
Abstract
With the purpose to assist the subject matter experts in specifying their Q-matrices, the authors used expectation–maximization (EM)–based algorithm to investigate three alternative Q-matrix validation methods, namely, the maximum likelihood estimation (MLE), the marginal maximum likelihood estimation (MMLE), and the intersection and difference (ID) method. Their efficiency was compared, respectively, with that of the sequential EM-based δ method and its extension (ς2), the γ method, and the nonparametric method in terms of correct recovery rate, true negative rate, and true positive rate under the deterministic-inputs, noisy “and” gate (DINA) model and the reduced reparameterized unified model (rRUM). Simulation results showed that for the rRUM, the MLE performed better for low-quality tests, whereas the MMLE worked better for high-quality tests. For the DINA model, the ID method tended to produce better quality Q-matrix estimates than other methods for large sample sizes (i.e., 500 or 1,000). In addition, the Q-matrix was more precisely estimated under the discrete uniform distribution than under the multivariate normal threshold model for all the above methods. On average, the ς2 and ID method with higher true negative rates are better for correcting misspecified Q-entries, whereas the MLE with higher true positive rates is better for retaining the correct Q-entries. Experiment results on real data set confirmed the effectiveness of the MLE.
In educational assessment, cognitive diagnostic assessment (CDA) that combines psychometrics and cognitive science has received increased attention (Leighton & Gierl, 2007; Rupp, Templin, & Henson, 2010; K. K. Tatsuoka, 2009). This approach potentially provides useful diagnostic information regarding students’ strengths and weaknesses, and can facilitate individualized learning (Chang, 2015; Chang & Wang, 2016). Cognitive diagnostic models (CDMs) often utilize a Q-matrix (Embretson, 1984; K. K. Tatsuoka, 1990, 1995, 2009), whose entries are 1 or 0,
Correct specification of the Q-matrix is a fundamental step to guarantee the test validity for CDA (McGlohen & Chang, 2008; Im & Corter, 2011). Its procedure is usually an iterative process (Buck et al., 1998; Jang, 2009): (a) The provisional Q-matrix is primarily exploratory based on a current related theory, subject matter experts’ judgment, and item analysis and (b) the modified Q-matrix is primarily confirmatory which is based on statistical methods. The above two steps represent the qualitative and quantitative methods, respectively, and either of them alone is not enough to guarantee the correctness of a Q-matrix.
In practice, expert judgment may introduce some uncertain elements into the provisional Q-matrix (DeCarlo, 2012), making it difficult to specify correctly in CDA (DeCarlo, 2011; Jang, 2009). Previous studies have shown that even a small amount of Q-matrix misspecification could degrade the precision of estimated item parameters, resulting in the decrease in the classification accuracy of CDMs (Baker, 1993; Rupp & Templin, 2008; Im & Corter, 2011). To improve the quality of a Q-matrix, researchers have proposed several quantitative methods for Q-matrix validation, such as the sequential expectation–maximization (EM)–based δ method or δ method (de la Torre, 2008) and its extension ς2 method (de la Torre & Chiu, 2016; Huo & de la Torre, 2013), the γ method (Tu, Cai, & Dai, 2012), the Bayesian approach (DeCarlo, 2012), the data-driven approach (Liu, Xu, & Ying, 2012, 2013), the nonparametric Q-matrix refinement method (Chiu, 2013), and the stepwise reduction algorithm (Hartz, 2002).
The primary advantage of those methods is that they can incorporate expert’s Q-matrix and item response data into Q-matrix validation. However, its disadvantages are very obvious. Five of them are as follows: (a) The δ, ς2, and γ methods rely on particular cutoff values. In fact, different values should be assigned to items with different number of attributes or item quality (de la Torre & Chiu, 2016; Huo & de la Torre, 2013); (b) the performance of the γ method is not very satisfactory when the number of attributes required in correctly solving an item is above three, which is illustrated in the simulation study below; (c) the Bayesian approach requires that the uncertain entries in the Q-matrix should be identified in advance. It could also be used in a more exploratory manner; however, the robustness of this method remains to be explored (DeCarlo, 2012); (d) the data-driven approach (Liu et al., 2012, 2013) is not easy to compute when the number of items and/or the number of attributes is large (Chiu, 2013), though it could be used without experts’ Q-matrix; and (e) the nonparametric method is preferred when the underlying model is unknown, but sometimes it would be less efficient than the parametric method if the underlying model fits the data. In spite of their respective limitations, all the above methods are being widely used.
The traditional methods like the maximum likelihood estimation (MLE) and the marginal maximum likelihood estimation (MMLE) were proposed to estimate the q-vector of an item because it is very similar to estimating attribute pattern of an examinee. Several online calibration approaches, including the MLE-based or MMLE-based method (Y. Chen, Liu, & Ying, 2015; P. Chen & Wang, 2016; P. Chen, Xin, Wang, & Chang, 2010, 2012; Wainer & Mislevy, 1990; W. Y. Wang, Ding, & You, 2011), have been proposed to estimate item parameters or the q-vector in computerized adaptive testing (CAT) or cognitive diagnostic computerized adaptive testing (CD-CAT). One important distinction between Q-matrix validation and online Q-matrix calibration is that the former is often applied to refine a provisional Q-matrix, whereas the latter is usually used to estimate the q-vectors of raw items. Whereas the fact is that little is known about how to extend the traditional online calibration methods to Q-matrix validation, nor are there enough related studies comparing the current Q-matrix validation methods. With this gap in mind, the authors in this article explore an EM-based approach to assist subject matter experts in specifying their Q-matrices. The authors propose three alternative Q-matrix validation methods based on their previous study (W. Y. Wang, Ding, & Song, 2013), none of which need to set cutoff values or give possible misspecified Q-entries.
An EM-Based Approach
The authors intend to make a comparison among the existing methods and the newly developed ones. As most of the existing methods are based on the deterministic-inputs, noisy “and” gate (DINA) model (Junker & Sijtsma, 2001) and the reduced reparameterized unified model (rRUM; Hartz, 2002), this article also chose these two models. Let

where
The item response function for the rRUM is as follows:
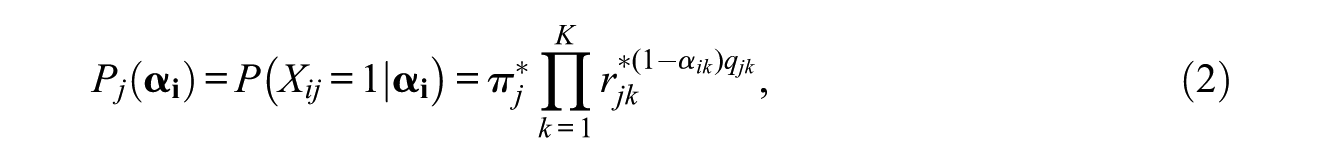
where the baseline parameter
The three methods proposed for Q-matrix validation in this study are the MLE, the MMLE, and an intersection and difference (ID) estimation. The ID method is based on two-set operations (intersection and difference) in terms of set theory. Before estimating the uncertain q-vector for an item, a parameter space or a reduced matrix
Given a provisional Q-matrix and response data, the MLE, MMLE, and ID methods can be friendly implemented in the EM algorithm (de la Torre, 2009; Feng, Habing, & Huebner, 2014) by considering q-vectors as item-specific parameters to be estimated. At cycle t of the EM algorithm, let
Step 1. Obtain a provisional Q-matrix from subject matter experts.
Step 2. Run one EM cycle to estimate the item parameters, the examinees’ attribute patterns, and their distributions.
Step 3. Estimate the q-vector for each item via the MLE, MMLE, or ID method, and then update the Q-matrix. The three methods differ in Step 3. Next, the authors will give a detailed description of the MLE, MMLE, and ID methods, followed by the comparison in between.
Step 4. Repeat the second and third step until the convergence criterion is satisfied (when the discrepancy of the relative log-marginalized likelihood between the previous and current estimate is smaller than 0.001, the convergence is reached).
MLE Method
At cycle t of EM algorithm, item parameter
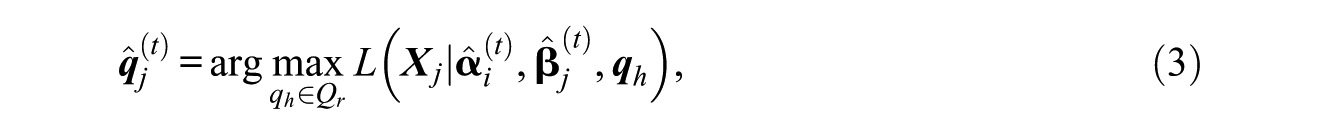
where

MMLE Method
In traditional item response theory, poorly calibrated items may result in an inaccurate estimation of the latent trait. For the purpose of a precise item parameter calibration, the MMLE method should take account of measurement errors derived from the latent trait estimates (Wainer & Mislevy, 1990), which can be effectively addressed, whereas the MLE method ignores these errors. The former has been widely used for the partial Bayesian models, and it only places a prior distribution on the examinees’ population parameters (DiBello, Roussos, & Stout, 2007). In the MMLE, posterior distribution
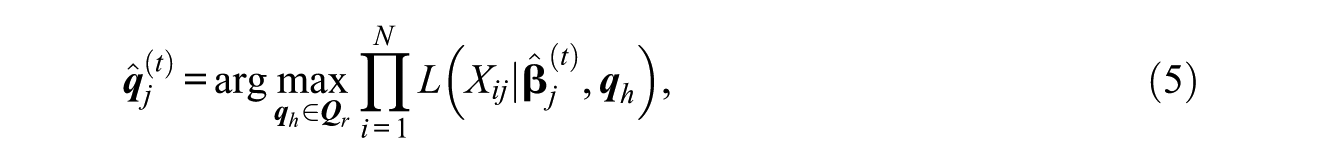
where
ID Method
Based on the definition of noncompensatory/conjunctive (DiBello et al., 2007), both the DINA model and rRUM are categorized into special cases of this model, as you can see in original Tables 4 and 5 in DiBello et al. (2007). For the noncompensatory/conjunctive model (DiBello et al., 2007), it is often reasonable to assume that if most examinees with an attribute pattern solved item
At cycle
Step 1. Let the candidate set
Step 2. Sort
Step 3. Select the attribute pattern with large
Step 4. Repeat Step 3 until
Similarities and Differences Between These Three Methods
All the three methods can successfully estimate the q-vector based on examinees’ attribute patterns. For the MLE method, the whole estimation process can be regarded as a joint maximum likelihood estimation (JMLE) method, while for the MMLE, it sometimes could be thought as empirical Bayes (Casella, 1985; Ivezic, Connolly, VanderPlas, & Gray, 2014). It is important to note that the inherent drawback of JMLE is that the estimators of the item parameters are not statistical consistent (de la Torre, 2009). However, JMLE can be applied to estimate item parameters and attribute patterns very effectively under various CDMs, including the DINA model, the rRUM, the deterministic input noisy or model, and the noisy input, deterministic and model (Y. Chen et al., 2015; Zheng, Chiu, & Douglas, 2015). The ID method can be regarded as a nonparametric method because it requires the estimation of examinees’ attribute patterns only, whereas the MLE and MMLE methods require a parametric model for calculating the likelihood function.
Simulation Study
Simulation Design
To investigate whether these methods can work under certain conditions, simulated data were generated using five attributes. In the simulation study, the correct Q-matrix was fixed as the reduced Q-matrix with 31 items including all the possible nonzero q-vectors to examine the robustness of the estimation methods. This Q-matrix, with an identity or a reachability (
Four important factors were included in the design of the simulation study under the DINA model or the rRUM: (a) the source of the examinees’ attribute patterns (discrete uniform distribution and multivariate normal threshold model), (b) the number of examinees (N = 300, 500, and 1,000), (c) the quality of items (items with s, g~U(0.05, 0.25) or
Simulation Data
For the discrete uniform distribution, attribute patterns were generated to take each of the 25 possible patterns with equal probability for each sample size. Attribute patterns were generated from the multivariate normal threshold model with all the means equal to 0, all the variances and covariances in the variance–covariance matrix equal to 1.00 and 0.50, respectively, following the process used in Chiu et al. (2009). Moreover, the correlation coefficient (ρ) between any pair of attributes is equal to 0.50. Item parameters were randomly generated across replications. The correct Q-matrix was used to generate the item responses based on the DINA model and the rRUM.
Random errors were added to the correct Q-matrix (i.e., error-free) by randomly changing a specified percentage of the elements. The percentage of the elements needed for the change was consistent with the error rates (from 0 to 0.4 with Step 0.1), so the number of elements changed in the correct Q-matrix varies from 0 to 62 equal to the error rates × the number of items (31) × the number of attributes (5). A computer program was designed to achieve this by first selecting an item and an attribute at random, and then reversing the current value of that cell (0 to 1 or 1 to 0) in the Q-matrix (Baker, 1993). The constraints imposed on the generation of the error Q-matrix were that each attribute was at least measured by one item, and each item measured at least one attribute. The provisional Q-matrices for each error rate thus resulted.
Methods and Evaluation Criteria
A computer program based on the EM algorithm (de la Torre, 2009; Feng et al., 2014) was written in MATLAB 2008. For each data set, the performance of three new methods under the DINA model was compared with the γ method, the δ method, and Chiu’s nonparametric method. In the pilot study, seven cutoff values (ε = 0, 0.01, 0.05, 0.10, 0.20, 0.25, and 0.30) in the δ method were used to select the candidate q-vectors. For similar simulation conditions as described above, the results indicated that the cutoff value ε between 0.10 and 0.20 could be regarded as a reasonable value (see Table B1 in Online Appendix B). Therefore, only one cutoff value (ε = 0.20) was used in the following simulation study. In the rRUM, the new methods were only compared with Chiu’s nonparametric method and the ς2 method because the γ method and the δ method cannot be implemented. The nonparametric method relies on the ideal response pattern which is computed following the method proposed by Chiu and Douglas (2013). For the ς2 method, based on earlier work by Huo and de la Torre (2013), two cutoff values of 0.005 (N = 300) and 0.0025 (N = 500 and 1,000) were applied.
The results reported in this study focused on the Q-matrix estimate, because it was directly related to the performance of each method. The correct recovery rate (CRR) is equal to the ratio of the number of correct Q-entries in the estimated Q-matrix to the total number of Q-entries (Chiu, 2013). For each condition, the mean and standard deviation of the CRR values of the 200 replications were reported for each method. In addition, the authors are interested in whether the differences of the largest mean values of CRR were statistically significant from the others. It should be noted that if their means were almost the same or statistically insignificantly different, there would be several promising candidates. In this case, it was advised to perform a paired t test with the null hypothesis H0 that the mean of the differences between the largest and other values of CRRs is equal to zero, against the alternative hypothesis H1 that the null is false. The null hypothesis was tested at the 5% level of significance. The results of test hypotheses were given in Tables B2 and B3 in Online Appendix B. The results of the paired t test were very similar to that of the Wilcoxon signed rank test. To obtain insight into the performance of these methods in two different aspects, the true positive and true negative rates of Q-entries were presented, which were also used for evaluating the performance of the ς2 method (de la Torre & Chiu, 2016). The true positive rate indicates the proportion of correctly specified Q-entries that was retained. The true negative rate indicates the proportion of misspecified Q-entries correctly estimated.
Results
The EM-based algorithm in the majority conditions had achieved convergence when the criterion was pegged at 0.001. The means of the CRR values of 200 replications for each method are shown in Tables B2 and B3, in which the largest CRRs were highlighted in boldface and nonsignificant CRRs associated with the largest rates in boldface italics. For all conditions, the distribution of the standard deviation of the CRR had a mean of 0.04 and a standard deviation of 0.03 (minimum = 0, maximum = 0.12). Detailed results of standard deviations are available by contacting the first author.
The impact of the source for attribute patterns
Tables B2 and B3 show that the quality of the provisional Q-matrix was improved. The Q-matrix was more precisely estimated under the discrete uniform distribution than under the realistic multivariate normal threshold model. This finding was aligned with the results by Chiu (2013). One reason for this result is that some attribute patterns contained too few examinees under multivariate normal threshold model to identify some misspecified q-vectors, noticing that if ρ = 0.5 was positive, then an individual with a specific attribute was more likely to have mastered the second attribute; the other reason is that the prior distribution only matched the discrete uniform distribution.
The impact of sample size
For three sample sizes, Tables B2 and B3 show the accuracy of Q-matrix estimates. In comparison, they showed a clear improvement from the sample size of 500 to 1,000. For the larger sample size (1,000), the mean of the CRR in many cases was above 0.9 for the MMLE and MLE methods within a low (0.1) or moderate (0.2) degree of Q-matrix misspecification. However, increasing sample size hardly improved the accuracy of Q-matrix estimates when the degree of the Q-matrix misspecification was high.
The impact of item parameter and Q-matrix misspecification
The smaller slipping and guessing parameters or penalty parameters corresponded to the better performance of Q-matrix estimates. This is because those smaller values contribute to higher correct classification rates for attribute patterns. The Q-matrix was better recovered from a slight or moderate misspecification than a serious one. Table B2 illustrates that CRRs decreased dramatically when a larger degree of Q-matrix misspecification (e.g., 0.30 or 0.40) was involved.
The impact of the items with different numbers of required attributes
To demonstrate the possible effects of the number of attributes required for an item on Q-matrix estimation, Figure B1 in Online Appendix B shows the mean of CRRs regarding different numbers of attributes. For all methods except the ID method, the accuracy decreased as the number of required attributes increased. It is expected that the performance of the γ method under the DINA model was unacceptable when the number of attributes measured by an item was above three. For other methods under the DINA model, there were relatively small differences across the different numbers of attributes. Similar results were obtained in the rRUM.
The impact of the estimation method
Results of the six methods compared under the DINA model are shown in Table B2. According to the hypothesized test results (see column 12 in Table B2), the MMLE method yielded more significantly accurate Q-matrix estimates than other methods when the data were from the multivariate normal threshold model. The average CRRs across 30 conditions for the γ, MLE, ID, MMLE, δ, and nonparametric methods were 0.7557, 0.8225, 0.7978, 0.8312, 0.7272, and 0.8245, respectively. However, when the data followed the discrete uniform distribution, the corresponding average CRRs were, respectively, 0.7900, 0.8772, 0.8976, 0.8925, 0.8678, and 0.8895, for the six methods. These results indicated that, the ID method, on average, produced better quality Q-matrix estimates than other methods, particularly when the sample size was large (i.e., 500 or 1,000). The table also shows that the nonparametric method resulted in better Q-matrix estimates only when 10% or 20% of the entries in a provisional Q-matrix were randomly changed.
For the results under the rRUM, see Table B3. It shows that (a) the MMLE method outperformed other methods when the data were generated from the multivariate normal threshold model and the quality of items was high (
Real Data and Analysis
The performance of the above Q-matrix validation methods was examined through real data analysis. These methods are applied to the fraction-subtraction data set (K. K. Tatsuoka, 1990; C. Tatsuoka, 2002), which consists of 536 examinees. The Q-matrix, which consists of 15 items, is the same as the one used by de la Torre (2008, see original Table 7) and DeCarlo (2012, see original Table 7). The labels of the attributes are (a) performing a basic fraction-subtraction operation, (b) simplifying/reducing, (c) separating whole numbers from fractions, (d) borrowing one from a whole number to a fraction, and (e) converting whole numbers to fractions. Based on existing results (de la Torre, 2008; Huo & de la Torre, 2013), a small cutoff value (ε or ϵ) of 0.005 was used for the δ and ς2 methods, respectively.
The DINA model and the rRUM were used to analyze the data. For the DINA model, the initial values of item parameters were randomly drawn from U(0.05, 0.4). For the rRUM, the initial values of item parameters were randomly drawn from
Table B7 in Online Appendix B shows the modified Q-matrix from the MLE method. Attributes
Conclusion and Discussion
In conclusion, this study introduced three methods for validating the Q-matrix given the provisional Q-matrix and response data. Simulation results showed that these methods exhibit varying degrees of effectiveness in terms of CRR under different conditions. When determining which method should be used, it is important to note that (a) the MLE method worked better for a test with low-quality items under the rRUM; (b) the MMLE method performed better for a test with high-quality items under the rRUM; (c) the ς2 and ID methods were better for correcting misspecified Q-entries, whereas the MLE method was better for retaining the correct Q-entries; (d) the Q-matrix was more precisely estimated for all methods under discrete uniform distribution than under multivariate normal threshold model; and (d) the ID, MMLE, and nonparametric methods performed well in different conditions under the DINA model.
The contributions of this study are that (a) the proposed validation methods do not need to set cutoff values and specify uncertain entries. Instead, it utilizes the expert’s judgment from the provisional Q-matrix; (b) the proposed validation methods can be easily implemented in the EM algorithm in the DINA model and the rRUM; and (c) the MLE method is an efficient approach for Q-matrix validation in both simulation and real data analyses, and its computation time is comparatively short. On a laptop computer with two 2.1-GHz processors and 2 GB of memory in the MATLAB 2008 software environment, the MLE, ID, and MMLE via the EM algorithm took an average of less than 20 s, 20 s, and 1 min, respectively, to run each data set with the sample size of 1,000. The MLE and MMLE methods should search through all possible q-vectors. When the number of attributes is high, an parallel implementation of the EM algorithm may be considered. An improved parallel EM algorithm has been proposed by von Davier (2017) for estimating generalized latent variable models. Moreover, MapReduce in cloud computing can increase the efficiency of all methods. For example, distributed computing can be used to estimate posterior distributions of attribute patterns separately in subsamples, and then estimate q-vectors of exclusive item sets separately by using a large number of computers (nodes).
The idea of the MLE and MMLE in this study is related to the previous studies in CD-CAT (Y. Chen et al., 2015; P. Chen & Xin, 2011; P. Chen et al., 2012). The MLE and MMLE are quite similar to three online calibration methods, namely, Cognitive Diagnostic-Method A (CD-Method A), Cognitive Diagnostic–Multiple EM Cycles (CD-MEM) proposed by P. Chen and Xin (2011), and the joint estimation algorithm (JEA) proposed by Y. Chen et al. (2015). The CD-Method A and CD-MEM firstly were used to estimate the q-vectors of new items. The CD-Method A and CD-MEM were then used to estimate the item parameters of new items by P. Chen et al. (2012). Based on these two studies, the JEA was developed to estimate both the q-vectors and item parameters of new items. This study further extends these methods to Q-matrix validation.
Some future research directions are also pointed out. First, it is necessary to consider how to determine the number of attributes for either Q-matrix validation method or the data-driven approach (Liu et al., 2012, 2013). It is important to recognize that the number of attributes was fixed to five in this study. Future research might investigate how to eliminate or add attributes by considering not only some fit statistics (J. Chen, de la Torre, & Zhang, 2013) but also the validity of classification results (Cui et al., 2012; W. Y. Wang, Song, Chen, Meng, & Ding, 2015). As the authors mentioned in the simulation study, they only used the cutoff value from the previous study by Huo and de la Torre (2013) for the ς2 method. It should be noted that de la Torre and Chiu (2016) proposed a cutoff value based on the proportion of variance accounted for (PVAF) by a particular q-vector relative to the maximum ς2. From the results of these two papers, the cutoff values specified in both Huo and de la Torre (2013) and de la Torre and Chiu (2016) performed very well. Thus, it would be interesting to compare the performance of the two cutoff values under the ς2 method.
Second, it is worthwhile to explore the impact of attribute hierarchy on Q-matrix specification, because only the independent structure was considered in the simulation study. If an attribute hierarchy is well-defined, on one hand, the reduced Q-matrix (Leighton, Gierl, & Hunka, 2004; K. K. Tatsuoka, 1995) could be taken as a parameter space, that is, all possible q-vectors for an item in the estimation are restricted by the rows of
Finally, one limitation of this study is that the upper bound of
Footnotes
Acknowledgements
The authors thank Dr. Hua-Hua Chang and two anonymous reviewers for their valuable comments on earlier versions of this article.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was partially supported by the National Natural Science Foundation of China (Grants 31500909, 31360237, and 31160203), the Key Project of National Education Science “Twelfth Five Year Plan” of Ministry of Education of China (Grant DHA150285), the National Social Science Foundation of China (Grant 16BYY096), the Humanities and Social Sciences Research Foundation of Ministry of Education of China (Grant 12YJA740057), the National Natural Science Foundation of Jiangxi (Grant 20161BAB212044), the Social Science Foundation of Jiangxi (Grant 17JY10), and the Education Science Foundation of Jiangxi (Grant 13YB032).
Supplemental Material
Supplementary material is available for this article online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.