
Abstract
For certain multiple-choice tests, it might be theorized that respondents evaluate response options in a stepwise fashion. Statistical models that assume such a process may compete against models that imply a process in which all response options are simultaneously compared, such as Bock’s nominal response model. In this article, a sequential response model for multiple-choice items (SRM-MC) is considered. The model is applied to a sentence correction test in which the recognition of error and correction of error can be viewed as separate steps in solving an item. The proposed model permits the introduction of different proficiencies across steps. A fully Bayesian approach to estimating the model is presented, and an empirical comparison is performed against competing models. Empirical results support the proposed model and suggest distinct proficiencies related to recognition and correction.
Many item response models have now been developed for multiple-choice items. A potentially useful distinction can be made between models that assume a divide-by-total structure (see Thissen & Steinberg, 1986) from those that are sequential (e.g., De Boeck & Partchev, 2012; Tutz, 1990). Divide-by-total models, including the nominal response model (NRM; Bock, 1972) and extensions (e.g., Revuelta, 2014; Samejima, 1979; Thissen, Cai, & Bock, 2010; Thissen & Steinberg, 1984), emphasize a single comparative evaluation of all response options that is influenced by one or more underlying latent traits. Such models emphasize a relationship between underlying latent trait(s) and an unobserved propensity toward each response option, with the chosen option influenced by the relative size of the propensities. Sequential models, by contrast, emphasize a stepwise response process, generally one in which particular response options are eliminated across steps, and can be represented using tree structures (see, e.g., Böckenholt, 2012b; De Boeck & Partchev, 2012; Jeon & De Boeck, 2015). To the extent that such tree structures are specified a priori, they impose restrictions on the assumed response process that can impact the statistical fit of model to test data, but to the benefit of potentially learning more about the process by which respondents are selecting among response options.
These two general modeling approaches can also be integrated. Examples included models where a divide-by-total model is used within a single step of a sequential model (see, e.g., Suh & Bolt, 2010), or where the same response can be achieved at different steps of the sequential process, such as in an extended cognitive miser model (Böckenholt, 2012a), or in the binary case, San Martin, del Pino, and De Boeck’s (2006) ability-based guessing model. In Böckenholt’s (2012b) cognitive miser model, a distinction is made between intuitive (immediate nondeliberative) responses and deliberative (thoughtful reasoning) responses, whereby an initial stage (described as “inhibitory control”) must be passed before a deliberative response can be achieved. Extended versions of the cognitive miser model allow the same response to be attained at different stages of the response process.
The model considered in this article bears a close structural resemblance to an extended cognitive miser model. Some fundamental differences include (a) the modeling of multiple-choice response options in this article as opposed to open-ended responses in Böckenholt (2012a), (b) the use of slope parameters in the initial step of the model, and (c) a restriction of the first step toward consideration of a single response option. Importantly, the first difference makes it possible to compare the current model against well-defined competitor models that in turn permit stronger conclusions regarding a hypothesized response process. In the later presentation of the currently proposed model, other parallels with an extended cognitive miser model will be considered.
A useful feature of a sequential modeling structure is the potential to attach unique proficiency dimensions to separate steps in the sequential process. In certain contexts, this allows the model to capture misconceptions that may be associated with the selection of particular distracters, and statistically provides a mechanism by which dependencies in distracter selection across items can be explained. Attending to such misconceptions within a model also allows for quantification of how the misconception may plague performance across the test. It is possible that a test score loses its validity when a single misconception disproportionately penalizes an examinee across multiple items. The proposed model in relation to a sentence correction test is illustrated.
Real Data Illustration: A Sentence Correction Test
The real data application in this article relates to a sentence correction test that is administered as part of an English placement examination to entering students in a university system. A multiple-choice format is used for all items, and the items are scored as binary (1 = correct; 0 = incorrect). Each item has five response categories. The item stem always consists of an underlined portion of a sentence that potentially contains a grammatical error. Examinees are asked to select among five response options the best substitute for the underlined portion of the sentence without changing the meaning of the original sentence. A consistent item feature is that the first option of each item, option A, is always an exact replica of the underlined portion of the sentence, implying no error. Two example items are as follows:
Example Item 1.
A. Heavy smoking and to overeat
B. Smoking heavily and to overeat
C. To smoke heavily and overeating
*D. Heavy smoking and overeating
E. Smoking heavy and to overeat
Example Item 2. In the smaller towns of Michigan,
A., where one can quickly walk
B. where one can quickly walk
C., where one can quickly walk,
D. one can, quickly walk
*E., one can quickly walk
For the above items, options “D and “E”, respectively, are the correct answers, as these represent the best substitutes. A variety of forms of actual errors are introduced on the test. These include errors related to the use of verb (e.g., subject–verb agreement, tense consistency), pronoun (e.g., consistency, case, agreement and reference), diction (e.g., idiom), modifier (e.g., adjective and adverb form and placement), and punctuation (e.g., fragment, comma fault, and punctuation for clarity). Similar sentence correction tests are used with many current standardized assessments, including the Scholastic Achievement Test (SAT) and the Graduate Management Admissions Test (GMAT), ACCUPLACER, the Praxis assessments, and several state tests, among others.
Data from 5,848 examinees to a 23-item form of the English sentence test were used in the current analysis. Table 1 displays descriptive statistics for correct total scores on the test. It is important to note that for the test form under consideration, the option “A” was the correct response for only 3 of the 23 items, specifically items 5, 14, and 19.
Descriptive Statistics of the Sentence Correction Test Total Scores.

A Sequential Response Model for Multiple-Choice Items (SRM-MC)
Under the proposed model, a two-step sequential response process is specified by which an examinee arrives at a final chosen response option for each sentence correction item. The first step entails recognizing an error (or the possibility of an error) in the sentence. If no error is believed to exist in the sentence, then option A, a replica of the underlined portion of the sentence (implying “no error”), is selected. Alternatively, if the potential for an error is believed to exist, the examinee proceeds to a second step of considering a proposed correction. In this step, all five response options are evaluated, and the best alternative is selected. These two steps are referred to as the recognition and correction steps, respectively. To the extent that option A represents no proposed change, the response process can also be viewed as one in which the first response option is evaluated prior to considering the remaining options. It is important to note that the labeling of the steps as recognition and correction steps refers to the examinee’s potential action at each step (based on a perception of error) rather than the reality of an error. Consequently “passing” the recognition step only means that the examinee proceeds to the correction step, regardless of whether the sentence in actuality contains an error. For the three items on this test where the sentence actually contains no error, not passing the recognition step leads to a correct response.
It is possible that different examinee proficiencies are involved for the recognition and correction steps. Indeed, the specification of the proposed model was driven in part by an observation that examinees tend to vary substantially in the frequency with which option A is chosen as a distracter and that such tendencies appeared imperfectly aligned with overall performance on the test (i.e., some well-performing examinees select option A with disproportionately high frequency). There are various possible explanations for why respondents may disproportionately select option A across items, including, for example, (a) a prior belief that a large number of items would be presented as correct, (b) rushed responding (as the test is a timed test), or (c) a high tolerance for incorrect grammar, among others. It will be assumed that all of these explanations are reflected through a poor recognition proficiency.
As shown below, the resulting model implies that an examinee can arrive at option A in two ways. First, the respondent may fail the recognition step and not proceed to evaluate other options. Alternatively, the respondent may pass the recognition step but after evaluating all five options consider option A to be better than the alternatives. Thus, the overall probability of selecting option A is viewed as the sum of probabilities associated with two pathways to that response. By contrast, in selecting options B through E, the only pathway is that the respondent first passes the recognition step and in the correction step views the option as the most preferred option among the five options. As noted earlier, this general modeling structure can be viewed as a form of the extended cognitive miser model of Böckenholt (2012a), but where a different interpretation is attached to the distinct steps. In the current application, the recognition step parallels an “inhibitory control” step of cognitive miser, and the correction step parallels a “deliberative reasoning step.”
Statistical Representation of the SRM-MC
Suppose a multiple-choice test is composed of
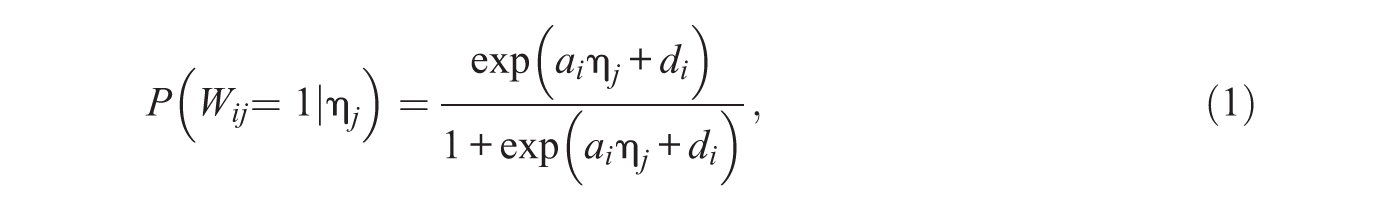
where
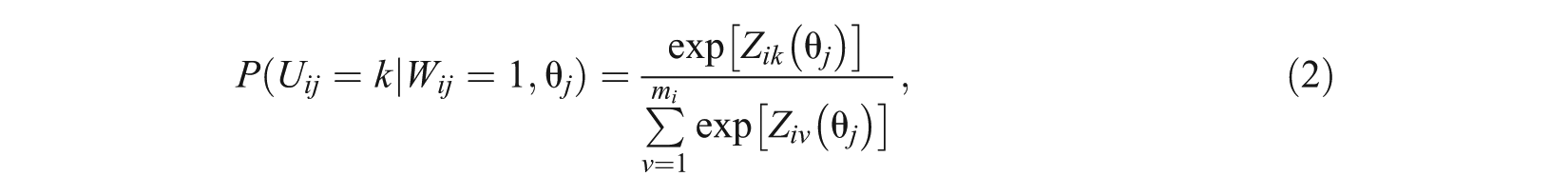
where a multivariate logit
The overall probability that examinee j selects category k on item i can be achieved by combining results across the two steps. For the current application, it is assumed that

A unidimensional version of SRM-MC can be applied by replacing
The item parameters of the recognition step of the SRM-MC (Equation 1) relate to aspects of the item that influence passing the recognition step. Items with larger more positive d parameters are items for which this step is easier to pass. The a parameter functions as a discrimination parameter implying that certain items may be more influenced by the recognition tendency than others.
Comparison Models for Multiple-Choice Items
To evaluate the plausibility of the proposed model for the sentence correction test, comparison models that provide alternative statistical representations that are aligned with alternative forms of response process are considered. Similar to the SRM-MC, each model can be written in unidimensional and two-dimensional forms. In the two-dimensional case,
NRM
A competing approach to the SRM-MC can be attained using the structure of the NRM. In unidimensional applications, the NRM defines a multinomial logit in reference to a single underlying latent trait. However, multidimensional extensions of the NRM have been considered, including Bolt and Johnson (2009), Thissen et al. (2010), and Revuelta (2014). By imposing appropriate constraints on a multidimensional NRM, the model can be used to define traits that represent over- or under-selection of particular response options, such as option A in the sentence correction test. Let

where
To make the NRM account for a similar trait (
A fundamental difference between the NRM and SRM-MC relates to their assumptions regarding response process. For the NRM, the trait
A unidimensional version of the NRM can also be applied for comparative purposes and is specified as
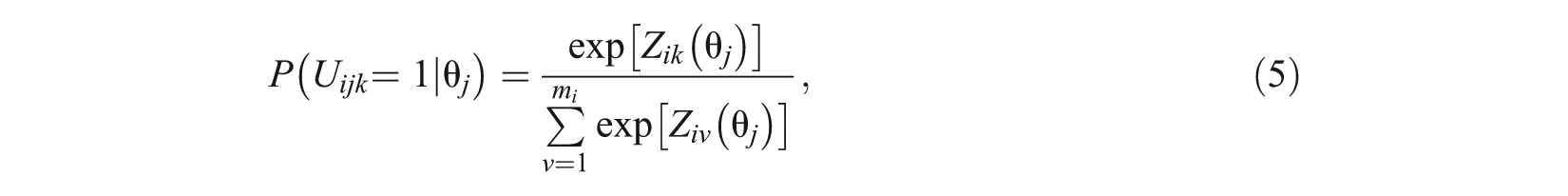
where
The unidimensional NRM naturally assumes that only one underlying trait influences the selection of response options across items.
Nested Logit Model (NLM)
A second modeling approach considered for comparison purposes is a two-dimensional NLM (2D-NLM, Bolt, Wollack, & Suh, 2012). The NLM has a similar structure to the SRM-MC but instead models the probability of distracter selection conditional upon an incorrect response. Let
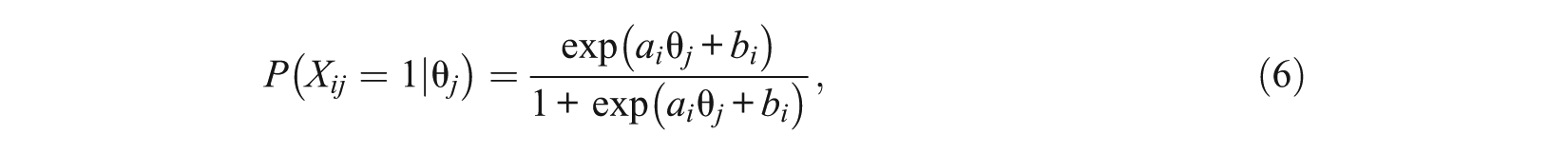
where
The probability that an examinee selects distracter category v on item i is modeled as the product of the probability of an incorrect response and the probability of choosing distracter v conditional on an incorrect response under Bock’s NRM. In the 2D-NLM, a different proficiency can be similarly introduced to the conditional probability relative to the proficiency assumed to underlie the correctness of the response. The probability of selecting a particular response option is then modeled as
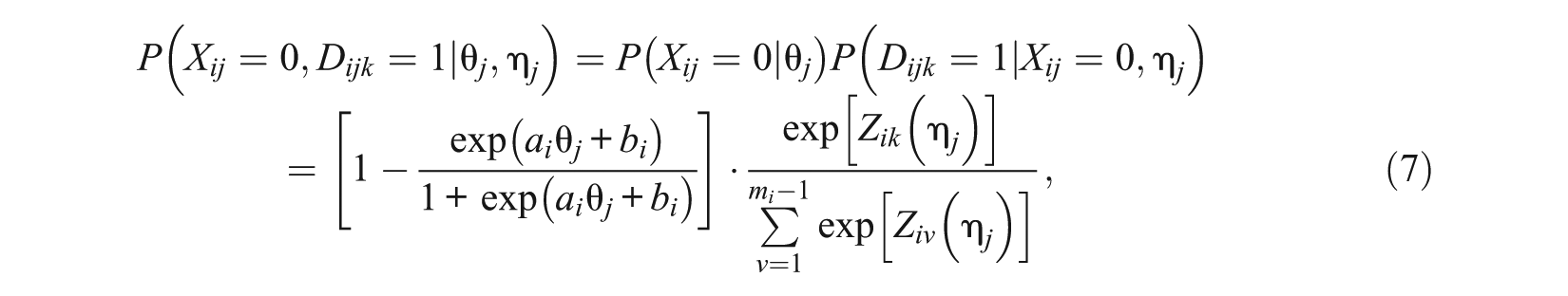
where
For the sentence correction test, the NLM may represent a condition where prior to examining any of the response options, the examinee attempts to determine how the underlined portion of the sentence should be changed and looks for that proposed change among the list of the provided response options. If that specific correction is not present, the examinee would then engage in a comparative evaluation of response options. It is theorized that such a response process was less plausible for the sentence correction test. In particular, it would not likely provide an account for why option A is chosen more frequently than the other response options by certain examinees. As with the NRM, a unidimensional NLM can be viewed as a special case of the two-dimensional NLM by setting
Fully Bayesian Estimation Algorithms
For both the SRM-MC and comparison models, a fully Bayesian approach was implemented for the estimation of model parameters. Markov Chain Monte Carlo (MCMC) methods were applied using WinBUGS 1.4 (Lunn, Thomas, Best, & Spiegelhalter, 2000). Based on the specified model and associated prior distributions for item parameters, parameter states are sampled in a fashion that permits estimation of the multivariate posterior distribution of model parameters. For each of the models under consideration, a Metropolis-Hastings sampling algorithm was used. Five simulated Markov chains were run out to 10,000 iterations. An initial run of 4,000 iterations was used to define proposal distributions, and parameter estimates were calculated based on the subsequent 6,000 iterations.
For the SRM-MC, the prior distributions of model parameters were set at levels commonly applied with related IRT models (Bolt et al., 2012; Patz & Junker, 1999).
Specifically, for the item parameters it is assumed that

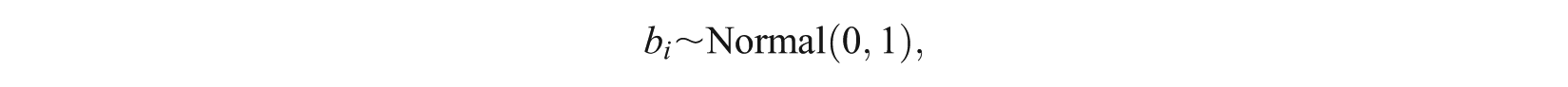
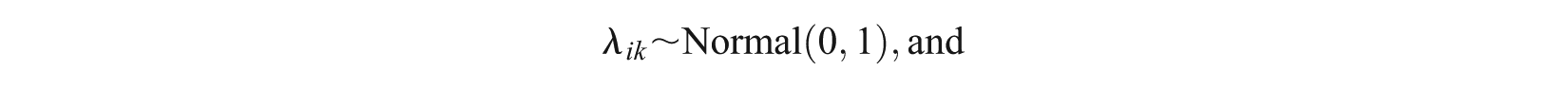
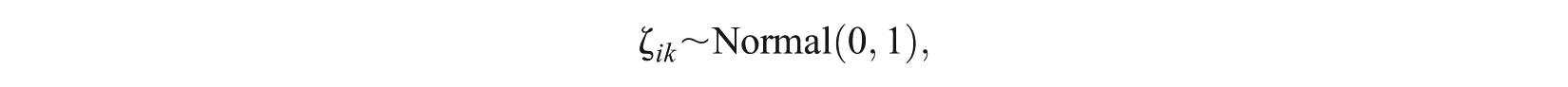
while for the person parameters, it is assumed that

where
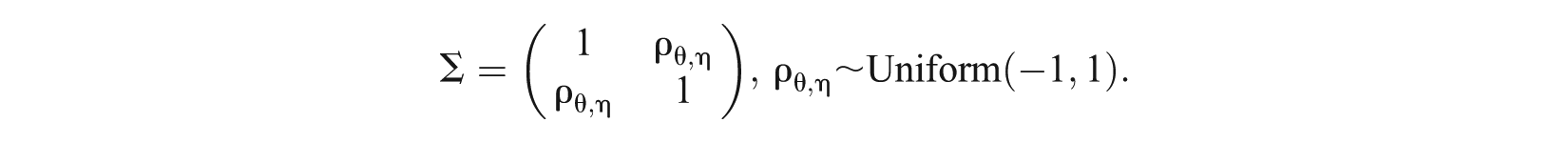
To make the NRM and NLM comparable to the SRM-MC, the priors used for these comparison models largely match those above. Priors for person parameters in the two-dimensional NRM and NLM are the same as those used for the two-dimensional SRM. Priors for item parameters are also similar to those in the two-dimensional SRM. For the two-dimensional NRM,

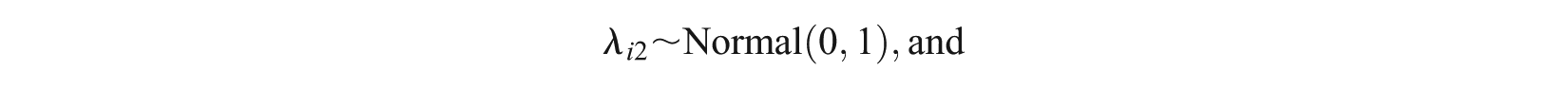
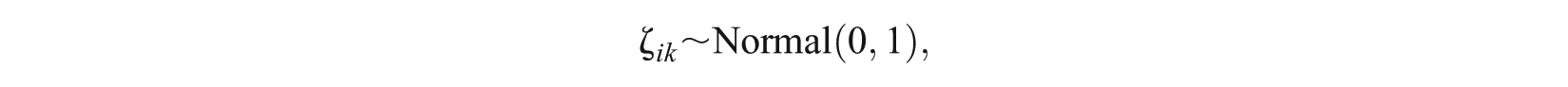
and for the two-dimensional NLM,

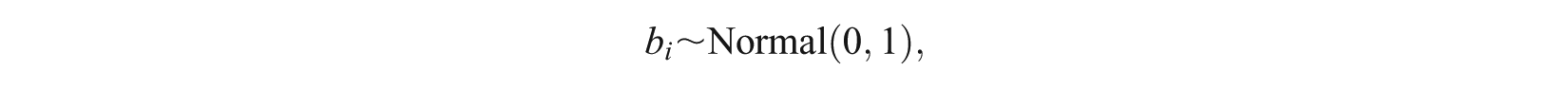
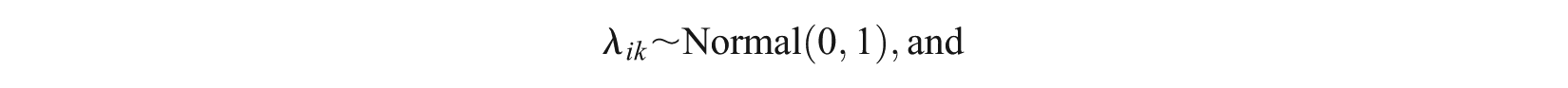
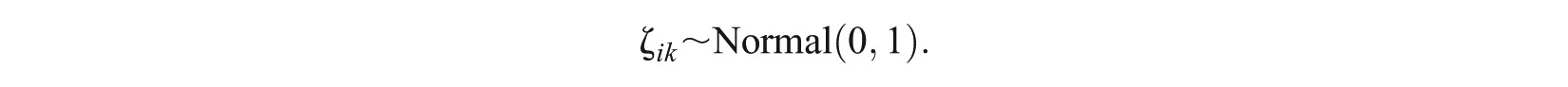
Unidimensional versions of the models used the same item parameter priors as the two-dimensional models, and for the person parameters set
The SRM-MC, NRM, and NLM models contain varying overall numbers of parameters. To statistically compare models, a penalty related to the number of parameters is taken into account. In a Bayesian estimation framework, the deviance information criterion (DIC; Spiegelhalter, Best, Carlin, & Van Der Linde, 2002) is an information-based model comparison index that is commonly used. The DIC is calculated as
Results
All models demonstrated good convergence properties with respect to the simulated Markov chains. Although the use of MCMC algorithms with unidimensional and two-dimensional NRM and NLM models has been studied in other articles (e.g., Bolt et al., 2012), the use of these methods with the SRM-MC model is new. Among other criteria, the potential scale reduction factor (PSRF) of Gelman and Rubin (1992) is examined using the five simulated chains out to 10,000 iterations. Virtually all of the parameters were below the recommended level of 1.1. Specifically, values below 1.1 were observed for 23/23 of the a parameters, 22/23 of the d parameters, 115/115 of the λ parameters, and 112/115 of the ζ parameters. Comparable convergence results were observed with respect to the examinee parameters. Despite good convergence results, the average posterior standard deviation (psd) for
Model Comparison Results
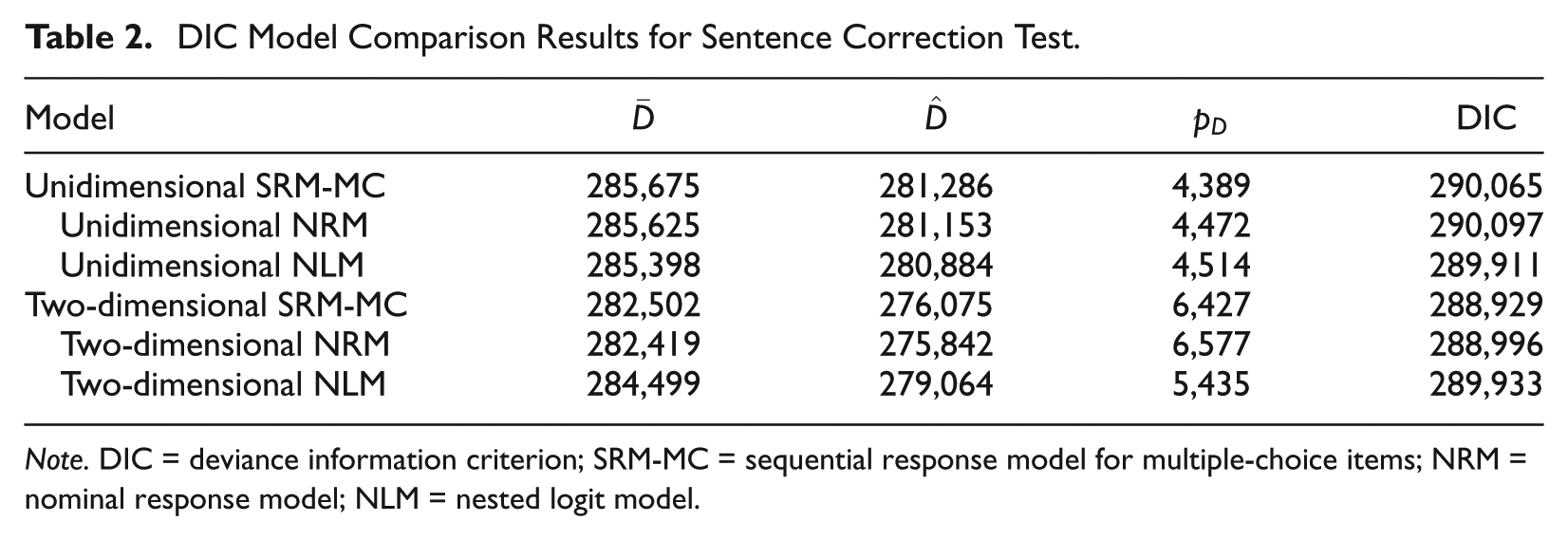
Table 2 displays model comparison results for unidimensional and two-dimensional versions of each of the models. For the NRM and SRM-MC models, the two-dimensional models appear to fit better than their unidimensional counterparts. For the NLM model, the unidimensional version appears slightly preferred to the two-dimensional model. Interestingly, among unidimensional models, the NLM appears to be the preferred model. The observation that the unidimensional model would be preferred to the two-dimensional model under the NLM importantly highlights how dimensionality can also be influenced by the specific structure assumed by the item response model.
DIC Model Comparison Results for Sentence Correction Test.
Note. DIC = deviance information criterion; SRM-MC = sequential response model for multiple-choice items; NRM = nominal response model; NLM = nested logit model.
Across all six models, the two-dimensional SRM-MC provides the best comparative fit. As noted, the two-dimensional NRM was viewed as providing the most meaningful comparison in terms of response process. The DIC estimates for the two-dimensional SRM-MC and NRM are quite close, with a slight preference for the SRM-MC, suggesting the response process represented by the SRM-MC may be more consistent with the sentence correct test. Such findings support the notion that certain examinees are more prone to select option A by not evaluating alternative response options, as this is the primary distinguishing structural feature of the SRM-MC and NRM models.
A further comparison of models can occur by correlating their resulting proficiency estimates. Tables 3 and 4 show the correlations between the examinee proficiency estimates across the two-dimensional versions of each model. In each case, the proficiency estimate is obtained as the mean of the sampling history for the corresponding person parameter (omitting burn-in iterations) in the MCMC estimation of each model. In Table 3, it is seen that the primary latent trait
Correlations Between Ability Estimates

Note. NRM = nominal response model; NLM = nested logit model; SRM = sequential response model.
Correlations Between Ability Estimates

Note. NRM = nominal response model; NLM = nested logit model; SRM = sequential response model.
Correlations Between
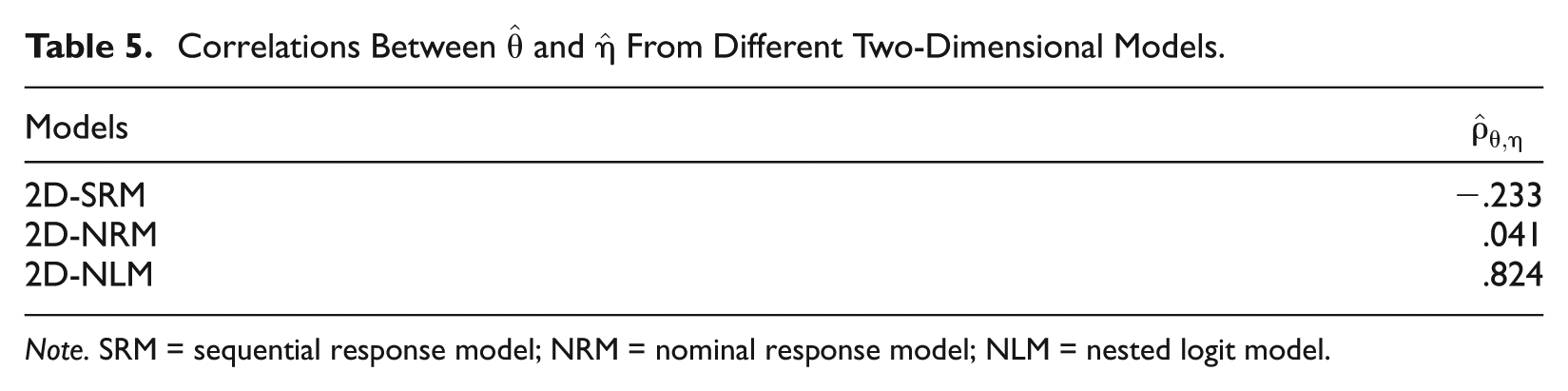
Note. SRM = sequential response model; NRM = nominal response model; NLM = nested logit model.
Results of the Sequential Response Model (SRM-MC)
Given its superior performance in the model comparison study, the results observed for the SRM-MC are considered in greater detail. As the item response process underlying the sentence correction items appears to more closely follow the response process assumed by the new model, the person and item parameter estimates may provide further insights into both individual examinees and the functioning of test items.
As noted above, a unique feature of the SRM-MC is its capacity to estimate an examinee’s disproportionate tendency toward selecting option A. This feature can be seen from the example response patterns presented in Table 6, which shows response patterns and corresponding
Example Response Patterns and SRM-MC Proficiency Estimates.

Note. SRM-MC = sequential response model for multiple-choice items; psd = posterior standard deviation.
Importantly, one of the characteristics that make the first examinee a low
As noted earlier, the emergence of
Regression Results Predicting Test Score as a Function of
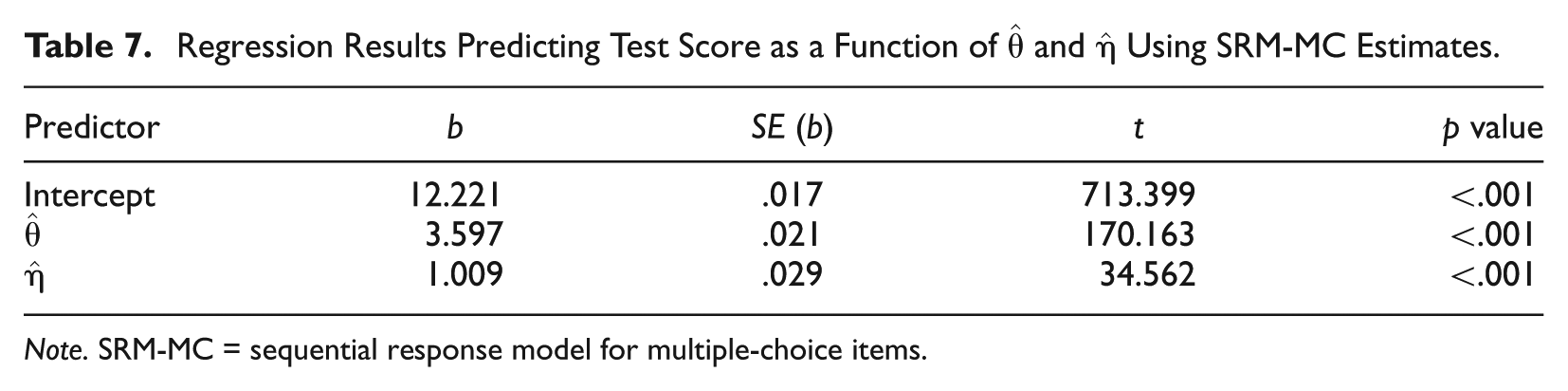
Note. SRM-MC = sequential response model for multiple-choice items.
From this analysis, it can be seen that both
Application of the SRM-MC model also permits study of the item characteristics in relation to the recognition and correction steps of the model. The focus is in particular on differences across items in relation to
Item Discrimination and Difficulty Involved in Step 1 Only, the Proportion Selecting Option A, and Proportion Correct.
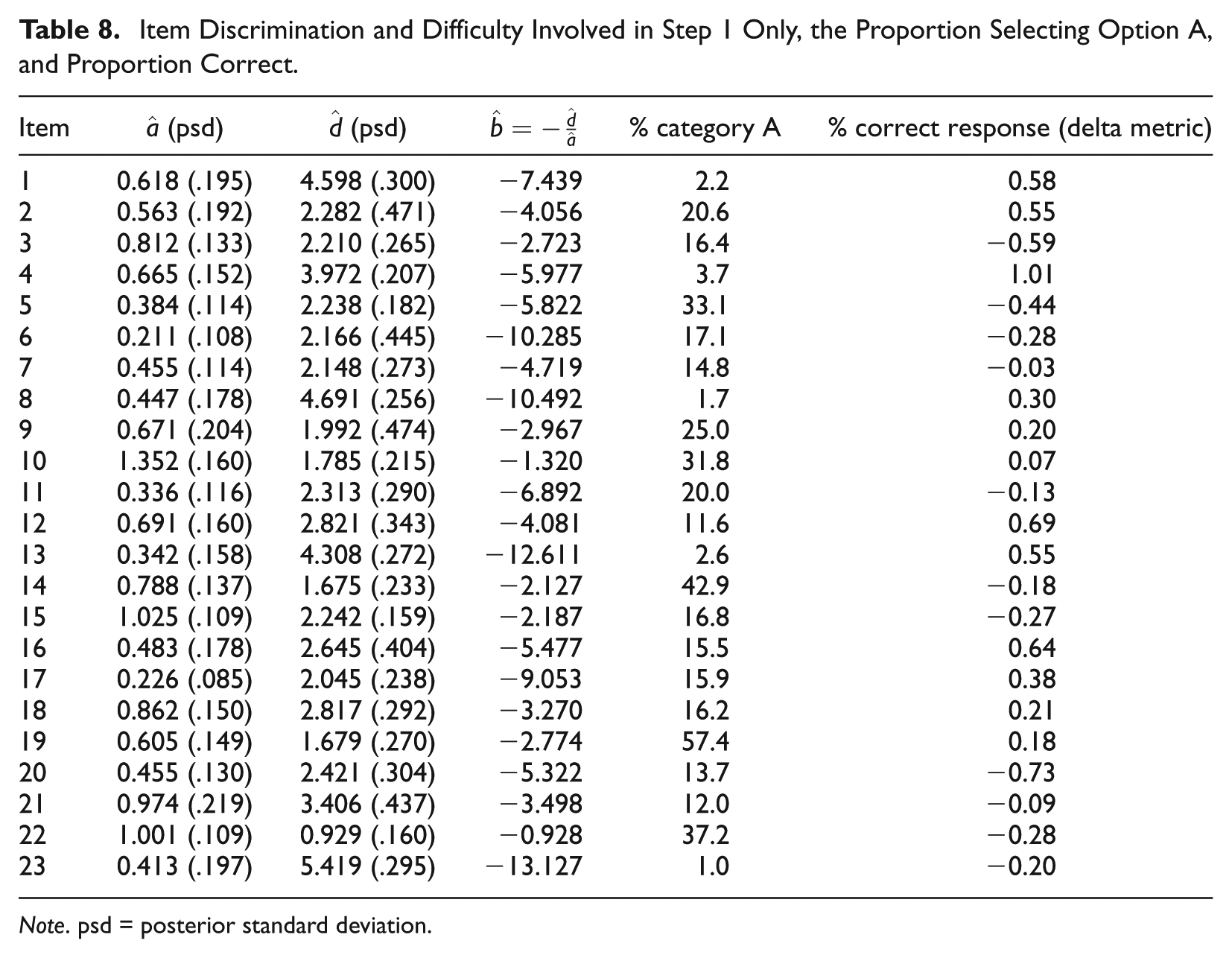
Note. psd = posterior standard deviation.
As noted earlier, under the SRM model, an examinee can arrive at option A in two ways, by not passing the recognition step, or by passing the recognition step but finding option A to be the most plausible response in the correction step. Not surprisingly, the estimated intercepts related to the recognition step are rather highly correlated with the category intercept estimates of option A in the correction step (
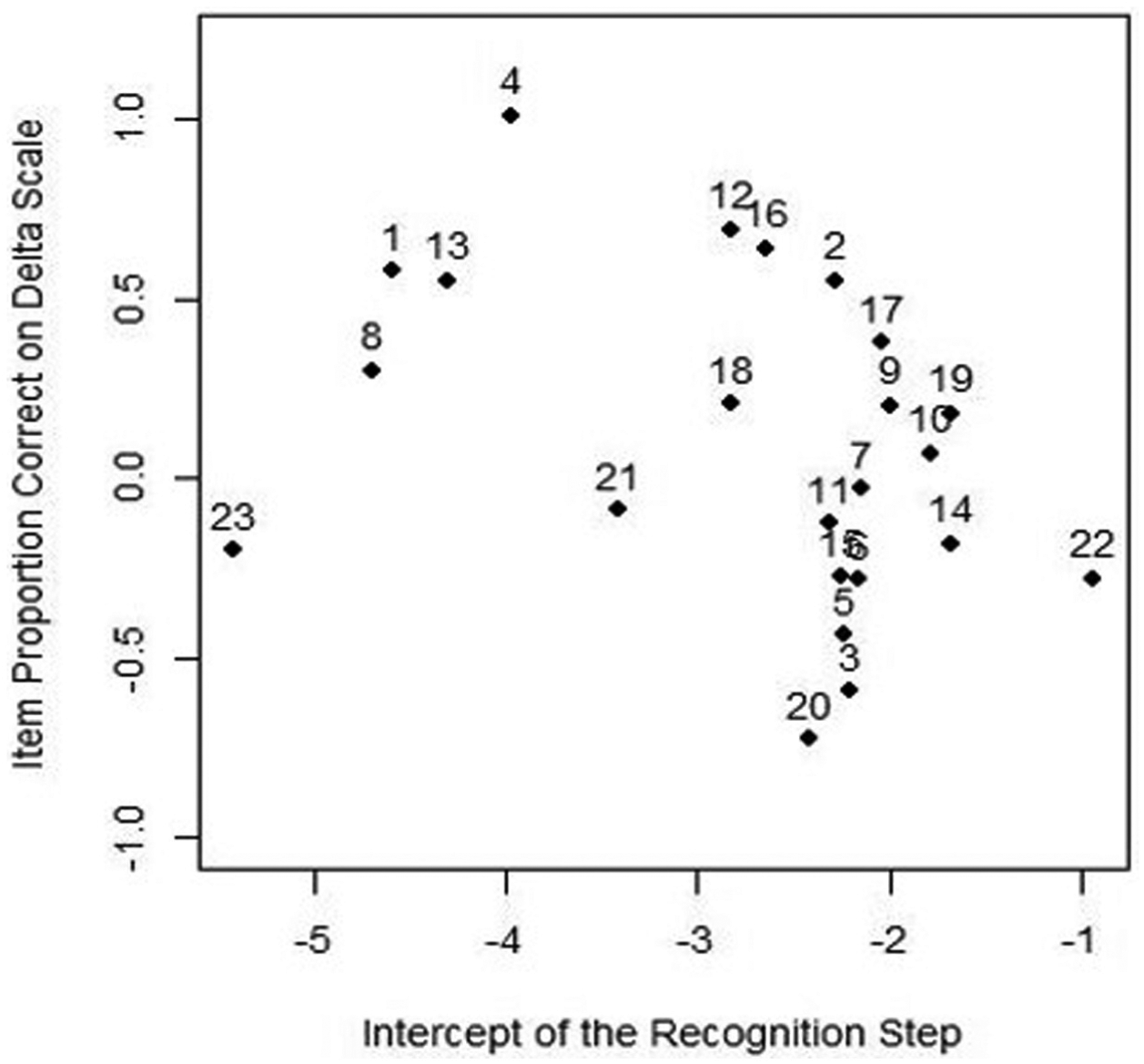
Scatterplot of intercept estimate from the recognition step against the item proportion correct on the delta metric.
Discussion and Conclusions
The sentence correction test analyzed in the article is frequently described as measuring a student’s ability to simultaneously recognize and correct sentence errors. The model considered in this article provides a method by which to statistically evaluate whether the traits underlying recognition and correction are in fact the same. By finding a better comparative fit for the two-dimensional SRM-MC model in comparison with both the NRM and unidimensional SRM-MC models, it would appear that a theorized response process in which examinees are in many cases failing to recognize an error in the sentence and selecting option A (without evaluation of alternatives) is plausible; moreover, it would appear that the recognition and correction traits that emerged in this analysis are quite distinguishable. The recognition tendency that emerged from this analysis appears particularly related to identification of punctuation (as opposed to word usage) errors in sentences. As punctuation is often a somewhat subjective determination, it is perhaps not surprising that items with punctuation errors emerge as the most difficult and discriminating with respect to the recognition proficiency.
As emphasized in the introduction, the model considered in this article can be viewed as a form of the extended cognitive miser model (Böckenholt, 2012a). When applied to multiple-choice items, the model provides a statistical mechanism by which a theorized sequential process underlying the evaluation of response options can be tested against an alternative model that assumes simultaneous evaluation of all response options. A sequential process appeared reasonable for the current test based on the consistent way in which option A was specified across items and the logical sequence in which the first response option would be evaluated in relation to the subsequent response options. Variations on this model could also be developed in other contexts. An alternative assessment where a similar type of model structure could be applied might be a medical practitioner certification test, where items correspond to decision-making scenarios and where incorrect decisions can be made based on limited amounts of information provided to the prospective practitioner. Recent innovations in computerized assessment has made the design and use of such item types attractive and plausible.
As seen in the regression analysis, the SRM-MC model can also provide a way of evaluating how the recognition and correction traits ultimately impact examinee scores on the test. From this analysis, it would appear that the correction proficiency carries approximately 3½ times the weight of the recognition tendency. To the extent that parallel measures of the test are desired, evaluation of the relative weighting of these traits across test forms may be a useful criterion to consider.
It is conceivable that the trait
Finally, there are a number of additional considerations regarding the use of the SRM-MC in the specific application considered in this article. Other approaches to validating the distinct recognition and correction steps in the SRM-MC model could be applied. For example, having think-aloud studies or post-test interviews with respondents could help in validating the presence of the two steps. In addition, attending to response times in the context of computerized assessments (the current analysis were based on paper-pencil test administrations) may demonstrate shorter response times for many of the “A” responses, a result that would lend further support to the SRM-MC.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.