
Abstract
When students solve problems, their proficiency in a particular subject may influence how well they perform in a similar, but different area of study. For example, studies have shown that science ability may have an effect on the mastery of mathematics skills, which in turn may affect how examinees respond to mathematics items. From this view, it becomes natural to examine the relationship of performance on a particular area of study to the mastery of attributes on a related subject. To examine such an influence, this study proposes a covariate extension to the deterministic input noisy “and” gate (DINA) model by applying a latent class regression framework. The DINA model has been selected for the study as it is known for its parsimony, easy interpretation, and potential extension of the covariate framework to more complex cognitive diagnostic models. In this approach, covariates can be specified to affect items or attributes. Real-world data analysis using the fourth-grade Trends in International Mathematics and Science Study (TIMSS) data showed significant relationships between science ability and attributes in mathematics. Simulation study results showed stable recovery of parameters and latent classes for varying sample sizes. These findings suggest further applications of covariates in a cognitive diagnostic modeling framework that can aid the understanding of how various factors influence mastery of fine-grained attributes.
When students solve problems, their proficiency in a particular subject may influence how well they perform in a similar, but different area of study. In particular, it is viewed that mathematics and science have a structural and functional relationship; mathematics can be used as a tool for science, and science can also function as a stimulus for further mathematical discoveries (Li, Shavelson, Kupermintz, & Ruiz-Primo, 2002). Educators have implemented this tradition into the curriculum by teaching the interconnectedness of mathematics and science domains (Halton, 1973). Assessments that require the use of skills from both subjects have been developed, and mathematics items from the Trends in International Mathematics and Science Study (TIMSS) are taken to demonstrate this idea (see Figure 1).
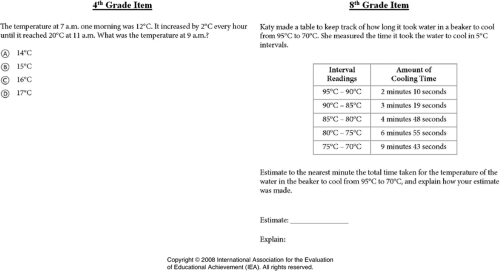
Exemplar mathematics items from the fourth- (Left: M031335) and eighth-grade (Right: M022232) TIMSS.
In Figure 1, two items are presented from two grade levels: fourth and eighth grade. Both items are mathematics items; however, they require basic knowledge in science, in particular the principle of temperature measurement. For the fourth-grade item on the left, examinees are asked to calculate the increase in temperature after 2 hours, assuming that temperature increases by intervals of 2° every hour. In addition to skills in whole numbers, students need to grasp the scientific context used in a Celsius scale to correctly apply the mathematical concepts. A similar idea is demonstrated in the eighth-grade item. In this item, the examinee is asked to estimate the time for the beaker to cool, given the temperature and duration provided in the table. Although this item does not require the sole knowledge of science skills, it does require basic principles of temperature and duration of heat to answer the item correctly. Although the two exemplar items do not infer causal relationships, there is an association in skills that extend beyond one specific subject of study.
From this view, it becomes natural to examine the relationship science ability may have on mathematics skills, which in turn may also affect how examinees respond to mathematics items. Again, the relationship may not necessarily be causal, but the direction and magnitude of association can be valuable information. In fact, the question that may be of value to instructors and researchers is whether features of science are related to specific mathematics skills; conversely, they can also ask whether mathematics ability affects specific attributes in science. This concept extends above and beyond calculating simple correlations of student performance in mathematics and science that is traditionally done in many studies. If the ability and knowledge from one subject area can influence the mastery of skills and concepts in another area, then identifying these specific fine-grained skills can improve not only instruction but also feedback to students that lack such skills. Although previous modes of research have investigated the relationship between mathematics and science education from broad content domains, there has not been a study that examined the effect that knowledge in either subject affects the likelihood of an examinee to master skills or improve solving questions in a different subject.
Cognitive diagnostic models (CDMs) provide an ideal framework for conducting such an analysis as it classifies examinees into attribute profiles that indicate their mastery in fine-grained skills. This study extends the deterministic input noisy “and” gate (DINA; Junker & Sijtsma, 2001) model by including a covariate. In the DINA model, a covariate can be specified at two levels; at the lower level, it can affect how examinees solve items (i.e., response probability), and at the higher level, it can influence the mastery of attributes (i.e., latent classification). That is, the DINA model can be specified to investigate the effect that science ability has on an examinee’s probability of solving mathematics items; it can also be parameterized to examine the influence that science ability has on the mastery of fine-grained mathematics skills.
This study introduces a framework for examining a covariate extension of the DINA model, demonstrated using real-world data from the TIMSS where science proficiency is modeled as a covariate for the mastery of skills required for mathematics items. A simulation study is supplemented to investigate parameter recovery and sensitivity of the model under various specifications of sample sizes, attributes, and its relationship to the covariate. The combination of both real-world data analysis and simulation study will inform researchers on the use of covariates to examine the relationship between factors that influence items and attributes as possible sources of additional diagnostic information. In addition, the results of this study provide a meaningful extension of the DINA model to answer questions of substantive need and also provide implications for more complex and generalized CDMs.
Theoretical Framework
DINA Model
The DINA model requires the identification of skills or attributes needed to answer a question and implements the construction of a Q-matrix (Tatsuoka, 1985). Let Yij be examinee i’s response for item j, and
The DINA model is a conjunctive model, which assumes that all specified attributes are required for an examinee to solve the problem. This is indicated by the binary latent variable,
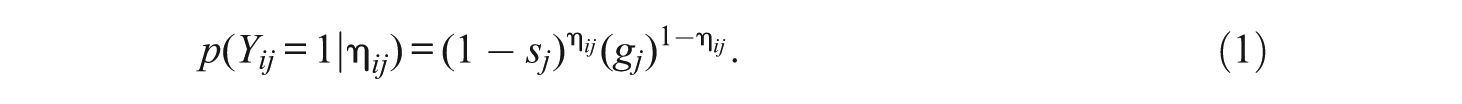
There are two parameters: the slip and the guessing parameters (Junker & Sijtsma, 2001). Students who possess all the attributes required for an item can slip and incorrectly answer the item, and students who do not possess all the attributes required for an item may guess and correctly answer the item. The DINA model defines the slip parameter as

In the reparameterized deterministic input noisy “and” gate model (RDINA; DeCarlo, 2011), the fj parameter provides the log odds estimates of the guessing parameter, whereas the dj parameter provides a measure of how well the item can discriminate an examinee with or without the mastery of the attribute. As noted in Junker and Sijtsma (2001), exponentiating the parameters yields the original guessing and slip parameters as follows:

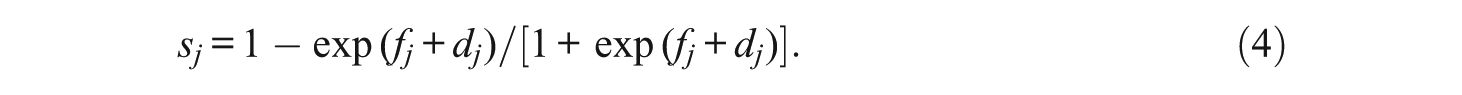
A Covariate Extension to the DINA Model
Various latent class models have incorporated covariates as extensions (Dayton & Macready, 1988; DeCarlo, 2005; van der Heijden, Dessens, & Böckenholt, 1996). In the DINA model, covariates can be specified at two levels: at the lower level, characterized by item parameters, and at the higher level that measures the attributes. Dayton and Macready (1988) introduced the view that covariates can affect the latent class (attribute) probabilities and demonstrated a case using a logistic model. This approach is meaningful in the CDM approach, because this allows an interpretation of covariates that can serve its diagnostic purpose. Treating the DINA model as a latent class model, examinee i’s response probabilities can be modeled as follows (DeCarlo, 2011):
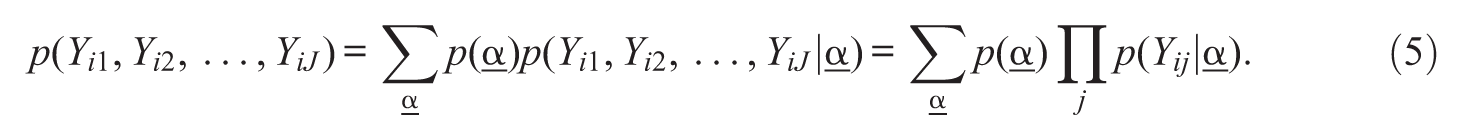
Equation 5 indicates that the unconditional response probability is the weighted sum of the conditional response probability across the latent classes (see first two terms of the equation). Applying the basic assumption of independence for the responses given latent classes (Clogg, 1995), the third term can be derived, where the p(Yij |
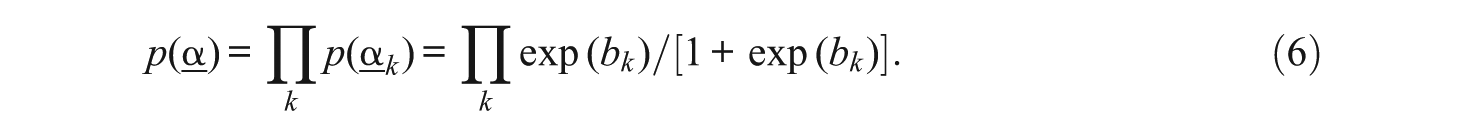
As expressed in Equation 6, the model for
When a discrete or a continuous covariate,
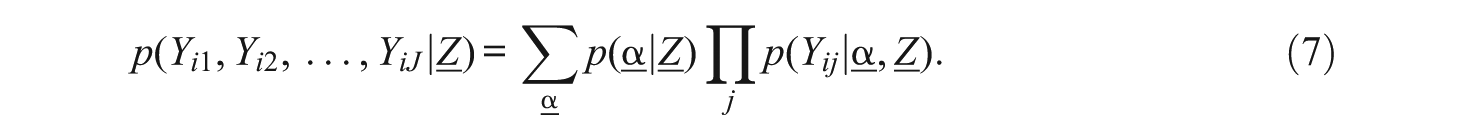
Equation 7 represents the response probability conditioning on the covariate
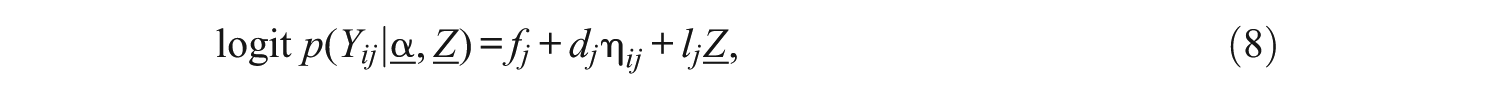

When the covariate is conditioned on the response probabilities, the covariate can shift the estimate of the guessing and slip parameters. For simplicity, if we assume that Z is a binary covariate, then the presence or the absence of the covariate (i.e., Z = 1 or 0) can influence the guessing and slip rates in the DINA model by a factor of lj, conditional on the value of the covariate. Equation 10 shows the increase in the guessing parameter for examinees with Z = 1, and Equation 11 shows the decrease in the slip parameter for examinees with Z = 1. For continuous covariates, the parameter lj indicates changes in the guessing and slip parameters for a unit increase in Z, conditional on the value of the covariate:
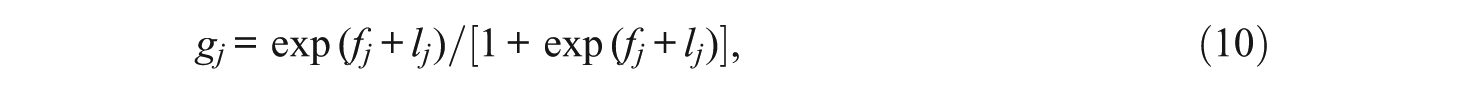
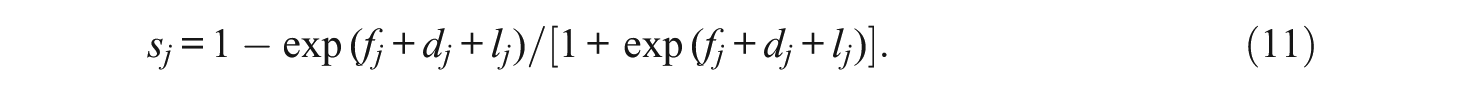
When the covariate is conditioned on the attribute probabilities as expressed in Equation 9, it becomes a predictor of the attribute patterns that affect the latent class membership. Similar to the interpretation of the item-level parameter, lj, the parameter hk reflects the shift in the attribute difficulty parameter, bk, when the covariate is present to affect the attribute. When a conditional independence model is assumed, the covariate extension could be added; for example, if a HO-DINA model is used to account for a higher order θ that uses the K attributes as indicators of a latent trait, then Equation 9 will be
Study I: Real-World Data Study
Method
The covariate extension of the DINA model is examined using the 2007 TIMSS fourth-grade data. The TIMSS releases data in block formats that provide about 20 to 30 items per group of examinees (Foy & Olson, 2009). The advantage of using TIMSS to conduct this study is that it is one of the rare international assessments that provides both mathematics and science performance at the item level for the same examinee. The data used for this study consisted of 25 mathematics items from Booklet 4 using combined data (n = 825) from the U.S. national sample and two benchmark states—Massachusetts and Minnesota. A Q-matrix was derived from Lee, Park, and Taylan (2011), which originally had 15 attributes; these attributes were collapsed by related skills in a particular domain to reduce the number of attributes to seven (see Table A1, in the online supplement). The collapsing of the attributes was conducted to resemble topic areas in the TIMSS 2007 framework.
Examinee’s number-correct score from the science assessment (27 items) was used as a covariate. At the fourth-grade level, students were tested on knowledge from physical science, life science, and earth science. In mathematics, three content domains, Number, Geometric Shapes and Measures, and Data Display, were tested. Using the empirical data, three models were fit: (a) RDINA model, (b) RDINA model with the science number-correct score affecting attributes (latent classification), and (c) RDINA model with the science number-correct score affecting items (response probabilities). Model fit indices were calculated using information criteria measures (Akaike information criterion [AIC] and Bayesian information criterion [BIC]) based on the maximum log likelihood estimates (−2LL) to select the best-fitting model.
Estimation was conducted using Latent GOLD 4.5 to fit the RDINA and covariate extensions of the RDINA model. The syntax for fitting the covariate RDINA in Latent GOLD is given in the Appendix (see the online supplement). Both Expectation-Maximization (EM) and Newton–Raphson algorithms were used to obtain maximum likelihood (ML) or posterior mode (PM) estimates. The use of PM estimation avoids boundary problems commonly associated with latent class models (DeCarlo, 2011); this method uses a prior distribution to smooth solutions that are near the boundary of the parameter space. In addition, to avoid problems of local maxima, 100 sets of starting values were used to obtain the global maximum. Finally, to check for local identification, the rank of the Jacobian matrix was examined to be of full rank as specified as a required condition for local identification in latent class regression models (Huang & Bandeen-Roche, 2004).
Results
Model fit
RDINA, RDINA with covariate affecting attributes, and RDINA with covariate affecting items were fit to examine the effect of science ability on mathematics items and on the mastery of mathematics attributes in a CDM framework. Table 1 shows the fit statistics of the three models used for this study.
Fit Statistics.

Note. AIC = Akaike information criterion; BIC = Bayesian information criterion; RDINA = reparameterized deterministic input noisy “and” gate.
The first model included no covariate (RDINA), which was fit as a baseline model for comparison. The next RDINA model specified science ability to affect mathematics attributes, which would influence the mastery classification of the seven attributes. The mathematics (M = 14.85, SD = 5.00) and science (M = 17.18, SD = 5.00) number-correct scores had a correlation of .66. Finally, the RDINA model with science ability affecting mathematics items was fit. To select the best-fitting model, results from model fit indices were examined. Both the AIC and BIC indicated that the item-level covariate model fits best with the lowest fit indices. In the RDINA model without covariate, there are 57 parameters from the 50 RDINA item parameters (fj and dj) and seven attribute parameters (attribute intercept, bk). In the models with covariates, additional parameters were estimated. For the attribute-level model, seven additional parameters were estimated for each of the attributes as regression coefficients for the covariate (hk). For the item-level model, 25 additional regression coefficients for the covariate affecting the items (lj) were estimated in addition to the original 57 parameters in the RDINA model.
RDINA item parameters
Table 2 presents the fj and dj parameters from the RDINA model (the original guessing and slip DINA parameters can be derived by exponentiating the RDINA parameters as indicated in Equations 3 and 4 above). In general, the fj and dj parameters were similar between the RDINA and the attribute-level covariate model. Items 1 (Number domain), 6 (Geometric Shapes and Measures domain), and 12 (Data Display domain) had the greatest guessing estimates. For the slip parameter, Items 11 (Geometric Shapes and Measures) and 21 (Number domain) had high estimates, respectively. When compared with the item-level covariate model, the guessing parameters were lower and the slip parameters were higher, indicating a shift in the parameter locations due to the effect of the covariate (lj) on the RDINA item parameters as expressed in Equations 10 and 11. The average guessing parameter estimates, derived using Equation 3, across the Number domain for the RDINA, RDINA with covariates affecting attributes, and RDINA with covariates affecting items were 0.33, 0.33, and 0.05, respectively; for the Geometric Shapes and Measures domain, they were 0.37, 0.38, and 0.09, respectively; and for the Data Display domain, they were 0.47, 0.48, and 0.10, respectively.
RDINA Item Parameters: f and d Parameters.

Note. The values in parentheses represent standard errors. The fj and dj parameters can be reparameterized to derive the guessing and slip parameters: guessing = exp(fj)/[(1 + exp(fj)] and slip = 1 − {exp(fj+ dj)/[(1 + exp(fj+ dj)]}. The discrimination index (de la Torre, 2008), δ = 1 − guessing − slip, can be calculated based on the following: {exp(fj+dj)/[(1 + exp(fj+dj)]} − {exp(fj)/[(1 + exp(fj)]}. RDINA = reparameterized deterministic input noisy “and” gate.
For the slip parameter derived using Equation 4, the average estimates across the Number domain for the three models were 0.25, 0.24, and 0.83, respectively; for the Geometric Shapes and Measures domain, they were 0.29, 0.28, and 0.66, respectively; and for the Data Display domain, they were 0.14, 0.14, and 0.71, respectively. As these values indicate, the guessing and slip parameter estimates for the RDINA and covariate model affecting attributes were very close. However, the parameter estimates for the covariate model affecting items were shifted down for the guessing and shifted up for the slip parameters.
Discrimination indices that represent how well an item is able to classify an examinee as having mastered an attribute were calculated for each item, δ = 1 −g−s (de la Torre, 2008). This discrimination index was calculated based on the RDINA using the following form: δ = 1 −g−s = {exp(fj+dj)/[(1 + exp(fj+dj)]} − {exp(fj)/[(1 + exp(fj)]}. For the Number domain, the mean discrimination estimates for RDINA, RDINA with covariates affecting attributes, and RDINA with covariates affecting items were 0.41, 0.42, and 0.12, respectively; for the Geometric Shapes and Measures domain, the mean estimates were 0.35, 0.36, and 0.18, respectively; and for the Data Display domain, the mean estimates were 0.36, 0.37, and 0.30, respectively. These estimates show that the discrimination indices decreased for the covariate model affecting items due to the lower guessing and higher slip parameter estimates; the extent that the slip parameters shifted up was greater than the extent that the guessing parameters shifted down.
Unique parameters from the covariate model affecting attributes
Table 3 shows the regression coefficients (hk) for the covariate model affecting attributes. Science score affected the response probabilities of all attributes, except Attribute 4 (Lines and Angles), which did not have a significant effect (p = .120). Among the attributes, science score had relatively large effects on Whole Numbers, Location and Movement, and Fractions and Decimals.
Attribute Parameters: Covariate (Science Score).

Note. Values represent regression coefficient (hk) in the covariate model affecting attributes; values in parentheses represent standard errors.
Unique parameters from the covariate model affecting items
Items 5, 16, and 23 from the Number domain; Items 19 and 25 from the Data Display domain; and Item 6 from the Geometric Shapes and Measures domain had the greatest estimates. On average, the parameter estimates for the Number, Geometric Shapes and Measures, and Data Display domains were 0.17, 0.13, and 0.18, respectively. Estimates of lj for items ranged between 0.05 and 0.27, and all estimates were p < .01; specific regression coefficients lj for the covariate model affecting items are presented in Table A2 (see online supplement). The significance of these estimates indicates that science score affected the item response probabilities for all 25 items tested.
Attribute prevalence
Table 4 presents the attribute prevalence of the seven attributes. Attribute prevalence is the latent class size of the seven attributes, α k (DeCarlo, 2011).
Attribute Prevalence.

Note. The values in parentheses represent standard errors.
For Attributes 3 (Number Sentences, Patterns, and Relationships) and 4 (Lines and Angles), the attribute prevalence was particularly high, above 0.90; this was consistent across the three models. The attribute prevalence for Attributes 1 (Whole Numbers) and 5 (Two- and Three-Dimensional Shapes) had lower probabilities, but remained consistent. However, for Attributes 2 (Fractions and Decimals), 6 (Location and Movement), and 7 (Reading, Interpreting, Organizing, & Representing), their prevalence was lower for the covariate model affecting attributes. The significance in the regression coefficient for these attributes affected the intercept parameter to decrease the attribute prevalence. However, given the large regression parameter (hk) for Attribute 1 (Whole Number), there was no change in its prevalence (change from 0.56 to 0.58 between the RDINA model without a covariate and the covariate model affecting the attribute, respectively). The marginal change in prevalence, given the large estimate of h1 (0.34, p < .001; see Table 3), was partly due to the structure of the Q-matrix for Attribute 1, which was specified in 18 items (see Table A1, online supplement). In comparison, for Attribute 2 with a similar parameter estimate (h2 = 0.33, p < .001; see Table 3) but specified in only 4 items, the attribute prevalence shifted from 0.81 to 0.57. These results indicate that the effect of hk on the prevalence of attribute k is affected not only by the covariate but also by the Q-matrix structure, which indicates how frequently the attribute is specified.
Study II: Simulation Study
Method
A simulation study was conducted to examine the parameter recovery of the (a) RDINA, (b) RDINA model with covariate affecting attributes, and (c) RDINA model with covariate affecting items. Four sample sizes of 500, 1,000, 2,000, and 5,000 were used across a specification of five and seven attributes. Data were generated using population (true) values derived from the TIMSS real-world data analyzed in the previous section (see Q-matrix in Table A1, online supplement). For creating the Q-matrix for five attributes, two attributes among the seven attributes were collapsed, based on recommendation from mathematics educators: Attributes 2 (Fractions and Decimals) and 3 (Number Sentences, Patterns, & Relationships) were combined, and Attributes 4 (Lines and Angles) and 5 (Two- and Three-Dimensional Shapes) were combined. The use of TIMSS estimates represents a realistic value of parameters, rather than selecting values defined by the authors. Similar to the real-world data analysis, only one continuous covariate (M = 17.18, SD = 5.00) was used in the simulation study. Depending on the model, the probabilities of the attributes (covariate model affecting attributes) and item responses (covariate model affecting items) were generated while being conditioned on the covariate. Moreover, to examine the effect of incorrect models fit to simulated data, data generated using the RDINA model with covariate affecting attributes were fit using the RDINA and RDINA model with covariate affecting items; similarly, RDINA model with covariate affecting items was generated and fit using RDINA and RDINA model with covariate affecting attributes. Together, these represent a total of 56 conditions (24 conditions fit using the correct model + 32 conditions fit using an incorrect model = 3 models × 4 sample sizes × 2 attribute sizes fit using the correct model + 2 covariate models × 4 sample sizes × 2 attribute sizes × 2 incorrect models).
Data were generated using Stata 12 for 100 replications of the 56 conditions studied in the simulation study. A DOS batch file was created to fit the results in Latent GOLD 4.5. Parameter estimates for the replications were summarized and compared with the population values used to generate data. Three measures of parameter recovery, (a) bias, (b) % bias, and (c) mean squared error (MSE), were calculated for each of the conditions. The specific formulas used for calculating bias, % bias, and MSE are presented as follows, where x is an arbitrary indicator of a parameter, e(x) is the generating (true) parameter value, and
Results
RDINA model
Table 5 presents the bias, % bias, and MSE estimates for the eight conditions studied in this model. Results are summarized by averaging the measures of recovery across the parameters to facilitate the presentation of the findings. Three parameters are presented, with one attribute-level parameter representing the intercept of the attribute (bk), and the remaining two item-level parameters representing the intercept (fj) and the coefficient (dj) of the latent class (η j ). For the RDINA model with five attributes, the parameter estimates had % bias estimates that were all below 4% (except for fj estimates for sample size of 500). The positive mean biases show that the estimates were overestimated. For this condition, estimates of the item intercepts (fj) had larger bias. In the RDINA model with seven attributes, % bias was larger, reaching 8.7% for the attribute intercept parameter (bk). In both five- and seven-attribute RDINA models, when sample size increased, the MSE estimates decreased accordingly.
Recovery of the RDINA, RDINA With Covariate Affecting Attributes, and RDINA With Covariate Affecting Items.

Note. The parameter bk is the intercept parameter affecting the attributes. The parameters hk and lj are the coefficient parameters of the covariate affecting the attributes and items, respectively. The parameters fj and dj are at the item level. RDINA = reparameterized deterministic input noisy “and” gate; MSE = mean squared error.
Moreover, when the sample size was 1,000 or above, the % bias was all below or equal to 4.5%. However, unlike the five-attribute conditions that had the greatest bias in the item intercept parameter (fj), in the seven-attribute conditions, the greatest bias was in the attribute intercept parameter (bk).
RDINA model with covariate affecting attributes
In this model, the hk parameter represents the coefficient estimate for the covariate affecting the attributes. For the five-attribute conditions, the greatest % bias was from the item intercept parameter (fj). However, for all sample sizes and parameters, the % bias was all below or equal to 4.4%. For the seven-attribute conditions, the intercept of the attribute-level parameter (bk) showed the greatest % bias, ranging from 7.6% to 12.8% across the sample sizes. At the attribute level, parameter bias was largest for attributes with population values close to the boundaries; the high bias may be attributed to estimation problems. Across both five- and seven-attribute conditions, the item parameters were underestimated as evidence from the negative bias estimates. Moreover, the MSE estimates decreased when sample size increased. Although the five-attribute condition showed consistent recovery of parameters for varying sample sizes, the % bias of the attribute intercept parameter for the seven-attribute condition was more than 10% even with a sample size of 5,000.
RDINA model with covariate affecting items
This model has the most parameters, as additional parameters have to be estimated for each item, leading to three parameters per item. In addition to the parameters in the RDINA model, the coefficients of the covariate affecting items (lj) are added. For the five-attribute condition, the parameter dj had the greatest % bias. The recovery of the lj parameters had the lowest bias. For the seven-attribute conditions, the greatest % bias was from the bk parameter; even with a sample size of 2,000, the % bias was above 5%. In general, for both five- and seven-attribute conditions, an increase in sample size decreased % bias and MSE. Furthermore, the dj parameter was underestimated in both models as indicated by the negative bias estimates. Moreover, for the five-attribute condition, a sample size of 1,000 showed % bias estimates to be less than 5%; a larger sample size more than 2,000 was needed for the seven-attribute condition.
Attribute prevalence and classification
Estimates of the maximum posterior probability were used to classify the mastery in each of the five- and seven-attribute conditions. These classifications were used to calculate the % bias of the attribute prevalence and the Pc statistics. Results are summarized in Table A3 (online supplement) for the five- and seven-attribute conditions across four sample sizes and for the three models examined in this study (RDINA, RDINA with covariate affecting attributes, and RDINA with covariate affecting items). Columns indicate the sample sizes for the two attribute conditions, and the rows indicate the % bias and Pc for each attribute of the three models. Overall, the % bias in attribute prevalence was all below or equal to 2.2% even with a sample size of 500 for the five-attribute condition, across the three models; Pc was all above 0.81. For the seven-attribute condition, the % bias was all below or equal to 14.2% for a sample size of 500, with the largest % bias from Attribute 4; Pc was all above or equal to 0.80. Although small differences in % bias and Pc were found between models, the recovery of attribute prevalence was relatively similar across conditions with only minor changes, indicating stability in attribute prevalence and classification.
Fitting simulated data to incorrect models
Data generated using the RDINA covariate extensions (affecting attributes or items) were fit with incorrect models (e.g., RDINA model with covariate affecting attributes fit using the RDINA model or RDINA model affecting items). Model fit indices, Pc, and % bias of parameters (item and attribute) are presented in the online supplement Table A4. Across the four sample sizes (500, 1,000, 2,000, and 5,000) and five- or seven-attribute conditions, both AIC and BIC selected the correct model. Moreover, the correct model had the highest Pc and the lowest % bias in item parameter estimates. Incorrect models had higher AIC and BIC values and lower Pc estimates. The greatest impact of using incorrect models was found in the % bias of item parameters. When data generated using RDINA with covariate affecting attributes were fit using the RDINA with covariate affecting items, % bias was more than 305% for the five-attribute condition and more than 132% for the seven-attribute condition; conversely, for the RDINA model with covariate affecting items fit using the RDINA with covariate affecting attributes, % bias was more than 102% for the five-attribute condition and more than 86% for the seven-attribute condition. In both cases, fitting the covariate models using the simple RDINA without a covariate resulted in the lower % bias than the incorrect covariate model.
Discussion and Conclusion
Researchers have long used broad domain-based scores from large-scale assessments to improve their educational systems. CDMs were developed to provide more targeted information in the form of score profiles that resolve the limitation of classical methods and unidimensional item response theory (IRT) models. Various CDMs have been proposed in the measurement literature. Although most CDMs provide an ideal framework for conducting an analysis to classify examinees into attribute profiles that indicate their mastery in fine-grained skills, this study extends the DINA framework by including a covariate in a reparameterized DINA model.
As described in this study, a covariate in the DINA model can be specified to affect examinees’ response probability at the lower level; it can also be specified to affect the latent classification by influencing the attributes at the higher level. To investigate how the covariate extension of the DINA model can be applied to real-world data, this study examined the effect of science ability (number-correct score on TIMSS science assessment) on an examinee’s probability of solving mathematics items; it was also parameterized to examine the influence that science ability had on the mastery of fine-grained mathematics skills. As indicated in the results, science ability had a significant effect on both items and attributes; students with higher science ability had a greater likelihood of solving mathematics items as well as being classified as having mastery in six of the seven attributes (all attributes except Lines and Angles) specified in the Q-matrix. These findings do not suggest a causal relationship between science scores and mathematics ability; however, the significant association for the attributes can provide additional studies that can lead to meaningful results for applied researchers.
Results from the simulation study showed stability in the model to recover parameters at various sample sizes, type of covariate model, and number of attributes. In particular, the findings from this study indicate that a sample size of 500 may be adequate to use a covariate within a DINA model when there are five attributes. When there are seven attributes, the required sample size may need to increase to 2,000 examinees for the bias in the parameter estimates to be reduced below a 5% level. Although this study investigated only one test length consisting of 25 items, various test lengths, attributes, and attribute specification in the Q-matrix should be studied. Moreover, different types of covariates (e.g., dichotomous or ordinal) as well as mix of continuous and discrete covariates that include demographic or learning characteristics of students should be examined in future simulations and empirical studies. Classification of latent classes and attribute prevalence were relatively similar across different conditions and models examined, indicating stability in attribute profiles in the framework of a covariate extension in the RDINA framework. Covariates can be specified at the item level as well as at the attribute level; this specification can be extended to parameterize covariates at both attribute and item levels (DeCarlo, 2005). Previous work by Templin (2005) indicated that specifying a covariate such as gender that can affect the higher order latent trait, can have different item parameters, leading to uniform differential item functioning (DIF) in the context of CDMs. Using the current covariate model, such uniform DIF studies can be studied, by examining estimates of parameters when covariates are specified at the item level.
The covariate extension in this article was conducted in the framework of the RDINA model, which used an independence model for the attribute specification. It is noted that the CDM specification is independent of the attribute specification; that is, CDMs can be used in conjunction with any attribute specification, such as saturated, independence, or conditional independence. While a saturated attribute structure that has no constraints represents the most general model for the attribute distribution, this study examined the use of constrained attribute specifications (independence and conditional independence). As such, comparisons of constrained and unconstrained attribute specifications, in the context of covariate extensions in CDMs, may need to be examined in future studies. In that manner, this study provides a basis for comparison and extensions to a wider array of more complex and generalized CDM frameworks in the literature, such as the generalized DINA model (de la Torre, 2011), general diagnostic model (von Davier, 2014), and the loglinear CDM (Henson, Templin, & Wilse, 2009). In addition to applying a covariate in a DINA model, this study provided an ideal demonstration of the TIMSS data to examine features of mathematics and science education and their consequence on international assessments. In the fields of medicine and public health where competency-based learning is emphasized, covariate extensions of CDMs can lead to understanding the interconnectedness between fine-grained constructs. This framework allows meaningful interpretations of the covariate to provide feedback to instructors and examinees and adds to the diagnostic utility of the model, which are central to CDMs.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.