
Abstract
The current study investigated the consequences of ignoring a multilevel structure for a mixture item response model to show when a multilevel mixture item response model is needed. Study 1 focused on examining the consequence of ignoring dependency for within-level latent classes. Simulation conditions that may affect model selection and parameter recovery in the context of a multilevel data structure were manipulated: class-specific ICC, cluster size, and number of clusters. The accuracy of model selection (based on information criteria) and quality of parameter recovery were used to evaluate the impact of ignoring a multilevel structure. Simulation results indicated that, for the range of class-specific ICCs examined here (.1 to .3), mixture item response models which ignored a higher level nesting structure resulted in less accurate estimates and standard errors (SEs) of item discrimination parameters when the number of clusters was larger than 24 and the cluster size was larger than six. Class-varying ICCs can have compensatory effects on bias. Also, the results suggested that a mixture item response model which ignored multilevel structure was not selected over the multilevel mixture item response model based on Bayesian information criterion (BIC) if the number of clusters and cluster size was at least 50, respectively. In Study 2, the consequences of unnecessarily fitting a multilevel mixture item response model to single-level data were examined. Reassuringly, in the context of single-level data, a multilevel mixture item response model was not selected by BIC, and its use would not distort the within-level item parameter estimates or SEs when the cluster size was at least 20. Based on these findings, it is concluded that, for class-specific ICC conditions examined here, a multilevel mixture item response model is recommended over a single-level item response model for a clustered dataset having cluster size
Single-level mixture item response models or categorical-item factor mixture models were proposed to account for both categorical latent variables (i.e., latent classes) and continuous latent variables (i.e., factors) in a population (e.g., Rost, 1990). The single-level mixture item response model is similar to a multigroup item response model (Bock & Zimowski, 1997), except that the group of interest is a latent class or categorical latent variable. The two-parameter single-level mixture item response model as an extension of mixture Rasch model (Rost, 1990) can be written as

where
Cluster or multistage sampling is common in educational and psychological research. When persons (e.g., students) are nested within a higher level structure (e.g., schools), the persons’ scores in the same higher level unit are likely to be more highly correlated with one another than those from different higher level units. If the dependency due to clustering is not accounted for when it exists, results from a latent variable model will be less accurate because of a violation of the (local) independence assumption. In this regard, multilevel mixture item response models (Vermunt, 2007) were developed to account for possible dependency due to cluster- or multistage sampling. In the model, dependency is taken into account by incorporating continuous and/or categorical latent variables at the higher level. The multilevel mixture item response models were applied to detect differential item functioning across latent classes in multilevel data (Bennink, Croon, Keuning, & Vermunt, 2014; Cho & Cohen, 2010; Finch & Finch, 2013) and to investigate the individual differences in math ability growth within latent classes over time in multilevel longitudinal data (Cho, Cohen, & Bottge, 2013; von Davier, Xu, & Carstensen, 2011). Although many data structures in educational and psychological research involve clustering, multilevel mixture item response models are seldom used over single-level mixture item response models. As an example, in a survey of Cho et al. (2016), five multilevel mixture item response model applications were found, whereas 19 single-level mixture item response model applications were found.
To examine the necessity of multilevel mixture item response models, additional research is needed to investigate the impact of inappropriately modeling multilevel data. Recent simulation studies showed that misspecified models which ignored a higher level nesting structure resulted in less accurate estimates and lower classification accuracy in a growth mixture model (Chen, Kwok, Luo, & Wilson, 2010) and a latent class model (Kaplan & Keller, 2011; Park & Yu, 2016). Chen et al. (2010) found that, compared with a fitted multilevel growth mixture model, the classification of persons using a growth mixture model was less accurate, and the classification accuracy was affected by the intraclass correlation (ICC), mixing proportions (i.e., the number of persons within a class), and within-class variances and covariances of random effects. Kaplan and Keller (2011) showed that a larger ICC and smaller sample size at the higher level resulted in misclassified persons in a latent class model, controlling for the total sample size. Park and Yu (2016) found inflated standard errors (hereafter, SEs) for parameter estimates of a latent class model when a higher level nesting structure was ignored, whereas SE deflation is often found when ignoring nesting in other modeling contexts (e.g., linear regression; Raudenbush & Bryk, 2002). The consequences were more severe as the between-level latent classes became more separated from one another in terms of the mixing proportion of within-level latent classes.
However, the impact of ignoring dependency in item responses (due to clustering) on parameter accuracy has not been investigated in mixture item response modeling. Dependency in item responses is explained by both continuous and categorical latent variables in mixture item response models, whereas it is explained only by categorical latent variables in latent class models. Because of this difference in complexity between the two models, the sample sizes and ICCs where the impact of ignoring dependency becomes consequential in mixture item response models may not be directly inferred from prior simulation results that used latent class models as in Park and Yu (2016) and Kaplan and Keller (2011). Different kinds of the latent variables are expected to yield different results regarding parameter recovery and model selection. The same design conditions can have very different effects on, for instance, mixture model selection and class enumeration depending on the complexity of the within-class model (e.g., Lubke & Muthén, 2007, vs. Tofighi & Enders, 2007).
Furthermore, in conventional mixture item response model applications, the number of latent classes is not a model parameter and is typically chosen using information criteria (IC) when comparing models having different numbers of latent classes. Thus, a researcher deciding whether to fit a single-level versus multilevel mixture item response model to multilevel data must consider not only the risk of biased estimates and SEs when fitting a misspecified single-level model but also whether the correct number of classes could be recovered when fitting a multilevel model. There have been studies investigating IC such as Akaike’s information criterion (AIC; Akaike, 1973) and the Bayesian information criterion (BIC; Schwarz, 1978) for class enumeration in (single-level) mixture item response models (e.g., Li, Cohen, Kim, & Cho, 2009; Preinerstorfer & Formann, 2012). These studies found that BIC performed best among model selection indices they considered. BIC includes the number of parameters and sample size in the penalty term. For multilevel data, Yu and Park (2014) compared different kinds of IC for multilevel latent class models. They reported that using the number of clusters leads to a slightly better performance than total sample size in BIC and consistent AIC (CAIC; Bozdogan, 1987). Akaike’s BIC (ABIC; Akaike, 1980) performed much better when total sample size is used. However, it has not been shown whether these findings from the multilevel latent class models can be generalized to multilevel mixture item response models having continuous latent variables.
Thus, the purpose of the current study is to investigate via simulation the consequences of fitting a single-level mixture item response model (a) in the presence of multilevel structure and (b) when it is not needed. Specifically, the accuracy of parameter recovery and model selection was compared when fitting single-level versus multilevel mixture item response models. For this comparison purpose, the performance of IC was investigated for selecting the “correct” number of latent classes in (multilevel) mixture item response models.
In the following, multilevel mixture item response models are described. Next, evaluation measures are shown. Subsequently, two simulation studies are presented to achieve the purpose of the study. Finally, simulation results are summarized and discussed.
Multilevel Mixture Item Response Models
Multilevel mixture item response models account for possible dependency due to clustering by incorporating continuous and/or categorical latent variables at the between level. Vermunt (2007) suggested eight possible versions of two-level (e.g., students nested within schools) mixture item response models. Because mixture models posit categorical latent variables and item response models posit continuous latent variables, latent variables at each level may be categorical, continuous, or both categorical and continuous. In the current study, the population-generating multilevel item response model has both categorical and continuous latent variables at the within level and a continuous latent variable at the between level for the following two reasons: First, it has been common for empirical applications using cross-sectional nested data to theorize and specify continuous latent variables rather than categorical latent variables (i.e., between-level latent classes) at the between level (see Asparouhov & Muthén, 2006). Second, when categorical latent variables at the between level are specified, they are often used simply to nonparametrically approximate continuous latent variable(s) at the between level (e.g., Rights & Sterba, 2016; Vermunt, 2008).
Online Appendix A depicts a two-level mixture item response model with within-level latent classes. In the figure, the squares represent item responses, and the ellipses represent latent variables. The 1 inside the triangle is given to represent a vector of 1s. As shown in the figure, dependency in item responses
The population-generating multilevel mixture item response model described in Online Appendix A can be specified as follows:
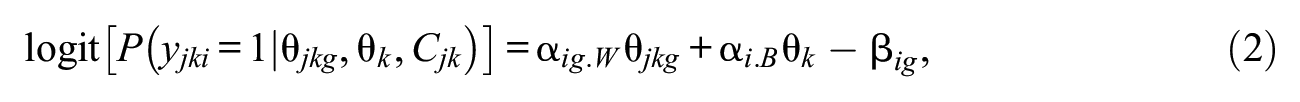
where
For model selection purposes, candidate-fitted models include not only Equation 1 and Equation 2 models but also the most complicated multilevel item response model having both categorical and continuous latent variables at the within level and at the between level. The latter model can be specified by adding a subscript (e.g.,
Class-Specific ICC
Dependency in item responses due to clustering at the between level can be characterized with ICC. In multilevel mixture item response models, a class-specific ICC can be specified for each item. It can be interpreted as the proportion of variance which is accounted for at the between level for that item. The class-specific ICC,
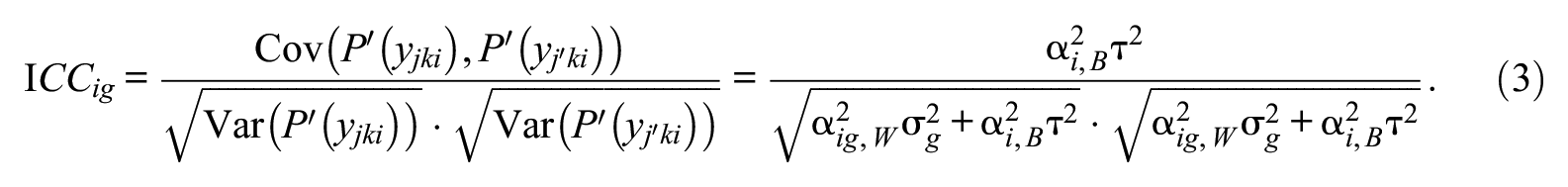
As shown in Equation 3,
Simulation studies were designed to investigate (a) the consequences of fitting a single-level mixture item response model in the presence of multilevel structure (characterized by ICC) in Simulation Study 1 and (b) the consequences of fitting a multilevel mixture item response model when it is not needed in Simulation Study 2. Below, evaluation measures were first presented.
Evaluation Measures
In Simulation Study 1, the impact of ignoring a multilevel structure is evaluated based on parameter recovery and model selection accuracy. The true model in Simulation Study 1 is a multilevel mixture item response model with two within-level latent classes (called multilevel model hereafter; that is, Equation 2), whereas the misspecified model is a single-level mixture item response model with two latent classes (called single-level model hereafter; that is, Equation 1). In Simulation Study 2, parameter recovery and model selection accuracy were also considered to examine the consequences of fitting multilevel models when they are not needed. The true model in Simulation Study 2 is a single-level model (Equation 1), whereas the misspecified model is the multilevel model (Equation 2). The accuracy of parameter recovery was compared between the true and misspecified models. In both simulation studies, several candidate models with different numbers of within-level and between-level classes were compared based on IC.
Parameter Recovery
Bias and root mean square error (RMSE) of item parameter estimates were compared between the true and misspecified models. Bias was calculated by
Model Selection
IC were used for model selection. The proportion of samples in which each information criterion selects the true model was compared with the proportion of samples where it selects the misspecified model.
A general form of IC is as follows:

where LL is a log likelihood and
Several kinds of IC have been suggested that differ in the penalty for complexity. AIC considers the number of model parameters in the penalty term as follows:

where
BIC uses the number of model parameters and sample size in the penalty term. For the sample size in BIC, it is common to use the number of persons in multilevel modeling (e.g., Hamaker, van Hattum, Kuiper, & Hoijtink, 2011) and in multilevel item response modeling (e.g., Cohen & Cho, 2016), as specified below:

where n the number of persons.
Simulation Study 1
Simulation Conditions
Three simulation conditions were theorized to affect model selection performance and parameter accuracy in the context of a multilevel data structure because they can lead to between-cluster responses that are more heterogeneous and within-cluster responses that are more homogeneous (e.g., Chen et al., 2010; Kaplan & Keller, 2011; Preacher, Zhang, & Zyphur, 2011): the number of clusters (two levels), cluster size (three levels), and class-specific ICC (three levels). The total number of simulation conditions is 18 (
Other conditions that may be less relevant specifically to ignoring multilevel data structure were considered fixed conditions in the simulation study. That is, factors that simply generically affect classification accuracy for mixture models—such as the number of items, the number of latent classes, mixing proportions, and different item profiles— were considered as fixed conditions. Twenty items were used, which is a reasonable size for mixture item response model studies (e.g., Finch & French, 2012). Eighty percent of the total items had class-specific item parameters, and 20% were class-invariant items. The two within-level latent classes (called Class 1 and Class 2 hereafter) in the true model had equal mixing proportions. Every cluster had the same proportion of within-level latent classes (because variation in these proportions could otherwise lead to detection of between-level latent classes). Differences in class-specific item discrimination parameters were manipulated by ICC (see Equation 3). The item profile of the two (within-level) latent classes was sufficiently distinct in terms of item difficulty parameters for there to be good parameter recovery if a single-level mixture item response model was fit to single-level data (e.g., Li et al., 2009). Below, each varying simulation condition is described.
Number of clusters
The number of clusters was set to
Cluster size
Balanced cluster sizes were selected as
The alternative numbers of clusters and cluster sizes imply six different total numbers of persons: J = 144, 300, 480, 1,000, 1,200, or 2,500.
ICC
To investigate the consequences of fitting a single-level mixture item response model when multilevel structure is needed, class-specific ICCs were manipulated as .1 and .3, .2 and .2, and .3 and .1 (for Class 1 and Class 2, respectively). For the level of .2 and .2, item discrimination parameters were identical between the two latent classes, and item difficulty parameters were different between the classes. For the levels of .1 and .3 and .3 and .1, both item discrimination and difficulty parameters differed between the two latent classes. The ICC was manipulated via differences between item discrimination parameters at the within level and at the between level. The ICC in a condition was the same across items to control for the effect of different degrees of ICC.
Data Generation
The true model is a multilevel model (i.e., Equation 2; a multilevel mixture item response model with two within-level latent classes). Binary responses were generated based on the latent variables and item parameter values. R (R Core Team, 2015) was used to generate item responses.
Class 1 and Class 2 had one common continuous latent variable at the between level (
Step 1. Twenty within-level item discrimination parameters of Class 1 (
Step 2. Between-level item discrimination parameters (
Step 3. Item difficulty parameters of Class 2 (
Analysis
Model identification and scale comparability constraints
If there are class-invariant items in single-level and multilevel mixture item response models, equality constraints can be set on item parameters across the latent classes (
Fitting models
As mentioned previously, the true model was Equation 2, a multilevel model with an across-class equality constraint (Items 17-20) for the levels of .1 and .3, .2 and .2, and .3 and .1 in the ICC simulation condition. When fitting the Equation 2 model, one true and eight other candidate specifications were compared (i.e., models with one or two between-level latent classes/one, two, three, or four within-level latent classes). When fitting the Equation 1 model, four candidate specifications were compared (i.e., models with one, two, three, or four latent classes). Therefore, 13 models were used for estimation per replication of each condition.
The equality constraint in the generating model was not imposed when fitting 12 of the candidate models, as often assumed in model selection (e.g., Li et al., 2009). Fifty replications were used for each condition. Accordingly, the number of total runs was 11,700 (= 50 replications × 13 models × 18 conditions).
Parameter estimation and prediction
Item parameter estimation and scoring were implemented using Mplus 7.4 (Muthén & Muthén, 1998-2015). Marginal maximum-likelihood estimation method with the MLR estimator option was used for parameter estimation. The MLR option provides a test statistic and SEs using the Huber–White sandwich estimator that are robust against nonnormality. 1 Expected a posteriori (EAP) scoring was used for latent variable predictions. An example Mplus code for the true model is provided in Online Appendix D.
For classification of persons to a within-level latent class
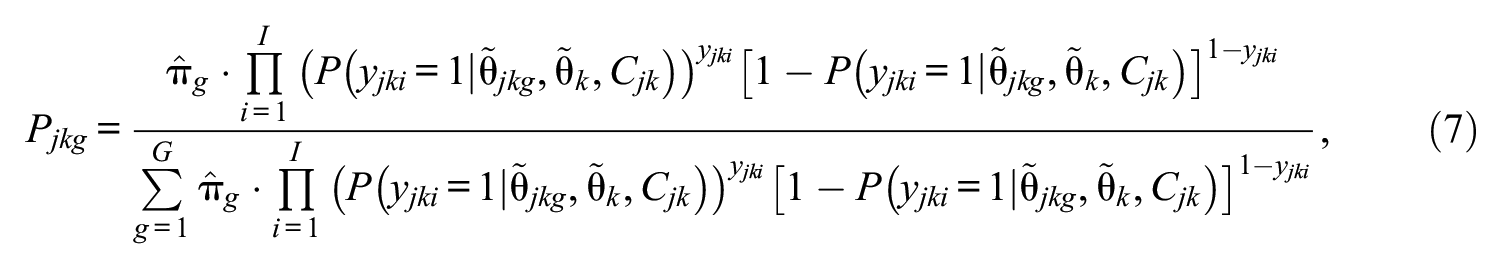
where
There are several issues to be considered specific to mixture modeling. One issue is label switching (see McLachlan & Peel, 2000, for details). To monitor the label switching problem, mean square error (MSE) was calculated based on the parameter for Class 1 and Class 2, respectively, prior to calculating bias and RMSE. At each replication, the MSEs of the item difficulty estimates with two kinds of item parameters were compared, and the latent classes were reassigned according to the smaller MSE. Because the item profile of the two latent classes in terms of item difficulty parameters was distinct, the reassignment of the latent classes was generally not problematic. When there was label switching, the measures for parameter recovery (i.e., bias, RMSE, and the ratio of SE) were calculated after the latent classes were renamed. To monitor local maxima for the mixture model likelihood, 200 random starting values were employed for initial iterations; the best 20 were iterated to completion (STARTS = 200 20 in Mplus).
Results
Out of 11,700 replications, 613 replications (5.2%) had convergence problems. The convergence problems occurred mainly when the cluster size was the smallest (
Parameter recovery
Figure 1 presents the item parameter recovery results under the multilevel model (i.e., true model with equality constraints on item parameters for class-invariant items) and the single-level model with two latent classes (i.e., a misspecified model). The smallest sample size condition (

Simulation Study 1: Bias, RMSE, and SE ratio of item parameter estimates.
Bias
For each class-specific parameter in a model, a three-way ANOVA was conducted with simulation conditions (
The top row in Figure 1 presents the bias results. Within-level item discrimination parameter estimates
Regarding item difficulty parameters, the bias from the single-level model was larger than the bias from the multilevel model with the following exceptions:
RMSE
ANOVA results were explained the most by the main effects of and interaction between
Figure 1 (middle) shows the RMSE of item parameter estimates. The RMSE from the single-level model was higher than that from the multilevel model when
Regarding the difficulty parameters, the RMSE ranged from 0.087 to 1.008 for the multilevel model and from 0.081 to 0.801 for the single-level model. The RMSE from the single-level model was higher than that from the multilevel model only in
The ratio of SE
The ratio of the mean of estimated SE across replications in the multilevel model to the standard deviation of estimates across replications in the multilevel model (indicated by multi/SD in Figure 1) and the ratio of the mean of estimated SE across replications in the single-level model to the standard deviation of estimates across replications in the multilevel model (indicated by single/SD in Figure 1) were calculated to evaluate the SE of item parameter estimates (see Figure 1, bottom). The ratio is greater than 1 if the estimated SE is overestimated compared with the SE of estimates in the multilevel model. Below, ANOVA results are first presented and then Figure 1 results are interpreted.
ANOVA result confirmed that cluster size explained the greatest variability in the ratio under the multilevel model (
The SEs of item parameter estimates tended to be overestimated when multilevel structures are ignored. As shown in Figure 1, the multilevel model had extremely large mean SE (>4.5) in
Model selection
Table 1 (top) presents the model selection results by AIC and BIC. The performance of AIC and BIC for the multilevel model (i.e., true model; the multilevel model with two within-level classes and equality constraint on item parameters for class-invariant items denoted by
Proportion of Model Selection for Simulation Study 1 (top) and Simulation Study 2 (bottom).
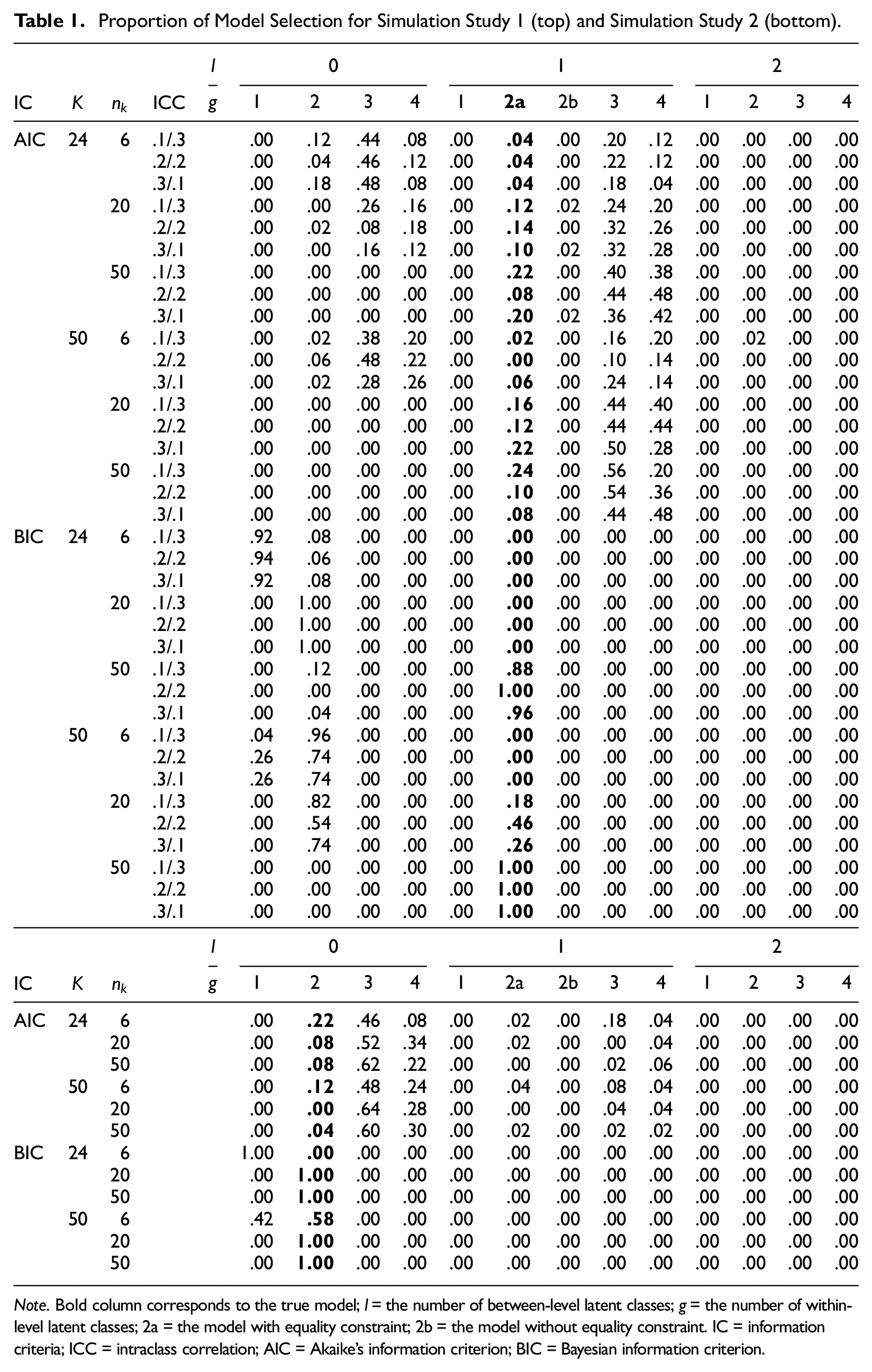
Note. Bold column corresponds to the true model;
Simulation Study 2
Simulation Study 1 found that, even when a nested data structure does exist, it is often but not always beneficial in terms of bias, RMSE, and/or SE ratio to fit a multilevel rather than single-level, mixture item response model. Hence, it is relevant in Simulation Study 2 to investigate the consequences of fitting a multilevel mixture item response model when there is actually no nested data structure.
Simulation Conditions
As in Simulation Study 1, two levels (
Data Generation
Item parameters for 20 items were generated. Item discrimination parameters were identical to Class 1 of .1 and .3 conditions in Simulation Study 1. The mean and variance of the item discrimination parameters are 1.13 and 1, respectively. The two latent classes had the same item discrimination parameters. Class-specific item difficulty parameters were the same as in Simulation Study 1. Person parameters (i.e., continuous latent variables) were also identical to the within-level latent variables in Simulation Study 1. Two class-specific person parameters were generated from a standard normal distribution, having the sample sizes of 72, 240, 600, 300, 500, and 1,250 for each condition.
Analysis
Model identification and scale comparability constraints
For model identification, the mean and variance of the person parameters of Class 1 were constrained to 0 and 1, respectively. An equality constraint on class-invariant item parameters between latent classes was imposed for scale comparability. The means and the variances of the person parameters of the other classes were estimated.
Fitting models
As Simulation Study 1, the true model (two latent classes with equality constraint on item parameters for class-invariant items) and eight candidate multilevel mixture item response models (i.e., models with one or two between-level latent classes/one, two, three, or four within-level latent classes) were compared. For a single-level mixture item response model, four candidate models (i.e., models with one, two, three, or four latent classes) were compared. Thus, 13 models were considered for estimation per replication of each condition. For each condition, 50 replications were used. Consequently, the number of total runs was 3,900 (= 50 replications × 13 models × six conditions).
Results
Two hundred twenty-two replications (5.7%) out of 3,900 did not produce a converged solution when the data were generated from the single-level mixture item response model. This rate was comparable with the conditions where the multilevel model was the true model. As in the multilevel model conditions, the convergence problems occurred mostly when the number of latent classes was set to 3 and 4. As shown in Online Appendix F, the classification accuracy, posterior probability, and entropy were similar between the single-level model and the multilevel model because factors that affect model selection for mixture models were fixed in simulation conditions.
Parameter recovery
Parameter estimation was not stable in the smallest sample size condition (
Bias
Figure 2 (top) presents the bias of the estimates under the single-level and multilevel models. When a between-level continuous latent variable did not exist, bias of within-level item discrimination estimates was close to 0 under the multilevel and single-level models except for one condition: The estimates of
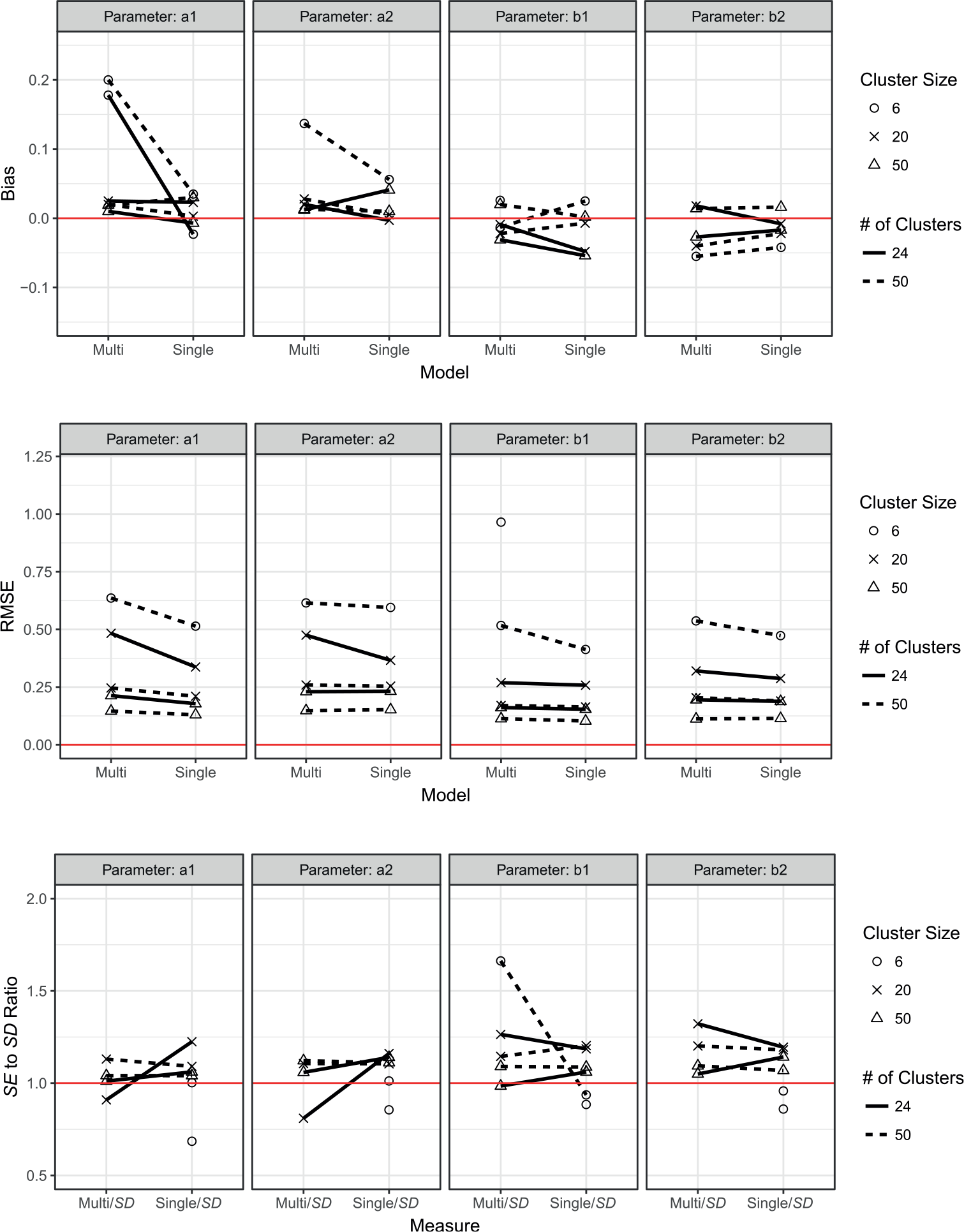
Simulation Study 2: Bias, RMSE, and SE ratio of item parameter estimates.
RMSE
Figure 2 (middle) depicts the RMSE of the estimates. The RMSE of item discrimination and difficulty parameter estimates under the multilevel model were larger than the single-level model in
The ratio of SE
As in Simulation Study 1, the ratio of the estimated SE (from the fitted model) and the standard deviation of estimates across replications (from the true—that is, single-level model) was calculated (see Figure 2, bottom). The SE from the multilevel model was extremely overestimated in
Model selection
The model selection results are presented in Table 1 (bottom). When a between-level continuous latent variable did not exist, BIC always selected the correct model when
Summary and Conclusion
The first purpose of the current study was to examine the consequences of ignoring multilevel structure when fitting a single-level mixture item response model. When the number of clusters is larger than 24 and the cluster size is larger than six, ignoring multilevel structure in the applications of single-level mixture item response models can be problematic regarding the accuracy of item discrimination estimates and SEs of item discrimination estimates. As long as the cluster size is greater than six, the bias of item discrimination parameter estimates from the single-level model was higher than those from multilevel model even when the number of latent classes is correctly specified; bias increased with increasing cluster size and number of clusters. The SEs of the item discrimination and difficulty parameter estimates were relatively overestimated in the single-level model compared with the multilevel model. A single-level model which ignored multilevel structure was not selected over the multilevel model based on BIC if the number of clusters and cluster size were at least 50, respectively. AIC always selected a model having incorrect number of latent classes. AIC is not recommended for detecting the within-level latent classes in the applications of multilevel mixture item response models. Note that, in small sample sizes (
The second purpose of this study was to examine the consequences of fitting a multilevel mixture item response model when there is no multilevel structure. It was expected that the multilevel mixture item response model as well as the single-level model would perform similarly in estimating within-level item parameters because the single-level mixture item response model is a special case of the multilevel model (when ICC = 0). As expected, when there is no continuous latent variable at the between level, using multilevel item response models did not distort the within-level item parameter estimates when the cluster size is as large as 20. The SE of item parameter estimates from the multilevel model was inflated in small cluster size, but they were comparable with the SE from the single-level model if the cluster size is larger than six. Reassuring, the multilevel model was not detected over the single-level model by AIC and BIC when a between-level continuous latent variable does not exist.
There are methodological limitations in the present study. First, the item parameter estimates were often extremely large for small cluster size (
Second, the simulation conditions affecting the classification accuracy and quality were not varied, and the latent classes were well separated across conditions because the investigation of the performance of IC in various item profiles between latent classes was not the primary goal of this study. Further studies are needed to investigate to what extent classification accuracy and quality depend on the number of items, the number of latent classes, mixing proportions, and different item profiles in the applications of multilevel mixture item response models.
Third, the population-generating multilevel mixture item response model chosen had categorical latent variables at the within level only, although there are continuous latent variables at the within level and at the between level. This generating model is chosen because categorical latent variables can be an approximation to a continuous latent variable at the between level. Thus, simulation results of the current study are limited to the case in which there are no between-level latent classes. Additional simulation studies are needed to generalize the simulation results to the other possible multilevel mixture item response models having categorical latent variables (i.e., between-level latent classes), or categorical and continuous latent variables at the between level.
To conclude, the findings in this study have implications for researchers. Ignoring a multilevel structure in mixture item response models results in less accurate model selection results, item discrimination estimates, and their SEs, particularly when there is a large number of clusters and cluster sizes. In multilevel linear modeling, the necessity of the multilevel modeling is typically justified with ICC (e.g., Raudenbush & Bryk, 2002). In this study, class-specific ICC derivations are presented in terms of discrimination parameters, and detailed steps are presented for generating a complex data structure relevant to multilevel mixture item response models, which can be useful information for researchers working with these models. However, as shown in this study, it is difficult to provide general guidelines in terms of class-specific ICC necessitating multilevel mixture modeling when ICC differs between (within-level) latent classes. Instead, the following guideline applies to the range of class-specific ICCs examined here: A multilevel mixture item response model is recommended for a dataset having
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Notes
Supplemental Material
Supplementary material is available for this article online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.