
Abstract
Testing item fit is an important step when calibrating and analyzing item response theory (IRT)-based tests, as model fit is a necessary prerequisite for drawing valid inferences from estimated parameters. In the literature, numerous item fit statistics exist, sometimes resulting in contradictory conclusions regarding which items should be excluded from the test. Recently, researchers argue to shift the focus from statistical item fit analyses to evaluating practical consequences of item misfit. This article introduces a method to quantify potential bias of relationship estimates (e.g., correlation coefficients) due to misfitting items. The potential deviation informs about whether item misfit is practically significant for outcomes of substantial analyses. The method is demonstrated using data from an educational test.
To draw valid inferences from an item response theory (IRT) model, the fit of the model needs to be assessed and evaluated (Embretson & Reise, 2000). Model misfit indicates that one or several model assumptions are violated. In unidimensional IRT, these assumptions include local stochastic independence between item responses and assumptions resulting from restrictions of parameters of the item characteristic curves (ICCs), such as setting all discrimination parameters equal to 1. In case of model misfit, the estimated ability and item parameters might be biased and cannot be interpreted reliably (Wainer & Thissen, 1987; Yen, 1981). Testing model fit is thus considered an important step when calibrating and analyzing IRT-based tests, as is documented in Standard 4.10 of the Standards for Educational and Psychological Testing (American Educational Research Association, American Psychological Association, & National Council for Measurement in Education, 2014).
Since no model perfectly fits any given data set, model misfit will always be present to some degree (Box & Draper, 1987). The important question researchers frequently find themselves confronted with revolves around how much misfit is acceptable. Swaminathan, Hambleton, and Rogers (2006) identify two main steps for assessing model fit: (a) Testing underlying assumptions, and (b) comparing predictions of the model with observed values. On a purely statistical level, numerous tools for evaluating model fit exist (see, for example, Ames & Penfield, 2015; Swaminathan et al., 2006). In educational assessments, commonly applied methods include differential item functioning (DIF) analyses to evaluate item parameter invariance across groups, testing for unidimensionality, comparing different scaling models, assessing reliability, and scrutinizing item fit indices (see, for example, Organisation for Economic Co-Operation and Development [OECD], 2012; Pohl & Carstensen, 2012). Practitioners often apply heuristics or rules of thumb in order to evaluate the significance of any deviations from the expected outcomes. With regard to item fit, such rules of thumb encompass the evaluation of item fit plots and cutoff scores. The consequences of item misfit oftentimes involve the collapsing of categories of polytomous items, changing the phrasing of the item, or removing the item from the test and/or the empirical analysis altogether.
In tests constructed under IRT, the strict model assumptions typically lead to at least some items to be identified as misfitting. In some instances, even large percentages of items show bad model fit. Having to remove items due to misfit is undesirable for test developers in several aspects: For one, item development costs time and money; another important aspect concerns the sufficient representation of the construct that is to be measured. Tests are often developed according to a specific theory, and the generated item pool is supposed to cover certain aspects of a construct. Each of these aspects (i.e., subdomains) are typically assessed via a limited number of items. If several items measuring a specific subdomain are removed because of model misfit, this aspect can no longer be appropriately assessed if the number of items in the respective subdomain is insufficiently large. All in all, retaining items in the test is commonly desired.
Considering that item misfit is not necessarily relevant with regard to the test outcome, the practice of removing items seems somewhat rash—especially in light of the ongoing debate about the validity of many item fit statistics (see, for example, Ames & Penfield, 2015; Orlando & Thissen, 2000; Swaminathan et al., 2006). The criticism mostly targets the validity of the derived cutoff scores. Recent work by Hambleton and Han (2005), Molenaar (1997), as well as Sinharay (2005) emphasizes the importance of looking beyond statistical significance of item fit and focusing more on its practical significance. The assessment of model fit should be viewed as a multifaceted process that also comprises an examination of the consequences of model misfit (Hambleton & Han, 2005; Sinharay, 2005; Sinharay & Haberman, 2014). Practical consequences pertain to the purpose of the test and the implications from the assessment. In high-stakes assessments, for example, tests might function as a selection criterion for admission into a certain program or educational institution. Sinharay and Haberman (2014) investigated data from three educational tests that were used to derive cut scores, categorizing students according to their competence levels: It was demonstrated that although item misfit was prevalent in all data sets, their practical significance was minor: In two out of the three examples, the removal of items resulted in negligible changes regarding the categorization of students. The authors propose that the decision of whether misfit is practically significant should be based on the change in test outcomes, and conclude that the removal of items is unnecessary if it has no practical relevance.
Note that Sinharay and Haberman (2014) focused on high-stakes testing, in which the accuracy of individual scores is of major importance. A study by van Rijn, Sinharay, Haberman, and Johnson (2016) investigated practical significance of item misfit in the area of low-stakes educational assessments. By low-stakes, the authors refer to tests where the assessment outcome has no immediate individual consequences for the examinee. In low-stakes educational assessments such as the Programme for International Student Assessment (PISA) or the National Assessment of Educational Progress (NAEP), most analyses revolve around relationships between competence and other variables or competence comparisons between groups. Van Rijn et al. estimated subgroup means and the percent of examinees at different ability levels to investigate practical significance of item misfit. The outcomes of these estimates were compared when misfitting items were kept in the measurement model versus when they were excluded from the model. Like Sinharay and Haberman (2014), they found that item misfit hardly impacted the outcome.
Note that in both studies on practical significance—Sinharay and Haberman (2014) and van Rijn et al. (2016)—the investigation regarding practical significance of item misfit was conducted separately for each of their empirical examples. Testing practical significance for each outcome of interest can be a quite demanding and cost consuming task. Up to date, no general approach exists to evaluate practical significance of misfitting items in educational tests, and no software program reports influences of misfitting items on important outcome variables. In this article, a method to assess consequences of keeping misfitting items in a low-stakes achievement test is proposed. The focus of this study lies on tests that are primarily used to compare competences across groups or to analyze relationships between competences and other variables. In most instances, these relationships are investigated through the analysis of variance components, for example, ANOVA, regression analysis, or correlation coefficients. Results from such analyses allow evaluating the size and significance of the relationship between variables. The correlation coefficient—and the according R-squared—is especially relevant for evaluating whether the relationship between two variables is substantial. The authors argue that if the correlation coefficient significantly changes due to misfitting items in the model, item misfit is practically significant. The authors consider a change in the correlation coefficient as significant when inferences on substantial research questions are altered, for example, if the estimated size of the relationship between ability and a covariate is distorted by including misfitting items in the measurement model so that an actually existing medium size relationship decreases to a low size relationship.
A general approach—applicable to any competence test—is offered to evaluate potential bias in the correlation coefficient when misfitting items are kept in the analysis. Note that the reader can choose which item fit statistics to use, and the debate on the most appropriate item fit statistic is disregarded in the current article. This study’s approach is basically an additional aspect in the process of evaluating model fit, and picks up after the researcher has decided—based on statistical item fit analyses and closer inspection of the items—which items might potentially be removed from the test. The approach can be used even when covariates of interest have not been assessed yet, for example, in trial administrations of new tests.
The next section describes this study’s approach in detail for the Rasch model (Rasch, 1960), followed by a short description of its generalization to the two-parameter logistic (2PL) model (Birnbaum, 1968). A small simulation that illustrates which factors influence the potential change of the correlation coefficient is subsequently provided. The authors then give an empirical example, demonstrating the effectiveness of the approach in evaluating practical significance of item misfit. Note that an R code was developed for easy implementation of this study’s method (see the Online Appendix).
Method
Approach for Rasch Model
To evaluate whether the exclusion of several items has an impact on any analysis of substantive interest, the researcher could simply compare the parameters of interest from the model where misfitting items are included in the measurement model for ability and the model where misfittings items are removed from the measurement model for ability. For example, if the substantive research question concerned the relationship between ability in mathematics and interest in mathematics, the correlation (or standardized regression coefficient) between ability and interest in mathematics could be calculated (a) using only fitting items in the measurement model for ability, so that the latent ability variable,
As this procedure has very limited generalizability and would require a new interpretation of practical significance of item misfit for each research question, a mathematical approach that allows establishing the potential bias in the correlation coefficient for all possible values of
The underlying idea of this study’s approach is based on the decomposition of variance components. The inclusion of misfitting items affects the variance of the latent variable as well as its correlation with the covariate. The potential change in the correlation coefficient is limited to a certain range, however, which can be mathematically computed. The minimum and maximum change depends on the amount of additional variance that is induced by the misfitting items, on the amount of misfitting items relative to the fitting items, and on the strength of the relationship between the latent variable and the covariate. Let
The minimum and maximum correlations,
Estimating
and
To calculate the minimum and maximum change of
For the manifest context, let
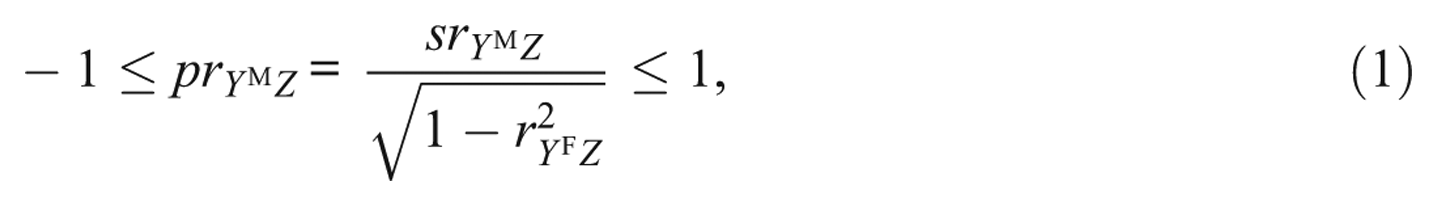
where
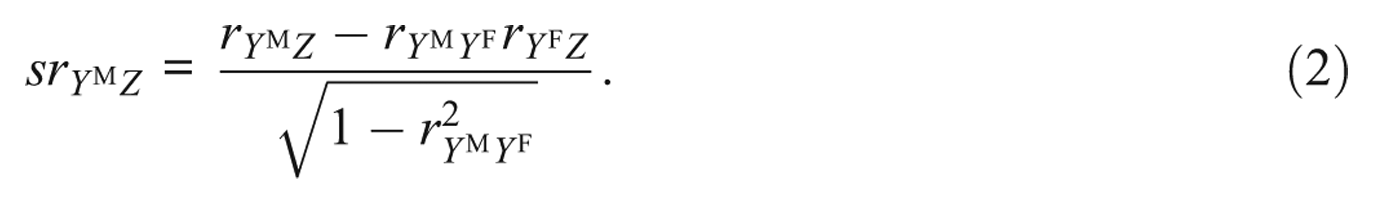
Equation 1 can be solved for
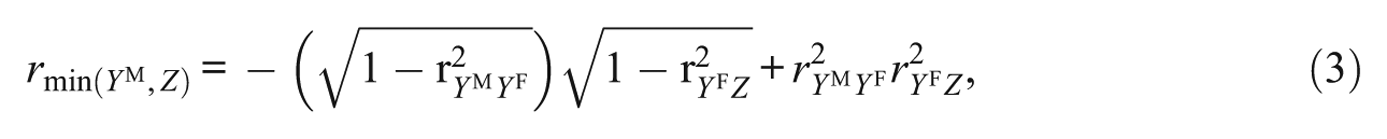
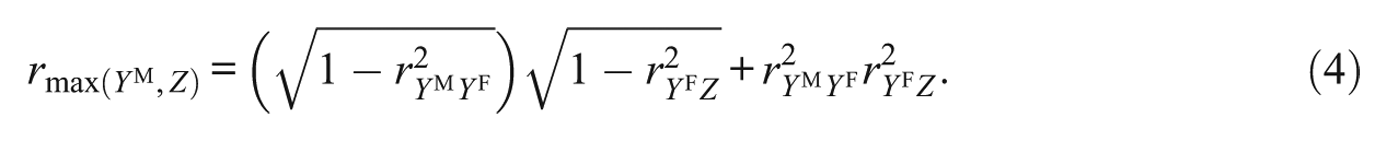
Estimating
and
As this study’s main interest does not lie in the minimum and maximum correlation between Z and
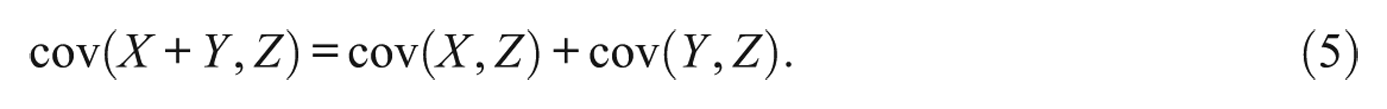
The variance of the aggregated variable is given by
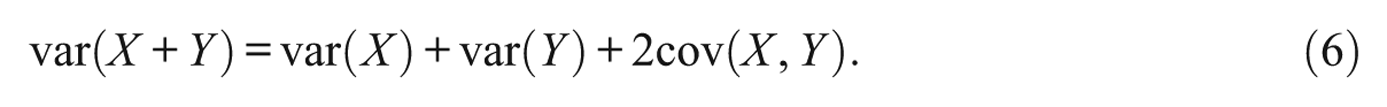
Keep in mind, however, that the latent variables
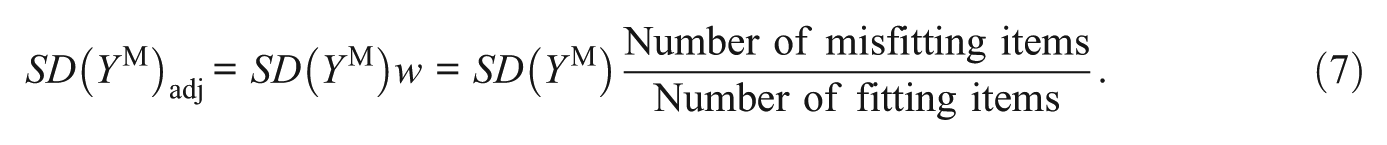
The minimum and maximum
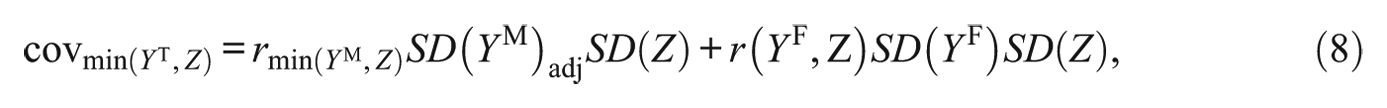
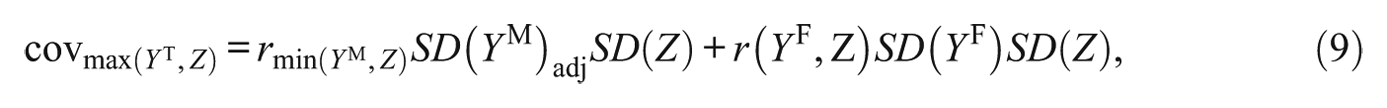
where the product on the left of the plus sign constitutes
The minimum and maximum correlation between


where the standard deviation of

In sum, all calculations can be realized given
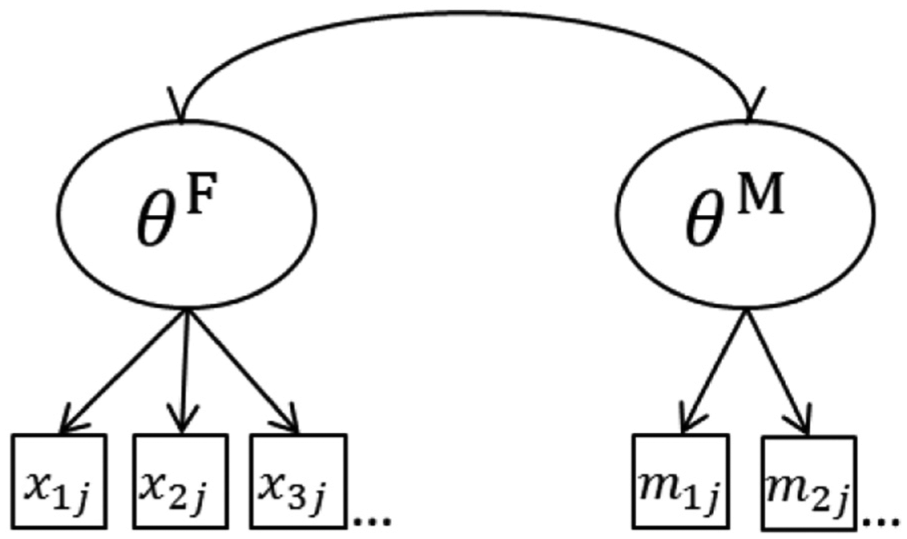
Between-item multidimensional IRT model with item indicators from fitting items, xij, loading on
The likelihood equation for the between-item multidimensional Rasch model is given by
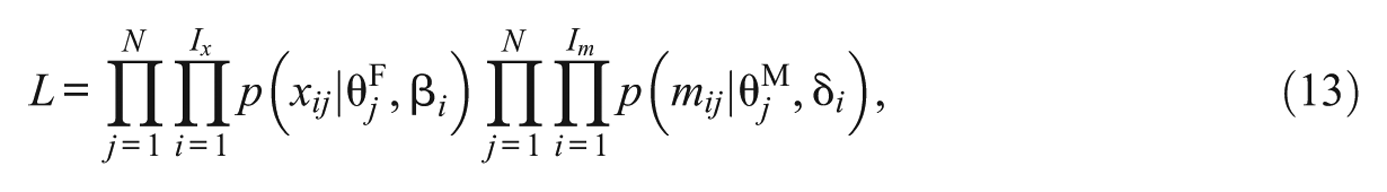
where
Take, for example, a test where five out of 20 items show misfit according to an arbitrary item fit index. The two-dimensional Rasch model would include the 15 fitting items measuring the first dimension,
Approach for 2PL Model
The previously described method for obtaining the minimum and maximum change in the correlation coefficient when misfitting items are included in the model is easily transferable to 2PL models. Instead of estimating a between-item multidimensional Rasch model, a between-item multidimensional model that allows for varying item discrimination parameters should be used (see, for example, Adams & Wu, 2007; Muraki, 1992). Such a model is identified by fixing the variance of both latent dimensions to 1. The relevant parameters for calculating
Simulation
The potential change in
The results of these analyses are displayed in Figure 2. The possible change in

Minimum and maximum change in the regression coefficient when misfitting items are included in the measurement model for varying levels of the amount of misfitting items and the size of correlation between the latent variable containing only fitting items,
Data Example
Method
Data from a pilot study were used to illustrate the applicability of the proposed method. The study was developed to assess different competence areas of German and English as a foreign language of ninth graders in Germany (DESI-Konsortium, 2008). The present data example, the subdomain German Communication and Argumentation, consisted of 28 dichotomously and polytomously scored items. The sample size in the pilot study comprised N = 529 students.
In a first step, a Rasch model including all items was estimated and the weighted mean square (WMNSQ) item fit indices were calculated using the package TAM (Kiefer, Robitzsch, & Wu, 2014) in the open source software R (R Core Team, 2016).
1
The WMNSQ is a residual based item fit statistic; Wu, Adams, Wilson, and Haldane (2007) developed it based on the Infit (see Wright & Masters, 1982). A value of 1.15 was chosen as critical for item misfit, and all items with a WMNSQ >1.15 were considered misfitting.
2
The two-dimensional Rasch model was subsequently estimated with the fitting items loading on
Results
Under the Rasch model, the WMNSQ of four out of the 28 items measuring German Communication and Argumentation exceeded 1.15. A two-dimensional between-item model with all 24 fitting items loading on

Change in regression coefficient when misfitting items are included in the measurement model for German communication and argumentation.
Note that the minimum and maximum possible change in the standardized regression coefficient when the misfitting items were included was rather small. The possible discrepancy between
Discussion
The goal of this article was to introduce a method that assists in determining practical significance of item misfit in educational low-stakes large-scale assessments. Testing the substantial consequences of item misfit should be an integral part of assessing model fit (Hambleton & Han, 2005). The proposed method is based on basic mathematical principles regarding correlations, and can be applied routinely to any sort of test that involves analyses of relationships. Thus far, hardly any approaches assessing practical significance of item misfit existed.
Compared with the approach by van Rijn et al. (2016), who specifically compared relevant outcomes when misfitting items were either included in the measurement model or not, a major advantage of the proposed method lies in its generalizability. In the R function (see the Online Appendix), only the item response data, the misfitting items, and the IRT model need to be specified, and it returns the minimum and maximum potential change in the correlation coefficient for possible correlations between −1 and 1. These potential changes apply to any variable that might be of interest. This is especially valuable for trial administrations of tests (i.e., pretests). In the pretest, relevant covariates are not always part of the assessment. Using the proposed method, potential consequences of misfitting items on contextual analyses can be evaluated nevertheless. It also works in large-scale assessments with a multi-matrix data sampling approach, since parameters of an IRT model are well approximated even if some items are missing by design. This also holds for the proposed approach, which is based on a multidimensional latent regression IRT model. As long as the misfitting items from different booklets measure the same trait (e.g., reading literacy), they can be grouped together and the influence of the misfitting items when regressing reading literacy on a covariate can be computed. Furthermore, the approach is generalizable to any scenario where researchers are interested in a potential change of the strength or direction of the relationship between two variables when the scope of the items measuring the latent variable changes. The potential change pertains to the parameter estimate given the respective latent measurement model the researcher chose to answer his research question with. Keep in mind that the calculated minimum and maximum values should be considered the worst cases, meaning that the (misfitting) items added to measuring the construct of interest differently relate to the covariate than the rest of the items. In cases where the items add no additional information to measuring the latent variable and only produce measurement error, their consequence on the estimated relationship with a covariate is limited.
The gain of retaining items that were pronounced misfitting depends on the purpose of the test. Certainly, an item that only produces irrelevant noise in the data, that has been translated improperly, or that simply lies outside the examinees’ ability range should be altered or removed from the test. The authors neither promote that investigating why items have a poor item fit becomes unnecessary, nor do they intend for their method to replace any of the existing methods. In some situations, however, the reason for item misfit is unclear and the test developers might be reluctant to delete an item for reasons of construct representation. The proposed method allows examining how the misfit influences relevant outcomes, thus giving an additional option of evaluating item and model fit. Another criterion for evaluating whether the items can be kept in the measurement model is to compare the reliability of the test when misfitting items are included in the test or not. A decrease in reliability after the removal of misfitting items could be regarded as a reason to keep them despite of the misfit.
An important finding from the empirical example is the robustness of the correlation coefficient against violations of model fit. Not only was the potential change of the standardized regression coefficient rather small, but the actual change when misfitting items were included in the model was even lower. Certainly, these results are restricted to the presented data example. As the simulated data examples show, the potential change might be greater for tests with relatively larger amounts of misfitting items and more dissimilarity between misfitting and fitting items. In cases where the potential change is large, keep in mind that the potential change should be considered the worst case scenario and that the actual parameter change lies somewhere in between the calculated boundaries. Therefore, large potential changes do not necessarily mean that the misfit is practically significant for all possible research questions, but makes it more likely. If a researcher wants to know the actual practical significance regarding a specific research question, the relevant outcome parameters need to be compared when the misfitting items are included in the measurement model or not.
So far, the presented approach is only applicable for bivariate analyses in which the explaining variable is either continuous or binary. This limits statements regarding multiple group comparisons, which are typically relevant in large-scale assessments such as NAEP or PISA. Furthermore, it would be interesting to apply the approach to more complex research questions which require, for example, multilevel models, latent multiple regression models, or multidimensional models. For other study designs such as computer adaptive testing (CAT), item fit might play a more crucial role. Practical significance for CAT goes beyond changes in the parameters that measure relationships, as the reliability and validity of a single item or several items play a role in which items will be presented to the individual. Thus, item misfit needs to be evaluated in terms of changes in item presentation when misfitting items remain in the test, and whether this change has an effect on crucial outcomes.
Finally, note that the presented method is not restricted to the area of item fit. It is a general method that allows estimating the minimum and maximum possible change in a correlation coefficient (or standardized regression coefficient) if some of the items are kept in the measurement model. It can thus be applied in any scenario where decisions on dropping items from a test have to be made.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.