
Abstract
Despite the increasing popularity, cognitive diagnosis models have been criticized for limited utility for small samples. In this study, the authors proposed to use Bayes modal (BM) estimation and monotonic constraints to stabilize item parameter estimation and facilitate person classification in small samples based on the generalized deterministic input noisy “and” gate (G-DINA) model. Both simulation study and real data analysis were used to assess the utility of the BM estimation and monotonic constraints. Results showed that in small samples, (a) the G-DINA model with BM estimation is more likely to converge successfully, (b) when prior distributions are specified reasonably, and monotonicity is not violated, the BM estimation with monotonicity tends to produce more stable item parameter estimates and more accurate person classification, and (c) the G-DINA model using the BM estimation with monotonicity is less likely to overfit the data and shows higher predictive power.
Keywords
Introduction
Cognitive diagnosis models (CDMs) have been developed recently and, unlike classical test theory and unidimensional item response models, CDMs aim to pinpoint whether students have already mastered a set of skills or attributes. This has the potential to provide finer grained information about students’ strengths and weaknesses, and thus could be used to facilitate classroom instruction and learning. In addition to the increasing applications in educational assessments (e.g., Ma et al., 2020; Wu, 2019), CDMs have also been used in psychology for psychological disorder diagnosis (e.g., de la Torre et al., 2018) and personnel selection (Sorrel et al., 2016).
Despite the rising popularity, CDMs have been criticized for limited utility for small samples (e.g., Henson, 2009; Sessoms & Henson, 2018). This could be attributed to various reasons, but one is the unsatisfactory performance of existing algorithms for model parameter estimation in small samples. As noted by Jiang and Ma (2018), parameters of parameteric CDMs are usually estimated using either the Markov chain Monte Carlo (MCMC) method or the expectation-maximization (EM; Dempster et al., 1977) algorithm, both of which, however, have some limitations. On one hand, the MCMC method (e.g., Culpepper & Hudson, 2018; Jiang & Carter, 2019; Zhan et al., 2019) tends to be very time-consuming, which makes it less applicable in real settings. On the other hand, although the EM algorithm is relatively fast for moderate number of attributes and theoretically guaranteed to converge to local maxima, it has been observed to fail to converge sometimes in practice. For example, Templin and Bradshaw (2014) conducted a simulation study on log-linear cognitive diagnostic model (LCDM) using Mplus, which implements the EM algorithm, and found that of 500 replications in each condition, only 330 to 447 converged successfully. It can be expected that the nonconvergence issue would be more severe when sample size is small. Also, the EM algorithm has been observed to produce boundary or near-boundary solutions (e.g., Ma & Guo, 2019). Chiu et al. (2018) noted that the EM algorithm may fail to “produce reasonable parameter estimates when samples are small” as in their real data analysis many estimates of success probabilities were either 0 or 1. Furthermore, the boundary solutions pose a challenge to inferences. For example, obtaining standard errors of boundary solutions could be challenging or even impossible, as noted by Ma and Guo (2019) and Philipp et al. (2018), and in turn, affects various hypothesis testing procedures for model comparison, differential item functioning detection and Q-matrix validation using the Wald and score tests (e.g., Ma & de la Torre, 2019; Sorrel et al., 2017).
Researchers have attempted to improve the performance of CDMs in small samples from several aspects. First, some researchers (Culpepper, 2015; Culpepper & Hudson, 2018; Zhang & Culpepper, 2017) have derived the Gibbs sampling methods for several CDMs, which tends to be much faster than a commonly employed Metropolis–Hastings (MH) algorithm (da Silva et al., 2018). Jiang and Carter (2019) investigated using a Hamilitonian procedure for estimating the LCDM, which is potentially more efficient than the MH and Gibbs samplers. Despite these advanced developments, the MCMC algorithms are still rather slow compared with the EM algorithm. The second direction that researchers have explored is nonparametric approaches (Chiu et al., 2009, 2018). Chiu et al. (2018) proposed a general nonparametric classification (GNPC) method, which is suitable for data conforming to a variety of parameteric forms. The GNPC approach has been shown to produce higher classification accuracy than the parametric CDMs estimated using the EM algorithm for small samples (Chiu et al., 2018), but it also has several limitations. For example, it only focuses on person classification and cannot be used to examine item properties, and psychometric tools for assessing the classification accuracy based on the GNPC method are lacking.
Unlike the aforementioned two directions, this study intends to address the issue of CDM applications in small samples by improving the performance of the EM algorithm. The challenges of the EM algorithm in small samples, as discussed above, do not only pertain to parametric CDMs, but also occur in many other modern psychometric models. For example, extremely large or implausible estimates for item response theory (IRT) models (Mislevy, 1986) and boundary solutions for latent class models (Garre & Vermunt, 2006) are often observed when the EM algorithm is employed in small samples. It has been well recognized that when sample size is small or data do not contain sufficient information, the use of prior distribution may become important for inferences (e.g., Gelman, 2002). The prior information about model parameters could be incorporated into the EM algorithm straightforwardly, which is usually referred to as Bayes modal (BM) estimation or posterior mode estimation (McLachlan & Krishnan, 2008). The BM estimation can be viewed as a computationally efficient variant of the MCMC algorithm. The BM estimation has been used for calibrating complex IRT models such as the three-parameter logistic model (Birnbaum, 1968), and Garre and Vermunt (2006) showed that the BM estimation could provide more accurate parameter estimation than the EM algorithm when some parameters were close to the boundary in latent class models. In CDMs, DeCarlo (2011) considered making use of the BM estimation to avoid the boundary problems for the estimation of joint attribute distribution parameters when analyzing C. Tatsuoka’s (2002) fraction subtraction data using the deterministic input noisy “and” gate (DINA) model.
The current study, however, focuses on the use of BM algorithm for the estimation of item parameters of the generalized deterministic input noisy “and” gate (G-DINA) model (de la Torre, 2011). The G-DINA model is considered in this study because it is one of the most general CDMs with many applications. The item parameter estimates of the G-DINA model have played a central role in assessing the quality of items, detecting potential misspecifications in the Q-matrix (de la Torre & Chiu, 2016), and comparing the G-DINA model with many reduced models it subsumes (de la Torre & Lee, 2013; Ma et al., 2016), and thus, the estimation precision is critical.
De la Torre (2011) derived the closed-form solutions for estimating item parameters of the G-DINA model, which, however, cannot accommodate monotonic constraints. Monotonicity is a fundamental assumption for many psychometric approaches such as the Mokken scale (Sijtsma & van der Ark, 2017) and most IRT models (De Ayala, 2013). In CDMs, the monotonic constraints are said to be satisfied for an item if mastering an additional required attribute would not yield a lower probability of success. The monotonicity is based on an “intuitively plausible assumption” (Rupp et al., 2010, p. 121), and imposing such constraints would be theoretically reasonable in many CDM applications. However, when analyzing real data using the G-DINA model, researchers sometimes chose not to impose such constraints because of the additional efforts required in model calibration (e.g., Sorrel et al., 2016). By doing so, the G-DINA model may produce parameter estimates that are hard to interpret (Chiu et al., 2018; Sorrel et al., 2016).
In sum, this study aims to investigate whether, or to what extent, imposing priors and monotonic constraints on item parameters could improve person classification accuracy for CDMs in small samples. The remainder of this article is laid out as follows. The next section provides an overview of the G-DINA model. In section “BM Estimation and Monotonicity Constraints,” the BM estimation and the monotonicity for the G-DINA model were introduced. Section “Simulation Study” describes in detail a simulation study for evaluating the utilities of priors and monotonic constraints in small samples. Then, a set of data was analyzed to further illustrate their performance in practice. The authors conclude in section “Summary and Discussion” with a brief summary as well as a discussion of directions for future studies.
An Overview of the G-DINA Model
Suppose a test with
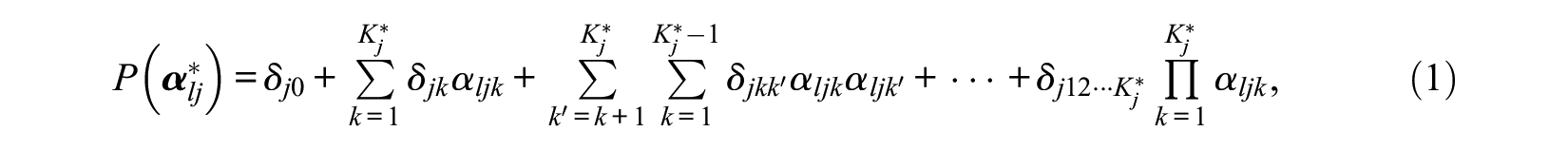
where

where
BM Estimation and Monotonicity Constraints
Based on the EM algorithm, de la Torre (2011) showed that the maximum likelihood estimate of

where

Note that the closed-form solution above was derived when the monotonicity is not assumed. The monotonicity of success probabilities of different latent groups can be represented using a Hasse diagram of a power set (Koshy, 2004), with an example displayed in Figure 1 for an item measuring three attributes. In the Hasse diagram, rounded rectangles represent latent groups (labeled by the corresponding reduced attribute profiles) and lines are used to connect latent groups that monotonic constraints should be imposed to. Specifically, when two latent groups are connected, the one in a higher position should not have a lower item success probability. Thus, the number of lines in a Hasse diagram represents the number of monotonic constraints for an item. From Figure 1, it is straightforward to identify the following constraints for monotonicity:

Note that some inequality constraints are not given in Equation 5 because they are implied. For example, it is obvious that
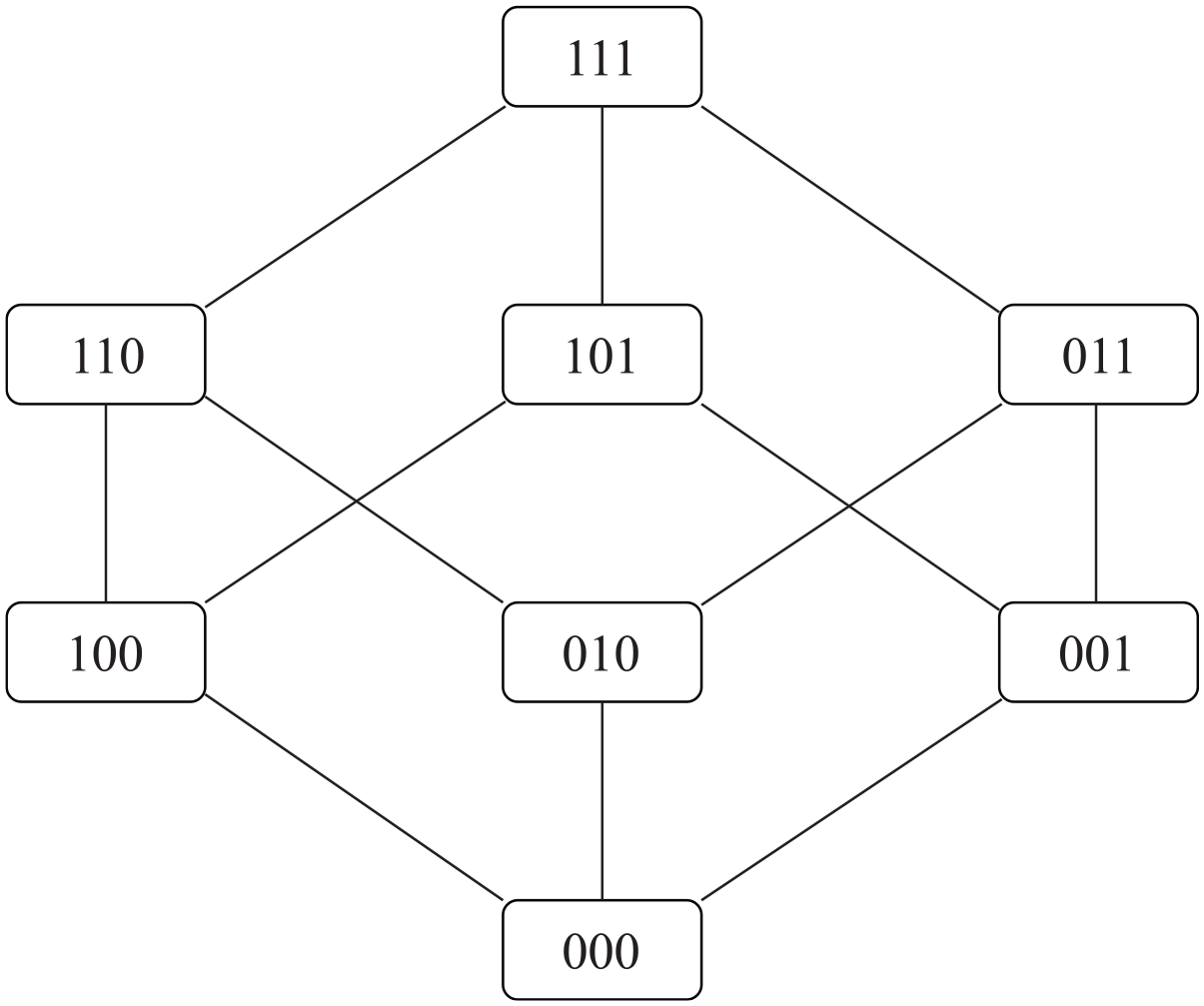
A Hasse diagram for monotonic constraints for an item measuring three attributes.
To accommodate monotonic constraints, Hong et al. (2016) proposed to adjust the parameter estimates of the G-DINA model based on the EM algorithm. However, their adjustments are implemented in a post hoc manner and thus is deemed statistically suboptimal. In this study, the constraints were accommodated in the process of model calibration using some optimization routines in M-step of the EM algorithm. For optimization purpose, the constraints in a Hasse diagram can be represented using a constraint matrix

Many optimization routines can be employed to accommodate the monotonic constraints, and in this study, the sequential quadratic programming (Kraft, 1988) implemented in R package nloptr was used (Johnson, 2019).
Simulation Study
Design
The simulation study intends to investigate the performance of the G-DINA model using different estimation algorithms, including the EM algorithm, EM algorithm with monotonic constraints, BM algorithm, and BM algorithm with monotonic constaints. The GNPC method serves as a benchmark because of its promising performance in small samples (Chiu et al., 2018). To compare the performance of different estimation algorithms, three factors were manipulated:
Sample size
Although most studies in CDMs used large samples of size more than 1,000 (Sessoms & Henson, 2018), this study focuses on samples of small to moderate sizes because CDMs are usually believed to be most useful in these settings. In the literature, Sessoms and Henson (2018) referred samples of between 50 and 150 as “relatively small” (p. 9). For studies with a focus on small samples, Chiu et al. (2018) considered samples of 30 to 500 and Chang et al. (2018) considered samples of 30, 50, and 100. This study considers samples of
Test length
As noted by Nájera et al. (2019), previous simulation studies in CDMs usually involved tests with 11 to 30 items. For CDM applications, Jurich and Bradshaw (2013) reported a diagnostic test with 17 items and Ma et al. (2020) reported a diagnostic test with 30 items. Therefore, this study considers two levels of test lengths:
Attribute correlation
It has been observed that attributes tend to be highly correlated in retrofitting applications (Sessoms & Henson, 2018), but a recent study found that attributes in a diagnostic assessment had correlations ranging between .07 and .95 (Ma et al., 2020). To consider varied levels of attribute associations, and to be consistent with previous simulation studies, three levels of attribute correlation were considered, namely,
Regarding item parameters, like J. Chen (2017) and Liu et al. (2009), the authors simulated
For each replication, the G-DINA model was fit to the data using different algorithms. To simplify the presentation, the EM algorithm with monotonic constraints and BM algorithm with monotonic constaints were abbreviated to the EM+M and BM+M algorithms, respectively. For the BM and BM+M algorithms, Beta (1.5, 2.5) was used as the prior distribution of
Criteria
First, person parameter recovery was evaluated using the proportion of correctly classified attribute vectors (PCV) defined as
Results
Before evaluating the performance of different estimation algorithms, it was examined whether the G-DINA model converged under all conditions. Table 1 gives the proportion of replications that the G-DINA model failed to converge
2
under varied conditions. Note that the G-DINA model using BM and BM+M algorithms converged under all conditions, so they are not presented in the table. Several findings can be observed from Table 1. First, the G-DINA model with the EM algorithm had higher nonconvergence rates than that with the EM+M algorithm consistently. For example, when
The Proportion of Replications Where the G-DINA Model Failed to Converge.
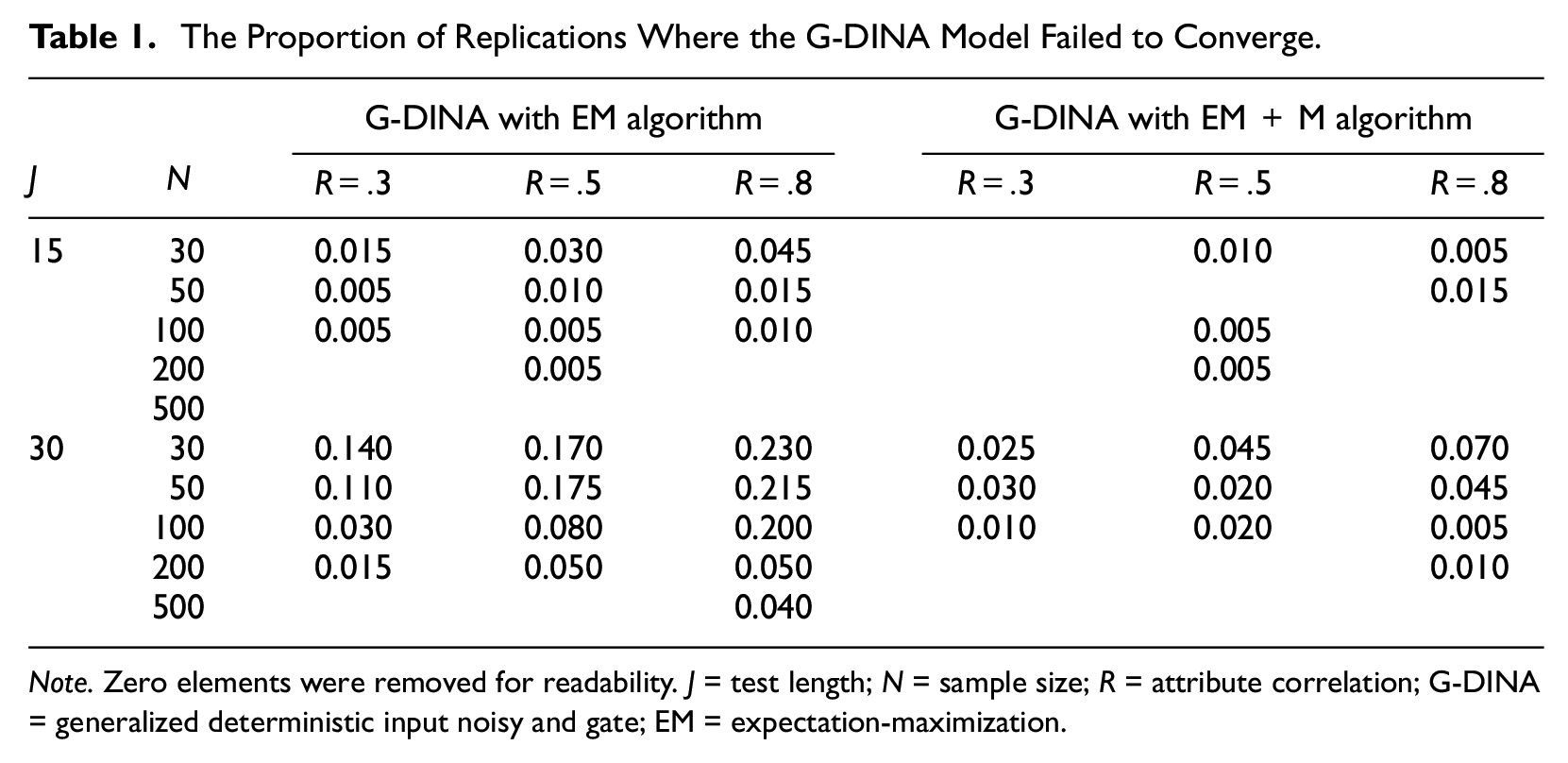
Note. Zero elements were removed for readability. J = test length; N = sample size; R = attribute correlation; G-DINA = generalized deterministic input noisy and gate; EM = expectation-maximization.
Attribute classification
With PCV as the dependent variable, mixed ANOVA showed that in addition to four main effects, two two-way interactions had nontrivial effects (i.e., Sample size × Method with
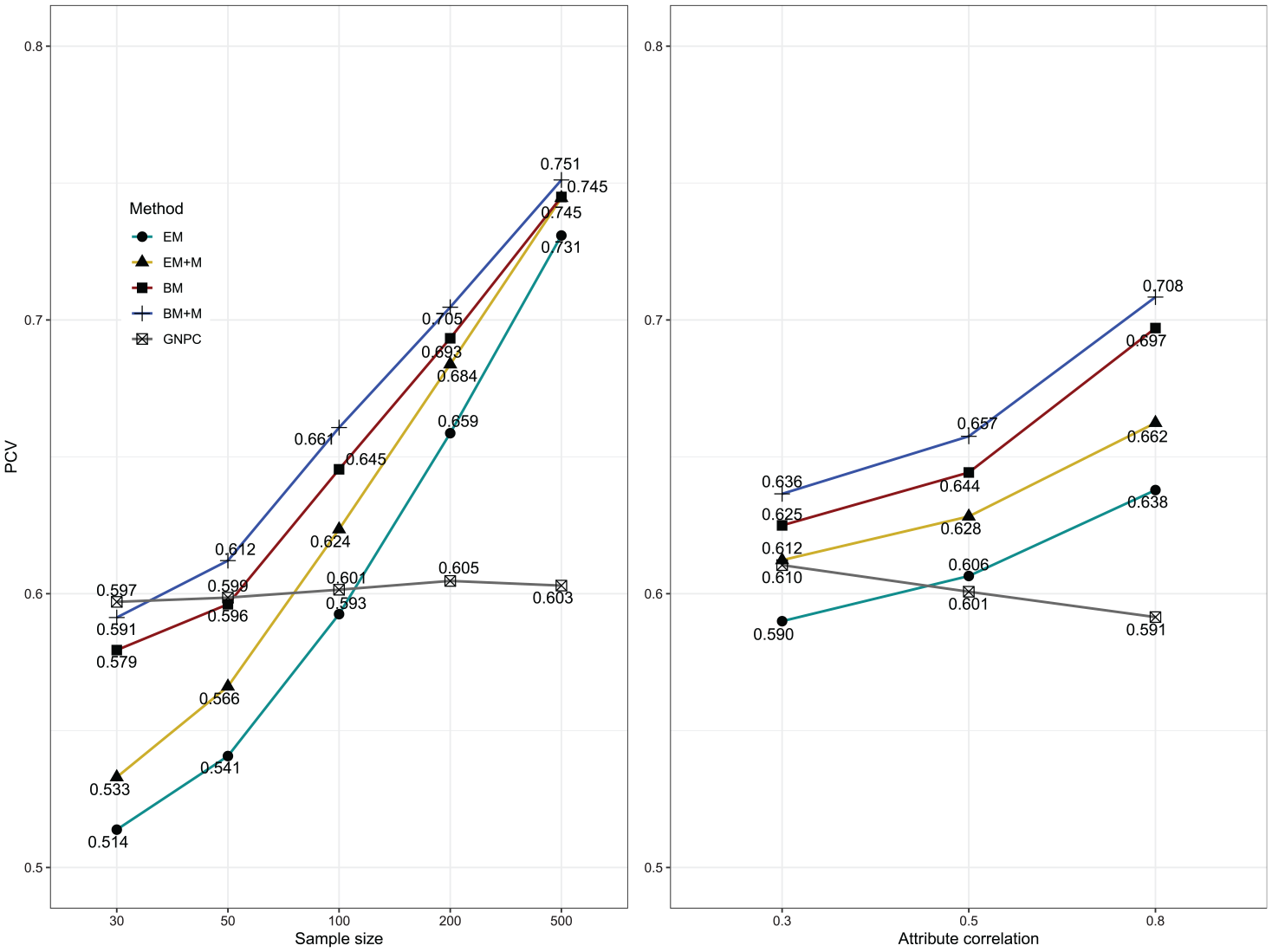
Two-way interactions of Sample size × Method and Attribute correlation × Method with PCV as the dependent variable.
Figure 2 reveals that the classification accuracy of the GNPC method was not affected by sample size (e.g., the averaged PCV
Concerning the comparison between the G-DINA model and GNPC method, it can be observed from Figure 2 that the GNPC method had higher classification accuracy than the G-DINA model when sample size was small but the G-DINA model gradually outperformed the GNPC method in terms of PCV as sample size increased. Specifically, when
Mean bias of item parameter estimates of the G-DINA model
Mixed ANOVA showed that all factors had nontrivial but small main effects for the bias of item parameters
Mean absolute bias of item parameters of the G-DINA model
Mixed ANOVA showed that the main effects of all factors as well as several two-way interactions were nontrivial for the mean absolute bias. The two-way interaction effects involving the Method factor were displayed in Figure 3, and several findings can be observed. First, the EM algorithm consistently produced highest mean absolute biases of item parameter estimates, whereas the BM+M algorithm, the smallest mean absolute biases. The BM algorithm performed better than the EM+M algorithm when
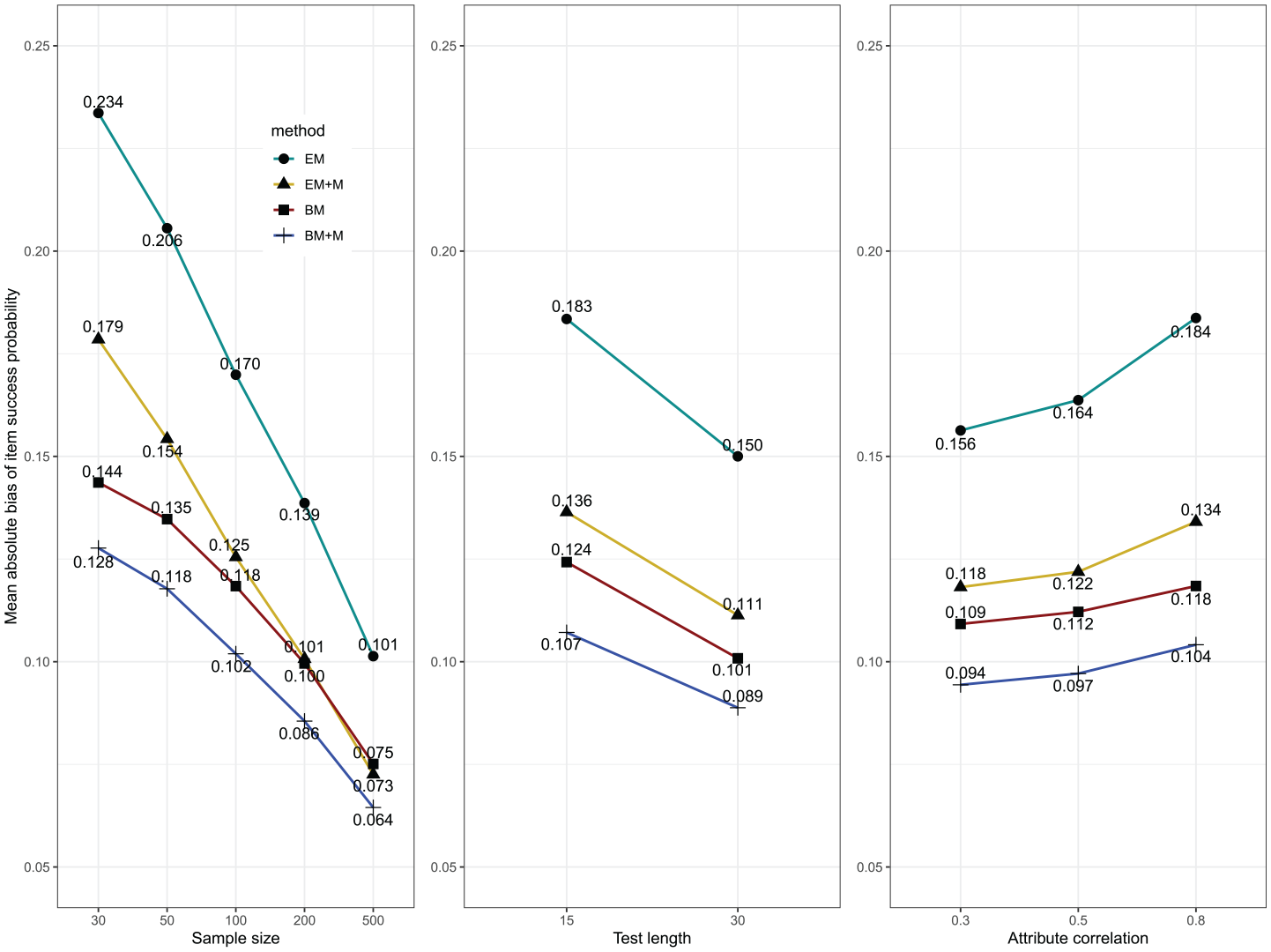
Two-way interactions with mean absolute bias as the dependent variable.
Real Data Illustration
For illustrative purposes, a set of data collected from a learning experiment at the University of Tuebingen in Germany in 2010 was analyzed in this study. The test consists of 12 items in elementary probability theory, which measured four attributes. Responses of 504 participants from the first part of the experiment were used. The same data have been previously analyzed by Ma and de la Torre (2020) and Philipp et al. (2018). The data and Q-matrix, as well as other relevant information, are available from the R package pks (Heller & Wickelmaier, 2013).
The G-DINA model was first fit to the data using the EM, EM+M, BM, and BM+M algorithms. The estimated item success probabilities and delta parameters of all items can be found in Online Appendix. Figure 4 gives the estimated success probabilities of Item 12 based on different estimation algorithms as an example. It can be observed that some of the estimates based on the EM and BM algorithms violated the assumption of monotonicity. For example,

Estimated success probabilities for Item 12 based on different algorithms.
Boundary or near-boundary solutions may indicate model overfitting, which occurs when the parameters were estimated such that the model fits the data too closely. To assess the accuracy or error of the G-DINA model’s predictions based on different estimation algorithms, the
Determining the value of
Average
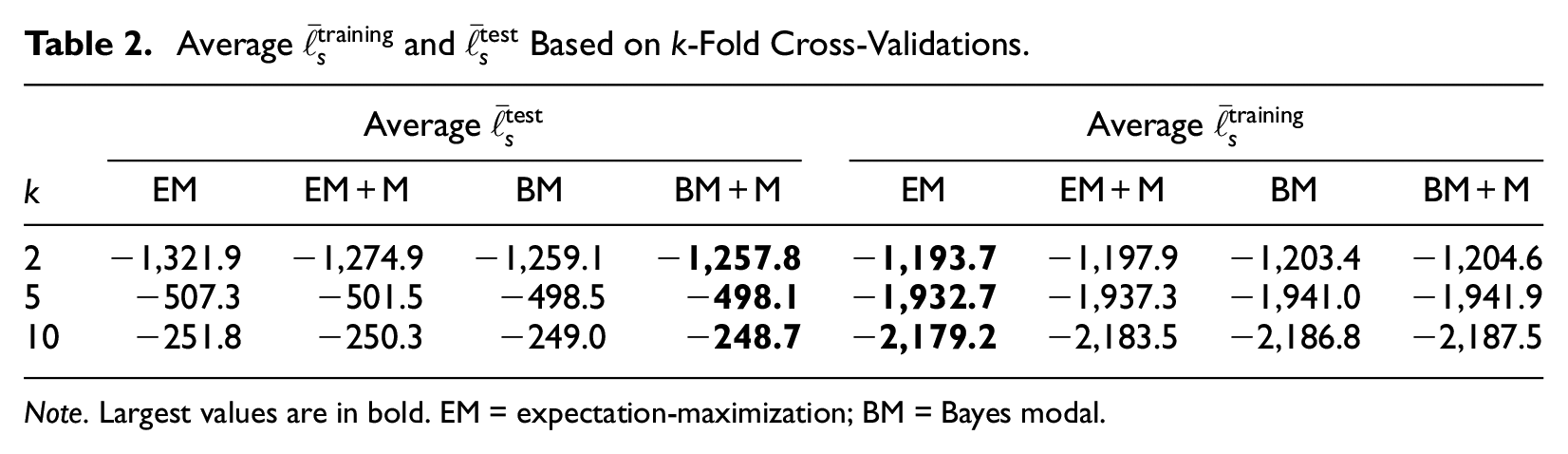
Note. Largest values are in bold. EM = expectation-maximization; BM = Bayes modal.
To further examine the impact of sample size on person classifications, 500 samples were randomly selected from the original data under each of the four sample size conditions:
The classification agreements for different estimation methods were given in Table 3. Although 500 samples were drawn under each sample size condition, some were removed because the G-DINA model using a certain algorithm failed to converge. The number of valid samples under each condition was given in Table 3 too. It can be observed that as
Person Classification Agreement Among Different Methods.
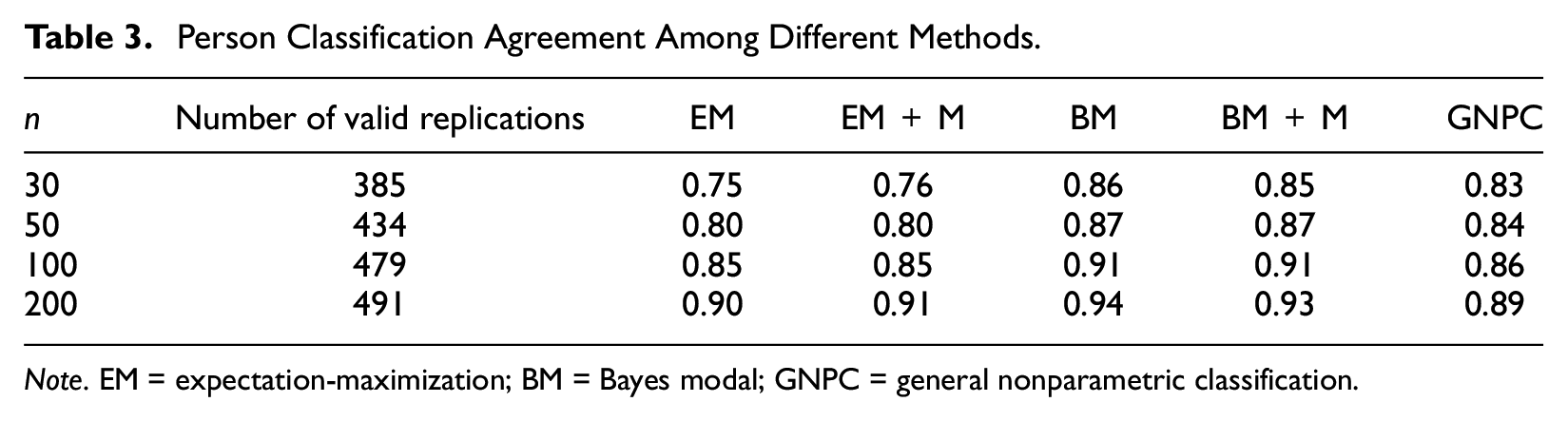
Note. EM = expectation-maximization; BM = Bayes modal; GNPC = general nonparametric classification.
Summary and Discussion
In response to the criticism of limited utility for small samples of CDMs, this study systematically examined the challenges the EM algorithm faces. Specifically, the results of the simulation study, which echoed the findings of previous studies, show that the G-DINA model based on the EM algorithm may fail to converge in small samples. The real data analysis also shows that the G-DINA model based on the EM algorithm tend to overfit the data in small samples and thus performed poorly in new samples.
This study examined whether incorporating priors and monotonic constraints into the EM algorithm could facilitate parameter estimation. By incorporating prior information into model calibration, the BM and BM+M algorithms are analogous with the MCMC algorithm. Compared with the MCMC algorithm, the BM and BM+M algorithms only provide point estimation of parameters of interest, but the computational time is typically much shorter. For the real data calibration in the previous section, the G-DINA model with the EM, EM+M, BM, and BM+M algorithms all converged in 2 s. It is observed that when items conform to monotonicity, imposing monotonic constraints and priors could improve the accuracy of person classification, especially when sample size is small, and imposing monotonic constraints and priors also prevents overfitting, at least to some extent, and thus demonstrates better predictive power in new samples.
Despite the potential advantages, monotonic constraints and priors need to be imposed with caution in practice. For one thing, the findings of the simulation study were observed when data were assumed to conform to the monotonicity, which appear reasonable but may not always be the case. de la Torre and Sorrel (2017) proposed an effect size measure to quantify the size of the monotonicity violation and also examined whether the likelihood ratio test could be used to determine the violation of monotonicity empirically. In addition to their approaches, model-data fit at both test and item level may be used to assess whether the model with monotonicity can fit data adequately. For another, the hyperparameters of the prior distributions used in this study may not be appropriate under some circumstances. A body of research has showed that priors could have a substantial impact on the estimation of model parameters (e.g., van Erp et al., 2018), and carelessly selected priors could produce misleading or even erroneous results, especially when sample size is small. In the CDM context, for example, if the item response models can be reasonably assumed to be conjunctive or disjunctive in nature, the priors should be adjusted to reflect this belief accordingly.
In addition, this study focuses on the identity link G-DINA model, but it can be expected that the nonconvergence and overfitting issues of the EM algorithm also pertain to other widely used CDMs. Therefore, examining the impact of imposing priors and monotonic constraints to other CDMs in small samples is needed. In addition, the Q-matrix is assumed to be known and correctly specified in this study, but it is unclear about the impact of misspecifications in the Q-matrix on the performance of the G-DINA model with the EM+M, BM, and BM+M algorithms. It is worth mentioning that a variety of approaches have been developed to estimate the Q-matrix either with or without experts’ input (e.g., Y. Chen, Culpepper, Chen, & Douglas, 2018; Y. Chen et al., 2015, 2020; Culpepper, 2019), which could be used when Q-matrix is not available or is potentially misspecified. Finally, this study only considers improving parameter estimation of CDMs based on cross-sectional data. It is possible that in small-scale educational programs, diagnostic assessments are administered multiple times, producing longitudinal data. An array of CDMs have been developed for analyzing longitudinal data (e.g., Y. Chen & Culpepper, 2020; Y. Chen, Culpepper, Wang, & Douglas, 2018; Kaya & Leite, 2017; Wang, Yang, Culpepper, & Douglas, 2018; Wang, Zhang, Douglas, & Culpepper, 2018; Zhan, 2020), and future research may explore if monotonic constraints and priors could be used in conjunction with these models.
Supplemental Material
sj-pdf-1-apm-10.1177_0146621620977681 – Supplemental material for Estimating Cognitive Diagnosis Models in Small Samples: Bayes Modal Estimation and Monotonic Constraints
Supplemental material, sj-pdf-1-apm-10.1177_0146621620977681 for Estimating Cognitive Diagnosis Models in Small Samples: Bayes Modal Estimation and Monotonic Constraints by Wenchao Ma and Zhehan Jiang in Applied Psychological Measurement
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Supplementary material is available for this article online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.