
Abstract
Many multilevel linear and item response theory models have been developed to account for multilevel data structures. However, most existing cognitive diagnostic models (CDMs) are unilevel in nature and become inapplicable when data have a multilevel structure. In this study, using the log-linear CDM as the item-level model, multilevel CDMs were developed based on the latent continuous variable approach and the multivariate Bernoulli distribution approach. In a series of simulations, the newly developed multilevel deterministic input, noisy, and gate (DINA) model was used as an example to evaluate the parameter recovery and consequences of ignoring the multilevel structures. The results indicated that all parameters in the new multilevel DINA were recovered fairly well by using the freeware Just Another Gibbs Sampler (JAGS) and that ignoring multilevel structures by fitting the standard unilevel DINA model resulted in poor estimates for the student-level covariates and underestimated standard errors, as well as led to poor recovery for the latent attribute profiles for individuals. An empirical example using the 2003 Trends in International Mathematics and Science Study eighth-grade mathematical test was provided.
In large-scale educational assessments, such as the Program for International Student Assessment (PISA), Trends in International Mathematics and Science Study (TIMSS), and the National Assessment of Educational Progress (NAEP), two-staged or multi-staged sampling is often used. A number of schools usually are sampled first, and a number of students then are selected from each sampled school. This two-staged sampling creates two levels of data: student-level and school-level data. Students sampled from the same school are likely to be more homogeneous in the outcome variables of interest than students sampled from different schools because school characteristics often are associated with student performance (Goldstein, 2010). Multilevel models have been developed and widely used to fit multilevel continuous data (Goldstein, 2010) as well as categorical item responses (Fox & Glas, 2001; W. C. Wang & Qiu, 2013). The consequences of ignoring multilevel structures have been well documented (Fox & Glas, 2001; Goldstein, 2010). Specifically, the fixed-effect estimates (e.g., item parameters), in general, are not biased. However, the variance of the ignored level (e.g., school level) is redistributed to the adjacent levels (e.g., student level), which results in inaccurate estimates of the variance–covariance of the student level. More important, the estimated standard errors of predictors at the student level will be underestimated. The underestimation of standard errors may lead to serious consequences when an important decision or practice is overturned due to the size of a standard error (Goldstein, 2010).
In the past decade, there has been a surge of interest in cognitive diagnostic assessment. Cognitive diagnostic models (CDMs) have been given different names, including diagnostic classification models, latent response models, and restricted (constrained) latent class models (Rupp, Templin, & Henson, 2010). General CDMs include the log-linear cognitive diagnostic model (LCDM; Henson, Templin, & Willse, 2009), the general diagnostic model (GDM; von Davier, 2010), and the generalized deterministic input, noisy, and gate (G-DINA) model (de la Torre, 2011). A vast amount of literature about CDMs is available (e.g., Rupp et al., 2010).
Most existing CDMs are unilevel. There have been some attempts at extending unilevel CDMs to multilevel ones. For example, von Davier (2010) introduced a hierarchical GDM to account for the property of clustered responses within a school, but the parameter recovery of the new multilevel GDM and the consequences of model misspecification were not evaluated with simulations, nor were the item or person covariates incorporated into the model, making the model somewhat restrictive. The expectation-maximization (EM) algorithms used in the study often suffer from the choices of initial values and inaccurate estimation for the asymptotic variance–covariance matrix of the maximum likelihood estimator (Karlis & Xekalaki, 2003). Moreover, these algorithms become infeasible because of the complexity in the integration and computation of inverse matrices when the number of attributes is large. All of these limitations may hinder applications of the new model.
Just as item or person covariates can be incorporated directly into item response theory (IRT) models, which calls for explanatory IRT models (de Boeck & Wilson, 2004), so does explanatory CDMs. A recent example is provided by Ayers, Rabe-Hesketh, and Nugent (2013), in which person-specific covariates are added to the deterministic input, noisy, and gate (DINA) model (Junker & Sijtsma, 2001). Specifically, each latent attribute k is assumed to follow a Bernoulli distribution with probability π k and be independent of other latent attributes. A logit link function then is used to combine person-level covariates. The model can be estimated using Bayesian Markov chain Monte Carlo (MCMC) methods. The resulting model, though improving the recovery of latent attributes, does not go beyond the person (student) level and, thus, becomes inapplicable when students are nested in schools.
The main purpose of this study was to develop a new class of multilevel CDMs, which use the general LCDM as the item-level model. Covariates can be incorporated directly into the student (Level 1) and school (Level 2) levels, and their effects on attribute mastery can be conveniently estimated. In addition, it is expected that fitting unilevel CDMs to multilevel data will not affect item parameter estimates and their standard errors, but will underestimate the standard errors of the predictors at the student level and the profile classification’s accuracy. Using the new multilevel CDMs, the standard errors of the covariates can be estimated accurately, which will result in appropriate statistical testing for the covariates, and improve the accuracy of attribute and profile classification for individuals.
The remainder of this article is organized as follows. First, the item-, student-, and school-level components of the multilevel CDMs are introduced, where the LCDM (Henson et al., 2009) is used as the item-level model without loss of generality. Second, the Bayesian estimation with the MCMC methods is described briefly. Third, the results of simulation studies that were conducted to assess parameter recovery and the consequences of ignoring multilevel structures are summarized. To facilitate the estimation, the popular and parsimonious DINA model, which is a special case of LCDM, is used for demonstration in this study. The resulting multilevel DINA (mDINA) model is evaluated and compared with the unilevel DINA (uDINA) model under various conditions. Fourth, the new models are applied to an empirical example retrieved from the TIMSS eighth-grade mathematical test to demonstrate the implication and applications of the newly developed multilevel CDMs. Finally, conclusions about the new models are drawn and the possibilities for future study are discussed.
Item-Level Models
There are D+ 1 components in a D-level CDM. For example, a two-level CDM has three components, including an item-level model of CDMs, a Level 1 model for persons (e.g., students), and a Level 2 model for groups (e.g., schools). The item-level CDMs are introduced in this section and Level 1 and Level 2 models are introduced in the next section.
Item-level models should be as flexible as possible. To meet the demand, the LCDM (Henson et al., 2009) is used as the item-level model because it can accommodate many CDMs. Other general CDMs, such as the GDM (von Davier, 2010) and G-DINA model (de la Torre, 2011), can be used as well. Let Yni be the response to item i (i = 1, . . . , I) of person n (n = 1,. . . , N) and

where λ
i,0 is the intercept and defines the log-odds of success for the examinees who have not mastered any of the attributes required by item i;

Setting appropriate constraints on Equation 2 creates a variety of CDMs (Henson et al., 2009), including the DINA model, the (compensatory) reparameterized unified model (Hartz, 2002), and the deterministic input, noisy, or gate (DINO) model (Templin & Henson, 2006).
Two Approaches to Multilevel CDMs
In multilevel linear models, Level 1 outcome variables (e.g., income) are continuous. In multilevel IRT models, the item-level model is an IRT model, and the Level 1 outcome variables are the corresponding latent trait(s), which are continuous, so that the formulation of multilevel IRT models becomes straightforward. In contrast, in multilevel CDMs, the item-level model is a CDM, which yields binary latent attributes rather than continuous latent traits. This dichotomy makes the formulation of multilevel CMDs less straightforward than that for their counterparts. In this study, two approaches were proposed for multilevel CDMs: the latent continuous variable (LCV) approach and the multivariate Bernoulli distribution (MBD) approach.
The LCV Approach
The LCV approach adopts Pearson’s (1900) concepts of tetrachoric correlation. Specifically, the LCV

The vector
Typically, there are three types of assumptions about the probability distribution of attributes in previous studies. In a saturated model, each of the
For illustrative simplicity, let there be two levels, a student level and a school level, and let

where β0ck is the intercept, representing the average level of school c on attribute k; β
lck
is the regression slope; ε
nck
is the error term; the vector (ε
nc1, ε
nc2, . . ., ε
ncK
) is assumed to follow a multivariate standard normal distribution with a mean vector of zero and a variance–covariance matrix of
At the school level, the β coefficients in Equation 4 can be regressed on school-level covariate Wlckm (m = 1, . . ., M; M is the number of school-level covariates), for example, school type,

where υ
l0k
is the intercept which is the grant mean across school on attribute k; υ
lmk
is the regression slope; elck is the error term; and the vector (e
lc1, elc2, . . ., elcK) is assumed to follow a multivariate normal distribution, with a mean vector of zero and a variance–covariance matrix of
The intraclass correlation coefficient (ICC), which is defined as the ratio of the Level 2 variance over the total variance (i.e., the sum of the Level 1 and Level 2 variances), often is reported in multilevel models. Attribute k’s ICC can be computed as,

where ω
kk
and σ
kk
denote the school-level and student-level variances of attribute k, respectively, assuming that there are no student-level and school-level covariates in Equations 4 and 5. Because the main diagonal elements of
The MBD Approach
In the MBD approach, let

where β0ck, β lck , and Xnckl are defined by Equation 4. At the school level, the β coefficients in Equation 7 can be regressed on school-level predictors, as done in Equation 5.
To derive the ICC in the MBD approach, one needs to compute the total variance and the within-school variance. Let π ck be the mean probability of mastering attribute k in school c and π k be the mean probability of mastering attribute k in the population. Thus, π ck (1 –π ck ) is the within-school variance for school c and π k (1 –π k ) is the total variance. The variance π ck (1 –π ck ) is not homogeneous across schools because it depends on π ck . Thus, one can take a mean across schools to represent the within-school variance: E(π ck (1 –π ck )). Attribute k’s ICC then is defined as follows:

Both the LCV and MBD approaches are viable. They should yield very similar estimates for the item parameters, attribute and profile classifications, and correlations among latent variables because both approaches use the same item-level model. However, they will yield rather different estimates for the intercepts and regression coefficients because they are not on the same metric. The two approaches have strengths and limitations. The LCV approach is easy to follow because it connects multilevel CDMs with multilevel linear models. It assumes a multivariate normality for the underlying latent variables, which can be specified with most computer programs. In addition, it often requires high-dimensional integration, especially when the number of attributes is large. In contrast, the MBD approach does not require assumptions on the LCVs and high-dimensional integration. Therefore, the model is more robust and its estimation will be less time-consuming. Unfortunately, the MBD is not very intelligible to practitioners, and to the best of the authors’ knowledge, none of the existing computer programs can accommodate the MBD, making its implementation very challenging to most users. In practice, one may first apply the univariate Bernoulli distribution by assuming independence among the attributes and then calculate the tetrachoric correlations of the estimated attributes. In this study, focus was on the LCV approach in the following simulations and both approaches were adopted in the empirical example.
Parameter Estimation of Multilevel CDMs
Both the LCV and the MBD approaches can be estimated using the EM and MCMC methods. For the LCV approach, a marginal likelihood can be obtained by summing over the school-level distribution and integrating out the multivariate standard normal distribution of the LCV
Let

where
The freeware, Just Another Gibbs Sampler (JAGS; Plummer, 2003), which provides users with a simple tool for performing MCMC methods, was used in this study. The deviance information criterion (DIC), which can be obtained easily from JAGS, can be used to compare models (Spiegelhalter, Best, Carlin, & van der Linden, 2002). The smaller the DIC is, the better the model. A difference of less than 5 in the DIC between models does not provide sufficient evidence that one model is more favorable than the other (Spiegelhalter et al., 2002).
For the LCV approach, the main diagonal elements of the Level 1 variance–covariance matrix
In this study, Fisher’s z was adopted to transform the correlation coefficient ρinto
Method
For demonstration, the DINA model was used as the item-level model because of its popularity and parsimony. In the simulation, the mDINA model was used to generate item responses, and both the data-generating model and the uDINA model were fit to the data. It was expected that fitting the data-generating mDINA model would result in good parameter estimates. It also was expected that ignoring the multilevel data structures by fitting the uDINA would result in poor estimation of the covariates and underestimated standard errors, as well as lower recovery rates for attributes and latent profiles for individuals. In addition, fitting the mDINA model to the data without multilevel structures would yield good parameter estimates and good recovery rates, indicating it did little harm to fit an unnecessarily complicated model.
Design
Four independent variables were manipulated: (a) number of attributes (3 and 5), (b) number of schools (30 and 100), (c) test length (10 and 30 items), and (d) ICC (0, 0.09, and 0.33). In the linear multilevel literature, 30 groups are often regarded as a minimum requirement and 100 groups as sufficient (Hox, 2010). The magnitude of ICC was manipulated to investigate the consequences of ignoring multilevel data structures on parameter estimation. In general, the necessity of multilevel analysis can be indicated by the design effect, which is defined as
The off-diagonal elements in the student-level variance–covariance matrix
When there were three attributes, each attribute was measured by half of the items (i.e., each attribute was measured by 15 items when there were 30 items in the test). When there were five attributes, each attribute was measured by fewer items; for example, when there were 10 items in the test, each attribute was measured by two or three items. Each item is designed to measure one to three attributes. These settings mimicked those in the CDM literature (e.g., Huang & Wang, 2014).
The mDINA model was used to generate data in which the item-level model was the DINA model. The student-level model was Equation 4, and the school-level model was Equation 5. A two-staged sampling was adopted in the generation of multilevel data. A total of 30 or 100 schools were first sampled, and 30 students then were sampled from each school, which resulted in a total of 900 and 3,000 students, respectively. The slip (s) and guessing (g) parameters of the DINA model were sampled from a uniform distribution between 0 and 0.3, which were similar to those used in the literature (Huang & Wang, 2014). The student-level covariate Xnck was a binary variable (e.g., gender: female = 0, male = 1) and was generated from a Bernoulli distribution with a parameter of 0.5. The intercept υ00k was set at zero for each attribute. The regression coefficients of covariate υ10k were set at −0.5, 0, and 0.5 for the three attributes, respectively, indicating that females have a higher, equal, and lower probability than males of mastering the three attributes, respectively. No school-level covariate was used in the simulation.
A MATLAB program was written to generate item responses. The LCV (
Data Analysis
The posterior mean and standard deviation were treated as the point estimate and the standard error, respectively. The bias and the root mean square error (RMSE) in the estimates across replications were computed to assess the parameter estimation. In addition, to evaluate the consequences of ignoring multilevel data structures, the estimates of the covariates and their standard errors obtained from the mDINA and uDINA models were compared. Moreover, the recovery rates of individual attributes and latent profiles from the models were compared as well.
Results
Visual inspections revealed that the chains for the estimated parameters converged to the stationary distribution. The following statistics also indicated the convergence of the chains. Monte Carlo error values for the posterior mean of the parameters were close to 0 and the estimated potential scale reduction factor (
Three Attributes Under Conditions ICC-H and ICC-L
Tables A1 and A2 in the online supplement show the generating values, bias, and RMSE for the regression coefficients, variances, and covariances across replications under the ICC-H and ICC-L conditions, respectively. When the data-generating mDINA model was fit to mDINA data, the parameter recovery for the g and s parameters was satisfactory, with the bias and RMSE in the third and second decimal places, respectively. For the intercept, slope, variance, and covariance parameters, the parameter recovery was also satisfactory. For example, as shown in Table A1, the bias was between −0.029 and 0.140 and the RMSE between 0.047 and 0.228 for 30 schools, and the bias was between −0.026 and 0.035 and the RMSE between 0.016 and 0.129 for 100 schools. As expected, the longer the test and the larger the number of schools, the better the parameter recovery.
When the uDINA model was fit to mDINA data (with the multilevel structures ignored), the estimation for the student covariates υ101 and υ103 was quite poor. For example, under the ICC-H condition, the bias for υ101 and υ103 across test lengths and school sizes was between −0.139 and 0.130, and the RMSE was between 0.100 and 0.175. The poor estimation for the regression coefficients of the student-level covariate was mainly due to the constraint on the main diagonal elements of
It appeared that the intercept parameters under the uDINA model (β01, β02, and β03) were recovered slightly better than those under the mDINA model (υ001, υ002, and υ003). This phenomenon, also found in the literature of multilevel models (Steenbergen & Jones, 2002; W. C. Wang & Qiu, 2013), was because the uDINA model combined Level 1 responses across Level 2 units to make use of all data and because it had fewer parameters than the mDINA model.
To examine the accuracy of the standard errors for the regression coefficients of the covariates, the authors computed the ratio of the standard deviation of the posterior means across replications over the mean of the empirical (estimated) standard errors across replications. A value close to 1 indicated a good estimate for the standard errors. It was found that, when the generating mDINA model was fit, the ratios were between 0.88 and 1.15 in the ICC-H condition and between 0.89 and 1.04 in the ICC-L condition. Thus, the standard error estimates of the mDINA model were satisfactory. In contrast, when the uDINA model was fit, they were between 2.65 and 4.87 in the ICC-H condition and between 1.91 and 4.76 in the ICC-L condition, suggesting the standard errors were underestimated. Take υ102 as an example. Under the condition of 10 items, 30 schools, and ICC-H, the mean of the estimated standard errors were 0.035 and 0.103 for the uDINA and mDINA models, respectively. Taking the standard error of the mDINA model as the gold standard, one found that the standard error of the uDINA model was underestimated by approximately 66%. Under the ICC-L condition, they were 0.064 and 0.096, respectively, and the underestimation was approximately 33%.
Figure 1 shows that the recovery rates of the latent profiles for the mDINA model were between 73.8% and 97.2% under the ICC-H condition and between 68.7% and 97.1% under the ICC-L condition. For the uDINA model, they were between 68.6% and 96.9% under the ICC-H condition and between 67.0% and 96.9% under the ICC-L condition. The recovery rates for the mDINA model were generally higher than those for the uDINA model by 0.3% to 5.2% with a median of 1.7% across the eight profiles under the ICC-H condition and by 0.1% to 3.3% with a median of 0.8% under the ICC-L condition. It appeared that ignoring multilevel data structures had substantial consequences on examinee classification. The recovery for profiles “100” (5%), “010” (6%), “110” (3%), and “101” (6%) was poorer than profiles “000” (28.7%), “001” (10.2%), “011” (13.8%), and “111” (27.3%), where the numbers in parentheses are the posterior probabilities of the corresponding profiles in the sample for the mDINA model under the ICC-H condition. It seemed that the smaller the proportion, the poorer the recovery of the profile. The recovery rates for the three attributes under the two models were almost identical, which might be due to the ceiling effect.
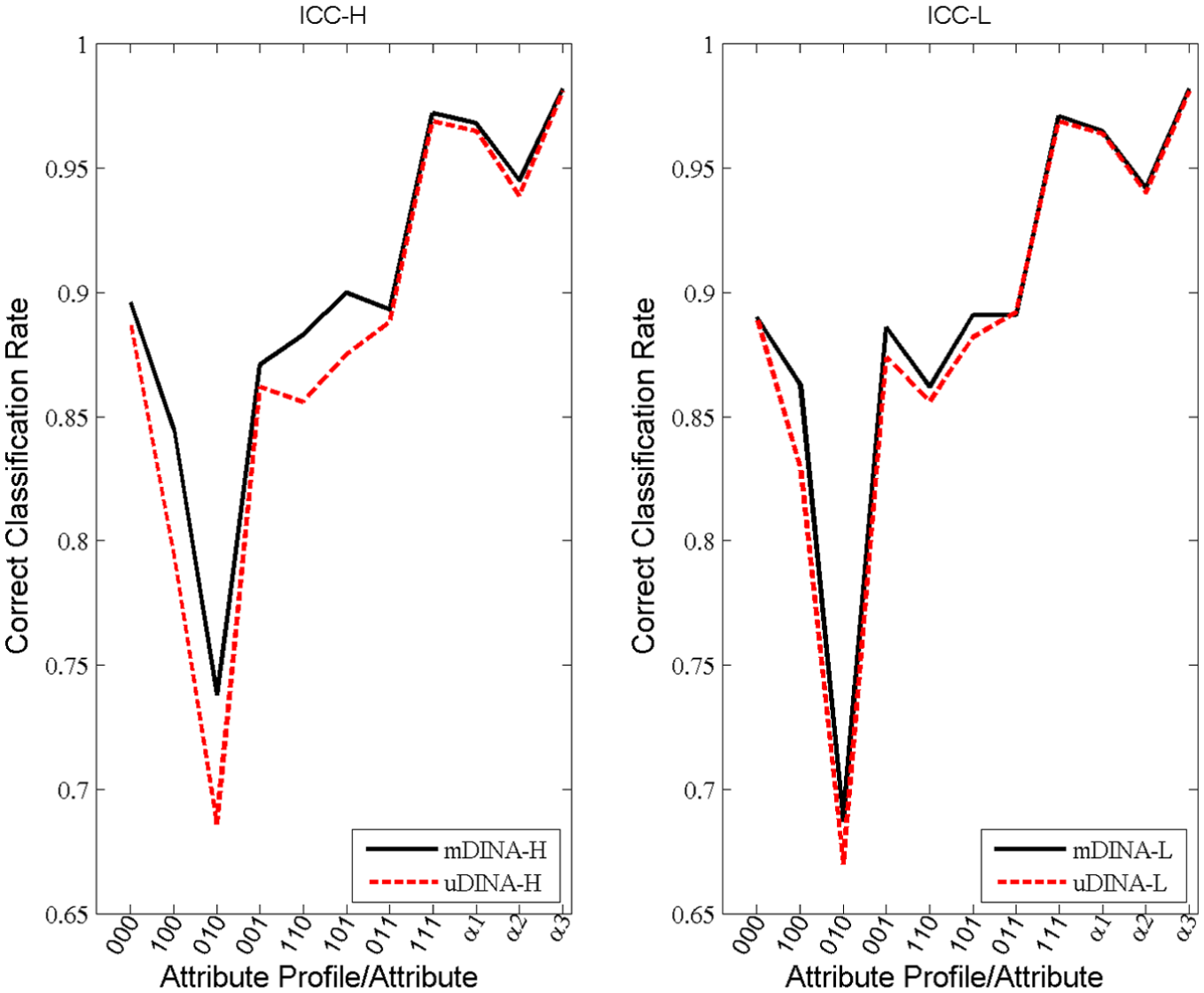
Correct classification rates of the attribute profiles and individual attributes under the ICC-H and ICC-L conditions in the simulation study.
According to the DIC statistic, the data-generating mDINA model was preferred to the uDINA model in 19 to 27 of the 30 replications under the ICC-H condition by an average 30.22 to 98.33 smaller number for the DIC. The mDINA model was preferred 17 to 22 times under the ICC-L condition by an average 10.91 to 49.97 smaller number for the DIC. In general, the longer the test and the larger the number for the schools, the higher the power of the DIC statistic in selecting the true model would be.
Three Attributes Under Condition ICC-0
Under the ICC-0 condition, the uDINA model was the true model and the mDINA model was an unnecessarily complicated model. Both the mDINA and uDINA models recovered the parameters very well, with the bias and RMSE in the second or third decimal places in general. For the estimation of
The Conditions Under the Five Attributes
The results for ICC-H, ICC-L, and ICC-0 under the conditions of the five attributes are shown in Tables A4 to A6 in the online supplement, respectively. The major findings were the same as those found in the conditions of the three attributes. However, when there were more attributes, the recovery for the individual attributes and attribute profiles became poorer.
An Empirical Study
Data and Analysis
Responses from eighth graders in the United States to the 2003 TIMSS mathematics test were analyzed. The test was designed to measure knowledge on five content domains: algebra, data, geometry, measurement, and number. An example item in the number domain on the relationships among numbers is as follows: “Show that the sum of any two odd numbers is an even number.” For illustrative purposes, the five domains were treated as five binary attributes in this study. The structure of the Q-matrix was not complex because each item measured only one of the five domains. Although the TIMSS test was not designed specifically to diagnose binary attributes, it was used to demonstrate the utilities of CDMs in previous studies (Lee, Park, & Taylan, 2011; Tatsuoka, Corter, & Tatsuoka, 2004).
The data consisted of 50 items and 100 schools (90% were public), which comprised 3,710 students (52% were girls). The original data set consisted of responses to 362 items from 8,912 students and 232 schools; among them there were 88, 52, 57, 57, and 108 items measuring algebra, data, geometry, measurement, and number, respectively. The number of students in each school ranged from 4 to 63 (M = 37.1). There were 12, four, 13, six, and 15 items for the five domains, respectively. Each student completed 1 to 9 (M = 5.88) items, and each item was responded to by 294 to 922 (M = 437.02) students. The data consisted of many missing values that were caused mainly by the matrix-sampling design used in the TIMSS, where a student was administered a subset of items or booklet (Mullis, Martin, Gonzalez, & Chrostowski, 2004). Thus, the data were missing by design and treated as missing at random in this study (Mislevy & Wu, 1996). The authors were particularly interested in the following three questions:
What was the school effect as indicated by the ICC?
What were the correlations among the five attributes?
What were the gender (girl = 0, boy = 1) and school type (private = 0, public = 1) differences in the five attributes?
Five models were fit to the data: (a) the uDINA model (which served as the baseline model), (b) the mDINA model, (c) the mDINA model with gender as a student-level covariate (denoted as mDINA-G), (d) the mDINA model with school type as a school-level covariate (denoted as mDINA-S), and (e) the mDINA model with gender as a student-level covariate and school type as a school-level covariate (denoted as mDINA-GS). The priors were specified as those in the simulation study. The MCMC procedure had a run length of 20,000 iterations with a burn-in length of 5,000 iterations. It took approximately 9 computer hours for the most complicated mDINA-GS model. The five models were compared according to the DIC values.
The posterior predictive model checking (PPMC; Gelman, Meng, & Stern, 1996) method was used to examine the fit of the models. This study focused on the person- and item-level fit statistics. For the person-level fit statistics, the number-correct score was used for each student, whose range was from 0 to 9. For the item-level fit, the percentage of correct answers was computed. The differences of the two statistics between the observed and replicated data were examined.
Results
The DIC values were 21,740 for mDINA-GS, 22,725 for mDINA-G, 22,745 for mDINA-S, 22,853 for mDINA, and 24,152 for uDINA. The mDINA-GS model had the smallest DIC value (JAGS code is shown in the online supplement). For PPMC results, both statistics indicated a good fit for the mDINA-GS model. The results are available upon request. As the mDINA model had a better fit than the uDINA model, a multilevel data structure was found. According to the mDINA model without any predictor, the ICC values were 0.50, 0.39, 0.41, 0.38, and 0.42 for the five attributes, respectively, and the design effect values were 18.92, 15.06, 15.89, 14.71, and 16.06, respectively, indicating a strong school effect. The results were consistent with previous findings, which found substantial between-school variations (ICC = 0.48) among eighth graders in the United States for the 2003 TIMSS mathematics test (Z. Wang, Osterlind, & Bergin, 2012).
Table 1 shows the parameter estimates and the standard errors for the regression coefficients, and the student-level and school-level variance–covariance matrices in the mDINA-GS model. The g- and s-parameter estimates, not listed due to space constraints, were between 0.01 and 0.42. The Wald test on the regression coefficients of gender for the five attributes suggested that boys had a statistically higher mastery level than girls in the measurement and number attributes, which was consistent with the findings in the TIMSS 2003 mathematics report (Mullis et al., 2004). The Wald test on the regression coefficients of school type for the five attributes indicated that private schools had a statistically higher mastery than public schools on algebra and number attributes. The school-type difference was also consistent with previous studies (Rutkowski & Rutkowski, 2010). The five attributes were moderately correlated in a range of 0.46 (between Attributes 1 and 4) and 0.63 (between Attributes 1 and 3).
Parameter Estimates Under the mDINA-GS in the Empirical Example With the LCV and MBD Approaches.

Note.υ001 to υ005 are the intercepts for the five attributes (algebra, data, geometry, measurement, and number); υ101 to υ105 are the regression coefficients of gender (boy = 1) for the five attributes; υ011 to υ015 are the regression coefficients of school type (public = 1) for the five attributes; σ is the student-level covariance; ω is the school-level covariance. The parameter estimates in the two approaches are not directly comparable because they are not on the same metric. mDINA-GS = multilevel deterministic input, noisy, and gate model with gender as a student-level covariate and school type as a school-level covariate; LCV = latent continuous variable; MBD = multivariate Bernoulli distribution.
The classification of examinees was taken from the best-fitting mDINA-GS model as a gold standard and Cohen’s kappa coefficient was computed to examine the agreement in the attribute and profile classifications between the mDINA-GS and the uDINA models. The coefficients were between 0.64 and 0.73 for the five attributes and the coefficient was 0.38 for the profiles, indicating a moderate agreement (Landis & Koch, 1977). Thus, ignoring multilevel data structures would affect the classification of attributes and profiles seriously.
For illustrative purposes, the MBD approach also was adopted (the JAGS code is shown in the online appendix). When fitting the model with student-level and school-level predictors, it took approximately 6 hr to converge in JAGS. The resulting DIC was 23,662, which was larger than that of the LCV approach (21,740). According to Equation 8, the MBD approach yielded an ICC of 0.25, 0.28, 0.25, 0.24, and 0.27 for the five attributes, respectively. Although these values were not the same as those from the LCV approach, they all suggested large school effects on the attributes. As expected, the estimates for g- and s-parameter from the two approaches were almost identical, with correlations around 0.99. The two approaches yielded substantial agreement in classification, with Cohen’s kappa coefficients between 0.73 and 0.83 for the five individual attributes and 0.80 for the attribute profiles. The other parameter estimates are shown in Table 1. Note that, although they were not on the same metric, the estimation patterns were very similar. For example, both approaches found that boys had a statistically higher mastery level in the measurement and number attributes and that Attribute 1 (algebra) and Attribute 3 (geometry) had the highest positive correlation.
An additional simulation study that mimicked the design of the empirical example was conducted to evaluate the parameter recovery for the LCV and MBD approaches. The item estimates, person estimates, and regression coefficients in Table 1 under each approach were used as generating values. The data-generating model was fit to the data using JAGS with priors and settings similar to those in the empirical example. Thirty replications were conducted. The bias and RMSE in the estimates were computed. The parameter recovery in both approaches was found to be satisfactory. The results are provided in the online supplement.
Conclusion and Discussion
Two-staged or multi-staged sampling has become popular, especially in large-scale assessments. Such a sampling creates multilevel data structures. The consequences of ignoring multilevel structures have been well documented in the literature, and a variety of multilevel linear models and IRT models have been developed. Most existing CDMs are unilevel and become infeasible for multilevel data. This study developed a new class of multilevel CDMs in which the general LCDM was used as the item-level model and the LCV and MBD approaches were proposed to formulate the Level 1 and Level 2 models. Covariates can be incorporated directly into each level, and their effects on attribute mastery can be conveniently estimated. The standard errors of the covariates can be estimated accurately, and the accuracy of attributes and profiles classification for individuals can be improved.
A series of simulations were conducted to evaluate the parameter recovery of the new multilevel CDMs and the consequences of ignoring multilevel structures on parameter estimation. Due to high dimensionality, Bayesian methods with MCMC algorithms were adopted. For simplicity, the mDINA and uDINA models were used for demonstration. It was found that, when the data-generating mDINA model was fit to mDINA data, all parameters were recovered fairly well. The longer the test was and the larger the number of schools were, the better the parameter recovery. When the mDINA model was fit to data generated from the uDINA model, there was little harm in parameter estimation, and the estimates for the school-level variance–covariance matrix were very close to zero.
On the contrary, when the uDINA model was fitted to mDINA data (and the multilevel structures were ignored), the estimates for the item parameters and their standard errors were not affected, but the standard errors of the student-level covariates were underestimated, which is consistent with the findings in multilevel linear models or IRT models. The estimates for the student-level covariates were poor, especially when the ICC was high, because the variance of the student level was constrained to be 1 for model identification. These results were different from those in multilevel linear models or IRT models, where it was found that the variance of the ignored level (e.g., school level) is redistributed to the adjacent level (e.g., student level) and the variance of the student level is estimated inaccurately. Finally, ignoring multilevel structures also resulted in poorer recovery of the latent profiles of individuals. As a conclusion, when there is a doubt about multilevel effects, fitting both unilevel and multilevel CDMs and comparing their differences are recommended.
The empirical example of the 2003 TIMSS mathematics test shows that boys and private schools had a higher percentage of mastering the attributes than girls and public schools, and the five attributes were moderately correlated. It will be valuable for future studies to apply the multilevel CDMs to real tests to investigate the effects of student-level and/or school-level covariates on attribute mastery when data have multilevel structures.
The LCV and MBD approaches yielded nearly identical estimates for item parameters, substantial agreement in attribute and profile classifications, and similar patterns for the regression coefficients of covariates and correlations among latent variables. The two approaches have strengths and limitations. The LCV approach is preferred because it is easier to implement with existing computer programs.
This study is not without limitations. Although the new models were developed using the LCDM (Henson et al., 2009) as the item-level model, they can be applied to other general CDMs, such as the GDM (von Davier, 2010) and G-DINA model (de la Torre, 2011). For simplicity, the mDINA model was used as an example in this study; however, formulation of other multilevel CDMs (e.g., the multilevel DINO and multilevel fusion models) are straightforward and can be used for future studies.
Item parameters in CDMs (e.g., the slip parameter and guessing parameter in the DINA model) often are treated as fixed effects, indicating that they are identical across persons. This assumption may be too strict in some situations. For example, the levels of slipping may depend on examinee motivation, and the levels of guessing may be related to the examinee’s ability. If so, it would be more flexible to treat the item parameters as random effects. When appropriate, the random-effect approach proposed by Huang and Wang (2014) can be incorporated in multilevel CDMs. In addition, this study focused on the random-intercept multilevel CDMs. It is valuable for future studies to investigate random-slope multilevel CDMs where the cross-level interactions among predictors at different levels are possible (Hox, 2010).
Supplemental Material
4online_supplements.R3_v2 – Supplemental material for Multilevel Modeling of Cognitive Diagnostic Assessment: The Multilevel DINA Example
Supplemental material, 4online_supplements.R3_v2 for Multilevel Modeling of Cognitive Diagnostic Assessment: The Multilevel DINA Example by Wen-ChungWang and Xue-Lan Qiu in Applied Psychological Measurement
Footnotes
Acknowledgements
The authors thank Dr. Jimmy de la Torre and two anonymous reviewers for their constructive comments on earlier drafts of this article.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was supported by General Research Fund, Research Grants Council (No. 18604515).
Supplementary Material
Supplemental material is available for this article online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.