
Abstract
Accurate item parameters and standard errors (SEs) are crucial for many multidimensional item response theory (MIRT) applications. A recent study proposed the Gaussian Variational Expectation Maximization (GVEM) algorithm to improve computational efficiency and estimation accuracy (Cho et al., 2021). However, the SE estimation procedure has yet to be fully addressed. To tackle this issue, the present study proposed an updated supplemented expectation maximization (USEM) method and a bootstrap method for SE estimation. These two methods were compared in terms of SE recovery accuracy. The simulation results demonstrated that the GVEM algorithm with bootstrap and item priors (GVEM-BSP) outperformed the other methods, exhibiting less bias and relative bias for SE estimates under most conditions. Although the GVEM with USEM (GVEM-USEM) was the most computationally efficient method, it yielded an upward bias for SE estimates.
Keywords
Introduction
Recently, multidimensional item response theory (MIRT) model has gained popularity for handling complex educational data, mostly due to its capability to simultaneously estimate multiple latent constructs with possible correlation. For example, several studies have shown that, compared to unidimensional IRT, MIRT can substantially improve the accuracy of parameter estimates when the test measures several highly correlated latent constructs with a small number of items (de la Torre & Patz, 2005; Wang et al., 2004).
For MIRT, accurate estimates of item parameters, as well as their standard errors (SEs), are important prerequisites for many applications (Chen & Wang, 2021; Wang & Zhang, 2019), including but not limited to multidimensional computerized adaptive testing (Yao, 2012), item parameter calibration (Chen, 2017), limited-information goodness-of-fit testing (Cai et al., 2006), as well as differential item functioning (Woods et al., 2013). However, estimating item parameters for high-dimensional MIRT models can be computationally challenging due to the intractable integrals in the likelihood function (Andersson & Xin, 2021). Several solutions have been proposed in the literature. For instance, the adaptive Gaussian quadrature method (Cagnone & Monari, 2013) and the Laplace approximation (Lindstrom & Bates, 1988) conduct direct numerical approximations to the integrals. Unfortunately, the former is known to be computationally demanding in high dimensions, whereas the latter, though being computationally efficient, becomes less accurate especially when there are only a few dichotomous items measuring each latent trait (Joe, 2008). Other approaches are based on stochastic approximation, such as the Metropolis–Hastings Robbins–Monro (MH-RM) method (Cai, 2010a, 2010b). This method has been implemented in several software programs (Bashkov & DeMars, 2017), but again, it could be computationally intensive since the procedure requires multiple sampling from a posterior distribution.
Recently, Cho et al. (2021) proposed an alternative algorithm, namely, the Gaussian variational expectation maximization (GVEM) algorithm, to further improve computational efficiency and estimation accuracy. To greatly reduce the computational complexity, the GVEM bypasses calculating intractable integrals by approximating the marginal likelihood with a more tractable variational lower bound, such that both the integration in E-step and solution to the score function in the M-step involve analytic closed forms. While Cho et al. (2021) show the GVEM outperforms the MH-RM regarding item parameter recovery under different conditions, their algorithm does not produce standard error (SE) estimates. Since SE is a key element for statistical inference, our study aims to fill this gap by proposing two SE estimation procedures under the GVEM framework: the updated version of supplemented EM (USEM; Tian et al., 2013) method and the bootstrap method.
So far, studies on SE estimation are scarce (Paek & Cai, 2014), especially for MIRT models. The gold standard approach to estimating SE is to take the square root of the diagonal entries of expected Fisher’s information matrix (FIS), computed by the second-order derivatives of the log-likelihood function. However, a key drawback of this method is that the computation cost increases exponentially as the test length increases (Paek & Cai, 2014; Wang & Zhang, 2019). Alternative approaches include the empirical cross-product approach (XPD) and supplemented EM (SEM; Cai, 2008; Meng & Rubin, 1991). XPD defines the information matrix as the expectation of the cross-product of the first derivative of the log-likelihood function. Although XPD is computationally most efficient, it could exhibit some upward bias when the test length is long and the sample size is relatively small (Paek & Cai, 2014). Alternatively, prior research suggests a robust SE estimation using a sandwich-type variance-covariance matrix, which is a weighted combination of XPD and FIS (Yuan et al., 2014). However, it is challenging to compute the observed information matrix, which is required in the sandwich covariance matrix. To address this issue, the SEM algorithm estimates SE based on the complete-data information matrix, which is obtained as a by-product from the EM algorithm. Compared with other approaches, SEM is easy to implement and produces accurate SE under different conditions (Tian et al., 2013). Recently, Tian et al. (2013) proposed an updated version of SEM (USEM) which is computationally more efficient than SEM and still maintains its accuracy. Due to these advantages, we aim to integrate the USEM into the GVEM framework to generate SE of MIRT item parameters in a fast and precise manner.
The aforementioned methods necessitate computing the first or second derivative of the likelihood function; however, in some cases, the likelihood is intractable analytically or challenging to obtain. To deal with this issue, the bootstrap method is an alternative for estimating SE, which has been applied in a wide range of statistical models (i.e., Efron & Tibshirani, 1986; Gonçalves & White, 2005). In the educational measurement field, the bootstrap approach is commonly used for estimating SE of IRT equating methods (i.e., Liu et al., 2008; Tsai et al., 2001; Zhang & Zhao, 2019), and providing accurate SEs for person parameter estimates (i.e., Fitzpatrick & Yen, 2001; Liou & Yu, 1991; Patton et al., 2014). Its application to SE estimation of item parameters in MIRT, however, is rarely discussed. While in general, bootstrap is computationally demanding due to resampling, by integrating it into the GVEM framework, we aim to maintain a decent computational cost.
The current study complements the work by Cho et al. (2021) by focusing on the SE estimation procedure under the GVEM framework. Two estimation methods are proposed: USEM and bootstrap. Their performance is evaluated via simulation studies. The rest of the article is organized as follows. We begin with an overview of current SE methods. Then, the general framework of the GVEM algorithm for MIRT models is introduced, followed by a modified version of the GVEM algorithm. Then the USEM as well as the bootstrap procedure for SE estimates within the GVEM framework are described. Next, simulation studies are presented to illustrate the performance of two proposed procedures, followed by a discussion of the results summary and directions for future studies.
An Overview of SE Methods
In this section, we will provide a brief review of three SE methods: FIS, XPD, and sandwich covariance matrix. The USEM and bootstrap methods will be introduced in subsequent sections. The exposition will be based on one of the most widely used MIRT models, the multidimensional two-parameter logistic model (M2PL). Suppose N examinees respond to J items, resulting in a binary response matrix
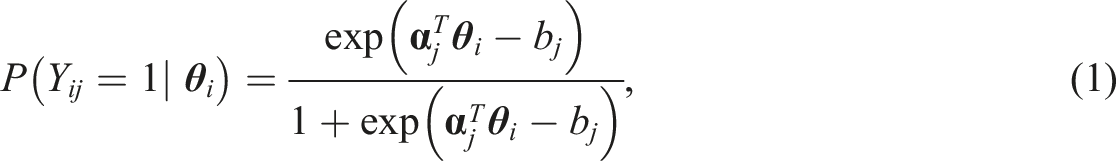
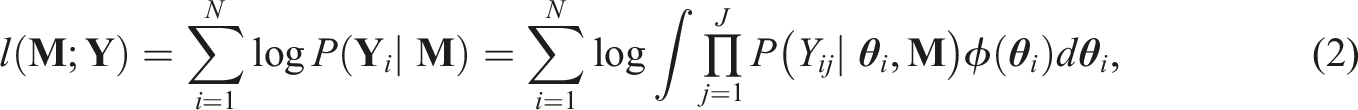
The FIS approach computes the observed information matrix using the negative expectation of the Hessian matrix, that is, the second-order derivatives of the log-likelihood function
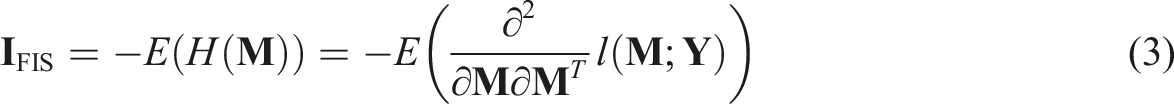


GVEM for MIRT
In this section, we will briefly introduce the key idea of the GVEM algorithm discussed in Cho et al. (2021). Maximizing this marginal likelihood function (i.e., Equation (2)) is often intractable under MIRT since it involves K-dimensional integrals. To solve this challenge, the variational approximation of Equation (2) could be employed. The derivation is shown as follows. First, the marginal log-likelihood in Equation (2) can be rewritten as
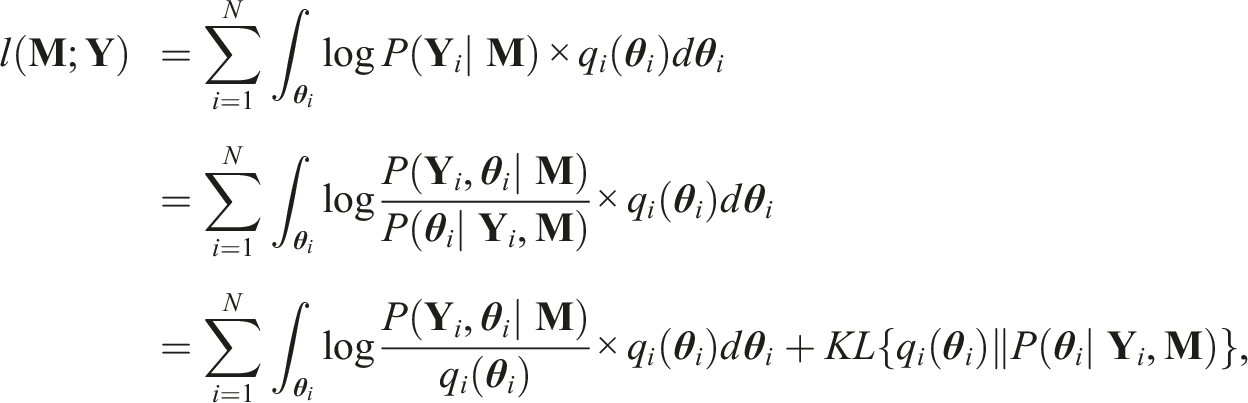

Since the equality in (6) holds if and only if q
i
(
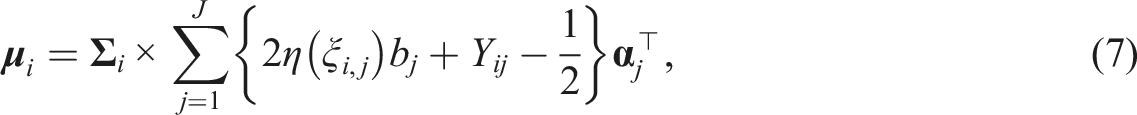

Let E(t)(
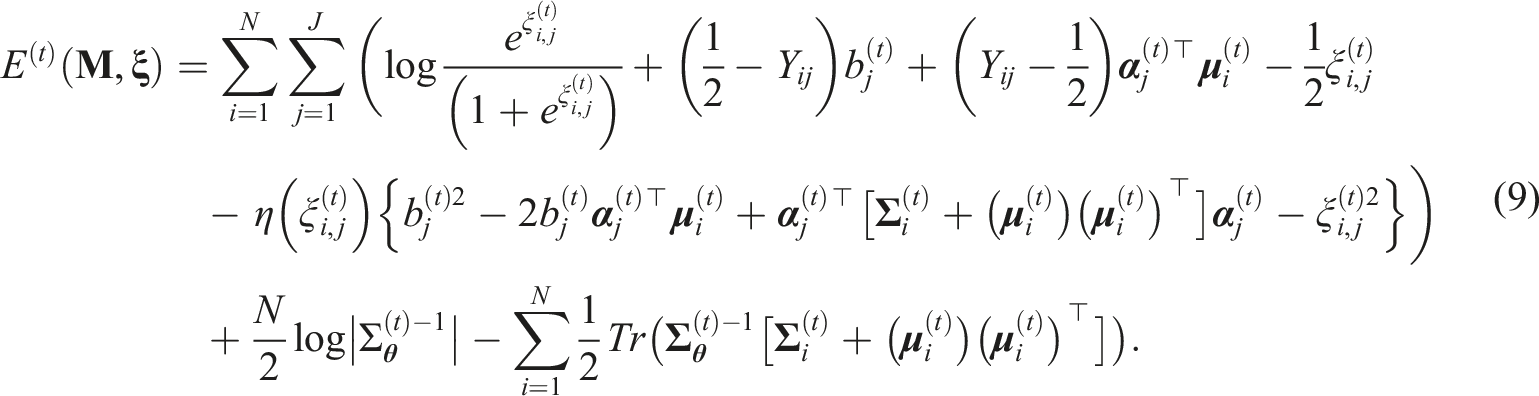
In every E step, the expectation function is updated iteratively with all recently updated model parameters. In every M step, we maximize the E(t)(
The current study modifies (9) by adding prior beliefs on item parameters. That is, we can assume some prior distributions of
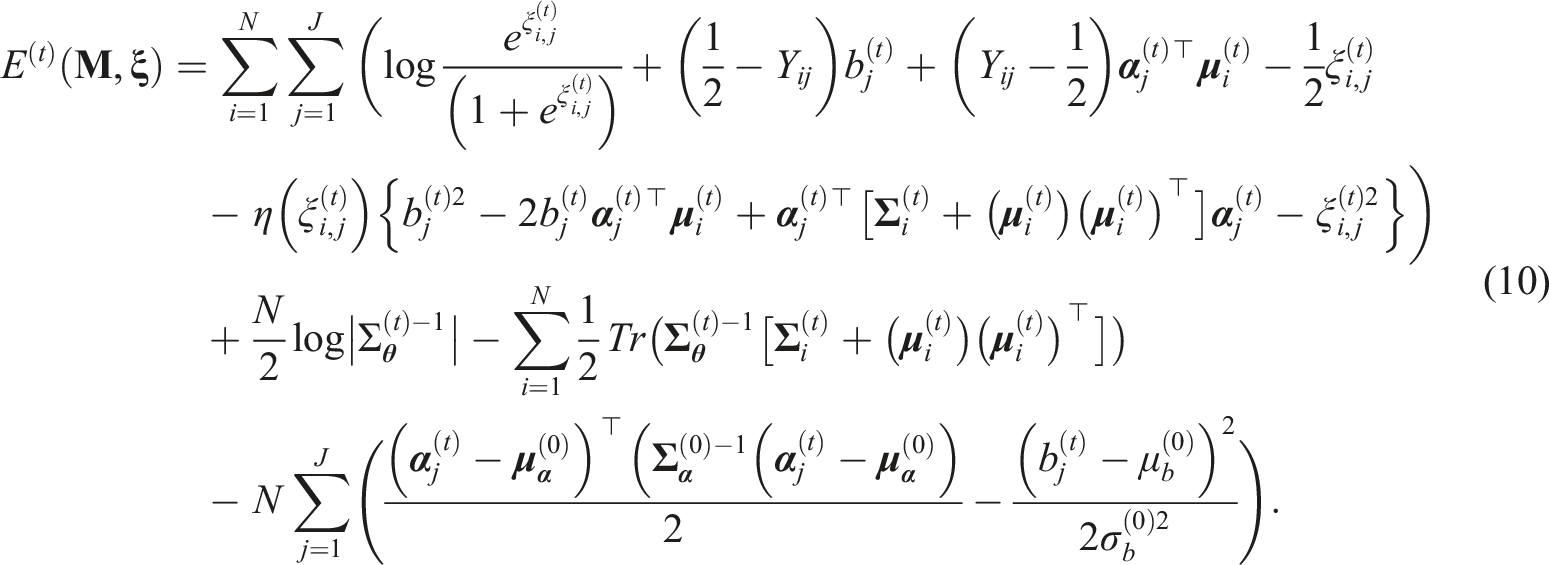
This is comparable to the Bayes modal estimation approach described by Tierney and Kadane (1986). Incorporating these priors could prevent abnormal parameter estimates and improve the accuracy and stability of the parameter estimates (Cho et al., 2022). The current study applied the bootstrap approach to the SE estimation procedure and denoted this version with prior information as Gaussian Variational EM with Bootstrap Sampling and Prior (GVEM-BSP). For the origianl GVEM, the USEM and the bootstrap approaches were implemented and denoted as GVEM-USEM and GVEM-BS, respectively. Details for the SE estimation procedure are presented in the next subsections.
USEM Approach Under the GVEM Framework
The USEM algorithm (Tian et al., 2013) is implemented to estimate SEs of item parameters. It is a more computationally efficient version of SEM (Cai, 2008), which calculates the observed-data information matrix according to the missing information principle (Orchard & Woodbury, 1972). This principle states that the observed-data information

Alternatively, GVEM computes
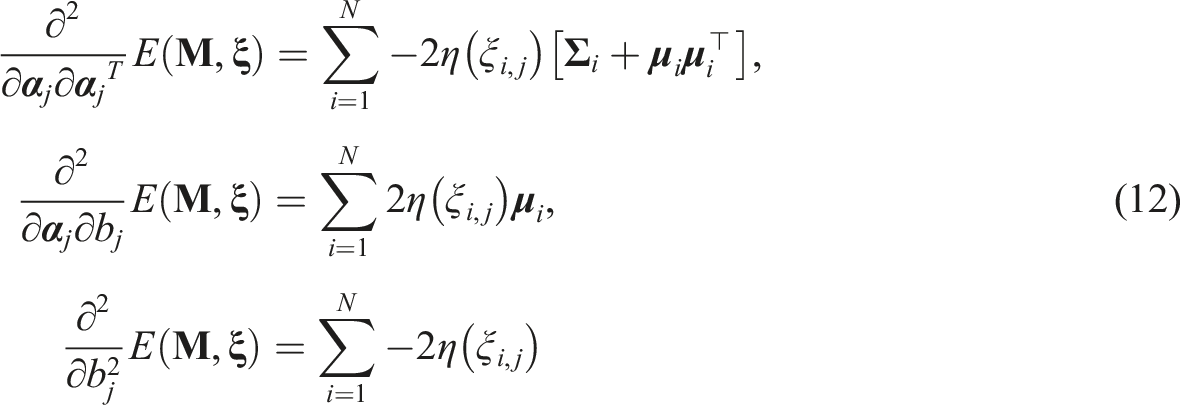
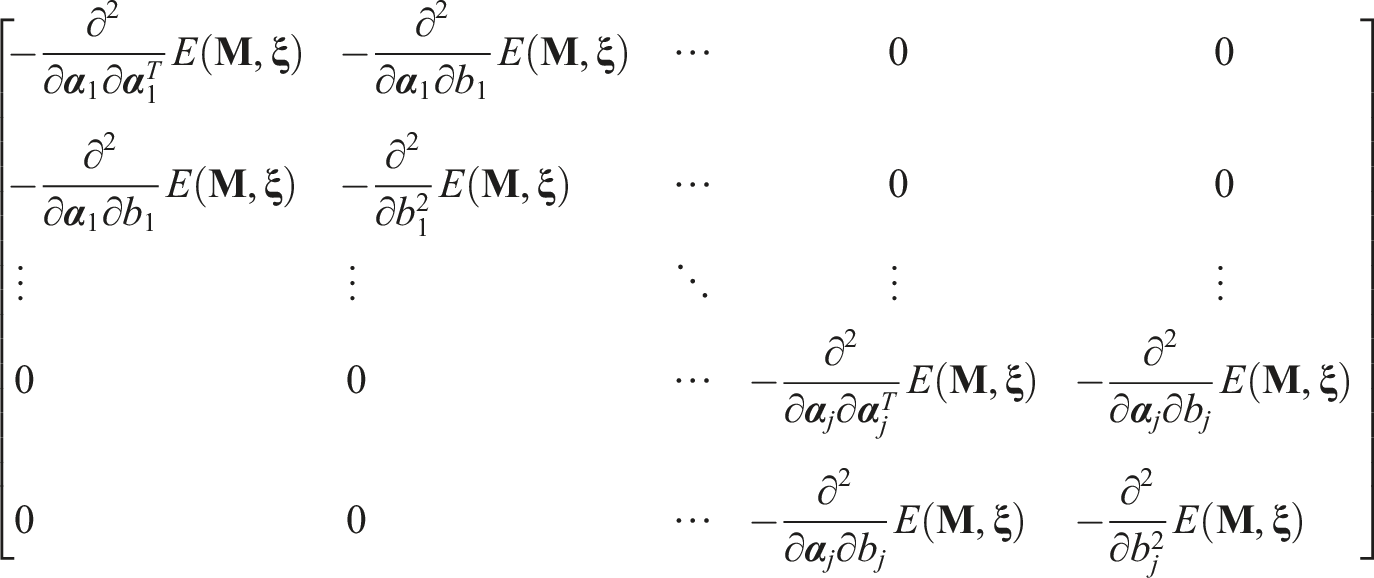
Then the key part is to compute Δ. Cai (2008) indicated

We conduct the “forced-EM” process (Meng & Rubin, 1991) to obtain Δ
ij
. Specifically, run one iteration of GVEM code to get
Bootstrap Approach Under the GVEM Framework
The bootstrap is an alternative approach to SE estimates of item parameters when the SE computation is mathematically intractable (Efron & Tibshirani, 1986). It is a resampling procedure that generates a large number of bootstrap samples in either a parametric fashion or a nonparametric fashion (Zhang & Zhao, 2019). From each bootstrap sample, the statistic of interest is calculated. The sampling distribution of the replications could be obtained to make some inferences related to the accuracy of the statistic (Patton et al., 2014). The current study implements the parametric bootstrap sampling and the steps are outlined below.
1. B bootstrap datasets are simulated based on GVEM estimates
2. The GVEM is conducted to estimate item parameters for each bootstrap dataset, and these item parameter estimates are denoted as
3. The SE estimates are simply the sample standard deviations of the estimated item parameters. The SE estimate for any item parameter M
j
(such as α
jk
or b
j
) could be expressed as
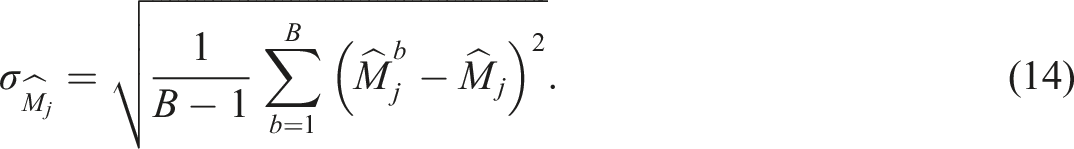
Simulation Study
A simulation study was conducted to evaluate the performance of three proposed SE estimation procedures (GVEM-USEM, GVEM-BS, and GVEM-BSP). The manipulated factors included: (1) the test length was fixed at 45 or 30; (2) the factor correlations were simulated from Unif(0.1, 0.3) or Unif(0.5, 0.7) to represent the low and high correlation conditions, respectively; (3) the multidimensional structure was either between-item M2PL or within-item M2PL; the number of factors was either 3 or 5 (i.e., K = 3, 5), representing either low or high dimensionality. In the between-item M2PL, with a test length of 45, 15 items were loaded onto each factor for K = 3, and 9 items were loaded onto each factor for K = 5. Similarly, at a test length of 30, 10 items were loaded per factor for K = 3 and 6 items for K = 5. For the within-item M2PL, when the test length was 45 and K = 3, about 60%, 24%, and 16% items were loaded onto one, two, and three factors, respectively. For K = 5, the proportions of items loaded onto one, two, and three factors were about 56%, 22%, and 22%, respectively. When the test length was 30 and K = 3, about 60%, 20%, and 20% were loaded onto one, two, and three factors respectively. For K = 5, about 33% items loaded onto one, two, and three factors, respectively. Under all conditions, true item discrimination parameters were drawn from Unif(1, 2) and true item difficulty parameters were drawn from N(0, 1), which is the same settings as Cho et al. (2021). The sample size was fixed at 1000. The ability parameters
As alluded to above, both GVEM-BS and GVEM-BSP generated 50 bootstrap samples per replication. For GVEM-BSP, the prior distribution for
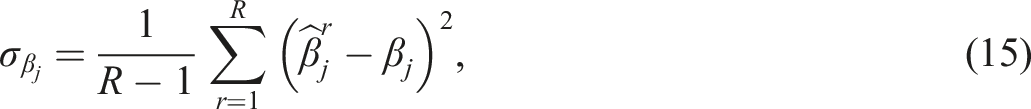
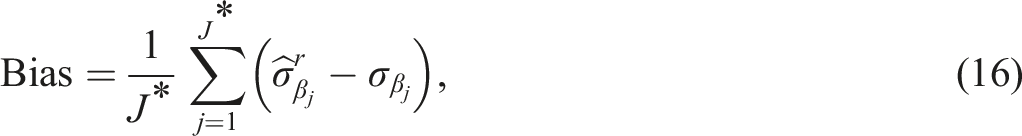


Results
It should be noted that the GVEM-USEM algorithm failed to estimate some SEs of item parameters under some replications and these values were excluded for further analysis. Table 1 in the appendix summarizes the number of unsuccessful replications with missing values for the GVEM-USEM method. The simulation results under various conditions are presented by boxplots to show the distribution of bias, relative bias, and estimated SEs. All three methods (GVEM-BSP, GVEM-BS, and GVEM-USEM) were consistently presented in the same order under each manipulated condition. Figures 1 and 2 illustrate bias and relative bias results for K = 3. In low-dimensional settings, the GVEM-USEM yielded nearly unbiased results for SE estimates of item discrimination parameters under the simplest condition (K = 3, J = 45, low factor correlations and between-item structure). However, it tended to overestimate SEs for item difficulty parameters. Both bootstrap methods, GVEM-BSP and GVEM-BS, slightly underestimated the SEs for item parameters. As conditions became more complex, GVEM-BSP and GVEM-BS methods performed better by producing close to 0 bias and relative bias results for SE estimates. Particularly, GVEM-BSP provided approximately unbiased SE estimates under most conditions. In contrast, the GVEM-USEM method consistently overestimated SEs of item parameters. Under the most complex condition (i.e., short test length, high latent correlations, and within-item structure), both GVEM-BS and GVEM-USEM methods overestimated item discrimination parameters and yielded some outliers. In contrast, the GVEM-BSP method yielded unbiased results for SE estimates of item discrimination parameters in terms of bias and relative bias results, but slightly underestimated SEs for item difficulty parameters. The bias and relative bias varied more for the within-item conditions than the between-item conditions. This was expected since the within-item model had a more complex loading structure. Bias comparison for item parameters’ standard errors estimates when K = 3. Relative bias comparison for item parameters’ standard errors estimates when K = 3.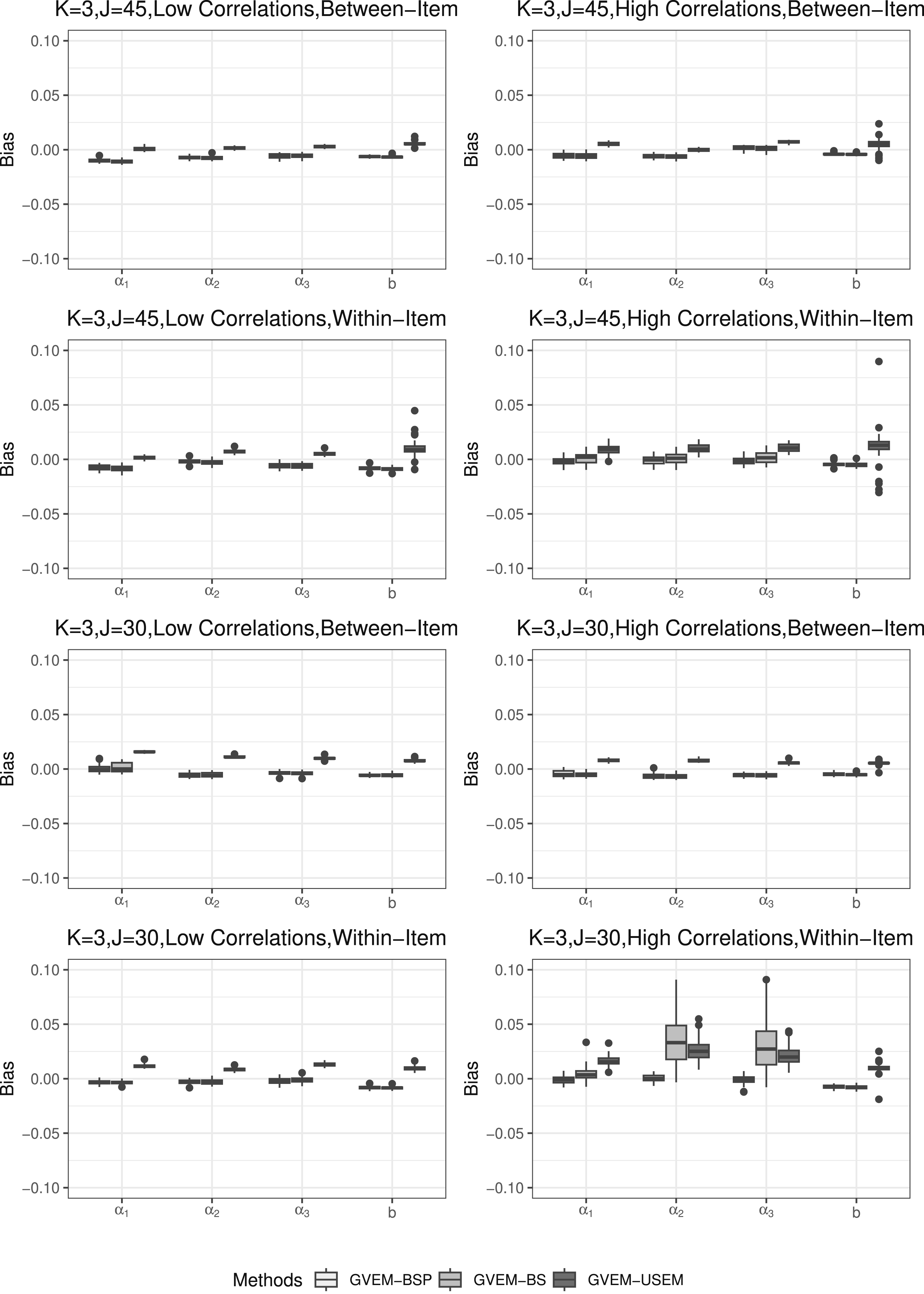

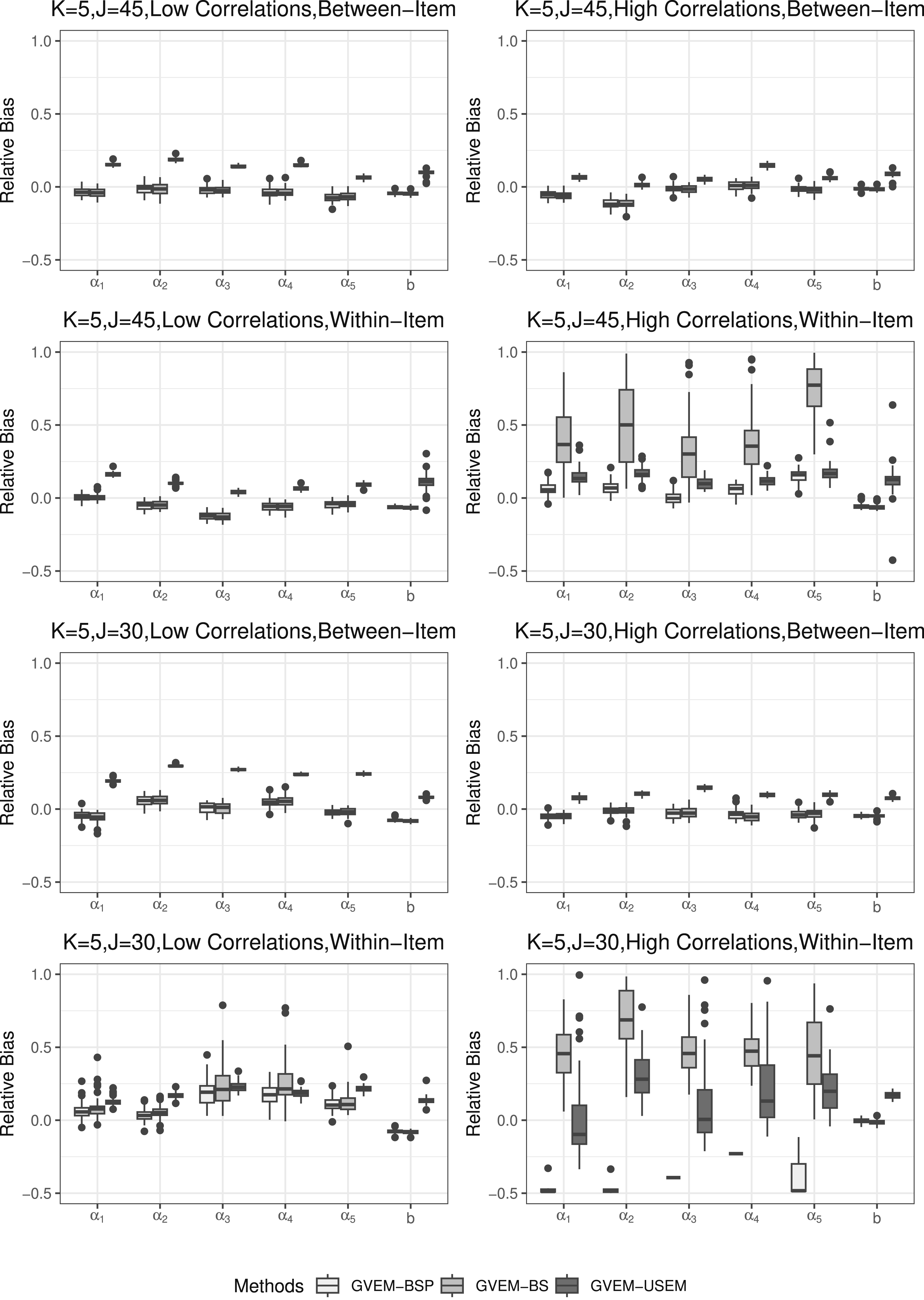
Figures 3 and 4 illustrate bias and relative bias results for K = 5. In high-dimensional conditions, both GVEM-BSP and GVEM-BS methods consistently outperformed the GVEM-USEM method, yielding approximately zero bias and relative bias results for SE estimates under all conditions, except when factor correlations were high and the item structure was within-item M2PL, for both test lengths of 45 and 30. Under these two conditions, all methods exhibited increased variability in SE estimates. The GVEM-BS method consistently yielded positive bias and relative bias results. When J = 45, the GVEM-BSP overestimated SEs, whereas it underestimated them when J = 30. The GVEM-USEM method yielded more outliers in scenarios where J = 30, factor correlations were high, and the item structure was within-item M2PL. Under other conditions, it tended to overestimate SEs, consistently with our findings for K = 3. The general trend of bias and relative bias results remained the same as in low-dimensional conditions. That is, the SE estimates became more challenging with high factor correlations and a within-item structure, although the GVEM-BSP consistently demonstrated superior performance across all conditions. Bias comparison for item parameters’ standard errors estimates when K = 5. Relative bias comparison for item parameters’ standard errors estimates when K = 5.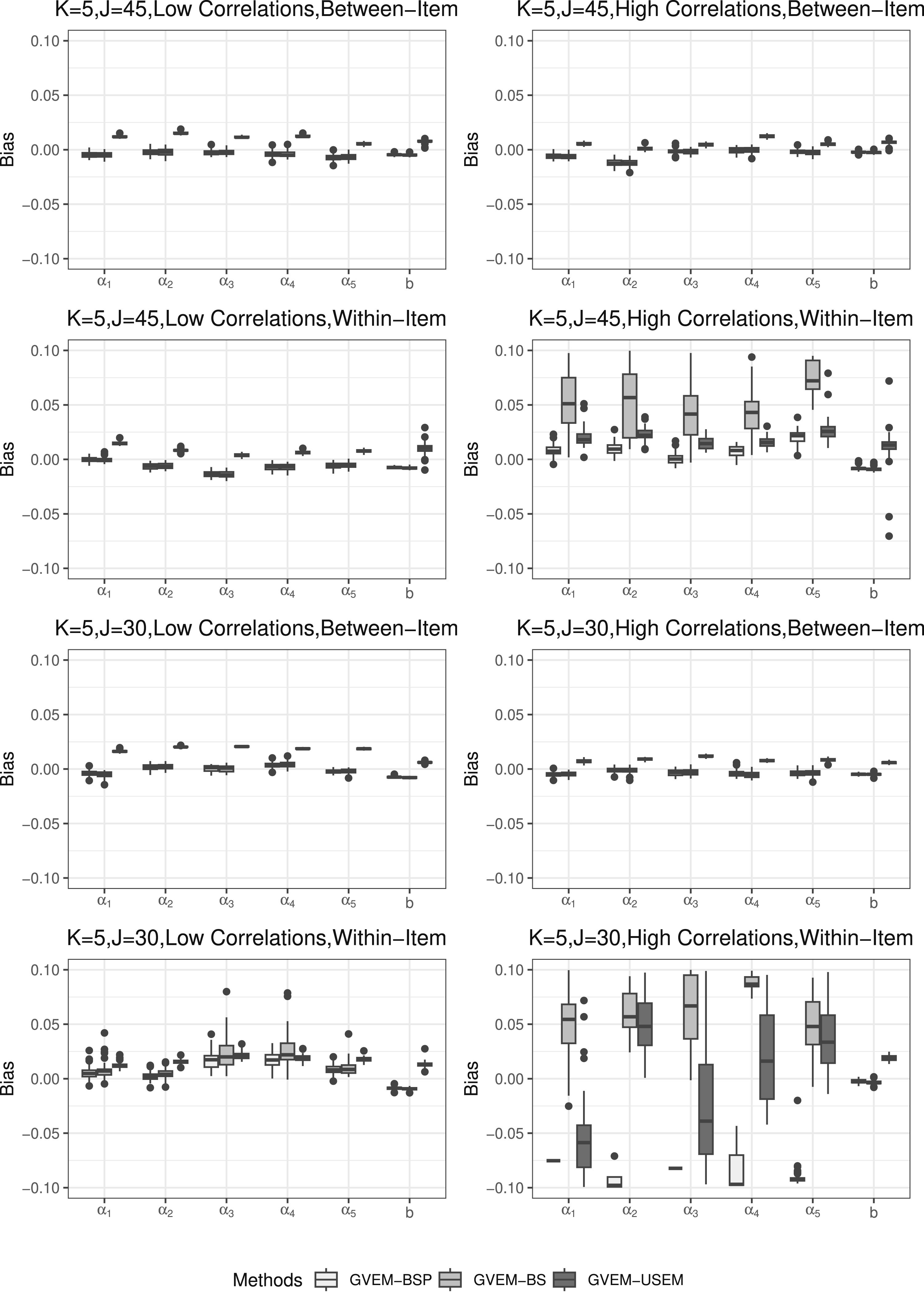
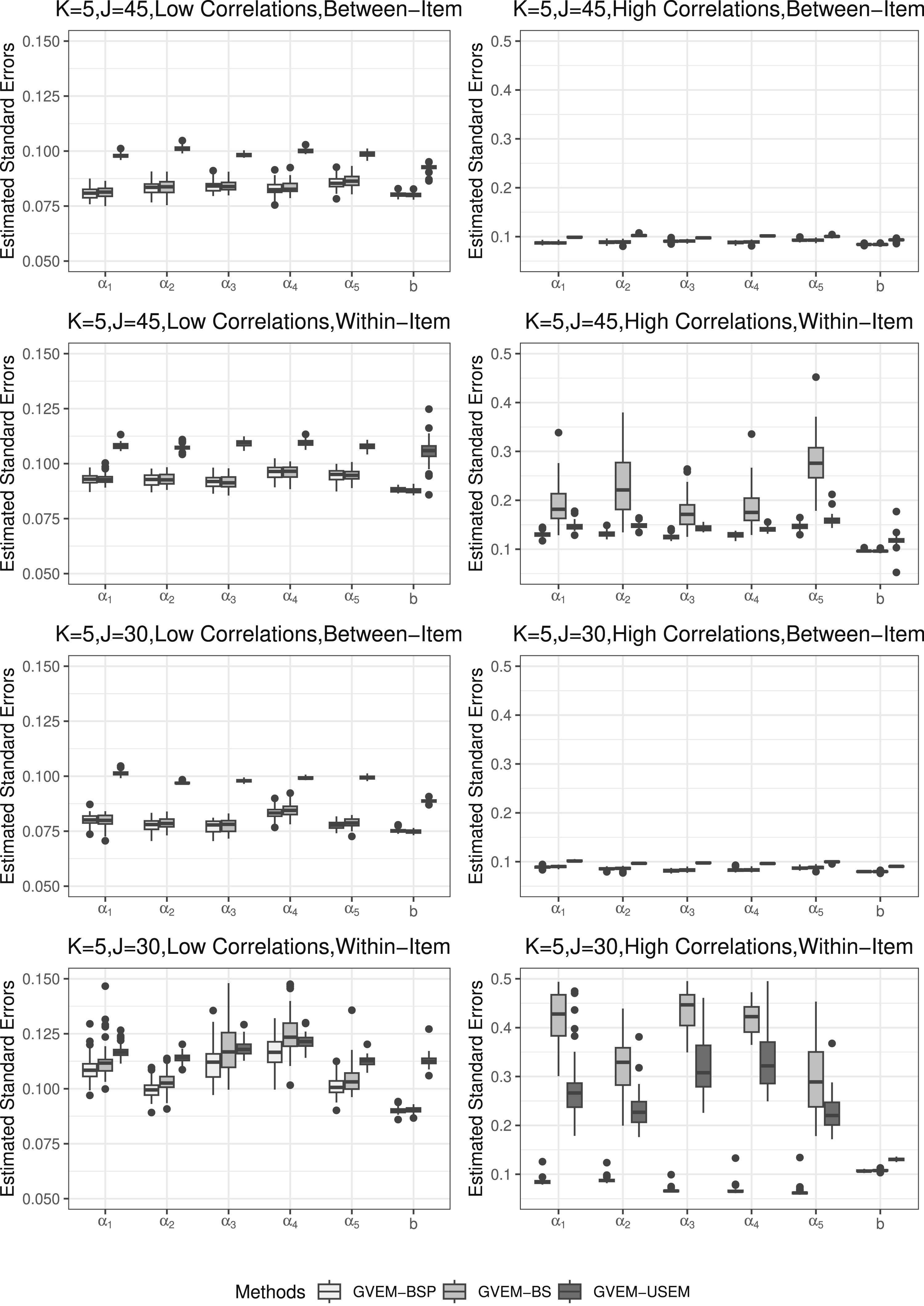
Figures 5 and 6 present estimated SEs for each method. It is important to note that different scales are employed for the left and right columns to enhance the visibility of differences between methods. In general, GVEM-BS and GVEM-BSP method produced comparable results in terms of estimating SEs smaller than 0.15. Three exceptions were observed: (1) when K = 3, J = 30, factor correlations with high factor correlations and a within-item M2PL structure; (2) when K = 5, J = 45, with high factor correlations and a within-item M2PL structure; (3) when K = 5, J = 30, with high factor correlations and a within-item M2PL structure. Under these three conditions, the GVEM-BS estimated larger SEs for item discrimination parameters, possibly contributing to increased variability in bias and relative bias results under high latent correlation and within-item M2PL conditions. The GVEM-USEM method estimated smaller SEs than the GVEM-BS under these three conditions, while generally estimating relatively larger SEs than the two bootstrap methods and presenting some outliers in other scenarios. Estimated standard errors comparison when K = 3. Estimated standard errors comparison when K = 5.
Discussions
The recent work of Cho et al. (2021) has shown the superiority of the GVEM algorithm in terms of computation efficiency and item parameter estimation accuracy, but its SE estimation is not fully discussed. Since obtaining accurate SEs is also an important prerequisite for many applications, the current study applied the USEM and bootstrap methods within the GVEM framework and compared the performance of three GVEM methods (GVEM-BSP, GVEM-BS, and GVEM-USEM) with respect to SE recovery. The simulation results showed that the GVEM-BSP performed the best under most conditions, because adding a prior could make parameter estimation more stable and robust. Although computationally more efficient, GVEM-USEM tended to exhibit an upward bias. GVEM-BS method demonstrated comparable performance to GVEM-BSP under conditions with low factor correlations and between-item structure, yet displayed increased variability under scenarios involving high factor correlations and within-item conditions.
The GVEM-BSP is a promising method to estimate SE. Moreover, our pilot study finds that it can produce accurate item parameter estimates. Besides, the GVEM-BSP can be extended to the Variational Bayesian (VB) estimation (Bishop, 2006), an alternative approximation technique to solve intractable integrals by specifying variational distributions of item parameters. The main advantage of VB is that SEs of item parameters can be derived with closed-form solutions. However, our pilot study shows that interestingly, it underestimates SE consistently, and we will defer a detailed examination of this method to a future study.
Although the literature demonstrates several great benefits of the USEM method in terms of SE estimation, incorporating it into the GVEM algorithm has several drawbacks. First, unlike traditional EM algorithms, GVEM requires additional derivation (e.g., the inverse of the complete-data information matrix
The current study can be extended in the following directions. First, all of the conditions were in a confirmatory mode, meaning that the factor loading structure was assumed to be known. For unknown cases such as exploratory factor analysis, the proposed SE estimation procedures can be combined with, for example, the GVEM with adaptive lasso penalty, which has been shown to accurately recover the model parameters and the loading structure for such purpose (Cho et al., 2021, 2022). Second, the current study was based on a two-parameter MIRT model. It is desirable to investigate the performance of different SE estimation procedures within the GVEM framework under other types of MIRT models, such as the M3PL model including guessing behaviors, or even the M4PL considering inattention situations. Lastly, the current simulation design was more of an ideal scenario where the response dataset did not have any missing values. However, missing data is ubiquitous in practice, which could result in biased parameter estimates and inflated SEs (Kalkan et al., 2018). Future studies are necessary to explore the performance of GVEM with different SE estimation procedures under various missing-data scenarios.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The study is funded by IES R305D200015 and NSF SES-1846747, SES-2150601, ECR-2300382.
Note
Appendix
The Number of Unsuccessful Replications for the GVEM-USEM.
Test length
Factor correlation
Model structure
Number of factors
Replications
45
0.1–0.3
Within-item
3
1
0.5–0.7
Between-item
3
3
Within-item
3
4
30
0.5–0.7
Within-item
3
1
The Elapsed Time for Three GVEM Methods per Replication Under Two Conditions. CPU: 2.40 GHz 20-Core Intel Xeon; RAM: 1.00 TB 2133 MHz DDR4.
Condition
Method
Elapsed time (mins)
Between-item M2PL, low correlations, K = 5, J = 45
GVEM-BS
0.87
GVEM-BSP
1.20
GVEM-USEM
0.08
Between-item M2PL, low correlations, K = 5, J = 30
GVEM-BS
1.17
GVEM-BSP
1.32
GVEM-USEM
0.04