
Abstract
This article focuses on four-parameter logistic (4PL) model as an extension of the usual three-parameter logistic (3PL) model with an upper asymptote possibly different from 1. For a given item with fixed item parameters, Lord derived the value of the latent ability level that maximizes the item information function under the 3PL model. The purpose of this article is to extend this result to the 4PL model. A generic and algebraic method is developed for that purpose. The result is practically illustrated by an example and several potential applications of this result are outlined.
In the field of dichotomous item response theory (IRT) models, the three-parameter logistic (3PL) model (Birnbaum, 1968) and the simpler one- and two-parameter logistic (1PL and 2PL) models have received most attention in the past decades. However, an extended version of the 3PL model was also suggested, by allowing an upper asymptote possibly smaller than 1. This four-parameter logistic (4PL) model, early proposed by Barton and Lord (1981) and barely mentioned by Hambleton and Swaminathan (1985), did not receive a lot of attention until recently. As Loken and Rulison (2010) pointed out, the strong dominancy of the 3PL model in the literature, the lack of consensus on its usefulness, and the technical difficulty in estimating the upper asymptote accurately, are strong arguments against the use of the 4PL model.
Despite these conceptual drawbacks, the 4PL model was reconsidered recently in the literature. One reason is the recent improvement in computational power and resources, together with the development of accurate statistical modeling software. Some early arguments toward accurate estimation of the upper asymptote can be found in Linacre (2004) and Rupp (2003). Very recently, Loken and Rulison (2010) developed a Bayesian framework to calibrate the items under a 4PL model, by using a Markov chain Monte Carlo (MCMC) approach and the WinBUGS software (Lunn, Thomas, Best, & Spiegelhalter, 2000). This software was obviously not available when the 4PL model was suggested first, and it constitutes a major breakthrough toward a broader consideration of that model for practical purposes.
Moreover, the main asset of the 4PL model is that it allows a nonzero probability of answering the item incorrectly for highly able respondents. This asset was exploited by Rulison and Loken (2009) in the computerized adaptive testing (CAT) environment. More precisely, they showed that the impact of early mistakes made by highly able respondents (due to stress for instance) can be strongly reduced with the 4PL model, and that fewer items need to be administered to cancel the related ability estimation bias (with respect to the 3PL model). Subsequent studies of the usefulness of the 4PL model in the CAT framework were performed by Green (2011); Liao, Ho, Yen, and Cheng (2012); and Yen, Ho, Liao, Chen, and Kuo (2012). Moreover, the 4PL model was recently introduced as the baseline IRT model for CAT generation in the R package catR (Magis & Raîche, 2012). It is also worth mentioning that the 4PL model will probably become a potentially useful model to detect person fit, and especially careless or inattention patterns (Tendeiro & Meijer, 2012).
The asset of this “upper asymptote” characteristic was also illustrated in several applied research fields. One example comes from the criminology context. Osgood, McMorris, and Potenza (2002) made use of a 2PL model to analyze a self-report delinquency scale and noticed that the use of a 4PL model (or any other model with an upper asymptote parameter), might permit to catch the propensity of most delinquent youth not to report some delinquent acts (see also Loken & Rulison, 2010). In the field of psychopathology research, Reise and Waller (2003; see also Waller & Reise, 2009) advocated for the need for nonstandard IRT models to analyze clinical and personality instruments. The genetics research field was also considered for applications of IRT models, and especially the 4PL model. Tavares, de Andrade, and Pereira (2004) proposed a 4PL model to allow low-disposition individuals to have the gene activated (which requires a lower asymptote parameter) as well as high-disposition individuals not to have the gene activated (by including an upper asymptote parameter).
As the 4PL model did not receive much attention yet, these practical examples are not numerous. However, they clearly highlight the potential and usefulness of this model, both from a methodological point of view and for practical purposes. It can therefore be expected that future research will focus on the 4PL model and promote it as a competing model in some particular situations.
The aim of this note is to focus on one specific but important aspect of the 4PL model that was not investigated yet: the characterization of its item information function. More precisely, deriving its maximum value, and the corresponding optimal latent ability yielding this maximum, might be of interest to the understanding of the model and also for practical applications. Among them, CAT (Chang & Yin, 2008; Rulison & Loken, 2009) and robust estimation of ability (Magis, 2012; Mislevy & Bock, 1982; Schuster & Yuan, 2011) are two promising fields of applications for the present developments. They are discussed in detail at the end of this note.
Deriving the optimal ability level that maximizes the information function is straightforward under the 1PL and 2PL models. With the 3PL model, the solution was provided by Birnbaum (1968; see also Lord, 1980). This article extends this solution to the 4PL model and draws parallelisms between the 4PL and simpler IRT models.
The Model and Its Information Function
Let us focus on any particular item j from a set of J items. The general form of the 4PL model is the following:
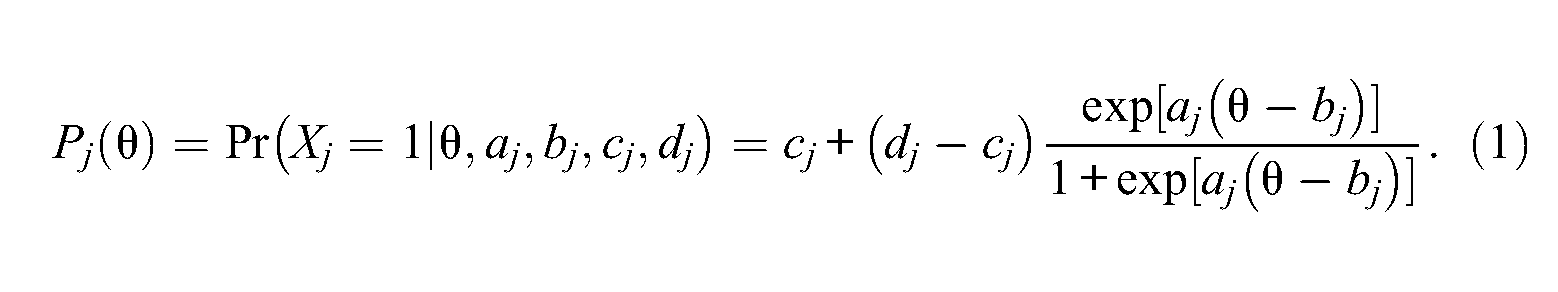
In this model, Xj is the binary response of the respondent with latent ability level θ to item j, coded as 1 for a correct response and 0 for an incorrect one. Moreover,
In this article, it is assumed that all four item parameters are fixed at known values. As a good practice, one may think about item parameter values as having arisen from previous model fit or by precalibration of the model to the data under study. This could be achieved, for instance, by using the Bayesian estimation approach recently proposed by Loken and Rulison (2010). Thus, only the latent ability level remains unknown and will constitute our variable of interest in the following discussion. Moreover, it is assumed that
One important feature of IRT models is the item information function. It is a mathematical function of the ability level θ and the item parameters that describes how informative the item is at any given θ level. Very easy items are usually more informative at low ability levels whereas highly difficult and discriminating items are more informative for larger ability levels. The general form of the item information function, given any dichotomous IRT model described by a response probability

where
Before focusing on the item information function more in detail, let us rewrite it in a simpler way that does not involve the first derivative
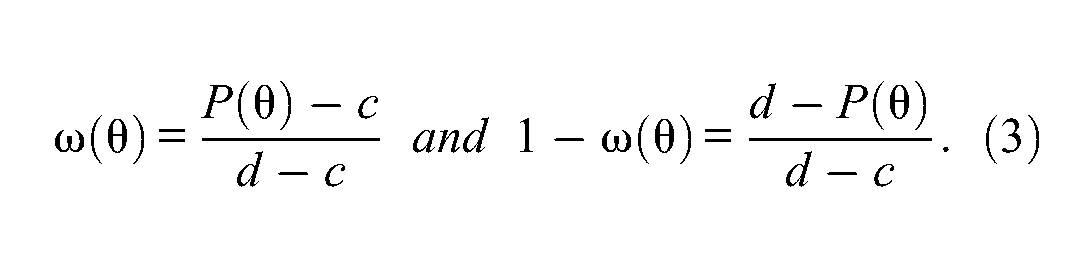
The first derivative of

by definition of
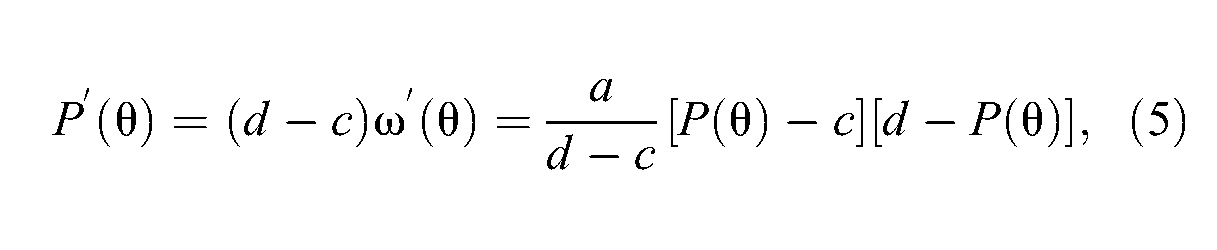
by using Equation 3. In sum, the item information function in Equation 2 can be directly related to the response probability of Equation 1 as follows:

The central result of this article is that the item information function has a single maximum value, corresponding to a specific
Maximizing the Information
First of all, rather than maximizing the information function with respect to θ directly, one will maximize it with respect to P(θ). This will greatly simplify the mathematical derivations, and because P(θ) is a strictly increasing function of θ, it will be straightforward to obtain the value of

as the function to be maximized for
A long but straightforward calculation leads to the first derivative of I(x) with respect to x:
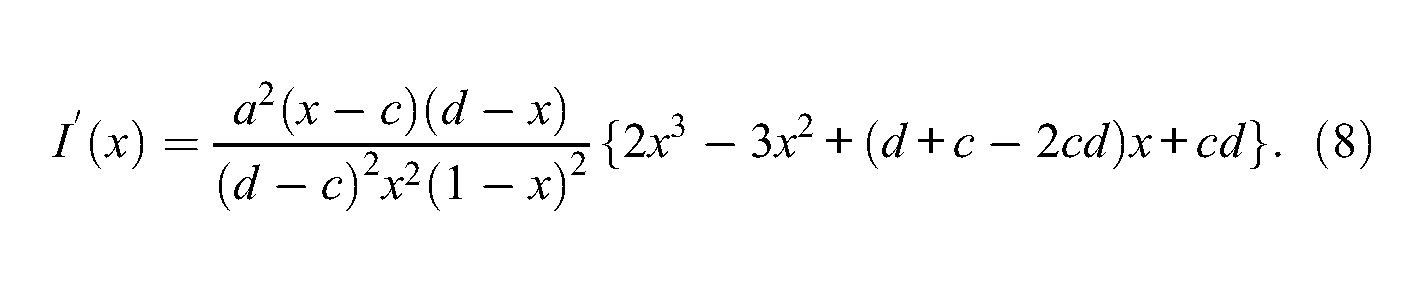
As x takes values in (c; d), the sign of this derivative is therefore determined by the sign of the polynomial

which may have at most three real roots, that is, the number of times the polynomial function crosses the horizontal axis set by p(x) = 0.
To further characterize p(x), and hence to extract useful information about the information function, for the moment let us consider x as a real value on the whole real axis. The first derivative of p(x) with respect to x is equal to

Note that

and because the function p(x) is continuous on the whole real scale, one may conclude from the intermediate value theorem that p(x) has actually three real roots, belonging respectively to the intervals
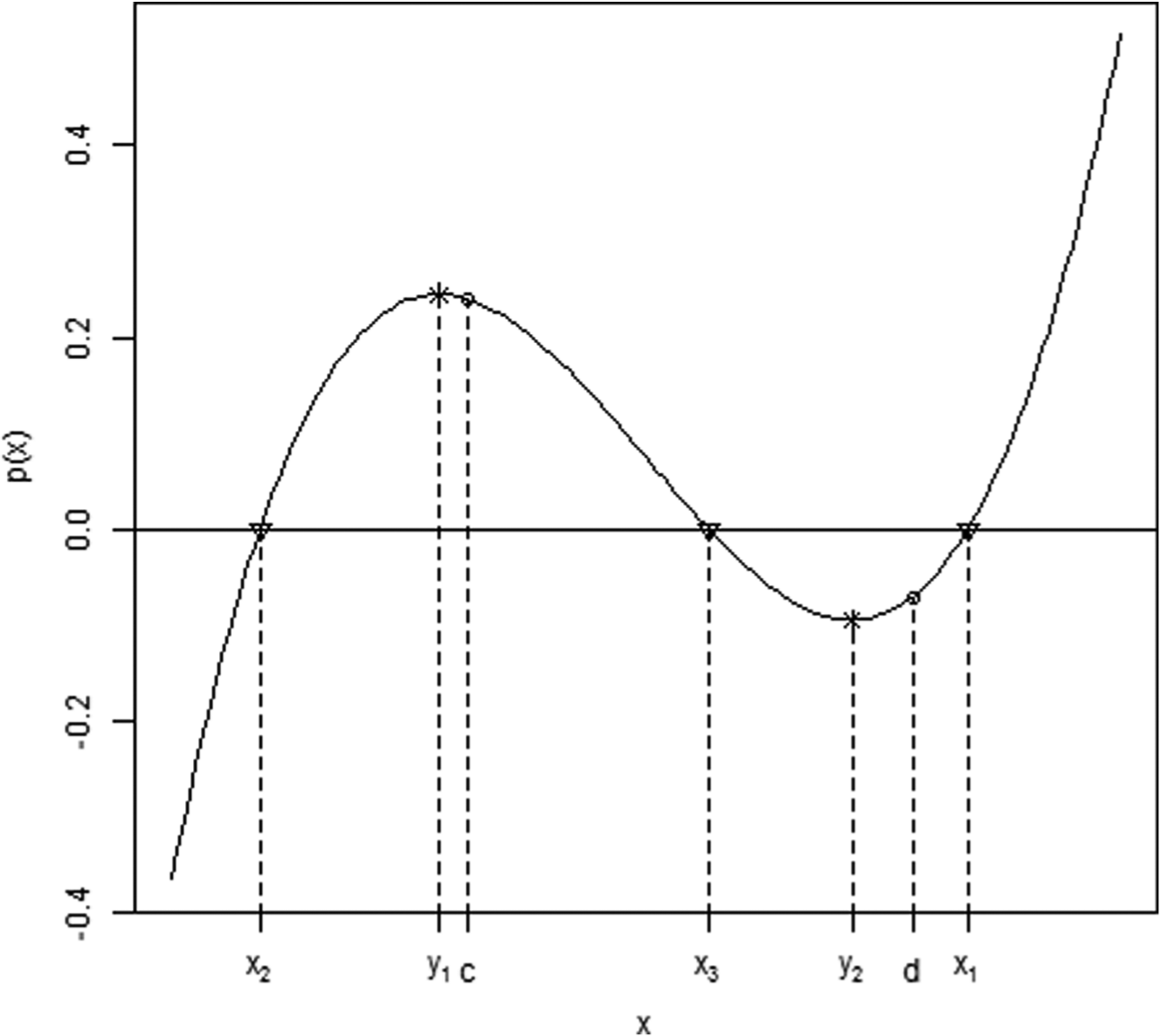
Graphical illustration of the polynomial p(x) with c = 0.2 and d = 0.95.
Now, to determine the roots of the polynomial p(x), one makes use of the so-called Cardano’s method to derive the roots of any third-order polynomial. The main steps of the method are described hereafter without proof; further details can be found in Jacobson (1985). Set first α, β, γ, and δ as the numeric coefficients of the polynomial p(x); that is,
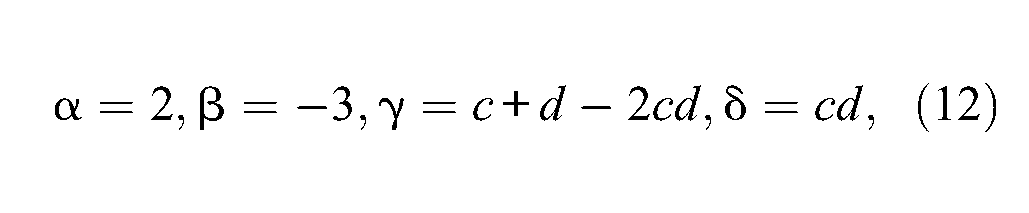
according to Equation 9. Set moreover
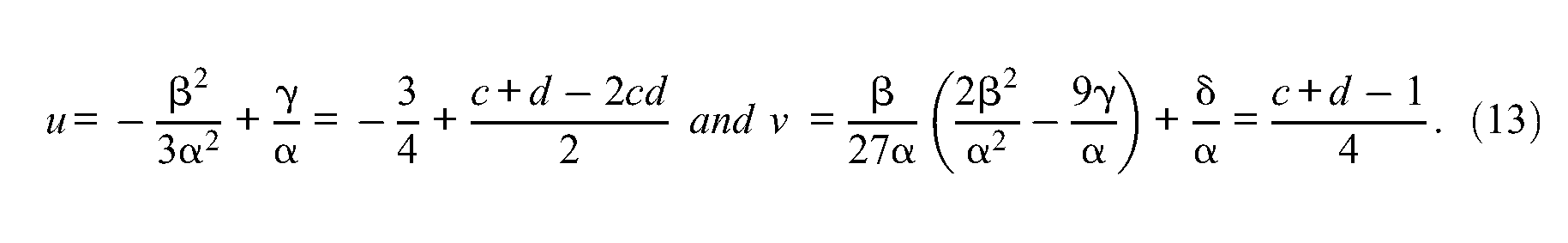
The sign of the discriminant

Eventually, the three real roots of polynomial p(x) are given by
Thus, the root of polynomial p(x) that belongs to (c; d) is one of the three roots
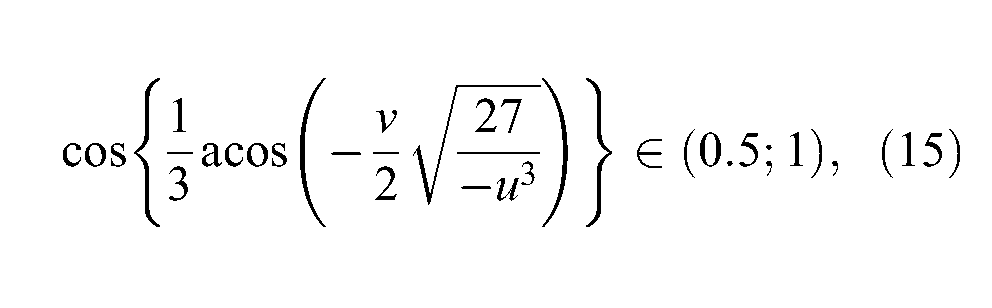

and
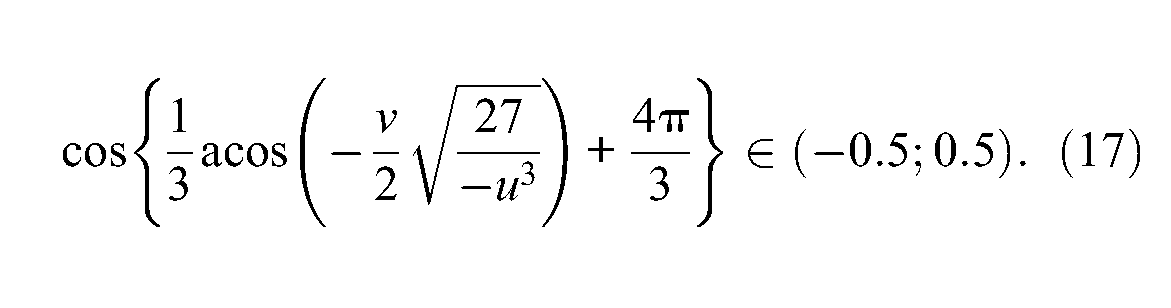
This implies finally that
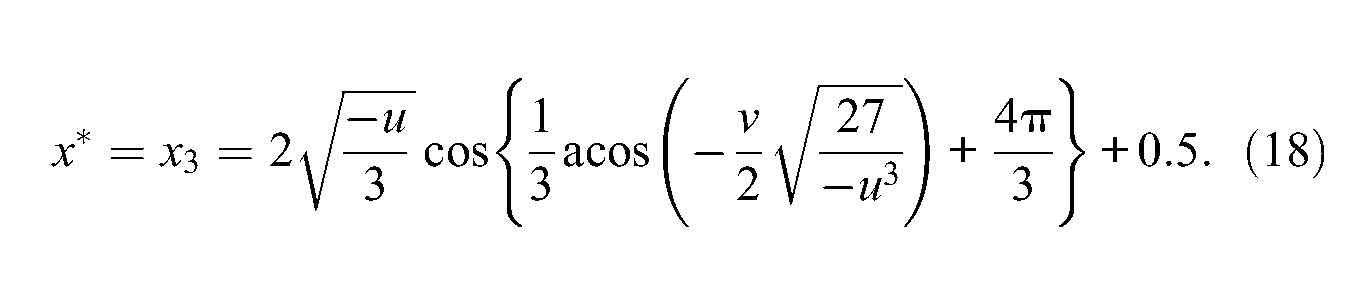
Let us now end up the maximization process of the information function. Due to the previous findings about the shape and the sign of p(x), one may conclude that the unique value
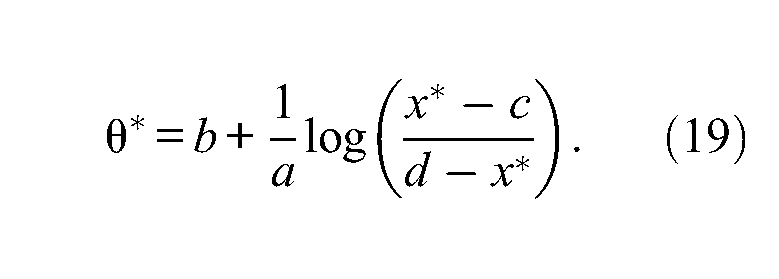
Although the previous mathematical developments were quite long, the process for determining the optimal
The optimal value
Relationship With Simpler Models
Because the 4PL model is an extension of the usual 1PL, 2PL, and 3PL models, well-known results can be found back when restricting the parameters of the 4PL model appropriately. Under the 3PL model, for which d = 1, the variable x = P(θ) takes values in (c; 1) and the information function of Equation 7 simplifies to
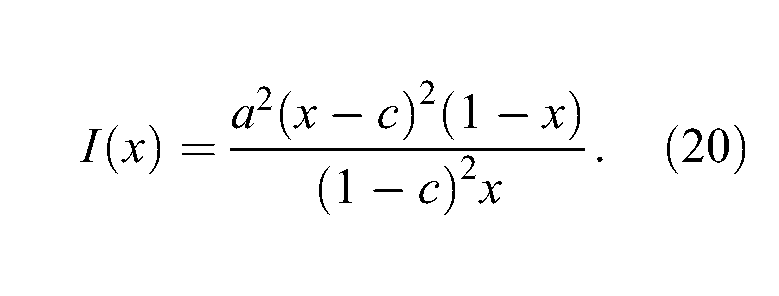
The first derivative then equals
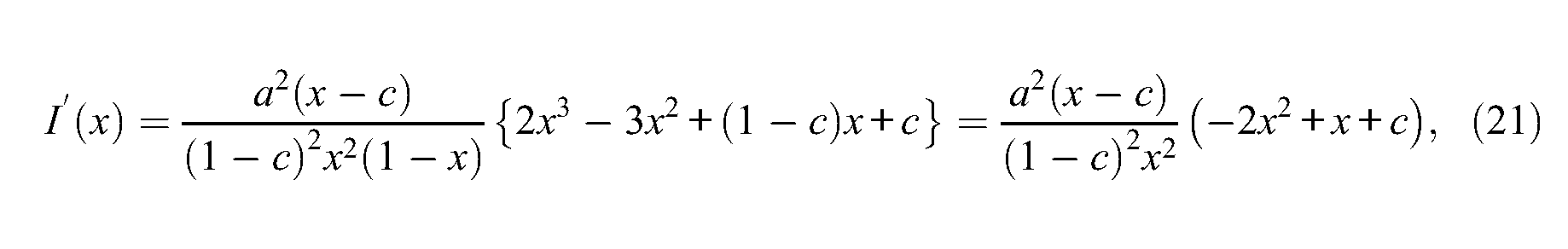
using Equation 8. The two roots of polynomial

with
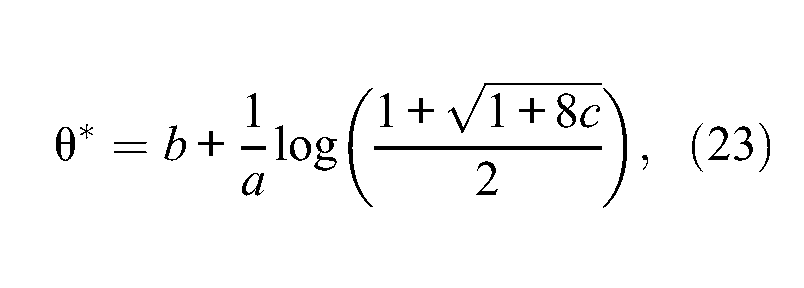
which corresponds exactly to the result provided by Lord (1980). Moreover, under the 2PL model for which c = 0 and d = 1, the item information function given by Equation 7 reduces to
Illustration
Let us provide a practical illustration. Consider an artificial item with the following parameters: a = 1.1, b = −1, c = 0.2, and d = 0.95. The polynomial p(x) for this item is actually depicted in the aforementioned Figure 1, while the item information function is displayed in Figure 2.

Item information function for an artificial item with parameters a = 1.1, b = −1, c = 0.2, and d = 0.95.
First,

so that
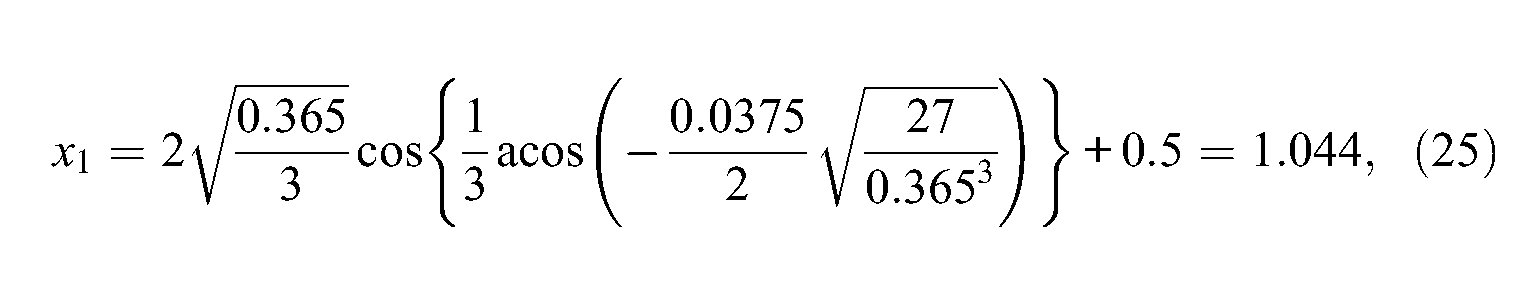
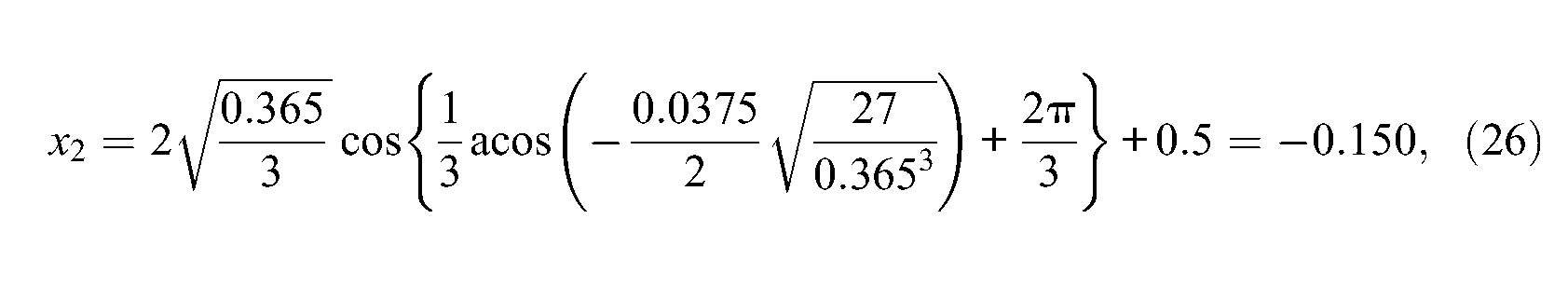
and
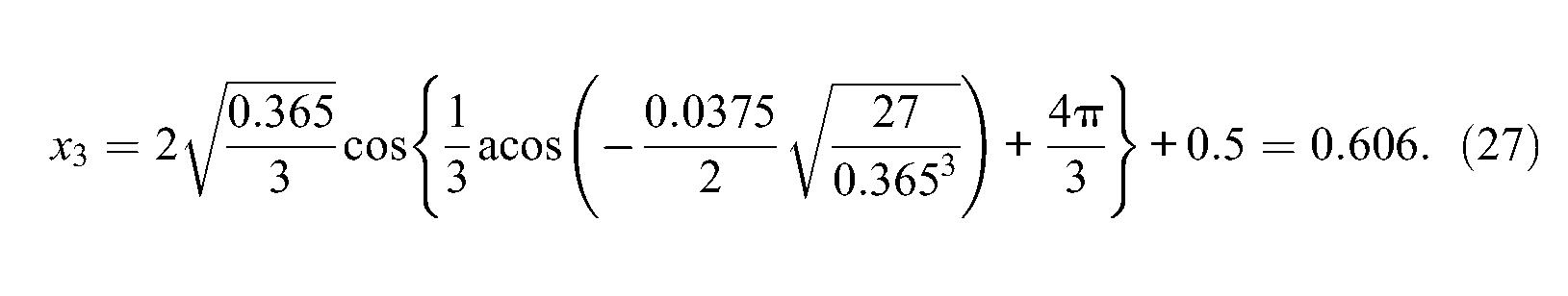
This confirms the previous findings and the expected ordering of the three real roots. These are displayed in Figure 1 by triangles. Finally, using Equation 19, one gets
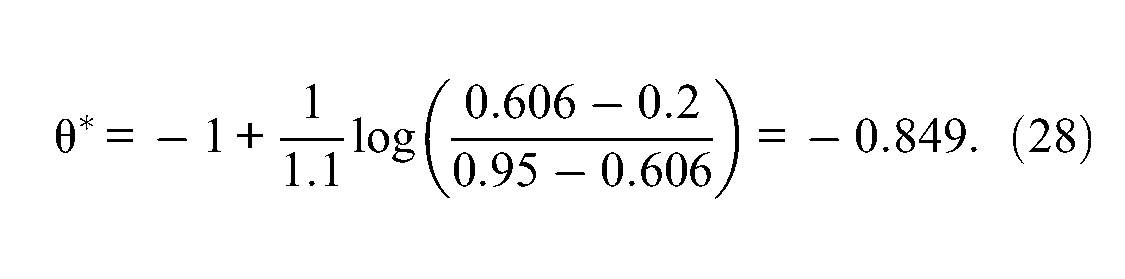
Hence, the item information function reaches its maximum value whenever θ = −0.849. This optimal value is also represented in Figure 2 and brings a visual confirmation of the accuracy of Equation 19.
Finally, the dependency of
Values of u, v,
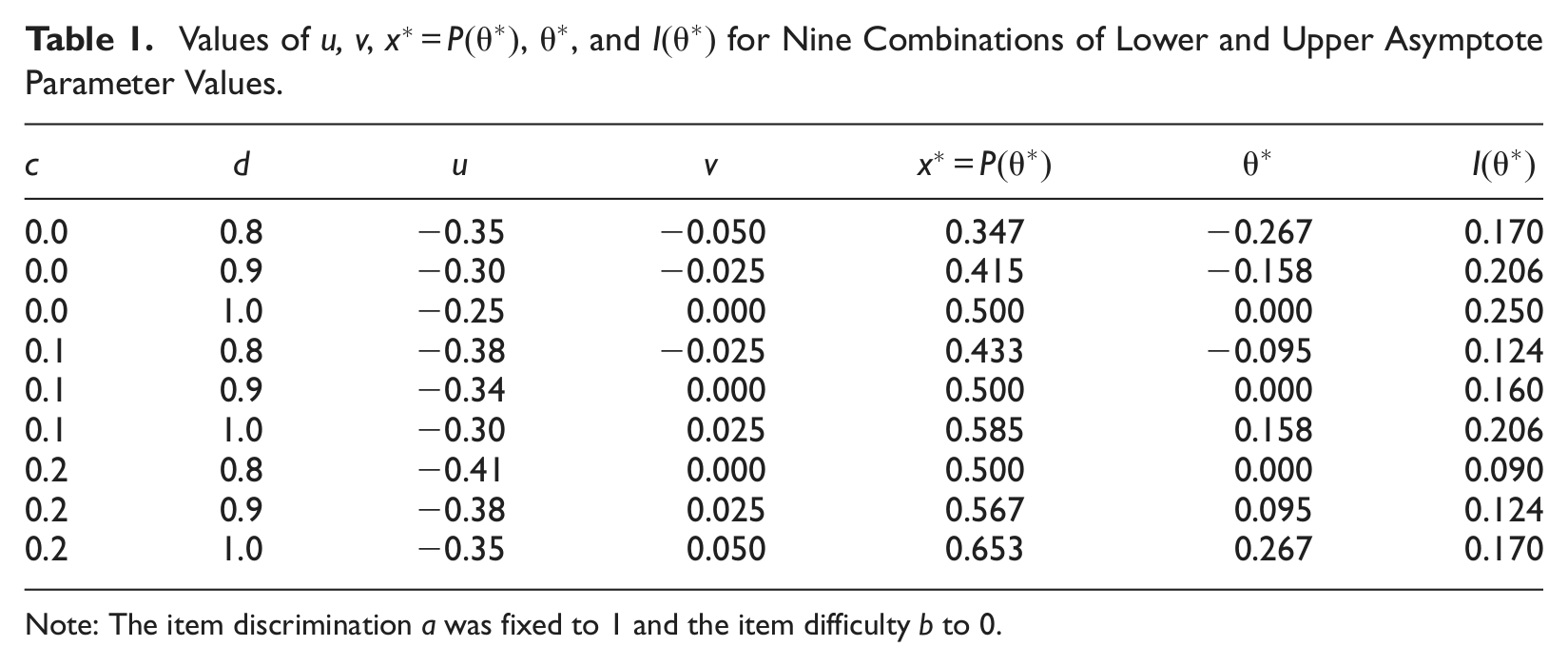
Note: The item discrimination a was fixed to 1 and the item difficulty b to 0.
Final Comments
The purpose of this article was to derive the value of the latent ability level that maximizes the item information function of the 4PL model. The computation is straightforward, and the algebraic formulas 18 and 19 provide the solution to the problem. Note that Equations 19 (for the 4PL model) and 23 (for the 4PL model) are identical, except for the optimal
Beyond the technical interest of the present study, the developments are most useful when the 4PL model is used in practice. This aspect is probably the most important as there is still a controversy about the usefulness and applicability of the 4PL model for practical purposes. Some such examples were listed earlier in this note. Further motivations are pointed out by Loken and Rulison (2010). It is expected that, besides its technical complexity in getting reliable item parameter estimates, the 4PL model will receive more attention in the years to come.
With respect to the usefulness of the present study under the 4PL model, at least two practical fields of application can be mentioned. The first one is the CAT framework, for which several applications of the 4PL model were mentioned earlier. A more straightforward and practical application of this result is the following. Chang and Yin (2008) characterized the reason why high-ability respondents might get lower scores than expected when answering a CAT and missing the first items of the test. Under this scenario, easy and highly discriminating items will be selected (under the maximum information criterion to select the next item), which breaks down the recovery of the ability estimates toward their true value, unless the test gets longer. In their mathematical derivations, the authors made use of Lord’s (1980) result displayed here in Equation 23. Furthermore, as already pointed out, Rulison and Loken (2009) illustrated how the 4PL model could limit this underestimating trend due to early mistakes in CAT. By setting the upper asymptotes smaller than 1, and thus allowing high-ability respondents to miss the first items with greater probability, one is able to lessen the underestimation at the first steps and thus, to recover quickly from early mistakes. The challenge for explaining this improvement under the 4PL model would then be to extend Chang and Yin’s (2008) discussion to this model. To this end, the present optimal value in Equation 19 will most probably be necessary to understand and characterize this mechanism.
The second potentially interesting field of application is the robust estimation of ability levels (Mislevy & Bock, 1982; Schuster & Yuan, 2011). When response disturbances (such as guessing, cheating, or inattention) interfere with the item response process, the classical estimators can return very biased estimates of ability. Robust alternatives were developed by weighting the log-likelihood function such that aberrant item responses are down-weighted and, consequently, have less impact on the final ability estimate. Although the process is straightforward and relies on an appropriate choice of a weighting function and a residual measure, the current suggested residuals measures rely only on the 2PL model. Recently, Magis (2012) introduced two generalizations of the residual measures that can be handled with any dichotomous item response model. One of the proposed residual measures relies on the maximization of the item information function, by giving maximal weight whenever this item information is maximized. The study discussed in detail the case of the 3PL model, for which Equation 23 is widely available. Under the 4PL model, the present algebraic result given by Equation 19 could also be used similarly, leading eventually to allow robust estimation of ability under the 4PL model with appropriate weights and residuals.
Footnotes
Appendix
Acknowledgements
The author wishes to thank two anonymous reviewers for their helpful comments.
Declaration of Conflicting Interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was financially supported by a Research Grant “Chargé de recherches” of the National Funds for Scientific Research (FNRS, Belgium), the IAP Research Network P7/06 of the Belgian State (Belgian Science Policy), and the Research Funds of the KU Leuven, Belgium.