
Abstract
A critical shortcoming of the maximum likelihood estimation (MLE) method for test score estimation is that it does not work with certain response patterns, including ones consisting only of all 0s or all 1s. This can be problematic in the early stages of computerized adaptive testing (CAT) administration and for tests short in length. To overcome this challenge, test practitioners often set lower and upper bounds of theta estimation and truncate the score estimation to be one of those bounds when the log likelihood function fails to yield a peak due to responses consisting only of 0s or 1s. Even so, this MLE with truncation (MLET) method still cannot handle response patterns in which all harder items are correct and all easy items are incorrect. Bayesian-based estimation methods such as the modal a posteriori (MAP) method or the expected a posteriori (EAP) method can be viable alternatives to MLE. The MAP or EAP methods, however, are known to result in estimates biased toward the center of a prior distribution, resulting in a shrunken score scale. This study introduces an alternative approach to MLE, called MLE with fences (MLEF). In MLEF, several imaginary “fence” items with fixed responses are introduced to form a workable log likelihood function even with abnormal response patterns. The findings of this study suggest that, unlike MLET, the MLEF can handle any response patterns and, unlike both MAP and EAP, results in score estimates that do not cause shrinkage of the theta scale.
Introduction
For score estimation based on the item response theory (IRT), the maximum likelihood estimation (MLE) method is one of the most frequently used methods because of its ability to provide unbiased estimates. A critical shortcoming of MLE, however, is that it cannot handle certain response strings, including ones that consist only of all 0s or all 1s. This is especially problematic when the test length is short (e.g., 10 or fewer items). It can also be problematic, for example, in the early stages of administering a computerized adaptive testing (CAT), when just a few responses have been recorded, resulting in an increased chance of extreme responses patterns—a situation that MLE cannot handle.
To date, two methods for overcoming this challenge have been put into practice, but with uneven results. The first solution establishes lower and upper bounds of theta estimation, and then assigns either the lower bound value as the estimated score when the response string consists only of 0s or the upper bound value as the score estimate if all responses are 1s. This solution, however, causes theoretical and computational discontinuation from the rest of the normal MLE estimation process. More importantly, even if a response string consists of both 0s and 1s, there are certain aberrant response patterns that the MLE method cannot handle.
A second means of handling responses with all 0s or all 1s is to use Bayesian-based estimation methods (Owen, 1975) such as the modal a posteriori (MAP; Samejima, 1969) method or the expected a posteriori (EAP; Bock & Aitkin, 1981) method. By imposing a prior distribution on the log likelihood function, MAP/EAP methods always have a peak from which to find a score estimate. The problem with this approach, however, is that the MAP or EAP methods are known to result in estimates biased toward the center of a prior distribution, resulting in a shrunken score scale (Weiss & McBride, 1984). Demands from the field for a score estimation method that can resolve these aforementioned issues are on the rise.
MLE
Given the administered items and examinee’s responses, the log likelihood function for a conventional MLE method is computed, for example, for unidimensional, dichotomously scored response data as follows:
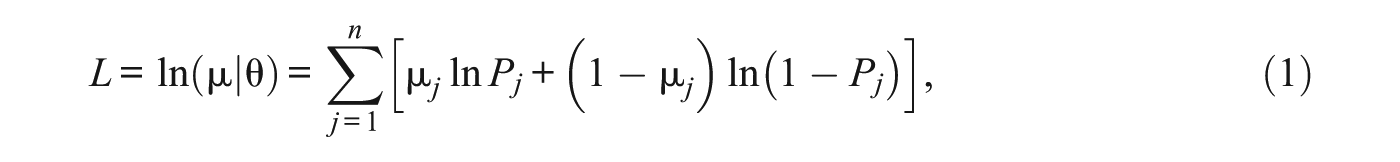
where µ is a response string of j items, which is (
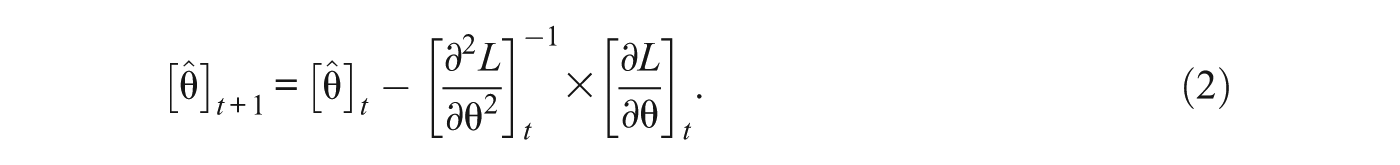
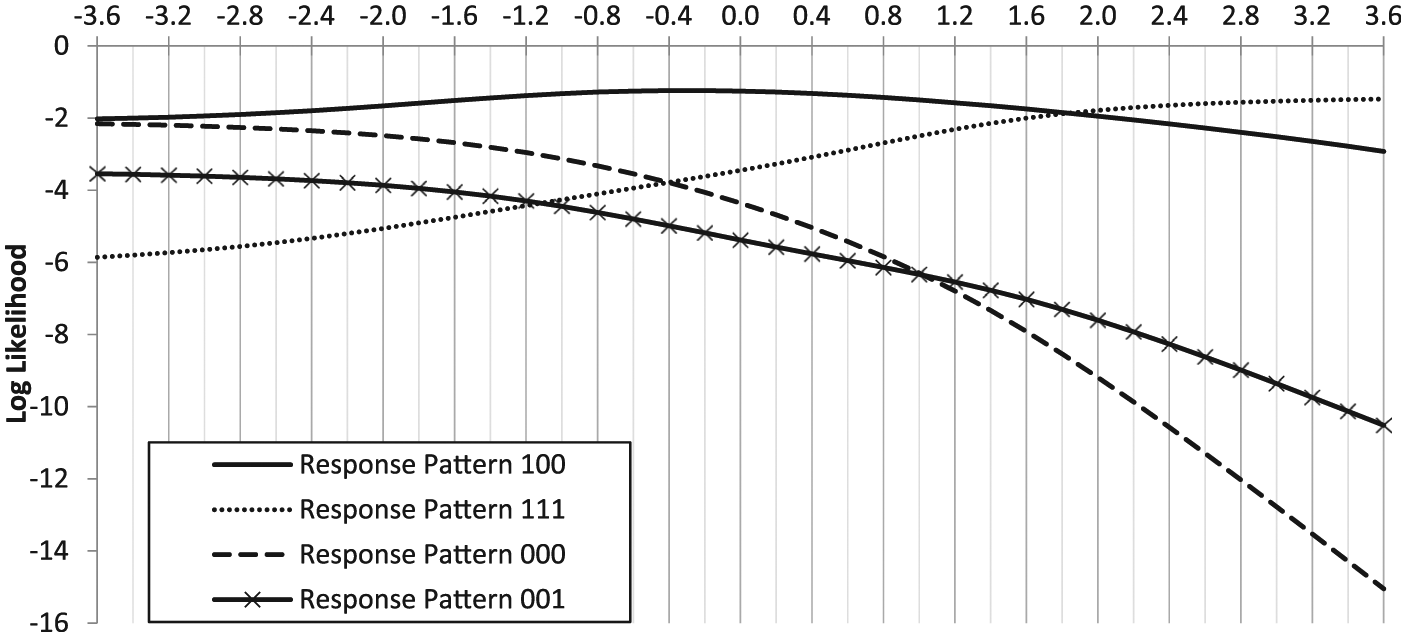
Log likelihood functions of three-item response patterns.
Item Parameters of Three Example Items.

As shown in Figure 1, when the response string is (1, 1, 1), the log likelihood function value continuously increases as θ approaches infinity. Also, when the response string is (0, 0, 0), the log likelihood function value keeps increasing as θ approaches negative infinity. In cases where the response string (µ) consists of only 1s or only 0s, there is no definite peak; as a result, the MLE method fails to find a definite solution for θ. To address this issue with the MLE method, a
MLE With Fences (MLEF)
An alternative method, henceforth referred to as the maximum likelihood estimation with fences (MLEF), basically functions the same as MLE with the following exception. Instead of placing the fixed upper and lower bounds to truncate the
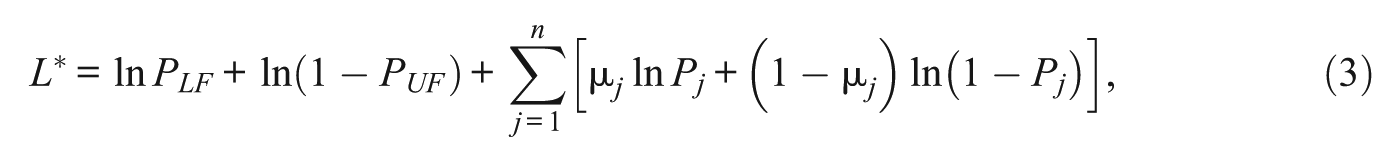
where

Log likelihood functions of three-item response patterns with fences.
The MLEF method has several interesting characteristics in comparison with some Bayesian-based estimation methods, such as the MAP. In the MAP method, the prior density information is imposed in the log likelihood function computation, whereas, in the MLEF method, the prior information regarding range of θ scale is reflected in
To investigate and evaluate the performance and behavior of MLEF in comparison with other established estimation methods, a series of simulation studies were conducted.
Study 1: Short, Fixed-Length Test
Data and Method
Study 1 examined the behavior and performance of MLEF compared with MLE (with and without truncation at −3.5 and 3.5), MAP, and EAP (with a standard normal distribution as a prior), when the test length was very short (between one and 10 items). The same 10 items that were administered to 7,000 simulees were drawn from a uniform distribution (−3.5, 3.5), and the 10 items were based on the 3PLM (Birnbaum, 1968) with b-parameter values ranging from −2.7 to 2.7 with an interval of 0.6 (see Table 2 for item parameters). The a- and c-parameter values were set at 1.0 and 0.2 for all items, respectively. The θ was estimated after each item administration to observe the interaction between the studied estimation methods and test length. The sequence of the 10 items was randomized across simulated test takers to cancel out the item effect from the test-length effect.
Item Parameters of the Short, Fixed-Length Test in Study 1.

For the condition with MLE, the Newton–Raphson method was used to find MLE. In the Newton–Raphson algorithm, the maximum absolute magnitude of update (the second term on the right-hand side of Equation 2) for each iteration was limited to 1, and the estimation procedure was iterated up to 20 times with the initial value set at 0.0. If the magnitude of update became smaller than 0.001, the estimation was considered converged and the Newton–Raphson cycle was stopped. In another condition—MLE with truncation (MLET)—everything was the same as the MLE condition except that
For the condition based on the Bayesian methods MAP and EAP, the prior density was set to follow N(0, 1). For the MAP condition, everything else was the same as the MLE condition (maximum of 20 iterations of the Newton–Raphson procedure with a maximum update magnitude of 1 for each iteration). For the EAP condition, 40 quadrature points between −4.0 and 4.0 were used.
The condition with MLEF used two (imaginary) fence items. The b parameter for the lower fence was −3.5; for the upper fence, it was 3.5. The a-parameter value was 3.0 for both fences. All other configurations remained the same as the MLE condition.
Once the θ estimation was performed under each condition, the estimation bias and the mean absolute error (MAE) statistics were computed and evaluated for each θ area. The simulation was implemented using the computer software, SimulCAT (Han, 2012), which is publicly available.
Results
The MLE condition in this study was not truly unrestricted on the scale of
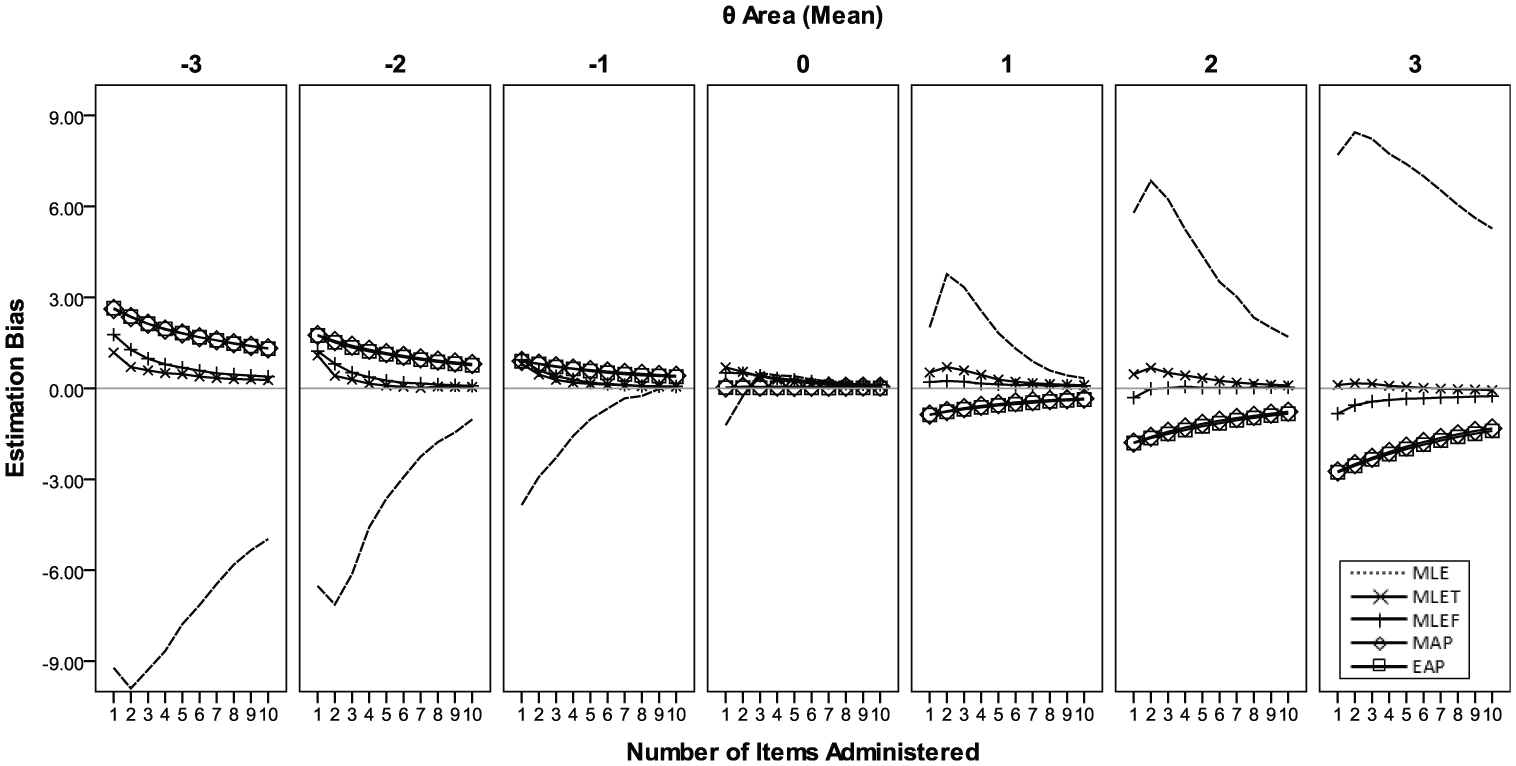
Conditional bias in score estimation for a test with 10 items with random sequence.
The MAP and EAP conditions resulted in almost identical estimation bias patterns when compared with each other. Because of the role of prior density information, the estimates were pulled toward the center of the prior (“0” in this study); as a result, θ was underestimated when θ > 0 and overestimated when θ < 0. This observation concurs with the property of Bayesian-based estimation methods, known as the shrinkage of scale (Baker & Kim, 2004; McBride, 1977; Novick & Jackson, 1974; Weiss & McBride, 1984). The estimation bias with MAP and EAP persisted even after all 10 items were administered when θ was far from the center of prior.
The estimation bias with the MLEF condition shows a pattern similar to the MLET condition (Figure 3). MLEF seemed to show slightly larger bias than MLET when θ was extreme (e.g., Areas −3 and 3) and when the test length was extremely short (<5 items). Most of the bias diminished across θ areas as the test length reach 10 items, however.
As shown in Figure 4, the MAEs with the MAP and EAP conditions moderately increased as
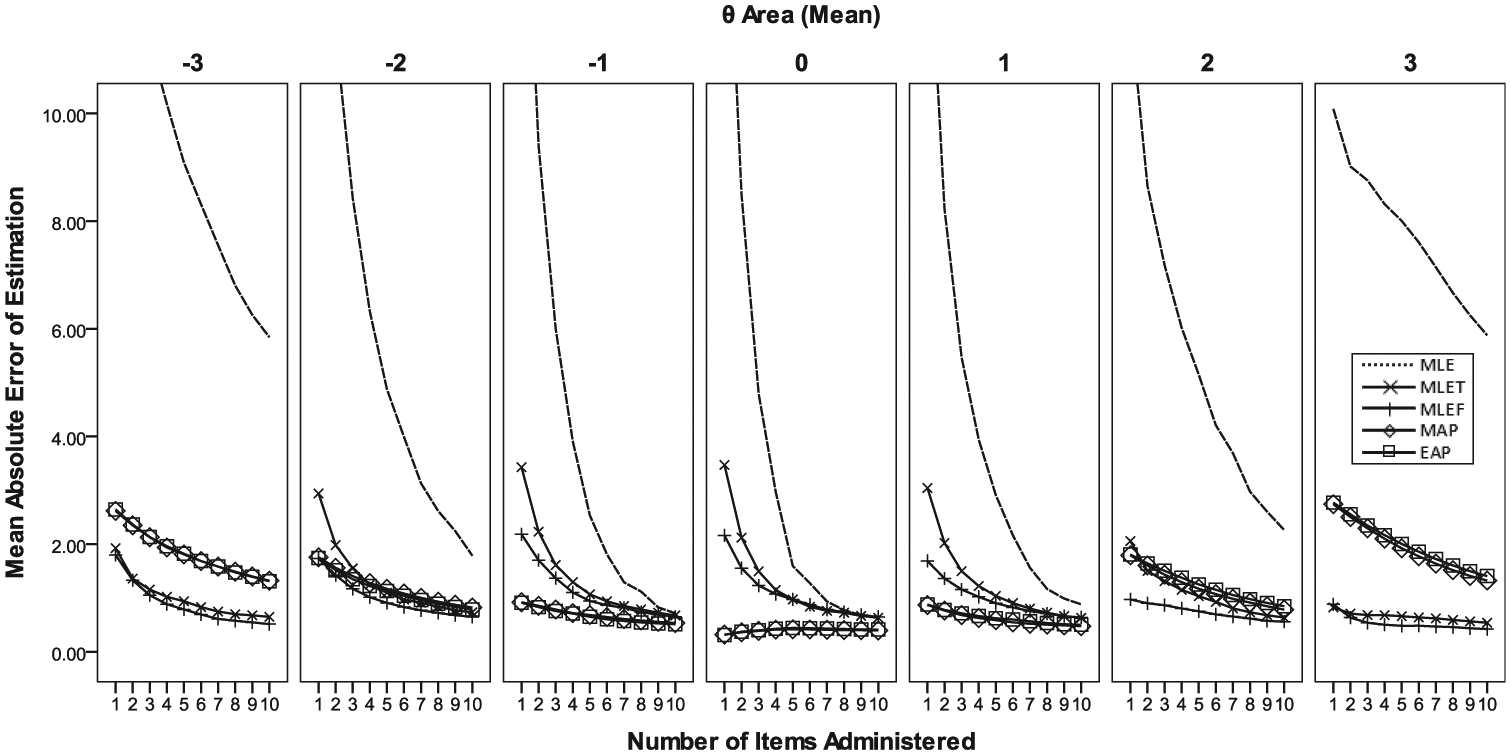
Conditional mean absolute errors of score estimation for a test with 10 items with random sequence.
Compared with MLET, MLEF tends to show slightly smaller MAE across all θ (Figure 4). Also, in terms of computation efficiency, MLEF solutions tend to get converged much faster than MLET, notably because MLEF always had an identifiable peak, especially when the test length was extremely short, for example, <5 (Figure 5).
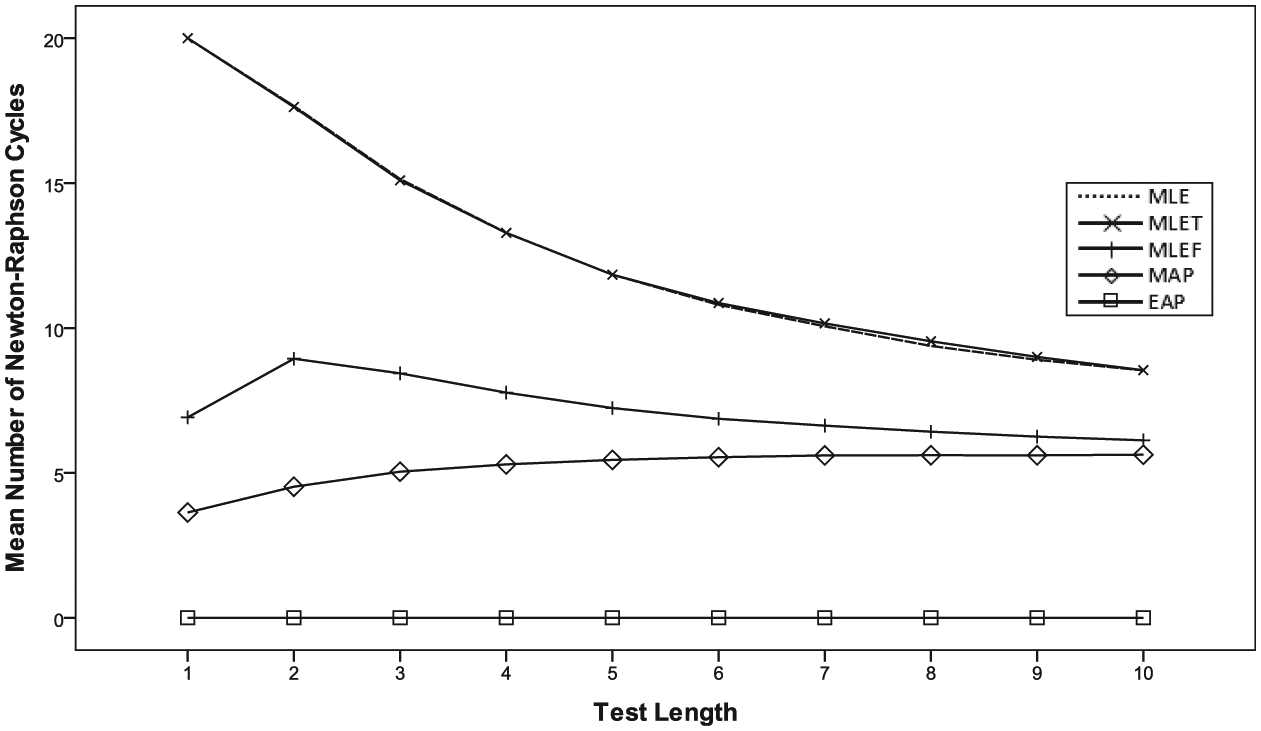
Average number of Newton–Raphson cycles before convergence for the MLEF and MLET conditions.
Overall, the observations from Study 1 suggest that the MLEF method retains the favorable properties of MLE, such as unbiased estimation, while being robust against some response patterns that pose a problem for typical MLE, and is capable of producing stable estimates within a very few Newton–Raphson cycles.
Study 2: CAT Simulation
Study 1 investigated test situations involving short test lengths. A more common test situation where practitioners encounter problems of MLE involves CAT. In CAT, after each item administration, an interim θ estimate needs to be computed to select the next item. Study 2 examined this situation.
Data and Method
Study 2 used the same simulee data examined in Study 1. To ensure that the results from the CAT simulation were as generalizable as possible and, more importantly, to eliminate all extraneous factors from the study, the CAT design was intentionally simplified. Item selection was based on the maximized Fisher information (MFI) criterion (Weiss, 1982). Content balancing and item exposure control were not considered. The items were based on the two-parameter logistic model (2PLM). To ensure an item pool sufficient to support ideal item selection, the item pool consisted of 800 items with b-parameter values ranging from −4.00 to 3.99 with an increment of 0.01. The test length was fixed and each administration used 30 items. As with Study 1, MLE, MLET, MAP, and EAP methods as well as MLEF were examined. All other study conditions remained the same as Study 1.
Results
With CAT, the estimation bias was close to none after about 10 to 15 item administrations under the MLE, MLET, and MLEF conditions (Figure 6). Under the MAP and EAP conditions, the magnitude of bias tended to be smaller with CAT than that observed with the non-CAT conditions from Study 1. It still persisted, however, except when θ was at the center of prior (=0). In terms of the MAE, all studied estimation methods showed a similar level after close to 10 items were administered, except when 2.5 ≤
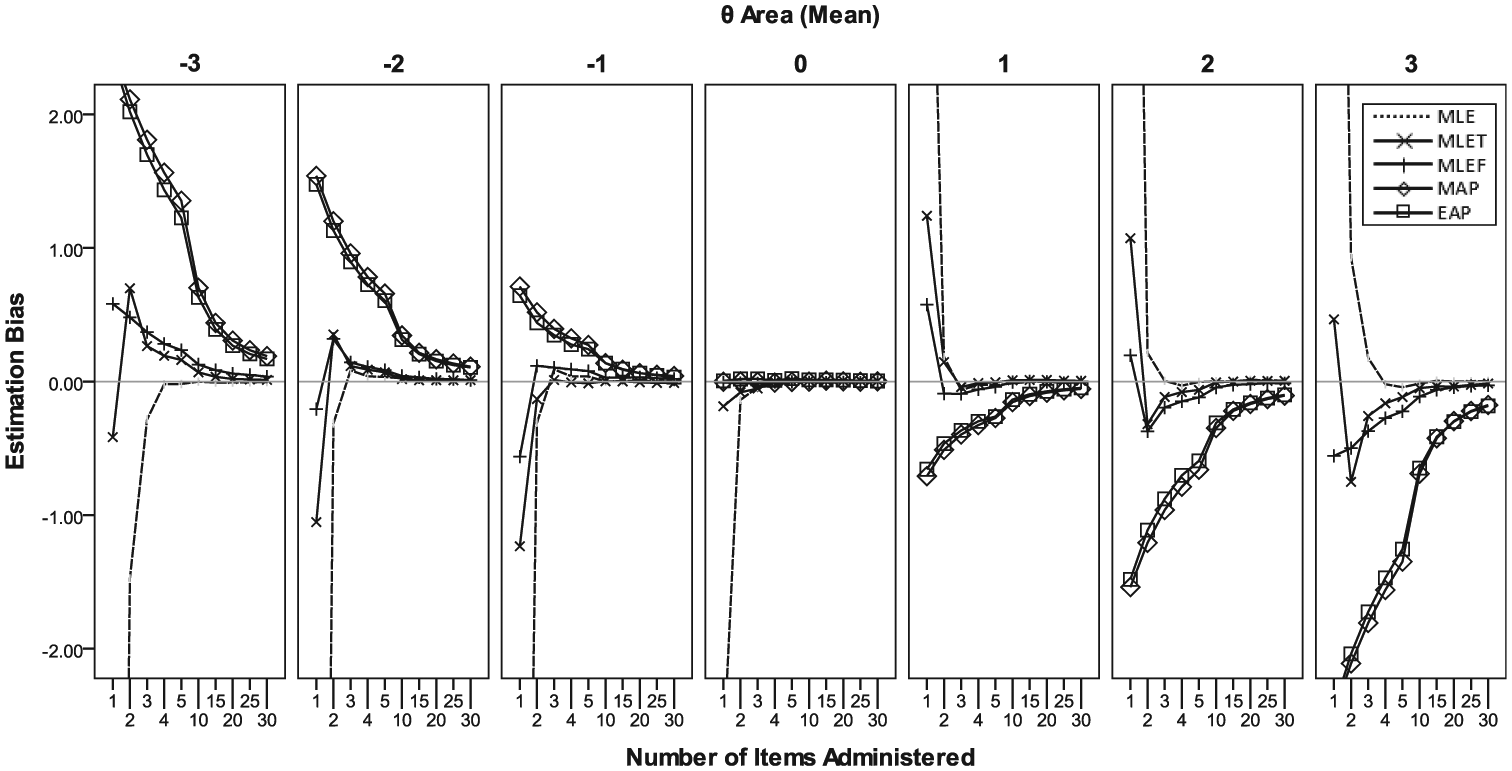
Conditional bias in score estimation from Study 2 (CAT).
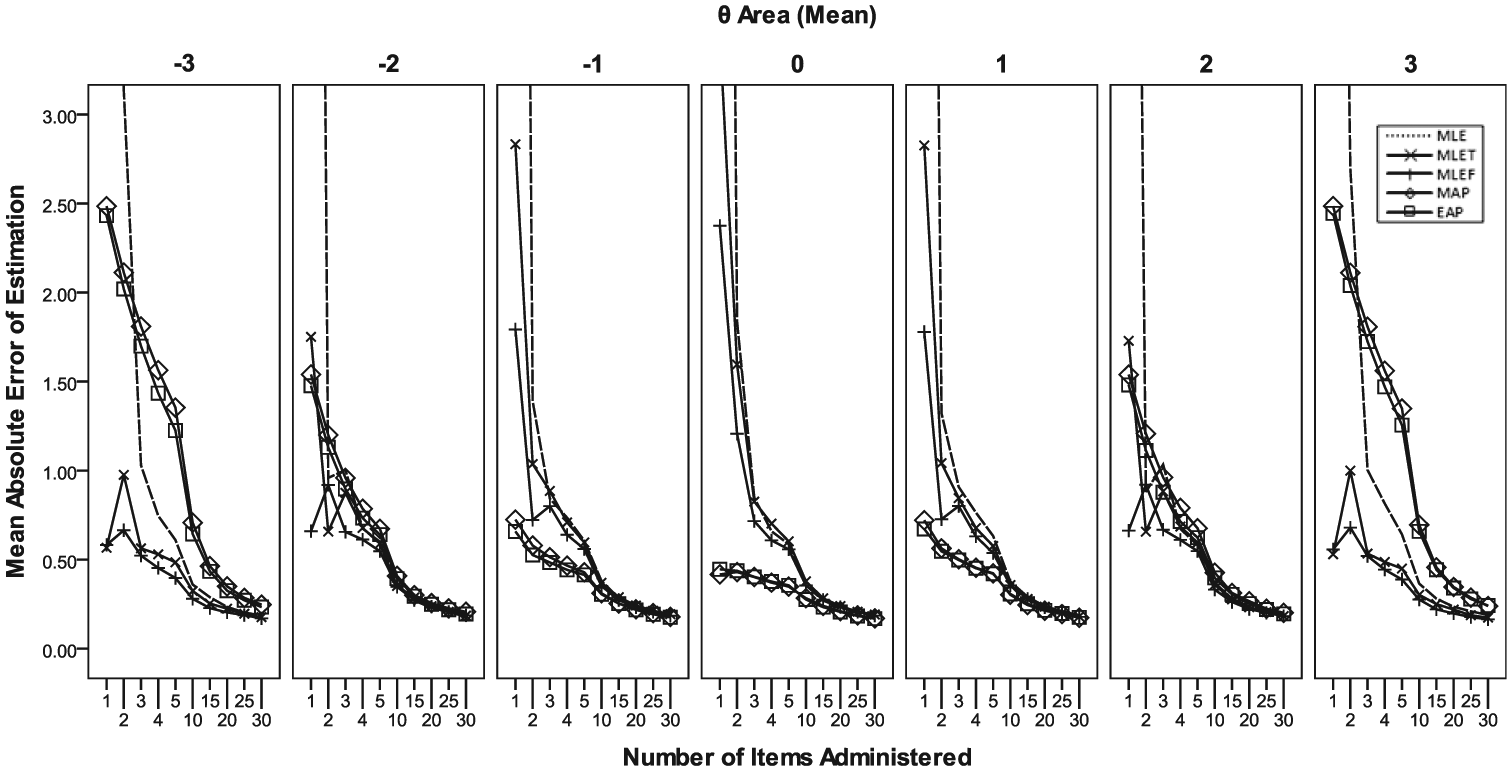
Conditional mean absolute errors of score estimation from Study 2 (CAT).
Figure 8 displays conditional MAE of final θ estimates (after 30 item administrations). Concurring with the results from previous studies (Wang & Vispoel, 1998; Weiss, 1982; Weiss & McBride, 1984), it shows that when the MAP and EAP methods were used, MAE was minimized around the center of the prior and increased as it moved away from the center. The MLE and MLET resulted in MAE that was slightly larger than the minimum MAE observed with the MAP and EAP methods but consistent across the θ scale. The MLEF condition showed an MAE pattern similar to those seen under the MLE and MLET conditions.
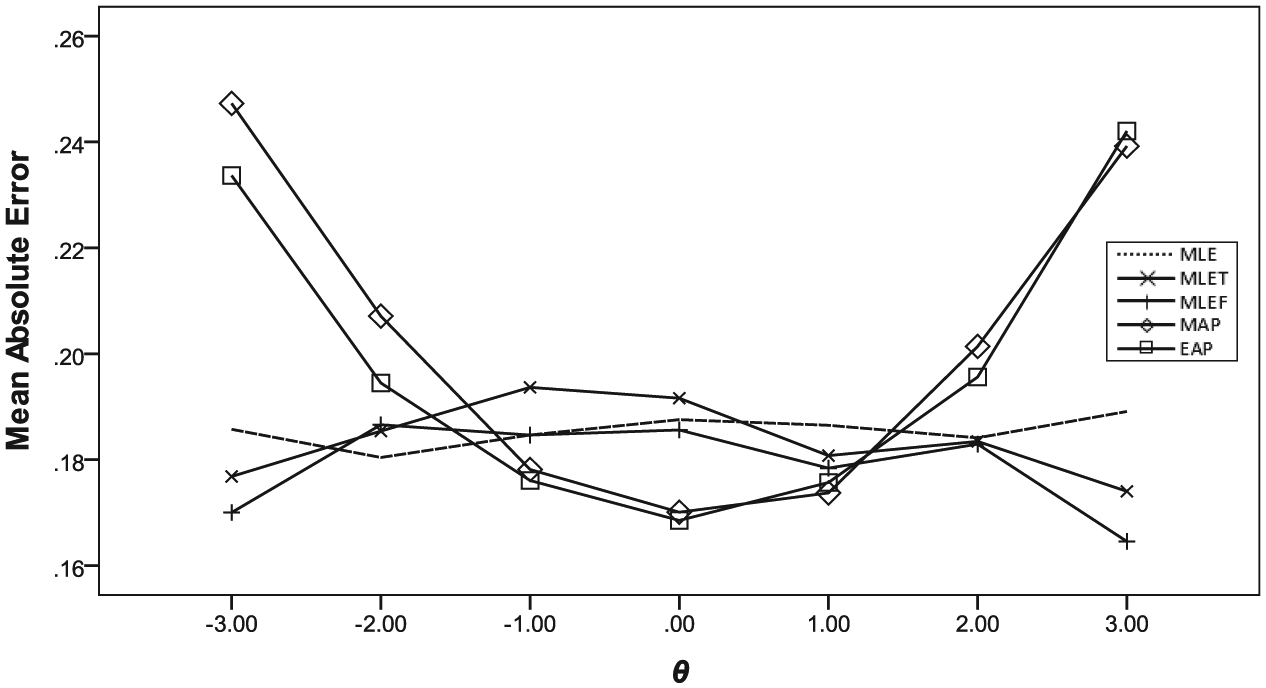
Conditional mean absolute errors of final score estimation from Study 2 (CAT).
Discussion
The results of Studies 1 and 2 reconfirmed the well-known properties of the existing estimation methods (MLE, MLET, MAP, and EAP) examined in previous studies (Wang & Vispoel, 1998; Weiss, 1982; Weiss & McBride, 1984) and revealed the behavior and performance of the MLEF method. Overall, the MLEF method exhibited the same characteristic of MLET—next to no estimation bias regardless of the test length and consistent estimation error across the θ scale. It should be noted, however, that MLEF is conceptually and computationally different from MLET, as discussed further.
Although the MLE condition (without truncation but with a restriction on the maximum magnitude of update from each Newton–Raphson cycle) was included in Studies 1 and 2, pure MLE without any restriction is rarely (if ever) used in operational testing programs due to its inability to deal with certain response patterns. MLET most often has been considered a practical alternative in real-world applications. Theoretically, MLET is a special case of MAP in which the prior probability distribution follows a uniform distribution (aka, a noninformative prior). With or without the use of the noninformative prior, however, if a log likelihood function does not have an identifiable peak, MLET will not result in a converged solution. It will still require definitional solutions, possibly with external restrictions such as the maximum number of Newton–Raphson cycles and the maximum limit in update amount of each Newton–Raphson iteration, all of which contribute to degraded efficiency of the estimation process. Also, because MLET’s definitional solutions (i.e., upper and lower bounds) treat all
However, with the lower and upper fences of MLEF, the log likelihood function itself (Equation 3) is transformed to always have an identifiable peak (especially when the test length is extremely short). Unlike MLET, where the upper and lower bounds are defined as absolute limits of the θ scale, the fences of MLEF technically do not place absolute limits on the scale. Instead, they help the log likelihood function form an identifiable peak between the lower and upper fences by causing substantial decrease in the log likelihood function outside of fences. Because of this, even for those examinees whose θ is close to either the lower or upper fence location, MLEF rarely results in exactly the same estimate unless the response pattern is exactly the same. With MLEF, extreme
Like MLET, which can be viewed as a special case of MAP (with a noninformative prior), MLEF may be viewed as another special case of MAP, as well. In addition to using directly observed response data for computing the log likelihood function, MAP incorporates a prior probability distribution. The choice of a prior of MAP has a great impact on

Log likelihood function of fence items (from the example of Figure 2).
Choosing a prior for MAP is often viewed as an ambiguous process. So too is the process for setting the fences for MLEF, because it ultimately involves human judgment. In theory, a prior for MAP (or any Bayesian-based method) can be a probability distribution of any shape. In practice, however, the prior of choice most often has a symmetric bell shape like a normal distribution. Ideally, the prior distribution should reflect the population, but in real-world practice, it is often unknown or does not follow a typical normal distribution. So, it is hard to choose a prior that exactly reflects the real world. The MLEF fences, however, contain limited information only in the areas where they locate. Also, MLEF requires no assumptions on the shape of θ distribution, so it is not hard to arrive at reasonable locations for the lower and upper fences. For example, setting the lower and upper fences at −3.5 and 3.5, respectively (as in Studies 1 and 2), would be good enough for most operational cases (assuming a standard normal distribution), and the scale with fences at −3.5 and 3.5 would cover 99.95% of the population. As for the choice of a-parameter value for the fence items, this study suggests it needs to be high (e.g., a = 3.0). If the a-parameter value for the fence items is too low, for example, 0.5, the shape of log likelihood function of the two fence items (Figure 9) becomes something close to a bell shape that peaks near the center between lower and upper fences (LF and UF). If that happens, the effect of fences will not be limited within the fence locations, and as a result, MLEF will behave more like a typical MAP with a normal prior, and the distinct advantages of MLEF over MAP will be diminished. Based on the results of Studies 1 and 2, MLEF seemed reasonably effective when a = 3.0 for the fence items. A more comprehensive study to evaluate the performance and behavior of MLEF with different a-parameter values for fence items, however, is in order.
The EAP method was not extensively discussed in this article because its estimation process is quite different from the other studied methods (MLE, MLET, MLEF, and MAP). The EAP method does not use the iterative Newton–Raphson process but instead computes the conditional posterior distribution for each quadrature point to find
Bayesian methods such as MAP and EAP may be a more appealing choice over MLEF under the following conditions: (a) the center of prior is where it matters the most (e.g., a cut score also locates where the center of prior locates), (b) the selected prior distribution reflects the real population reasonably well, and (c) large estimation biases for examinees who are distant from the center of prior do not matter. Such a test situation is rare, however, especially under CAT.
Like MLE and other studied estimation methods, MLEF is theoretically feasible and directly applicable under the multidimensional IRT (MIRT) context by placing lower and upper fences for each dimension. The actual merits of MLEF under MIRT, however, still need to be evaluated in future studies.
Conclusion
The MLEF method is not a one-size-fits-all solution for all test situations, but the findings from Studies 1 and 2 clearly suggest that the MLEF offers several advantages over existing estimation methods such as MLE, MAP, and EAP:
easy to implement (existing MLE or MAP algorithm/code can be used without major modifications),
robust against some response patterns that would have caused non-convergence issues with other MLE methods,
no procedural scale discontinuation (i.e., no score truncation required),
unbiased estimation, similar to a typical MLE,
no need for a strong or informative prior,
single method for both interim and final score estimation in CAT, and
more consistent estimation precision across the θ scale.
Although the settings of fence items in this study worked effectively under the studied conditions, it does not necessarily mean they will be effective for other test situations. Future studies are suggested to continue fine tuning the fence item characteristics to test in various other conditions.
Footnotes
Acknowledgements
The author would like to thank Seock-Ho Kim of the University of Georgia for his valuable comments on the earlier version of this study. The author is also grateful to Paula Bruggeman of Graduate Management Admission Council for review and valuable comments on the article.
Author’s Note
The views and opinions expressed in this article are those of the author and do not necessarily reflect those of the Graduate Management Admission Council® (GMAC®).
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.