
Abstract
Self-report questionnaires are widely used in research and practice. In most applications, the vulnerability of these questionnaires to response biases like faking is ignored. However, especially in high-stakes situations such as personnel selection, measurement can be severely biased when test-takers engage in faking to present themselves more favorably. To separate faking-related variance from substantive trait variance, the Multidimensional Nominal Response Model (MNRM) has been used to reduce systematic bias in trait estimation by allowing for item-specific relations between response categories and social desirability. A critical but untested assumption of this approach is that perceptions of social desirability are homogeneous across test-takers. However, individuals may differ considerably in how they perceive the desirability of the item content. Here, we conducted simulation studies to investigate how violations of this assumption affect the MNRM’s ability to recover substantive trait person parameters. We implemented three distinct manipulations of heterogeneous desirability perceptions and examined their impact on person parameter recovery. Results showed that the MNRM is robust against violations of homogeneous social desirability perceptions as long as test-takers’ faking behavior is aligned with their perceived desirability of the item content. In contrast, when test-takers fake responses in ways that are inconsistent with item-wise desirability perceptions, parameter recovery seems to decline. Implications for practice and possible model extensions are discussed.
Keywords
Self-report questionnaires are an indispensable tool in research (Ziegler, 2015) and personnel selection (Ones et al., 2007). However, test scores may be subject to response biases, which are defined as sources of variance that are not attributable to the substantive trait (Paulhus, 1991). A potential bias is socially desirable responding (SDR; Paulhus, 2002). It describes the tendency to provide an exceedingly positive self-description (Paulhus, 2002). SDR can be directed toward oneself or toward others. For example, test-takers might respond as being more conscientious than they actually are in order to manage their own image or to manage their impression on others. In the context of personnel selection, SDR directed toward others is the primary focus. Here, the term faking is commonly used (MacCann et al., 2011). Definitions of faking characterize it as (1) a behavior rather than a trait, which (2) is goal-directed, (3) results in an inaccurate or enhanced impression, and (4) involves an interaction between personal and situational variables (MacCann et al., 2011). In the context of personnel selection, faking refers to the act of intentionally misrepresenting oneself (Paulhus, 2002) in order to be accepted for a particular job.
Faking can be seen as a systematic source of variance in personality assessment (e.g., Jackson & Messick, 1958; Paulhus, 1991; Wetzel et al., 2016). Consequently, the assessed differences between test-takers in their item responses do not only reflect actual differences in the substantive trait, but also differences in test-takers’ faking tendency. An accurate interpretation of test scores is hence in danger. Rating scales—still commonly employed in personnel selection (e.g., Diekmann & König, 2015; Nikolaou & Foti, 2018)—are particularly vulnerable to faking, as test-takers can easily choose the response categories they see as socially desirable (Wetzel et al., 2016). As a result, the comparison of scores both between different test-takers and within the same test-taker across time is problematic, as these scores may be influenced by faking to varying degrees (Ziegler, 2015). However, not only faking tendencies with regard to the response behavior can vary, but also mere perceptions of what is desirable in a particular social context (Ludeke et al., 2013). This adds another layer of complexity when dealing with faking in personality assessments.
Approaches to Faking in Personality Assessments
To deal with the problem of faking, a variety of approaches and interventions have been proposed. One approach is trying to prevent faking from the outset. A prominent example of this approach is the multidimensional forced-choice (MFC) response format (see Lee et al., 2025, for an overview). Here, test-takers have to rank items within blocks of two or more items according to how well the items characterize their personality. Importantly, all items in one block should have the same social desirability. If this is the case, test-takers’ item rankings within blocks should not be influenced by desirability characteristics. Even though several meta-analyses have shown good performance of MFC tests in the prevention of faking (e.g., Cao & Drasgow, 2019; Speer et al., 2023), MFC tests have several disadvantages. First, the reliability of MFC tests is often too low for individual diagnostics (Bürkner et al., 2019; Schulte et al., 2021). Second, the scores of MFC tests can only be compared within and not between persons when classical methods are used (i.e., ipsative test scores; Brown, 2010). Even more complex methods like Thurstonian item response models make it hard to achieve truly normative test scores (Schünemann, 2025).
Another approach to faking is trying to detect faking in classical rating scale data (see Goldammer et al., 2024). Common examples include (1) the use of person-fit indices in item response theory (IRT) models to measure response inconsistency (e.g., LaHuis & Copeland, 2009), (2) identifying latent faking classes using exploratory mixture models (e.g., Zickar et al., 2004), and (3) measures of extreme responding (e.g., Sun et al., 2022). These approaches provide a more or less valid piece of information regarding the trustworthiness of test-taker’s given responses. However, they do not readily yield estimates of substantive trait scores that are properly adjusted for the influence of faking.
To bridge the gap between faking detection approaches and faking prevention approaches, several latent variable models of faking have been developed in recent years (e.g., Böckenholt, 2014; Brown & Böckenholt, 2022; Hendy et al., 2021; Ziegler et al., 2015). These models yield a quantification of each test-taker’s faking degree as well as faking-adjusted estimates of substantive trait scores. The majority of these models assume a linear or at least strictly monotonic relationship between items and a latent faking dimension. That means, high faking levels are always assumed to make the selection of higher item response categories more likely. However, as Kuncel and Tellegen (2009) and Borkenau et al. (2009) showed, social desirability does not necessarily increase linearly or even monotonically with higher response categories for all items of a personality questionnaire. Instead, there can be many items where the scale point that is associated with the highest desirability is a non-extreme or even the midpoint category of the rating scale. A psychometric model that can account for such item-specific desirability characteristics is the Multidimensional Nominal Response Model (MNRM) of faking (Seitz et al., 2024; Seitz, Spengler & Meiser, 2025). The MNRM has already been successfully applied in different high-stakes personality datasets, showing improved model fit, higher divergent validity of personality scales, and adequately adjusted estimates of substantive trait scores (e.g., Seitz, Spengler & Meiser, 2025). Nevertheless, what has been largely ignored so far in the modeling of faking using the MNRM is the fact that test-takers, as mentioned above, can differ in their perceptions of social desirability (Ludeke et al., 2013).
The goal of this study is to address this gap and test the applicability of the MNRM to account for faking if test-takers differ in how they perceive the social desirability of items. In particular, we simulated varying perceptions of social desirability and investigated their influence on the model’s ability to recover substantive trait person parameters. Before coming to the details on the simulation study, we will first technically introduce the MNRM and describe how the model can generally be applied to account for faking in personality assessments.
Multidimensional Nominal Response Model (MNRM) of Faking
The MNRM was originally introduced by Takane and de Leeuw (1987) as a multidimensional generalization of Bock’s (1972) approach to modeling nominal item responses based on one latent trait. Falk and Cai (2016) published a parametrization of the MNRM to account for response styles and added a slope parameter to reflect the impact of different dimensions on the item response. While this parametrization of the MNRM was first used to account for response styles (Falk & Cai, 2016; Henninger & Meiser, 2020), it can also be used to account for faking (e.g., Seitz, Spengler & Meiser, 2025). A softmax function is used to model the probability of a test-taker n choosing an item response category k out of all K + 1 item response categories on item i, assuming that D different latent dimensions (i.e., substantive traits and faking) influence the item response. The parametrization can be seen in equation (1):
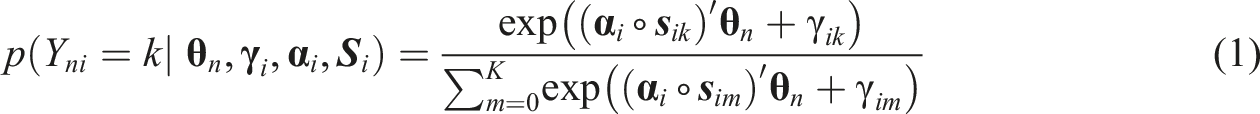
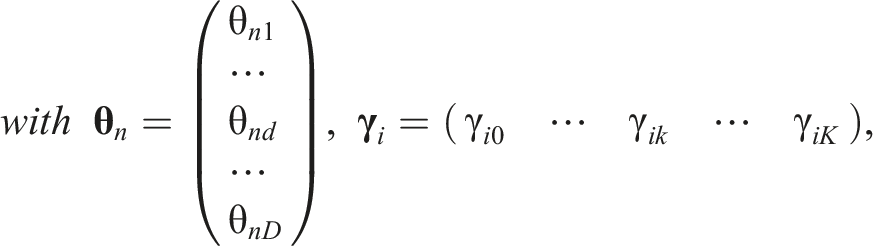
Let the discrete random variable
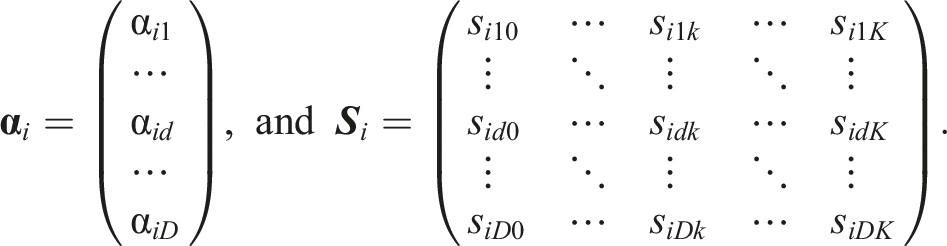
The D dimensions and their relation to the response categories are defined in the scoring weight matrix
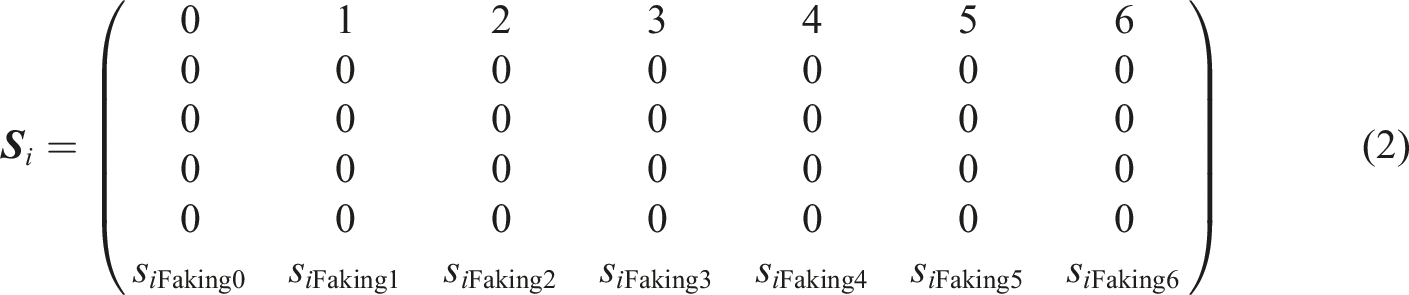
Here, it is assumed that item i only measures the first substantive trait and that—following the Likert scale logic—a higher level of the substantive trait causes the selection of higher item response categories. Thus, the scoring weights pertaining to substantive traits follow the item endorsement level. In the case of only one substantive trait being measured, the scoring weights can be set in increasing order and with equal spacing (following the item endorsement level). Such a model is equivalent to a partial credit model (PCM; Masters, 1982) or a generalized partial credit model (GPCM; Muraki, 1992), depending on whether the slopes are constrained to be constant across items. With respect to faking, scoring weights can be set such that they reflect the social desirability of the respective response category on the given item (Seitz, Spengler & Meiser, 2025). 1 Note that, because scoring weights of faking are category-specific for a given item, non-monotonic relationships between an item’s endorsement level and social desirability can be modeled. To set scoring weights of faking in an empirical setting, one requires information about the social desirability of each response category in the social context in which the assessment takes place (e.g., in an application setting for a particular job). For instance, the faking dimension’s scoring weights can be assessed by letting participants of a pilot sample rate the social desirability of each response category of each item (as demonstrated by Seitz, Spengler & Meiser, 2025; see also Kuncel & Tellegen, 2009).
To sum up, the MNRM represents a flexible framework that can be applied to account for faking. In contrast to other approaches, it can be applied even if the relation between response categories and their social desirability is non-linear and non-monotonic. Furthermore, it allows for correlations between faking and substantive traits as well as between substantive traits. In previous research, it has been shown that the MNRM improves parameter recovery (e.g., person parameters) when faking is present and that it does not diminish the recovery when faking is not present (Seitz et al., 2024; Seitz, Spengler & Meiser, 2025).
Differences in Social Desirability Perceptions
As described previously, the scoring weights of the faking dimension are item- and category-specific; however, they are constant across persons. Thus, it is assumed that all test-takers agree upon the social desirability of each item response category. However, there are multiple studies showing that people in fact differ in their perceptions of social desirability. For instance, the pilot study in Seitz, Spengler, and Meiser (2025) already shows that the variance in desirability ratings of item-category combinations is not 0 but can occasionally be substantial. Also, Ludeke et al. (2013) found that the perception of the desirability of entire traits varies between people and that these differences in perception predict the extent to which people overclaim on the particular trait. The finding of varying perceptions of social desirability fits well with the definition of faking that characterizes it as involving an interaction between personal and situational variables (MacCann et al., 2011). In the literature, one finds several potential explanations for the occurrence of individual differences in desirability perceptions. Firstly, test-takers must be able to identify the specific social desirability of the given situation. This ability is described as ability to identify criteria (ATIC; Klehe et al., 2012), and has been shown to represent an interindividual difference variable that can cause differences in the perception of social desirability (Kleinmann et al., 2011). Secondly, cultural differences may be a source of different desirability perceptions. Differences were found in previous research (Ryan et al., 2021), but the authors noted that they were smaller than one might expect. Thirdly, demographics like gender can also cause differences in desirability perceptions (Pavlov et al., 2021). Last but not least, university students of different majors have been shown to fake differently (Ziegler, 2015): When applying for a bachelor’s degree in psychology, actual psychology students faked themselves to be lower in neuroticism while students of other majors faked themselves to be higher—a behavior that might be caused by systematically different learning experiences about what is desirable in this context and what is not.
Thus, both theoretical considerations as well as empirical findings indicate that test-takers differ in their perception of social desirability. However, previous applications of the MNRM for the modeling of faking have treated desirability in a person-invariant way. Actual differences in desirability perceptions imply a misspecification of the MNRM, which could lead to systematic biases in parameter estimation. Therefore, we investigated the robustness of the MNRM against violations of constant desirability perceptions in a series of three simulation studies. Particularly, we compared the recovery of substantive trait person parameters, as an accurate recovery of these parameters is of primary interest in applied measurement settings. The primary focus of this study was the change in recovery with increasing heterogeneity of social desirability perceptions.
Simulation Design
In all our simulations, we designed each item to have one of three different social desirability trajectories. Social desirability trajectories refer to the vector of the faking dimension’s scoring weights for a given item (i.e., the last row in equation (2)). We used varying trajectories between items to simulate a realistic scenario of a personality questionnaire with varying relations between item endorsement level and social desirability (Borkenau et al., 2009; Kuncel & Tellegen, 2009; Seitz et al., 2024). Thus, we assumed that the faking behavior of test-takers was based on the item content itself. All trajectories used in the simulation are presented in Figure 1. A third of the items had a monotonically increasing desirability trajectory, with the last response category being the most desirable. Another third of the items had a non-monotonically increasing desirability trajectory, with non-extreme response categories above the scale midpoint being the most desirable. For the remaining third of the items, the desirability trajectory of the item response categories was inverted-U-shaped, with the highest desirability at the midscale response category. We used these three trajectory types because prior research has found these types to be prevalent in different personality questionnaires (Borkenau et al., 2009; Kuncel & Tellegen, 2009; Seitz et al., 2024). Since the exact proportions vary between questionnaires, we chose a situation with equal proportions in the present simulation. Social desirability trajectories used in the simulation.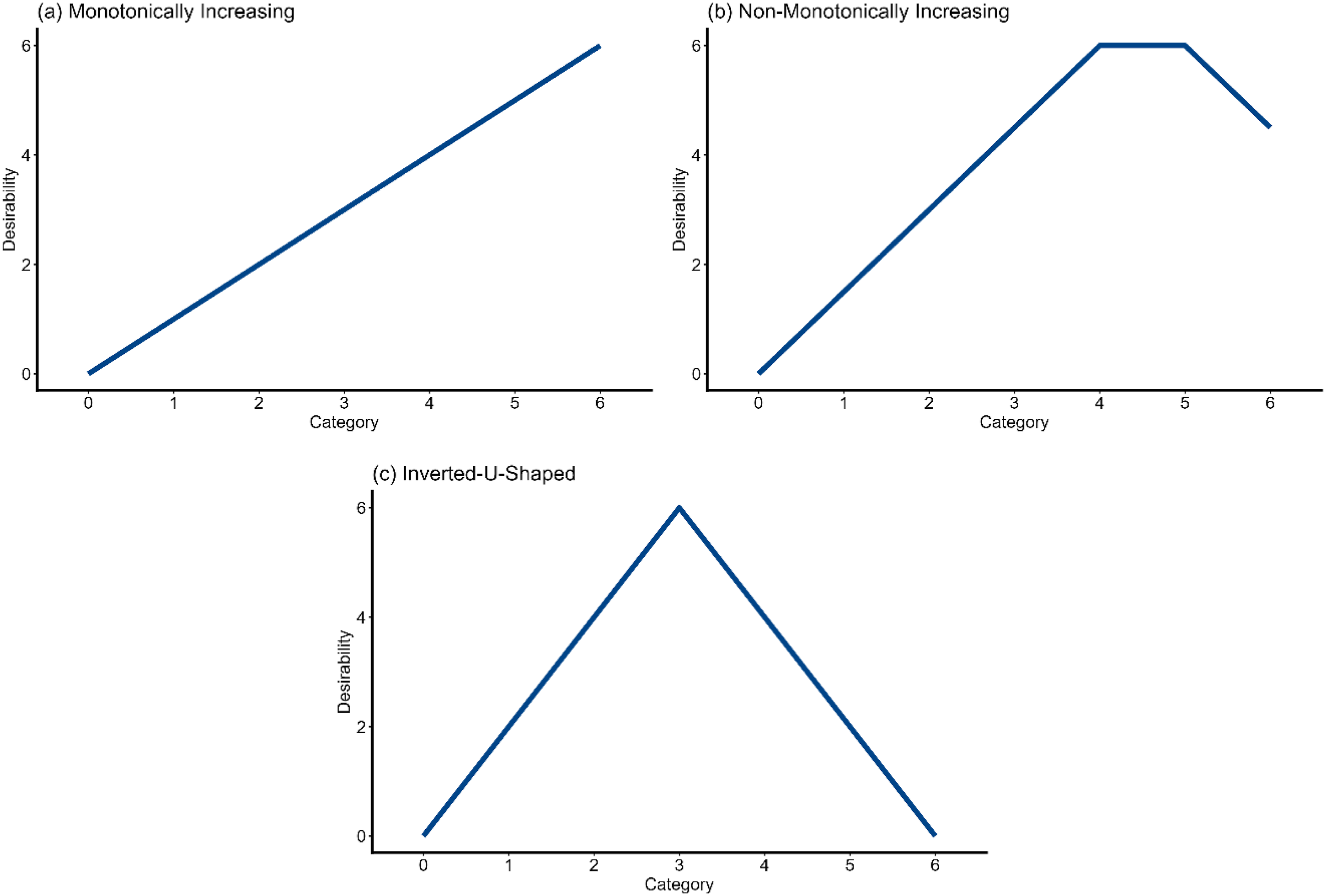
We used a 4 x 2 x 2 x 2 design for all simulations. The factors were Heterogeneity (none, weak, strong, and extreme), Sample Size (500 and 1500), Test Length (6 and 12 items per substantive trait), and Faking Impact (weak and strong). As we fully crossed all factors, each simulation consisted of 32 conditions in total. To examine very different levels of Heterogeneity, we chose a non-linear increase between the levels of this factor (see section below). For Sample Size and Test Length, we set the levels to reflect a realistic scenario and to be in line with recent recommendations for polytomous IRT models (Dai et al., 2021). We manipulated the faking impact by varying the size of the faking dimension’s slope parameters in relation to substantive trait dimensions’ slope parameters. All our simulations featured 100 repetitions per condition. Thus, 3,200 datasets were generated in each simulation study.
Heterogeneity
As test-takers may differ in their desirability perceptions in various ways, there is not just one manipulation of heterogeneity that covers all the potential differences. Thus, we used three different manipulations of heterogeneity in the three simulation studies.
Quantitative Heterogeneity (Simulation Study 1)
The first manipulation of Heterogeneity (Simulation Study 1) followed the idea that there is a desirability trajectory per item that applies to the average test-taker, but test-takers’ individual desirability perceptions fluctuate unsystematically around the average trajectory. We call this type of heterogeneity Quantitative Heterogeneity henceforth. We applied the same procedure to all items regardless of their trajectory. Depending on the level of Heterogeneity, we added random noise to each test-taker’s scoring weights of faking in the population model. Random noise was drawn from a normal distribution with a mean μ = 0 and a varying standard deviation (SD) depending on the level of Heterogeneity. We set the standard deviation to SD = 0.3 for the weak, to SD = 0.8 for the strong, and to SD = 1.5 for the extreme level. This procedure meant that the faking dimension’s scoring weights were person-specific in the data generation. Note, however, the MNRM assumes person-invariant scoring weights. Hence, in the model estimation, we used the average trajectory of each item as the vector of the faking dimension’s scoring weights. This mirrors an empirical scenario where both actual test-takers and pilot study participants have unsystematically different perceptions of desirability, and the average desirability ratings from the pilot study are used as scoring weights of faking. The specific values of the standard deviations used to simulate the different levels of Heterogeneity were oriented on empirical evidence regarding the heterogeneity of desirability perceptions. In particular, reanalyzing the desirability ratings from the pilot study by Seitz, Spengler, and Meiser (2025), we found that standard deviations of item- and category-specific desirability ratings mainly varied between SD = 0.3 and SD = 1.5. Figure 2 shows the faking dimension’s scoring weights of each simulated test-taker in the population model for a non-monotonically increasing item. Quantitative heterogeneity of social desirability trajectories (exemplarily for a non-monotonically increasing trajectory).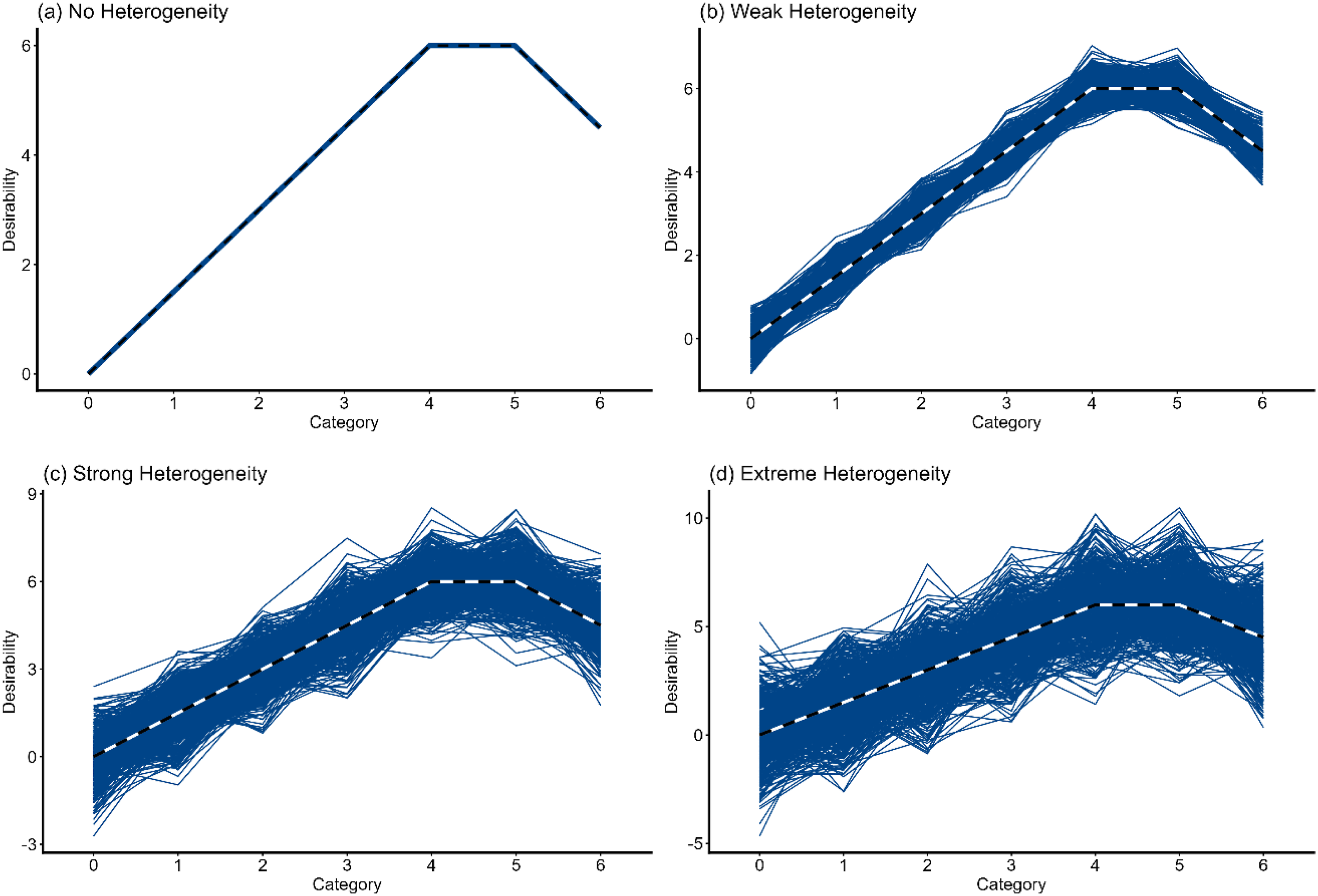
Qualitative Heterogeneity (Simulation Study 2)
The second manipulation of Heterogeneity (Simulation Study 2) was based on the premise that test-takers may differ systematically in their perception of the most desirable response category. We call this type of heterogeneity Qualitative Heterogeneity henceforth. In the population model, we defined three different groups following qualitatively different social desirability trajectories. There was a focal group following the three trajectories as described above. The two subgroups each followed one of the other two trajectories per item. We realized the different levels of Heterogeneity by the proportions of the three groups in the sample. The proportion of the focal group decreased with increasing Heterogeneity from 100% to 90%, 80%, and finally 50%. The test-takers not belonging to the focal group were equally split between the two subgroups. Seitz, Spengler, and Meiser’s (2025) pilot data of item- and category-specific desirability ratings were once again used as an orientation for the operationalization of Heterogeneity on this manipulation. Specifically, using k-means clustering, we found three clusters for most items, with one cluster being dominant (making up between 50% and 70% of the sample) and two smaller clusters. The black dashed line in Figure 3 shows the average scoring weights of faking across all test-takers. These average scoring weights from the population model were used as the scoring weights of faking in the estimated model. Thus, this simulation mirrors an empirical scenario where both actual test-takers and pilot study participants have systematically different perceptions of desirability, but the desirability ratings from the pilot study are just averaged across participants. Figure 3 shows the social desirability trajectories of the modeled groups for a non-monotonically increasing item. Qualitative heterogeneity of social desirability trajectories (exemplarily for a non-monotonically increasing trajectory).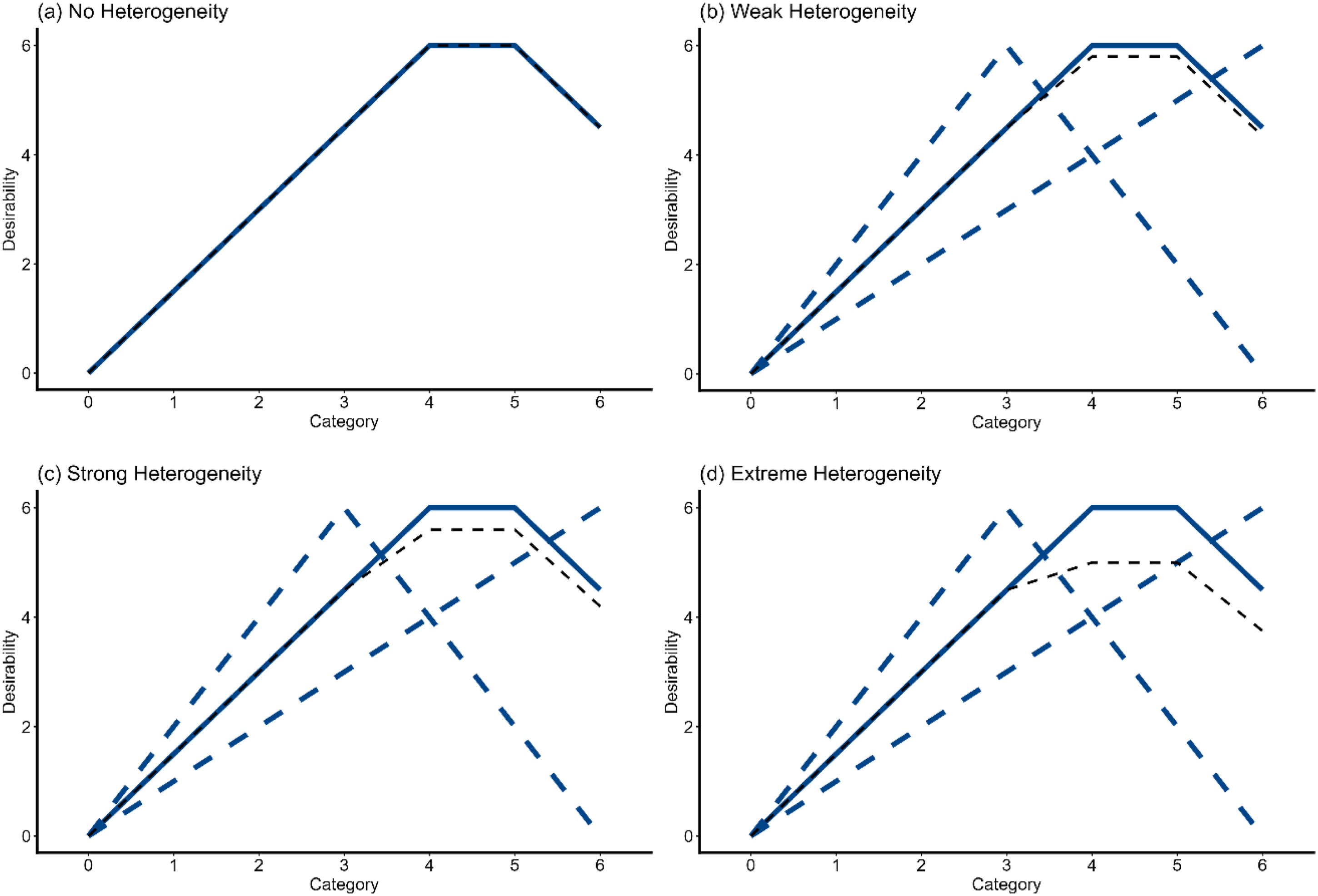
Heterogeneity With Constant Fakers (Simulation Study 3)
The third manipulation of Heterogeneity (Simulation Study 3) predicated on the idea that there may be test-takers who are faking without considering for each item separately which category is most desirable. For example, there may be test-takers assuming that the test will be scored by summing scores across all items. Thus, to increase one’s chance of being selected for the job, always faking toward the highest response category in the direction of high trait levels (i.e., regardless of the item content) can be a viable strategy in a job application context. Moreover, there may also be test-takers following a similar strategy but being afraid that always faking toward a high response category may seem unrealistic or that they might be detected as liars or impostors. Thus, they constantly fake toward a non-extreme agreement. We call this type of heterogeneity Heterogeneity With Constant Fakers henceforth. In the population model, we defined a focal group whose faking behavior aligned with the three trajectories as described above. As in Simulation Study 2, we manipulated the level of Heterogeneity based on the group proportions in the sample. The proportion of the focal group decreased with increasing Heterogeneity from 100% to 90%, 80%, and 50%. The remaining test-takers were again evenly split into two subgroups in the population model. In one subgroup, all test-takers constantly faked toward the extreme agreement aligning with a monotonically increasing trajectory. In the other subgroup, all test-takers constantly faked toward a non-extreme agreement aligning with a non-monotonically increasing trajectory. Hence, the test-takers in the subgroups did not fake towards the social desirability of the item content for each item. For the estimated model, we set the faking dimension’s scoring weights equal to those of the focal group. This was done to once again mirror an empirical scenario where scoring weights of faking are assessed using a pilot sample. As pilot participants are asked to rate the social desirability of the response categories for the specific content, their rating should be based on the content of an item, as in the focal group, and not follow a constant faking strategy. In line with this rationale, this manipulation of Heterogeneity was not based on an empirical foundation but rather on the theoretical idea that test-takers following a constant faking strategy might be present in high-stakes contexts, but not in a pilot study. Therefore, this manipulation can be seen as a stress test for the model above the kinds of heterogeneity that have so far been demonstrated empirically. Figure 4 shows a visualization of this manipulation. Heterogeneity with constant fakers.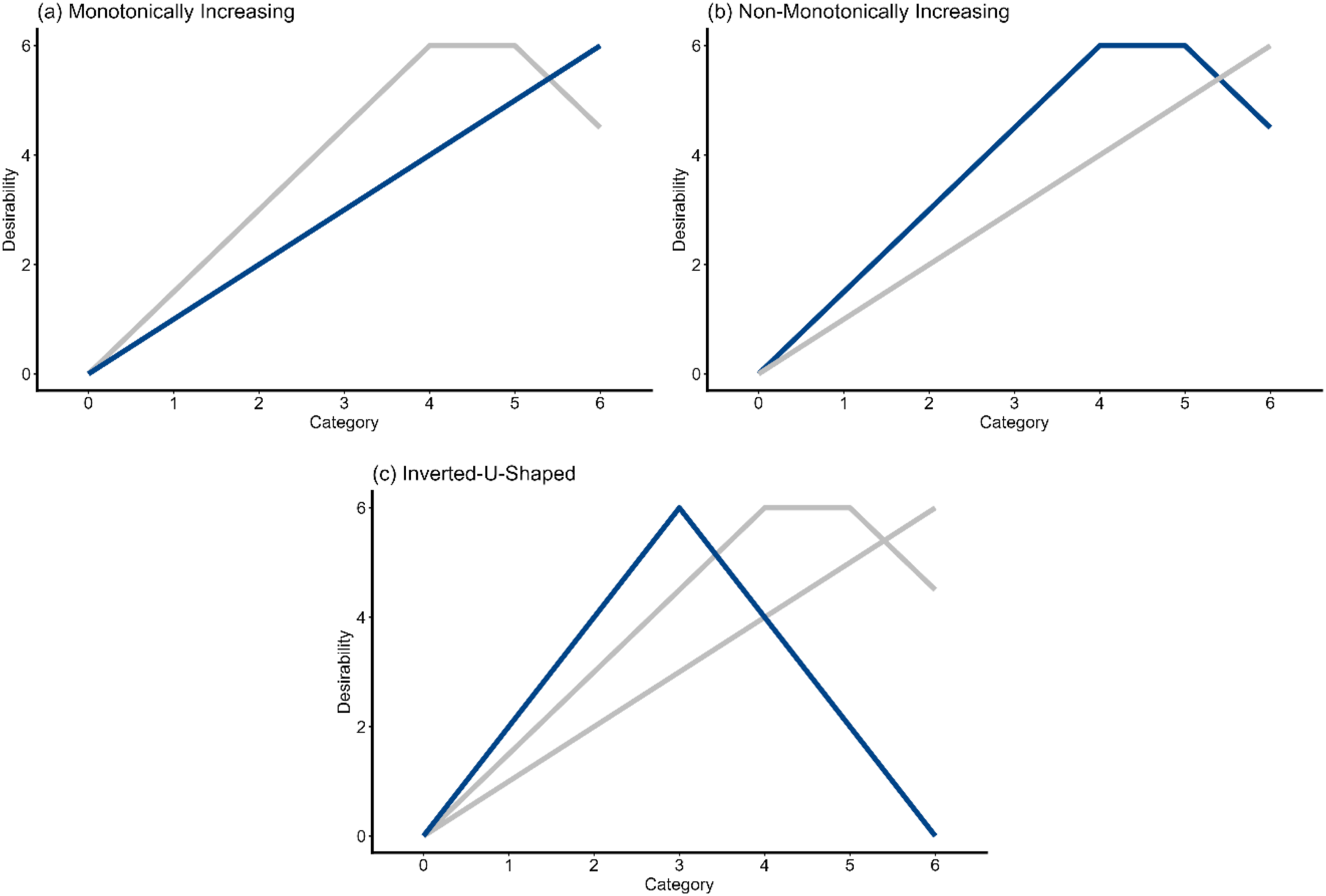
Data Generation
A situation where five substantive traits were measured by six or twelve items, respectively, on a 7-point Likert scale was simulated.
2
We set the parameters to simulate the data in the following way: o Person parameters o Item category intercept parameters o Item slope parameters o Scoring weights
Using the softmax function presented in equation (1), item responses were simulated based on the generated item and person parameters. This procedure was repeated 100 times for each condition, resulting in 3,200 simulated datasets per simulation. R 4.3.3 with the packages mirt (Chalmers, 2012), MASS (Venables & Ripley, 2010), and SimDesign (Chalmers & Adkins, 2020) was used for the data generation. The simulation syntax is available on OSF (https://osf.io/x3rpa/).
Data Analysis
For the analysis, we fitted two models to the simulated dataset of each repetition. The first model accounted only for the five substantive traits (trait model), while the second model also included faking (trait-faking model). We imposed several constraints for model identification: Firstly, the first category’s intercept of each item was fixed to 0. Secondly, the expectations of all latent dimensions were fixed to 0 and their latent variances to 1. Thirdly, all scoring weights were fixed as shown in equation (2) for the substantive traits and as described in the section Simulation Design for the faking dimension. Given the high dimensionality of the models, both models were estimated using the Metropolis-Hastings Robbins-Monro (MHRM) algorithm (Cai, 2010) as implemented in the R package mirt. The MHRM algorithm is a Bayesian estimation approach integrating concepts from Markov Chain Monte Carlo (MCMC) methods like the Metropolis-Hasting (MH) algorithm (Hastings, 1970) and stochastic approximation techniques like the Robbins-Monro (RM) method (Robbins & Monro, 1951). It converges to the maximum likelihood solution. To estimate the person parameters in the high-dimensional models, maximum a-posteriori (MAP) scores were calculated (see Embretson & Reise, 2000) as implemented in mirt.
To evaluate the recovery of the substantive trait person parameters, we calculated the correlation between the estimated and the true parameters. The impact of different conditions on the recovery of substantive trait person parameters was compared using a multi-way analysis of variance (ANOVA). In order to perform the ANOVAs on a continuously and normally distributed dependent variable, correlation coefficients were transformed for the analysis using Fisher’s z-transformation. As the trait model and the trait-faking model were estimated for each repetition, the factor Model was treated as a repeated-measures factor. Given the high number of observations and hence high power, interpreting effect sizes was more informative than focusing on p-values. Following the recommendation of Olejnik and Algina (2003) for mixed ANOVA designs, generalized
Results
Main and Interaction Effects on the Recovery of Substantive Trait Person Parameters
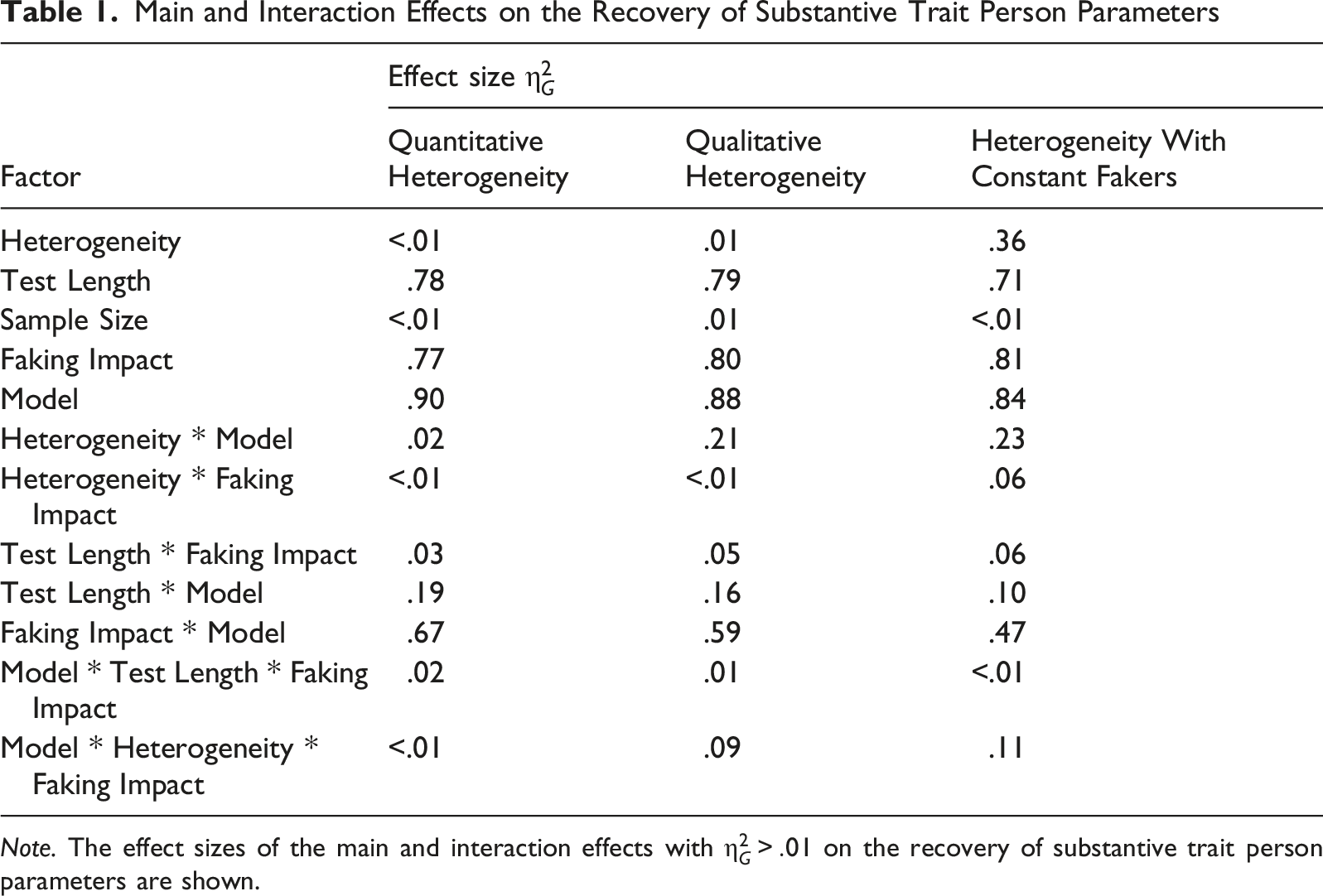
Note. The effect sizes of the main and interaction effects with
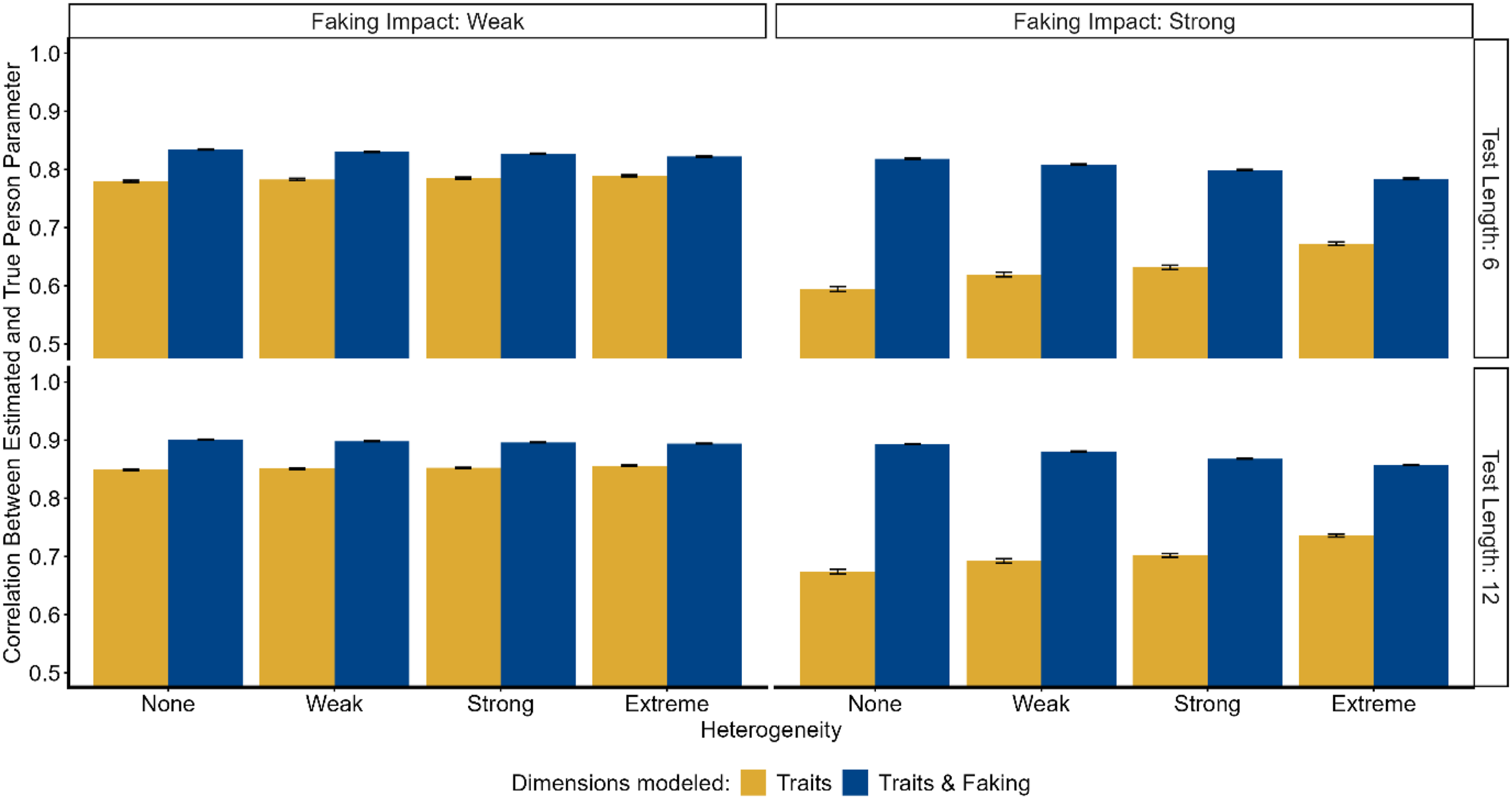
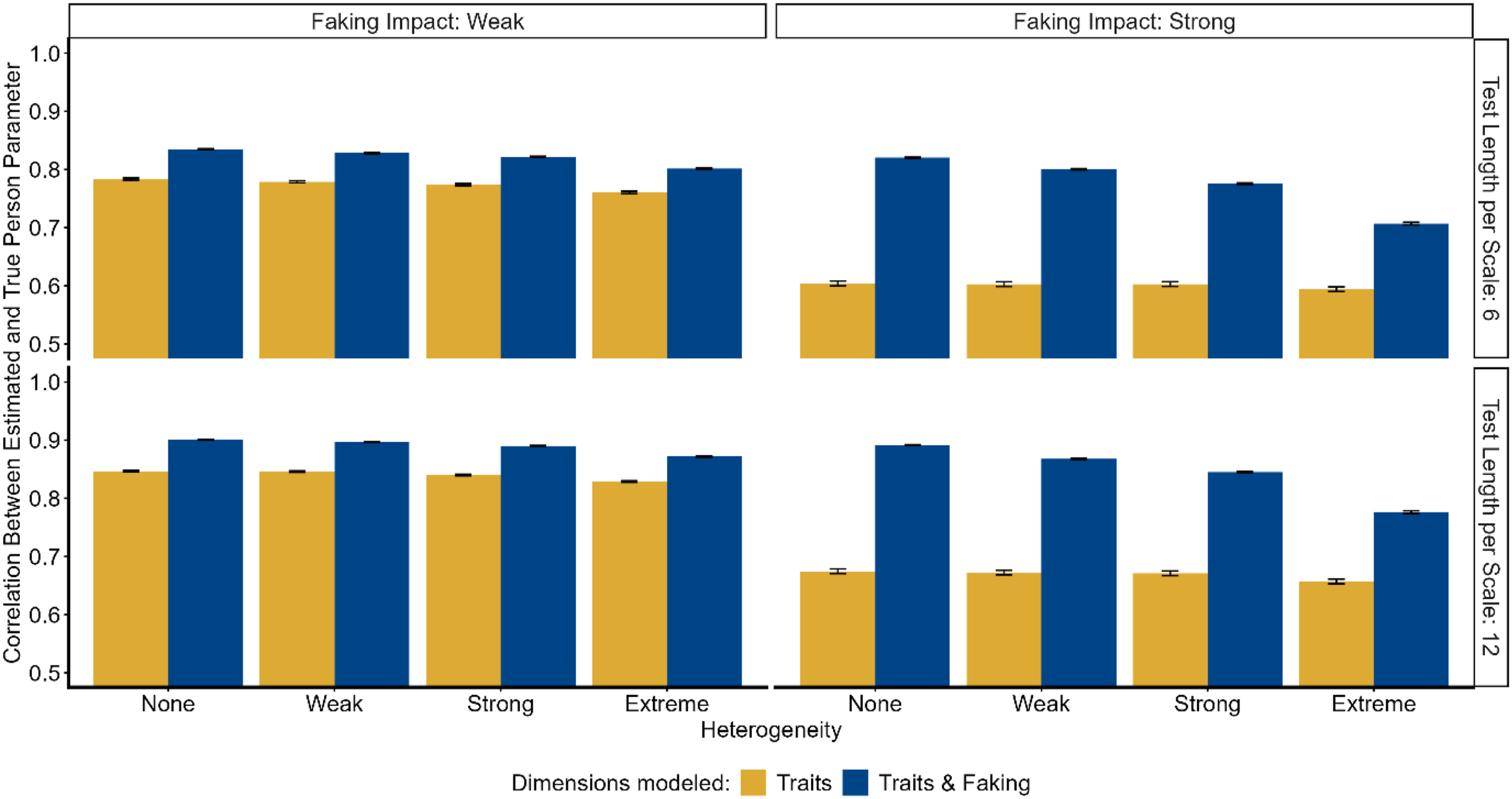
Across all studies, the factor Model exhibited the strongest main effect ( Correlation between estimated and true substantive trait person parameters for quantitative heterogeneity. Correlation between estimated and true substantive trait person parameters for qualitative heterogeneity. Correlation between estimated and true substantive trait person parameters for heterogeneity with constant fakers.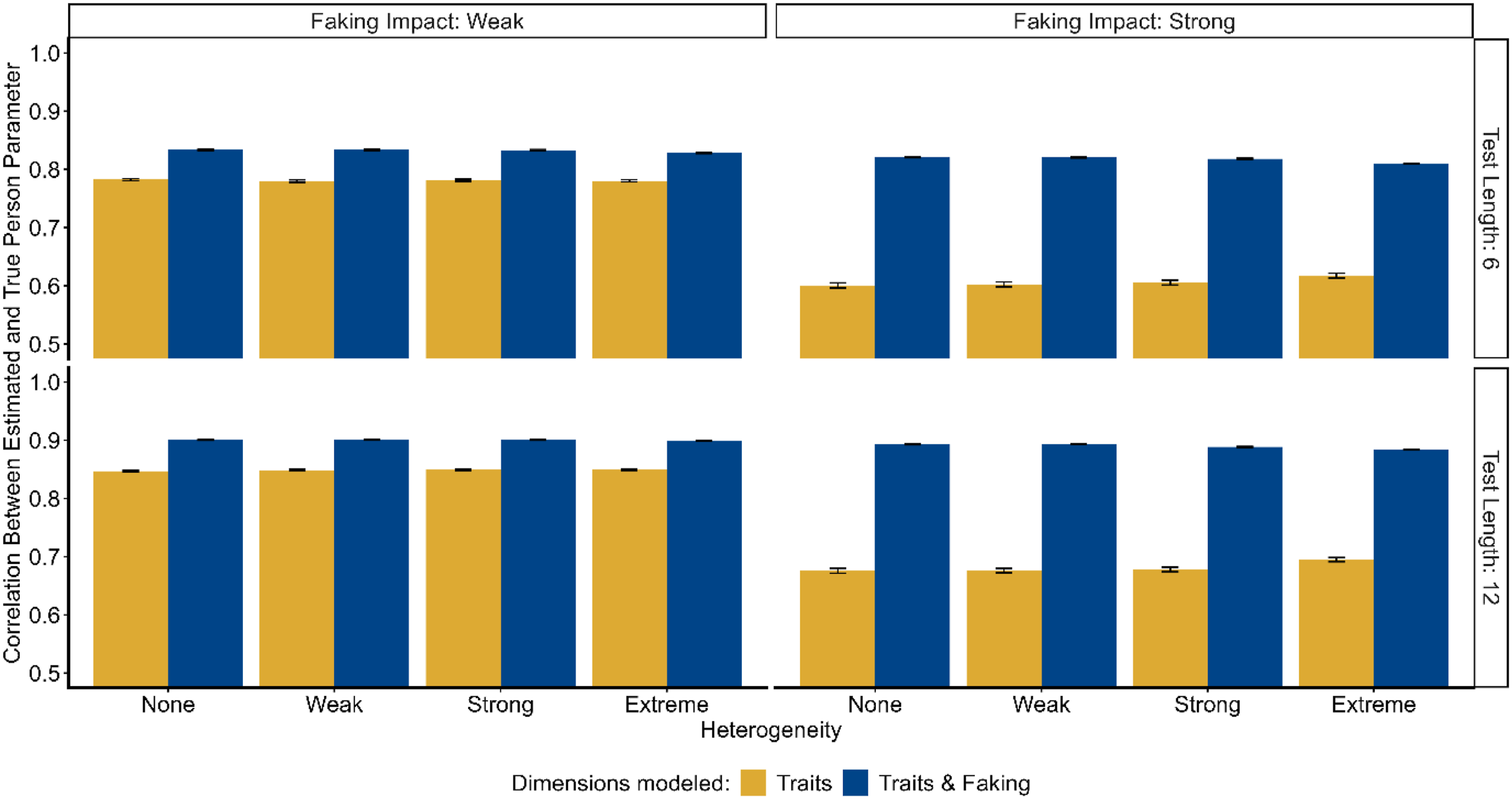
Quantitative Heterogeneity (Simulation Study 1)
Heterogeneity did not show a meaningful main effect in the study of Quantitative Heterogeneity (
Qualitative Heterogeneity (Simulation Study 2)
For Qualitative Heterogeneity, there was no meaningful main effect of Heterogeneity as well (
Heterogeneity With Constant Fakers (Simulation Study 3)
We found a main effect of Heterogeneity in the study of Heterogeneity With Constant Fakers (
Discussion
In this paper, the robustness of the MNRM accounting for faking was examined when test-takers differ in their perception of social desirability. We conducted three simulation studies with varying manipulations of heterogeneity in the perception of social desirability. The results indicate that the MNRM is generally well able to recover substantive trait person parameters even if test-takers differ in their perceptions of social desirability.
Summary and Interpretation of Results
The trait-faking model (including dimensions for the substantive traits and faking) consistently outperformed the trait model in all studies regarding the recovery of substantive trait person parameters. Given that data were generated using the trait-faking model, it is not surprising that this superiority was observed in the condition of no heterogeneity. More interestingly, even under conditions of extreme heterogeneity (where the estimated trait-faking model is technically not correctly specified because it does not include person-specific scoring weights of faking), the model accounting for faking maintained its superiority in parameter recovery over the model not accounting for faking. In the study of Quantitative Heterogeneity (Simulation Study 1), where perceptions of social desirability varied unsystematically between test-takers, the recovery of person parameters was not hindered by increasing heterogeneity. In the study of Qualitative Heterogeneity (Simulation Study 2), where there were groups of test-takers differing systematically in their desirability perceptions, the recovery was only marginally affected by increasing heterogeneity. In contrast, the presence of test-takers following a constant faking strategy (e.g., always faking toward the highest response category) instead of all test-takers' faking based on the social desirability of the item content (Simulation Study 3) reduced parameter recovery to a non-negligible extent. Here, it was found that the recovery decreased with increasing proportions of these constant fakers. But, even when the MNRM was correctly specified for only half the test-takers, the recovery was still significantly better than in the more parsimonious model without a faking dimension. Thus, as long as test-takers engage in faking based on the social desirability of the item content, differences between test-takers in their perception of social desirability seem not to pose a threat to the MNRM modeling approach.
We found an interaction between the factors Heterogeneity and Model in the simulation studies of Qualitative Heterogeneity and Heterogeneity With Constant Fakers. The superiority of the trait-faking model decreased with increasing heterogeneity. This was partly driven by the described decrease in the recovery of the trait-faking model with increasing heterogeneity. Additionally, for Qualitative (and slightly for Quantitative) Heterogeneity, the recovery of the trait model increased with increasing heterogeneity. This latter finding can be explained by considering the following: In general, parameter recovery in the trait model is systematically biased because the model ignores the systematic variance components due to faking. However, with increasing heterogeneity in desirability perceptions, the bias introduced through faking becomes less systematic in the sense that faking is not anymore characterized by a general (i.e., person-invariant) tendency toward a certain response category, but by idiosyncratic (i.e., person-specific) tendencies toward different categories. Increasing heterogeneity thus reduces the extent of the systematic bias due to faking in the trait model. Consequently, parameter recovery improves compared to a situation where all test-takers perceive desirability equivalently.
Implications for Practice
As long as test-takers follow their perceptions of social desirability based on the item content, differences in the perceptions of social desirability seem to be negligible for the recovery of substantive trait person parameters. Here, we set the scoring weights of faking in the estimated model equal to each item’s average desirability trajectory in the population model. Thus, for the current simulation results to be transferable to empirical applications, it is crucial to conduct pilot studies with samples being highly similar to the sample of actual test-takers in order to closely approximate each item’s underlying average desirability trajectory. However, provided that the underlying average desirability trajectory of each item is indeed accurately measured, the results of the current article do suggest that relying on the mean perceptions of social desirability is sufficient to adequately model faking.
However, if test-takers following a constant faking strategy are present, a well-fitting pilot sample cannot solve the issue. Instead, it can be sensible to prevent constant faking behavior in the first place. One ad-hoc intervention in this regard may be to communicate to test-takers that their thorough answer to all individual items is of importance for the selection process, in order to draw test-takers’ focus to the content of individual items. Whether or not an intervention like that can be effective remains the topic of further research. Another option would be to adjust the model itself. Here, a further dimension for constant faking could be added to the model while using a mixture-distribution approach. Such a model could be used to classify test-takers into fakers following the social desirability of the item content versus following a constant strategy, which would allow for the correct measurement model to be specified for the respective faking strategy (cf. Seitz, Alagöz & Meiser, 2025; Seitz & Ulitzsch, 2026).
Limitations and Future Research
Only a scenario with three social desirability trajectories (monotonically increasing, non-monotonically increasing, inverted-U-shaped) that had equal proportions across items was considered in the current article. This was done because previous research has shown that personality questionnaires usually consist of items with these social desirability trajectories (Borkenau et al., 2009; Kuncel & Tellegen, 2009). Nevertheless, for other questionnaires, there can be other compositions of social desirability trajectories, be in terms of other trajectory types or unequal proportions. Since the recovery of substantive trait person parameters generally depends on the composition of items’ social desirability trajectories (see Seitz et al., 2024), this limitation regarding the design choice of the simulation has to be kept in mind when generalizing the reported results. Future research could examine the influence of using other item compositions in more detail.
This research has been focused on differences in the perception of desirability, assuming that the perceived desirability translates directly into how test-takers engage in faking. However, previous research has shown that heterogeneity can also arise from qualitatively different faking-related response strategies test-takers use (Seitz, Alagöz & Meiser, 2025). Future studies can examine how the interplay of a heterogeneous perception of desirability and a heterogeneous use of faking-related response strategies affects the modeling of faking using the MNRM.
As mentioned at the beginning of the article, besides approaches dealing with faking when assessment data have already been collected (like the MNRM), there are also approaches like MFC tests that try to prevent faking in the first place. Here, differences in the perceptions of desirability are important to consider as well. Pavlov et al. (2021) showed that taking heterogeneity of desirability perceptions into account is indeed beneficial for the construction of MFC tests. Thus, the presented work can be seen as an addition to Pavlov et al.’s (2021) work for the case of model-based approaches to dealing with faking. Generally, we encourage future research to systematically examine under which circumstances the different approaches to faking are to be preferred. This can help to build a foundation for researchers and practitioners to decide which approach to choose in a given applied measurement context.
To sum up, given the general robustness of the model shown in the simulations, the results of the present article underline the applicability of the MNRM even when test-takers do not perceive social desirability equivalently. Thus, the MNRM of faking presents already a solid basis for the psychometric modeling of faking. The above-mentioned future research directions and possible model extensions are nevertheless fruitful to improve the modeling further.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.