
Abstract
Imposing content constraints is very important in most operational computerized adaptive testing (CAT) programs in educational measurement. Shadow test approach to CAT (Shadow CAT) offers an elegant solution to imposing statistical and nonstatistical constraints by projecting future consequences of item selection. The original form of Shadow CAT presumes fixed test lengths. The goal of the current study was to extend Shadow CAT to tests under variable-length termination conditions and evaluate its performance relative to other content balancing approaches. The study demonstrated the feasibility of constructing Shadow CAT with variable test lengths and in operational CAT programs. The results indicated the superiority of the approach compared with other content balancing methods.
Computerized adaptive testing (CAT) has been widely used in many disciplines and rigorously studied in the educational measurement arena. One of the important and practical issues in building an operational CAT system in educational measurement is related to implementing content balancing and imposing statistical and nonstatistical constraints on item selection while ensuring the efficiency and measurement precision of the test.
Several content balancing methods have been studied in the literature, such as the weighted deviation method (WDM; Stocking & Swanson, 1993), maximum priority index (MPI; Cheng & Chang, 2009), shadow test approach to CAT (Shadow CAT; van der Linden & Reese, 1998), normalized weighted absolute deviation heuristic (NWADH; Luecht, 1998), and the weighted penalty model (WPM; Shin, Chien, Way, & Swanson, 2009). Among the methods, WDM, MPI, NWADH, and WPM are heuristic. In contrast, Shadow CAT is based on linear programming.
The goal of content balancing is primarily to impose the same test specifications and blueprint requirements for all test takers. However, this task is challenging because optimal ability estimation requires sequential item-level adaptation, whereas constraint realization typically requires simultaneous selection. One solution provided by Shadow CAT is to project future consequences of item selection assuming a fixed-length test. During a CAT administration, a sequence of full-length “shadow tests” are assembled in real time; each shadow test satisfies all statistical and nonstatistical constraints, includes all previously administered items, and provides maximum information at the current ability estimate (van der Linden & Glas, 2010). It has been shown that Shadow CAT outperforms heuristic content balancing methods in terms of providing the optimal solution to CAT (e.g., He, Diao, & Hauser, 2014; Patton, Diao, & Boughton, 2013).
One important component of CAT is termination rules, that is, how to end each examinee’s test. Several termination rules have been proposed in the literature. They generally fall into two main categories: fixed-length termination and variable-length termination (Weiss & Kingsbury, 1984). Under a fixed-length termination condition, the CAT procedure terminates when a fixed number of items have been administered. In comparison, variable-length approaches generally aim to end the CAT when as soon as a prespecified level of measurement precision has been achieved, which potentially allows all examinees to achieve the same level of measurement precision. There are several methods for variable-length termination rules in the literature, such as the standard error (SE) termination rule (Weiss & Kingsbury, 1984), Minimum Fisher Information (MFI) termination rule (Gialluca & Weiss, 1979; Maurelli & Weiss, 1981), and predictive standard error reduction (PSER) termination rule (Choi, Grady, & Dodd, 2011). Termination rules have also been proposed for computerized classification testing, such as sequential probability ratio testing (SPRT; Reckase, 1983; Wald, 1947) and generalized likelihood ratio (GLR; Thompson, 2009). Variable-length termination may also place an upper/lower limit on the number of items to administer to prevent unexpectedly long/short tests. Compared with fixed-length termination, variable-length termination can provide better measurement efficiency and provide fair tests by ensuring equal measurement precision for all examinees.
Shadow CAT has previously been used with fixed-length tests, although van der Linden (2005) has mentioned the possibility of using Shadow CAT for variable-length tests. However, no details were provided as to how to construct such tests apart from the traditional Shadow CAT framework that assumes a fixed-length test. Under the original conceptualization of Shadow CAT, a full-length test is constructed for each item selection, satisfying all constraints and requirements (called a shadow test), using an automated test assembly (ATA) model (van der Linden, 2005). The primary goal of this study is to develop an approach for using Shadow CAT with a variable test-length termination rule and to evaluate the feasibility of the approach in operational CAT programs. This study has three research objectives:
Construct linear models for Shadow CAT using variable-length termination rules;
Evaluate the approach by assessing the extent to which all content constraints are met and equal measurement precision is achieved; and
Evaluate the performance of the approach in comparison with WDM and MPI content balancing methods.
Content Balancing Methods
Three content balancing methods were included in this study: WDM, MPI, and shadow test approach. The first two are heuristic methods and Shadow CAT is based on linear programming. The WDM and MPI methods are well known and widely used. A full list of heuristic methods was not included in this study because the focus of the study was to extend Shadow CAT to variable-length termination rules. A brief description of each method is given below.
WDM
The WDM (Stocking & Swanson, 1993) works by calculating the weighted sum of two components: the deviation from the content targets and the deviation from the item information target for each available item. The item with the smallest sum is selected and administered to the examinee. To be more specific, the target is to minimize
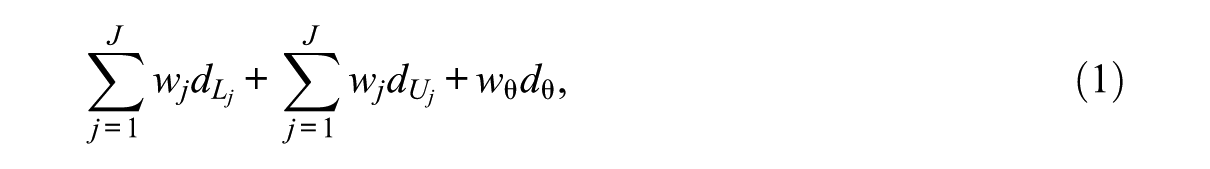
subject to
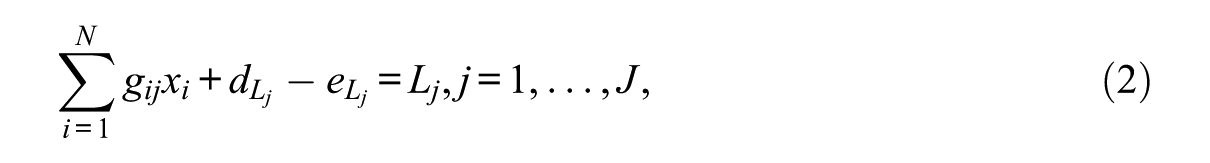
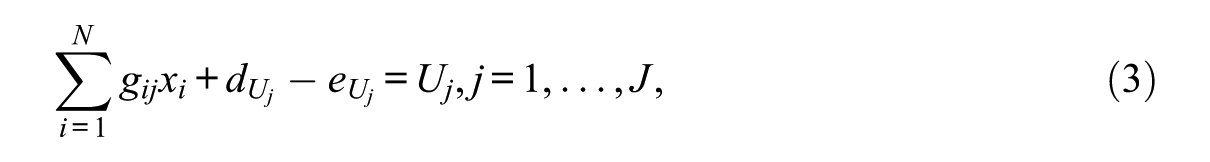

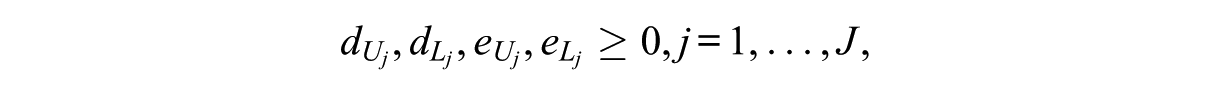
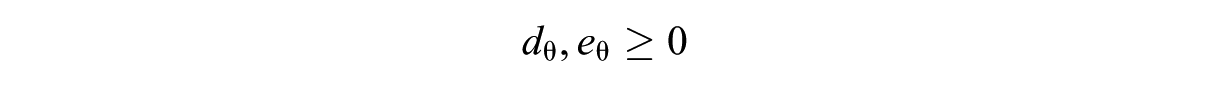
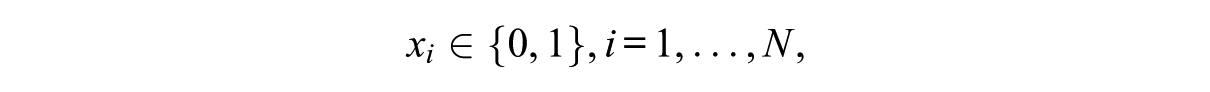
where J denotes the number of constraints; N denotes the total number of items;
MPI Method
This method was proposed by Cheng and Chang (2009) with the goal of achieving fewer constraint violations and better exposure control than WDM. It works by calculating the priority index for each available item in the pool, and selecting the item with the largest index as the next item to administer. The priority index is defined as in Equation 5:

A constraint relevancy matrix


Shadow Test Approach to CAT
Most CAT approaches select items for administration directly from the item pool. In contrast, a typical Shadow CAT works in two steps: (a) from the item pool, assembles a complete form called shadow test, which satisfies all the statistical and nonstatistical constraints, includes all previously administered items, and maximizes the test information given the current ability estimate and (b) selects the optimal item from the free items, that is, items not selected and administered to the students, in the shadow test. As each step is optimal, the final test is optimal. Shadow CAT will be successful in avoiding constraint violations, which cannot be guaranteed when applying heuristic methods. The process of assembling the shadow is handled by ATA and it uses mathematical programming techniques. A mixed-integer programming (MIP) solver is needed to find the optimal solutions for the mathematical model used in the ATA. There are commercial solvers available, such as Xpress, Gurobi, OPL-CPLEX 6.3, and LINGO 12.0 (LINDO), and freely available solvers, such as lp_solve version 5.5 (Diao & van der Linden, 2011; Konis, 2009). An example of a basic ATA model can be found in van der Linden and Diao (2011).
Termination Rules
Two variable-length termination rules were used in this study, namely, the SE termination rule and the PSER termination rule. SPRT and GLR termination rules are for computerized classification tests and were not included in this study. Under the usual regularity conditions, the inverse of Fisher information is asymptotically equal to the variance of the ability parameter. So asymptotically, SE and MFI termination rules should be equivalent based on their definitions. However, with a limited number of items, the inverse of Fisher information is only an approximate estimate of the variance of the ability parameter. Therefore, in adaptive testing with a limited number of items, it is difficult, if not impossible, to set the thresholds for SE and MFI termination for direct comparisons between them. As a result, this study only included the SE and PSER termination rules. The SE and PSER rules are briefly described below. Detailed descriptions of each rule can be found in Weiss and Kingsbury (1984) and Choi et al. (2011).
Standard Error Termination Rule
A CAT will end when the SE of an examinee’s ability estimate,
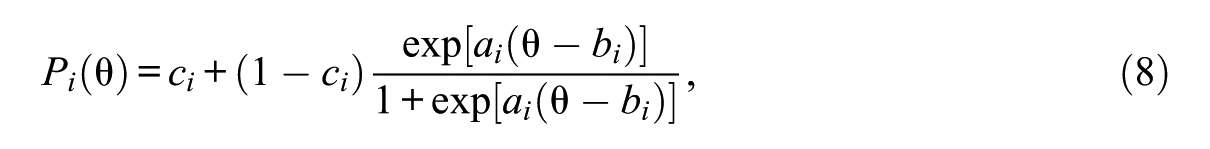
where
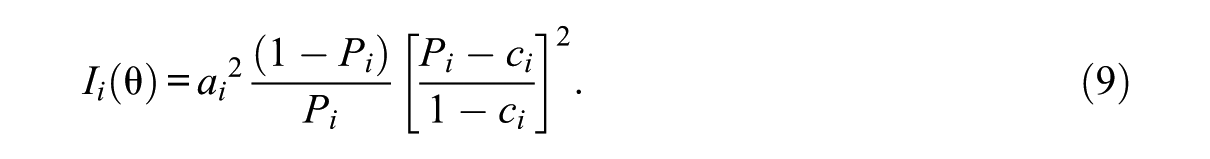
And the Fisher information value for the k administered items is as follows:

The formula for computing SE of

According to the fixed SE termination rule, if the calculated SE value is smaller than the prespecified SE threshold, then the test is terminated. In addition to Fisher information, observed information is another choice for the SE computation in real testing.
PSER Termination Rule
The PSER rule examines whether the SE would be reduced significantly by administering additional items. The PSER index is defined as
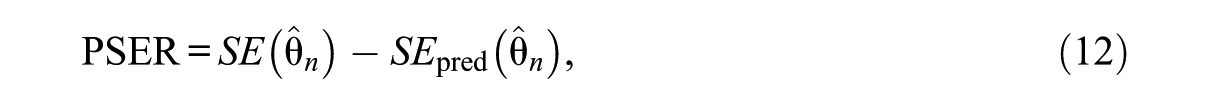
and
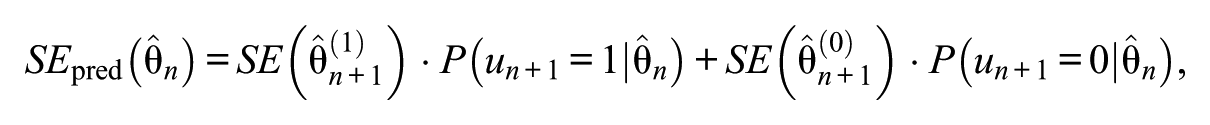
where
Shadow Test Approach for Constructing Variable-Length Tests
For practical reasons, most CAT applications set lower and upper boundaries on the test length in addition to the termination rule to avoid unexpectedly short/long tests. When constructing Shadow CAT with variable-length termination rules, the lower boundary is set to ensure that all minimum content constraints could be satisfied within the first stage. This allows the test to freely terminate in the second stage.
There are two stages in constructing a Shadow CAT with variable-length termination rules. In the first stage, shadow tests are constructed using the minimum test length as a fixed test-length constraint. That is, each shadow test in the first stage has the same test length and the test length is the minimum test length required for the CAT. The authors use n to represent number of items administered to the examinee and
Assemble a shadow test based on the current ability estimate
Select the item with the maximum Fisher’s information value from the free items in the shadow test, and administer the item to the examinee as the (n+ 1)th item.
After the examinee gives a response, update the ability estimate to
Repeat Steps 1 to 3 until the number of items administered reaches the minimum test length.
After the test reaches the minimum test-length requirement, a new test construction method is used for the second stage of the test. Namely, the maximum test length is used as the fixed test-length constraint and it is check whether the test should be stopped according to the termination rule. If the test reaches the maximum test length without reaching the termination rule criteria, the test will be terminated. Detailed steps are given below for both the SE termination rule and PSER termination rules in the second stage (i.e., when n is larger than the minimum test length and smaller than the maximum test length).
In conjunction with the SE termination rule, the second stage of the Shadow CAT approach works by calculating the SE(
If the SE(
If the SE(
When using Shadow CAT together with the PSER termination rule, the following steps are taken.
Assemble a shadow based on
Calculate the SE(
Compare the SE( If the SE( If Otherwise, the test is terminated. If the SE( If Otherwise, CAT is terminated.
A primary difference between the SE and PSER termination rules is that the SE termination rule checks the SE of the ability estimate first in determining whether to continue the test; if the current SE is not below the specified threshold, the shadow test is constructed for selecting the next item to administer. In contrast, the PSER termination rule constructs the shadow test first to calculate the PSER of the next item to administer. If the test continues, the next item is administered without constructing another shadow test.
Simulation
Item Pool
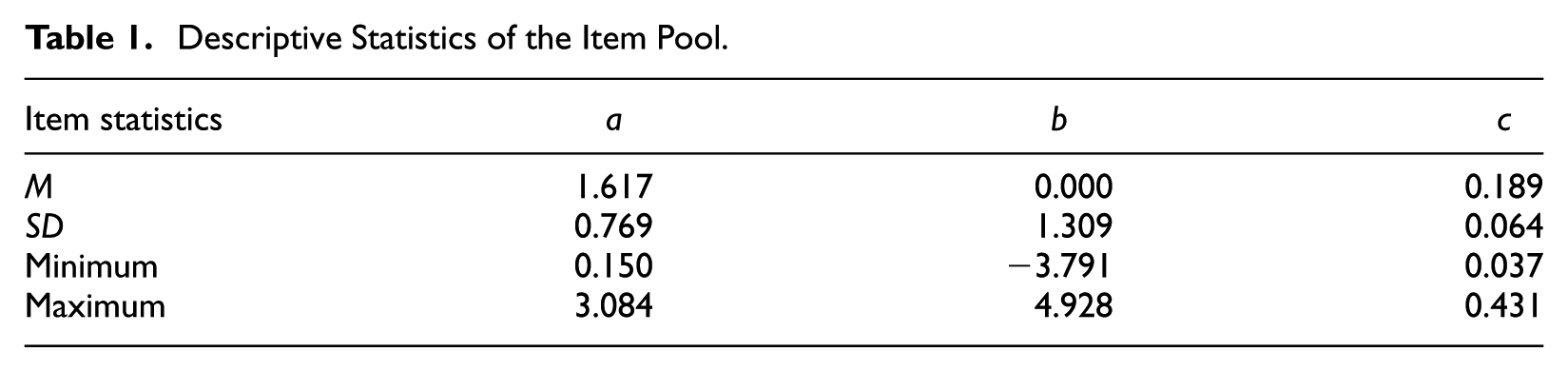
The item pool consisted of 165 items from a large-scale formative assessment program calibrated under the 3PLM based on responses from more than 5,000 students. Descriptive statistics of the item response theory (IRT) parameter estimates are given in Table 1. The constraints imposed by the operational program are summarized in Table 2. In total, there were 27 content-based constraints (54 when considering lower/upper bounds) and corresponding weights for the heuristic approaches (WDM and MPI). All constraints in Table 2 required the number of items from each content category to be between the corresponding lower and upper bounds.
Descriptive Statistics of the Item Pool.
Constraints and Associated Weights of the Simulated CAT.
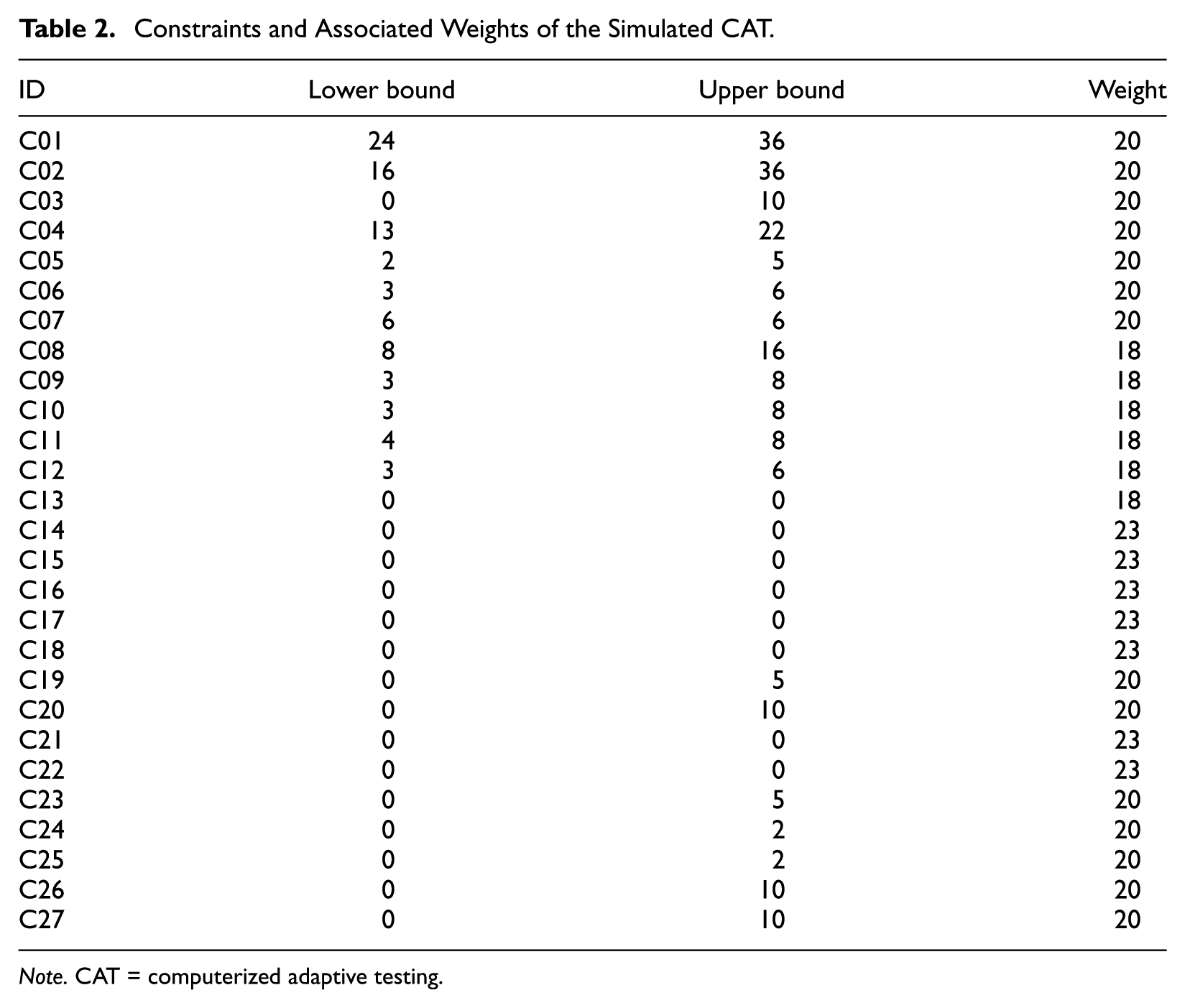
Note. CAT = computerized adaptive testing.
Simulation Setup
The simulation study was split into the following two cases. The first case examined the degree to which each method met the test constraints. The second case obtained a conditional sample, which was used to evaluate the measurement precision of each method. In Case 1, a sample of 1,000 simulated examinees was drawn from a standard normal distribution. In Case 2, tests were replicated 500 times at each of −3.0(0.5)3.0 points. The minimum and maximum test lengths were 24 and 36, respectively.
The adaptive tests used expected a posteriori (EAP) as the interim ability estimates and maximum likelihood estimates as the final ability estimates. The prior distribution was taken to be the standard normal.
In total, six scenarios were simulated with combinations of two termination rules, that is, SE and PSER, and three content balancing methods, that is, WDM, MPI, and Shadow CAT. Each combination was simulated with both Case 1 and Case 2 samples. For termination rules, the prespecified SE criterion was set equal to 0.2. For the PSER method, the prespecified SE criterion was set equal to 0.2,
Evaluation Criteria
Constraint violation was assessed by calculating the total number of times the constraints were met out of 1,000 simulees, and the average constraint value over 1,000 simulees. Measurement precision was assessed by calculating the overall bias, root mean square error (RMSE), mean standard error (SE) of the final estimates, and the standard deviation (SD) of the final SE. Average test length was also calculated.
Results
Case 1 Results
Case 1 examined constraint satisfaction. Tables 3 and 4 report the measures of constraint satisfaction for the content balancing methods for each termination rule. Across the six conditions, Shadow CAT met the test constraints for all 1,000 examinees. The MPI method also met the constraint requirements for both SE and PSER termination rules. The WDM method generally met the constraints when using the SE termination rule, albeit with two exceptions. Out of 1,000 examinees, nine of the tests did not meet constraint C26, and eight of the tests did not meet constraint C27. The WDM method generally met the constraints when using the PSER termination rule, albeit with one exception. Out of 1,000 examinees, 20 of the tests did not meet constraint C11. Because only a small number of examinees using WDM method did not meet the constraints, the average constraint values of those constraints were similar to the ones from Shadow CAT and MPI methods.
Number of Times Constraints Met and Average Values of the Constraints With SE Termination Rule.
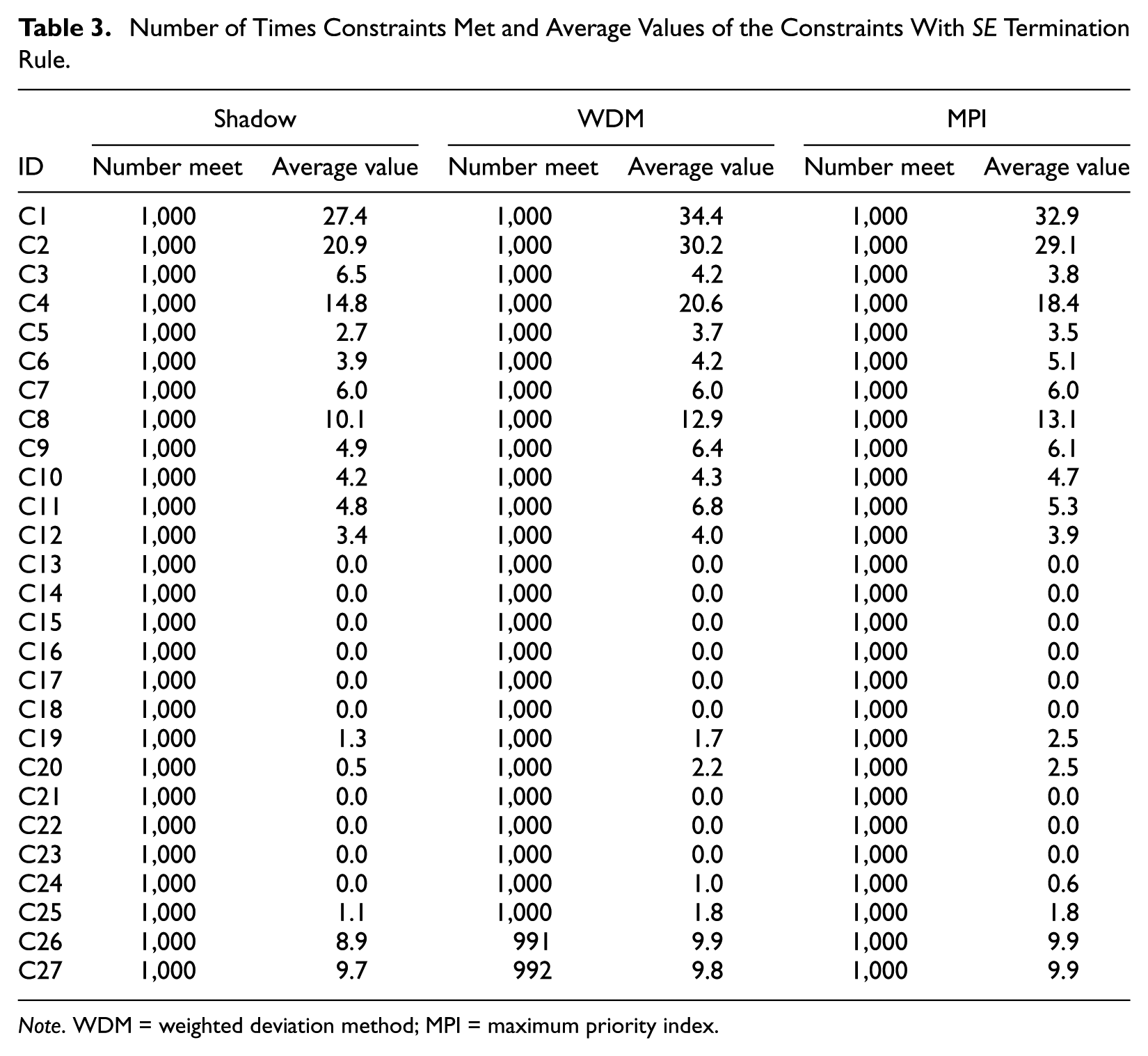
Note. WDM = weighted deviation method; MPI = maximum priority index.
Number of Times Constraints Met and Average Values of the Constraints With PSER Termination Rule.
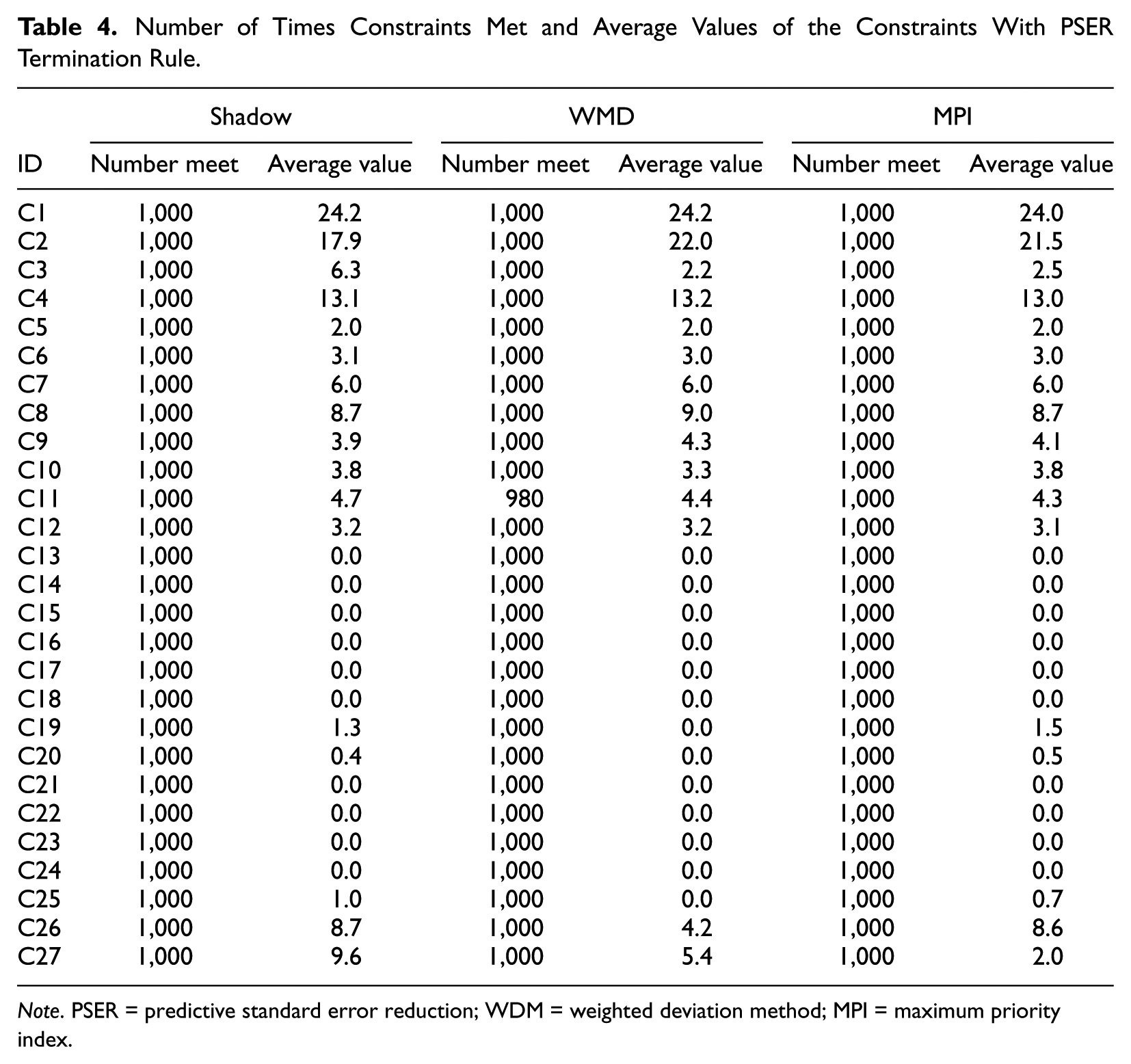
Note. PSER = predictive standard error reduction; WDM = weighted deviation method; MPI = maximum priority index.
The measures of precision for the Case 1 results are summarized in Table 5. The Shadow CAT had the smallest bias, RMSE, final SE, and SD of the final SE across both termination rules. Between the two heuristic methods, MPI outperformed WDM for most of the measures.
Bias, RMSE, Final SE, and SD of Final SE for All Conditions Based on Case 1 Results.
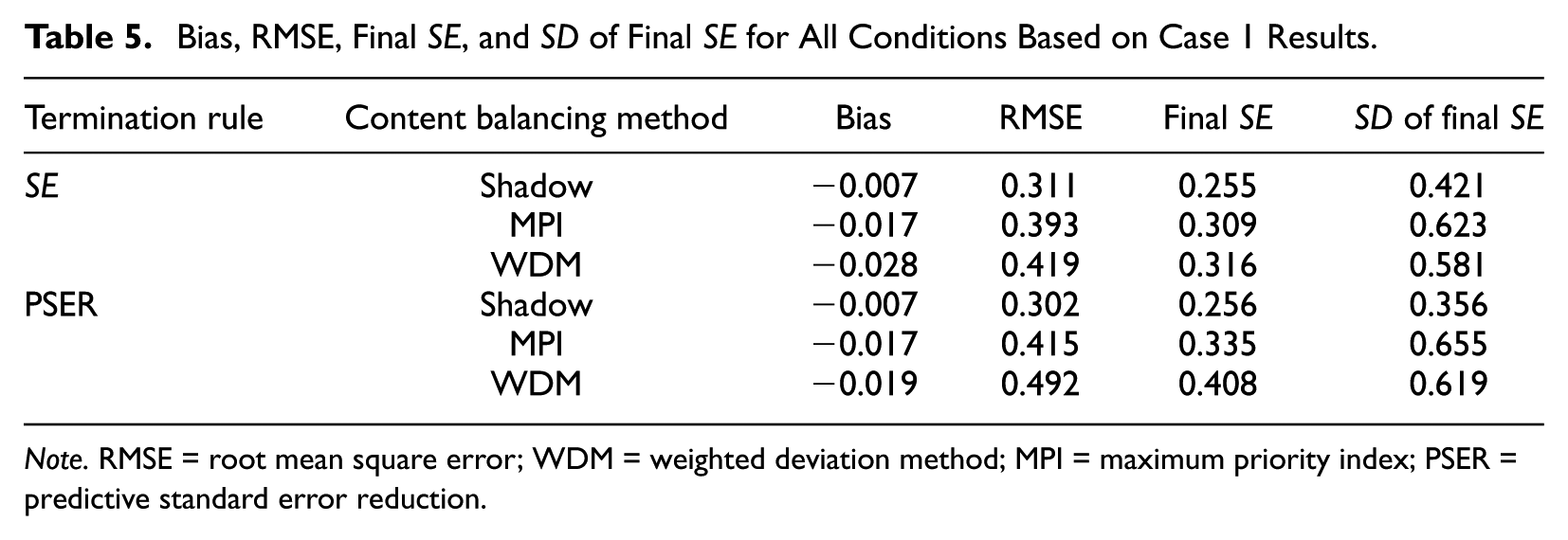
Note. RMSE = root mean square error; WDM = weighted deviation method; MPI = maximum priority index; PSER = predictive standard error reduction.
Case 2 Results
Case 2 used conditional samples to evaluate the measurement precision of each method. Figure 1 shows bias, RMSE, SE of the final estimates, and SD of SE of the final estimates for all the methods. The first row of the graph shows that Shadow CAT had the smallest bias of all the content balancing methods, regardless of the termination rule; MPI had smaller bias than WDM for both termination rules. The second row shows that Shadow CAT had the smallest mean square errors (MSEs), especially at the extreme true ability points. The pattern was consistent across both termination rules. The third and fourth rows of the graph show the SE of the final estimates and SD of the SE of the final estimates. Shadow CAT outperformed WDM and MPI in these measures as well, and the pattern was consistent across both termination rules. Between WMD and MPI, MPI had better measurement precision.
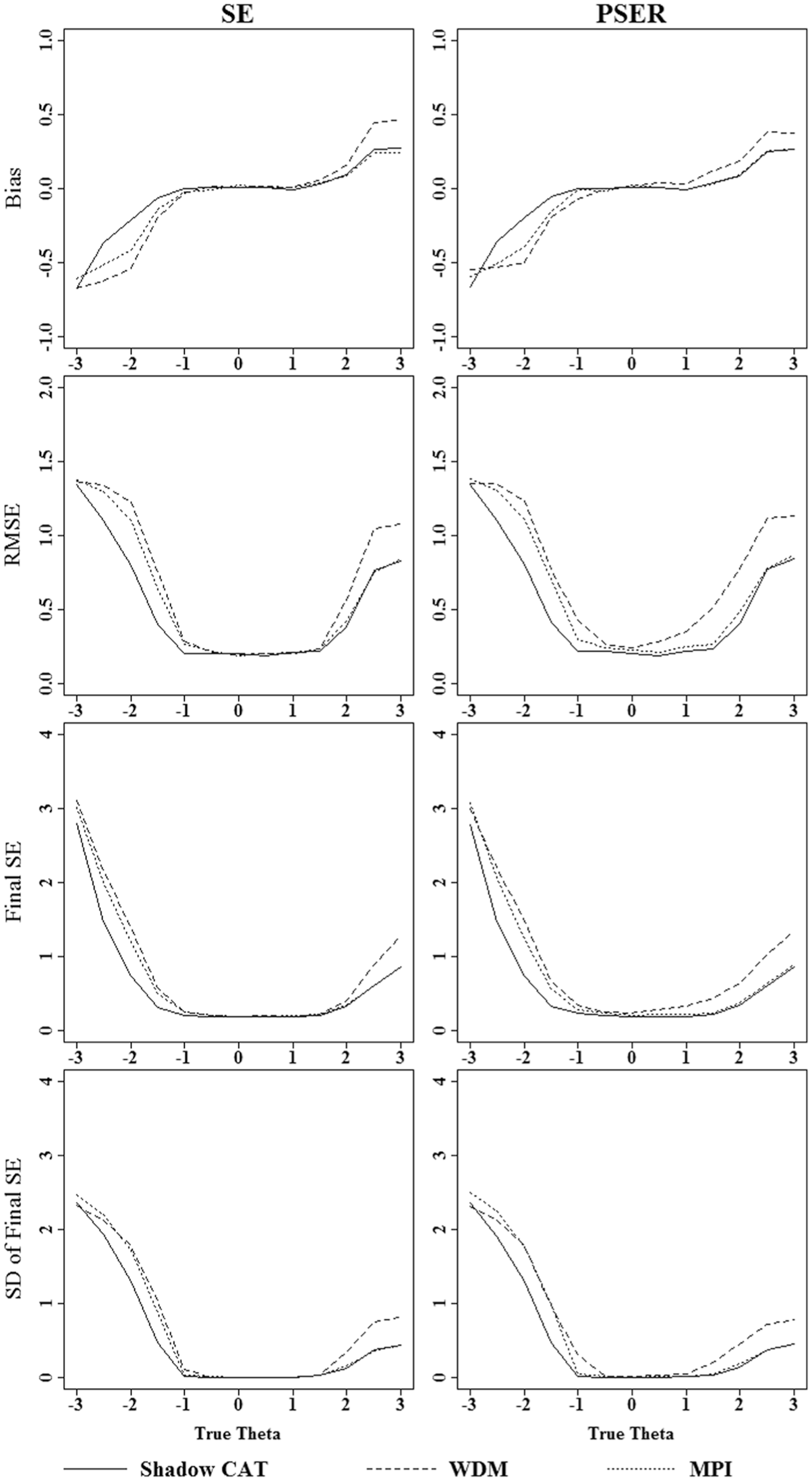
Bias, RMSE, final SE of estimates, and SD of final SE of estimates for all three content balancing methods under different stopping rules.
Figure 2 shows the average test length for the three content balancing methods. The test length indicated the efficiency of the method. Namely, the method with the shortest average test length was the most efficient method because the method was able to meet the same test requirements as the other methods, albeit with fewer items.
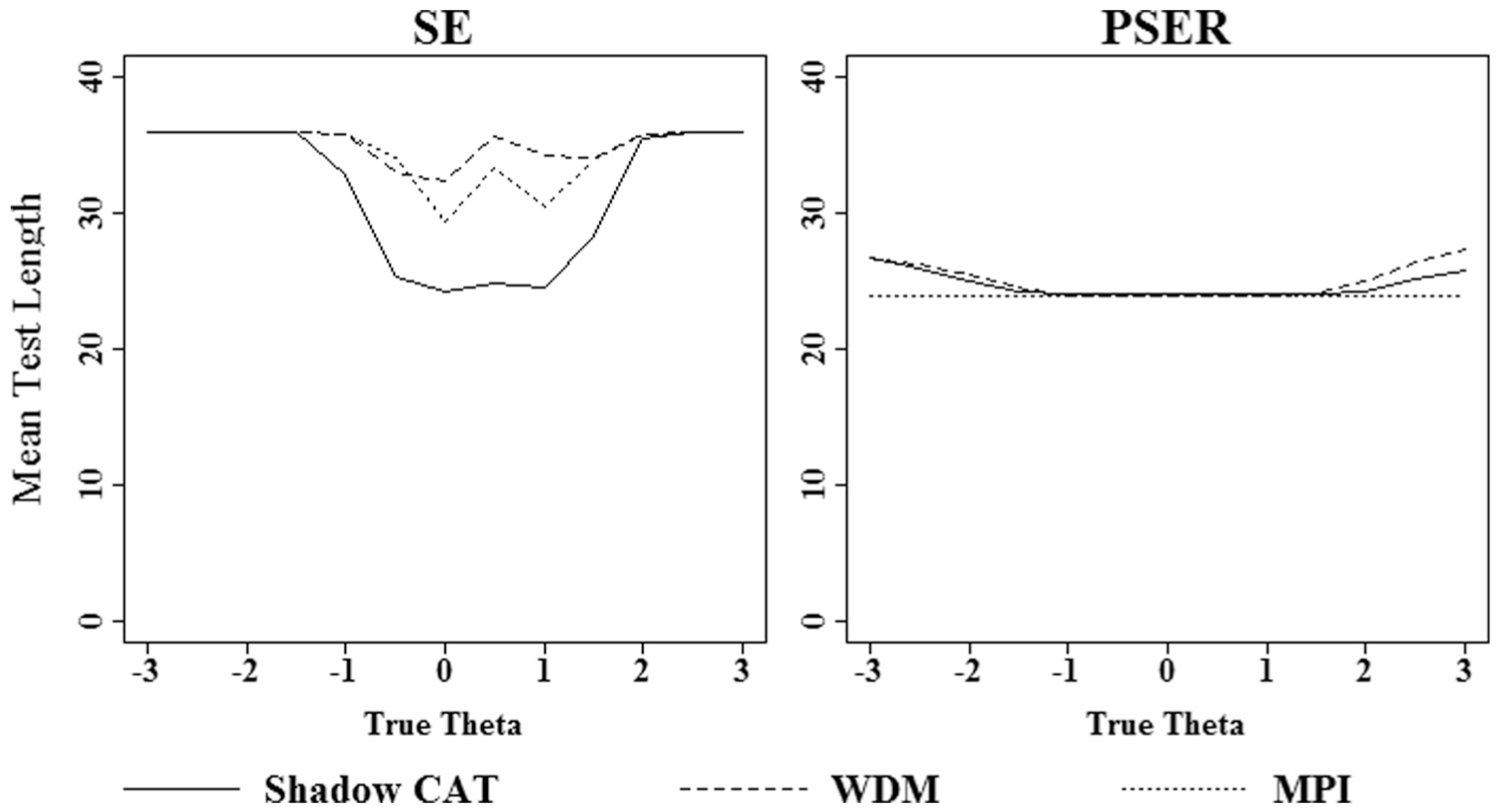
Average test length for all three content balancing methods under different stopping rules.
The first panel shows that Shadow CAT had the shortest average test length when the SE termination rule was used, whereas WDM had the longest average test length. The PSER termination rule is similar to SE, but can override the SE criterion in favor of improving measurement precision through the administration of additional items. When PSER termination rule was used, the three content balancing methods had similar average test lengths except for the extreme ability values, where MPI had shorter test lengths. The average test lengths of MPI were the same as the minimum test length set by the simulation.
The total number of items used in the simulation for each method as an index of item utilization was also counted. For PSER termination, the numbers are 135, 97, and 75 for the Shadow CAT, MPI, and WDM methods, respectively. For SE termination, the numbers are 136, 105, and 103 for the Shadow CAT, MPI, and WDM methods, respectively.
In terms of constraint satisfaction, the three methods performed similarly to Case 1. Out of 6,500 examinees, both Shadow CAT and MPI had no violations. WDM had violations to two constraints when combined with the SE termination rule and had violations to one constraint when combined with the PSER termination rule.
Conclusion and Discussion
This study had three goals. The first and most important one was to construct Shadow CAT with a variable-length termination rule. Variable-length termination is commonly used in CAT and can achieve better measurement efficiency than fixed-length termination. Yet no previous research attempted to combine Shadow CAT with variable-length termination rules. This study demonstrated that variable-length Shadow CAT can be constructed and implemented in operational programs.
The second goal of the study was to examine constraint satisfaction and measurement precision under the variable-length approach. In the simulation study, the Shadow CAT method was shown to meet all test constraints, which is noteworthy considering the complexity of the constraints. The measurement precision of the examinee scores was similar, although the scores at the extreme ends of the scale were measured with less precision. The reduced measurement precision was a byproduct of item pool quality. Namely, there were not enough items at the extreme ends of the scale to support sound measurement of the corresponding ability scores. Thus, to better utilize adaptive testing, that is, to truly tailor the test to each individual student, a sound item pool design is needed (He & Diao, 2014).
The third goal of the study was to compare the performance of Shadow CAT with WDM and MPI. The results of the simulation study showed that both Shadow CAT and MPI satisfied all constraint requirements, whereas the WDM method had some violations. In terms of measurement precision, Shadow CAT consistently outperformed WDM and MPI across all criteria, including bias, MSE, SE of final estimates, SD of SE of final estimates. In most cases, Shadow CAT also had better item utilization. For the extreme cases, MPI had better item utilization when PSER termination rule was applied. The optimality of the Shadow CAT comes from the linear programming method it uses. The method uses a mathematical model to achieve optimal measurement precision while satisfying all test constraints. Namely, the linear programming technique selects the most informative test at a particular ability level, from all possible test forms that satisfy the constraints. In contrast, heuristic methods such as WDM and MPI endorse sequential item selection and attempt to balance the trade-off between measurement precision and constraint satisfaction by means of weights. For example, the observed failure of the WDM to meet all test constraints may have been caused by low weights for some of the constraints. However, if the constraint weights had been increased, the measurement precision could be compromised. Because extending Shadow CAT to variable test length is the focus of the study, only two content balancing methods were used for comparison. In the future, more content balancing approaches can be included for comparison.
The success of any CAT depends largely on the quality of the item pool. If the quality of the item pool is poor, Shadow CAT may run into infeasibility. And heuristic methods may have even more severe constraint violations. In the current study, the measurement precision of extreme abilities was poor across all methods, which was largely caused by the quality of the item pool. That is, there were not enough quality items in the pool to support the measurement of examinees with extreme abilities. In future studies, various item pools should be used as an additional condition to better evaluate the impact of the item pool.
In the simulation study, the minimum test length was derived to accommodate the lower bounds of various content constraints. However, from a measurement precision perspective, a smaller minimum test length should be set to better utilize the measurement efficiency provided by the variable-length termination rule. For example, if a smaller minimum test length had been set for the PSER termination rule, the authors may have observed more tests terminating before reaching 24 items. In future studies, it would be interesting to examine the relationship between the minimum test length specified and the actual test length observed. Maximum likelihood estimates were used as the final ability estimates, and it was noticed that in some cases (less than 1% of the sample), the final abilities did not converge for students with extreme true abilities. The authors would recommend adding using EAP as both the interim and final ability estimation method as an additional condition, especially when the item pool does not support sufficient measurement for students with extreme abilities. In addition, it would be interesting to conduct future studies on comparing variable-length Shadow CAT with the fixed-length Shadow CAT. The studies need to take into consideration how to choose the test length for the fixed-length CAT so a fair comparison between variable-length CAT and fixed-length CAT can be conducted.
Content balancing is key to establishing validity, especially in educational measurement. Of the various approaches to content balancing currently available, Shadow CAT provides a flexible framework for adaptive testing solutions that require complex sets of constraints. This study showed how to construct Shadow CAT with two variable-length termination rules, SE and PSER, and demonstrated the superiority of the approach in comparison with two other popular heuristic methods, WDM and MPI. The new method extends the utility of the Shadow Test approach by allowing for the construction of variable-length tests. Namely, the new method allows for optimal test solutions to be delivered efficiently and/or with high measurement precision, depending on the needs of the testing program.
Footnotes
Acknowledgements
The authors thank the editor, Hua-Hua Chang, the associate editor, Chih-Hung Chang, and three anonymous reviewers for their helpful comments. The authors also thank Wim van der Linden, Seung Choi, and David King for their inputs.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.