
Abstract
It is common to assume during a statistical analysis of a multiscale assessment that the assessment is composed of several unidimensional subtests or that it has simple structure. Under this assumption, the unidimensional and multidimensional approaches can be used to estimate item parameters. These two approaches are equivalent in parameter estimation if the joint maximum likelihood method is used. However, they are different from each other if the marginal maximum likelihood method is applied. A simulation study is conducted to further compare the unidimensional and multidimensional approaches with the marginal maximum likelihood method. The simulation results indicate that when the number of items is small, the multidimensional approach provides more accurate estimates of item parameters, whereas the unidimensional approach prevails if the number of items in each subtest is large enough. Furthermore, the impact of the violation of the simple structure assumption is also investigated theoretically and numerically. The results demonstrate that when a set of response data does not have a simple structure but is specified as such in calibration, the models will be incorrectly estimated and the correlation coefficients between abilities will be overestimated.
Introduction
Educational and psychological tests are usually designed to measure several domains based on content areas, strands, attributes, or skills. These tests, such as the Graduate Record Examinations® (GRE®) general test, the Test of English as a Foreign Language™ (TOEFL®), and the SAT® Reasoning test, are typically composed of several sections or subsets of items (called subtests in this article) that measure different domains. For instance, the SAT is a test with verbal and mathematics subtests that measure verbal and mathematical reasoning skills of high school students. In such testing programs, domain scores and an overall composite score are typically reported. The domain scores are determined by examinees' performance on the corresponding subtests and the overall composite score is the sum, a weighted sum, or a weighted average of the domain scores. In the process of analyzing response data, it is typically assumed, explicitly or implicitly, that each subtest is unidimensional. Specifically, if item response theory (IRT) is used to analyze such a data set, it is assumed that each content-based subtest can be modeled by a unidimensional IRT model. From the perspective of multidimensional item response theory (MIRT), this is equivalent to assuming that the test is multidimensional with simple structure, which is called a simple structure test (SST) in this article. One example of the application of simple structure involves the National Assessment of Educational Progress (NAEP). The main NAEP mathematics, reading, science, history, and geography assessments are all assumed to be SSTs (see Allen, Carlson, & Zelenak, 1999; Allen, Donoghue, & Schoeps, 2001). For example, the Grade 4 NAEP reading assessment is assumed to be a two-dimensional SST with each dimension representing one of the two general types of text and reading situations: reading for literary experience and reading for information. In other words, it is composed of two unidimensional subtests: literature and information. Typically, this substantive simple structure is predetermined by the test framework and/or test developers. The major advantage of such a substantive simple structure assumption is that all domain scores can be reported along with an overall composite score and have substantive meanings, such as reading for literary experience and reading for information in the NAEP reading assessment or algebra and geometry scores in a mathematics test.
As each subtest in an SST is unidimensional, a common way of using IRT to analyze such response data is to estimate item parameters of each unidimensional subtest separately with a unidimensional estimation program, such as BILOG (Mislevy & Bock, 1982) or PARSCALE (Muraki & Bock, 1991). This approach, commonly used in operational data analysis, is called the unidimensional approach in this article. For example, NAEP uses the unidimensional approach in item parameter estimation in the national reading assessment (see Zhang, Isham, & Worthington, 2001).
One major issue with the unidimensional approach is that the information between domains is ignored although the domains of a subject are usually highly correlated. When estimating item parameters for a subtest, one could use items in other subtests to provide additional information possibly to get more accurate item parameter estimates for that subtest if the corresponding domain is highly correlated with other domains, and examinees do not just respond to that subtest only. If the number of items in that subtest is small, then this additional information might be very helpful in getting more accurate parameter estimates. To use the additional information, item parameters from different subtests must be estimated jointly using an MIRT estimation program.
There is extensive literature on MIRT model estimation. NOHARM (normal ogive harmonic analysis related method; Fraser, 1988; Fraser & McDonald, 1988) and TESTFACT (test scoring, item statistics, and item factor analysis; Wilson, Wood, & Gibbons, 1991) are the two most commonly used multidimensional item response estimation programs for dichotomously scored items. NOHARM uses the common factor analysis methodology to estimate item parameters for unidimensional and multidimensional two-parameter normal ogive models, whereas TESTFACT applies the full-information factor analysis methodology. These two programs yield similar results (Miller, 1991). Bayesian methods, especially the Markov chain Monte Carlo (MCMC) techniques, have also been widely used to estimate IRT and MIRT models. To obtain the posterior distribution of parameters given response data, MCMC draws simulated samples from appropriately selected and adjusted distributions, and after a certain “burn-in” period, the new samples are regarded as random draws from the target posterior distribution. Patz and Junker (1999a, 1999b) developed an MCMC methodology based on Metropolis-Hastings sampling to estimate various IRT models. Presently, there are several MCMC-based MIRT estimation programs available. One of them is BMIRT (Bayesian multivariate item response theory; Yao, 2003; Yao & Boughton, 2007; Yao & Schwarz, 2006), which uses the MCMC method to estimate MIRT models in exploratory and confirmatory modes. Cai (2010a) proposed a Metropolis-Hastings Robbins-Monro algorithm for high-dimensional maximum marginal likelihood exploratory item factor analysis. The algorithm was implemented as a part of the numeric engine in the prototype IRTPRO program (Cai, du Toit, & Thissen, 2009). The MCMC methodology provides a promising procedure for MIRT model estimation.
One advantage of the multidimensional approach is that it can be applied to response data with structures beyond simple structure. The simple structure assumption is very restrictive in practice as it requires that every item measure exactly one domain or content area. It may be the case that only single-strand knowledge is needed to answer a content-specific item correctly. However, it is more common that examinees need to master knowledge of more than one strand to answer a comprehensive item correctly. In other words, although content-specific items measure one domain only, comprehensive items measure several domains. In an algebra–geometry mathematics test, for example, there are possibly three kinds of items: items measuring algebra only, items measuring geometry only, and items measuring algebra and geometry. If items of the third kind do not exist, then the test has a simple structure. Otherwise, the test dimensional structure goes beyond the simple structure and is called a mixed structure. When a set of response data displays a mixed structure, the multidimensional approach should be applied to analyze the data. Another advantage of the multidimensional approach (either with or without the simple structure constraint) is that one can obtain estimates of correlation coefficients between domains as a by-product. The models with mixed structures discussed here are similar to testlet models (Bradlow, Wainer, & Wang, 1999; Wainer, Bradlow, & Wang, 2007) and two-tier item factor models (Cai, 2010b). The major difference is that all of the latent traits are common factors in the models with mixed structures, whereas in testlet and two-tier models, there are unique (or secondary) factors as well as common factors, and items typically load only on one common factor and possibly on several unique factors.
The main purposes of this article are (a) to examine whether the multidimensional approach can improve IRT model estimation compared with the unidimensional approach for response data under the constraint of simple structure and (b) to investigate the impact of the violation of the simple structure assumption. The rest of the article proceeds as follows: The section “Unidimensional and Multidimensional Approaches Under Simple Structure” compares the unidimensional and multidimensional approaches theoretically when the joint maximum likelihood estimation (JMLE) and marginal maximum likelihood estimation (MMLE) methods are used for item parameter estimation under the constraint of simple structure. In the section “A Simulation Study With Simple Structure,” a simulation study is conducted to further investigate the performance of these two approaches with the MMLE method. The section “Mixed Structure” theoretically investigates the impact of the violation of the simple structure assumption on item parameter estimation. The section “A Simulation Study With Mixed Structure” presents a simulation study to numerically investigate the impact of the violation of the simple structure assumption. Some discussion is presented in the last section.
Unidimensional and Multidimensional Approaches Under Simple Structure
Suppose there is a test with n dichotomously scored items, and X
i
is the score for item i of a randomly selected examinee from a certain population. The item response function (IRF) is defined as the probability of answering an item correctly by a randomly selected examinee with ability vector
One widely used multidimensional item response model is the multidimensional compensatory three-parameter logistic (M3PL) model. The IRF for this model is
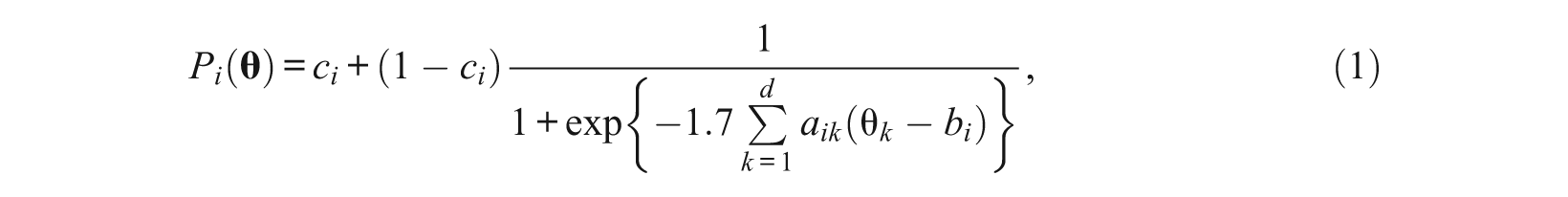
where a ik s are the discrimination parameters (nonnegative and not all zero), b i is the difficulty parameter, and c i is the lower asymptote parameter (0 ≤ c i < 1) When c i is fixed at zero, the M3PL model becomes a multidimensional two-parameter logistic (M2PL) model (see Reckase, 1985; Reckase & McKinley, 1991). In practice, a multiple-choice item is modeled by the M3PL model, and the M2PL model is used for a dichotomously scored constructed-response (open-ended) item.
Theoretically, any coordinate system may be used in MIRT. To ensure that IRFs are monotone increasing (or nondecreasing) with respect to each ability, a constraint that all discrimination parameters are nonnegative is imposed on the MIRT models. Hence, a coordinate system has to be chosen such that all discrimination vectors lie in the first quadrant. As such, the coordinate axes are chosen to be the d directions of the most separated items in this article so that other items are in the first quadrant as shown in Figure 1, when d = 2. Here, the discrimination vector of an item is used to represent the item in the latent space. In practice, the coordinate axes are usually the target abilities that a test measures. For convenience, these coordinate axes are called the target subscales in this article. Note that these coordinate axes are oblique in the sense that they (e.g., algebra and geometry) are usually positively correlated. When speaking of content-specific or comprehensive items (i.e., items measuring one subscale or more than one subscale), this article always refers to this coordinate system.
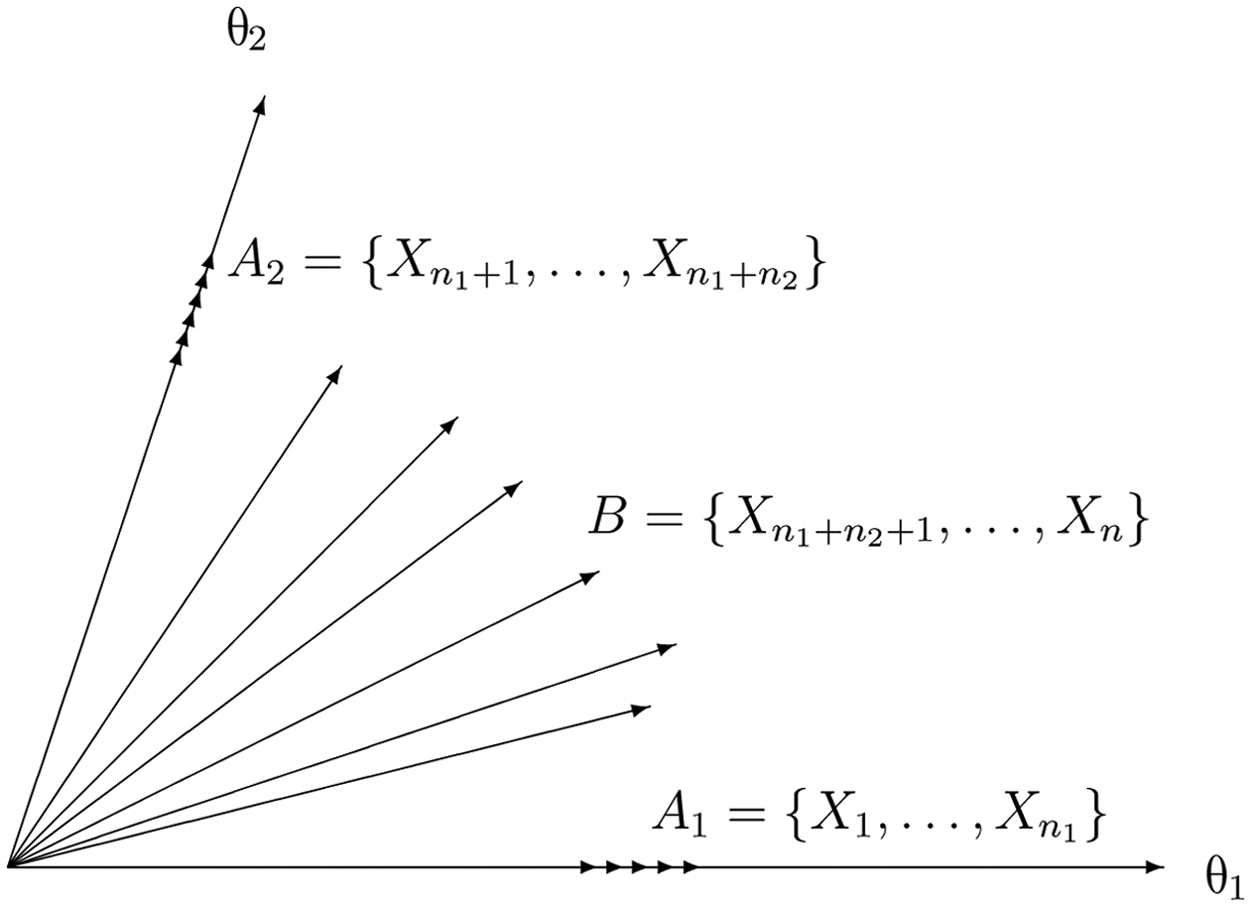
A two-dimensional test with mixed structure
Simple Structure
Let
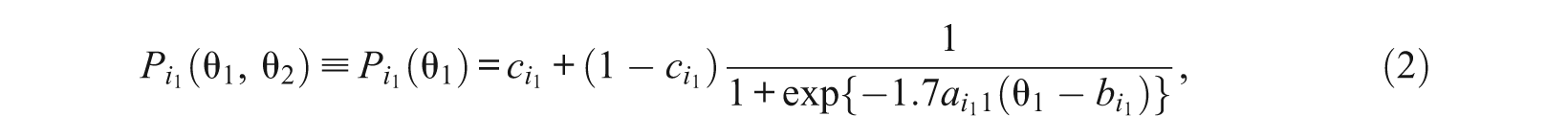
for i1 = 1, 2, …, n1. It is a unidimensional 3PL or 2PL model when

for i2 = n1 + 1, n1 + 2, …, n. That is,
Clearly, an SST is a special case of a multidimensional test as Equations 2 and 3 are special cases of the larger model (Equation 1) under the constraint that one, and only one, of a ik , k = 1, …, d, is positive. A multidimensional calibration program can also be applied to estimate item parameters for all items simultaneously under the constraint that each item measures only one domain.
Maximum likelihood estimation (MLE) is the most popular method used to estimate unknown parameters. In IRT, the item parameters are the structural parameters and the ability parameters are the incidental parameters (Hambleton & Swaminathan, 1985). Depending on how one treats the incidental parameters, there are two popular methods in IRT to estimate parameters: the JMLE and MMLE methods. The major difference between the JMLE and the MMLE is the treatment of abilities. In the JMLE method, abilities are treated as fixed unknown parameters, whereas in the MMLE method, abilities are treated as random variables with a prior distribution. In the following, the unidimensional and multidimensional approaches are compared for an SST when the JMLE or the MMLE method is used to estimate item parameters.
JMLE
Let
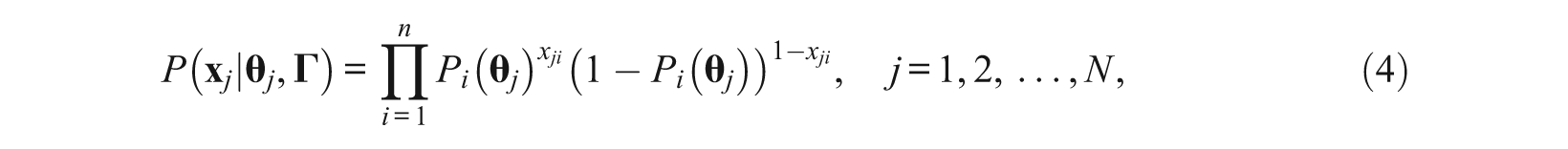
where P
i
(

When the test is a d-dimensional SST, it consists of d subtests with n1, n2, …, n
d
items, respectively. Here, n = n1 + n2 + … + n
d
. The response vector of examinee j can be decomposed into d parts:
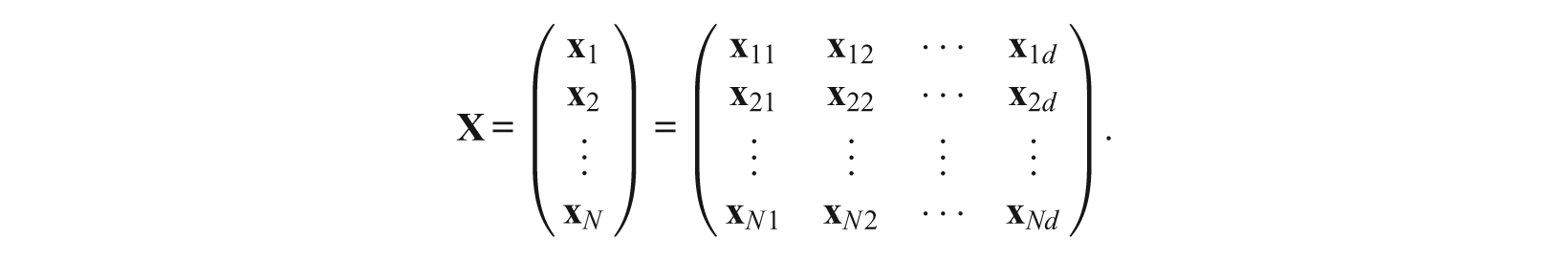
As each item is only associated with one dimension, the joint probability (Equation 4) of the response vector
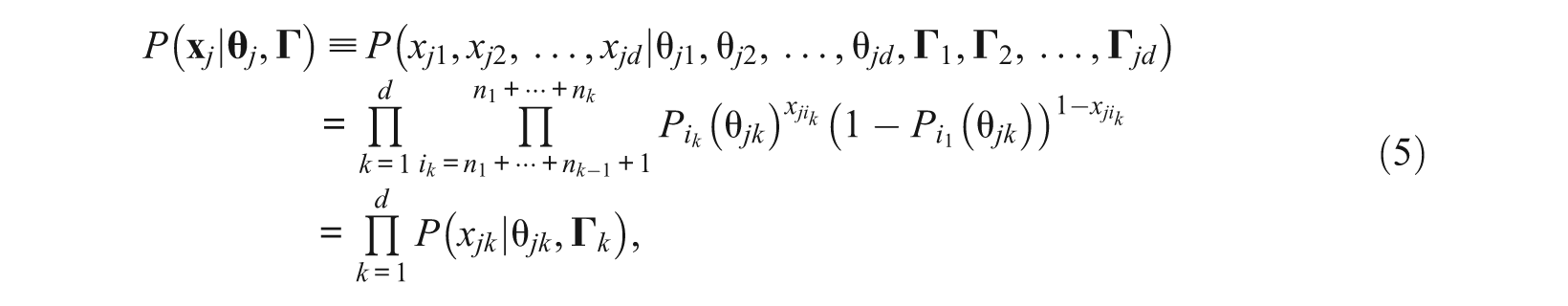
where
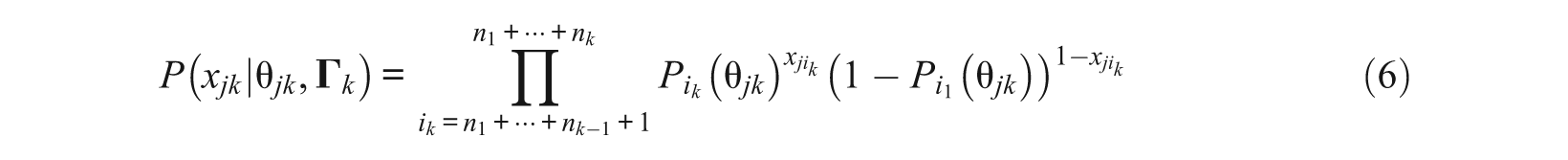
are the joint probabilities of the kth subtest. Equation 5 shows that the joint probability of a response vector of a whole test with simple structure can be decomposed into the product of the joint probabilities of the d subtests.
Let L(
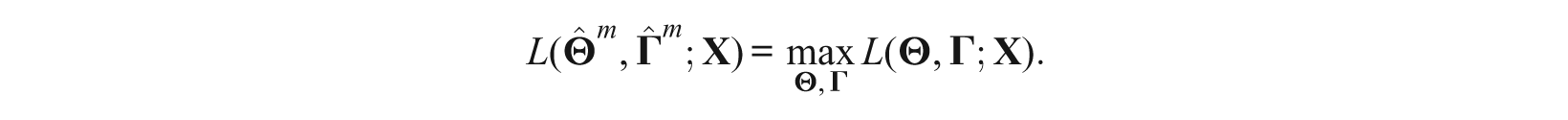
Let L
k
(

From Equation 5, the joint likelihood function of the response patterns
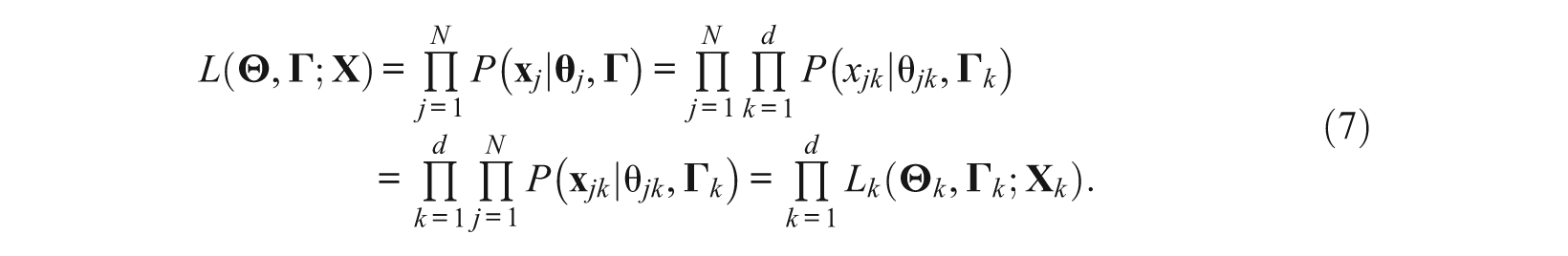
Equation 7 shows that the joint likelihood function of a whole test with simple structure can be decomposed into the product of the joint likelihood functions of subtests. According to Equation 7, maximizing L(
However, JMLE estimates are not consistent. Lord (1986) found that JMLE obtains biased estimates of ability and item parameters in unidimensional cases when there are only 10 or 15 items, even when the number of examinees is large. JMLE will not be discussed any further in this article.
MMLE
The MMLE approach (Bock & Aitkin, 1981) is the most widely used method in IRT for the estimation of item parameters. BILOG and PARSCALE use this method. In the MMLE method, latent abilities are treated as random variables. The (prior) distribution of the latent ability vector is typically assumed to be a multivariate normal distribution. Without loss of generality, one can standardize the latent traits so that they have means of zero and variances of one.
For the multidimensional approach, the marginal likelihood function can be calculated as below. From Equation 5, the marginal probability of an observed response pattern

where

Under the multidimensional approach, MMLE tries to find

For the unidimensional approach, the marginal probability of response pattern

where φ(θ
jk
) is the marginal density function of the kth ability and is the standard normal density function if φ(θ1j, …, θ
jd
|

Under the unidimensional approach, MMLE tries to find
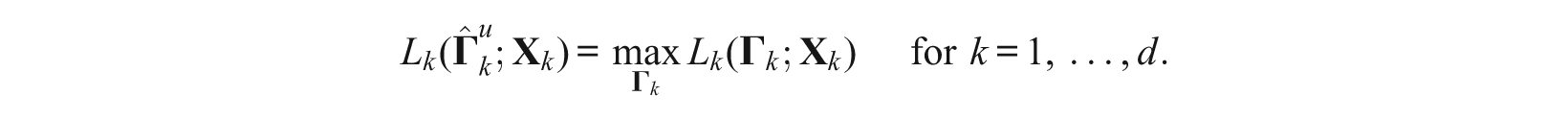
From Equations 8 and 10, in general,
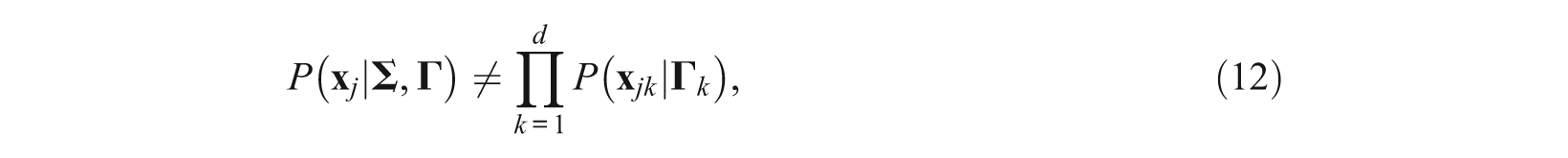
unless abilities (i.e., underlying dimensions) are uncorrelated (i.e., independent if abilities are multivariate normal); that is,
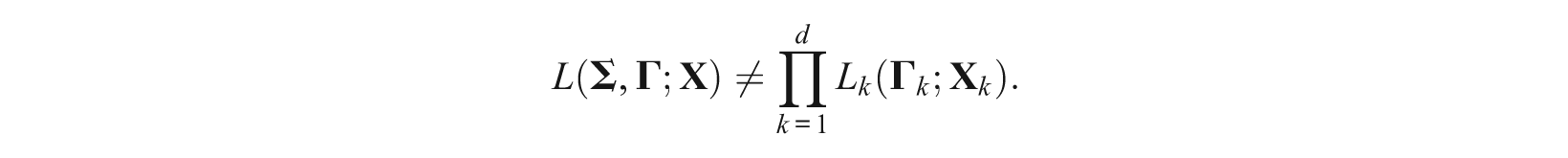
Hence, the MMLE of
The essential difference between the unidimensional and multidimensional approaches for an SST is how the population distribution of abilities is applied. The multidimensional approach uses the joint distribution of abilities and estimates the correlations at the same stage as when estimating item parameters, whereas the unidimensional approach only uses the marginal distributions of abilities and the correlations are typically estimated after estimating item parameters. For example, NAEP uses the unidimensional approach to estimate item parameters and then the plausible value methodology (Mislevy, 1991) to obtain the estimated correlation coefficients. It should be noted that the unidimensional approach regards the correlations between abilities as unknown; therefore, they need to be estimated at a later stage. Thus, the values of correlations between abilities do not have an effect on the estimation of item parameters when the unidimensional approach is applied. However, it does not mean that the unidimensional approach assumes that abilities are uncorrelated or independent.
The preceding result shows that two different sets of item parameter estimates will be obtained from the unidimensional and multidimensional approaches using the MMLE method for an SST. As the unidimensional approach is usually used in operational data analyses for an SST, it is of interest to know whether the multidimensional approach can improve the accuracy of item parameter estimates. To investigate which approach provides better recovery of item parameters, a simulation study is conducted in the following section.
A Simulation Study With Simple Structure
Simulated response data were used to compare the accuracy of item parameter estimates obtained from the unidimensional and multidimensional approaches when the MMLE method was applied. Many unidimensional and multidimensional estimation programs based on the MMLE method are available for use. Considering that the effect of different dimensional approaches on the accuracy of item parameter estimation may be confounded with the effect of other factors (such as differences in algorithms and differences in levels of numerical accuracy obtained from different computer programs), it is not appropriate to compare the two approaches using different estimation programs. For comparison purposes, one has to choose the same estimation program (software) that can estimate item parameters for unidimensional and multidimensional IRT models. In both simulation studies in this article, an estimation program, called ASSEST (Zhang, 2005), was selected to estimate item parameters.
ASSEST is designed to estimate item parameters for unidimensional and multidimensional IRT models with mixed structures. It adopts an expectation-maximization–genetic algorithm (EM-GA) to estimate item parameters using the MMLE method. The EM algorithm is an iterative method for finding maximum likelihood estimates of parameters for probability models (e.g., Bock & Aitkin, 1981). Each iteration consists of two steps: the E step (expectation) and the M step (maximization). The EM algorithm is applied to estimate the parameters for each item individually, and then the iteration process is repeated until certain convergence criteria are met (e.g., the changes of likelihood function values and all item parameter estimates are smaller than preselected values). The algorithm is called the EM-GA algorithm because a GA is used in the maximization step of the EM algorithm. A GA is a computational algorithm that takes ideas from genetics and/or evolution (e.g., breeding, mutation, crossover, and survival of the fittest) and can be used to solve any optimization problem, such as adaptive control, cognitive modeling, optimal control problems, and traveling salesman problems (Michalewicsz, 1994). A GA starts with a set of potential solutions (called individuals) to a problem at hand. Then it stochastically optimally selects individuals as parents of the next generation and lets the selected individuals clone, mutate, and combine some of their components to form new individuals (offspring). This process is repeated over successive generations until one cannot find another individual better than the optimal individual one has gotten thus far. By using a well-designed GA in the maximization step of the EM algorithm, the chance of obtaining the global maximum value is increased. For details about ASSEST, see Zhang (2005). As ASSEST uses the same algorithm to estimate unidimensional and multidimensional IRT models, it is appropriate to apply ASSEST to compare the unidimensional and multidimensional approaches without algorithm and numerical accuracy complications. When running ASSEST, one can choose the unidimensional approach by specifying each subtest as unidimensional and estimating its item parameters separately from other subtests, or choose the multidimensional approach by estimating item parameters of all subtests simultaneously.
Simulation Design
The test length in this simulation was set to be either 30, 46, or 62 items. The estimated item parameters of dichotomous items from the analysis of the 1998 NAEP Grade 4 reading assessment (see Appendix E of Allen et al., 2001) were used as “true” item parameters in these simulation studies. There are 31 dichotomous items measuring the first subscale of reading for literary experience, and 32 dichotomous items measuring the second subscale of reading to gain information. An item in the second subscale with b = 3.921 was dropped from these simulation studies. Therefore, there are a total of 62 items with 35 multiple-choice and 27 constructed-response items. A 3PL model is used for the multiple-choice items and a 2PL model for the constructed-response items. For completeness, these item parameters are given in Table 1. For tests with 30 or 46 items, the first 15 or 23 items from each subscale were chosen. For instance, the items in the 30-item test are Items 1 to 15 and Items 32 to 46 are shown in Table 1.
Item Parameters From 1998 NAEP Grade 4 Reading Assessment
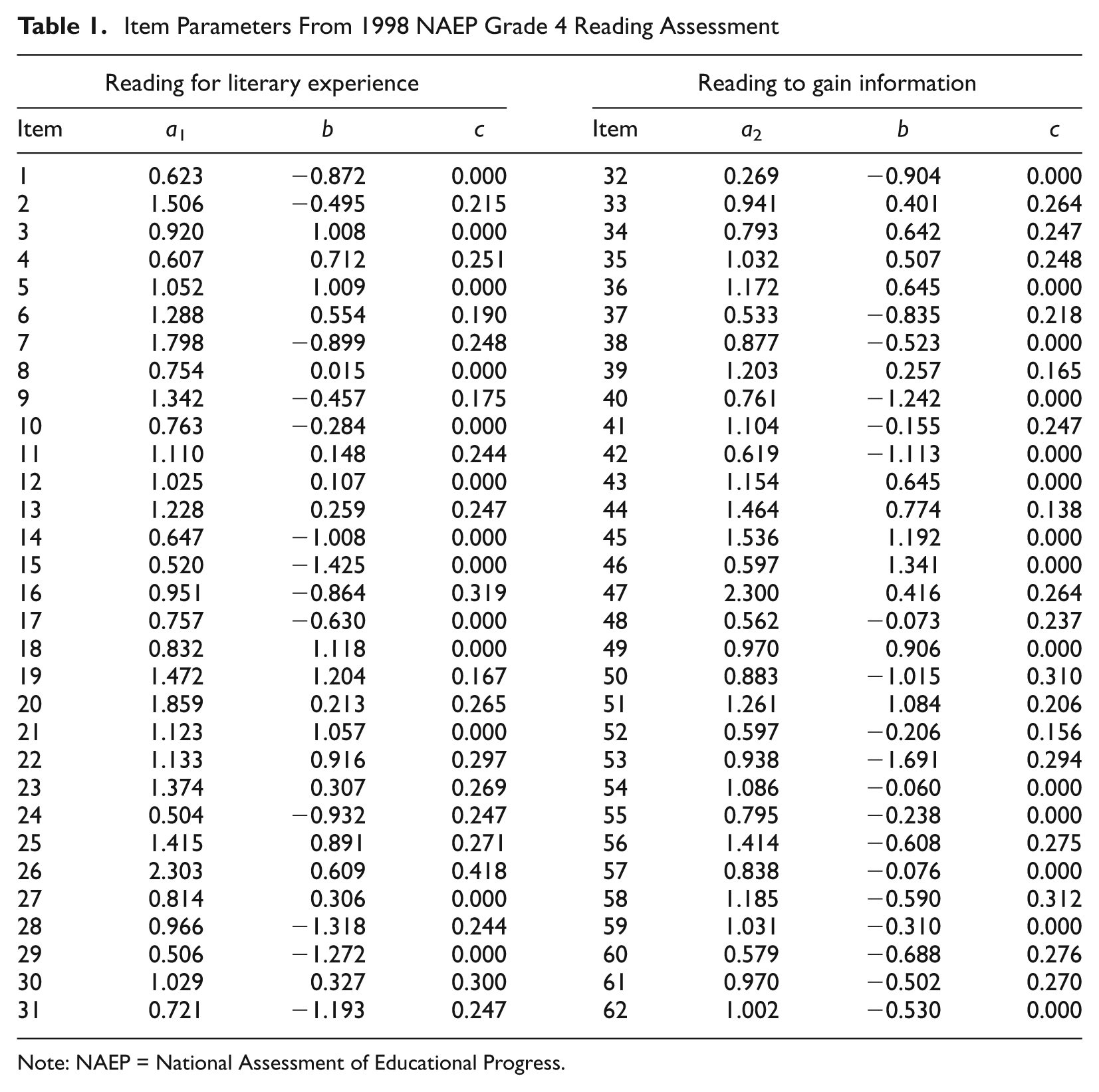
Note: NAEP = National Assessment of Educational Progress.
The number of simulated examinees was 500, 1,000, 2,000, 3,000, 4,000, or 5,000 in this study. Examinees’ (true) ability scores were generated independently from bivariate normal distributions with means of 0, variances of 1, and a (population) correlation of 0, .5, or .8. When the correlation coefficient is zero, theoretically, there should be no difference between the unidimensional and multidimensional approaches. Any difference between the unidimensional and multidimensional approaches when the correlation coefficient is zero is caused by numerical rounding error in the calibration program, which provides a reference when comparing differences in other cases. Of course, the multidimensional approach has additional errors from estimation of the correlation. However, the impact should be small, if not negligible, as the errors from estimation of the correlation are typically small.
Simulated response data were generated using the following (standard) IRT method. Given ability score
In summary, the following three factors were considered in this simulation study:
The number of items: 30, 46, or 62
The number of simulated examinees: 500, 1,000, 2,000, 3,000, 4,000, or 5,000
The correlation coefficient between two subscales: 0, .5, or .8
Given these factors, there were 54 combinations in this simulation. For each combination, ASSEST was applied to a simulated response data set twice to get two sets of parameter estimates under two different specifications, corresponding to the unidimensional and multidimensional approaches. This process was repeated 100 times for each combination.
Criterion for Comparisons
In this simulation study, two different kinds of root mean squared errors (RMSEs) were calculated as comparison criterions. The first kind focuses on the recovery of item parameters and the second kind on the direct recovery of IRFs.
The RMSE of estimated parameters is commonly used as a criterion for the recovery of item parameters in simulation studies. The RMSE is the square root of the average of the squared deviations of estimated parameters from the corresponding true ones. Let γ
i
represent a parameter of item i, a
i1
, a
i2
, b
i
, or c
i
, and
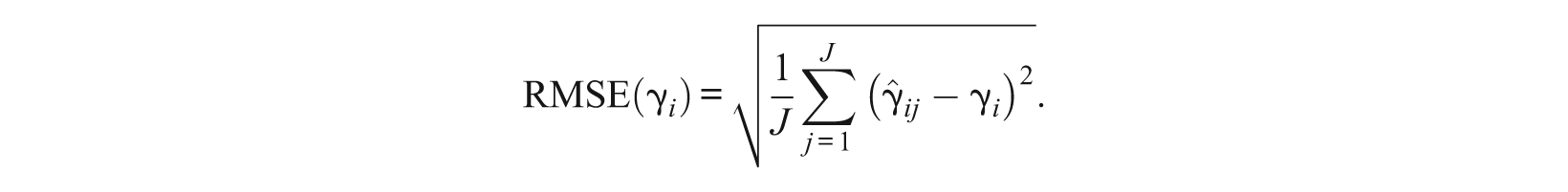
Given an SST with n items, the total number of item parameters is 2n (n discrimination and n difficulty parameters) plus the number of lower asymptote parameters (i.e., the number of items in the test modeled by the M3PL model). The number of RMSEs is the same as the number of item parameters. To make the comparison feasible, these RMSEs are further summarized by types of item parameters. If the test has two subtests, then there are four types of item parameters: the discrimination parameter for the first subscale a1, the discrimination parameter for the second subscale a2, the difficulty parameter b, and the lower asymptote parameter c for multiple-choice items. To further summarize the RMSE, the average of the RMSEs (ARMSE) for each of these four kinds of item parameters is defined as
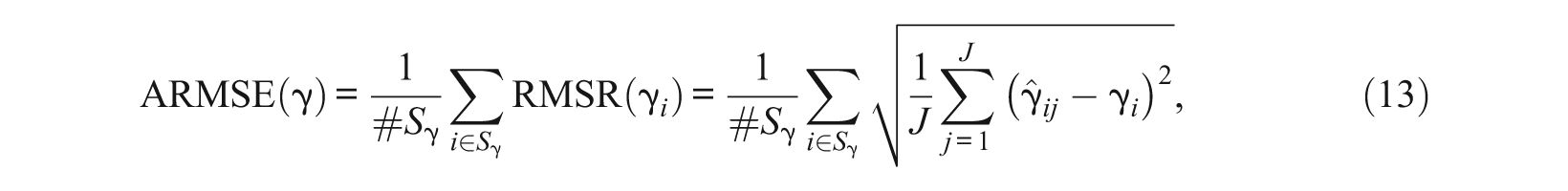
where γ represents one of the four kinds of item parameters, S γ is the set of item sequence numbers that have γ parameter and #S γ is the number of elements in S γ . If γ is the discrimination parameter of the second subscale, for example, then Sa2 = {n1 + 1, n1 + 2, …, n} and #Sa2 = n2. If γ is the lower asymptote parameter, then S c = {i: item i is a multiple-choice item, 1 ≤i≤n} and #S c is the number of items modeled by M3PL models. For each of the two different dimensional estimation approaches, there are four ARMSE(γ)s for each of the 54 combinations considered in the simulation study. These values (total of 2 × 4 × 54 = 432) together with ARMSE of estimated IRF defined later are reported in Table 2, which is discussed later.
ARMSE of Estimated Item Parameters and IRF When the Correlation Between Subscales Is 0 (Based on 100 Replications Using Unidimensional [U] and Multidimensional [M] Approaches)
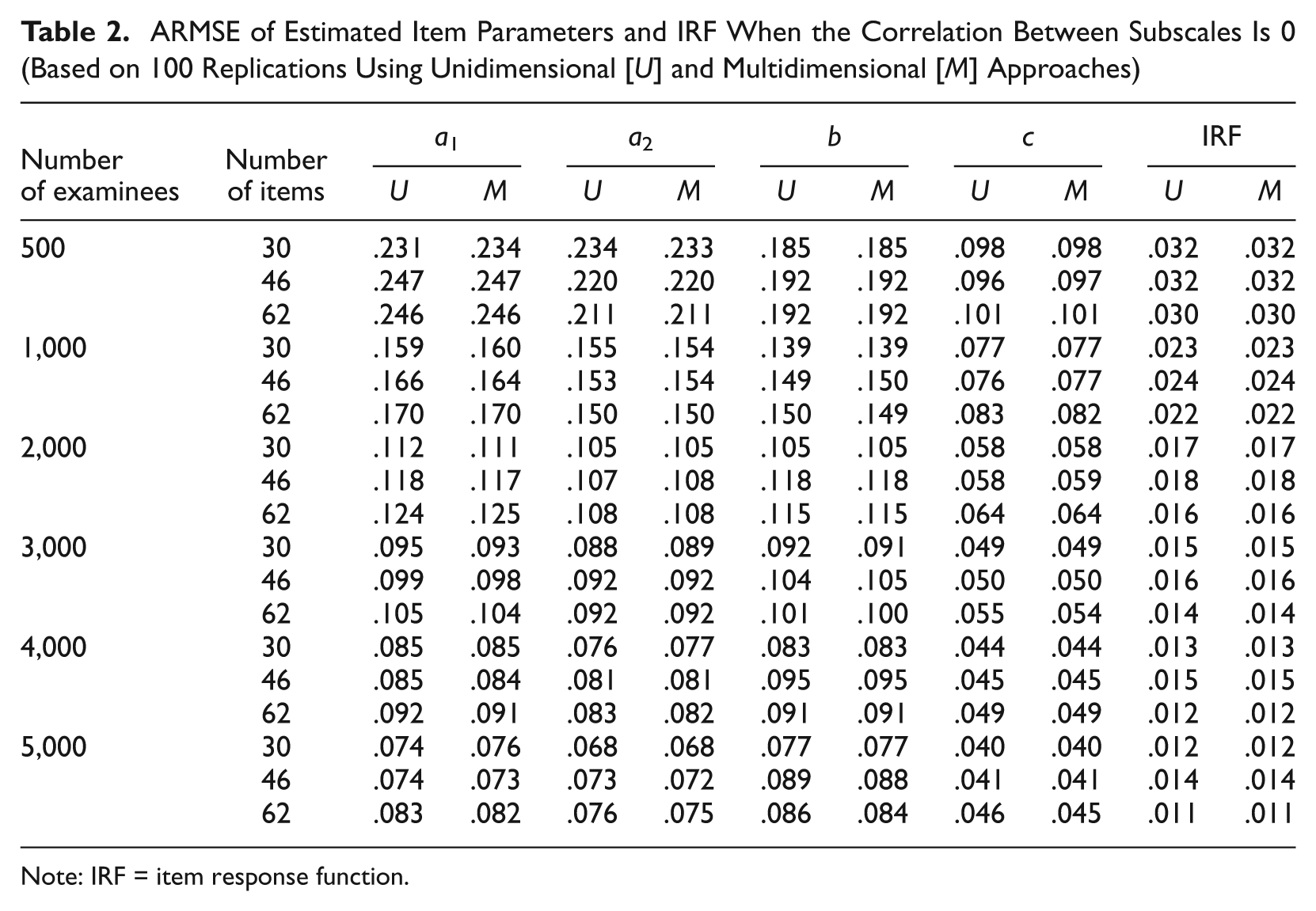
Note: IRF = item response function.
The estimates of item parameters are usually treated as fixed in any further analysis of response data such as estimating abilities of examinees. In the process of such analysis, the IRF is more directly relevant than item parameters themselves in operational applications as most statistical analysis is based on the likelihood function formed by the IRFs. In addition, different sets of item parameters may produce very similar item characteristic curves or surfaces. Therefore, it is more appropriate and vital to check the closeness of estimated IRF (curves or surfaces) to the true IRF than the item parameter estimates to the true values. Moreover, it is possible when making comparisons using the ARMSE of estimated parameters, one approach is better than the other for some parameters (e.g., discrimination parameters), but worse for other parameters (e.g., the lower asymptote parameter). This happened in the simulation study, for instance, in the cases of 62 items with .8 correlation (see the third part of Table 2). Hence, it is necessary to directly use the RMSE for the estimated IRF. Let

where φ(
The RMSEs of different IRFs in the same test may be quite different from each other because of different item characteristics. The average of the RMSEs among the items in a test across all replications will be used as an overall measure of the accuracy of the estimation, that is, the overall average
ARMSE of Estimated Item Parameters and IRF When the Correlation Between Subscales Is .5 (Based on 100 Replications Using Unidimensional [U] and Multidimensional [M] Approaches)
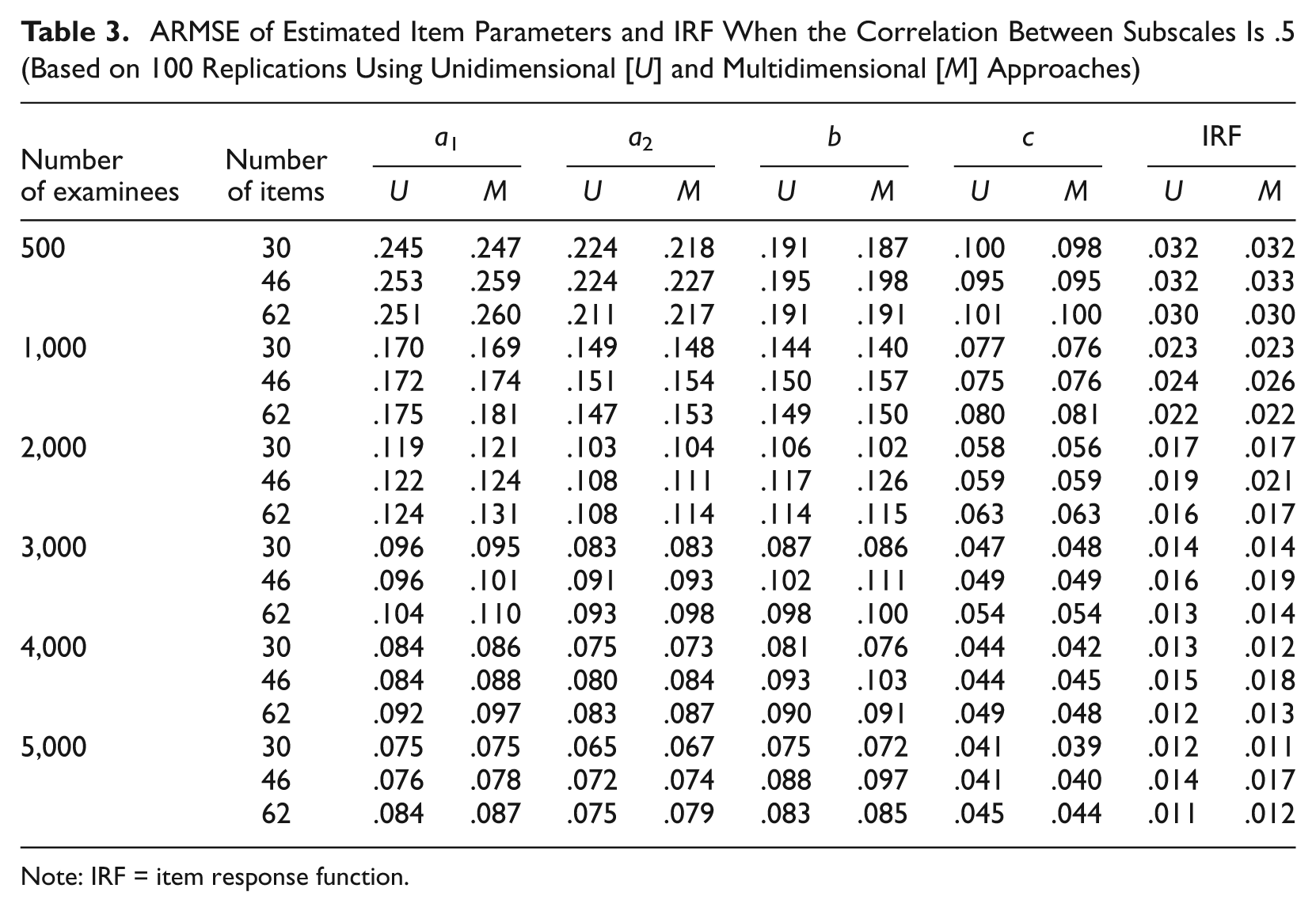
Note: IRF = item response function.
ARMSE of Estimated Item Parameters and IRF When the Correlation Between Subscales Is .8 (Based on 100 Replications Using Unidimensional [U] and Multidimensional [M] Approaches)
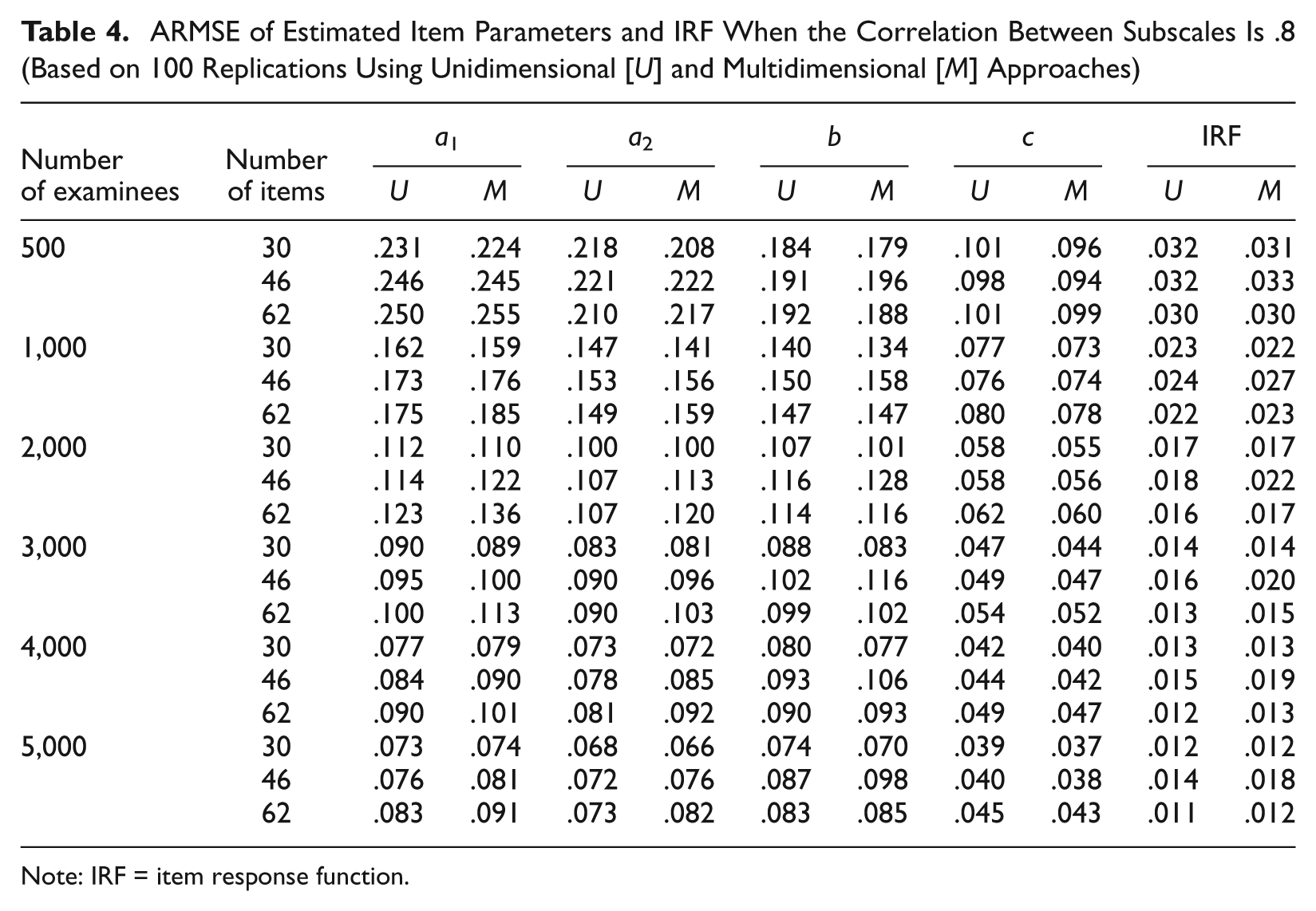
Note: IRF = item response function.
Simulation Results
Tables 2 to 4 present the ARMSEs of the estimated item parameters and the estimated IRFs. Each table shows one of the three levels of correlation (0, .5, and .8, respectively). In columns 3 to 7, each cell has two numbers for the ARMSEs: The first comes from the unidimensional approach and the second from the multidimensional approach. Columns 3 to 6 are the ARMSEs for the discrimination parameter for the first subscale a1, the discrimination parameter for the second subscale a2, the difficulty parameter b, and the lower asymptote parameter c for multiple-choice items modeled by M3PL models. Note that the constructed-response items using 2PL models are not included in the calculation of RMSE of the lower asymptote parameter (see Equation 13). The last column in Tables 2 to 4 presents the ARMSE of the estimated IRFs. As expected, when the correlation between subscales and the number of items are fixed, the ARMSEs from both approaches decrease as the number of examinees increases. That is, the larger the number of examinees, the better the estimates from both approaches. Tables 2 to 4 show that when using the unidimensional approach, the ARMSEs are very close to each other when there are the same number of examinees and test length, regardless of which level of correlation between the subscales is used, which confirms that the correlation between subscales should have no impact on the performance of the unidimensional approach. Small differences may come from sampling variations across different levels of correlation. These tables also confirm that when the correlation between subscales is zero, these two approaches are basically the same. The slight difference of ARMSEs between these two approaches may come from the fact that in the multidimensional approach, the correlation coefficient is estimated, thereby causing an additional parameter to be estimated.
In most cases, the ARMSEs for the four kinds of item parameters give consistent results. However, in some cases, one approach yields smaller ARMSEs for some item parameters while yielding larger ARMSEs for other parameters (e.g., see Table 4). In such cases, the ARMSE of the IRFs is used as the final criterion. It is interesting to note that, in most cases, the multidimensional approach gives better estimates for the lower asymptote parameters.
Tables 2 to 4 may be too large and complex to show the performance pattern of the two approaches clearly. The portions containing the ARMSEs for IRFs in these tables are reorganized and presented in Table 5, which shows that when the test length is 30 and the correlation is either .5 or .8, the average of the ARMSEs from the multidimensional approach is uniformly smaller than the corresponding average of the ARMSEs from the unidimensional approach across all numbers of examinees considered here. In contrast, when the test length is increased to 46 or 62, although the correlation still remains .5 or .8, the unidimensional approach is uniformly better (with smaller ARMSEs) than the multidimensional approach across all numbers of examinees. These results suggest that when the test length is relatively short, the additional information from other subscales’ items is helpful in obtaining more accurate IRF estimates if these scales are positively correlated. Otherwise, the additional information from other subscales may not be as helpful, and may even be harmful to the accuracy of parameter/IRF estimation, as additional statistical and numerical noises are also likely to be introduced when employing the multidimensional approach.
ARMSE of Estimated IRF (Based on 100 Replications Using Unidimensional [U] and Multidimensional [M] Approaches)
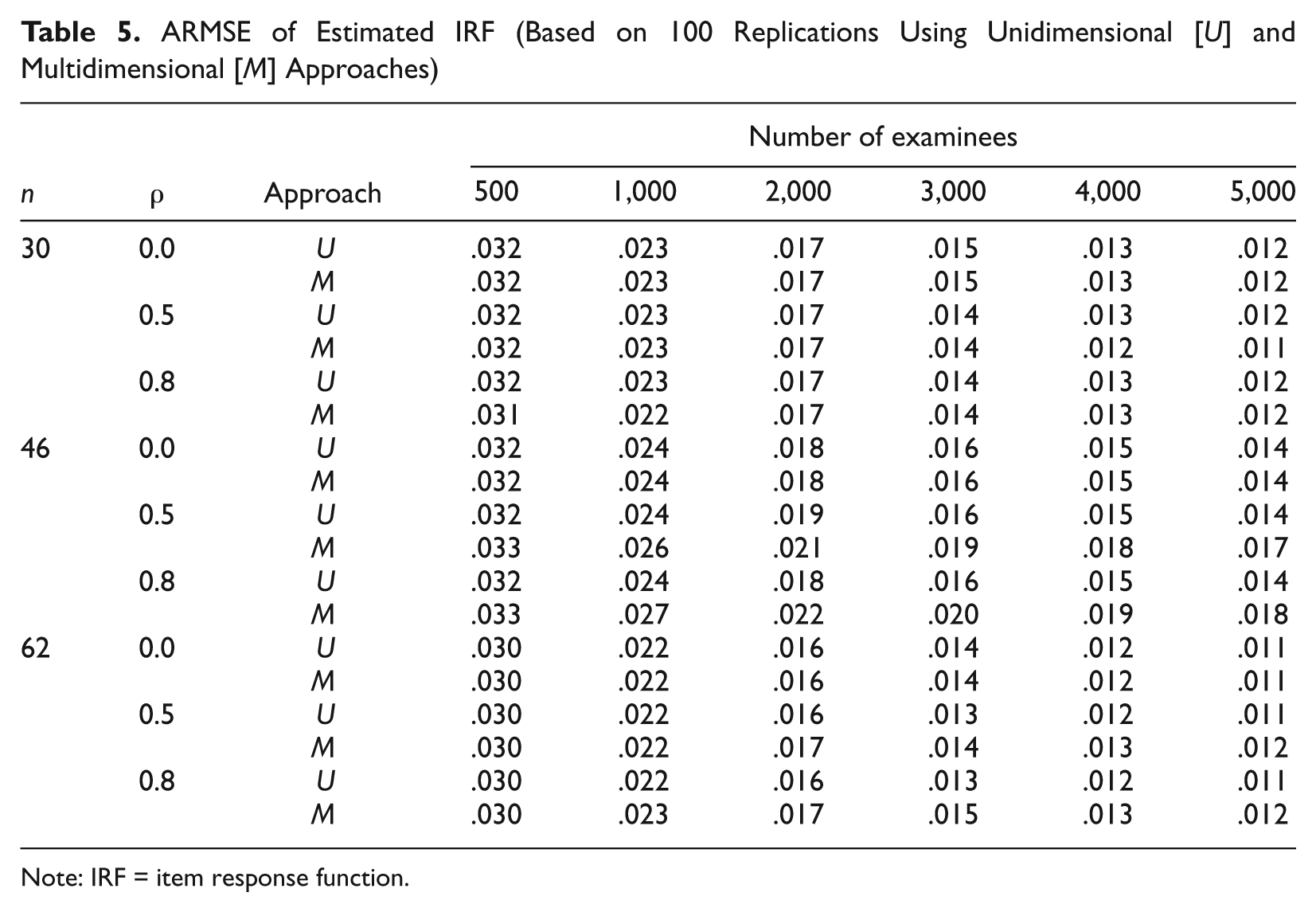
Note: IRF = item response function.
Tables 2 to 5 only display the overall performance of the unidimensional and multidimensional approaches. To show results at the item level, this article introduces the percentage of counts where the multidimensional approach is better than the unidimensional approach based on the RMSE of the estimated IRF. Let

where
Percentage of Cases Where RMSE of Estimated IRF From Multidimensional Approach Is Smaller Than Unidimensional Approach (Comparing Each Items in Each Replication)

Note: RMSE = root mean squared error; IRF = item response function.
When using the multidimensional approach, the estimates of correlation coefficients between abilities are also obtained as a by-product. These estimates are relatively close to their corresponding true correlations. Table 7 presents the RMSEs of estimated correlations. As shown in Table 7, the largest RMSE is .038, which appears in the 30-item, 500-examinee, 0-correlation case, whereas the smallest RMSE is .008 in the 30-item, 5,000-examinee, .8-correlation case. Generally speaking, the greater the number of examinees, the better the estimated correlation is. However, the impact of test length and the correlation between subscales on the estimation of the correlation is not so straightforward. It seems that some interactions exist among these three factors. For example, when the test length is 30, for any fixed number of examinees, the RMSE decreases as the correlation increases. But when the number of items is 62, this pattern holds only in the case of 500 examinees (see Table 7). In uncorrelated cases (ρ = 0), with any fixed number of examinees, the RMSE decreases as the number of items increases. In contrast, when the correlation is either .5 or .8, the RMSE increases as the number of items increases except for the cases of 500 (with ρ = .5 or .8) or 1,000 (with ρ = .5 only) examinees as shown in Table 7. Note that in practice, subscales to be measured by a test are usually highly correlated. The cases of correlation between subscales being .5 or .8 are more important than uncorrelated cases. Focusing on the cases of correlation being .8, to get the same level of accuracy as in the 30-item case, more examinees were needed in the 62-item case. For instance, to achieve the same level of accuracy in the case of 30 items with 1,000 examinees, 3,000 examinees are needed in the case of 62 items.
RMSE of Estimated Correlations (Based on 100 Replications)
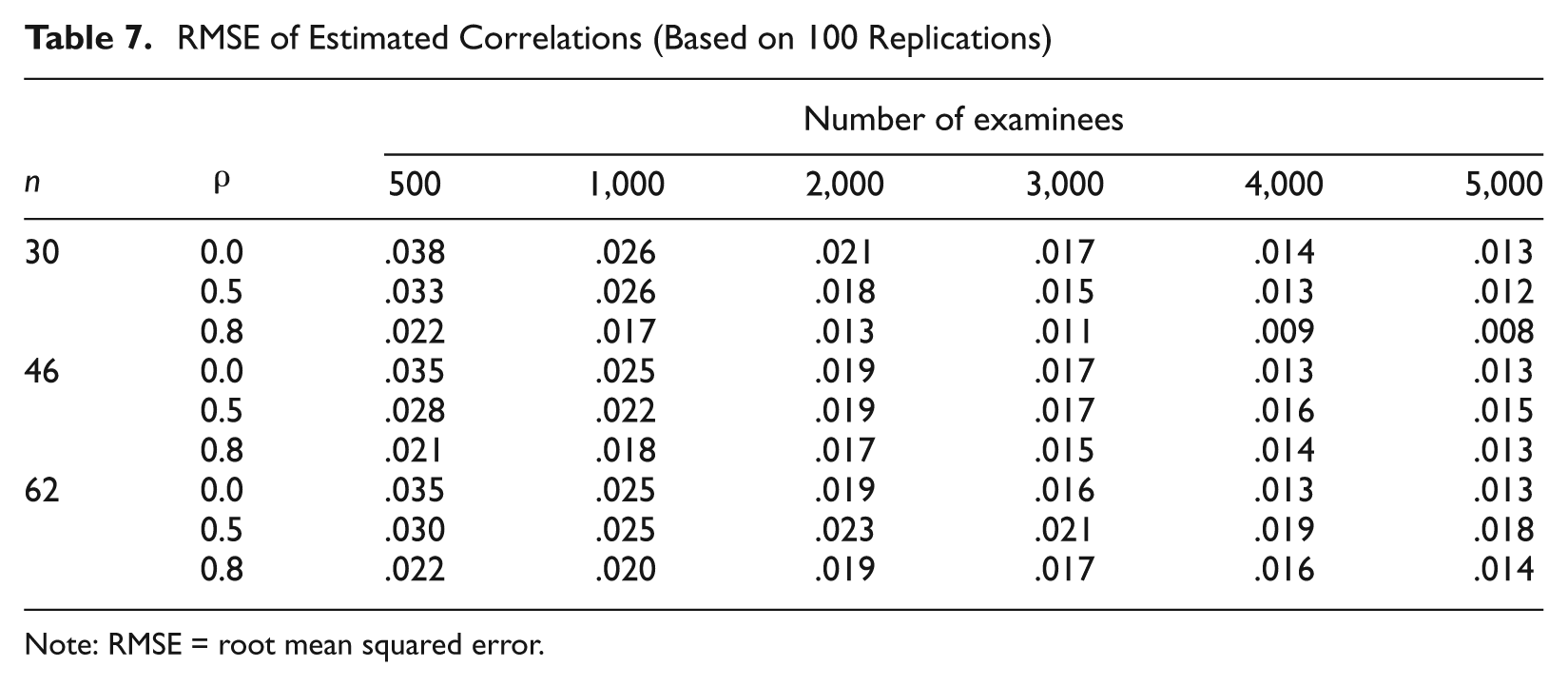
Note: RMSE = root mean squared error.
Mixed Structure
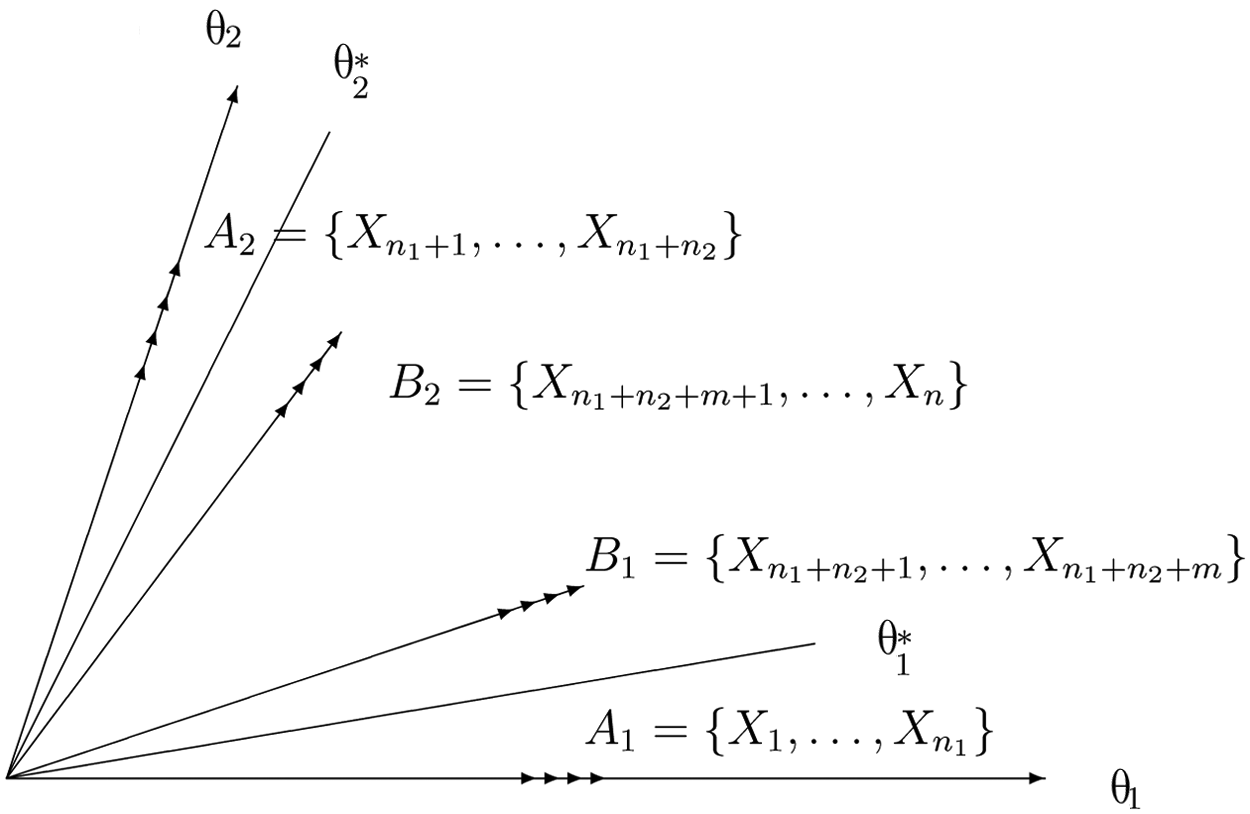
Simple structure requires that each item measures only one subscale. However, some items may turn out to measure several subscales although the test is designed to have simple structure. A test may require that some of its items measure more than one subscale according to its framework (see National Assessment Governing Board, 1994). Suppose a test is designed to measure d (d > 1) distinct subscales, A k is the subset of items measuring subscale k only, and B is the subset of all comprehensive items measuring more than one subscale. This test is called a d-dimensional mixed structure test (MST). Figure 1 presents an example of a two-dimensional test with a mixed structure. When B is empty (i.e., there are no comprehensive items), the MST becomes an SST.
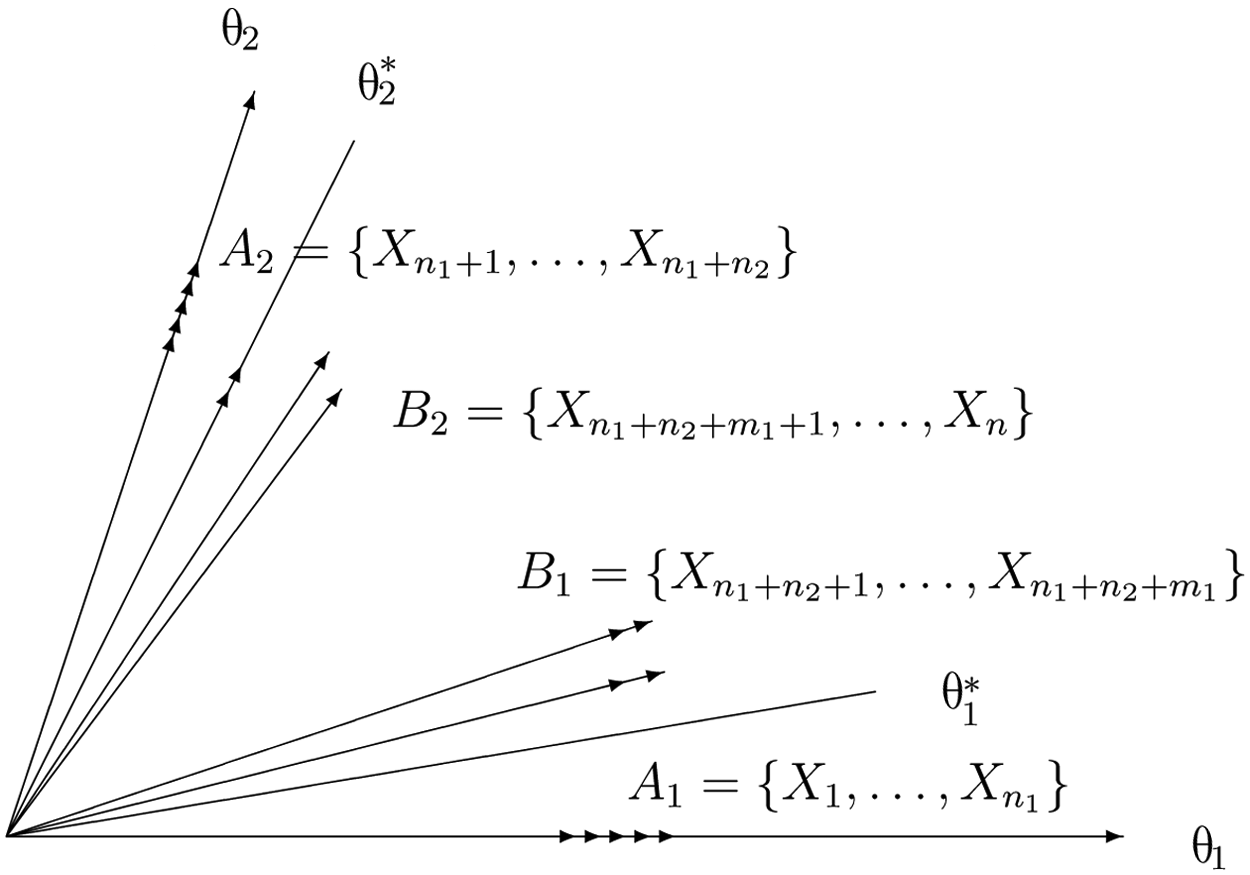
As mentioned earlier, even when the test framework requires that each item measure one subscale, some items may actually be “contaminated” in the sense that knowledge measured by the other subscales is helpful for an examinee to get correct answers for these items. Such an item usually has its target subscale as its dominant dimension although it is a comprehensive item. Such a test is called an approximate simple structure test (ASST), which consists of several subtests and each subtest is essentially unidimensional or has only one dominant distinct dimension. Clearly, approximate simple structure can be regarded as a special case of mixed structure when every comprehensive item has one of the subscales as its dominant dimension (or when no item measures two or more subscales equally well). When every subtest of an ASST is unidimensional, the ASST is an SST. A response data set with approximate simple structure is often treated as an SST in its statistical analysis, especially when the test is designed to be an SST. In the following, the author investigates the impact when an ASST is incorrectly specified as an SST in calibration.
As shown in Figure 2, there are two kinds of comprehensive items in a two-dimensional ASST: items in B1 that mainly measure θ1 and items in B2 that mainly measure θ2. For a d-dimensional ASST, the set of comprehensive items, B, can be decomposed into d subsets B
k
for k = 1, …, d, where B
k
is the subset of comprehensive items that mainly measure subscale k. Clearly,
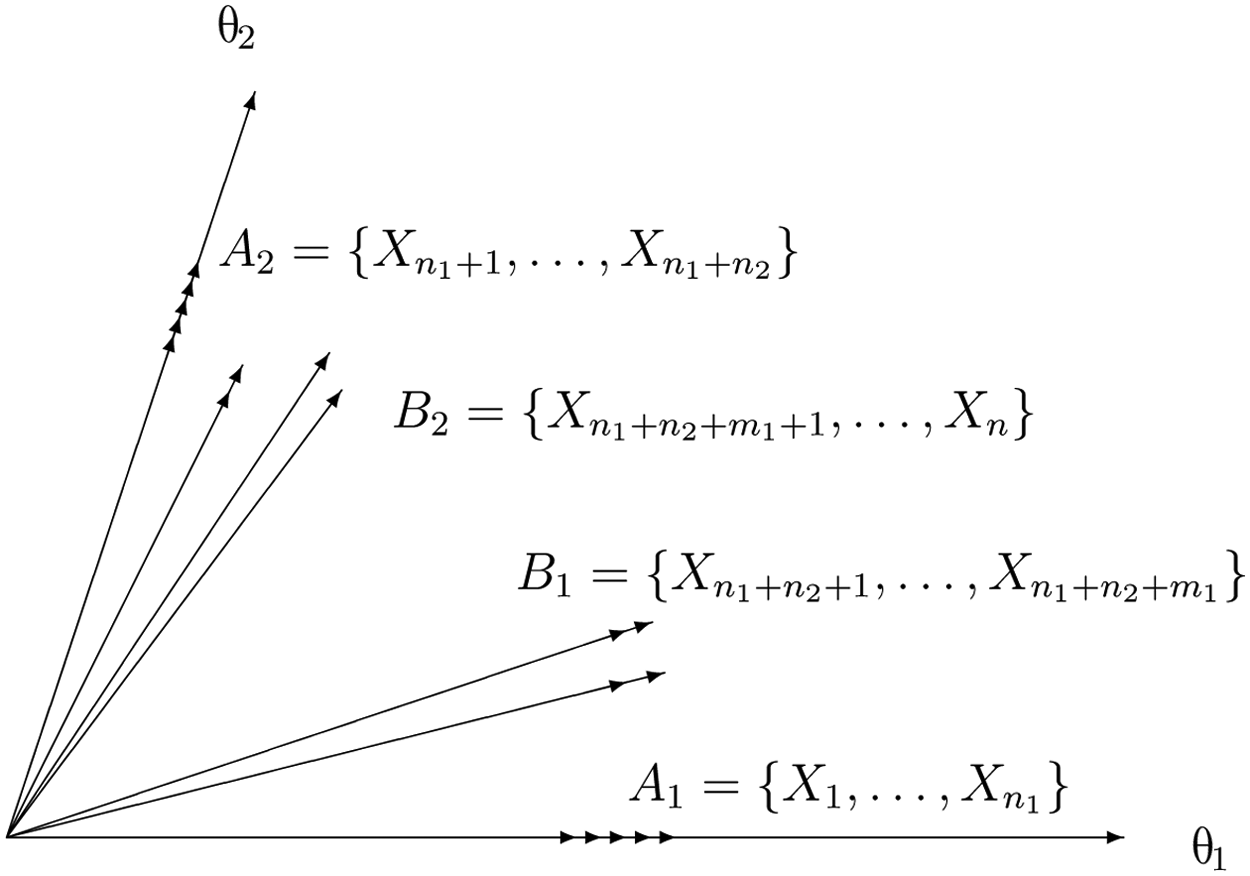
A two-dimensional test with approximate simple structure
Usually, it is not difficult to identify the optimal partition of items into d subtests S
k
= A
k
∪ B
k
, k = 1, …, d, from a dimensionality analysis when the sample size is moderately large. If S
k
is calibrated as unidimensional, the subscale actually calibrated is

where α
kl
(l =1, …, d) are the (unnormalized) weights that need to be determined, and c
k
is the normalization factor so that
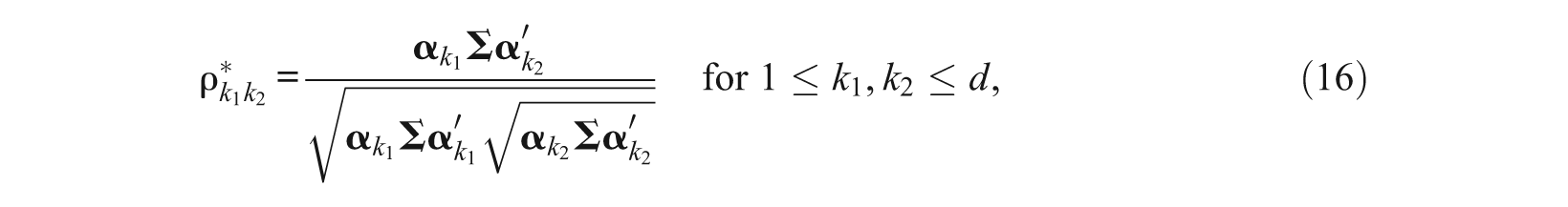
where
The subscales calibrated are actually
Equation 16 gives the relationship between the correlation coefficients of the target subscales and the correlation coefficients of the calibrated subscales. Zhang and Stout (1999) theoretically defined a reference as the composite at which the expected multidimensional critical ratio function achieves its maximum value. According to Theorem 3 of Zhang and Stout (1999), the weights of the composite are mainly determined by the discrimination parameters. For subtest k (1 ≤ k ≤ d), an approximate formula of weights is
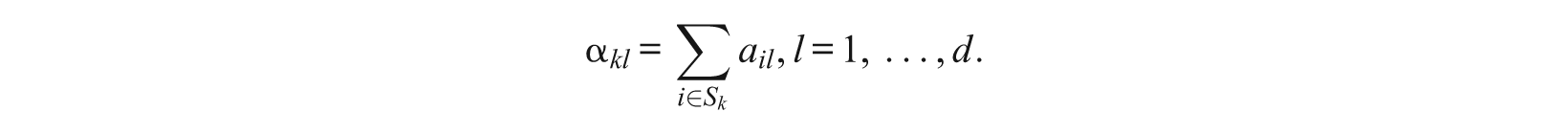
Specifically,
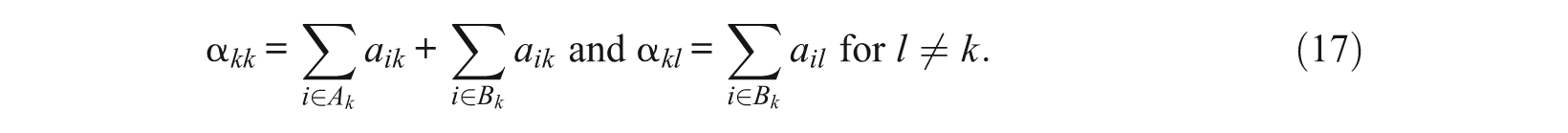
As B
k
is the subset of items that mainly measure subscale k, a
ik
> a
il
(l ≠ k) for all items in B
k
. Hence, for any fixed k, α
kk
is always the largest weight among α
kl
, l = 1, …, d}. In fact, {α
kk
is usually much larger than the others. Thus, the
Theorem
If an ASST is treated as an SST, the actual calibrated subscales are no longer the target subscales, although they could still be close to each other. The deviation of a calibrated subscale from its corresponding target subscale depends on how much the subtest departs from unidimensionality with the target subscale. The correlation coefficients between calibrated subscales given in Equation 16 are larger than those between their respective target subscales.
The theorem shows that when an ASST or an MST is incorrectly treated as an SST (i.e., MIRT models are misspecified), the calibrated subscales are no longer the target subscales and the correlation coefficients of the latent traits will be overestimated. From Equations 16 and 17, one may approximately calculate the expected correlation coefficients between the calibrated subscales. Next, a hypothetical example is used to illustrate how large the difference is between the calibrated subscales’ correlation and the target subscales’ correlation.
Example 1
Suppose that all items in B1 measure the composite θ1 + (2/3)θ2 in the sense that the discrimination parameters of their secondary dimension (e.g., ai2) equal two thirds of the discrimination parameters of their dominant dimension (e.g., ai1), and all items in B2 measure the composite (2/3)θ1 + θ2 as shown in Figure 4. If the magnitude of discrimination parameters and the numbers of items in all subsets are balanced, then according to Equation 15,
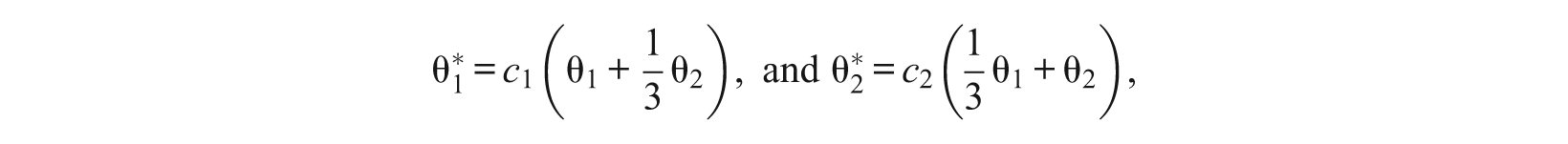
where c1 and c2 are the normalization constants. Let ρ be the correlation coefficient between the original two subscales, θ1 and θ2. Then, the correlation coefficient between
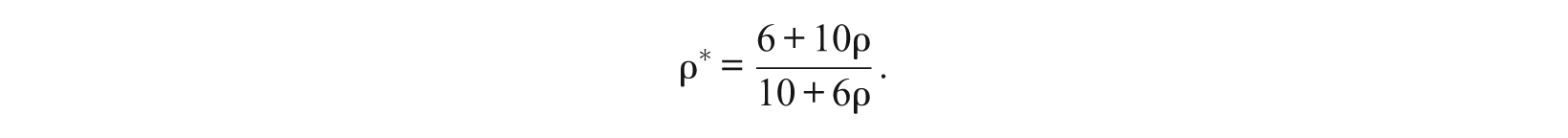
The correlation between the calibrated subscales
If the correlation between θ1 and θ2 is 0, .2, .4, .6, or .8, then the corresponding correlation between
A Simulation Study With Mixed Structure
To explore the consequences of the violation of simple structure, a second simulation study was conducted for an MST. Here, only the cases of 30 items with 1,000, 3,000, or 5,000 examinees with correlation .8 are reported.
To get an MST, the original two-dimensional SST was modified by changing some content-specific items into comprehensive items. Recall that each item in an SST has one and only one nonzero discrimination parameter (i.e., only one loading). By giving some positive value as its other discrimination parameter, a content-specific item becomes a comprehensive one. In this study, the first five items from each subscale (i.e., Items 1-5 and 32-36 in Table 1) were selected to become comprehensive items (measuring both subscales) by assigning two thirds of their existing discrimination parameter as their other discrimination parameter so that these modified items would still mainly measure their originally measured subscale. For example, the new second discrimination parameter was set to be 0.415 (i.e., 0:623 × 2/3) for the first item in Table 1. Consequently, the new 30-item test had 20 content-specific items (10 first-subscale items and 10 second-subscale items) and 10 comprehensive items (5 first-subscale dominated items and 5 second-subscale dominated items). This new set of item parameters and the originally generated ability scores with a population correlation of .8 from the simulation study in the section “A Simulation Study With Simple Structure” were used to generate new simulated item response data.
ASSEST was applied to each set of the simulated response data with two different specifications: First, the simulated response data set was incorrectly specified as two dimensional with simple structure, and second, the data set was correctly identified as two dimensional with mixed structure. In the former, the unidimensional and multidimensional approaches can be applied as before. The results from the unidimensional approach are not reported here as they are similar to the results from the multidimensional approach. In the latter case, only the multidimensional approach can be applied. The whole process was replicated 100 times, and the results are summarized in columns 2 and 3 of Table 8.
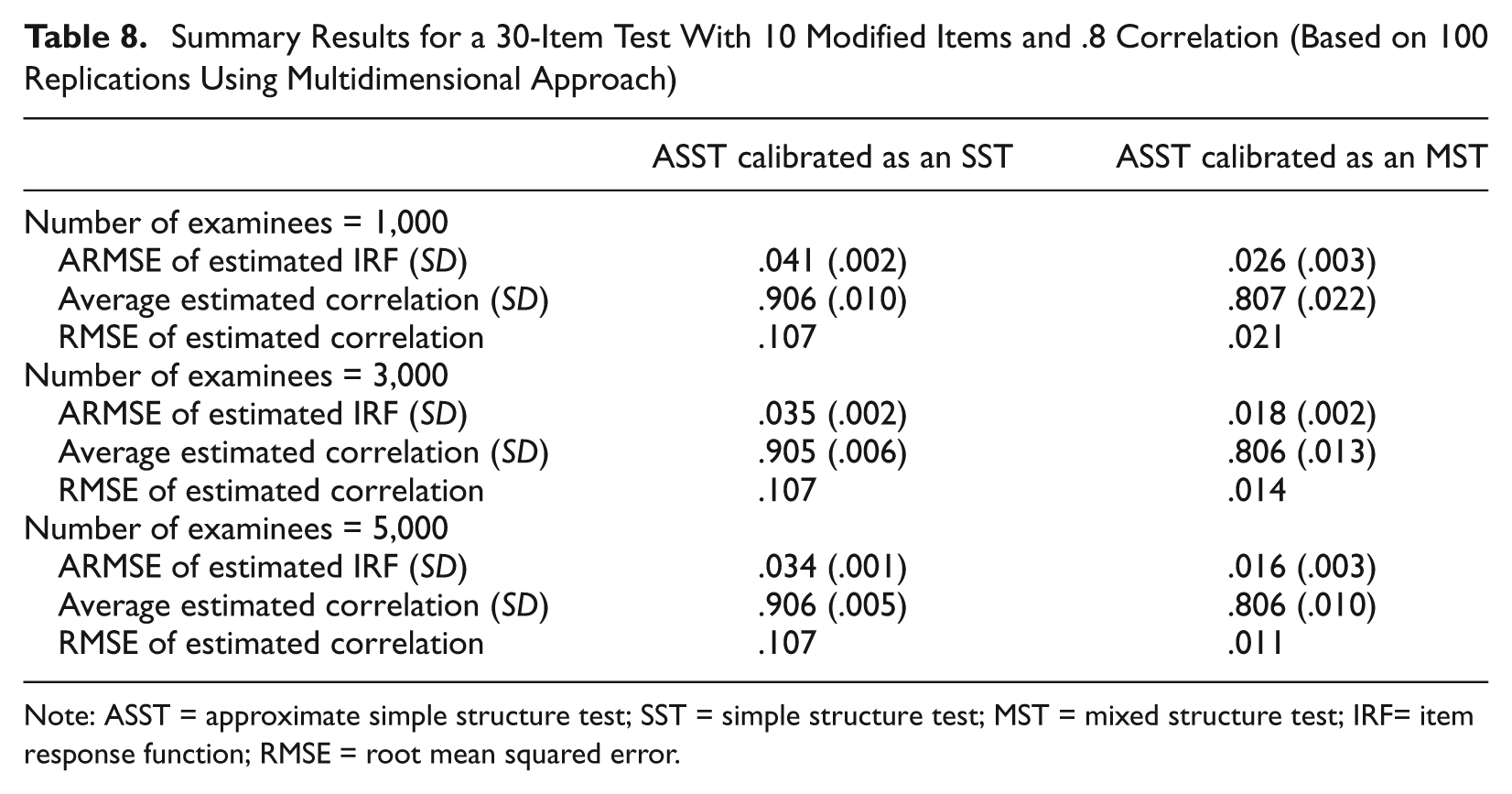
Summary Results for a 30-Item Test With 10 Modified Items and .8 Correlation (Based on 100 Replications Using Multidimensional Approach)
Note: ASST = approximate simple structure test; SST = simple structure test; MST = mixed structure test; IRF= item response function; RMSE = root mean squared error.
Table 8 shows that when the 10 modified items were incorrectly regarded as content-specific items (i.e., each data set was treated as though it had simple structure), the ARMSE of the estimated IRFs and the RMSE of the estimated correlation were relatively large (see column 2). When the 10 modified items were correctly treated as comprehensive items, the ARMSE of the estimated IRF and the RMSE of the estimated correlation were dramatically reduced (see column 3). For instance, the ARMSE of the estimated IRFs is .026 for 1,000 examinees compared with .041 when the modified items were incorrectly treated as content-specific items. The RMSE of estimated correlation is .021 in the case of 1,000 examinees whereas its counterpart is .107 in the mistreated case.
As shown in Table 8, the average estimated correlation between subscales when the test was misspecified as an SST is more than .9, whereas the true correlation is .8, which indicates the correlation was overestimated. If the test was correctly specified, the average of estimated correlations is between .806 and .807, and the RMSE is much smaller than that when the test was misspecified. When the 10 comprehensive items were incorrectly specified as content-specific items, one actually calibrated two composites, which were the combinations of the target subscales, as discussed in the preceding section. These two composites leaned closer to each other than the target subscales did. Not surprisingly, the correlation between target subscales was overestimated. From Equation 17, one may calculate the weights of the two calibrated subscales in the case here, α11 = 15.183, α12 = 3.139, α21 = 2.805, and α22 = 14.055. Hence, from Equation 16, the expected value of the correlation between the calibrated composites is approximately .907. When the models are incorrectly specified and the number of examinees is 5,000, the average estimated correlation is .906 (see column 2 of Table 8), which is very close to this expected value.
In sum, simulation results and the theorem in the section “Mixed Structure” demonstrate that it is not appropriate to treat an ASST or MST as an SST. One must examine the simple structure assumption before proceeding statistical analyses based on the assumption.
Discussion
In typical IRT applications, the estimated item parameters are treated as fixed in subsequent analyses of response data after item parameter estimation. Therefore, the accuracy of item parameter estimates plays an important role in the analyses. Under the simple structure assumption, the unidimensional and multidimensional approaches can be used to estimate item parameters. These two approaches are theoretically equivalent to each other if the JMLE method is used to estimate item parameters. However, when the MMLE method is applied, the estimates of item parameters obtained from these two approaches are different. A simulation study was conducted to further compare the unidimensional and multidimensional approaches with the MMLE method. The simulation results reveal that when the number of items is small, the multidimensional approach provides relatively more accurate estimates of item parameters; otherwise, the unidimensional approach prevails. Thus, when a test (e.g., NAEP) has enough items (say, 20) for each subscale, the unidimensional approach is better as long as the simple structure assumption is tenable.
The simple structure assumption is widely used in statistical analyses of response data from tests with multiple domains. Although it is less stringent than the unidimensionality assumption for the whole response data, the simple structure assumption is still a strong assumption. In many cases, it can be expected that this assumption will be violated. The results in the sections “Mixed Structure” and “A Simulation Study With Mixed Structure” demonstrate that inaccurate estimation results may be obtained if an MST is incorrectly specified as an SST. The simple structure assumption should be verified before doing any statistical analysis based on it. When a test does not have a simple structure, the multidimensional approach with an appropriate specification is recommended.
It should be noted that the unidimensional approach discussed in this article has a different focus than the unidimensional approximation approach which applies unidimensional models to multidimensional item response data (see Ackerman, 1989, 1994; Kahraman & Kamata, 2004; Reckase, Carlson, Ackerman, & Spray, 1986; Walker & Beretvas, 2003; Wang, 1988). The former applies unidimensional models to each unidimensional subtest, and the latter tries to approximate a whole test with unidimensional models. When the simple structure assumption does not hold, the unidimensional approach deals with the same problem as the unidimensional approximation approach does with each subtest.
Footnotes
Acknowledgements
The author would like to thank Ting Lu, Sarah Zhang, and two anonymous reviewers for their comments and suggestions.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.