
Abstract
This research focuses on developing item-level fit checking procedures in the context of diagnostic classification models (DCMs), and more specifically for the “Deterministic Input; Noisy ‘And’ gate” (DINA) model. Although there is a growing body of literature discussing model fit checking methods for DCM, the item-level fit analysis is not adequately discussed in literature. This study intends to take an initiative to fill in this gap. Two approaches are proposed, one stems from classical goodness-of-fit test statistics coupled with the Expectation-Maximization algorithm for model estimation, and the other is the posterior predictive model checking (PPMC) method coupled with the Markov chain Monte Carlo estimation. For both approaches, the chi-square statistic and a power-divergence index are considered, along with Stone’s method for considering uncertainty in latent attribute estimation. A simulation study with varying manipulated factors is carried out. Results show that both approaches are promising if Stone’s method is imposed, but the classical goodness-of-fit approach has a much higher detection rate (i.e., proportion of misfit items that are correctly detected) than the PPMC method.
Keywords
Cognitive diagnosis has recently gained prominence in educational and psychological assessment, psychiatric evaluation, and many other disciplines (Rupp, Templin, & Henson, 2010). In cognitive diagnosis, one attempts to identify the tasks, subtasks, cognitive processes, and/or skills involved in responding to items on an assessment. Each task or skill is generally referred to as an attribute. For example, the attributes of a math test might include converting mixed numbers to improper fractions, finding a common denominator, or multiplying fractions.
The main objective of cognitive diagnosis is to discover the participants’ latent profiles (e.g., mastery of skills, presence of disease or disorders) based on their responses to item questions (e.g., answers to exam problems, occurrence of symptoms) and the item information (e.g., item parameters, item-attribute relationship).
Psychometric models designed for cognitive diagnosis are divided into two general camps: continuous latent trait models and latent class models. Latent trait models, such as item response theory (IRT), posit that each examinee can be represented as a point in a K-dimensional space, where K denotes the number of dimensions underlying a series of test items (Reckase, 2009; Wang & Nydick, 2015). Latent class models, such as diagnostic classification models (DCMs), assume that the latent space consists of a constellation of 0-1 discrete cognitive states (denoted by α). Within this framework, each participant is thus provided with a profile detailing the skills (also called “attributes”) that he or she masters. For example, psychiatrists identify patients’ presence or absence of disorders based on their symptoms through their responses to diagnostic questions; teachers learn students’ mastery of different skills based on their answers to exam questions. In doing so, DCM has been shown to potentially support fine-grained diagnosis that can be used for developing targeted interventions (Rupp et al., 2010; Wang, Chang, & Huebner, 2011).
A number of DCMs have been proposed in the literature. One of the earliest, and probably the simplest DCM is the “Deterministic Input; Noisy ‘And’ gate” (DINA) model (Haertel, 1989; Junker & Sijtsma, 2001). The DINA model assumes that, in principle, an examinee must have mastered every attribute associated with a particular item to respond correctly to that item. This model has been studied extensively not only in method-dominant research (e.g., de la Torre & Douglas, 2004; J. Liu, Xu, & Ying, 2012; Wang, 2013), but also in a few applications. For instance, the DINA model is fitted to middle school students’ solutions of mixed-number subtraction problems by different researchers (also known as the fraction-subtraction data hereafter; de la Torre & Douglas, 2004; Sinharay, 2006; Sinharay & Almond, 2007), and more pronouncedly, it guides the large-scale pilot cognitive diagnostic assessment project in China. The assessment project is designed to measure Level 2 1 English proficiency for Grade 6 students (H. Liu, You, Wang, Ding, & Chang, 2014). All stages of this project, from item writing to test assembly, are executed closely conforming to the DINA model.
Like any model-based assessment, one critical step toward implementing the model is to check model-data fit, that is, the agreement between model predictions and observed data. When a model does not fit the data, the validity of using estimated parameters for inference may be compromised. In DCM, the source of misfit could come from the attribute structure, the type of models, the item–attribute relationship matrix (named as
Relative model fit has typically been evaluated using conventional information-based indices (e.g., de la Torre & Douglas, 2008; Rupp et al., 2010; Sinharay & Almond, 2007) such as the Akaike’s information criterion (Akaike, 1974), the Bayesian information criterion (Schwarz, 1978), and the deviance information criterion (Spiegelhalter, Best, Carlin, & Van Der Linde, 2002). Absolute model fit is gauged by a variety of discrepancy-based statistics. An incomplete list includes residuals between observed and model predicted correlations, log-odds ratios of item pairs, proportion of correct individual items (de la Torre & Douglas, 2008; Sinharay & Almond, 2007), model-level chi-square and G2 statistics (Rupp et al., 2010), item-level mean absolute difference (MAD), and item-level root mean square error of approximation (RMSEA; Kunina-Habenicht, Rupp, & Wilhelm, 2012). Person fit is checked by either a generalized likelihood ratio test (Y. Liu, Douglas, & Henson, 2009) or the hierarchy consistency index (Cui & Leighton, 2009).
Only a few studies have ever looked into item-level fit analysis (Kunina-Habenicht, Rupp, & Wilhelm, 2012; Oliveri & von Davier, 2011; Sinharay & Almond, 2007). Item-fit analysis describes model-data fit for every item by comparing model predictions and actual responses via a certain discrepancy measure. Item-fit analysis helps identify aberrant items, the deletion or revision of which will improve overall model-data fit for the entire test. Whereas a large body of research exists on item fit for unidimensional and multidimensional IRT models, corresponding research for DCMs is very limited. Sinharay and Almond (2007) presented a case study in which they use chi-square statistics and a Bayesian residual plot to evaluate item fit using a real data set; however, they do not provide any simulation results to evaluate the performance of the fit statistics. von Davier (2008) applied the general diagnostic model (GDM) to the language testing data and he uses mdltm software that provides item-fit information, yet limited details are provided. Oliveri and von Davier (2011) used item-level RMSEA to evaluate item-level fit when fitting the GDM to the PISA (Programme for International Student Assessment) data. In particular, they treated RMSEA as a diagnostic index and compared it with a cut-off value of 0.1. Items with RMSEA > 0.1 are considered poor-fit. Kunina-Habenicht et al. (2012) presented a thorough simulation study showing the Type I error rate and power of two item-fit indices—MAD and RMSEA. Both of the indices rely on the point estimate of examinees’ latent profiles (denoted as α hereafter), which is a multidimensional, binary vector indicating the mastery status of an examinee on all attributes measured by a test. It is subject to potentially large measurement errors for short tests. This study systemically explores the procedures for several item-level fit statistics with Stone’s (2000) method for adjusting for measurement errors in α, using the deterministic input noisy-and-gate model (DINA; Junker & Sijtsma, 2001) as an illustration. This study, therefore, complemented the existing account of item-fit checking methods in the realm of DCMs. The DINA model is chosen because it is one of the earliest, simplest, and most widely used DCMs in practice (e.g., de la Torre, 2009). As the article unfolds below, it will be clear that the proposed approaches as well as the discrepancy measures are not dependent on any specific parameterizations, and thus they can be applied to any DCMs.
Almost all item-fit indices are built upon the discrepancy between the observed and the model predicted responses, with larger discrepancy indicating poorer fit. To compute model prediction, the model parameters need to be properly estimated. The DINA model, and many existing DCMs, can be estimated via either the maximum likelihood procedure (more specifically, the Expectation-Maximization [EM] algorithm) or the Bayesian procedure (i.e., the Markov chain Monte Carlo [MCMC] algorithm; de la Torre, 2009). Depending on the specific model estimation procedure that is used, the resulting item-fit statistics and their sampling distributions need to be carefully scrutinized. It is, therefore, the contribution of the study to explore the performances of two item discrepancy indices coupled with both the EM and the MCMC estimation procedures.
The rest of the article is organized as follows. First, the authors briefly review the DCMs with a special focus on the DINA model and the type of misfit they plan to elaborate upon. Then, they present two item-level discrepancy indices and the procedures of using them with the EM and the MCMC estimation methods. The authors next present a simulation study designed to evaluate whether the proposed methods can correctly identify misfitting items. They finally detail results of the simulation study, explore their methods for item-fit analysis in a real data set, and discuss implications and future studies.
Method
DCMs
The available DCMs are typically divided into conjunctive and disjunctive models. Conjunctive models require that a participant possesses all attributes comprising an item to have a high probability of correctly responding to or endorsing that item. A short list of conjunctive models includes the DINA model, the noisy input deterministic-and-gate model (NIDA; Maris, 1999), and the fusion model (Roussos, DiBello, et al., 2007; Roussos, Templin, & Henson, 2007). Disjunctive models, however, require examinees to possess at least one of the attributes composing an item to have a high probability of correctly responding to that item, including the deterministic noisy-or-gate (DINO) model and noisy input deterministic-or-gate (NIDO) model. Despite the diversity of available parametric models and the existence of non-parametric techniques, there has been a trend toward unifying DCMs within a global modeling framework or family. The three most widely discussed families are the log-linear cognitive diagnostic model family (Henson, Templin, & Willse, 2009), the generalized DINA model family (de la Torre, 2011), and the GDM family (von Davier, 2008). Central to all these models is the
Because the DINA model is a relatively simple conjunctive model that has received the greatest attention in the past decade, the authors focus on the DINA model throughout the article. Let
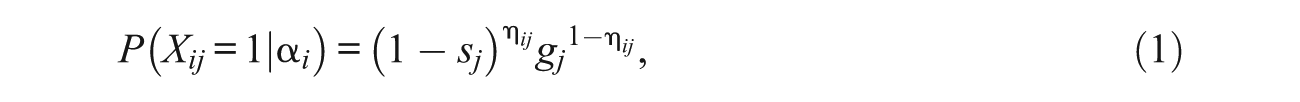
where sj is the slipping parameter (i.e., the probability of an incorrect response given an examinee with all the required attributes for solving an item) and gj is the guessing parameter for item j. Both parameters reflect the “noisy” feature of the model.
In cognitive diagnosis,
Model misspecification is another potential source of model-data misfit, and it refers to incorrect parameterization of the psychometric component of the modeling process (Chen, Torre, & Zhang, 2013). As alluded to earlier in this section, different attributes interact through either a conjunctive, or a disjunctive rule, to produce an answer to an item. As a result, researchers need to formalize their conceptualization of the hypothesized cognitive processes involved in each item when choosing an appropriate DCM parameterization. Failure to correctly identify the parameterization will, in theory, yield biased parameter estimates and invalid inference. The item-fit analysis methods that are introduced in the subsequent sections are expected to capture those items with misspecified parameterization.
Because almost all DCMs tend to involve a vector of binary latent traits (i.e., α), as opposed to the vector of continuous latent traits in multidimensional IRT models (Hong, Wang, Lim, & Douglas, 2015; Wang & Nydick, 2015), another possible form of misspecification in DCM is thus the misspecification of α. When the psychological constructs represented by the latent variables are generally understood as broadly defined abilities, such as math ability, it may be unrealistic to model the latent variable as binary, or even discrete. In that case, a continuous ability variable may make more sense (Hong et al., 2015). Misspecifying certain elements in α may result in model or item misfit.
Item-fit analysis procedures
The principal idea of item-fit analysis is to classify the examinees into several ability groups and calculate the average discrepancy between the observed and the expected responses pertaining to each ability group. Large discrepancy usually signals a misfitting item. A slew of indices emanating from non-parametric and parametric frameworks within IRT has been proposed for item fit (Orlando & Thissen, 2000) in the second half of the last century and has recently been adapted to the context of DCM (e.g., Sinharay & Almond, 2007). In this section, a list of item-fit analysis procedures will be introduced.
Classical goodness-of-fit statistics
Assume the DINA model is estimated using the EM algorithm (de la Torre, 2009), and the estimated slipping and guessing parameters are denoted by
Appropriate discrepancy measure needs to be selected to quantify the difference between Elj and Olj. Following the status quo from IRT fit analysis, one of the most widely used discrepancy measures is Yen’s (1981)Q1 statistic, which takes the form of
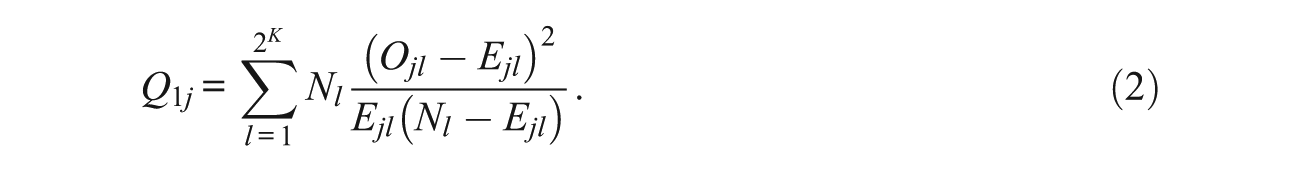
As shown in Equation 2, the Q1 statistic is algebraically equivalent to the chi-square goodness-of-fit statistic in typical categorical data analysis with two categories (Sinharay & Almond, 2007). This statistic has been studied by many researchers, such as Sinharay (2006) with Bayesian networks (see Equation 6 of his paper), or Toribio and Albert (2011) with unidimensional IRT models.
Yen (1981) showed that in IRT modeling, when the model fits the data, Q1 is distributed as approximately chi-square with 2 K −mdf, where m is the number of item parameters. 3 This df takes into account the estimated item parameters in constructing the expected frequency Elj, but it does not adjust for the estimation of person parameters. Moreover, when the number of examinees in certain equivalent classes is few, yielding sparse data, the sampling distribution of Q1 might not be well approximated by a chi-square distribution.
Another widely used discrepancy measure is a likelihood ratio G2 statistic (McKinley & Mills, 1985). Both the likelihood ratio and chi-square statistics are widely used in IRT-based item-fit analysis (Levy, Mislevy, & Sinharay, 2009; Orlando & Thissen, 2000) and latent class model diagnosis (Collins, Fidler, Wugalter, & Long, 1993). Moreover, they both can be viewed as a member of the power-divergence (PD) family (Read & Cressie, 1988). This family consists of a group of indices that take the following form, differing only by the parameter λ:

where T is the number of groups, Cl is the observed counts in group l, and El is the expected counts in group l. Chi-square statistic is the case when λ = 1 and G2 is the limit as
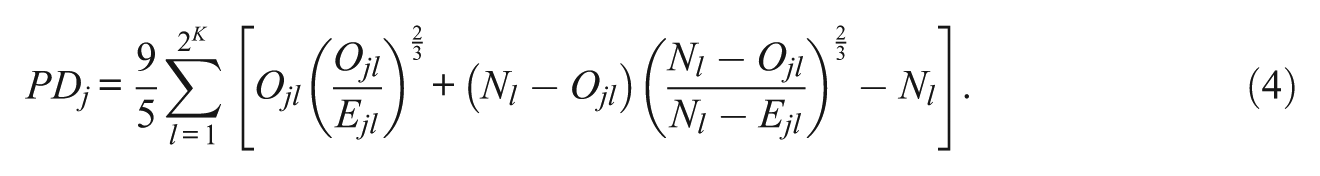
The sampling distribution of the PD index is also approximately a chi-square distribution with
Stone’s method
Notice that all current discrepancy measures defined in Equations 2 to 4 rely on

where xij denotes the response of the ith examinee to item j;
Because all equivalent classes are not independent due to the fact that each examinee can be assigned to multiple groups with corresponding probabilities, the chi-square distribution is no longer a good approximation to the sampling distribution of the discrepancy measures. Instead, a Monte Carlo resampling technique can be used to construct an empirical null sampling distribution for inference (Stone, 2000).
The resampling procedure involved (a) simulating item response data using the DINA model with item parameters fixed at their estimated values (obtained by calibrating the observed response matrix via the EM algorithm),
Posterior predictive model checking (PPMC)
In addition to the classical goodness-of-fit approach that estimates model parameters first and computes discrepancy measures second, an alternative model checking approach, namely, the PPMC method (Levy et al., 2009; Sinharay, 2006; Toribio & Albert, 2011), has been developed in recent years. The primary idea of PPMC is to compare the test statistics (such as discrepancy measures) from the observed data with the test statistics from the simulated data. The simulated data are obtained via draws of parameter values from the posterior distribution (Meng, 1994), avoiding statistical assumptions about the distributions of the test statistics (Muthén & Asparouhov, 2012). Analytic solutions to the posterior distribution and the posterior predictive distribution of the model parameters are intractable for the DINA model. Instead a MCMC (de la Torre, 2009; Templin, Henson, Templin, & Roussos, 2008) estimation routine forms a good basis to carry out the PPMC method by obtaining M simulated draws from the posterior distribution. In fact, PPMC is often used along with the MCMC estimation algorithm as a Bayesian model checking tool (Meng, 1994). MCMC procedures have been widely used in the DINA model estimation and proven reliable and accurate in simulation settings (e.g., Henson, 2008).
For the ease of exposition, let ω denote the set of parameters (including the item and person parameters); let
A quantitative measure of lack-of-fit in the PPMC method is calculated as
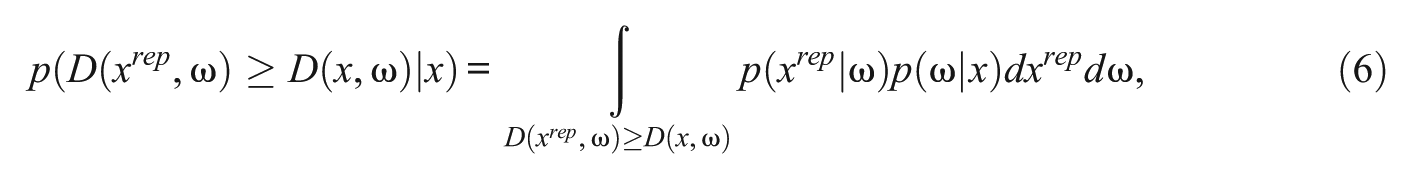
which is a tail-area probability also named as the PPP value (i.e., posterior predictive p value). Usually, PPP values close to .5 indicate that the realized discrepancies fall in the middle of the distribution of discrepancy measures based on the posterior predictive distribution and are indicative of adequate model-data fit. PPP values near 0 or 1 indicate that the observed discrepancy falls far out in the upper or lower tail of the distribution, implying that the model is under-predicting or over-predicting the quantity of interest (Levy et al., 2009). With the chi-square type of discrepancy measures defined in Equations 3 to 5, the authors sought for PPP values smaller than .05 (for a significance level of .05) in identifying misfitting items, because they were interested in the upper tail area where the observed discrepancy is large.
There are several advantages of the PPMC method. First, the uncertainty in the parameter estimates from the model calibration is taken into account in the computation of the empirical posterior predictive distribution. This is especially beneficial for short tests and small sample size, when both item and person parameter estimates are prone to large measurement errors. Second, this method requires no additional assumptions or regularity conditions (such as zero counts), thus PPMC is valid even when the sample size is too small to warrant the use of asymptotic sampling distributions. Third, it is a general approach and can be applied to any statistical models. Even armed with the prominent advantages, the PPMC method is also open to criticism, mainly because the PPP values are not uniformly distributed (Robins, van der Vaart, & Ventura, 2000), instead, the distribution is centered at .5 and is less dispersed than a uniform distribution (Meng, 1994; Robins et al., 2000). As a result, using PPP values in a typical hypothesis testing framework leads to empirical Type I error rates below nominal levels (Sinharay, Johnson, & Stern, 2006). Consequently, the power of the PPMC method might also be relatively low.
Simulation Study
A simulation study was designed to evaluate the performance of the two item-fit analysis approaches—the classical goodness-of-fit approach versus the PPMC method. Both the false positive rate (proportion of fit items that are mistakenly flagged as misfit items, that is, Type I error rate) and the correct detection rate (proportion of misfit items that are correctly flagged, that is, power) were computed. Because discrepancy measures play important roles in both approaches, the authors also intended to compare the performance of the Q1 statistic and the PD statistic with and without Stone’s method. It should be emphasized that with Stone’s method in a classical goodness-of-fit approach, a resampling technique was employed to form an empirical sampling distribution of the discrepancy statistics. In the PPMC approach, however, Stone’s method was adopted with minimum effort, that is, only
Results
The false positive rate and correct detection rate for the classical goodness-of-fit indices coupled with the EM algorithm are presented in Tables 1 and 2. Several conclusions can be drawn from the results. First, the false positive rate was well kept below .05 for most of the cells except for the high-proportion condition, in which the false positive rate was in the range of .05 and .15 for
The False Positive Rate for the EM-Based Goodness-of-Fit Indices.
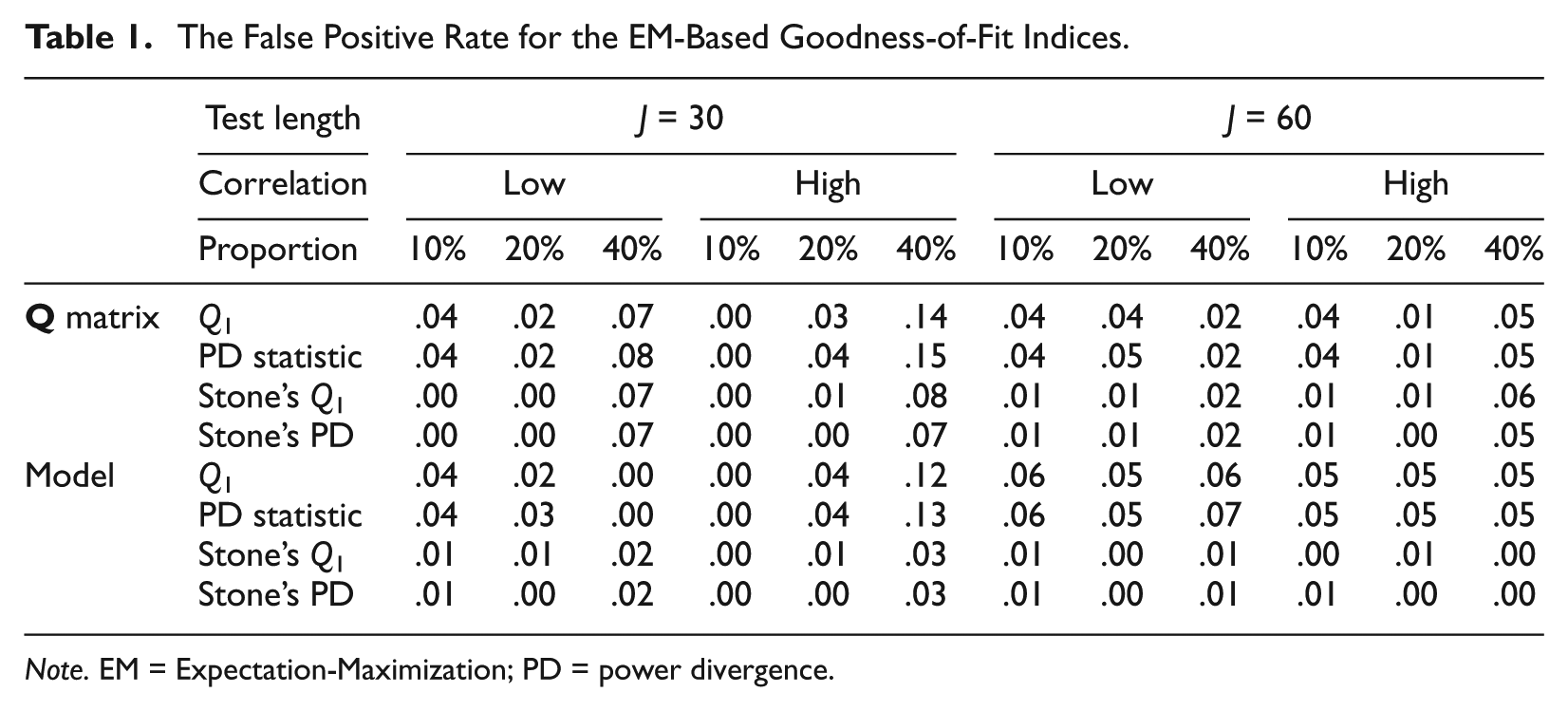
Note. EM = Expectation-Maximization; PD = power divergence.
The Correct Detection Rate for the EM-Based Goodness-of-Fit Indices.
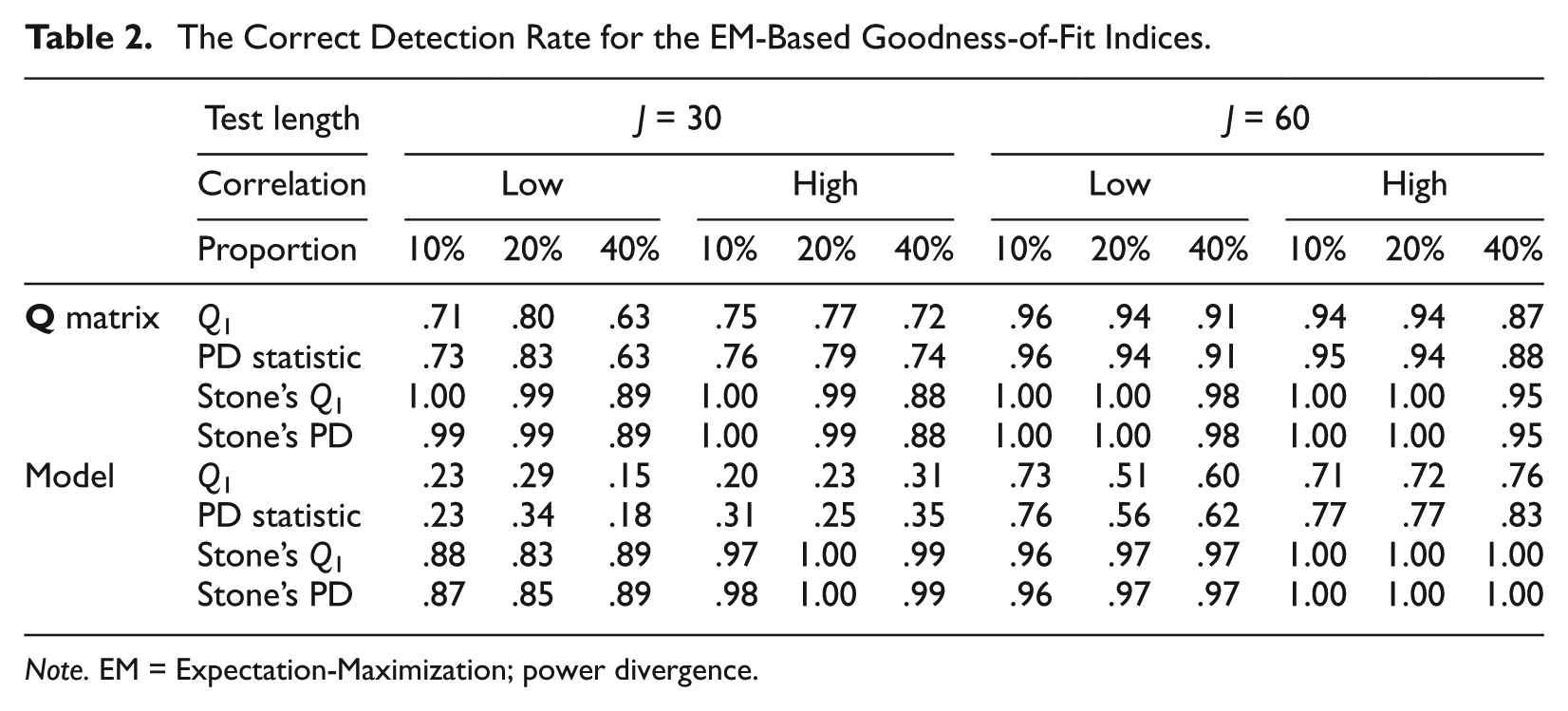
Note. EM = Expectation-Maximization; power divergence.
More interestingly, the empirical power, under model misspecification conditions, tended to be low for short test length and low correlation (actually extremely low without Stone’s method). The primary reason is that the correct detection of misfitting items due to a misspecified model relies more heavily on the correct recovery of
The false positive rate and detection rate obtained from the PPMC method are presented in Tables 3 and 4. In general, the PPMC method produced comparable false positive rates as opposed to the classical approach, but with much lower detection rate. This is because the PPP values were shown to be conservative with most values around .5. The general trends of the manipulated conditions stayed the same, and they were summarized as follows: Increasing the test length and decreasing the proportion of misfitting items increased the power, using Stone’s method dramatically improved the power, there was no appreciable difference between the two discrepancy measures, and the level of correlation did not seem to have a clear effect on the performance of the PPMC method.
The False Positive Rate for the PPMC Method.
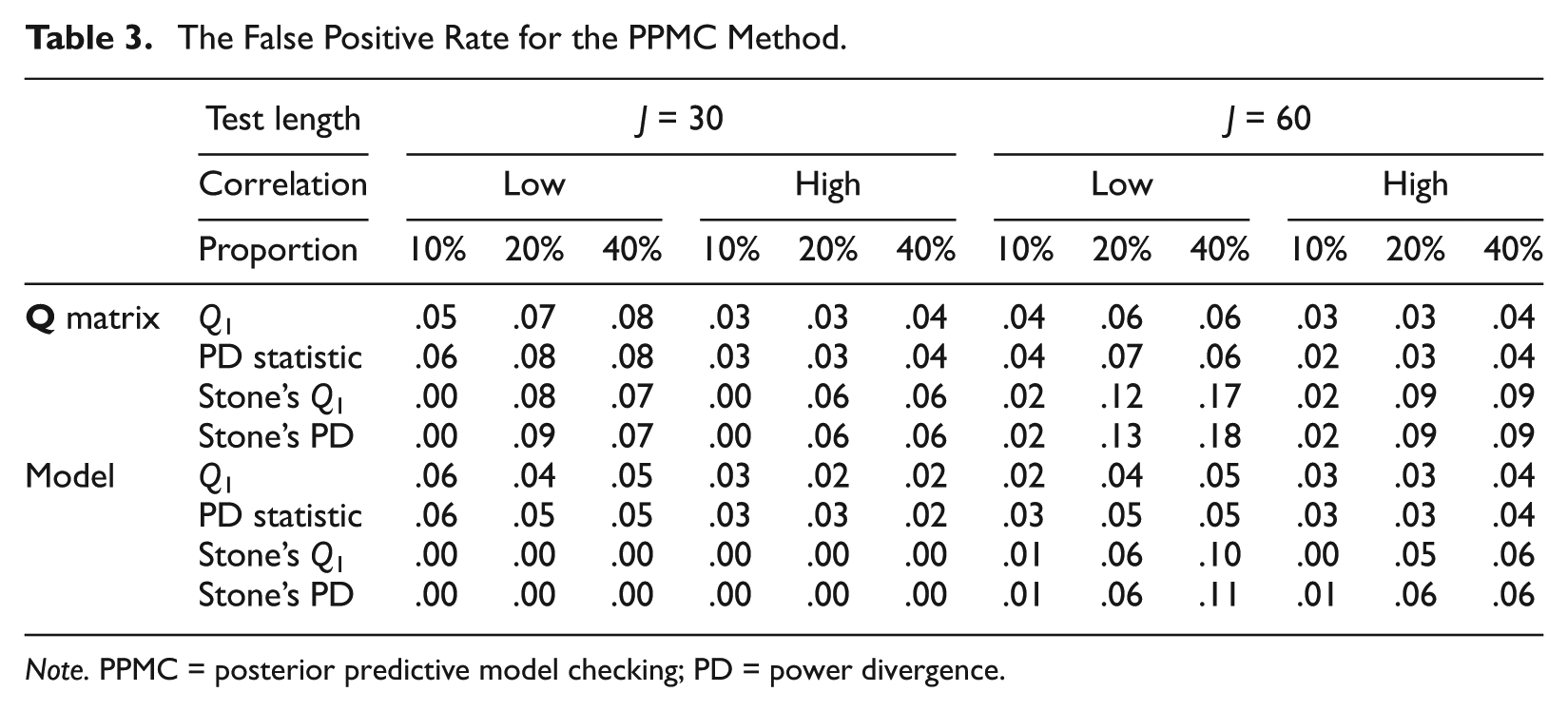
Note. PPMC = posterior predictive model checking; PD = power divergence.
The Correct Detection Rate for the PPMC Method.
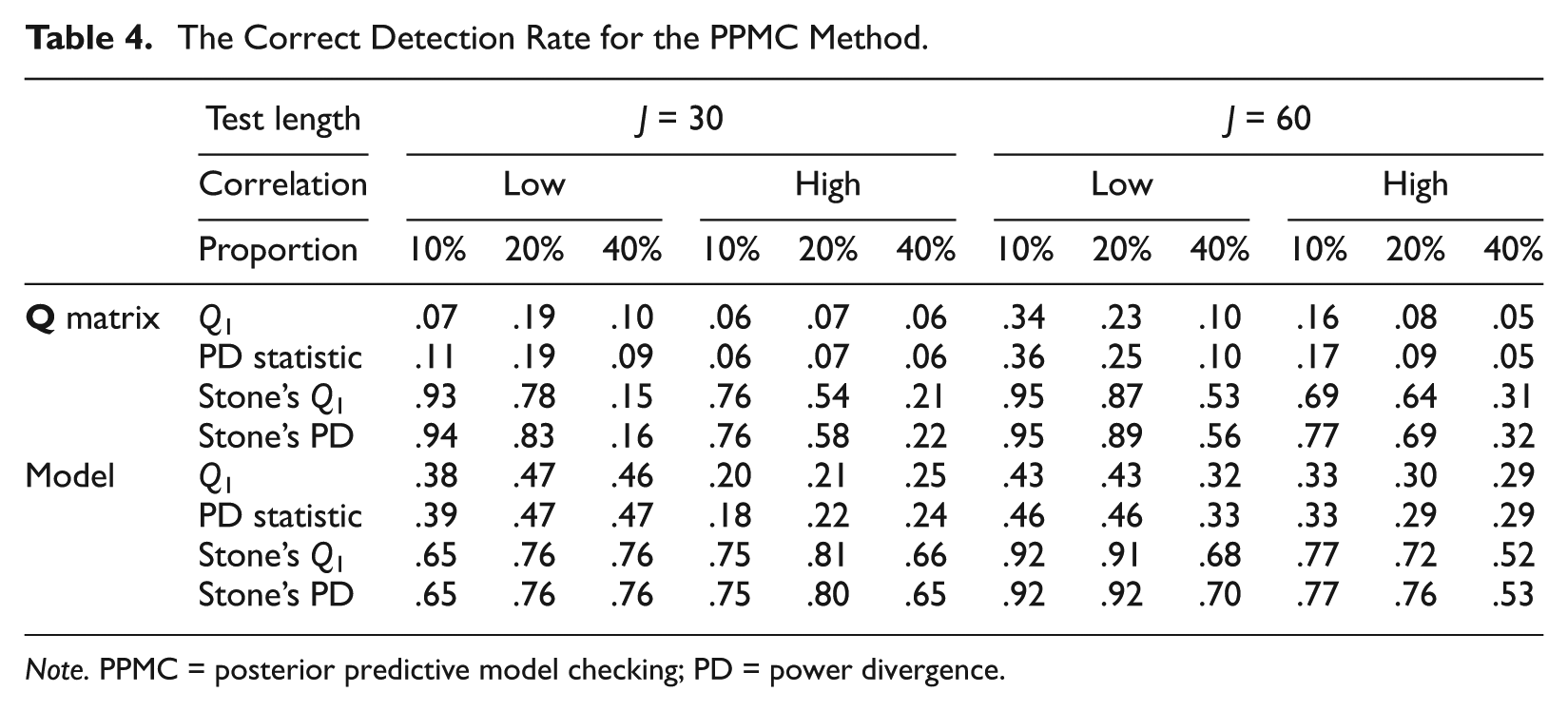
Note. PPMC = posterior predictive model checking; PD = power divergence.
From the results, the classical goodness-of-fit method should be preferred to the PPMC method. One possible reason is the PPP value does not behave like a p value in a typical hypothesis testing framework (Hjort, Dahl, & Steinbakk, 2006; Muthén & Asparouhov, 2012) because the actual Type I error rate for a correct model is not the nominal significance level. Furthermore, there is no rigorous supporting theory showing how the PPP values vary when the model/
A real data example illustrating the item-fit analysis methods using the fraction-subtraction data is provided in the online appendix, with detailed steps, results, and discussions.
Discussion
Over the past 30 years, obtaining diagnostic information from examinees’ item responses has become an increasingly important feature of educational and psychological testing. For instance, in addition to providing a summary score for accountability purpose, providing diagnostic information to promote instructional improvement becomes an important goal of the next-generation assessment. Diagnostic classification modeling, a family of restricted latent class models, has been widely recognized as one promising future direction. DCMs contain “latent variables that typically operationalize more narrowly defined constructs—so that each item requires multiple component skills” (Rupp & Templin, 2008, p. 230). Because of the finer grained dichotomy of latent spaces and the within-item dimensionalities, DCMs are known to poorly retrofit assessments originally designed for broadly based, IRT traits. To implement DCMs in real testing scenarios, model-data fit should be carefully checked and scrutinized. Very recently, Chen et al. (2013) evaluated both the relative and absolute fit of DCMs focusing on the model-level fit. They checked −2 log likelihood, Akaike information criterion (AIC), Bayesian information criterion (BIC), and residuals-based statistics, and their simulation results showed that all these indices can detect misspecification efficiently. As they acknowledged, “investigation of fit statistics at the item level is needed to fine-tune detection of model or
Given the fact that most DCMs are usually estimated either via the EM algorithm or the MCMC algorithm, this study evaluates two discrepancy measures coupled with both estimation algorithms. One innovation of the current approach is to apply Stone’s method in the context of DCMs so as to avoid inflated Type I and Type II errors introduced by fallible latent profile estimates. The results showed that the PPMC method was less sensitive than classical goodness-of-fit checking in detecting model/
Future studies can be expanded in a number of ways. First, only two discrepancy indices were considered, whereas Kunina-Habenicht et al. (2012) explored the performance of the MAD and RMSEA and found they both exhibit high power of detecting misfitting items. Thus, it will be interesting to compare the present study’s discrepancy measures against theirs side-by-side. Second, even though the proposed item-fit analysis procedures are not restricted to any specific DCM, simulation studies were carried out only for the DINA model. Therefore, future studies can consider more flexible and complex models, such as the generalized DINA model (de la Torre, 2011), or the log-linear cognitive diagnosis model (Henson et al., 2009). Moreover, in the simulation study,
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This project is partially supported by 2010 CTB/McGraw-Hill R&D research grant.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.