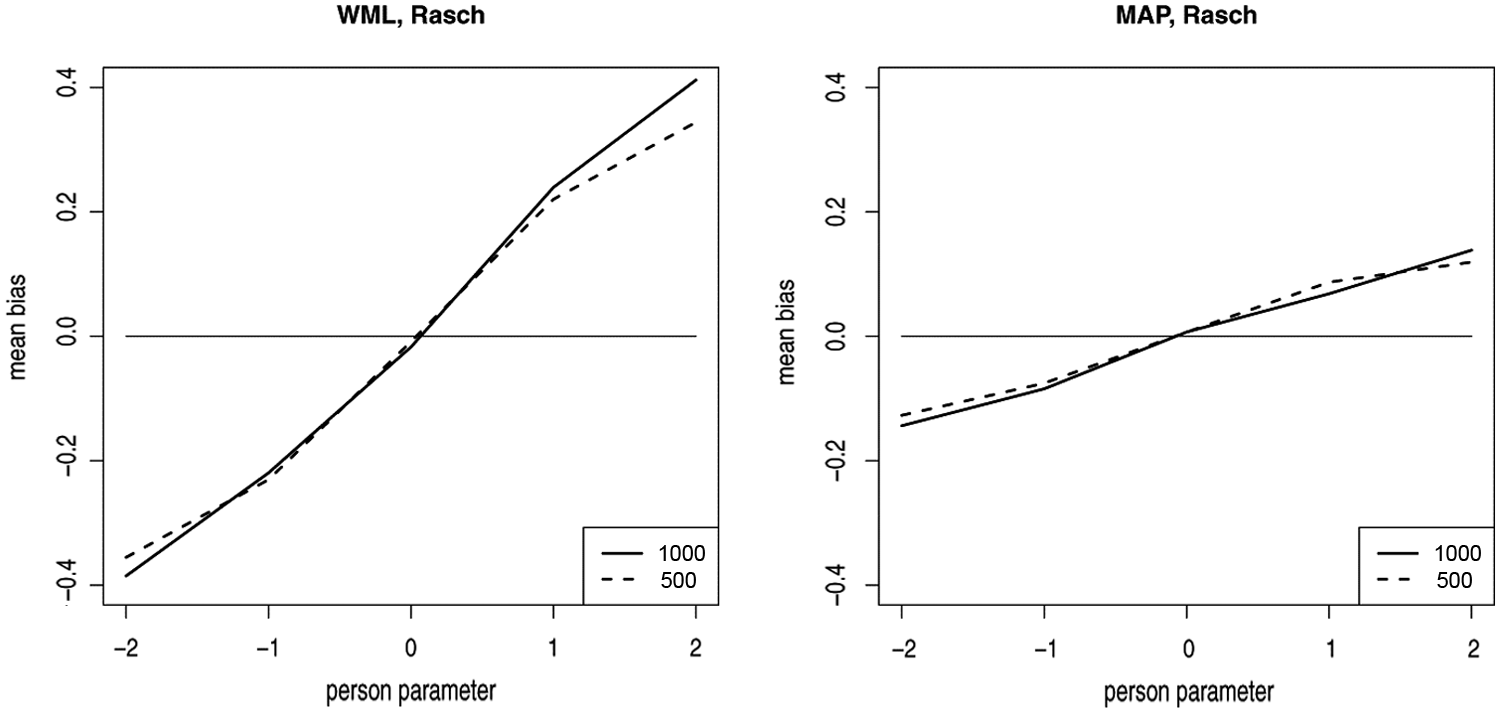
Deviations of the estimated from the true person parameters for item pools of size 500 and 1,000, respectively
Dependence on the Estimator
Table 1 shows that, if the test length is sufficiently long, the effect occurs for all estimators. However, it is less distinct for the Bayesian estimators. Depending on the prior distribution and the test length, estimates obtained from MAP and EAP estimators are shifted toward the mean, which partially counteracts the bias induced by imprecise difficulty parameters. In Table 1, systematic bias toward the mean is indicated by negative slope parameters, which occur for the Bayesian estimators mainly in testing situations where the error variance of the difficulty parameters is zero or the test length is small.
Comparing the two likelihood and the two Bayesian estimators, respectively, the effect of biased person parameter estimation caused by imprecise item parameter estimates is marginally stronger for the ML than for the WML, and slightly more pronounced for the EAP than for the MAP estimator.
As an example, Figure 4 shows the dependence of the effect of biased person parameter estimation on the estimator for all three models for specific testing situations. As the WML and the ML, as well as the MAP and the EAP estimator, are very similar for all models, Figures 5 to 7 only show results for WML and MAP estimators.
Dependence on the Model
The dependence of the observed effect on the model is indicated in Table 1 and Figure 4. As the information functions of the 2PL and 3PL models depend on the difficulty and the discrimination parameters, and, in the case of the 3PL model, also on the guessing parameter, it is expected that the effect of biased person parameter estimation will be most noticeable for the Rasch models. This can indeed be observed in the case of ML estimation, although the differences between the three models are not very distinct. For Bayesian estimators, however, the effect is for test lengths of 30 and 50 items in most cases even more pronounced for the 2PL and 3PL models than for the Rasch model. The explanation for this apparently contradictory result is that the bias toward the mean, which is induced by the Bayesian estimators, is (at least in the setting described here) stronger for the Rasch model than for the 2PL or 3PL model, as indicated in the last panel of Figure 4. Highly discriminating items, which are commonly chosen by the adaptive testing algorithm in the case of 2PL and 3PL models, provide more information than do Rasch-scaled items, therefore the prior distribution, which in turn causes the shift toward the mean, is here less decisive. However, as the influence of the prior decreases as test length increases, the effect of biased person parameter estimation is again strongest for the Rasch model for long tests (
Dependence on the Error Variance
Table 1 and Figure 5 indicate the dependence on the error variance of item difficulty parameters. As expected, the effect becomes more pronounced with increasing error variance. When there is no error variance, estimates seem to be unbiased in the case of likelihood estimation and slightly biased in the opposite direction due to a shift to the mean in the case of Bayesian estimation.
Dependence on the Test Length
At least for tests with fewer than 100 items, test length has a stronger effect on biased person parameter estimation for Bayesian than for likelihood estimators, as indicated in Table 1 and Figure 6. For a short test length of only 15 items, the bias toward the mean induced by the Bayesian estimators is in most cases even stronger than the reverse bias induced by imprecise item difficulty parameters. The dependence on the test length in the case of the Bayesian estimators is caused by the fact that for short tests, the prior assumption is quite decisive for the posterior distribution, whereas for long tests, the likelihood is the dominating factor. Therefore, the shift toward the mean, which is induced by using a Bayesian estimator, becomes smaller with increasing test length.
Dependence on the Size of the Item Pool
Table 1 and Figure 7 show that the effect of biased person parameter estimation caused by imprecise item difficulty parameters is slightly stronger for an item pool of size 1,000 than of size 500, at least for the more extreme values of theta. This is not surprising, as tests become more “adaptive” the larger the item pool is. This result is independent of the estimator and the model.
Discussion
In adaptive testing, deviations of the true from the estimated difficulty parameters can lead to systematic overestimation for positive person parameters and to systematic underestimation for negative person parameters, even when the errors of the item parameters are unbiased. The given theoretical explanation for this phenomenon is very general and (as long as the difficulty parameter is decisive in the item selection process) can therefore be assumed to hold for many situations in adaptive testing.
Decisive Factors
The actual influence of the described effect on person parameter estimation depends mainly on the following factors: (a) the exactness of item calibration, (b) the amount of person- and/or group-specific differences in item difficulty parameters, (c) the presence of local item dependence (testlets), (d) the possible use of rule-based item generation, (e) other possible sources of variation in item difficulty parameters, (f) the distribution of the true item difficulty parameters in the pool, (g) the distribution of the errors of the item difficulty parameters, (h) the estimator, (i) the model, (j) the test length, (k) the size of the item pool, (l) the item selection criterion, and (m) additional constraints in the item selection procedure.
At least to a certain degree, calibration errors and person- or group-specific differences in item difficulty parameters can be assumed to be present in most real testing situations. The impact of the latter seems especially important for models with comparatively few item parameters. An example of such a model is the linear logistic test model (LLTM; Fischer, 1973), which comprises only a certain number K of basic parameters that determine the difficulty of
However, it is a known problem of the LLTM that it often does not fit real data sufficiently, even when most of the variation in the item difficulties can be explained (Rijmen & De Boeck, 2002). For this reason, some authors have already suggested modeling some or all of the basic parameters as person-specific random effects (Rijmen & De Boeck, 2002) or introducing an additive item-specific random parameter that contributes to the difficulty parameter (De Boeck, 2008). Rijmen and De Boeck (2002), analyzing data from a test of deductive reasoning, report that some of the variances associated with random basic parameters were estimated to be rather large. Therefore, it seems reasonable that, in the case of the LLTM, most of the error variance of estimated item difficulty parameters is due to individual differences in item difficulties rather than to calibration errors.
Generally, when the model is comparatively simple with only a few item parameters, the calibration is expected to be more exact, but the effects of the neglect of individual differences are often larger. However, when the model is more complex and comprises more item parameters, calibration errors might be more predominant than the deviations due to the approximation by the model.
Testlets and rule-based item generation are especially useful in adaptive testing. However, the possible side effect of additional error variation of the difficulty parameters can be particularly severe in precisely this testing format.
When modeling testlet effects with additional random effects that are added to item difficulty parameters (cf. Wainer et al., 2007), the error variances associated with deviations of true from estimated (mean) difficulty parameters due to these testlet effects can be directly assessed. However, error variances can only be specified for particular testing situations, so that general statements about the magnitudes of these variances are limited. Yet, in this context, it might be interesting to note that Wainer et al. (2007) report various examples of testlet applications where these variances are often quite large.
Concerning rule-based item generation, there are no studies so far that investigate the magnitudes of possible error variances of item difficulty parameters within families of cloned items. Like the variances arising from person-specific differences or testlets, these variances are assumed to be strongly dependent on content-related aspects and can probably be best assessed by random effects modeling.
The distribution of the difficulty parameters in the item pool plays an important role in explaining the observed effect. Generally, as indicated in Figure 2, the bias is expected to be larger for person parameters for which the gradient of this distribution is high (note that the person and difficulty parameter scales coincide). To prevent systematic bias in person parameter estimation caused by imprecise item parameters, a uniform distribution over the whole range of person parameters would be necessary.
The choice of the estimator can be quite decisive for the bias in person parameter estimation. As Bayesian estimators bias the estimates toward the mean, the effect observed here is generally stronger for likelihood estimators. Especially in the case of short tests, the bias caused by imprecise item difficulty parameters is often balanced by the bias induced through the prior distribution, and in some cases the latter is still predominant. However, the influence of the prior distribution on the posterior, and hence the bias toward the mean, decreases with increasing test length. Therefore, the choice of the estimator becomes less important for longer tests.
In the case of Rasch models, the item selection algorithm based on maximal Fisher information chooses the next item in such a way that an optimal match is obtained between the difficulty parameter and the current estimate of the person parameter. For models with more item parameters, the criterion of maximal Fisher information is generally also influenced by other parameters. However, in this study, the simulation for the 2PL and 3PL models shows that the bias is very similar to the one obtained under the Rasch model. In the case of Bayesian estimators, the bias is often even slightly stronger for the 2PL and 3PL models, as the bias toward the mean is marginally more distinct for the Rasch model.
The dependence of the bias in person parameter estimation in adaptive testing on the test lengths is more distinct for Bayesian estimators, as the induced bias toward the mean, which counteracts the bias caused by imprecise item parameters, is test-length dependent. Larger item pools slightly intensify the bias, as corresponding tests are “more adaptive.”
In this study, the author only examined the item selection criterion of maximal Fisher information. However, other criteria also depend on the difficulty parameter, though sometimes more indirectly. For example, in a Bayesian context, it is common to weigh a measure of information (which commonly depends on the difficulty parameter) with the posterior distribution and to maximize the corresponding integral over a certain interval (van der Linden, 2010). With respect to the discrimination parameter, using a Bayesian criterion can indeed lead to a significantly different choice of items, as the information function becomes steeper and more focused when the discrimination parameter increases. However, in the case of the difficulty parameter, there is no comparable phenomenon that might suggest the use of Bayesian criteria, and therefore, the choice of the actual criterion is not expected to make much difference.
Dealing With the Resulting Bias
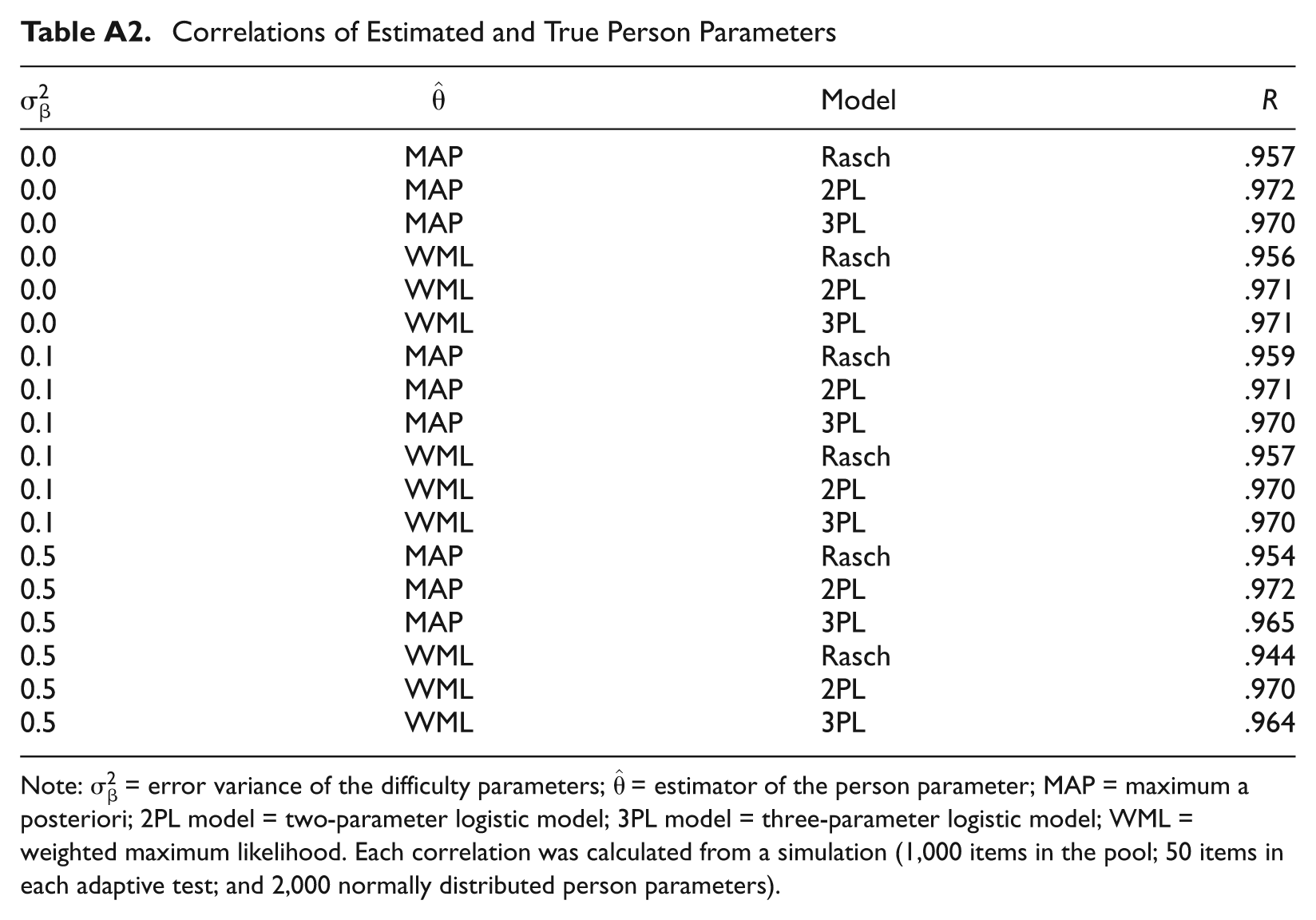
From a practical point of view, an important question is how to deal with the problem of possibly biased person parameter estimation in adaptive testing. The left panel of Figure 2 as well as the results of the simulation studies indicate that in many cases a sufficient rescaling of the person parameter estimates might be possible by a multiplicative factor. This can be assumed to hold when the distribution of true item difficulty parameters in the pool is approximately “well behaved,” that is, symmetric, centered around the origin, and with a moderate gradient. The item pools used in the preceding simulation studies correspond to this situation and correlations of estimated and true values of person parameters, even with error variances of 0.5, are indeed not much different here from those obtained under precise item parameters (for more details, compare Table A2 in the Appendix). Therefore, if the only purpose of testing is to decide on the relative standing of examinees, the observed bias might be negligible.
However, in most cases the aim of adaptive testing is the assessment of individual persons based on a predefined scale that is obtained during the calibration process. In this case, a sufficiently exact rescaling of the person parameter scale might be necessary, as otherwise person parameter estimation can be systematically biased.
Furthermore, as the right panel of Figure 2 shows, the situation can be much more difficult for more complicated distributions of item difficulties. In such cases, the assumption of a simple correction factor might not be realistic, and therefore, relative decision making as well as more precise individual assessment might both be affected.
Another approach to deal with possible bias in adaptive testing is to try to reduce its underlying causes. In the context of the problem of capitalization on chance, van der Linden and Glas (2000) point out some ways of reducing calibration errors in adaptive testing, most of which are probably also useful here. However, a further strategy these authors suggest is to use Rasch models rather than models with more parameters, as capitalization on chance in adaptive testing is caused by imprecisely calibrated discrimination parameters. Ironically, to avoid the phenomenon observed in the current study, one might, at least when likelihood estimators are used or when the test is sufficiently long, recommend just the opposite strategy: In Rasch models, the dependence of the Fisher information on the difficulty parameter is more pronounced than in models with further item parameters; hence, the bias in person parameter estimation for Rasch models is in many cases expected to be larger.
Errors in item calibration can be controlled at least to a certain extent; however, it is much more difficult to deal with deviations arising from person-specific differences in difficulty parameters, testlets, or rule-based item generation. Using random effects models would provide a straightforward way of directly modeling the error variance arising from these sources. However, random effects models are most useful when the objective is to estimate population characteristics. In the case of adaptive testing, where the focus is on the measurement of individual persons, they do not make a big difference, as for an individual examinee and a given item the values of corresponding random effects would still be unknown, so that the means would continue to be the best approximations. Hence, with respect to the difficulty parameter, the item selection algorithm would still pick the same items as under a standard fixed effects model.
Further research could aim to quantify the magnitudes of error variation in item difficulty parameters in diverse practical applications by using random effects models. Based on the obtained estimates of error variances, the effect of biased person parameter estimation could then be evaluated for various IRT models, estimators, and item pools, to investigate how serious its consequences are for the actual practice of adaptive testing.
Footnotes
Appendix
Correlations of Estimated and True Person Parameters
|
|
|
Model | R |
|---|---|---|---|
| 0.0 | MAP | Rasch | .957 |
| 0.0 | MAP | 2PL | .972 |
| 0.0 | MAP | 3PL | .970 |
| 0.0 | WML | Rasch | .956 |
| 0.0 | WML | 2PL | .971 |
| 0.0 | WML | 3PL | .971 |
| 0.1 | MAP | Rasch | .959 |
| 0.1 | MAP | 2PL | .971 |
| 0.1 | MAP | 3PL | .970 |
| 0.1 | WML | Rasch | .957 |
| 0.1 | WML | 2PL | .970 |
| 0.1 | WML | 3PL | .970 |
| 0.5 | MAP | Rasch | .954 |
| 0.5 | MAP | 2PL | .972 |
| 0.5 | MAP | 3PL | .965 |
| 0.5 | WML | Rasch | .944 |
| 0.5 | WML | 2PL | .970 |
| 0.5 | WML | 3PL | .964 |
Note:
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
The author received no financial support for the research, authorship, and/or publication of this article.